Using Local Toponyms to Reconstruct the Historical River Networks in Hubei Province, China


Abstract
1. Introduction
2. Related Research
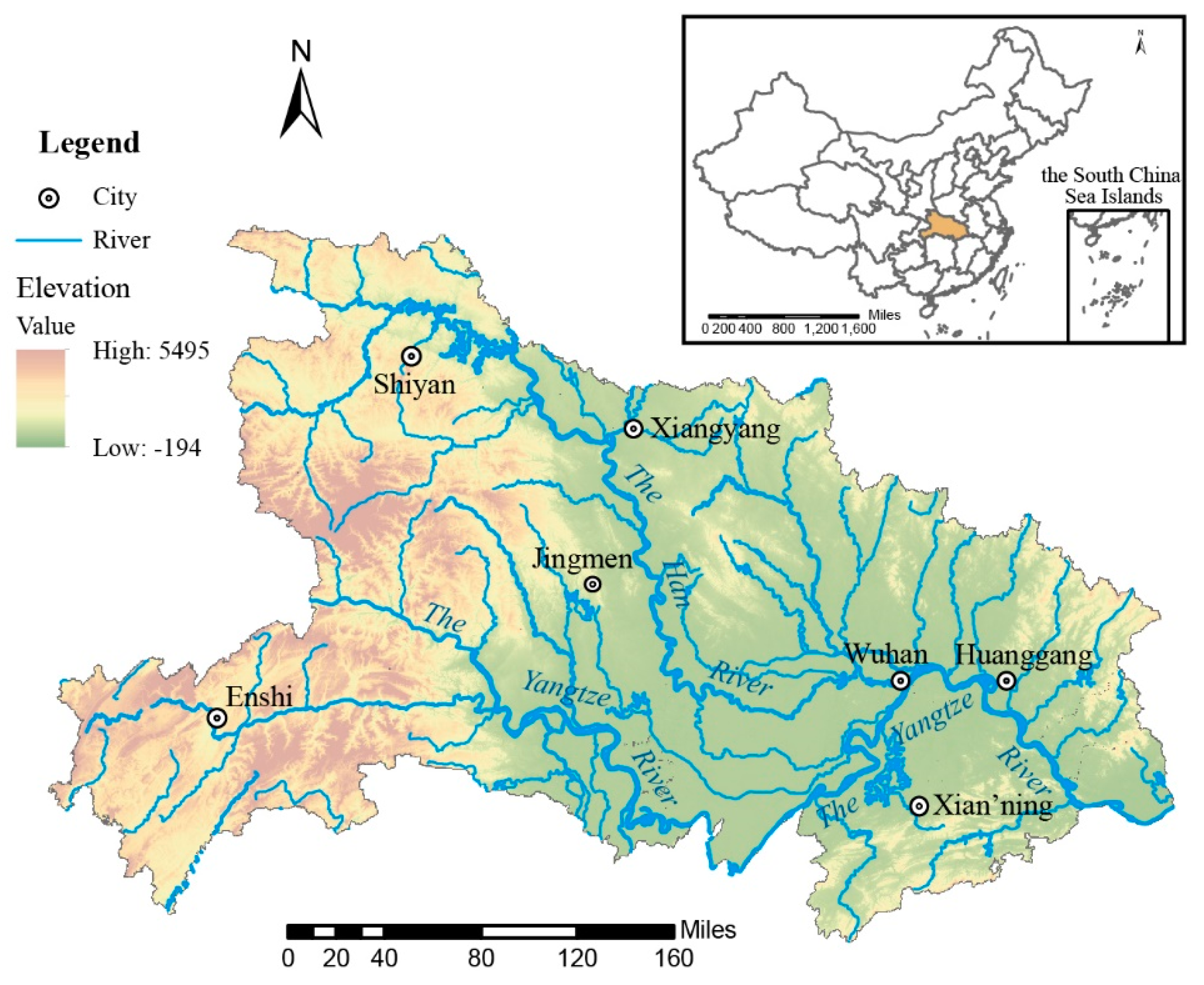
3. Study Area and Data Sources
4. Methods
4.1. Extraction of the Water-Related Toponym and Direction-Related Toponym Datasets
4.2. Correlation Analysis Between the River Network and Toponyms
4.3. Reconstruction of the Historical River Network
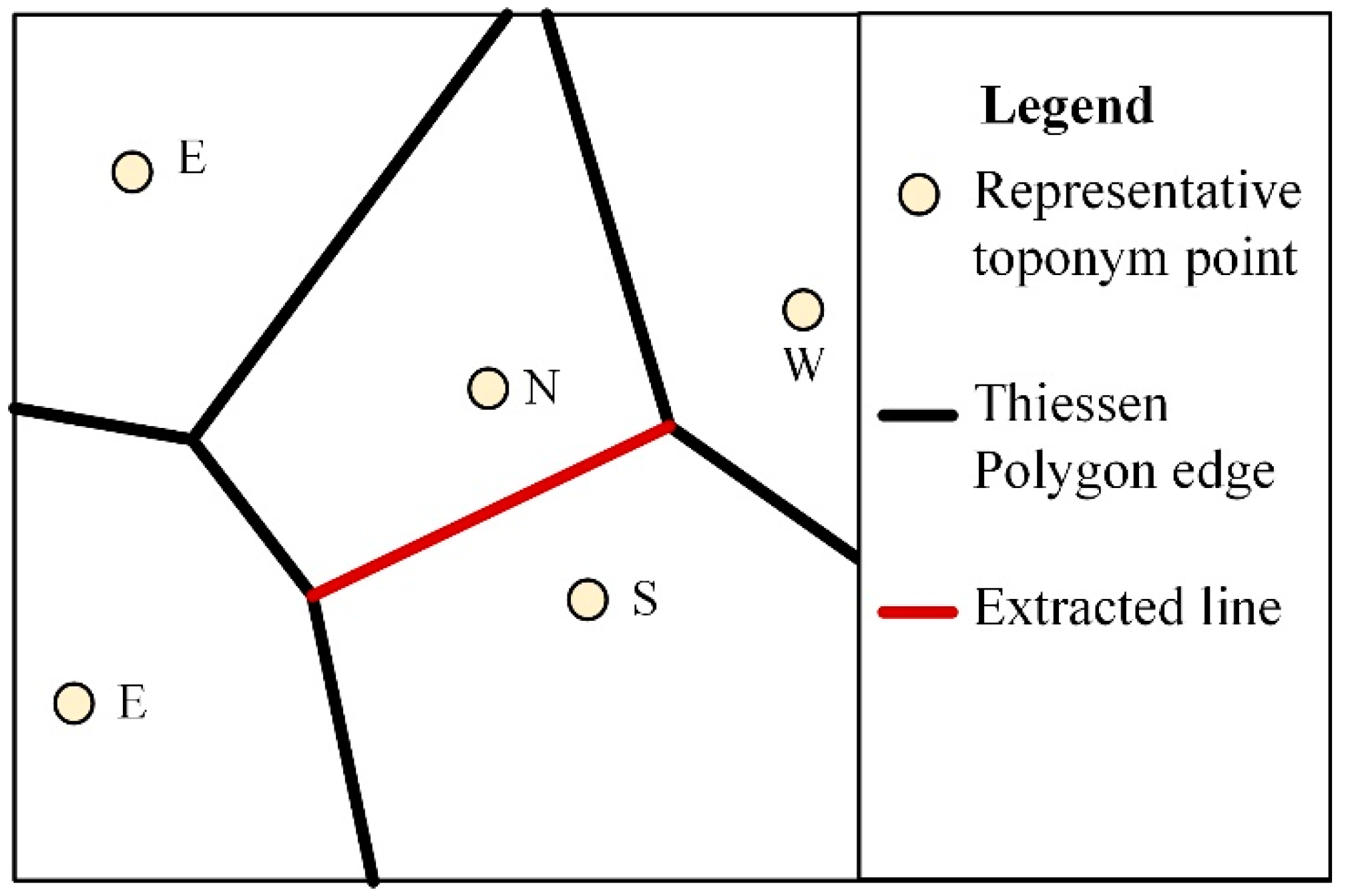
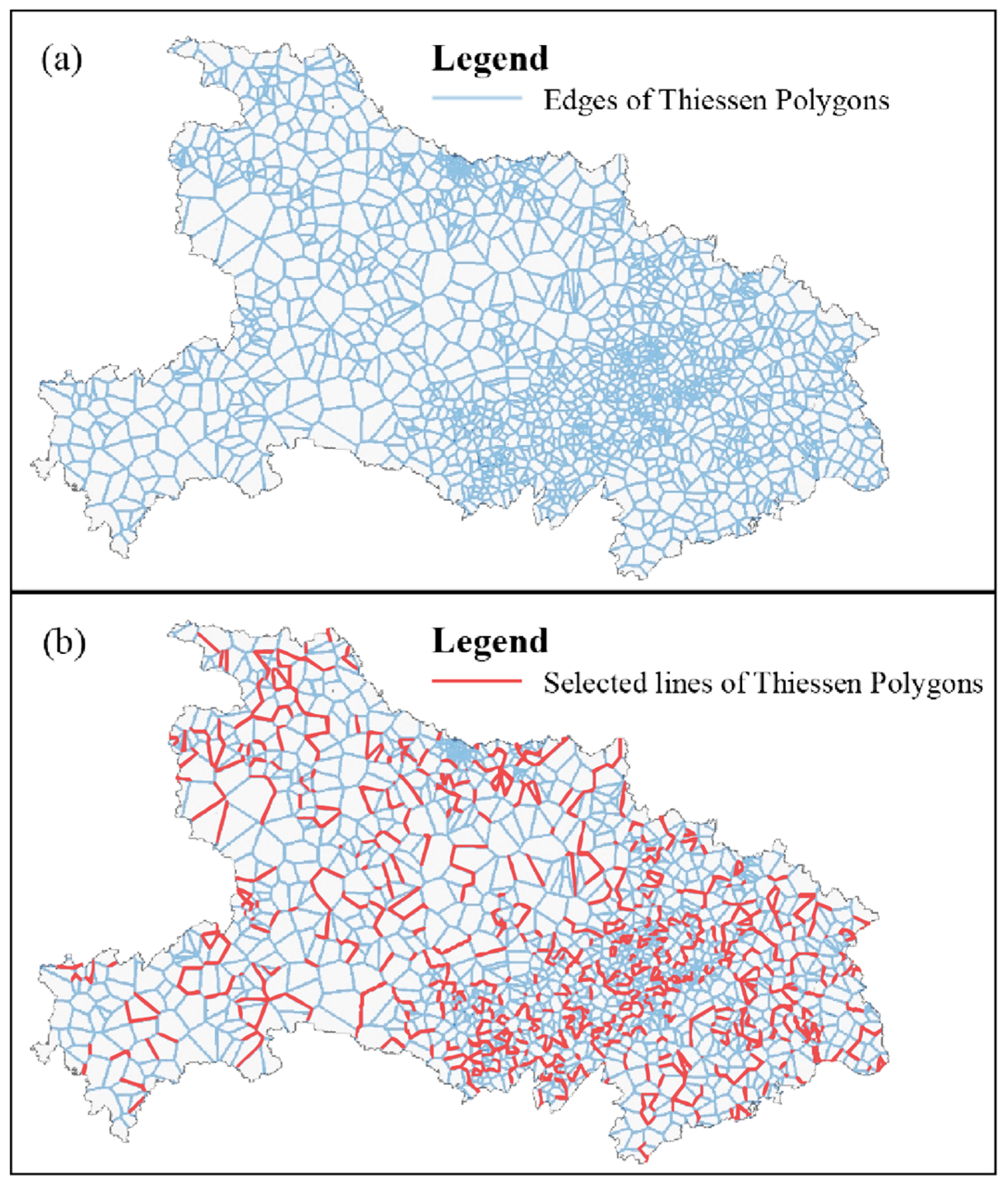
4.3.1. Raw Reconstruction Results
- take representative points of the DRTD as the input to generate Thiessen polygons;
- turn the Thiessen polygons into lines while identifying the directions on either side, e.g., Ad(N, S);
- extract the edges that reflect opposite directions on either side with Ad(N, S) or Ad(E, W), as shown in Figure 2.
4.3.2. Continuous Reconstruction Results
- classify toponyms in the WRTD into different categories according to the levels of rivers they refer to, where Li represents each category;
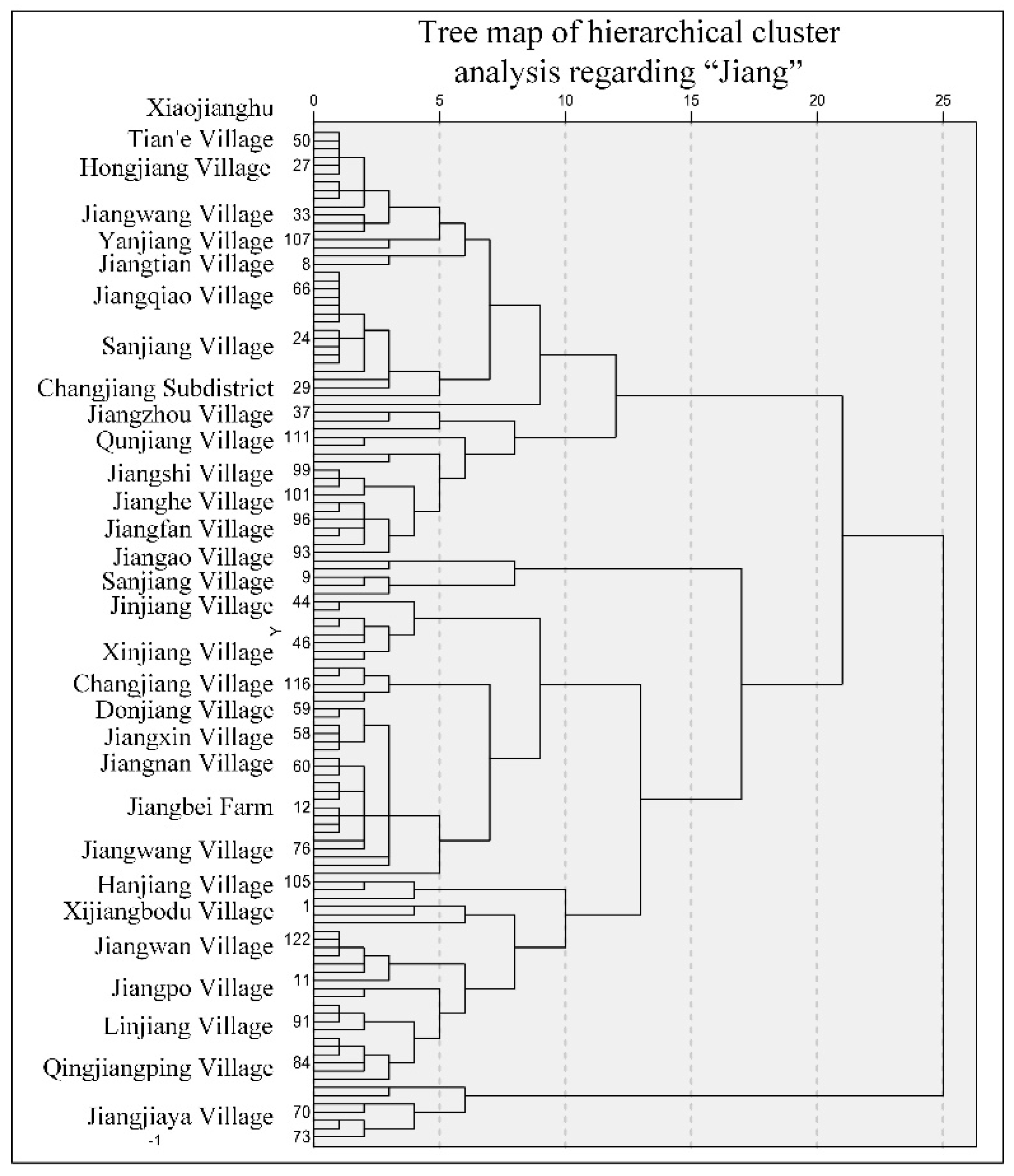
- take the representative points of Li as the input to conduct hierarchical clustering in SPSS on the basis of the Euclidean distances between those points;
- determine an appropriate number of clusters as Nc according to the tree map from the previous step;
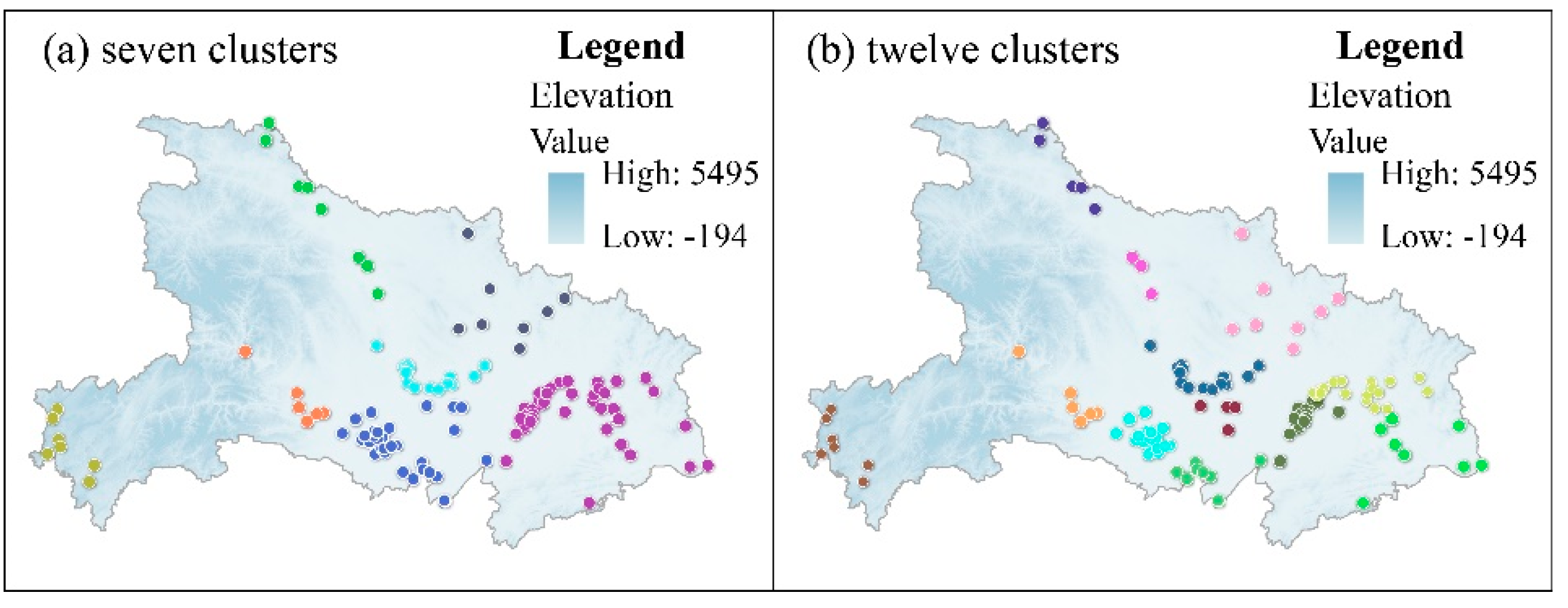
- conduct the group clustering of Nc using the ArcGIS toolbox to obtain clusters;
- add layers of grouping analysis on Li to the raw reconstruction results, after which a continuous historical river skeleton at each level can be drawn from the overlay based on trend identification and qualitative knowledge. The connection is completed with some algorithm and manual supervision, according to following principles:(1) Raw reconstruction results within two standard deviational ellipse polygons of clustering result should be extracted as baseline.(2) Search nearest neighbor points around line segments from clustering result, then connect both ends with each nearest neighbor points and repeat this step to form continuous feature.(3) Make sure the local direction of connection is consistent with manually identified trend about clustering result.
4.3.3. River Shape Optimization
5. Results and Discussion
5.1. Results of the WRTD and DRTD Extraction
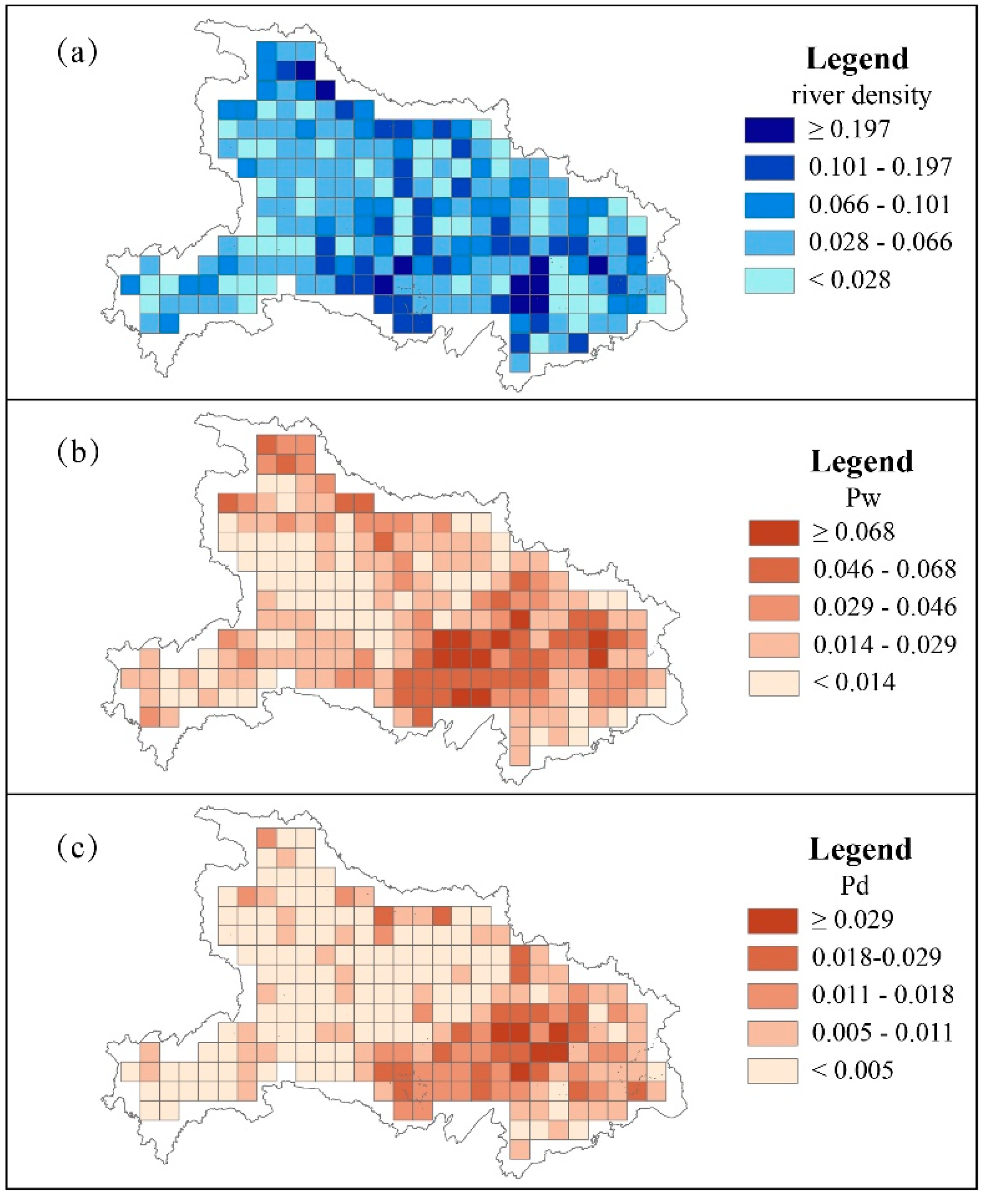
5.2. Variables of Statistical Units
5.3. Correlation Analysis
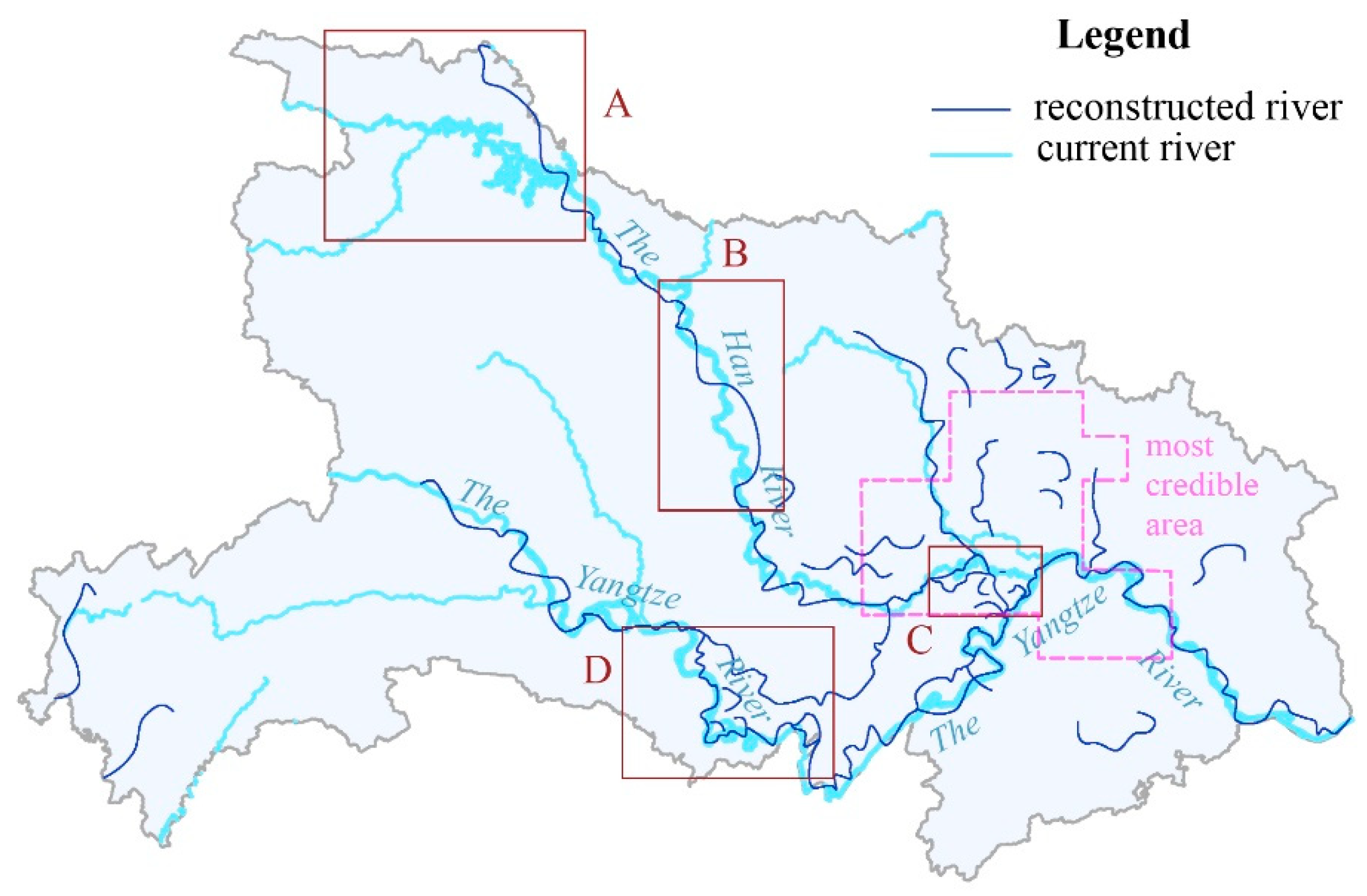
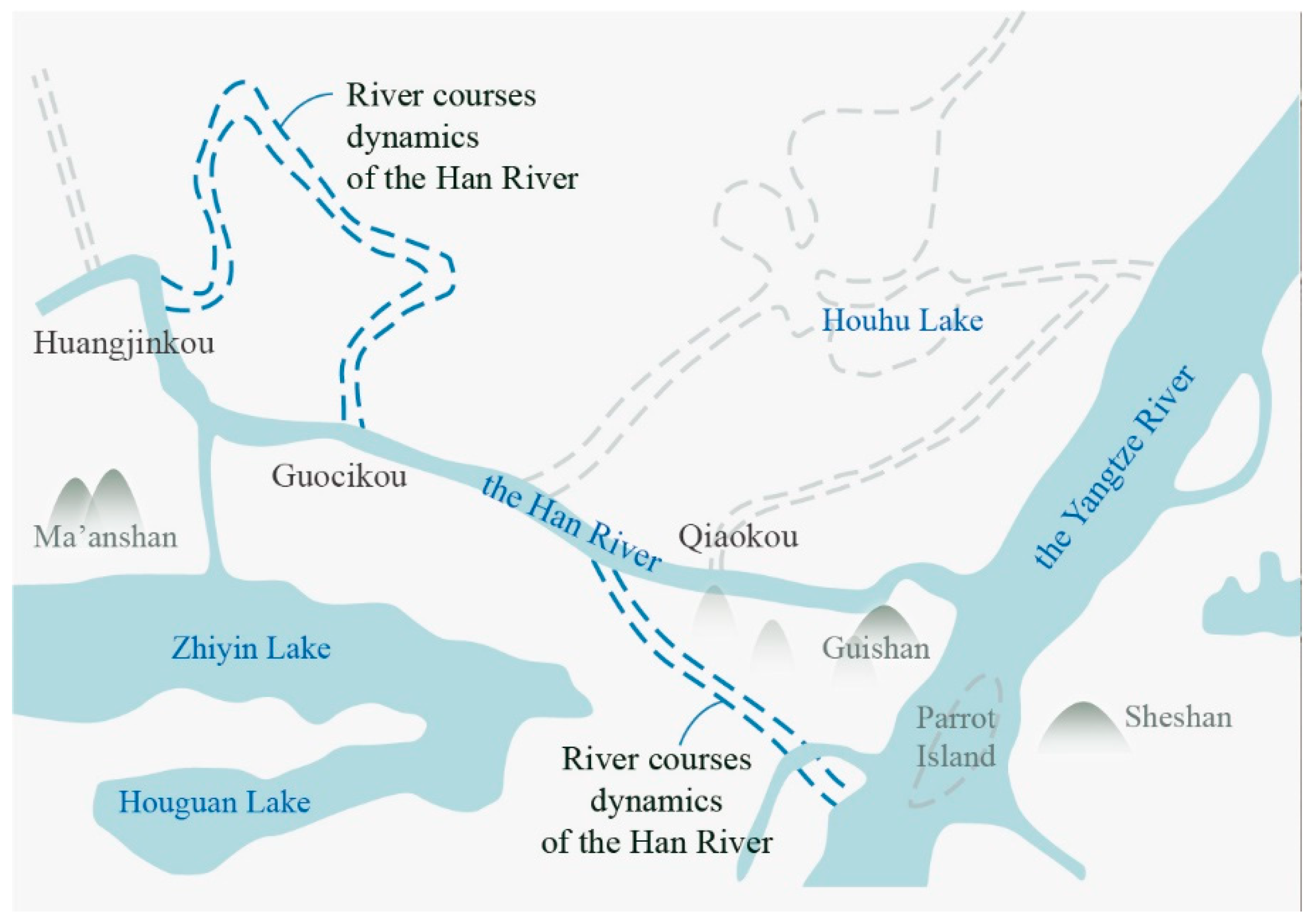
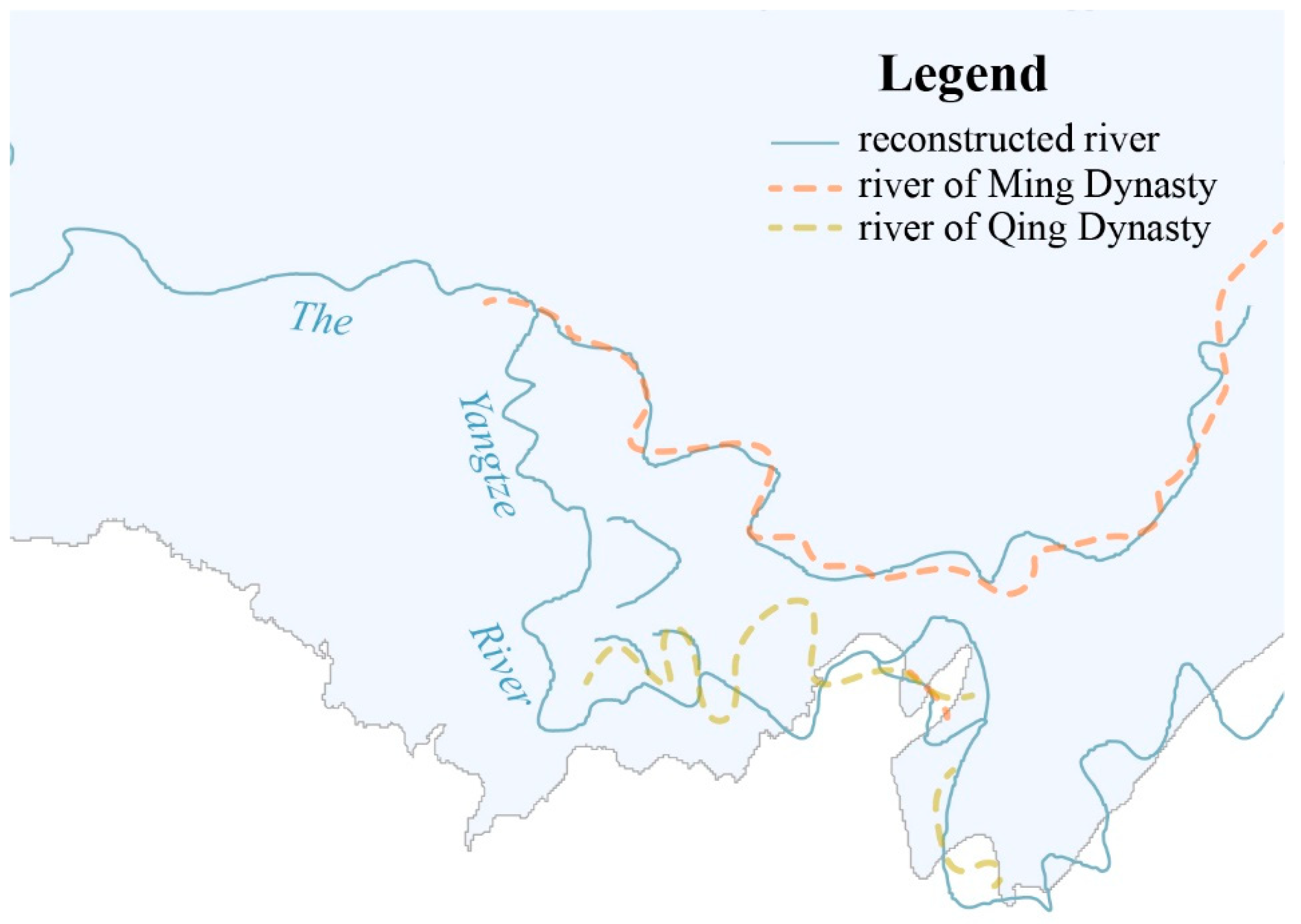
5.4. Reconstruction of the Historical River Network
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| River | Toponym |
|---|---|
| The Baishi River | Baishi Village |
| Baishi Ping Village | |
| The Shigu River | Shigu Village |
| The Qi River | Qilin Village |
| The Nie River | Niexing Village |
| The Dongjing River | Jingan Qiao Village |
| Dongjing Village | |
| Zijing Village | |
| Huangjing Village | |
| Dongjing Forest Farm | |
| The Jing River | Jingzhong Village |
| Jinghua Village | |
| Jingfeng Village | |
| Jingnan Village | |
| Jinggan Village | |
| Jinglan Village | |
| Jingtan Village | |
| Jingghong Village | |
| Jingshi Village | |
| Jingsha Village | |
| Jingdong Village | |
| Jingsong Village | |
| Jingbei Village | |
| Jingan Village | |
| The Qing River | Qingyuan Village |
| Qingping Village | |
| The Tian River | Yitian Men Village |
| Ertian Men Village | |
| Santian Men Village | |
| The Mian River | Mianyang Village |
| Miancheng Village |
References
- Li, J.; Zhang, X.; Fan, X. Spatial-Temporal Expression of Chinese Toponym. Geogr. Geo-Inf. Sci. 2010, 26, 6–10, 23. [Google Scholar]
- Jett, S.C. Place-Naming, Environment, and Perception among the Canyon de Chelly Navajo of Arizona. Prof. Geogr. 1997, 49, 481–493. [Google Scholar] [CrossRef]
- Oyamada, Y. Second United Nations Conference on the Standardization of Geographical Names; United Nations: London, UK, 1972. [Google Scholar]
- Tateosian, L.G.; Glatz, M.; Shukunobe, M.; Chopra, P. GazeGIS: A Gaze-Based Reading and Dynamic Geographic Information System; Springer International Publishing: Cham, Switzerland, 2017. [Google Scholar]
- Addink, E.A.; Marra, W.A.; Kleinhans, M.G. Dynamic Channel Network Extraction from Satellite Imagery of the Jamuna River. In AGU Fall Meeting; AGU Fall Meeting Abstracts: San Francisco, CA, USA, 2010. [Google Scholar]
- Chen, D.; Ying, C.; Chen, X. Analysis of Minimum Error at River Source to Extract River Network Based on DEM. Geo-Inf. Sci. 2011, 13, 240–244. [Google Scholar] [CrossRef]
- Li, S.; Lai, Z.; Wang, Q.; Wang, Z.; Li, C.; Song, X. Distributed simulation for hydrological process in Plain River network region using SWAT model. Trans. Chin. Soc. Agric. Eng. 2013, 29, 106–112. [Google Scholar]
- Zheng, W. Study on Generic Characters of District Names in Hubei Province. In Chinese Philology; Sichuan International Studies University: Sichuan, China, 2016. [Google Scholar]
- Han, G. The development of toponym in China. China Hist. Mater. Sci. Technol. 1993, 14, 3–14. [Google Scholar]
- Rose-Redwood, R.; Alderman, D.; Azaryahu, M. Geographies of toponymic inscription: New directions in critical place-name studies. Prog. Hum. Geogr. 2010, 34, 453–470. [Google Scholar] [CrossRef]
- Conedera, M.; Vassere, S.; Neff, C.; Meurer, M.; Krebs, P. Using toponymy to reconstruct past land use: A case study of ‘brüsáda’ (burn) in southern Switzerland. J. Hist. Geogr. 2007, 33, 729–748. [Google Scholar] [CrossRef]
- Xiaomei, J.; Weiping, W.; Jie, C.; Zhuomin, T.; Yeqin, F. Review and prospect of toponymy research since the 1980s. Prog. Geogr. 2016, 35, 910–919. [Google Scholar]
- Yang, X. Study of the Place Names from the Perspective of Category Theory. In Workshop on Chinese Lexical Semantics; Springer International Publishing: Cham, Switzerland, 2015. [Google Scholar]
- Gelling, M. Place-Names in the Landscape; Dent: London, UK, 1984. [Google Scholar]
- Mcdavid, R.I. Linguistic Geograpllic and Toponymic Research. Names 1958, 6, 65–73. [Google Scholar] [CrossRef]
- Wen, P.; Xu, J. The application of mathematical statistics method in the research of place names in towns of Jiangsu. J. Nanjing Norm. Univ. Nat. Sci. 1998, 21, 116–120. [Google Scholar]
- Calvo-Iglesias, M.S.; Díaz-Varela, R.A.; Méndez-Martínez, G.; Fra Paleo, U. Using place names for mapping the distribution of vanishing historical landscape features: The Agras field system in northwest Spain. Landsc. Res. 2012, 37, 501–517. [Google Scholar] [CrossRef]
- Sandred, K.I. English stead—A Changeable Place-Name Element in a Changing Community. Stud. Neophilol. 2010, 73, 164–170. [Google Scholar] [CrossRef]
- Shi, G.; Ren, F.; Du, Q.; Gao, N. Phytotoponyms, Geographical Features and Vegetation Coverage in Western Hubei, China. Entropy 2015, 17, 984–1006. [Google Scholar] [CrossRef]
- Sousa, A.; Murillo, P.G. Can place names be used as indicators of landscape changes? Application to the Doñana Natural Park (Spain). Landsc. Ecol. 2001, 16, 391–406. [Google Scholar] [CrossRef]
- Mcclure, P. Patterns of Migration in the Late Middle Ages: The Evidence of English Place-Name Surnames. Econ. Hist. Rev. 2008, 32, 167–182. [Google Scholar] [CrossRef]
- Shi, C.; Qian, Q.; Chen, Y. Historical Evolution and Contemporary Argument of the Geographical Senses of the Toponym “Yuedong”. Trop. Geogr. 2013, 5, 16. [Google Scholar]
- Wang, F.; Wang, G.; Hartmann, J.; Luo, W. Sinification of Zhuang place names in Guangxi, China: A GIS-based spatial analysis approach. Trans. Inst. Br. Geogr. 2012, 37, 317–333. [Google Scholar] [CrossRef]
- Zeini, N.; Abdel-Hamid, A.M.; Soliman, A.S.; E Okasha, A. An exploratory study of place-names in Sinai Peninsula, Egypt: A spatial approach. Ann. GIS 2018, 24, 177–194. [Google Scholar] [CrossRef]
- Cox, J.J.; Maehr, D.S.; Larkin, J.L. The Biogeography of Faunal Place Names in the United States. Conserv. Biol. 2002, 16, 1143–1150. [Google Scholar] [CrossRef]
- Fei, S. The Geography of American Tree Species and Associated Place Names. J. For. 2007, 105, 84–90. [Google Scholar]
- Luo, W.; Hartmann, J.F.; Wang, F. Terrain characteristics and Tai toponyms: A GIS analysis of Muang, Chiang and Viang. GeoJournal 2010, 75, 93–104. [Google Scholar] [CrossRef]
- Fagúndez, J.; Izco, J. Spatial analysis of heath toponymy in relation to present-day heathland distribution. Int. J. Geogr. Inf. Sci. 2015, 73, 164–170. [Google Scholar] [CrossRef]
- Fagúndez, J.; Izco, J. Diversity patterns of plant place names reveal connections with environmental and social factors. Appl. Geogr. 2016, 74, 23–29. [Google Scholar] [CrossRef]
- Qian, S.; Kang, M.; Weng, M. Toponym mapping: A case for distribution of ethnic groups and landscape features in Guangdong, China. J. Maps 2016, 12 (Suppl. 1), 546–550. [Google Scholar] [CrossRef]
- Qian, S.; Kang, M.; Wang, M. An analysis of spatial patterns of toponyms in Guangdong, China. J. Cult. Geogr. 2016, 33, 1–20. [Google Scholar] [CrossRef]
- Dark, S.J.; Bram, D. The Modifiable Areal Unit Problem (MAUP) in Physical Geography. Prog. Phys. Geogr. 2007, 31, 471–479. [Google Scholar] [CrossRef]
- Lili, Q.I.; Yanchen, B.O. MAUP Effects on the Detection of Spatial Hot Spots in Socio-economic Statistical Data. Acta Geogr. Sin. 2012, 67, 1317–1326. [Google Scholar]
- Tobler, W.R. A Computer Movie Simulating Urban Growth in the Detroit Region. Econ. Geogr. 1970, 46 (Suppl. 1), 234–240. [Google Scholar] [CrossRef]
- Fotheringham, A.S.; Brunsdon, C.; Charlton, M. Geographically Weighted Regression: The Analysis of Spatially Varying Relationships; International Union of Crystallography: New York, NY, USA, 2002; pp. 125–126. [Google Scholar]
- Taylor, R. Interpretation of the Correlation Coefficient: A Basic Review. J. Diagn. Med. Sonogr. 1990, 6, 35–39. [Google Scholar] [CrossRef]
- Dong, Y. Old Place Names in Wuhan. Old Wuhan; Wuhan Publishing House: Wuhan, China, 2008; pp. 3–4, 10–12. [Google Scholar]
- Tan, Q. The Historical Atlas of China; China Cartographic Publishing House: Beijing, China, 1982. [Google Scholar]










| Generic Name | Example |
|---|---|
| Bin | Hubin Village |
| Cao | Changcao Village |
| Cha | Chahe Village |
| Chao | Gaochao Village |
| Chi | Meichi Village |
| Chuan | Gaochuan Village |
| Di | Yuedi Village |
| Du | Dadu Village |
| Fu | Fushui Village |
| Gang | Gangbian Village |
| Gou | Changgou Village |
| Hai | Honghai Village |
| He | Shahe Village |
| Hong | Hanhong Village |
| Hu | Donghu Village |
| Ji | Niji Village |
| Jian | Jianchi Village |
| Jiang | Bianjiang Village |
| Kou | Hekou Village |
| Liu | Heiliu Village |
| Qu | Changqu Village |
| Quan | Jinquan Village |
| Shui | Shuiping Village |
| Tan | Xiaotan Village |
| Tang | Shatang Village |
| Tuo | Liantuo Village |
| Wan | Wujia Wan Village |
| Xi | Lingxi Village |
| Yan | Shangyan Village |
| Yang | Baiyang Village |
| Yuan | Longyuan Village |
| Zhou | Longzhou Village |
| Specific Name | Meaning | Example | Ad |
|---|---|---|---|
| Dong | East | Hedong Village | E |
| Nan | South | Jiangnan Village | N |
| Xi | West | Huxi Village | W |
| Bei | North | Hongbei Village | N |
| Yin | Usually the north of the water | Xiangyinwan Village | N |
| Yang | Usually the south of the water | Chaoyang Village | S |
| Buffer radius (km) | Number | Proportion (%) |
|---|---|---|
| 1 | 924 | 17.65 |
| 3 | 2071 | 39.57 |
| 5 | 2826 | 53.99 |
| 8 | 3707 | 70.83 |
| 10 | 4159 | 79.46 |
| Buffer Radius (km) | Number | Proportion (%) |
|---|---|---|
| 1 | 247 | 15.68 |
| 3 | 594 | 37.71 |
| 5 | 842 | 53.46 |
| 8 | 1086 | 68.95 |
| 10 | 1205 | 76.51 |
| Variables | Mean Value | Standard Deviation | Max Value | Minimum Value |
|---|---|---|---|---|
| Dw | 0.094 | 0.077 | 0.387 | 0.00 |
| Pw | 0.189 | 0.071 | 0.500 | 0.00 |
| Pd | 0.054 | 0.036 | 0.182 | 0.00 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhong, A.; Wu, Y.; Nie, K.; Kang, M. Using Local Toponyms to Reconstruct the Historical River Networks in Hubei Province, China. ISPRS Int. J. Geo-Inf. 2020, 9, 318. https://doi.org/10.3390/ijgi9050318
Zhong A, Wu Y, Nie K, Kang M. Using Local Toponyms to Reconstruct the Historical River Networks in Hubei Province, China. ISPRS International Journal of Geo-Information. 2020; 9(5):318. https://doi.org/10.3390/ijgi9050318
Chicago/Turabian StyleZhong, Aini, Yukun Wu, Ke Nie, and Mengjun Kang. 2020. "Using Local Toponyms to Reconstruct the Historical River Networks in Hubei Province, China" ISPRS International Journal of Geo-Information 9, no. 5: 318. https://doi.org/10.3390/ijgi9050318
APA StyleZhong, A., Wu, Y., Nie, K., & Kang, M. (2020). Using Local Toponyms to Reconstruct the Historical River Networks in Hubei Province, China. ISPRS International Journal of Geo-Information, 9(5), 318. https://doi.org/10.3390/ijgi9050318