
Blossom: Cluster-Based Routing for Preserving Privacy in Opportunistic Networks



Abstract
1. Introduction
- Proposing an innovative routing algorithm according to clustering nodes in order to improve the network performance in terms of messages delivery probability, dropped message probability, and network overhead;
- Comparing the proposed algorithm performance with the First Contact, Epidemic, and PRoPHET algorithms and results validation;
- Analyzing the network performance with the presence and absence of malicious nodes in the network;
- Preserving node’s privacy by cloaking.
2. Related Work

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Approach | Privacy Aspect | Advantage | Disadvantage |
|---|---|---|---|---|
| [21] | Bloom Filter to obscure the friends’ list | Identity privacy | Identity authentication based on zero knowledge | No comparison No malicious nodes |
| Privo [22] | Paillier Homomorphic Encryption, Binary anonymization, and neighborhood randomization | Identity and attribute privacy | The cryptography costs are blowing . | No comparison No malicious nodes |
| [23] | Optimized version of Millionaire’s Problem | Attribute privacy | A good coverage level, high receivers’ accuracy | No comparison No malicious nodes |
| 4PR [24] | Community based routing to conceal nodes’ mobility | Location privacy | Predicting routing path, preserving privacy | No malicious nodes. |
| PIDGIN [25] | Policy tree that represents access structure | Attribute privacy | It does not leakage information to untrusted nodes. It is implemented on a smartphone. | No comparison No malicious nodes |
| PPUR [26] | Bilinear mapping technology, Hashing, Symmetric encryption | Information privacy | It provides messages confidentiality and integrity | No malicious nodes |
| [27] | Multiparty computation, homomorphic encryption | Location privacy | By authenticated encryption it provides mutual authentication, non-repudiation, and conditional privacy preserving. | No comparison No malicious nodes |
| PEON [28] | Layered cryptography | Information privacy | Anonymous communication and rerouting messages via peer nodes. | No comparison No malicious nodes |
| PPHB [29] | Nodes produce a polynomial and hide their identity in the polynomial. | Identity and location privacy | Zero knowledge | Complex calculation |
| ePRIVO [30] | A time-varying neighboring graph was used | Information privacy | Nodes can make routing decisions without knowledge of private information. | No malicious nodes |
| PPERP [31] | Bilinear mapping technology | Information privacy | Providing confidentiality, integrity, and nonrepudiation of encounter records | Focused on privacy preserving for only nondelivery nodes. No malicious nodes |
| [32] | Lightweight cryptographic encryption | Identity, data privacy, and anonymity for nodes | High reliability of packet notification forwarding, Validating the algorithm implementing | No comparison, No malicious nodes, hardware and software limitations |
| [33] | Blockchain | Information privacy | Do not need trust management. Protecting data from manipulation, eavesdropping, masquerading, and other passive attacks. | Block size increases quickly and there are buffer limitations. |
3. Blossom Structure
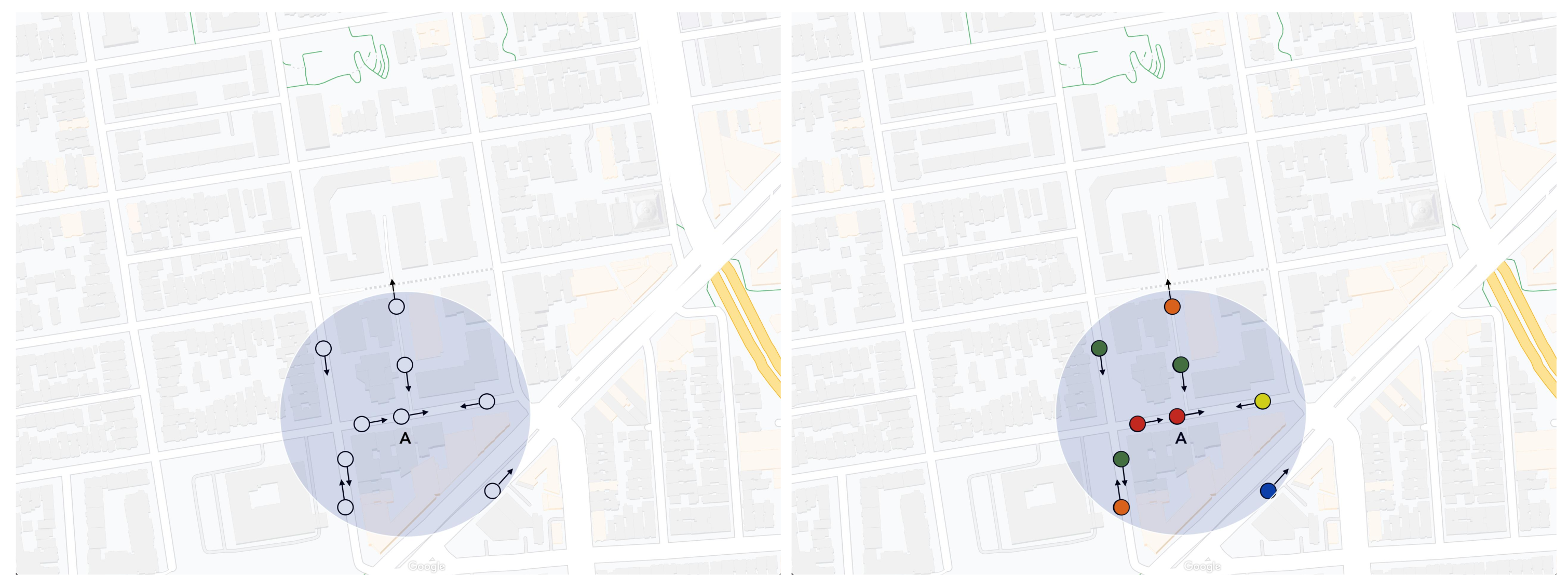
3.1. Calculating Directions
3.2. Clustering Analysis and Homogeneous Group of Clusters Merging
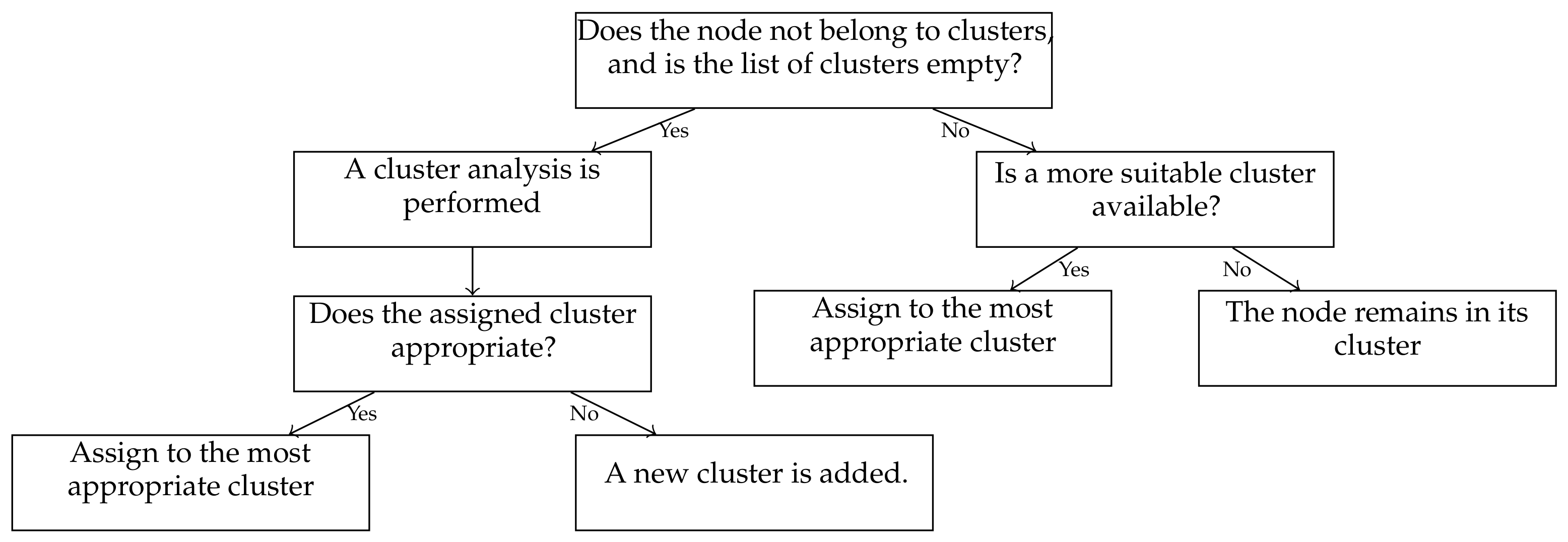
3.3. Clusters
- If a node does not belong to any cluster, a new cluster analysis performs at the beginning of the simulation. The most appropriate cluster for node A is the cluster with a significant number of members. Under this premise, A is assignable to B’s cluster when A’s direction is not greater than the average direction of the cluster that the stopping rules allow. A new cluster is created if no suitable cluster is found or does not belong to a cluster yet. At the end of this assignment process, all new clusters get once-in-a-lifetime initialized with their current average directions.
- If the first method is invalid, the second method is performed. It attempts to assign a single node to an existing cluster with a significant number of members and fit with the node’s direction. Therefore, if the node does not find a cluster, it will not create a new one but will look for an appropriate one while moving along. Hence, this method is only valid for reducing the injecting message into the network by increasing the size of existing clusters and preserving the node’s privacy.

3.4. Message Routing
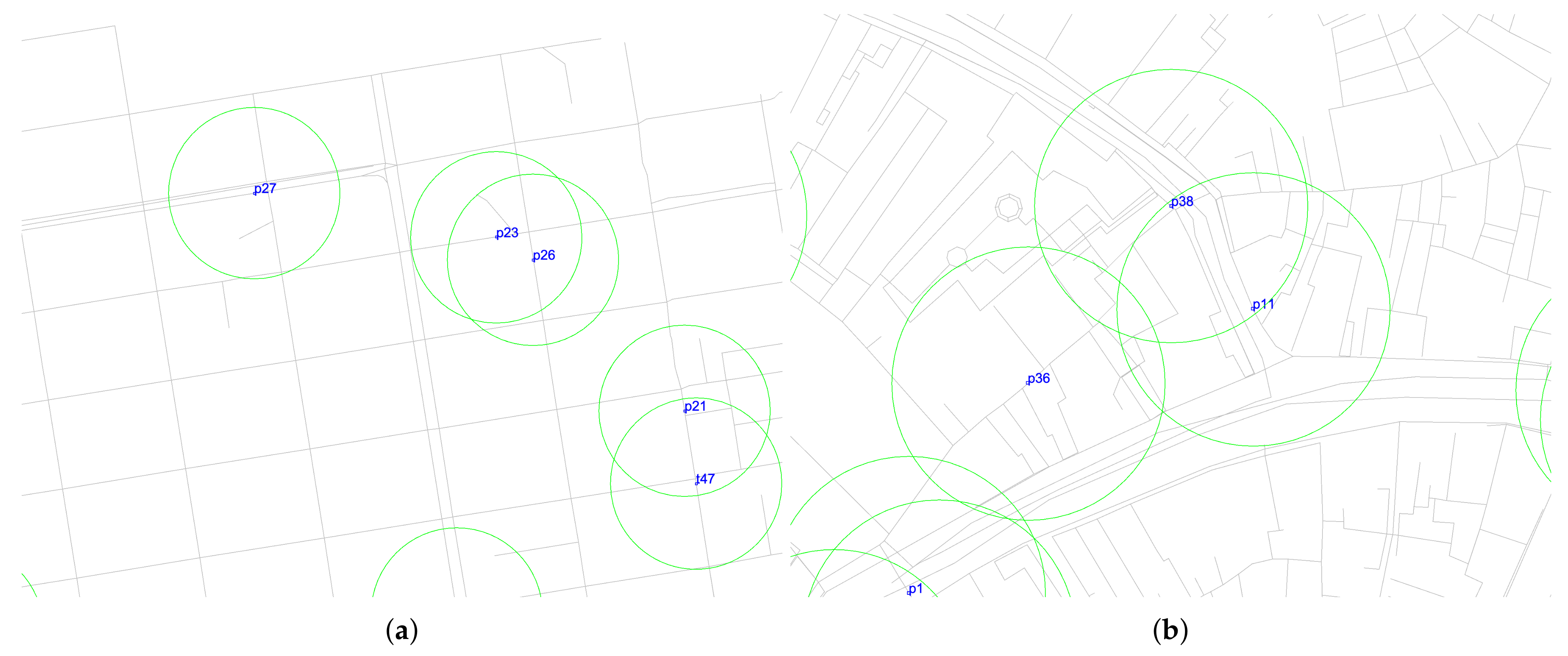
3.5. Security Layer
4. Evaluation
4.1. Settings Investigation
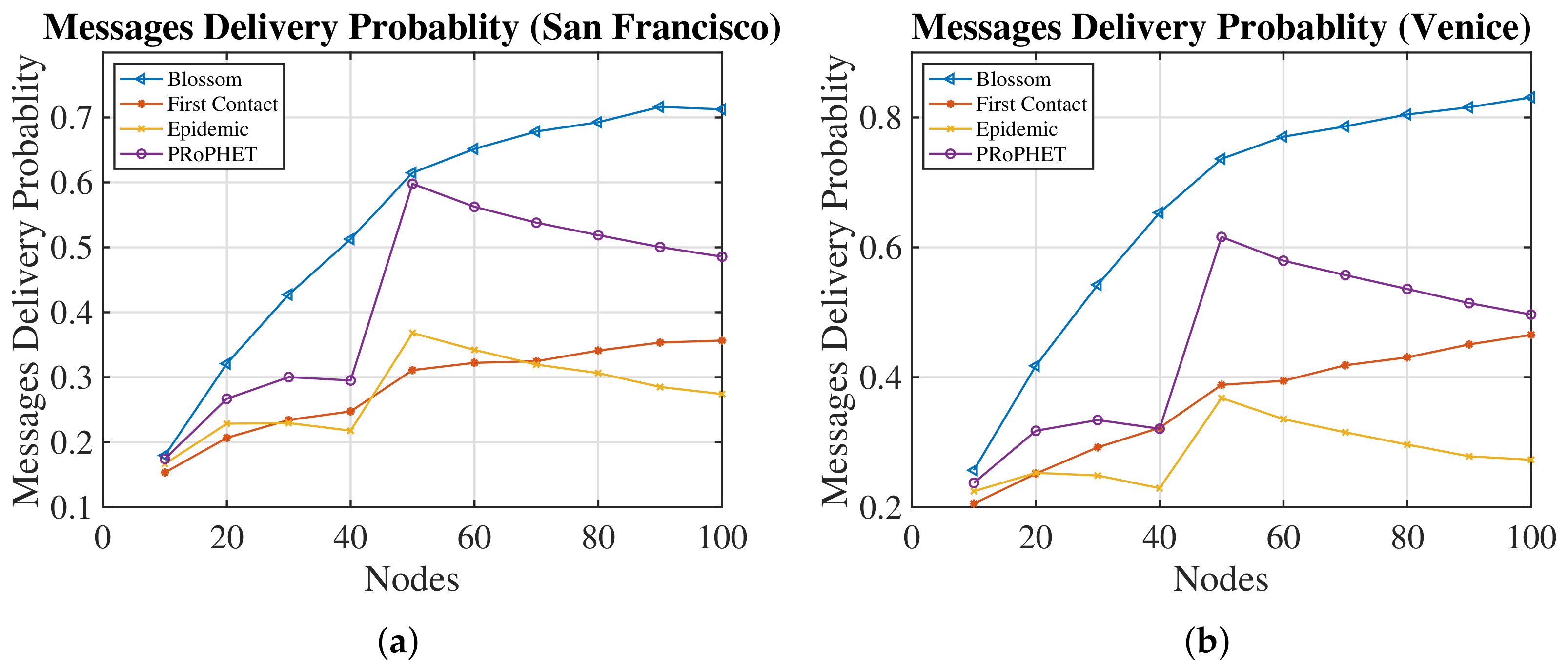
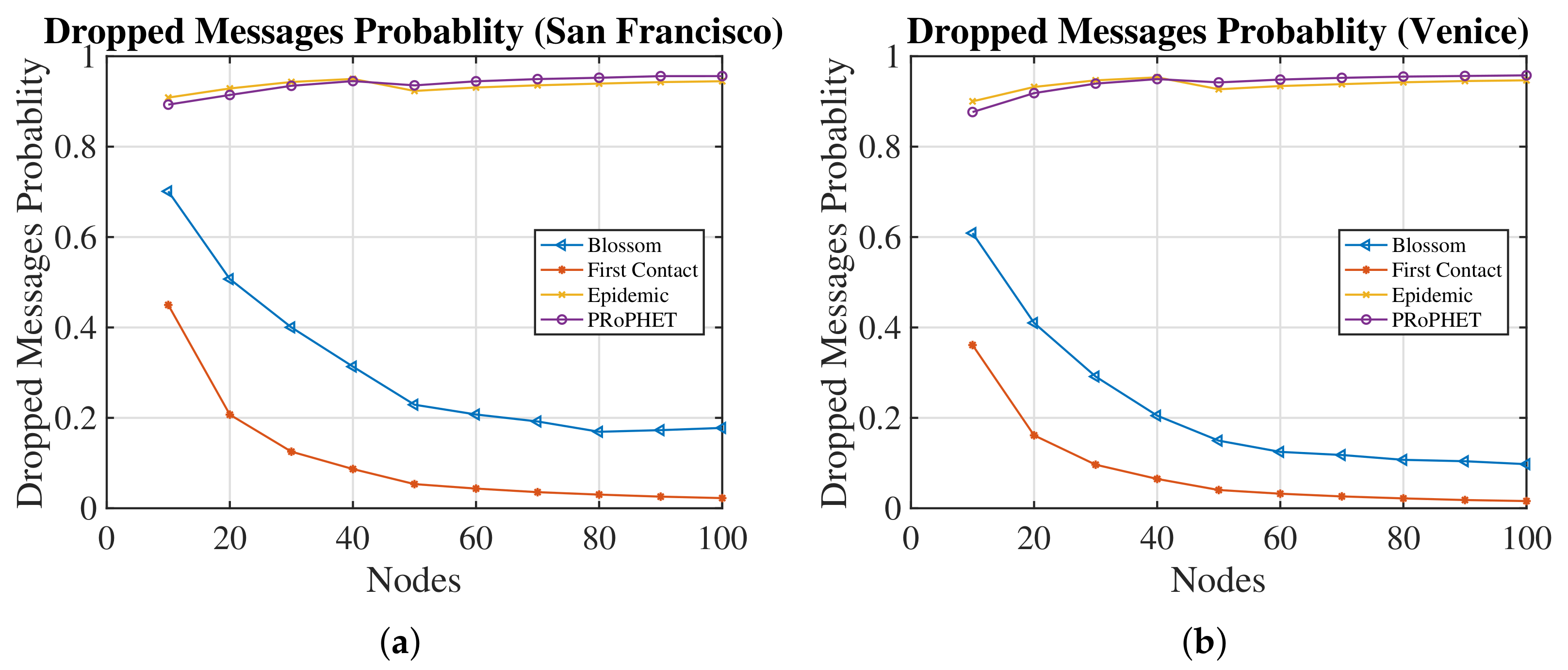
4.2. Comparison against Other Routing Algorithms
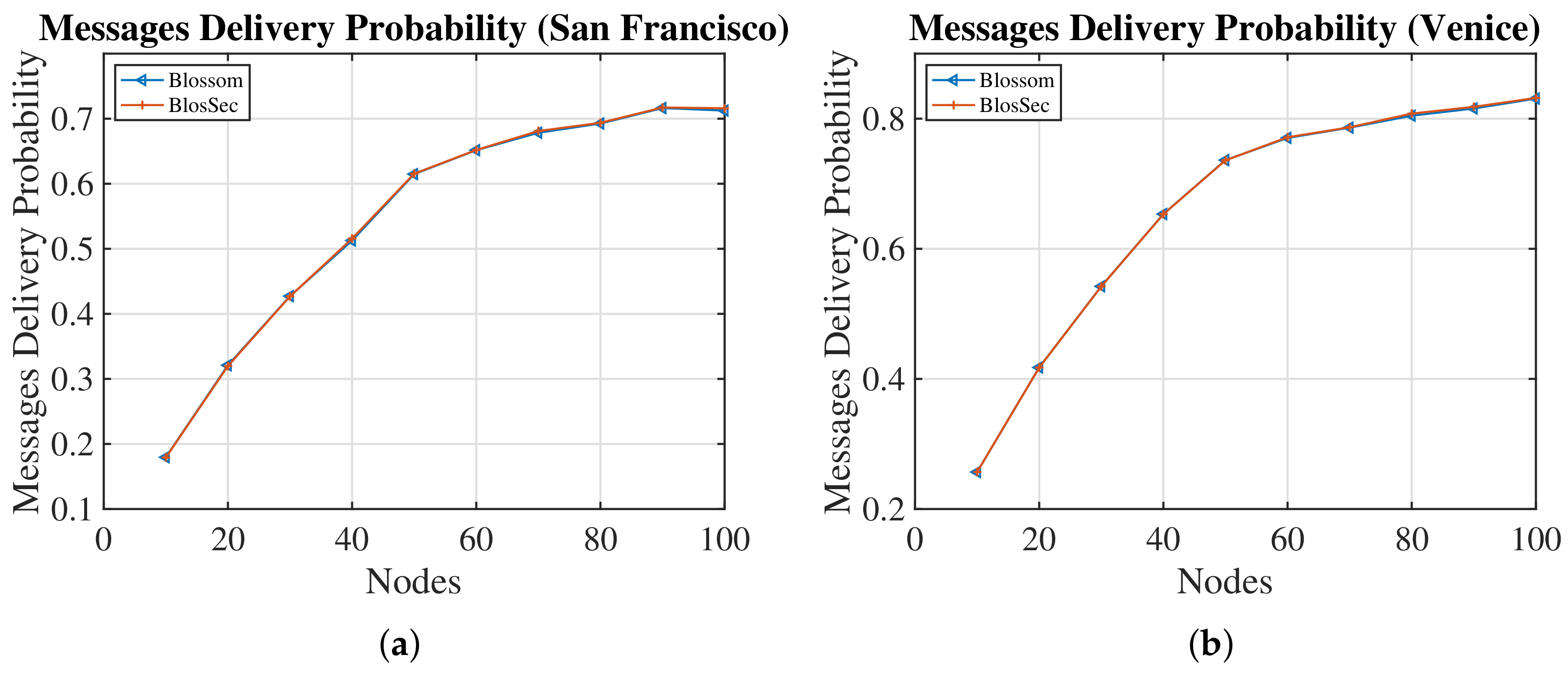
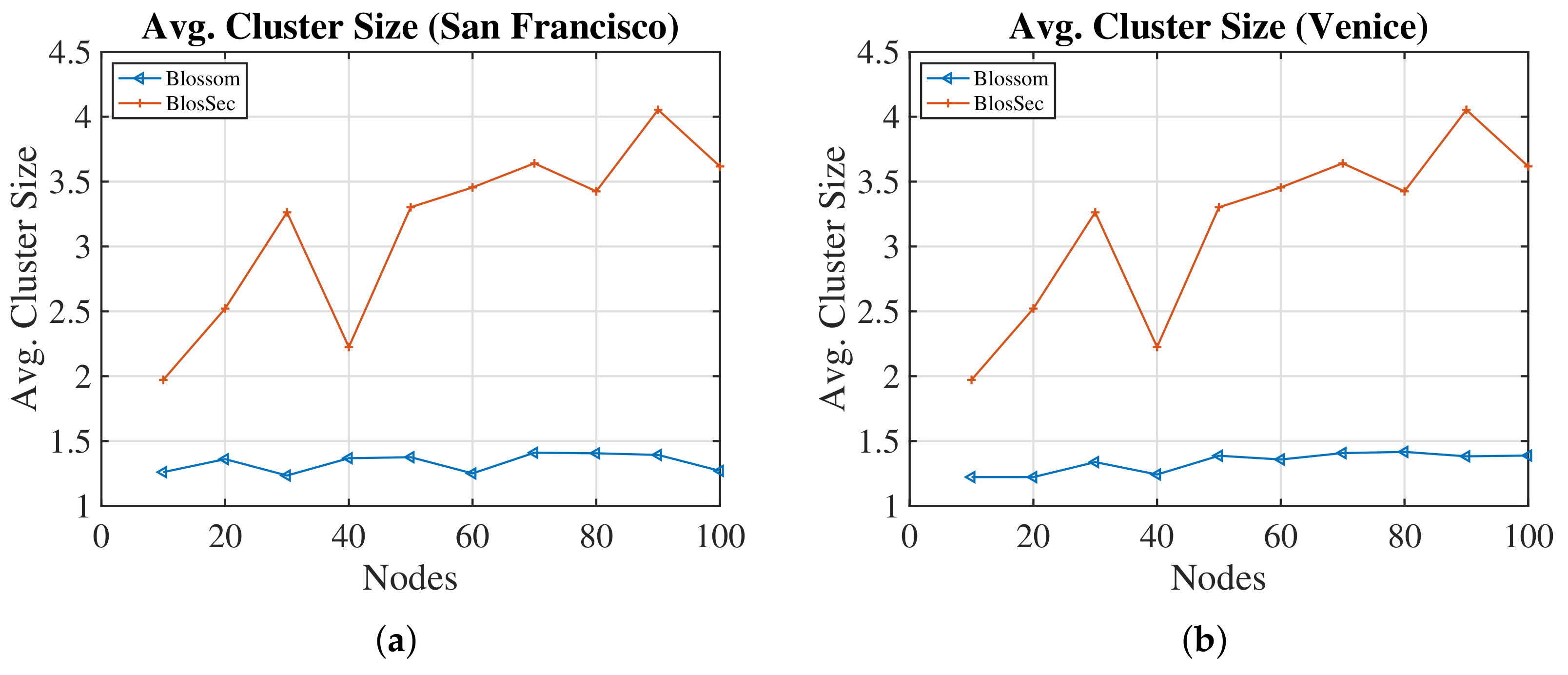
4.3. Investigation of the Security Layer’s Impact
4.4. Restrictions of the Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| OppNet | Opportunistic Network |
| H | Max cluster’s height |
| S | Sleep time |
| A | Adjustment of the direction |
| BlosSec | Blossom Security |
References
- Weber, R.H.; Weber, R. Internet of Things; Springer: Berlin/Heidelberg, Germany, 2010; Volume 12. [Google Scholar]
- Cha, H.; Lee, W.; Jeon, J. Standardization strategy for the Internet of wearable things. In Proceedings of the 2015 International Conference on Information and Communication Technology Convergence (ICTC), Jeju, Republic of Korea, 28–30 October 2015; pp. 1138–1142. [Google Scholar]
- Pozza, R.; Nati, M.; Georgoulas, S.; Moessner, K.; Gluhak, A. Neighbor discovery for opportunistic networking in internet of things scenarios: A survey. IEEE Access 2015, 3, 1101–1131. [Google Scholar] [CrossRef]
- Chourabi, H.; Nam, T.; Walker, S.; Gil-Garcia, J.R.; Mellouli, S.; Nahon, K.; Pardo, T.A.; Scholl, H.J. Understanding smart cities: An integrative framework. In Proceedings of the 2012 45th Hawaii International Conference on System Sciences, Maui, HI, USA, 4–7 January 2012; pp. 2289–2297. [Google Scholar]
- Woungang, I.; Dhurandher, S.K.; Anpalagan, A.; Vasilakos, A.V. Routing in Opportunistic Networks; Springer: New York, NY, USA, 2013. [Google Scholar]
- Denko, M.K. Mobile Opportunistic Networks: Architectures, Protocols and Applications; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]
- Guo, B.; Yu, Z.; Zhou, X.; Zhang, D. Opportunistic IoT: Exploring the social side of the internet of things. In Proceedings of the 2012 IEEE 16th International Conference on Computer Supported Cooperative Work in Design (CSCWD), Wuhan, China, 23–25 May 2012; pp. 925–929. [Google Scholar]
- Guo, B.; Zhang, D.; Wang, Z.; Yu, Z.; Zhou, X. Opportunistic IoT: Exploring the harmonious interaction between human and the internet of things. J. Netw. Comput. Appl. 2013, 36, 1531–1539. [Google Scholar] [CrossRef]
- Chilipirea, C.; Petre, A.C.; Dobre, C. Energy-aware social-based routing in opportunistic networks. In Proceedings of the 2013 27th International Conference on Advanced Information Networking and Applications Workshops, Barcelona, Spain, 25–28 March 2013; pp. 791–796. [Google Scholar]
- Huang, C.M.; Lan, K.c.; Tsai, C.Z. A survey of opportunistic networks. In Proceedings of the 22nd International Conference on Advanced Information Networking and Applications-Workshops (Aina Workshops 2008), Washington, DC, USA, 25–28 March 2008; pp. 1672–1677. [Google Scholar]
- Pan, D.; Zhang, H.; Chen, W.; Lu, K. Transmission of multimedia contents in opportunistic networks with social selfish nodes. Multimed. Syst. 2015, 21, 277–288. [Google Scholar] [CrossRef]
- Kumar, P.; Chauhan, N.; Chand, N.; Awasthi, L.K. SF-APP: A secure framework for authentication and privacy preservation in opportunistic networks. Int. J. Web Serv. Res. 2018, 15, 47–66. [Google Scholar] [CrossRef]
- Amah, T.E.; Kamat, M.; Bakar, K.; Moreira, W.; Oliveira, A., Jr.; Batista, M.A. Preparing opportunistic networks for smart cities: Collecting sensed data with minimal knowledge. J. Parallel Distrib. Comput. 2020, 135, 21–55. [Google Scholar] [CrossRef]
- Zakhary, S.; Benslimane, A. On location-privacy in opportunistic mobile networks, a survey. J. Netw. Comput. Appl. 2018, 103, 157–170. [Google Scholar] [CrossRef]
- Chen, D.; Borrego, C.; Navarro-Arribas, G. A Privacy-Preserving Routing Protocol Using Mix Networks in Opportunistic Networks. Electronics 2020, 9, 1754. [Google Scholar] [CrossRef]
- Gruteser, M.; Grunwald, D. Anonymous usage of location-based services through spatial and temporal cloaking. In Proceedings of the 1st International Conference on Mobile Systems, Applications and Services, San Francisco, CA, USA, 5–8 May 2003; ACM: New York, NY, USA, 2003; pp. 31–42. [Google Scholar]
- Jain, S.; Fall, K.; Patra, R. Routing in a delay tolerant network. In Proceedings of the 2004 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications, Portland, OR, USA, 30 August–3 September 2004; ACM: New York, NY, USA, 2004; pp. 145–158. [Google Scholar]
- Vahdat, A.; Becker, D. Epidemic Routing for Partially Connected Ad Hoc Networks; Duke University: Durham, NC, USA, 2000. [Google Scholar]
- Lindgren, A.; Doria, A.; Schelén, O. Probabilistic Routing in Intermittently Connected Networks. In Service Assurance with Partial and Intermittent Resources; Springer: Berlin/Heidelberg, Germany, 2004; Volume 3126, pp. 239–254. [Google Scholar]
- Rashidibajgan, S.; Hupperich, T.; Doss, R.; Förster, A. NSecure and privacy-preserving structure in opportunistic networks. Comput. Secur. 2021, 104, 102208. [Google Scholar] [CrossRef]
- Qin, Y.; Zhang, T.; Li, M. Privacy Protection Routing and a Self-organized Key Management Scheme in Opportunistic Networks. In International Conference on Heterogeneous Networking for Quality, Reliability, Security and Robustness; Springer: Cham, Switzerland, 2019; Volume 300, pp. 252–268. [Google Scholar]
- Magaia, N.; Borrego, C.; Pereira, P.; Correia, M. PRIVO: A privacy-preserving opportunistic routing protocol for delay tolerant networks. In Proceedings of the 2017 IFIP Networking Conference (IFIP Networking) and Workshops, Stockholm, Sweden, 12–15 June 2017; pp. 1–9. [Google Scholar]
- Costantino, G.; Martinelli, F.; Santi, P. Privacy-preserving interest-casting in opportunistic networks. In Proceedings of the 2017 IFIP Networking Conference (IFIP Networking) and Workshops, Paris, France, 1–4 April 2012; pp. 2829–2834. [Google Scholar]
- Miao, J.; Hasan, O.; Mokhtar, S.B.; Brunie, L.; Hasan, A. 4PR: Privacy preserving routing in mobile delay tolerant networks. Comput. Netw. 2016, 111, 17–28. [Google Scholar] [CrossRef]
- Asghar, M.R.; Gehani, A.; Crispo, B.; Russello, G. PIDGIN: Privacy-preserving interest and content sharing in opportunistic networks. In Proceedings of the 9th ACM Symposium on Information, Computer and Communications Security, Kyoto, Japan, 4–6 June 2014; ACM: New York, NY, USA, 2014; pp. 135–146. [Google Scholar]
- Jiang, Q.; Deng, K.; Zhang, L.; Liu, C. A privacy-preserving protocol for utility-based routing in DTNs. Information 2019, 10, 128. [Google Scholar] [CrossRef]
- Song, J.; He, C.; Yang, F.; Zhang, H. A privacy-preserving distance-based incentive scheme in opportunistic VANETs. Secur. Commun. Netw. 2016, 9, 2789–2801. [Google Scholar] [CrossRef]
- Song, J.; He, C.; Yang, F.; Zhang, H. PEON: Privacy-enhanced opportunistic networks with applications in assistive environments. In Proceedings of the 2nd International Conference on PErvasive Technologies Related to Assistive Environments, Corfu, Greece, 9–13 June 2009; ACM: New York, NY, USA, 2009; pp. 1–8. [Google Scholar]
- Rashidibajgan, S.; Doss, R. Privacy-preserving history-based routing in Opportunistic Networks. Comput. Secur. 2019, 84, 244–255. [Google Scholar] [CrossRef]
- Magaia, N.; Borrego, C.; Pereira, P.R.; Correia, M. ePRIVO: An enhanced privacy-preserving opportunistic routing protocol for vehicular delay-tolerant networks. IEEE Trans. Veh. Technol. 2018, 67, 11154–11168. [Google Scholar] [CrossRef]
- Jiang, Q. A Privacy-Preserving Exchange-Based Routing Protocol for Opportunistic Networks. Secur. Commun. Netw. 2022, 2022, 6815911. [Google Scholar] [CrossRef]
- Adu-Gyamfi, D.; Zhang, F.; Takyi, A. Anonymising group data sharing in opportunistic mobile social networks. Wirel. Netw. 2021, 27, 1477–1490. [Google Scholar] [CrossRef]
- Dhurandher, S.K.; Singh, J.; Nicopolitidis, P.; Kumar, R.; Gupta, G. A blockchain-based secure routing protocol for opportunistic networks. J. Ambient. Intell. Humaniz. Comput. 2022, 13, 2191–2203. [Google Scholar] [CrossRef]
- Will, G. Visualizing and Clustering Data that Includes Circular Variables; Writing Project; Montana State University: Bozeman, MT, USA, 2016. [Google Scholar]
- Kaufman, L.; Rousseeuw, P.J. Finding Groups in Data: An Introduction to Cluster Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2009; Volume 344. [Google Scholar]
- Sokal, R.R.; Michener, C.D. A Statistical Method for Evaluating Systematic Relationships. Univ. Kansas Sci. Bull. 1958, 38, 1409–1438. [Google Scholar]
- Xu, D.; Tian, Y. A comprehensive survey of clustering algorithms. Ann. Data Sci. 2015, 2, 165–193. [Google Scholar] [CrossRef]
- Ghavami, P. Big Data Analytics Methods; De Gruyte: Boston, MA, USA; Berlin, Germany, 2019. [Google Scholar]
- Machanavajjhala, A.; Kifer, D.; Gehrke, J.; Venkitasubramaniam, M. L-Diversity: Privacy beyond k-Anonymity; ACM: New York, NY, USA, 2007; Volume 1, pp. 1–52. [Google Scholar]
- Dangs, Q. Secure Hash Standard; NIST FIPS: Gaithersburg, MD, USA, 2015. [Google Scholar]
- Keränen, A.; Ott, J.; Kärkkäinen, T. The ONE simulator for DTN protocol evaluation. In Proceedings of the 2nd International Conference on Simulation Tools and Techniques, Rome, Italy, 2–6 March 2009; ACM: New York, NY, USA, 2009; pp. 1–10. [Google Scholar]
- Collotta, M.; Pau, G.; Talty, T.; Tongu, O.K. Bluetooth 5: A Concrete Step Forward toward the IoT. IEEE Commun. Mag. 2018, 56, 125–131. [Google Scholar] [CrossRef]










| Group | Pedestrian | Car | Tram |
|---|---|---|---|
| Number of Hosts | about | about | 3 (if host ) |
| Buffer Size | 5 MB | 5 MB | 50 MB |
| Movement speed in m/s | 0.5–1.5 | 2.7–13.9 | 7–10 |
| Movement speed in km/h | 1.8–5.5 | 10–50 | 26–37 |
| Movement Waiting Time | 0–120 s | 0–120 s | 10–30 s |
| Transmit Speed | 250 KB/s | 250 KB/s | 10 MB/s |
| Transmit Range | 100 m | 100 m | 1000 m |
| Max Cluster’s Height (H) | Sleep Time (S) | Adjustment of the Direction (A) |
|---|---|---|
| 0.1 | 0 | 1 |
| 0.2 | 10,000 | 0.8 |
| - | 20,000 | - |
| C 1 | 0.1 H | 0.0 S | 0.8 A |
| C 2 | 0.1 H | 0.0 S | 1 A |
| C 3 | 0.1 H | 10,000.0 S | 0.8 A |
| C 4 | 0.1 H | 10,000.0 S | 1 A |
| C 5 | 0.1 H | 20,000.0 S | 0.8 A |
| C 6 | 0.1 H | 20,000.0 S | 1 A |
| C 7 | 0.2 H | 0.0 S | 0.8 A |
| C 8 | 0.2 H | 0.0 S | 1 A |
| C 9 | 0.2 H | 10,000.0 S | 0.8 A |
| C 10 | 0.2 H | 10,000.0 S | 1 A |
| C 11 | 0.2 H | 20,000.0 S | 0.8 A |
| C 12 | 0.2 H | 20,000.0 S | 1 A |
| Parameter | Message Delivery Probability | Network Overhead | ||
|---|---|---|---|---|
| San Francisco | Venice | San Francisco | Venice | |
| 0.1 H | 0.46 | 0.55 | 19.22 | 31.26 |
| 0.2 H | 0.46 | 0.55 | 18.53 | 29.19 |
| 0 S | 0.3 | 0.34 | 56.06 | 90.34 |
| 10,000 S | 0.53 | 0.65 | 0.47 | 0.25 |
| 20,000 S | 0.55 | 0.66 | 0.1 | 0.09 |
| 0.8 A | 0.46 | 0.55 | 18.90 | 30.33 |
| 1 A | 0.46 | 0.55 | 18.84 | 30.13 |
| San Francisco | Venice | |||||
|---|---|---|---|---|---|---|
| Nr. of Nodes | Max Cluster’s Height (H) | Sleep Time (S) | Adjustment of the Direction (A) | Max Cluster’s Cluster’s Height (H) | Sleep Time (S) | Adjustment of the Direction (A) |
| 10 | 0.1 | 10,000 | 0.8 | 0.1 | 10,000 | 0.8 |
| 20 | 0.2 | 20,000 | 0.8 | 0.1 | 20,000 | 0.8 |
| 30 | 0.1 | 20,000 | 0.8 | 0.2 | 20,000 | 0.8 |
| 40 | 0.1 | 20,000 | 0.8 | 0.1 | 20,000 | 0.8 |
| 50 | 0.2 | 20,000 | 0.8 | 0.2 | 20,000 | 1.0 |
| 60 | 0.1 | 20,000 | 0.8 | 0.2 | 20,000 | 0.8 |
| 70 | 0.1 | 20,000 | 0.8 | 0.2 | 20,000 | 1.0 |
| 80 | 0.2 | 20,000 | 0.8 | 0.2 | 20,000 | 1.0 |
| 90 | 0.1 | 20,000 | 0.8 | 0.2 | 20,000 | 0.8 |
| 100 | 0.1 | 20,000 | 0.8 | 0.2 | 20,000 | 0.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kluss, B.; Rashidibajgan, S.; Hupperich, T. Blossom: Cluster-Based Routing for Preserving Privacy in Opportunistic Networks. J. Sens. Actuator Netw. 2022, 11, 75. https://doi.org/10.3390/jsan11040075
Kluss B, Rashidibajgan S, Hupperich T. Blossom: Cluster-Based Routing for Preserving Privacy in Opportunistic Networks. Journal of Sensor and Actuator Networks. 2022; 11(4):75. https://doi.org/10.3390/jsan11040075
Chicago/Turabian StyleKluss, Benedikt, Samaneh Rashidibajgan, and Thomas Hupperich. 2022. "Blossom: Cluster-Based Routing for Preserving Privacy in Opportunistic Networks" Journal of Sensor and Actuator Networks 11, no. 4: 75. https://doi.org/10.3390/jsan11040075
APA StyleKluss, B., Rashidibajgan, S., & Hupperich, T. (2022). Blossom: Cluster-Based Routing for Preserving Privacy in Opportunistic Networks. Journal of Sensor and Actuator Networks, 11(4), 75. https://doi.org/10.3390/jsan11040075