1. Introduction
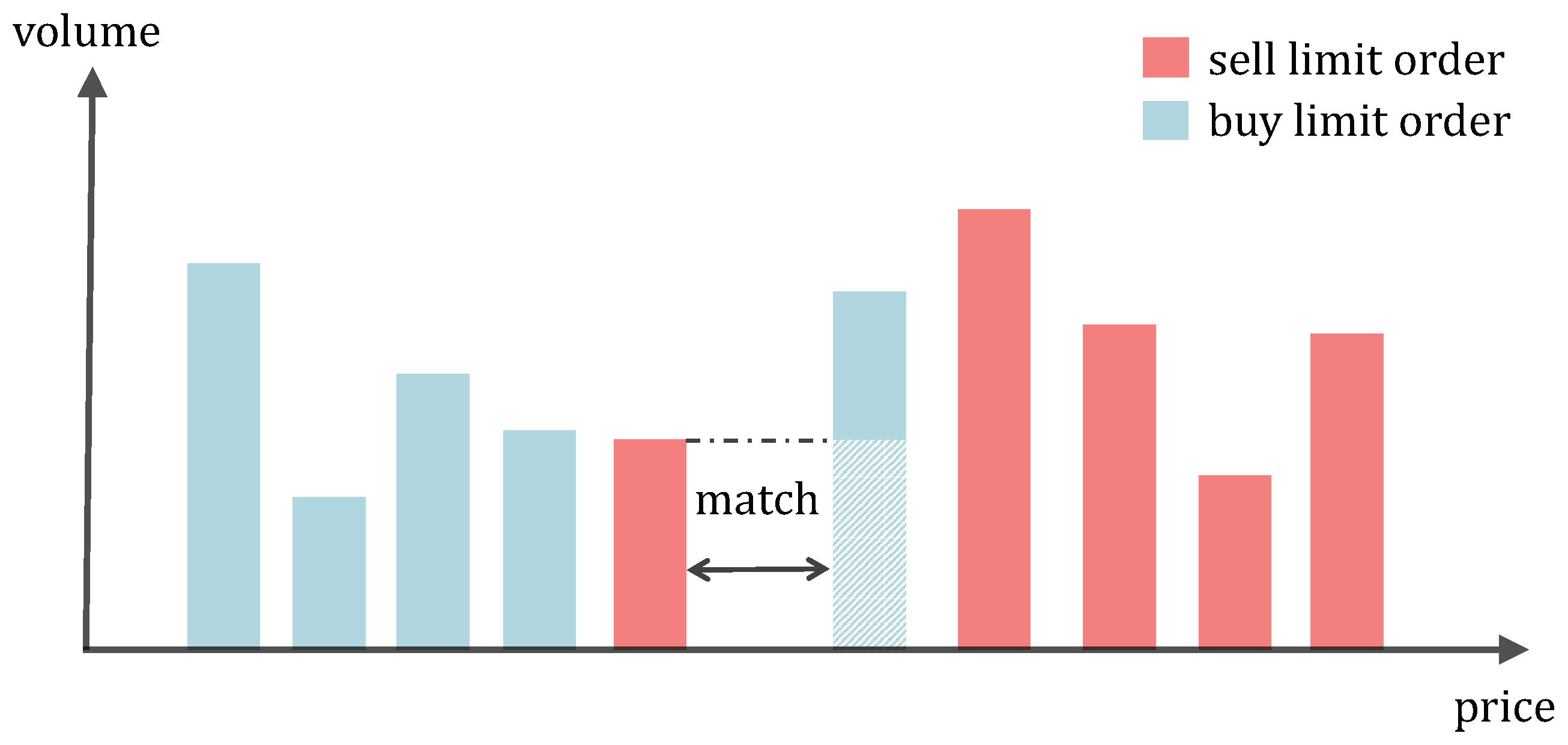
More and more investment institutions have entered the trading practice as the financial markets have significantly grown in recent years. This has led to a rapid increase in the amount of financial time-series data generated through high-frequency trading on the financial markets, presenting both opportunities and challenges for researchers to tackle. Our study in this paper focuses on analyzing the time-series data of limit order books (LOBs) for high-frequency trading (HFT). LOBs are records of outstanding limit orders maintained by the security specialists who work at the exchange. A limit order is a type of order to buy or sell a security at a specific price or higher. LOBs can be regarded as financial time series that reflect expected price levels for traders. By using a limit order book, traders can specify the exact price at which they want to buy or sell a security, such as an asset stock, so that the involved risk can be properly managed and the prospective returns can be maximized. However, LOBs are characterized by a low signal-to-noise ratio, non-stationarity, and non-linearity (
Henrique et al. 2019), making it a challenge to effectively and efficiently analyze them.
Stock (or more generally, security) price prediction is a key task in analyzing LOB data, which helps investors develop trading strategies and select investment portfolios that are more likely to produce high returns with low risks. Accurate forecasting of stock prices requires a robust and efficient model. Despite the abundance of research in this field, the challenges associated with the speed of computing such models remain. The main objective of our paper was to develop a fast online hybrid neural network model to predict stock prices.
To prepare for this development, a brief review of the current methods for stock price prediction is presented in the following. Overall, most of these methods fall into three categories: statistical parametric models, machine learning techniques, and deep learning approaches.
Regarding the statistical parametric models for stock price prediction,
Cenesizoglu et al. (
2016) extracted the informative variables that characterize LOBs, so as to establish a vector auto-regressive (VAR) model to analyze how various features of the LOBs affect prices.
Mondal et al. (
2014) evaluated the accuracy and variability of stock price forecasts using an auto-regressive integrated moving average (ARIMA) model. They employed the model selection criterion AICc to estimate the optimum ARIMA model and also analyzed the impact of altering the time frame of historical data on prediction accuracy.
Tran et al. (
2017) employed multi-linear discriminant analysis (MDA) to forecast large-scale mid-price movements through high-frequency limit order book data.
Catania et al. (
2022) introduced a multi-variate model for discrete high-frequency stock price changes using a hierarchical hidden Markov model based on the Skellam distribution, which accounts for the large proportion of zero returns and the co-staleness phenomenon. Although statistical parametric models are computationally efficient, they have limitations when applied to complex stock prices data and may not yield the desired results due to their strong dependence on assumptions that may not be met by these data.
A data-driven machine learning model is not typically constrained by assumptions. Rather, it uses the data themselves to identify patterns and relationships that can inform predictions.
Yun et al. (
2021) proposed a system for predicting the direction of stock price movements that emphasizes an enhanced feature engineering process. The system utilizes a hybrid of genetic algorithms and extreme gradient boosting (GA-XGBoost) to optimize the selection of features used in the prediction.
Kercheval and Zhang (
2015) used a multi-class support vector machine to capture the dynamics of high-frequency LOBs, which automatically predicts mid-price movement and other indicators in real time. Previous works in machine learning for stock price prediction have highlighted the importance of extracting relevant features from the underpinning big data for prediction.
Deep learning is a branch of machine learning that uses neural networks, each with multiple layers, to analyze data. These layers sequentially transform the raw data into informative statistics, allowing the model to extract important features and patterns from the raw data. A convolutional neural network (CNN) is a typical example.
Tsantekidis et al. (
2017) applied a deep learning approach that forecasts stock price movements by utilizing a CNN. Experiments show that the results of the CNN outperform many other machine learning models such as support vector machines. However, compared to other network structures, a CNN is relatively unsophisticated and underperforms in analyzing high-frequency trading data.
Recurrent neural networks (RNNs), such as long short-term memory (LSTM) (
Hochreiter and Schmidhuber 1997) and gated recurrent unit (GRU) (
Cho et al. 2014), have been widely used to predict stock prices. These architectures are well suited for time-series data, such as stock data, because they have the ability to keep previous inputs in their memory, which is important for incorporating the temporal dependencies from the inputs into the prediction process.
Chen and Zhou (
2020) proposed a stock prediction model that combines genetic algorithm feature selection with LSTM neural networks, demonstrating improved performance over benchmark models. As the complexity of financial data increases, more advanced neural network architectures have emerged to address these challenges. The transformer (
Vaswani et al. 2017) architecture, which utilizes a self-attention mechanism to weigh the importance of various input sequences, has been particularly useful for stock prediction, as it enables the model to weigh the importance of all financial indicators from the past, such as previous stock prices and volumes.
Ding et al. (
2020) developed a novel transformer-based approach for stock movement prediction, introducing enhancements such as multi-scale Gaussian prior, orthogonal regularization, and trading gap splitter. These improvements increased locality, reduced redundant head learning in multi-head self-attention, and captured hierarchical features in high-frequency financial data.
Hybrid neural networks, which combine different types of neural networks, can have better overall performance in stock prediction because they take advantage of the strengths of their respective architectures.
Zhang et al. (
2019) proposed deep convolutional neural networks for limit order books (DeepLOB). Three building blocks make up the network architecture of DeepLOB: convolutional layers, parallel inception layers, and an LSTM layer.
Zhang and Zohren (
2021) proposed DeepAcc for LOBs, which combines DeepLOB with a hardware acceleration mechanism for performing stock prediction. Both DeepLOB and DeepAcc utilize a CNN model as the encoder, which transforms the stock data into a vector. This is followed by a decoder that produces the final output.
While the accuracy of price prediction is undoubtedly a key performance indicator, the issue of computing speed by these deep learning methods is largely ignored in assessing the methods’ performance in the literature. In fact, in high-frequency trading, speed is crucial to a number of strategies, e.g., cross-market arbitrage and market making.
Baron et al. (
2019) discovered that variations in the relative latency can have a significant impact on the trading performance of HFT firms when they investigated the competition among these firms. Therefore, it is necessary to improve the prediction speed of their methods for investors to obtain more profits without undue risks.
Motivated by the above review and discussion, we propose an online hybrid neural network method for predicting stock prices based on high-frequency LOB time-series data, where we focus on achieving optimal computing speed while maintaining a high prediction accuracy and feasible computing memory. Our proposed method was developed by integrating the three neural network deep learning models LSTM, GRU, and transformer into an online architecture; hence, it is named online LGT or O-LGT. The key innovation underlying O-LGT is its efficient storage management, enabling super-fast computing. Specifically, when computing the stock forecast for the immediate future, we only use the output calculated from the previous trading data (rather than the previous trading data themselves) together with the current trading data. Thus, the computing only involves updating the current data in the process. Details of the method are presented in
Section 3.
Comparisons of our proposed method with the currently available stock price prediction methods reviewed above are also presented in this paper. For the Chinese stock market LOB data that are used in this paper, we found the best of the reviewed methods typically took at least 2.21 ms of computing time to reach the level of accuracy achieved by the O-LGT method. On the other hand, on the same computer with the same computing power, it typically took O-LGT 0.0579 ms of computing time to reach the same level of accuracy, approximately 40 times faster than the best reviewed method. More details of the comparison are presented in
Section 4. The improvement of the computing speed has significant implications for the traders in HFT, because it gives them more time to make decisions and execute orders than their competitors.
This paper is structured as follows. In
Section 2, we describe the LOB data used in our work in this paper. Next, we present the development of the methods in
Section 3, including the problem statement, the methods of RNN, LSTM, GRU, and transformer, and the framework of our O-LGT method.
Section 4 presents the details and results of our experiments. Finally, we conclude the paper with a summary in
Section 5.
3. Methods
3.1. Problem Statement
The problem tackled in this paper relates to developing an online hybrid neural network model for continuous prediction of stock prices based on high-frequency LOB data. Let
be the price of a stock at time
T, with
denoting the number of time units passed from the beginning of trading on each day. For the Chinese LOB data, the time unit is 3 s. Predicting
is equivalent to predicting the target variable
, defined as
, which represents the percentage change in the stock price between time
T and
h units of time earlier. In the Chinese HFT market, one typically predicts
at time
T with
, i.e., predicts the price 5 min forward. If
is denoted as the
features of the Chinese LOB data recorded at time
t as defined in
Section 2.2, then the prediction
of
by the LOB features recorded in the previous
s time steps can be generically formulated as the following:
where
denotes a generic neural network and
is an estimate of
obtained from the training data. The best predictions
across all values of
T are to be computed by minimizing
, where
is a customized discrepancy function that measures the proximity of an estimate to its actual value.
We developed an online hybrid neural network method to formulate and optimally estimate . This method is named O-LGT since it is in the form of a general recurrent neural network (RNN) containing multiple latent layers, which are specified by the long short-term memory (LSTM) model, the gated recurrent unit (GRU) model, and the transformer model in that sequence. In addition, the method is implemented in an online way, i.e., it is updated once the time moves forward by one unit. In order to give a detailed description of O-LGT, we first review all of its layers in the following.
3.2. Recurrent Neural Network (RNN)
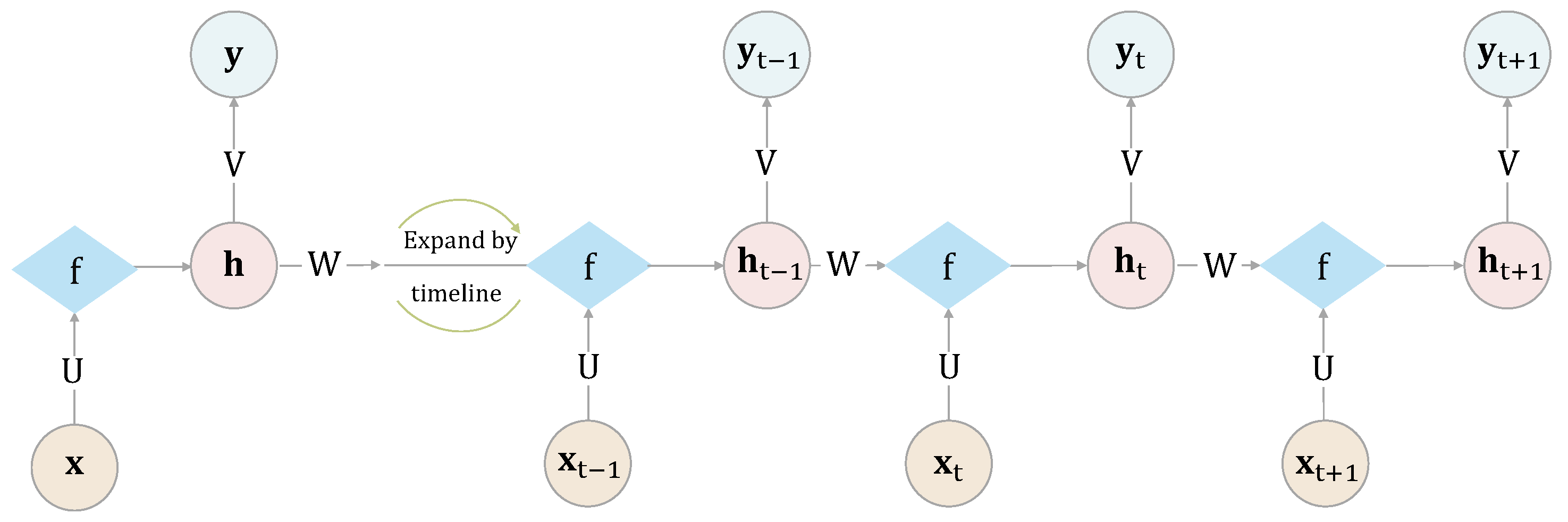
First, recall that recurrent neural networks (RNNs) are a type of neural network that are designed to process sequential data, such as time-series data. An RNN contains a hidden compartment that inputs information on the data from both the previous and the current time steps, and outputs predictions for future time steps. This hidden compartment is updated once at each new time step, by passing the input through to generate the output.
The structure of an RNN is cyclical, meaning that the same computation is performed at each step using the same parameters, which is why it is called recurrent. The architecture of RNNs can be unrolled to show the sequence of computations that occur over time.
Figure 2 is a typical RNN structure diagram, where
, the output vector of the hidden layer at time
t, depends not only on the input vector
at time
t, but also on
. The
is calculated using an activation function
as follows:
where
U is the input layer weight matrix and
W represents the hidden layer weight matrix. The RNN is initialized at time
with
where
is the activation function for the output layer and
V is the associated weight matrix. It then proceeds with the following operations at each time stamp
:
3.3. Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU)
Hochreiter and Schmidhuber (
1997) introduced the long short-term memory (LSTM) architecture to address the problem of vanishing gradients in traditional recurrent neural networks (RNNs) when trying to model long-term dependencies in sequential data.
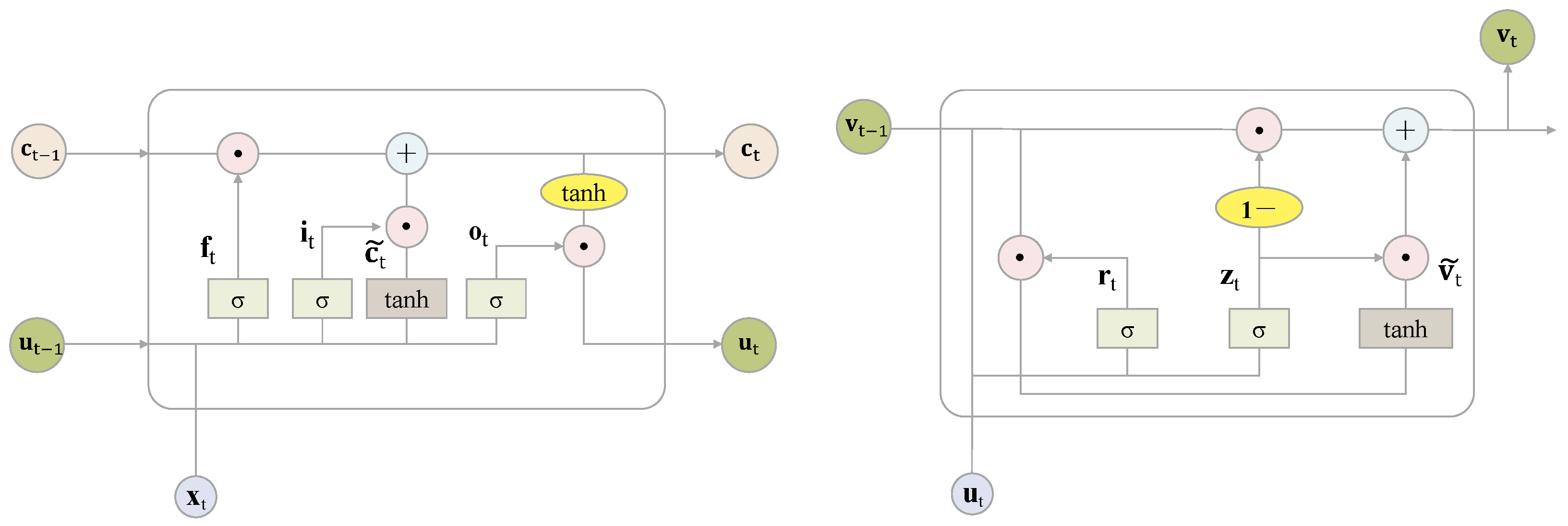
The core of LSTM is a cell consisting of an input gate
, a forget gate
, a candidate state
, and an output gate
, normally in the form of column vectors, as shown in the left panel of
Figure 3. The forget gate
determines the information to be directly passed to the cell state output
, the input gate
determines the information to be further used in the cell together with the candidate state
, and the output gate
together with the cell state output
gives the hidden layer output
.
The “long” in LSTM stands for the capability of the model to retain information for a long period of time. The memory cells in LSTMs, which can keep information for multiple time steps, enable the model to effectively identify long-term dependencies in sequential data. The “short” in LSTM stands for the model’s ability to discard irrelevant information promptly. An LSTM model uses the forget gate and input gate to appropriately store and retrieve selected information from the memory cells.
At each time
t, an LSTM model with a hidden layer dimension
loads the
feature vector
, the
hidden layer output vector
at the previous time stamp, and the
cell state vector
at the previous time stamp as the input. It then uses certain activation functions to generate
, which is a
matrix. Finally, it outputs the updates
and
. An update in LSTM at time
t can be expressed as follows:
where
,
,
, and
are the
weight matrices of the input gate, the forget gate, the output gate, and the cell state, respectively;
,
,
, and
are the
bias vector parameters of the input gate, the forget gate, the output gate, and the cell state, respectively. In addition, ⊙ is the Hadamard product operation. Moreover,
and
are activation functions defined as
The GRU model is a simplified version of the LSTM model and was introduced by
Cho et al. (
2014). Compared with LSTM, the GRU has fewer parameters and is computationally less expensive to train, while still being capable of capturing long-term dependencies in sequential data and robust against overfitting. The main difference between LSTM and the GRU is that the GRU combines the omission and input gates of LSTMs into a single update gate
. The GRU structure is depicted in the right panel of
Figure 3. The core of the GRU is a cell consisting of a reset gate
, an update gate
, and an output
.
The “Gated” in GRU refers to the use of gates to control the flow of information in and out of the hidden layer. “Recurrent” refers to the fact that the GRU is a type of recurrent neural network (RNN) that processes sequential data by passing information from one time step to the next.
At each time
t, a GRU model with a hidden layer dimension
loads the
LTSM hidden layer output
and the
GRU output vector
at the previous time stamp as the input. It then uses the activation functions
and
to compute
, which is a
matrix. Finally, it generates the updated GRU output vector
. An update in the GRU at time
t can be expressed as follows:
where
,
, and
are the
weight matrices of the GRU output, the update gate, and the reset gate, respectively; and
,
, and
are the
bias vector parameters of the GRU output, the reset gate, and the update gate, respectively.
Note that the reset gate is used to control the extent to which the output information of the previous time moment is ignored. Typically, the smaller the value of the reset gate, the more likely it is ignored. In addition, a larger value of the update gate indicates that the neural unit at the current time moment is less influenced by the output information of the neural unit from the previous time moment.
3.4. Transformer
After being processed by LSTM and GRU, the multi-headed transformer aids in extracting useful information regarding the interactions in outputs between various time steps.
There are significant differences between the transformer (
Vaswani et al. 2017) and the traditional RNN model, in that the attention mechanism in the former completely determines the structure of the entire network. Attention allows the model to focus on specific parts of the input by assigning different weights to different positions in the input sequence. This is in contrast to the traditional RNNs, which use the same weights for all positions in the input sequence.
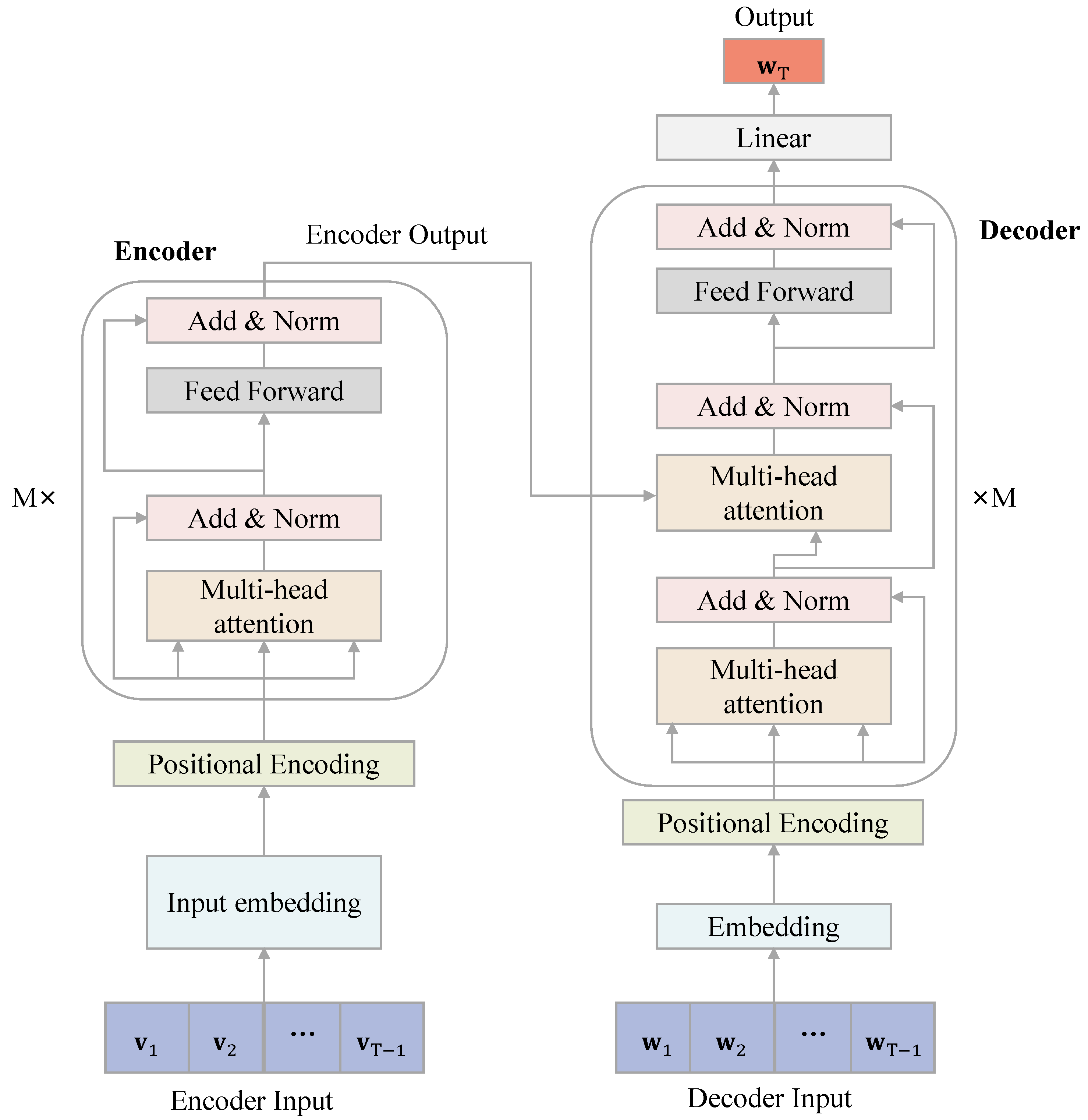
The transformer model uses the encoder–decoder architecture that is most commonly used in Neuro-linguistic programming. This architecture provides an effective way to handle long sequence data (
Bahdanau et al. 2014). In the transformer model, the encoder has four layers: The first layer uses a multi-head attention mechanism (multi-head attention) to assign multiple sets of different attention weights to the model for extending the model’s ability to focus on different locations, thus capturing richer information than otherwise. The second layer is the summation and normalization layer, where the summation, also named the residual connection, adds the interim output of the layer to its input before being normalized to produce the layer’s final output. The second layer passes the information from the previous layer to the next layer without differences to solve the gradient disappearance problem more quickly. The third layer is a feed forward neural network (FNN) layer. The fourth layer then goes through another summation and normalization layer to generate the intermediate semantic coding vector and transmit it to the decoder. The decoder has six layers, similar to the encoder structure, but the first layer is a multi-headed attention layer with a MASK (masking) operation, because at output time
t, the information at time
is not available, so the output of the decoder needs to be shifted right and the subsequent items are masked for prediction. Finally, the decoder goes through linear regression and the Softmax layer to output the final prediction result.
Figure 4 displays the block diagram for the transformer model.
3.5. Online LGT (O-LGT)
In this section, we present the details of our developed stock price prediction method, O-LGT, having reviewed the necessary RNNs. We will first provide a brief description of the sweep matrix operator, which serves as the core computing engine for O-LGT. We will then describe the framework of O-LGT and its practical implementation. Finally, we will discuss the standardization and transformation of input data before using them in O-LGT execution.
3.5.1. Sweep Operator
Computations involved in all neural network layers in O-LGT are essential for solving weighted regression normal equations
. The sweep matrix operator (
Beaton 1964) provides a very efficient method to solve these normal equations. Following
Goodnight (
1979), a square matrix
is said to have been swept on the
kth row and column (or
kth pivotal element) when it has been transformed into a matrix
, such that
Via a sweep operation on each pivotal element of M, each element of M is updated, essentially by one division operation. By applying sweep operations on all pivotal elements of , the normal equation can be solved in approximately divisions, with being the number of elements in matrix , which is the same computing complexity as that involved in the classical Gauss–Jordan elimination operator. However, when an extra column of data is augmented to X, the resultant new normal equation can be solved by updating the process of solving the previous normal equation by applying just one more sweep operation on the new pivotal element, which only takes extra divisions. This suggests the sweep operation is a much faster algorithm than the classical Gauss–Jordan elimination algorithm in online computing where the new data feeds into the process sequentially. This is the major reason our proposed O-LGT method uses the sweep operator in its core computing engine.
3.5.2. O-LGT Framework
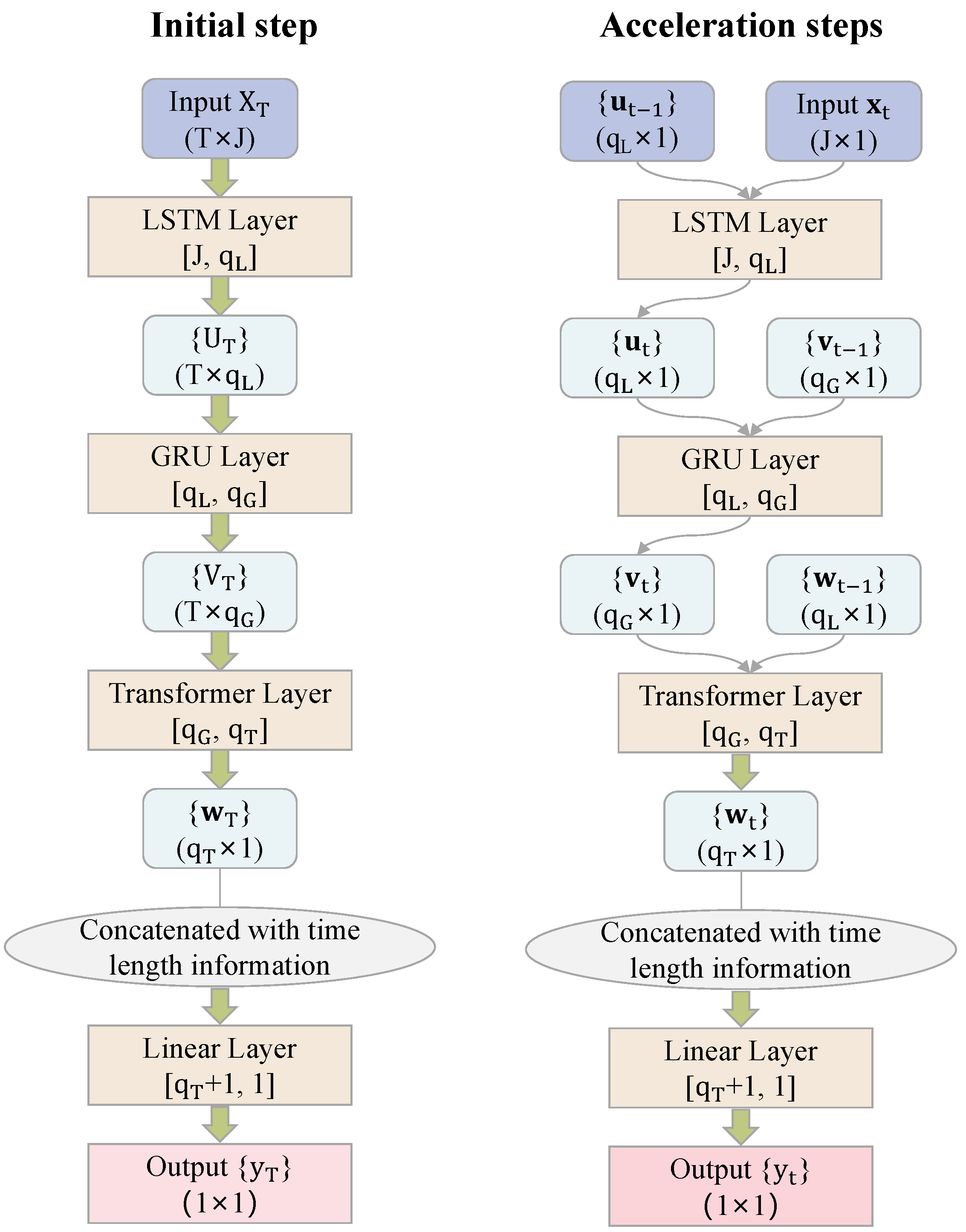
The O-LGT model combines LSTM, GRU, and transformer as three sequential layers into a composite RNN to predict stock prices in high-frequency trading (HFT). The LSTM layer is for capturing important information from the input data to return an accurate LSTM output. The GRU layer takes the LSTM output as the input, which is then processed in a condensed way to prevent overfitting. Then, the transformer layer takes the GRU layer output as the input, which is processed in such a way that the interaction effects between different time steps are incorporated into the output at a more granular level. Finally, the predictions are made by concatenating the transformer output with its time length information and feeding the result through a linear regression layer.
We used the instrument PyTorch to implement the O-LGT model, with the parameters and hyper-parameters being those presented in the paper. The detailed implementation steps are as follows:
The notation in
Figure 5 corresponds to the notation in
Section 3.3 and
Section 3.4, and the modeling principles for each layer are shown in
Section 3.3 and
Section 3.4. We used PyTorch to integrate each layer into the final hybrid model. The model architecture schematic of O-LGT is displayed in
Figure 5 and is explained in the following.
In the initial step, the model inputs , the matrix of observed features of the LOB data for the previous T moments, into an LSTM layer, and the output of this layer, , is stored. This output is then input into the next layer, a GRU layer, and the output of this layer, , is stored. The output of the GRU layer is then fed into a transformer layer, and the output, , is stored. This output and time length information are concatenated into the final linear regression layer to make the final predictions.
Input layer: (matrix of observed LOB features for the previous T moments);
LSTM layer: output (capture important information from the input data);
GRU layer: output (process in a condensed way to prevent overfitting);
Transformer layer: output (incorporating interaction effects between different time steps);
Concatenation: combine transformer output with time length information;
Linear regression layer: make final predictions .
In the acceleration steps, the O-LGT model uses a similar process but with the added input of the previous moment’s output for each layer.
Input layer: (vector of observed LOB features at time T) and (previous LSTM layer output);
LSTM layer: output (updated LSTM output);
GRU layer: output (updated GRU output), using and previous GRU layer output, ;
Transformer layer: output (updated transformer output), using and previous transformer layer output, ;
Concatenation: combine updated transformer output with time length information;
Linear regression layer: make latest prediction .
Our innovative implementation setting for O-LGT was shown to have the capacity to accelerate the computation of O-LGT without compromising its accuracy. In addition, the structure of each neural network layer in O-LGT is easy to understand, train, and compute on its own.
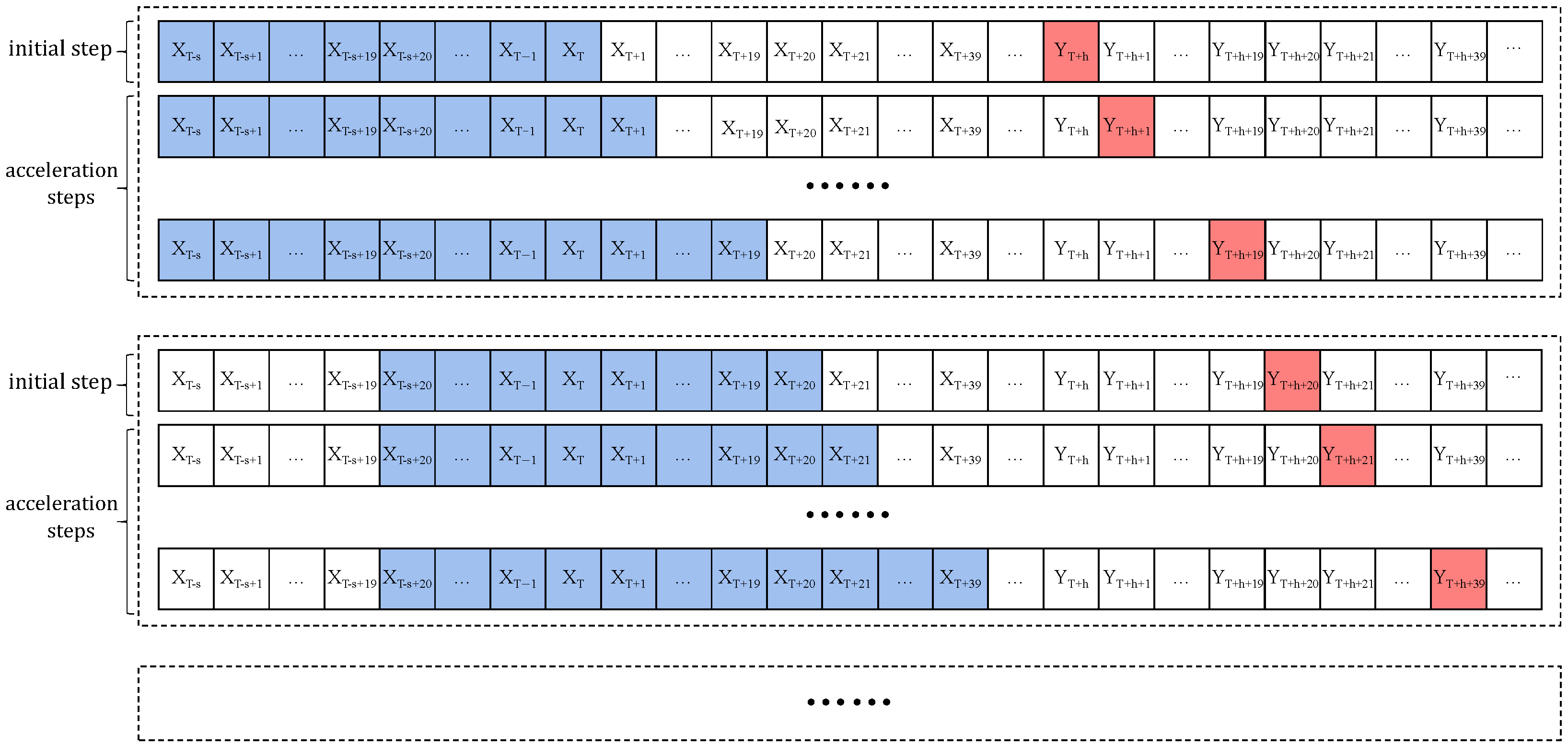
3.5.3. Experimental Design for Implementation
In an HFT market, the LOB data arrives at a very high frequency (every 3 s in the case of the Chinese HFT market). It is both computationally and logistically impractical to predict stock prices for the time steps immediately after the current time step when the latest LOB data arrives. Thus, we propose to predict the prices (in terms of price percentage change) using O-LGT for time step
when standing at the current time step
T, where
(i.e., 5 min) was chosen for our Chinese market case study. On the other hand, there is no need to use the LOB data from all past time steps until the current time step
T to predict the prices for time step
, because the stock price dynamics manifest an LSTM behavior. This behavior is fully utilized by our O-LGT framework in that, when the current time step is between
T and
(inclusive), we only use the LOB data from time step
T back to time step
to make predictions for time steps
until
. In this way, the required feature input data for processing O-LGT at a time step between
T and
is of a time length not more than
. It, thus, requires a very limited amount of computer memory, resulting in a significant acceleration of the predicting process with O-LGT. We term the implementation procedure just described for O-LGT the moving window-based prediction technique, with the back, current, and future window sizes being
s,
b, and
h, respectively. For the Chinese HFT market case study, we chose
(4 min 57 s),
(57 s), and
(5 min). This moving window technique is illustrated in
Figure 6, where the blue box represents the input features of the model and the red box represents the output of the model.
Our O-LGT method also ensures a higher prediction accuracy than the other RNN methods. Denote
as the sequence of the input feature data from time
c to time
d for a stock. Given
of arbitrary time length
T and the future window size
h, the online sequential way that the target variable
is predicted by the O-LGT model suggests
can be formulated as follows:
where
is a generic function,
is the summary information obtained from executing O-LGT at time
, and
s is the back window size. Here, the back window size
s cannot be too small, otherwise, the result is easy to underfit, and
s cannot be too large, otherwise, there is not enough space for storage. Typically, we selected the appropriate
s according to the performance of the training data. It can be observed that the O-LGT processing of the input data sequence follows a Markov dependence pattern. Only the latest input data block
at time
T and the previously aggregated information
are related to the prediction
at the current time moment
T. Hence, it is reasonable to conclude that an optimal value of
s can be found based on the training data so that the O-LGT algorithm with this optimal
s value will produce highly accurate predictions. However, we acknowledge that the optimal
s value determined this way may be too large to impact the computing complexity and speed. Fine-tuning the back window size
s based on trader’s experience is still important and even necessary.
3.5.4. Data Standardization and Transformation
Recall that an RNN is characterized by the fact that all the data at different moments share the same structure and coefficient specifications. Therefore, when the model inputs are of the same length, the data will follow the same distribution at . However, for some variables with cumulative effects over time, such as current prices, the cumulative effects result in different variances. For example, the price at moment is different from that at moment . Therefore, for variables with cumulative time effects, we transform the input from the absolute value to the percentage change of the current moment with respect to the previous moment. Therefore, the transformed variable will follow exactly the same distribution regardless of the time length. This treatment is more consistent with RNNs sharing the same network structure at different time lengths.
4. Experiment
In this paper, several experiments are presented on the CSI Smallcap 500 Index (CSI-500) in China to demonstrate the performance of the O-LGT model in stock market forecasting.
4.1. Data Pre-Processing for CSI-500
The dataset and the involved features are described in
Section 2. Since stock prices are influenced by various factors that are not known to us, the collected data appear to contain a large amount of noise and fluctuations that are actually determined by these unknown factors. If the original stock data are directly entered into the modeling and analysis process without data pre-processing, it may reduce the accuracy of the results significantly. To increase the prediction accuracy, an appropriate data pre-processing step is necessary, as shown below.
To prevent excessive data volatility, Equations (
10)–(
14) were also processed, with
denoting the day’s opening volume on the stock market. This keeps the data regularized and maintains the same distribution for the same variable.
4.2. Setting and Specification
In the experiments, computations by the O-LGT model were performed under the Python environment and the PyTorch framework. The Adam optimization method was used with a learning rate of 0.001 and an exponential linear decay of 0.95 after each epoch. The model’s parameters were updated based on the gradients of the mean square error loss function, and the model was trained for 100 epochs using the training dataset.
Table 2 lists the values of the tuning-parameters used in the model, while
Table 3 lists the software and hardware configurations used for the experiments.
4.3. Prediction Error Evaluation
The best prediction for stock prices was achieved by minimizing the loss function, which calculates the total differences between the predicted and the true price values. The resultant minimum loss provides a measure of prediction accuracy. Commonly used loss functions include mean squared error (MSE) and mean absolute error (MAE), which are defined below.
Mean Squared Error (MSE):
Mean Absolute Error (MAE):
where
denotes the predicted return of rate for stock
i at time
t;
denotes the true return of rate for stock
i at time
t;
N is the number of stocks;
n is the number of time steps. It is easy to see that a small MSE or MAE value corresponds to a high accuracy prediction.
4.4. Implementation Details
In this section, we present details of applying the O-LGT approach for analyzing the Chinese LOB data. The dataset includes 100 stocks from the CSI Smallcap 500 Index market for a total of one month. As per
Section 3.1, we set
, where
and
represents the price of a stock at time
T. In addition, recall that
is a
J-dimensional vector time series of the LOB features with
and
.
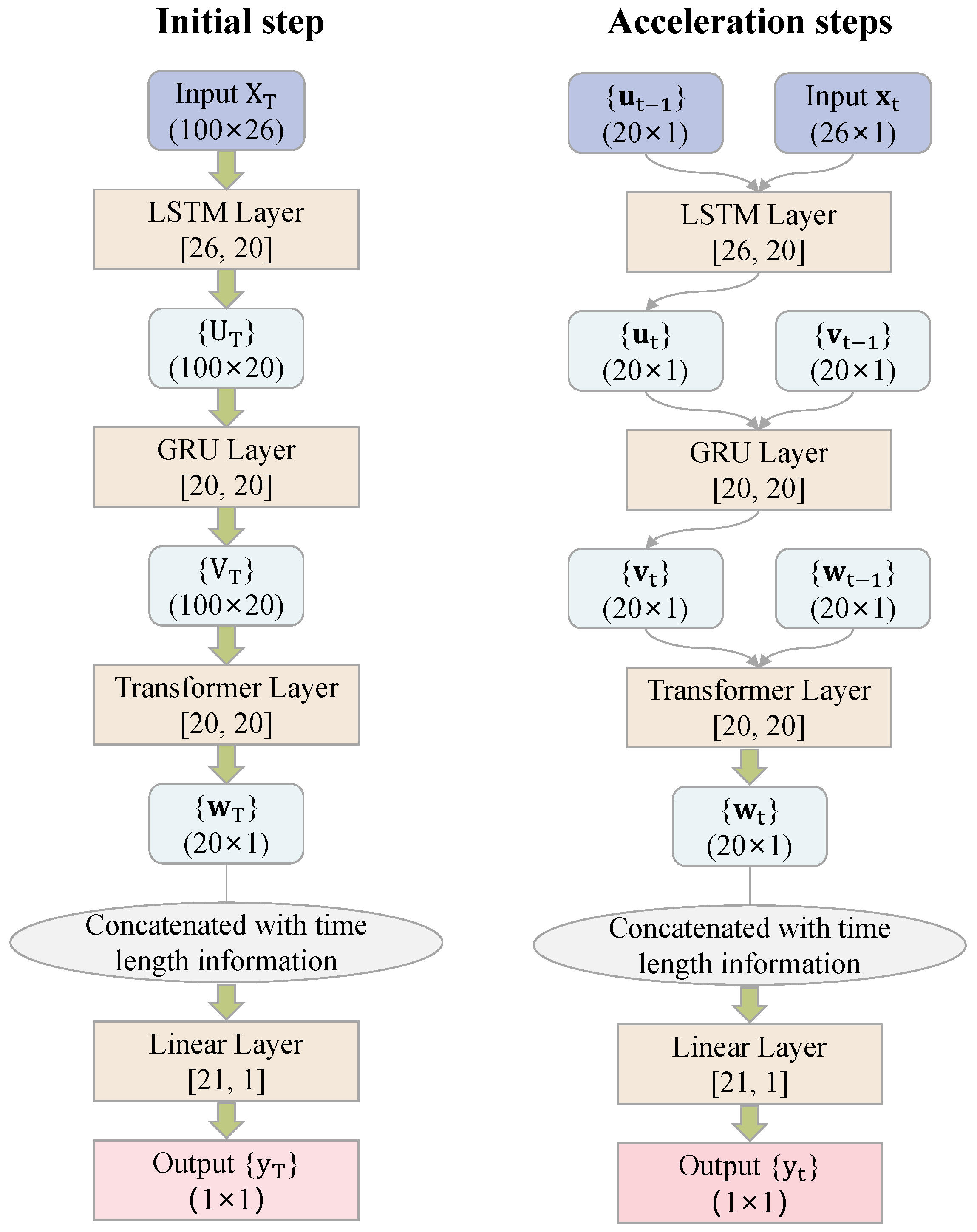
The left panel of
Figure 7 gives a flow chart of the modeling and prediction process for
at time
T for the initial step. The right panel is for the acceleration steps, where the back, current, and future window size of the associated moving window method are
,
, and
, respectively.
This demonstrates that, in the initial step, when time is at T, —a matrix of feature observations in all previous 100 time moments—is the input data we need for O-LGT. The input and output of the LSTM layer are both 20 dimensional. The GRU layer and the multi-head attention transformer layer are also 20 dimensional for both their input and output. The output of the transformer layer and the information with the length of time are concatenated together, i.e., 21 dimensional. This is then loaded as the input into the linear layer. The final output is the prediction of the stock price percentage change value .
In the acceleration steps when , has features in time t; , , and are vectors at time ; , , and are vectors at time t. The dimensions of the inputs and outputs are the same for each layer and the final output is the prediction of the stock price percentage change value .
Regarding the input of O-LGT, recall that we have 4740 time steps for each stock every trading day and there were 22 trading days in November 2021 in the Chinese HFT market. LOB information from every segment of 100 (i.e., ) plus up to 19 (i.e., ) consecutive time steps is used as a single input, and the rate of return after 5 min (i.e., ) is the corresponding output. For prediction in each time step , the feature data is used as the input, where T is a sharp minute time step (e.g., 9 h:50 m:00 s:am sharp), (57 s), and (4 min 57 s). Thus, we have around 4610 consecutive and overlapping segments of input data of the form on every trading day. Instead of testing the performance of O-LGT on all these 4610 segments of input data on each trading day (which is referred to as fixed testing), we were able to do it on a stratified random sample from these 4610 segments. For example, one such random sample could be obtained by first partitioning the 4610 segments into 461 consecutive sections and then randomly choosing a segment from each section. This testing, based on random sampling, is referred to as random testing. A possible advantage of using random testing is the reduced auto-correlations in the random sample. Instead of using a fixed back window size s for training the model, one could use a randomly selected s value at each updating step for the training. For example, s could be randomly selected from the interval . Selecting s at random is referred to as random training.
4.5. Experiment Results
In this section, we report the results of experiments to demonstrate the performance of our O-LGT model. We performed experimental studies for the CSI-500 dataset under three setups: Setting I, Setting II, and Setting III. Setting I simulated three comparative experiments specified by the fixed/random training/testing combinations. Setting II simulated a missing value scenario, under which O-LGT was compared with LGT and the linear model. Setting III was a scenario with no missing values in the input data, under which O-LGT was compared with XGBoost, DeepLOB, and DeepAcc, in addition to the linear model and LGT.
First, to confirm the validity of the experimental design, we carried out three comparison experiments in Setting I:
The moving window for model training had a fixed back section size . The model testing was performed on all 4610 input segments;
The moving window for model training had a fixed back section size , while the model testing was performed on a stratified random sample of 461 input segments;
The moving window for model training had its back section size s, which was chosen from at random, while the model testing was performed on a stratified random sample of 461 input segments.
Table 4 demonstrates that the performances of the O-LGT method were similar to each other under the three experiments, verifying the validity of our design. There was no significant difference in MSE and MAE when the input lengths of both the training and test sets were randomized compared to when the input lengths of both the training and test sets were fixed.
Next, we considered the scenario with missing values in Setting II. Specifically, values at five time steps in each segment of input data were removed at random.
Table 5 shows that when there were missing values, the prediction performance of LGT and O-LGT was much better than that of the linear model. Comparing LGT and O-LGT, we found no significant difference between MSE and MAE. The superiority of O-LGT in the presence of missing values was determined by its design features, as it was more flexible in the choice of input length, meaning the prediction accuracy was unaffected even in the presence of missing values.
In the absence of missing values in Setting III, we compared the O-LGT with not only the traditional models mentioned above, i.e., the linear model and GRU, but also with the DeepLOB and DeepAcc models reviewed in
Section 1, which are two powerful hybrid models with a superior overall performance.
Table 6 demonstrates that O-LGT and LGT had clear advantages over the other comparative models in terms of prediction accuracy. In terms of the computing time, O-LGT was about 38 times faster than LGT, about 64 times faster than DeepLOB, and about 12 times faster than DeepAcc. This shows that our O-LGT model can significantly speed up prediction while maintaining prediction accuracy, which is very beneficial for early risk assessment in the stock market.
In summary, our O-LGT model has the capacity to quickly and accurately predict stock price in high-frequency trading markets. The results confirm the validity of the experimental design and demonstrate the superior performance of O-LGT in terms of both prediction accuracy and computational speed compared to other models.
5. Conclusions
In this study, we developed O-LGT, an online hybrid recurrent neural network model tailored for analyzing LOB data and predicting stock price fluctuations in a high-frequency trading (HFT) environment. The O-LGT model combines LSTM, GRU, and transformer layers, and features efficient storage management, enabling rapid computation while maintaining high prediction accuracy and feasible memory usage. Our experimental results on the CSI-500 dataset confirmed the validity of our experimental design and demonstrated the superior performance of O-LGT in terms of both prediction accuracy and computational speed in comparison with other network integration models, such as LGT, DeepLOB, and DeepAcc. We addressed the often-overlooked aspect of computation speed in high-frequency trading, providing traders with a significant advantage in HFT environments by enabling faster decision-making and order execution. Specifically, it shows that, in most cases, our model achieves a similar speed but with a much higher accuracy than the conventional fast supervised learning models for HFT. On the other hand, with a slight sacrifice in accuracy, O-LGT is approximately 12 to 64 times faster than the existing high-accuracy neural network models for the LOB data in the Chinese market.
Future work can focus on further improving O-LGT’s performance and generalizability, and exploring its applications in other financial markets with high-frequency data and its performance in predicting other financial instruments.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}