A Filtering-Based Approach for Improving Crowdsourced GNSS Traces in a Data Update Context


Abstract
1. Introduction
2. Literature Review
3. Methodology
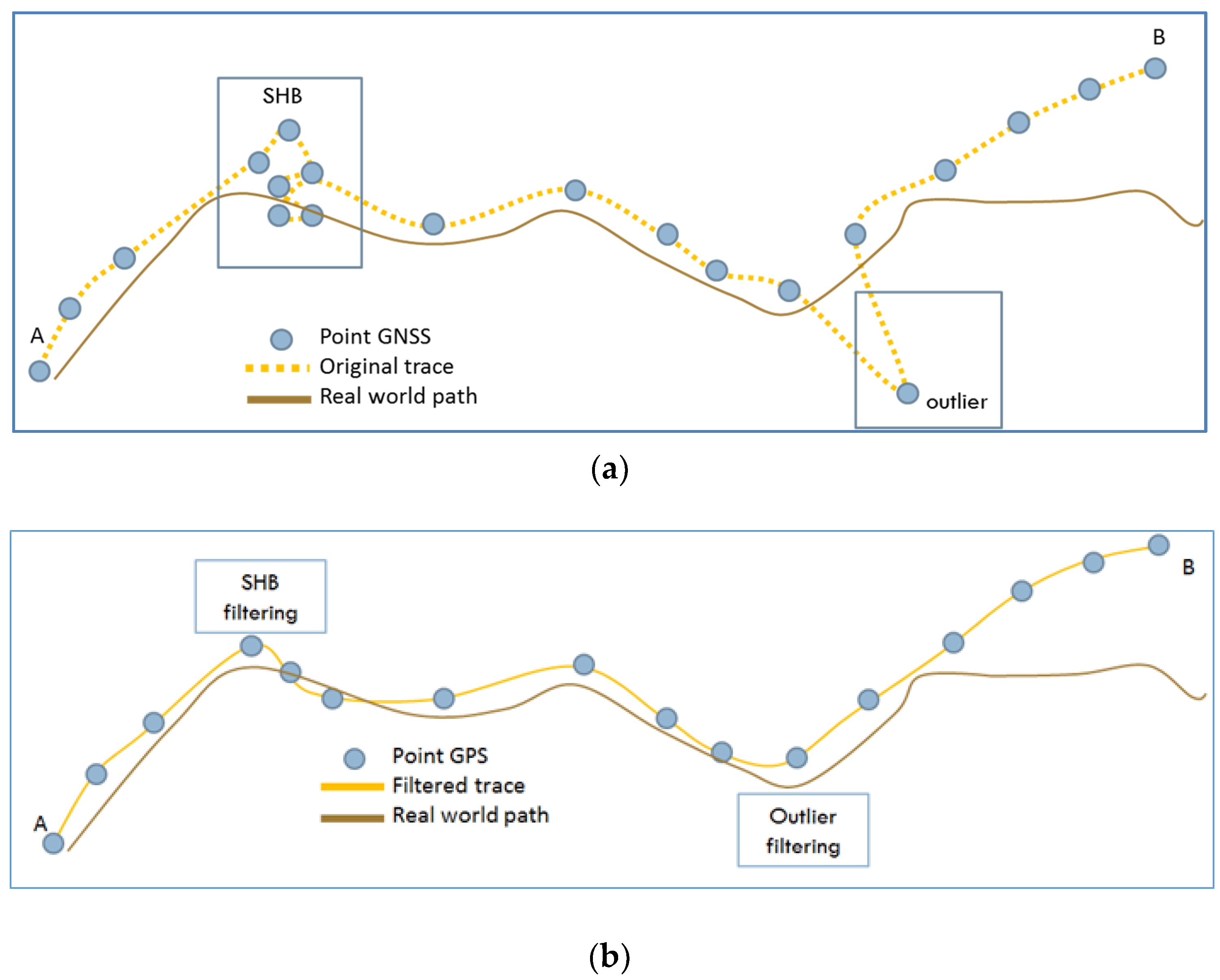
3.1. Pre-Processing Filtering
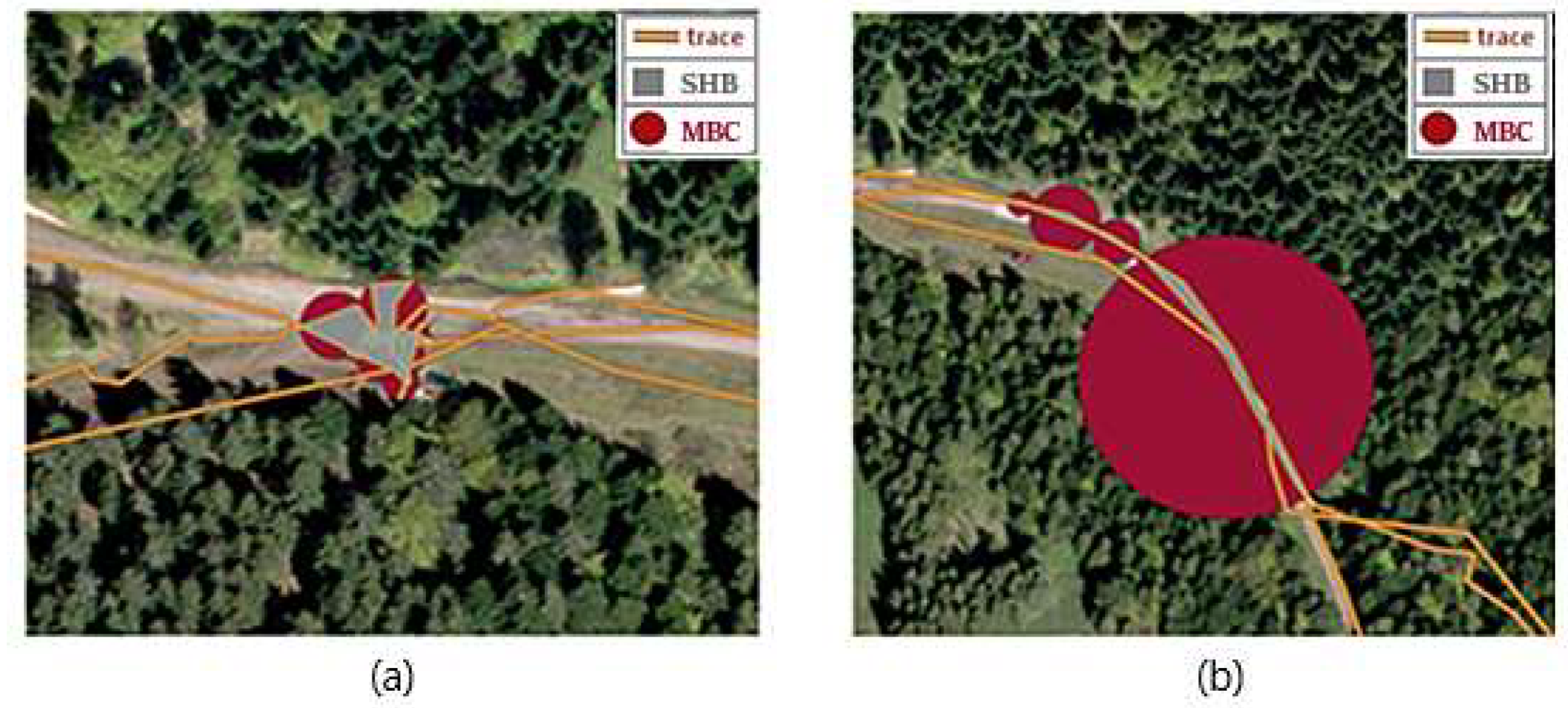
3.2. Filtering Secondary Human Behaviour
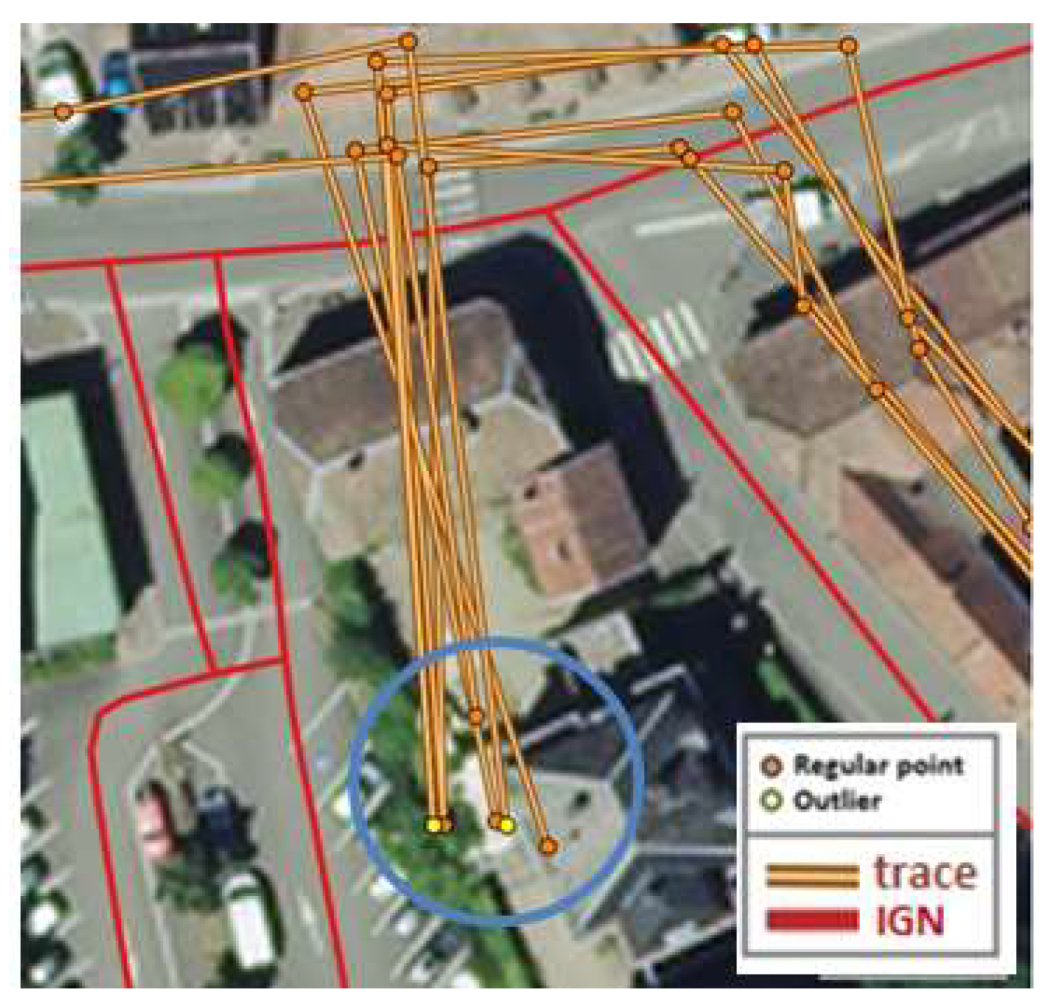
3.3. Filtering Outliers
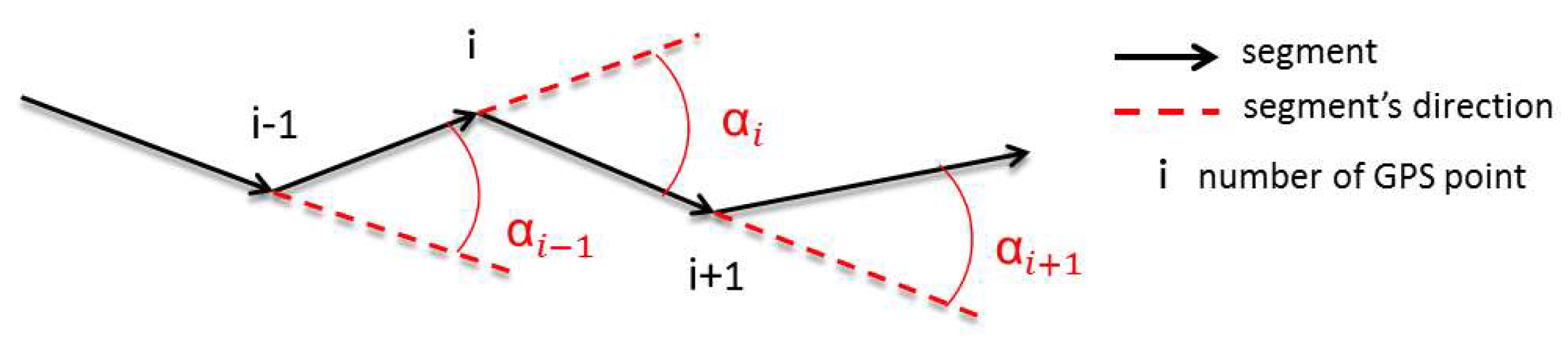
Definition of Intrinsic and Extrinsic Indicators for Describing GNSS Points
4. Experimental Results
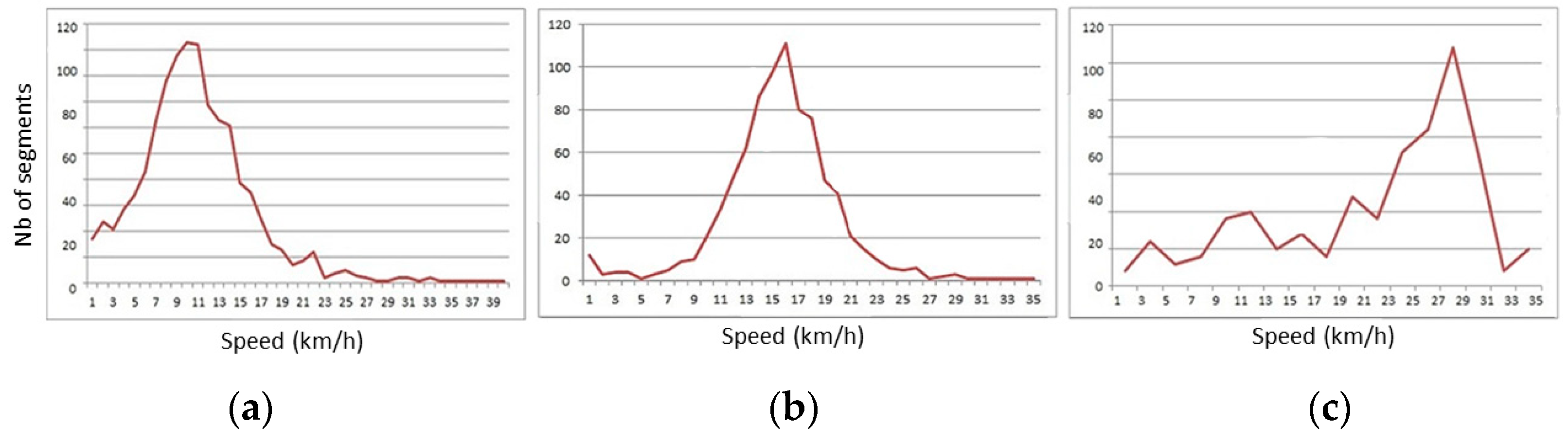
4.1. Test Data Description
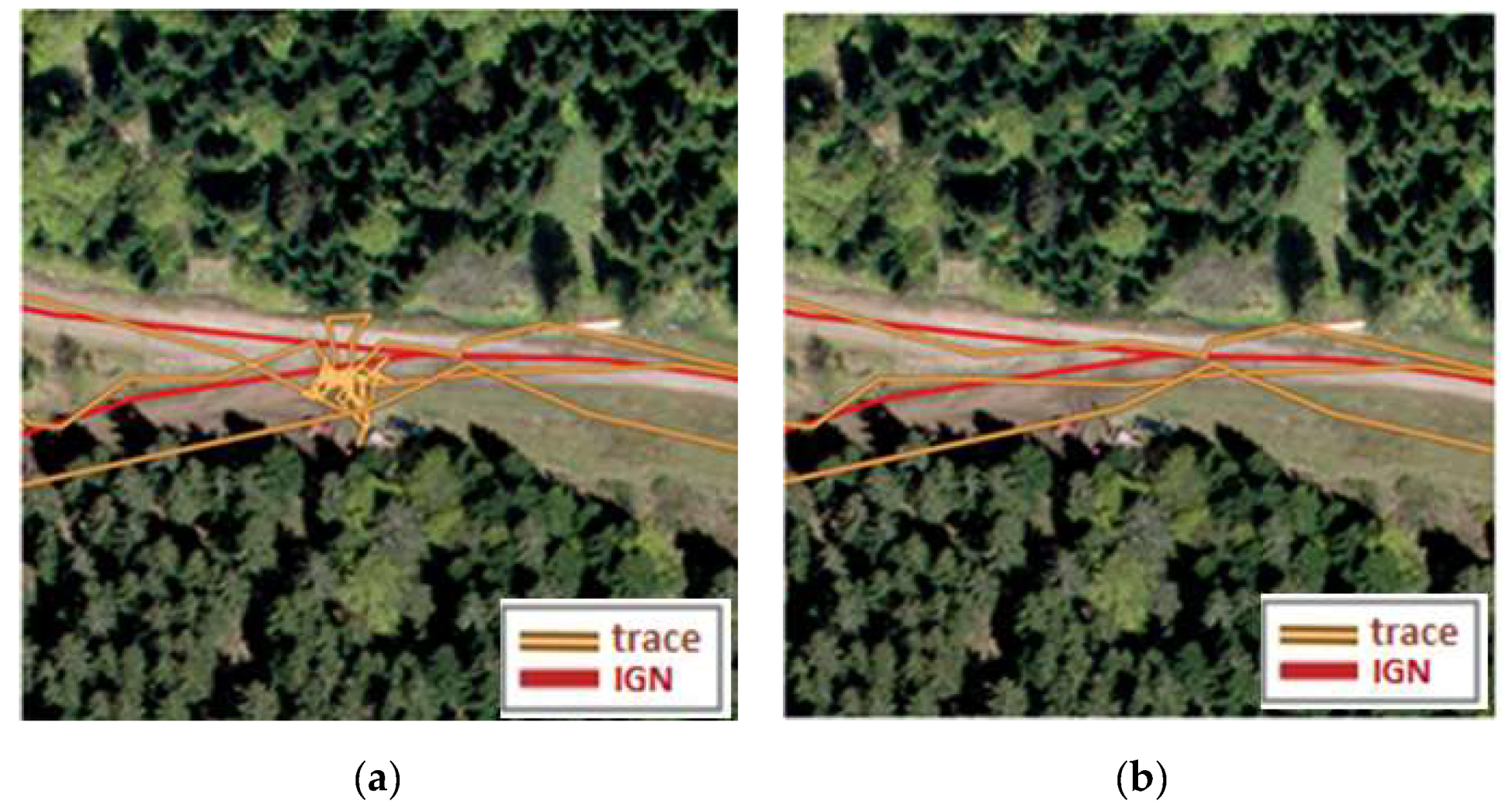
4.2. Detection of Secondary Human Behaviour
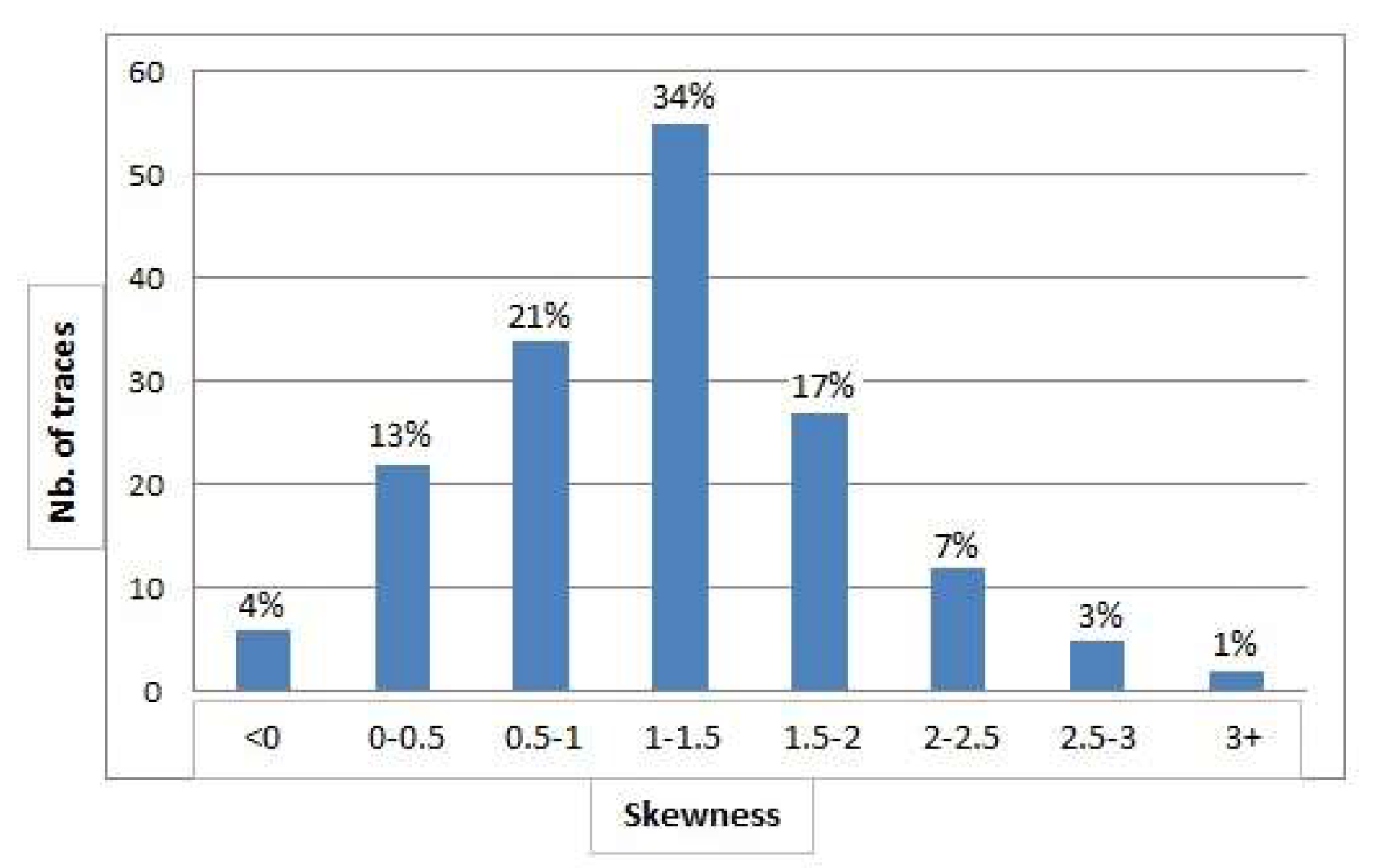
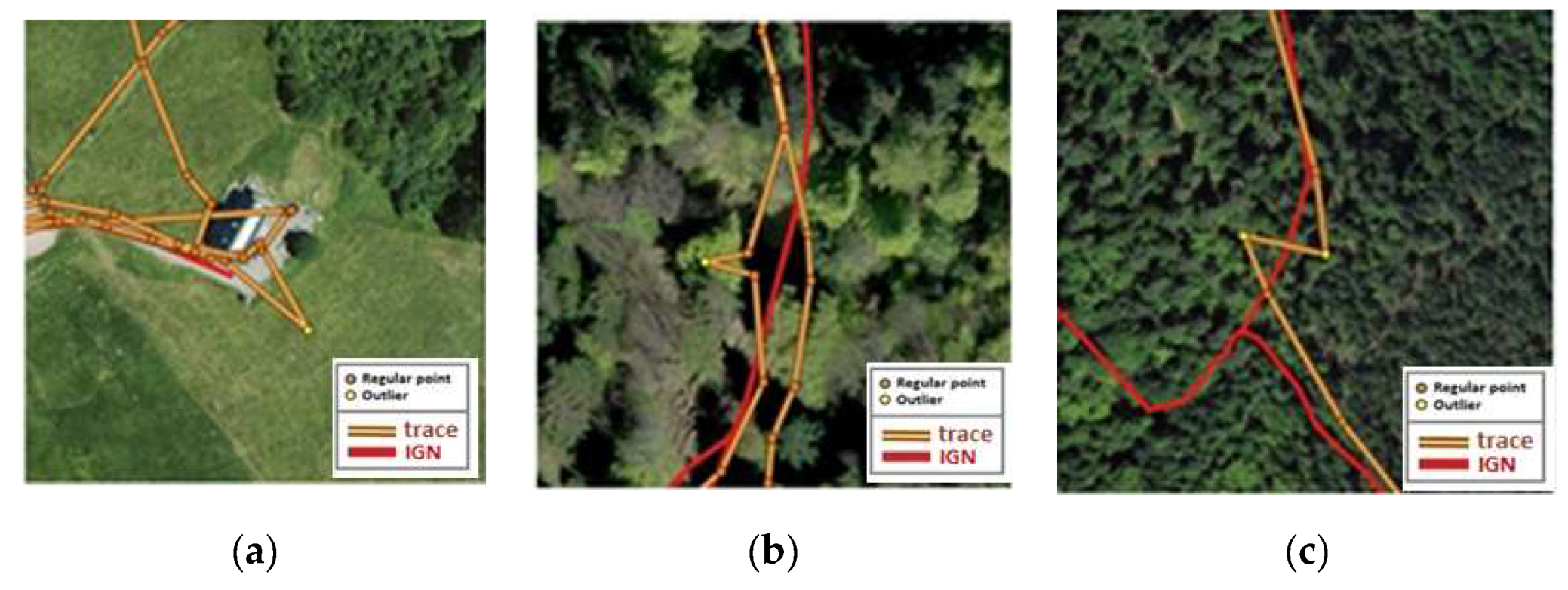
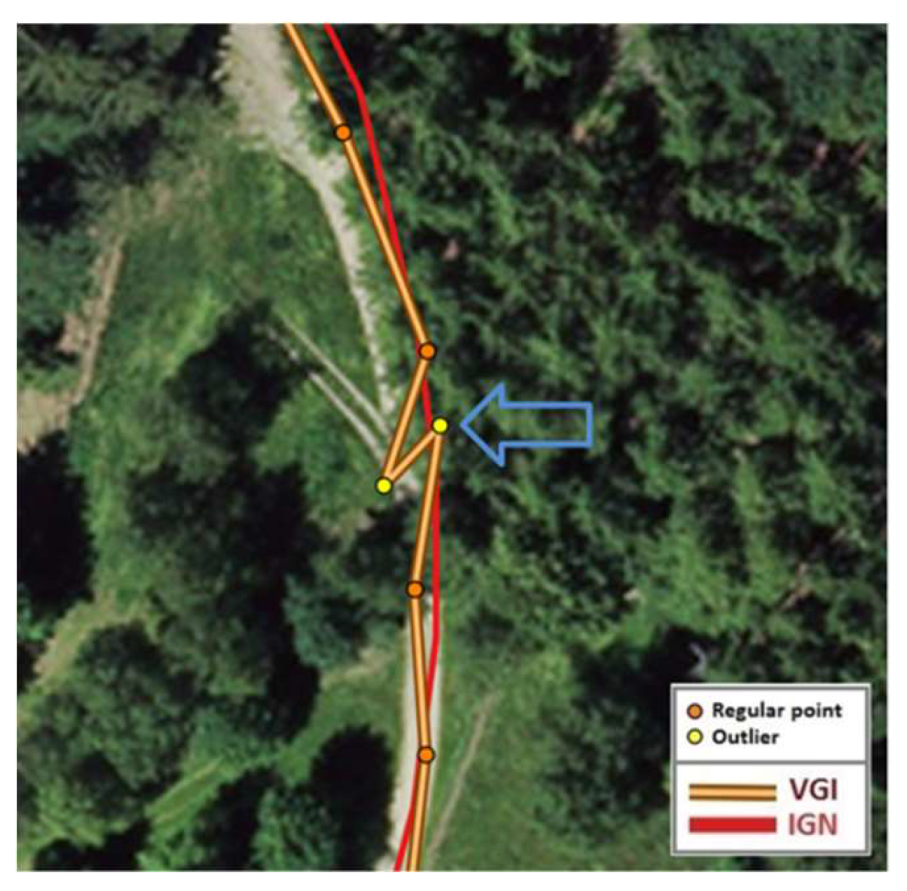
4.3. Detection of Outliers
5. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Bruns, A. Blogs, Wikipedia, Second Life, and Beyond: From Production to Produsage; Peter Lang: New York, NY, USA, 2008. [Google Scholar]
- See, L.; Mooney, P.; Foody, G.; Bastin, L.; Comber, A.; Estima, J.; Fritz, S.; Kerle, N.; Jiang, B.; Laakso, M.; et al. Crowdsourcing, Citizen Science or Volunteered Geographic Information? The Current State of Crowdsourced Geographic Information. ISPRS Int. J. Geo Inf. 2016, 5, 55. [Google Scholar] [CrossRef]
- Turner, A. Introduction to Neogeography; O’Reilly Media: Newton, MA, USA, 2006; p. 54. [Google Scholar]
- Haklay, M. How good is volunteered geographical information? A comparative study of OpenStreetMap and Ordnance Survey datasets. Environ. Plan. B Plan. Des. 2010, 37, 682–703. [Google Scholar] [CrossRef]
- Antoniou, V.; Morley, J.; Haklay, M. The Role of User Generated Spatial Content in Mapping Agencies. In Proceedings of the GISRUK Conference, Durham, UK, 1–3 April 2009. [Google Scholar]
- Estellés-Arolas, E.; González-Ladrón-De-Guevara, F. Towards an integrated crowdsourcing definition. J. Inf. Sci. 2012, 38, 189–200. [Google Scholar] [CrossRef]
- Spink, A.; Cresswell, B.; Koelzsch, A.; Langevelde, F.; Neefjes, M.; Noldus, L.; Oeveren, H.; Prins, H.; van der Wal, T.; de Weerd, N.; et al. Animal Behaviour Analysis with GPS and 3D Accelerometers. In Proceedings of the 6th European Conference on Precision Livestock Farming, Leuven, Belgium, 10–12 September 2013. [Google Scholar]
- Fuentes, A.; Heaslip, K.; Sisneros-Kidd, A.M.; D’Antonio, A.; Kelarestaghi, K.B. Decision Tree Approach to Predicting Vehicle Stopping from GPS Tracks in a National Park Scenic Corridor. Transp. Res. Rec. J. Transp. Res. Board 2019, 2673, 86–96. [Google Scholar] [CrossRef]
- D’Antonio, A.; Monz, C.; Lawson, S.; Newman, P.; Pettebone, D.; Courtemanch, A. GPS-based measurements of backcountry visitors in parks and protected areas: Examples of methods and applications from three case studies. J. Park Recreat. Admi. 2010, 28, 11–13. [Google Scholar]
- Bauer, C. On the Accuracy of GPS Measures of Smartphones: A Study of Running Tracking Applications. In Proceedings of the ACM International Conference Proceeding, Niagara, ON, Canada, 25–28 August 2013. [Google Scholar]
- Mooney, P.; Minghini, M.; Laakso, M.; Antoniou, V.; Olteanu-Raimond, A.-M.; Skopeliti, A. Towards a Protocol for the Collection of VGI Vector Data. ISPRS Int. J. Geo Inf. 2016, 5, 217. [Google Scholar] [CrossRef]
- Thierry, B.; Chaix, B.; Kestens, Y. Detecting activity locations from raw GPS data: A novel kernel-based algorithm. Int. J. Health Geogr. 2013, 12, 14. [Google Scholar] [CrossRef]
- Ester, M.; peter Kriegel, H.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise; AAAI Press: Menlo Park, CA, USA, 1996; pp. 226–231. [Google Scholar]
- Buard, E. Dynamiques des Interactions Espèces Espace, Mise en Relation des Pratiques de Déplacement des Populations D’herbivores et de L’évolution de L’occupation du Sol Dans le Parc de Hwange; Université Paris: Paris, France, 2013. (In Zimbabwe) [Google Scholar]
- Alvares, L.O.; Bogorny, V.; Kuijpers, B.; De Macedo, J.A.F.; Moelans, B.; Vaisman, A. A Model for Enriching Trajectories with Semantic Geographical Information. In Proceedings of the 15th Annual ACM International Symposium, Seattle, WA, USA, 7–9 November 2007. [Google Scholar]
- Zimmermann, M.; Kirste, T.; Spiliopoulou, M. Finding Stops in Error-Prone Trajectories of Moving Objects with Time-Based Clustering. In Creativity in Intelligent Technologies and Data Science; Springer Science and Business Media LLC: Berlin, Germany, 2009; Volume 53, pp. 275–286. [Google Scholar]
- Rocha, J.A.M.R.; Times, V.C.; Oliveira, G.; Alvares, L.O.; Bogorny, V. DB-SMoT: A Direction-Based Spatio-Temporal Clustering Method. In Proceedings of the 2010 5th IEEE International Conference Intelligent Systems, London, UK, 7–9 July 2010. [Google Scholar]
- Olteanu Raimond, A.M.; Couronné, T.; Fen-Chong, J.; Smoreda, Z. Le Paris des visiteurs étrangers, qu’en disent les téléphones mobiles ? Inférence des pratiques spatiales et fréquentations des sites touristiques en Île-de-France. Rev. Int. Géomatique 2012, 22, 413–437. [Google Scholar] [CrossRef]
- Palma, A.T.; Bogorny, V.; Kuijpers, B.; Alvares, L.O. A Clustering-Based Approach for Discovering Interesting Places in Trajectories. In Proceedings of the 2008 ACM Symposium, Fortaleza, Brazil, 16–20 March 2008. [Google Scholar]
- Yan, Z.; Parent, C.; Spaccapietra, S.; Chakraborty, D. A Hybrid Model and Computing Platform for Spatio-Semantic Trajectories. In Information Security Applications; Springer Science and Business Media LLC: Berlin, Germany, 2010; Volume 6088, pp. 60–75. [Google Scholar]
- Knight, N.L.; Wang, J. A Comparison of Outlier Detection Procedures and Robust Estimation Methods in GPS Positioning. J. Navig. 2009, 62, 699–709. [Google Scholar] [CrossRef]
- Galán, C.O.; Rodriguez-Perez, J.R.; Torres, J.M.; Nieto, P.G. Analysis of the influence of forest environments on the accuracy of GPS measurements by using genetic algorithms. Math. Comput. Model. 2011, 54, 1829–1834. [Google Scholar] [CrossRef]
- Duran, A.; Earleywine, M. GPS Data Filtration Method for Drive Cycle Analysis Applications. SAE Tech. Paper Ser. 2012, 4–5. [Google Scholar]
- Eliasson, M. A Kalman Filter Approach to Reduce Position Error for Pedestrian Applications in Areas of Bad GPS Reception; Universitet Umea: Umea, Sweden, 2014. [Google Scholar]
- Gomez-Gil, J.; Ruiz-González, R.; Alonso-Garcia, S.; Gomez-Gil, F.J. A Kalman Filter Implementation for Precision Improvement in Low-Cost GPS Positioning of Tractors. Sensors 2013, 13, 15307–15323. [Google Scholar] [CrossRef] [PubMed]
- Gil, P.; Ariza-Lopez, F.; Mozas, A. Detection of Outliers in Sets of Gnss Tracks from Volunteered Geographic Information. In Proceedings of the 18th AGILE International Conference on Geographic Information Science, Lisbon, Portugal, 9–12 June 2015. [Google Scholar]
- Etienne, L.; Devogele, T.; Buchin, M.; McArdle, G. Trajectory Box Plot: A new pattern to summarize movements. Int. J. Geogr. Inf. Sci. 2016, 30, 835–853. [Google Scholar] [CrossRef]
- Goodchild, F.M.; Li, L. Assuring the Quality of Volunteered Geographic Information. Spat. Stat. 2012, 1, 110–120. [Google Scholar] [CrossRef]
- Barron, C.; Neis, P.; Zipf, A. A Comprehensive Framework for Intrinsic OpenStreetMap Quality Analysis. Trans. GIS 2014, 18, 877–895. [Google Scholar] [CrossRef]
- van Exel, M.V.; Dias, E.; Fruijtier, S. The impact of Crowdsourcing on Spatial Data Quality Indicators. Proc. GiSci. 2011. [Google Scholar]
- Comber, A.; See, L.; Fritz, S.; Van Der Velde, M.; Perger, C.; Foody, G. Using control data to determine the reliability of volunteered geographic information about land cover. Int. J. Appl. Earth Obs. Geoinf. 2013, 23, 37–48. [Google Scholar] [CrossRef]
- Jolivet, L.; Olteanu-Raimond, A.M. Crowd and Community Sourced Data Quality Assessment. Lect. Notes Geoinf. Cartogr. 2017, 47–60. [Google Scholar]
- Flanagin, A.J.; Metzger, M.J. The credibility of volunteered geographic information. GeoJournal 2008, 72, 137–148. [Google Scholar] [CrossRef]
- ISO. ISO 19157:2013, Geographic Information—Data Quality; ISO: Geneva, Switzerland, 2013. [Google Scholar]
- Arsanjani, J.J.; Zipf, A.; Mooney, P.; Helbich, M. OpenStreetMap in GIScience: Experiences, Research, and Applications; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Antoniou, V.; Skopeliti, A. Measures and Indicators of Vgi Quality: An Overview. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, II-3/W5, 345–351. [Google Scholar] [CrossRef]
- Touya, G.; Girres, J.F.; Girres, J. Quality Assessment of the French OpenStreetMap Dataset. Trans. GIS 2010, 14, 435–459. [Google Scholar]
- Touya, G.; Antoniou, V.; Olteanu-Raimond, A.-M.; Van Damme, M.-D. Assessing Crowdsourced POI Quality: Combining Methods Based on Reference Data, History, and Spatial Relations. ISPRS Int. J. Geo Inf. 2017, 6, 80. [Google Scholar] [CrossRef]
- Kaplan, E.D.; Hegarty, C. Understanding GPS: Principles and Applications, 2nd ed.; Artech House: Norwood, MA, USA, 2006. [Google Scholar]
- Janeau, G.; Adrados, C.; Joachim, J.; Gendner, J.-P.; Pépin, D. Performance of differential GPS collars in temperate mountain forest. Comptes Rendus Biol. 2004, 327, 1143–1149. [Google Scholar] [CrossRef]
- DeCesare, N.J.; Squires, J.R.; Kolbe, J.A. Effect of forest canopy on GPS-based movement data. Wildl. Soc. Bull. 2005, 33, 935–941. [Google Scholar] [CrossRef]
- Lewis, J.S.; Rachlow, J.L.; Garton, E.O.; Vierling, L.A. Effects of habitat on GPS collar performance: Using data screening to reduce location error. J. Appl. Ecol. 2007, 44, 663–671. [Google Scholar] [CrossRef]
- Jiang, Z.; Sugita, M.; Kitahara, M.; Takatsuki, S.; Goto, T.; Yoshida, Y. Effects of habitat feature, antenna position, movement, and fix interval on GPS radio collar performance in Mount Fuji, central Japan. Ecol. Res. 2008, 23, 581–588. [Google Scholar] [CrossRef]
- Blunck, H.; Kjærgaard, M.B.; Toftegaard, T.S. Sensing and Classifying Impairments of GPS Reception on Mobile Devices. In Computer Vision–ECCV 2012; Springer Science and Business Media LLC: Berlin, Germany, 2011; Volume 6696, pp. 350–367. [Google Scholar]
- Liu, C.; Xiong, L.; Hu, X.; Shan, J. A Progressive Buffering Method for Road Map Update Using OpenStreetMap Data. ISPRS Int. J. Geo Inf. 2015, 4, 1246–1264. [Google Scholar] [CrossRef]
- Heard, D.; Ciarniello, L.; Seip, D. Grizzly Bear Behaviour and Global Positioning System Collar Fix Rates. J. Wildl. Manage. 2008, 72, 596–602. [Google Scholar] [CrossRef]
- Klimanek, M. Analysis of the accuracy of GPS Trimble JUNO ST measurement in the conditions of forest canopy. J. For. Sci. 2010, 56, 84–91. [Google Scholar] [CrossRef]
- Tucek, J.; Ligoš, J. Forest canopy influence on the precision of location with GPS receivers. J. For. Sci. 2002, 48, 399–407. [Google Scholar] [CrossRef]
- Cain, J.W.; Krausman, P.R.; Jansen, B.D.; Morgart, J.R. Influence of topography and GPS fix interval on GPS collar performance. Wildl. Soc. Bull. 2005, 33, 926–934. [Google Scholar] [CrossRef]
- Ivanovic, S.; Olteanu Raimond, A.M.; Mustiere, S.; Devogele, T. Detection of Outliers in Crowdsourced GPS Traces. In Proceedings of the Spatial Accuracy 2016 Symposium, Montpellier, France, 5–8 July 2016. [Google Scholar]
- Van Winden, K.; Biljecki, F.; Van Der Spek, S. Automatic Update of Road Attributes by Mining GPS Tracks. Trans. GIS 2016, 20, 664–683. [Google Scholar] [CrossRef]
- Heselton, R.R.; Carstensen, L.W.; Campbell, J.B.; Oderwald, R. Elevation Effects on GPS Positional Accuracy. Master Sci. Geogr. 1998, 22. [Google Scholar]
- Thangaraj, M.; Vijayalakshmi, C.R. Performance Study on Rule-based Classification Techniques across Multiple Database Relations. Int. J. Appl. Inf. Syst. 2013, 5, 1–7. [Google Scholar]
- Medad, A.; Gaio, M.; Mustiere, S.; Mustiere@ensg, S. Appariement Automatique de Données Hétérogènes: Textes, Traces GPS et Ressources Géographiques. In Proceedings of the 14th Spatial Analysis and Geomatics Conference, Montpellier, France, 6–9 November 2018. [Google Scholar]
- Camp, M.J.; Rachlow, J.L.; Cisneros, R.; Roon, D.; Camp, R.J. Evaluation of Global Positioning System telemetry collar performance in the tropical Andes of southern Ecuador. Nat. Conserv. 2016, 14, 128–131. [Google Scholar] [CrossRef]
- Kubat, M.; Holte, R.C.; Matwin, S. Machine Learning for the Detection of Oil Spills in Satellite Radar Images. Mach. Learn. 1998, 30, 195–215. [Google Scholar] [CrossRef]
- Pazzani, M.; Merz, C.; Murphy, P.; Ali, K.; Hume, T.; Brunk, C. Reducing Misclassification Costs. In Machine Learning Proceedings 1994; Cohen, W.W., Hirsh, H., Eds.; Morgan Kaufmann: San Francisco, CA, USA, 1994; pp. 217–225. [Google Scholar]
- Japkowicz, N. Learning from Imbalanced Data Sets: A Comparison of Various Strategies; AAAI: Nova Scotia, Canada, 2000. [Google Scholar]
- Batista, G.E.; Prati, R.C.; Monard, M.C. A Study of the Behaviour of Several Methods for Balancing Machine Learning Training Data. Sigkdd Explor. Newsl. 2004, 6, 20–29. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Indicators | Description | Formula |
|---|---|---|
| AngleMean | Average value of 3 direction change (see Figure 4) | |
| DistDiffN | Normalized distance | () |
| DistDiffMed | Relation between distance and median distance of a trace | |
| DistMean | Mean distance | 2 |
| SpeedDiffN | Normalized speed | () |
| SpeedMean | Mean speed | 2 |
| SpeedRate | Speed rate | |
| DiffElev | Maximal height difference | max| − , − | |
| Indicators | Description | Formula |
|---|---|---|
| DiffElevDTM | Correlation between elevation (GNSS and DTM) | |ZDTM − ZGNSS| |
| Slope | Gradient of line | tan(Ɵ), −90° < Ɵ < 90° |
| Obstacles | Proximity of obstacles | true if close to obstacles, false otherwise |
| Curvature | Convexity of slope | 1/R |
| Vegetation | Type of forest | f (Landcover) |
| CanopyCover | Point in the forest? | f (Landcover), boolean |
| InBuildingWater | Point in building or water? | f (Topographic data), boolean |
| Algorithm | Precision | Recall | F1 |
|---|---|---|---|
| PART | 0.67 | 0.78 | 0.72 |
| OneR | 0.72 | 0.69 | 0.7 |
| RIPPER | 0.79 | 0.79 | 0.79 |
| M5Rules | 0.75 | 0.72 | 0.73 |
| Rule Number | Description |
|---|---|
| Rule 1 | IF DistDiffMed >= 1.05 AND AngleMean >= 87.54 → outlier OR |
| Rule 2 | IF AngleMean >= 71.25 AND SpeedRate >= 1.50 → outlier OR |
| Rule 3 | IF AngleMean >= 74.80 AND DistDiffN <= 0.21→ outlier OR |
| Rule 4 | IF AngleMean >= 83.15 AND SpeedRate <= 0.85→ outlier OR |
| Rule 5 | IF AngleMean >= 56.43 AND DistMean >= 8847.31 → outlier |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ivanovic, S.S.; Olteanu-Raimond, A.-M.; Mustière, S.; Devogele, T. A Filtering-Based Approach for Improving Crowdsourced GNSS Traces in a Data Update Context. ISPRS Int. J. Geo-Inf. 2019, 8, 380. https://doi.org/10.3390/ijgi8090380
Ivanovic SS, Olteanu-Raimond A-M, Mustière S, Devogele T. A Filtering-Based Approach for Improving Crowdsourced GNSS Traces in a Data Update Context. ISPRS International Journal of Geo-Information. 2019; 8(9):380. https://doi.org/10.3390/ijgi8090380
Chicago/Turabian StyleIvanovic, Stefan S., Ana-Maria Olteanu-Raimond, Sébastien Mustière, and Thomas Devogele. 2019. "A Filtering-Based Approach for Improving Crowdsourced GNSS Traces in a Data Update Context" ISPRS International Journal of Geo-Information 8, no. 9: 380. https://doi.org/10.3390/ijgi8090380
APA StyleIvanovic, S. S., Olteanu-Raimond, A.-M., Mustière, S., & Devogele, T. (2019). A Filtering-Based Approach for Improving Crowdsourced GNSS Traces in a Data Update Context. ISPRS International Journal of Geo-Information, 8(9), 380. https://doi.org/10.3390/ijgi8090380