1. Introduction
Spatial dependence represents a situation where values observed at one location or region depend on the values of neighboring observations at nearby locations. One may ask two questions: first, does this dependence stay the same over time; and second, what might cause the dependence to change? This paper answers the first question by proposing a likelihood ratio test of the null hypothesis of no change against the alternative hypothesis of a one-time change. In case there is evidence against the null hypothesis, the paper consequently proposes a break-date estimator. The second question has been reflected upon through an empirical application of budget spillovers in the U.S. states.
In the setup of spatial panel models with N individual units (geographic locations, such as countries and zip codes, or network units, like firms and individuals) observed over T number of periods, where the outcome of each unit depends on its “neighbor’s” outcome, there exists a problem of endogeneity. Hence, such models are estimated using maximum likelihood or the generalized method of moments. Similar to the univariate time series case, in this paper a sup LR test is proposed, and the asymptotics are derived for large T cases.
In comparison to the vast literature on the change point for univariate series, the corresponding literature for panel data is quite small. One of the most popular and early tests in the univariate literature is the popular
F test of Chow (1960) [
1], which has been modified for cases of unknown and multiple break dates in Andrews (1993) [
2], Andrews and Ploberger (1994) [
3], and Bai and Perron (1998) [
4], among others. Bai (1997) [
5], Bai et al. (1998) [
6], and Qu and Perron (2007) [
7] have extended the single equation break models to multiple ones. They show that using multiple system improves the estimation precision of the break dates and the power of the tests. Perron (2006) [
8] provides a survey of the literature.
In the panel data literature, Bai (2010) [
9] establishes the consistency of the estimated common break point, achievable even if there is a single observation in a regime. The paper proposes a new framework for developing the limiting distribution for the estimated break point and lays down steps to construct confidence intervals. The least squares method is used for estimating breaks in means. Feng et al. (2009) [
10] study a multiple regression model in a panel setting where a break occurs at an unknown common date. They establish the consistency and rate of convergence both for a fixed time horizon and large panels. In Feng et al. (2009) [
10], the limiting distribution is derived without the assumption of shrinking magnitude of break. Liao (2008) [
11] uses the Bayesian method for estimation and inference about structural breaks in a panel.
Han and Park (1989) [
12] develop a multivariate CUSUM test in order to test for a structural break in panel data, and they apply the test to U.S. manufacturing goods trade data. Kao (2000) [
13] proposes two classes of test statistics for detecting a break at an unknown date in panel data models with the time trend. The first is a fluctuation test, while the second is based on the mean and exponential Wald statistics of Andrews and Ploberger (1994) [
3] and the maximum Wald statistic of Andrews (1993) [
2]. De Wachter and Tzavalis (2012) [
14] develop a break detecting testing procedure for the AR(p) linear panel data with exogenous or pre-determined regressors. The method accommodates structural break in the slope parameters, as well as fixed effects, and no assumption is imposed on the homogeneity of cross-sectional fixed effects. Pauwels et al. (2012) [
15] provide a structural break test for heterogeneous panel data models, where the break affects some, but not all cross-section units in the panel. The test is robust to auto-correlated errors. The test statistic is based on comparing pre- and post-break sample statistics as in Chow (1960) [
1].
A higher availability of geocoded socio-economic datasets has led to a vast expansion of the study of spatial interaction between economics agents. Moreover, the recursive relationship between agents in a network can be modeled using spatial econometric methods. Spatial dependence represents the transmission of developments across “neighboring” agents. Elhorst (2010) [
16] provides detailed methodologies for estimating spatial panels and to compare competing models. The above tests in the panel literature do not explicitly consider the endogeneity problem in the model, which arises from the spatial dependence. We consider a spatial autoregressive model and provide a test for a break in the spatial lag parameter. To test for a change in the spatial dependence parameter, we propose a
sup LR test similar to Bai (1999) [
17]. Yu et al. (2008) [
18] and Lee and Yu (2010) [
19] provide the asymptotic properties of quasi-maximum likelihood estimators for spatial autoregressive panel data models with fixed effects. The results from Yu et al. (2008) [
18] are used to derive the limit distribution of the
sup LR test for large
T. An estimator for the break date is proposed that can be employed once evidence against no break in the spatial lag parameter is obtained. The performance of this estimator, as well as the proposed test statistic in small samples is evaluated via a Monte Carlo study. Wied (2013) [
20] develops a CUSUM-type test for time-varying parameters in a spatial autoregressive model for stock returns.
Case et al. (1993) [
21] show that a state’s budget expenditure depends on the spending of similar
1 states. Therefore, a rise in a “neighboring” state’s expenditure results in an increase in the state’s own expenditure. As an empirical application, we apply the likelihood ratio test to the budget dependence of U.S. states over time. The data consist of annual observations for the continental United States during the period 1960–2011. States that are economically similar are defined as neighbors. The test result shows that the null hypothesis of no break in the spatial dependence parameter is rejected, and the break date is estimated as 1982. The budget spillover is more pronounced post-break. Details of the results and intuitions on why there might be a break are discussed.
The paper is organized as follows: in
Section 2, the spatial lag model is presented and discussed.
Section 3 provides motivating examples where the test can be applied. We propose a
sup LR test, which is described in
Section 4. The limiting distribution of the test is stated in
Section 5. The outline of the proof is also provided in this section (details are in the
Appendix A). In the event of a rejection of the null hypothesis, we propose a break date estimator in
Section 6. The finite sample properties of the test and the estimator are discussed in
Section 7. Finally, we apply the test to budget spillovers in U.S. states, in
Section 8. It shows that there was a change in the budget dependence between similar income states. In
Section 9, we provide the conclusion and possible next steps in research.
2. Spatial Lag Model
Let us consider a simple pooled linear regression model
where
i is an index of cross-sectional dimension, with
i = 1,...,
N, and
t is an index for the time dimension, with
t = 1,...,
T. We discuss all of the results using “time” as the second dimension; however, for a general spatial lag model, the second dimension could very well reflect another cross-sectional characteristic, such as the industry sector or the number of classes or groups.
is an observation on the dependent variable at
i and
t,
a
vector of observations on the (exogenous) explanatory variables including the intercept,
β a matching
K × 1 vector of regression coefficients and
an error term. In stacked form, the simple pooled regression can be written as
with
y a
× 1 vector, X a
×
K matrix and
ϵ a
× 1 vector. In general, spatial dependence is present whenever the correlation across cross-sectional units is non-zero, and the pattern of non-zero correlations conforms to a specified neighbor relation. When the spatial correlation pertains to the dependent variable, it is known as a spatial lag model. The neighbor relation is expressed by means of a spatial weight matrix.
A spatial weights matrix W is a positive matrix in which the rows and columns correspond to the cross-sectional observations. An element of the matrix expresses the prior strength of the interaction between location i (in the row of the matrix) and location j (column). This can be interpreted as the presence and strength of a link between nodes (the observations) in a network representation that matches the spatial weights’ structure. In the simplest case, the weights matrix is binary, with = 1 when i and j are neighbors and = 0 when they are not. The choice of the weights is typically driven by geographic criteria, such as contiguity (sharing a common border) or distance. However, generalizations that incorporate notions of “economic” distance are increasingly being used, as well. By convention, the diagonal elements = 0. For computational simplicity and to aid the interpretation of the spatial variables, the weights are almost always standardized, such that the elements in each row sum to one, or = . Using the subscript to designate the matrix dimension, with as the weights for the cross-sectional dimension and the observations stacked, the full weights matrix becomes: , with an identity matrix of dimension T.
Unlike the time series case, where “neighboring” observations are directly incorporated into a model specification through a shift operator (example
), in the spatial literature, the neighboring observations are included in the model specification by applying a spatial lag operator (
W) to the dependent variable. A spatial lag operator constructs a new variable, which consists of the weighted average of the neighboring observations, with the weights as specified in
W. The spatial lag model or mixed regressive spatial autoregressive model includes a spatially-lagged dependent variable as an explanatory variable in the regression specification. The word “spatial lag” is used to specify the inclusion of the neighboring observations. Similar to the time series “lag operator”,
emphasizes the first-order location lag in the dependent variable. The spatial lag model can be written as
where
ρ is the spatial autoregressive parameter and the parameter of interest in this paper.
2.1. Endogeneity Problem
The problem in the estimation of the model (
3) is that, unlike the time series case, the spatial lag term is endogenous. This is the result of the two-directionality of the neighbor relation in space (“I am my neighbor’s neighbor”), in contrast to the one-directionality in time dependence. Rewriting equation (
3) in a reduced form:
indicating that the joint determination of the values of the dependent variable in the spatial system is a function of the explanatory variables and error terms at all locations in the system. The presence of the spatially lagged errors in the reduced form illustrates the joint dependence of
and
in each cross-section. In model estimation, the simultaneity is usually accounted for through instrumentation (IV and GMM estimation) or by specifying a complete distributional model (maximum likelihood estimation). In this paper, we use maximum likelihood estimation.
2.2. Maximum Likelihood Estimation
Assuming a Gaussian distribution for the error term, with
), the log-likelihood can be written as:
where
and
is the Jacobian of the spatial transformation. To avoid singularity or explosive processes, the parameter space
for the true spatial autoregressive parameter
ρ is compact, and
is in the interior of
.
Lee (2004) [
22] discusses the asymptotic properties of the maximum likelihood estimators for the cross-section case. Yu et al. (2008) [
18] and Lee and Yu (2010) [
19] derive the properties for the spatial panel model with fixed effects. We use the properties of the maximum likelihood estimators to derive the asymptotic distribution of the test statistic.
4. Test
In this section, we describe the test statistic. The spatial lag model is given by:
where
). We want to test the null hypothesis:
H0:
and and against the alternative
H1:
and , but there is an integer , , such that .
Rewriting the panel model with a change point at
in the parameter
ρ,
where
≠
means there is a change at an unknown date
. The problem can be described as testing
against
.
Let us write twice the likelihood ratio as
where
is the log-likelihood defined for the sample that includes the observations
is the log-likelihood defined for the sample that includes the observations
is the log-likelihood defined for the sample that includes the observations
As
is unknown, we use a maximally selected likelihood ratio and reject
if
is large, where
, typically a small number is the trimming and [.] denotes the largest integer that is less than or equal to the argument. Therefore, the suggested test is to calculate the difference between the log-likelihood under an alternative hypothesis and the log-likelihood under null for every
, and then, the test statistic is the maximum difference between them.
7. Monte Carlo Results
To evaluate the finite sample performance of the LR test and the performance of the estimator, this section reports the results of a limited set of sampling experiments. All results reported are for 1000 simulations. We consider the data generating process:
where
from
and
from
.
We first look into the power of the proposed test. Let
, and the actual break date is
in each of the cases. We find that the test has high power even with
N and
T = 50, as seen in
Table 1. The power increases with increases in
N and/or
T (see
Table 2).
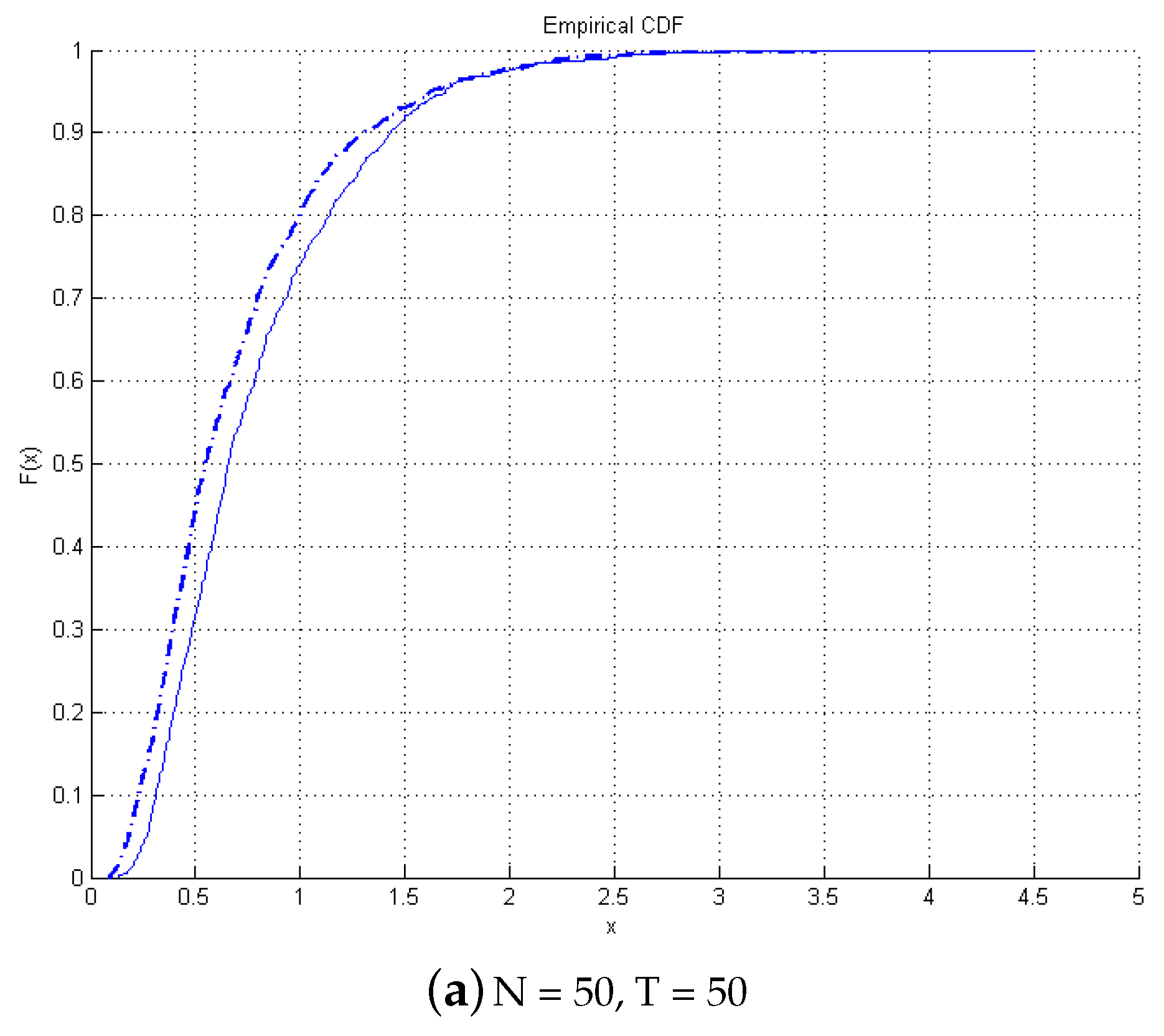
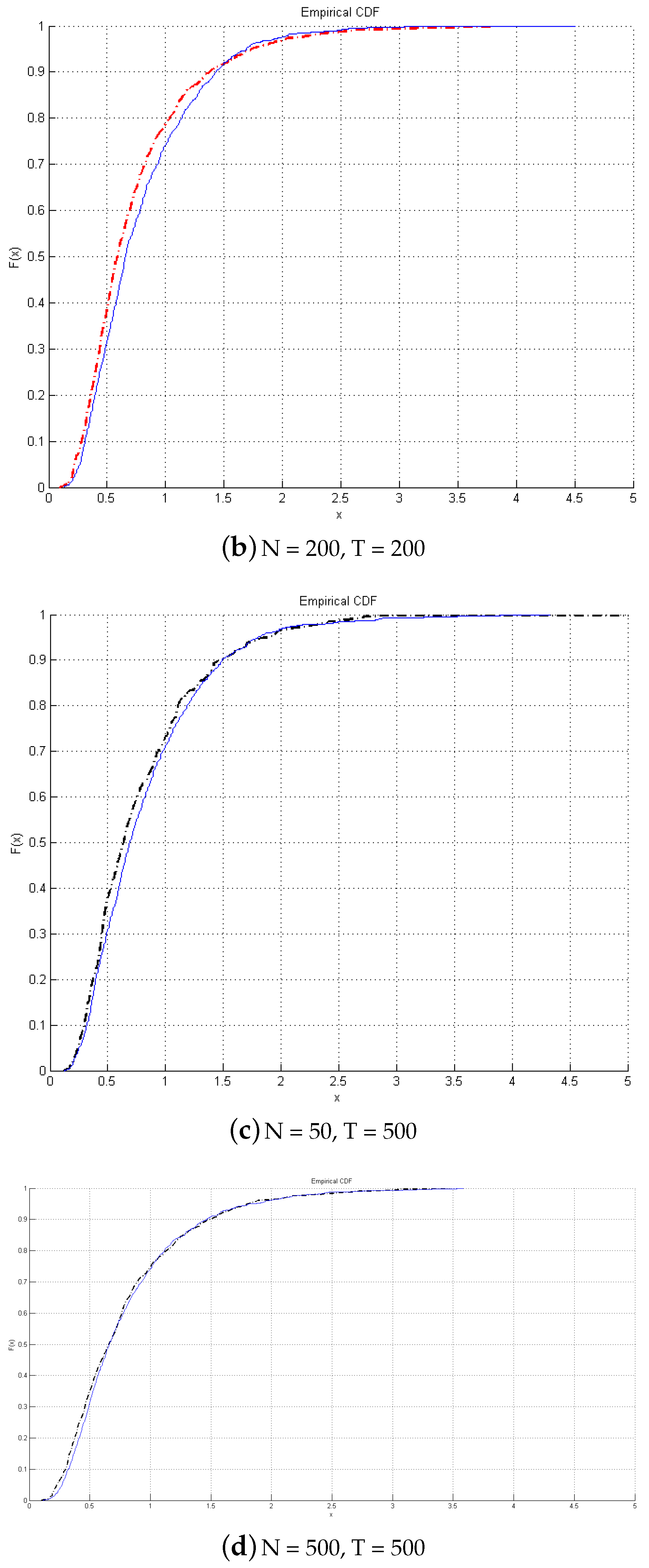
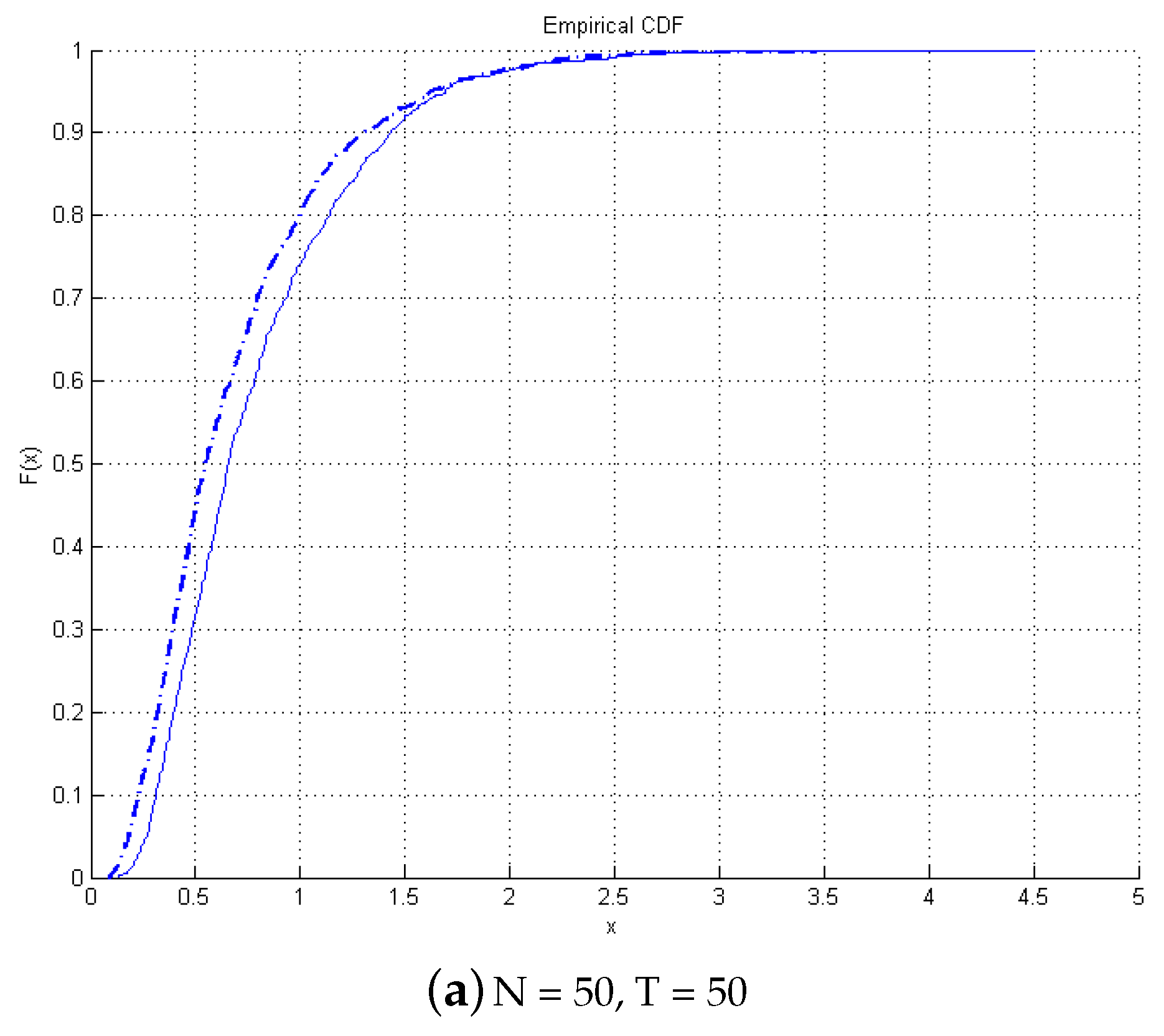
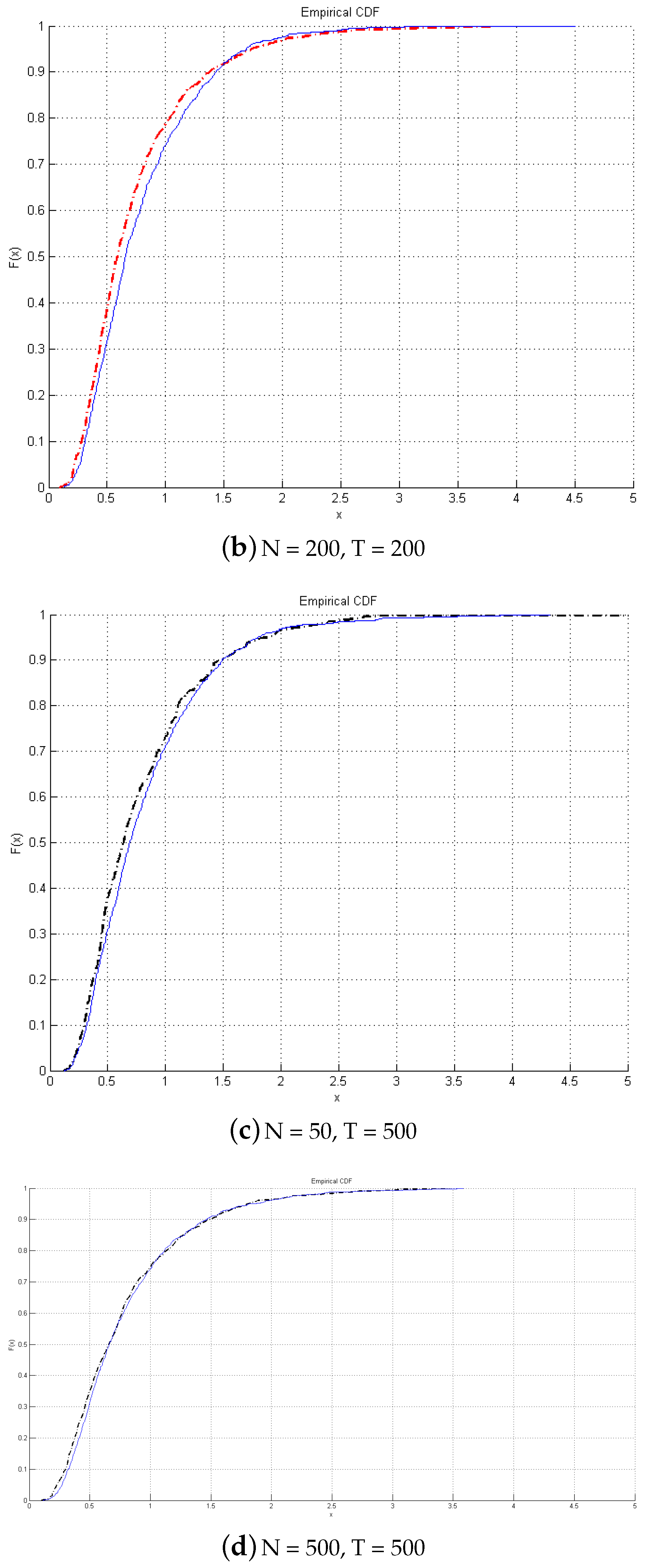
Next, we look into graphical comparisons between empirical and asymptotic distributions of the test presented in
Figure 1. The continuous lines are the asymptotic distributions, and the dotted lines are the empirical CDF. It is found that even with a small
T, there is no size distortion, and the empirical distribution matches closely the asymptotic distribution. As
T increases, the two distributions overlap.
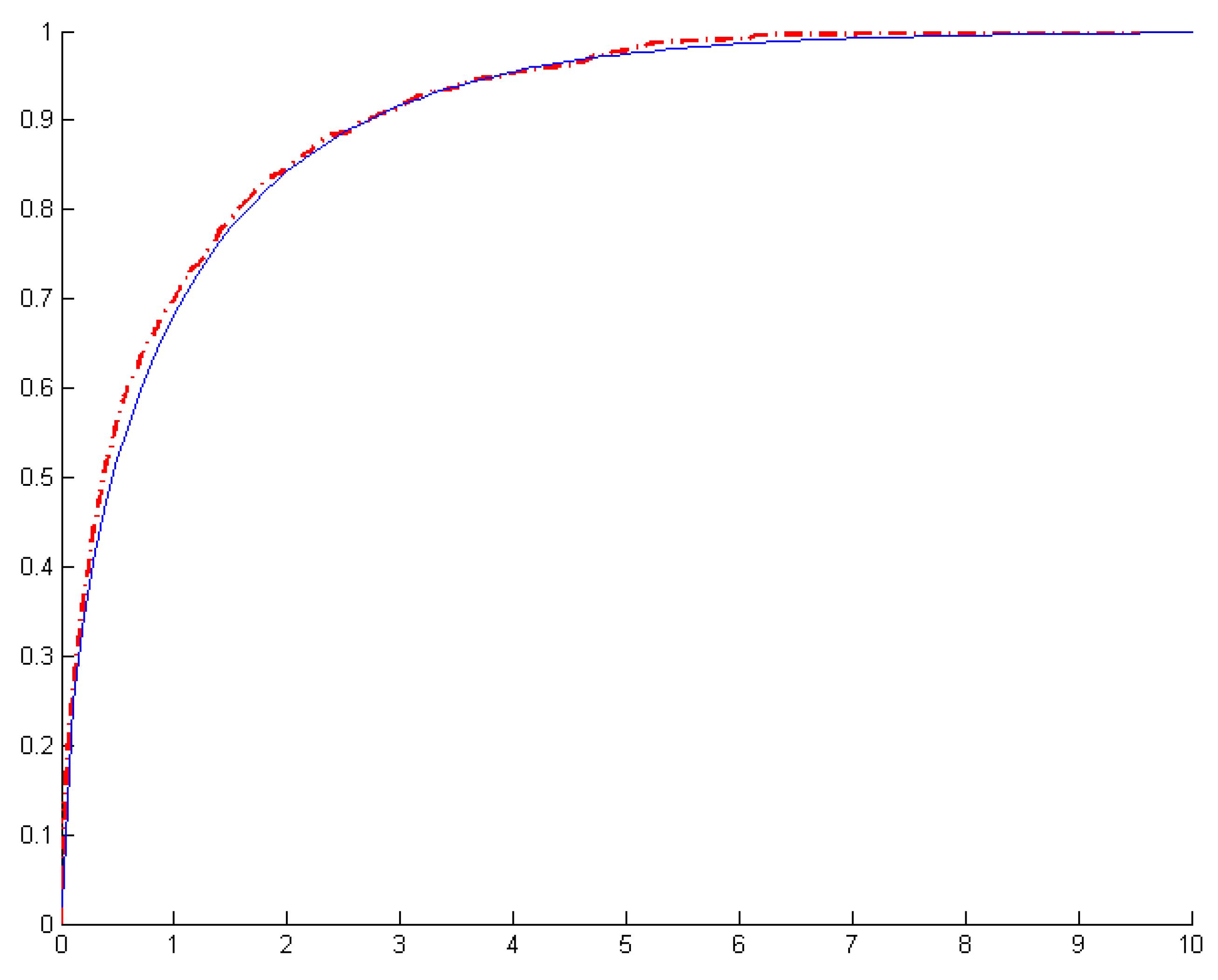
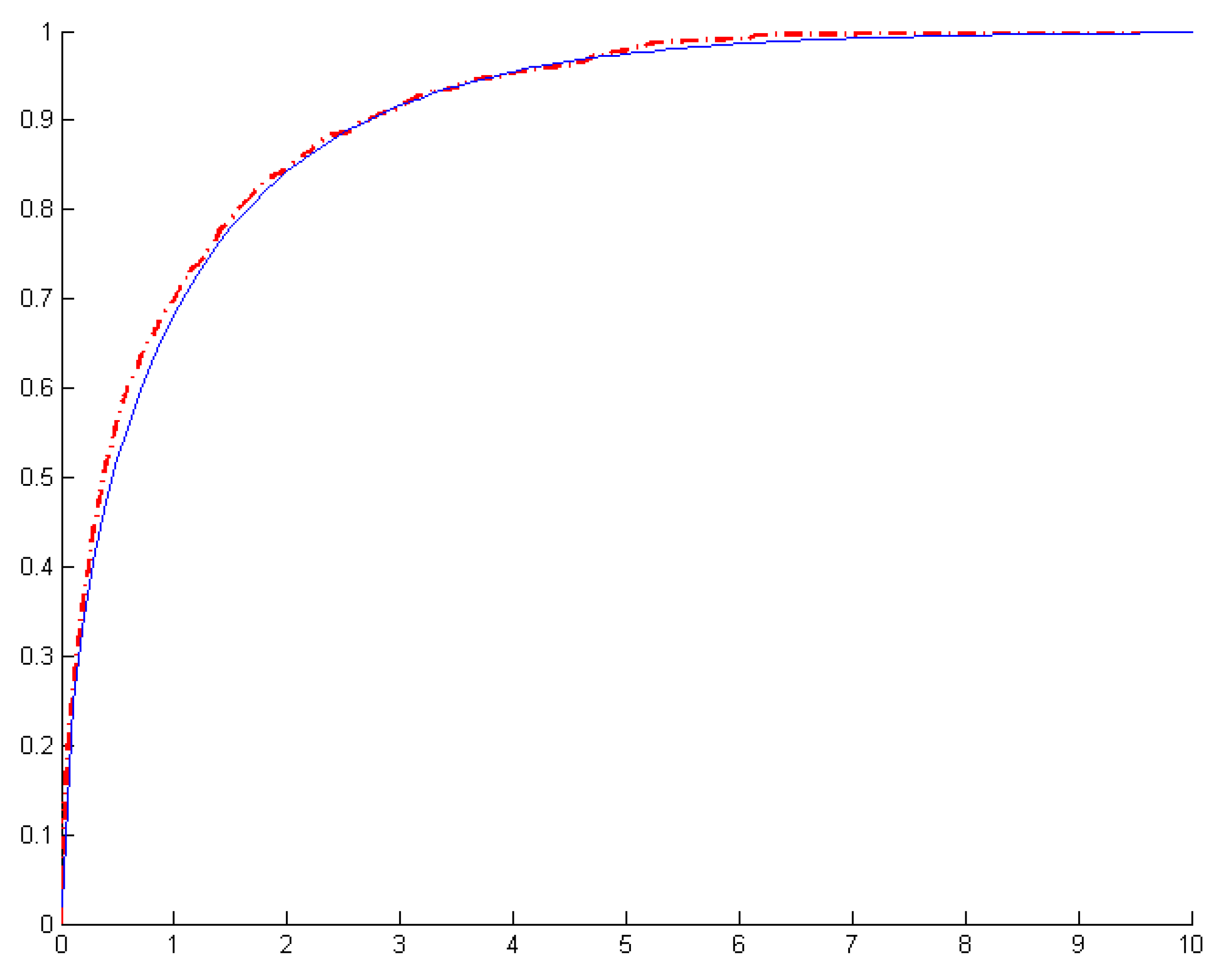
For a known break date, the asymptotic distribution is chi-square with one degree of freedom. The graphical comparison presented in
Figure 2 shows that even with
N = 50,
T = 50, with a known break date, the empirical distribution is very close to the asymptotic chi-square distribution.
Next, we compare the performance of the break-date estimator (see
Table 3). The bias is almost negligible. The root mean square decreases with increases in
N. With increases in
T, the standard deviation does not go down. This is a well-known result in the univariate time series literature: only the break fraction can be consistently estimated, not the break date.
Furthermore, we make a quick comparison with the ordinary least squares residuals-based method (see
Table 4), with the estimator defined by
Here, is the sum of squared residuals of the model under the alternative assuming a break at date k. The bias is comparable in the two cases, but the standard deviation and root mean square are higher for the OLS residual-based estimate of break date.
Looking at the tables closely, an interesting pattern is observed: there is an asymmetry in the behavior of the estimator and the power of the test. When , the power of the test is lower compared to that when . Similarly, the break date estimator has a lower standard deviation and root mean square when the post-break parameter is increasing () as compared to a comparable reduction in the post-break parameter (). An explanation for such behavior could be that, when the post-break parameter is increasing (), there is a higher signal of spatial dependence. This leads to reduction in the variance and makes it easier to assess whether a break is present and locate it. However, when the post-break parameter is comparably lower (), the signal is lower, giving rise to more variation and making it more difficult to assess whether a break is present and to locate it.
The proposed likelihood-based estimator performs well in a finite sample. As N increases, the root mean square error decreases, suggesting that the estimator is consistent.
8. Budget Spillovers
Case et al. (1993) [
21] showed how a U.S. state’s budget expenditure depends on the spending of similar states. Quoting Arkansas state Senator Doug Brandon (1989)
2 describing his state’s budgetary policy as
“We do everything everyone else does.”
The proposed sup LR test is used to check the hypothesis that a state’s dependence on another’s budget remained the same in the U.S. or has changed over time. The data consists of an annual panel of U.S. states from 1960–2011. All dollar figures are calculated on a per capita basis and deflated using the GDP deflator (the base year being 2009). The dependent variable is the government expenditure of state i in the year t (). The budget expenditure is the sum of the direct spending of state and local governments. The variables included in other than the intercept are: the real per-capita personal income (Y), income squared (), real per capita total intergovernmental federal revenue to state and local governments (F), population density (), proportion of the population at least 65 years old (), proportion of the population between five and 14 years old () and proportion of the population that is black (). The income and revenue are the resources the state government can use. The square of the income picks up possible non-linear effects of changing resources. The population density captures the possibility that there are potential congestion effects and scale economies in the provision of state and local government services. States with different age and racial structures may have different demands for publicly-provided goods. Hence, demographic variables are included.
The model can be written as:
where
X includes all of the control variables. We consider
T = 52 from 1960–2011 and
N = 49 states in the U.S. Case et al. (1993) [
21] use three different ways to define the weight matrix. We define the elements of the weight matrix as
=
, where
is the mean income over the sample period and
is the sum
. According to this definition of the weight matrix, rich states are neighbors to rich states, and poor states are neighbors to poor states. The full model (1960–2011) estimation results are presented in
Table 5.
All of the test results are based on tests with size . We reject the null hypothesis of no break, implying evidence for a break. The break date is estimated at 1982. The pre-break budget spillover coefficient is estimated as 0.0229, while the post-break budget spillover coefficient is estimated as 0.1056. As to why there might be a break, there could be two reasons: (1) in 1981, Ronald Reagan became the president of the United States and advocated many different policies across the U.S. states (also known as Reagonomics); (2) the number of Democratic governors in the U.S. started decreasing post-1983, suggesting synchronized Republican economic policies in different states.
To differentiate between trend behaviors and fluctuations, a Hodrick-Prescott filter is applied on all of the dollar value variables to closely look into idiosyncratic budget spillovers in the U.S. states. We reject the null hypothesis of no break. The break date is then estimated to be in 1977. The pre-break ρ coefficient is 0.5718, and the post-break ρ coefficient is 0.3746. Firstly, this suggests that the idiosyncrasy in budget expenditure for a state depends on “similarly”-situated states. Secondly, the dependence goes down post-break. This can be attributed to more power given to the governors in the 1980s. For the federal government (central planner), the budget policies for each state will be similar; compared to individual governors in each state who will adjust the budget expenditures for their states based on individual needs. Therefore, overall, even though the spillovers increase (capturing overall trend in the economy), the budget spillovers in the case of idiosyncracies reduce over time.
9. Conclusions
We consider the problem of structural break in the spatial dependence parameter in a panel model and provide a likelihood ratio test.
We first describe the spatial panel model and the interpretation of the spatial lag or spatial autoregressive parameter. Next we motivate the problem of structural break in such parameter. The sup LR test statistic is proposed, and under large T, the limiting distribution is derived. The test is easy to implement, and the critical values can be analytically obtained.
In case there is evidence to reject the null hypothesis, we propose a break date estimator based on the argument that maximizes the likelihood ratio. The finite sample properties of the test and the break-date estimator are provided. The Monte Carlo simulations show that the test has good power even in small samples. The estimator of the break date shows negligible bias, and the root mean square decreases with increases in N, suggesting a consistent break-date estimator for a panel model.
We then consider the problem of budget spillovers across the U.S. states and the change in the spatial dependence over time. The test rejects the null hypothesis of no break in budget spillovers for (1) the spillover in the overall budget expenditure of the U.S. states and (2) the spillover in the fluctuations of budget expenditure. The overall trend of spatial dependence in budget expenditure is found to have increased post-break, but the idiosyncrasies in budget expenditure are less spatially dependent post-break.
The following extensions to the paper are being considered: (1) the asymptotic limit distribution of the test statistic for large N; (2) proving the consistency of the break date estimator and deriving the limiting distribution; and (3) extending the test to multiple structural breaks.




{kind=link}
{kind=link}
{kind=link}