
Plant and Disease Recognition Based on PMF Pipeline Domain Adaptation Method: Using Bark Images as Meta-Dataset

Abstract
:1. Introduction
2. Materials and Methods
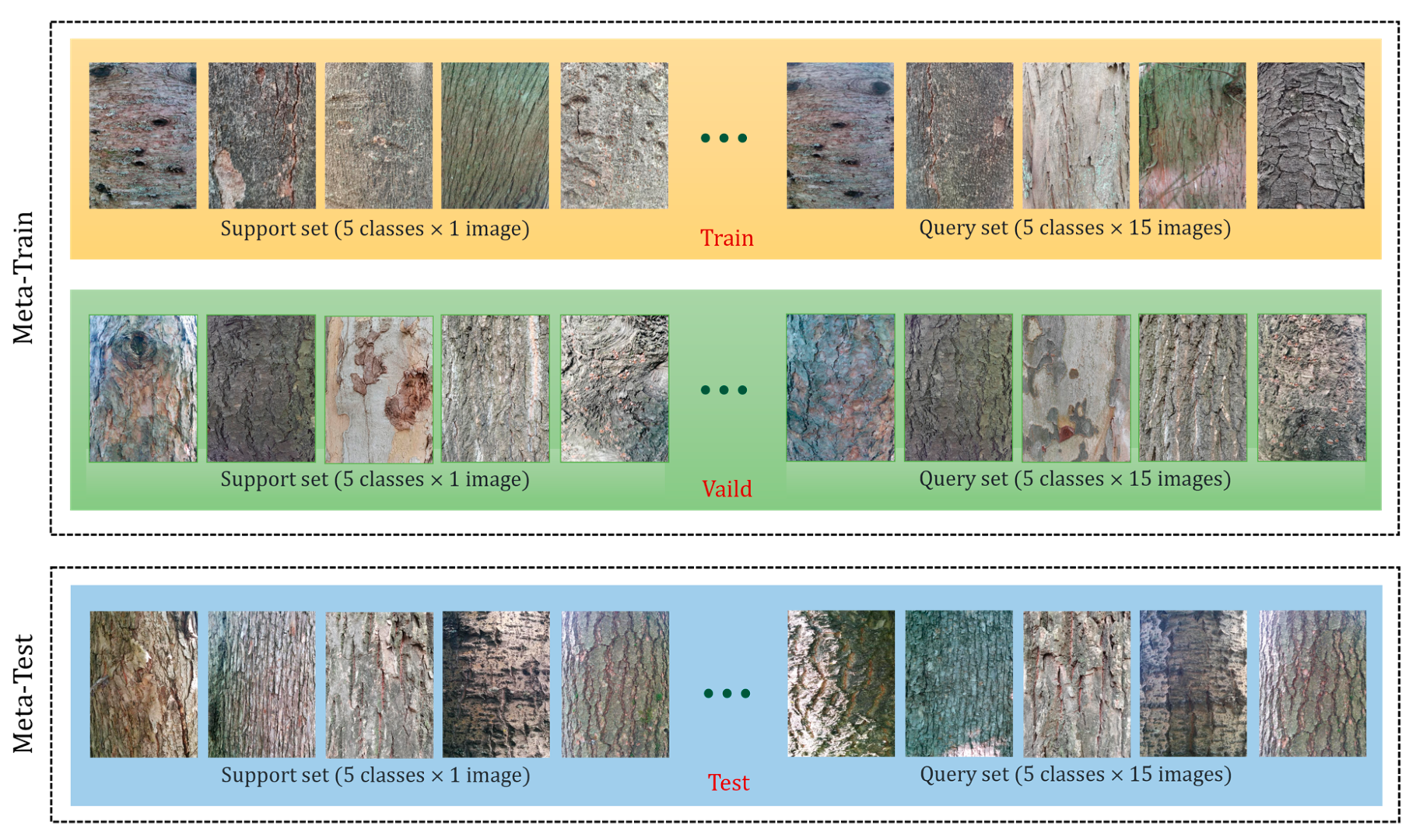
2.1. Datasets
2.2. Methodology
2.2.1. Backbone of Pre-Train
2.2.2. Algorithm of Meta-Train
2.2.3. Task-Specific Fine-Tune
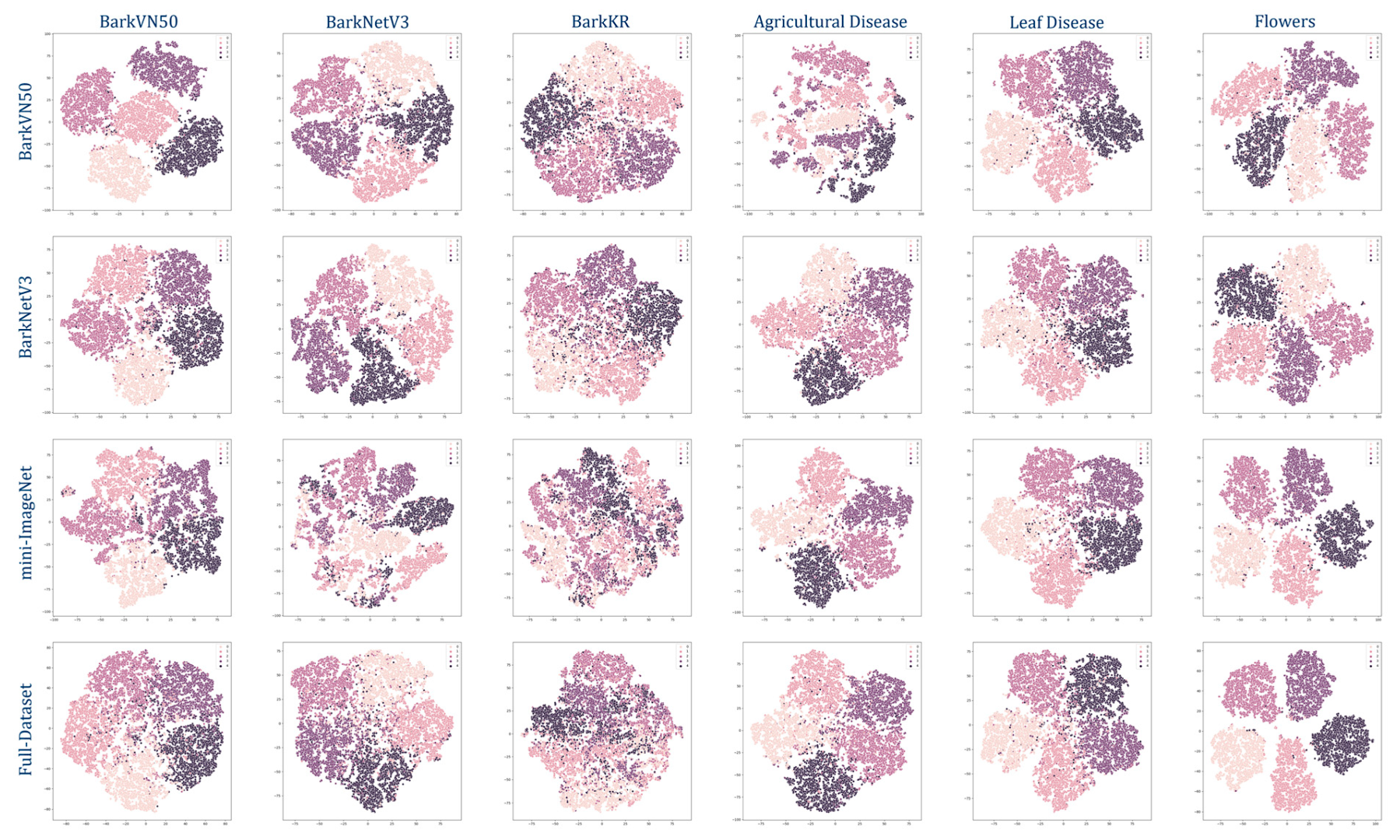
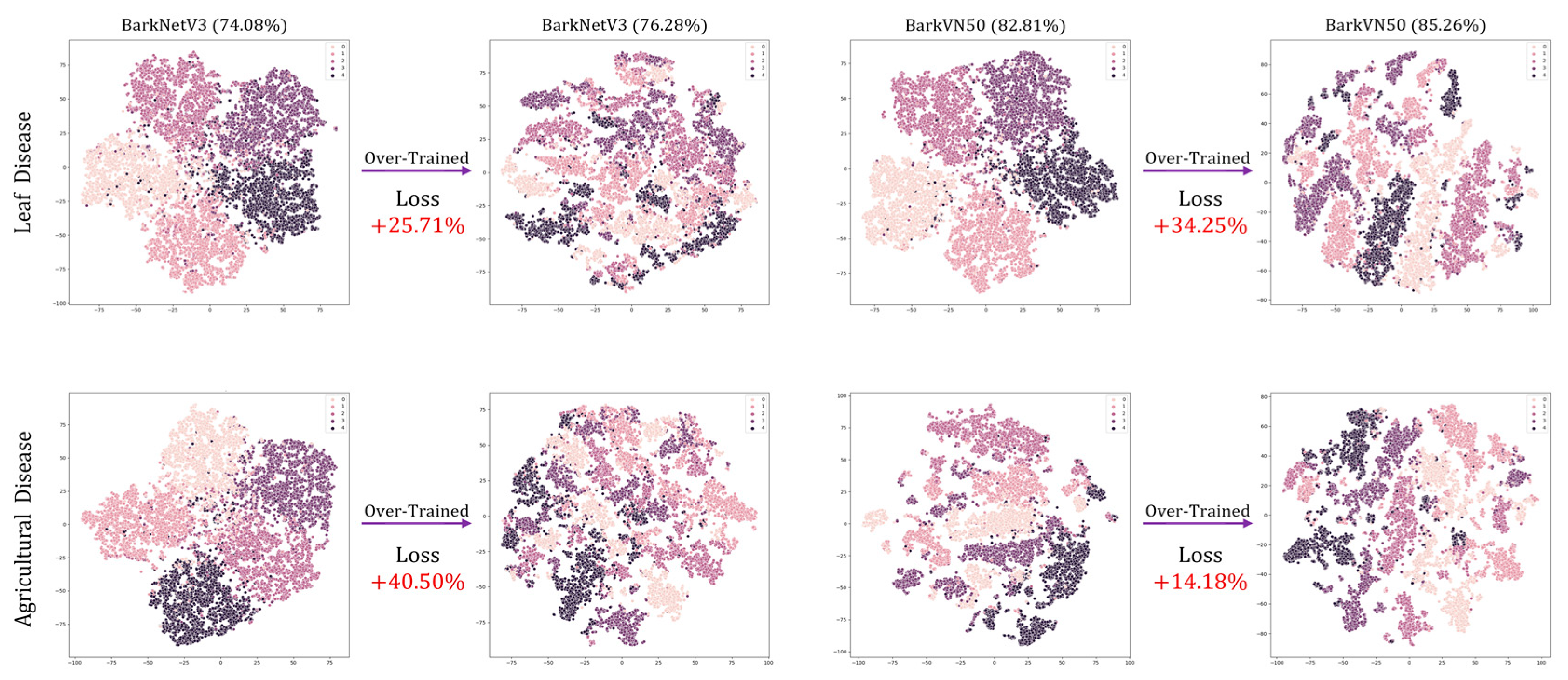
2.2.4. Visualization
- (1)
- T-distributed stochastic neighbor embedding (t-SNE). t-SNE is a technique for visualizing high-dimensional data in a low-dimensional space [72]. It aims to preserve the local structure of the data by minimizing the Kullback-Leibler divergence between the joint probabilities of the high-dimensional data and the low-dimensional embedding. By using pseudo-labels as conditional variables, t-SNE can discount the known structure of the data given the true labels and highlight the conditional structure of the data given the pseudo-labels [63,64]. This can reveal more meaningful and relevant patterns in the embedding, such as clusters, outliers, or subgroups that the standard t-SNE may not capture. Pseudo-labels can also help to reduce the noise and ambiguity in the high-dimensional data and improve the stability and robustness of the t-SNE optimization.
- (2)
- Smooth Grad CAM++. It is an advanced variation of the popular Grad-CAM (Gradient-weighted Class Activation Mapping) technique [73]. It is used in deep learning and computer vision to visualize and interpret the decision-making process of neural networks by highlighting regions in an input image that influence the network’s classification or prediction. Smooth Grad CAM++ can also visualize different layers, feature maps, or neurons within a model at the inference level, which means when the model is making predictions.
2.3. Parameters Setting
3. Results and Analysis
3.1. Meta-Train
3.2. Meta-Test
3.3. Visualization
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, J.; Wang, X. Plant Diseases and Pests Detection Based on Deep Learning: A Review. Plant Methods 2021, 17, 22. [Google Scholar] [CrossRef] [PubMed]
- Benos, L.; Tagarakis, A.C.; Dolias, G.; Berruto, R.; Kateris, D.; Bochtis, D. Machine Learning in Agriculture: A Comprehensive Updated Review. Sensors 2021, 21, 3758. [Google Scholar] [CrossRef]
- van Dijk, A.D.J.; Kootstra, G.; Kruijer, W.; de Ridder, D. Machine Learning in Plant Science and Plant Breeding. iScience 2021, 24, 101890. [Google Scholar] [CrossRef] [PubMed]
- Hesami, M.; Jones, A.M.P. Application of Artificial Intelligence Models and Optimization Algorithms in Plant Cell and Tissue Culture. Appl. Microbiol. Biotechnol. 2020, 104, 9449–9485. [Google Scholar] [CrossRef] [PubMed]
- Singh, A.; Ganapathysubramanian, B.; Singh, A.K.; Sarkar, S. Machine Learning for High-Throughput Stress Phenotyping in Plants. Trends Plant Sci. 2016, 21, 110–124. [Google Scholar] [CrossRef]
- Jafari, M.; Shahsavar, A. The Application of Artificial Neural Networks in Modeling and Predicting the Effects of Melatonin on Morphological Responses of Citrus to Drought Stress. PLoS ONE 2020, 15, e0240427. [Google Scholar] [CrossRef]
- Hesami, M.; Alizadeh, M.; Jones, A.; Torkamaneh, D. Machine Learning: Its Challenges and Opportunities in Plant System Biology. Appl. Microbiol. Biotechnol. 2022, 106, 3507–3530. [Google Scholar] [CrossRef]
- Grinblat, G.L.; Uzal, L.C.; Larese, M.G.; Granitto, P.M. Deep Learning for Plant Identification Using Vein Morphological Patterns. Comput. Electron. Agric. 2016, 127, 418–424. [Google Scholar] [CrossRef]
- Hesami, M.; Alizadeh, M.; Naderi, R.; Tohidfar, M. Forecasting and Optimizing Agrobacterium-Mediated Genetic Transformation via Ensemble Model-Fruit Fly Optimization Algorithm: A Data Mining Approach Using Chrysanthemum Databases. PLoS ONE 2020, 15, e0239901. [Google Scholar] [CrossRef]
- Mishra, B.; Kumar, N.; Mukhtar, M.S. Systems Biology and Machine Learning in Plant–Pathogen Interactions. MPMI 2019, 32, 45–55. [Google Scholar] [CrossRef]
- Sarker, I.H. Machine Learning: Algorithms, Real-World Applications and Research Directions. SN Comput. Sci. 2021, 2, 160. [Google Scholar] [CrossRef] [PubMed]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of Deep Learning: Concepts, CNN Architectures, Challenges, Applications, Future Directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef] [PubMed]
- Hatcher, W.G.; Yu, W. A Survey of Deep Learning: Platforms, Applications and Emerging Research Trends. IEEE Access 2018, 6, 24411–24432. [Google Scholar] [CrossRef]
- Deng, L.; Yu, D. Deep Learning: Methods and Applications. Found. Trends® Signal Process. 2014, 7, 197–387. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, W.; Gao, R.; Jin, Z.; Wang, X. Recent Advances in the Application of Deep Learning Methods to Forestry. Wood Sci. Technol. 2021, 55, 1171–1202. [Google Scholar] [CrossRef]
- Ferentinos, K.P. Deep Learning Models for Plant Disease Detection and Diagnosis. Comput. Electron. Agric. 2018, 145, 311–318. [Google Scholar] [CrossRef]
- Santos, L.; Santos, F.N.; Oliveira, P.M.; Shinde, P. Deep Learning Applications in Agriculture: A Short Review. In Proceedings of the Robot 2019: Fourth Iberian Robotics Conference, Porto, Portugal, 20–22 November 2019; Silva, M.F., Luís Lima, J., Reis, L.P., Sanfeliu, A., Tardioli, D., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 139–151. [Google Scholar] [CrossRef]
- Bouguettaya, A.; Zarzour, H.; Kechida, A.; Taberkit, A.M. Deep Learning Techniques to Classify Agricultural Crops through UAV Imagery: A Review. Neural Comput. Applic. 2022, 34, 9511–9536. [Google Scholar] [CrossRef]
- Wang, D.; Cao, W.; Zhang, F.; Li, Z.; Xu, S.; Wu, X. A Review of Deep Learning in Multiscale Agricultural Sensing. Remote Sens. 2022, 14, 559. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep Learning in Agriculture: A Survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- O’Mahony, N.; Campbell, S.; Carvalho, A.; Harapanahalli, S.; Hernandez, G.V.; Krpalkova, L.; Riordan, D.; Walsh, J. Deep Learning vs. Traditional Computer Vision. In Proceedings of the Advances in Computer Vision, Las Vegas, NV, USA, 2–3 May 2019; Arai, K., Kapoor, S., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 128–144. [Google Scholar] [CrossRef]
- Sarker, I.H. Deep Learning: A Comprehensive Overview on Techniques, Taxonomy, Applications and Research Directions. SN Comput. Sci. 2021, 2, 420. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from a Few Examples: A Survey on Few-Shot Learning. ACM Comput. Surv. 2020, 53, 63:1–63:34. [Google Scholar] [CrossRef]
- Hospedales, T.; Antoniou, A.; Micaelli, P.; Storkey, A. Meta-Learning in Neural Networks: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 5149–5169. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.X. Meta-Learning in Natural and Artificial Intelligence. Curr. Opin. Behav. Sci. 2021, 38, 90–95. [Google Scholar] [CrossRef]
- Tian, Y.; Zhao, X.; Huang, W. Meta-Learning Approaches for Learning-to-Learn in Deep Learning: A Survey. Neurocomputing 2022, 494, 203–223. [Google Scholar] [CrossRef]
- Wang, S.; Fang, H.; Khabsa, M.; Mao, H.; Ma, H. Entailment as Few-Shot Learner. arXiv 2021, arXiv:2104.14690. [Google Scholar]
- Song, Y.; Wang, T.; Cai, P.; Mondal, S.K.; Sahoo, J.P. A Comprehensive Survey of Few-Shot Learning: Evolution, Applications, Challenges, and Opportunities. ACM Comput. Surv. 2023, 55, 271:1–271:40. [Google Scholar] [CrossRef]
- Yang, J.; Guo, X.; Li, Y.; Marinello, F.; Ercisli, S.; Zhang, Z. A Survey of Few-Shot Learning in Smart Agriculture: Developments, Applications, and Challenges. Plant Methods 2022, 18, 28. [Google Scholar] [CrossRef]
- Sun, J.; Cao, W.; Fu, X.; Ochi, S.; Yamanaka, T. Few-Shot Learning for Plant Disease Recognition: A Review. Agron. J. 2023. [Google Scholar] [CrossRef]
- Lin, H.; Tse, R.; Tang, S.-K.; Qiang, Z.; Pau, G. Few-Shot Learning for Plant-Disease Recognition in the Frequency Domain. Plants 2022, 11, 2814. [Google Scholar] [CrossRef]
- Egusquiza, I.; Picon, A.; Irusta, U.; Bereciartua-Perez, A.; Eggers, T.; Klukas, C.; Aramendi, E.; Navarra-Mestre, R. Analysis of Few-Shot Techniques for Fungal Plant Disease Classification and Evaluation of Clustering Capabilities Over Real Datasets. Front. Plant Sci. 2022, 13, 813237. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Xiao, S.; Kumar, P.; Demir, B. Data-Driven Few-Shot Crop Pest Detection Based on Object Pyramid for Smart Agriculture. JEI 2023, 32, 052403. [Google Scholar] [CrossRef]
- Ragu, N.; Teo, J. Object Detection and Classification Using Few-Shot Learning in Smart Agriculture: A Scoping Mini Review. Front. Sustain. Food Syst. 2023, 6, 1039299. [Google Scholar] [CrossRef]
- Argüeso, D.; Picon, A.; Irusta, U.; Medela, A.; San-Emeterio, M.G.; Bereciartua, A.; Alvarez-Gila, A. Few-Shot Learning Approach for Plant Disease Classification Using Images Taken in the Field. Comput. Electron. Agric. 2020, 175, 105542. [Google Scholar] [CrossRef]
- Li, Y.; Chao, X. Semi-Supervised Few-Shot Learning Approach for Plant Diseases Recognition. Plant Methods 2021, 17, 68. [Google Scholar] [CrossRef]
- Nuthalapati, S.V.; Tunga, A. Multi-Domain Few-Shot Learning and Dataset for Agricultural Applications. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 1399–1408. [Google Scholar] [CrossRef]
- Lin, H.; Tse, R.; Tang, S.-K.; Qiang, Z.; Pau, G. Few-Shot Learning Approach with Multi-Scale Feature Fusion and Attention for Plant Disease Recognition. Front. Plant Sci. 2022, 13, 907916. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Cui, X.; Li, W. Meta-Learning for Few-Shot Plant Disease Detection. Foods 2021, 10, 2441. [Google Scholar] [CrossRef]
- Puthumanaillam, G.; Verma, U. Texture Based Prototypical Network for Few-Shot Semantic Segmentation of Forest Cover: Generalizing for Different Geographical Regions. Neurocomputing 2023, 538, 126201. [Google Scholar] [CrossRef]
- Wang, S.; Han, Y.; Chen, J.; He, X.; Zhang, Z.; Liu, X.; Zhang, K. Weed Density Extraction Based on Few-Shot Learning through UAV Remote Sensing RGB and Multispectral Images in Ecological Irrigation Area. Front. Plant Sci. 2022, 12, 735230. [Google Scholar] [CrossRef]
- Tian, X.; Chen, L.; Zhang, X.; Chen, E. Improved Prototypical Network Model for Forest Species Classification in Complex Stand. Remote Sens. 2020, 12, 3839. [Google Scholar] [CrossRef]
- Hu, S.X.; Li, D.; Stühmer, J.; Kim, M.; Hospedales, T.M. Pushing the Limits of Simple Pipelines for Few-Shot Learning: External Data and Fine-Tuning Make a Difference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 9068–9077. [Google Scholar] [CrossRef]
- Carpentier, M.; Giguère, P.; Gaudreault, J. Tree Species Identification from Bark Images Using Convolutional Neural Networks. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1075–1081. [Google Scholar] [CrossRef]
- Kim, T.K.; Hong, J.; Ryu, D.; Kim, S.; Byeon, S.Y.; Huh, W.; Kim, K.; Baek, G.H.; Kim, H.S. Identifying and Extracting Bark Key Features of 42 Tree Species Using Convolutional Neural Networks and Class Activation Mapping. Sci. Rep. 2022, 12, 4772. [Google Scholar] [CrossRef] [PubMed]
- Cui, Z.; Li, X.; Li, T.; Li, M. Improvement and Assessment of Convolutional Neural Network for Tree Species Identification Based on Bark Characteristics. Forests 2023, 14, 1292. [Google Scholar] [CrossRef]
- Hughes, D.P.; Salathe, M. An Open Access Repository of Images on Plant Health to Enable the Development of Mobile Disease Diagnostics. arXiv 2016, arXiv:1511.08060. [Google Scholar]
- Nilsback, M.-E.; Zisserman, A. Automated Flower Classification over a Large Number of Classes. In Proceedings of the 2008 Sixth Indian Conference on Computer Vision, Graphics & Image Processing, Bhubaneswar, India, 16–19 December 2008; pp. 722–729. [Google Scholar] [CrossRef]
- Guan, X. A Novel Method of Plant Leaf Disease Detection Based on Deep Learning and Convolutional Neural Network. In Proceedings of the 6th International Conference on Intelligent Computing and Signal (ICSP), Xi’an, China, 9–11 April 2021; pp. 816–819. [Google Scholar] [CrossRef]
- Hoang, V.T. BarkVN-50. Available online: https://data.mendeley.com/datasets/gbt4tdmttn/1 (accessed on 14 August 2023).
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Kavukcuoglu, K.; Wierstra, D. Matching Networks for One Shot Learning. arXiv 2017, arXiv:1606.04080. [Google Scholar]
- Jadon, S.; Jadon, A. An Overview of Deep Learning Architectures in Few-Shot Learning Domain. arXiv 2023, arXiv:2008.06365. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging Properties in Self-Supervised Vision Transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 9630–9640. [Google Scholar] [CrossRef]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jegou, H. Training Data-Efficient Image Transformers & Distillation through Attention. In Proceedings of the 38th International Conference on Machine Learning, PMLR, Virtual, 1 July 2021; pp. 10347–10357. [Google Scholar] [CrossRef]
- Zagoruyko, S.; Komodakis, N. Wide Residual Networks. arXiv 2017, arXiv:1605.07146. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Snell, J.; Swersky, K.; Zemel, R.S. Prototypical Networks for Few-Shot Learning. arXiv 2017, arXiv:1703.05175. [Google Scholar]
- Hou, M.; Sato, I. A Closer Look at Prototype Classifier for Few-Shot Image Classification. arXiv 2022, arXiv:2110.05076. [Google Scholar]
- Liu, T.; Ke, Z.; Li, Y.; Silamu, W. Knowledge-Enhanced Prototypical Network with Class Cluster Loss for Few-Shot Relation Classification. PLoS ONE 2023, 18, e0286915. [Google Scholar] [CrossRef]
- Gogoi, M.; Tiwari, S.; Verma, S. Adaptive Prototypical Networks. arXiv 2022, arXiv:2211.12479. [Google Scholar]
- Huang, K.; Geng, J.; Jiang, W.; Deng, X.; Xu, Z. Pseudo-Loss Confidence Metric for Semi-Supervised Few-Shot Learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 8671–8680. [Google Scholar] [CrossRef]
- Jang, H.; Lee, H.; Shin, J. Unsupervised Meta-Learning via Few-Shot Pseudo-Supervised Contrastive Learning. arXiv 2023, arXiv:2303.00996. [Google Scholar]
- Li, W.-H.; Liu, X.; Bilen, H. Improving Task Adaptation for Cross-Domain Few-Shot Learning. arXiv 2022, arXiv:2107.00358. [Google Scholar]
- Guo, Y.; Codella, N.C.; Karlinsky, L.; Codella, J.V.; Smith, J.R.; Saenko, K.; Rosing, T.; Feris, R. A Broader Study of Cross-Domain Few-Shot Learning. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 124–141. [Google Scholar] [CrossRef]
- Liu, B.; Wang, X.; Dixit, M.; Kwitt, R.; Vasconcelos, N. Feature Space Transfer for Data Augmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9090–9098. [Google Scholar] [CrossRef]
- Kumar, V.; Glaude, H.; de Lichy, C.; Campbell, W. A Closer Look At Feature Space Data Augmentation For Few-Shot Intent Classification. In Proceedings of the 2nd Workshop on Deep Learning Approaches for Low-Resource NLP, Hong Kong, China, 3 November 2019; pp. 1–10. [Google Scholar] [CrossRef]
- Chen, Z.; Fu, Y.; Zhang, Y.; Jiang, Y.-G.; Xue, X.; Sigal, L. Multi-Level Semantic Feature Augmentation for One-Shot Learning. IEEE Trans. Image Process 2019, 28, 4594–4605. [Google Scholar] [CrossRef]
- Liu, K.; Lyu, S.; Shivakumara, P.; Lu, Y. Few-Shot Object Segmentation with a New Feature Aggregation Module. Displays 2023, 78, 102459. [Google Scholar] [CrossRef]
- Peng, P.; Wang, J. How to Fine-Tune Deep Neural Networks in Few-Shot Learning? arXiv 2020, arXiv:2012.00204. [Google Scholar]
- Rogovschi, N.; Kitazono, J.; Grozavu, N.; Omori, T.; Ozawa, S. T-Distributed Stochastic Neighbor Embedding Spectral Clustering. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 1628–1632. [Google Scholar] [CrossRef]
- Omeiza, D.; Speakman, S.; Cintas, C.; Weldermariam, K. Smooth Grad-CAM++: An Enhanced Inference Level Visualization Technique for Deep Convolutional Neural Network Models. arXiv 2019, arXiv:1908.01224. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Domain | Dataset | Collaborators | Categories | Images | Meta-Dataset |
|---|---|---|---|---|---|
| Tree species classification | BarkNet 1.0 | Carpentier et al. (2018) [45] | 23 | 23,616 | 20 × 600 |
| BarkNJ | Ours (2023) [47] | 20 | 14,681 | 20 × 600 | |
| BarkNetV3 | Ours (2023) [45,47] | 40 | 24,000 | 40 × 600 | |
| BarkVN50 | Truong Hoang (2017) [51] | 50 | 5578 | 50 × 80 | |
| BarkKR | Tae Kyung et al. (2022) [46] | 54 | 6918 | 25 × 50 | |
| Leaf Diseases | PlantVillage | Hughes et al. (2015) [48] | 40 | 61,484 | 38 × 600 |
| Crop Diseases | Agricultural Diseases | Xulang Guan et al. (2021) [50] | 60 | 36,258 | 55 × 100 |
| Flower Identification | Flowers 102 | Nilsback et al. (2008) [49] | 102 | 8189 | 85 × 40 |
| Multi-Classification | mini-ImageNet | Vinyals et al. (2016) [52] | 100 | 60,000 | 100 × 600 |
| Full-Dataset | Hu et al. (2022) [44] | 8 datasets | - | - |
| Dataset | Backbone | nEpisode | Lr | DWCP (%) | nQuery | nClsEpisode |
|---|---|---|---|---|---|---|
| BarkVN50 | DINO-ViT | (200, 300) | 5 × 10−4 | (20, 10, 10, 20) | 15 | 5 |
| DeiT-ViT | (200, 300) | 5 × 10−4 | (20, 10, 10, 20) | 15 | 5 | |
| ResNet | (300, 500) | 1 × 10−4 | (20, 10, 20, 10) | 15 | 5 | |
| DINO-ResNet | (200, 300) | 1 × 10−4 | (20, 10, 20, 10) | 15 | 5 | |
| BarkNetV3 | DINO-ViT | (200, 500) | 5 × 10−4 | (10, 10, 10, 20) | 15 | 5 |
| DeiT-ViT | (200, 500) | 5 × 10−4 | (10, 10, 10, 20) | 15 | 5 | |
| ResNet | (300, 500) | 1 × 10−4 | (10, 10, 20, 10) | 15 | 5 | |
| DINO-ResNet | (200, 500) | 1 × 10−4 | (10, 10, 20, 10) | 15 | 5 |
| Dataset | Backbone | Accuracy (1-Shot) | Loss (1-Shot) | Accuracy (5-Shot) | Loss (5-Shot) | Saturation |
|---|---|---|---|---|---|---|
| BarkVN50 | DINO-ViT | 71.81% | 0.744 | 82.81% | 0.504 | 25–26th |
| DeiT-ViT | 67.37% | 0.893 | 80.37% | 0.683 | 21–25th | |
| ResNet | 60.59% | 1.044 | 74.59% | 0.754 | 24–28th | |
| DINO-ResNet | 64.80% | 1.139 | 77.80% | 0.859 | 20–27th | |
| BarkNetV3 | DINO-ViT | 62.08% | 1.034 | 74.08% | 0.774 | 26–28th |
| DeiT-ViT | 60.26% | 1.103 | 72.26% | 0.803 | 22–28th | |
| ResNet | 57.78% | 1.112 | 67.78% | 0.862 | 24–30th | |
| DINO-ResNet | 60.35% | 1.217 | 71.35% | 0.977 | 23–30th |
| Train on | Test on | 1-Shot (%) | Loss | 5-Shot (%) | Loss |
|---|---|---|---|---|---|
| BarkVN50 | BarkVN50 (I) | 88.78 ± 0.99 | 0.339 | 96.95 ± 0.42 | 0.119 |
| BarkNetV3 (I) | 81.64 ± 1.33 | 0.527 | 93.30 ± 0.73 | 0.242 | |
| BarkKR (I) | 63.28 ± 1.44 | 1.010 | 82.91 ± 1.07 | 0.494 | |
| Agricultural Disease (O) | 82.05 ± 1.43 | 0.508 | 94.07 ± 0.82 | 0.460 | |
| PlantVillage (O) | 81.57 ± 1.26 | 0.705 | 93.96 ± 0.65 | 0.332 | |
| Flowers (O) | 81.01 ± 1.34 | 0.592 | 95.37 ± 0.63 | 0.501 | |
| BarkNetV3 | BarkVN50 (I) | 77.24 ± 1.30 | 0.655 | 92.04 ± 0.68 | 0.319 |
| BarkNetV3 (I) | 83.91 ± 1.17 | 0.449 | 93.39 ± 0.67 | 0.204 | |
| BarkKR (I) | 59.53 ± 1.54 | 1.136 | 80.21 ± 1.08 | 0.554 | |
| Agricultural Disease (O) | 76.21 ± 1.46 | 0.676 | 90.55 ± 0.95 | 0.354 | |
| PlantVillage (O) | 75.35 ± 1.41 | 0.778 | 90.15 ± 0.87 | 0.340 | |
| Flowers (O) | 78.47 ± 1.61 | 0.722 | 94.65 ± 0.61 | 0.467 | |
| mini-ImageNet | BarkVN50 (O) | 79.73 ± 1.27 | 0.594 | 94.85 ± 0.55 | 0.447 |
| BarkNetV3 (O) | 77.25 ± 1.49 | 0.707 | 91.47 ± 0.71 | 0.463 | |
| BarkKR (O) | 56.97 ± 1.50 | 0.567 | 79.70 ± 1.19 | 0.708 | |
| Agricultural Disease (O) | 79.95 ± 1.50 | 0.645 | 93.88 ± 0.86 | 0.318 | |
| PlantVillage (O) | 80.10 ± 1.34 | 0.753 | 92.33 ± 0.79 | 0.291 | |
| Flowers (I) | 83.84 ± 1.42 | 0.873 | 96.95 ± 0.39 | 0.252 | |
| Full-Dataset | BarkVN50 (O) | 68.91 ± 1.35 | 0.864 | 88.79 ± 0.83 | 0.375 |
| BarkNetV3 (O) | 62.88 ± 1.41 | 1.038 | 84.91 ± 0.96 | 0.468 | |
| BarkKR (O) | 51.86 ± 1.58 | 1.298 | 74.71 ± 1.32 | 0.712 | |
| Agricultural Disease (O) | 73.55 ± 1.63 | 0.724 | 91.01 ± 0.94 | 0.322 | |
| PlantVillage (O) | 68.57 ± 1.53 | 0.873 | 91.17 ± 0.88 | 0.346 | |
| Flowers (I) | 95.93 ± 0.64 | 0.152 | 98.97 ± 0.25 | 0.044 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, Z.; Li, K.; Kang, C.; Wu, Y.; Li, T.; Li, M. Plant and Disease Recognition Based on PMF Pipeline Domain Adaptation Method: Using Bark Images as Meta-Dataset. Plants 2023, 12, 3280. https://doi.org/10.3390/plants12183280
Cui Z, Li K, Kang C, Wu Y, Li T, Li M. Plant and Disease Recognition Based on PMF Pipeline Domain Adaptation Method: Using Bark Images as Meta-Dataset. Plants. 2023; 12(18):3280. https://doi.org/10.3390/plants12183280
Chicago/Turabian StyleCui, Zhelin, Kanglong Li, Chunyan Kang, Yi Wu, Tao Li, and Mingyang Li. 2023. "Plant and Disease Recognition Based on PMF Pipeline Domain Adaptation Method: Using Bark Images as Meta-Dataset" Plants 12, no. 18: 3280. https://doi.org/10.3390/plants12183280
APA StyleCui, Z., Li, K., Kang, C., Wu, Y., Li, T., & Li, M. (2023). Plant and Disease Recognition Based on PMF Pipeline Domain Adaptation Method: Using Bark Images as Meta-Dataset. Plants, 12(18), 3280. https://doi.org/10.3390/plants12183280