1. Introduction
The development of intelligent surveillance systems (ISS) has become significantly popular due to increasing demand for security and safety in public spaces [
1,
2]. The ISS configures a set of vision sensors, e.g., closed circuit television (CCTV), installed in different areas and a server/command center connected to a computer network. The ISS can analyze the image, audio, and video generated by the vision sensor to identify anomalous events with limited human intervention in the monitoring area using artificial intelligence technologies such as computer vision, pattern recognition, machine learning, etc. [
2]. For example, the ISS might contain various modules that analyze a specific anomaly case.
As one of its applications, the ISS could be used to reduce crime rates, for example, in theft cases. In this case, the ISS should be able to prevent theft incidents. So, we need a module integrated with ISS to detect possible theft cases before the incident occurs.
One way to detect possible theft cases is to identify the suspicious behavior of human objects in the monitoring area, namely loitering. In loitering detection, the system must be able to detect the presence of human objects and track their movements. The movement of human objects involves the spatial domain associated with the position of the object in the monitoring area, as well as the temporal domain related to the duration of the event. However, only some previous papers have exploited these two pieces of information in detecting loitering. Therefore, we propose to use both pieces of information as part of the feature extraction stage.
Several previous studies related to loitering detection used two approaches. The first approach uses handcrafted features [
3,
4,
5,
6,
7,
8], while the second uses non-handcrafted features (deep learning) [
9,
10]. In the handcrafted feature approach, the steps can be divided into three parts: (1) the person-detection process, (2) the feature extraction used to distinguish normal videos and videos that contain people loitering based on the detected person’s movements, and (3) the video classification process. As for the non-handcrafted feature approach, the video input goes directly into a deep-learning architecture. The neural network layers in the deep-learning architecture function as a feature extractor and a classifier.
The features used to identify loitering can vary in the handcrafted feature approach. For example, the total time a person is in the area on the surveillance camera could be used as a feature. The system will detect loitering if the occurrence of a person exceeds the duration limit in the surveillance area. After the person detection and tracking stage, each duration in a particular area will be compared with the safe time limit of 10 s [
3]. If people are in a specific area for over 10 s, then that person is identified as loitering. Patel et al. [
4] used the same features, but only the time limit is adjusted adaptively based on the movement of the person in the frame.
Another feature that can be used is the angle formed by the movement of a person in a sequenced frame. Angle refers to the change in the center of gravity (CoG) of the detected person in a particular frame with the same person in the next frame [
5]. The larger the angle formed, the greater the chance the person will do the lottery and vice versa.
Some researchers have tried combining time and changing angles as features [
6,
7]. The time limit was adjusted based on various video shooting areas (bus stops, shopping malls, railway stations, etc.) [
6]. When a person passes the time threshold and has a significant angle change, that person is indicated to be loitering. If the values for these two features exceed the limit, the person in the frame loiters.
Apart from time and angle changes, optical flow is another handcrafted feature that can be used for loitering detection. Zhang et al. [
8] associate the optical flows between multiple frames to capture short-term trajectories. The optical flow is then represented in a histogram. The next stage is clustering using k-nearest neighbor (KNN). The outlier data generated after the clustering process are assumed to be videos with a loitering person.
In the non-handcrafted feature approach, several deep-learning architectures can be used for loitering detection. The deep-learning architecture used is 2-Stream 3D-Convolutional Neural Network (3D-CNN) [
9]. One branch uses input RGB frames, while the other uses optical flow frames. Asad et al. [
10], used the deep-learning architecture in the form of a 3D convolutional autoencoder (3D-CAE). First, the spatiotemporal features of the last layer output of the 3D max polling are clustered using k-means. Then, the clusters are separated using Support Vector Machine (SVM) to distinguish between normal videos and videos with a loitering person.
We aim to integrate the loitering-detection module into a CCTV-based intelligent surveillance system (ISS). In the ISS, the speed of the process is crucial in responding quickly to detected abnormal events to prevent criminal activities as early as possible. Because of this requirement, the integrated module should be executed in real-time but still maintain performance. Therefore, this paper proposed a loitering-detection method based on spatial and temporal information and machine learning to achieve real-time processing and high accuracy in performance. Overall, the main contributions of the work are summarized as follows:
Proposing a novel feature extraction based on spatial and temporal information for loitering detection.
Integrating the visual background extractor (ViBe) in human detection and tracking for better accuracy and processing time performance.
Introducing the novel dataset containing comprehensive video for evaluating loitering detection.
The rest of the paper is composed of several sections.
Section 2 explains the proposed method for loitering detection.
Section 3 shows the experiment and result.
Section 4 concludes our report.
2. The Proposed Framework
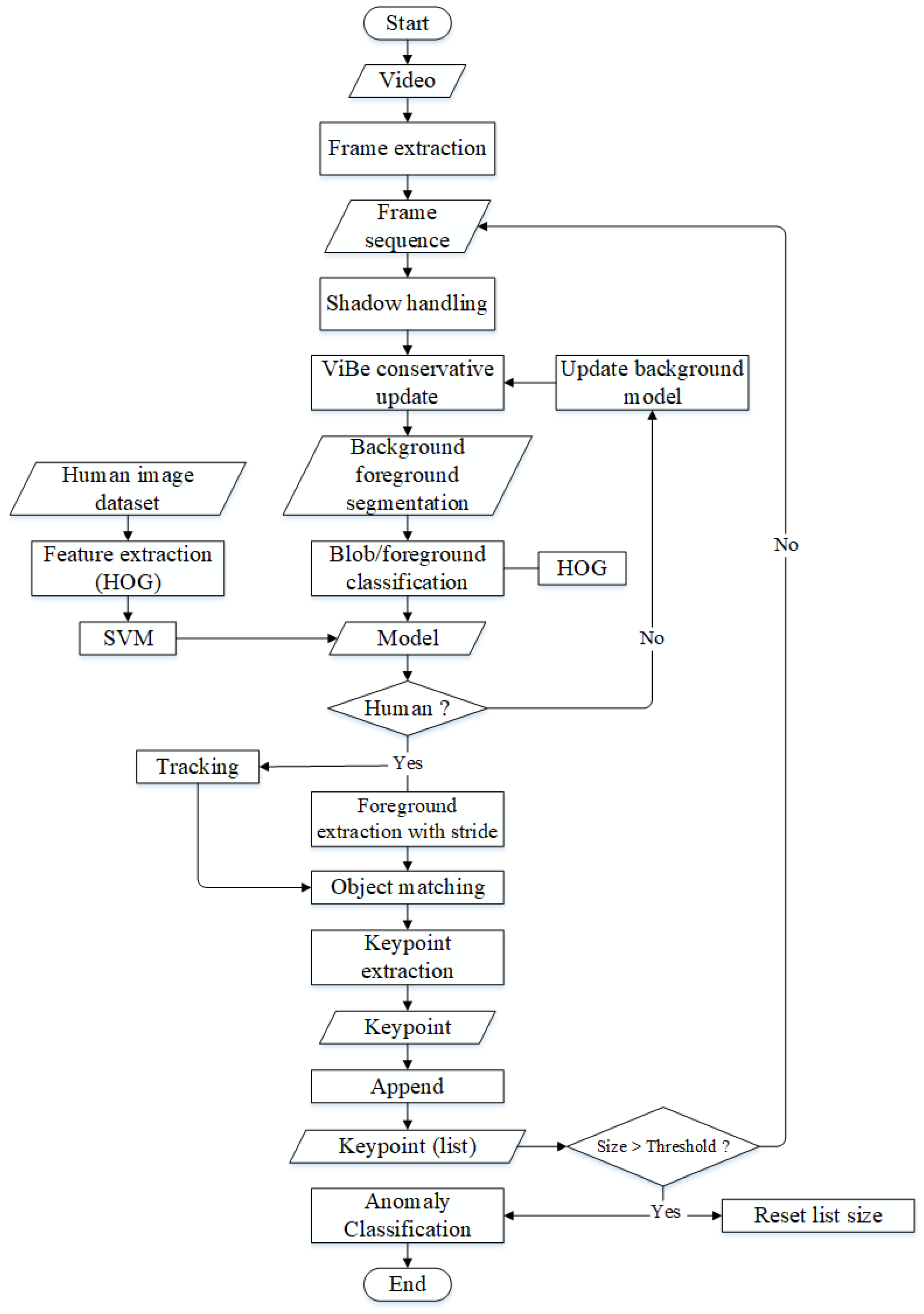
The loitering-detection system starts with video-data acquisition. The video data obtained is extracted into video frames. The video frame is a sequential image. The object shadows on the video frame are removed using a mixture of Gaussian, so as not to affect the background frame modeling results. The background video-modeling process uses the ViBe conservative method. The resulting background model is used for the segmentation process, which results in human objects. Human objects are trained using the histogram of oriented gradient (HOG) method. If a human object is in the video frame, a bounding box will appear, and the tracking process will be carried out. The results of this tracking are in the form of key points from the same human object in video frames. This key point uses the mid-point of the human bounding box. This key point is stored to determine whether the video is normal or abnormal. The angle feature of human steps is used in this study’s analysis. The proposed framework in this research is shown in
Figure 1.
2.1. Data Acquisition
In the data acquisition stage, we use two types of data: augmented data and video data. The augmented data describe the movement of objects in a specific time duration to determine whether this object’s movement is an anomaly. An anomaly object represents a human object loitering in a monitoring area. These augmented data are only used for training purposes. In contrast, the second dataset is a collection of video data taken directly using CCTV cameras and shows the movement of humans in various scenarios.
2.1.1. Augmented Data Acquisition for Training
This research uses augmented data which are generated through the program. The augmented data in this research consist of normal and abnormal movement classes.
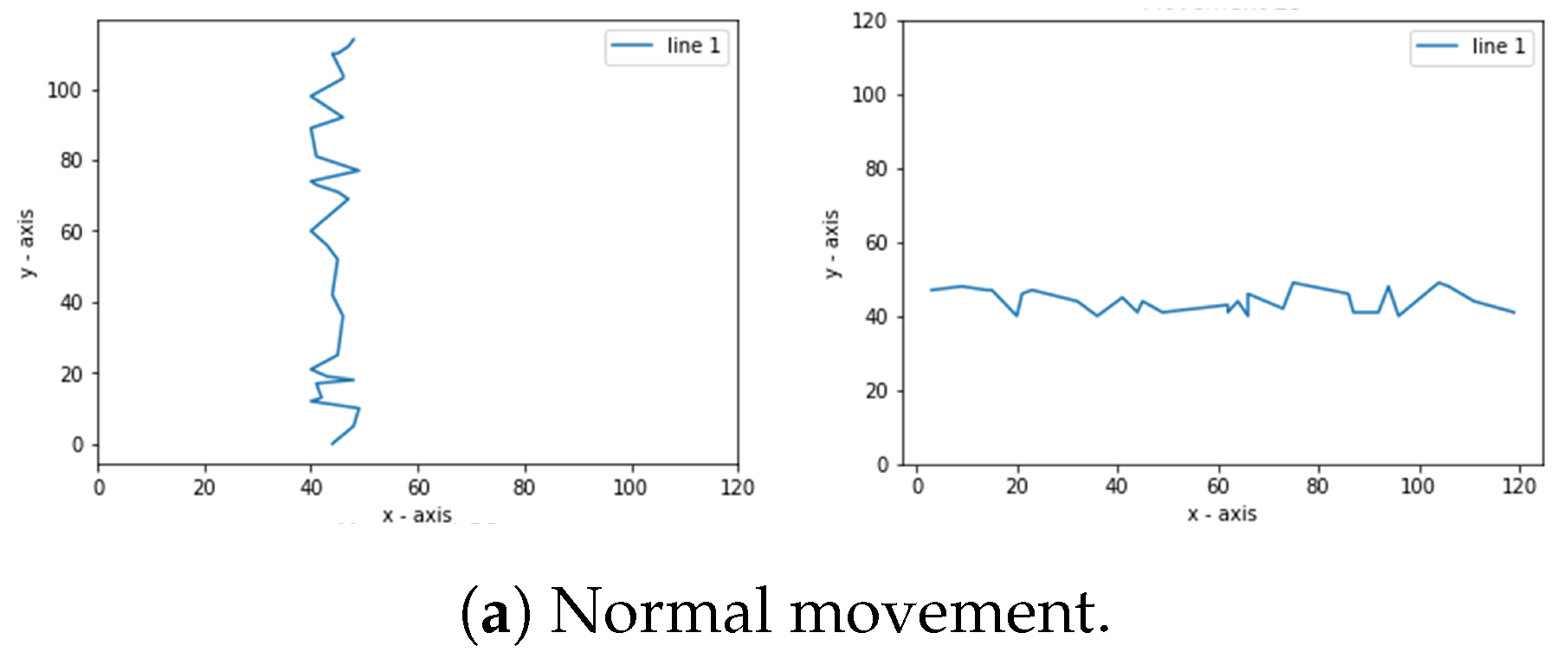
Figure 2 shows the algorithm to get the normal path, while
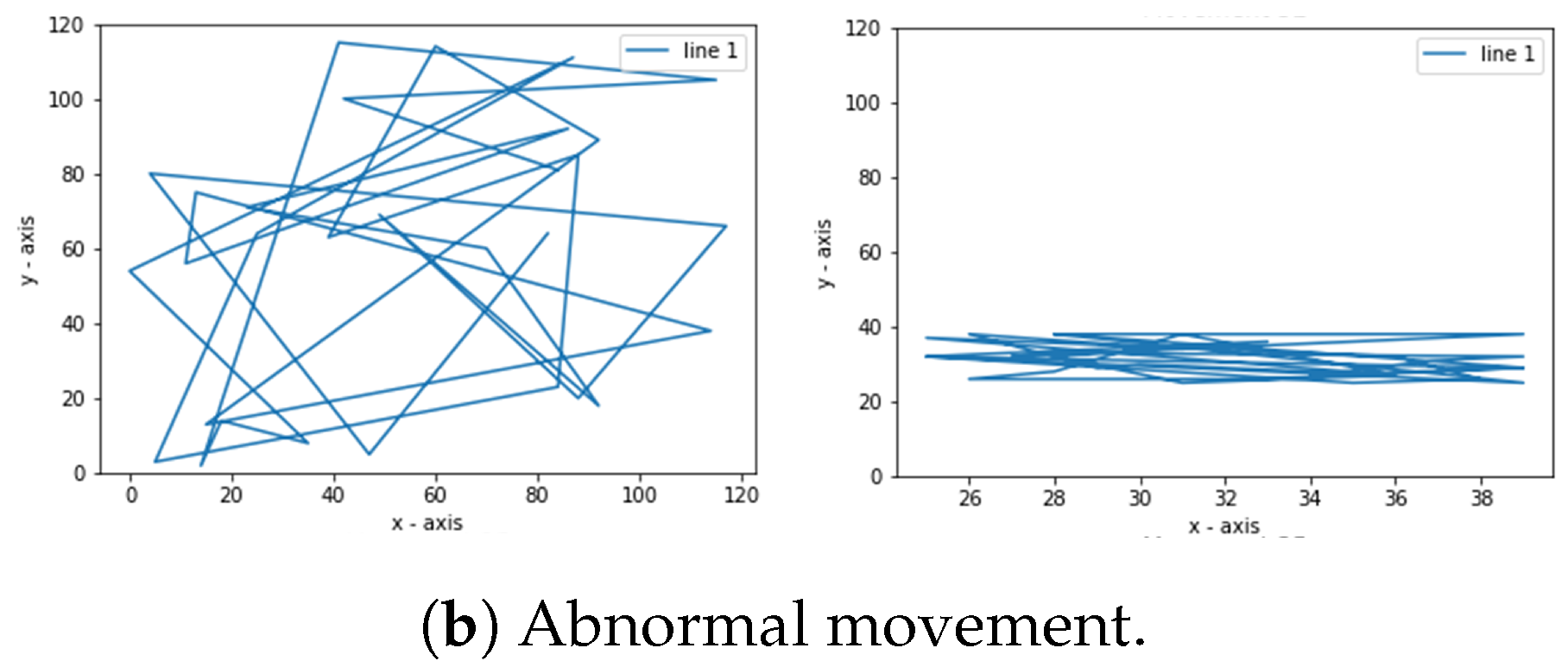
Figure 3 shows the algorithm to get the abnormal path. The number of steps (points) generated in this research was 10, 15, 20, 25, and 30. The data used in this study are 480 in each class, so the total amount of data is 960. The data distribution is 75% for training data and 25% for testing data. The data used for the training process are 720, while the amount for testing is 240.
The step process is obtained by making a simulation with
x and
y coordinates. A normal movement is a straightforward step or a zigzag in a straight line. In the simulation, as shown in
Figure 2, for the program created using the ascending sorting function. This sorting function can be placed on the
x or
y coordinates or both. The sorting function here is to sequence the steps so that the coordinates appear in the same direction. On the other hand, abnormal movements are back-and-forth motions. In
Figure 3, the program does not use the sorting function, which means it only creates random points. Instead, the resulting dots are connected using lines.
Figure 4 shows examples of normal and abnormal steps.
2.1.2. Video Data Acquisition
A total of 20 videos were collected to evaluate the proposed model and features in the testing stage. As many as 7 of the 20 videos contain movements of people who do not loiter, so they are categorized as normal videos. On the other hand, the other 13 videos have scenarios of people loitering in the monitoring area, so those videos are classified as abnormal. The camera used for data collection has full high definition (Full HD) resolution (1080 p) with a 15 fps sampling process. The camera is placed at 2 to 2.5 m in height with a depression angle of 10
–45
. In detail, the characteristics of each video used in the testing process are shown in
Table 1.
2.2. Background Modeling
The initial stage of the proposed method is extracting human region candidates from a video. Due to static video characteristics, we may use background modeling to perform this task. The candidate region we will extract is assumed to be a moving human object. Human object movement is detected using ViBe conservative update [
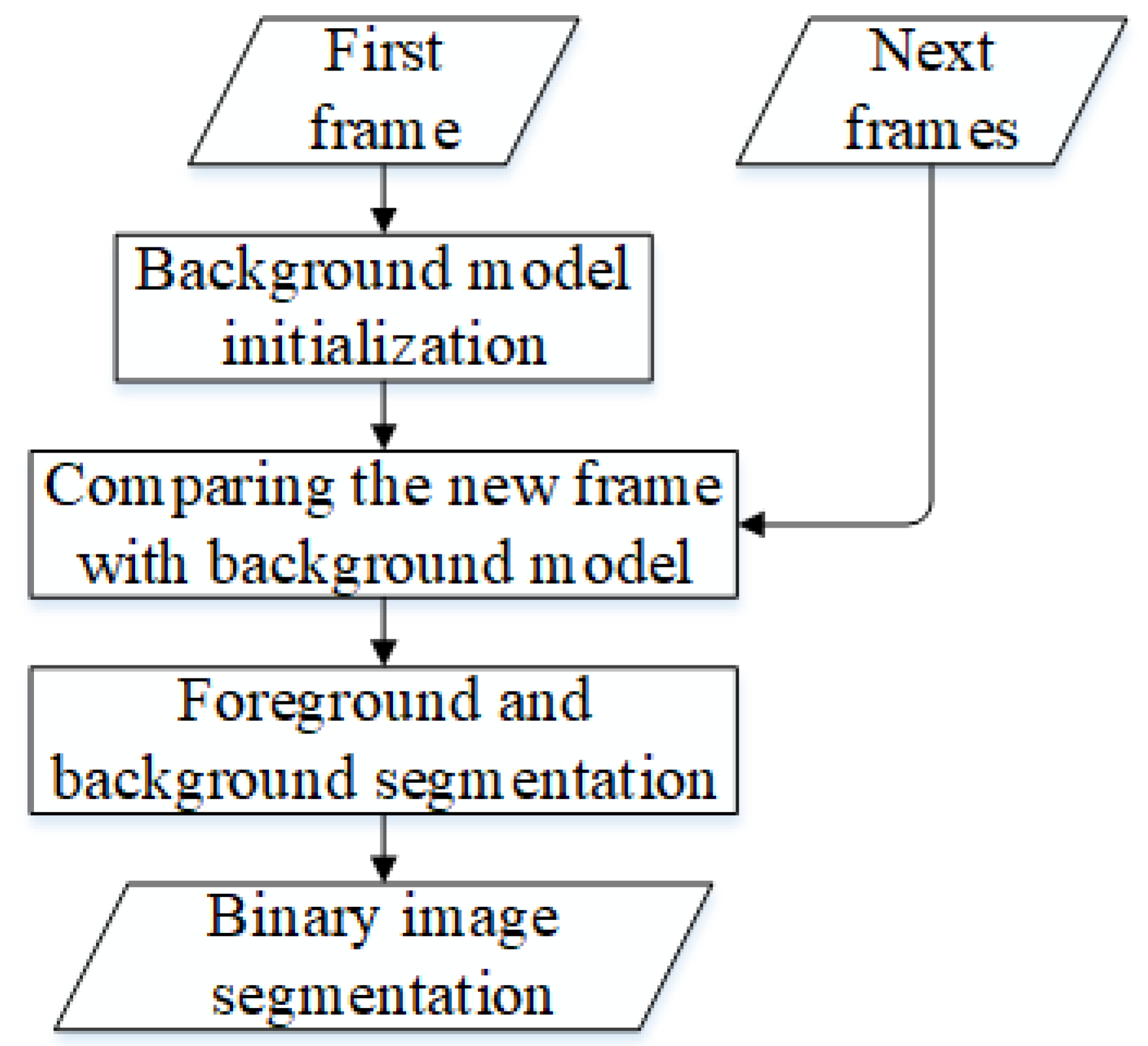
11]. This method has three stages: background modeling, comparing new frames with background models, and foreground and background segments.
Figure 5 shows a flowchart of the ViBe conservative method. The model of each background pixel is initialized in the first frame. This model contains
sample values
v taken randomly from the 8-connected region in the pixel. If the background model on the pixel with location
x, i.e.,
and
, is the set of neighboring pixels with location
x, then
will contain an Equation (
1).
The pixel
is classified by comparing
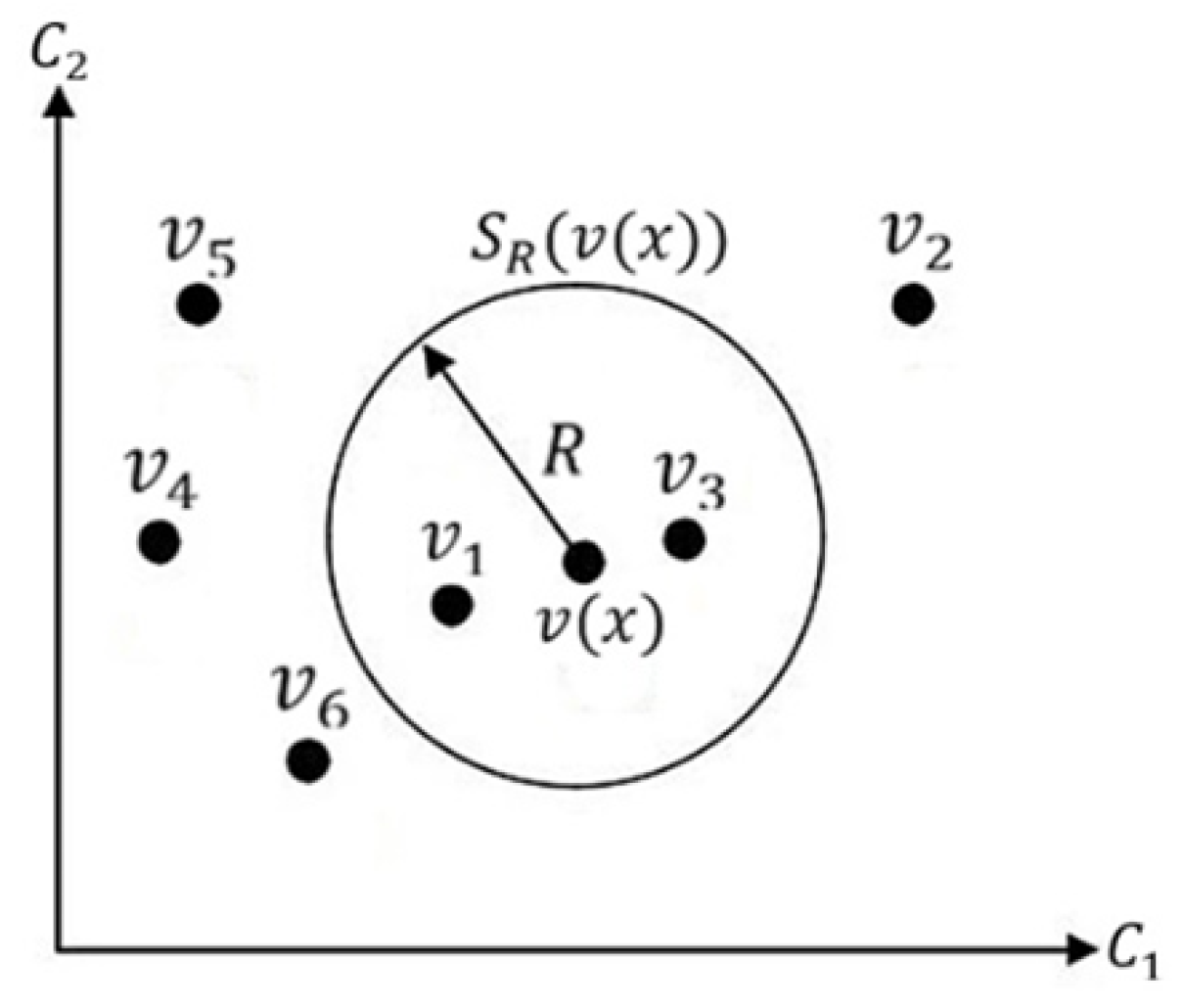
values in the next frame. This comparison is made by defining a circular area
, which has a radius
R and a center point
. An illustration of this stage can be seen in
Figure 6.
Next, the minimum cardinality
threshold value is set. If the number of samples contained in
from the
circle area is more significant than #min, then the pixel
is set as background. If it is smaller, then it is set as foreground. After classifying a pixel as either the background or foreground, the pixel is segmented by giving a value of 0 for the background and 1 for the foreground. Then, the median filtering technique was applied to reduce noise, resulting in a binary image of each frame, with moving objects detected in white while the background is black.
Figure 7 shows an example of the segmentation results.
2.3. Human Detection and Tracking
The background modeling method in the previous stage might extract the non-human object region. Therefore, the extracted foreground regions should be verified in the human detection and tracking stage. In this stage, we utilize the classification model of a human object based on the support vector machine (SVM) with the histogram of oriented gradient (HOG) as feature input. Before starting the verification stage, a human image dataset for the training and validation process was prepared, consisting of 665 humans and 665 non-human samples. The human and non-human datasets used in the process were obtained from the image collection of the The Pedestrian Attribute (PETA) dataset [
12].
The foreground, classified as a human object, will then be extracted based on the specified stride parameters. The stride parameter is the number of separator frames between two frames containing human foreground at different times. The smaller the value of the stride parameter, the more foreground frames are extracted, and vice versa. In the experiments carried out, the stride parameter used is fps/5.
The tracking method used is tracking by particle filter. There are two steps in tracking using a particle filter: prediction and correction. In performing the two steps, it is necessary to define a target state representation, a dynamic model that describes how the states transition, and an observation model that measures the possibility of new measurements. In this study, the target representation is a foreground object classified as a human.
Figure 8 is an example of a tracking particle filter.
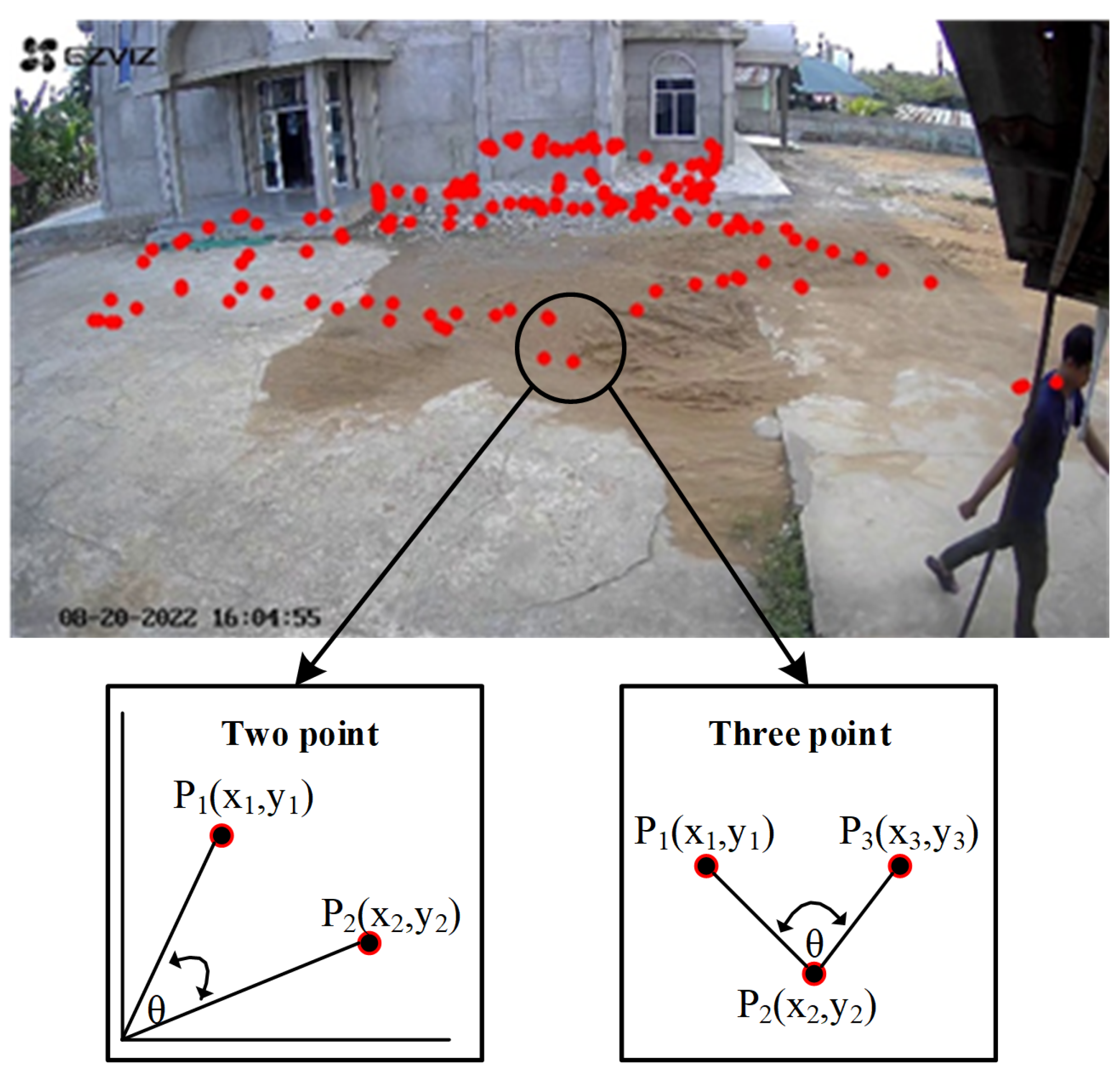
Key point extraction is performed when the similarity value between objects in the bounding box tracking and objects in the bounding box foreground is greater than 80%. Here are some examples of key point extraction results (the extracted key point positions are marked with a red dot).
Figure 9 shows an example of the points of detection of both abnormal and normal human movement.
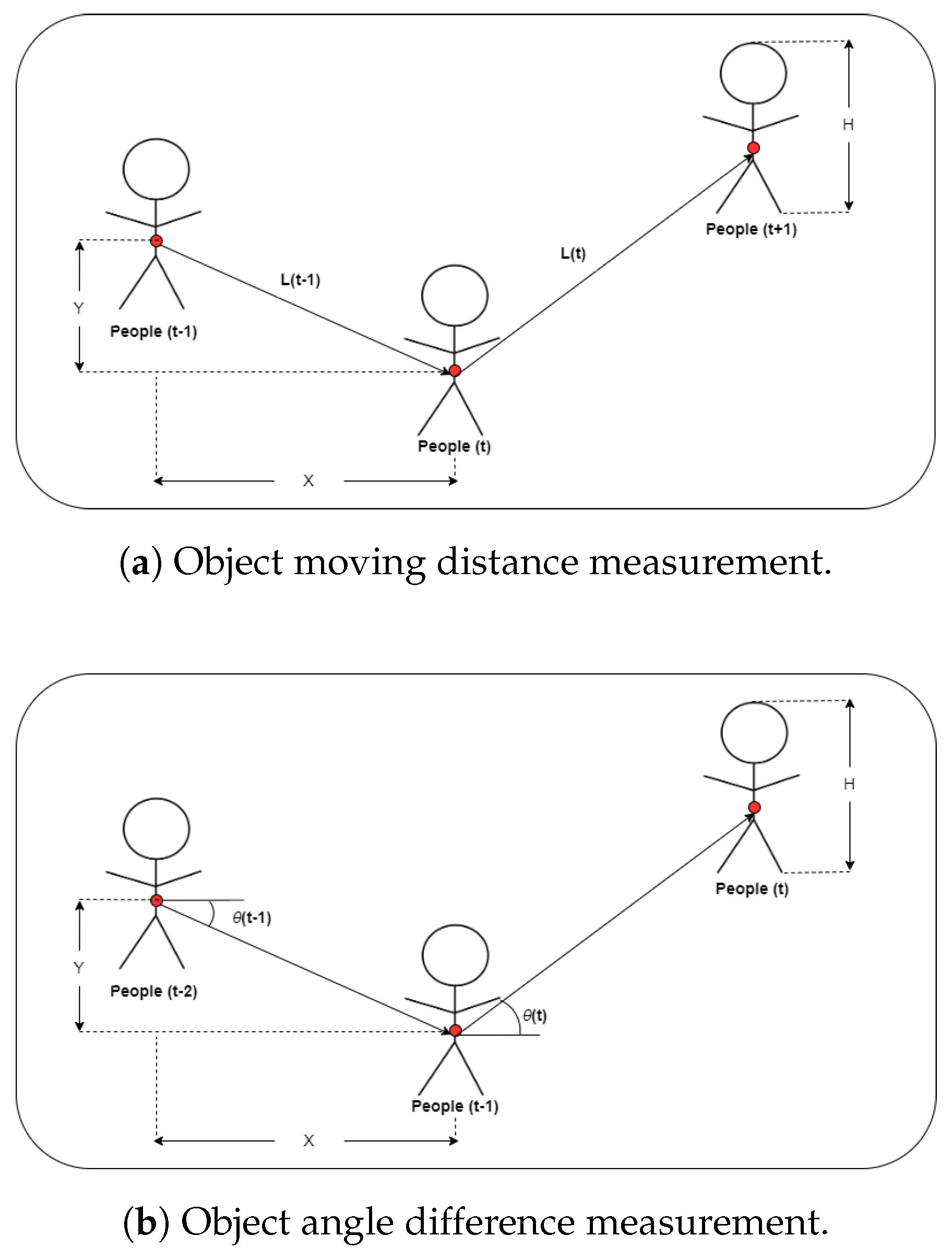
2.4. Spatial-Temporal Feature Extraction
Loitering events are highly dependent not only on the position of the human object in a particular frame, referred to as spatial information, but also on the specific time duration the object appears, defined as temporal information. Therefore, we propose both pieces of information as a novel feature for loitering detection, defined as spatial-temporal features. These features were obtained by calculating the angle at each step. Then, the resulting steps in the video frame are converted into angles. The angle is from
to
. The visualization of the point in the step converted into an angle is shown in
Figure 10. In this research, the angle is obtained from two or three points. The definition of the tangent of an angle between two points is
, or
. This means that
returns the angle between the two locations that constitute the coordinates base of the axis.
Figure 11 shows the algorithm for finding the angles originating from two points. Then, the angle obtained from the three points makes the second angle or
axis,
, and
as the endpoint. The algorithm for calculating angles at three points is shown in
Figure 12.
The angle results are relatively large, namely 0 to 360. Therefore, the angle is normalized from 0 to 1 to reduce the gap in data. The normalization process is carried out by dividing the angle obtained by 360. The normalization equation is shown in Equation (
2).
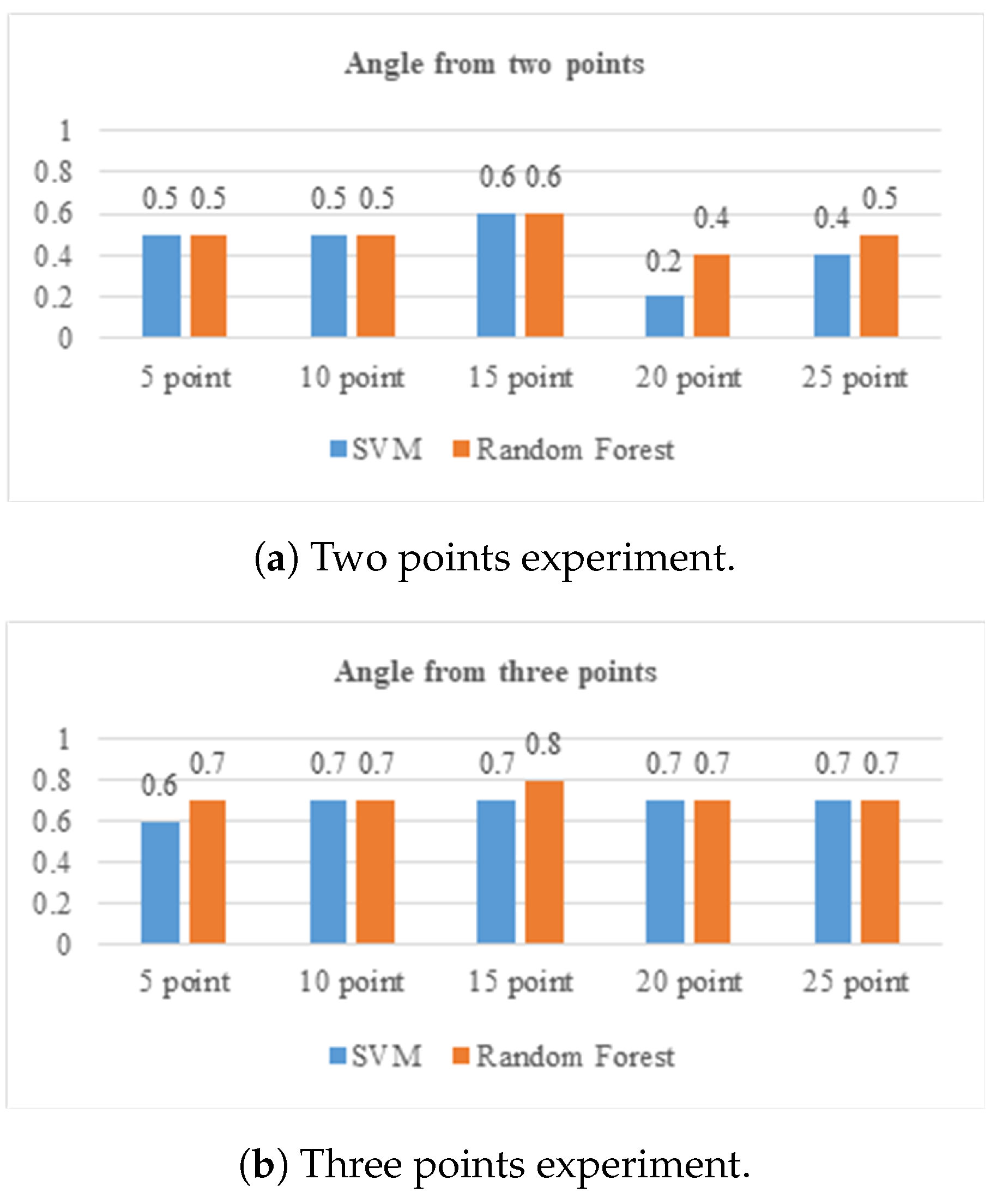
Finally, the final feature will represent the video with 10, 15, 20, or 25 angle values. The extracted feature is then used to classify whether the video is normal or abnormal. This research uses labels for abnormal and for normal movements.
2.5. Decision of Loitering Event
In this research, three supervised learning methods will be explored: the k-nearest neighbor [
13], support vector machine [
14], and random forest [
15].
2.5.1. K-Nearest Neighbor
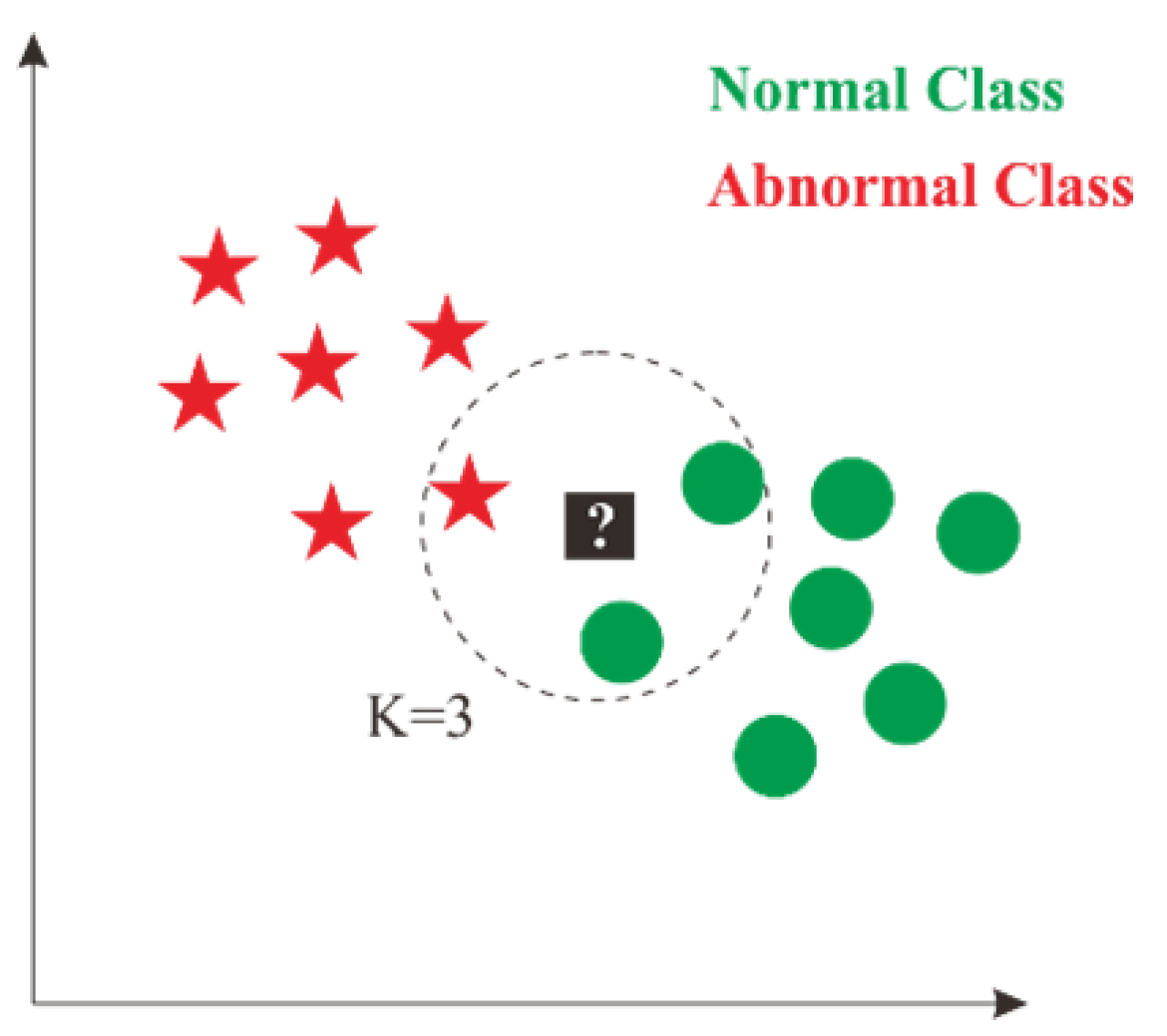
The k-nearest neighbor (KNN) approach classifies objects based on the learning data nearest to the database. KNN is a supervised classification technique in which input data are labeled before training. This technique is utilized frequently in pattern recognition [
16,
17] and image processing [
18]. The data will be projected onto multidimensional spaces, with each dimension representing a data characteristic. This area is separated into categories based on the classification of learning data, including normal and abnormal.
Figure 13 illustrates an example of the KNN approach.
2.5.2. Random Forest
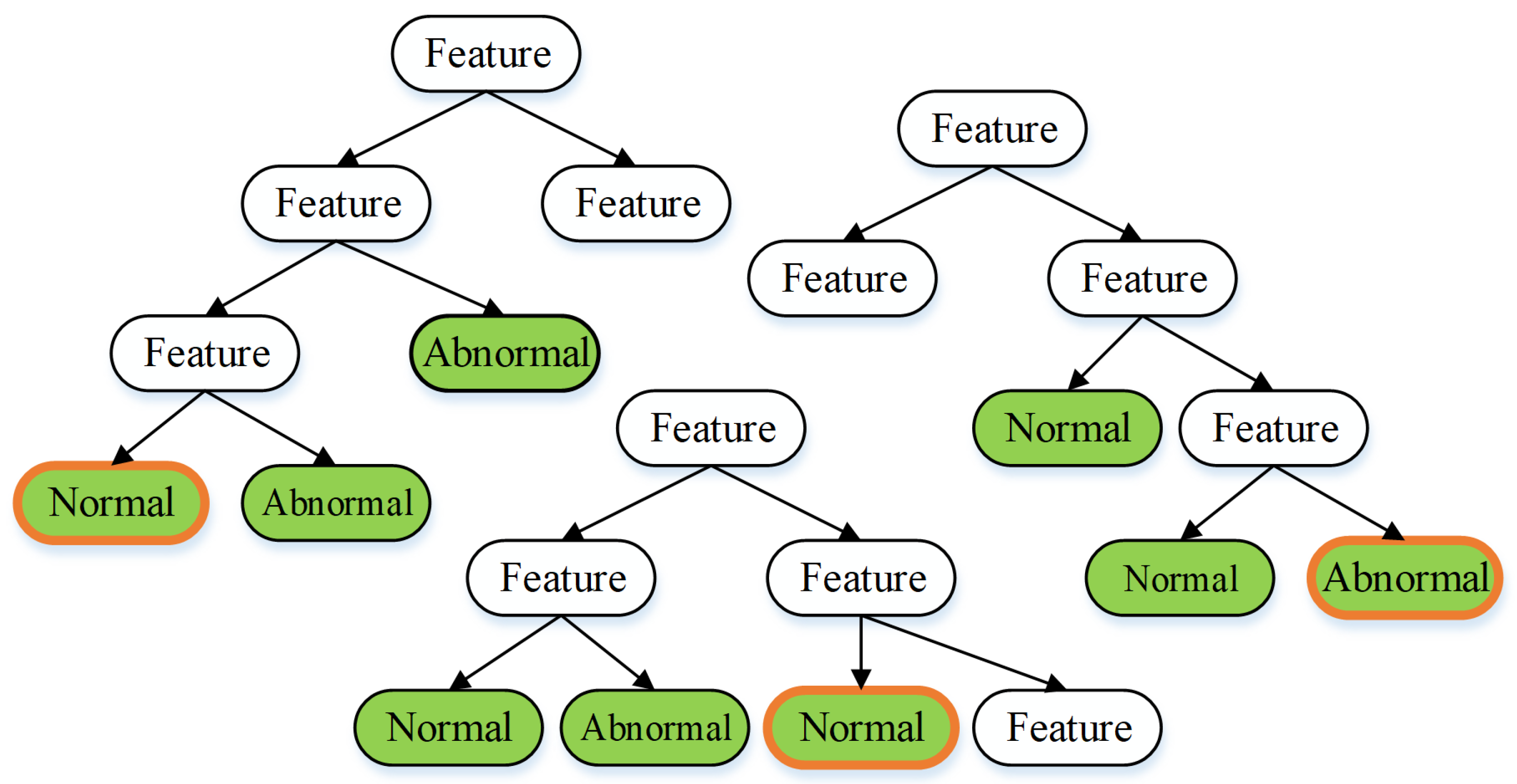
Random forest is a commonly used predictive model method for classification [
15]. Random forest generates an arbitrary number of random decision trees. The decision tree includes the characteristics of each class. The decision or categorization procedure is derived from most voting decisions on the decision tree. Then,
Figure 14 depicts the application of the random forest approach to the investigation.
In
Figure 14, for instance, there are three trees. Then, every node in the tree represents a property of each class. Two normal classes and one abnormal class are derived from the three trees. Hence, it can be inferred that the random forest approach yields the normal class.
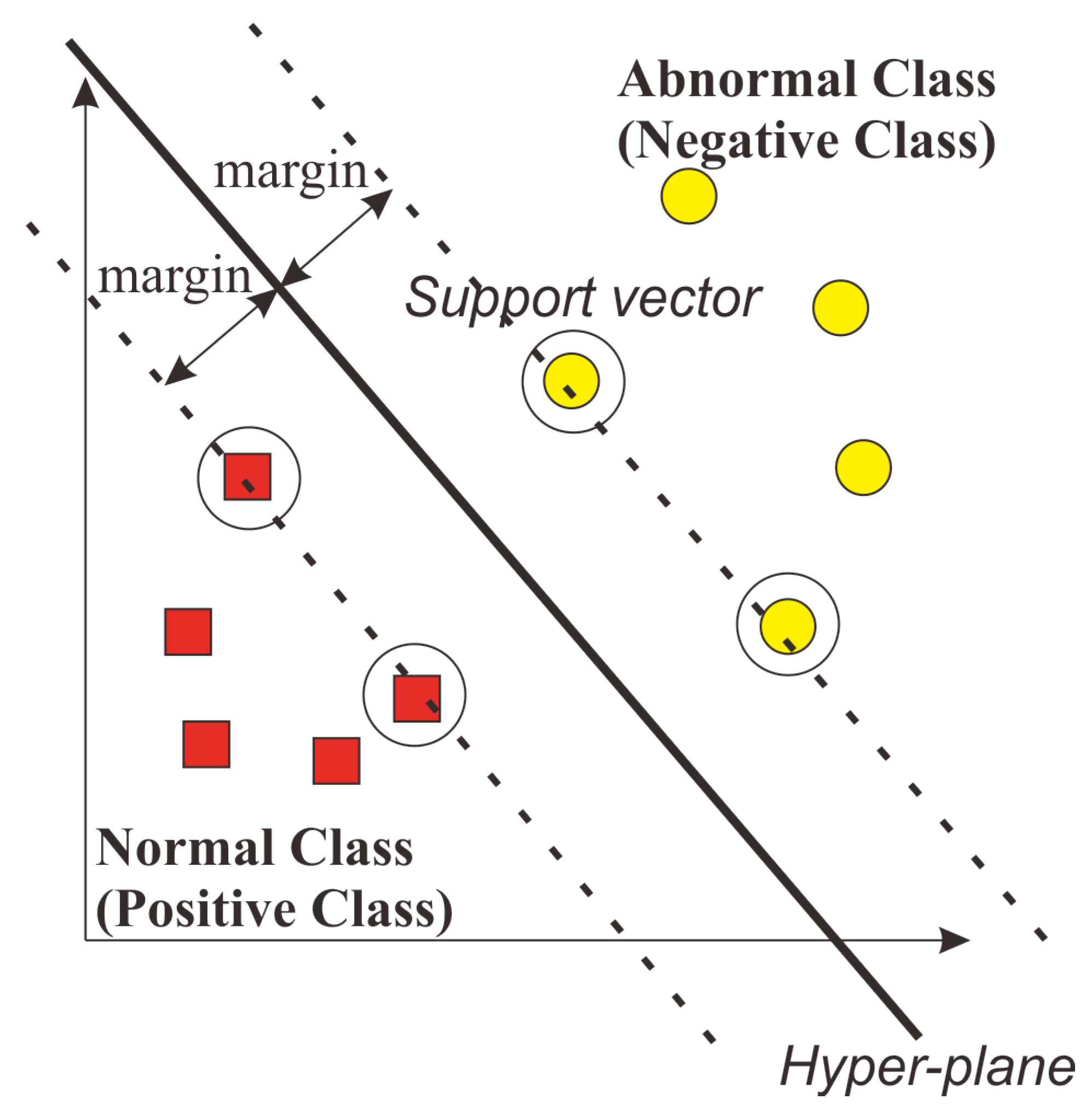
2.5.3. Support Vector Machine
Support vector machine (SVM) is one of the classification techniques commonly employed in supervised learning [
14]. By maximizing the distance between classes, SVM is used to discover the optimal hyperplane. The hyperplane is a function that can be utilized to divide classes. The hyperplane discovered by SVM is depicted in
Figure 15. The hyperplane is located between the two classes. The hyperplane should maximize the margin between the support vector from each class, as described in red and yellow circles.


 ,
, 



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}