1. Introduction
The average countrywide insurance expenditure tends to rise from year to year. Analyzing insurance data to predict future insurance claim costs is of enormous interest to the insurance industry. In particular, the accurate prediction of claim cost is fundamental in determining policy premiums, as it prevents potentially losing customers due to overcharging and potential loss of profits due to undercharging.
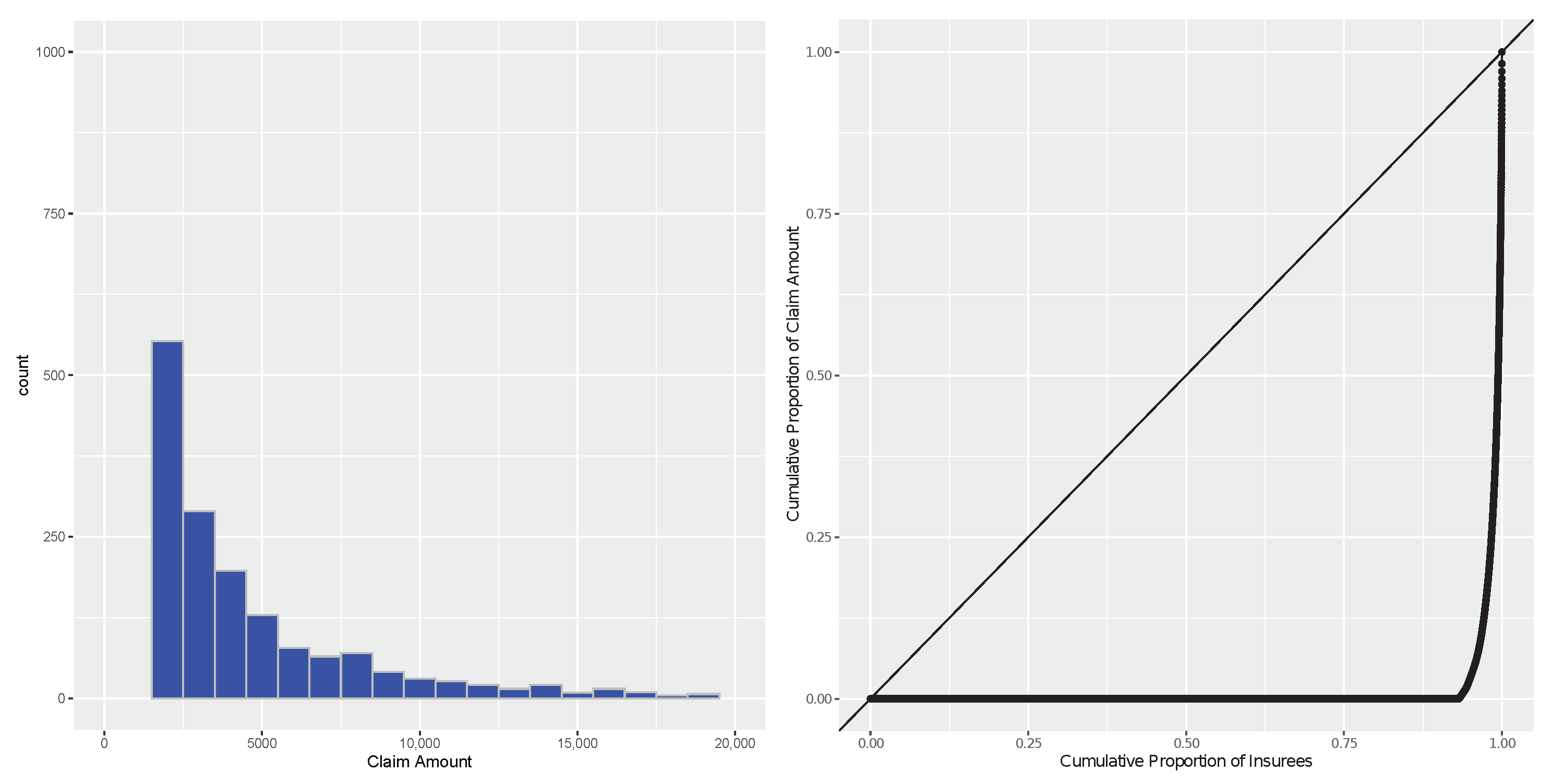
Non-life insurance data are distinct from common regression data due to their “low frequency and high severity” (LFHS) characteristic—i.e., the distribution of the claim cost is highly right-skewed and features a large point mass at zero. This paper focuses on improving the prediction accuracy for such insurance data by model combination/averaging.
Researchers have developed various methods for analyzing insurance data in recent decades.
Bailey and Simon (
1960) proposed the minimum bias procedure as an insurance pricing technique for multi-dimensional classification. However, the minimum bias procedure lacks a statistical evaluation of the model. See
Feldblum and Brosius (
2003) for a detailed overview of the minimum bias procedure and its extensions. In the late 1990s, the generalized linear models (GLM) framework (
Nelder and Wedderburn 1972) was applied to model the insurance data; this is now the standard method used in the insurance industry for modeling claim costs.
Jørgensen and Paes De Souza (
1994) proposed the classical compound Poisson–Gamma model, which assumes the number of claims to follow a Poisson distribution and be independent of the average claim cost that has a Gamma distribution.
Gschlößl and Czado (
2007) extended this approach and allowed dependency between the number of claims and the claim size through a fully Bayesian approach.
Smyth and Jørgensen (
2002) used double generalized linear models for the case where we only observe the claim cost but not the frequency. Many authors have proposed methods for insurance pricing using different frameworks other than GLM, including quantile regression (
Heras et al. 2018), hierarchical modeling (
Frees and Valdez 2008), machine learning (
Kašćelan et al. 2015;
Yang et al. 2016), the copula model (
Czado et al. 2012), and the spatial model (
Gschlößl and Czado 2007).
Given the availability of many useful statistical models, empirical evidence has shown that combining models, in general, is a robust and effective way to improve predictive performance. Many works have improved the prediction accuracy by combining different models, which can be different types of models or same-type models with different tuning parameters. For instance,
Wolpert (
1992) proposed the use of Stacked Generalization to take prediction results from the first-layer base learners as meta-features to produce model-based combined forecasts in the second layer. A gradient-boosting machine (
Friedman 2001), known as greedy function approximation, suggests that using a weighted average of many weak learners can produce an accurate prediction.
Yang (
2001) proposed performing adaptive regression by mixing (ARM), a weighted average method that works well for both parametric and nonparametric regression with an unknown error variance.
Hansen and Racine (
2012) proposed Jackknife model averaging, which involves a linearly weighted average of linear estimators searching for the optimal weight of each base regression model.
Zhang et al. (
2016) proposed the use of a weight choice criterion for optimal estimation in generalized linear models. We refer readers to
Wang et al. (
2014) for a detailed literature review on the theory and methodology of model combination.
However, in the specific context of insurance data, little research has been carried out on combining predictions, except for
Ohlsson (
2008);
Sen et al. (
2018). In particular,
Sen et al. (
2018) proposed a method to merge some levels of a categorical predictor in the model, which is a pre-step of applying model averaging.
Ohlsson (
2008) proposed to combine the generalized linear model and the credibility model, with special focus on the car model classification problem for auto insurance. These two works are not directly related to combining predictions generated from different models for highly zero-inflated insurance data. To the best of our knowledge, no previous work has been done. Given the apparent importance of accurately predicting insurance claim costs, we propose a model combination method to capture such data characteristics.
Our paper focuses on improving the prediction accuracy of individual models/predictions by combining multiple predictions. We investigate how different model combination methods perform under different measures of prediction accuracy for LFHS data. We propose a model combination method named ARM-Tweedie, assuming the claim cost follows a Tweedie distribution. The Tweedie distribution family includes both continuous distributions (e.g., normal, Inverse Gaussian, gamma) and discrete distributions (e.g., Poisson, compound Poisson-gamma). In particular, we use the compound Poisson-gamma distribution in the Tweedie family (with the parameter ) since it allows a mixture of zeros and positive continuous numbers. It is a popular choice in the application of claim cost modeling.
The contributions of this paper are threefold. First, we design a novel model combination method for zero-inflated non-negative response data, where most current model combination methods fail to capture such a characteristic in theory. Second, we show that our method achieves the optimal rate of convergence offered by the candidates. From the risk-bound perspective, our method adapts to the optimal estimation of the mean function. Third, the conclusions of our analysis on a real-life data set provide both tools and guidance, especially to practitioners, on applying model combination methods to claim cost data for both adaptation and improvement.
More specifically, we try to answer several interesting questions: Do model combination methods improve over the best candidate prediction for insurance data? Is the so-called “forecast combination puzzle” (
Qian et al. 2019;
Stock and Watson 2004) still relevant when dealing with insurance data? Under different measures of prediction accuracy, which model combination methods work the best? We carry out a real-data analysis in this work. Thirteen analysts participated by building models to predict the claim cost of each insurance policy in a holdout data set. Based on their predictions, we apply different model combination methods to obtain new predictions in the hope of achieving a higher prediction accuracy. Different measures of prediction accuracy are considered due to the existence of various constraints or preferences in practice. For example, a reasonable prediction should identify the most costly customer and provide the correct scale of the claim amount. Specifically, our paper includes five measures: mean absolute error, root-mean-square error, rebalanced root-mean-square error, the relative difference between the total predicted cost and the actual total cost, and the Normalized Gini index.
The remainder of this paper is organized as follows. We describe the general methodology in
Section 2, a data summary in
Section 2.1, a description of the project in
Section 2.2, and the measures of performance in
Section 2.3.
Section 3 describes the performance of the predictions provided by the analysts. The results of the model combination methods are given in
Section 4, while we introduce the proposed ARM-Tweedie method in
Section 4.1.2. We end our paper with a discussion in
Section 5. The proof of the main theoretical result is included in
Appendix A.
3. Performances of the Candidate Predictions
The 13 candidate predictions can be categorized into two types. One type is based on distinct predictions of the number of claims (frequency) and the claim cost (severity). This approach typically generates predictions with values of zero. The other type directly predicts the claim cost, typically producing many small non-zero-valued predictions. Four out of the 13 candidate predictions belong to the first type (distinct predictions).
Table 2 shows the performances of the 13 candidate predictions. We also provide in
Table 3 the partial correlation matrix of the candidate predictions given the true value of the response. No prediction outperformed all its competitors in every measure of prediction accuracy. For instance, A5 has the largest/worst RMSE among all the predictions, while its Gini index (0.95) is overwhelmingly better than that of any other analyst (none of the values are more than 0.26). The MAE values of the predictions are closely related to SUM. Since the response
contains too many zeros, a prediction
will have a relatively small MAE if
is small, such as A1 with a SUM around −1. For the SUM error, most predictions have negative values, except A5. Specifically, the SUM errors of A1 and A2 almost reach −1. We checked the predictions of A1 and A2 and found that all the predicted values were less than 10. In practice, it is unreasonable to use such small-scale values as a final prediction of the claim cost, even with their acceptable performance on MAE and Gini. Thus, we suggest the use of more than one measure of prediction accuracy in this context.
4. Model Combination
Usually, model combination has two goals. Following the terms in (
Wang et al. 2014;
Yang 2004), these are combining for improvement and combining for adaptation. For improvement, we hope to combine the candidate models to exceed the prediction performance of all the candidate models. As for adaptation, it targets capturing the best model (usually unknown) out of all the candidate models. In this paper, both goals are of interest.
Let denote the response vector for the holdout set. Denote as the candidate prediction matrix, with each column representing a candidate prediction to be combined for the holdout set. Let denote the combined prediction.
4.1. Model Combination Methods
4.1.1. Some Existing Methods
Simple Average (SA)
The simple average method is the most basic procedure in model combination. We simply set
In the literature, it is often reported that the simple average method has a better or similar performance to that of other complicated methods; this is known as the “forecast combination puzzle” (
Stock and Watson 2004). However, we are curious about its performance in our case, where a dominant prediction exists among the candidate predictions.
Linear Regression
Treating the candidate predictions as the regressors and as the response, we fit a constrained linear regression (LR-C): a linear regression of on , with the constraint that all the coefficients are non-negative and add up to 1. The estimated coefficients become the corresponding weights for model combination.
We also tried the usual linear regression that allows negative coefficients. The performance (of the most interest, the Gini index is 0.93) is worse than linear regression with positive coefficients (Gini index being 0.95). Normalizing the coefficients by a positive number does not change the Gini index. So we decided not to present the usual linear regression and other methods, including quadratic optimization of the coefficients and linear regression with bounded coefficients.
Quantile Regression (QR) and Gradient Boosting (GB)
We fit a quantile (median) regression model and a gradient boosting regression model with candidate predictions as the features and as the response. Then, the estimated coefficients will be the weights.
Remark 5. The quantile regression predicts the median (when the quantile equals 0.5) rather than the mean of the response. In this case, we also use the estimated coefficients as the weights in the combination. We consider quantile regression because quantile regression does not require the assumption of normality for error distribution and is robust to outliers.
Adaptive Regression by Mixing (ARM)
Adaptive regression by mixing, proposed by
Yang (
2001), is a model combination method that involves data splitting and cross-assessment.
Yang (
2001) proves that the ARM weighting captures the optimal rate of convergence among the candidate procedures for regression estimation. The advantage is that under mild conditions, the resulting estimator is theoretically shown to perform optimally in terms of rates of convergence without knowing which candidate method works the best. Additionally, ARM typically works better than AIC and BIC when the error variance is not small. In our application, we use the standard normal distribution for the noise distribution in ARM.
4.1.2. ARM-Tweedie
In this subsection, we propose a model combination method for auto insurance claim data. Consider a random variable
Y that belongs to the Tweedie distribution family with a probability density function
. It is known that
and
with the Tweedie power parameter
. Denote the above Tweedie distribution as
with the mean
,
and the dispersion parameter
. We assume that the data
are generated from a Tweedie distribution
where
is known. We assume that the distribution of the multivariate explanatory variable
x is
and suppose that we have
as the candidate estimated functions for
f.
We propose the following ARM-Tweedie algorithm (Algorithm 1):
| Algorithm 1 The ARM-Tweedie algorithm. |
Randomly and equally split the data into two subsamples and . For each k, implement the estimation procedure on and obtain the estimated function . Repeat the above steps L times and take the average as the final weighting option: . Define as the combined procedure.
|
Remark 6. In practice, we use the data to obtain an estimator of :where and denotes the sample size of . Such an estimator is still plausible, although we allow nonparametric f as in . Given μ, it is still a parametric model in terms of the parameters of and p. The estimator only uses the true value of the response ’s to estimate μ, which is indeed a method of moment estimator regardless of the format of . Remark 7. The value of p is chosen as 1.5 in our specific data application. The Tweedie distribution has two parameters: and p. Given p, the dispersion parameter can be estimated by the method of moment estimator as in Remark 6. The best value of p can be chosen by applying cross-validation on a set of training data. In our data example, we found that the performance of our method is quite stable against . So we set p as the middle point of its range for simplicity.
Remark 8. The procedures ’s are pre-determined by the researchers/practitioners. For example, one can choose to directly apply a linear regression to obtain the predictions for the claim cost. Since the prediction for claim cost should be non-negative, we can set our final prediction as zero if it is smaller than a cutoff and otherwise keep it unchanged. Such a modeling procedure is considered and the estimated predictions is denoted as . Assume that a statistician in an insurance company tries methods to predict the auto insurance claim cost. It is also worth pointing out that our focus is on the model combination stage. That is, we focus to further improve the prediction accuracy by combining the 10 methods.
Assumption 1. - 1.
There exist two positive constants such that at any x for , where .
- 2.
There exist two constants such that .
Let
for any function
f. Let
n be the data sample size. Thus, we obtain the following theorem.
Theorem 1. Suppose that Assumptions 1 and 2 hold. Based on a set of estimation procedures , the combined estimator constructed by the ARM-Tweedie algorithm has the following risk bound:where depends on and p. The theorem indicates the adaptation of ARM-Tweedie for different procedures.
4.2. Performance of the Model Combination Methods
We consider three scenarios based on the Gini index (of the most interest) of the candidate predictions: (i) —i.e., combining the 13 available candidate predictions; (ii) —i.e., there is no dominantly better prediction (combining all the candidate predictions except for A5); and (iii) —i.e., all the candidate predictions are weak (combining A1, A2, A3, A4, A6, A10, and A12, whose Gini index is no greater than 0.2). The performance of some model combination methods varies drastically under these scenarios that are commonly encountered in practice.
Table 2 summarizes the performance of the combined predictions under the five measures of prediction accuracy for each scenario. Among all the model combination methods, ARM, ARM-Tweedie, and LR-C overall perform well in both Gini and SUM. Note that Gini is only related to the order of predictions, while SUM is more concerned with the scale of the total cost of the claims. For RMSE and RE-RMSE, only small differences are seen among the predictions, perhaps partly because of the large sample size of the data. MAE is not suitable for measuring the prediction performance alone. For example, in the table, QR
(quantile regression for combining all candidate predictions but A5) takes 0 as its prediction for every customer, giving no useful information. However, the MAE of QR
is the smallest. If one has to use a single measure, Gini is recommended. Otherwise, we suggest the use of a combination of at least two measures, including Gini.
From the perspective of a specific measure of prediction accuracy, when there is a dominant candidate for prediction, such as A5 with respect to the Gini index, it may be hard to achieve the goal of combining for improvement. When there is no dominant candidate prediction, such as under MAE, RMSE, Re-RMSE, and SUM in this paper, there is a better chance of improving the performance through model combination. Specifically, for MAE and RMSE, we have an approximately 10% relative improvement (from the best candidate prediction to the best combined prediction). For Re-RMSE and SUM, the improvement is 25% and 30%, respectively. For all the three scenarios, from the perspective of improving both Gini and SUM, three methods (ARM, ARM-Tweedie, and LR-C) stand out from all the model combination methods. It is also worth pointing out that GB or QR can improve Gini or SUM, but not simultaneously. When there is no dominant prediction, as in Scenarios 2 and 3, model combination methods can improve the Gini index, even when there are only weak learners.
The individual performance in
Table 2 is the second version of the models from the analysts. More specifically, when the analysts submitted their first prediction, the prediction performances evaluated on the validation set were provided. Then, they modified their models (they were allowed not to modify them) and submitted the second version of their predictions. Indeed, some analysts changed their predictions significantly. For example, A8 has a negative Gini index in the first version of predictions. However, the model combination results are not very affected. This is because some candidate predictions (more importantly, those with better predictive performance) show little change after modification. Compared to the candidate predictions, model combination methods are more stable than using a single method for predictive modeling.
5. Conclusions and Discussion
We start this section by answering the questions raised in the introduction.
Can model combination methods improve the results compared to the best individual prediction when there is a dominant candidate prediction? From our results, it is hard to achieve the goal of “combining for improvement” when there is a dominant candidate prediction. One reason for this may be that these general model combination methods weaken the predictive power of the dominant prediction. However, this does not exclude the possibility that model combination methods unknown to us at this time can achieve a better predictive performance than that of the best candidate. A follow-up question is: when do model combination methods perform better than the best individual prediction? Based on our results, when all candidates are weak or when no dominant candidate exists, model combination is a valuable way to improve the prediction performance.
Does the “forecast combination puzzle” still exist in our project for insurance data? There are two possible scenarios where simple average outperforms other model combination methods. First, when all the candidates have the same level of bias, taking the average reduces the variability. Second, the biases among the candidates cancel each other out through the simple average method. However, our project concludes that the simple average method does not provide competitive performance with that of other model combination methods. Specifically, the Gini index of SA was the smallest and significantly worse than that of other model combination methods in our results. The set of candidate predictions is of great importance when considering the simple average method. When a dominant prediction exists for a particular measure (the Gini index in our data analysis), simply averaging all the candidate predictions may lead to performance deterioration. In that case, we need to use a model combination method that adaptively learns better from the data.
Under different measures of prediction accuracy, which model combination methods work the best? When researchers and insurance companies are concerned with different aspects of a prediction, their preferences differ accordingly. For the criteria we considered, most combination methods improve the performance of the best candidate prediction. The measure is crucial in highly skewed zero-inflated data. We highly recommend “using at least two measures” rather than just relying on one single measure. For example, Gini is of the most interest when evaluating the prediction of the claim cost. It only evaluates the rank of the predictions. In the real world, the scale of the predicted claim cost is crucial in determining the premium for a customer. Thus, if the Gini index is large and the SUM is small in absolute value, the predictions do not need any scale adjustment. Otherwise, a third measure such as RMSE should be considered after adjusting the scales of the predictions. Based on our analysis, we suggest not using MAE as a performance measure for predicting the claim cost.
In our data analysis, the details of the generation of the 13 candidate models are unknown. It is possible that two models were built using the same model class but with different parameters, which may have led to a high correlation between the two predictions. It would also be of interest to study whether the details of the models will improve the performance of the model combination methods. Additionally, it would be worth investigating a model combination method that assigns weights according to a specific performance measure (concerning the data type). Another option for model combination is to combine all the subsets (
candidate predictions), which may produce a higher variability or more potential (
Wang et al. 2014) than combining the 13 candidate predictions. However, this is more time-consuming. This may even be computationally infeasible when the number of candidate predictions is large. One should consider the practical cost when conducting model combination methods based on all the subsets. In addition, we may pay a much higher price in modeling variability when including all the subsets rather than the candidate predictions. In our project, combining all the subsets led to a slightly better performance than combining the 13 candidate predictions only in some cases; thus, we did not include the results in the table.





{kind=link}