




Enhancing Optical Character Recognition on Images with Mixed Text Using Semantic Segmentation

 ,
,  , , , and
, , , and 
Abstract
1. Introduction
1.1. Machine Printed and Handwritten Text
- Machine printed or formatted text: typed text that follows a given font and format, most commonly found in printed images. This type of text displays characteristics such as font, uniform size, varying styles and colors, bolding, italics, etc.
- Handwritten text: text that a human writes. This type of text is variable, non-replicable non-uniform. It cannot be categorized into different styles and fonts that are minute enough to capture all of the features that distinguish handwriting from one another.
1.2. An Overview of Optical Character Recognition
- Noise reduction: This technique clears the image of all extraneous dots and patches.
- Text alignment issues: Some text may be skewed. Skew correction aids with text alignment.
- Slant Removal: This technique is used to eliminate the slant from the text that may appear in some images in the dataset [12].
1.3. An Overview of Semantic Segmentation Using Deep Learning
- (1)
- This research aims to explore an elaborate pre-processing methodology to enhance the recognition of images containing mixed-type text (i.e., handwritten and machine-printed text).
- (2)
- The work gives background study, limitations and the new approach for data digitization.
- (3)
- The proposed pixel-wise classification technique to accurately identify the area of an image containing relevant text, to feed them to a conventional OCR engine in the hopes of improving the quality of the output.
- (4)
- The proposed methodology also supports the digitization of mixed typed text documents with amended performance. Experimental study shows that the proposed pipeline architecture provides reliable and quality inputs through complex image preprocessing to Conventional OCR, which results in better accuracy and improved performance.
2. Related Work
3. Proposed Idea and Methodology
3.1. Background Issue Overview
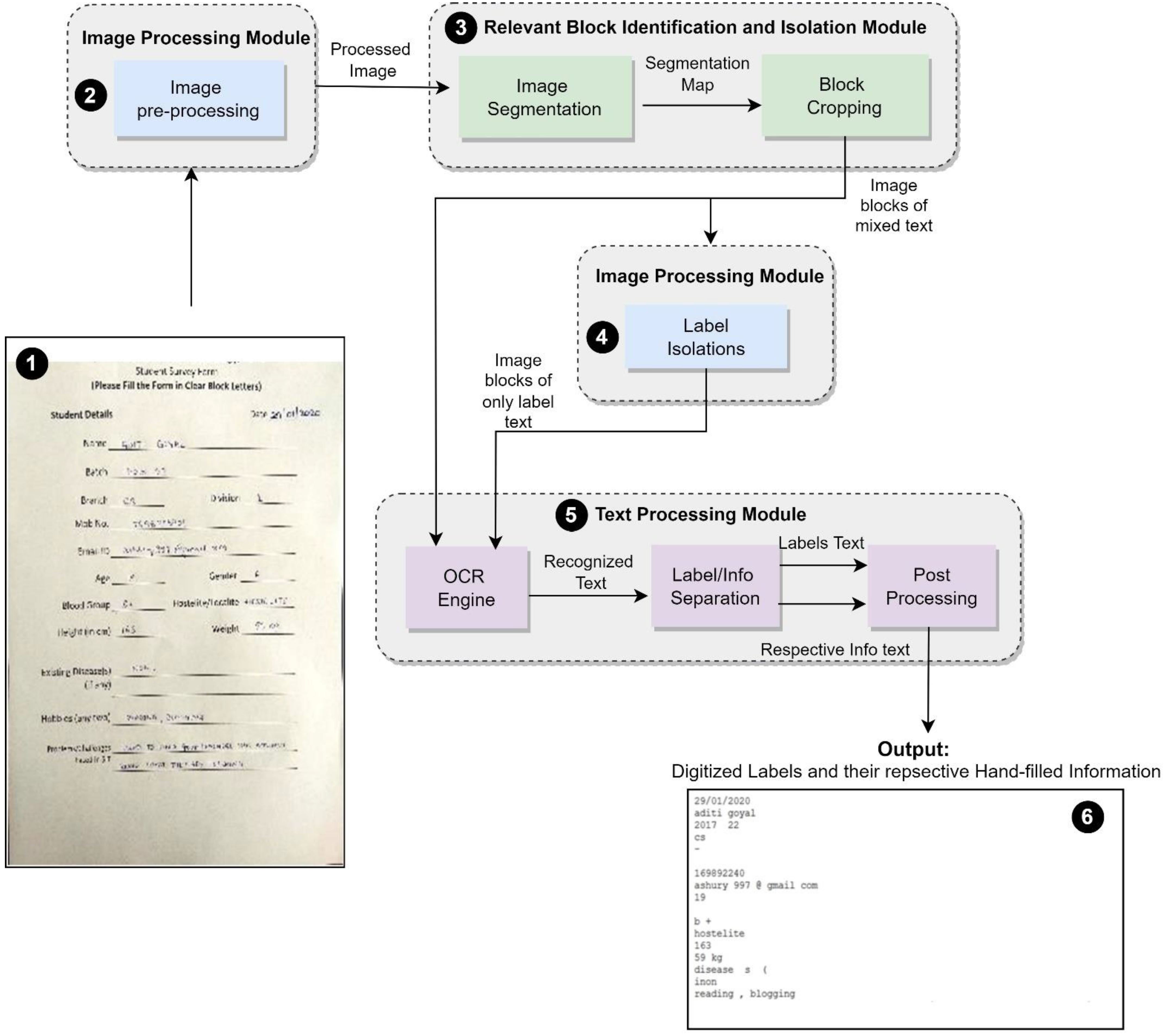
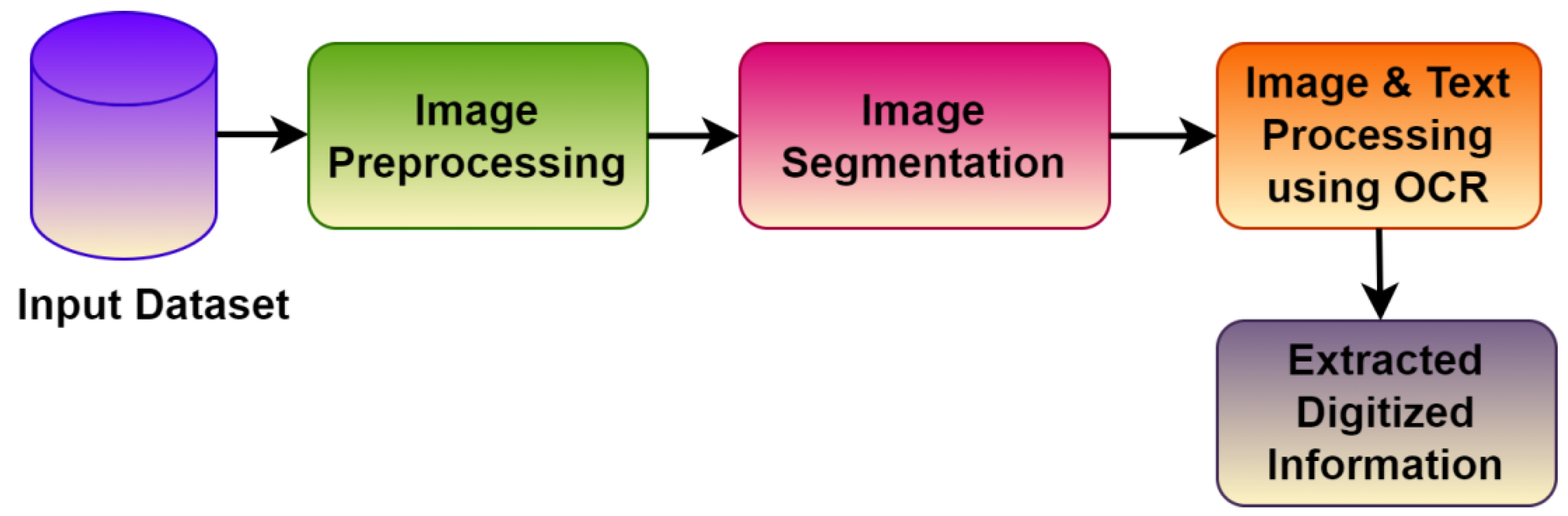
3.2. Overview of Pipeline and Components
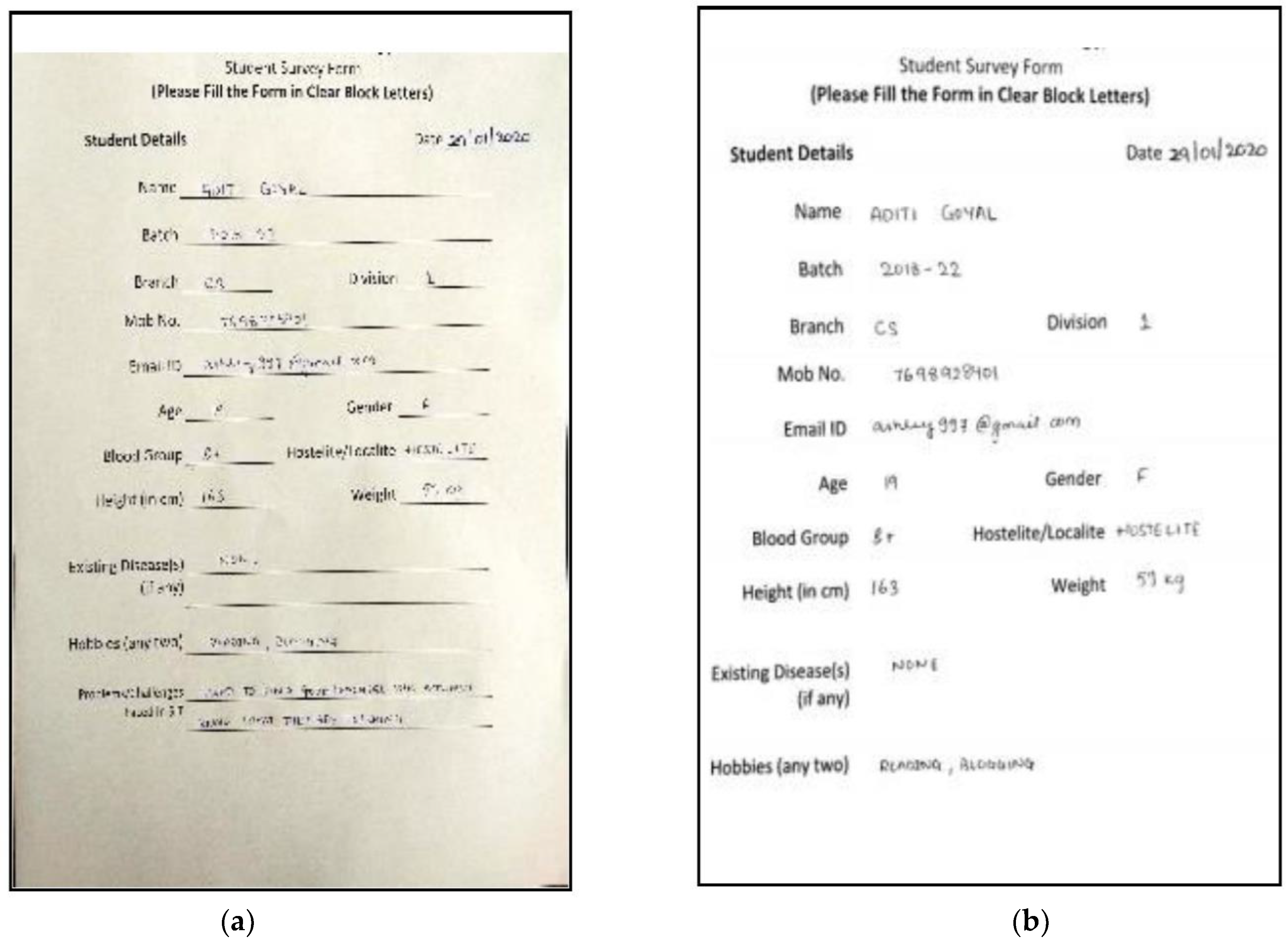
- An image of a hand-filled form of (3, 512, 512) pixels dimensions is input to the Image Pre-Processing Component. (3, 512, 512) are three dimensions of an input of a sample image. Various image processing techniques are applied to enhance the image and make it suitable for prediction during the segmentation phase.
- The processed image enters the Block Identification and Isolation Module, where first it is used as an input to the semantic segmentation algorithm. The output of the semantic segmentation algorithm is a segmentation map. This segmentation map is used in the Block Cropping component to reference crops and store the relevant areas of the text identified by the segmentation algorithm.
- The blocks of relevant text are sent to the Text Processing Module as well as the Label Isolation Component.
- The Label Isolation component erases any handwritten text present in each block and outputs blocks with the only machine-printed text present.
- The OCR Engine in the Text Processing Module accepts the collection of blocks containing all relevant text and the collection of blocks containing only labels. It uses Optical Character Recognition to recognize the text in all the blocks it has received regardless of the type of text present.
- The recognized text, Label/Info Separation component, separates the labels from the respective information filled.
- The post-processing component accepts both types of text and processes them to be suitable for further use.
3.3. Modules in Detail
- (1)
- Dataset Generation Module
- (2)
- Image Processing Module
- Line Removal
- Gray Scale Conversion
- Gaussian Blurring
- Thresholding
- 3-Channel Re-Conversion
- (3)
- Relevant Block Identification and Isolation Module
- (a)
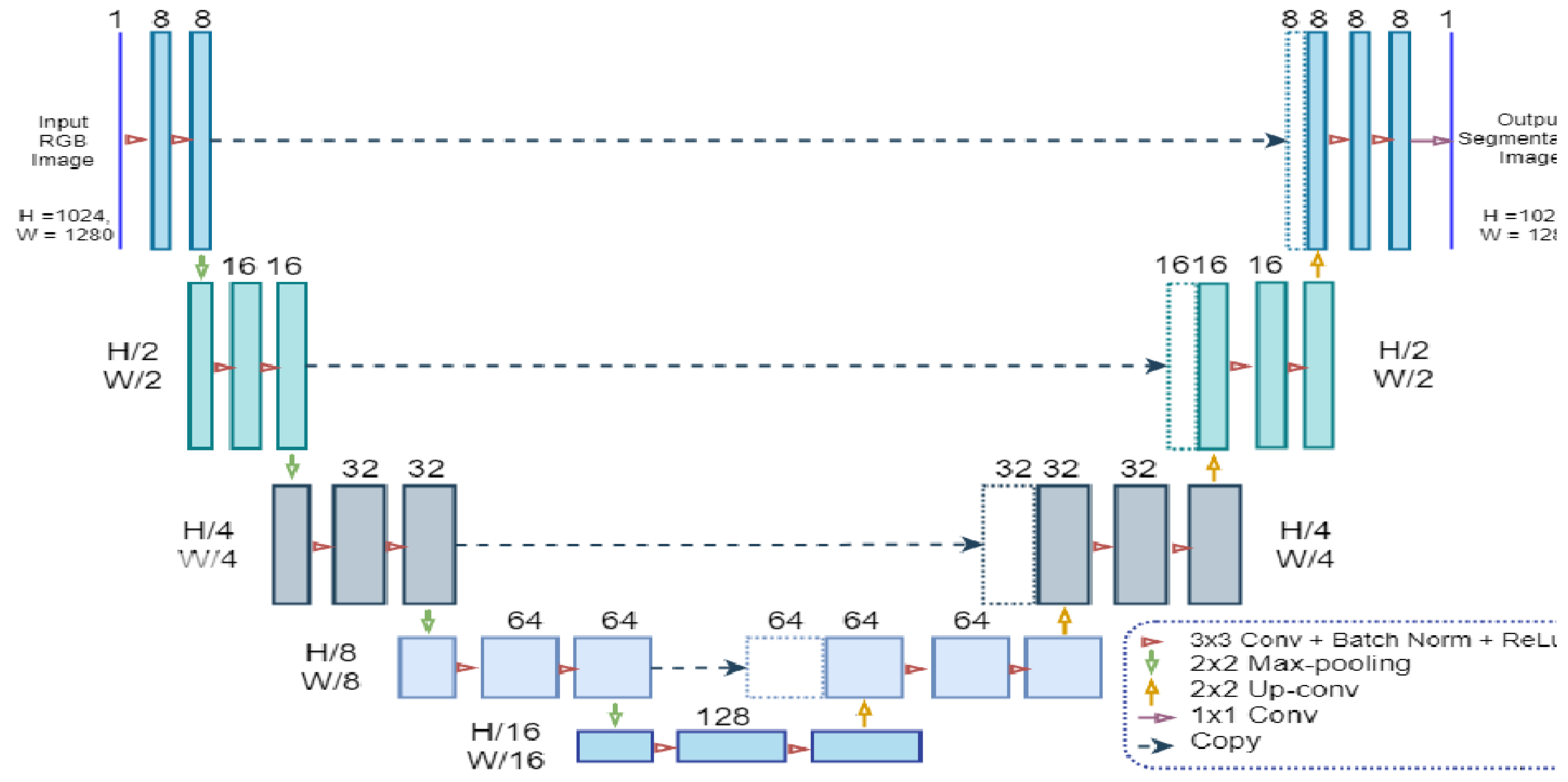
- Image Segmentation using U-Net:
- Create an active flag and set it as False. This flag is used to indicate the first time a row containing black pixels has been encountered and indicate when the parsing of a single block is finished before starting the next one.
- For every row in the segmentation map image, check whether that row contains one or more black pixels.
- If it contains one or more black pixels, it means that that row has a part of the segmented class in it. Append the values of the entire row of the segmentation map to one list and the same respective row of the original image to another list. These lists represent a single continuous box. Set the active flag as True.
- If the row does not contain any black pixels, and if active is True, append the above lists to two other lists that house entire boxes. Empty out the lists that represent single boxes. Set active to False and continue.
- If the row does not contain any black pixels, and if active is False, continue.
- End parsing when all rows have been parsed.
- For every box within the lists that represent entire boxes, perform steps 1–6 with transposed boxes as input. Figure 12 depicts some sample results of this algorithm on the given segmentation map.
- Re-transpose all the boxes obtained from 7.
- End.
- (4)
- Text Processing Module
- (a)
- Optical Character Recognition Engine
- (b)
- Label/Info Separation Component
- (1)
- Instances of printed text that did not correspond to any handwritten data. This included machine-printed texts like titles and serial numbers, etc.
- (2)
- Instances where there are actual labels, but there was no corresponding handwritten data text (the missing text was usually in the line below).
- (3)
- Substring replacement had to be done on a word-by-word basis and not on an entire sentence basis to avoid stray words staying behind.
- (4)
- Instances where the removal of binary option labels (e.g., “Yes/No”) removed the actual data filled in for that label correspondingly.
- (5)
- Instances where random blank spaces appeared.
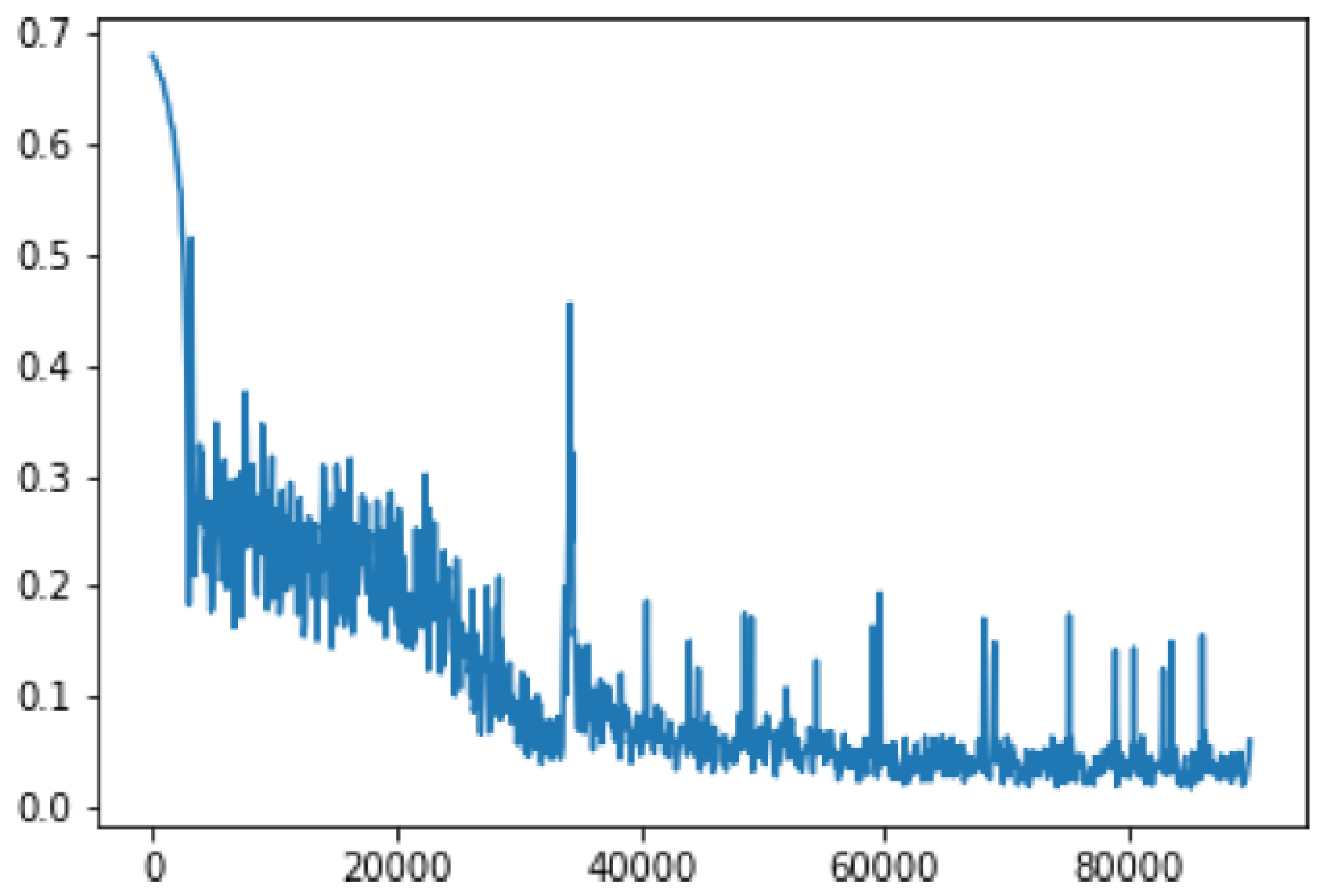
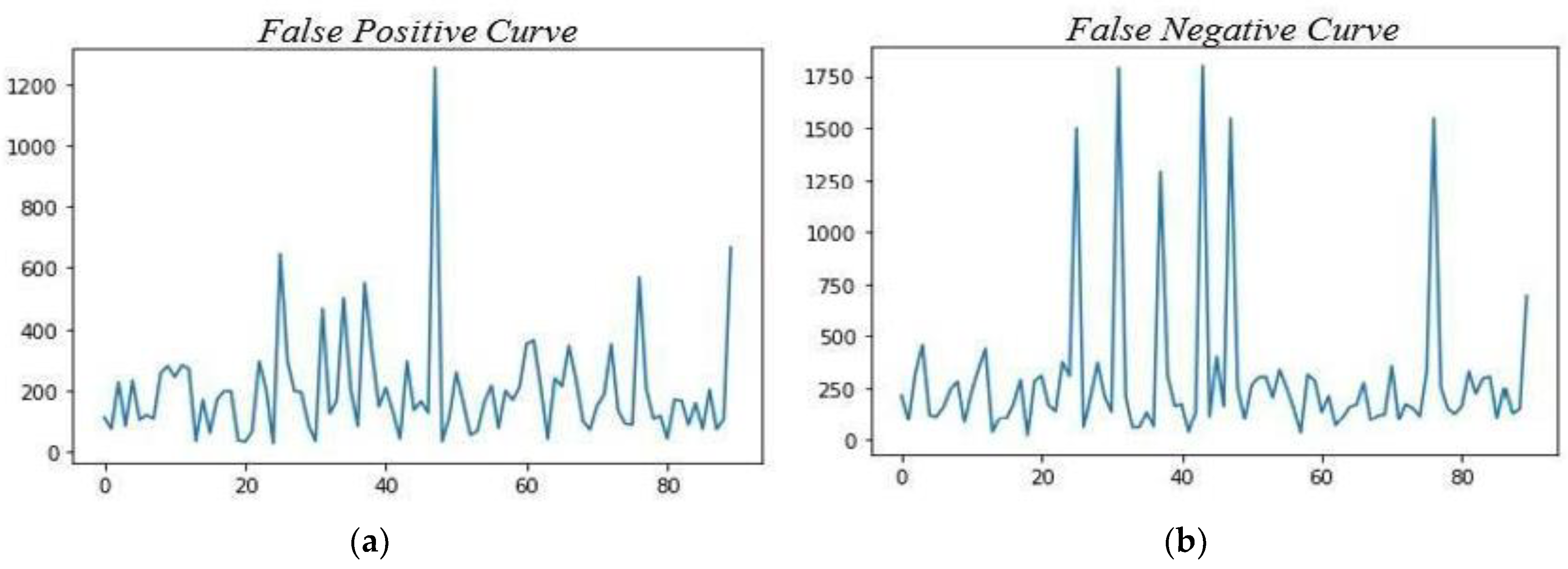
4. Results, Observations and Discussions
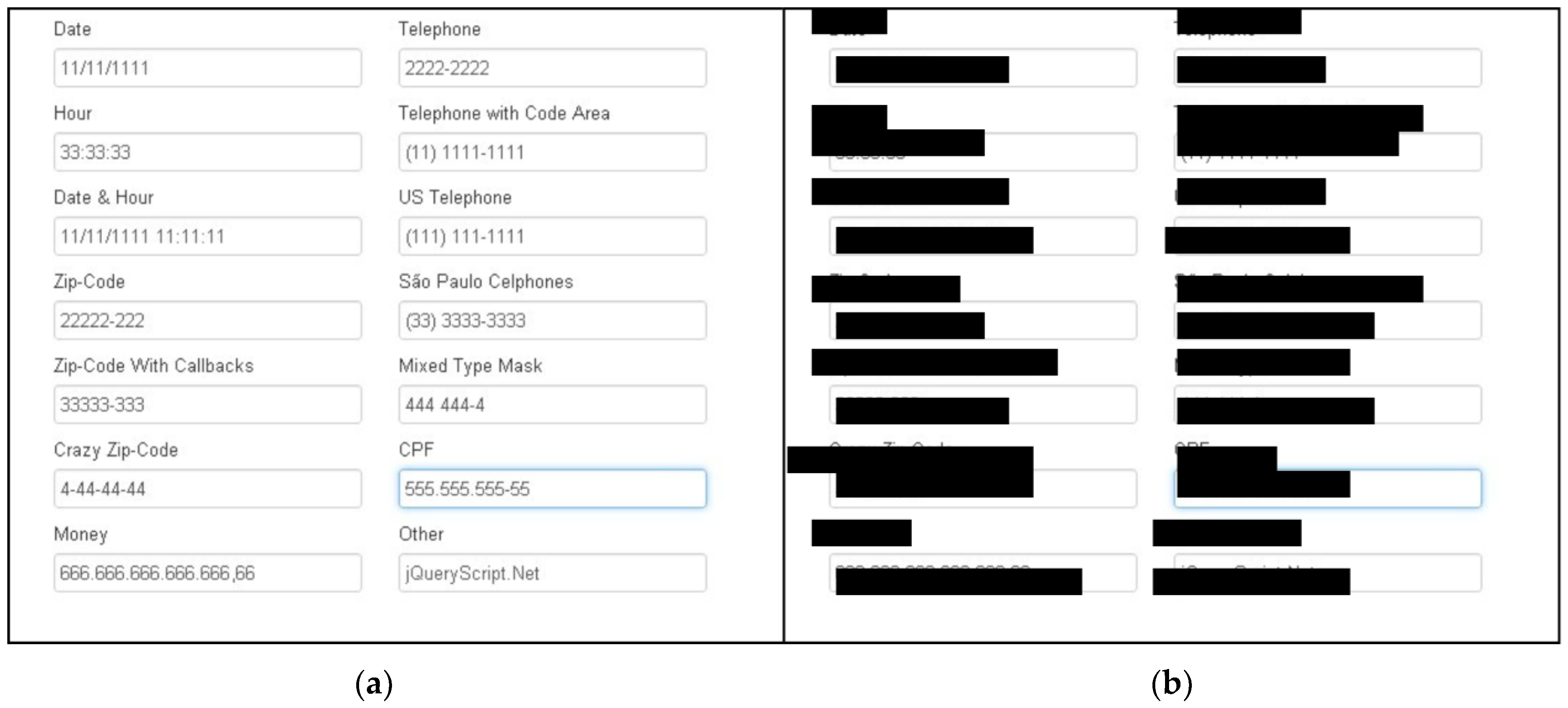
4.1. Defining Instances for Evaluation
- (a)
- the actual handwritten text translated manually by a human being, and
- (b)
- text that is extracted by Google OCR without using our pipeline for the same input.
4.2. Results
- (a)
- Are the D-Rex pipeline output results of a good enough level to be used for production? and,
- (b)
- Did the D-Rex pipeline enhance the results of a conventional OCR Engine on mixed-type data?
- A.
- D-Rex Pipeline Results measured against True Strings
- B.
- Google Cloud Vision API’s OCR Engine Results measured against True Strings. Upon giving the same OCR engine the same image without first running it through the D-Rex Pipeline, the results are displayed in Table 7.
4.3. Observations and Discussions
5. Conclusions
6. Limitations and Future Scope
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ranjan, A.; Behera, V.N.J.; Reza, M. OCR Using Computer Vision and Machine Learning. In Machine Learning Algorithms for Industrial Applications; Springer: Cham, Switzerland, 2021; pp. 83–105. [Google Scholar]
- Available online: http://www.capturedocs.com/thread/handwritten-invoices/ (accessed on 5 January 2022).
- Rabby, A.K.M.; Islam, M.; Hasan, N.; Nahar, J.; Rahman, F. A Deep Learning Solution to Detect Text-Types Using a Convolutional Neural Network. In Proceedings of the International Conference on Machine Intelligence and Data Science Applications; Springer: Singapore, 2021; pp. 727–736. [Google Scholar]
- Zheng, Y.; Li, H.; Doermann, D. Machine printed text and handwriting identification in noisy document images. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 337–353. [Google Scholar] [CrossRef] [PubMed]
- Patil, S.; Joshi, S. Demystifying User Data Privacy in the World of IOT. Int. J. Innov. Technol. Explor. Eng. 2019, 8, 4412–4418. [Google Scholar] [CrossRef]
- Bidwe, R.V.; Mishra, S.; Patil, S.; Shaw, K.; Vora, D.R.; Kotecha, K.; Zope, B. Deep Learning Approaches for Video Compression: A Bibliometric Analysis. Big Data Cogn. Comput. 2022, 6, 44. [Google Scholar] [CrossRef]
- Baviskar, D.; Ahirrao, S.; Potdar, V.; Kotecha, K. Efficient Automated Processing of the Unstructured Documents Using Artificial Intelligence: A Systematic Literature Review and Future Directions. IEEE Access 2021, 9, 72894–72936. [Google Scholar] [CrossRef]
- Sayyad, S.; Kumar, S.; Bongale, A.; Bongale, A.M.; Patil, S. Estimating Remaining Useful Life in Machines Using Artificial Intelligence: A Scoping Review. Libr. Philos. Pract. 2021, 2021, 4798. [Google Scholar]
- Chaudhuri, A.; Mandaviya, K.; Badelia, P.; Ghosh, S.K. Optical Character Recognition Systems. In Optical Character Recognition Systems for Different Languages with Soft Computing; Springer: Cham, Switzerland, 2016; pp. 9–41. [Google Scholar] [CrossRef]
- Chen, X.; Jin, L.; Zhu, Y.; Luo, C.; Wang, T. Text recognition in the wild: A survey. ACM Comput. Surv. (CSUR) 2021, 54, 1–35. [Google Scholar]
- Memon, J.; Sami, M.; Khan, R.A.; Uddin, M. Handwritten Optical Character Recognition (OCR): A Comprehensive Systematic Literature Review (SLR). IEEE Access 2020, 8, 142642–142668. [Google Scholar] [CrossRef]
- Guo, Y.; Liu, Y.; Georgiou, T.; Lew, M.S. A review of semantic segmentation using deep neural networks. Int. J. Multimed. Inf. Retr. 2017, 7, 87–93. [Google Scholar] [CrossRef]
- Yang, J.; Zhu, J.; Wang, H.; Yang, X. Dilated MultiResUNet: Dilated multiresidual blocks network based on U-Net for biomedical image segmentation. Biomed. Signal Process. Control 2021, 68, 102643. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Kaur, S.; Mann, P.; Khurana, S. Page Segmentation in OCR System-A Review. Int. J. Comput. Sci. Inf. Technol. 2013, 4, 420–422. [Google Scholar]
- Reisswig, C.; Katti, A.; Spinaci, M.; Höhne, J. Chargrid-OCR: End-to-end trainable Optical Character Recognition through Semantic Segmentation and Object Detection. In Proceedings of the Workshop on Document Intelligence at NeurIPS 2019, Vancouver, BC, Canada, 14 December 2019. [Google Scholar]
- Shubh, M.A.; Hassan, F.; Pandey, G.; Ghosh, S. Handwriting Recognition Using Deep Learning. Emerg. Trends Data Driven Comput. Commun. Proc. 2021, 2021, 67. [Google Scholar]
- Boualam, M.; Elfakir, Y.; Khaissidi, G.; Mrabti, M. Arabic Handwriting Word Recognition Based on Convolutional Recurrent Neural Network. In WITS 2020; Springer: Singapore, 2021; pp. 877–885. [Google Scholar] [CrossRef]
- Huo, Q. Underline Detection and Removal in a Document Image Usingmultiple Strategies. 2001. Available online: https://www.researchgate.net/publication/4090302_Underline_detection_and_removal_in_a_document_image_using_multiple_strategies (accessed on 12 February 2022).
- Abuhaiba, I.S. Skew Correction of Textural Documents. J. King Saud Univ.-Comput. Inf. Sci. 2003, 15, 73–93. [Google Scholar] [CrossRef]
- Patrick, J. Handprinted Forms and Character Database, NIST Special Database 19; National Institute of Standards and Technology: Gaithersburg, MD, USA, 1995. [Google Scholar]
- Google Cloud Vision API Documentation. Available online: https://cloud.google.com/vision/docs/drag-and-drop (accessed on 20 February 2022).
- Dataturks.com. Image Text Recognition APIs Showdown. Google Vision vs Microsoft Cognitive Services vs AWS Rekognition. Available online: https://dataturks.com/blog/compare-image-text-recognition-apis.php (accessed on 1 March 2022).
- Li, X.; Qian, W.; Xu, D.; Liu, C. Image Segmentation Based on Improved Unet. In Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2021; Volume 1815, p. 12018. [Google Scholar]
- Nasir, T.; Malik, M.K.; Shahzad, K. MMU-OCR-21: Towards End-to-End Urdu Text Recognition Using Deep Learning. IEEE Access 2021, 9, 124945–124962. [Google Scholar] [CrossRef]
- U-Net Architecture Image, 2011, LMB, University of Freiburg Department of Computer Science Faculty of Engineering. Available online: https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/ (accessed on 4 April 2022).
- Hwang, S.-M.; Yeom, H.-G. An Implementation of a System for Video Translation Using OCR. In Software Engineering in IoT, Big Data, Cloud and Mobile Computing; Springer: Cham, Switzerland, 2021; pp. 49–57. [Google Scholar]
- Edupuganti, S.A.; Koganti, V.D.; Lakshmi, C.S.; Kumar, R.N.; Paruchuri, R. Text and Speech Recognition for Visually Impaired People using Google Vision. In Proceedings of the 2021 2nd International Conference on Smart Electronics and Communication (ICOSEC), Tiruchirappalli, India, 7–9 October 2021; pp. 1325–1330. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Provider | No. Correct | No. Incorrect | No. No Result | Precision | Recall |
|---|---|---|---|---|---|
| Microsoft Cognitive Services | 142 | 76 | 283 | 65% | 44% |
| Google Cloud Vision | 322 | 80 | 99 | 80% | 80% |
| AWS Recognition | 58 | 213 | 230 | 21% | 54% |
| Architecture | Model | Layers | Advantage | Disadvantage |
|---|---|---|---|---|
| U-Net | Built upon the Fully Convolutional Network (FCN) which is modified in a manner that yields better segmentation in medical imaging. | Separated into 3 parts: The contracting/ down sampling path bottleneck The expanding/up sampling path | Combines location information with contextual information to obtain general information which is necessary to predict a good segmentation map. | Instance segmentation is difficult because the output is a binary segmentation mask for the whole input image. |
| Mask R-CNN | Built on top of Faster R-CNN. So, in addition to the class label and bounding box coordinates for each object, it will also return the object mask. | Combines the 2 networks—Faster RCNN and FCN in one mega architecture. | Efficiently detects objects in an image while simultaneously generating a high-quality segmentation mask for each instance. | Although it does not cost a lot to modify the Mask RCNN, it still has the limitation that the mask generation cannot completely cover the edge of the target. |
| Technique | Summary | Layers | Advantage | Disadvantage |
|---|---|---|---|---|
| Object detection | Classifies patches of an image into different object classes and creates a bounding box around that object. | There are 2 classes of object classification- object bounding boxes and non-object bounding boxes. | Acts as a combination of image classification and object localization. | Bounding boxes are always rectangular, so it does not help in determining the shape of the object if it contains some curvature part. It cannot accurately estimate measurements such as the area or perimeter of an object from the image. |
| Semantic segmentation | Gives a pixel-level classification in an image, that is, classification of pixels into its corresponding classes. | Each pixel is labeled with the class of the object (person, dog...) and non-objects (tree, road...). | A further extension of object detection. | This technique is more granular than bounding box generation, hence it helps in determining the shape of each object present in the image. |
| Total Params | 7,760,353 |
| Trainable Params | 7,760,353 |
| Non-Trainable Params | 0 |
| Input Size (MB) | 3.00 |
| Forward/Backward Pass Size (MB) | 178,256,520.00 |
| Params Size (MB) | 29.60 |
| Estimated Total Size (MB) | 178,256,552.60 |
| (a) | Predicted Positive | Predicted Negative |
| True Positive | True Positive: 245194.68888888 | False Negative: 296.6111111111111 |
| True Negative | False Positive: 198.422222222222 | True Negative: 16454.277777777777 |
| (b) Sr. No. | Evaluation Metric | Score |
| 01. | Average Accuracy | 0.9981115976969401 |
| 02. | Precision | 0.9991914107884944 |
| 03. | Recall | 0.9987917652841012 |
| 04. | F1 | 0.9991914107884944 |
| 05. | Jaccard Index | 0.9980515790200687 |
| Sr. No. | Metric | Result |
|---|---|---|
| 01. | Jaccard Index for String Similarity | 0.6892857142857143 |
| 02. | Jaro-Winkler Score | 0.8248173731109226 |
| Sr. No. | Metric | Result |
|---|---|---|
| 01. | Jaccard Index for String Similarity | 0.254951690821256 |
| 02. | Jaro-Winkler Score | 0.8248173731109226 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Patil, S.; Varadarajan, V.; Mahadevkar, S.; Athawade, R.; Maheshwari, L.; Kumbhare, S.; Garg, Y.; Dharrao, D.; Kamat, P.; Kotecha, K. Enhancing Optical Character Recognition on Images with Mixed Text Using Semantic Segmentation. J. Sens. Actuator Netw. 2022, 11, 63. https://doi.org/10.3390/jsan11040063
Patil S, Varadarajan V, Mahadevkar S, Athawade R, Maheshwari L, Kumbhare S, Garg Y, Dharrao D, Kamat P, Kotecha K. Enhancing Optical Character Recognition on Images with Mixed Text Using Semantic Segmentation. Journal of Sensor and Actuator Networks. 2022; 11(4):63. https://doi.org/10.3390/jsan11040063
Chicago/Turabian StylePatil, Shruti, Vijayakumar Varadarajan, Supriya Mahadevkar, Rohan Athawade, Lakhan Maheshwari, Shrushti Kumbhare, Yash Garg, Deepak Dharrao, Pooja Kamat, and Ketan Kotecha. 2022. "Enhancing Optical Character Recognition on Images with Mixed Text Using Semantic Segmentation" Journal of Sensor and Actuator Networks 11, no. 4: 63. https://doi.org/10.3390/jsan11040063
APA StylePatil, S., Varadarajan, V., Mahadevkar, S., Athawade, R., Maheshwari, L., Kumbhare, S., Garg, Y., Dharrao, D., Kamat, P., & Kotecha, K. (2022). Enhancing Optical Character Recognition on Images with Mixed Text Using Semantic Segmentation. Journal of Sensor and Actuator Networks, 11(4), 63. https://doi.org/10.3390/jsan11040063