2.1. Active and Passive Sensing
Even though extensive research has been carried out on automatic road damage recognition, the majority has focused on potholes since they are the worst structural failures on roads. No road surface is purely impermeable, and moisture, in addition to overloaded vehicles and a lack of maintenance, is the main cause of pothole formation. Current research on pothole detection algorithms can be clustered into three groups: 2D vision based [
6,
7,
8,
9,
10,
11,
12,
13,
14], 3D reconstruction based [
6,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25], and IoT based [
26,
27,
28,
29]. Usually, this last group proposes to fit Internet of Things (IoT) sensors (accelerometer, gyroscope, and GPS sensors) onto citizens’ vehicles to map surface irregularities while driving. Nevertheless, the IoT strategy was initially discarded for this work not only because it requires tracking users continuously, but also because it was proven to cause many false positives due to bumps, train tracks, or trash [
7]. Due to privacy concerns, more research may be needed to collect pothole information with this approach.
Three-dimensional reconstruction for road surface modelling is the main technique applied by private companies that offer road monitoring services [
30]. Two major sensing modalities are used in 3D reconstruction for road modelling, namely active sensing with RGB-D cameras [
15,
16], LiDAR sensors [
17], or laser scanners [
6,
18], and passive sensing with two or more synchronised stereo vision cameras [
19,
20,
21,
22,
23,
24,
25]. A major problem of active sensing is that a shortage of funding can make it inaccessible to low-income governments. Although there have been significant attempts to make active sensing accessible to the public using affordable devices such as Microsoft Kinect, these devices do not work outdoors or under sunlight. To cope with these problems, the researchers in [
16] proposed to use four Kinect sensors inside a closed box heading to the ground in order to detect road anomalies. Furthermore, the authors in [
18] posed the combination of a single camera and a laser pointer to reconstruct potholes by recognising the light patterns; however, this strategy is not effective in wet conditions [
7].
In contrast with active sensing, 3D reconstruction based on passive sensing benefits from lower costs and greater accessibility. The main passive sensing technology is stereo vision, which can be implemented in road condition assessment using two regular cameras aligned at the same height, calibrated with a chessboard, and pointed at the surface. Then, both input images can be compared to estimate the depth or distance per pixel in the scene. The result, also known as a disparity map, can be compared later with the disparity map of a regular road surface to find potential anomalies [
7]. Even though the authors in [
20,
21] proposed new techniques to more accurately calculate the disparity between normal and irregular surfaces, these approaches would be severely affected by the road surface variability present in unstructured urban environments where streets are not well delineated and maintained. In addition, stereo vision also demands detecting matching points and extrinsic/intrinsic parameters frequently for accurate alignment and calibration, which might require expert knowledge to use the tool. Although the authors in [
19,
20,
21,
22,
23,
24,
25] highlighted that stereo vision is not affected by illumination changes and is more accurate when volume/distance measurements are needed, its major drawback is that it is not widely available. Thus, this approach would limit public engagement for crowdsourcing for road data collection.
This review led us to focus on 2D vision methods, whose data can be collected by digital cameras, mobile devices, and embedded systems. Furthermore, this type of data is predominantly present in the pothole reporting systems listed in
Table 1. Due to the ever-increasing availability of embedded cameras, many studies have focused on real-time pothole avoidance for autonomous and conventional vehicles [
10,
11], while others have prioritised offline automatic analysis for maintenance optimisation [
8]. Two groups of 2D vision-based strategies can be clearly recognised in this research thread [
7]: image processing and feature extraction techniques for road distress segmentation and deep learning for automatic pothole detection. The former commonly enhances images using point processing and image filtering techniques and then applies classical thresholding algorithms such as Otsu’s method [
12,
13] or watershed segmentation [
13]. In contrast, the latter leverages the recent progress of deep neural networks to obtain better generalisation than overly elaborate processing pipelines [
7]. For example, the researchers in [
7] compared the results of stereo-vision-based techniques with deep-learning-based models, and they found that fine-tuning Mask-RCNN and YOLOv2 with the CIMAT Challenging Sequences for Autonomous Driving dataset (CCSAD) [
31] could be used to detect potholes under very challenging weather conditions, whereas stereo vision failed in this attempt.
2.2. Deep-Learning-Based Road Assessment
Several comprehensive studies have covered the application of deep neural networks for pothole detection. For instance, the authors in [
10] collected and annotated images of real-world scenes and fine-tuned various object detection models. An average precision of 82% using a combination of R-CNN and Resnet101 ended up being their best experiment. In 2020, Silva et al. [
14] proposed the use of YOLOv4 for pothole detection from images taken by a drone, where the model achieved a promising accuracy of 95%. Furthermore, the authors in [
11] presented the implementation of YOLOv3 for geolocated potholes in 330 images sampled in Malaysia. These and other papers showed that learning methods to address the pothole detection problem have become the norm currently. Nonetheless, progress in the development of methods for locating and classifying different types of road defects remain slower, as a consequence of the lack of large public datasets.
By 2016, some research centres collected and published large street image datasets such as KITTI [
32] (2013) and CityScapes [
33] (2016). Nevertheless, the majority of samples was collected in well-structured street scenarios where drivers, as well as pedestrians behave in a predictable manner. In such scenarios, roads are well defined and properly maintained during the year. Since then, the advent of more powerful cameras embedded in mobile phones allowed access to low-cost outdoor data collection. For example, in 2018, researchers at the University of Tokyo [
34] presented a new road damage dataset (RDD) [
5], which was collected in many Japanese municipalities. Over the years, this dataset has become the biggest multi-country road damage dataset as new samples per damage category and from different cities were included.
The class distribution and current damage categories of the last version of RDD (as of October 2021) are summarised in
Table 2. In addition, the authors also launched three contests named the Global Road Damage Detection Challenge (2018, 2019, and 2020) that yielded compelling proposals for road damage localisation and classification [
34]. For instance, V. Hegde et al. [
35] won the last version of this contest by training an Ultralytics-YOLO (u-YOLO) model with data generated from the test time data augmentation method. Then, they applied non-maximum suppression to select the best bounding boxes and obtained an F1-score of 0.67. This paper motivated us to choose Ultralytics-YOLO, which evolved to become YOLOv5, to perform our experiments.
Table 2 reveals that the dataset is unbalanced and requires further work to equalise the number of damage instances per category. Furthermore, some state-of-the-art papers, which are listed in
Table 3, used the dataset and proposed models considering the most meaningful categories for better performance: D00, D10, D20, and D40. Apart from the works listed in
Table 3, the researchers in [
36] posited the application of YOLO with a dataset of 45,788 images that were collected in the streets of Shanghai with an industrial high-resolution camera for damage classification. This approach deviates from what is proposed in the current paper: analysing images taken by mid-range mobile phones. On the other hand, Reference [
37] proposed to use an algorithm to collect street images from Google Earth for road irregularity classification and localisation. Although the annotation process was the main constraint for taking advantage of this source, it would be a compelling strategy for future works.
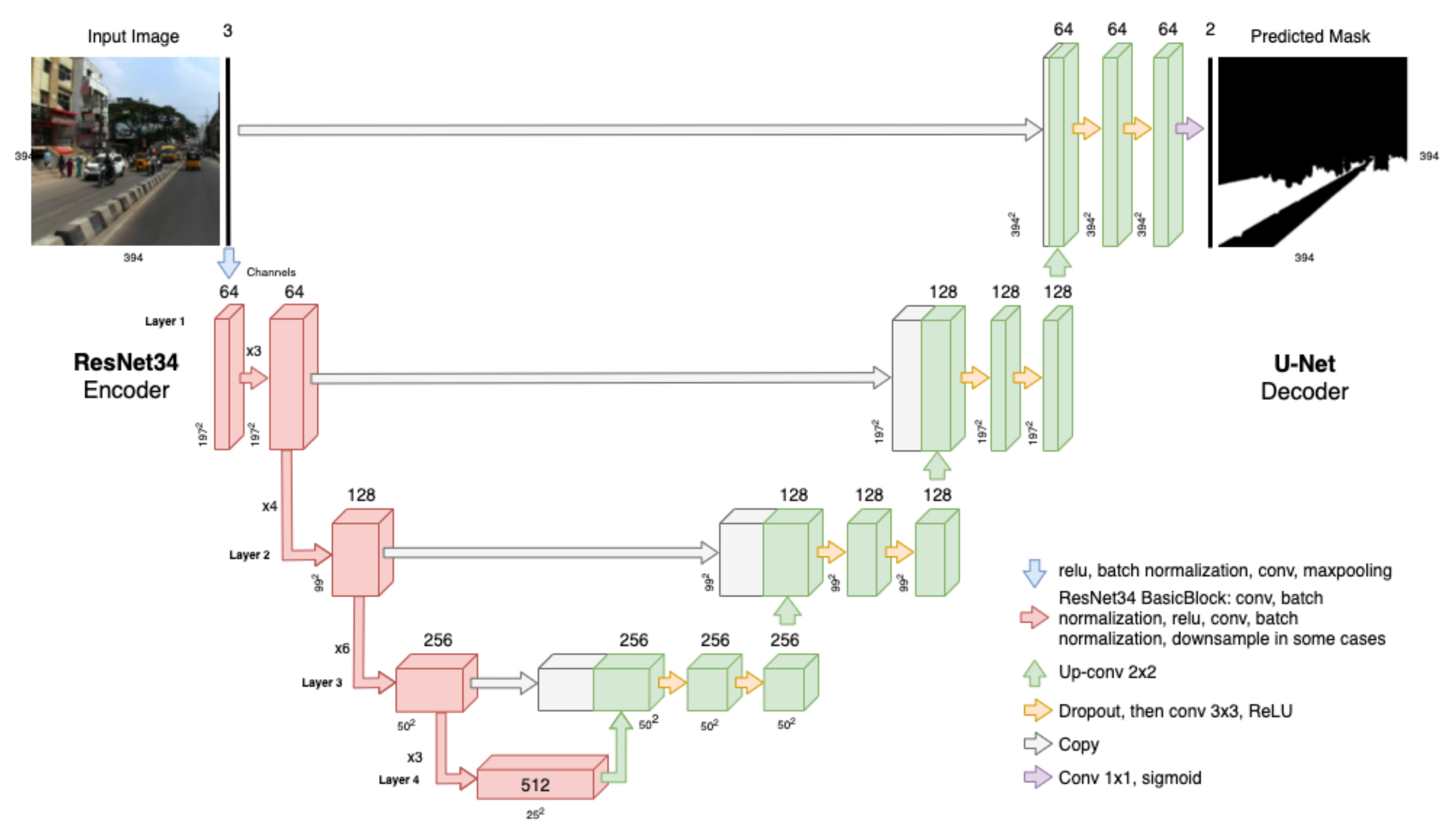
Although images with street scenes contain rich information, only parts with road segments are important for road damage analysis. Such segments would contribute later to finding potential duplicated or fake repair requests. Semantic segmentation is the task of labelling each pixel in an image with a single class such as lane, road, or traffic sign. The Indian Driving Dataset (IDD) [
4] is currently one of the biggest image collections with 16,062 unstructured urban images annotated for semantic segmentation tasks. Similar to the RDD dataset, researchers at IIIT Hyderabad, Intel Bangalore, and University of California San Diego created a dataset for autonomous navigation suitable for the needs of the Indian context. Later, they organised the AutoNUE 2019 and NCVPRIPG 2019 contests where the best teams achieved meaningful results. The first part of our methodology was inspired by the NCVPRIPG 2019 winners [
40], who proposed a transfer-learning-based architecture named Eff-UNet. This proposal combines EfficientNet as the encoder for feature extraction, with UNet as the decoder. Different from our problem, the NCVPRIPG 2019 organisers challenged the participants to use a subset of IDD, known as IDD Lite, in order to develop resource-constrained models. The proposal developed by [
40] managed to achieve a 0.7376 and 0.6276 mean Intersection over Union (mIoU) on the validation and test subsets, respectively.
2.3. Road Maintenance Prioritisation
The management and optimisation of road maintenance based on computational modelling is not a recent approach and dates back at least to the 1980s, when road information computer systems were available [
41]. Since then, many maintenance systems have been proposed to optimise how resources are located from a series of financial, location, social, and political perspectives. For instance, in 2018, Ma et al. [
42] introduced a dynamic programming method to minimise the traffic caused by road maintenance in cities. The method was capable of identifying the best combination of roads to be maintained at the same time and considered the available resources, the vehicle fluency per street, and the travel time to go through them. A similar research problem was investigated by Ankang et al. [
43] in 2020, who presented the application of particle swarm optimisation and Markov chains to predict the pavement post-conditions after simulating multiple maintenance strategies. Consequently, the approach was able to find the optimal strategy while meeting multiple constraints.
Different from the optimisation strategies, clustering approaches can be applied to real scenarios when available data is unstructured or when the optimisation search space becomes high dimensional. Road damage clusters can provide meaningful information about the similitude among their samples. In the present paper, visual data attached to reports can provide factual information about road damages in an area and can notably help find clustering patterns. The researchers in [
44] considered this approach to cluster potholes and road distress sensed by moving vehicles with accelerometers. Given that these sensors can register false positives due to trash or mud, the proposal introduced a clustering algorithm to find true anomalies in multiple records. Even more sophisticated clustering algorithms were applied in [
45], where the authors combined georeferenced data on roads and crashes to identify streets that needed urgent, regular, or any maintenance.





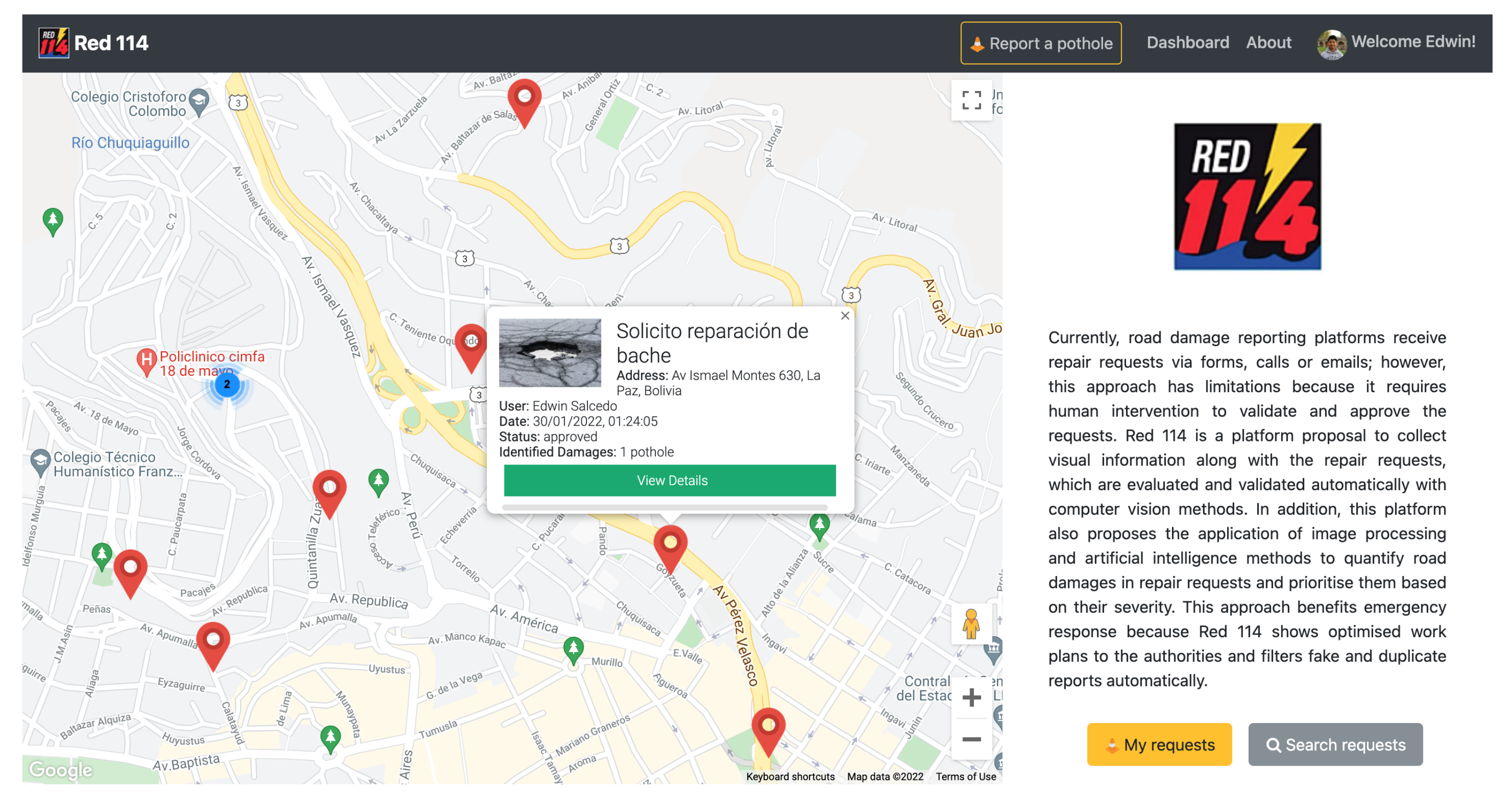


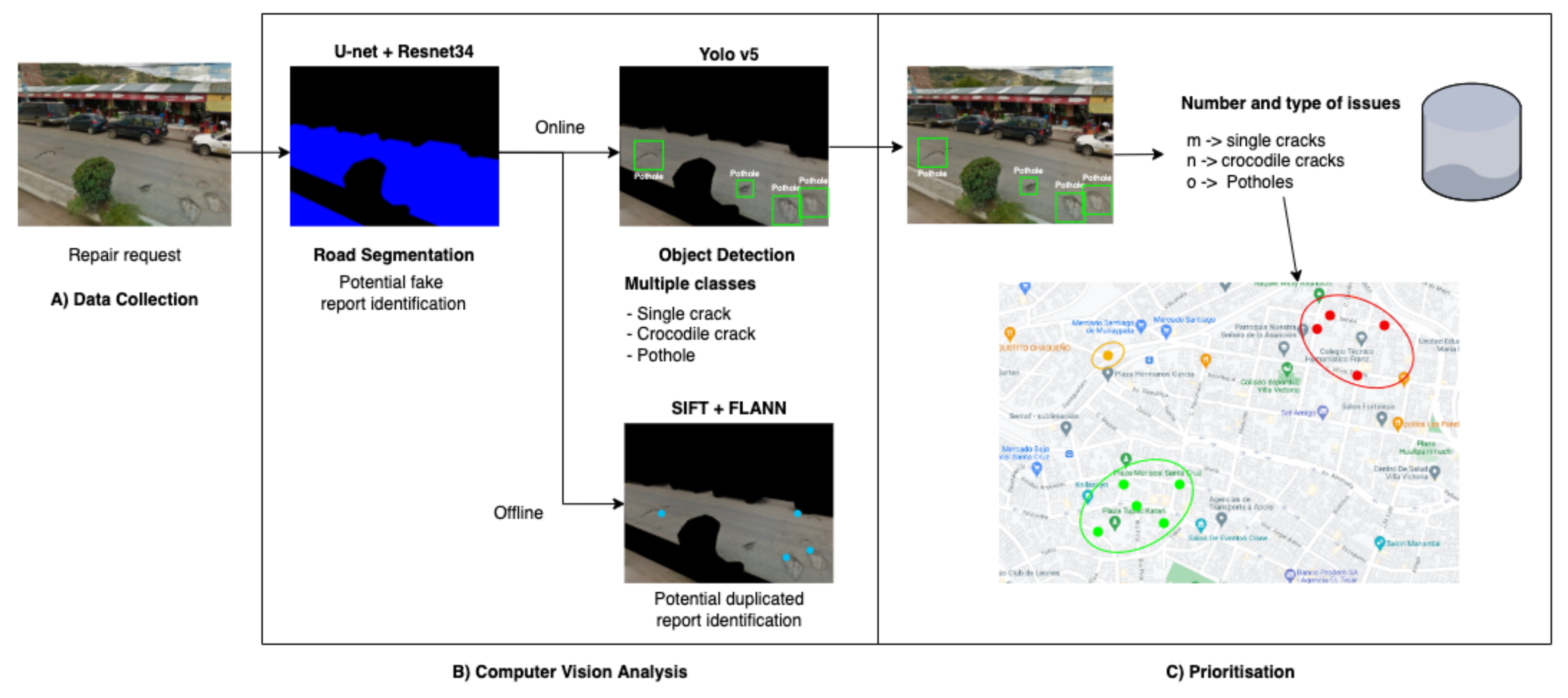



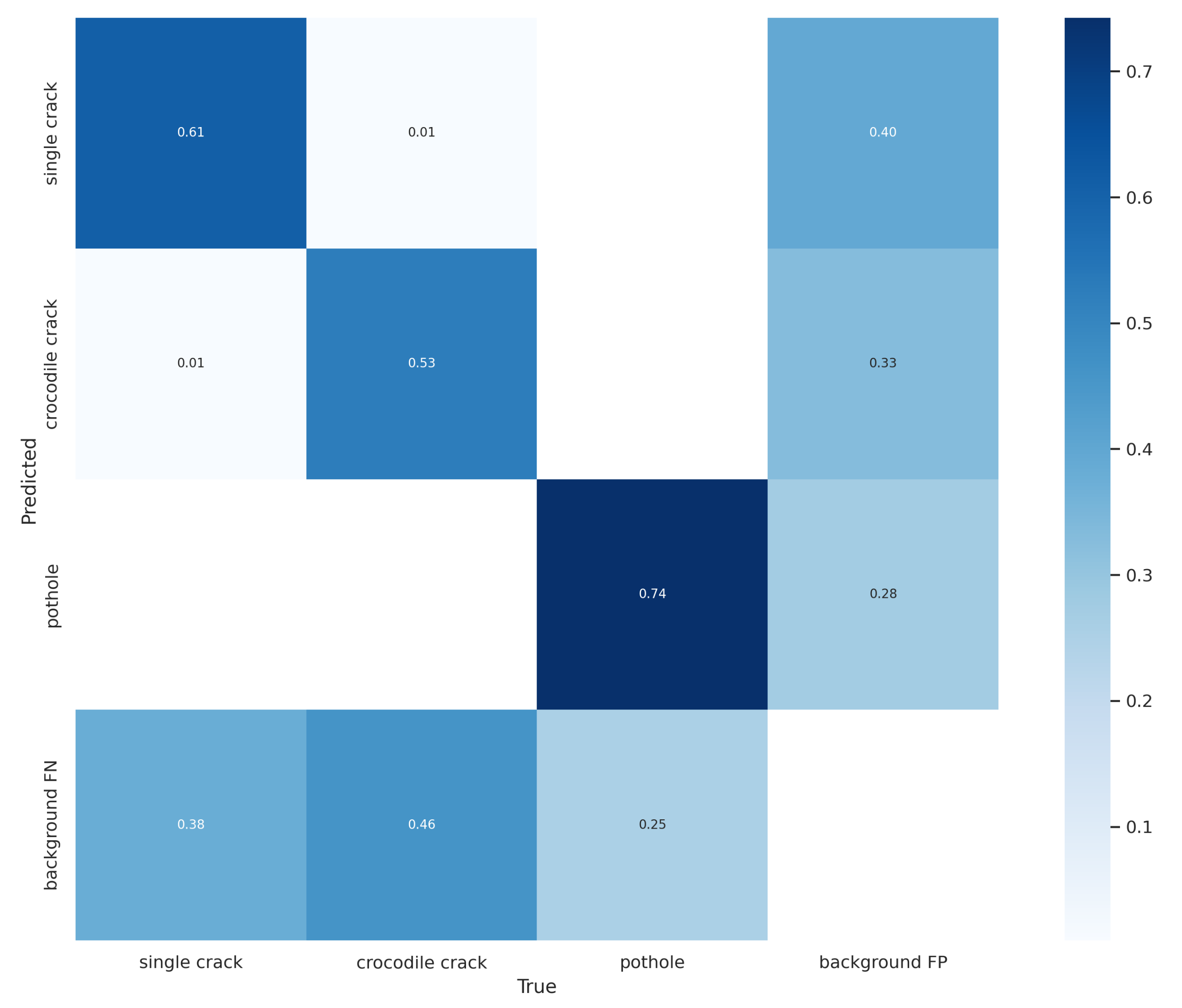



{kind=link}
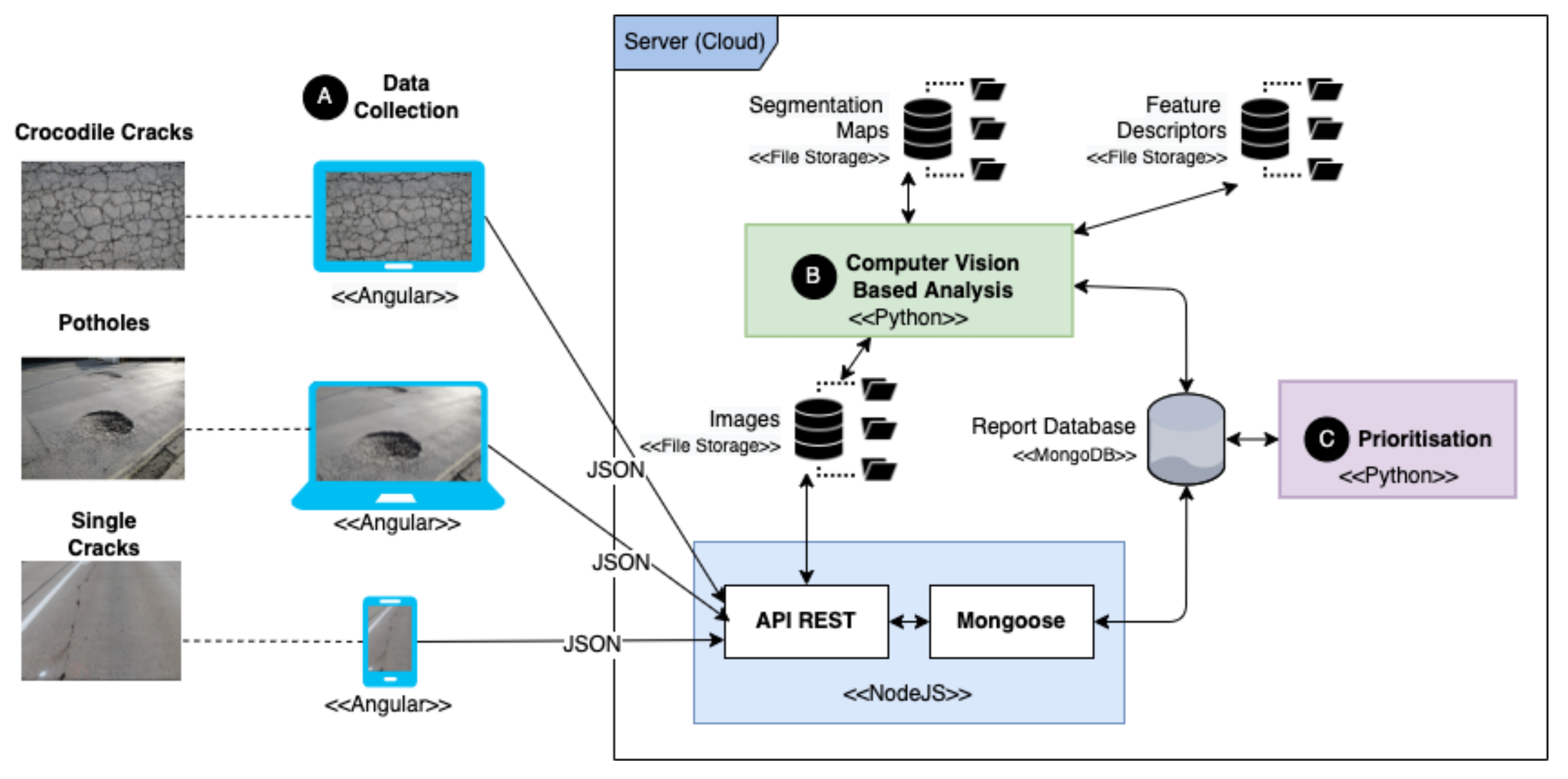{kind=link}
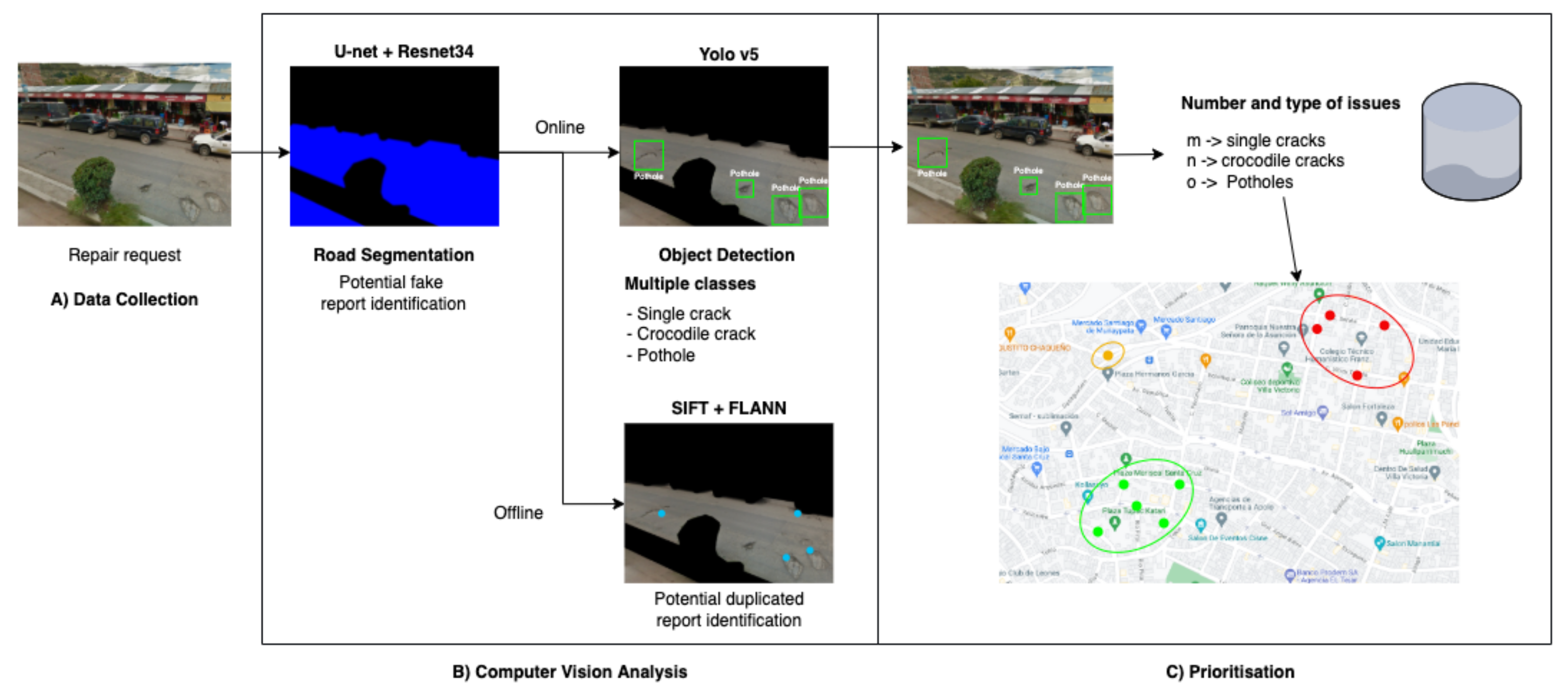{kind=link}
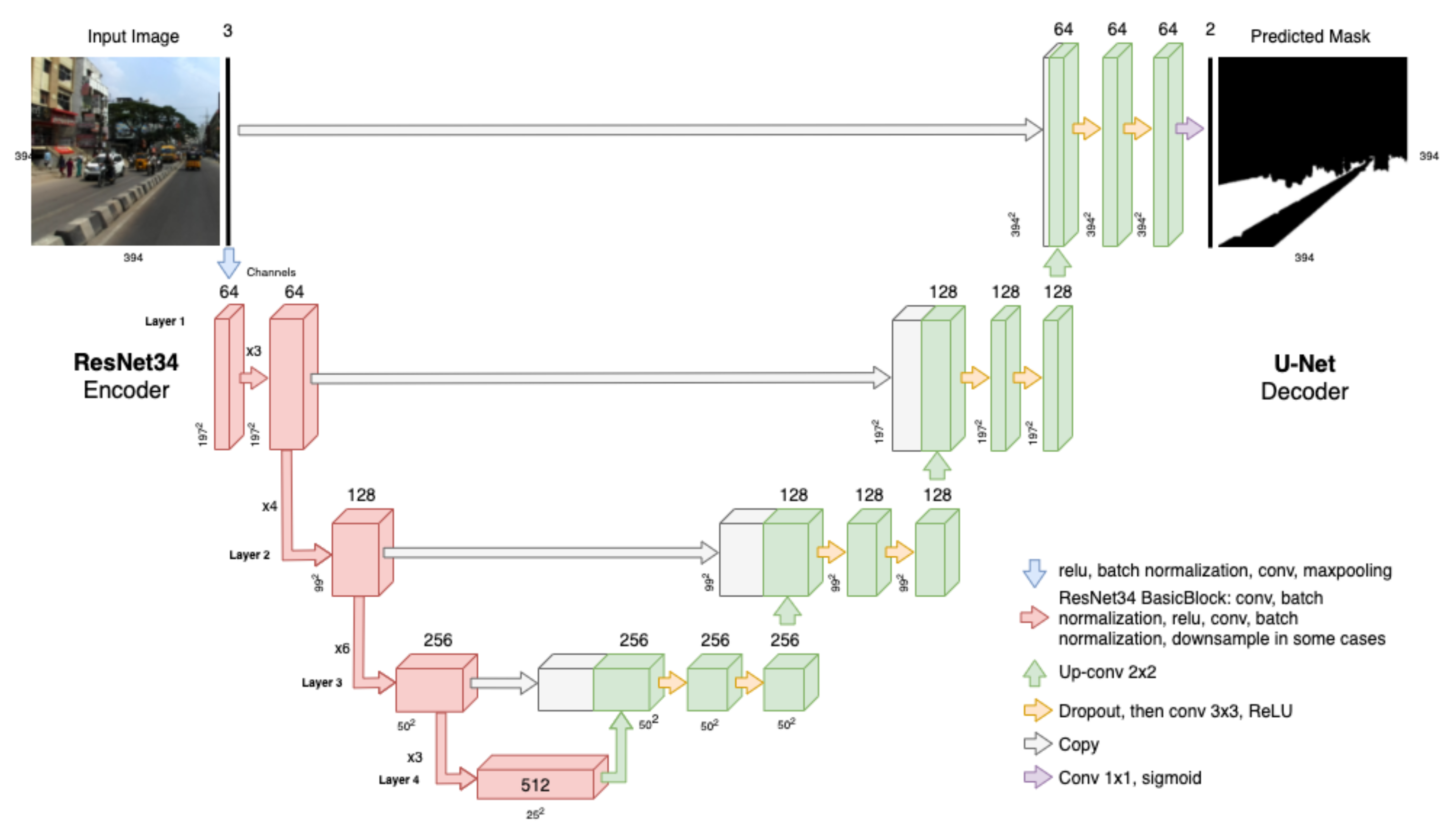{kind=link}
{kind=link}
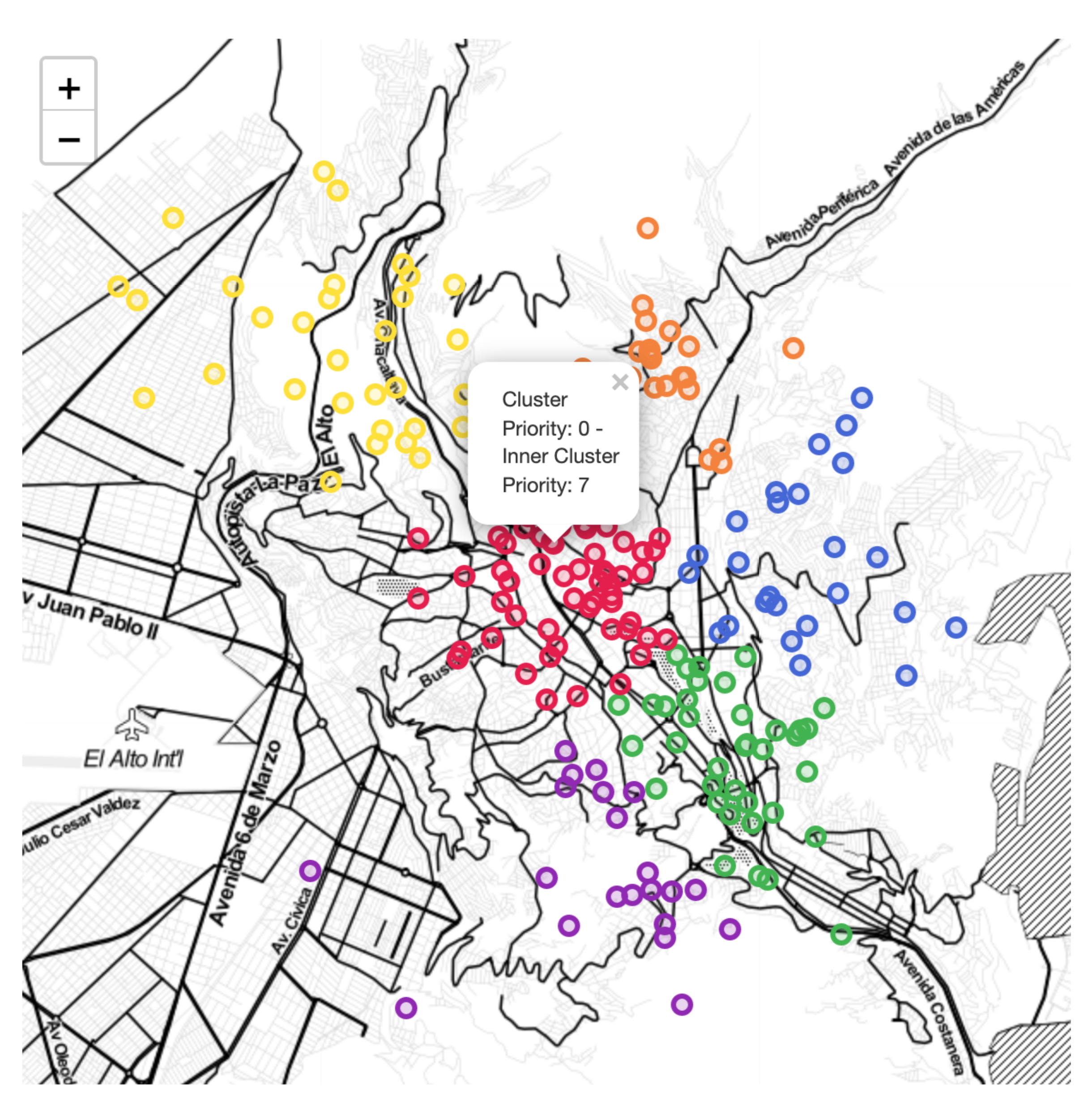{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}