A Review of Techniques for 3D Reconstruction of Indoor Environments



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
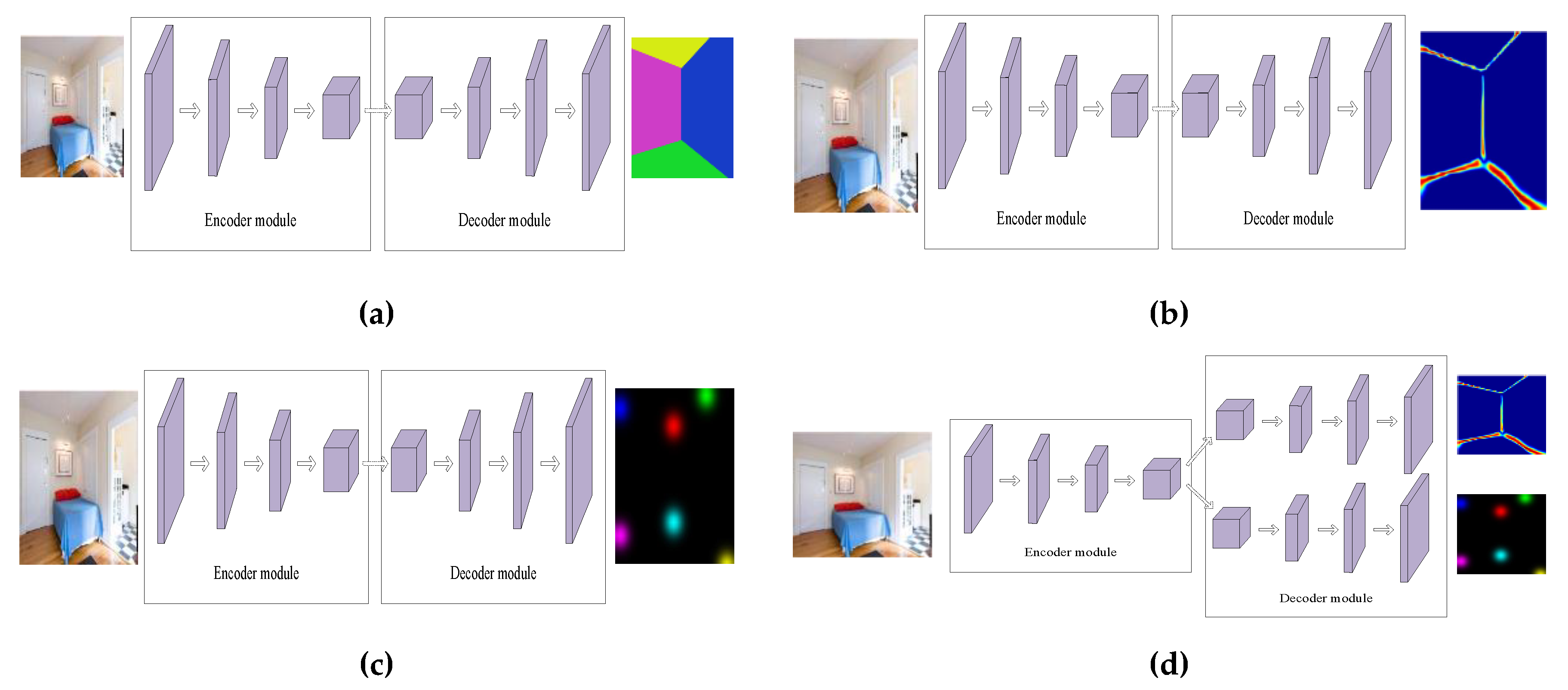{kind=link}
{kind=link}
{kind=link}
{kind=link}
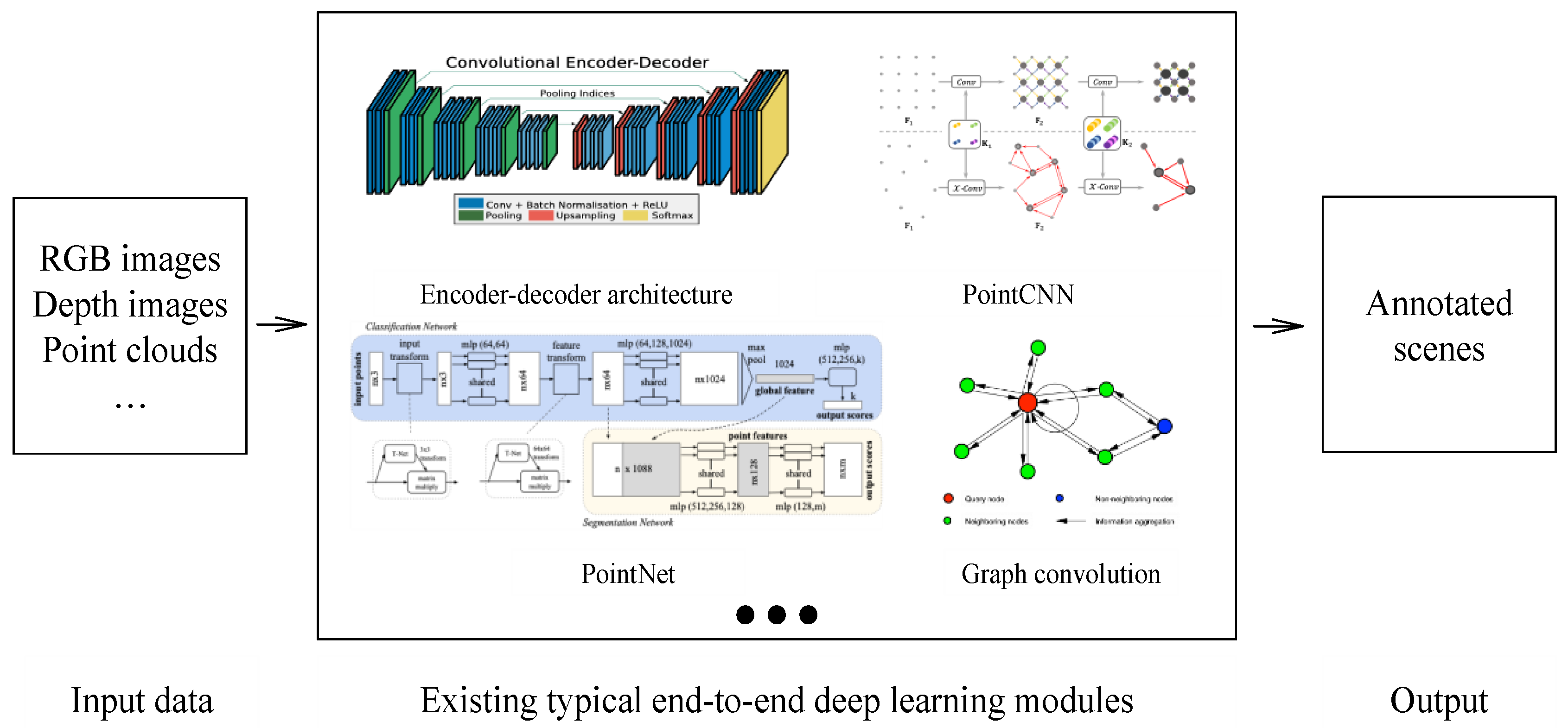{kind=link}
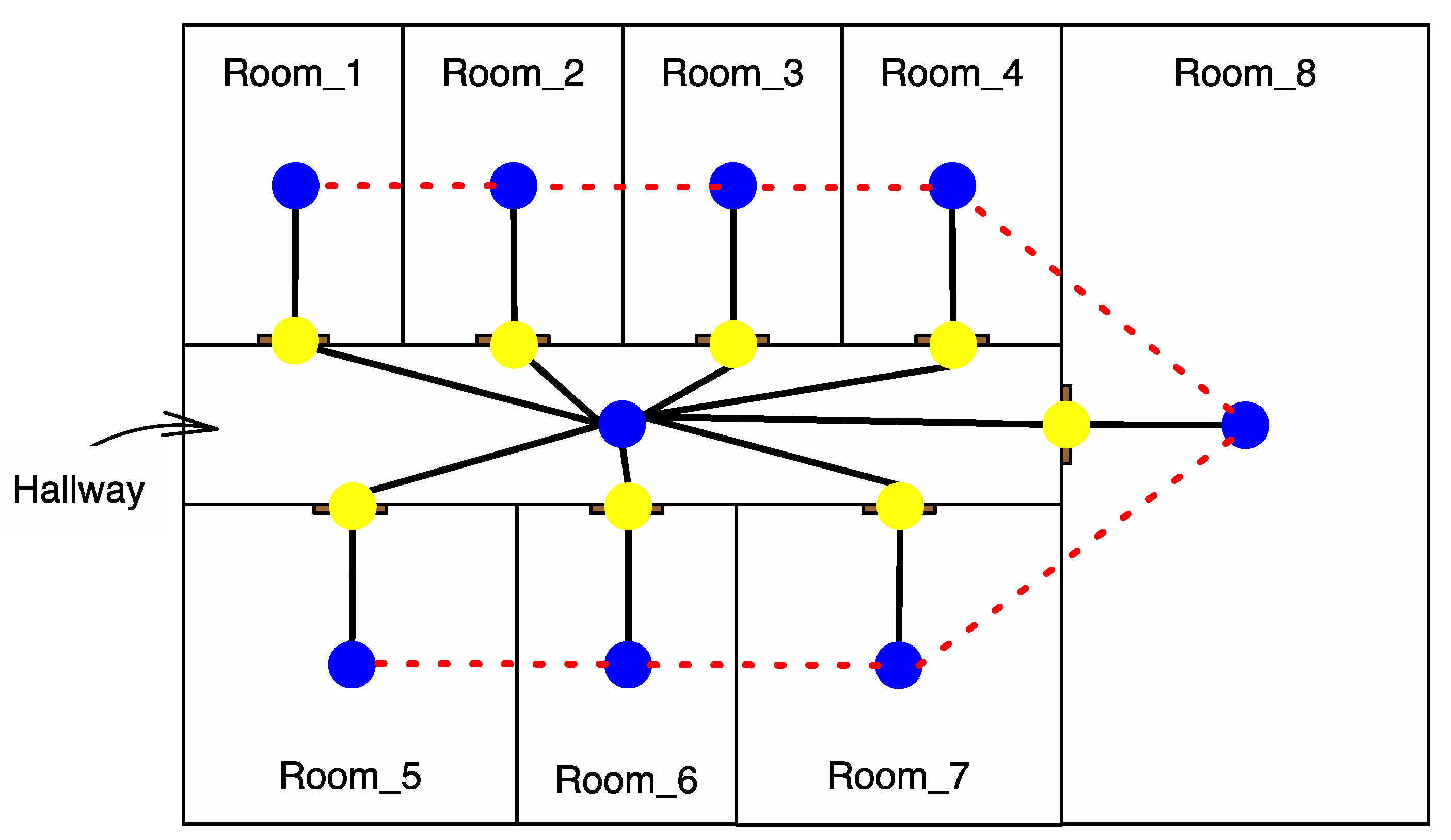{kind=link}
Abstract
1. Introduction
2. Benchmark Datasets
2.1. Geometric Modeling Benchmark Datasets
2.1.1. Imperial College London and National University of Ireland Maynooth (ICL-NUIM)
2.1.2. Technical University of Munich (TUM)
2.1.3. European Robotics Challenge (EuRoc)
2.1.4. Multisensory Indoor Mapping and Position (MiMAP)
2.1.5. International Society for Photogrammetry and Remote Sensing (ISPRS) Benchmark on Indoor Modeling
2.2. Semantic Modeling Benchmark Datasets
2.2.1. SUN RGB-D
2.2.2. ScanNet
2.2.3. New York University (NYU) Depth
2.2.4. Stanford Two-Dimensional-Three-Dimensional (2D-3D)-Semantic Dataset
2.2.5. Matterport3D
3. Data Collection of 3D Indoor Spaces
3.1. Single-View Depth Estimation
3.2. Multi-View Depth Estimation
3.3. Simultaneous Localization and Mapping (SLAM)
4. Overview of the Research Methodology for 3D Reconstruction of Indoor Environments
4.1. Geometry Modeling
4.1.1. Polygonal-Structured Model
4.1.2. Room Layout Estimation
4.1.3. Indoor–Outdoor Seamless Modeling
4.2. Semantic Modeling
4.3. Topological Modeling
5. Trends and Challenges
5.1. Non-Manhattan Assumption
5.2. Multi-Task Collaborative Optimization
5.3. Indoor Scene Understanding by Combining Both Spatial and Temporal Consistencies
5.4. Automatic Reconstruction of Indoor Models with Different Levels of Detail
5.5. Indoor–Outdoor Space Seamless Integration
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- US Environmental Protection Agency. Buildings and Their Impact on the Environment: A Statistical Summary; US Environmental Protection Agency Green Building Workgroup: Washington, DC, USA, 2009.
- Dasgupta, S.; Fang, K.; Chen, K.; Savarese, S. Delay: Robust spatial layout estimation for cluttered indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 616–624. [Google Scholar]
- Husain, F.; Schulz, H.; Dellen, B.; Torras, C.; Behnke, S. Combining semantic and geometric features for object class segmentation of indoor scenes. IEEE Robot. Autom. Lett. 2016, 2, 49–55. [Google Scholar] [CrossRef]
- Sequeira, V.; Gonçalves, J.G.; Ribeiro, M.I. 3D reconstruction of indoor environments. In Proceedings of the 3rd IEEE International Conference on Image Processing, Lausanne, Switzerland, 19 September 1996; pp. 405–408. [Google Scholar]
- Isikdag, U.; Zlatanova, S.; Underwood, J. A BIM-Oriented Model for supporting indoor navigation requirements. Comput. Environ. Urban Syst. 2013, 41, 112–123. [Google Scholar] [CrossRef]
- Ahmed, A.A.; Al-Shaboti, M.; Al-Zubairi, A. An indoor emergency guidance algorithm based on wireless sensor networks. In Proceedings of the 2015 International Conference on Cloud Computing (ICCC), Riyadh, Saudi Arabia, 26–29 April 2015; pp. 1–5. [Google Scholar]
- Chen, C.; Tang, L. BIM-based integrated management workflow design for schedule and cost planning of building fabric maintenance. Autom. Constr. 2019, 107, 102944. [Google Scholar] [CrossRef]
- Tian, X.; Shen, R.; Liu, D.; Wen, Y.; Wang, X. Performance analysis of RSS fingerprinting based indoor localization. IEEE Trans. Mob. Comput. 2016, 16, 2847–2861. [Google Scholar] [CrossRef]
- Chen, K.; Lai, Y.-K.; Hu, S.-M. 3D indoor scene modeling from RGB-D data: A survey. Comput. Vis. Media 2015, 1, 267–278. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, Z.; Miao, Z.; Wu, W.; Liu, K.; Sun, Z. Single image-based data-driven indoor scene modeling. Comput. Graph. 2015, 53, 210–223. [Google Scholar] [CrossRef]
- Engel, J.; Stückler, J.; Cremers, D. Large-scale direct SLAM with stereo cameras. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 1935–1942. [Google Scholar]
- Leiva, J.; Martinez, P.; Perez, E.; Urdiales, C.; Sandoval, F. 3D reconstruction of static indoor environment by fusion of sonar and video data. In Proceedings of the International Symposium on Intelligent Robotic Systems, Toulouse, France, 18–20 July 2001. [Google Scholar]
- Yang, H.; Zhang, H. Modeling room structure from indoor panorama. In Proceedings of the 13th ACM SIGGRAPH International Conference on Virtual-Reality Continuum and Its Applications in Industry, Shenzhen, China, 30 November–2 December 2014; pp. 47–55. [Google Scholar]
- Wang, C.; Hou, S.; Wen, C.; Gong, Z.; Li, Q.; Sun, X.; Li, J. Semantic line framework-based indoor building modeling using backpacked laser scanning point cloud. ISPRS J. Photogramm. Remote Sens. 2018, 143, 150–166. [Google Scholar] [CrossRef]
- Bokaris, P.-A.; Muselet, D.; Trémeau, A. 3D reconstruction of indoor scenes using a single RGB-D image. In Proceedings of the 12th International Conference on Computer Vision Theory and Applications (VISAPP 2017), Porto, Portugal, 27 February–1 March 2017. [Google Scholar]
- Valentin, J.P.; Sengupta, S.; Warrell, J.; Shahrokni, A.; Torr, P.H. Mesh based semantic modelling for indoor and outdoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2067–2074. [Google Scholar]
- Jung, J.; Hong, S.; Yoon, S.; Kim, J.; Heo, J. Automated 3D wireframe modeling of indoor structures from point clouds using constrained least-squares adjustment for as-built BIM. J. Comput. Civ. Eng. 2015, 30, 04015074. [Google Scholar] [CrossRef]
- Shao, T.; Xu, W.; Zhou, K.; Wang, J.; Li, D.; Guo, B. An interactive approach to semantic modeling of indoor scenes with an rgbd camera. ACM Trans. Graph. TOG 2012, 31, 136. [Google Scholar] [CrossRef]
- Ochmann, S.; Vock, R.; Wessel, R.; Klein, R. Automatic reconstruction of parametric building models from indoor point clouds. Comput. Graph. 2016, 54, 94–103. [Google Scholar] [CrossRef]
- Yang, F.; Zhou, G.; Su, F.; Zuo, X.; Tang, L.; Liang, Y.; Zhu, H.; Li, L. Automatic Indoor Reconstruction from Point Clouds in Multi-room Environments with Curved Walls. Sensors 2019, 19, 3798. [Google Scholar] [CrossRef] [PubMed]
- Froese, T.; Grobler, F.; Ritzenthaler, J.; Yu, K.; Akinci, B.; Akbas, R.; Koo, B.; Barron, A.; Kunz, J.C. Industry Foundation Classes for Project Management-A Trial Implementation. ITcon 1999, 4, 17–36. [Google Scholar]
- Gröger, G.; Kolbe, T.H.; Nagel, C.; Häfele, K.-H. OGC City Geography Markup Language (CityGML) Encoding Standard; Open Geospatial Consortium, 2012. Available online: http://www.opengis.net/spec/citygml/2.0 (accessed on 17 May 2020).
- Naseer, M.; Khan, S.; Porikli, F. Indoor scene understanding in 2.5/3d for autonomous agents: A survey. IEEE Access 2018, 7, 1859–1887. [Google Scholar] [CrossRef]
- Li, Y.; Dai, A.; Guibas, L.; Nießner, M. Database-assisted object retrieval for real-time 3d reconstruction. Computer Graph. Forum 2015, 34, 435–446. [Google Scholar] [CrossRef]
- Schwing, A.G.; Hazan, T.; Pollefeys, M.; Urtasun, R. Efficient structured prediction for 3d indoor scene understanding. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2815–2822. [Google Scholar]
- Handa, A.; Whelan, T.; McDonald, J.; Davison, A.J. A benchmark for RGB-D visual odometry, 3D reconstruction and SLAM. In Proceedings of the 2014 IEEE international conference on Robotics and automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 1524–1531. [Google Scholar]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar]
- Burri, M.; Nikolic, J.; Gohl, P.; Schneider, T.; Rehder, J.; Omari, S.; Achtelik, M.W.; Siegwart, R. The EuRoC micro aerial vehicle datasets. Int. J. Robot. Res. 2016, 35, 1157–1163. [Google Scholar] [CrossRef]
- Wang, C.; Dai, Y.; El-Sheimy, N.; Wen, C.; Retscher, G.; Kang, Z.; Lingua, A. Progress on Isprs Benchmark on Multisensory Indoor Mapping and Positioning. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, XLII-2/W13, 1709–1713. [Google Scholar] [CrossRef]
- Khoshelham, K.; Vilariño, L.D.; Peter, M.; Kang, Z.; Acharya, D. The Isprs Benchmark on Indoor Modelling. Int. Arch. Photogramm. Remote Sen. Spat. Inf. Sci. 2017, 42, 367–372. [Google Scholar] [CrossRef]
- Song, S.; Lichtenberg, S.P.; Xiao, J. Sun rgb-d: A rgb-d scene understanding benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 567–576. [Google Scholar]
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Nießner, M. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Barcelona, Spain, 6–13 November 2011; pp. 5828–5839. [Google Scholar]
- Silberman, N.; Fergus, R. Indoor scene segmentation using a structured light sensor. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 601–608. [Google Scholar]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor segmentation and support inference from rgbd images. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Armeni, I.; Sax, S.; Zamir, A.R.; Savarese, S. Joint 2d-3d-semantic data for indoor scene understanding. arXiv 2017, arXiv:1702.01105. [Google Scholar]
- Chang, A.; Dai, A.; Funkhouser, T.; Halber, M.; Niessner, M.; Savva, M.; Song, S.; Zeng, A.; Zhang, Y. Matterport3d: Learning from rgb-d data in indoor environments. arXiv 2017, arXiv:1709.06158. [Google Scholar]
- Marck, J.W.; Mohamoud, A.; vd Houwen, E.; van Heijster, R. Indoor radar SLAM A radar application for vision and GPS denied environments. In Proceedings of the 2013 European Radar Conference, Nuremberg, Germany, 9–11 October 2013; pp. 471–474. [Google Scholar]
- van Dijk, T.; de Croon, G.C. How Do Neural Networks See Depth in Single Images? In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 2183–2191. [Google Scholar]
- Liu, M.; Salzmann, M.; He, X. Discrete-continuous depth estimation from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 716–723. [Google Scholar]
- Zhuo, W.; Salzmann, M.; He, X.; Liu, M. Indoor scene structure analysis for single image depth estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 614–622. [Google Scholar]
- Eder, M.; Moulon, P.; Guan, L. Pano Popups: Indoor 3D Reconstruction with a Plane-Aware Network. In Proceedings of the 2019 International Conference on 3D Vision (3DV), Québec, QC, Canada, 16–19 September 2019; pp. 76–84. [Google Scholar]
- Roy, A.; Todorovic, S. Monocular depth estimation using neural regression forest. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5506–5514. [Google Scholar]
- Liu, F.; Shen, C.; Lin, G. Deep convolutional neural fields for depth estimation from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5162–5170. [Google Scholar]
- Goldlücke, B.; Aubry, M.; Kolev, K.; Cremers, D. A super-resolution framework for high-accuracy multiview reconstruction. Int. J. Comput. Vis. 2014, 106, 172–191. [Google Scholar] [CrossRef]
- Collins, R.T. A space-sweep approach to true multi-image matching. In Proceedings of the CVPR IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 18–20 June 1996; pp. 358–363. [Google Scholar]
- Furukawa, Y.; Ponce, J. Accurate, dense, and robust multiview stereopsis. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1362–1376. [Google Scholar] [CrossRef] [PubMed]
- Galliani, S.; Lasinger, K.; Schindler, K. Massively parallel multiview stereopsis by surface normal diffusion. In Proceedings of the IEEE International Conference on Computer Vision, Las Condes, Chile, 11–18 December 2015; pp. 873–881. [Google Scholar]
- Langguth, F.; Sunkavalli, K.; Hadap, S.; Goesele, M. Shading-aware multi-view stereo. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Häne, C.; Zach, C.; Cohen, A.; Pollefeys, M. Dense semantic 3d reconstruction. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1730–1743. [Google Scholar] [CrossRef] [PubMed]
- Ullman, S. The interpretation of structure from motion. Proc. R. Soc. Lond. Ser. B Biol. Sci. 1979, 203, 405–426. [Google Scholar]
- Hartmann, W.; Galliani, S.; Havlena, M.; Van Gool, L.; Schindler, K. Learned multi-patch similarity. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1586–1594. [Google Scholar]
- Ji, M.; Gall, J.; Zheng, H.; Liu, Y.; Fang, L. Surfacenet: An end-to-end 3d neural network for multiview stereopsis. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2307–2315. [Google Scholar]
- Huang, P.-H.; Matzen, K.; Kopf, J.; Ahuja, N.; Huang, J.-B. Deepmvs: Learning multi-view stereopsis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2821–2830. [Google Scholar]
- Yao, Y.; Luo, Z.; Li, S.; Fang, T.; Quan, L. Mvsnet: Depth inference for unstructured multi-view stereo. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 767–783. [Google Scholar]
- Yao, Y.; Luo, Z.; Li, S.; Shen, T.; Fang, T.; Quan, L. Recurrent mvsnet for high-resolution multi-view stereo depth inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5525–5534. [Google Scholar]
- Bailey, T.; Durrant-Whyte, H. Simultaneous localization and mapping (SLAM): Part II. IEEE Robot. Autom. Mag. 2006, 13, 108–117. [Google Scholar] [CrossRef]
- Aouina, A.; Devy, M.; Hernandez, A.M. 3d modeling with a moving tilting laser sensor for indoor environments. IFAC Proc. Vol. 2014, 47, 7604–7609. [Google Scholar] [CrossRef]
- Salas-Moreno, R.F.; Newcombe, R.A.; Strasdat, H.; Kelly, P.H.; Davison, A.J. Slam++: Simultaneous localisation and mapping at the level of objects. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1352–1359. [Google Scholar]
- Davison, A.J.; Reid, I.D.; Molton, N.D.; Stasse, O. MonoSLAM: Real-time single camera SLAM. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1052–1067. [Google Scholar] [CrossRef]
- Schulz, V.H.; Bombardelli, F.G.; Todt, E. A SoC with FPGA Landmark Acquisition System for Binocular Visual SLAM. In Proceedings of the 2015 12th Latin American Robotics Symposium and 2015 3rd Brazilian Symposium on Robotics (LARS-SBR), Uberlândia, Brazil, 28 October 28–1 November 2015; pp. 336–341. [Google Scholar]
- Leonard, J.J.; Durrant-Whyte, H.F. Mobile robot localization by tracking geometric beacons. IEEE Trans. Robot. Autom. 1991, 7, 376–382. [Google Scholar] [CrossRef]
- Gomez-Ojeda, R.; Briales, J.; Gonzalez-Jimenez, J. PL-SVO: Semi-direct Monocular Visual Odometry by combining points and line segments. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 4211–4216. [Google Scholar]
- Pumarola, A.; Vakhitov, A.; Agudo, A.; Sanfeliu, A.; Moreno-Noguer, F. PL-SLAM: Real-time monocular visual SLAM with points and lines. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 4503–4508. [Google Scholar]
- Wang, R.; Di, K.; Wan, W.; Wang, Y. Improved Point-Line Feature Based Visual SLAM Method for Indoor Scenes. Sensors 2018, 18, 3559. [Google Scholar] [CrossRef]
- Bowman, S.L.; Atanasov, N.; Daniilidis, K.; Pappas, G.J. Probabilistic data association for semantic slam. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1722–1729. [Google Scholar]
- So, C.; Baciu, G.; Sun, H. Reconstruction of 3D virtual buildings from 2D architectural floor plans. In Proceedings of the ACM Symposium on Virtual Reality Software and Technology, Taipei, Taiwan, 2–5 November 1998; pp. 17–23. [Google Scholar]
- Lu, T.; Tai, C.-L.; Bao, L.; Su, F.; Cai, S. 3D reconstruction of detailed buildings from architectural drawings. Comput. Aided Des. Appl. 2005, 2, 527–536. [Google Scholar] [CrossRef]
- Lee, S.; Feng, D.; Grimm, C.; Gooch, B. A Sketch-Based User Interface for Reconstructing Architectural Drawings. Comput. Graph. Forum 2008, 27, 81–90. [Google Scholar] [CrossRef]
- Horna, S.; Meneveaux, D.; Damiand, G.; Bertrand, Y. Consistency constraints and 3D building reconstruction. Comput. Aided Des. 2009, 41, 13–27. [Google Scholar] [CrossRef]
- Li, T.; Shu, B.; Qiu, X.; Wang, Z. Efficient reconstruction from architectural drawings. Int. J. Comput. Appl. Technol. 2010, 38, 177–184. [Google Scholar] [CrossRef]
- Yin, X.; Wonka, P.; Razdan, A. Generating 3d building models from architectural drawings: A survey. IEEE Comput. Graph. Appl. 2008, 29, 20–30. [Google Scholar] [CrossRef] [PubMed]
- Ning, X.; Ma, J.; Lv, Z.; Xu, Q.; Wang, Y. Structure Reconstruction of Indoor Scene from Terrestrial Laser Scanner. In International Conference on E-Learning and Games; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Edelsbrunner, H. Alpha shapes—A survey. Tessellations Sci. 2010, 27, 1–25. [Google Scholar]
- Previtali, M.; Díaz-Vilariño, L.; Scaioni, M. Indoor building reconstruction from occluded point clouds using graph-cut and ray-tracing. Appl. Sci. 2018, 8, 1529. [Google Scholar] [CrossRef]
- Kang, Z.; Zhong, R.; Wu, A.; Shi, Z.; Luo, Z. An efficient planar feature fitting method using point cloud simplification and threshold-independent BaySAC. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1842–1846. [Google Scholar] [CrossRef]
- Jung, J.; Hong, S.; Jeong, S.; Kim, S.; Cho, H.; Hong, S.; Heo, J. Productive modeling for development of as-built BIM of existing indoor structures. Autom. Constr. 2014, 42, 68–77. [Google Scholar] [CrossRef]
- Wang, C.; Cho, Y.K.; Kim, C. Automatic BIM component extraction from point clouds of existing buildings for sustainability applications. Autom. Constr. 2015, 56, 1–13. [Google Scholar] [CrossRef]
- Shi, W.; Ahmed, W.; Li, N.; Fan, W.; Xiang, H.; Wang, M. Semantic Geometric Modelling of Unstructured Indoor Point Cloud. ISPRS Int. J. Geo-Inf. 2019, 8, 9. [Google Scholar] [CrossRef]
- Hong, S.; Jung, J.; Kim, S.; Cho, H.; Lee, J.; Heo, J. Semi-automated approach to indoor mapping for 3D as-built building information modeling. Comput. Environ. Urban Syst. 2015, 51, 34–46. [Google Scholar] [CrossRef]
- Michailidis, G.-T.; Pajarola, R. Bayesian graph-cut optimization for wall surfaces reconstruction in indoor environments. Vis. Comput. 2017, 33, 1347–1355. [Google Scholar] [CrossRef]
- Mura, C.; Mattausch, O.; Villanueva, A.J.; Gobbetti, E.; Pajarola, R. Automatic room detection and reconstruction in cluttered indoor environments with complex room layouts. Comput. Graph. 2014, 44, 20–32. [Google Scholar] [CrossRef]
- Tang, S.; Zhang, Y.; Li, Y.; Yuan, Z.; Wang, Y.; Zhang, X.; Li, X.; Zhang, Y.; Guo, R.; Wang, W. Fast and Automatic Reconstruction of Semantically Rich 3D Indoor Maps from Low-quality RGB-D Sequences. Sensors 2019, 19, 533. [Google Scholar] [CrossRef]
- Wang, R.; Xie, L.; Chen, D. Modeling indoor spaces using decomposition and reconstruction of structural elements. Photogramm. Eng. Remote Sens. 2017, 83, 827–841. [Google Scholar] [CrossRef]
- Li, L.; Su, F.; Yang, F.; Zhu, H.; Li, D.; Zuo, X.; Li, F.; Liu, Y.; Ying, S. Reconstruction of Three-Dimensional (3D) Indoor Interiors with Multiple Stories via Comprehensive Segmentation. Remote Sens. 2018, 10, 1281. [Google Scholar] [CrossRef]
- Pang, Y.; Zhang, C.; Zhou, L.; Lin, B.; Lv, G. Extracting Indoor Space Information in Complex Building Environments. ISPRS Int. J. Geo-Inf. 2018, 7, 321. [Google Scholar] [CrossRef]
- Chen, J.; Chen, B. Architectural modeling from sparsely scanned range data. Int. J. Comput. Vis. 2008, 78, 223–236. [Google Scholar] [CrossRef]
- Chen, K.; Lai, Y.; Wu, Y.-X.; Martin, R.R.; Hu, S.-M. Automatic semantic modeling of indoor scenes from low-quality RGB-D data using contextual information. ACM Trans. Graph. 2014, 33, 208. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, Y.; Wu, W.; Liu, K.; Sun, Z. Model-driven indoor scenes modeling from a single image. In Proceedings of the 41st Graphics Interface Conference, Halifax, NS, Canada, 3–5 June 2015. [Google Scholar]
- Tran, H.; Khoshelham, K.; Kealy, A. Geometric comparison and quality evaluation of 3D models of indoor environments. ISPRS J. Photogramm. Remote Sens. 2019, 149, 29–39. [Google Scholar] [CrossRef]
- Chen, J.; Shao, J.; Zhang, D.; Wu, X. A Fast End-to-End Method with Style Transfer for Room Layout Estimation. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 964–969. [Google Scholar]
- Fernandez-Labrador, C.; Facil, J.M.; Perez-Yus, A.; Demonceaux, C.; Civera, J.; Guerrero, J.J. Corners for Layout: End-to-End Layout Recovery from 360 Images. arXiv 2019, arXiv:1903.08094. [Google Scholar] [CrossRef]
- Lin, H.J.; Huang, S.W.; Lai, S.H.; Chiang, C.K. Indoor scene layout estimation from a single image. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018. [Google Scholar]
- Zhang, W.; Zhang, W.; Liu, K.; Gu, J. Learning to predict high-quality edge maps for room layout estimation. IEEE Trans. Multimed. 2016, 19, 935–943. [Google Scholar] [CrossRef]
- Lee, C.-Y.; Badrinarayanan, V.; Malisiewicz, T.; Rabinovich, A. Roomnet: End-to-end room layout estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4865–4874. [Google Scholar]
- Zou, C.; Colburn, A.; Shan, Q.; Doiem, D. Layoutnet: Reconstructing the 3d room layout from a single rgb image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 18–23 June 2018. [Google Scholar]
- Hedau, V.; Hoiem, D.; Forsyth, D. Recovering the spatial layout of cluttered rooms. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009. [Google Scholar]
- Chao, Y.-W.; Choi, W.; Pantofaru, C.; Savarese, S. Layout estimation of highly cluttered indoor scenes using geometric and semantic cues. In International Conference on Image Analysis and Processing; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Park, S.-J.; Hong, K.-S. Recovering an indoor 3D layout with top-down semantic segmentation from a single image. Pattern Recognit. Lett. 2015, 68, 70–75. [Google Scholar] [CrossRef]
- Mallya, A.; Lazebnik, S. Learning informative edge maps for indoor scene layout prediction. In Proceedings of the IEEE International Conference on Computer Vision, Las Condes, Chile, 11–18 December 2015; pp. 936–944. [Google Scholar]
- Jahromi, A.B.; Sohn, G. Edge Based 3d Indoor Corridor Modeling Using a Single Image. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, 2. [Google Scholar]
- Hirzer, M.; Roth, P.M.; Lepetit, V. Smart Hypothesis Generation for Efficient and Robust Room Layout Estimation. arXiv 2019, arXiv:1910.12257. [Google Scholar]
- Chang, H.-C.; Huang, S.-H.; Lai, S.-H. Using line consistency to estimate 3D indoor Manhattan scene layout from a single image. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec, QC, Canada, 27–30 September 2015; pp. 4723–4727. [Google Scholar]
- Kruzhilov, I.; Romanov, M.; Konushin, A. Double Refinement Network for Room Layout Estimation. In Asian Conference on Pattern Recognition; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Gupta, A.; Hebert, M.; Kanade, T.; Blei, D.M. Estimating spatial layout of rooms using volumetric reasoning about objects and surfaces. In Advances in Neural Information Processing Systems; Curran Associates, Inc., 2010; pp. 1288–1296. Available online: http://papers.nips.cc/paper/4120-estimating-spatial-layout-of-rooms-using-volumetric-reasoning-about-objects-and-surfaces.pdf (accessed on 17 May 2020).
- Del Pero, L.; Bowdish, J.; Fried, D.; Kermgard, B.; Hartley, E.; Barnard, K. Bayesian geometric modeling of indoor scenes. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2719–2726. [Google Scholar]
- Schwing, A.G.; Fidler, S.; Pollefeys, M.; Urtasun, R. Box in the box: Joint 3d layout and object reasoning from single images. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 353–360. [Google Scholar]
- Zhang, J.; Kan, C.; Schwing, A.G.; Urtasun, R. Estimating the 3d layout of indoor scenes and its clutter from depth sensors. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1273–1280. [Google Scholar]
- Bao, S.Y.; Furlan, A.; Fei-Fei, L.; Savarese, S. Understanding the 3D layout of a cluttered room from multiple images. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Steamboat Springs, CO, USA, 24–26 March 2014; pp. 690–697. [Google Scholar]
- Zhang, W.; Zhang, W.; Gu, J. Edge-semantic learning strategy for layout estimation in indoor environment. IEEE Trans. Cybern. 2020, 50, 2730–2739. [Google Scholar] [CrossRef] [PubMed]
- Cohen, A.; Schönberger, J.L.; Speciale, P.; Sattler, T.; Frahm, J.-M.; Pollefeys, M. Indoor-outdoor 3d reconstruction alignment. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 285–300. [Google Scholar]
- Koch, T.; Korner, M.; Fraundorfer, F. Automatic alignment of indoor and outdoor building models using 3D line segments. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Khan, S.H.; Bennamoun, M.; Sohel, F.; Togneri, R. Geometry driven semantic labeling of indoor scenes. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Ren, X.; Bo, L.; Fox, D. Rgb-(d) scene labeling: Features and algorithms. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2759–2766. [Google Scholar]
- Gupta, S.; Arbelaez, P.; Malik, J. Perceptual organization and recognition of indoor scenes from RGB-D images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 564–571. [Google Scholar]
- Müller, A.C.; Behnke, S. Learning depth-sensitive conditional random fields for semantic segmentation of RGB-D images. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 6232–6237. [Google Scholar]
- Deng, Z.; Todorovic, S.; Jan Latecki, L. Semantic segmentation of rgbd images with mutex constraints. In Proceedings of the IEEE International Conference on Computer Vision, Las Condes, Chile, 11–18 December 2015; pp. 1733–1741. [Google Scholar]
- Farabet, C.; Couprie, C.; Najman, L.; LeCun, Y. Learning hierarchical features for scene labeling. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 1915–1929. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Gupta, S.; Girshick, R.; Arbeláez, P.; Malik, J. Learning rich features from RGB-D images for object detection and segmentation. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. Pointcnn: Convolution on x-transformed points. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 820–830. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Hazirbas, C.; Ma, L.; Domokos, C.; Cremers, D. Fusenet: Incorporating depth into semantic segmentation via fusion-based cnn architecture. In Asian Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Jiang, J.; Zhang, Z.; Huang, Y.; Zheng, L. Incorporating depth into both cnn and crf for indoor semantic segmentation. In Proceedings of the 2017 8th IEEE International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 24–26 November 2017; pp. 525–530. [Google Scholar]
- Cheng, Y.; Cai, R.; Li, Z.; Zhao, X.; Huang, K. Locality-sensitive deconvolution networks with gated fusion for rgb-d indoor semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3029–3037. [Google Scholar]
- Lin, D.; Chen, G.; Cohen-Or, D.; Heng, P.-A.; Huang, H. Cascaded feature network for semantic segmentation of RGB-D images. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 1311–1319. [Google Scholar]
- Li, Y.; Zhang, J.; Cheng, Y.; Huang, K.; Tan, T. Semantics-guided multi-level RGB-D feature fusion for indoor semantic segmentation. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 1262–1266. [Google Scholar]
- Jiang, J.; Zheng, L.; Luo, F.; Zhang, Z. Rednet: Residual encoder-decoder network for indoor rgb-d semantic segmentation. arXiv 2018, arXiv:1806.01054. [Google Scholar]
- Guo, Y.; Chen, T. Semantic segmentation of RGBD images based on deep depth regression. Pattern Recognit. Lett. 2018, 109, 55–64. [Google Scholar] [CrossRef]
- Kim, Y.; Kang, H.; Lee, J. Development of indoor spatial data model using CityGML ADE. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2013, 40, 41–45. [Google Scholar] [CrossRef]
- Jamali, A.; Rahman, A.A.; Boguslawski, P.; Kumar, P.; Gold, C.M. An automated 3D modeling of topological indoor navigation network. GeoJournal 2017, 82, 157–170. [Google Scholar] [CrossRef]
- Tran, H.; Khoshelham, K.; Kealy, A.; Díaz-Vilariño, L. Extracting topological relations between indoor spaces from point clouds. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 4, 401. [Google Scholar] [CrossRef]
- Sarda, N. Development of navigational structure for buildings from their valid 3D CityGML models. In Proceedings of the 2016 3rd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 16–18 March 2016; pp. 3341–3346. [Google Scholar]
- Thrun, S.; Bücken, A. Integrating grid-based and topological maps for mobile robot navigation. In Proceedings of the National Conference on Artificial Intelligence, Portland, OR, USA, 4–6 August 1996. [Google Scholar]
- Joo, K.; Lee, T.-K.; Baek, S.; Oh, S.-Y. Generating topological map from occupancy grid-map using virtual door detection. In Proceedings of the IEEE Congress on Evolutionary Computation, Barcelona, Spain, 18–23 July 2010. [Google Scholar]
- Portugal, D.; Rocha, R.P. Extracting Topological Information from Grid Maps for Robot Navigation. In Proceedings of the 4th International Conference on Agents and Artificial Intelligence (ICAART-2012), Algarve, Portugal, 6–8 February 2012; pp. 137–143. [Google Scholar] [CrossRef]
- Yang, L.; Worboys, M. Generation of navigation graphs for indoor space. Int. J. Geograph. Inf. Sci. 2015, 29, 1737–1756. [Google Scholar] [CrossRef]
- Sithole, G. Indoor Space Routing Graphs: Visibility, Encoding, Encryption and Attenuation. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, XLII-4, 579–585. [Google Scholar] [CrossRef]
- Demyen, D.; Buro, M. Efficient triangulation-based pathfinding. In Proceedings of the Twenty-First National Conference on Artificial Intelligence (AAAI 06), Boston, MA, USA, 16–20 July 2006. [Google Scholar]
- Li, X.; Claramunt, C.; Ray, C. A grid graph-based model for the analysis of 2D indoor spaces. Comput. Environ. Urban Syst. 2010, 34, 532–540. [Google Scholar] [CrossRef]
- Gonzalez-Arjona, D.; Sanchez, A.; López-Colino, F.; De Castro, A.; Garrido, J. Simplified occupancy grid indoor mapping optimized for low-cost robots. ISPRS Int. J. Geo-Inf. 2013, 2, 959–977. [Google Scholar] [CrossRef]
- Xu, M.; Wei, S.; Zlatanova, S.; Zhang, R. BIM-based indoor path planning considering obstacles. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 417–423. [Google Scholar] [CrossRef]
- Li, D.; Lee, D.L. A lattice-based semantic location model for indoor navigation. In Proceedings of the Ninth International Conference on Mobile Data Management (mdm 2008), Beijing, China, 27–30 April 2008; pp. 17–24. [Google Scholar]
- Lin, Z.; Xu, Z.; Hu, D.; Hu, Q.; Li, W. Hybrid spatial data model for indoor space: Combined topology and grid. ISPRS Int. J. Geo-Inf. 2017, 6, 343. [Google Scholar] [CrossRef]
- Lee, J.; Li, K.; Zlatanova, S.; Kolbe, T.; Nagel, C.; Becker, T. OGC IndoorGML–with Corrigendum. 2016. Available online: http://www.opengis.net/doc/IS/indoorgml/1.0 (accessed on 17 May 2020).
- Khan, A.; Donaubauer, A.; Kolbe, T.H. A multi-step transformation process for automatically generating indoor routing graphs from semantic 3D building models. In Proceedings of the 9th 3D GeoInfo Conference, Dubai, UAE, 11–13 Novermber 2014. [Google Scholar]
- Mirvahabi, S.; Abbaspour, R.A. Automatic extraction of IndoorGML core model from OpenStreetMap. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, 40, 459. [Google Scholar] [CrossRef]
- Zhu, Q.; Li, Y.; Xiong, Q.; Zlatanova, S.; Ding, Y.; Zhang, Y.; Zhou, Y. Indoor multi-dimensional location gml and its application for ubiquitous indoor location services. ISPRS Int. J. Geo-Inf. 2016, 5, 220. [Google Scholar] [CrossRef]
- Teo, T.-A.; Yu, S.-C. The Extraction of Indoor Building Information from Bim to Ogc Indoorgml. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 42, 167–170. [Google Scholar] [CrossRef]
- Srivastavaa, S.; Maheshwarib, N.; Rajanc, K. Towards Generating Semantically-Rich Indoorgml Data from Architectural Plans. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 42, 4. [Google Scholar] [CrossRef]
- Tessema, L.S.; Jäger, R.; Stilla, U. Extraction of IndoorGML Model from an Occupancy Grid Map Constructed Using 2D LiDAR. In Proceedings of the German Society for Photogrammetry, Remote Sensing and Geoinformation, 39st Conference, Vienna, Austria, February 2020; Available online: https://www.researchgate.net/publication/338690496_Extraction_of_IndoorGML_Model_from_an_Occupancy_Grid_Map_Constructed_Using_2D_LiDAR (accessed on 17 May 2020).
- Kontarinis, A.; Zeitouni, K.; Marinica, C.; Vodislav, D.; Kotzinos, D. Towards a Semantic Indoor Trajectory Model. In Proceedings of the 2nd International Workshop on ”Big Mobility Data Analytics” (BMDA) with EDBT, Lisbon, Portugal, 26 March 2019. [Google Scholar]
- Flikweert, P.; Peters, R.; Díaz-Vilariño, L.; Voûte, R.; Staats, B. Automatic Extraction of a Navigation Graph Intended for Indoorgml from an Indoor Point Cloud. ISPRS Ann. Photogramm. Remote Sens. Spat.Inf. Sci. 2019, 4, 271–278. [Google Scholar] [CrossRef]
- Mortari, F.; Clementini, E.; Zlatanova, S.; Liu, L. An indoor navigation model and its network extraction. Appl. Geomat. 2019, 11, 413–427. [Google Scholar] [CrossRef]
- Nikoohemat, S.; Diakité, A.; Zlatanova, S.; Vosselman, G. Indoor 3d Modeling and Flexible Space Subdivision from Point Clouds. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, 4, 285–292. [Google Scholar] [CrossRef]
- Kang, H.-K.; Li, K.-J. A standard indoor spatial data model—OGC IndoorGML and implementation approaches. ISPRS Int. J. Geo-Inf. 2017, 6, 116. [Google Scholar] [CrossRef]
- Kim, J.-S.; Yoo, S.-J.; Li, K.-J. Integrating IndoorGML and CityGML for indoor space. In International Symposium on Web and Wireless Geographical Information Systems; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Liu, L.; Zlatanova, S.; Zhu, Q.; Li, K. Towards the integration of IndoorGML and IndoorlocationGML for indoor applications. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 4, 343. [Google Scholar] [CrossRef]
- Tang, L.; Li, L.; Ying, S.; Lei, Y. A Full Level-of-Detail Specification for 3D Building Models Combining Indoor and Outdoor Scenes. ISPRS Int. J. Geo-Inf. 2018, 7, 419. [Google Scholar] [CrossRef]
- Zeng, L.; Kang, Z. Automatic Recognition of Indoor Navigation Elements from Kinect Point Clouds. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 42, 431–437. [Google Scholar] [CrossRef]
- Alattas, A.; Zlatanova, S.; Van Oosterom, P.; Chatzinikolaou, E.; Lemmen, C.; Li, K.-J. Supporting indoor navigation using access rights to spaces based on combined use of IndoorGML and LADM models. ISPRS Int. J. Geo-Inf. 2017, 6, 384. [Google Scholar] [CrossRef]
- Diakité, A.A.; Zlatanov, S.; Li, K.-J. About the Subdivision of Indoor Spaces in Indoorgml. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 4, 41–48. [Google Scholar] [CrossRef]
- Mura, C.; Villanueva, A.J.; Mattausch, O.; Gobbetti, E.; Pajarola, R. Reconstructing Complex Indoor Environments with Arbitrary Wall Orientations. Eurograph. Posters 2014, 19, 38–40. [Google Scholar]
- Nakagawa, M.; Kataoka, K.; Yamamoto, T.; Shiozaki, M.; Ohhashi, T. Panoramic Rendering-Based Polygon Extraction from Indoor Mobile Lidar Data. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2014, 2, 181–186. [Google Scholar] [CrossRef]
- Mura, C.; Mattausch, O.; Pajarola, R. Piecewise-planar Reconstruction of Multi-room Interiors with Arbitrary Wall Arrangements. Comput. Graph. Forum 2016, 35, 179–188. [Google Scholar] [CrossRef]
- Hsiao, C.-W.; Sun, C.; Sun, M.; Chen, H.-T. Flat2Layout: Flat Representation for Estimating Layout of General Room Types. arXiv 2019, arXiv:1905.12571. [Google Scholar]
- Yang, Y.; Jin, S.; Liu, R.; Bing Kang, S.; Yu, J. Automatic 3d indoor scene modeling from single panorama. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3926–3934. [Google Scholar]
- Nekrasov, V.; Dharmasiri, T.; Spek, A.; Drummond, T.; Shen, C.; Reid, I. Real-time joint semantic segmentation and depth estimation using asymmetric annotations. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 7101–7107. [Google Scholar]
- Sarlin, P.-E.; Cadena, C.; Siegwart, R.; Dymczyk, M. From coarse to fine: Robust hierarchical localization at large scale. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 12716–12725. [Google Scholar]
- Zhao, Z.; Chen, X. Towards Spatio-Temporally Consistent Semantic Mapping. In Robot Soccer World Cup; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Zhao, Z.; Chen, X. Building temporal consistent semantic maps for indoor scenes. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 88–95. [Google Scholar]
- Gupta, S.; Arbeláez, P.; Girshick, R.; Malik, J. Indoor scene understanding with rgb-d images: Bottom-up segmentation, object detection and semantic segmentation. Int. J. Comput. Vis. 2015, 112, 133–149. [Google Scholar] [CrossRef]
- Lei, P.; Todorovic, S. Recurrent temporal deep field for semantic video labeling. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Mustafa, A.; Kim, H.; Guillemaut, J.-Y.; Hilton, A. Temporally coherent 4d reconstruction of complex dynamic scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4660–4669. [Google Scholar]
- He, Y.; Chiu, W.-C.; Keuper, M.; Fritz, M. Std2p: Rgbd semantic segmentation using spatio-temporal data-driven pooling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4837–4846. [Google Scholar]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. SemanticKITTI: A dataset for semantic scene understanding of lidar sequences. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 9297–9307. [Google Scholar]
- Choy, C.; Gwak, J.; Savarese, S. 4d spatio-temporal convnets: Minkowski convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3075–3084. [Google Scholar]
- Mustafa, A.; Hilton, A. Semantically coherent co-segmentation and reconstruction of dynamic scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 422–431. [Google Scholar]
- Previtali, M.; Barazzetti, L.; Brumana, R.; Scaioni, M. Towards automatic indoor reconstruction of cluttered building rooms from point clouds. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2014, 2, 281–288. [Google Scholar] [CrossRef]
- Tran, H.; Khoshelham, K.; Kealy, A.; Díaz-Vilariño, L. Shape Grammar Approach to 3D Modeling of Indoor Environments Using Point Clouds. J. Comput. Civ. Eng. 2019, 33, 04018055. [Google Scholar] [CrossRef]
- Diakité, A.A.; Zlatanova, S. Spatial subdivision of complex indoor environments for 3D indoor navigation. Int. J. Geograph. Inf. Sci. 2018, 32, 213–235. [Google Scholar] [CrossRef]
- Zhang, Y.; Xu, W.; Tong, Y.; Zhou, K. Online structure analysis for real-time indoor scene reconstruction. ACM Trans. Graph. TOG 2015, 34, 1–13. [Google Scholar] [CrossRef]
- Teo, T.-A.; Cho, K.-H. BIM-oriented indoor network model for indoor and outdoor combined route planning. Adv. Eng. Inform. 2016, 30, 268–282. [Google Scholar] [CrossRef]
- Vanclooster, A.; Van de Weghe, N.; De Maeyer, P. Integrating indoor and outdoor spaces for pedestrian navigation guidance: A review. Trans. GIS 2016, 20, 491–525. [Google Scholar] [CrossRef]














© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kang, Z.; Yang, J.; Yang, Z.; Cheng, S. A Review of Techniques for 3D Reconstruction of Indoor Environments. ISPRS Int. J. Geo-Inf. 2020, 9, 330. https://doi.org/10.3390/ijgi9050330
Kang Z, Yang J, Yang Z, Cheng S. A Review of Techniques for 3D Reconstruction of Indoor Environments. ISPRS International Journal of Geo-Information. 2020; 9(5):330. https://doi.org/10.3390/ijgi9050330
Chicago/Turabian StyleKang, Zhizhong, Juntao Yang, Zhou Yang, and Sai Cheng. 2020. "A Review of Techniques for 3D Reconstruction of Indoor Environments" ISPRS International Journal of Geo-Information 9, no. 5: 330. https://doi.org/10.3390/ijgi9050330
APA StyleKang, Z., Yang, J., Yang, Z., & Cheng, S. (2020). A Review of Techniques for 3D Reconstruction of Indoor Environments. ISPRS International Journal of Geo-Information, 9(5), 330. https://doi.org/10.3390/ijgi9050330