1. Introduction
Smart devices, and in particular smartphones, are ubiquitous devices much more than communication tools, as they combine features of a cell phone along with computing functionalities. Ubiquitous devices mingle and sometimes interfere with a person’s everyday life. Smartphones hold on to a plethora of personal, yet heterogeneous data generated from various software applications, hardware components and embedded sensors, constituting a very rich set of private information. Consequently, a smartphone can be considered as a well-informed, about its owner’s interests, ubiquitous digital companion that comprises a diverse set of sensors and strong computational and networking capabilities. Thanks to these features, information available to a smartphone can be used in many circumstances to assist its owner with suggestions and recommendations.
In this work, we focus on the sets of personal data of smart devices and consider how they can be used to make touristic contextual suggestions to their owners. Whatever may attract a tourist can be considered a point of interest (POI), and tourists often are overwhelmed by the large number and variety of POIs in the places they visit. Typically, a tourist has to make his or her choices in a short time and without being fully informed about his or her options regarding the available POIs. Assuming that a contemporary tourist owns a smartphone equipped with a number of sensors and is familiar with mobile applications (apps), mobile recommender systems can become valuable tools. In fact, mobile tourism services are currently a very active research topic; for a collection of related papers, see, e.g., [
1].
A recommender system for tourism aims to advise its user on which POIs to visit while staying in a certain area. Such suggestions are produced based on inputs, and a simple approach would be to ask the user about his or her preferences and to include information, such as user needs, interests and constraints, enter those into some system and then have the system correlate these preferences with POIs that have similar parameters [
2]. Another option is to use additional input evaluations and ratings of other tourists with similar interests in a collaborative filtering fashion [
3]. Additionally, travelers who are in close spatial and temporal proximity often share common travel interests or needs in a crowd-sourced manner [
4,
5]. A common requirement of all of these approaches is that users have to enter
themselves their personal information and build their profile into some system. In this paper, we propose an approach to automatically build a POI-based user profile and show how this profile can be used as input to a contextual suggestion mechanism.
Another, possibly more important, requirement of existing recommender systems is that user profiles have to be stored and managed by the recommender service. User profiles, however, contain personal data, some of which may be considered
sensitive personal data according to the Data Protection Directive 95/46/EC [
6], the current draft of the forthcoming General Data Protection Regulation (GDPR) [
7], which regulates the processing of personal data within the European Union, and similar regulations, which hold in other regions. This, in turn, raises privacy concerns for potential users of such systems. Moreover, the privacy issues can be further aggravated when user profiles are combined among recommender systems in order to expand the data pool and enable more intelligent recommendations [
8]. The privacy concerns are even more serious in mobile recommender systems, due to the wide range of sensitive personal data (e.g., location) that are available to mobile platforms and can be accessed by mobile apps and transparently be uploaded to remote servers. In fact, user awareness of threats against location and identity privacy aspects has been recognized as one of the greatest barriers to the adoption of context-aware services [
9].
In this work, we employ a
privacy by design approach to address the privacy issues of the proposed recommendation system. Privacy by design generally refers to a holistic approach for handling the privacy issues within each step of the design, implementation and operation of a system (see, for example, [
10] and the references therein). For the Pythia system, a very important architectural choice we made under the privacy by design approach is to manage the user data at the user side. We will show that the overall design of Pythia indeed enables strong and effective privacy guarantees for the users.
The exact challenge addressed in this work is to propose a privacy-enhanced, non-invasive contextual suggestion system for tourism. The targeted functionality of the system is in line with the Contextual Suggestion Track of the Text Retrieval Conferences (TREC) [
11] and is about making suggestions to the user considering as context only the user’s location, as well as user interests via personal preferences and past history. In other words, the recommendation focuses on a single, but common situation:
A user with a mobile device with limited interaction, but some sort of a user profile, who is in a strange town and who is looking for something to do. There is no explicit query; the implicit query is: Here I am, what should I do?
In the future, context may be enriched to include, for example, temporal information (time, day, season of the year,
etc.), weather conditions or other contextual information [
14,
15].
An important additional requirement (beyond TREC’s definition) addressed in this work is the protection of user privacy. More precisely, we require that no personal data should be leaked to any party, including the service provider. Finally, the non-invasiveness property requires the system to operate in the background, to automatically infer the user preferences and gradually build the user profile without requesting the user’s attention.
The Pythia system proposed in this paper is a privacy-enhanced contextual suggestion system for tourism, which satisfies the above challenge. The presented system innovates in several fronts by design and implementation choices to guarantee non-invasiveness and privacy preservation. We consider this combination of features, which, to our knowledge, is unique in the field of mobile recommendation systems, the main novelty of our work. More specifically, Pythia offers:
User-centric architecture: Pythia is based on a user-centric architecture in which all user data are stored at the user-side. The contextual suggestion algorithms are also executed at the user-side. This design offers the users a high level of control over the system and their personal data.
Privacy-preserving recommendations: The system is designed so that no personal data are disclosed to any party, including the recommender service itself. Moreover, Pythia ensures strong privacy guarantees for the user, without relying on trusted third parties and data obfuscation or heavy cryptographic techniques.
Rich user profiles: As the profiles and the contextual suggestion engine reside on the user’s mobile device, the system has access to his or her digital trace, which comprises a virtually unbounded, in size and type, set of personal data. In the current design, Pythia generates POI-based user profiles automatically from the raw location data.
Non-invasive operation: The Pythia components operate non-invasively, without requiring user interaction. The user profile representing the user’s interests is automatically built and updated.
Note that while the contextual suggestion engine has access to the local user profile, which may contain a very rich set of personal data, the suggestion algorithms base their computations only on a single profile, in contrast to collaborative filtering approaches. The comprehensiveness of the user-owned profile can counterbalance the fact that only single-user profiles are used in computing recommendations.
The rest of this paper is organized as follows. In
Section 2 we discuss our approach with respect to past related work.
Section 3 presents the Pythia system architecture with its components, while
Section 4 details the algorithmic aspects of these components.
Section 5 describes the implementation of the Pythia system. The results from the evaluation of the contextual suggestion algorithms and the user experience feedback from volunteers who used the prototype are presented in
Section 6. We conclude in
Section 7 with a discussion and directions for future research.
4. How Pythia Works
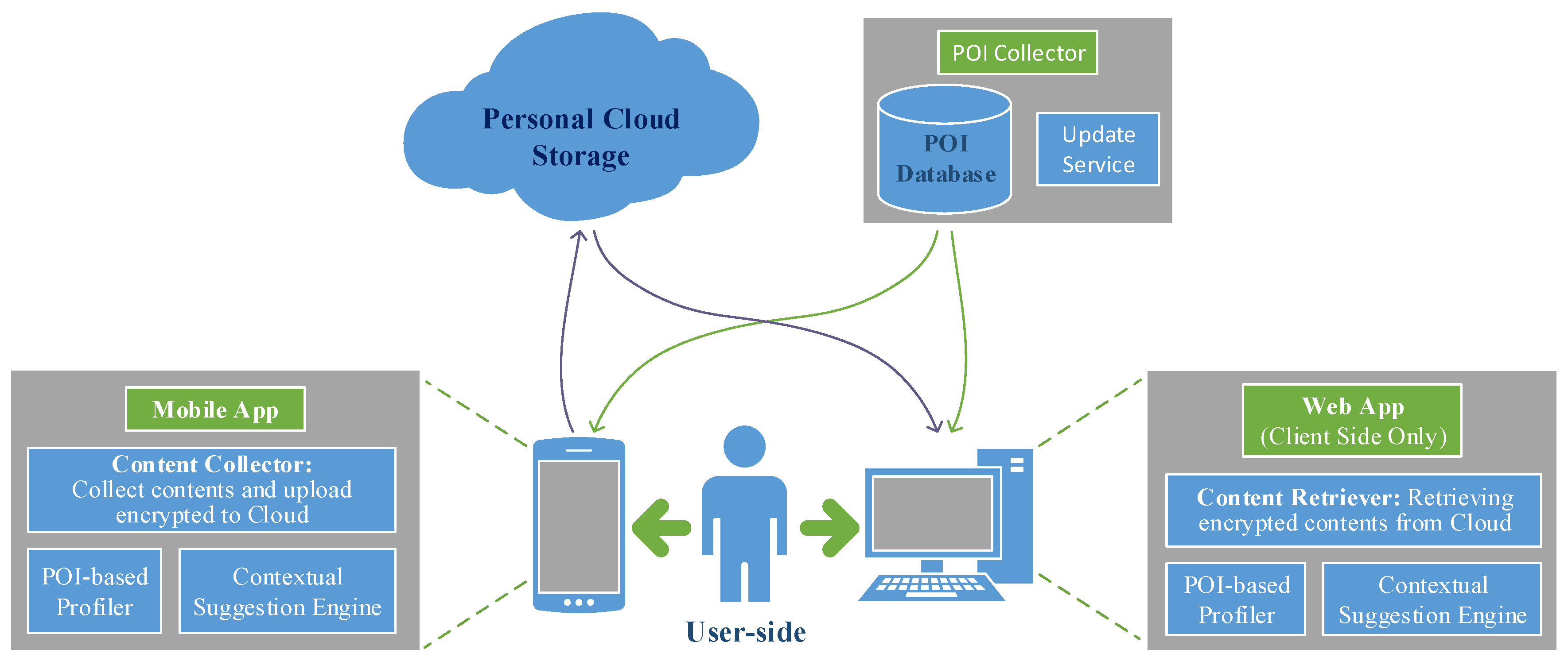
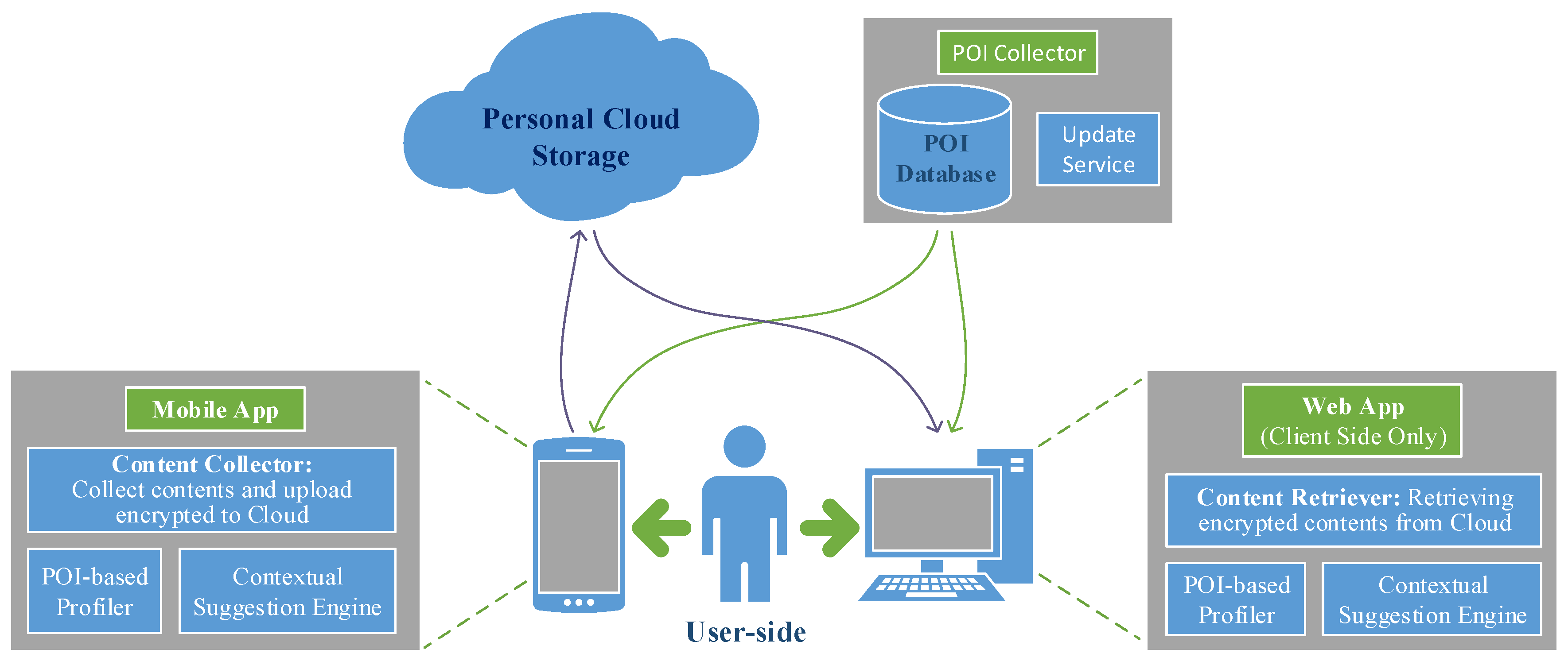
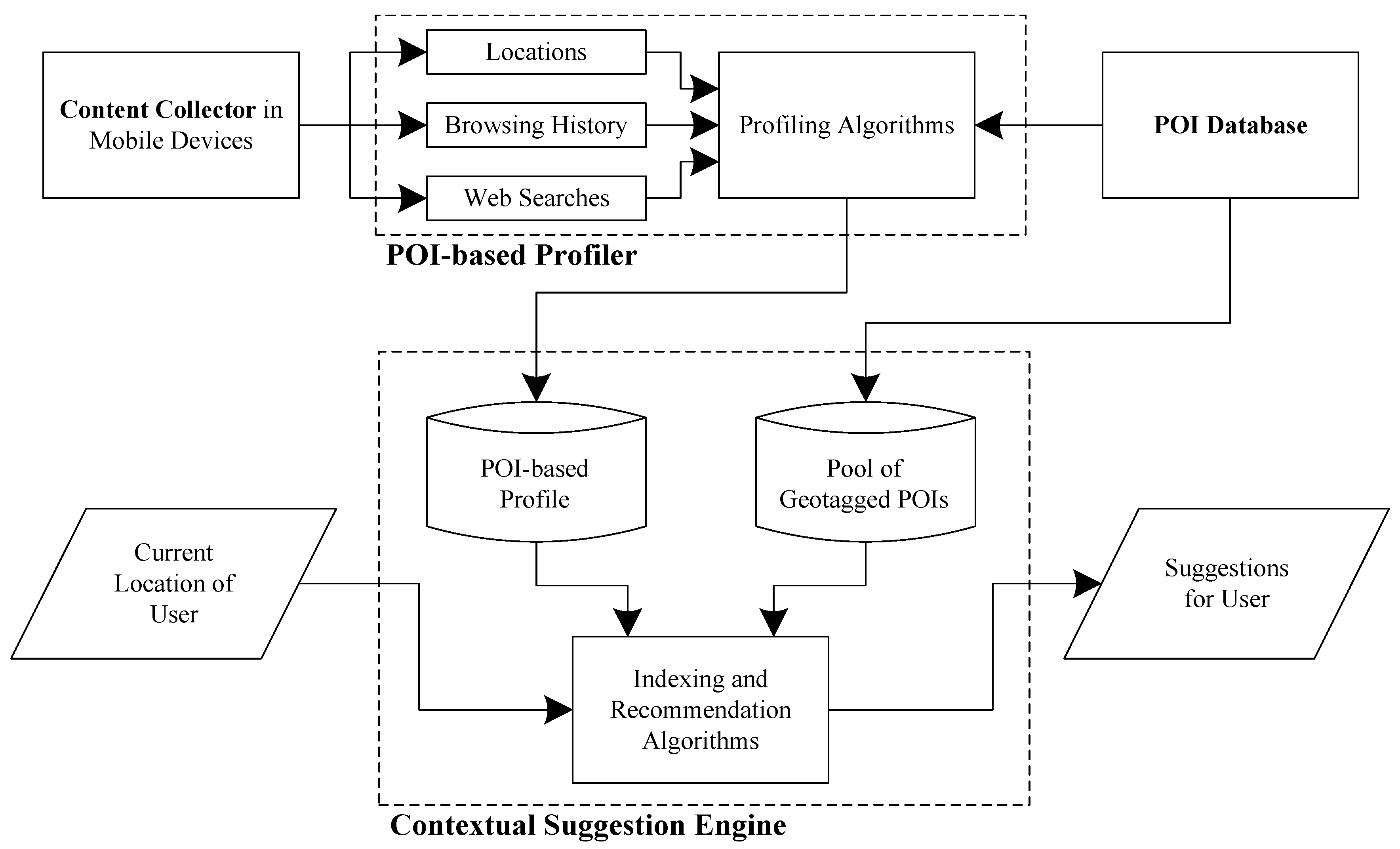
In this section, we describe how the Pythia system works, with emphasis on the algorithmic and computational aspects of its components. The content collector and the POI collection framework are responsible for collecting the data that are used by the POI profiler and the contextual suggestion engine. The content retriever and the personal cloud storage support the data flow between the application components. The way the independent components interact is shown in
Figure 2.
4.1. Personal Data Collection
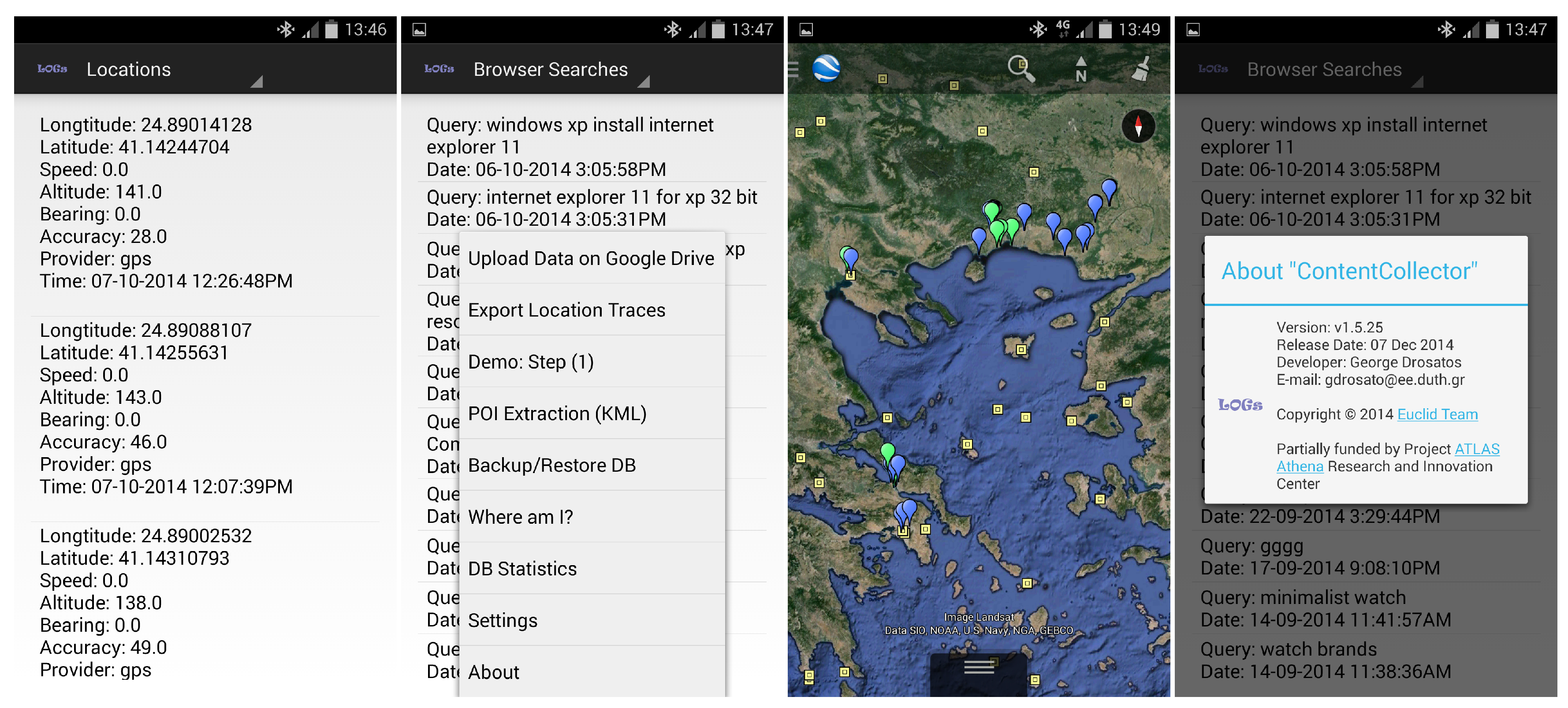
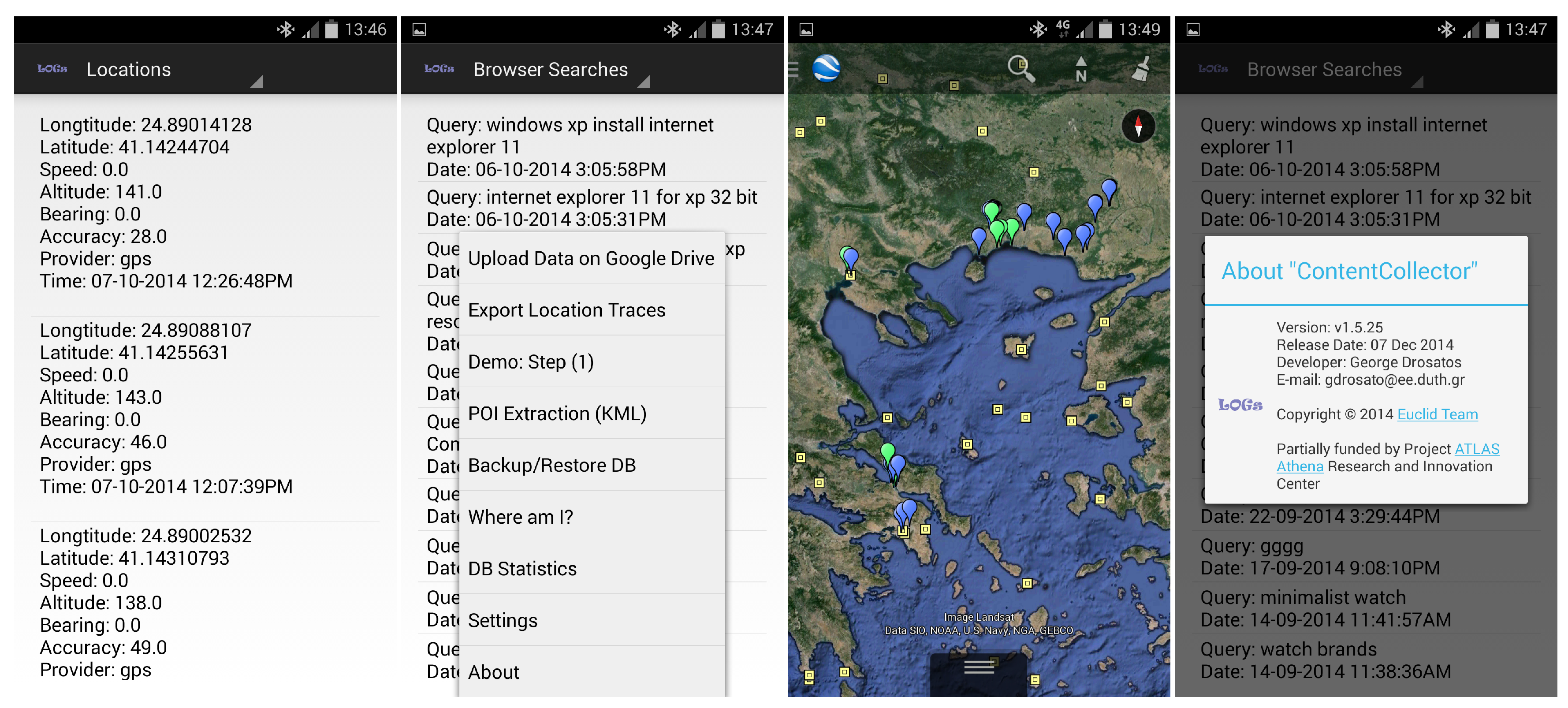
As noted earlier, the content collector collects personal data of the digital trace generated by the everyday usage of the devices. These data are stored locally on each device. Currently, we focus on the following types of personal data.
Location traces: The content collector records the location of the mobile device periodically, with a period (e.g., min). The location is requested from the GPS provider of the device. In case the GPS provider fails to coordinate (for example, if the user is inside a building), the location is requested from the network provider (the network provider determines location based on the availability of cell tower and WiFi access points). If both location providers fail to retrieve location information, the content collector temporarily reduces the frequency of location data requests to avoid unnecessary power consumption.
Browsing history: The browsing history of the user is collected with a content observer that is triggered when the user visits a web site with a mobile web browser. For each visited URL, a browsing history record is kept with the following data fields: title, url, number of visits and time of last visit.
Web searches: Web searches are a special type of URL and can reveal important information about the user’s interests. The content collector detects and records the web search queries submitted by the user. For each web search, the query and the submission time are recorded.
Additionally, the current version of the content collector can optionally collect data from the sensors of mobile devices, such as barometric pressure, ambient temperature, relative humidity, ambient light, acceleration, rotation and geomagnetic field. These data, however, are presently not used in Pythia.
4.2. POI Collection Framework
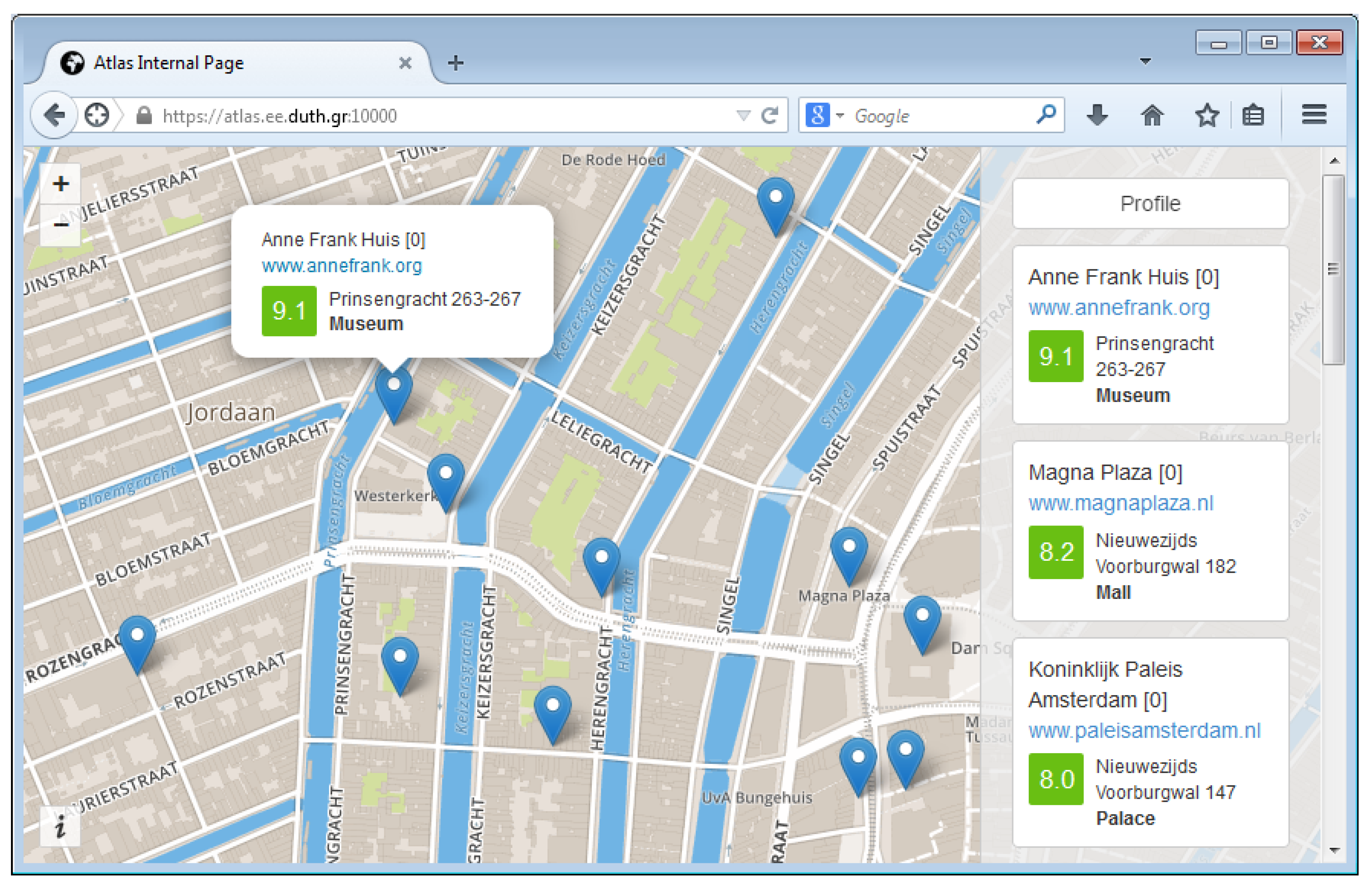
The POI collection framework implements a web API, which is used by other Pythia components to access the POI database. POIs can be retrieved either one by one or as chunks corresponding to a specific county or area.
The following data are available for each POI: title, geo-location (i.e., geographical coordinates of location), address, phone number, categories, several URLs (e.g., website, Foursquare URL, Google+ page, etc.), rating, total unique (physical) visitors and total visits (as measured by Foursquare) and a collection of terms describing the POI. The POI data are obtained from two popular place search engines, namely Foursquare and Google Places, with Foursquare as the main source of information. The update service continuously updates and extends the database with new information about POIs in the defined areas of interest.
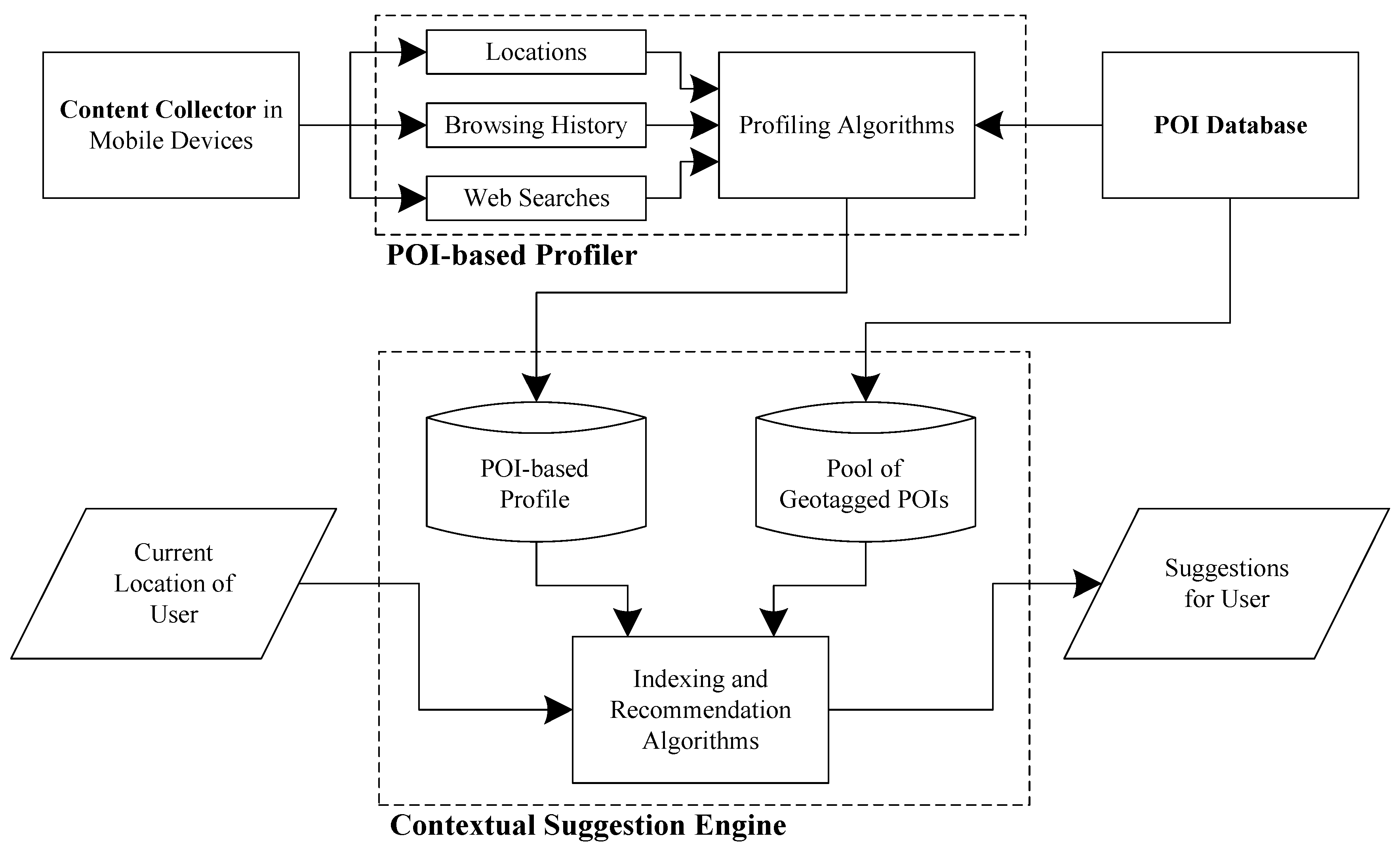
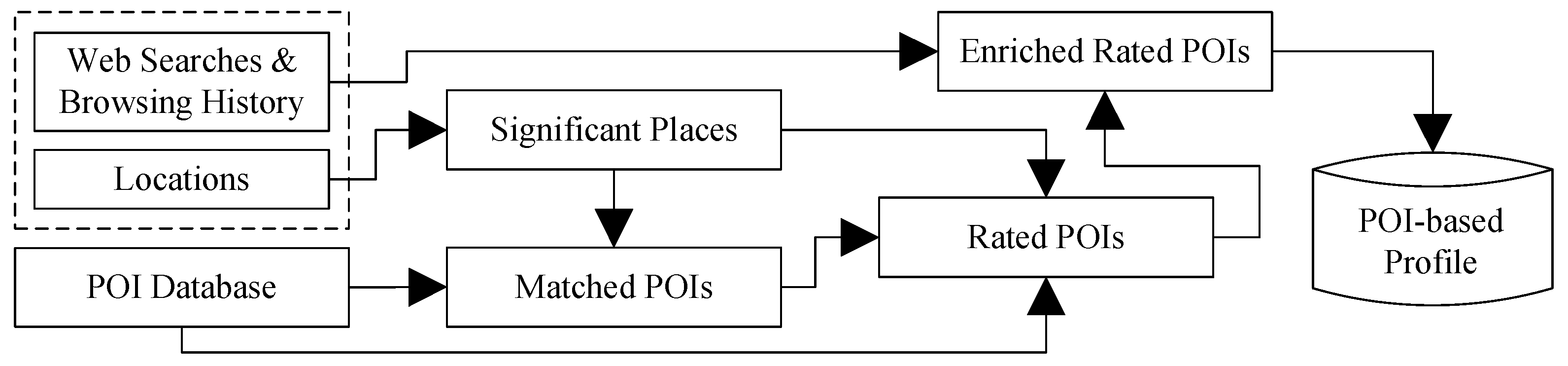
4.3. POI-Based Profiling
The raw data used by the POI-based profiler consist mainly of a series of locations the user has been, plus the browsing and web search history. These data are processed in the following steps (
Figure 3):
First, the location traces of the user are used to extract significant places, which are defined as places where the user spends a significant amount of time and/or visits frequently. The extraction process is based on a time-based location clustering algorithm.
Then, the extracted significant places are matched (if possible) with existing POIs of the POI database. The matching is based on distance and popularity criteria of each particular significant place and the nearby POIs.
Next, the user’s rating for each matched POI is estimated. This is also done automatically, using the user’s number of visits and the average number of visits per user to this POI.
These steps are described in more detail, next.
4.3.1. Significant Places Extraction
The significant places for a user are extracted from his or her raw location traces with the
time-based cluster algorithm of [
34]. The algorithm processes one by one, in one pass, the stored locations and clusters them along the time axis. Each new location measurement is compared to previous locations. Depending on how far the new location is moving away from previous locations, it is considered either part of the previous cluster or the start of a new cluster.
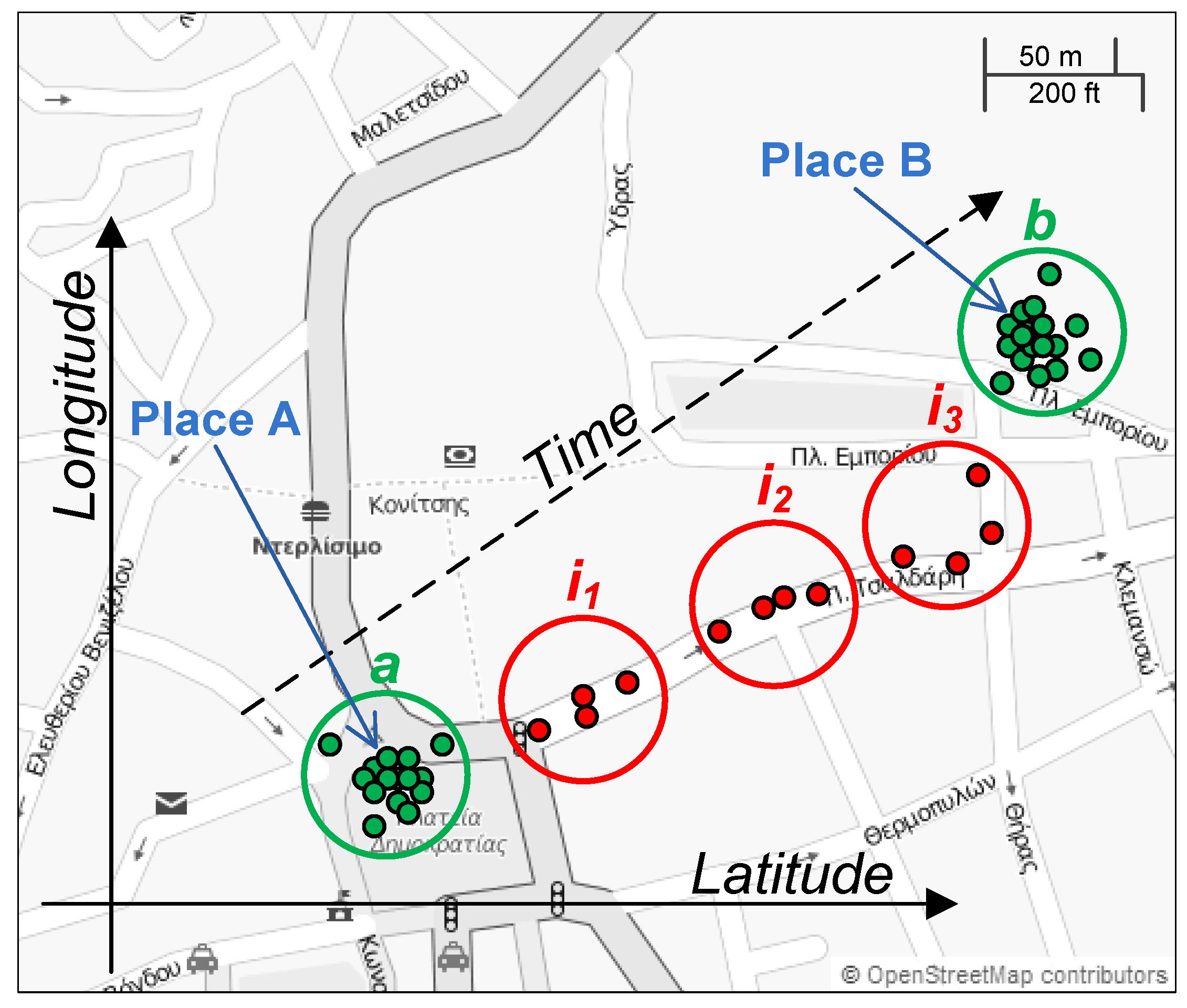
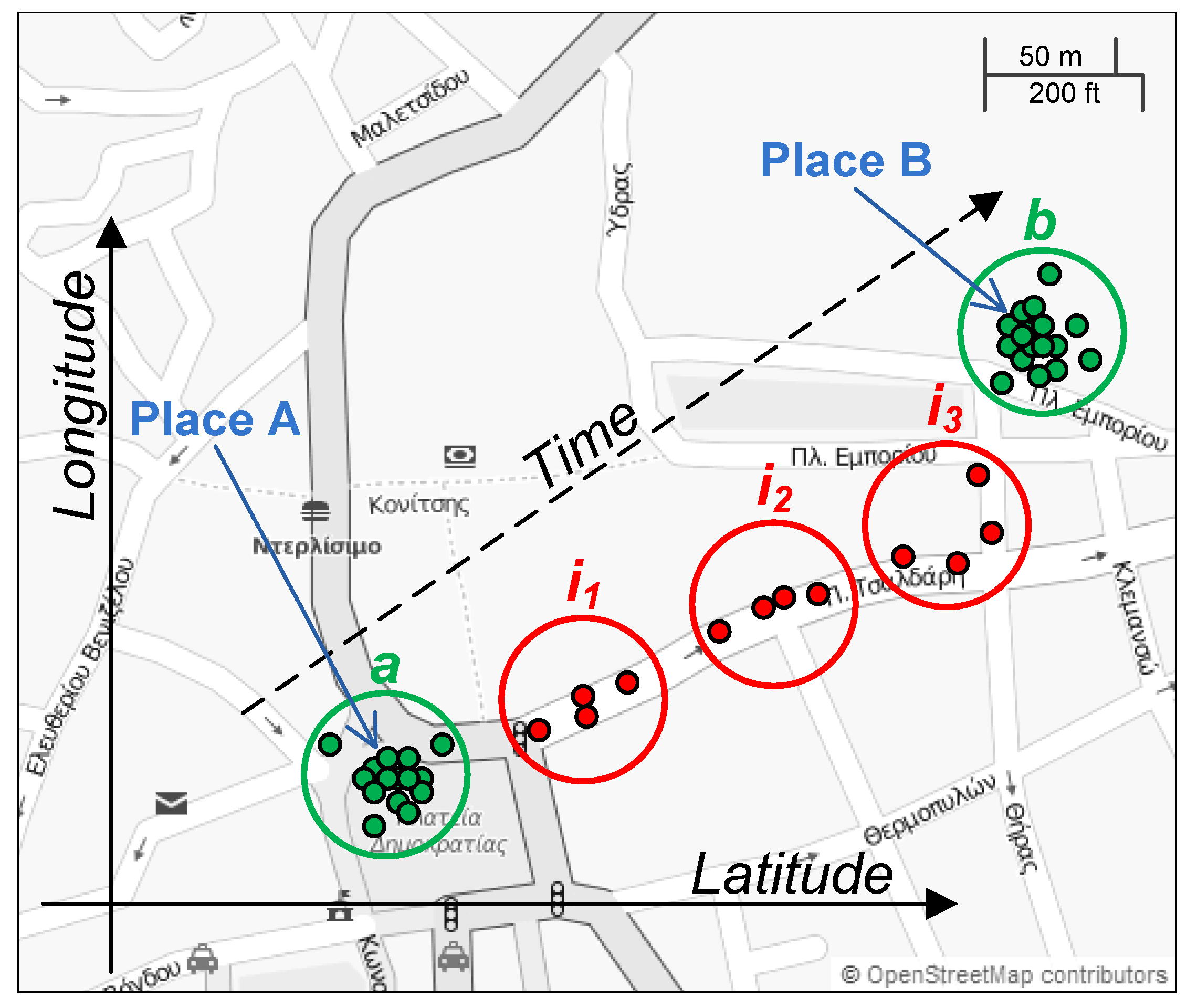
The time-based clustering approach is illustrated in
Figure 4. Suppose that the user moves from place
A to place
B. While the user is at place
A, the location measurements are within a certain distance (a parameter of the algorithm) of each other and considered to belong to one cluster; in this example, cluster
a. As the user moves towards place
B, the location measurements move away from cluster
a. On the way to place
B, a few small intermediate clusters are generated (
,
and
). Finally, when the user gets to place
B and stays there for a while, a new cluster (cluster
b) is formed. If a cluster’s time duration is longer than a threshold (specified as the second parameter of the algorithm), the cluster is considered to be a significant place. In the figure, clusters
a and
b meet the distance and duration criteria and are classified as significant places, whereas the other clusters in between are ignored.
The default parameter values used in the prototype implementation of Pythia are 30 m for the distance threshold and 30 min for the minimum time duration threshold. For each significant place, the extraction process also estimates the number of visits, the duration of each visit and the arrival date and time of each visit.
4.3.2. POI Matching
After identifying significant places from the location traces of a user, these significant places are matched with POIs of the POI database. More precisely, given a significant place
c, for each POI
within a distance of at most
from
c, we calculate a score:
where “
” is the average estimated accuracy of the locations in the cluster of a significant place,
is the distance between
c and
and
is a popularity measure of
(e.g., the rating of the POI in Foursquare). A usable and effective value of the weighting coefficient
a has to be experimentally estimated; its value does not only depend on the relative importance of distance and popularity, but also on the units used for measuring distance (e.g., meters, kilometers, miles,
etc.) and on the range of the popularity values
. The significant place is matched to the POI that achieves the highest score.
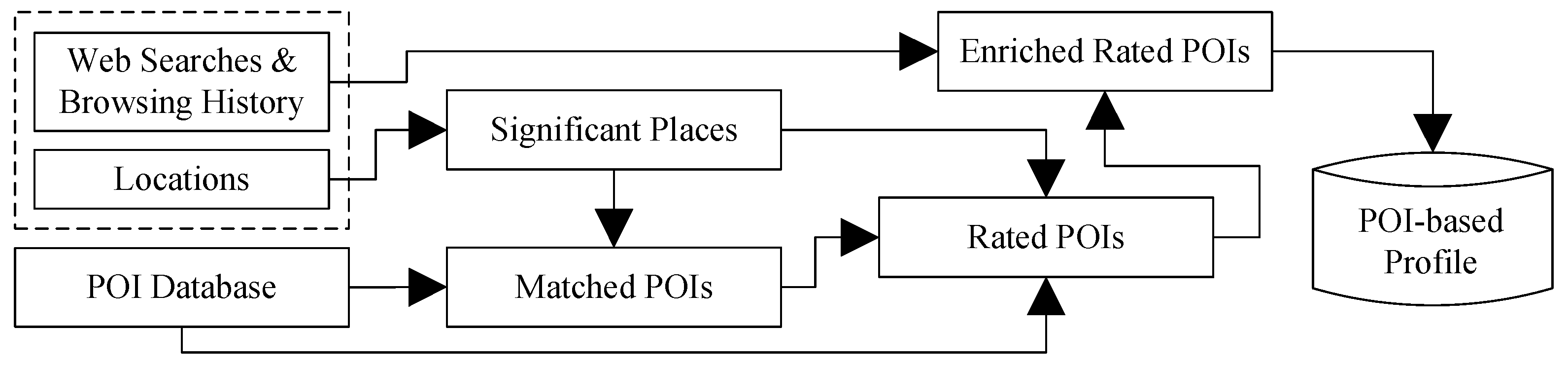
Note that even though each of the initial significant places is in some sense important to the user, not necessary all of them are POIs of general interest. Thus, some of them will not be matched with POIs in the POI database. Only significant places that are actually matched to POIs play a role in the POI-based profile of the user.
We underline that the POI matching procedure is executed at the user-side, by the application client running on the mobile device or the browser of the user. The client application retrieves the POIs in the area of interest from the central POI database of the Pythia system. To avoid significant leaks about the locations the user is interested in, the client retrieves the related POIs in chunks that correspond either to predefined regions of counties or to predefined divisions of the geographical area (e.g., km squares). This way, only a wide area containing the actual location of interest of the user is disclosed to the POI collection framework of Pythia.
4.3.3. POI Rating
Finally, a rating
for each matched POI is calculated in an automated way. This rating is an estimation of the user’s interest for the POI. We use the five-point Likert scale rating of the Contextual Suggestion Track of TREC 2013, that is each rating is an integer in
, where 0 means strongly uninterested, 2 means neutral and 4 strongly interested. Given a user, first, we calculate for each matched POI in his or her profile an index:
where
is the number of the user’s visits to
and
is the average number of visits per user to the specific POI, taking into account only those users who have visited the POI
at least once. The average number can be calculated from public data from the place search engine.
The value of
represents how much more (or less) frequently the user visits
, with respect to the rest of the users, normalized in the scale of 0–4. Using
to directly estimate a user’s preference on a POI
would be inadequate in several cases. For example,
the user could be very outgoing, or
the user could be running Pythia’s content collector for a longer period and inevitably have higher values on all POIs, or
could be a popular local attraction with a high visitation rate; thus, a high value of is not necessarily indicative of the user’s preference.
Therefore, in order to create a metric that properly reflects the user’s preference over , it is appropriate to perform a normalization of on two scales: one over the POI’s visitation rate of other users, which confronts a situation like 3, and one over the user’s own check-in rates for all of the places her or she has been, which handles Scenarios 1 and 2.
The first kind of normalization is achieved by dividing with
and is depicted in Equation (
2), whereas the second one is described next. Let
and
be the POIs with the highest and lowest index, respectively. Then,
is given a rating of four,
a rating of zero and each of the other POIs a rating proportional to its index value. The outcome of the POI matching and automatic rating algorithms described is the POI-based profile of the user,
i.e., a set of rated POIs.
Web searches and browsing history: The basic POI-based profile obtained from the location traces of the user can potentially be enhanced by exploiting the browsing history and the web search logs of the user. More precisely, we propose to use these personal data to adjust the POI ratings of the basic profile. For the adjustment, we apply an information retrieval approach. The terms of the web searches and the titles of the browsing history are used to generate a query, which is then submitted to the collection of descriptions of the matched POIs. Depending on how high each POI is ranked, the score of the POI can be adjusted by a small factor. Understandably, this procedure may introduce additional noise into the POI ratings, and for this reason, it is used only for small adjustments. Our current approach is based on rough heuristics, which have not been properly evaluated yet; thus, we do not present them here. We plan to further elaborate on this matter in our future work.
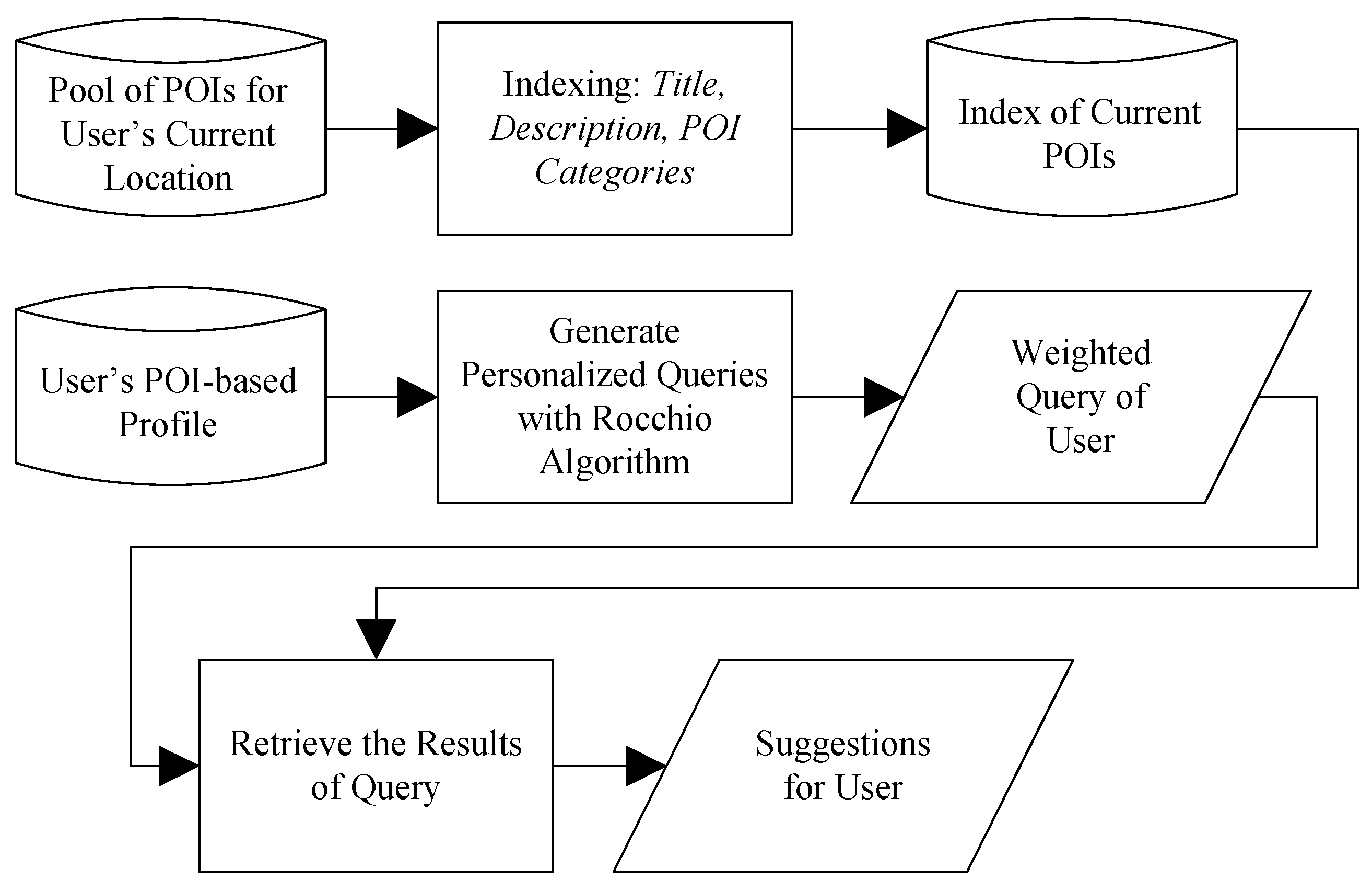
4.4. Contextual Suggestion Algorithm
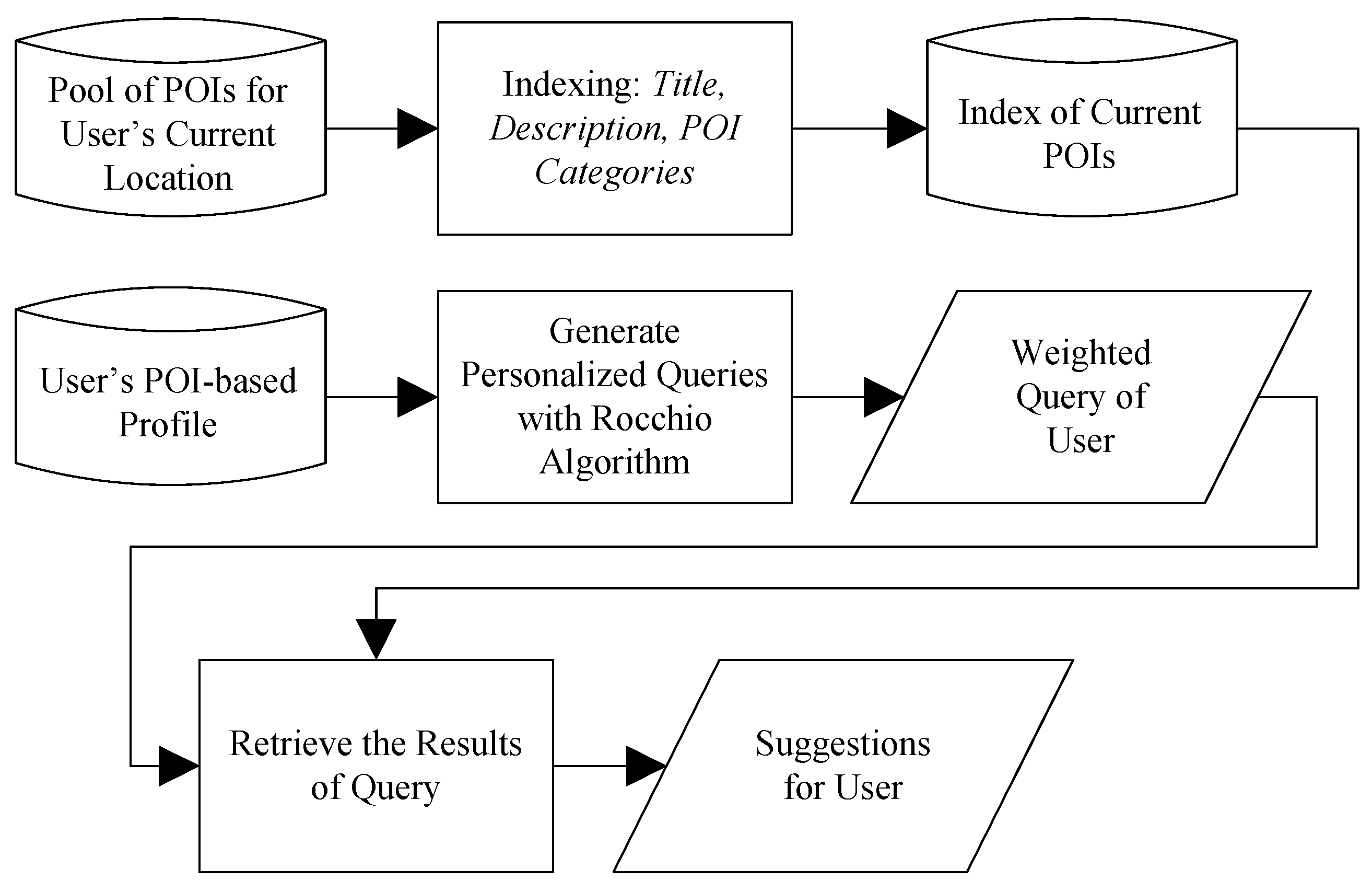
Given the POI-based profile of a user and a location of interest, the Pythia system returns a set of suggested POIs that are expected to be of interest to the user. The underlying algorithm that makes the POI selection is based on a Rocchio-like relevance feedback method [
35,
36], and its main steps are depicted in
Figure 5. First, the user’s POI-based profile is used to generate/train a text query. Then, the generated query is used to score and rank all candidate POIs using their textual representations.
The model is implemented in three main steps:
Step 1: Indexing all candidate POIs. In the first step, a text document is built for each candidate POI. The document is a concatenation of the title, description and categories of the POI; this information is likely to implicitly identify the type of activity that the user was performing at this POI. The description consists of a collection of terms that describes the POI, and it is taken by the POI’s web page. The POI documents are indexed with with Indri (the search engine of the Lemur Project [
37]) v5.5, using the default settings and Krovetz stemming [
38].
Step 2: Building a query in a Rocchio-like relevance feedback fashion. A personalized weighted query is generated from the POI-based profile of the user using a Rocchio-like relevance feedback method. This query represents the user’s preferences. First, a text document is built this time for each POI in the POI-based profile of the user. Let
N be the number of distinct terms appearing in these documents. Each POI
of the POI-based profile is rated and can be used as a training POI. Let
be a weighted vector representing
, where
is the weight of term
j in
; we use a standard tf-only (
i.e., term frequency) logarithmic weighting:
, where the
is the frequency of term
j in the textual representation of POI
i. Then, the trained weighted query of the user is the vector:
where the
is the set of all POIs in the POI-based profile of the user having a rating of
. In other words, we take the centroids per rating
j, multiply them with the normalized rating
(so that the neutral rating’s centroid,
i.e.,
, does not contribute anything; it is zeroed) and then add the centroids in a Rocchio relevance feedback fashion. All of the terms of the weighted query
Q that have a weight less than or equal to zero are excluded from the query. The weight of every term is included in the query by using the Indri Query Language and has, e.g., the following form:
Step 3: Retrieving suggestions. The personalized weighted query Q of the user is submitted to the index generated in Step 1 for the POIs near the user’s current location. The search engine is again Indri v5.5 with the default (LM) retrieval model. The results of the query, with a possible cutoff threshold (e.g., top 50 results), are the suggestions to the user for the specific location.
6. Evaluation and Feedback
The evaluation of Pythia is a challenging task. The system features several functionalities, has to be installed on devices of volunteers and be active a sufficient period of time in order to accumulate at least a minimum amount of data and then manages and processes the personal data at the user-side in a privacy-preserving way. Consequently, it seems very difficult to obtain a large dataset with raw input from all components of the system. Instead, we applied a component-wise evaluation of the critical components of the system and, in addition, asked volunteers for their impression about the whole application. More precisely, we evaluated or obtained feedback on four distinct aspects of the current prototype of the system: the stability and resource consumption of the mobile app, the contextual suggestion algorithms, the POI matching algorithms and the impressions of an admittedly small set of volunteers who agreed to install the application on their Android device and let it record (locally) their activities for some time period.
6.1. Mobile App
The main application component running on the mobile device is the content collector service, which is implemented as a background task. Based on our experiments and the feedback from the volunteers that installed the content collector (see
Section 6.4), the app did not cause any noticeable performance degradation on the smart devices. Moreover, the app did not cause any significant increase in energy consumption for the default location sample rate of one location every five minutes.
In particular, the battery usage data of the devices showed for smartphones with low overall usage an energy consumption of about 5%, whereas for smartphones with heavy usage or power-hungry apps, like the Facebook client, the relevant energy consumption of the content collector app was lower; in many cases, the relevant consumption was so low that the app was not even listed in the battery usage data. In any case, none of the volunteers using the content collector reported any case where the energy consumption was an issue. Naturally, the energy consumption grows proportionally to the location sampling frequency, and as such, we tweaked the default settings to allow accurate measurements while minimizing the energy cost. The rest of the functionalities of Pythia, at least in its current version, are executed on demand. For example, generating a profile can take from a few seconds to about one minute for data of two years on a mid-range modern smartphone. If we assume that a user queries the recommendation system only once in a while, the corresponding energy consumption is not an issue.
6.2. Contextual Suggestion
The proposed Rocchio-like model was evaluated in the Contextual Suggestion Track of TREC 2013 [
13], where we (the DUTH (Democritus University of Thrace) group) ranked with this algorithm among the best groups of the 15 participants. The track’s goal was to investigate POI-search techniques considering as context only the user’s location, as well as user interests via personal preferences and past history. In other words, the track focused on one situation: a user with a mobile device with limited interaction, but some sort of a user profile; who is in a strange town and is looking for something to do. There is no explicit query; the implicit query is:
Here I am, what should I do? The above situation matches very well Pythia’s goals.
More precisely, DUTH participated in the “open web” category of the track, i.e., set to find interesting POIs from the full web instead of a smaller controlled data collection. This category was more challenging since it involved processing of big heterogeneous data, requiring computational and network-use efficiency. We presented an approach for context processing that comprised a newly-designed and fine-tuned POI data collection technique, a crowdsourcing approach to speed up data collection and two radically different approaches for suggestion processing (k-NN based and a Rocchio-like).
In the context processing, we collected POIs from three popular place search engines, Google Places, Foursquare and Yelp. The collected POIs were enriched by adding snippets from the Google and Bing search engines using crowd-sourcing techniques. In the suggestion processing, we proposed two methods. The first submitted each candidate place as a query to an index of a user’s rated examples and scored it based on the top k results. The second method was based on Rocchio’s algorithm and used the rated examples per user profile to generate a personal query, which was then submitted to an index of all candidate places.
The official track evaluation showed that both approaches are working well; especially the Rocchio-like approach was the most promising, since it scored almost firmly above the median system and achieved the best system result in almost half of the judged context-profile pairs. Consequently, the Rocchio-like method was employed in Pythia, which, due to the analytical nature of its main formula (in contrast to iterative learning methods), is also light-weight in computational resources. In the final TREC system rankings, DUTH was found to be the second best group in MRR (Mean Reciprocal Rank) and TBG (a modified Time-Biased Gain) evaluation measures and the third best group in Precision@5 (Precision at Rank 5), out of 15 groups in the category in which we participated. More details on our methods and the description of the track (goals, datasets, evaluation measures,
etc.) can be found in [
12,
13], respectively.
6.3. POI Matching
The implicit creation of the POI-based user profiles is based on the automatic identification of the POIs that the users visit and the inference of the user ratings for each of these POIs. The whole approach is built upon a POI matching procedure that processes the location trace of the user and identifies POIs that the user has visited.
In order to get an indication of how effective the current POI matching procedure is, we focused on the lists of POIs that are generated by the POI matching procedure and checked which of these POIs the users actually visited. More precisely, we asked the owners of the two largest profiles of a field experiment (
Section 6.4) to assess the correctness of the list of matched POIs in their profiles. The corresponding statistical results are presented in
Table 1.
The collected data cover a period of more than two years with two, by now, mid-range smartphones. User 1 used a Samsung Galaxy S4, while User 2 initially a Galaxy S4, which was later upgraded to a Galaxy S5.
We consider the POI matching results very promising. Even though they certainly contain noise, the overall procedure seems to work surprisingly well; the accuracy is fairly high, and definitely higher than we expected for a prototype. Moreover, there are several reasons why these numbers can be improved. Some of the false POI matches can be attributed to inaccurate or incomplete POI data of the POI search engines for certain areas. In certain geographic areas related to the experiment, the POI data of the POI search engines is still not very accurate. One should expect the amount and the quality of the POI data offered by the POI search engines to constantly improve within the near future. Another observation is that some of the noise in the POI matching procedure follows specific patterns. For example, the current POI matching procedure generates many false matches near the places that a user visits on a daily basis. We believe that we can overcome such issues with a combination of appropriate heuristics and fine-tuning of our algorithms.
Finally, we note that we have no formal procedure for assessing the quality of the automatically-inferred POI ratings yet. As a first step in this direction, we present user feedback obtained from a field experiment with a group of volunteers who used the Pythia application.
6.4. User Experience Feedback
An inherent problem in many privacy-enhanced solutions is the privacy
vs. utility tradeoff, that is balancing the measures taken to protect privacy against the deterioration of the utility and the usability of the system. We have, by design, ensured the privacy-preserving properties of our system and its non-invasive operation. To obtain user experience feedback about the usability of the system and the quality of its contextual suggestions, we designed a field experiment and started it in January 2015. In total, 26 users volunteered to evaluate the current Pythia system, and 17 of them have installed the content collector (which is the first step to start using Pythia). The study needs to run for at least a few months, for the personal profiles to accumulate a significant amount of personal data. Nevertheless, we asked the users to anonymously answer a questionnaire based on their preliminary impressions about the system. The summary results from a total of 12 questionnaires is shown in
Table 2. In this case, too, a five-point Likert scale is adopted, as in TREC 2013: 0 is the lowest rate, 2 is neutral and 4 is the highest rate.
The main objective of the experiment was to collect user experience feedback using a small number of simple questions about the overall user experience. In particular, the users were asked to respond about the stability of the application (good stability implies higher credibility for the rest of the answers of the users), any noticeable increase in energy consumption (due to the user-centric architecture, certain computations are executed on the user platform), the quality of the profiler and the contextual suggestions (to ensure that the measures taken to enhance privacy did not degrade the utility of the system) and the overall impression about system and the importance of privacy in such applications.
From the results, it is evident that the overall impression of the users is positive, since all questions achieved on average above the neutral value of two. The content collector, which is the most mature of the Pythia components, performs well with respect to usability and efficiency and is very effective with respect to its tasks (collecting data). The web-based automatic profile generation tools achieve lower, but still above neutral scores. The prototype shows that Pythia is feasible, while the other criteria, i.e., usability, efficiency and effectiveness, could be further improved. Similarly, the implementation of the contextual suggestion engine also provides room for improvements. The POI collection framework is not visible to the users and could not be evaluated in the questionnaire. From our experience, however, the POI collection framework, just like the content collector, is a mature component of the Pythia system (it is up and running without problems since the spring of 2014) and does its job well. Finally, the general questions show that the users value privacy in tourism-related applications almost as high as their general privacy protection and that a system like Pythia is important for tourism.
Admittedly, the number of users in our experiment is very small in order to draw conclusive results. Nevertheless, we still consider the feedback that we obtained very valuable, at least in this stage of the development of the system. Of course, running a large-scale user study on Pythia, once the system has reached a higher technology readiness level, for example TRL7 (as noted earlier, the current implementation is somewhere between TRL5 and TRL6), would be very useful.
7. Discussion and Conclusions
The Pythia system is a privacy-enhanced, non-invasive contextual suggestion system for tourists, with important architectural innovations. The main system components operate in the background without user interaction, and all personal data of the user are kept on his or her own device. The system’s architecture, obtained with a privacy by design approach, allows one to use sensitive personal data for personalized suggestions of touristic attractions without violating the individuals’ privacy. The resulting recommendations are context-based (i.e., related to the current geographical place of the user), and the whole system operates non-invasively. The protection of user privacy is achieved by placing the profiling and recommendation procedures at the user-side, either on a mobile device or a browser. Finally, we developed a prototype implementation of Pythia and presented preliminary results with user feedback that confirm the feasibility of our approach.
There are two main lessons we learned from designing and deploying Pythia. First is that the system design, especially the architectural choice to keep all user data on his or her own side, ensures a high level of privacy for the users. This is an innovative feature for a mobile contextual suggestion system. The only leakage is the information about which general areas the user is interested. This leakage can be controlled by masking the actual place of interest within a larger area when the application retrieves data from the POI database. This technique, which is known as generalization or coarsening, achieves (in the context of the Pythia system) a plausible tradeoff between network load and privacy.
The second lesson learned is that not disclosing user data to the service provider affects the nature of the recommendation service. Collaborative filtering approaches, which are very popular in recommender systems, do not seem to fit our settings. However, this drawback of enforcing non-collaborative users can be counterbalanced by the richness of the single user profile.
We faced several technical challenges during the development and testing of the system, and we addressed most of them successfully, including issues related to low energy consumption, application stability and application usability. A major challenge was the implementation of the contextual suggestion engine within a browser, as a web client application. Even though the core contextual suggestion algorithms were already implemented, converting them into web applications proved to have several difficulties. As a result, in the current prototype, these algorithms are slightly modified, and the contextual suggestion results are not of the same quality as the `mobile’ algorithms. This issue will be addressed by further improving the web client implementations of our algorithms.
Overall, the prototype built has demonstrated that the approach taken in the Pythia system is feasible and can lead to effective contextual suggestion systems.
An interesting observation that we made during our interaction with users and potential users of Pythia is that certain users are reluctant to install an application like the content collector on their mobile devices, even if they are assured that their personal data is not sent anywhere. These users were getting anxious because of the simple existence of a profile containing their personal data and, in particular, their web searches and browser history. These indications led us to include in the questionnaire a question to get some feedback about the relative importance of the protection privacy of the three main types of personal data in Pythia. The outcome provided some evidence that users value the privacy of browser history and web searches, at least as high as their location privacy (
Table 3). In conclusion, based on the overall feedback from the users that participated in the experiment and answered the questionnaire, but also from the users who did not accept to participate in the experiment, we believe that we have to investigate how to make more users trust such an application.
Another important challenge that we faced is how to evaluate our system. Regarding the contextual suggestion engine, there is strong evidence that the applied algorithms work well because of their good performance at TREC 2013. However, the other half, the automatic profiling algorithms, as well as the effectiveness of the overall system could not be evaluated in the same way. The fact that the algorithms of the systems work on the personal data of users practically excludes the possibility to make a centralized assessment of the effectiveness of the system. One can use questionnaires like we did already or, for example, run A/B testing, where each hypothesis of the system is experimentally tested on random sets of users. An interesting research problem would be to work on a privacy-preserving method for evaluating the effectiveness of such systems.
The development of the Pythia system is continuing. Our current plans are to upgrade the implementation of Pythia to a more complete and stable system, to perform a more extensive evaluation of the complete system and to investigate further applications of Pythia in the context of smart cities and personal e-health systems.
Finally, we are currently examining two distinct directions for enhancing the profiler and the contextual suggestion engine. First, we are looking into how to use additional information from the smartphones to improve the accuracy of the POI matching procedure; for example, in order to distinguish the case where the user stays for a while in front of a POI (e.g., a cafeteria), from the case that the user actually visits the POI. Second, we are investigating how to enhance the user profile with additional information, beyond the matched POIs. For example, we already support the collection of web search and browser history, but do use these data in the suggestion algorithms. If we could manage to use more (sensor) data from the smartphone or even identify user activities at different locations, this could be used to improved both of the above directions.



 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}