Methods for Distributed Compressed Sensing

Abstract
:1. Introduction
1.1. Notation
2. Distributed Compressed Sensing Setup
2.1. Single Node Reconstruction Problem
2.2. Distributed Setups vs. Distributed Solvers
3. Network Models
3.1. Fixed Network Models
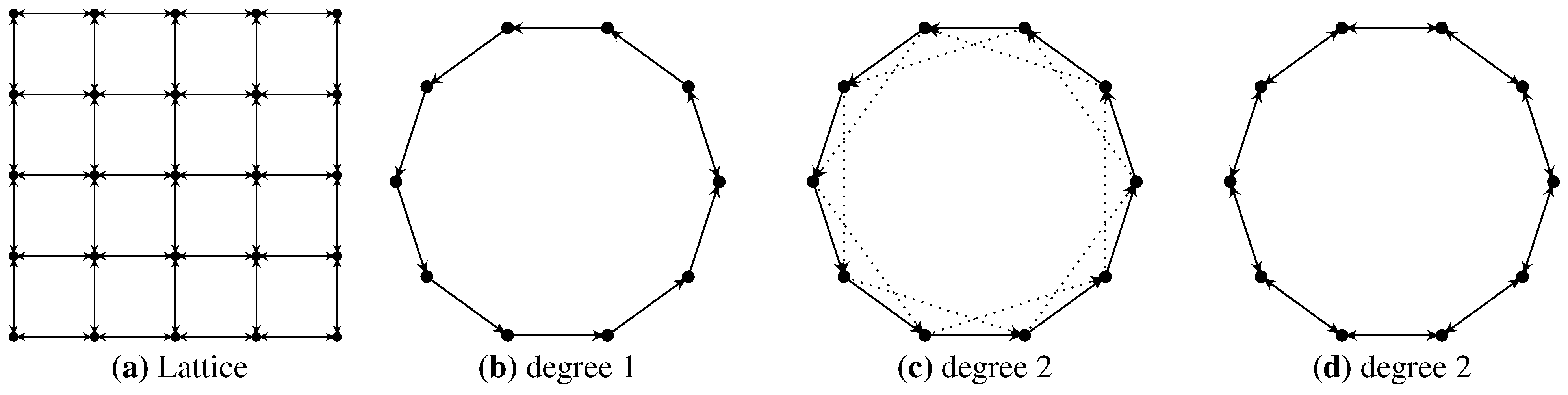
3.2. Random Network Models
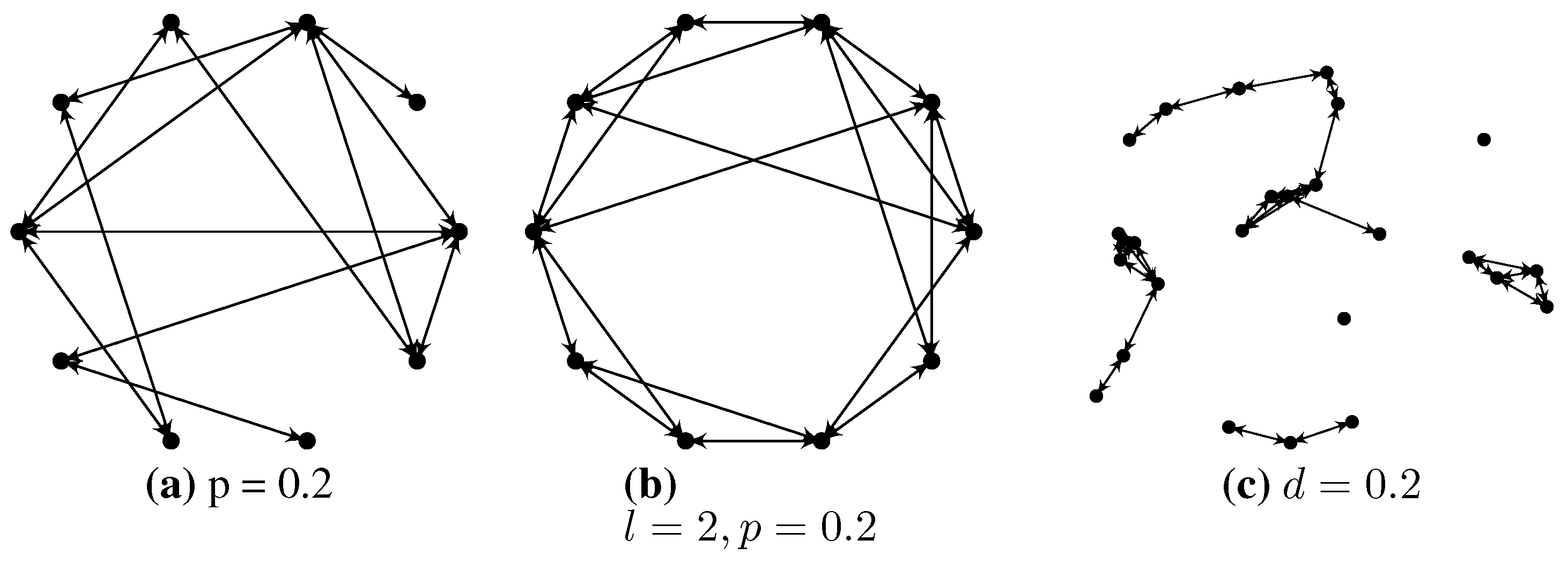
3.3. A Comment on Fundamental Limits in Networks
4. Signal Models
4.1. Common Signal Model
4.2. Mixed Signal Model
4.3. Extended Mixed Signal Model
4.4. Common Support-Set Model
4.5. Mixed Support-Set Model
4.6. Mixed Support-Set Model with Correlations
4.7. Common Dense Signal Model
4.8. Limitations in the Signal Models
5. Convex Solvers for DCS
5.1. Distributed Basis Pursuit
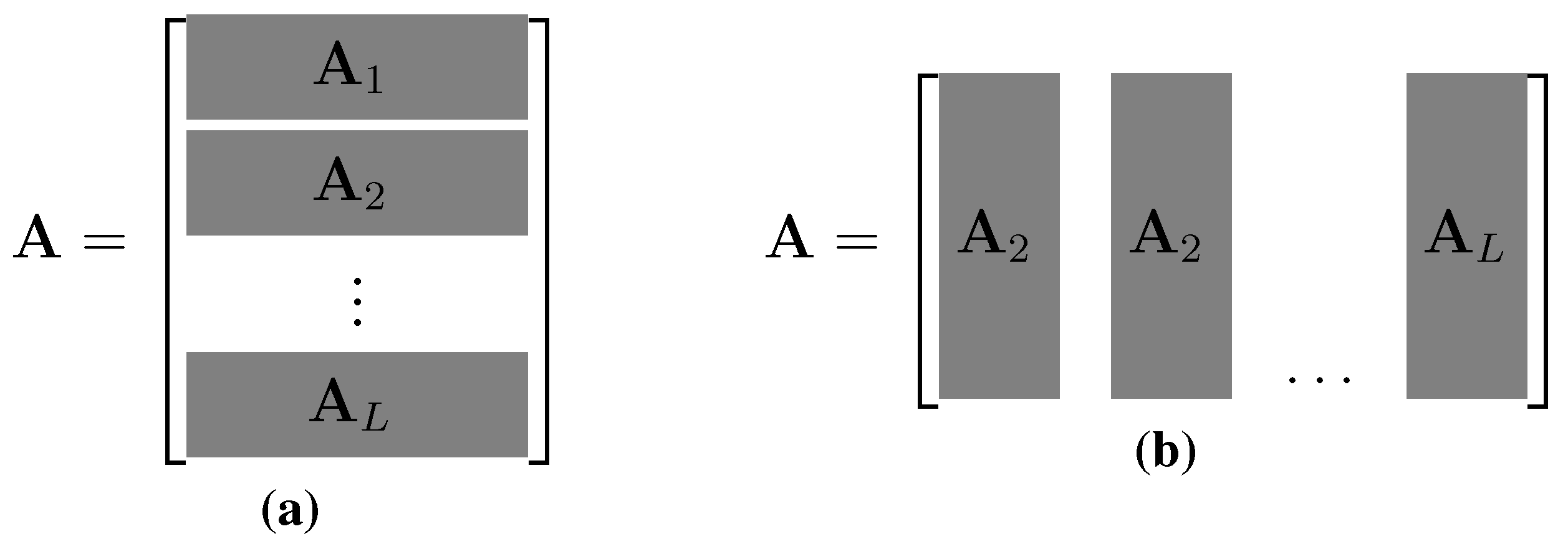
5.2. D-LASSO
6. Greedy Solvers
6.1. Single-Sensor: Orthogonal Matching Pursuit
| Algorithm 1 Orthogonal matching pursuit (OMP). |
| Input: , , s |
| Initialization: |
| Iteration: |
| 1: repeat |
| 2: |
| 3: |
| 4: |
| 5: |
| 6: |
| 7: until or |
| Output: |
6.2. Single Sensor: Subspace Pursuit
| Algorithm 2 Subspace pursuit (SP). |
| Input: , s, |
| Initialization: |
| 1: |
| 2: |
| 3: |
| Iteration: |
| 1: repeat |
| 2: |
| 3: |
| 4: |
| 5: |
| 6: |
| 7: |
| 8: |
| 9: |
| Output: |
6.3. S-OMP
6.4. SiOMP
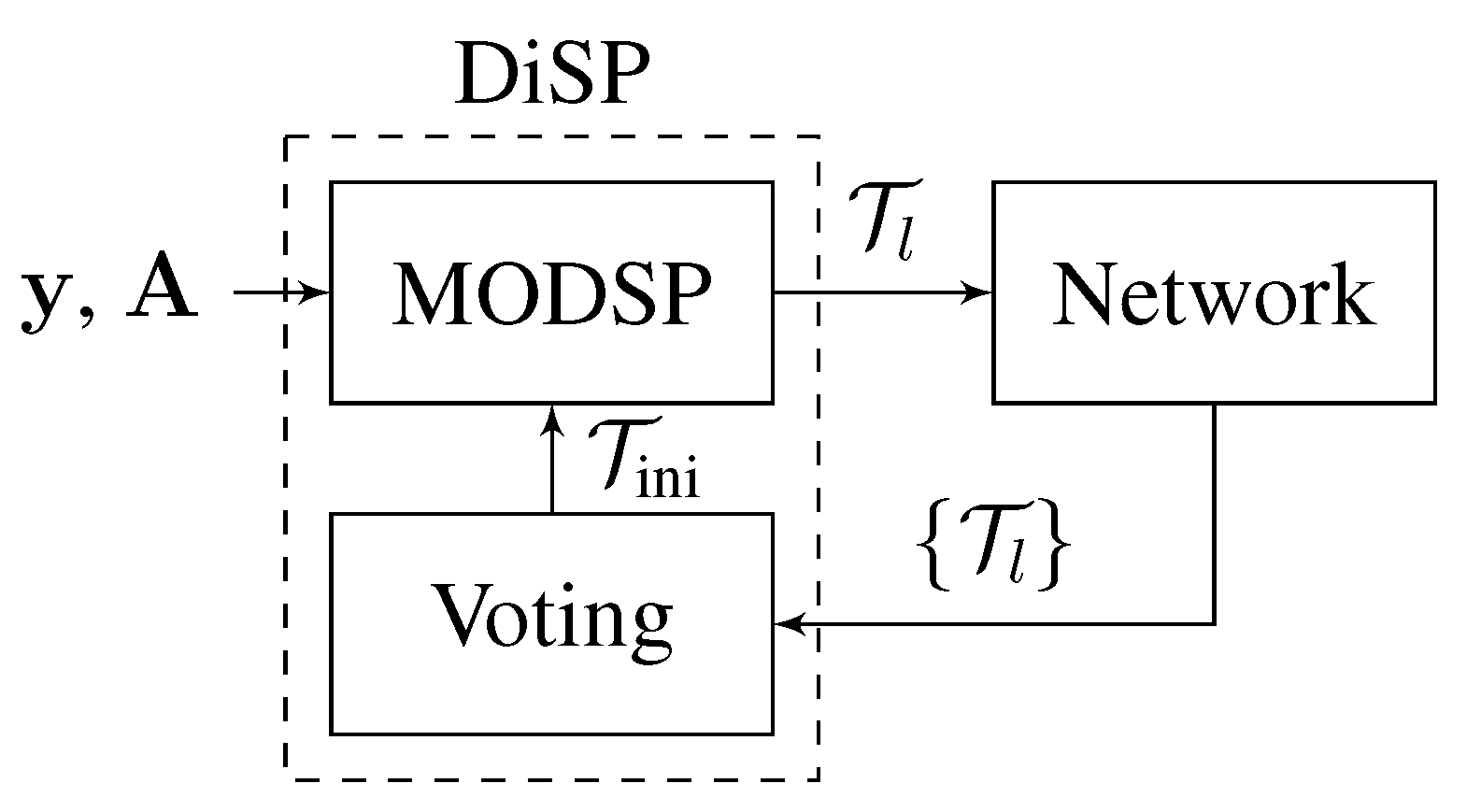
6.5. DiSP
6.6. DC-OMP
6.7. DPrSP
6.8. D-IHT
6.9. Overview of Distributed Greedy Pursuits


{kind=link}
{kind=link}
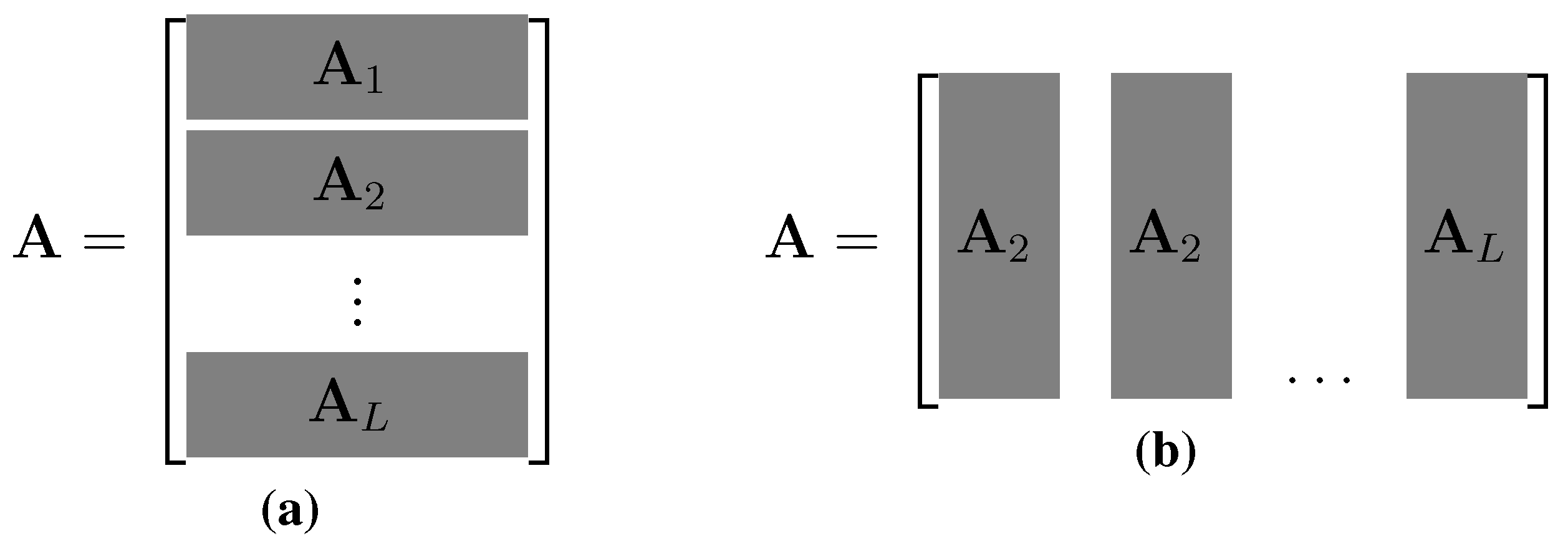{kind=link}
{kind=link}
{kind=link}
{kind=link}
7. Simulations
7.1. Performance Measures
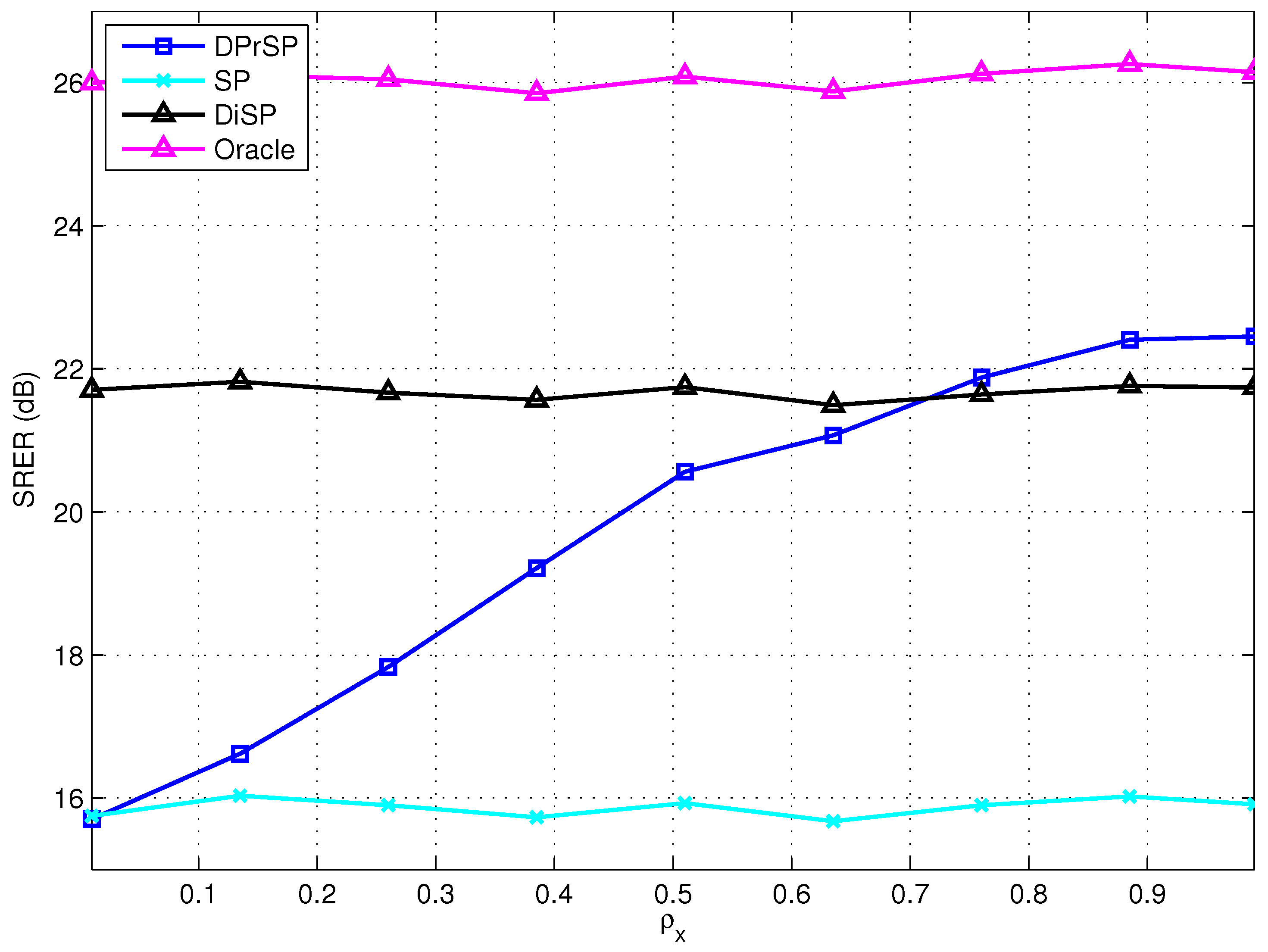
7.2. Experiments
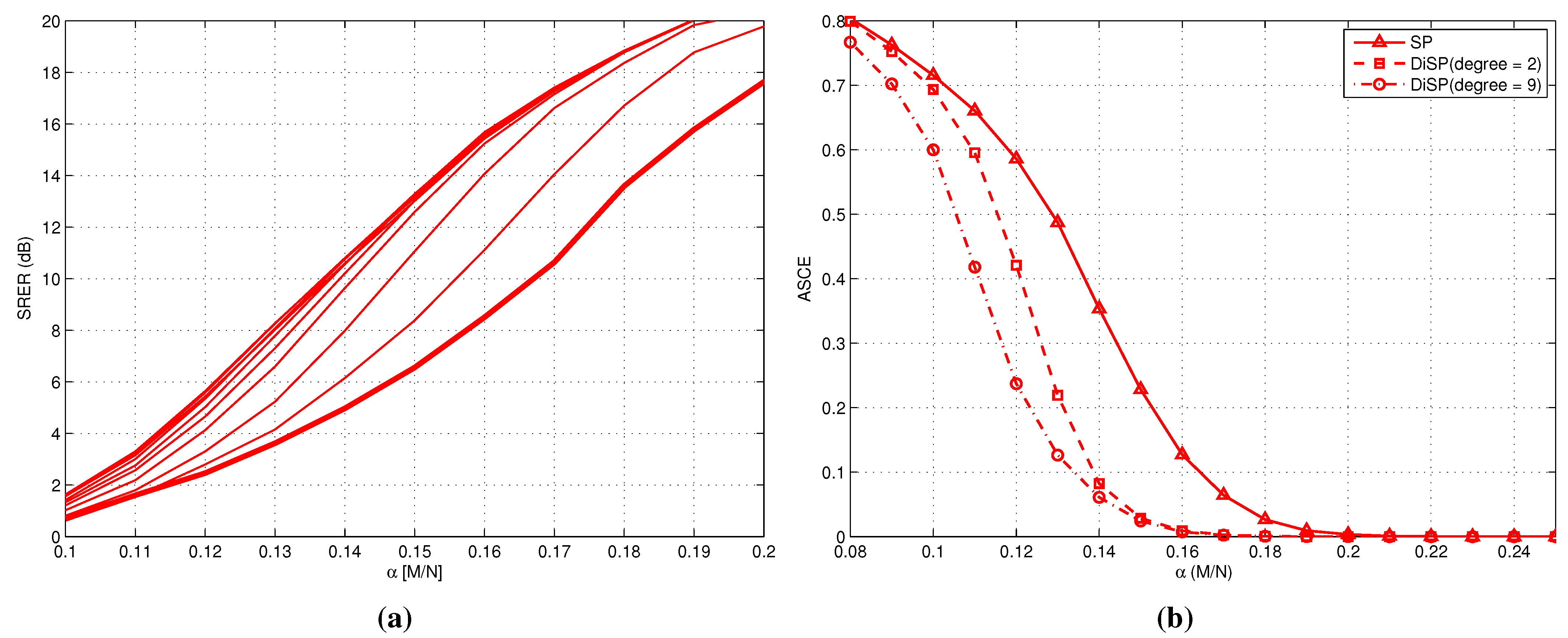
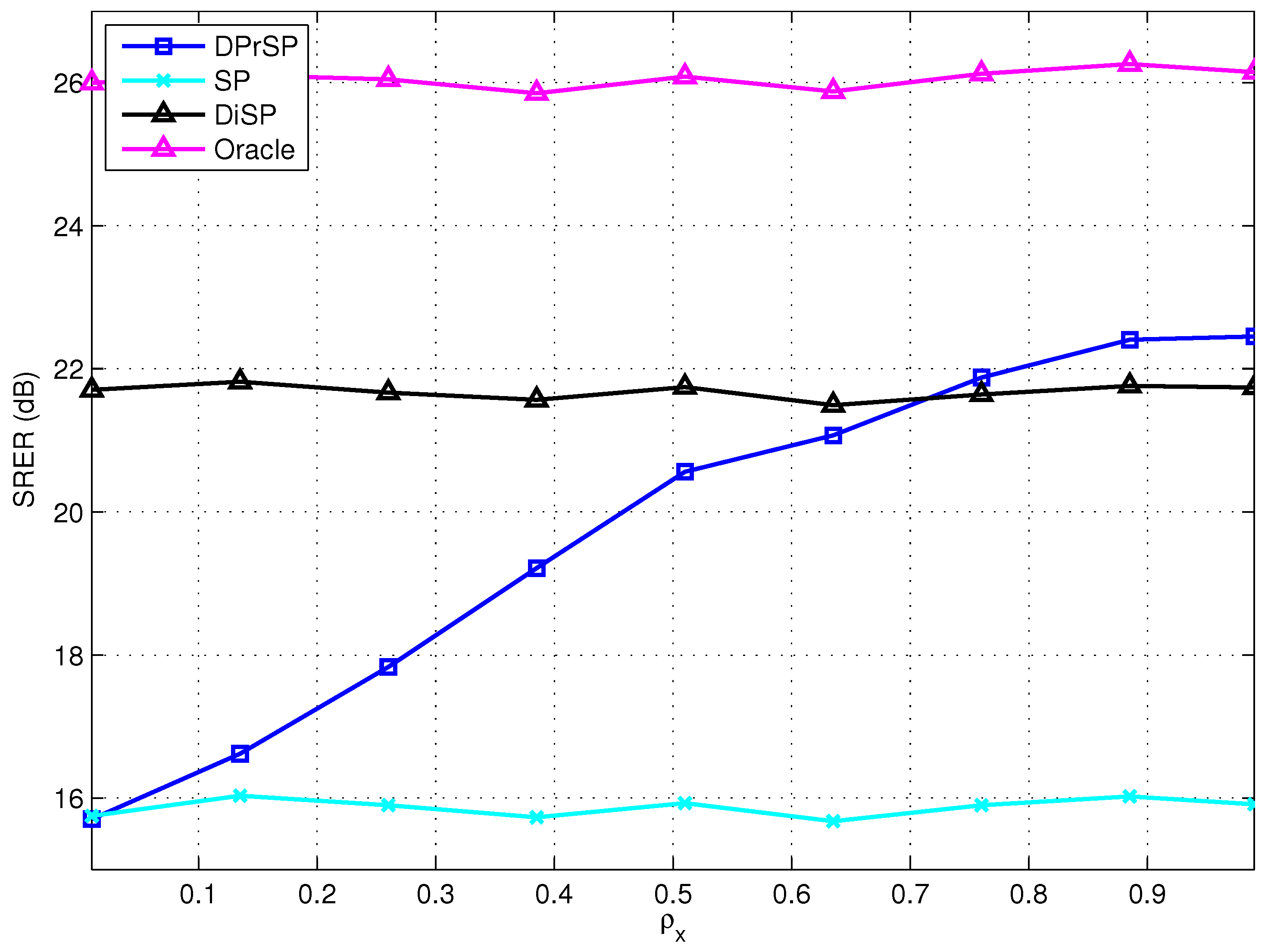
8. Discussion and Open Problems
Conflicts of Interest
References
- Donoho, D.L. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Candés, E.J.; Tao, T. Near-optimal signal recovery from random projections: Universal encoding strategies? IEEE Trans. Inf. Theory 2006, 52, 5406–5425. [Google Scholar] [CrossRef]
- Giryes, R.; Elad, M. RIP-based near-oracle performance guarantees for SP, CoSaMP, and IT. IEEE Trans. Signal Process. 2012, 60, 1465–1468. [Google Scholar] [CrossRef]
- Candés, E.J.; Tao, T. Decoding by linear programming. IEEE Trans. Inf. Theory 2005, 51, 4203–4215. [Google Scholar] [CrossRef]
- Donoho, D.L.; Huo, X. Uncertainty principles and ideal atomic decomposition. IEEE Trans. Inf. Theory 2001, 47, 2845–2862. [Google Scholar] [CrossRef]
- Cohen, A.; Dahmen, W.; Devore, R. Compressed sensing and best k-term approximation. J. Amr. Math. Soc. 2009, 211–231. [Google Scholar]
- Feuer, A.; Nemirovski, A. On sparse representation in pairs of bases. IEEE Trans. Inf. Theory 2003, 49, 1579–1581. [Google Scholar] [CrossRef]
- Raskutti, G.; Wainwright, M.; Martin, J.; Yu, B. Restricted eigenvalue properties for correlated gaussian designs. J. Mach. Learn. Res. 2010, 11, 2241–2259. [Google Scholar]
- Sundman, D.; Chatterjee, S.; Skoglund, M. Distributed Greedy Pursuit Algorithms. Available online: http://arxiv.org/abs/0901.3403 (accessed on 10 December 2013).
- Erdős, P.; Rényi, A. On random graphs. Publ. Math. 1959, 6, 290–297. [Google Scholar]
- Watts, D.; Strogatz, S. Collective dynamics of “small-world” networks. Nature 1998, 393, 409–410. [Google Scholar] [CrossRef] [PubMed]
- Penrose, M. Random Geometric Graphs. In Random Geometric Graphs; Oxford University Press: Oxford, UK, 2004. [Google Scholar]
- Barabási, A.; Albert, R. Emergence of scaling in random networks. Science 1999, 286, 509–512. [Google Scholar] [PubMed]
- Elias, P.; Feinstein, A.; Shannon, C.E. A note on the maximum flow through a network. IRE Trans. Inf. Theory 1956, 4, 117–119. [Google Scholar] [CrossRef]
- Ford, L.R.; Fulkerson, D.R. Maximal flow through a network. Can. J. Math. 1956, 8, 399–404. [Google Scholar] [CrossRef]
- Blasco-Serrano, R.; Zachariah, D.; Sundman, D.; Thobaben, R.; Skoglund, M. An Achievable Measurement Rate-MSE Tradeoff in Compressive Sensing through Partial Support Recovery. In Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2013), Vancouver, BC, Canada, 26–31 May 2013; pp. 6426–6430.
- Feizi, S.; Medard, M. A Power Efficient Sensing/Communication Scheme: Joint Source-Channel-Network Coding by Using Compressive Sensing. In Proceedings of AnnualAllerton Conference on Communication, Control, and Computing (Allerton 2011), Champaign, IL, USA, 2–4 October 2013; pp. 1048–1054.
- Feizi, S.; Medard, M.; Effros, M. Compressive Sensing over Networks. In Proceedings of IEEE Annual Allerton Conference on Communication, Control, and Computing (Allerton 2010), Monticello, IL, USA, 29 September–1 October; pp. 1129–1136.
- Goyal, V.K.; Fletcher, A.K.; Rangan, S. Compressive sampling and lossy compression. IEEE Signal Process. Mag. 2008, 25, 48–56. [Google Scholar] [CrossRef]
- Sun, J.Z.; Goyal, V.K. Optimal Quantization of Random Measurements in Compressed Sensing. In Proceedings of 2009 IEEE International Symposium on Information Theory, Seoul, Korea, 28 June–3 July 2009; pp. 6–10.
- Shirazinia, A.; Chatterjee, S.; Skoglund, M. Analysis-by-synthesis quantization for compressed sensing measurements. IEEE Trans. Signal Process. 2013, 61, 5789–5800. [Google Scholar] [CrossRef]
- Ming, Y.; Yi, Y.; Osher, S. Robust 1-bit compressive sensing using adaptive outlier pursuit. IEEE Trans. Signal Process. 2012, 60, 3868–3875. [Google Scholar] [CrossRef]
- Wei, D.; Milenkovic, O. Information theoretical and algorithmic approaches to quantized compressive sensing. IEEE Trans. Commun. 2011, 59, 1857–1866. [Google Scholar]
- Zymnis, A.; Boyd, S.; Candés, E. Compressed sensing with quantized measurements. IEEE Signal Process. Lett. 2010, 17, 149–152. [Google Scholar] [CrossRef]
- Mota, J.F.C.; Xavier, J.M.F.; Aguiar, P.M.Q.; Püschel, M. Distributed basis pursuit. IEEE Trans. Signal Process. 2012, 60, 1942–1956. [Google Scholar] [CrossRef]
- Baron, D.; Duarte, M.F.; Wakin, M.B.; Sarvotham, S.; Baraniuk, R.G. Distributed Compressive Sensing. Available online: http://arxiv.org/abs/0901.3403 (accessed on 10 December 2013).
- Park, J.; Hwang, S.; Yang, J.; Kim, D.K. Generalized Distributed Compressive Sensing. Available online: http://arxiv.org/abs/1211.6522 (accessed on 10 December 2013).
- Sundman, D.; Chatterjee, S.; Skoglund, M. On the Use of Compressive Sampling for Wide-Band Spectrum Sensing. In Proceedings of IEEE International Symposium on Signal Processing and Information Technology (ISSPIT 2010), Luxor, Egypt, 15–18 December 2010; pp. 354–359.
- Kirmani, A.; Colaco, A.; Wong, F.N.C.; Goyal, V.K. CoDAC: A Compressive Depth Acquisition Camera Rramework. In Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2012), Kyoto, Japan, 25–30 March 2012; pp. 5425–5428.
- Wu, P.K.T.; Epain, N.; Jin, C. A Dereverberation Algorithm for Spherical Microphone Arrays Using Compressed Sensing Techniques. In Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2012), Kyoto, Japan, 25–30 March 2012; pp. 4053–4056.
- Sundman, D.; Zachariah, D.; Chatterjee, S.; Skoglund, M. Distributed Predictive Subspace Pursuit. In Proceedings of International Conference on Acoustics, Speech, and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013.
- Candés, E. The restricted isometry property and its implications for compressed sensing. Rendus Math. 2008, 346, 589–592. [Google Scholar] [CrossRef]
- Candés, E.J.; Wakin, M.B. An introduction to compressive sampling. IEEE Signal Process. Mag. 2008, 25, 21–30. [Google Scholar] [CrossRef]
- Davenport, M.A.; Boufounos, P.T.; Wakin, M.B.; Baraniuk, R.G. Signal processing with compressive measurements. IEEE J. Sel. Topics Signal Process. 2010, 4, 445–460. [Google Scholar] [CrossRef]
- Boyd, S.; Parikh, E.; Chu, E.; Peleato, B.; Eckstein, J. Distributed optimization and statistical learning via the alternating method of multipliers. Found. Trends Mach. Learn. 2011, 3, 1–122. [Google Scholar] [CrossRef]
- Dantzig, G.B. Linear Programming and Extensions; Princeton University Press: Princeton, NJ, USA, 1963. [Google Scholar]
- Dutta, H.; Kargupta, H. Distributed Linear Programming and Resource Management for Data Mining in Distributed Environments. In Proceedings of IEEE International Conference on Data Mining Workshops (ICDMW 2008), Pita, Italy, 15–19 December 2008; pp. 543–552.
- Yarmish, G. A Distributed Implementation of the Simplex Method. Ph.D. Thesis, Polytechnic University, HongKong, China, 2001. [Google Scholar]
- Hall, J.A.J.; McKinnon, K.I.M. Update Procedures for the Parallel Revised Simplex Method; Technical Report; University of Edingburgh: Edinburgh, UK, 1992. [Google Scholar]
- Craig, S.; Reed, D. Hypercube Implementation of the Simplex Algorithm. In Proceedings of the Third Conference on Hypercube Concurrent Computers and Applications, Pasadena, CA, USA, 19–20 January 1988; pp. 1473–1482.
- Neelamani, R.; Krohn, C.E.; Krebs, J.R.; Deffenbaugh, M.; Anderson, J.E.; Romberg, J.K. Efficient Seismic Forward Modeling Using Simultaneous Random Sources and Sparsity. In Proceedings of SEG International Exposition and 78th Annual Meeting, Las Vegas, NV, USA, 9–14 November 2008.
- Bazerque, J.A.; Giannakis, G.B. Distributed spectrum sensing for cognitive radio networks by exploiting sparsity. IEEE Trans. Signal Process. 2010, 58, 1847–1862. [Google Scholar] [CrossRef]
- Tropp, J.A.; Gilbert, A.C. Signal recovery from random measurements via orthogonal matching pursuit. IEEE Trans. Inf. Theory 2007, 53, 4655–4666. [Google Scholar] [CrossRef]
- Dai, W.; Milenkovic, O. Subspace pursuit for compressive sensing signal reconstruction. IEEE Trans. Inf. Theory 2009, 55, 2230–2249. [Google Scholar] [CrossRef]
- Needell, D.; Tropp, J.A. CoSaMP: Iterative signal recovery from incomplete and inaccurate samples. Appl. Comput. Harmon. Anal. 2009, 26, 301–321. [Google Scholar] [CrossRef]
- Needell, D.; Vershynin, R. Signal recovery from incomplete and inaccurate measurements via regularized orthogonal matching pursuit. IEEE J. Sel. Topics Signal Process. 2010, 4, 310–316. [Google Scholar] [CrossRef]
- Blumensath, T.; Davies, M.E. Iterative hard thresholding for compressed sensing. Appl. Comput. Harmon. Anal. 2009, 27, 265–274. [Google Scholar] [CrossRef]
- Chatterjee, S.; Sundman, D.; Vehkapera, M.; Skoglund, M. Projection-based and look-ahead strategies for atom selection. IEEE Trans. Signal Process. 2012, 60, 634–647. [Google Scholar] [CrossRef]
- Sundman, D.; Chatterjee, S.; Skoglund, M. Look Ahead Parallel Pursuit. In Proceedings of IEEE Swedish Communication Technologies Workshop (Swe-CTW 2011), Stockholm, Sweden, 19–21 October 2011; pp. 114–117.
- Sundman, D.; Chatterjee, S.; Skoglund, M. FROGS: A Serial Reversible Greedy Search Algorithm. In Proceedings of IEEE Swedish Communication Technologies Workshop (Swe-CTW 2012), Lund, Sweden, 24–26 October 2012.
- Sundin, M.; Sundman, D.; Jansson, M. Beamformers for Sparse Recovery. In Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2013), Vancouver, BC, Canada, 26–31 May 2013; pp. 5920–5924.
- Pati, Y.C.; Rezaiifar, R.; Krishnaprasad, P.S. Orthogonal Matching Pursuit: Recursive Function Approximation with Applications to Wavelet Decomposition. In Proceedings of the 27th Annual Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 3–6 November 2013; pp. 40–44.
- Davenport, M.A.; Wakin, M.B. Analysis of orthogonal matching pursuit using the restricted isometry property. IEEE Trans. Inf. Theory 1993, 56, 4395–4401. [Google Scholar] [CrossRef]
- Liu, E.; Temlyakov, V.N. The orthogonal super greedy algorithm and applications in compressed sensing. IEEE Trans. Inf. Theory 2012, 58, 2040–2047. [Google Scholar] [CrossRef]
- Maleh, R. Improved RIP Analysis of Orthogonal Matching Pursuit. Available online: http://arxiv.org/abs/1102.4311 (accessed on 10 December 2013).
- Tropp, J.A.; Gilbert, A.C.; Strauss, M.J. Simultaneous Sparse Approximation via Greedy Pursuit. In Proceedings of IEEE International Conference on Acoustics, Speech, and Signal Processing, Honolulu, HI, USA, 18–23 March 2005; pp. 721–724.
- Tropp, J.A.; Gilbert, A.C.; Strauss, M.J. Algorithms for simultaneous sparse approximation. Part I: Greedy pursuit. Signal Process. 2006, 86, 572–588. [Google Scholar] [CrossRef]
- Zhang, W.; Ma, C.; Wang, W.; Liu, Y.; Zhang, L. Side Information Based Orthogonal Matching Pursuit in Distributed Compressed Sensing. In Proceedings of IEEE International Conference on Network Infrastructure and Digital Content (ICNIDC 2010), Beijing, China, 24–26 September 2010; pp. 80–84.
- Sundman, D.; Chatterjee, S.; Skoglund, M. A Greedy Pursuit Algorithm for Distributed Compressed Sensing. In Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2012), Kyoto, Japan, 25–30 March 2012; pp. 2729–2732.
- Wimalajeewa, T.; Varshney, P.K. Cooperative Sparsity Pattern Recovery in Distributed Networks via Distributed-OMP. In Proceedings of IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2013), Vancouver, BC, Canada, 26–31 May 2013.
- Zachariah, D.; Chatterjee, S.; Jansson, M. Dynamic Subspace Pursuit. In Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2012), Kyoto, Japan, 25–30 March 2012; pp. 3605–3608.
- Zachariah, D.; Chatterjee, S.; Jansson, M. Dynamic iterative pursuit. IEEE Trans. Signal Process. 2012, 60, 4967–4972. [Google Scholar] [CrossRef]
- Patterson, S.; Eldar, Y.C.; Keidar, I. Distributed Sparse Signal Recovery for Sensor Networks. In Proceedings of IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2013), Vancouver, BC, Canada, 26–31 May 2013.
- Reeves, G.; Gastpar, M. A Note on Optimal Support Recovery in Compressed Sensing. In Proceedings of the Annual Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 4–7 November 2009; pp. 1576–1580.
© 2013 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Sundman, D.; Chatterjee, S.; Skoglund, M. Methods for Distributed Compressed Sensing. J. Sens. Actuator Netw. 2014, 3, 1-25. https://doi.org/10.3390/jsan3010001
Sundman D, Chatterjee S, Skoglund M. Methods for Distributed Compressed Sensing. Journal of Sensor and Actuator Networks. 2014; 3(1):1-25. https://doi.org/10.3390/jsan3010001
Chicago/Turabian StyleSundman, Dennis, Saikat Chatterjee, and Mikael Skoglund. 2014. "Methods for Distributed Compressed Sensing" Journal of Sensor and Actuator Networks 3, no. 1: 1-25. https://doi.org/10.3390/jsan3010001
APA StyleSundman, D., Chatterjee, S., & Skoglund, M. (2014). Methods for Distributed Compressed Sensing. Journal of Sensor and Actuator Networks, 3(1), 1-25. https://doi.org/10.3390/jsan3010001