1. Introduction
Most empirical work in the social sciences is based on observational data that are incomplete. There are many types of selection mechanisms that result in a non random sample. Some of them are due to sample design, while others depend on the behavior of the units being sampled, other than non-response or attrition.
In the first case, data are usually missing for all the variables of interest; for example, in estimating a saving function for all the families of a given country, a bias would arise if only families whose household head shows certain characteristics were sampled. However, when causes of missingness are appropriately exogenous, using a sub-sample has no serious consequences. In the second case, instead, there is a self-selection of the sample units and data availability on a key variable depends on the behavior of the units for another variable. The classical example is the estimation of the wage offer equation for people of working age, where we want to estimate the expected wage of an individual using a set of exogenous characteristics (gender, age, education, etc). This equation, by definition, should be valid for people of working age, independently of their working conditions at the time of the survey. On the contrary, we can only observe the wage offer for employed individuals; in regressing wages on their characteristics, we are not making inferences for the population as a whole. In other words, people in employment are a selected sample of the population and their wages are higher than the unemployed would have had. Hence, the results will tend to be biased (sample selection bias).To avoid this bias, we should take into account the selection mechanism due to the individual’s decision to take a job and then receive a wage.
As is well known,
Heckman (
1979) proposed a useful framework for handling estimation when the sample is subject to a selection mechanism. In the original framework, the dependent variable in the outcome equation (the wage equation in the above example) is continuous and can be explained by a linear regression model with a normal random component. In addition to the output equation, a selection equation describes the selection rule by means of a binary choice model (probit).
In our work, we focus on the problem that arises when the selection mechanism is particularly severe and gives rise to a large amount of censored observations. This situation might occur for example when the event of interest is infrequent or fragmented or no frames are available for standard sampling procedures. Relevant examples are the surveys on elusive populations (such as working children, homeless persons, illegal immigrants, tax evaders, and drug users); in these populations, by virtue of their characteristics or difficulties in obtaining the required information, adequate samples cannot be defined, drawn or implemented using the standard procedures of random sampling. In this case, no or very partial frames are available for sampling, or many units are not available or willing to participate in the survey. Consequently, random sampling is either not feasible or inefficient, because it is very costly (due to the high number of total units to be sampled to obtain a sufficient number of uncensored observations).
One solution is given by the response-based sampling scheme, also known as case-control setting. In this design (see
Hosmer and Lemeshow 2013), samples of a fixed size are randomly chosen from the two strata identified by the dependent variable.
In the more specific context of binary choice models with response-based sampling and sample selection bias, a solution is given by
Greene (
2008), who extended the work of
Manski and Lerman (
1977). In both proposals, however, the estimator requires the knowledge of the true proportion of occurrences in the outcome equation. In some applications, this requirement can be a serious limitation.
Our work fits into this last framework and aims to overcome these shortfalls.
The remainder of the paper is organized as follows. In
Section 2, we start by describing the methodological background and then we illustrate the proposed estimation procedure. In
Section 3, a simulation study compares our approach with Greene’s. In
Section 4, the proposed method is applied to real data on credit scoring. In
Section 5, a discussion and some concluding remarks are provided.
2. Methods
2.1. General Background
2.1.1. Sample Selection
Let us first introduce some notations and briefly illustrate the sample selection framework with a binary choice model for both the selection and the output equations (
Dubin and Rivers 1989).
Let
and
be two latent (unobservable) variables characterizing the output and the selection equations, respectively. The model, in its general form, is:
where
is a vector of exogenous variables (namely,
for
and
for
), containing all the relevant covariates, and
and
are the vectors of regression coefficients. Let us define
and
as two observable variables such that:
The p.d.f. of is Bernoulli, with probability of success depending on the parameters and respectively.
Model (
3) defines the mechanism which governs the censoring process: we can observe
if and only if
. On the contrary, if
,
will be missing.
In the general case, if we were to estimate the parameters of Equation (
1a) without considering the selection process in (
1b), a bias would arise. This is because the processes represented by the two equations are related, i.e.,
is not null (see for example
Cameron and Trivedi (
2005) for further details).
The likelihood function for model (
1a-
1b) is:
where
is the vector of parameters to be estimated,
and the function
gives the probability that an observation is uncensored.
2.1.2. Response-Based Sampling
Let us now briefly review the main characteristics of the response-based sampling scheme relevant to our method. In this context, samples of fixed size are randomly chosen from the two strata identified by the dependent variable A (note that, for our purposes, in the context of sample selection, it corresponds to the dependent variable of the selection equation). In particular, units are drawn at random from the cases and units from the controls.
The likelihood function is the product of the stratum-specific likelihoods, and depends on the probability that the individual is in the sample and on the joint density of the covariates (
Hosmer and Lemeshow 2013):
where
is a binary variable which takes value 1 if the
i-th individual is in the sample and 0 otherwise.
2.2. A Binary Choice Model with Sample Selection under a Response-Based Sampling
2.2.1. The Weighted Endogenous Sampling Likelihood
The estimator, first proposed by
Manski and Lerman (
1977), is designed for a binary response model under a response based sampling framework and it is called the Weighted Endogenous Sampling Maximum Likelihood (WESML) estimator, because it assigns weights to the likelihood function. The weights are given by the ratio between the proportion of individuals in the population for which
and the corresponding proportion in the sample.
2.2.2. The WESML Estimator Corrected for Selection Bias
Greene (
2008) extended the work of Manski and Lerman to the context of a binary response model with selection bias and response-based sampling; in that work, the goal was to estimate the probability of loan defaults
) from a sample of individuals whose credit card application was accepted (
). The corresponding likelihood is:
where again
and, according to Manski and Lerman, the weights are given by the ratio of two proportions: we have population-level quantities at the numerator and the corresponding sampling quantities at the denominator. More precisely, in Greene’s application
represents the fraction of non-cardholders in the population and
is the homologous in the sample; coherently,
is the prevalence of defaults (
) and non defaults (
) in the population, while
is the sample counterpart.
It is important to note that Greene’s estimator (GE) requires knowledge of the proportion in the population not only for the controls (i.e., ), but also for the response variable (namely and ). This requirement can be an insurmountable obstacle in some applications.
2.2.3. The Sample-Selection Response-Based-Sampling Likelihood
In the following, we provide our main result which is the likelihood function in the framework of interest, i.e., a sample selection mechanism with a severe censoring process assuming that the population prevalences
and
are unknown. The full proof is given in the
Appendix.
We make the following very general and non restrictive assumptions:
We have a set of fully informative and exogenous covariates .
Conditional on the covariates, the probability that an observation is uncensored does not depend on its value, i.e., .
The set of covariates , specific for , and the set , specific for , may have common elements but they cannot fully overlap. In particular, we assume that there is at least one covariate in the selection equation which is not in the outcome.
Assumption 1 means that a correlation between the covariates and the residual terms in Equations (
1a) and (
1b) does not exist . Assumption 2 is justified because, as the covariates are informative, all the information brought by
is contained in
. Assumption 3 is necessary for parameter identification (exclusion condition).
Under the conditions stated, the likelihood function for a binary-choice model with sample-selection response-based sampling is:
where
is the probability of observing
given that the observation is uncensored and
is the amount of uncensored units in the sample having
, with
. Moreover, as previously said,
is the probability that an observation is uncensored,
is the number of units sampled from the
uncensored observations and
is the number of units sampled from the
censored observations.
It is easy to see that the likelihood (
6) is a weighted version of (
4), and the weights simply take into account the sampling scheme. In addition, note that, in the maximization process, the term
is non influential, as it does not contain any information on the vector of parameters
, and that the only known quantities at the population level are
and
N.
The estimator for obtained by maximizing this likelihood will be referred to as Sample Selection Response-based Sampling (SSRS hereafter).
3. Simulation Results
In this section, we will compare the results obtained using the SSRS and GE estimators through a Monte Carlo experiment.
The generating model is:
where all
Xs are independently generated from a univariate standard normal. Note that, in Equation (
7b),
governs the proportion of uncensored observations in the population (i.e.,
). In particular, in the following, we consider three (approximate) proportions: 4% (ensured by
), 15% (
) and 30% (
).
Even though in the derivation of Equation (
6) we have not assumed any probability model for
and for
, we had to do it for the Monte Carlo experiment. More precisely, we set:
From Equation (
8) and referring to the probabilities
and
in (
6), it follows:
where
and
are c.d.f. of the univariate and the bivariate normal respectively.
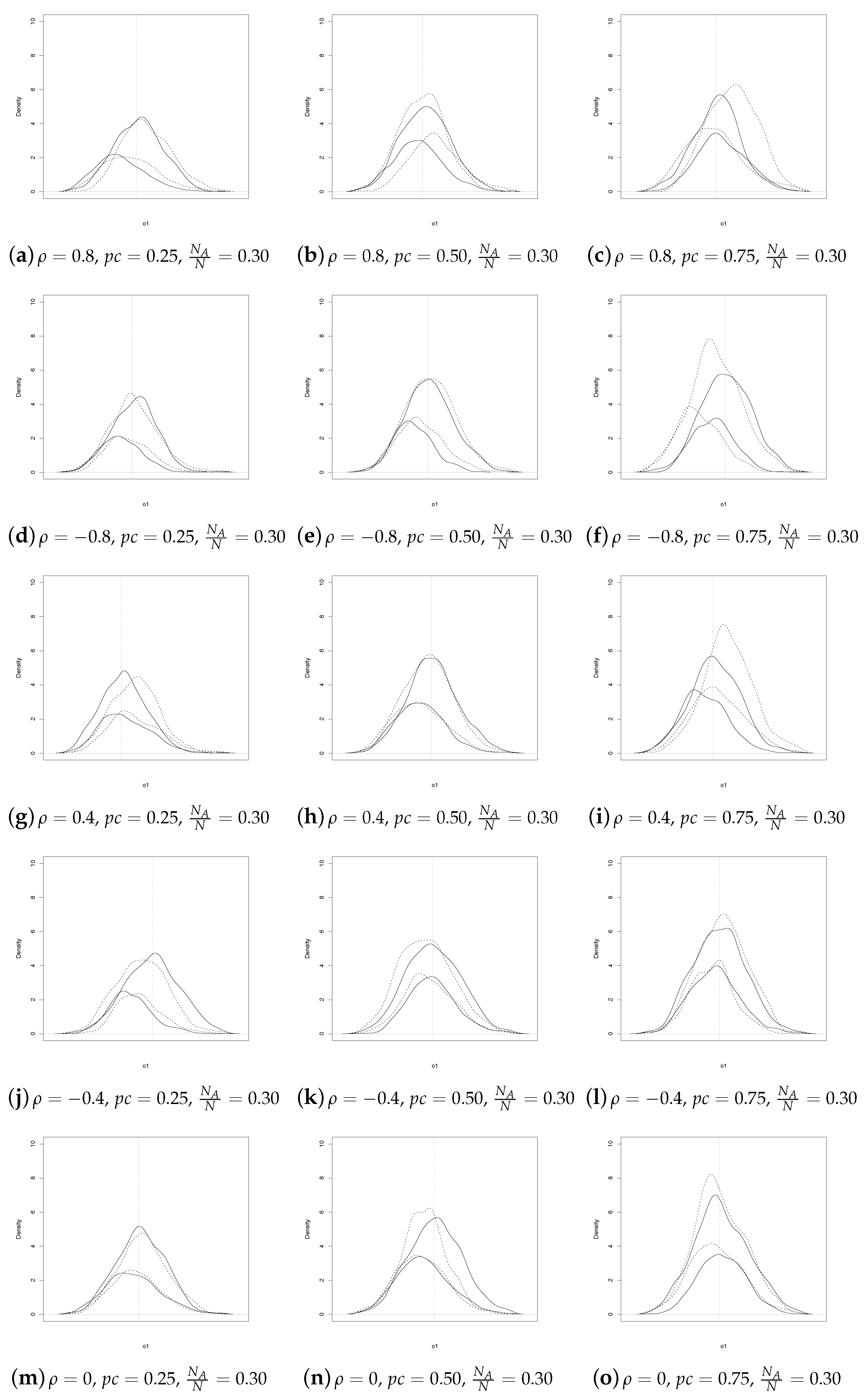
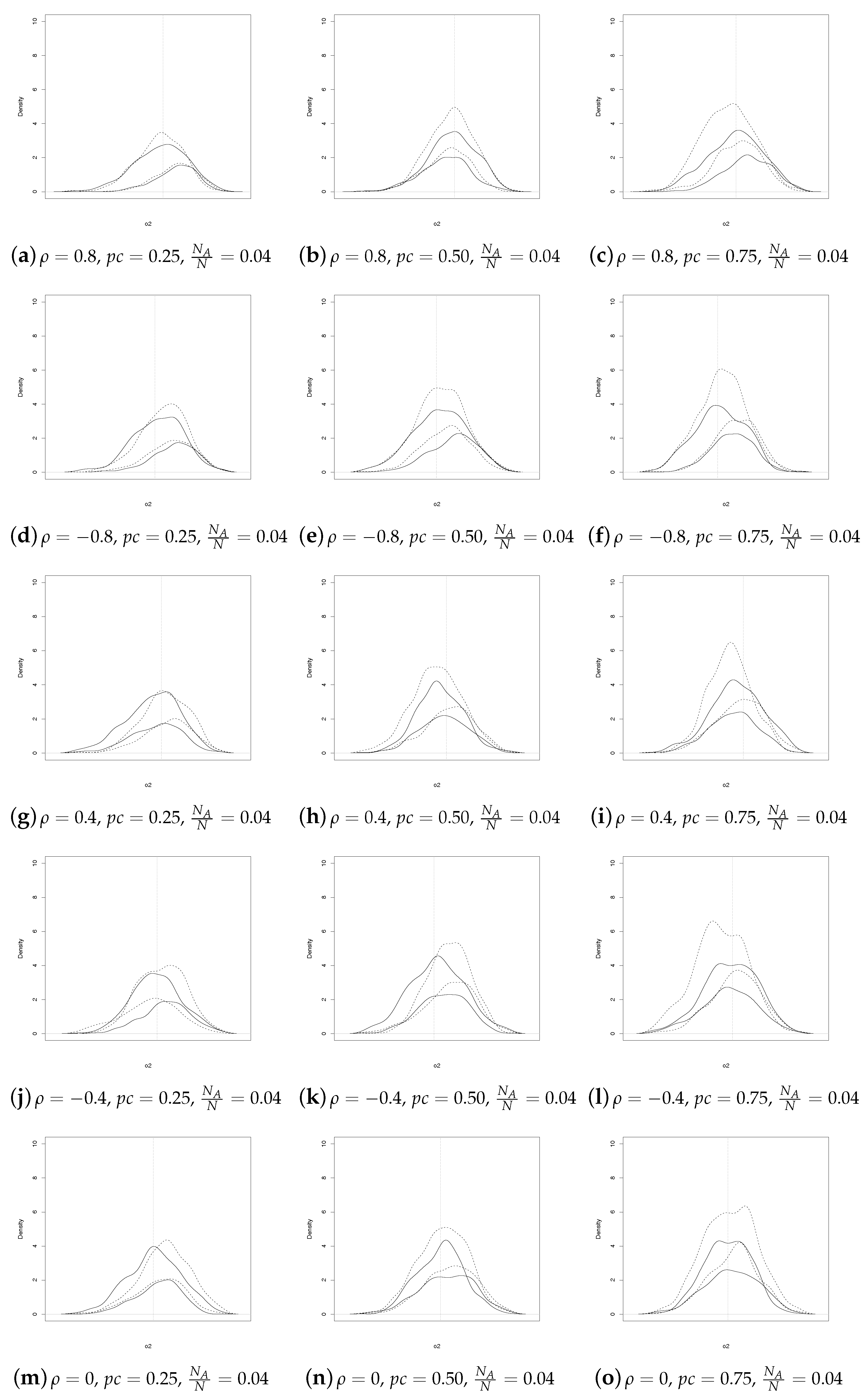
For each censoring scheme (), we performed 500 replications for any with a step of 0.1 and for three different sampling proportions of cases and controls (i.e., ). From a population of size , we drew samples of different size to evaluate the performances of the two estimators. More precisely, we drew sample with dimension spanning from to by 500.
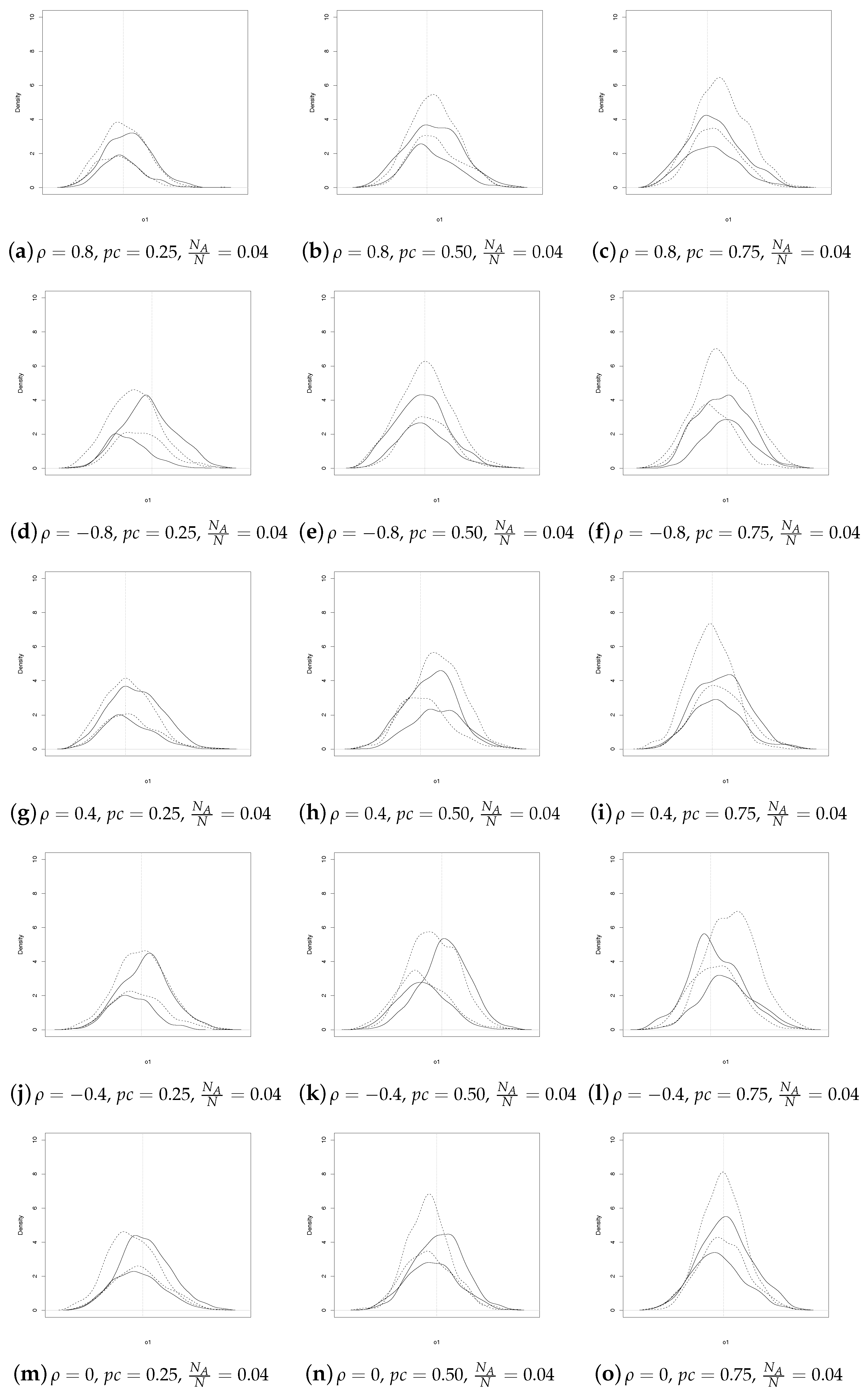
In commenting on the results, we begin by comparing the empirical densities of SSRS and GE estimators for
and
, for each censoring scheme
1. Rather than overwhelm the reader with statistics, we prefer to present information in a summary graphical form.
As regards
, for
(see
Figure 1), we note that the patterns are similar for
, whereas the behavior differs more as
increases. Furthermore, the SSRS estimator is almost always more concentrated except for few combinations of
and
.
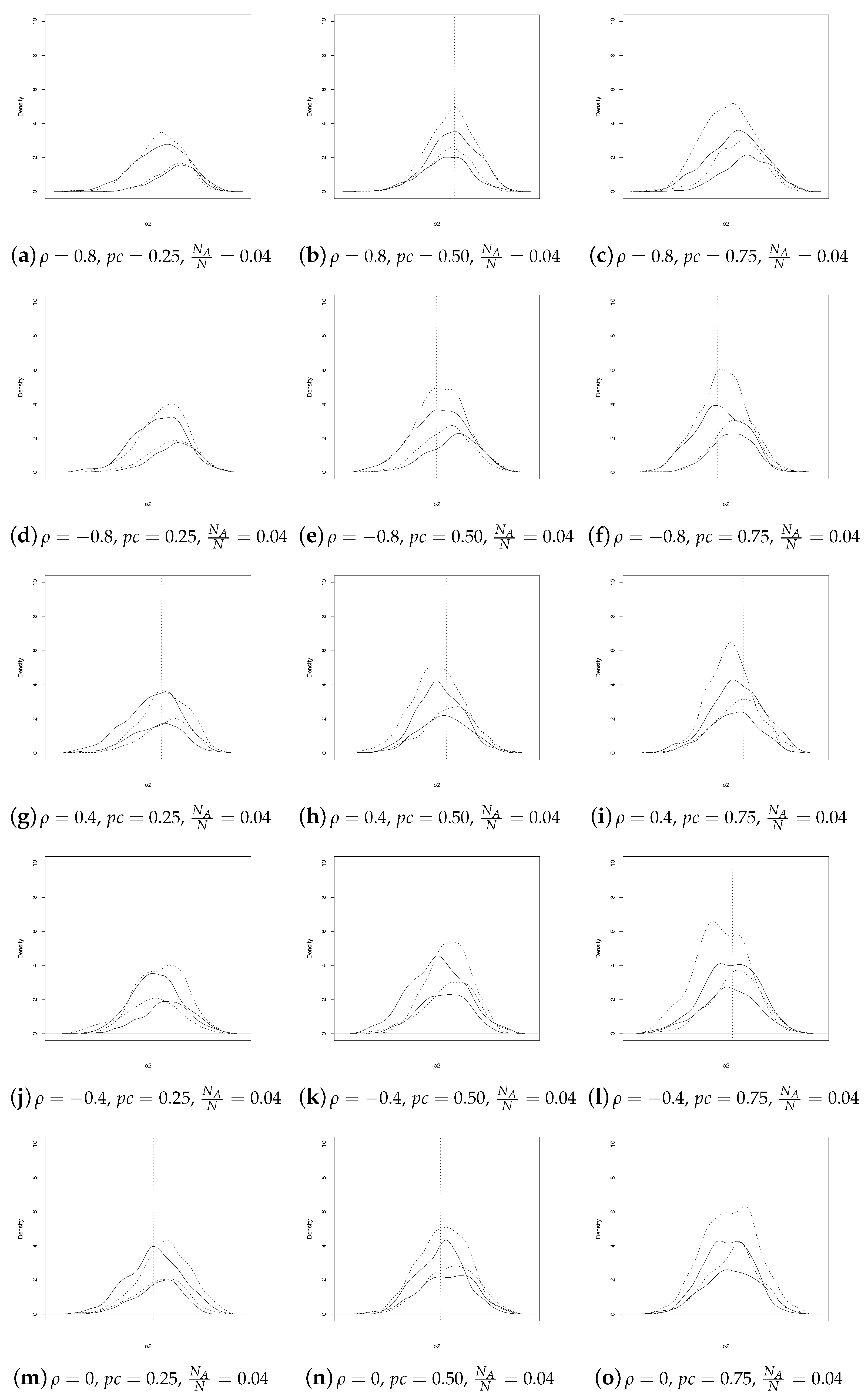
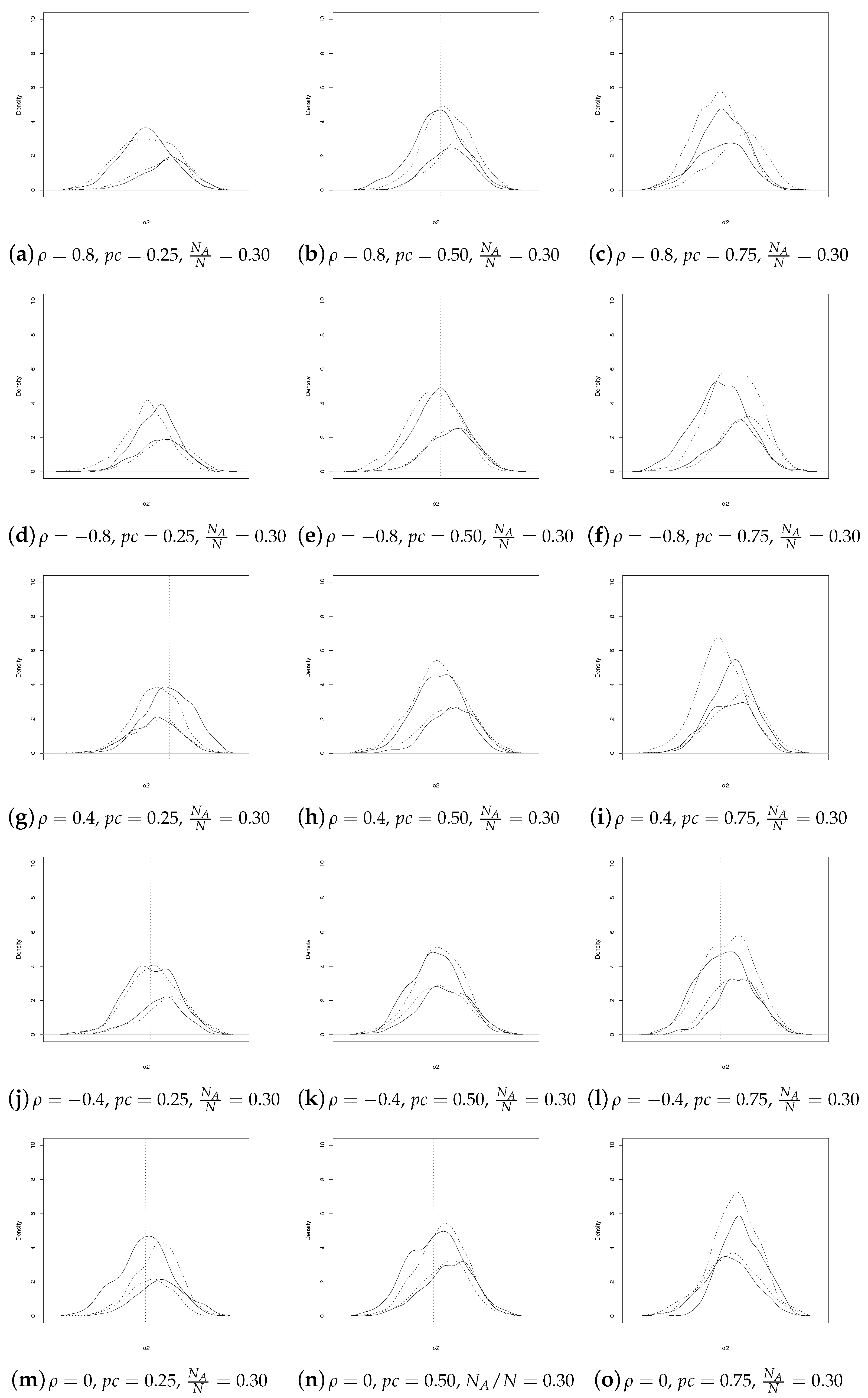
As expected, when
increases, the discrepancies between SSRS and GE estimators fade away (see
Figure 2).
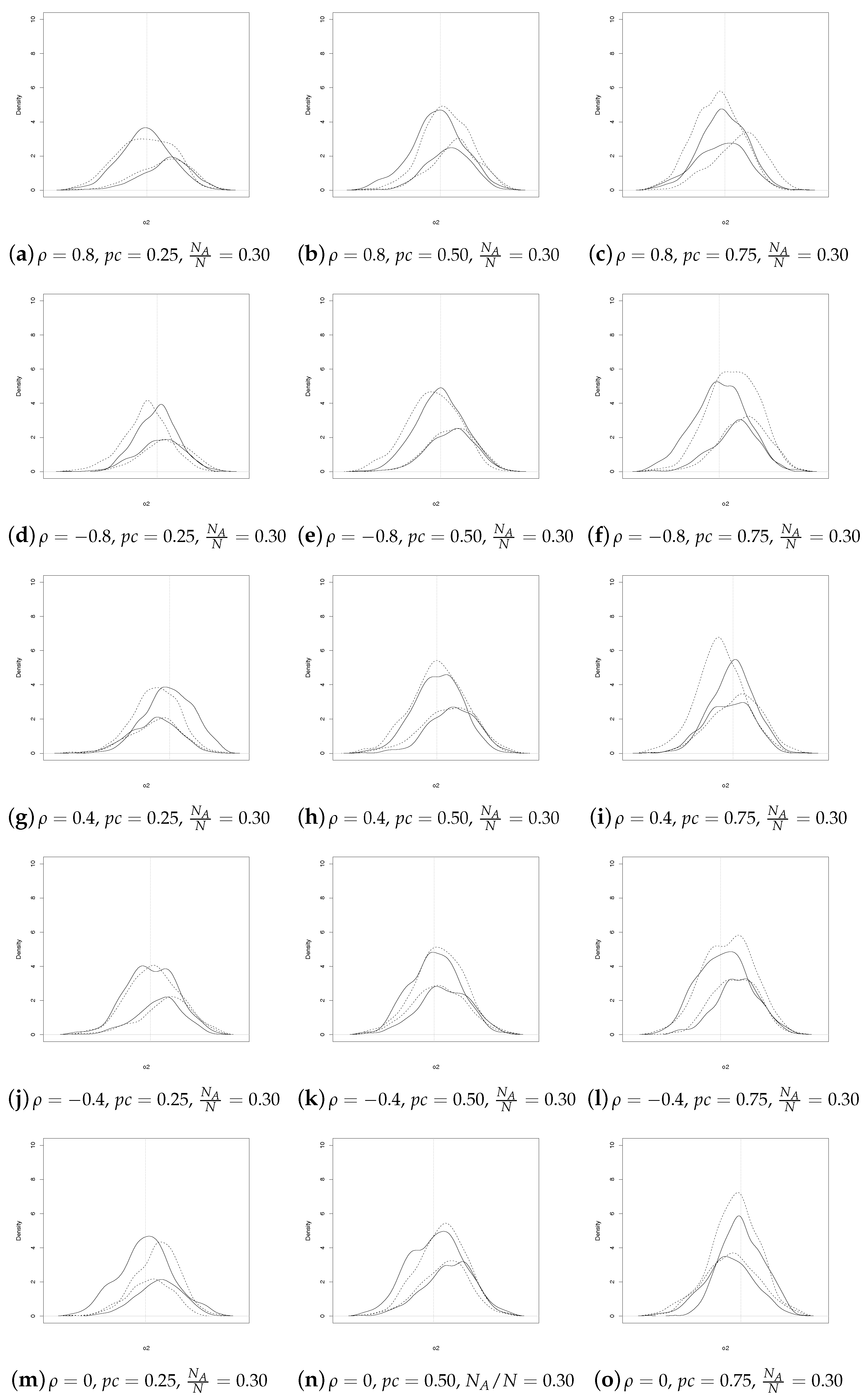
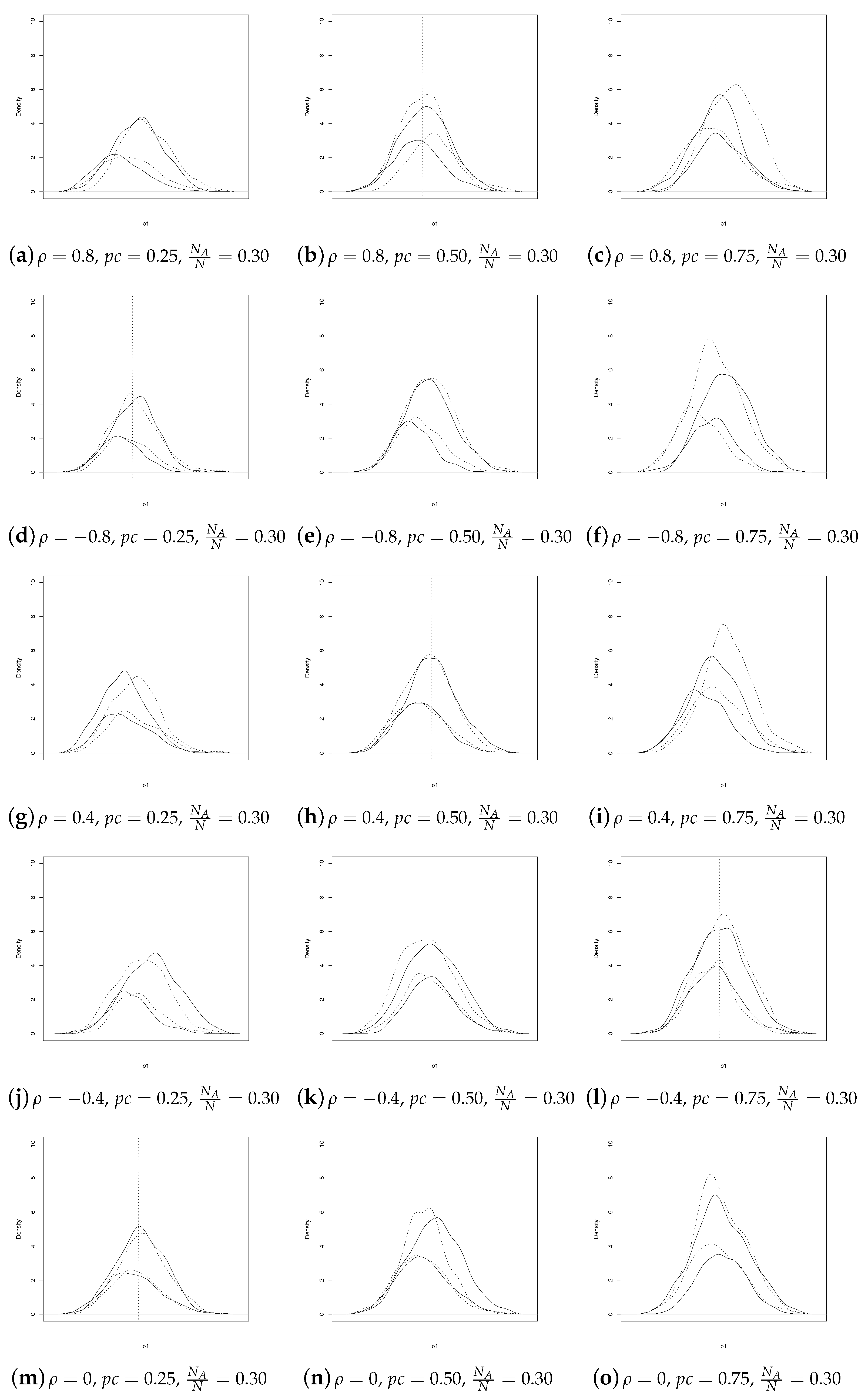
Analogous considerations apply for
(see
Figure 3 and
Figure 4). In summary,
Figure 1,
Figure 2,
Figure 3 and
Figure 4 show that the SSRS and GE estimators have comparable behavior, even though the former uses less information at population level. It should be underlined that a direct comparison between the two sets of coefficient estimates may not always be appropriate. In fact, as noted by
Mroz and Zayats (
2008), a better comparison would be based on the relative effect, that is on the coefficients ratio. For these reasons we computed the average ratios
and
in the simulations, for each
. The results, available upon request, are very close to the true ratios,
and
, for both GE and SSRS estimators and they show once again that GE slightly outperforms SSRS in the selection equation, while the reverse seems to happen for the outcome equation.
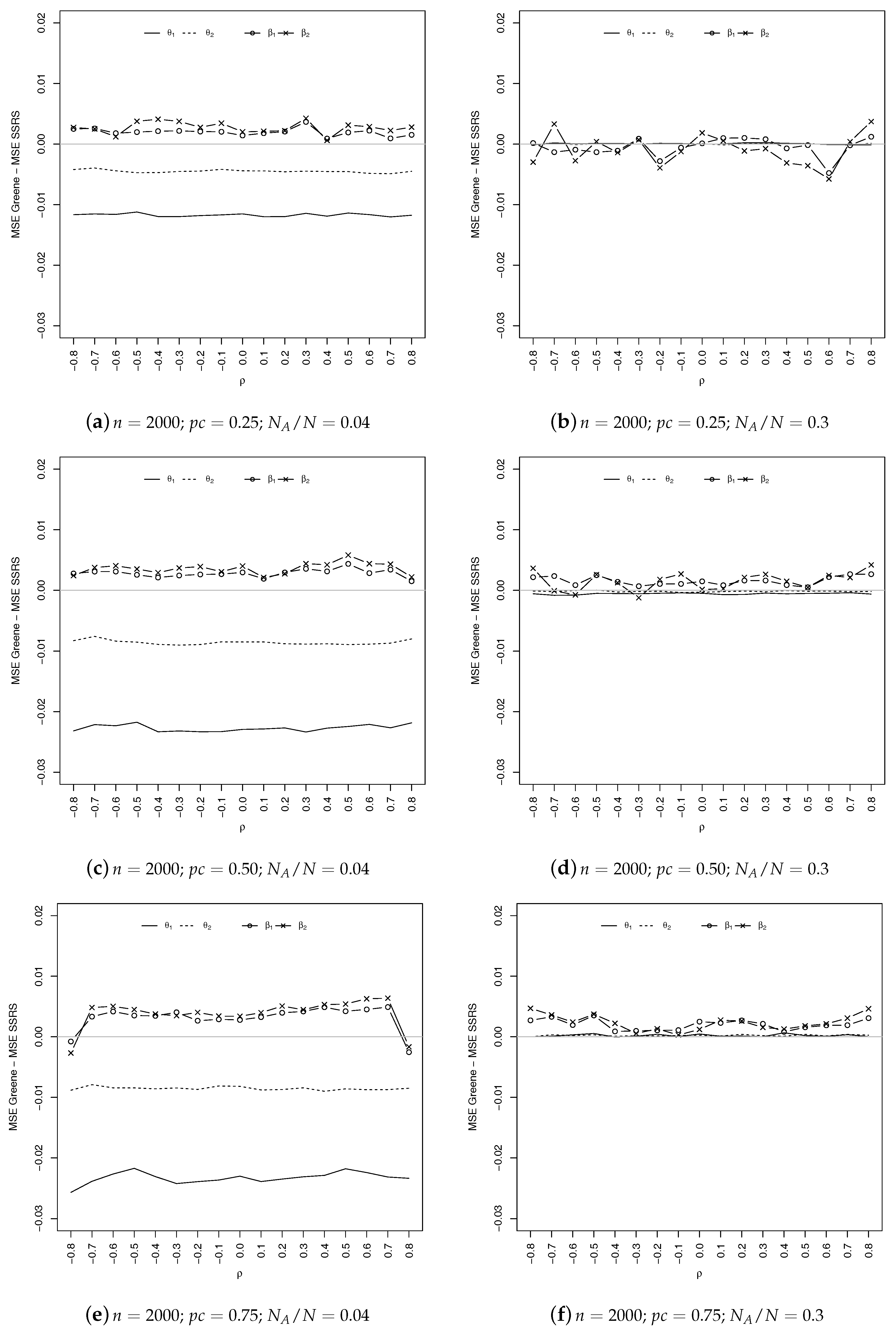
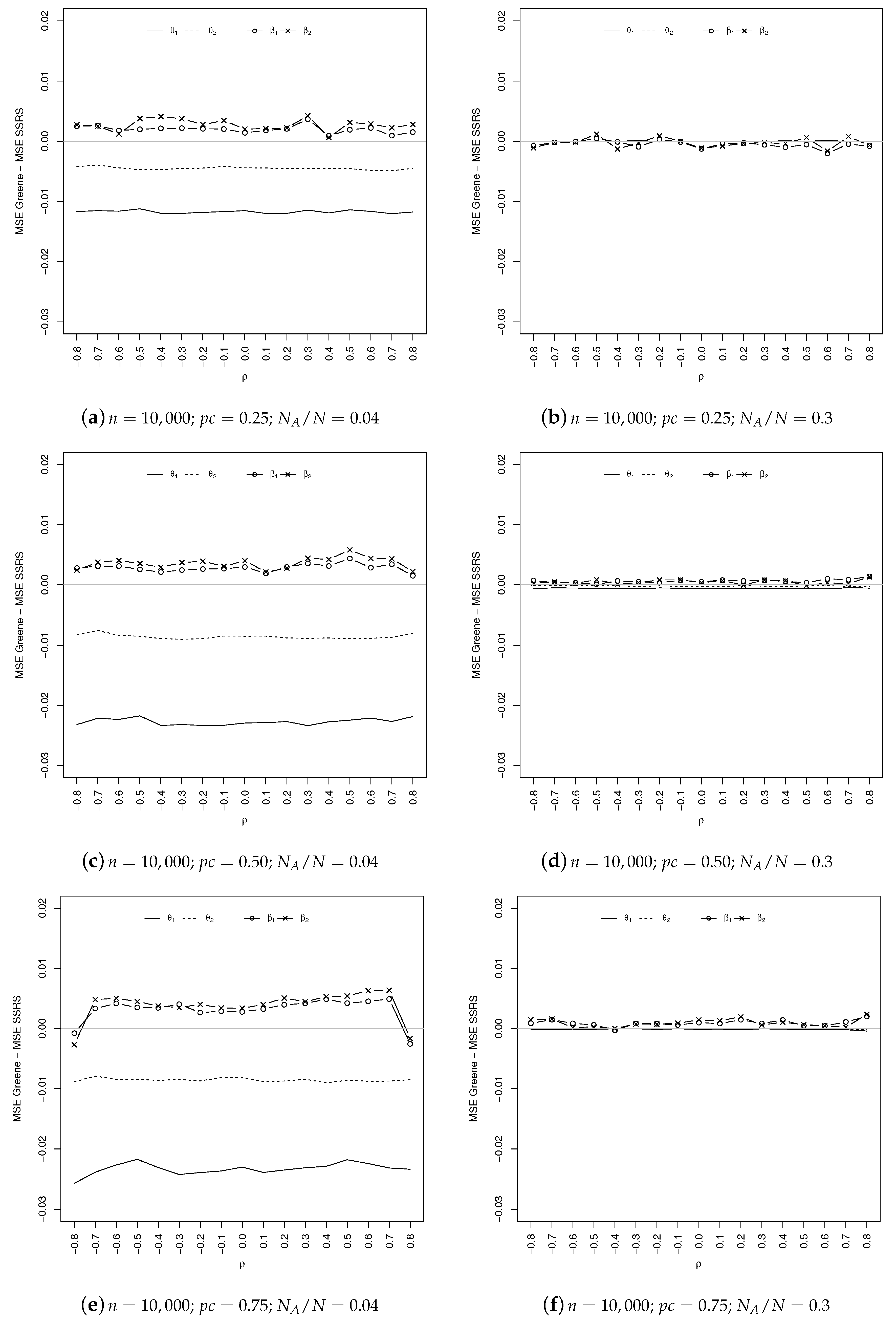
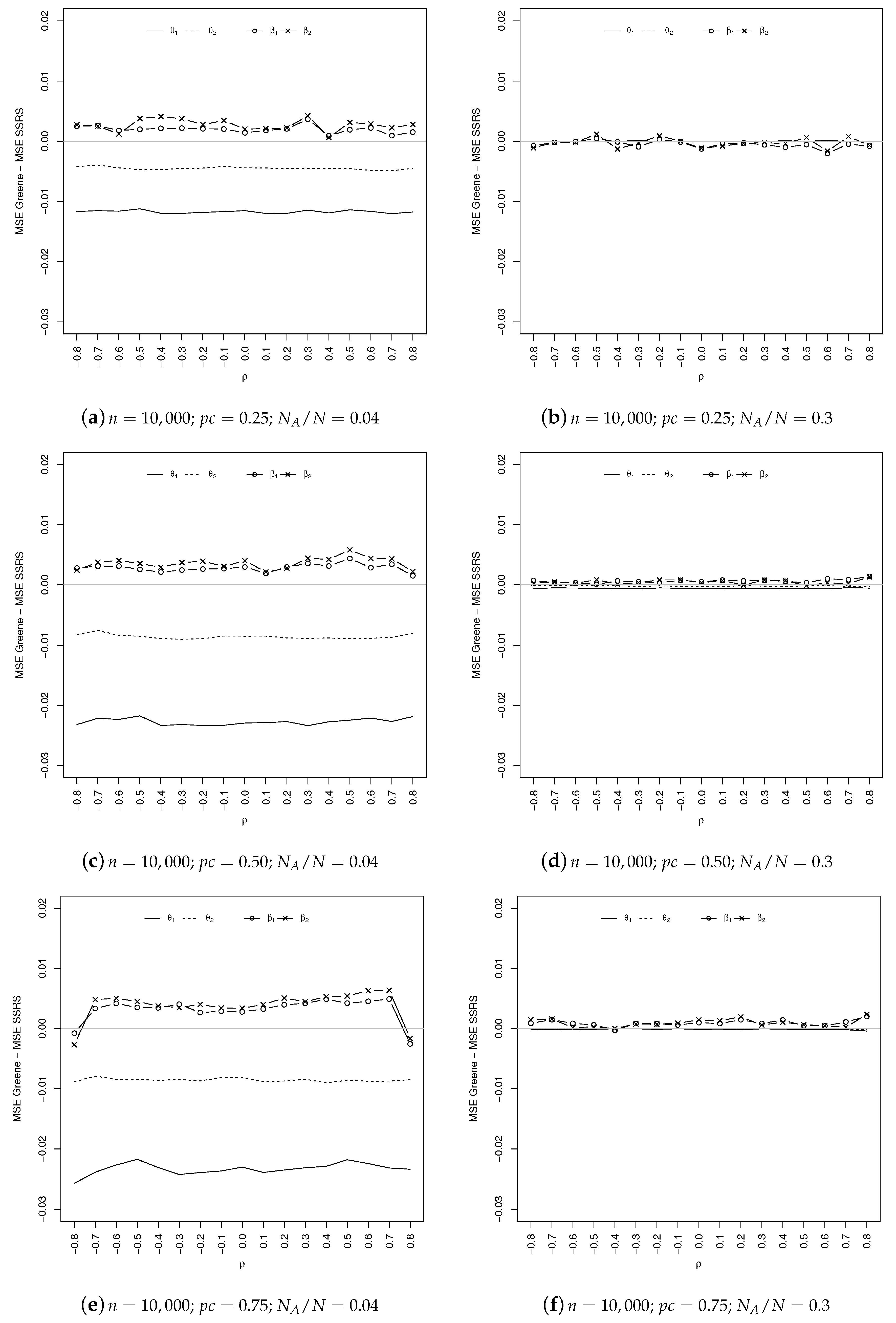
Coming to the comparison of the estimated MSEs, as shown in
Figure 5 and
Figure 6, the overall results obtained by the SSRS estimator are quite similar to Greene’s. Specifically, it seems that SSRS gives better results in estimating the parameters of the outcome equation (which are, generally speaking, those of greater interest), especially in the case of a severe censoring mechanism (
). The situation is reversed for the selection equation.
When , the two estimators are substantially equivalent for the selection equation, while SSRS continues to slightly outperform GE for the outcome (except for ).
As expected, when increases, the differences between the MSEs of the two estimators decrease in absolute value. Everything we said holds for both sample sizes.
Finally, in
Figure 7, we present the trend of the MSEs as the sample size increases, to have a first idea of the possible consistency of our estimator. Clearly, the property of consistency can only be proven analytically. The evaluation has been made only for the SSRS estimator, as it is proven that GE is consistent (
Greene 2008;
Manski and Lerman 1977). As usual, we consider the three sampling percentages and we compute the MSE for
,
,
and
. Once again, to save space, we present only the former, but all are available upon request.
As suggested by a referee, we made further simulations to study the behavior of the two estimators when the true generating model of the disturbances is not normal, while the likelihood function is based on the probabilities specified in Equations (
9)–(
11) (normal distribution). In particular, the generating model considered here is a bivariate skew-T; we then simulated 500 samples of size
and
,
,
and
. The behavior of the two estimators remains comparable in terms of bias and mean square error. In particular, comparing the mean square errors, GE outperforms SSRS in the estimation of the selection equation; the situation is often reversed for the outcome equation. Furthermore, to compare the robustness to distribution mispecification of the two estimators, we computed the ratio between the bias obtained when the true generating model is a skew-T and the bias obtained when the model is correctly specified: the closer to one the ratio (in absolute value), the more robust the estimator. It emerges that the SSRS estimator is more robust than GE, especially for the selection equation parameters. All results are available upon request.
4. Application on Real Data: Estimation of Credit Scoring
In the following, we consider the problem of estimating the risk of a loan default for credit-card holders. The population of interest is that of loan applicants, for whom some requests are approved and some are rejected according to their loan default risk.
The idea is to use the model to assign a default probability to a random individual who applies for a loan, but the only information that exists about default probabilities comes from previous loan recipients. The problem is that the probability of default for the overall population of applicants is not necessarily the same as for those who have already received a credit card (in fact, we expect that the probability for the whole population is greater than that of cardholders). To avoid this kind of selection bias, we need to consider the selection mechanism explicitly, that is a selection equation which explains the cardholder status.
The dataset considered here
2 contains a subset of the covariates used in
Greene (
2008). On
cardholders, the following characteristics are measured: cardholder status (CH), taking 1 if the application for a credit card was accepted and 0 if not; default status (D), taking 1 if defaulted and 0 if not (observed only when CH = 1, that is for 10,499 observations); age in years plus twelfths of a year (Age); number of dependents (Adepcnt); months living at current address (Acadmos); number of major derogatory reports (Mjrg); number of minor derogatory reports (Mndrg); owner or tenant (Ownrent), taking 1 if the applicant owns his/her home, 0 if renting; monthly income in US dollars divided by 100 (Income); self employment status (Selfempl), taking 1 if self employed, 0 if not; and ratio of monthly credit card expenditure to yearly income (ExpInc).
We used the following specification:
and we estimated the parameters by SSRS and GE estimators. The results, shown in
Table 1, are quite similar for the outcome equation (the one of greater interest because it gives the credit scoring), where the signs are coherent with expectations.
To evaluate the predictive performance of the two models, we computed the confusion matrices (see
Table 2), which allowed us to compute the percentages of correct predictions.
From these matrices, it is easy to obtain the percentages of correct predictions for both estimation procedures. In particular, the overall percentages are 0.724 and 0.317 for SSRS and GE, respectively, showing a strong dominance of the former estimation method over the latter. This dominance is even more evident in the percentages conditioned on the default status: for non defaulters, the percentage is 0.969 for SSRS and 0.160 for GE, while, for defaulters, it is 0.043 for SSRS and 0 for GE. On the other hand, GE outperforms SSRS in the prediction of non cardholder status: the values are 0.164 for SSRS and 0.933 for GE.
5. Conclusions
In this paper, we propose a method for estimating the regression coefficients in binary response models with sample selection, when a censoring mechanism intervenes to make a vast majority of units unobservable. We derive the likelihood function analytically, taking advantage of the response-based sampling framework and find that it is a weighted version of Heckman’s likelihood.
A simulation study highlights that the finite sample performance of the point estimators are very satisfactory even when compared to a similar estimator (
Greene 2008), which in turn assumes knowledge of the population proportion of occurrences in the outcome equation. Specifically, our estimator slightly outperforms Greene’s in estimating the parameters of the outcome equation (which are, generally speaking, those of greater interest), especially in the case of a severe censoring mechanism (
). Under this censoring scenario, the situation is reversed for the selection equation. When the censoring is less severe, the two estimators are substantially equivalent for the selection equation, while in general ours still outperforms Greene’s for the outcome.
An analogous result is obtained in an empirical analysis aimed to estimate the risk of loan default: our estimator performs better in the prediction of the dependent variable of the outcome equation (i.e., the default status), while Greene’s does better in the selection equation (i.e., the prediction of the cardholder status).
The fact that the best results refer to the outcome equation is an advantage, since it is generally the one of greater interest. The main result is that we do not require knowledge of the true prevalence of occurrences, that is, our estimator can be successfully used when are unknown.
Future research will be devoted to the problems arising from measurement errors, either in the dependent variable or in the covariates of the outcome equation. In the first case, the problem is obviously simpler and a modified version of the likelihood can take into account the bias arising from this kind of error. In the second case, an endogeneity issue arises and it is necessary to consider further information, for example, instrumental variables.



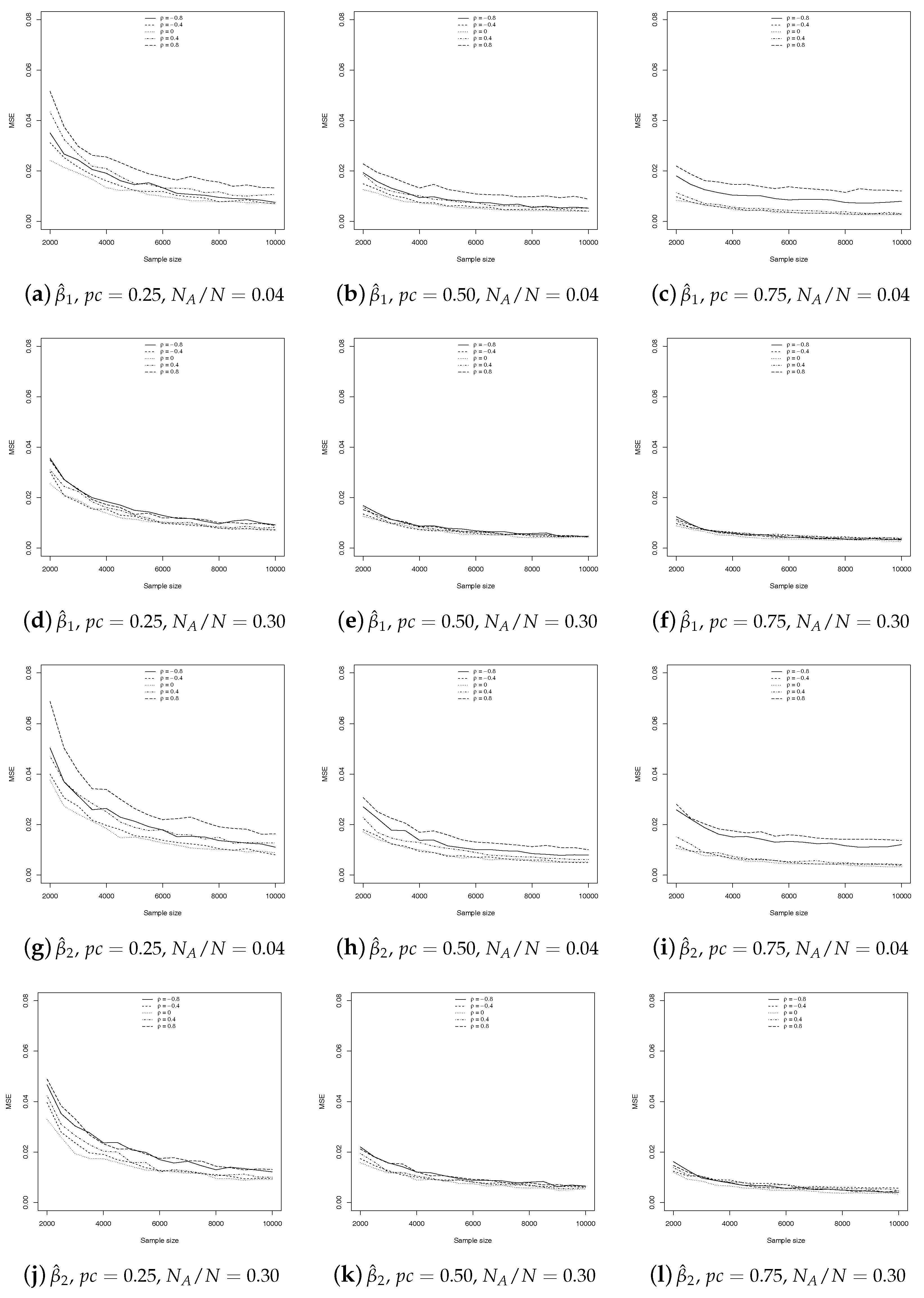

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
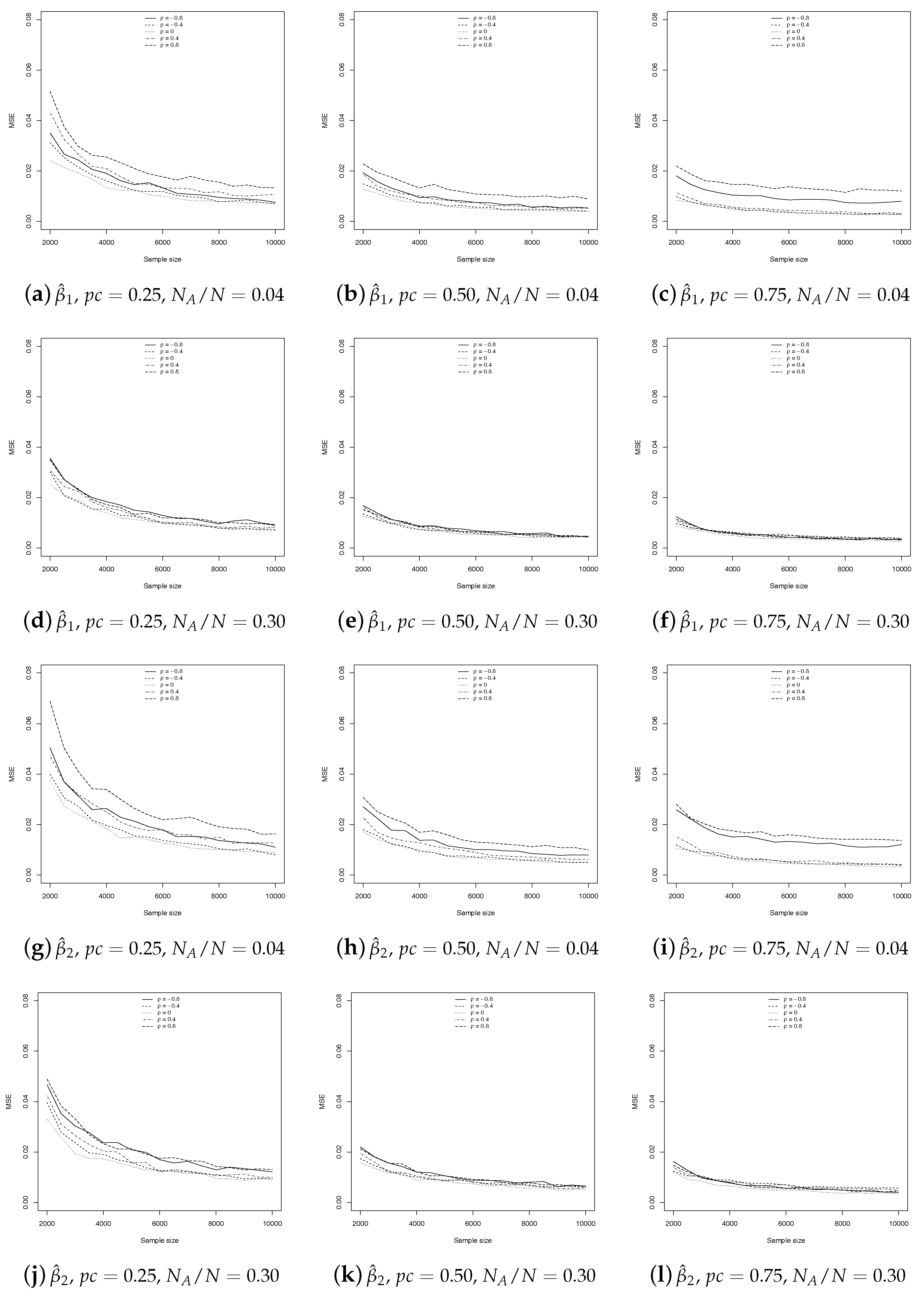{kind=link}