Quantifying the Characteristics of the Local Urban Environment through Geotagged Flickr Photographs and Image Recognition


Abstract
1. Introduction
2. Literature Review
2.1. Previous Studies on Geotagged Images from Social Media
2.2. Image Recognition and Urban Analytics
2.3. Recent Approaches to Image Recognition
3. Methods
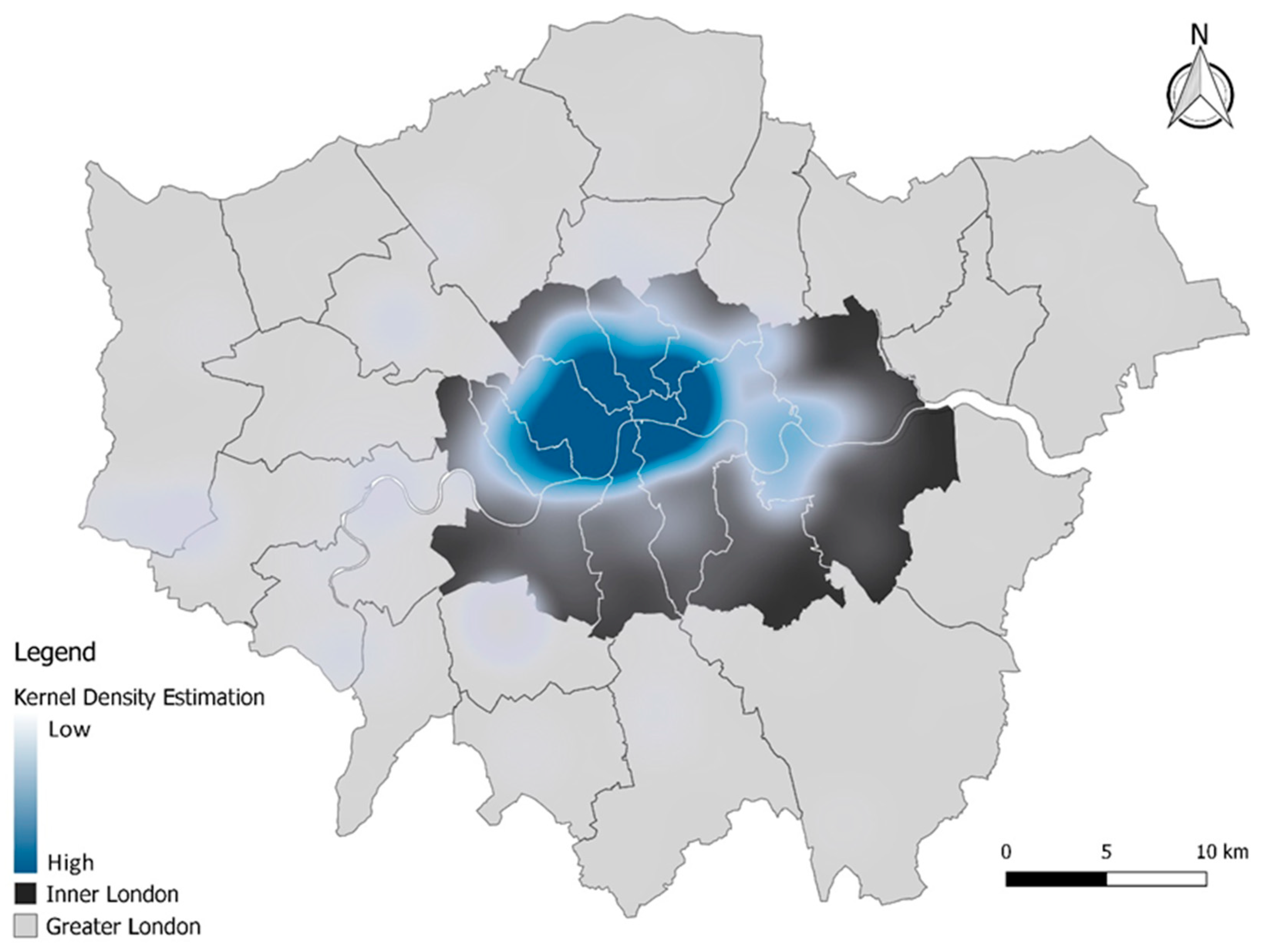
3.1. Data and UAOI Extraction
3.2. Extracting the Characteristics from UAOIs and Outer Areas
4. Results and Discussion
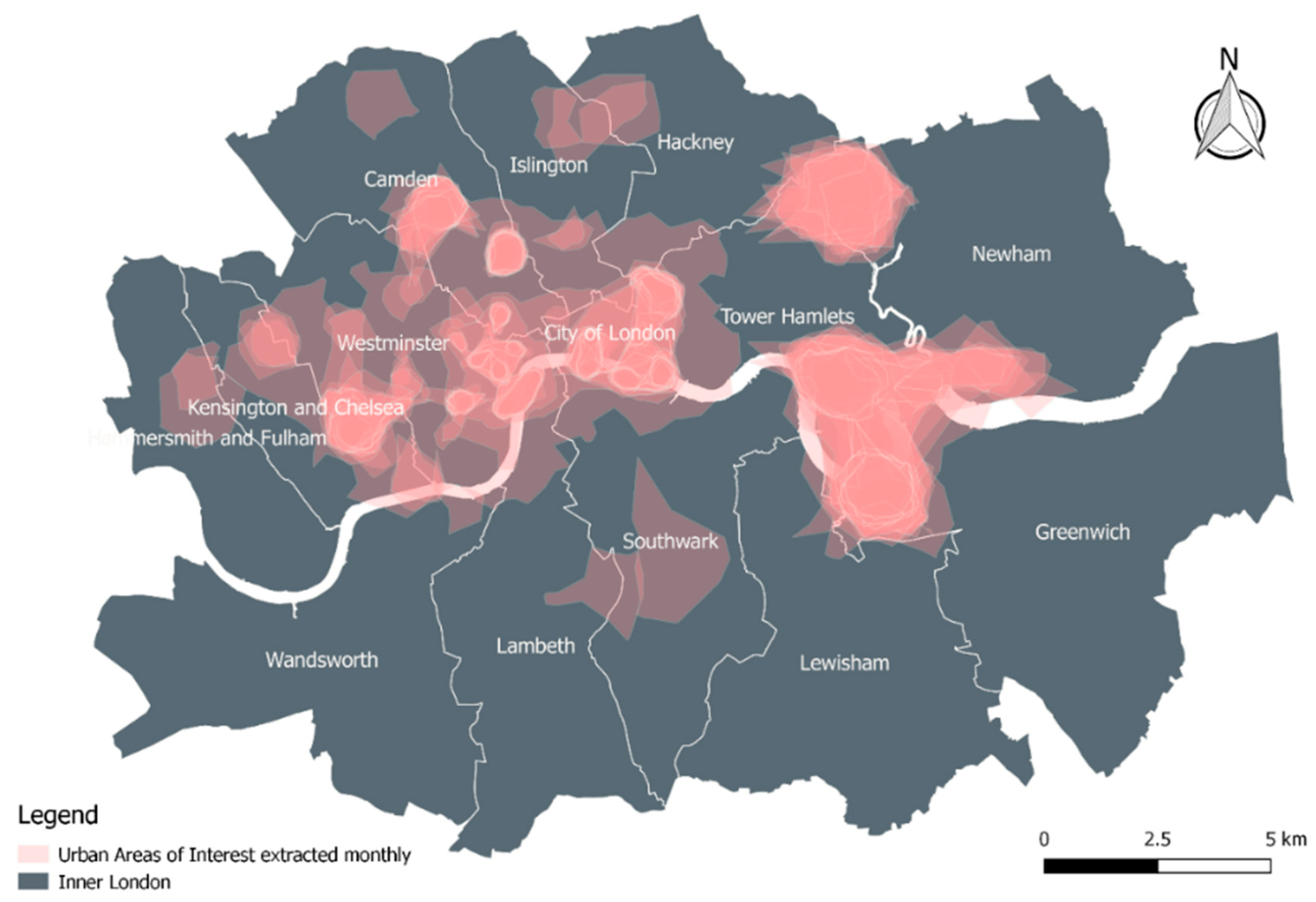
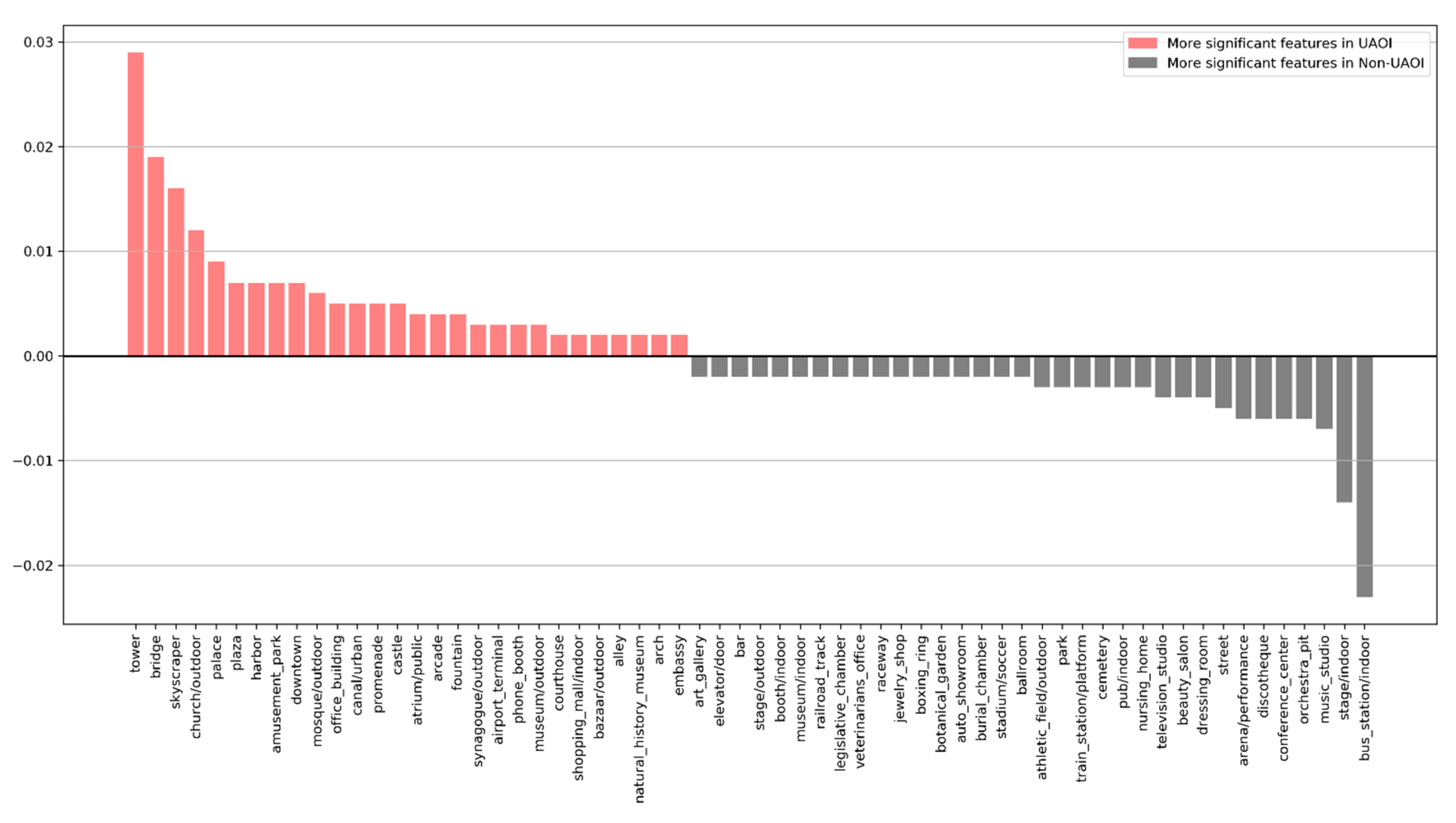
4.1. Regular Characteristics of UAOIs and Non-UAOIs
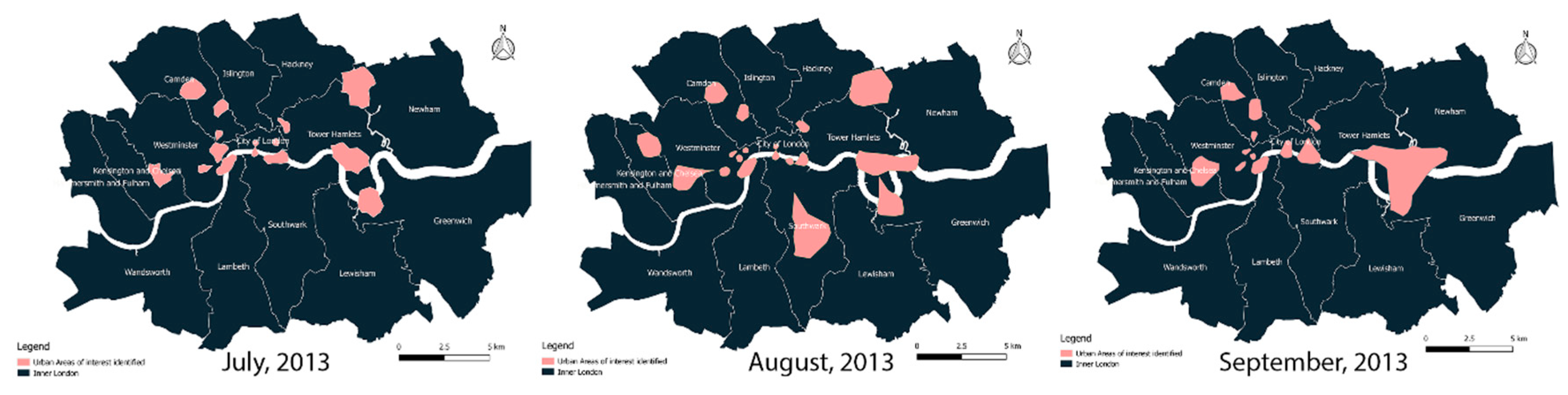
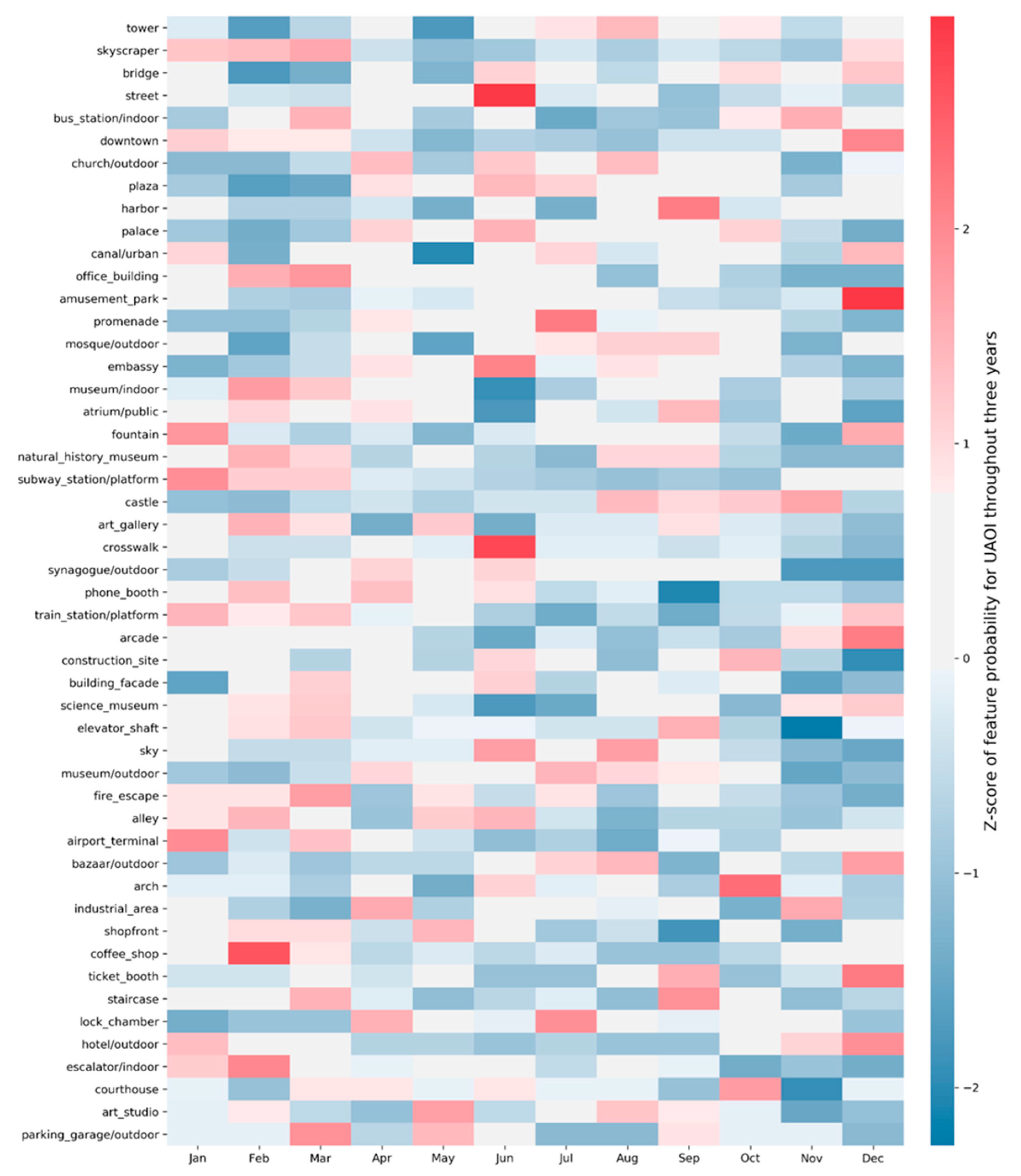
4.2. Dynamic Characteristics of UAOIs
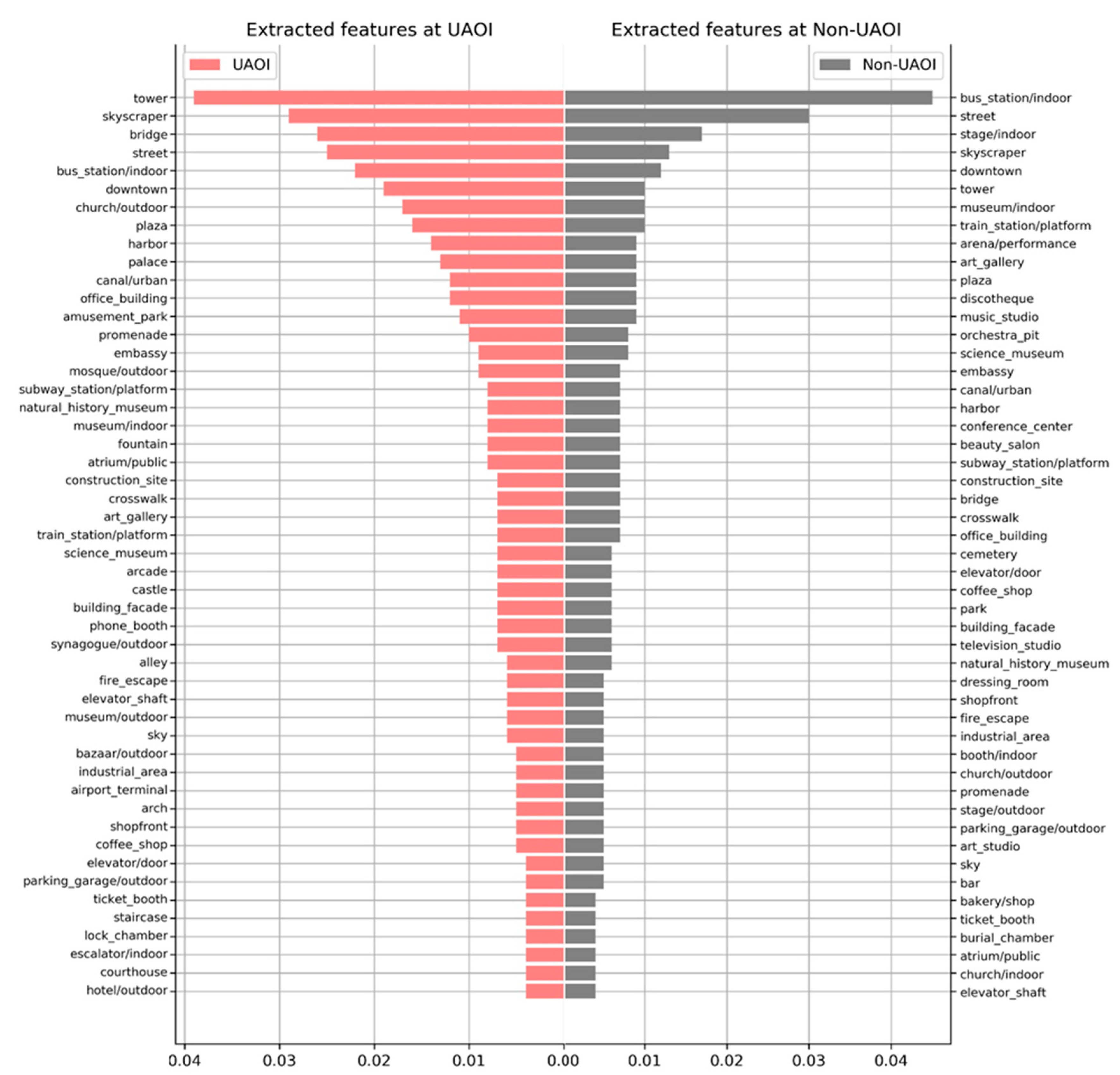
4.3. Capacity and Bias of Using Places365-CNN within This Context
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Singleton, A.D.; Spielman, S.E.; Folch, D.C. Urban Analytics; Sage: London, UK, 2018. [Google Scholar]
- Stubbings, P.; Peskett, J.; Rowe, F.; Arribas-Bel, D. A hierarchical Urban forest index using street-level imagery and deep learning. Remote Sens. 2019, 11, 1395. [Google Scholar] [CrossRef]
- Arribas-Bel, D. Accidental, open and everywhere: Emerging data sources for the understanding of cities. Appl. Geogr. 2014, 49, 45–53. [Google Scholar] [CrossRef]
- Hollenstein, L.; Purves, R.S. Exploring place through user-generated content: Using Flickr tags to describe city cores. J. Spat. Inf. Sci. 2010, 2010, 21–48. [Google Scholar]
- Dorwart, C.E.; Moore, R.L.; Leung, Y.F. Visitors’ perceptions of a trail environment and effects on experiences: A model for nature-based recreation experiences. Leis. Sci. 2009, 32, 33–54. [Google Scholar] [CrossRef]
- Crandall, D.; Backstrom, L.; Huttenlocher, D.; Kleinberg, J. Mapping the world’s photos. In Proceedings of the WWW’09—18th International World Wide Web Conference, Madrid, Spain, 20–24 April 2009. [Google Scholar]
- Kisilevich, S.; Krstajic, M.; Keim, D.; Andrienko, N.; Andrienko, G. Event-based analysis of people’s activities and behavior using Flickr and Panoramio geotagged photo collections. In Proceedings of the International Conference on Information Visualisation, London, UK, 26–29 July 2010. [Google Scholar]
- Hu, Y.; Gao, S.; Janowicz, K.; Yu, B.; Li, W.; Prasad, S. Extracting and understanding urban areas of interest using geotagged photos. Comput. Environ. Urban Syst. 2015, 54, 240–254. [Google Scholar] [CrossRef]
- Chen, M.; Arribas-Bel, D.; Singleton, A. Understanding the dynamics of urban areas of interest through volunteered geographic information. J. Geogr. Syst. 2019, 21, 89–109. [Google Scholar] [CrossRef]
- Naik, N.; Kominers, S.D.; Raskar, R.; Glaeser, E.L.; Hidalgo, C.A. Computer vision uncovers predictors of physical urban change. Proc. Natl. Acad. Sci. USA 2017, 114, 7571–7576. [Google Scholar] [CrossRef]
- Zhang, F.; Zhang, D.; Liu, Y.; Lin, H. Representing place locales using scene elements. Comput. Environ. Urban Syst. 2018, 71, 153–164. [Google Scholar] [CrossRef]
- Seresinhe, C.I.; Moat, H.S.; Preis, T. Quantifying scenic areas using crowdsourced data. Environ. Plan. B Urban Anal. City Sci. 2018, 45, 567–582. [Google Scholar] [CrossRef]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Crooks, A.T.; Croitoru, A.; Jenkins, A.; Mahabir, R.; Agouris, P.; Stefanidis, A. User-generated big data and urban morphology. Built Environ. 2016, 42, 396–414. [Google Scholar] [CrossRef]
- Dunkel, A. Visualizing the perceived environment using crowdsourced photo geodata. Landsc. Urban Plan. 2015, 142, 173–186. [Google Scholar] [CrossRef]
- Antoniou, V.; Morley, J.; Haklay, M. Web 2.0 geotagged photos: Assessing the spatial dimension of the phenomenon. Geomatica 2010, 64, 99–110. [Google Scholar]
- Miah, S.J.; Vu, H.Q.; Gammack, J.; McGrath, M. A big data analytics method for tourist behaviour analysis. Inf. Manag. 2017, 54, 771–785. [Google Scholar] [CrossRef]
- Rattenbury, T.; Good, N.; Naaman, M. Towards automatic extraction of event and place semantics from flickr tags. In Proceedings of the 30th annual international ACM SIGIR conference on Research and development in information retrieval, Amsterdam, The Netherlands, 23–27 July 2007. [Google Scholar]
- Papadopoulos, S.; Zigkolis, C.; Kompatsiaris, Y.; Vakali, A. Cluster-based landmark and event detection for tagged photo collections. IEEE Multimed. 2011, 1, 52–63. [Google Scholar] [CrossRef]
- Zheng, Y.T.; Zha, Z.J.; Chua, T.S. Mining travel patterns from geotagged photos. ACM Trans. Intell. Syst. Technol. 2012, 3, 1–8. [Google Scholar] [CrossRef]
- Sun, Y.; Fan, H.; Bakillah, M.; Zipf, A. Road-based travel recommendation using geo-tagged images. Comput. Environ. Urban Syst. 2015, 53, 110–122. [Google Scholar] [CrossRef]
- Li, L.; Goodchild, M.F.; Xu, B. Spatial, temporal, and socioeconomic patterns in the use of twitter and flickr. Cartogr. Geogr. Inf. Sci. 2013, 40, 61–77. [Google Scholar] [CrossRef]
- Lee, I.; Cai, G.; Lee, K. Exploration of geo-tagged photos through data mining approaches. Expert Syst. Appl. 2014, 41, 397–405. [Google Scholar] [CrossRef]
- Hristova, D.; Aiello, L.M.; Quercia, D. The new urban success: How culture pays. Front. Phys. 2018, 6, 27. [Google Scholar] [CrossRef]
- Richards, D.R.; Friess, D.A. A rapid indicator of cultural ecosystem service usage at a fine spatial scale: Content analysis of social media photographs. Ecol. Indic. 2015, 53, 187–195. [Google Scholar] [CrossRef]
- Goodchild, M.F. Citizens as sensors: The world of volunteered geography. GeoJournal 2007, 69, 211–221. [Google Scholar] [CrossRef]
- Salesses, P.; Schechtner, K.; Hidalgo, C.A. The collaborative image of the city: Mapping the inequality of urban perception. PLoS ONE 2013, 8, e68400. [Google Scholar] [CrossRef] [PubMed]
- Law, S.; Shen, Y.; Seresinhe, C. An application of convolutional neural network in street image classification: The case study of London. In Proceedings of the 1st Workshop on Artificial Intelligence and Deep Learning for Geographic Knowledge Discovery, Los Angeles, CA, USA, 7–10 November 2017; pp. 5–9. [Google Scholar]
- Liu, L.; Wang, H.; Wu, C. A machine learning method for the large-scale evaluation of urban visual environment. arXiv 2016, arXiv:1608.03396. [Google Scholar]
- Kang, J.; Körner, M.; Wang, Y.; Taubenböck, H.; Zhu, X.X. Building instance classification using street view images. ISPRS J. Photogramm. Remote Sens. 2018, 145, 44–59. [Google Scholar] [CrossRef]
- Antoniou, V.; Fonte, C.C.; See, L.; Estima, J.; Arsanjani, J.J.; Lupia, F.; Minghini, M.; Foody, G.; Fritz, S. Investigating the feasibility of geo-Tagged photographs as sources of land cover input data. ISPRS Int. J. Geo Inf. 2016, 5, 64. [Google Scholar] [CrossRef]
- Xing, H.; Meng, Y.; Wang, Z.; Fan, K.; Hou, D. Exploring geo-tagged photos for land cover validation with deep learning. ISPRS J. Photogramm. Remote Sens. 2018, 141, 237–251. [Google Scholar] [CrossRef]
- Richards, D.R.; Tunçer, B.; Tunçer, B. Using image recognition to automate assessment of cultural ecosystem services from social media photographs. Ecosyst. Serv. 2018, 31, 318–325. [Google Scholar] [CrossRef]
- Naik, N.; Philipoom, J.; Raskar, R.; Hidalgo, C. Streetscore-predicting the perceived safety of one million streetscapes. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 779–785. [Google Scholar]
- Seresinhe, C.I.; Preis, T.; Moat, H.S. Using deep learning to quantify the beauty of outdoor places. R. Soc. Open Sci. 2017, 4, 170170. [Google Scholar] [CrossRef]
- Ilic, L.; Sawada, M.; Zarzelli, A. Deep mapping gentrification in a large Canadian city using deep learning and Google Street View. PLoS ONE 2019, 14, e0212814. [Google Scholar] [CrossRef]
- Karpathy, A. CS231n convolutional neural networks for visual recognition. Stanf. Univ. 2016, 1, 1. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-ResNet and the impact of residual connections on learning. In Proceedings of the 31st AAAI Conference on Artificial Intelligence (AAAI 2017), San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Murali, S. An Analysis on Computer Vision Problems. Available online: https://medium.com/deep-dimension/an-analysis-on-computer-vision-problems-6c68d56030c3 (accessed on 5 August 2019).
- Gandhi, R. R-CNN, Fast R-CNN, Faster R-CNN, YOLO—Object Detection Algorithms. Available online: https://towardsdatascience.com/r-cnn-fast-r-cnn-faster-r-cnn-yolo-object-detection-algorithms-36d53571365e (accessed on 28 November 2018).
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 91–99. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- COCO COCO—Common Objects in Context. Available online: http://cocodataset.org/#home (accessed on 29 November 2018).
- Papandreou, G.; Zhu, T.; Kanazawa, N.; Toshev, A.; Tompson, J.; Bregler, C.; Murphy, K. Towards accurate multi-person pose estimation in the wild. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Johnson, J.W. Adapting mask-RCNN for automatic nucleus segmentation. In Proceedings of the 2019 Computer Vision Conference, Las Vegas, NV, USA, 2–3 May 2018; Volume 2. [Google Scholar]
- Shaifee, M.J.; Chywl, B.; Li, F.; Wong, A. Fast YOLO: A fast you only look once system for real-time embedded object detection in video. J. Comput. Vis. Imaging Syst. 2017, arXiv:1709.05943. [Google Scholar] [CrossRef]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 million image database for scene recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1452–1464. [Google Scholar] [CrossRef] [PubMed]
- London City Hall Policy 2.9 Inner London. Available online: https://www.london.gov.uk/what-we-do/planning/london-plan/current-london-plan/london-plan-chapter-two-londons-places/policy-29/ (accessed on 1 August 2019).
- O’Sullivan, D.; Unwin, D.J. Geographic Information Analysis: Second Edition; John Wiley & Sons: Hoboken, NJ, USA, 2010; ISBN 9780470288573. [Google Scholar]
- Smith, C. 20 Interesting Flickr Stats and Facts (2019)|By the Numebrs. Available online: https://expandedramblings.com/index.php/flickr-stats/ (accessed on 2 February 2019).
- Google Maps Street View Google-Contributed Street View Imagery Policy. Available online: https://www.google.com/streetview/policy/#blurring-policy (accessed on 9 July 2019).
- Onaverage Average walking speed. Available online: http://www.onaverage.co.uk/speed-averages/average-walking-speed/ (accessed on 26 August 2018).
- McInnes, L.; Healy, J.; Astels, S. Hdbscan: Hierarchical density based clustering. J. Open Source Softw. 2017, 2, 205. [Google Scholar] [CrossRef]
- Akkiraju, N.; Edelsbrunner, H.; Facello, M.; Fu, P.; Mücke, E.P.; Varela, C. Alpha shapes: Definition and software. In Proceedings of the 1st International Computational Geometry Software Workshop, Minneapolis, MN, USA, 20 January 1995; pp. 63–66. [Google Scholar]
- Wonderland, H.P.W. Visit London’s Christmas Extravaganza! Available online: https://hydeparkwinterwonderland.com (accessed on 23 February 2019).
- London City Hall Christmas at Trafalgar Square. Available online: https://www.london.gov.uk/about-us/our-building-and-squares/christmas-trafalgar-square# (accessed on 24 February 2019).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Bus Station | Street | Stage | Skyscraper | Downtown | Tower | Museum | Train Station | Music Studio | |
|---|---|---|---|---|---|---|---|---|---|
| UAOI | 0.0223 | 0.0253 | 0.0032 | 0.0291 | 0.0191 | 0.0385 | 0.0084 | 0.0071 | 0.0020 |
| Non-UAOI | 0.0448 | 0.0301 | 0.0169 | 0.0133 | 0.0115 | 0.0104 | 0.0096 | 0.0096 | 0.0094 |
| Jan | Feb | Mar | Apr | May | Jun | Jul | Aug | Sep | Oct | Nov | Dec | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| tower | 0.038 | 0.032 | 0.036 | 0.039 | 0.032 | 0.041 | 0.042 | 0.044 | 0.041 | 0.042 | 0.036 | 0.041 |
| skyscraper | 0.034 | 0.034 | 0.035 | 0.028 | 0.025 | 0.026 | 0.028 | 0.026 | 0.028 | 0.027 | 0.026 | 0.033 |
| bridge | 0.026 | 0.021 | 0.022 | 0.026 | 0.023 | 0.029 | 0.027 | 0.024 | 0.027 | 0.028 | 0.027 | 0.029 |
| street | 0.026 | 0.024 | 0.023 | 0.026 | 0.025 | 0.038 | 0.024 | 0.026 | 0.021 | 0.023 | 0.025 | 0.022 |
| hospital | 0.002 | 0.003 | 0.003 | 0.002 | 0.002 | 0.003 | 0.002 | 0.002 | 0.002 | 0.002 | 0.003 | 0.002 |
| outdoor library | 0.002 | 0.002 | 0.002 | 0.002 | 0.003 | 0.003 | 0.004 | 0.002 | 0.003 | 0.003 | 0.001 | 0.001 |
| jewellery shop | 0.002 | 0.003 | 0.002 | 0.002 | 0.003 | 0.001 | 0.003 | 0.002 | 0.002 | 0.002 | 0.003 | 0.003 |
| carousel | 0.002 | 0.002 | 0.001 | 0.001 | 0.001 | 0.001 | 0.002 | 0.002 | 0.001 | 0.001 | 0.003 | 0.010 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, M.; Arribas-Bel, D.; Singleton, A. Quantifying the Characteristics of the Local Urban Environment through Geotagged Flickr Photographs and Image Recognition. ISPRS Int. J. Geo-Inf. 2020, 9, 264. https://doi.org/10.3390/ijgi9040264
Chen M, Arribas-Bel D, Singleton A. Quantifying the Characteristics of the Local Urban Environment through Geotagged Flickr Photographs and Image Recognition. ISPRS International Journal of Geo-Information. 2020; 9(4):264. https://doi.org/10.3390/ijgi9040264
Chicago/Turabian StyleChen, Meixu, Dani Arribas-Bel, and Alex Singleton. 2020. "Quantifying the Characteristics of the Local Urban Environment through Geotagged Flickr Photographs and Image Recognition" ISPRS International Journal of Geo-Information 9, no. 4: 264. https://doi.org/10.3390/ijgi9040264
APA StyleChen, M., Arribas-Bel, D., & Singleton, A. (2020). Quantifying the Characteristics of the Local Urban Environment through Geotagged Flickr Photographs and Image Recognition. ISPRS International Journal of Geo-Information, 9(4), 264. https://doi.org/10.3390/ijgi9040264