
A Survey of Outlier Detection Techniques in IoT: Review and Classification



Abstract
:1. Introduction
- We select papers between 2010 and 2021 (80 papers) from the leading scientific online databases (MDPI, Science Direct, SpringerLink, IEEE Explorer, ACM Digital Library, etc.). Moreover, we consider some required and original papers before 2010 (13 papers). The papers are selected based on the following research keywords: outlier detection, outlier classification, anomaly detection, anomaly classification, WSN, IoT.
- We take the most relevant articles that focus on the outlier detection techniques in WSN/IoT.
- We take the most relevant articles that focus on the classification of outlier detection techniques in WSN/IoT.
- The fundamentals of outlier detection in IoT are provided while discussing the different sources of an outlier, the approaches that can be adopted, and how we can evaluate an outlier detection technique.
- A summary of the challenges that can face the design of an outlier detection solution for IoT is provided.
- A comparison and discussion of the more recent outlier detection techniques are presented and classified while:
- –
- The main seven categories of outlier detection techniques are highlighted by showing the advantages and the disadvantages of each of them.
- –
- The related works of each category are presented.
- –
- The study of the spatial-temporal correlation for outlier detection techniques in IoT is provided.
2. Outlier Detection Fundamentals in IoT Context
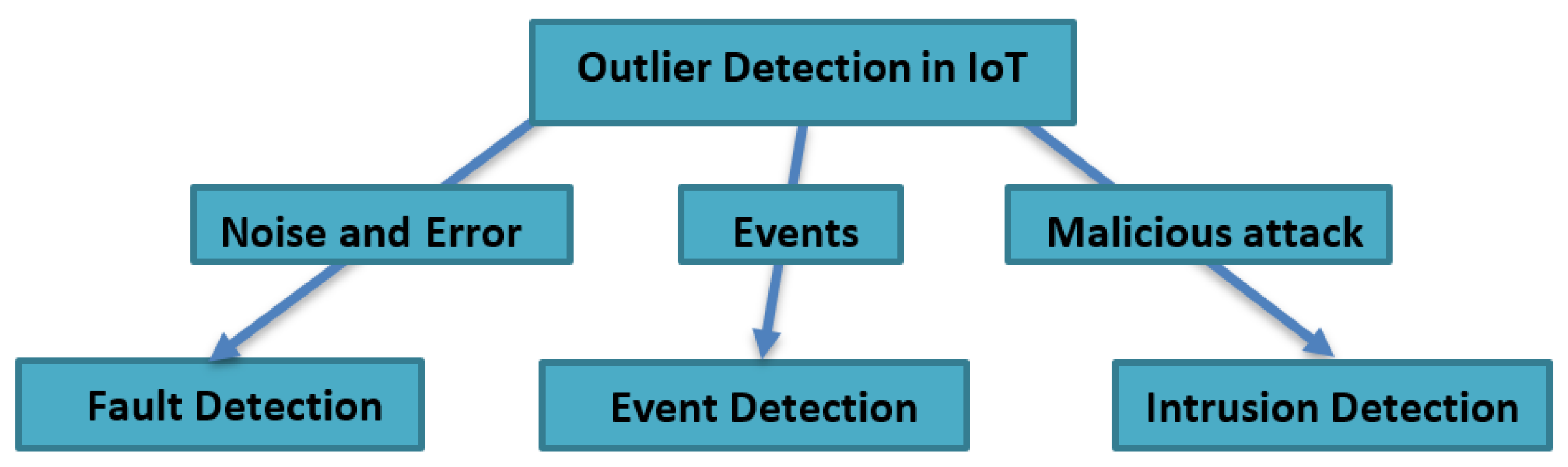
2.1. Sources of an Outlier in IoT
- Error and noiseThe sensors are generally deployed in a harsh environment so that they are exposed to interference such as noise. An error means noisy data measurement or data that come from a faulty node. This means values that differ greatly from the true state of the phenomenon being measured. Outliers resulting from errors are more likely to occur often, while outliers resulting from events appear to have a very low probability of occurrence [14]. Normally, the error values are represented as a random change and are greatly different from other data. These errors may affect the gathered data quality, and thus must be detected. In addition, if they are faulty or noisy data, they will be corrected or discarded to keep the energy of the sensor.
- EventWe can talk about an event while finding the data values that represent a change in the real environment state, compared to the predefined normal behaviour. Events may occur due to a gradual or sudden change in the real environment, as a temperature change caused by air pollution, forest fire, chemical spill, flood, earthquake, volcanic, etc. It is very important to distinguish between errors and events, because faulty sensors may give false events, so it is difficult to differentiate them. Thus, the outlier detection techniques need to depend on the reality that noisy measured data values and sensor failures are likely to be randomly unrelated to each other. Meanwhile, event measurements are likely to be geographically correlated [15]. As marked in [16], an event is a “succession of outliers or erroneous data values in data streaming”. So, the events must be detected and treated because they have important information.
- Malicious attackThe third source of an outlier is the malicious attacks, which can be defined as a security threat to the network. There are many types of attacks on the sensor node. The attacked node will behave as a normal node and give unreliable data values in the network. This will affect the whole functionality and the performance of the system. These attacks must be treated in the intrusion detection techniques, which are out of the scope of this paper.
- Point outliers: an individual data value that is deviated from the standard data values pattern. Those forms of outliers can easily be recognized.
- Contextual outliers: a data value that deviate from the standard pattern in a particular context.
- Collective outliers: a group of related data values which deviate from the whole data set.
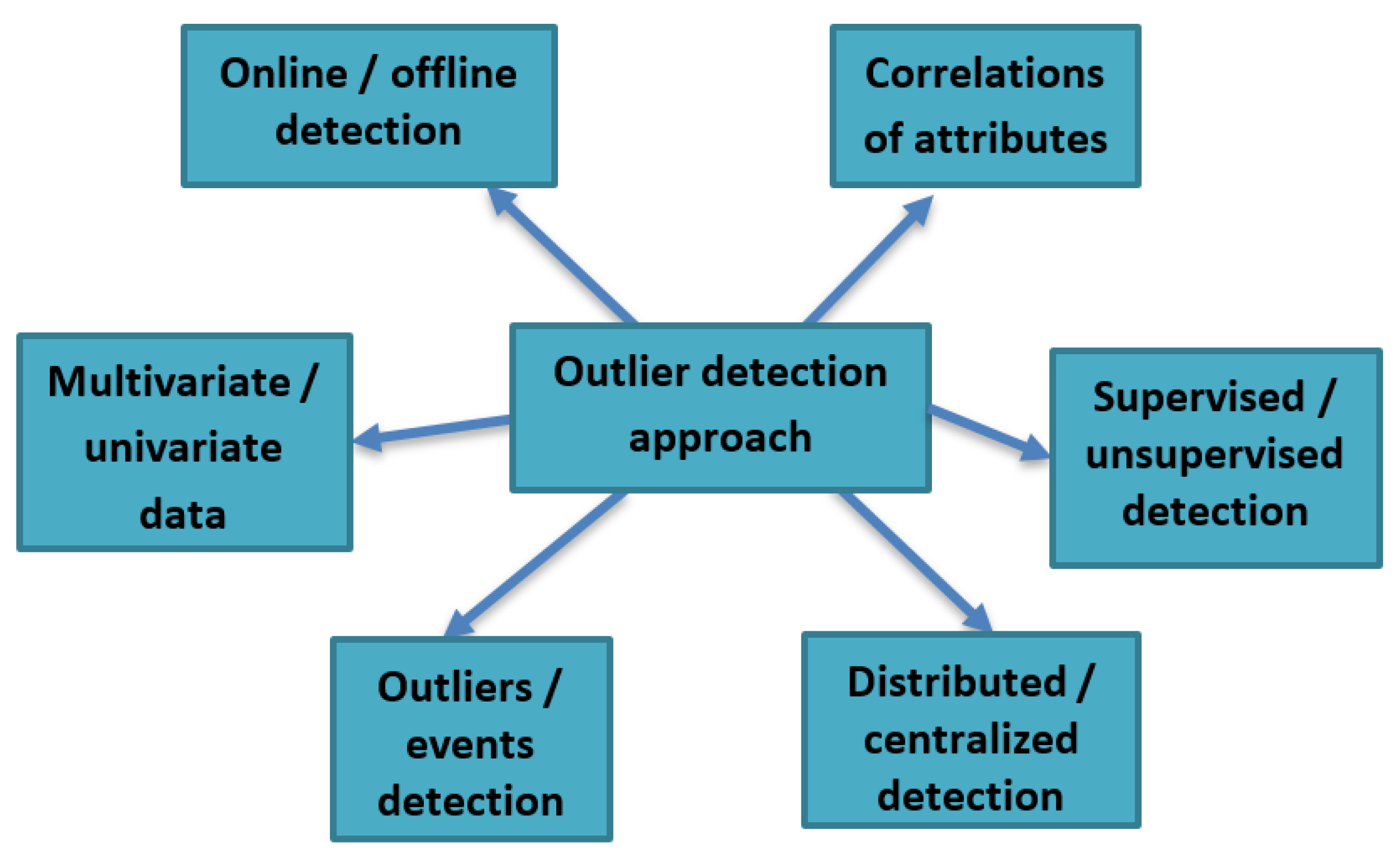
2.2. Outlier Detection Approach
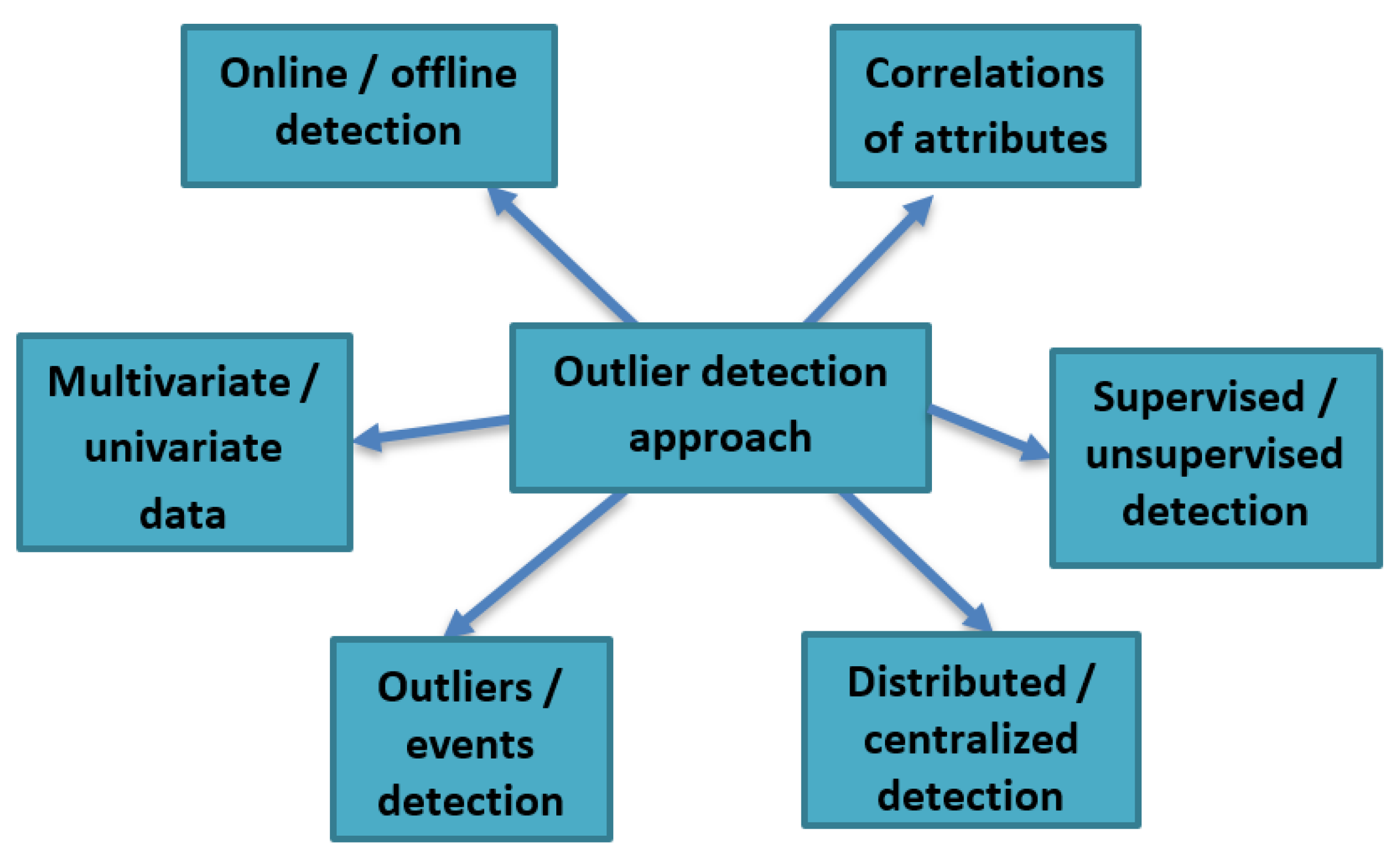
- Outlier detection and event detectionFrom Figure 2, we could notice that event detection is part of outlier detection, but there are some differences between them in the IoT context. These differences can be listed as follows:
- When detecting outliers, there is no previous knowledge of trigger conditions or semantic of any event. Meanwhile, there is a trigger condition or specific event semantic provided by the central node in detecting events.
- Detecting outliers need to compare sensor data values with each other. Meanwhile, detecting events need to compare sensor data values with the trigger condition or predefined pattern.
- Detecting outliers need to avoid classifying normal data as outliers to maintain a high detection rate (DR) and low false alarm rate (FAR). Meanwhile, detecting events need to avoid considering the erroneous data values that conform to the predefined state or condition of the event to affect the detection’s reliability.
- The sensor nodes must report an event once it happened to the base station node on time.
- Distributed detection and centralized detectionDistributed outlier detection techniques detect outliers at the sensor node. Meanwhile, centralized outlier detection techniques identify outliers at the parent node, cluster head, or base station. With the distributed method, the transfer of raw sensor data values can be reduced, allowing one not to broadcast the entire data to the base station. Besides, the node deals with its data values and sends only some parameters, which leads to using network resources, such as power and bandwidth, in a highly efficient way. However, distributed outlier detection accuracy might not be as good as centralized detection, due to a lack of appropriate sensor data for modelling purposes [17].
- Online and offline detectionThe online detection detects outliers in real-time or near real-time. Meanwhile, offline detection detects outliers after collecting a massive amount of sensed data values from the sensors. The offline detection is not suitable for WSN because the distributed streaming data require online processing.
- Supervised and unsupervised detectionThe supervised techniques characterize all the outliers and the non-outliers depending on the model built using the pre-labelled data in the training phase. These pre-labelled data mean the need for specific predefined data in the training phase to create a normal or abnormal data model before detecting outliers. These supervised techniques may be helpful for intrusion detection applications. However, it is crucial to notice that these pre-labelled data are not easy to obtain or unavailable in many real-life IoT applications. In addition to the enormous online streaming data coming, the supervised model may be valid for specific time instances, but invalid for other time instances. The unsupervised techniques do not require pre-labelled data, but they utilize specialized metrics to identify outliers. For example, some techniques use distance measures, while others use a familiar statistical distribution model.
- Multivariate Data and univariateIn the univariate data, the data value has a single attribute, whereas, in the multivariate data, the sensor data value has many attributes. Thus, we have an outlier if the data value has abnormal values in its attributes. The outlier detection technique must be able to deal with the multivariate data and consider their correlations. It must also consider the complexity of computations of these multivariate data. Otherwise, the technique will not be suitable for IoT applications.
- Correlation of DataIn sensor data, two types of correlations can exist:
- Correlation between data attributes.
- Correlation between the observations of the sensor node itself and its neighbouring node observations.
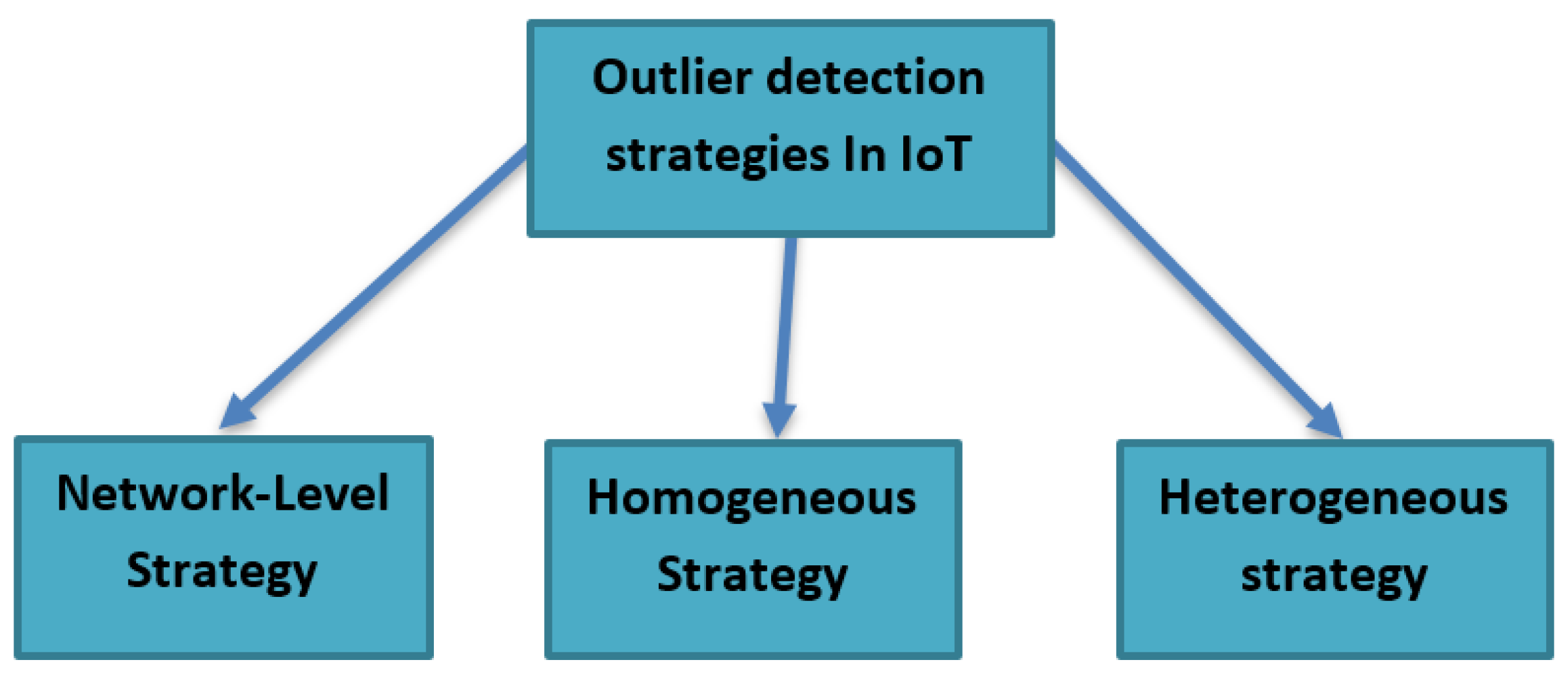
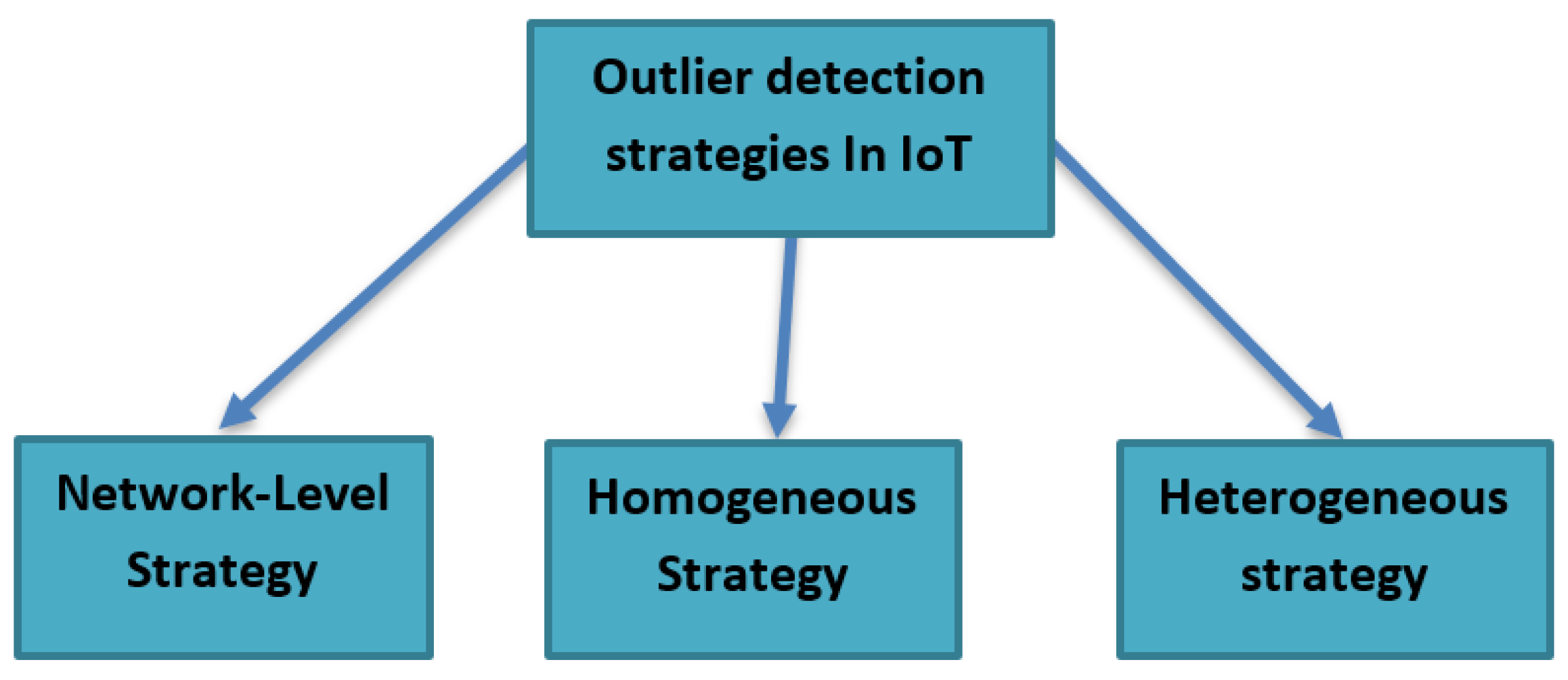
2.3. Sensor Failure Detection Strategies in IoT
- Network-level strategy: with this strategy, the aim is to monitor the data at the network level to detect any failure in the sensors. The Markov models can be used to characterize the behaviour of the normal and the abnormal sensors, where the sensors can monitor each other in the IoT situation.
- Homogeneous strategy: the aim here is to use many spatially correlated similar sensors to detect any abnormal sensor behaviours. We use the Auto-Regressive Integrated Moving Average (ARIMA) time-series model [18], which compares the data value measured by the sensor with predicted measured.
- Heterogeneous strategy: the aim here is to group different sensors to detect the sensor’s failure by classifying the sensors data values output. The Outlier Detection Module (ODM) proposed in [1] is an example of a heterogeneous strategy in IoTs, where the heterogeneous sensors are connected to this module and to a microcontroller, and they send their sensed data values to both. The microcontroller will monitor the data received from the sensors while running the multi-agent deep reinforcement learning-based and distributed outlier detection on the module to identify the outliers.
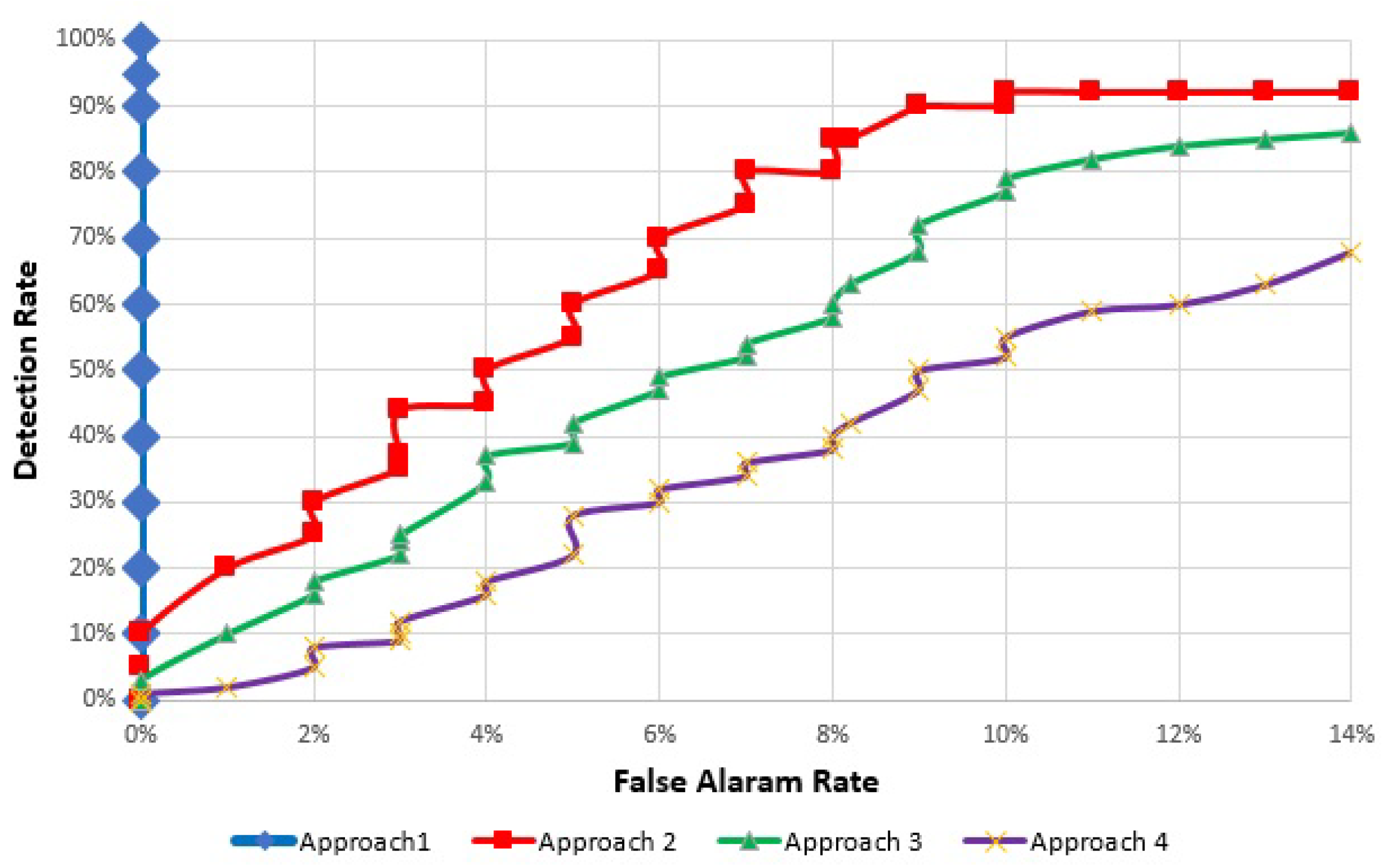
2.4. Evaluation of Outlier Detection Techniques in IoTs
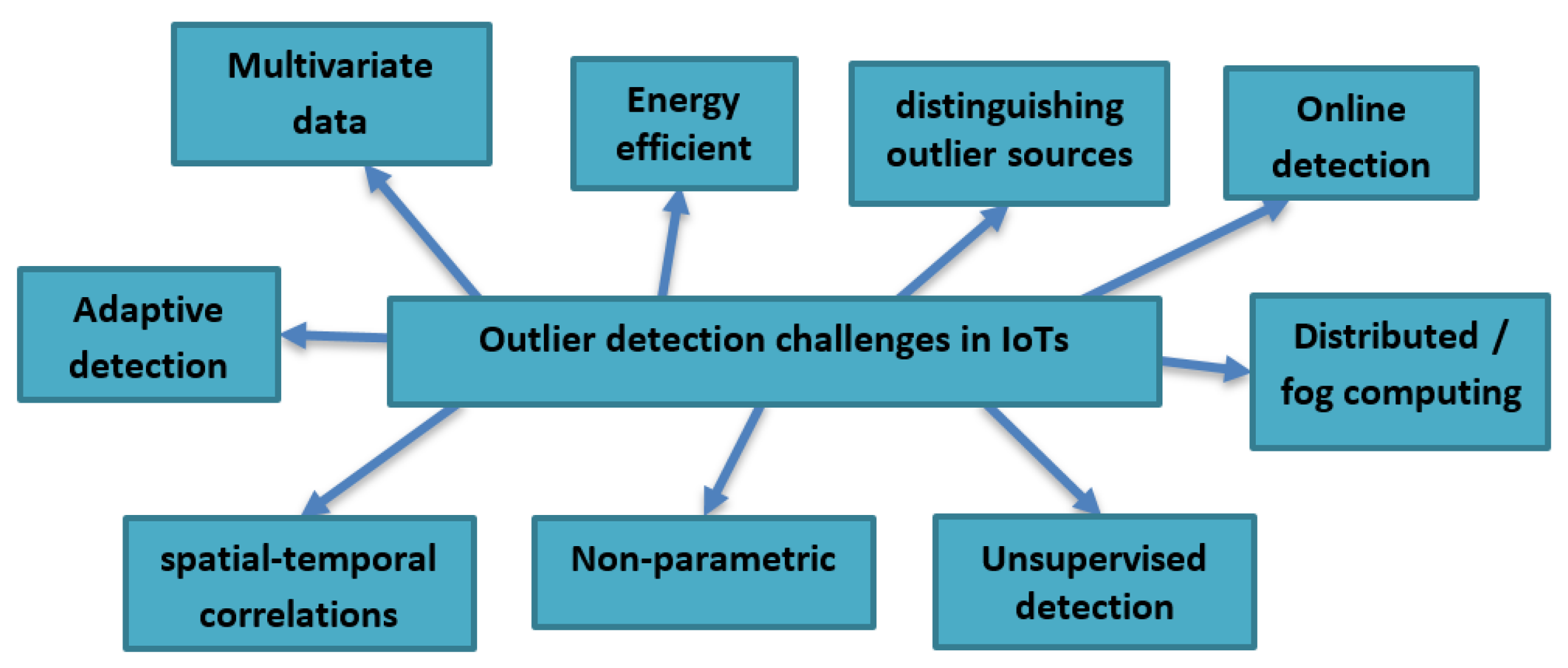
2.5. Outlier Detection Challenges in IoT Context
- Taking into consideration contextual information, which includes the spatial-temporal correlations of sensed data values and the external context of data [21].
- The majority of the existing techniques are for univariate data. Meanwhile, they should consider the multivariate data where each data value has many attributes.
- The outlier detection technique in IoTs must consider how reducing the consumption of the available resources such as memory, energy, and communication bandwidth.
- Due to the nature of sensor devices, they are subjected to failure, missing, duplicated data or may be affected by noise. So, it is crucial to detect outliers and distinguish between errors, events, and malicious attacks, while not losing important events by considering them as errors.
- Because of the lack of previous knowledge about data distribution, the outlier detection technique should be non-parametric.
- The prelabeled data is not always available or not easy to obtain, so the outlier detection technique should be unsupervised.
- Sensors are susceptible to environmental changes such as humidity and temperature. In addition, they are also vulnerable to dynamic network topology changes, communication failures, and the non-stationary of streaming data.
- It is essential to process data as soon as possible to take the necessary decision. So, detecting outliers should be in a distributed manner or fog computing manner. As a result, unnecessary communications will be reduced, which will lead to low energy consumption and extend the network lifetime.
- Another challenge facing the design of an outlier technique is to be an online one. Offline detection can be applied to the past recorded collected data. Meanwhile, the online detection runs on data as they arrive in real-time, so that outliers can be detected directly, which will reduce the detection time. Thus, the outlier detection technique should operate online to deal with distributed real-time streaming data (or near real-time) applications. We notice that some techniques start to work offline to build the right model to work after in an online manner. The techniques which work totally in an offline mode are not suitable for sensor data.
- Because of the large amount of coming streaming data values, it is efficient and easier for analysis to deal with data using incremental windows instead of dealing with the whole data set.
- Because of the large number of sensor nodes deployed in the environment, the outlier detection technique in IoT needs to scale well to process a considerable amount of coming streaming data values in an online manner.
- The different types of malicious attacks add a significant challenge to the design of outlier detection techniques in IoT.
- Each technique is suitable for a specific application and it may not be possible to reuse it in other domains. Thus, the outlier detection technique should be generalized to be easily reused and deployed for many applications.
- Another challenge is to make the appropriate choice of threshold, sliding windows size, the neighbourhood threshold, and the cluster radius during the design of the outlier technique.
- They should be simple to implement, with low computational cost and high energy efficiency.
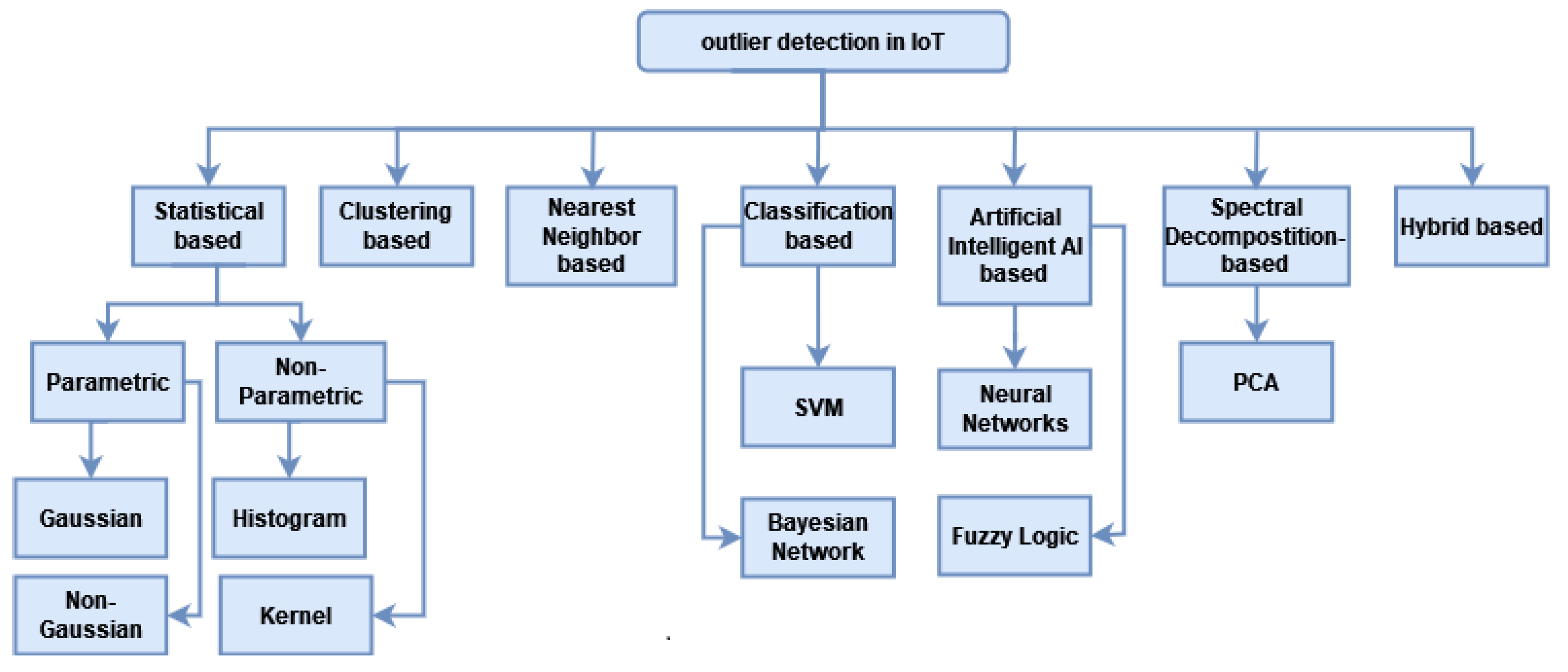
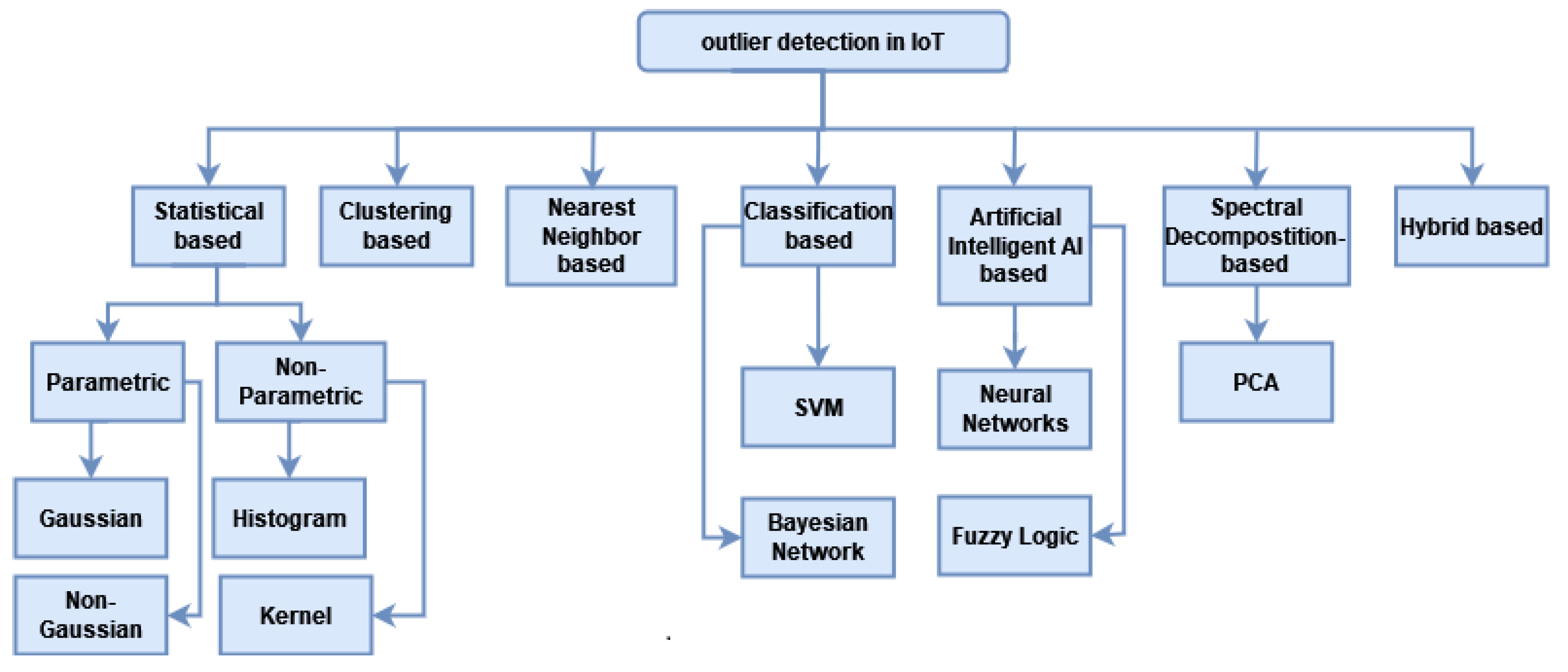
3. Outlier Detection Techniques in IoT
3.1. Statistical-Based Techniques
- Parametric techniques: include methods with knowing data distribution, which means that data is generated from a well-known model, for example, a normal distribution model. In this case, the distribution parameters are estimated based on available data. When a data value is highly different from the data model, it is considered an outlier.
- Non-parametric techniques: include methods with no known data distribution, which means that they are depending on a distance measure between the new data value and the statistical model. Then, define a threshold on this distance value to decide if the observed value is an outlier or not. In these techniques, it is not easy to define or to choose this threshold.
3.2. Clustering-Based Outlier Detection Techniques
3.3. Nearest Neighbour-Based Techniques
- Euclidean distance, which is suitable for univariate data.
- Mahalanobis distance (MD), which is suitable for multivariate data.
- Hamming distance.
3.4. Classification-Based Techniques
3.5. Artificial Intelligence Techniques
3.6. Spectral Decomposition Techniques
3.7. Hybrid Techniques
4. Comparative Study of Outlier Detection Techniques in IoT
Summary of Outlier Detection Techniques
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gaddam, A.; Wilkin, T.; Angelova, M.; Gaddam, J. Detecting sensor faults, anomalies and outliers in the internet of things: A survey on the challenges and solutions. Electronics 2020, 9, 511. [Google Scholar] [CrossRef] [Green Version]
- Leppänen, R.F.; Hämäläinen, T. Network Anomaly Detection in Wireless Sensor Networks: A Review. In Internet of Things, Smart Spaces, and Next Generation Networks and Systems; Galinina, O., Andreev, S., Balandin, S., Koucheryavy, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 196–207. [Google Scholar]
- Joyia, G.J.; Liaqat, R.M.; Farooq, A.; Rehman, S. Internet of medical things (IOMT): Applications, benefits and future challenges in healthcare domain. J. Commun. 2017, 12, 240–247. [Google Scholar] [CrossRef] [Green Version]
- Amendola, S.; Lodato, R.; Manzari, S.; Occhiuzzi, C.; Marrocco, G. RFID technology for IoT-based personal healthcare in smart spaces. IEEE Internet Things J. 2014, 1, 144–152. [Google Scholar] [CrossRef]
- Perera, C.; Liu, C.H.; Jayawardena, S.; Chen, M. A Survey on Internet of Things from Industrial Market Perspective. IEEE Access 2015, 2, 1660–1679. [Google Scholar] [CrossRef]
- Dai, H.N.; Wang, H.; Xu, G.; Wan, J.; Imran, M. Big data analytics for manufacturing internet of things: Opportunities, challenges and enabling technologies. Enterp. Inf. Syst. 2020, 14, 1279–1303. [Google Scholar] [CrossRef] [Green Version]
- Baranwal, T.; Nitika; Pateriya, P.K. Development of IoT based smart security and monitoring devices for agriculture. In Proceedings of the 2016 6th International Conference—Cloud System and Big Data Engineering (Confluence), Noida, India, 14–15 January 2016; pp. 597–602. [Google Scholar] [CrossRef]
- Baskaran, S.B.M. Internet of things security. J. ICT Stand. 2019, 7, 21–39. [Google Scholar] [CrossRef]
- Ayadi, A.; Ghorbel, O.; BenSalah, M.S.; Abid, M. Spatio-temporal correlations for damages identification and localization in water pipeline systems based on WSNs. Comput. Netw. 2020, 171, 107134. [Google Scholar] [CrossRef]
- Kanhere, P.; Khanuja, H.K. A methodology for outlier detection in audit logs for financial transactions. In Proceedings of the 1st International Conference on Computing, Communication, Control and Automation, ICCUBEA’15, Pune, India, 26–27 February 2015; pp. 837–840. [Google Scholar] [CrossRef]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. (CSUR) 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Castillo, A.; Thierer, A.D. Projecting the Growth and Economic Impact of the Internet of Things. SSRN Electron. J. 2015. [Google Scholar] [CrossRef] [Green Version]
- Branch, J.W.; Giannella, C.; Szymanski, B.; Wolff, R.; Kargupta, H. In-network outlier detection in wireless sensor networks. Knowl. Inf. Syst. 2013, 34, 23–54. [Google Scholar] [CrossRef] [Green Version]
- Martincic, F.; Schwiebert, L. Distributed event detection in sensor networks. In Proceedings of the International Conference on Systems and Networks Communications (ICSNC 2006), Tahiti, French Polynesia, 29 October–3 November 2006; p. 43. [Google Scholar] [CrossRef]
- Krishnamachari, B.; Iyengar, S. Distributed Bayesian algorithms for fault-tolerant event region detection in wireless sensor networks. IEEE Trans. Comput. 2004, 53, 241–250. [Google Scholar] [CrossRef]
- Shahid, N.; Naqvi, I.H.; Qaisar, S.B. Characteristics and classification of outlier detection techniques for wireless sensor networks in harsh environments: A survey. Artif. Intell. Rev. 2012, 43, 193–228. [Google Scholar] [CrossRef]
- Zhang, Y.; Meratnia, N.; Havinga, P. Outlier detection techniques for wireless sensor networks: A survey. IEEE Commun. Surv. Tutor. 2010, 12, 159–170. [Google Scholar] [CrossRef] [Green Version]
- Ding, M.; Chen, D.; Xing, K.; Cheng, X. Localized fault-tolerant event boundary detection in sensor networks. In Proceedings of the IEEE 24th Annual Joint Conference of the IEEE Computer and Communications Societies, Miami, FL, USA, 13–17 March 2005; Volume 2, pp. 902–913. [Google Scholar] [CrossRef] [Green Version]
- Lazarevic, A.; Ertoz, L.; Kumar, V.; Ozgur, A.; Srivastava, J. A Comparative Study of Anomaly Detection Schemes in Network Intrusion Detection. In Proceedings of the 2003 SIAM International Conference on Data Mining, San Francisco, CA, USA, 1–3 May 2003; pp. 25–36. [Google Scholar] [CrossRef] [Green Version]
- Ganesh Kumar, D.; Insozhan, N.; Parthasarathy, V. Recognition of faulty node detection using fuzzy logic in iot. Int. J. Sci. Technol. Res. 2019, 8, 1112–1116. [Google Scholar]
- Cook, A.A.; Misirli, G.; Fan, Z. Anomaly Detection for IoT Time-Series Data: A Survey. IEEE Internet Things J. 2020, 7, 6481–6494. [Google Scholar] [CrossRef]
- Ayadi, A.; Ghorbel, O.; Obeid, A.M.; Abid, M. Outlier detection approaches for wireless sensor networks: A survey. Comput. Netw. 2017, 129, 319–333. [Google Scholar] [CrossRef]
- Jiang, J.; Han, G.; Liu, L.; Shu, L.; Guizani, M. Outlier detection approaches based on machine learning in the internet-of-things. IEEE Wirel. Commun. 2020, 27, 53–59. [Google Scholar] [CrossRef]
- Kumar Dwivedi, R.; Pandey, S.; Kumar, R. A Study on Machine Learning Approaches for Outlier Detection in Wireless Sensor Network. In Proceedings of the 8th International Conference Confluence 2018 on Cloud Computing, Data Science and Engineering (Confluence), Noida, India, 11–12 January 2018; pp. 189–192. [Google Scholar] [CrossRef]
- Ghosh, N.; Maity, K.; Paul, R.; Maity, S. Outlier detection in sensor data using machine learning techniques for IoT framework and wireless sensor networks: A brief study. In Proceedings of the 2019 International Conference on Applied Machine Learning (ICAML’19), Bhubaneswar, India, 25–26 May 2019; pp. 187–190. [Google Scholar] [CrossRef]
- Wang, H.; Bah, M.J.; Hammad, M. Progress in Outlier Detection Techniques: A Survey. IEEE Access 2019, 7, 107964–108000. [Google Scholar] [CrossRef]
- Morales, L.V.V.; López-Vizcaíno, M.; Iglesias, D.F.; Díaz, V.M.C. Anomaly Detection in IoT: Methods, Techniques and Tools. Proceedings 2019, 21, 4. [Google Scholar] [CrossRef] [Green Version]
- Sheng, B.; Li, Q.; Mao, W.; Jin, W. Outlier detection in sensor networks. In Proceedings of the International Symposium on Mobile Ad Hoc Networking and Computing (MobiHoc), Montreal QC Canada, 9–14 September 2007; pp. 219–228. [Google Scholar] [CrossRef] [Green Version]
- Palpanas, T.; Papadopoulos, D.; Kalogeraki, V.; Gunopulos, D. Distributed deviation detection in sensor networks. ACM Sigmod Rec. 2003, 32, 77–82. [Google Scholar] [CrossRef]
- Panda, M.; Khilar, P.M. Distributed soft fault detection algorithm in wireless sensor networks using statistical test. In Proceedings of the 2012 2nd IEEE International Conference on Parallel, Distributed and Grid Computing (PDGC 2012), lSolan, India, 6–8 December 2012; pp. 195–198. [Google Scholar] [CrossRef]
- Zhang, Y.; Hamm, N.A.; Meratnia, N.; Stein, A.; van de Voort, M.; Havinga, P.J. Statistics-based outlier detection for wireless sensor networks. Int. J. Geogr. Inf. Sci. 2012, 26, 1373–1392. [Google Scholar] [CrossRef]
- Xie, M.; Hu, J.; Tian, B. Histogram-based online anomaly detection in hierarchical wireless sensor networks. In Proceedings of the 11th IEEE International Conference on Trust, Security and Privacy in Computing and Communications, TrustCom-2012—11th IEEE International Conference on Ubiquitous Computing and Communications, IUCC-2012, Liverpool, UK, 25–27 June 2012; pp. 751–759. [Google Scholar] [CrossRef]
- Boedihardjo, A.P.; Lu, C.T.; Chen, F. Fast adaptive kernel density estimator for data streams. Knowl. Inf. Syst. 2015, 42, 285–317. [Google Scholar] [CrossRef]
- Lv, Y. An Adaptive Real-time Outlier Detection Algorithm Based on ARMA Model for Radar’s Health Monitoring. In Proceedings of the 2015 IEEE AUTOTESTCON, National Harbor, MD, USA, 2–5 November 2015. [Google Scholar]
- Nesa, N.; Ghosh, T.; Banerjee, I. Outlier detection in sensed data using statistical learning models for IoT. In Proceedings of the IEEE Wireless Communications and Networking Conference, WCNC, Barcelona, Spain, 15–18 April 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Ahmed, M.; Mahmood, A.N. A novel approach for outlier detection and clustering improvement. In Proceedings of the 2013 IEEE 8th Conference on Industrial Electronics and Applications, ICIEA 2013, Melbourne, VIC, Australia, 19–21 June 2013; pp. 577–582. [Google Scholar] [CrossRef]
- Souza, A.M.; Amazonas, J.R. An outlier detect algorithm using big data processing and Internet of Things architecture. Procedia Comput. Sci. 2015, 52, 1010–1015. [Google Scholar] [CrossRef] [Green Version]
- Hydra Technology Project—In-JeT ApS. Available online: https://www.in-jet.eu/portfolio-items/hydra/ (accessed on 20 December 2021).
- Cordova, I.; Moh, T.S. DBSCAN on Resilient Distributed Datasets. In Proceedings of the 2015 International Conference on High Performance Computing and Simulation, HPCS 2015, Amsterdam, The Netherlands, 20–24 July 2015; pp. 531–540. [Google Scholar] [CrossRef]
- Christy, A.; Gandhi, M.G.; Vaithyasubramanian, S. Cluster based outlier detection algorithm for healthcare data. Procedia Comput. Sci. 2015, 50, 209–215. [Google Scholar] [CrossRef] [Green Version]
- Bai, M.; Wang, X.; Xin, J.; Wang, G. An efficient algorithm for distributed density-based outlier detection on big data. Neurocomputing 2016, 181, 19–28. [Google Scholar] [CrossRef]
- Breunig, M.M.; Kriegel, H.P.; Ng, R.T.; Sander, J. LOF: Identifying Density-Based Local Outliers. Int. J. Gynecol. Obstet. 2009, 107, S93. [Google Scholar]
- Tian, H.X.; Liu, X.J.; Han, M. An outliers detection method of time series data for soft sensor modeling. In Proceedings of the 28th Chinese Control and Decision Conference, CCDC 2016, Yinchuan, China, 28–30 May 2016; pp. 3918–3922. [Google Scholar] [CrossRef]
- Xie, M.; Hu, J.; Guo, S.; Zomaya, A.Y. Distributed Segment-based Anomaly Detection with Kullback-Leibler Divergence in Wireless Sensor Networks. IEEE Trans. Inf. Forensics Secur. 2016, 12, 101–110. [Google Scholar] [CrossRef]
- Lyu, L.; Jin, J.; Rajasegarar, S.; He, X.; Palaniswami, M. Fog-empowered anomaly detection in IoT using hyperellipsoidal clustering. IEEE Internet Things J. 2017, 4, 1174–1184. [Google Scholar] [CrossRef]
- Abid, A.; Kachouri, A.; Mahfoudhi, A. Outlier detection for wireless sensor networks using density-based clustering approach. IET Wirel. Sens. Syst. 2017, 7, 83–90. [Google Scholar] [CrossRef]
- Alguliyev, R.; Aliguliyev, R.; Sukhostat, L. Anomaly detection in Big data based on clustering. Stat. Optim. Inf. Comput. 2017, 5, 325–340. [Google Scholar] [CrossRef]
- Gan, G.; Ng, M.K.P. K-Means Clustering with Outlier Removal. Pattern Recognit. Lett. 2017, 90, 8–14. [Google Scholar] [CrossRef]
- Santos, J.; Leroux, P.; Wauters, T.; Volckaert, B.; De Turck, F. Anomaly detection for Smart City applications over 5G low power wide area networks. In Proceedings of the IEEE/IFIP Network Operations and Management Symposium: Cognitive Management in a Cyber World, NOMS 2018, Taipei, Taiwan, 23–27 April 2018; pp. 1–9. [Google Scholar] [CrossRef] [Green Version]
- Ghallab, H.; Fahmy, H.; Nasr, M. Detection outliers on internet of things using big data technology. Egypt. Inform. J. 2020, 21, 131–138. [Google Scholar] [CrossRef]
- Yang, D.; Rundensteiner, E.A.; Ward, M.O. Neighbor-based pattern detection for windows over streaming data. In Proceedings of the 12th International Conference on Extending Database Technology: Advances in Database Technology, EDBT’09, Petersburg, Russia, 24–26 March 2009; pp. 529–540. [Google Scholar] [CrossRef] [Green Version]
- Kontaki, M.; Gounaris, A.; Papadopoulos, A.N.; Tsichlas, K.; Manolopoulos, Y. Continuous monitoring of distance-based outliers over data streams. In Proceedings of the International Conference on Data Engineering, Hannover, Germany, 11–16 April 2011; pp. 135–146. [Google Scholar] [CrossRef]
- Cao, L.; Yang, D.; Wang, Q.; Yu, Y.; Wang, J.; Rundensteiner, E.A. Scalable distance-based outlier detection over high-volume data streams. In Proceedings of the International Conference on Data Engineering, Chicago, IL, USA, 31 March–4 April 2014; pp. 76–87. [Google Scholar] [CrossRef]
- Abid, A.; Kachouri, A.; Mahfoudhi, A. Anomaly detection through outlier and neighborhood data in Wireless Sensor Networks. In Proceedings of the 2nd International Conference on Advanced Technologies for Signal and Image Processing, ATSIP 2016, Monastir, Tunisia, 21–23 March 2016; pp. 26–30. [Google Scholar] [CrossRef]
- Tang, B.; He, H. A local density-based approach for outlier detection. Neurocomputing 2017, 241, 171–180. [Google Scholar] [CrossRef] [Green Version]
- Bosman, H.H.W.J.; Hwj, H.; Iacca, G.; Tejada, A.; Wörtche, H.J.; Liotta, A. Spatial anomaly detection in sensor networks using neighborhood information. Inf. Fusion 2017, 33, 41–56. [Google Scholar] [CrossRef] [Green Version]
- Zhu, R.; Ji, X.; Yu, D.; Tan, Z.; Zhao, L.; Li, J.; Xia, X. KNN-Based Approximate Outlier Detection Algorithm over IoT Streaming Data. IEEE Access 2020, 8, 42749–42759. [Google Scholar] [CrossRef]
- Zhang, Y.; Meratnia, N.; Havinga, P. Adaptive and online one-class support vector machine-based outlier detection techniques for wireless sensor networks. In Proceedings of the International Conference on Advanced Information Networking and Applications, AINA, Bradford, UK, 26–29 May 2009; pp. 990–995. [Google Scholar] [CrossRef] [Green Version]
- Rajasegarar, S.; Leckie, C.; Bezdek, J.C.; Palaniswami, M. Centered hyperspherical and hyperellipsoidal one-class support vector machines for anomaly detection in sensor networks. IEEE Trans. Inf. Forensics Secur. 2010, 5, 518–533. [Google Scholar] [CrossRef]
- Shahid, N.; Naqvi, I.H.; Qaisar, S.B. Quarter-sphere SVM: Attribute and spatio-temporal correlations based outlier & event detection in wireless sensor networks. In Proceedings of the IEEE Wireless Communications and Networking Conference, WCNC, Paris, France, 1–4 April 2012; pp. 2048–2053. [Google Scholar] [CrossRef]
- Zhang, Y.; Meratnia, N.; Havinga, P.J. Distributed online outlier detection in wireless sensor networks using ellipsoidal support vector machine. Ad Hoc Netw. 2013, 11, 1062–1074. [Google Scholar] [CrossRef]
- Rajasegarar, S.; Gluhak, A.; Ali Imran, M.; Nati, M.; Moshtaghi, M.; Leckie, C.; Palaniswami, M. Ellipsoidal neighbourhood outlier factor for distributed anomaly detection in resource constrained networks. Pattern Recognit. 2014, 47, 2867–2879. [Google Scholar] [CrossRef]
- De Paola, A.; Gaglio, S.; Re, G.L.; Milazzo, F.; Ortolani, M. Adaptive distributed outlier detection for WSNs. IEEE Trans. Cybern. 2015, 45, 902–913. [Google Scholar] [CrossRef] [PubMed]
- Yuan, H.; Zhao, X.; Yu, L. A Distributed Bayesian Algorithm for Data Fault Detection in Wireless Sensor Networks. In Proceedings of the 2015 International Conference on Information Networking (ICOIN), Siem Reap, Cambodia, 12–14 January 2015; pp. 63–68. [Google Scholar]
- Chen, J.; Kher, S.; Somani, A. Distributed fault detection of wireless sensor networks. In Proceedings of the 2006 Workshop on Dependability Issues in Wireless Ad Hoc Networks and Sensor Networks, Los Angeles, CA, USA, 26 September 2006; Volume 2006, pp. 65–71. [Google Scholar] [CrossRef]
- Uddin, M.S.; Kuh, A. Online least-squares one-class support vector machine for outlier detection in power grid data. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing—Proceedings, Shanghai, China, 20–25 March 2016; pp. 2628–2632. [Google Scholar] [CrossRef]
- Gao, J.; Wang, J.; Zhong, P.; Wang, H. On threshold-free error detection for industrial wireless sensor networks. IEEE Trans. Ind. Inform. 2018, 14, 2199–2209. [Google Scholar] [CrossRef]
- Deng, X.; Jiang, P.; Peng, X.; Mi, C. An intelligent outlier detection method with one class support tucker machine and genetic algorithm toward big sensor data in internet of things. IEEE Trans. Ind. Electron. 2019, 66, 4672–4683. [Google Scholar] [CrossRef]
- Titouna, C.; Naït-Abdesselam, F.; Khokhar, A. DODS: A Distributed Outlier Detection Scheme for Wireless Sensor Networks. Comput. Netw. 2019, 161, 93–101. [Google Scholar] [CrossRef]
- Fawzy, A.; Mokhtar, H.M.; Hegazy, O. Outliers detection and classification in wireless sensor networks. Egypt. Inform. J. 2013, 14, 157–164. [Google Scholar] [CrossRef] [Green Version]
- Shih, K.P.; Wang, S.S.; Yang, P.H.; Chang, C.C. CollECT: Collaborative Event deteCtion and Tracking in Wireless Heterogeneous Sensor Networks. In Proceedings of the 11th IEEE Symposium on Computers and Communications (ISCC’06), Cagliari, Italy, 26–29 June 2006; pp. 1–6. [Google Scholar]
- Chang, S.H.; Huang, T.S. A fuzzy knowledge based fault tolerance algorithm in wireless sensor networks. In Proceedings of the 26th IEEE International Conference on Advanced Information Networking and Applications Workshops, WAINA 2012, Fukuoka, Japan, 26–29 March 2012; pp. 891–896. [Google Scholar] [CrossRef]
- Swain, R.R.; Khilar, P.M.; Bhoi, S.K. Heterogeneous fault diagnosis for wireless sensor networks. Ad Hoc Netw. 2018, 69, 15–37. [Google Scholar] [CrossRef]
- Panda, M.; Khilar, P.M. Distributed self fault diagnosis algorithm for large scale wireless sensor networks using modified three sigma edit test. Ad Hoc Netw. 2015, 25, 170–184. [Google Scholar] [CrossRef]
- Luo, T.; Nagarajany, S.G. Distributed anomaly detection using autoencoder neural networks in WSN for IoT. In Proceedings of the IEEE International Conference on Communications, Kansas City, MO, USA, 20–24 May 2018. [Google Scholar] [CrossRef] [Green Version]
- Gao, Y.; Xiao, F.; Liu, J.; Wang, R. Distributed Soft Fault Detection for Interval Type-2 Fuzzy-Model-Based Stochastic Systems with Wireless Sensor Networks. IEEE Trans. Ind. Inform. 2019, 15, 334–347. [Google Scholar] [CrossRef]
- Arthi, M.; Arulmozhivarman, P. A Flexible and Cost-Effective Heterogeneous Network Deployment Scheme for Beyond 4G. Arab. J. Sci. Eng. 2016, 41, 5093–5109. [Google Scholar] [CrossRef]
- Masdari, M.; Özdemir, S. Towards Coverage-Aware Fuzzy Logic-Based Faulty Node Detection in Heterogeneous Wireless Sensor Networks. Wirel. Pers. Commun. 2020, 111, 581–610. [Google Scholar] [CrossRef]
- Chanak, P. Green fault detection scheme for IoT-enabled wireless sensor networks. Int. J. Commun. Syst. 2020, 33, e4611. [Google Scholar] [CrossRef]
- Liu, Y.; Pang, Z.; Karlsson, M.; Gong, S. Anomaly detection based on machine learning in IoT-based vertical plant wall for indoor climate control. Build. Environ. 2020, 183, 107212. [Google Scholar] [CrossRef]
- Rassam, M.A.; Zainal, A.; Maarof, M.A. An Efficient Distributed Anomaly Detection Model for Wireless Sensor Networks. AASRI Procedia 2013, 5, 9–14. [Google Scholar] [CrossRef]
- Ghorbel, O.; Abid, M.; Snoussi, H. Kernel principal subspace based outlier detection method in wireless sensor networks. In Proceedings of the 2014 IEEE 28th International Conference on Advanced Information Networking and Applications Workshops, IEEE WAINA 2014, Victoria, BC, Canada, 13–16 May 2014; pp. 737–742. [Google Scholar] [CrossRef]
- Ghorbel, O.; Abid, M.; Snoussi, H. Improved KPCA for outlier detection in Wireless Sensor Networks. In Proceedings of the 2014 1st International Conference on Advanced Technologies for Signal and Image Processing, ATSIP 2014, Sousse, Tunisia, 17–19 March 2014; pp. 507–511. [Google Scholar] [CrossRef]
- Ghorbel, O.; Ayedi, W.; Snoussi, H.; Abid, M. Fast and efficient outlier detection method in wireless sensor networks. IEEE Sens. J. 2015, 15, 3403–3411. [Google Scholar] [CrossRef]
- Rajasegarar, S.; Leckie, C.; Palaniswami, M.; Bezdek, J.C. Distributed anomaly detection in wireless sensor networks. In Proceedings of the 2006 10th IEEE Singapore International Conference on Communication Systems, Singapore, 30 October–1 November 2006. [Google Scholar] [CrossRef]
- Xu, S.; Hu, C.; Wang, L.; Zhang, G. Support Vector Machines based on K Nearest WSNs. In Proceedings of the 2012 8th International Conference on Wireless Communications, Networking and Mobile Computing (WiCOM), Shanghai, China, 21–23 September 2012; pp. 12–15. [Google Scholar]
- Hong, D.; Zhao, D.; Zhang, Y. The Entropy and PCA Based Anomaly Prediction in Data Streams. Procedia Comput. Sci. 2016, 96, 139–146. [Google Scholar] [CrossRef] [Green Version]
- Yu, T.; Wang, X.; Shami, A. Recursive Principal Component Analysis-Based Data Outlier Detection and Sensor Data Aggregation in IoT Systems. IEEE Internet Things J. 2017, 4, 2207–2216. [Google Scholar] [CrossRef]
- Saeedi Emadi, H.; Mazinani, S.M. A novel anomaly detection algorithm using DBSCAN and SVM in wireless sensor networks. Wirel. Pers. Commun. 2018, 98, 2025–2035. [Google Scholar] [CrossRef]
- Zidi, S.; Moulahi, T.; Alaya, B. Fault detection in wireless sensor networks through SVM classifier. IEEE Sens. J. 2018, 18, 340–347. [Google Scholar] [CrossRef]
- Spanos, G.; Giannoutakis, K.M.; Votis, K.; Tzovaras, D. Combining statistical and machine learning techniques in IoT anomaly detection for smart homes. In Proceedings of the IEEE International Workshop on Computer Aided Modeling and Design of Communication Links and Networks, CAMAD, Limassol, Cyprus, 11–13 September 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Shukla, R.M.; Sengupta, S. Scalable and Robust Outlier Detector using Hierarchical Clustering and Long Short-Term Memory (LSTM) Neural Network for the Internet of Things. Internet Things 2020, 9, 100167. [Google Scholar] [CrossRef]
- De Vita, F.; Bruneo, D.; Das, S.K. A novel data collection framework for telemetry and anomaly detection in industrial iot systems. In Proceedings of the 5th ACM/IEEE Conference on Internet of Things Design and Implementation, IoTDI 2020, Sydney, NSW, Australia, 21–24 April 2020; pp. 245–251. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Surveys | Categories Number | Technique Type | Outlier Detection for WSN | Outlier Detection for IoT | Outlier Detection for General Fields | Comparative Study of All Categories | Pros/Cons | Related Works Discussion |
|---|---|---|---|---|---|---|---|---|
| Our Work | 7 | all | ✓ | ✓ | - | ✓ | ✓ | ✓ |
| [1] 2020 | 5 | partially | - | ✓ | - | - | partially | partially |
| [11] 2009 | 6 | partially | - | - | ✓ | - | ✓ | ✓ |
| [17] 2010 | 5 | partially | ✓ | - | - | partially | partially | partially |
| [22] 2017 | 6 | all | ✓ | - | - | partially | ✓ | ✓ |
| [23] 2020 | 4 | machine learning | - | ✓ | - | partially | partially | partially |
| [24] 2018 | 4 | machine learning | ✓ | - | - | partially | partially | ✓ |
| [25] 2019 | 5 | machine learning | ✓ | ✓ | - | partially | - | partially |
| [26] 2019 | 6 | outlier detection progress | - | - | ✓ | partially | ✓ | ✓ |
| Work and Year | Contribution Key Words | Nature of Data | Approach | Suitable for | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Online | Offline | Distributed | Centralized | Univariate | Multivariate | Supervised | Unsupervised | Correlation S/T | Outlier Detection | Event Detection | ||||
| [30] 2012 | z-test, neighbouring coordination | Simulation | ✓ | x | ✓ | x | ✓ | x | x | ✓ | x | ✓ | x | WSN |
| [31] 2012 | TSOD, ARMA model | Experiments on real data | ✓ | x | ✓ | x | ✓ | x | ✓ | x | ✓ | ✓ | ✓ | WSN |
| [32] 2012 | Histogram | Experiments on real data | ✓ | x | ✓ | x | ✓ | x | x | ✓ | x | ✓ | x | WSN |
| [33] 2015 | AKDE–kernel, PDF | Experiments on real and synthetic data | ✓ | x | - | - | ✓ | x | x | ✓ | x | ✓ | x | Streaming data |
| [34] 2015 | ARMA model | radar’s health observations | ✓ | x | x | ✓ | ✓ | x | ✓ | x | x | ✓ | x | - |
| [35] 2018 | 4 Statistical models: CART, RF, GBM, LDA | Simulation on real collected data | x | ✓ | x | ✓ | ✓ | x | ✓ | × | ✓ | ✓ | ✓ | IoT |
| Work and Year | Contribution Key Words | Nature of Data | Approach | Suitable for | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Online | Offline | Distributed | Centralized | Univariate | Multivariate | Supervised | Unsupervised | Correlation S/T | Outlier Detection | Event Detection | ||||
| [36] 2013 | K-means | Experiments on real and synthetic data | - | - | - | - | x | ✓ | x | ✓ | x | ✓ | x | - |
| [37] 2015 | K-means, Bigdata, Hadoop, Mahout, MapReduce | Implement on Real data | x | ✓ | - | - | - | - | x | ✓ | x | ✓ | x | IoT Big Data |
| [40] 2015 | Cluster-based K-means, Distance-based, Euclidean distance | Simulation on R | x | ✓ | - | - | ✓ | x | x | ✓ | x | ✓ | x | - |
| [39] 2015 | RDD-DBSCAN | Synthetic data set | - | - | ✓ | x | ✓ | x | x | ✓ | x | ✓ | x | - |
| [41] 2016 | Clustering LOF | Experiments on real data | ✓ | x | ✓ | x | x | ✓ | x | ✓ | x | ✓ | x | Big Data |
| [43] 2016 | DBSCAN, Soft sensor modeling | Experiments on real data | - | - | - | - | ✓ | x | x | ✓ | x | ✓ | x | Time Series Data |
| [44] 2016 | KL divergence, Kernel density function | Experiments on real data | ✓ | x | ✓ | x | x | ✓ | x | ✓ | x | ✓ | x | WSN |
| [46] 2017 | DBSCAN | Experiments on real and synthetic data | ✓ | x | ✓ | - | ✓ | x | x | ✓ | x | ✓ | x | WSN |
| [45] 2017 | Clustering, ENOF, Fog computing | Experiments on real and synthetic data | ✓ | x | x | x | x | ✓ | x | ✓ | x | ✓ | x | IoT |
| [47] 2017 | Clustering | Experiments on real and synthetic data | - | - | - | - | x | ✓ | x | ✓ | x | ✓ | x | Big Data |
| [48] 2017 | K-means, KMOR | Experiments on real and synthetic data | - | - | - | - | x | ✓ | x | ✓ | x | ✓ | x | - |
| [49] 2018 | Birch Clustering, RC, Fog computing, Air quality monitoring | Antwerp’s City of Things testbed | - | - | x | x | x | ✓ | x | ✓ | x | ✓ | x | IoT |
| [50] 2020 | NRDD-DBSCAN | synthetic data set | - | - | ✓ | x | x | ✓ | x | ✓ | x | ✓ | x | IoT |
| Work and Year | Contribution Key Words | Nature of Data | Approach | Suitable for | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Online | Offline | Distributed | Centralized | Univariate | Multivariate | Supervised | Unsupervised | Correlation S/T | Outlier Detection | Event Detection | ||||
| [51] 2009 | neighbour-based sliding window, monitoring | Experiments on real and synthetic data | - | - | - | - | x | ✓ | x | ✓ | x | ✓ | x | Streaming Data |
| [52] 2011 | MCOD Sliding window | Experiments on real and synthetic data | - | - | - | - | ✓ | x | x | ✓ | x | ✓ | x | Streaming Data |
| [53] 2014 | KNN-LEAP | Experiments on real streaming datasets | - | - | - | - | x | ✓ | x | ✓ | x | ✓ | x | Streaming Data |
| [54] 2016 | DNOD | Experiments on real and synthetic data | x | ✓ | - | - | ✓ | x | x | ✓ | x | ✓ | x | WSN |
| [55] 2017 | RDOS, KDE | Experiments on real and synthetic data | - | - | - | - | ✓ | x | x | ✓ | x | ✓ | x | - |
| [56] 2017 | neighbourhood information | Experiments on real data | ✓ | x | ✓ | x | x | ✓ | x | ✓ | ✓ | ✓ | ✓ | WSN |
| [57] 2020 | GAAOD, neighbour-based | Experiments on real data | - | - | - | - | x | ✓ | x | ✓ | x | ✓ | x | IoT |
| Work and Year | Contribution Key Words | Nature of Data | Approach | Suitable for | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Online | Offline | Distributed | Centralized | Univariate | Multivariate | Supervised | Unsupervised | Correlation S/T | Outlier Detection | Event Detection | ||||
| [58] 2009 | OCSVM | Experiments on real and synthetic data | ✓ | x | ✓ | x | - | - | x | ✓ | ✓ | ✓ | x | WSN |
| [59] 2010 | QSSVM | Experiments on real and synthetic data | x | ✓ | ✓ | x | x | ✓ | x | ✓ | x | ✓ | x | WSN |
| [60] 2012 | STA-QS-SVM | Experiments on synthetic data | ✓ | x | ✓ | x | x | ✓ | x | ✓ | ✓ | ✓ | ✓ | WSN |
| [61] 2013 | hyper-ellipsoid OCSVM | Experiments on real and synthetic data | ✓ | x | ✓ | x | x | ✓ | x | ✓ | ✓ | ✓ | x | WSN |
| [62] 2014 | ENOF | Experiments on real and synthetic data | - | - | ✓ | x | x | ✓ | - | - | x | ✓ | x | WSN |
| [63] 2015 | Bayesian | Experiments on real and synthetic data | ✓ | x | ✓ | x | - | - | ✓ | x | - | ✓ | x | WSN |
| [64] 2015 | Bayesian | Simulation | - | - | ✓ | x | ✓ | x | ✓ | x | x | ✓ | x | WSN |
| [66] 2016 | LS-OC-SVM | Experiments on two dimensions synthetic data | ✓ | x | - | - | ✓ | x | x | ✓ | x | ✓ | x | Power Grid Sensor Data |
| [67] 2018 | TED-OCSVM, Monitoring | Experiments on real data and simulation data | x | ✓ | x | ✓ | - | - | ✓ | x | ✓ | ✓ | x | IWSN |
| [68] 2019 | OCSTuM, GA-OCSTuM | Experiments on real data | x | ✓ | x | ✓ | x | ✓ | x | ✓ | x | ✓ | x | IoT Big Data |
| [69] 2019 | DODS, Bayesian classifier | Experiments on real and synthetic data | x | ✓ | ✓ | x | ✓ | x | ✓ | x | T | ✓ | x | WSN |
| Work and Year | Contribution Key Words | Nature of Data | Approach | Suitable for | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Online | Offline | Distributed | Centralized | Univariate | Multivariate | Supervised | Unsupervised | Correlation S/T | Outlier Detection | Event Detection | ||||
| [72] 2012 | FKBC, clustering framework | Simulation | - | - | x | ✓ | ✓ | x | - | - | x | ✓ | x | WSN |
| [73] 2017 | HFD, PNN | Simulation and testbed experiments | x | ✓ | x | ✓ | ✓ | x | - | - | x | ✓ | × | WSN |
| [24] 2018 | Bayesian Belief Network, COMIS | Simulation | - | - | - | - | - | - | ✓ | x | x | ✓ | x | WSN |
| [75] 2018 | Autoencoder Neural Network | Experiments on WSN testbed | - | - | ✓ | x | ✓ | x | x | ✓ | x | ✓ | x | IoT-WSN |
| [76] 2019 | IT2 T-S fuzzy models | Simulation on truck-trailer system | - | - | ✓ | x | ✓ | x | - | - | x | ✓ | x | WSN |
| [20] 2019 | FIS, fuzzy rules | Simulation | - | - | x | ✓ | ✓ | x | - | - | x | ✓ | x | IoT-WSN |
| [78] 2020 | DFLFND, FLC | Simulation | - | - | ✓ | x | ✓ | x | - | - | ✓ | ✓ | ✓ | WSN |
| [79] 2020 | Vague set Fuzzy logic | Simulation | - | - | ✓ | x | ✓ | x | - | - | x | ✓ | x | IoT-WSN |
| [80] 2020 | Autoencoder, LSTM | Simulation | ✓ | x | - | - | ✓ | x | x | ✓ | x | ✓ | x | IoT |
| Work and Year | Contribution Key Words | Nature of Data | Approach | Suitable for | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Online | Offline | Distributed | Centralized | Univariate | Multivariate | Supervised | Unsupervised | Correlation S/T | Outlier Detection | Event Detection | ||||
| [81] 2013 | PCA | Experiments on real data | ✓ | x | ✓ | x | ✓ | x | x | ✓ | x | ✓ | x | WSN |
| [84] 2015 | KPCA, MD, RE | Experimental on real data | x | ✓ | x | ✓ | x | ✓ | x | ✓ | x | ✓ | x | WSN |
| Work and Year | Contribution Key Words | Nature of Data | Approach | Suitable for | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Online | Offline | Distributed | Centralized | Univariate | Multivariate | Supervised | Unsupervised | Correlation S/T | Outlier Detection | Event Detection | ||||
| [85] 2006 | DAD, K-NN, Clustering | Simulation based on real data | x | ✓ | ✓ | x | x | ✓ | x | ✓ | T | ✓ | x | WSN |
| [86] 2012 | KNN, SVM, Incident monitoring | Experiments on real data | x | ✓ | x | ✓ | x | ✓ | x | ✓ | ✓ | ✓ | x | WSN |
| [70] 2013 | K-NN, Clustering | Experiments on real data | x | ✓ | ✓ | x | ✓ | x | x | ✓ | ✓ | ✓ | ✓ | WSN |
| [87] 2016 | PCA, information entropy theory support vector regression | Experiments on real data | x | ✓ | - | - | x | ✓ | ✓ | x | x | ✓ | x | Streaming data |
| [88] 2017 | RPCA, K-means | Experiments on real data | - | ✓ | x | ✓ | x | ✓ | x | ✓ | S | ✓ | x | IoT |
| [90] 2018 | Statistical learning, SVM based on Kernel function | Experiments on real data | - | - | x | ✓ | x | ✓ | ✓ | x | x | ✓ | x | WSN |
| [89] 2018 | DBSCAN, SVM | Experiments on real data | x | ✓ | x | ✓ | x | ✓ | x | ✓ | x | ✓ | × | WSN |
| [91] 2019 | statistic, machine learning | Real smart home dataset | - | - | x | ✓ | - | - | ✓ | x | x | ✓ | x | IoT |
| [92] 2020 | Hierarchical clustering, LSTM Neural Network, M-estimators | Experiments on real data | (Step 2) | (Step 1) | x | ✓ | ✓ | x | x | ✓ | x | ✓ | x | IoT |
| [93] 2020 | Deep learning, Neural Networks, PCA, K-means | Industrial S4T framework created data and synthetic data | - | - | x | ✓ | ✓ | x | x | ✓ | x | ✓ | x | IoT |
| Technique | Pros | Cons |
|---|---|---|
| Statistical Based |
|
|
| Clustering Based |
|
|
| Nearest neighbour Based |
|
|
| Classification Based |
|
|
| Artificial Intelligent Based |
|
|
| PCA Based |
|
|
| Hybrid Based |
|
|
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Samara, M.A.; Bennis, I.; Abouaissa, A.; Lorenz, P. A Survey of Outlier Detection Techniques in IoT: Review and Classification. J. Sens. Actuator Netw. 2022, 11, 4. https://doi.org/10.3390/jsan11010004
Samara MA, Bennis I, Abouaissa A, Lorenz P. A Survey of Outlier Detection Techniques in IoT: Review and Classification. Journal of Sensor and Actuator Networks. 2022; 11(1):4. https://doi.org/10.3390/jsan11010004
Chicago/Turabian StyleSamara, Mustafa Al, Ismail Bennis, Abdelhafid Abouaissa, and Pascal Lorenz. 2022. "A Survey of Outlier Detection Techniques in IoT: Review and Classification" Journal of Sensor and Actuator Networks 11, no. 1: 4. https://doi.org/10.3390/jsan11010004
APA StyleSamara, M. A., Bennis, I., Abouaissa, A., & Lorenz, P. (2022). A Survey of Outlier Detection Techniques in IoT: Review and Classification. Journal of Sensor and Actuator Networks, 11(1), 4. https://doi.org/10.3390/jsan11010004