Two-Part Models for Fractional Responses Defined as Ratios of Integers

Abstract
:1. Introduction
2. Two-Part Fractional Response Models for Responses Defined as Ratios of Integers
2.1. The Binomial Two-Part Model
2.2. The Beta-Binomial Two-Part Model
3. An Empirical Application: The 401(k) Pension Plan Participation Rates

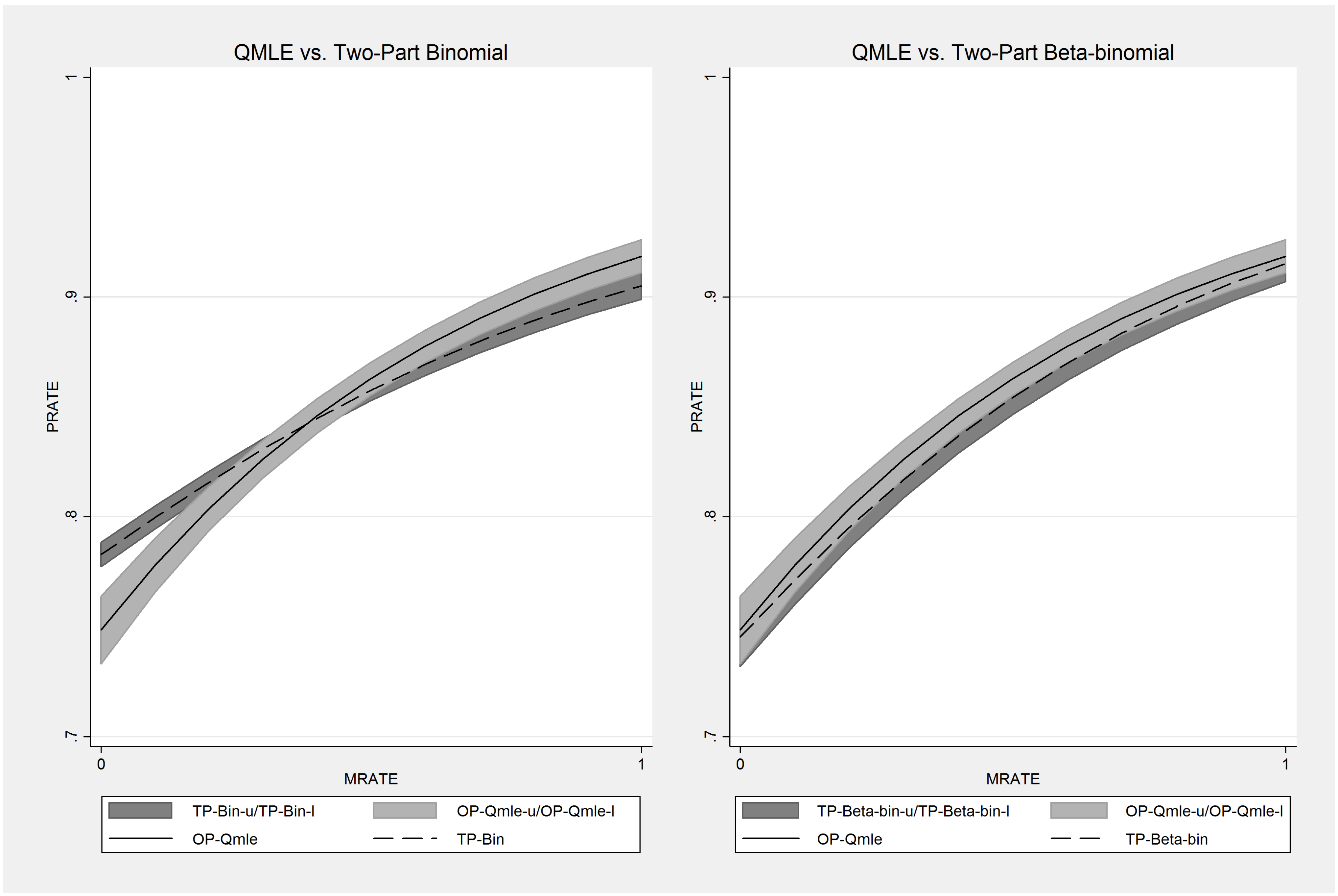{kind=link}
| Variable | (1) | (2) | (3) | (4) | (5) | (6) | (7) | (8) |
|---|---|---|---|---|---|---|---|---|
| First Part | ||||||||
| 1.313 *** | 1.372 *** | 1.349 *** | 1.779 *** | 1.203 *** | 1.220 *** | |||
| (0.083) | (0.002) | (0.085) | (0.085) | (0.097) | (0.068) | |||
| −0.221 *** | −0.290 *** | −0.228 *** | −0.312 *** | −0.246 *** | −0.288 *** | |||
| (0.022) | (0.001) | (0.022) | (0.022) | (0.024) | (0.018) | |||
| 0.403 *** | −0.602 *** | −0.203 * | −0.597 *** | −0.310 ** | −0.674 *** | |||
| (0.111) | (0.004) | (0.115) | (0.111) | (0.131) | (0.075) | |||
| 0.029 *** | 0.029 *** | 0.015 ** | 0.032 *** | 0.002 | 0.035 *** | |||
| (0.007) | (0.000) | (0.007) | (0.007) | (0.011) | (0.005) | |||
| −0.004 | 0.058 *** | −0.004 | 0.006 | 0.011 | 0.044 *** | |||
| (0.009) | (0.000) | (0.009) | (0.009) | (0.010) | (0.006) | |||
| 0.000 * | −0.001 *** | 0.000 * | 0.000 | 0.000 ** | −0.000 *** | |||
| (0.000) | (0.000) | (0.000) | (0.000) | (0.000) | (0.000) | |||
| 0.389 *** | 0.053 *** | 0.400 *** | 0.416 *** | 0.416 *** | 0.118 *** | |||
| (0.047) | (0.002) | (0.048) | (0.048) | (0.050) | (0.035) | |||
| 1.944 *** | 3.466 *** | 3.347 *** | 3.532 *** | 3.748 *** | 3.307 *** | |||
| (0.425) | (0.018) | (0.437) | (0.428) | (0.501) | (0.298) | |||
| Second Part/One Part | ||||||||
| 1.665 *** | 1.372 *** | 0.514 *** | 1.372 *** | 0.936 *** | 1.779 *** | 0.942 *** | 1.220 *** | |
| (0.089) | (0.169) | (0.003) | (0.002) | (0.079) | (0.085) | (0.082) | (0.068) | |
| −0.332 *** | −0.290 *** | −0.178 *** | −0.290 *** | −0.226 *** | −0.312 *** | −0.238 *** | −0.288 *** | |
| (0.021) | (0.041) | (0.001) | (0.001) | (0.019) | (0.022) | (0.022) | (0.018) | |
| −1.031 *** | −0.602 ** | −0.629 *** | −0.602 *** | −0.594 *** | −0.597 *** | −0.607 *** | −0.674 *** | |
| (0.112) | (0.256) | (0.004) | (0.004) | (0.088) | (0.111) | (0.088) | (0.075) | |
| 0.054 *** | 0.029 ** | 0.032 *** | 0.029 *** | 0.032 *** | 0.032 *** | 0.032 *** | 0.035 *** | |
| (0.007) | (0.013) | (0.000) | (0.000) | (0.006) | (0.007) | (0.006) | (0.005) | |
| 0.055 *** | 0.058 *** | 0.061 *** | 0.058 *** | 0.048 *** | 0.006 | 0.050 *** | 0.044 *** | |
| (0.008) | (0.008) | (0.000) | (0.000) | (0.006) | (0.009) | (0.006) | (0.006) | |
| −0.001 *** | −0.001 *** | −0.001 *** | −0.001 *** | −0.001 *** | 0.000 | −0.001 *** | −0.000 *** | |
| (0.000) | (0.000) | (0.000) | (0.000) | (0.000) | (0.000) | (0.000) | (0.000) | |
| 0.064 | 0.053 | −0.170 *** | 0.053 *** | −0.120 *** | 0.416 *** | −0.107 *** | 0.118 *** | |
| (0.047) | (0.127) | (0.002) | (0.002) | (0.038) | (0.048) | (0.037) | (0.035) | |
| 5.105 *** | 3.466 *** | 3.376 *** | 3.466 *** | 3.040 *** | 3.532 *** | 3.119 *** | 3.307 *** | |
| (0.431) | (1.204) | (0.019) | (0.018) | (0.336) | (0.428) | (0.333) | (0.298) | |
| Intra-group correlation | ||||||||
| −0.202 *** | −0.191 *** | |||||||
| (0.037) | (0.011) | |||||||
| −0.236 *** | −0.088 *** | |||||||
| (0.028) | (0.009 ) | |||||||
| 0.014 *** | 0.008 *** | |||||||
| (0.003) | (0.002) | |||||||
| 2.648 *** | 1.517 *** | 3.315 *** | 1.440 *** | |||||
| (0.026) | (0.023) | (0.124) | (0.070) | |||||
| Tests | ||||||||
| LM/LR Test () | 204.46 *** | 2702.33 *** | 489.28 *** | |||||
| Robust LM Test () | 977.72 *** | |||||||
| Wald Test () | 82322.39 *** | 5020.01 *** | 619.41 *** | |||||
| ρ | 0.132 | 0.360 | 0.131 | 0.404 | ||||
| Nagelkerke- | 0.109 | 0.056 | 0.216 | 0.056 | 0.569 | 0.237 | 0.576 | 0.223 |
| Observations | 4734 | 4734 | 4734 | 4734 | 4734 | 4734 | 4734 | 4734 |

| Decile | Obs. | MRATE | TP-Bin | OP-QMLE | TP-Beta-bin | OP-Beta-bin |
|---|---|---|---|---|---|---|
| 1 | 379 | 0.091 | 0.163 | 0.213 | 0.242 | 0.209 |
| 2 | 378 | 0.173 | 0.156 | 0.198 | 0.228 | 0.194 |
| 3 | 379 | 0.228 | 0.148 | 0.181 | 0.212 | 0.177 |
| 4 | 378 | 0.295 | 0.139 | 0.169 | 0.199 | 0.168 |
| 5 | 378 | 0.351 | 0.131 | 0.153 | 0.184 | 0.151 |
| 6 | 379 | 0.399 | 0.127 | 0.145 | 0.175 | 0.140 |
| 7 | 378 | 0.457 | 0.116 | 0.129 | 0.156 | 0.123 |
| 8 | 379 | 0.540 | 0.106 | 0.115 | 0.140 | 0.109 |
| 9 | 378 | 0.675 | 0.087 | 0.092 | 0.110 | 0.083 |
| 10 | 378 | 0.872 | 0.066 | 0.068 | 0.080 | 0.060 |
| Total/Average | 3.784 | 0.408 | 0.124 | 0.146 | 0.172 | 0.141 |
4. Conclusions
Acknowledgments
Author Contributions
Appendix
A. LM and Wald Tests for the Binomial Two-Part Model
A.1. Derivation of the LM Test
A.2. Derivation of the Wald Test
B. The Beta-Binomial Two-Part Fractional Response Model
C. Calculation of Marginal Effects in the Two-Part Models
Conflicts of Interest
- 4.In the case of zero boundary values the conditional mean of this two-part fractional response model modifies to:
- 5.In a related setting, Lin and Schmidt (1984) [18] derive an LM test for testing a Tobit model against the more general Cragg’s (1971) [20] two-part hurdle model under normality using a similar nesting hypothesis. Mullahy (1986) [7] proposes LM and Hausman test statistics in order to discriminate between one- and two-part (hurdle) count data models.
- 6.In the quasi maximum likelihood framework, the literature commonly applies non-nested P tests to discriminate between the one-part and two-part fractional response models. Following Davidson and MacKinnon (1981) [16] and Ramalho et al. (2011) [3], the P test for the null hypothesis that the one-part model is the true one and the two-part model is the alternative is based on an artificial regression. However, in their Propositions 4.1.2 and 4.3.2, Gourieroux, Monfort and Trognon (1984) [21] prove that under the nested parametrization, this test is not applicable.
- 8.Note, this model only allows for positive intra-group correlation, as one has to assume that and . Prentice (1986) [24] proposes a transformation of the beta-binomial distribution that is also able to handle negative intra-group correlation.
References
- L.E. Papke, and J.M. Wooldridge. “Econometric Methods for Fractional Response Variables with an Application to 401(k) Plan Participation Rates.” J. Appl. Econom. 11 (1996): 619–632. [Google Scholar] [CrossRef]
- L.E. Papke, and J.M. Wooldridge. “Panel Data Methods for Fractional Response Variables with an Application to Test Pass Rates.” J. Econom. 145 (2008): 121–133. [Google Scholar] [CrossRef]
- J.M.R. Murteira, E.A. Ramalho, and J.J.S. Ramalho. “Alternative Estimating and Testing Empirical Strategies for Fractional Regression Models.” J. Econ. Surv. 25 (2011): 19–68. [Google Scholar]
- P. Paolino. “Maximum Likelihood Estimation of Models with Beta-Distributed Dependent Variables.” Polit. Anal. 9 (2001): 325–346. [Google Scholar] [CrossRef]
- R. Kieschnick, and B.D. McCullough. “Regression Analysis of Variates Observed on (0, 1): Percentages, Proportions and Fractions.” Stat. Model. 3 (2003): 193–213. [Google Scholar] [CrossRef]
- F. Cribari-Neto, and S.L.P. Ferrari. “Beta Regression for Modelling Rates and Proportions.” J. Appl. Stat. 31 (2004): 799–815. [Google Scholar]
- J. Mullahy. “Specification and Testing of Some Modified Count Data Models.” J. Econom. 33 (1986): 341–365. [Google Scholar] [CrossRef]
- D. Lambert. “Zero-inflated Poisson Regression, with an Application to Defects in Manufacturing.” Technometrics 34 (1992): 1–14. [Google Scholar] [CrossRef]
- C.A. Cameron, and P.K. Trivedi. Microeconometrics: Methods and Applications. Cambridge, UK: Cambridge University Press, 2005. [Google Scholar]
- J.M. Wooldridge. Econometric Analysis of Cross Section and Panel Data. Cambridge, MA, USA: MIT, 2002. [Google Scholar]
- J.V. Da Silva, and J.J.S. Ramalho. “A Two-Part Fractional Regression Model for the Financial Leverage Decisions of Micro, Small, Medium and Large Firms.” Quant. Financ. 9 (2009): 621–636. [Google Scholar]
- J.V. Da Silva, and J.J.S. Ramalho. “Functional Form Issues in the Regression Analysis of Corporate Capital Structure.” Empir. Econ. 44 (2013): 799–831. [Google Scholar]
- H. Oberhofer, and M. Pfaffermayr. “Fractional Response Models—A Replication Exercise of Papke and Wooldridge (1996).” Contemp. Econ. 6 (2012): 56–64. [Google Scholar] [CrossRef]
- D.O. Cook, R. Kieschnick, and B.D. McCullough. “Regression Analysis of Proportions in Finance with Self Selection.” J. Empir. Financ. 15 (2008): 860–867. [Google Scholar] [CrossRef]
- S.L.P. Ferrari, and R. Ospina. “A General Class of Zero-or-One Inflated Beta Regression Models.” Comput. Stat. Data Anal. 56 (2012): 1609–1623. [Google Scholar]
- R. Davidson, and J.G. MacKinnon. “Several Tests for Model Specification in the Presence of Alternative Hypotheses.” Econometrica 49 (1981): 781–793. [Google Scholar] [CrossRef]
- L.E. Papke, and J.M. Wooldridge. Econometric Methods for Fractional Response Variables with an Application to 401(k) Plan Participation Rates. National Bureau of Economic Research Technical Working Paper No. 147; Cambridge, MA, USA: National Bureau of Economic Research, 1993. [Google Scholar]
- T.F. Lin, and P. Schmidt. “A Test of the Tobit Specification Against an Alternative Suggested by Cragg.” Rev. Econ. Stat. 66 (1984): 174–177. [Google Scholar] [CrossRef]
- J.M.R. Murteira, E.A. Ramalho, and J.J.S. Ramalho. “A Generalized Goodness-of-Functional Form Test for Binary and Fractional Regression Models.” Manch. Sch. 82 (2013): 488–507. [Google Scholar]
- J.G. Cragg. “Some Statistical Models for Limited Dependent Variables with Application to the Demand for Durable Goods.” Econometrica 39 (1971): 829–844. [Google Scholar] [CrossRef]
- C. Gourieroux, A. Monfort, and A. Trognon. “Pseudo-maximum Likelihood Methods: Theory.” Econometrica 52 (1984): 681–700. [Google Scholar] [CrossRef]
- J.J. Heckman, and R.J. Willis. “A Beta-Logistic Model for the Analysis of Sequential Labor Force Participation by Married Women.” J. Polit. Econ. 85 (1977): 27–58. [Google Scholar] [CrossRef]
- C.E. McCulloch, and A.F.M. Searle. Generalized, Linear and Mixed Models. Hoboken, NJ, USA: John Wiley & Sons, 2001. [Google Scholar]
- R.L. Prentice. “Binary Regression Using an Extended Beta-Binomial Distribution, with Discussion of Correlation Induced by Covariate Measurement Errors.” J. Am. Stat. Assoc. 81 (1986): 321–327. [Google Scholar] [CrossRef]
- J.M.R. Murteira, and J.M.C. Santo Silva. “Estimation of Default Probabilities Using Incomplete Contracts Data.” J. Empir. Financ. 16 (2009): 457–465. [Google Scholar]
- N.L. Johnson, A.W. Kemp, and S. Kotz. Univariate Discrete Distributions, 3rd ed. Hoboken, NJ, USA: John Wiley & Sons, 2005. [Google Scholar]
- J. Mullahy. Multivariate Fractional Regression Estimation of Econometric Share Models. NBER Working Papers 16354; Cambridge, MA, USA: National Bureau of Economic Research, 2010. [Google Scholar]
- J.M.R. Murteira, and J.J.S. Ramalho. “Regression Analysis of Multivariate Fractional Data.” Econom. Rev., 2014. forthcoming. [Google Scholar] [CrossRef]
- H. Oberhofer, and M. Pfaffermayr. Two-Part Models for Fractional Responses Defined as Ratios of Integers. WIFO Working Papers 472; Vienna, Austria: Austrian Institute of Economic Research, 2014. [Google Scholar]
- “Journal of Applied Econometrics Data Archive.” Available online: http://qed.econ.queensu.ca/jae/1996-v11.6/papke-wooldridge/ (accessed on 27 August 2014).
- N.J.D. Nagelkerke. “A Note on a General Definition of the Coefficient of Determination.” Biometrika 78 (1991): 691–692. [Google Scholar] [CrossRef]
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oberhofer, H.; Pfaffermayr, M. Two-Part Models for Fractional Responses Defined as Ratios of Integers. Econometrics 2014, 2, 123-144. https://doi.org/10.3390/econometrics2030123
Oberhofer H, Pfaffermayr M. Two-Part Models for Fractional Responses Defined as Ratios of Integers. Econometrics. 2014; 2(3):123-144. https://doi.org/10.3390/econometrics2030123
Chicago/Turabian StyleOberhofer, Harald, and Michael Pfaffermayr. 2014. "Two-Part Models for Fractional Responses Defined as Ratios of Integers" Econometrics 2, no. 3: 123-144. https://doi.org/10.3390/econometrics2030123
APA StyleOberhofer, H., & Pfaffermayr, M. (2014). Two-Part Models for Fractional Responses Defined as Ratios of Integers. Econometrics, 2(3), 123-144. https://doi.org/10.3390/econometrics2030123