Abstract
We provide new analytical results for the implementation of the Hausman specification test statistic in a standard panel data model, comparing the version based on the estimators computed from the untransformed random effects model specification under Feasible Generalized Least Squares and the one computed from the quasi-demeaned model estimated by Ordinary Least Squares. We show that the quasi-demeaned model cannot provide a reliable magnitude when implementing the Hausman test in a finite sample setting, although it is the most common approach used to produce the test statistic in econometric software. The difference between the Hausman statistics computed under the two methods can be substantial and even lead to opposite conclusions for the test of orthogonality between the regressors and the individual-specific effects. Furthermore, this difference remains important even with large cross-sectional dimensions as it mainly depends on the within-between structure of the regressors and on the presence of a significant correlation between the individual effects and the covariates in the data. We propose to supplement the test outcomes that are provided in the main econometric software packages with some metrics to address the issue at hand.
JEL Classification:
C12; C23
1. Introduction
As is well known, the implementation of the Hausman specification test (Hausman 1978) might be affected, in practice and in a finite sample setting, by a non-positive definiteness or (in-) definiteness problem for the variance-covariance matrix corresponding to the difference between the efficient estimator and the consistent estimator1. This, in turn, can potentially lead to a negative value of the test statistic, which makes it unreliable for interpreting the test outcome. This problem is usually mentioned in the context of models using instrumental variables (IV) (Baum et al. 2003, pp. 19–22; Staiger and Stock 1997, pp. 567–68) where the Hausman test is performed to assess the endogeneity of the regressors, given a set of instruments. In this case, one solution to ensure a symmetric positive definite (hereafter, SPD) covariance matrix is to use a common and identical estimator for the variance of the (idiosyncratic) error term when confronting the Ordinary Least Squares (OLS) and the IV estimators (Hayashi 2000, pp. 220–33; Baum et al. 2003, pp. 19–22).
Yet, although the issue has been pointed out as a warning by Hausman himself when he addressed the case of a static balanced, panel data model in his seminal presentation of the test (Hausman 1978, footnote 25, p. 1267), it has not been, to the best of our knowledge, further formally examined in this specific framework2. This is surprising, as one of the most widespread applications of the Hausman test is for assessing the relevance of the random (RE) versus fixed effects (FE) specification in a panel data model. From our point of view, this application, however, deserves attention in its own right, and this article aims at filling this gap. Specifically, our contributions are twofold.
We first provide new and detailed analytical results for the implementation of the Hausman test in the case of a static and balanced panel data model with individual effects. In particular, we show that the test statistic is unreliable in a finite sample if the variance of the RE estimator is computed on the basis of the estimation of the quasi-demeaned model (we denote it in what follows QDM)3 rather than the conventional and direct implementation of the Feasible Generalized Least Squares (FGLS) on the RE panel data model. This result directly follows from the way in which standard errors are computed under the QDM approach and which can lead to a positive definiteness problem for the covariance matrix in the Hausman test statistic formula. To establish the unreliability, we perform a systematic analysis of the difference between the Hausman statistics computed under the two approaches as well as of the behavior of the statistic that uses the estimates based on the QDM regression framework. In particular, we show that the latter mainly depends on the within-between structure of the regressors and on the presence of a significant correlation between the individual effects and the covariates in the data4.
Second, based on a review of the main existing econometric software programs that deal with panel data models, we show that the vast majority of the related packages in those programs implement, by default, the Hausman test using the unreliable statistic. This leads us to assess different ways to supplement the test outcomes provided by those programs and/or to circumvent the reliability problem potentially raised by the use of the statistic involved.
The outline of the paper is as follows. First, in Section 2, we show how the two versions of the Hausman test statistics can produce diverging results for some well-known textbook examples in the context of panel data models. Then, in Section 3, we formalize the implications of the two approaches for the Hausman statistic and derive new analytical results regarding the comparison of the two versions of the statistic that follows from each of the two approaches. We also revisit textbook examples and provide some simulation results in the one-regressor case. Finally, in Section 4, we detail how the Hausman test is implemented in a variety of econometric software programs dealing with panel data models and discuss, on the basis of this review, some possible ways to implement this test in a reliable and robust manner with this software. The last section concludes.
2. Motivation
In this section, we illustrate the extent to which significant differences in the values of the Hausman test statistic may arise depending on the approach adopted to estimate the panel data model parameters and, more particularly, those pertaining to the variance components under the random effects (RE) specification.
2.1. Notation
All the case studies considered below are for a standard, linear, static, and balanced panel data model with individual effects (also called the one-way error component-panel data-model). Accordingly, we consider the following relationship:
where denotes the cross-section dimension; the time-series dimension; the -th observation of the dependent variable; a column vector of the -th observation on K explanatory variables; an unknown scalar and a vector of unknown parameters, both to be estimated5. The error term is assumed to take the following composite form:
where denotes the (unobservable) individual-specific (or individual) effect-also called the individual component of and denotes the idiosyncratic component of . Furthermore, we assume that and are independent of each other and that and . It is also assumed that for all .
As is well known, two alternative specifications are usually considered regarding the correlation between the individual effect, and the regressors contained in . On the one hand, the random-effects (RE) model assumes that this correlation is zero, ensuring that is strictly exogenous for in (1). On the other hand, the ‘fixed effects’ model allows for a non-zero correlation between the individual effect and the regressors. The Within transformation is then used to obtain an unbiased estimate for .
The Hausman specification test (Hausman 1978) is widely used for testing the no-correlation assumption underlying the RE specification. In our setting, the test is based on the asymptotic properties of the RE and Within (or fixed-effects) estimators of . Both estimators are consistent under the null hypothesis (of no correlation) while, under the alternative, only the Within estimator is consistent as the RE estimator is (asymptotically) biased. Accordingly, the test statistic is built on a distance measure between the Within and RE estimators. In its implementable version, the statistic writes as:
where and denote the Within (or fixed effects) estimator of and a consistent estimator of its asymptotic covariance matrix, respectively; and denote the RE estimator of and a consistent estimator of its asymptotic covariance matrix, respectively. The index indicates that two approaches can be considered to obtain a consistent estimator of the asymptotic covariance matrix, leading to two versions of the test statistic (see Section 3.3).
2.2. Motivating Examples
We reproduce some outcomes of panel model estimations for well-known case study applications taken from main textbooks in the field. In the following tables, Std Err._1 and Std. Err._2 denote the two sets of standard errors for the parameters implied by the use of two different estimators for the covariance matrix of the RE estimator (detailed below). The values of the two related versions of Hausman test statistics are denoted and . Other variables and parameters are shown in the tables, the definitions and interpretations of which are left for discussion in Section 3 where we further comment on those results.
2.2.1. Motivating Example 1: Gasoline
Baltagi (2005) provides an interesting example of an important difference between the two versions of the Hausman test statistic in a study on the determinants of gasoline demand over the period 1960–1978 across 18 OECD countries6. The following specification is adopted:
where is motor gasoline consumption per auto, is real income per capita, is real motor gasoline price and denotes the stock of cars per capita.
Table 1 clearly shows that the two values of the Hausman statistic deviate strongly from each other, even if the null hypothesis is rejected in both cases. It is also interesting to observe that the two sets of standard errors remain close to each other7.

Table 1.
Estimation results for motivating example 1, Gasoline.
2.2.2. Motivating Example 2: Airline
Greene (2000) relies on the following specification concerning the cost function in the airline industry8:
where is the total cost, in $1000; Q is output, measured in “revenue passenger miles” (index number); is fuel price and is a rate of capacity utilization: it is the average rate at which seats on the airline’s planes are filled. The dataset consists of six firms observed yearly for 15 years (1970 to 1984).
In this case (Table 2), while the two values are much closer and clearly lower than in the previous case. They both lead to the rejection of the null. Also, the two sets of standard errors are quite close.
Table 2.
Estimation results for motivating example 2, Airline.
The airline case provides further interesting outcomes when the specification is estimated with two covariates. We single out the regression with and as the two covariates. The corresponding estimation results are provided in Table 3.
Table 3.
Estimation results for motivating example 2, Airline, two covariates.
This new set of results is interesting for the negative sign of the computed and furthermore in that . Using the absolute value of the statistic to perform the Hausman test (as some software packages do), the null hypothesis would not be rejected contrary to the outcome implied by . Note at this point that these results are obtained for a sample distribution of the covariate’s observations featuring a structure of the variance largely skewed in its within dimension.
2.2.3. Motivating Example 3: Wage determination
In another application, Greene (2012) relies on Cornwell and Rupert (2008)’s study about the determinants of the returns to schooling. The dataset is a balanced panel of 595 observations on heads of households that runs over the period (1976–1982). Among the specifications examined by Greene, we consider the following one:
where denotes the number of years of full-time work experience; , the number of weeks worked; if the status of the occupation is blue-collar occupation, 0 if not; if the individual works in a manufacturing industry, 0 if not; if the individual resides in the south, 0 if not; if the individual resides in a city, 0 if not; if the individual is married, 0 if not; if the individual wage is set by a union contract, 0 if not; lastly denotes the log of the (yearly) wage9.
The estimation results are presented in Table 4. Here, even with a large sample (4765 observations), we observe significant differences between the two Hausman statistics (which are very large) as well as the two sets of the standard errors for the random effects model (the ratio of the latter that is provided by (see later) is close to ).
Table 4.
Estimation results for Motivating example 3, Wage.
3. The Two Versions of the Hausman Test Statistic
The two versions of the Hausman statistic refer to two possible approaches for estimating the covariance matrix of the estimator of the parameters of the model given in its RE specification (1) and (2). We first start with a formal and explicit presentation of these approaches since their implications for the computation of the Hausman test statistic have remained largely unnoticed.
3.1. The Original Hausman Test Specification in a Balanced Panel Data Model
We rewrite model (1) and (2), stacking the observations over the time and cross-sectional dimensions:
where is the vector for the observations of the dependent variable; a vector of ones of dimension and is the matrix including the observations of the K explanatory variables; is the vector for the composite error terms. The covariance matrix of is denoted by . Given the properties of and , it takes the following form:
with , , , (the Between operator), (the Within operator), where ⊗ is the Kronecker product, (resp. ) the (resp. ) identity matrix and a matrix of ones of dimension T.
It is useful to define such that with denoting the centered Between operator defined as and with . We also use defined as . As B and W are symmetric and idempotent, and, in turn: . The same applies to and with replacing B in the previous formulas.
Assume first, that the variance components (and thus , and ) are known. Then, it is well established that:
(1) The RE estimator of corresponds to the Generalized Least Squares (GLS) estimator of in (3), noted , and is given by (4) with its covariance matrix by (5):
(2) The Within (or fixed effects) estimator of , , is given by (6) and its covariance matrix by (7):
with and .
The GLS estimator can alternatively be obtained, using the quasi-demeaned model (also called the partial Within transformation model) built from (3) with the premultiplying factor10 :
with ; . It is easy to check that the OLS estimator of in (8)-denoted as -corresponds to 11. Also:
where which corresponds to (5) as
Based on the former estimators, the Hausman specification test statistic initially proposed by Hausman (1978) is:
with and denoting the (finite sample) exact covariance matrix of . Under the null hypothesis of no-correlation, is asymptotically distributed as a .
3.2. Two Estimation Procedures
In practice, and are unknown and replaced by consistent estimators (noted , and , respectively12). In this case, the Hausman test statistic is written as:
where:
(1) with, now, indicating that the RE estimator corresponds to the Feasible Generalized Least Squares (FGLS) estimator for (), accounting for the use of instead of .
(2) is a consistent estimator of the asymptotic covariance matrix of built upon the finite-sample estimator of the (exact) variance of and with indicating that, for the RE estimator, two approaches are available to compute this matrix.
Under suitable conditions assumed to hold in what follows13, and are asymptotically equivalent and is, as , asymptotically distributed as a .
We now discuss the choice of variance component estimators that are required to compute .
First, a consistent estimator for is: , where denotes the consistent estimator for built from the OLS estimation associated with the Within (transformed) regression model, denoting the vector of the related residuals.
Second, to obtain , two approaches are possible.
3.2.1. Approach 1: The (Direct) FGLS Approach
Relying on the asymptotic equivalence between and , the computation of a consistent, asymptotic covariance matrix estimator for can be considered directly from the expression (5) where is substituted for and for , which yields:
with and . in (11) should logically be chosen as the same estimator as the one entering into14 for computing also appearing in (11). One usually relies on the estimator based on the ‘fixed effects model’ for this purpose, so that we set (Swamy-Arora approach). We use that correspondence in what follows.
3.2.2. Approach 2: The Quasi-Demeaning Approach
A consistent (asymptotic) covariance matrix estimator for can alternatively be obtained from the quasi-demeaned regression model (8) considered in its feasible version with substituting for where and . We note this feasible version of the QDM model as the FQDM regression model. In this case, and relying again on the asymptotic equivalence between and , the resulting “plug-in” estimator can then be computed from the formula giving the covariance matrix for the OLS estimator of in (8), i.e., (9), where substitutes for and for :
In line with the quasi-demeaning approach, the computation of is, here, usually considered as a byproduct of the OLS estimation process at work for the FQDM regression model. Accordingly, is computed as where denotes the vector of the OLS residuals in the FQDM regression model.
From (11) and (12), we observe that as . Thus, the two approaches differ in providing two distinct estimators for the variance of the (RE) estimator insofar as they rely on two different estimators of the variance component, . This leads to what we call, in the following, a disturbance variance disconnect problem.15
3.3. Comparing the Two Versions
From the previous results, it follows that two possible expressions are available for an implementable version of the Hausman test statistic, depending on which estimator of the asymptotic covariance matrix for is chosen.
3.3.1. Two Statistics
Using , we have:
or, using , we have:
Hausman (1978) originally proposed using , which he considered as the legitimate computational version of (Hausman 1978, footnote 25, p. 1267):16
“Note that the elements of and its standard errors are simply calculated given the estimates and of and their standarderrors, making sure to adjust to use the fixed effects estimate of ”.
On the other hand, as we will see in Section 4, most software programs compute the Hausman test statistic based on the second measure, . Consequently, it is important to analyze how behaves in relation to in finite sample settings. For that purpose, define the ratio h as . can then be rewritten as:
Comparing with (13), we note that diverges from as .
3.3.2. Main Results
To go further into the comparison of the two versions of the Hausman test statistic, we rewrite their expressions as:
where we define and .
From (16) and (17), the comparison between and is based on the one between and . Note that with and can be rewritten as where . It follows that writes as and as .
Finally, define and with denoting the spectrum of and with: .
We establish the following results (see Appendix A for details and related proofs):
- is a symmetric positive definite (SPD) matrix. It follows that is a positive-definite quadratic form.
- can be either a symmetric positive or a negative definite matrix or even an indefinite matrix depending on specific conditions holding for h. As a consequence, can be of either sign (and even of indeterminate sign a priori) depending on the values taken by h. Specifically, we have:
- (a)
- is a symmetric positive definite (SPD) matrix iff . In this case, is a positive-definite quadratic form
- (b)
- is a symmetric negative definite (SND) matrix iff . In this case, is a negative-definite quadratic form
- (c)
- is indefinite iff . In this case, can be of either sign, which is indeterminate a priori.
Based on those results, comparing relative to depends on whether is SPD or SND. We then have:
- If is SPD, the relevant comparison relies upon the magnitude . We have whenever
- If is SND, it necessarily follows that .
In establishing those results, we directly echo the discussions, mentioned in the introduction, about the positive definiteness of the variance-covariance matrix estimator in the expression of the Hausman test statistic. As we observe, whether this matrix is SPD or not (which translates into whether or is SPD or not) depends on the choice of the estimator for , which, itself, hinges on the approach that is adopted to estimate the variance components associated with the RE model. In other terms, is, by construction, an SPD matrix, and this has to be related to the use of the same estimator for , i.e., , in the computation of the covariance matrix estimator. On the other hand, this is not necessarily the case for and this has to do with the fact that two different estimators have been considered for , and ().
Table 5 provides an overview of all possible cases. A wide spectrum of outcomes can be obtained for the value of depending on the value of h. Unreliable results for the test may arise notably when is negative.
Table 5.
Review of all cases.
3.3.3. Back to the Case Studies
Based on h and the proposed metrics for , we can now analyze the mechanisms driving the various outcomes observed for the case studies selected in Section 2.2.
From Table 1, Table 2, Table 3 and Table 4, in 3 cases out of 4, . It follows that in those cases, is an indefinite matrix. As a consequence, the sign of is a priori indeterminate as well the relative magnitudes of and . The observed outcome depends on the specific value taken by for the sample considered.
Conversely, in the two covariates’ regression case drawn from Greene, where is computed as a negative scalar, we logically have and even which is consistent with , what we, by the way, also observe.
3.4. What about h?
As we have shown, the value of h is key for determining the outcome of the Hausman test if it is measured through . In this section, we analyze the main determinants for this ratio and provide an illustration through simulations in the single regressor case.
3.4.1. Determinants
The value of h essentially derives from the comparison between and and therefore, in turn, from the two residual sums of squares that are associated with, respectively, the Within model and the feasible, quasi demeaning model . We show (see Appendix B) that the following relationship holds between the two expressions:
where denotes the vector of the OLS regression residuals for the Between (transformed) regression model with , and where is defined as:
where is defined as in (16) and can be written as: . From the definition of and , we obtain and , so that (18) can be rewritten as:
from which it follows that:
with . Furthermore, considering the definition of given in (16), we have: and therefore:
so that whenever .
Taking advantage of the relationship between h and , we identify two categories of determinants for and h from (16) and (21):
- The first category is related to the structure of the data at hand, i.e., the Between and Within components of the (empirical) covariance matrix of the explanatory variables. They are captured by the matrices and , which influence the structure of (and therefore the magnitude of its eigenvalues).
- The second category is linked to the correlation between the individual effects and the regressors contained in , which determines the extent of the (asymptotic as well as finite sample) bias for (with respect to ). This affects the gap between (that is unbiased) and and therefore the value of .
These same factors in turn influence the determination of , the value of which is mostly linked to the comparison between h and the eigenvalues of .
With respect to the behavior of compared to , two mechanisms are at work. Assume that is large because of a significant distance between the RE and Within estimator. On the one hand, we could expect that will also be large and therefore that both statistics will correctly lead to reject the null hypothesis. This is because when is large, the further h will be from 1 from the upside, and in turn, the more likely it will be for the condition to prevail, which leads to as long as h remains below . On the other hand, the larger , the more likely it will actually be that and this could be all the more the case as the structure of the covariance matrix would be such that (or even ) is relatively small. In this case, the sign of becomes indeterminate which does not allow for a clear conclusion about the relative magnitude of the two test statistics and creates a possible divergence for the interpretation of the test.
3.4.2. Illustrations in the Single Regressor Case
To illustrate the role of the previous factors as well as to clarify their interpretation, we perform Monte-Carlo simulations on the behavior of the main magnitudes involved in the comparison between () and () in a single-regressor model .
Preliminary Results
In such a setting, and the various expressions for the main estimators and statistics simplify accordingly. We measure the total sample variance in the observations for with where and , with . We then define and . By construction, we have Hence, and can be used as a measure of, respectively, the Within and the Between components (up to a - factor) of the total (empirical) variance in the NT observations contained in . Finally, define the share of the Within variance in the total variance. Then, substituting, we obtain:
with and .
Design of Simulations
We perform Monte-Carlo simulations on the behavior of the previous four quantities, , h, and . The details of the simulation design are presented in Appendix C. We generate several series of based on a model , where we fix and we let the other parameters of the simulation vary: , , , , , and with the same notations as before, is the correlation between x and u (on the cross-sectional dimension) and is the intra-class coefficient of the error term (share of the within variance in the total variance in u)17. Then, for each combination of the parameters, we perform 199 replications and compute the median of and . To explore the main dimensions of variability of and , we perform an ANCOVA analysis (Table A2 in Appendix C) where we regress, respectively, each of the means and medians on the levels of the different parameters and the interactions that we found significant.
Results of the Simulations
The results are similar whether we consider the mean or the medians over the replications of the levels of and for each combination of parameters. The value of and significantly depend on T, , high absolute values of and . Conversely, the scale parameters and do not have a significant impact on and .
The visual representation of the behavior of (the median) and for , , and is in Figure 1. This illustrates the strong dependence of the values of the Hausman statistics on on the one hand and on the correlation between and on the other hand. In particular, for high absolute values of and high values of , even yields negative values.
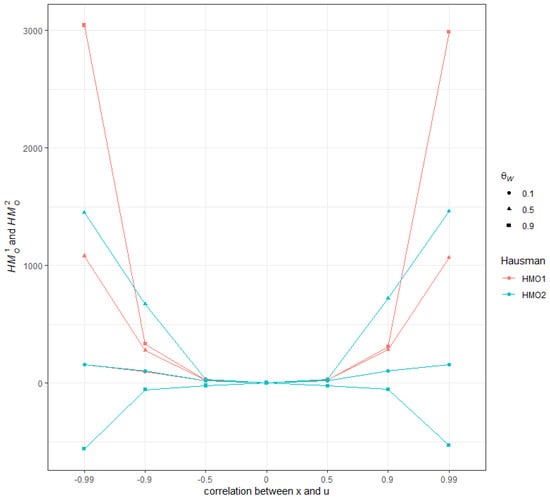
Figure 1.
Distribution of the median of and , , , and .
This latter result is, for example, consistent with the regression outcomes obtained with as a single covariate in the framework of motivating Example 2 [Airline]. In this case (see Table A3), is computed as a negative scalar with . Note also the extremely large value of for the covariate which partly drives the values taken by and h.
Finally, looking more closely at the distribution of negative values for (Figure A1 in Appendix C), we clearly see that they are an increasing function of , and (correlation between x and u) in absolute value. While the empirical size of both tests remains around with little variations for the various values of the parameters, the power of consequently drops to 0 for the highest values of , and (Figure A2 in Appendix C).
4. The Implementation of the Hausman Test in Standard Econometric Software Packages for Panel Data: A Brief Review and Discussion
In this section, we review how six well-known econometric software packages deal with the implementation of the Hausman test in a standard panel data model and provide some discussion.
4.1. Review
- STATA programming commands for the estimation of the random-effects panel data models (xtreg with the re option) rely on the specification of the quasi-demeaned model in (8). As a consequence, the random effects parameter estimates as well as its “conventional” covariance matrix estimate are provided as standard outputs of the OLS regression performed on that model. In particular, the vce(conventional) - default - command yields the (asymptotic) covariance matrix estimate based on the standard variance estimator for OLS regression. This corresponds to with, accordingly, used for the residual variance estimate. The default version of the command for implementing the standard Hausman test (the hausman command) corresponds accordingly to .
- The R PLM package developed by Croissant and Millo (2008) allows estimating a wide range of panel data models with R software. Regarding the random-effects specification, the estimation process can be implemented via the plm function, whose model argument takes the random option. Croissant and Millo (2008) point out that it could have been possible to program the computation of the covariance matrix estimator for directly from the formula (11), “once the variance components have been estimated and hence the covariance matrix of errors”. However, to limit the computational costs associated with the inversion of the () matrix () or () and the related memory limits to store it, plm resorts to the specification and estimation of the quasi-demeaning estimator (8). Then, the coefficients’ covariance matrix estimator is readily calculated by applying the standard OLS formulas which, in the R language, go through the vcov() command.The phtest command computes the Hausman test in plm. Its main arguments are the two-panel model objects that underlie the comparison (ex. model = within and model = random). The corresponding estimates of the asymptotic covariances matrices provided under both models are thus used to compute the Hausman statistic corresponding to .
- EViews estimates the random effects models using feasible GLS. The first step refers to the estimation of the covariance matrix for the composite error formed by the effects and the idiosyncratic disturbance. The EViews 9 User’s Guide II notes “Once the component variances have been estimated, we form an estimator of the composite residual covariance, and then GLS transform the dependent and regressor data”. As for the computation of the FGLS estimate, Eviews uses the quasi-demeaned model specification and proceeds on this basis. However, the calculation of the related coefficients’ covariance matrix is based on the direct application of the formula (11) and thus corresponds to . The procedure for the Hausman test then corresponds to .
- MATLAB provides estimation methods for the standard fixed (Within), between, and random effects models with the the panel data toolbox. Panel data models are estimated using the panel(·) function with the options argument set to re for the random effects model specification. The random effects FGLS estimates are based on the quasi-demeaned model and the asymptotic variance-covariance matrix for statistical inference is accordingly provided by (see Equation (18) in Alvarez et al. (2017)). Then, hausmantest computes the Hausman test where the input of the hausmantest function requires the output structures of the two estimations to be compared. Accordingly, the statistics that are computed correspond to .
- GAUSS: The GAUSS Times Serie∞s MT 3.0 TSMT provides a fixed effects and random effects models (TSCS) package that can be implemented through the tsmt library and the one-in-all tscsFit procedure. Another possibility is to use the pdlib GAUSS library and the randomEffects procedure in it. Both procedures implement the quasi-demeaning transformation on the original dataset and apply the standard OLS estimator on the transformed data so as to form the FGLS estimate. The covariance matrix estimate comes as a direct by-product of the OLS outcome so that is used. The Hausman test provided in the tscsFit procedure is implemented accordingly and corresponds to .
- SAS (SAS ETS 13.2) provides estimation methods for the standard fixed (Within), between, and random effects models in the balanced and unbalanced cases with the PANEL procedure toolbox. Standard panel data models are estimated using the PROC PANEL command with the MODEL statement specifying the regression model and the assumptions for the error structure. Specifically, FIXONE and RANONE must be used to specify the fixed-effect and the random-effect models, respectively (in the cross-sectional one-way case). In the latter case, various methods (but not the Swamy-Arora approach) are proposed to estimate, in the first stage, the variance components (through the VCOMP = option). It is explicitly indicated that the random effects FGLS estimates are then based, in the balanced case, on these variance components estimates through the quasi-demeaning approach, where ‘the random effects is then the result of simple OLS on the transformed data’ (see SAS ETS 13.2 User Manual (2014), p. 1417). The estimator for the asymptotic variance-covariance matrix is thus provided by . The Hausman statistic is automatically generated and reported as a conventional F statistic, with the statistic computed as .
4.2. Discussion
As the previous review indicates, in all but one of the packages discussed above, the Hausman test is, by default, implemented through the computation of with the quasi-demeaning estimator. The rationale for such a choice is computational. Indeed, the quasi-demeaning approach allows avoiding the inversion of the () matrix or , which can be computationally costly (in terms of time and rounding errors). Conversely, the quasi-demeaned model only requires partially demeaning the variables with as the partial demeaning factor. Yet, as a counterpart of this standard OLS regression, is naturally chosen to compute the residual variance estimate and, in turn, yields to , which might, as we have seen, be an unreliable statistic for the Hausman test. In what follows, we explore some ways to circumvent the problems posed by the use of this statistic.
(1) First, it is possible to compute and still rely on the quasi-demeaning approach to estimate the parameters of the RE model (which, as mentioned before, is the default case in the vast majority of available econometric software). This can been easily seen from the relationship (21) that we established between h and . Once h has been determined, which only requires the OLS residual sums of squares from the estimation of the Within and the quasi-demeaning estimator, we can derive . Hence, the following procedure can be suggested, if required, to supplement the existing programs.
- Use the quasi-demeaning estimator to compute the RE estimator for and .
- Use and (within regression) to compute h.
- Rearranging (21), obtain from h as: .
- Implement the Hausman test on the basis of
(2) Second, depending on the software packages considered, some programming options can be used to fix the potential ‘variance disconnect’ problem associated with the use of the statistic .
For example, in STATA, it is possible to use the sigmamore and/or sigmaless option commands when implementing the Hausman test. As indicated in STATA instructions: “sigmamore and sigmaless specify that the two covariance matrices used in the test be based on a common estimate of disturbance variance. sigmamore specifies that the covariance matrices be based on the estimated disturbance variance from the efficient estimator. sigmaless specifies that the covariance matrices be based on the estimated disturbance variance from the consistent estimator”. Following the lines of Hausman’s seminal approach would lead to the choice of sigmaless option, whereby the variance estimator, is based on the Within model, would be used18. This would ensure the test to be performed upon the statistics. The choice of sigmamore19 would imply to consider a third test statistics, , where the common disturbance variance estimator would be based on the quasi-demeaned model, so that we would have: . Comparing and , we observe that whenever . Thus, the more likely it would be to favor (even unduly) the rejection of the null hypothesis on the basis of when .
Some packages also offer the possibility to rely on an alternative expression for the Hausman statistic that does not involve the use of the RE estimator, so that it is immune to the variance disconnect problem. This expression was initially proposed by Hausman and Taylor (1981) and is based on the difference between the Between and Within estimators . Hausman and Taylor (1981, pp. 1382–83), establish that the resulting version of the Hausman statistic is numerically exactly identical to the one that is built upon and used above, that is: . Such a solution can be notably implemented in the R PLM package using the phtest command and specifying as arguments model = within and model = between.
(3) Finally, two other approaches that depart from the separate estimation of the FE and RE model parameters - which underlies the standard implementation of the Hausman test - can be emphasized. They have the advantage of solving the disturbance variance estimator disconnect problem, while allowing, more generally, for a robust implementation of the Hausman test20.
(3.1) The first of these approaches relies on implementing an auxiliary regression, that was initially proposed by Hausman himself together with the presentation of the standard specification test (see also Mundlak 1978). This regression takes the following form:
with where and and a vector of standard random disturbances.
It can be shown that the formula of the standard Wald test statistic for testing whether in the previous regression framework is equivalent to the one of the standard Hausman test statistic as expressed in terms of the difference between the Between and Within estimators (see Hausman and Taylor 1981 and above)21. Resorting to this auxiliary regression framework has two advantages. First, it involves only one estimator for the covariance matrix in the Wald test statistic formula, that one for , which is immune to the positive definiteness problem that can be encountered with the standard Hausman test statistic. Second, and as underlined by Baltagi and Liu (2007), it can be made robust to heteroskedasticity of unknown form (see, also, Arellano 1993).22 Once the variables have been transformed to be included as regressors in the auxiliary regression framework, the latter can be implemented in a rather standard way in any of the software econometric packages we have reviewed supra.
(3.2) The second approach goes through implementing White (1982)’s reformulated Hausman specification test that is based on the Maximum Likelihood (ML) estimation of the FE and RE model parameters. The related test statistic takes the form:
with and (resp. ) denoting the ML estimator related to the Within (resp RE) regression framework; would serve as the covariance matrix estimator and involves the information matrices for both estimators of , as well as outer products of scores within and between the two models under concern. White (1982) shows that remains positive definite even under misspecification (including heteroskedasticity).
The last two procedures we have presented could even be suggested to be used in the first place when assessing the relevance of the RE-model specification as they allow for globally robust implementation of the Hausman test in the context of panel data models (if only, insofar as they do not require to be directly based on the use of the RE (FGLS) disturbance variance estimator).
5. Conclusions
In this paper, we provide new analytical results of the behavior of the Hausman statistic for the test of orthogonality between the individual effects and the error term in a static and balanced panel data model. We compare the Hausman statistic computed with direct FGLS implementation and the Hausman statistic computed on the quasi-demeaned model. We show that this difference depends upon several parameters; in particular, the between-within structure of the regressors. We show by means of a Monte Carlo simulation in the single regressor case and of a set of well-known textbook examples that the difference can be substantial and that in some cases, the Hausman statistic computed on the basis of the quasi-demeaned model can yield strong negative values. Therefore, despite its computational advantage, the quasi-demeaned model should not be used prima facie as the basis of the computation of the Hausman statistic. We suggest, if needed, to supplement the existing software instructions so as to be able to compute in any case the relevant statistic. Extensions can include deriving these analytical results for unbalanced panel data models, two-way component models and dynamic panel models.
Author Contributions
Conceptualization, M.-A.S.; methodology, J.L.G. and M.-A.S.; validation, J.L.G.; formal analysis, M.-A.S.; investigation, M.-A.S.; resources, J.L.G.; data curation, J.L.G. and M.-A.S.; writing—original draft preparation, M.-A.S.; writing—review and editing, J.L.G. and M.-A.S.; visualization, J.L.G.; supervision, J.L.G.; project administration, M.-A.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The data are available upon request from the authors.
Acknowledgments
The authors thank the referees for their very useful comments and their careful reading of the first version submitted, which allowed to improve the paper. They also gratefully acknowledge the precious help of Alain Bachelot about the analysis of the definiteness of some matrices in the paper.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Hausman Test Statistics
Appendix A.1. Matrix Conditions
We first prove the following lemma (denoted below as Lemma A1):
Lemma A1.
Let R and M be two (square) matrices of size K. We assume that R and are symmetric positive definite (SPD). Then, M can be diagonalized and there exists a non singular matrix P such that:
and
with denoting the i-th eigenvalue of matrix M and the diagonal matrix whose elements are the eigenvalues of matrix M .
Proof.
According to the spectral theorem (see Axler 2014), there exists a non-singular matrix such that
with denoting the i-th eigenvalue of matrix R and the diagonal matrix whose elements are the eigenvalues of matrix R
It follows that:
so that:
We then consider the symmetric (positive definite) matrix C, defined as:
Consider in turn the matrix that is symmetric. The spectral theorem ensures that there is an non-singular matrix that satisfies:
Define the following matrix:
(A4) ensures that
We have:
which leads to (A1).
Taking into account this result and refering on (A6), we see that:
Appendix A.2. Applications
We obtain the following properties and results:
- We first note that and are two symmetric (real valued) matrices. This comes from the definition of which is computed as the sum of two symmetric matrices, .
As defined in the main text, while . Then:
- Note and . By construction R and are two real positive symmetric definite matrices (this is because and that R can be written as which is the inverse of the sum of two symmetric positive definite matrices).We then deduce from Lemma1 that can be diagonalised and that there exists a non singular matrix P such that:As is SPD (given that is itself SPD), this ensures that the spectrum of is only composed of strictly positive elements.
- Let and . By construction, R and are again two real symmetric positive matrices. We deduce from Lemma1 that can be diagonalised and that there exists a non singular matrix P such that:
- Noticing that , then, on the basis of the results above, we can write as:Then, let denote a non-null vector, and setting , we obtain the spectral decomposition of as:Since we know that is SPD, we obtain from the latter decomposition that . which implies that .
- Further, noticing that and proceeding as for above, we can write as:Let denote a non-null vector, and setting , we obtain the spectral decomposition of as:From this spectral decomposition, we conclude that
- –
- will be SPD if and only if , that is, if and only if is fulfilled.
- –
- will be SND if and only if , that is, if and only if is fulfilled.
We now use the previous results to compare and . For that purpose, we must distinguish according to whether is (for sure) a positive or (for sure) a non-positive quadratic form. This does in turn depend on whether is SPD or SND.
- If is SPD, the relevant comparison can be built on the magnitude . The former can be written as:with .Thus, whenever is SPD or SND. Given the definition of , and since is SPD, this, in turn, depends on whether is SPD or SND.Then, observe that .As is SPD, it follows that whether is SPD or SND depends on whether .
- If is SND, the relevant comparison is between and , and can be built on . The former magnitude can be written as:where and .Thus, whenever is SPD or SND. Given the definition of , and as is SPD (since is SND), this, in turn, depends on whether is SND or SPD.Then, observe that .Proceeding as for above, we can write as:Note by a non-null vector, and setting , we obtain the spectral decomposition of as:From this spectral decomposition, we conclude that:
- –
- will be SPD if and only if , that is, if and only if .
- –
- Conversely, will be SND if and only if , that is, if and only if .
Hence, we obtain the following table covering all cases:
Table A1.
Review of all cases.
Table A1.
Review of all cases.
| ( is SPD and ) | ||
| ( and sign of a priori indefinite) | ||
| indefinite | ||
| ( is SND and ) | ||
| indefinite | ||
Appendix B. Relation between Within Residuals and Quasi-Demeaned Residuals
Preliminary Result: We first show that:
Proof.
We start with the definition of , the vector of the OLS residuals in the FQDM regression model. We have:
with . Using the definition of , we can rewrite (A8) as:
where denotes the vector of the OLS regression residuals for the Between (transformed) regression model; and is the OLS estimator of in the Between transformed model which can be expressed as with and (as a reminder) denoting the centered Between operator defined as with .
Then, noting that for , which leads to: and using the following relationship between and :
with and, as a reminder, , we can rewrite equation (A9) as:
with:
□
Using the property according to which , we deduce, after manipulations, from (A12), the following relationship between the two residual sums of squares and :
which corresponds to the equation provided in the main text in Section 3.4.1 and where:
and25:
Define . Using the definition of and , this can be written as:
with being written as: .
Replacing in (A14), we have:
which is the expression provided in the main text for .
Appendix C. Simulations in the Single Regressor Case
In the simulations for , we focus on the role played by the structure in and in u on the values taken by h and as well as by the Hausman statistics and . Those structural features are captured, respectively, by and on the one hand and by and on the other hand where and ( is called the intra-class correlation coefficient in the variance component literature). We let also the degree of correlation between the regressor and the (composite) error term on the cross-sectional dimension vary across the experiments (we call it ).
Accordingly, for a given value of as well as for a given size of the sample (N and T given), we generate (with replications) one series for and one for and consequently one series for ), on the basis of which the different estimation procedures and the computation of the statistics of interest can be implemented.
Appendix C.1. Generating u it and x it
Each series for and is built such that the (sample) values of their total variances and Within variance shares in the total variance correspond to the ones that we set beforehand. To compute those series we adopt Nerlove’s approach (Nerlove 1971) and proceed in two steps.
- First, we draw N pairs for the random vector in the bivariate normal distribution with: , ; and .
- Second, for each , we draw T pairs for the random vector in the bivariate normal distribution with with and .
Then, the following variables are built:
with for : ; ; .
Finally we compute as and as .
This design ensures that , , and with (resp. ) denoting the sample variance for (resp. ).
Appendix C.2. Shaping the Experiment
We generate the different series for according to the following relationship:
In the simulations, we set . We let the other parameters of the simulation vary: , , , , , and .
Appendix C.3. ANCOVA Results
Table A2.
ANCOVA on simulation results.
Table A2.
ANCOVA on simulation results.
| Dependent Variable: | ||||
|---|---|---|---|---|
| Mean (1) | Mean (2) | Median (3) | Median (4) | |
| (ref = 20) | −24.158 | 134.826 ** | −24.132 | 136.294 ** |
| (37.475) | (56.029) | (36.677) | (55.435) | |
| (ref = 20) | −72.354 * | 405.306 *** | −72.281 ** | 409.057 *** |
| (37.475) | (56.029) | (36.677) | (55.435) | |
| (ref = 20) | 63.206 *** | 111.042 *** | 60.953 *** | 110.473 *** |
| (16.759) | (25.057) | (16.402) | (24.791) | |
| (ref = 20) | 126.892 *** | 306.754 *** | 122.040 *** | 303.316 *** |
| (16.759) | (25.057) | (16.402) | (24.791) | |
| (ref = 0.01) | 0.039 | −1.105 | 0.322 | −0.300 |
| (16.759) | (25.057) | (16.402) | (24.791) | |
| (ref = 0.01) | 0.277 | 2.784 | 0.803 | −0.171 |
| (16.759) | (25.057) | (16.402) | (24.791) | |
| (ref = 0.1) | 90.452 *** | −18.134 | 83.656 *** | −16.453 |
| (29.028) | (43.400) | (28.410) | (42.940) | |
| (ref = 0.1) | 184.362 *** | −35.323 | 167.161 *** | −30.374 |
| (29.028) | (43.400) | (28.410) | (42.940) | |
| (ref = 0) | 1083.156 *** | 640.633 *** | 1057.507 *** | 643.296 *** |
| (25.600) | (38.275) | (25.055) | (37.869) | |
| (ref = 0) | 147.213 *** | 214.549 *** | 141.792 *** | 202.157 *** |
| (25.600) | (38.275) | (25.055) | (37.869) | |
| (ref = 0) | 13.481 | 14.882 | 12.514 | 5.921 |
| (25.600) | (38.275) | (25.055) | (37.869) | |
| (ref = 0) | 13.436 | 3.664 | 12.469 | 5.878 |
| (25.600) | (38.275) | (25.055) | (37.869) | |
| (ref = 0) | 147.237 *** | 215.027 *** | 141.974 *** | 201.985 *** |
| (25.600) | (38.275) | (25.055) | (37.869) | |
| (ref = 0) | 1083.935 *** | 641.078 *** | 1058.341 *** | 643.762 *** |
| (25.600) | (38.275) | (25.055) | (37.869) | |
| (ref = 0.01) | −0.265 | 3.723 | 0.343 | 0.056 |
| (16.759) | (25.057) | (16.402) | (24.791) | |
| (ref = 0.01) | 0.400 | 0.780 | 1.234 | −0.119 |
| (16.759) | (25.057) | (16.402) | (24.791) | |
| (ref = 0.1) | 90.544 *** | −20.710 | 83.885 *** | −15.796 |
| (29.028) | (43.400) | (28.410) | (42.940) | |
| (ref = 0.1) | 184.478 *** | −31.878 | 167.171 *** | −29.092 |
| (29.028) | (43.400) | (28.410) | (42.940) | |
| : | 86.977 ** | −16.080 | 87.205 ** | −15.864 |
| (41.052) | (61.376) | (40.177) | (60.726) | |
| : | 261.702 *** | −41.165 | 262.250 *** | −48.630 |
| (41.052) | (61.376) | (40.177) | (60.726) | |
| : | 175.791 *** | −27.656 | 176.433 *** | −30.434 |
| (41.052) | (61.376) | (40.177) | (60.726) | |
| : | 525.795 *** | −89.808 | 526.255 *** | −92.123 |
| (41.052) | (61.376) | (40.177) | (60.726) | |
| : | 86.826 ** | −13.059 | 86.837 ** | −16.015 |
| (41.052) | (61.376) | (40.177) | (60.726) | |
| : | 261.064 *** | −45.820 | 261.054 *** | −48.512 |
| (41.052) | (61.376) | (40.177) | (60.726) | |
| : | 175.736 *** | −30.548 | 176.043 *** | −31.087 |
| (41.052) | (61.376) | (40.177) | (60.726) | |
| : | 526.388 *** | −84.972 | 526.704 *** | −92.531 |
| (41.052) | (61.376) | (40.177) | (60.726) | |
| Constant | −446.938 *** | −246.347 *** | −430.229 *** | −246.886 *** |
| (35.552) | (53.154) | (34.795) | (52.590) | |
| Observations | 5103 | 5103 | 5103 | 5103 |
| R2 | 0.580 | 0.165 | 0.579 | 0.169 |
| Adjusted R2 | 0.578 | 0.161 | 0.577 | 0.165 |
| Residual Std. Error (df = 5076) | 488.758 | 730.740 | 478.346 | 722.994 |
| F Statistic (df = 26; 5076) | 269.238 *** | 38.691 *** | 268.675 *** | 39.743 *** |
Note: * 0.1; ** 0.05; *** 0.01.
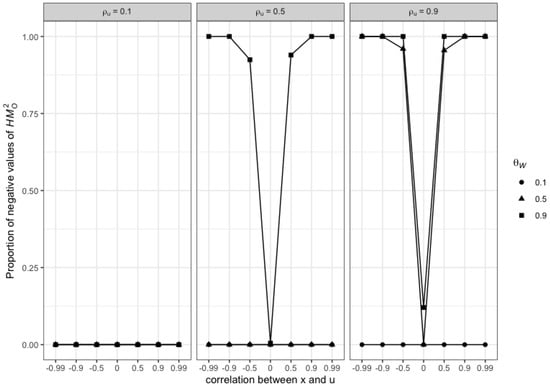
Figure A1.
Distribution of the proportion of negative values of , , , .
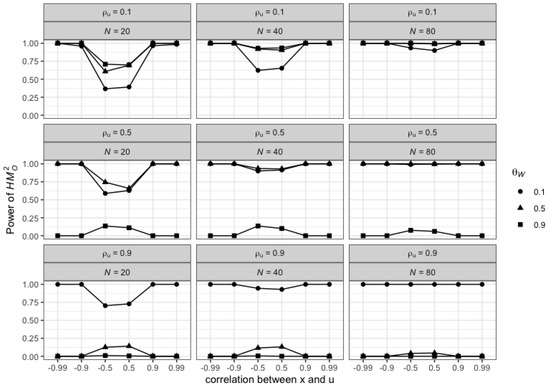
Figure A2.
Power of , , .
Appendix D. Regression Outcomes in the Single Regressor Case for the Motivating Example 2 [Airline]
Table A3.
Estimation results for Motivating example 2, Airline, single covariate.
Table A3.
Estimation results for Motivating example 2, Airline, single covariate.
| Specification | Intercept | ||
|---|---|---|---|
| Within specification | Coef. | − | |
| Std Err. | − | ||
| Between specification | Coef. | ||
| Std Err. | |||
| Random effect specification | Coef. | ||
| Std Err. 1 | |||
| Std Err. 2 | |||
| h | |||
| Within variance | |||
| Between variance | |||
| Within variance/Total variance (in %) | |||
| Between variance/Total variance (in %) |
Notes
| 1 | Schreiber (2008), based on Holly (1982), examines cases in which this problem can arise even asymptotically, when the alternative hypothesis is true. |
| 2 | In particular, this issue is generally not addressed in the leading textbooks in panel data econometrics. An exception is Wooldridge (2010), (chp. 10, pp. 289–90), but he merely mentions the possibility of obtaining a non-positive definite covariance matrix if different estimates of the error term variance are used, suggesting a way out, which we further discuss below. |
| 3 | See Nerlove (1971) and Fuller and Battese (1973), for an original exposition of the transformed, quasi-demeaned model and the related approach. |
| 4 | Schreiber (2008) also considers a panel data framework as an illustration for the asymptotic results and highlights cases where the matrix is not SPD in a context where the error term variance estimates differ. He does not, however, focus on the comparison of the different estimation approaches in the random effects model and their implications for the computation of the Hausman test statistic, as we do. |
| 5 | We assume in what follows that there is no time-invariant regressor in , so that it is possible to compute the -estimator with the Within transformation of (see below). |
| 6 | See the initial study by Baltagi and Griffin (1973). The dataset is available at: https://www.wiley.com/legacy/wileychi/baltagi/datasets.html, accessed on 2 May 2023. |
| 7 | Interestingly, in an updated version of his textbook, Baltagi (2021) modified the presentation of the Gasoline case study compared to the one provided in 2005 and presented here. In this update, there is no more disconnection between the two versions of the statistic, and only one version is considered, . While, in both presentations, the estimations are drawn from the STATA software package, the second presentation benefits from the use of the sigmaless option command that fixes the computation of the estimator for the idiosyncratic component of the error term. See infra in Section 4.2. |
| 8 | The original study is from Greene (1999). The dataset is available at: http://pages.stern.nyu.edu/~wgreene/Text/tables/tablelist5.htm, accessed on 2 May 2023. |
| 9 | The dataset is available at: http://pages.stern.nyu.edu/~wgreene/Text/Edition7/tablelist8new.htm, accessed on 2 May 2023. |
| 10 | A typical -observation for is given by where and . A similar transformation is applied for each of the components of , hence the quasi-demeaning expression for the transformed model that is obtained in that way. |
| 11 | Indeed, , which is equivalent to (4) given the definition of , and . |
| 12 | Given the definition of those matrices, this replacement relies on the use of consistent estimators for the variance components, i.e., , and/or . For a discussion about these variance component estimators, see, among others, Amemiya (1971); Fuller and Battese (1974); Maddala (1971); Nerlove (1971); Swamy and Arora (1972); Wallace and Hussain (1969). |
| 13 | In particular, we assume that (resp. ) is a consistent estimator for (resp. ). See Wooldridge (2010) for a discussion on these conditions. |
| 14 | The estimator for is usually computed from the sum of the squares of the OLS regression residuals, , for the Between (transformed) regression model with . (Swamy-Arora approach), see infra. |
| 15 | It can be easily checked that the two approaches give rise to the same (RE) estimator for the parameters, and . |
| 16 | The emphasis is added by us. The notation used by Hausman for the fixed-effects estimate of corresponds to our . |
| 17 | The intra-class coefficient drives the value of . It can be shown, indeed, that: . |
| 18 | Note that this estimator is also used to compute and in turn , which makes it fully, logically consistent with respect to the FGLS regression model framework. |
| 19 | This is, e.g., recommended by Cameron and Trivedi (2009), p. 360. |
| 20 | We thank both referees for having highlighted those approaches and suggested to account for them in this discussion subsection. |
| 21 | In this case, indeed, . |
| 22 | Baltagi and Liu show in (Baltagi and Liu 2007) that the Hausman test can be obtained equivalently from other artificial regressions, involving the use of the set of Between-transformed regressor variables, , or even the set of the initial regressor variables, . They also discuss the case where the auxiliary regression can accommodate the presence of potentially endogenous regressors. With respect to the issue of weak instruments in this context, see also (Staiger and Stock 1997). |
| 23 | Take two symmetric matrices A and B. We denote by the property according to which is a positive definite matrix (what we can also write as ). |
| 24 | If A and B are two symmetric positive definite matrices and are non-singular, then . |
| 25 | As a reminder, note that . |
References
- Alvarez, Inmaculada C., Javier Barbero, and José L. Zofío. 2017. A Panel Data Toolbox for MATLAB. Journal of Statistical Software 76: 1–17. [Google Scholar] [CrossRef]
- Amemiya, Takeshi. 1971. The Estimation of the Variances in a Variance-Components Model. International Economic Review 12: 1–13. [Google Scholar] [CrossRef]
- Arellano, Manuel. 1993. On the testing of correlated effects with panel data. Journal of Econometrics 59: 87–97. [Google Scholar] [CrossRef]
- Axler, Sheldon. 2014. Linear Algebra Done Right. New York: Springer. [Google Scholar]
- Baltagi, Badi H. 2005. Econometric Analysis of Panel Data, 3rd ed. Chichester and Hoboken: J. Wiley & Sons. [Google Scholar]
- Baltagi, Badi H. 2021. Econometric Analysis of Panel Data, 6th ed. Springer texts in Business and Economics. Cham: Springer. [Google Scholar] [CrossRef]
- Baltagi, Badi H., and James M. Griffin. 1973. Gasoline demand in the oecd: An application of pooling and testing procedures. European Economic Review 22: 626–32. [Google Scholar] [CrossRef]
- Baltagi, Badi H., and Long Liu. 2007. Alternative ways of obtaining Hausman’s test using artificial regressions. Statistics & Probability Letters 77: 1413–17. [Google Scholar] [CrossRef]
- Baum, Christopher F., Mark E. Schaffer, and Steven Stillman. 2003. Instrumental Variables and GMM: Estimation and Testing. The Stata Journal: Promoting Communications on Statistics and Stata 3: 1–31. [Google Scholar] [CrossRef]
- Cameron, Adrian Colin, and Pravin K. Trivedi. 2009. Microeconometrics Using Stata. College Station: Stata Press. [Google Scholar]
- Cornwell, Christopher, and Peter Rupert. 2008. Efficient estimation with panel data: An empirical comparison of instrumental variable estimators. Journal of Applied Econometrics 3: 149–55. [Google Scholar]
- Croissant, Yves, and Giovanni Millo. 2008. Panel Data Econometrics in R: The plm Package. Journal of Statistical Software 27: 1–43. [Google Scholar] [CrossRef]
- Fuller, Wayne A., and George E. Battese. 1973. Transformations for Estimation of Linear Models with Nested-Error Structure. Journal of the American Statistical Association 68: 626–32. [Google Scholar] [CrossRef]
- Fuller, Wayne A., and George E. Battese. 1974. Estimation of linear models with crossed-error structure. Journal of Econometrics 2: 67–78. [Google Scholar] [CrossRef]
- Greene, William. 1999. Frontier Production Functions. In Handbook of Applied Econometrics Volume II: Microeconomics. Edited by Pesaran M. Hashem and Schmidt Peter. Oxford: Blackwell Publishing Ltd., pp. 75–153. [Google Scholar] [CrossRef]
- Greene, William. 2000. Econometric Analysis, 4th ed. Upper Saddle River: Prentice Hall Internat. [Google Scholar]
- Greene, William. 2012. Econometric Analysis, 7th ed. Pearson Series in Economics; Boston and Munich: Pearson. [Google Scholar]
- Hausman, Jerry A. 1978. Specification Tests in Econometrics. Econometrica 46: 1251–71. [Google Scholar] [CrossRef]
- Hausman, Jerry A., and William E. Taylor. 1981. Panel data and unobservable individual effects. Econometrica 49: 1377–98. [Google Scholar]
- Hayashi, Fumio. 2000. Econometrics. Princeton: Princeton University Press. [Google Scholar]
- Holly, Alberto. 1982. A Remark on Hausman’s Specification Test. Econometrica 50: 749–60. [Google Scholar] [CrossRef]
- Maddala, Gangadharrao Soundalyara. 1971. The Use of Variance Components Models in Pooling Cross-Section and Time Series Data. Econometrica 39: 341–57. [Google Scholar]
- Mundlak, Yair. 1978. On the pooling of time series and cross section data. Econometrics 46: 69–85. [Google Scholar]
- Nerlove, Marc. 1971. A Note on Error Components Models. Econometrica 39: 383–96. [Google Scholar] [CrossRef]
- Schreiber, Sven. 2008. The Hausman Test Statistic Can Be Negative even Asymptotically. Jahrbücher für Nationalökonomie und Statistik 228: 394–405. [Google Scholar] [CrossRef]
- Staiger, Douglas, and James H. Stock. 1997. Instrumental Variables Regression with Weak Instruments. Econometrica 65: 557–86. [Google Scholar] [CrossRef]
- Swamy, Paravastu Aananta Venkata Bhattandha, and Swarnjit S. Arora. 1972. The Exact Finite Sample Properties of the Estimators of Coefficients in the Error Components Regression Models. Econometrica 40: 261–75. [Google Scholar] [CrossRef]
- Wallace, T. Dudley, and Ashiq Hussain. 1969. The Use of Error Components Models in Combining Cross Section with Time Series Data. Econometrica 37: 55. [Google Scholar] [CrossRef]
- White, Halbert. 1982. Maximum Likelihood Estimation of Misspecified Models. Econometrica 50: 1–25. [Google Scholar] [CrossRef]
- Wooldridge, Jeffrey M. 2010. Econometric Analysis of Cross Section and Panel Data, 2nd ed. Cambridge, MA: MIT Press. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).