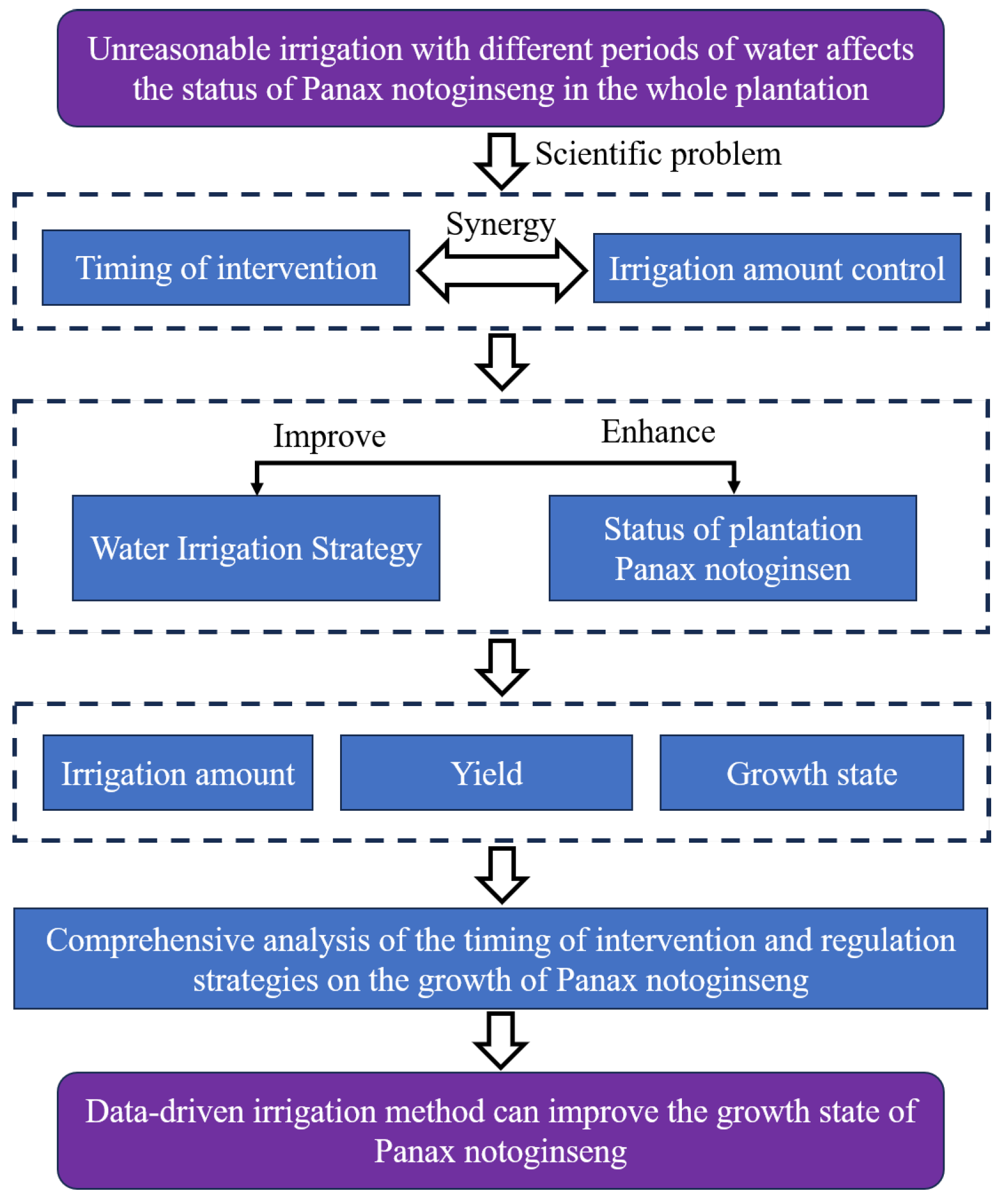
1. Introduction
To advance modern agriculture, China has implemented a series of policies aimed at supporting agricultural modernization [
1,
2]. These irrigation modernization policies play a crucial role in promoting sustainable strategies for developing countries [
3]. In recent years, many scholars have adopted deep-learning- or data-driven-based approaches to study various types of crops in order to improve the yield of crops. One of the keys to increasing crop yields is controlling the amount of water irrigated at the planting field [
4].
Moisture has an important effect on crop growth, and different amounts of irrigation are required at different growth stages to maintain crop health [
5]. In addition, different irrigation methods can have different effects on crops [
6]. In order to obtain the characteristics of soil irrigation systems, mobile platforms and data processing algorithms can be developed in conjunction with portable environmental sensors [
7]. What is more, the effective combination of deep learning and IoT can optimize the irrigation strategy of the planting site so as to increase the crop yield [
8,
9].
Many different crop-growth models have been developed based on different climatic conditions such as light and temperature [
10,
11]. These traditional approaches are knowledge based and estimate crop growth based on external factors [
12]. However, in modern agriculture, obtaining the right intervention time at the planting field is still faced with great challenges. This is why some scholars have started to study the growth trend of crops in order to increase the yield of crops in the planted field [
13]. In order to help the farmer find the right time to take action on their planting sites (irrigation, weeding, etc.), plant growth is predicted by neural networks, and this is used as a basis for farming strategies [
14]. By predicting the shape of future images of plants through a plant-growth prediction algorithm based on deep learning and spatial transformation, predicting the growth behavior of plants can help managers perform a timely intervention [
15]. But the process of plant growth and development is highly unstable in many aspects. For example, the spatial correlation or temporal dependence of localized pixel values in plant images are factors that seriously affect the accuracy of prediction [
16].
The extensive use of machine learning in agriculture, especially deep-learning methods, can predict crop status early and provide appropriate intervention measures [
17]. Predictive modeling that combines IoT with Long Short-Term Memory (LSTM) networks can effectively help farmers take timely protective measures for their crops [
18]. Early prediction and sensing of crop status ensures safety for subsequent planning and enables farmers to plan with comprehensive spatial and temporal information [
19]. The data decision scheme is conducive to the improvement of agricultural productivity and product quality [
20]. In modern agriculture, there are many models of crop growth of different types and in various environments, which include a variety of environmental factors along with human management factors [
21]. Since the growth of crops is affected by many external conditions, it is very challenging to predict the growth state of crops [
15].
In the study of agricultural irrigation strategies, traditional inefficient irrigation methods have been proven to significantly constrain crop yields [
22]. In recent years, the application of smart irrigation systems has provided new solutions for improving water-use efficiency [
23]. Research has shown that irrigation strategies optimized based on differential evolution algorithms can significantly enhance crop yields [
24]. Furthermore, by integrating the CERES-Wheat model with a non-dominated sorting genetic algorithm, not only has the optimization of irrigation strategies been achieved, but accurate prediction of crop yields has also been realized [
25]. Moreover, scholars have introduced an innovative Spatial Fuzzy Strategic Planning (SFSP) framework, integrating Multi-Criteria Decision-Making (MCDM) with a conceptual agricultural water-use model to systematically support sustainable agricultural water management strategies [
26].
However, these methods primarily optimize irrigation strategies based on soil moisture status, failing to adequately address the growth requirements of the crops themselves. To address this limitation, this study proposes a dynamic irrigation approach based on crop-growth status. By real-time monitoring of crop-growth conditions and adjusting irrigation schemes, this method achieves more precise and efficient irrigation management.
To validate this crop-centric strategy, we focus on Panax notoginseng, a high-value medicinal crop in China with documented pharmacological significance [
27,
28] that exhibits hypersensitive responses to soil moisture dynamics [
29]. To maximize yield and sustain commercial viability, optimized cultivation practices are critical. Recent advancements in greenhouse cultivation technology [
30] offer promising solutions for precise environmental control, particularly in managing critical growth parameters. This study therefore employs Panax notoginseng as a model crop to investigate how greenhouse-based interventions, specifically those integrating soil moisture regulation and controlled growing conditions, can enhance productivity while addressing the plant’s ecological constraints. The research aims to establish a framework for targeted agricultural management, ultimately supporting the sustainable development of this pharmaceutically valuable species.
In this paper, environmental data of the planting field and morphological data of the crop in a glass greenhouse are collected. Then, the data is combined with a proposed Informer–LSTM–EWMA approach to predict the growth trend of the crop. The trend prediction of Panax notoginseng enables the manager to be notified to take irrigation measures in advance. The proposed method has the following features:
Multi-source Data Fusion: Real-time collection of environmental data such as soil, temperature, and humidity through sensors, combined with IoT technology for precise perception.
Lifecycle Prediction and Optimization: Integration of historical and real-time data to predict the growth stages of Panax notoginseng using the Informer–LSTM–EWMA method, optimizing management strategies.
Irrigation optimization: An event-triggered irrigation strategy for water conservation and efficiency enhancement.
Here, we used the plant height of the entire experimental field during the growing period as the phenotype. The past environmental data and morphological data of the crop are used as inputs to predicate the future growth trend of the crop. The main contributions of this paper are as follows:
A distributed detection system for greenhouse environmental data acquisition collects various parameters and transmits them to the cloud via 4G for storage and display.
The Informer–LSTM–EWMA model is developed to predict Panax notoginseng growth trends, leveraging historical data to accurately forecast intervention timings, ensuring sufficient time for action.
This study optimizes intervention strategies based on an intervention timing prediction model and experimentally validates the significant effectiveness of this optimized approach in enhancing the yield of Panax notoginseng.
2. Materials
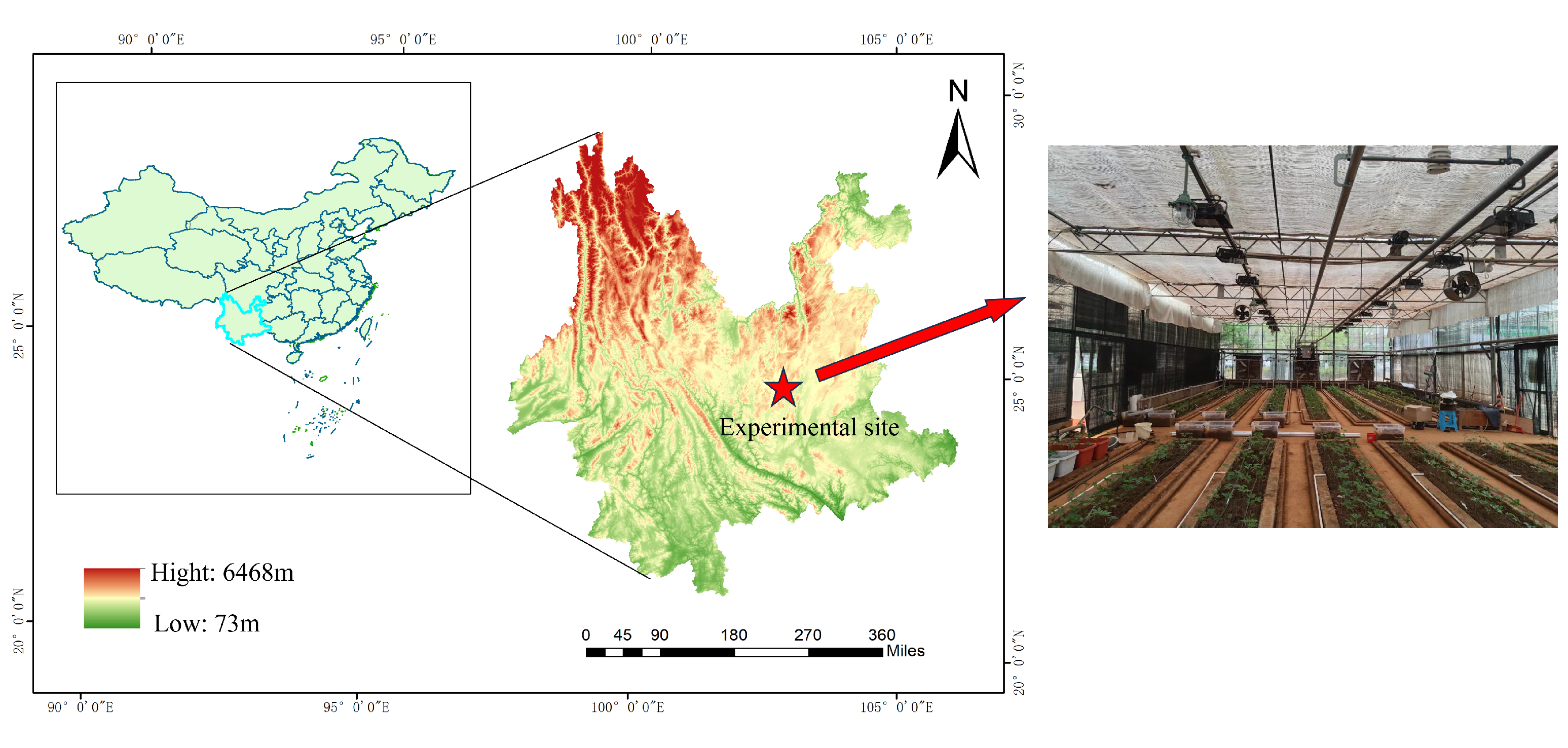
2.1. Description of the Experimental Field
Field experiments were conduct at the Tianyuan Panax notoginseng planting base of Kunming University of Science and Technology in Kunming City, Yunnan Province, China (latitude
N, longitude
E), from September 2023 to June 2024. The altitude of the experiment site is 2067 m. The location has a subtropical monsoon climate. The experimental site is shown in
Figure 1.
The experimental site is characterize by a spring-like climate throughout the year, classified as a plateau mountain monsoon climate. The monthly average temperature ranges from 3 °C to 27 °C, with an average high of 22 °C and an average low of 12 °C. The annual average rainfall is 797.5 mm. The month with the highest relative humidity is July (
), while the month with the lowest relative humidity is March (
). The annual evaporation is between 1200 and 1500 mm. Each experimental field is a separate concrete recess, and the experimental fields did not interfere with one another. The transpiration rates of the crops are shown in
Table 1. Because the experimental fields are set in a glass greenhouse (as seen in the right of
Figure 1), the interference of the external environment to the shed can be ignored.
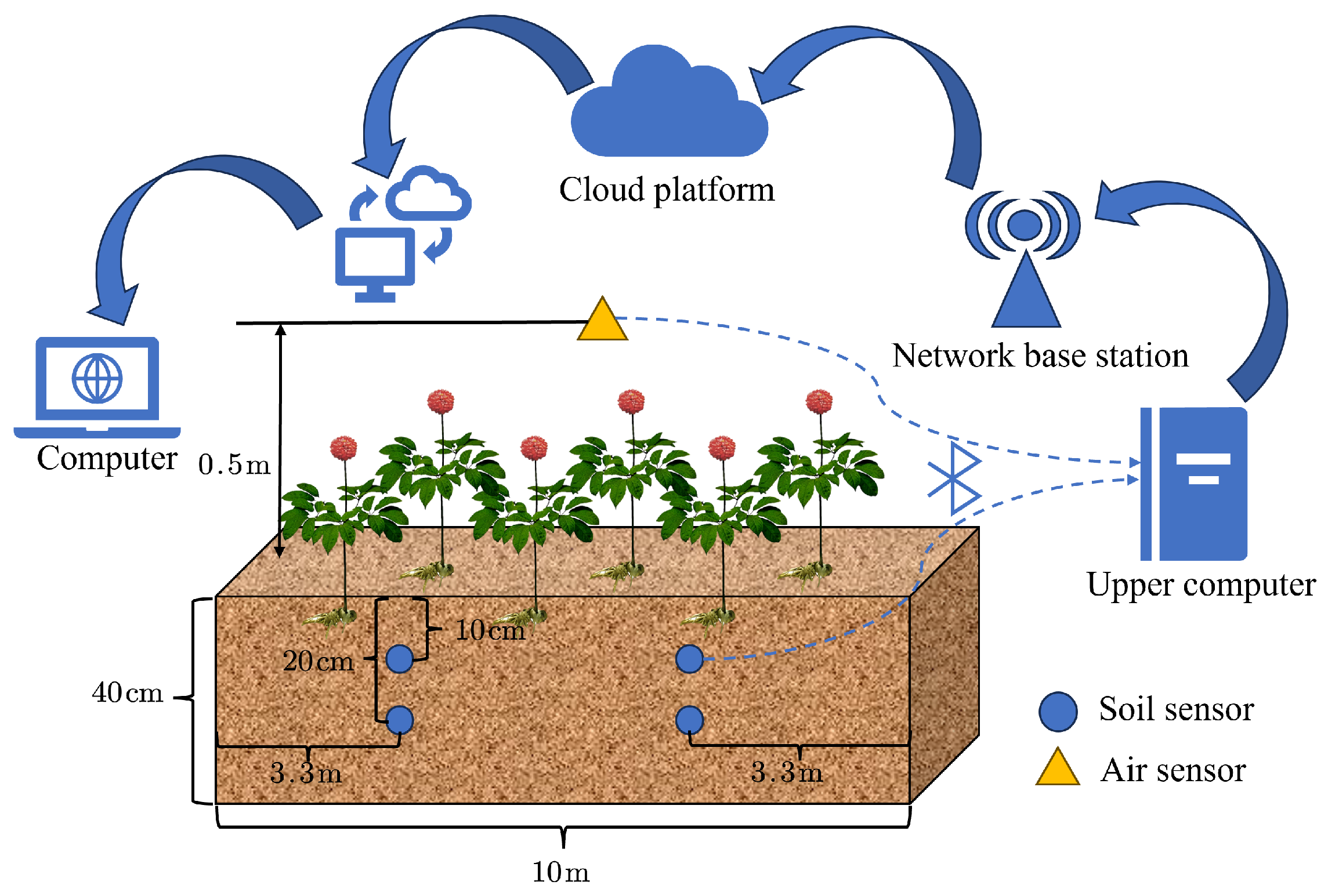
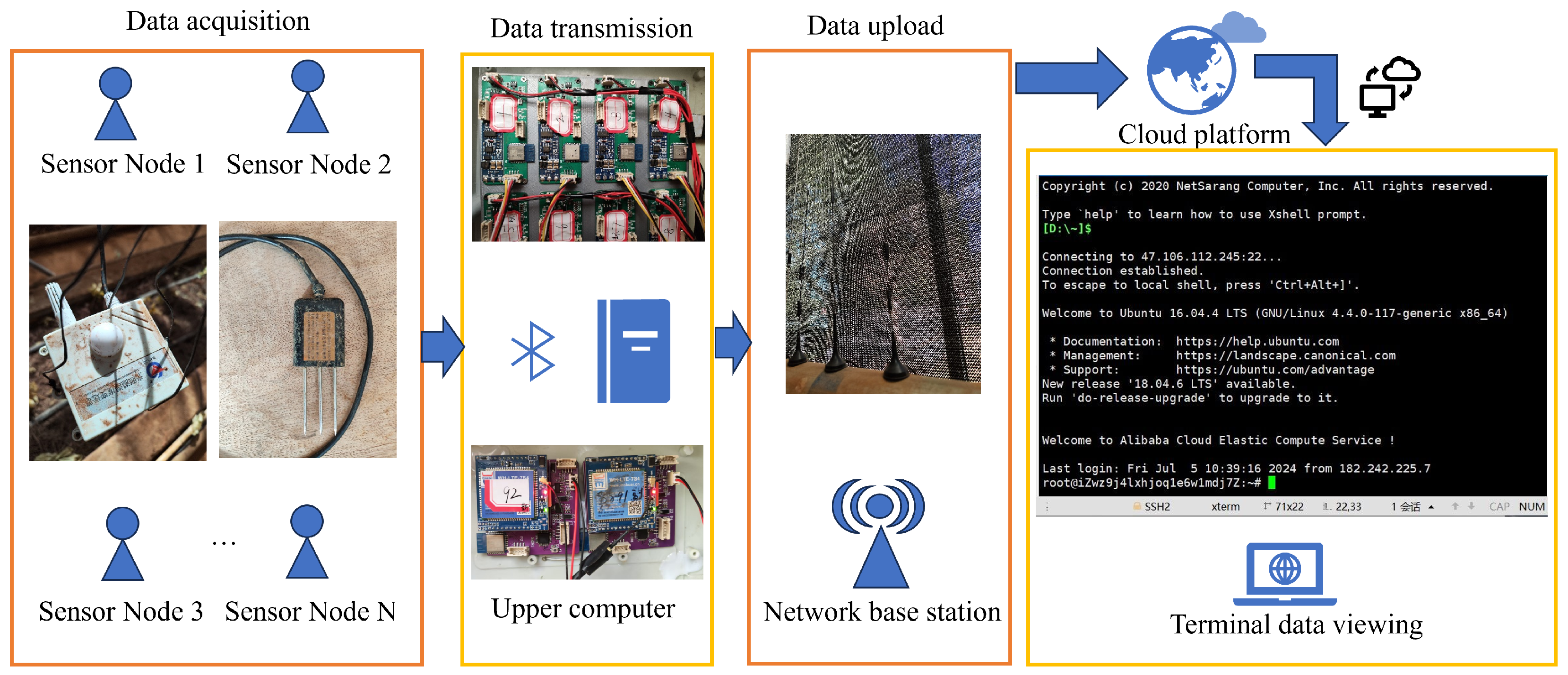
2.2. Data Acquisition System
In order to collect the environmental data of air and soil, an IoT-based data collection and transmission system is design in this experiment, as shown in
Figure 2. The sensors collect data once per hour, resulting in 24 data points per day. The sensor nodes upload the collect data to local terminal devices via the Bluetooth communication protocol. Each terminal device is equipped with multi-channel access capability, enabling them to simultaneously receive data streams from multiple distribute sensor groups. After the data are transmitted to the cloud server via a 4G wireless network, authorized users can access the web-based visualization platform through identity authentication, achieving real-time monitoring of measurement parameters and historical data traceability.
During the experimental process, conditions such as soil and light are consistent across all experimental plots, with the timing of interventions and the amount of irrigation being the sole controlled variables. Soil and air sensors collected data hourly, while the morphological data of Panax notoginseng are measure weekly. Throughout the experiment, we accumulated approximately more than 6800 data entries. Each entry included soil temperature, moisture, and conductivity collected by various soil sensors; air temperature and humidity; temperature, moisture, and conductivity differences between different soil layers; and average temperature, moisture, and conductivity of adjacent sensors; as well as the morphological data of Panax notoginseng, such as plant height and stem diameter. A total of
soil sensors and one air sensor are arranged. The arrangement of the sensors is shown in
Figure 3.
The sensor sends the collected data to the upper computer via a Bluetooth module. A computer can receive data from multiple sensors and uploads the data to the cloud via a 4G base station. Therefore, the user can access the cloud to view the data in real time. The workflow is shown in
Figure 4.
The soil sensor collects soil temperature, soil moisture, and conductivity. The air sensor collects the temperature and humidity data of the air. All these parameters are collected by the system per hour. Sensor data acquisition parameters are shown in
Table 2. The technical parameters of the air sensor and soil sensor are shown in
Table 3 and
Table 4, respectively.
Morphological measurements of Panax notoginseng plants are conducted weekly in each experimental field. Plant height is measure using a ruler, and stem diameter is determined at the stem bifurcation point using a vernier caliper. Each measurement is performed in triplicate, and the mean value is calculated as the final result [
31]. All plants within the experimental fields are systematically measured. This experiment utilizes two-year-old Panax notoginseng as the research subject, with the experimental field adopting a double-row planting pattern. The row spacing is set at 0.3 m, and the plant spacing is controlled at 0.1 m. The average plant height per plot, crop survival rate, and growth rate are used as key evaluation metrics for comparative analysis.
2.3. Data Processing
Since the sensor in this experiment collects data, the collected data naturally contains some noise. In order to minimize the effect of noise, this paper uses Gaussian filtering [
32] to reduce the noise of the data, as shown in Equation (
1).
Let represent the output signal after Gaussian denoising, x represent the value of the input signal, and represent the standard deviation of the Gaussian distribution. In this paper, is set to 10.
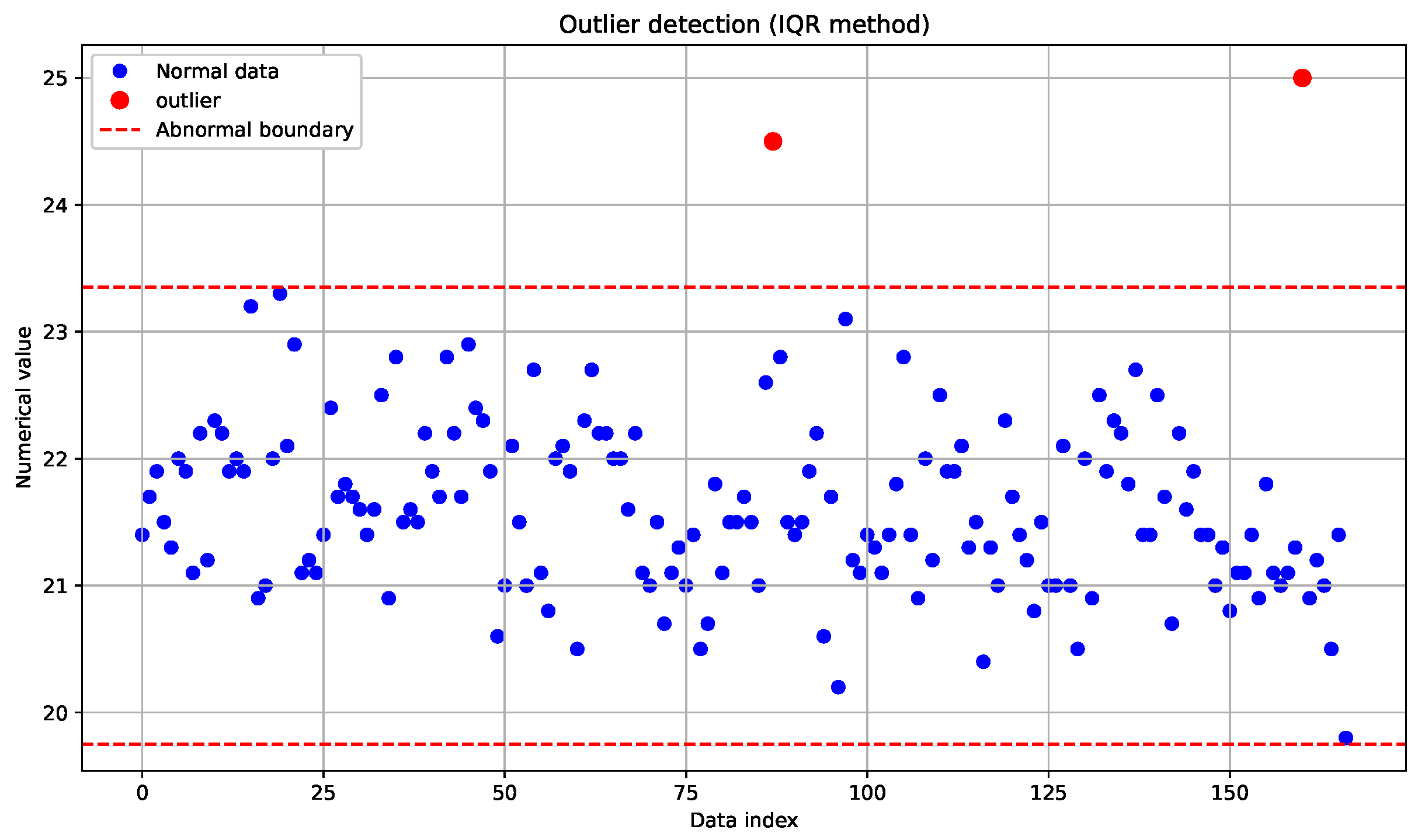
During the data collection process in the Panax notoginseng experimental field, anomalies may occur due to errors in data collection, storage, processing, noise during data capturing, or variations in data generation. These anomalous data points can negatively impact the accuracy and effectiveness of data analysis and machine-learning models. Therefore, this paper employs the Interquartile Range (IQR) method to detect and handle such data anomalies.
The Interquartile Range (IQR) method divides the data into quartiles. The first quartile,
, also known as the “lower quartile”, corresponds to the value at the 25th percentile when all data points in the sample are arrange in ascending order. The second quartile,
, also known as the “median”, corresponds to the value at the 50th percentile. The third quartile,
, also known as the “upper quartile”, corresponds to the value at the 75th percentile. The difference between the third quartile and the first quartile is referred to as the Interquartile Range (IQR), also known as the quartile deviation. The calculation equation is shown in Equation (
2).
Then, a threshold is set (in this paper, the threshold is set to
), and data points smaller than
or larger than
are considered outliers. The outlier determination mechanism follows a two-stage analytical workflow: statistical methods are initially applied to establish valid distribution boundaries (upper and lower limits), with subsequent observational data points exceeding these thresholds being formally classified as outliers. The data from 5 July 2023 to 13 July 2023 are select for outlier detection and analysis, as shown in
Figure 5.
The red data points exceeding the defined boundaries in
Figure 5 represent identified outliers. In our processing methodology, these anomalous values are systematically removed and replaced with the mean value of the dataset.
The handling of missing data in this study employed linear interpolation for imputation, with the mathematical formulation explicitly provided as show in Equation (
3).
In the equation,
denotes the data value at time
. When the sensor data
at time
is missing, the missing value can be computed using Equation (
3) by leveraging the known data
from the preceding time instant
and the known data
from the subsequent time instant
.
2.4. Experimental Design and Management
In the experimental environment of the greenhouse, each Panax notoginseng field has a fixed amount of water irrigation every week. Traditional irrigation is carried out using a drip irrigation method, with watering conducted once a week, each time using approximately 135 L of water. The traditional fixed-water irrigation method does not give much consideration to the crop’s water demand. However, too much or too little irrigation has different effects on Panax notoginseng [
33], and the crop has different water needs at different stages of the crop’s life. Unsuitable irrigation water can lead to slow growth or even serious crop death, influencing the product quality and yields of the planting field.
Within the experimental field, other external conditions, such as soil, light, etc., are kept at the same level in the experimental field, and the only control parameter is the amount of water.
In the experimental design stage, within-group control and between-group control are two common types of control, which have different characteristics and application scenarios. In addition to the mutual experimental control between the five test fields, this experiment divided each field into experimental and control groups (about 1/3 of the experimental group and 2/3 of the control group) to form a within-group control. The experimental field is divided as shown in
Figure 6.
In
Figure 6, we established five experimental fields numbered 1 to 5, each subjected to different irrigation strategies for treatment. The specific irrigation schemes for individual experiments are detailed in the subsequent
Table 5 and its accompanying descriptions.
The experiment is designed with five experimental fields, and the timing of irrigation obtained by our proposed method in each field is shown in
Table 5. The morphological data of total plant height and stem thickness of Panax notoginseng in each experimental field are selected as the status indicator. The accuracy of the proposed method and the rationality are verify by the growth trends before and after the intervention.
Within each experimental field, within-group controls are conducted. For example, A1 vs. A2, B1 vs. B2, C1 vs. C2, D1 vs. D2, and E1 vs. E2; the former used data-driven decision making to irrigate the experimental fields, while the latter used traditional fixed water irrigation. To ensuring that the effects of the different treatments are compared under the same environmental conditions, the goodness of adopting the data-driven decision-making approach is evaluate by comparing the final Panax notoginseng growth status of the respective fields.
Intergroup controls are also conducted between different fields: A1, B1, C1, D1, and E1. A data-driven decision-making-based program is implemented at different stages to evaluate the effectiveness of the intervention timing through the growth status of the post-intervention Panax notoginseng fields. This design allowed a more comprehensive assessment of the impact of the experimental treatments on the results and improved the scientific validity and reliability of the experiment.
3. Methods
3.1. Timing of Intervention
In order to investigate the accuracy of the intervention timing and the effectiveness of the intervention regulation on Panax notoginseng, the research steps in this paper are shown in
Figure 7.
During the entire experiment, the choice of pre-intervention and post-intervention periods is an important feature of conditioning. In this scenario, it is essential to find a suitable timing for intervention. For example, Sun et al. [
34] set up a multi-group orthogonal experiment. Intervention irrigation is regulated at different time periods, and the intervention time is obtained by comparing the state of the final crop. Thus, the intervention time is a hypothetical point in the time series after which the intervention regulator has been imposed. In order to predict the timing for intervention in advance, this paper proposes a type of combined framework called deep-learning-based intervention timing prediction, as shown in
Figure 8.
First, the Informer model is employed to preprocess the time-series data and generate initial predictions. By leveraging the self-attention mechanism, the Informer model effectively captures long-range dependencies within the time series, thereby producing preliminary prediction results. Subsequently, the output of the Informer is fed into an LSTM (Long Short-Term Memory) network. The LSTM further refines and optimizes the predictions through its gating mechanisms, capturing more complex non-linear relationships in the time series. Finally, an Exponentially Weighted Moving Average (EWMA) is applied to smooth the LSTM-adjusted results, reducing noise and enhancing the stability of the predictions.
The Informer–LSTM–EWMA integrated model fully leverages the strengths of the Informer model and the LSTM model, combining long-term dependency modeling and multi-scale information fusion. By integrating the multi-scale information fusion capability of the Informer model with the long-term dependency modeling ability of the LSTM model, this integrated model can more comprehensively capture the features in time-series data. The EWMA model is capable of responding in real-time to incoming new data and continuously updating the smoothing coefficient to promptly reflect changes in the data as well as trends.
3.2. Model
3.2.1. Informer
ProbSparse Self-Attention [
35] is used to select important
pairs that describe the similarity between the
i-th query and the key. The attention value of the
i query to the key can be expressed as
with probability. The closer the distribution
p is to the uniform distribution
q, the less important it is. The sparsity measurement
M of the
i-th query can be approximated as Equation (
4).
Based on the proposed metric, the number of
dominated queries is defined. ProbSparse self-attention can be defined as Equation (
5).
where
is a sparse matrix that includes only the largest
u queries in
M, with
d representing the input dimension.
Self-attention distilling [
35] can significantly reduce the input dimension. Essentially, it is a tandem combination of
Conv1d,
ELU activation function, and maxpooling. The formula for advancing from layer
j to layer
is shown in Equation (
6).
where
denotes an attention block.
3.2.2. LSTM
LSTM is a deep-learning model for processing sequential data. It contains a storage unit and three gates: an oblivion gate, an input gate, and an output gate. These gates serve to selectively control the flow of information, allowing the model to capture long-term dependencies more efficiently in time sequences.
Each gate produces a state variable
,
, and
at time
t and an output unit
, respectively. The state update process is shown in Equations (
7)–(
12).
where
,
,
, and
correspond to the weight matrix and bias term of the forgetting gate
, cell state
, input gate
, and output gate
, respectively, at time
t.
is the output in the hidden layer at time
and the input at time
t, respectively, and
is the input node state.
Based on this mechanism, LSTM can retain important information in sequence data and perform prediction or classification tasks accordingly.
3.2.3. EWMA
The EWMA model is a method used to estimate trends and cyclical variations in time-series data. It performs a weighted average of historical data to better capture the trend of recent observations. It is widely used for the smoothing and trend forecasting of time-series data. In an EWMA model, newer observations are given a larger weight while older observations are given a smaller weight. This allows the model to be more flexible in adapting to changes in the data and also reduces the impact of random noise on the predictions. The formula for the EWMA model is as in Equation (
13).
where
is the EWMA value at time
t.
is the observed value at time
t.
is a smoothing parameter that determines the relative weight of the observation to the previous EWMA value.
The model parameters during training are set as follows: Input sequence length of the message encoder . Start token length of Informer decoder . Prediction sequence length . Number of heads of attention mechanisms . The sampling factor , . The number of training epochs . This paper adopts the Adam optimizer.
3.3. Probability Density Function
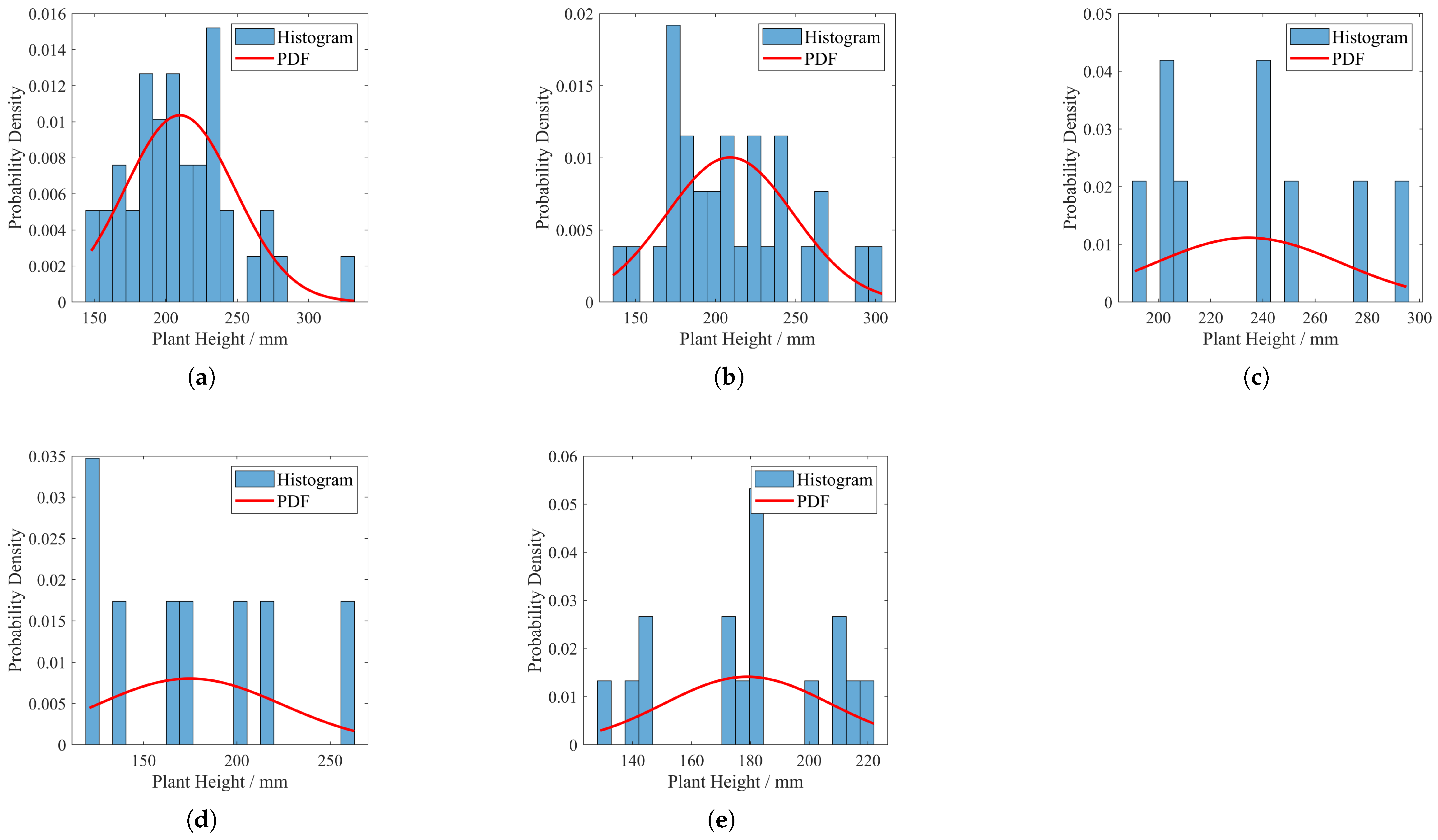
Before the beginning of the experiment, the state of Panax notoginseng planted in each experimental field is quite different. The morphological data of some plants will be more prominent due to the individuality of the plants, but this does not affect the whole experiment. To provide an intuitive characterization of the spatial distribution patterns of Panax notoginseng crops, this study employs the Probability Density Function (PDF) for quantitative analysis. The methodological workflow comprises the following key steps:
Step1: Histogram Construction and Normalization. The methodological workflow initiates by inputting the dataset to determine the bin count
p for histogram configuration. Subsequently, normalization is performed to derive the Probability Density Function (PDF). The normalized value of each histogram bin is calculated according to Equation (
14).
Let K denote the total number of data points, represent the number of data points within the interval, L be the width of each interval, indicate the value of the i-th histogram bin, and
Step2: Generation of Theoretical Distribution Coordinates. To provide plotting coordinates for subsequent theoretical distribution curves (e.g., the normal distribution) and ensure consistency with the histogram range, a linearly spaced abscissa vector is generated, as shown in Equation (
15).
In the formula, denotes the maximum value of the dataset, represents the minimum value of the dataset, and g specifies the number of equidistant points to be generated.
Step3: Calculation of the Normal Distribution Probability Density Function. The Probability Density Function (PDF) of the normal distribution is given by Equation (
16).
where
is the mean, which determines the center position of the distribution, and
is the standard deviation, which controls the width of the distribution (the larger the
, the flatter the curve).
Due to too few bins (<10) masking the details and too many bins (>30) leading to significant noise, the number of bins in this paper is set to , with the number of equidistant points .
3.4. Prediction
Before the experiment, it is essential to ensure that the crop conditions in each experimental plot are consistent to guarantee the fairness and comparability of the experiment. This is achieved through the following measures:
Crop condition consistency: In the early stages of the experiment, the growth status of crops in all experimental plots is measure and assessed to ensure they are at similar levels;
Environmental condition control: The soil type, fertility levels, and other environmental factors of each experimental plot are kept as consistent as possible to eliminate external factors that could interfere with the results;
Randomized design: A randomized grouping method is employ to assign the experimental plots to different treatment groups, further reducing potential biases.
Through these measures, this experiment ensures consistency in initial conditions, laying a foundation for the reliability and scientific validity of the subsequent results.
In the Panax notoginseng growth intervention experiment, we predict the growth condition of Panax notoginseng in the next cycle. The aim is to intervene early before the growth transitions down to ensure normal growth of Panax notoginseng.
When prediction processes run, the historical data collected from the above features are used as inputs to the model, and the crop height pattern data are used as outputs. During the experiment, we only need to know the growth status of the crop; we do not need to know the exact value of the morphological data such as plant height. When a prediction is carried out, we normalize the output data so that its output is in the range of .
Similarly, in the Panax notoginseng experimental field, we use previously collected historical datasets to train a model to predict the growth performance of Panax notoginseng in the coming week. The model can predict the growth status of the crop for the coming growth period. We have the following expectations for the outcome of the forecast:
When we make a growth prediction for Panax notoginseng, our main purpose is not to predict the real status but to obtain the time of intervention.
The model should have the ability to generalize and be able to make predictions, even in different experimental sites.
The prediction of the intervention timing should not be later than the point at which the actual decline in the growth state of Panax notoginseng occurs. Due to the characteristics of the crop, delayed intervention may lead to irreversible damage or even death of the plant.
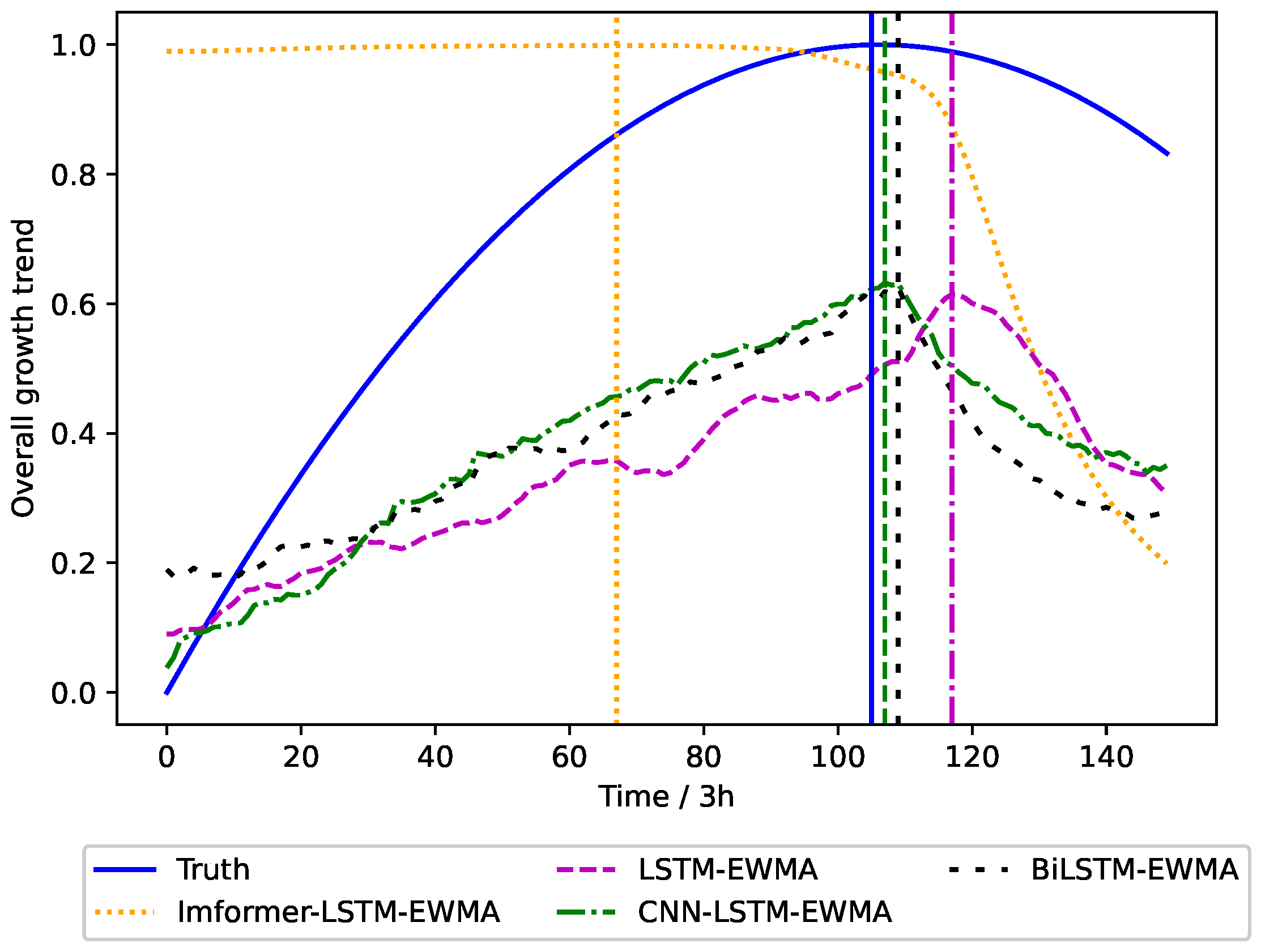
In order to illustrate the rationality of our method, we choose the LSTM, CNN-LSTM, and BiLSTM models as a comparison. The prediction of intervention timing is shown in
Figure 9.
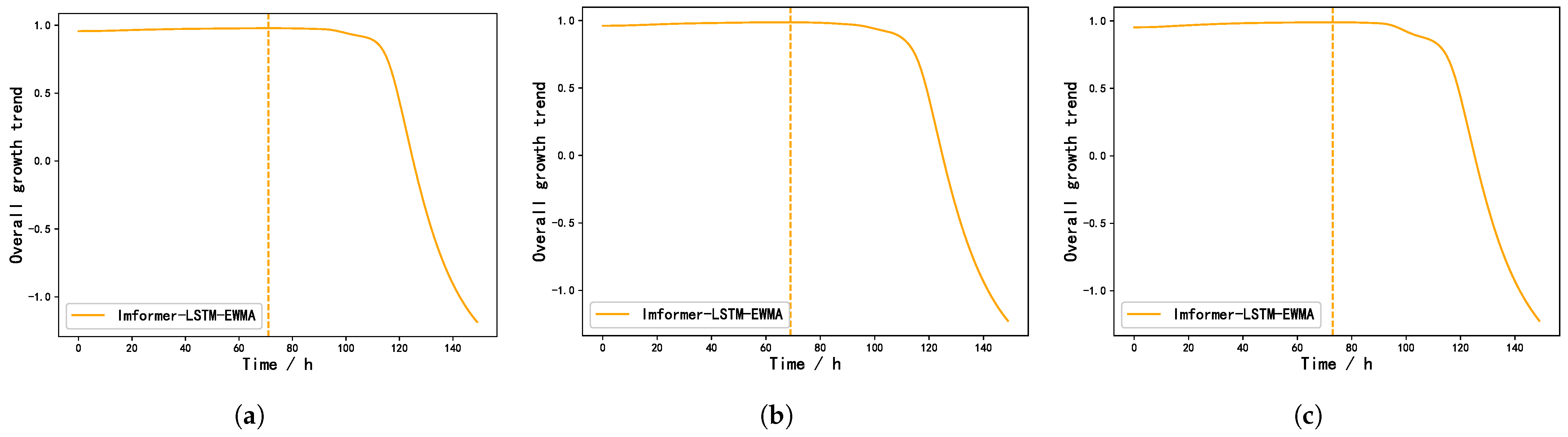
As evidenced by the comparative analysis in
Figure 9, the Informer–LSTM–EWMA model provides approximately 5-day advance warnings for irrigation scheduling prior to crop status deterioration, while other forecasting models show different lag (after multiple predictions, our model is able to give the irrigation time 3–5 days before the crop condition declined). According to the predicted irrigation time, the manager can intervene by timely water supply when the plant does not appear to have irreversible water stress, so as to maintain the normal physiological metabolism of Panax notoginseng.
5. Discussion
The proposed model effectively integrates deep learning with the Exponentially Weighted Moving Average (EWMA) method by utilizing historical data and real-time monitoring data. This integration enables accurate prediction of crop status decline trends 3–5 days in advance, allowing for timely irrigation warning signals to be sent to administrators. In contrast, traditional prediction methods, such as the LSTM-EWMA, CNN-LSTM-EWMA, and BiLSTM-EWMA models, exhibit significant latency, often issuing warning signals only after crops have already shown signs of status deterioration. This delayed warning may result in missing the optimal irrigation window, prolonging the period of water stress in crops and thereby affecting their normal physiological and metabolic processes [
36].
Specifically, water stress can inhibit the photosynthetic efficiency of crops, reduce the rate of dry matter accumulation, and hinder plant growth [
37]. More critically, prolonged water stress may lead to irreversible damage to crops. Therefore, the timely warning function of the Informer–LSTM–EWMA model is of practical significance for ensuring normal crop growth and maintaining stable yields, providing reliable technical support for the implementation of precision agriculture.
Extensive research indicates that rational irrigation strategies positively influence the alteration of crops’ physiological and ecological traits [
38,
39,
40]. Contemporary studies suggest that both low-level and high-level irrigation could detrimentally impact plant development [
41]. This research validates earlier findings, and data from control experimental field 5 substantiate that inappropriate irrigation methods negatively influence crop productivity.
The experimental findings substantiate the superiority of the proposed irrigation strategy over conventional methods, which is manifested in three key dimensions:
- (a)
Spatial Distribution Pattern: Figure 11,
Figure 12 and
Figure 13 illustrate that crops under the proposed irrigation system exhibit a more clustered distribution compared to the dispersed and sparse arrangement observed in traditional irrigation practices.
- (b)
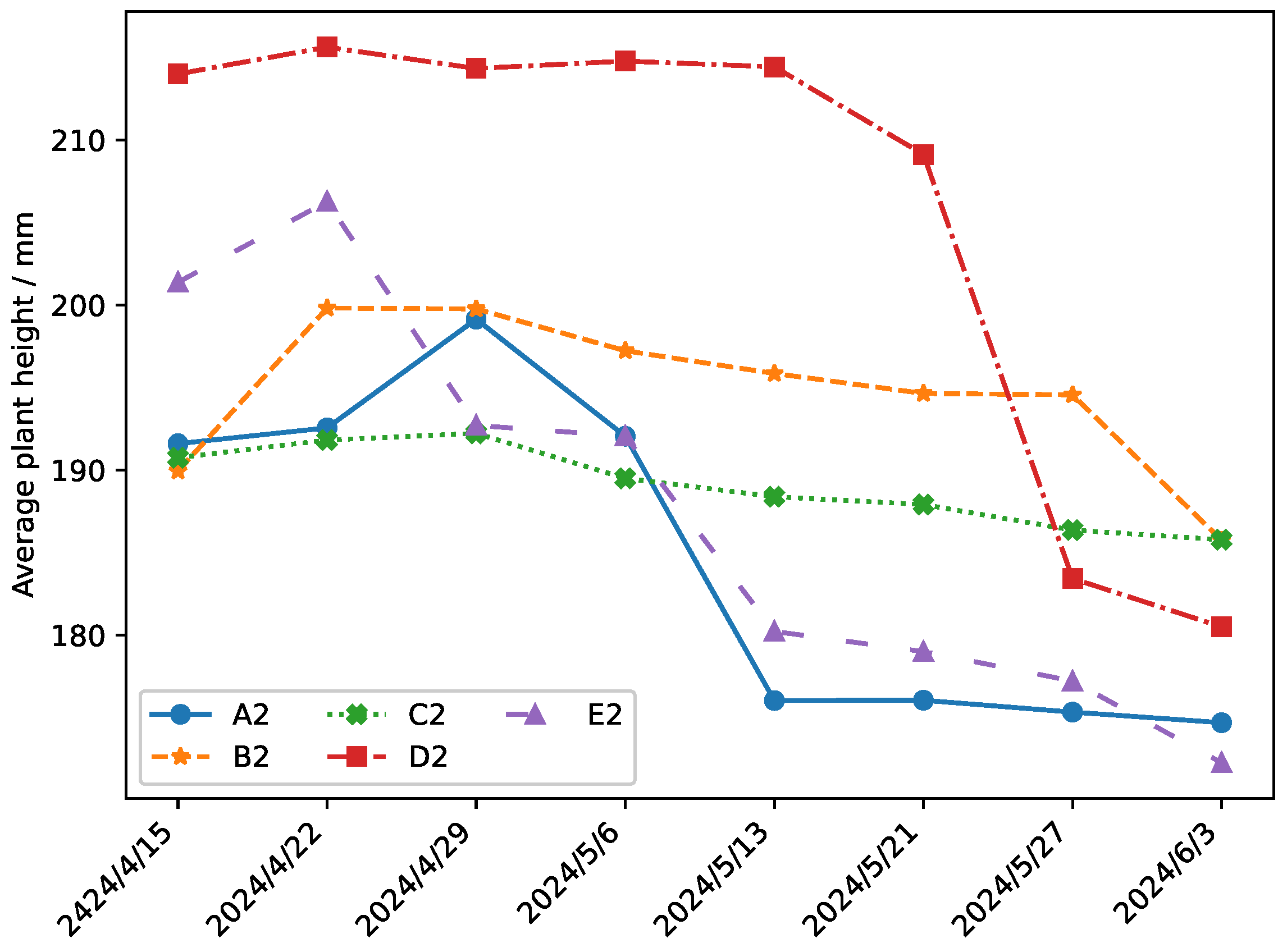
Mean Plant Height: The data presented in
Figure 14 and
Figure 15 demonstrate a significant 21.8% increase in average plant height when using the proposed irrigation method relative to the control group.
- (c)
Crop Density and Growth Rate: As evidenced by
Table 10, the proposed irrigation approach yields higher final crop density and enhanced growth rates compared to traditional irrigation techniques.
Precision irrigation offers substantial socio-economic and environmental benefits, reducing water and energy use while boosting crop yields [
42]. Cotton irrigation trials confirm its effectiveness in enhancing production [
43]. Developing a predictive platform can provide optimal irrigation strategies, further improving agricultural outcomes [
44].
As can be seen before and after the experiment, the use of data-driven irrigation can effectively guide farmers to take effective interventions in the field. The method ensures that the crop is in a healthy state, and the method has the following benefits:
The method does not predict the true value, but predicts the time of intervention when the crop will need to be intervened. This avoids growth uncertainty caused by different crops for their own reasons.
Data-driven irrigation is more scientific than traditional experiential irrigation, and in the context of modern smart agriculture, a data-driven approach makes it easier to create a plant factory that increases yields.
The method is not only applicable to Panax notoginseng but can also be used in the cultivation of other economic crops. This method greatly helps managers obtain higher quality and yield with less energy input.



 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}