Abstract
This paper studies the asymptotic normality for the kernel deconvolution estimator when the noise distribution is logarithmic chi-square; both identical and independently distributed observations and strong mixing observations are considered. The dependent case of the result is applied to obtain the pointwise asymptotic distribution of the deconvolution volatility density estimator in discrete-time stochastic volatility models.
JEL classifications:
C13; C22; C46; C58
1. Introduction
Consider the measurement error model:
where X is the signal, while ε is the noise. Assume X is independent of ε; X has density , and ε has density k, so the density of Y, denoted as , is the convolution of and k:
where the * denotes convolution.
Assume we observe the realizations of Y and that the function k is fully known; one possible estimator for from the noisy observations is the kernel deconvolution estimator:
where:
is the empirical characteristic function of density , is a kernel function, and are the Fourier transform of K and k, respectively1. The kernel deconvolution estimator was first proposed forthe measurement error model by Carroll and Hall [1] and Stefanski and Carroll [2].
Define the kernel deconvolution function as follows:
the kernel deconvolution estimator can be written compactly as:
In this paper, I show the asymptotic normality for the estimator when the distribution of ε is logarithmic chi-square. The asymptotic distribution of the kernel deconvolution estimator has been considered in Fan [3], Fan and Liu [4], Van Es and Uh [5] and Van Es and Uh [6] for identically independently distributed (i.i.d.) observations. Masry [7] and Kulik [8] consider various cases for the weakly-dependent observations. However, none of the above research allows the error distribution to be the logarithmic chi-square distribution. I consider both the identical and independently distributed (i.i.d.) observations and strong mixing observations in this paper, which complements the above-mentioned literature.
The results obtained in this paper can be applied to obtain the asymptotic distribution of the deconvolution volatility density estimator. The problem of estimating volatility density has been gaining increasing interest in econometrics in recent years; see, e.g., Van Es, Spreij, and Van Zanten [9] and and Van Es, Spreij, and Van Zanten [10] for the kernel deconvolution estimator, Comte and Genon-Catalot [11] for the penalized projection estimator and Todorov and Tauchen [12] for the study in the context of high-frequency data. Kernel deconvolution with logarithmic chi-square noise arises naturally when estimating the volatility density in stochastic volatility (SV) models. Existing research (e.g., Van Es, Spreij, and Van Zanten [9] and Van Es, Spreij, and Van Zanten [10]) focuses on the convergence rates of the estimators, and the asymptotic distribution of the estimators is not available.
In Section 2, I review the probabilistic properties of the logarithmic chi-square distribution; Section 3 presents the asymptotic normality of the estimator, for both i.i.d. observations and dependent observations; Section 4 discusses the application of the results to volatility density estimation in SV models; Section 5 concludes the paper.
2. Logarithmic Chi-Square Distribution
The logarithmic chi-square distribution is obtained by taking the logarithm of a chi-square distribution with degrees of freedom of one. The density function of logarithmic chi-square distribution is:
The density function of the logarithmic chi-square distribution is asymmetric and is plotted in Figure 1.
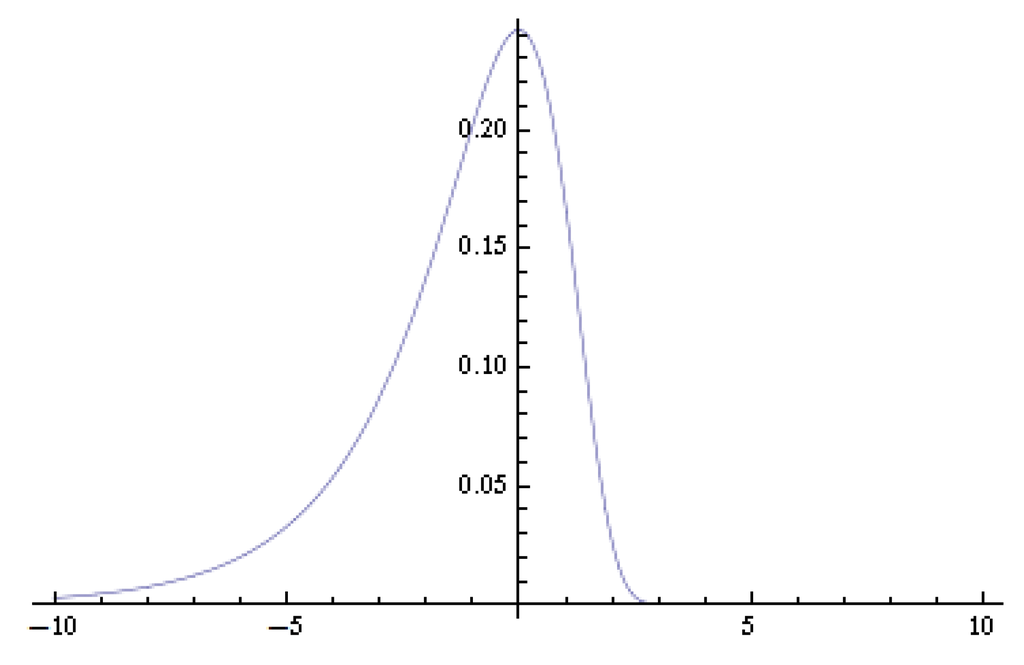
Figure 1.
Density function of the logarithmic chi-square distribution.
Figure 1.
Density function of the logarithmic chi-square distribution.
The characteristic function of the logarithmic chi-square distribution is:
where is the gamma function.
Fan [3] studies the quadratic mean convergence rate of the kernel deconvolution estimator; it turns out that the convergence rate of the estimator depends heavily on the type of error distribution. In particular, it is determined by the tail behaviour of the modulus of the characteristic function of the error distribution: the faster the modulus function goes to zero in the tail, the slower the converge rate. The following lemma, which is from Van Es, Spreij, and Van Zanten [10], gives the tail behaviour of .
Lemma 1.
(Lemma 5.1 of Van Es, Spreij, and Van Zanten [10]) For , we have:
and:
From (3), it is known that the modulus of decays exponentially fast as . It thus belongs to the super-smooth density according to the classification in Fan [13]. According to Fan [13], the optimal convergence rate of the estimator is , when . Figure 2 plots the modulus function and its approximation ; we notice that the two functions almost coincide at both tails.
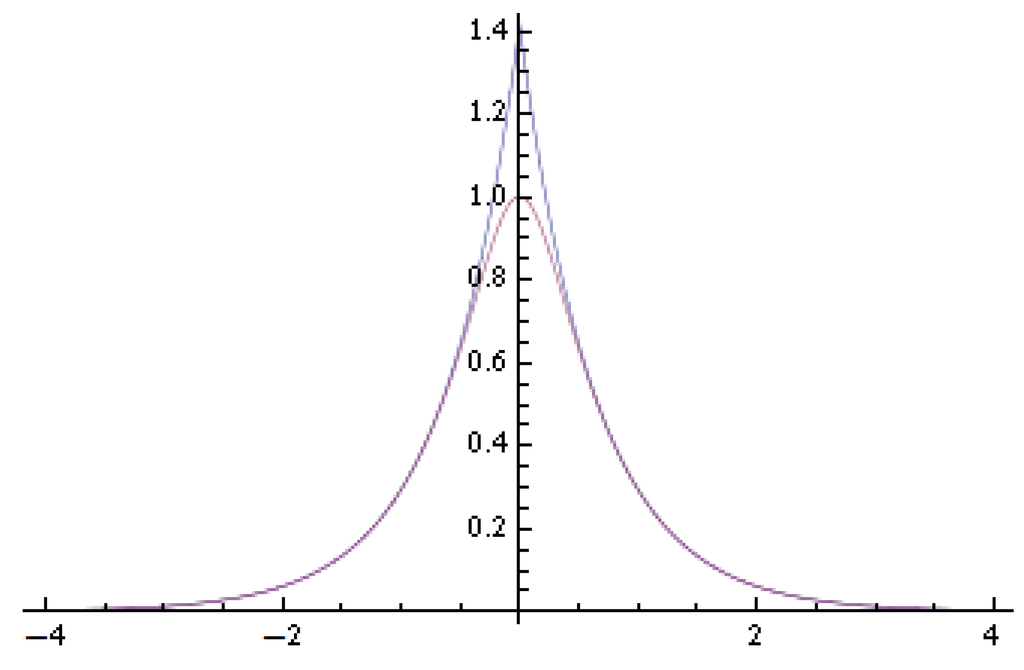
Figure 2.
Modulus function of the characteristic function of logarithmic chi-square distribution and its approximation: the higher peak curve is the approximating function .
Figure 2.
Modulus function of the characteristic function of logarithmic chi-square distribution and its approximation: the higher peak curve is the approximating function .
From (4) and (5), it is known that in both tails, neither the real part nor imaginary part of the characteristic function can dominate the other; this violates the assumptions in the previous works by, e.g., Fan [3] and Masry [7], on studying the asymptotic normality; for super-smooth error distributions, these papers assume either the real part or the imaginary part to be dominant.
3. Asymptotic Normality
In this paper, I consider one particular kernel function, namely the sinc kernel function:
The sinc kernel function is favoured in theoretical literature because of the simplicity of its Fourier transform and is thus used here. 3
(C1)
with Fourier transform2: The sinc kernel function is defined as:
3.1. i.i.d. Observations
In this section, I prove the asymptotic normality of the estimator when the observations are i.i.d.
Theorem 1.
When the observations are i.i.d. and ε is distributed as logarithmic chi-square, if Assumption (C1) holds, when as and , it holds that,
where .
Proof.
Denote:
then:
First:
Second, I evaluate ,
where the last equality is obtained because as , and . The latter result is shown as follows,
where M is a very big number. The first term in the brackets is a constant depending on M; the order of the second term can be evaluated as follows,
where I use the fact that when M is big, can be replaced by its asymptotic approximation. The second term clearly dominates the first term, which is a constant, such that:
Here, I use the argument of Butucea [15] to split the integral and show that the tail part of the integral dominates.
A sufficient condition for asymptotic normality is the Lyapunov condition, which reduces to:
for i.i.d. data.
For an upper bound for the numerator,
3.2. Strong Mixing Observations
In this section, I consider the model:
where X’s realizations of are strictly stationary and strong mixing, while the noise realizations are i.i.d. logarithmic chi-square variables, independent of X, such that the observations are also strictly stationary and strong mixing.
There are various concepts of dependence; here, I consider the case of α mixing, also called strong mixing, which is the weakest among all of the dependence concepts.
Definition 1.
Let , be an infinite sequence of strictly stationary random variables and be the σ-algebra generated by ; then, the α-mixing coefficient is defined as:
The sequence , , is called α-mixing if as .
For the dependent case, a bounded assumption on the joint density of observations is also needed.
(C2)
The probability density function of any joint distribution , , exists and is bounded by a constant.
Now, I give the asymptotic normality theorem. Notice that the mixing assumption here is a litter weaker than that in Masry [7].
Theorem 2.
In model (11), let be strictly stationary, α-mixing with:
for some ; the noises are i.i.d. logarithmic chi-square variables, independent of X; if (C1) and (C2) hold, when as and , then:
Proof.
First, by strict stationarity and using the ergodic theorem for strong mixing sequences, similarly as in the proof of Theorem 1,
Next, the variance of the estimator is evaluated; first:
Knowing from Theorem 1 that the first term is:
For the covariance term, first notice:
as . Now, because:
where C is a constant; continuing on (14), I get:
On the other hand, using the assumption on the α-mixing coefficients and the covariance inequality for strong mixing sequence in Proposition 2.5 in Fan and Yao [17], for ,
Therefore, using (15) and (16),
if one chooses , then and , then obviously the first term is ; the second term is also by noticing the mixing assumption in (12). Then, it is shown that:
Now, I prove the central limit theorem, for which I use the classical large block-small block argument of proving the central limit theorem for the dependent sequence. First, I make some normalizations, define , and:
then has mean zero and unit variance and:
and it will be shown that:
which is the result that needed to be shown.
First, the set is partitioned into subsets with large blocks of size and small blocks of size , such that , so the last remaining block has size . The sizes are such that , , . Then, we can write:
where:
which are the sum of large blocks, small blocks and the last block, respectively. Then, as a standard procedure for the small block-big block argument, I show the following:
for . (18) and (19) say that the small blocks and the last block are of smaller order. (20) says that the large blocks are as if independent in the sense of the characteristic function. Then, (21) and (22) are the Lindeberg-Feller condition for the asymptotic normality for under independence.
For (18) and (19), using the moment inequality for the α-mixing sequence in Proposition 2.7 (i) in Fan and Yao [17], it can be shown that:
notice that the conditions for Proposition 2.7 (i) are satisfied, because by (10), for ; and the mixing assumption (12) implies that for , which is ; take and , so the mixing condition is also satisfied.
For (20), using the covariance inequality in Proposition 2.6 in Fan and Yao [17], we have:
this is by choosing for example , for . Then, , such that for some ,
obviously, the above expression is by the assumption that , so (20) is proven.
For Feller’s condition (21), first use the same strategy as calculating the variance of the estimator; it holds that:
for any j, because is also an infinite sum of the observations. Therefore,
Finally, for Lindeberg’s condition (22), first observe that:
where I first use Holder’s inequality and then Markov’s inequality. Using again the moment inequality for the strong mixing sequence in Proposition 2.7 in Fan and Yao [17],
so:
4. Application to Density Estimation in the Stochastic Volatility Model
In this section, I consider applying the results of Theorem 2 to obtain the asymptotic distribution of the kernel deconvolution volatility density estimator in SV models. A generic SV model has the following form,
where , are i.i.d. ; is a latent stochastic process called the volatility process; is the observed financial returns. The SV model is a popular model used in financial econometrics to describe the evolution of financial returns. Model (23) incorporates popular discrete-time SV models (e.g., Taylor [18]) and the discretized continuous-time SV models, which assume the volatility process to be stationary as special cases (see, e.g., Shephard [19] for a review). Van Es, Spreij, and Van Zanten [9] and Van Es, Spreij, and Van Zanten [10] considered estimating the volatility density using the kernel deconvolution estimator in this model.
Remark 1.
By using the term “stochastic volatility”, here, I consider the so-called “genuine stochastic volatility” models, where the volatility process has a separate stochastic driving factor (see, e.g., Shephard and Andersen [20] and Andersen, Bollerslev, Diebold, and Labys [21] for detailed discussions). It thus does not include the ARCH/GARCH class models, where one has explicitly specified one-step-ahead predictive densities. Van Es, Spreij, and Van Zanten [10] considered estimating volatility density in the context of the ARCH/GARCH class of models and had given the rate of convergence for their estimator.
To apply the general theory derived in Section 3, it is further assumed that the volatility process is strictly stationary, and it is independent of for The independence assumption rules out the leverage effect in stochastic volatility models and, thus, is suitable to apply to, say, exchange rate data, where the leverage effect is rarely observed. Extending the model to allow for the leverage effect is an important, yet challenging task, which is thus left for future research.
The SV model can be written as a measurement error model (11) by taking squares and logarithms on both sides of equation (23),
such that the variable is the convolution of with a completely known distribution logarithmic chi-square. Following the notations in the previous sections, write the density functions of , and to be , and k, respectively.
If we want to recover the density of from the observations , this is a problem of deconvolution with logarithmic chi-square error, and the kernel deconvolution estimator can be used. Van Es, Spreij, and Van Zanten [9] and Van Es, Spreij, and Van Zanten [10] first noticed this connection. Define ; they use the following estimator to recover ,
where is the Fourier transform of a kernel function K and is the characteristic function of the variable. Van Es, Spreij, and Van Zanten [9] and Van Es, Spreij, and Van Zanten [10] derive the convergence rate of the estimator, but a central limit theorem is missing.
If we assume the observed return sequence , is generated by the SV model (23) with a strict stationary, the α-mixing volatility process satisfies (12) and i.i.d. errors; a simple application of Theorem 2 will lead to the following corollary.
Corollary 1.
Since the density can be estimated with the observed return sequence consistently using the classical kernel density estimator for any x (see e.g., Fan and Yao [17]), the above result can be used to construct pointwise confidence intervals for the kernel deconvolution density estimator.
5. Conclusions
In this paper, I have proven the asymptotic normality for the kernel deconvolution estimator with logarithmic chi-square noise. I consider both the case of identical and independently distributed observations and strong mixing observations. The results are applied to prove the asymptotic normality of the kernel deconvolution estimator for volatility density in stochastic volatility models.
Acknowledgements
I am grateful for Kerry Patterson and the two anonymous referees for helpful comments, which greatly improved the paper. The usual disclaimer applies.
Conflicts of Interest
The author declares no conflict of interest.
References
- R. Carroll, and P. Hall. “Optimal rates of convergence for deconvolving a density.” J. Am. Stat. Assoc. 83 (1988): 1184–1186. [Google Scholar] [CrossRef]
- L. Stefanski, and R. Carroll. “Deconvoluting kernel density estimators.” Statistics 21 (1990): 169–184. [Google Scholar] [CrossRef]
- J. Fan. “Asymptotic normality for deconvolution kernel density estimators.” Sankhya Indian J. Stat. A 53 (1991): 97–110. [Google Scholar]
- Y. Fan, and Y. Liu. “A note on asymptotic normality for deconvolution kernel density estimators.” Sankhya Indian J. Stat. A 59 (1997): 138–141. [Google Scholar]
- B. Van Es, and H. Uh. “Asymptotic normality of nonparametric kernel type deconvolution density estimators: Crossing the Cauchy boundary.” J. Nonparametr. Stat. 16 (2004): 261–277. [Google Scholar] [CrossRef]
- B. Van Es, and H. Uh. “Asymptotic normality of kernel-type deconvolution estimators.” Scand. J. Stat. 32 (2005): 467–483. [Google Scholar]
- E. Masry. “Asymptotic normality for deconvolution estimators of multivariate densities of stationary processes.” J. Multivar. Anal. 44 (1993): 47–68. [Google Scholar] [CrossRef]
- R. Kulik. “Nonparametric deconvolution problem for dependent sequences.” Electron. J. Stat. 2 (2008): 722–740. [Google Scholar] [CrossRef]
- B. Van Es, P. Spreij, and H. van Zanten. “Nonparametric volatility density estimation.” Bernoulli 9 (2003): 451–465. [Google Scholar] [CrossRef]
- B. Van Es, P. Spreij, and H. van Zanten. “Nonparametric volatility density estimation for discrete time models.” Nonparametr. Stat. 17 (2005): 237–251. [Google Scholar] [CrossRef]
- F. Comte, and V. Genon-Catalot. “Penalized projection estimator for volatility density.” Scand. J. Stat. 33 (2006): 875–893. [Google Scholar] [CrossRef]
- V. Todorov, and G. Tauchen. “Inverse realized laplace transforms for nonparametric volatility density estimation in jump-diffusions.” J. Am. Stat. Assoc. 107 (2012): 622–635. [Google Scholar] [CrossRef]
- J. Fan. “On the optimal rates of convergence for nonparametric deconvolution problems.” Ann. Stat. 19 (1991): 1257–1272. [Google Scholar] [CrossRef]
- A. Delaigle, and I. Gijbels. “Practical bandwidth selection in deconvolution kernel density estimation.” Comput. Stat. Data Anal. 45 (2004): 249–267. [Google Scholar] [CrossRef]
- C. Butucea. “Asymptotic normality of the integrated square error of a density estimator in the convolution model.” Sort 28 (2004): 9–26. [Google Scholar]
- E. Masry. “Multivariate probability density deconvolution for stationary random processes.” IEEE Trans. Inf. Theory 37 (1991): 1105–1115. [Google Scholar] [CrossRef]
- J. Fan, and Q. Yao. Nonlinear Time Series. Berlin, Germany: Springer, 2002, Volume 2. [Google Scholar]
- S.J. Taylor. “Financial returns modelled by the product of two stochastic processes-a study of the daily sugar prices 1961–1975.” Time Ser. Anal. Theory Pract. 1 (1982): 203–226. [Google Scholar]
- N. Shephard, ed. Stochastic Volatility: Selected Readings. Oxford, UK: Oxford University Press, 2005.
- N. Shephard, and T.G. Andersen. “Stochastic volatility: Origins and overview.” In Handbook of Financial Time Series. Edited by T.G. Andersen, R.A. Davis, J.P. Kreiß and T. Mikosch. Berlin, Germany: Springer, 2009, pp. 233–254. [Google Scholar]
- T.G. Andersen, T. Bollerslev, F.X. Diebold, and P. Labys. “Parametric and nonparametric volatility measurement.” Handb. Financ. Econom. 1 (2009): 67–138. [Google Scholar]
- 1The characteristic function of a random variable with density f is defined as .
- 2In this paper, I follow the convention to define the Fourier transform of a function f to be
- 3Usually, for practical implementations, the following kernels:with Fourier transform:are used because they have better numerical properties; see Delaigle and Gijbels [14] for the discussions.
- 4This is easy to see by noticing for .
- 5Here, again, the splitting integral argument as in proving (7) is used; I omit the details for the ease of exposition.
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license ( http://creativecommons.org/licenses/by/4.0/).