Using Vehicle Synthesis Generative Adversarial Networks to Improve Vehicle Detection in Remote Sensing Images




Abstract
:1. Introduction
- —
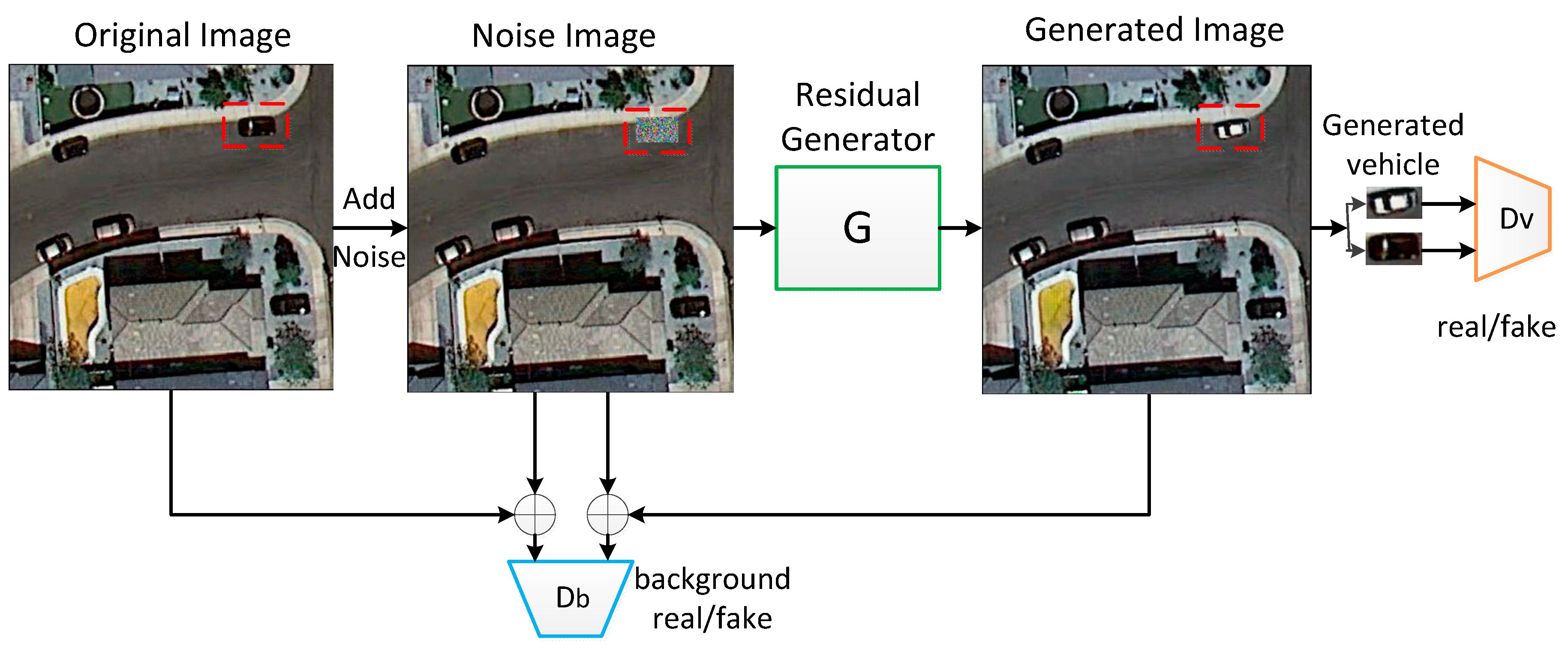
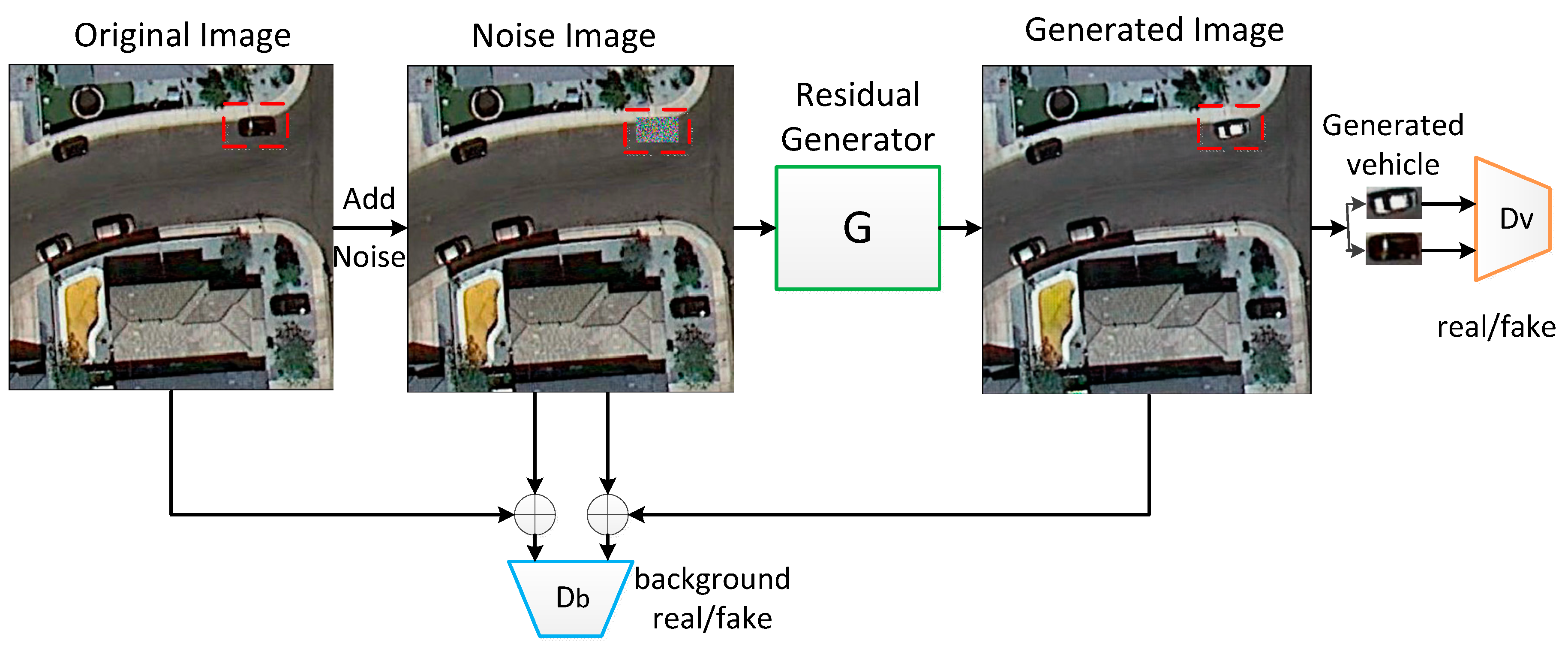
- Our proposed model is capable of generating clear and photorealistic vehicle images in remote sensing images and can fit the background well in real images.
- —
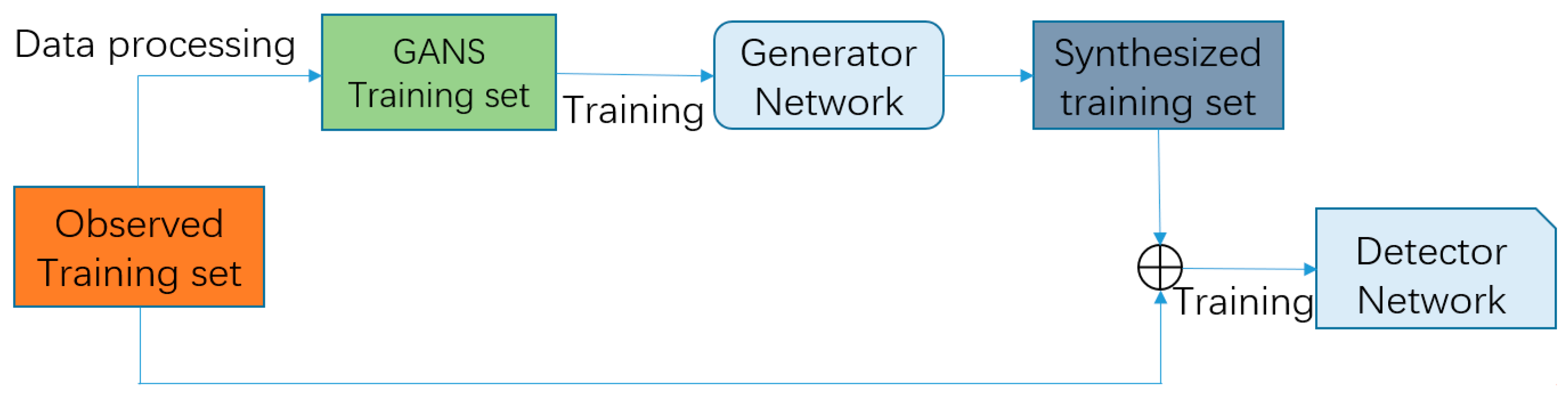
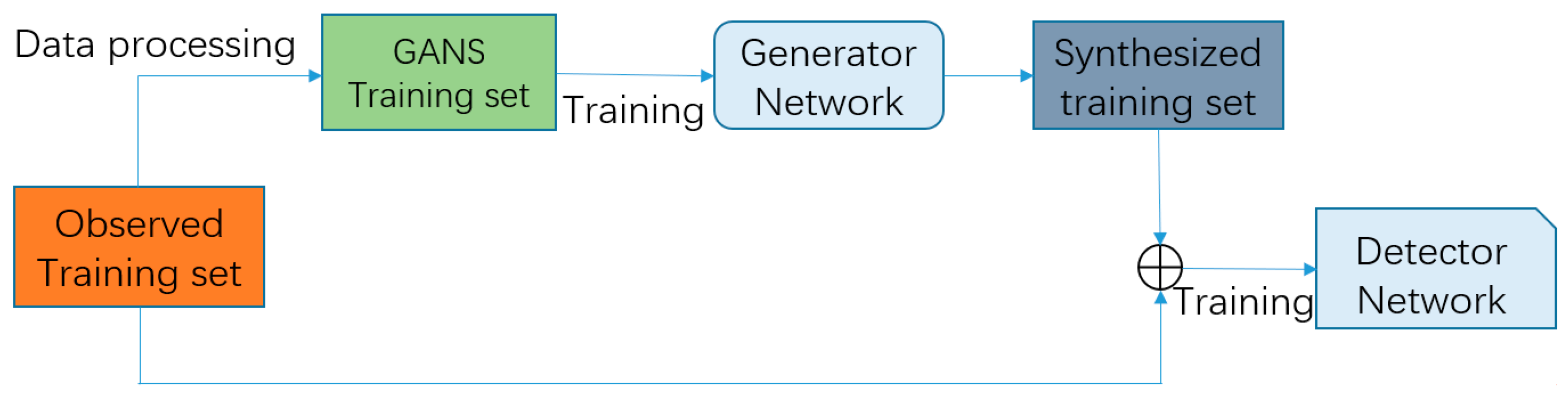
- The data generated by our model can be combined with real datasets to train CNN-based detectors. This data augmentation step can improve both detection performance and robustness compared with the baseline method.
- —
- The proposed method is convenient to apply within the training process of the CNN-based detector.
2. Vehicle Generation Model
2.1. Generative Adversarial Networks
2.2. Vehicle Synthesis-GAN
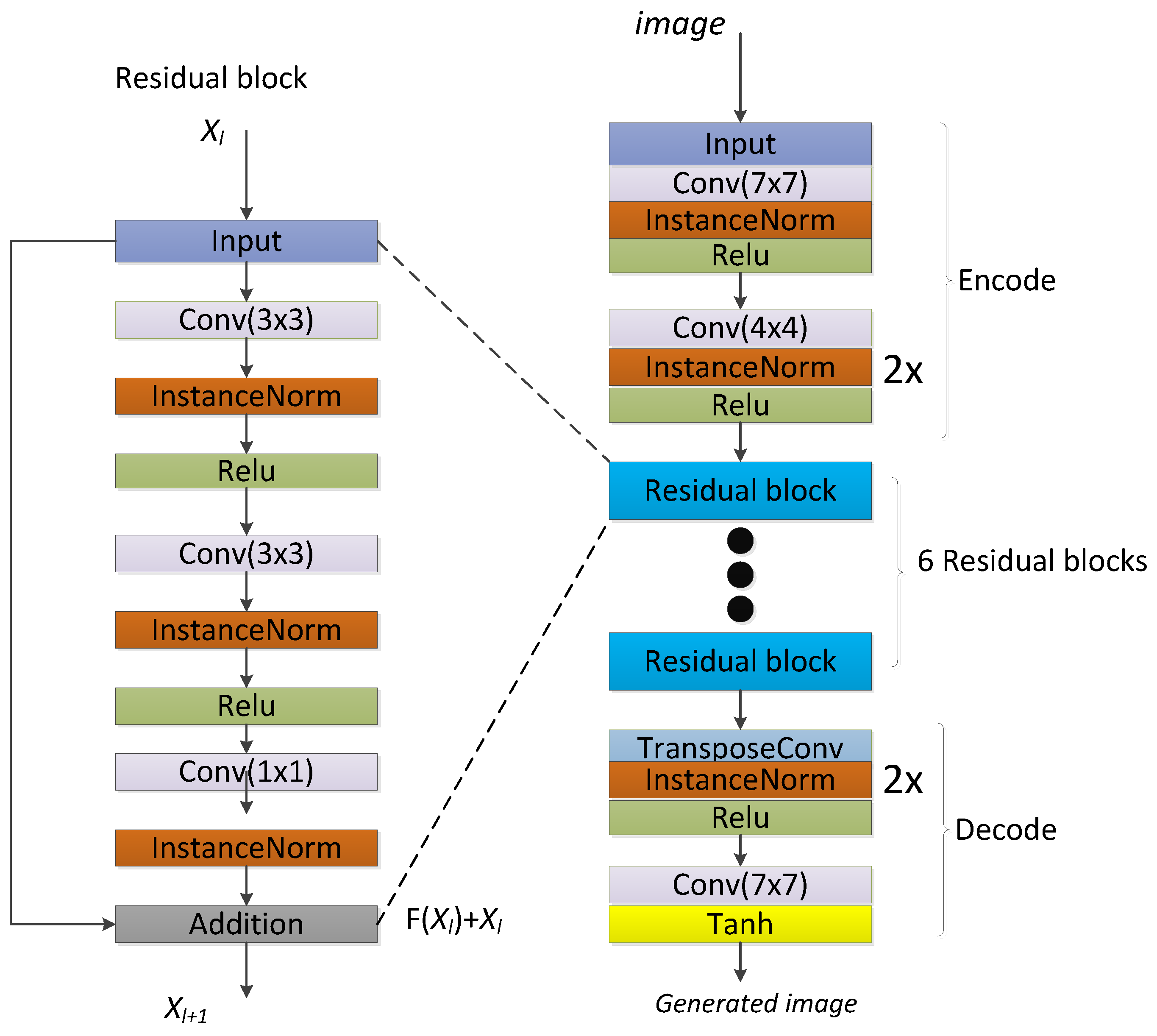
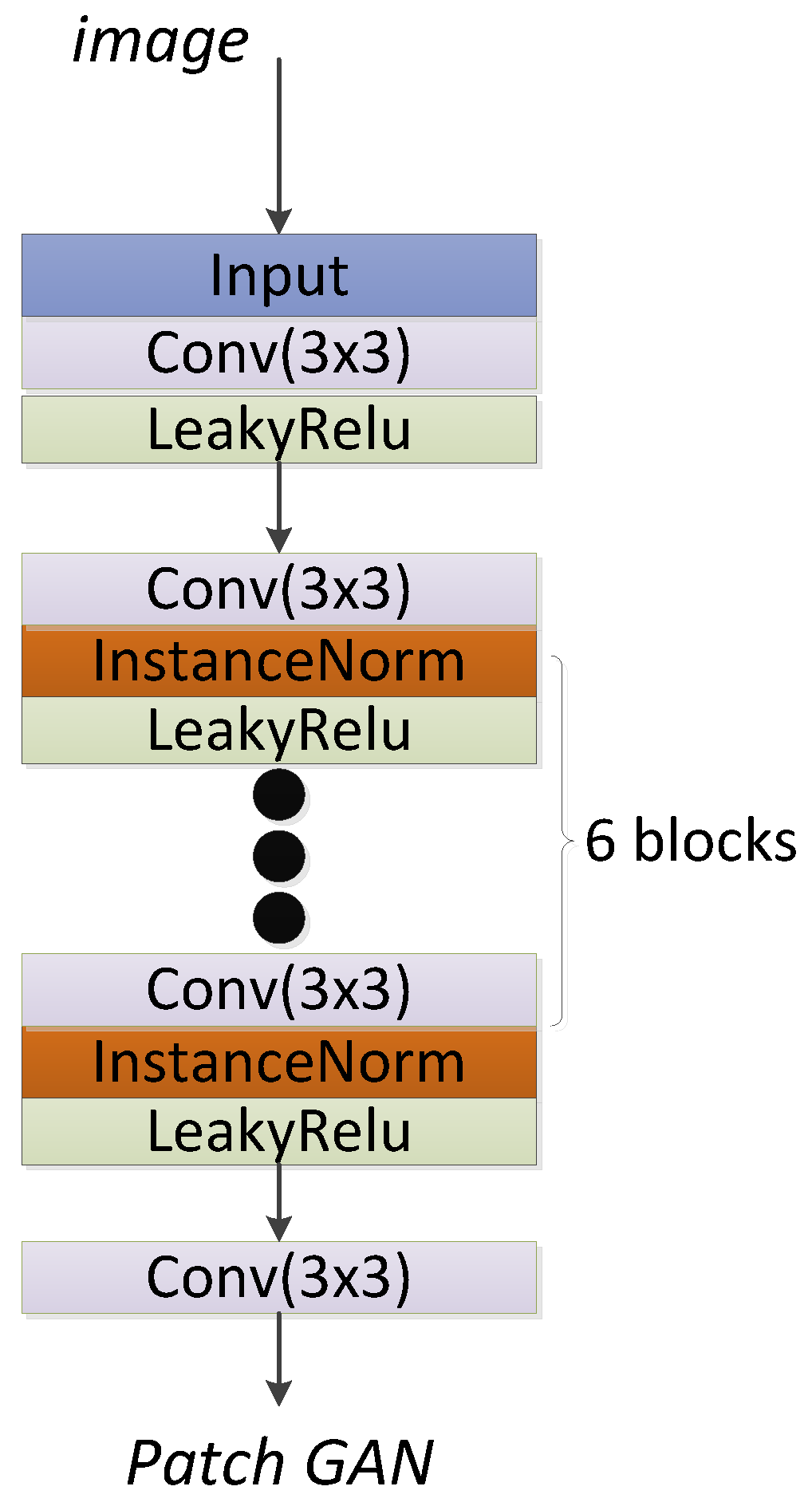
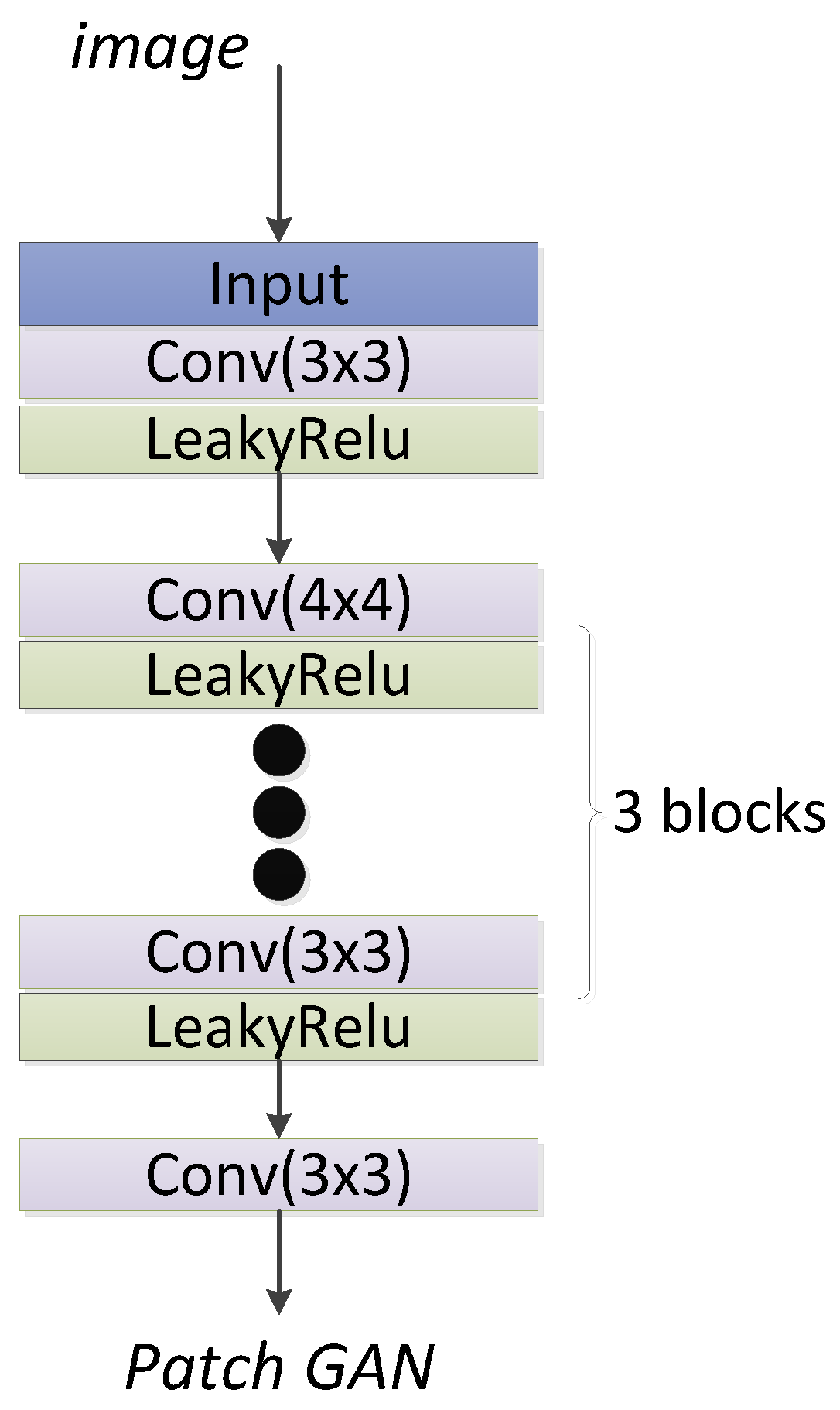
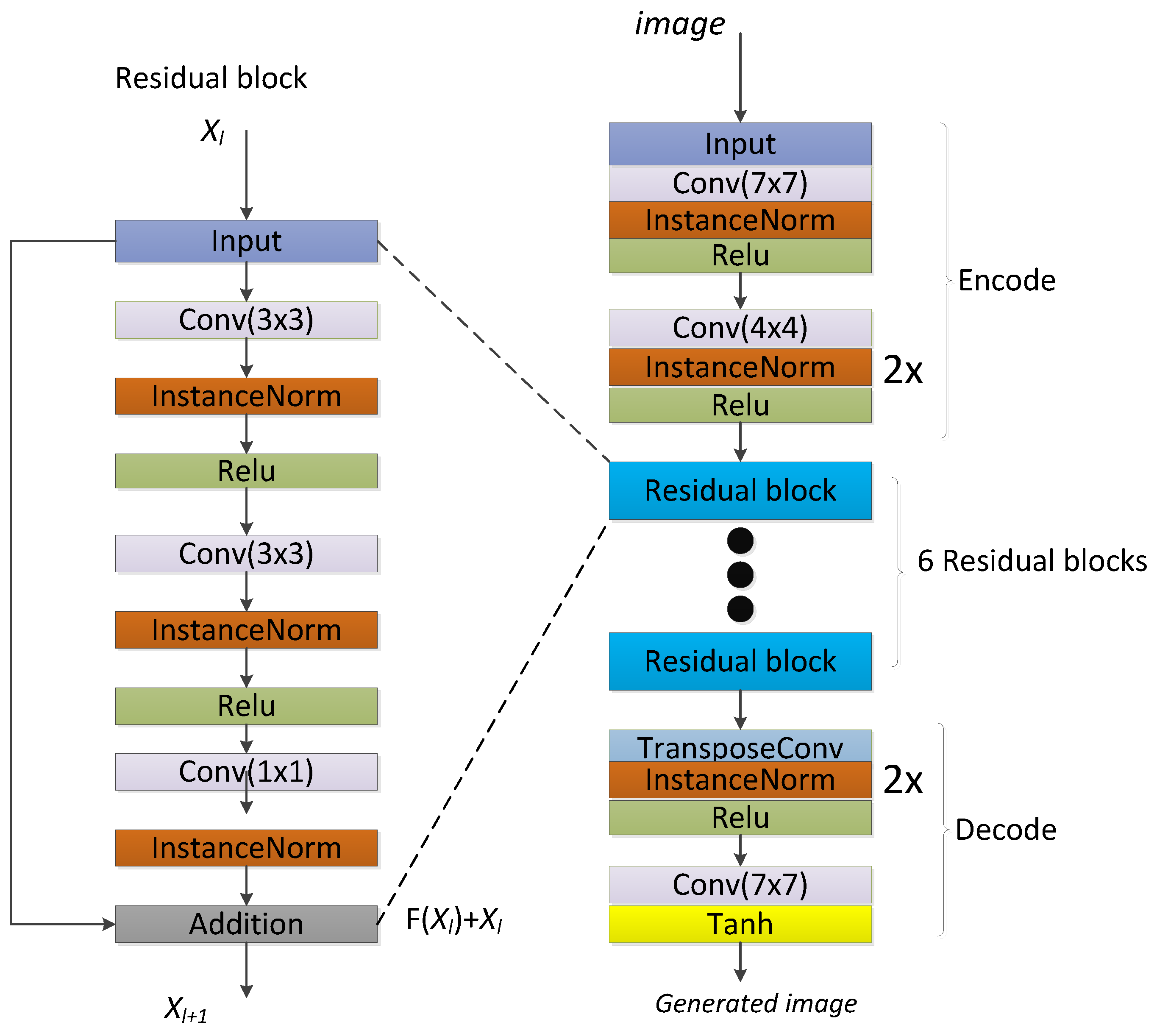
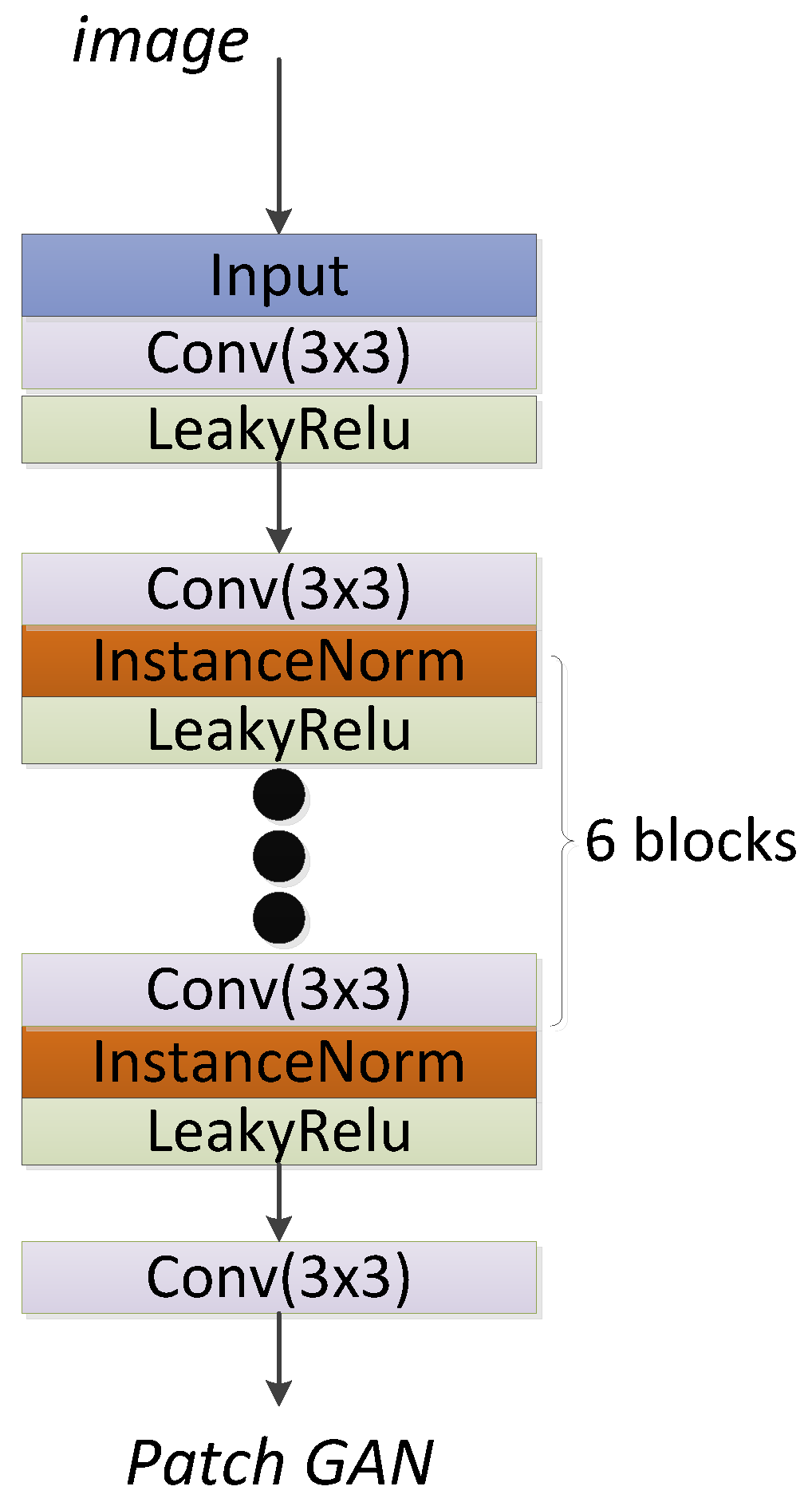
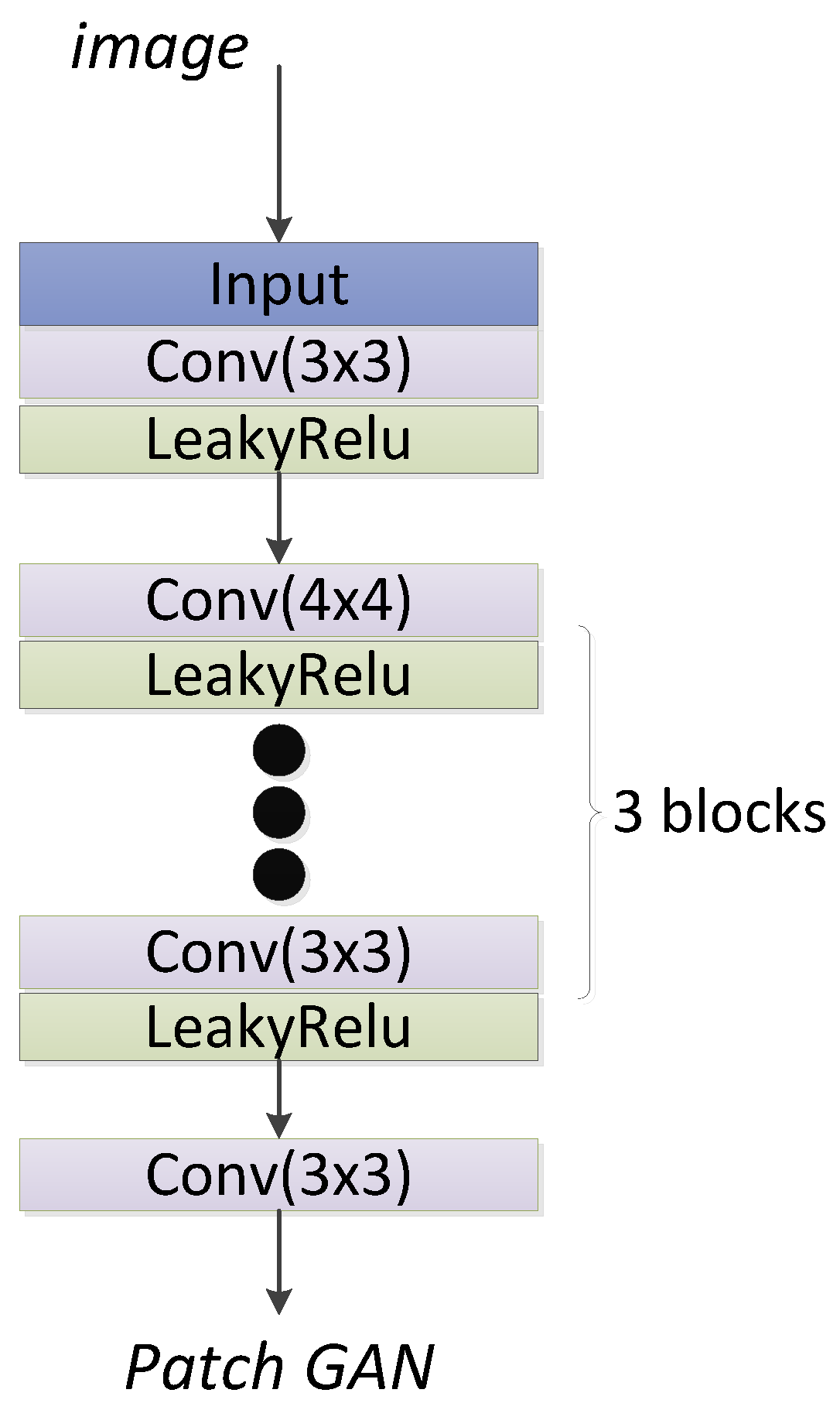
2.2.1. The Structure of the VS-GANs Model
2.2.2. Loss Function of VS-GANs
3. Experimental Results
3.1. Datasets
3.2. Qualitative Analysis of the Generated Vehicle Samples
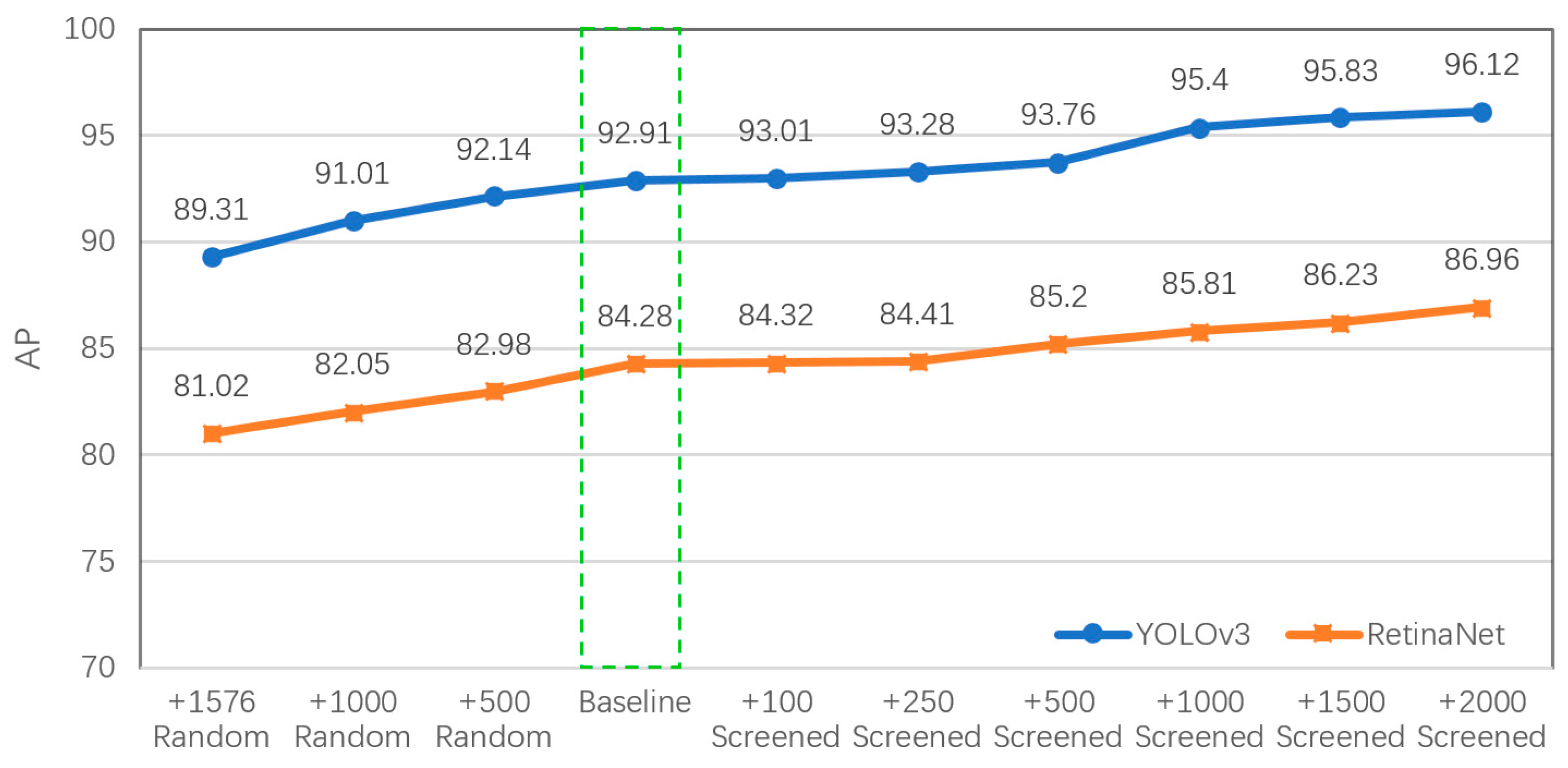
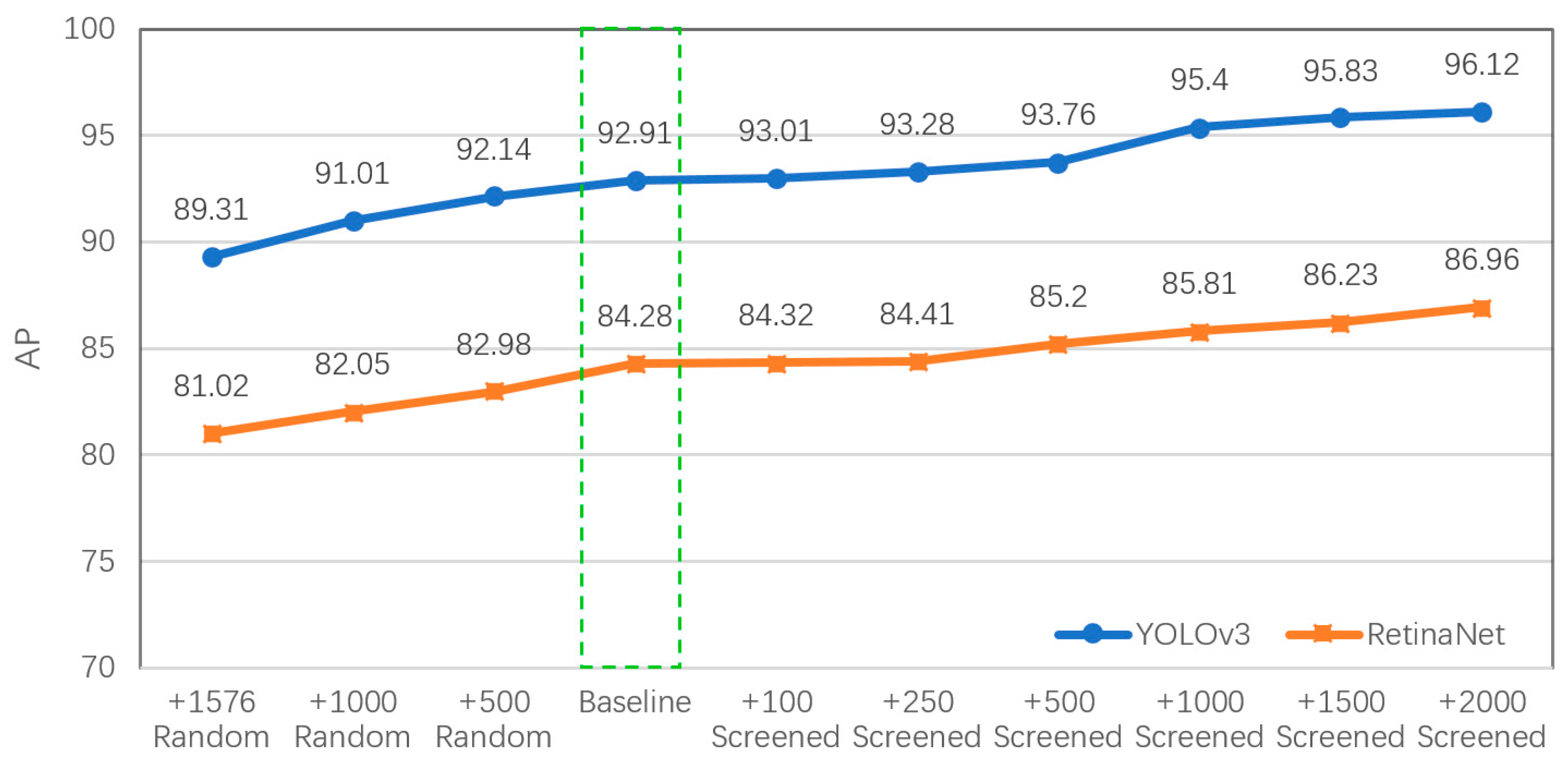
3.3. Vehicle Detection Experiments
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Shao, W.; Yang, W.; Liu, G.; Liu, J. Car detection from high-resolution aerial imagery using multiple features. In Proceedings of the Geoscience and Remote Sensing Symposium, Munich, Germany, 22–27 July 2012; pp. 4379–4382. [Google Scholar] [CrossRef]
- Kluckner, S.; Pacher, G.; Grabner, H.; Bischof, H.; Bauer, J. A 3D teacher for car detection in aerial images. In Proceedings of the International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar] [CrossRef]
- Tuermer, S.; Kurz, F.; Reinartz, P.; Stilla, U. Airborne vehicle detection in dense urban areas using HoG features and disparity maps. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 2327–2337. [Google Scholar] [CrossRef]
- Tianyu, T.; Shilin, Z.; Zhipeng, D.; Huanxin, Z.; Lin, L. Vehicle detection in aerial images based on region convolutional neural networks and hard negative example mining. Sensors 2017, 17, 336. [Google Scholar] [CrossRef]
- Yang, M.Y.; Liao, W.; Li, X.; Rosenhahn, B. Deep Learning for Vehicle Detection in Aerial Images. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018. [Google Scholar]
- Van Etten, A. You Only Look Twice: Rapid Multi-Scale Object Detection in Satellite Imagery. Available online: https://arxiv.org/abs/1805.09512 (accessed on 20 August 2019).
- Zhao, T.; Nevatia, R. Car detection in low resolution aerial images. Image Vis. Comput. 2003, 21, 693–703. [Google Scholar] [CrossRef]
- Line, E.; Lars, A.; Hans, K. Classification-based vehicle detection in high-resolution satellite images. ISPRS J. Photogramm. Remote Sens. 2009, 64, 65–72. [Google Scholar] [CrossRef]
- Zheng, H.; Pan, L.; Li, L. A morphological neural network approach for vehicle detection from high resolution satellite imagery. In Proceedings of the International Conference on Neural Information Processing, Hong Kong, China, 3–6 October 2006. [Google Scholar] [CrossRef]
- Qu, T.; Zhang, Q.; Sun, S. Vehicle detection from high-resolution aerial images using spatial pyramid pooling-based deep convolutional neural networks. Multimed. Tools Appl. 2016, 76, 21651–21663. [Google Scholar] [CrossRef]
- Li, H.; Fu, K.; Yan, M.; Sun, X.; Sun, H.; Diao, W. Vehicle detection in remote sensing images using denoising-based convolutional neural networks. Remote Sens. Lett. 2017, 8, 262–270. [Google Scholar] [CrossRef]
- Chauhan, R.; Ghanshala, K.K.; Joshi, R.C. Convolutional Neural Network (CNN) for Image Detection and Recognition. In Proceedings of the 2018 First International Conference on Secure Cyber Computing and Communication (ICSCCC), Jalandhar, India, 15–17 December 2018. [Google Scholar]
- Zhai, S.; Cheng, Y.; Feris, R.; Zhang, Z. Generative Adversarial Networks as Variational Training of Energy Based Models. Available online: https://arxiv.org/abs/1611.01799 (accessed on 20 August 2019).
- Hu, X.; Xu, X.; Xiao, Y.; Chen, H.; He, S.; Qin, J.; Heng, P.-A. SINet: A Scale-Insensitive Convolutional Neural Network for Fast Vehicle Detection. IEEE Trans. Intell. Transp. Syst. 2019, 20, 1010–1019. [Google Scholar] [CrossRef]
- Gao, X.; Li, H.; Zhang, Y.; Yuan, M.; Zhang, Z.; Sun, X.; Sun, H.; Yu, H. Vehicle Detection in Remote Sensing Images of Dense Areas Based on Deformable Convolution Neural Network. J. Electron. Inf. Technol. 2018, 40, 2812–2819. [Google Scholar]
- Zhao, W.; Ma, W.; Jiao, L.; Chen, P.; Yang, S.; Hou, B. Multi-Scale Image Block-Level F-CNN for Remote Sensing Images Object Detection. IEEE Access 2019, 7, 43607–43621. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Y.; Huang, X.; Yuille, A.L. Deep networks under scene-level supervision for multi-class geospatial object detection from remote sensing images. ISPRS J. Photogramm. Remote Sens. 2018, 146, 182–196. [Google Scholar] [CrossRef]
- Montserrat, D.M.; Lin, Q.; Allebach, J.; Delp, E. Training object detection and recognition cnn models using data augmentation. Electron. Imaging 2017, 27–36. [Google Scholar] [CrossRef]
- Oliveira, Í.; Medeiros, J.; de Sousa, V. A Data Augmentation Methodology to Improve Age Estimation using Convolutional Neural Networks. In Proceedings of the SIBGRAPI—Conference on Graphics Patterns and Images, Sao Paulo, Brazil, 4–7 October 2016. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Bing, X.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the International Conference on Neural Information Processing Systems, Kuching, Malaysia, 3–6 November 2014. [Google Scholar]
- Toan, T.; Pham, T.; Carneiro, G.; Palmer, L.; Reid, L. A Bayesian Data Augmentation Approach for Learning Deep Model. Available online: https://arxiv.org/pdf/1710.10564 (accessed on 20 August 2019).
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.K.; Wang, Z. Least squares generative adversarial networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar] [CrossRef]
- Denton, E.; Chintala, S.; Szlam, A.; Fergus, R. Deep Generative Image Models Using a Laplacian Pyramid of Adversarial Networks. Available online: https://arxiv.org/abs/1506.05751 (accessed on 20 August 2019).
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein GAN. Available online: https://arxiv.org/abs/1701.07875 (accessed on 20 August 2019).
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. Available online: https://arxiv.org/abs/1511.06434 (accessed on 20 August 2019).
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. Available online: https://arxiv.org/abs/1703.10593 (accessed on 20 August 2019).
- Liu, M.Y.; Breuel, T.; Kautz, J. Unsupervised image-to-image translation networks. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Taigman, Y.; Polyak, A.; Wolf, L. Unsupervised Cross-Domain Image Generation. Available online: https://arxiv.org/abs/1611.02200 (accessed on 20 August 2019).
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Yeh, R.A.; Chen, C.; Lim, T.Y.; Schwing, A.G.; Hasegawa-Johnson, M.; Do, M.N. Semantic image inpainting with deep generative models. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Denton, E.; Gross, S.; Fergus, R. Semi-Supervised Learning with Context-Conditional Generative Adversarial Networks. Available online: https://arxiv.org/pdf/1611.06430 (accessed on 20 August 2019).
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context encoders: Feature learning by inpainting. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Liu, W.; Liu, X.; Ma, H.; Cheng, P. Beyond Human-level License Plate Super-resolution with Progressive Vehicle Search and Domain Priori GAN. In Proceedings of the 25th ACM international conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 1618–1626. [Google Scholar]
- Inoue, N.; Furuta, R.; Yamasaki, T.; Aizawa, K. Cross-domain weakly-supervised object detection through progressive domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]
- Li, J.; Liang, X.; Wei, Y.; Xu, T.; Feng, J.; Yan, S. Perceptual generative adversarial networks for small object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. Available online: https://arxiv.org/abs/1512.03385 (accessed on 20 August 2019).
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved Training of Wasserstein Gans. Available online: https://arxiv.org/abs/1704.00028 (accessed on 20 August 2019).
- Zhu, H.; Chen, X.; Dai, W.; Fu, K.; Ye, Q.; Jiao, J. Orientation robust object detection in aerial images using deep convolutional neural network. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An Incremental Improvement. Available online: https://arxiv.org/pdf/1804.02767 (accessed on 20 August 2019).
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Piotr, D. Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 2999–3007. [Google Scholar] [CrossRef]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. Dota: A large-scale dataset for object detection in aerial images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Source of Vehicle Samples | YOLOv3 | RetinaNet |
|---|---|---|
| UCAS + NWPU (8850 vehicles) | 92.91% | 84.28% |
| +VS-GANs augmentation | 96.12% | 90.78% |
| Source of Vehicle Samples | DCGAN | LSGAN | WGAN-GP | VS-GANs |
|---|---|---|---|---|
| UCAS + NWPU (8850 vehicles) | 92.91% (0.66) * | |||
| +125 images (1000 synthesized vehicles) | 93.84% (0.46) | 93.65% (0.65) | 94.16% (0.34) | 95.40% (0.33) |
| +250 images (2000 synthesized vehicles) | 94.17% (0.41) | 94.77% (0.38) | 95.44% (0.18) | 96.12% (0.21) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, K.; Wei, M.; Sun, G.; Anas, B.; Li, Y. Using Vehicle Synthesis Generative Adversarial Networks to Improve Vehicle Detection in Remote Sensing Images. ISPRS Int. J. Geo-Inf. 2019, 8, 390. https://doi.org/10.3390/ijgi8090390
Zheng K, Wei M, Sun G, Anas B, Li Y. Using Vehicle Synthesis Generative Adversarial Networks to Improve Vehicle Detection in Remote Sensing Images. ISPRS International Journal of Geo-Information. 2019; 8(9):390. https://doi.org/10.3390/ijgi8090390
Chicago/Turabian StyleZheng, Kun, Mengfei Wei, Guangmin Sun, Bilal Anas, and Yu Li. 2019. "Using Vehicle Synthesis Generative Adversarial Networks to Improve Vehicle Detection in Remote Sensing Images" ISPRS International Journal of Geo-Information 8, no. 9: 390. https://doi.org/10.3390/ijgi8090390
APA StyleZheng, K., Wei, M., Sun, G., Anas, B., & Li, Y. (2019). Using Vehicle Synthesis Generative Adversarial Networks to Improve Vehicle Detection in Remote Sensing Images. ISPRS International Journal of Geo-Information, 8(9), 390. https://doi.org/10.3390/ijgi8090390