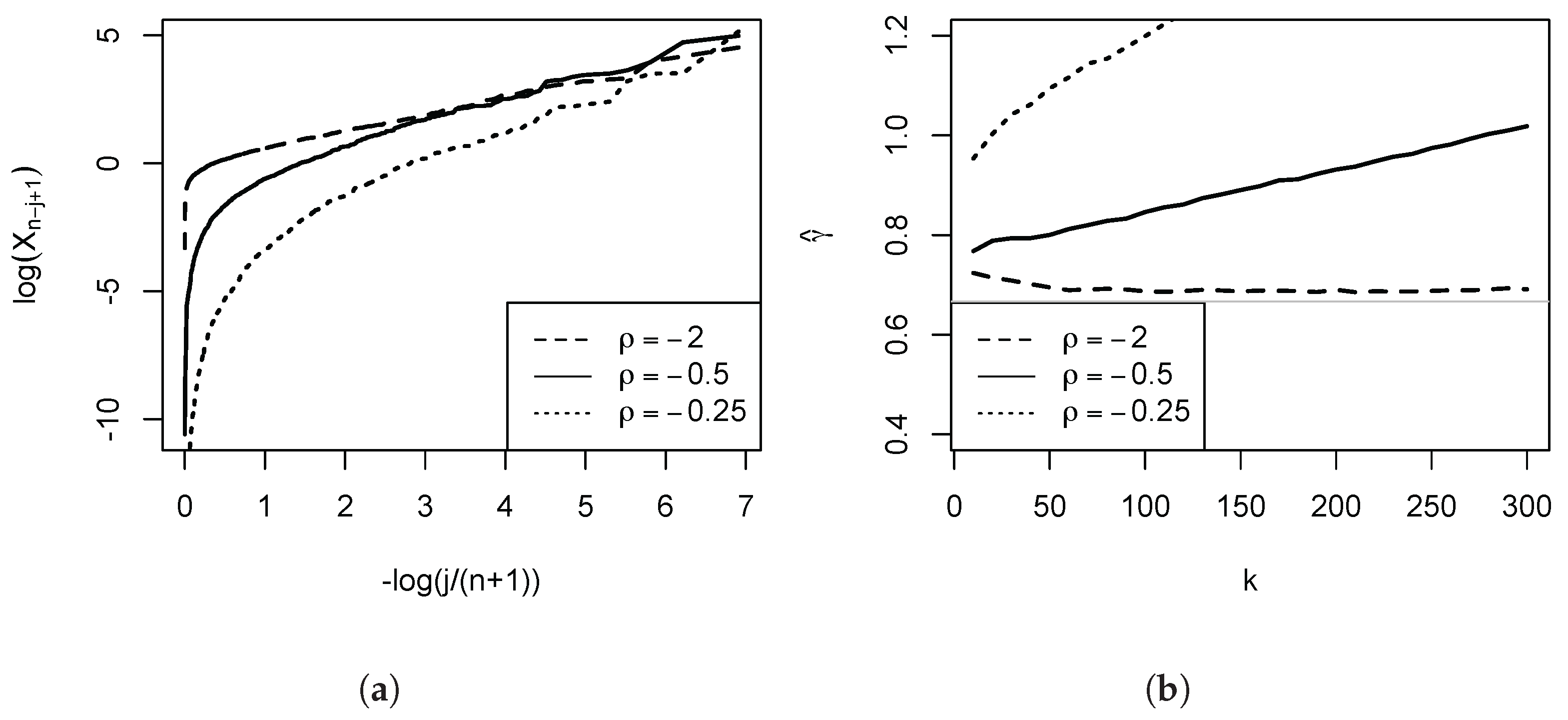1. Introduction
Income distributions exhibit, like many other size distributions in economics and the natural science, upper tails that decay like power functions (see e.g.,
Schluter and Trede 2017). The recent and rapidly growing literature on top incomes focuses on this upper tail, and its presence has important consequences for the measurement of inequality.
1 However, estimating the heaviness of the upper tail is challenging, since real world size distributions usually are Pareto-like (i.e., tails are regularly varying) rather than strictly Pareto.
To be precise, let
be a sequence of positive independent and identically distributed random variables (e.g., incomes) with distribution function
F that is regularly varying, so for large
x
where
l is slowly varying at infinity, i.e.,
as
. The parameter
, usually referred to as extreme value index (and
as the tail exponent), is unknown and needs to be estimated. Many estimators have been proposed in the statistical literature (see e.g., the textbook treatments in (
Embrechts et al. 1997 or
Beirlant et al. 2004).
An estimator popular among economists is based on a simple ordinary least squares (OLS) regression of log sizes on log ranks (e.g.,
Jenkins 2017 and
Atkinson 2017, and references therein, in the income distribution and top incomes literature, this regression is ubiquitous in the city size literature). The enduring popularity of the OLS estimator is partly due to its simplicity, and partly due to a powerful intuition based on a Pareto quantile-quantile (QQ)-plot, the regression estimating its slope coefficient. However, if the tail of the distribution varies regularly, the Pareto QQ-plot will become linear only
eventually. In particular, (
1) can be expressed equivalently, using the tail quantile function
where
, as
where
is a slowly varying function. Hence, as
,
since then
. Replacing these population quantities with their empirical counterparts gives the Pareto QQ-plot, and
is its ultimate slope. This qualification (usually ignored by practitioners in economics) has important consequences for the behaviour of the estimator: Since the OLS estimator estimates the slope parameter of this QQ-plot, deviations from the strict Pareto model -captured by the nuisance function
l- will induce distortions.
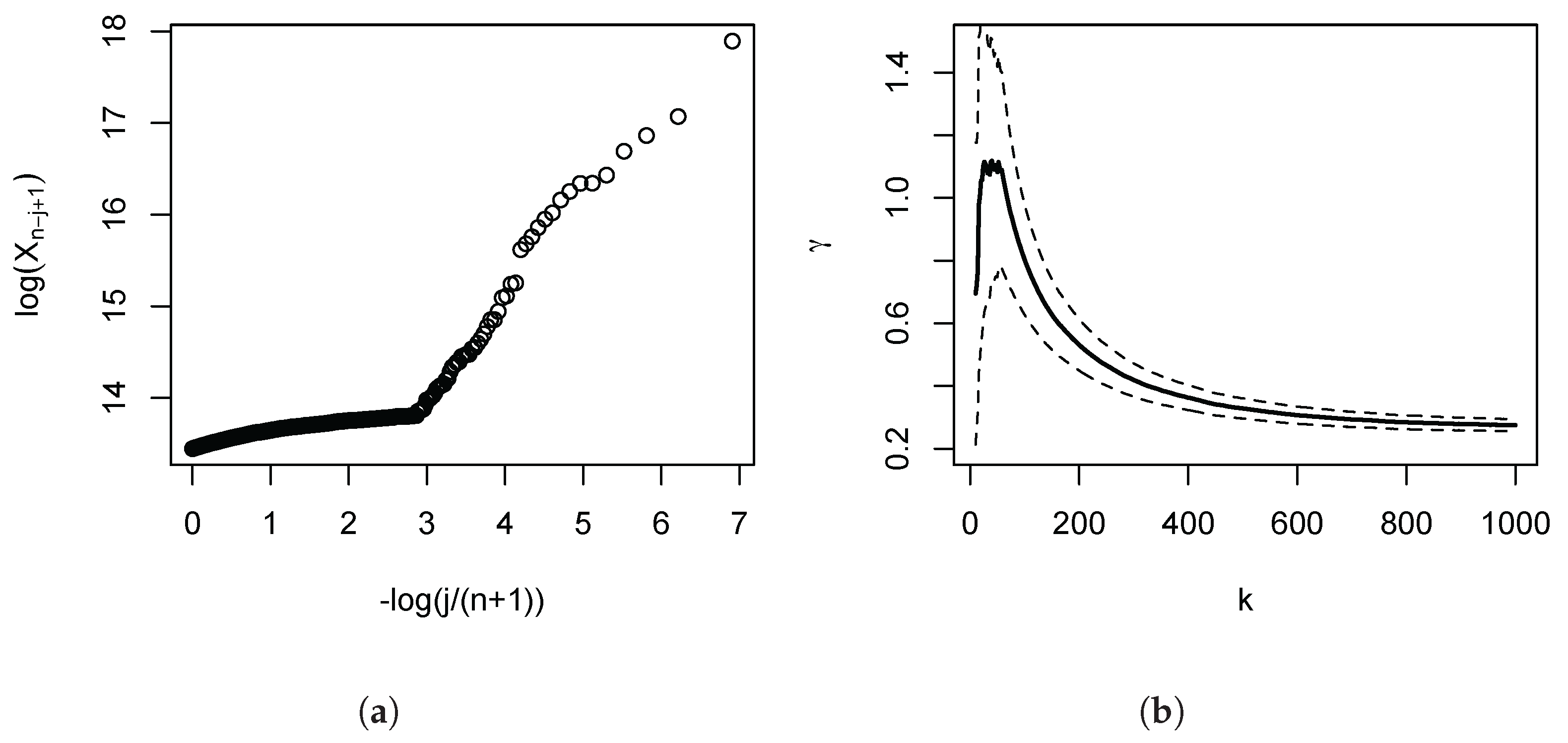
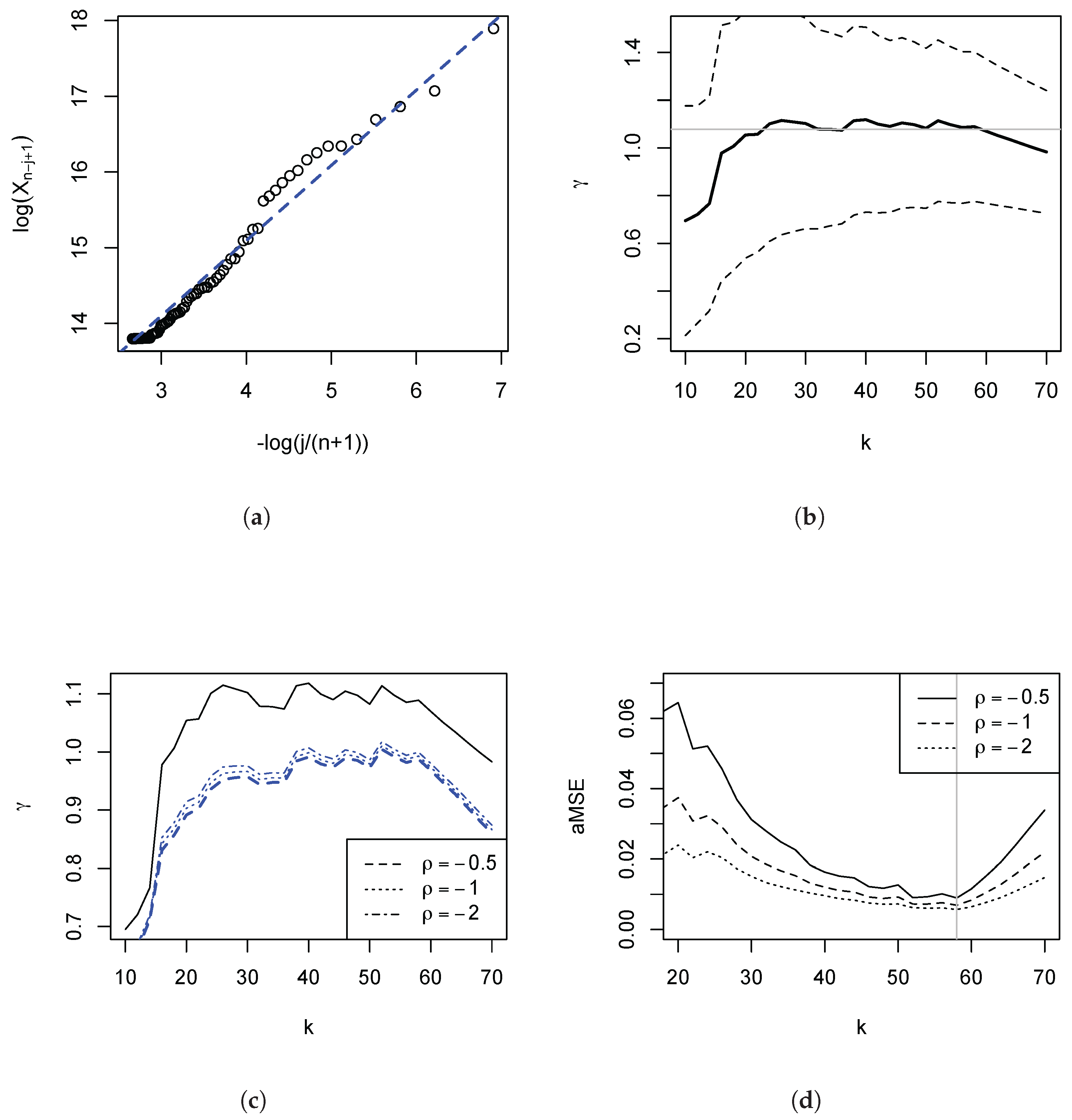
The empirical importance of this is illustrated in
Figure 1, which depicts the Pareto QQ-plot for our administrative income data for the UK (the subject of our empirical application developed in
Section 4 below), using the 1000 largest incomes. The plot exhibits a pronounced kink, and approximate linearity of the QQ-plot only holds for the very highest upper order statistics. Panel (b) shows the consequences for the OLS estimates: As we move in the QQ-plot from the right to the left, the departures from linearity become progressively more severe, and the OLS estimates progressively fall. Based on this first diagnostic QQ-plot, once the lower upper order statistics have been discarded as a source of downward bias, the subsequent analysis can then more clearly focus on the approximate linear part, the remaining distortions, and the choice of the number of order statistics.
Figure 2 provides a further illustration for three Burr (Singh-Maddala) distributions (examined in detail in
Section 3 below, being the leading parametric income distribution model) possessing the same
. Here, the speed of decay of the nuisance function
l is parametrised by the absolute value of the parameter
. The smaller the magnitude of
, the greater the initial curvature and steepness of the Pareto QQ-plot, and the larger the induced positive distortions of the OLS estimator of the slope coefficient.
In this paper, we examine the asymptotic distortions of the OLS estimator that arise in these circumstances, caused by the slow decay of the nuisance function
l and modeled here as higher order regular variation. The theory is presented in
Section 2 (proofs are collected in
Appendix A), and numerical illustrations and quantifications of the distortions are provided in
Section 3, as well as of the stark consequence for inference. More specifically, we show formally that the OLS estimator over-estimates the true value in the leading heavy-tailed model (i.e., the Hall class, which includes the Burr (Singh-Maddala) distribution, as well as the student, Fréchet, and Cauchy distributions). An empirical illustration in the context of top incomes in the UK using data on tax returns is the subject of
Section 4.
1.1. The Log-Log Rank-Size Regression
We briefly review the rank size regression. Let
denote the order statistics of
, and consider the
k upper order statistics. Let ranks be shifted by a constant
. The regression of sizes on ranks leads to the minimisation of the least squares criterion
with respect to
g, where
and
. The classic case is
. However, since the OLS estimator of the slope coefficient is not invariant to shifts in the data, it is conceivable that a purposefully chosen shift could yield an asymptotic refinement (
Gabaix and Ibragimov 2011 consider this in the strict Pareto model
). The analysis below allows for this possibility.
The justification of considering regression (
2) is based on a Pareto QQ-plot (
Beirlant et al. 1996): For a sufficiently high threshold
where
, the Pareto quantile plot in model (
1) with coordinates
becomes ultimately linear. The line through point
with slope
g is thus given by
and the data points are
. The regression estimator estimates this slope parameter. In particular, the OLS estimator of the slope coefficient
g is
Note that the denominator
is a Riemann approximation to
. An asymptotic expansion of the denominator reveals that
From
Kratz and Resnick (
1996, proof of their Equation 2.4, p. 704) we know that the numerator
converges in probability to
, hence the estimator is weakly consistent:
as
and
. We proceed in the next Section to refine this result by obtaining higher order expansions of the estimator in (
3).
The literature contains several variants of regression (
2). Rather regressing log sizes on log ranks, one could regress log ranks on log sizes, thus obtaining the ‘dual’ regression. In view of (
3), our asymptotic analysis of the numerator carries immediately over to this dual regression. Another variant of (
2) includes the additional estimation of a regression constant:
is regressed on a constant and
.
Kratz and Resnick (
1996) obtain the distributional theory for this alternative estimator and show that its asymptotic variance is
, which exceeds, as will be shown below, the asymptotic variance of
given by (
3). Hence this regression variant is less efficient.
Schultze and Steinebach (
1996) also prove weak consistency of the estimator in this setting.
3. Numerical Illustrations
We illustrate numerically several of our results in a Monte Carlo study. First, we verify the distributional theory, then show that most of the empirical distortion is captured by the bias function . At the same time, we show that the distortions can be sizeable, leading to substantial test size distortions, while a bias correction using would reconcile nominal and actual test sizes.
Our Monte Carlo study is based on the Burr distribution, a member of the Hall class, parametrised here as
with parameters
and
. In the income distribution and inequality literature, this distribution is also know as the Singh-Maddala distribution, and used frequently in parametric income models. Specifically, we set
, and
to begin with. Qualitatively similar results are obtained for the student, Fréchet, and Cauchy distributions, all of which are members of the Hall class, and therefore not reported here. Since
we consider a situation of fairly heavy tails (as second moments of the distribution do not exist). However, the qualitative insights depend little on the actual choice of
. We have chosen
as our leading example since we are interested in the consequences of deviating from a strict Pareto model. As
falls in magnitude the nuisance part of
l in (
1) decays more slowly. This is illustrated in
Figure 2, where we depict three Pareto QQ-plots for different
. For
, the plot is almost linear throughout. The deviations from the strict Pareto model become increasingly more pronounced in the left part of the plot as
falls in magnitude.
For the simulation study, we draw
samples of size
at first (then
), and consider the upper
k order statistics. In order to choose a particular
k, we follow standard practice and minimise the theoretical asymptotic Mean Squared Error (AMSE) (e.g.,
Hall 1982, or
Beirlant et al. 1996), given by
, trading off distortion and dispersion. The theoretical higher order bias in
induced by higher order regular variation in this Burr case is
which is, of course, increasing in
k. The theoretical AMSE is minimised around
, which also corresponds to the minimiser of the empirical AMSE based on the
R samples. The mean of
at this
is 0.739, and exceeds, as predicted by the theory, the population value
.
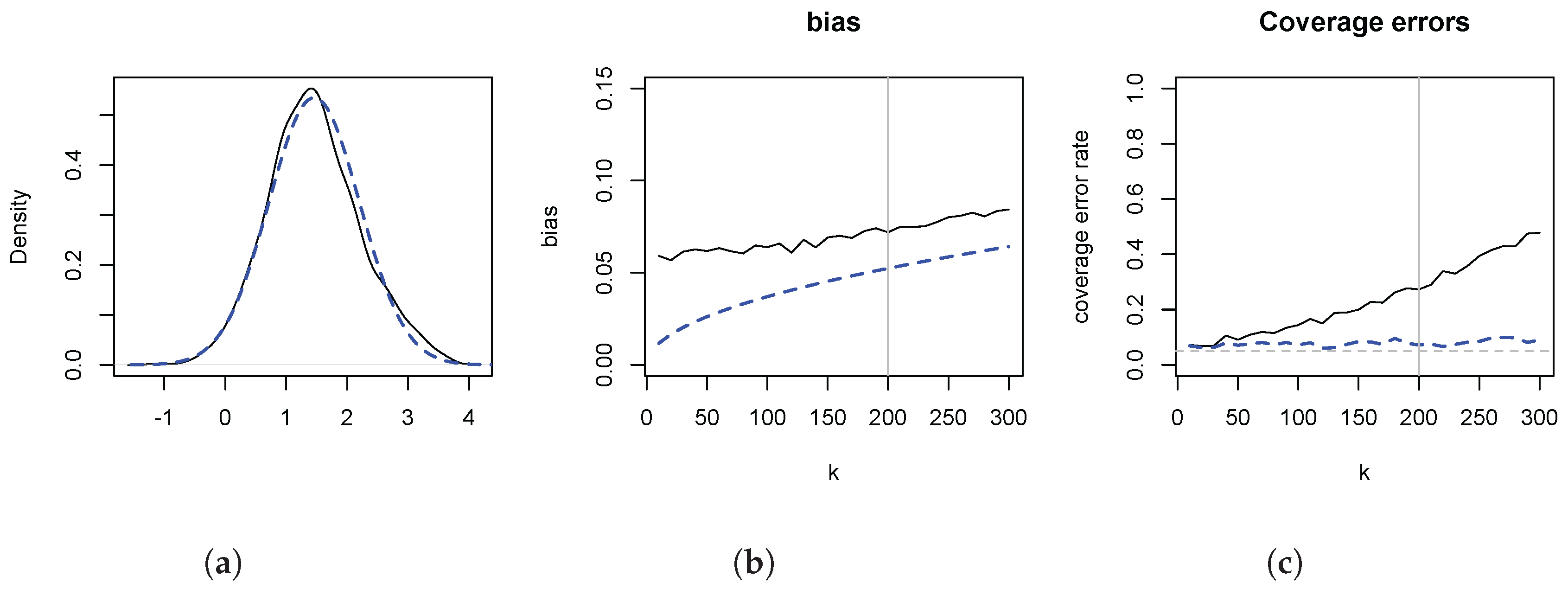
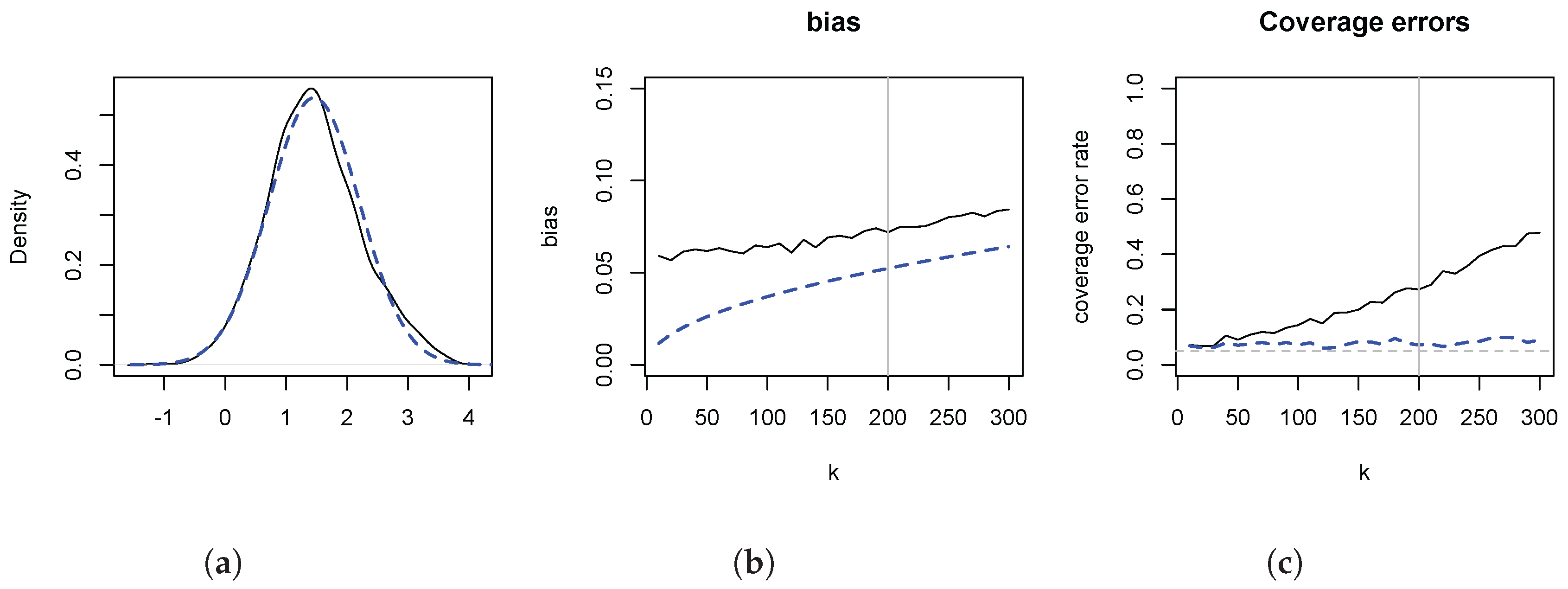
Figure 3 depicts the results. In panel (a) we illustrate the distributional theory, given by (
8), for
, by plotting a kernel density estimate of
(solid line), as well as a normal density with variance
, centered on the empirical mean of the simulated data. The two are in close agreement. The figure also implies that any inferential problems are due to location shifts. In panel (b) we contrast the empirical distortions (solid line) with
(dashed line).
overestimates
, and the distortion increases in
k. It is evident that most of the distortion is captured by
. In panel (c) we illustrate the consequences of the distortions for statistical inference, by plotting the empirical coverage error rates of the usual 95% symmetric confidence intervals. The higher order distortions lead to undermining inference because of the considerable size distortions. For instance, at
, the empirical coverage error rate is 30% for a nominal 5% rate. Shifting the estimate by
reduces the coverage error rate to 7%.
Next, we consider the role of the sample size n. Reducing the sample sizes in the Monte Carlo to yields results that are in line with the above theory, and therefore not depicted. The bias of increases by a factor predicted by the theory, namely . The optimal shrinks by a factor of 4, as now . The density of is in good agreement with the theory, and empirical coverage error rates at this are 32% for the uncorrected and 11% for the corrected estimator. The empirical coverage error rate for the uncorrected estimator rises steeply after , reaching 64% at . Reducing the sample sizes further to 100 results in , and an empirical coverage error rate for the uncorrected estimator of 46% at this . Biases are increased by a factor .
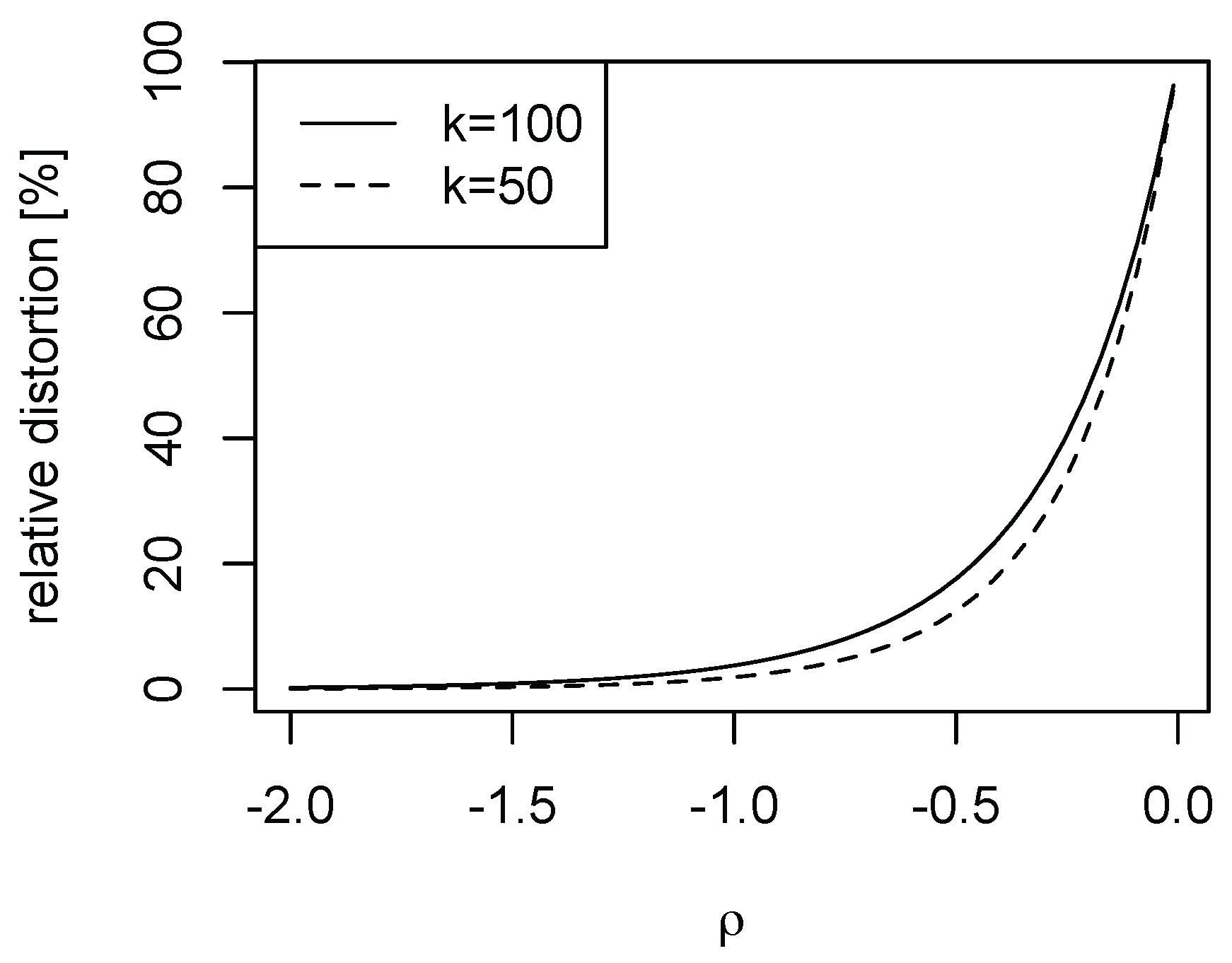
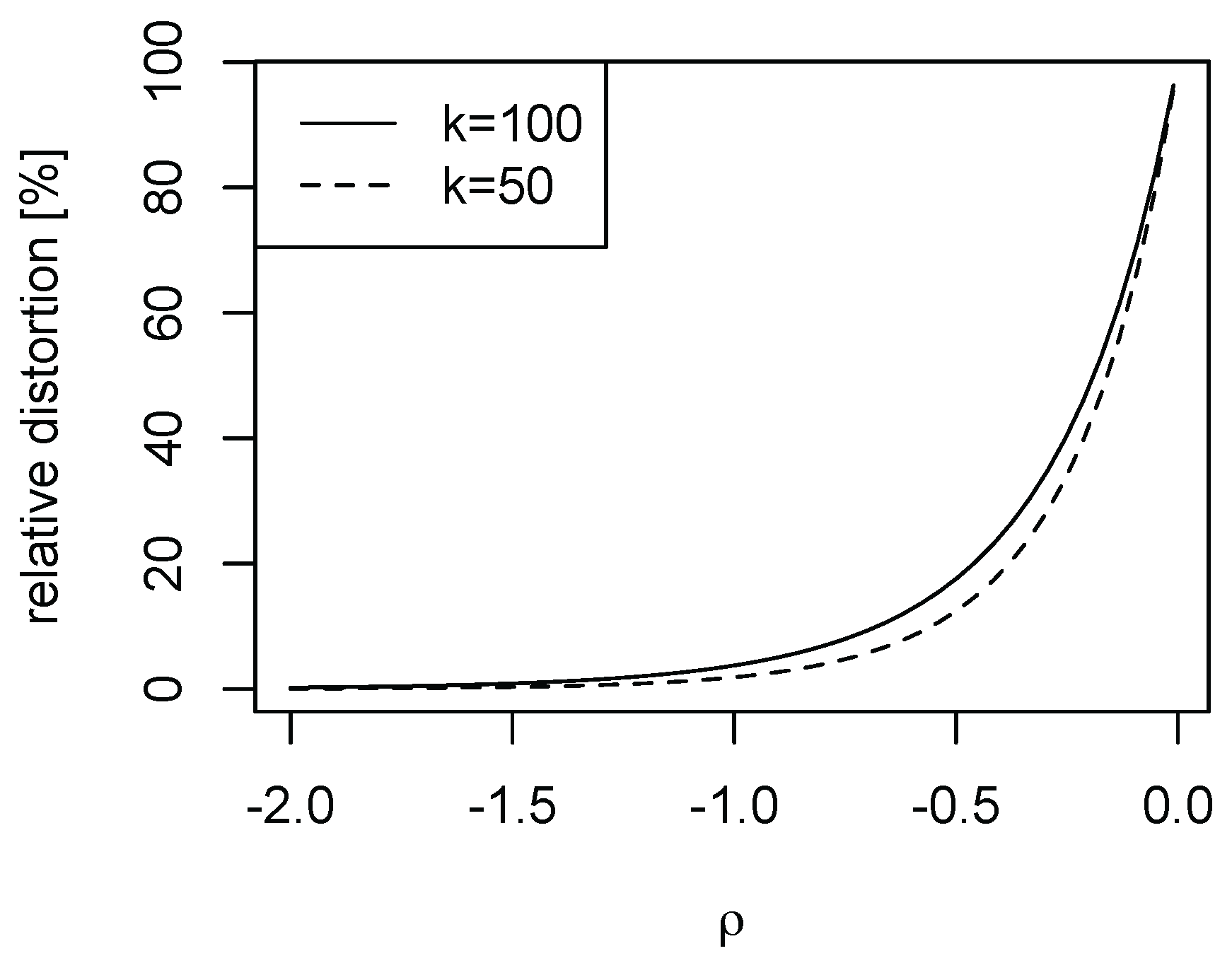
Finally, we illustrate the importance of the speed of decay in the nuisance function
l of model (
1). As
falls in magnitude, the nuisance function
l decays more slowly. For the Burr case with
, we depict in
Figure 4 as
falls in magnitude for
and selected
k. While for
the distortions are negligible (in line with
Figure 2, it is evident that for small magnitudes of
the higher order distortions cannot be ignored).
As the purpose of our simulation study is the provision of numerical evidence for our theory, we have used the theoretical bias function
in the Burr case. When no such external knowledge is available, estimating the bias function requires non-parametric estimates of the second order parameter
and the function
. However, existing methods perform poorly, yielding excessively volatile estimates. The theory then informs a sensitivity analysis which is described in
Section 4.1 in the context of our empirical application.
4. Empirical Illustration: Top incomes in the UK
Our empirical application uses administrative income tax return data are from the public-release files of the Survey of Personal Incomes (SPI) for the year 2009/10 (see e.g.,
Jenkins 2017 for a detailed description, and an analysis that includes rank size regressions). The SPI data underlie the UK top income share estimates in the World Top Incomes Database (WTID), and is a stratified sample of the universe of tax returns. The unit of taxation is the individual, and we use total taxable income as the income variable. The file contains 674,715 individuals, and we consider the
n largest incomes.
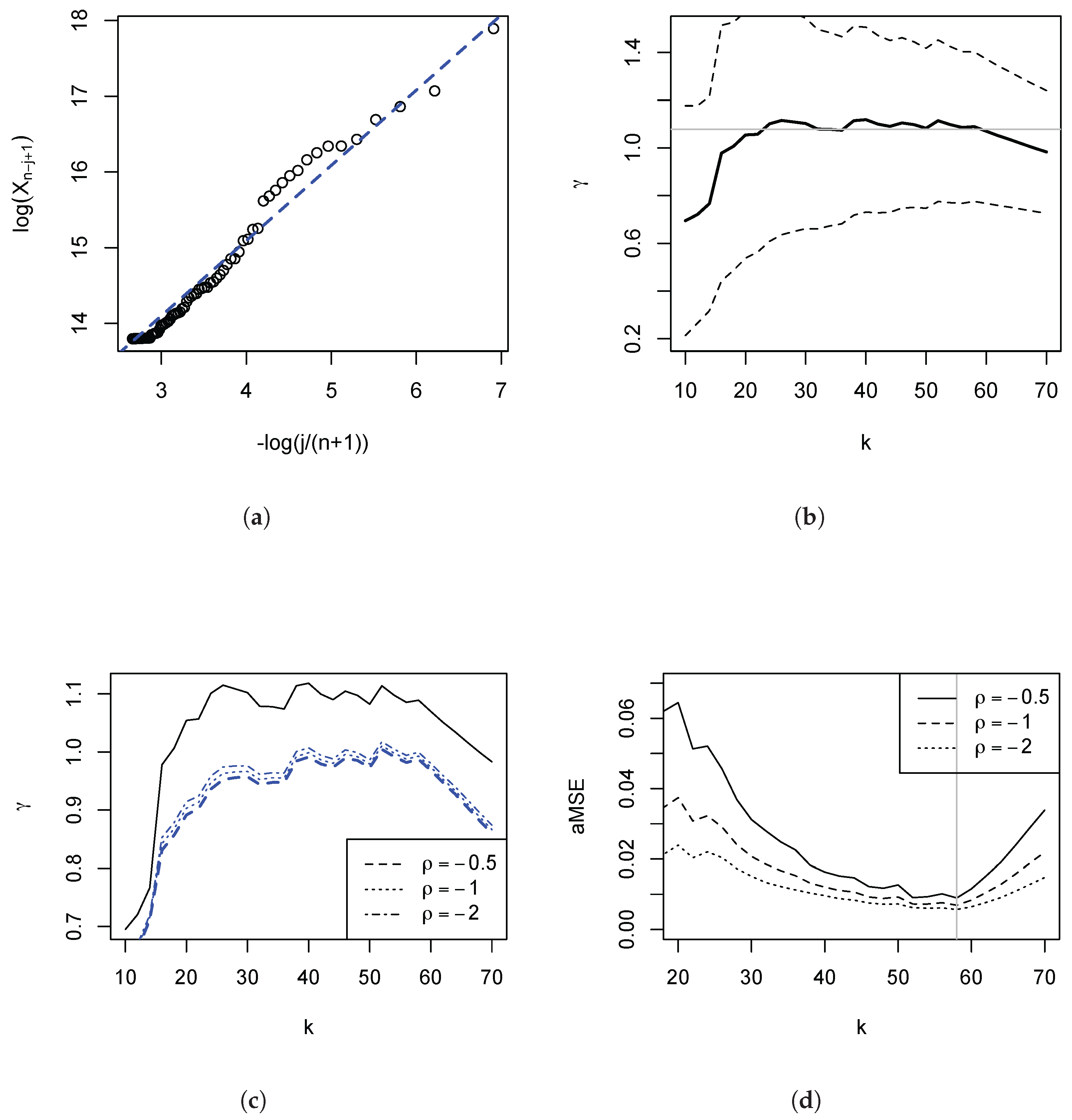
In
Figure 1 panel (a), we have depicted the Pareto QQ-plot for the 1000 largest incomes. It is evident that the data clearly reject a strict Pareto model: The plot exhibits a pronounced kink, and approximate linearity of the QQ plot only holds for the very highest upper order statistics. The function
l in (
1) captures this significant departure from the strict Pareto model. The Pareto QQ-plot thus conveys crucial information that is usually ignored by practitioners in economics, making it a key diagnostic device. For instance, a common mechanical approach is to set
k by choosing ‘blindly’ (i.e., without reference to the Pareto QQ-plot) e.g., the top 1% or the top 1000 observations. Since the approximate linearity only obtains for about the 70 largest observations, the estimate of the slope parameter of the Pareto QQ-plot, i.e., the OLS estimator (
3), will be severely biased if
k is set to 1000 or higher. This is illustrated in panel (b) of the figure: The estimates fall for higher values of
k, since the estimation procedure then attributes increasing weights to the left of the kink in the Pareto QQ-plot.
In the light of these observations, we restrict our subsequent analysis to the range of
k in which the Pareto QQ-plot is approximately linear. We confirm this in
Figure 5 panel (a), having restricted the plot to the
highest incomes. The plot now appears fairly linear. In panel (b), we depict the regression estimates
and the 95% symmetric pointwise confidence intervals. One first visual way of choosing an estimate is to consider an area of the plot where the estimate is fairly stable (as is done by inspecting Hill or so-called alternative Hill plots) and picking the largest such
k since the variance of the estimate falls in
k. Such subjective choice would be around
with an estimate of
(indicated by the horizontal faint line in the figure).
4 Overall, the visual method would suggest an estimate of
between 0.9 and 1, implying very heavy tails. Taking into consideration the variability of the estimate, one cannot reject the hypothesis that the tail index be unity, i.e., Zipf’s law. Returning to panel (a) we have also plotted the line with slope 1. This line does well in describing the data. We turn to a method that permits an objective choice of a particular
k, and examine the remaining distortions in the estimate of
.
4.1. Sensitivity Analysis, and the Choice of k
The preceding analysis has shown that is likely to suffer from positive higher order distortions, captured by . Estimating this bias function requires non-parametric estimates of the second order parameter and the function , but existing methods perform poorly, yielding excessively volatile estimates. Hence we limit ourselves to a sensitivity analysis, taking as a sensitivity parameter, whose objective is to gauge plausible values of the potential distortions based on diagnostics of the rank size regression. This approach is sketched next.
Following
Beirlant et al. (
1996), we observe that the mean weighted theoretical squared deviation
equals, to first order,
for some coefficients
depending only on
k, and
depending on
k and
(these are stated explicitly in the
Appendix A). Set
. An estimate of the mean theoretical deviation is the mean of the squared residuals
of the rank size regression. In view of the usual bias-variance trade-off for our estimator
for fixed
n, we ascribe all the measured deviation
to the bias, thereby defining a very conservative bound, and let
This conservative sensitivity analysis then consists of examining for a range of values of .
Figure 5 panel (c) reports the results of such a sensitivity analysis for
k being restricted to the
highest incomes. Since under this restriction the Pareto QQ-plot is approximately linear, we expect that the remaining distortions are fairly modest. This is borne out in the sensitivity plot, as the precise value of
now plays only a minor role.
Should a researcher wish to choose a particular
k by minimising an approximation to the AMSE, Equation (
10) is the basis of the procedure proposed in
Beirlant et al. (
1996): Apply two weighting schemes
(
), estimate the corresponding two mean weighted theoretical deviations using the residuals, and compute a linear combination thereof such that
obtains. We have carried out this programme (see
Appendix A for further details) for weights
and
for given
, and
Figure 5 panel (d) depicts the results. Minimising this approximation to the AMSE yields
, which, for
, resulted in
across the selected
, for which
obtains. In view of the results depicted in panel (c) it is not surprising that changing
has only a small effect. This estimate of
is very close to the subjective visual choice of
of 1.075, reported above, based on
Figure 5b.
5. Conclusions
The OLS estimator of the slope coefficient in the rank size regression (shifted or unshifted) can suffer significant higher order distortions that arise from the slow decay of the nuisance function
l in the model
for
. Modeling the tail as second order regular variation, we have shown that the estimator over-estimates the true value in models in which
l converges to a constant at a polynomial rate (i.e., in the leading heavy-tailed distributions). Our numerical illustrations have shown that these distortions can be dramatic, leading to test size distortions in which actual error rates are multiples of nominal error rates. The empirical illustration based on the Pareto QQ-plot has revealed a further distortion, namely the presence of a pronounced kink.
Figure 1 has revealed that using the common rule to choose 1% of the observation for tail estimation would lead to a severe under-estimation of how heavy the tail is.
The higher order distortions are functions of
and the second order regular variation parameter
. Since existing methods usually result in poor estimates of these, reliable bias corrections are not feasible. In view of this we have proposed a sensitivity analysis based on diagnostics from the rank size regression. When applied to our data on top incomes, we still cannot reject the hypothesis
be unity, a situation often described in several fields as Zipf’s law (e.g.,
Schluter and Trede 2017).
The simplicity of the regression estimator is undoubtedly the principal reason for its popularity among practitioners in economics. This paper has shown that in many situations the naive (i.e., ‘blind’) use of this estimator should be considered with care: Pareto QQ-plot, the sensitivity plot and the AMSE plot convey jointly important information about the behaviour of the estimator.

{kind=link}
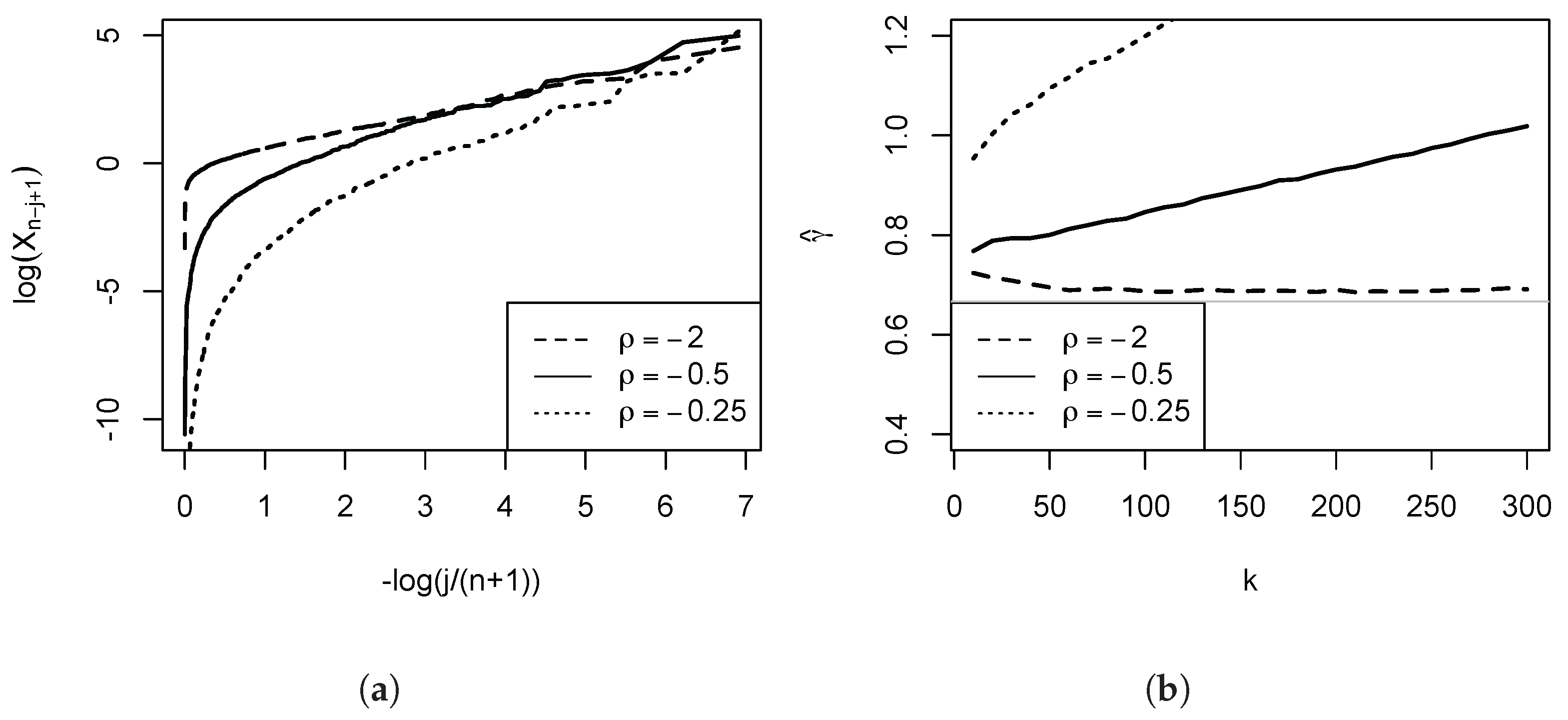{kind=link}
{kind=link}
{kind=link}
{kind=link}