Feature Extraction and Selection of Sentinel-1 Dual-Pol Data for Global-Scale Local Climate Zone Classification




Abstract
1. Introduction
2. Study Area and Data Set
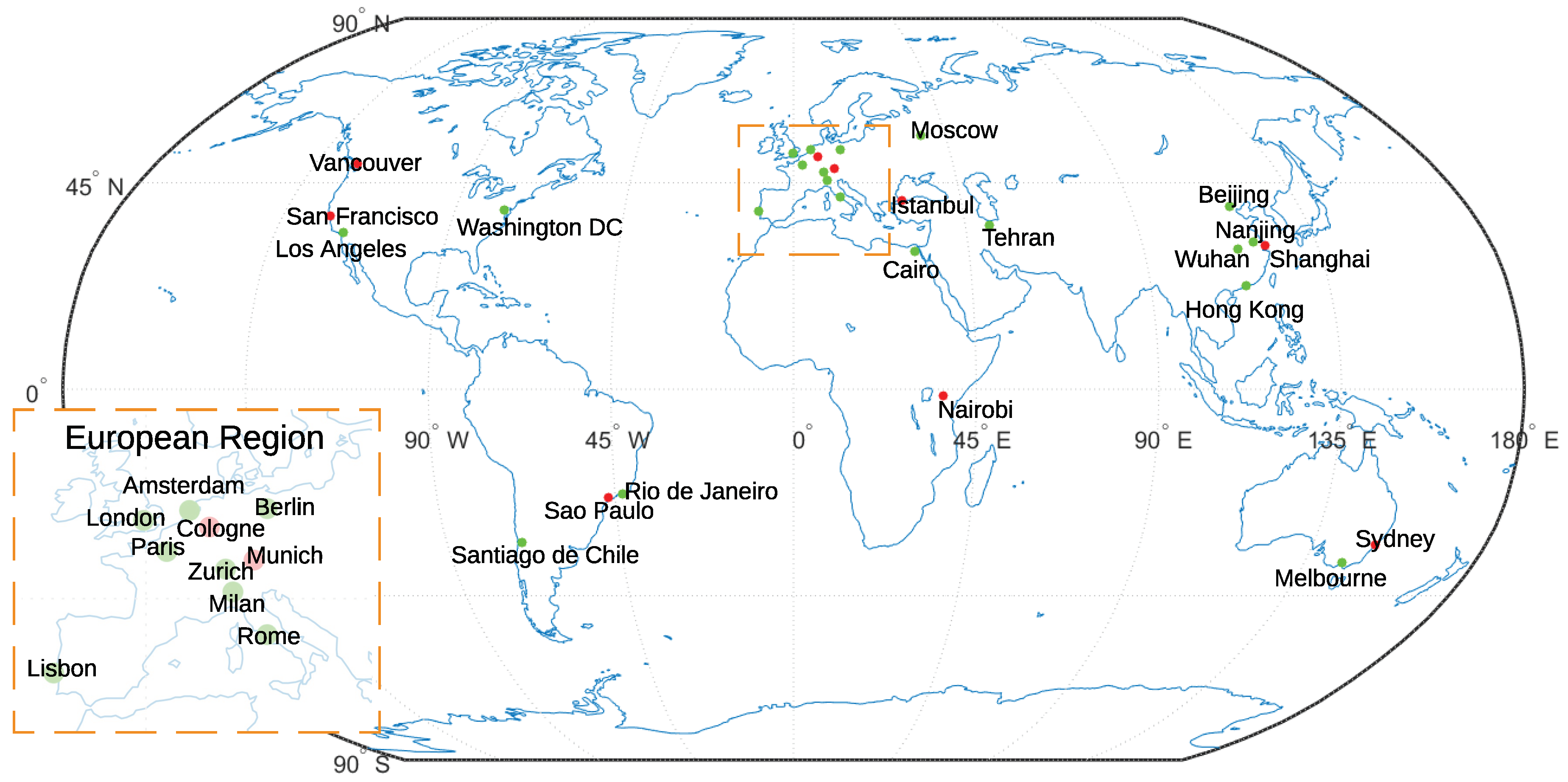
2.1. Study Areas
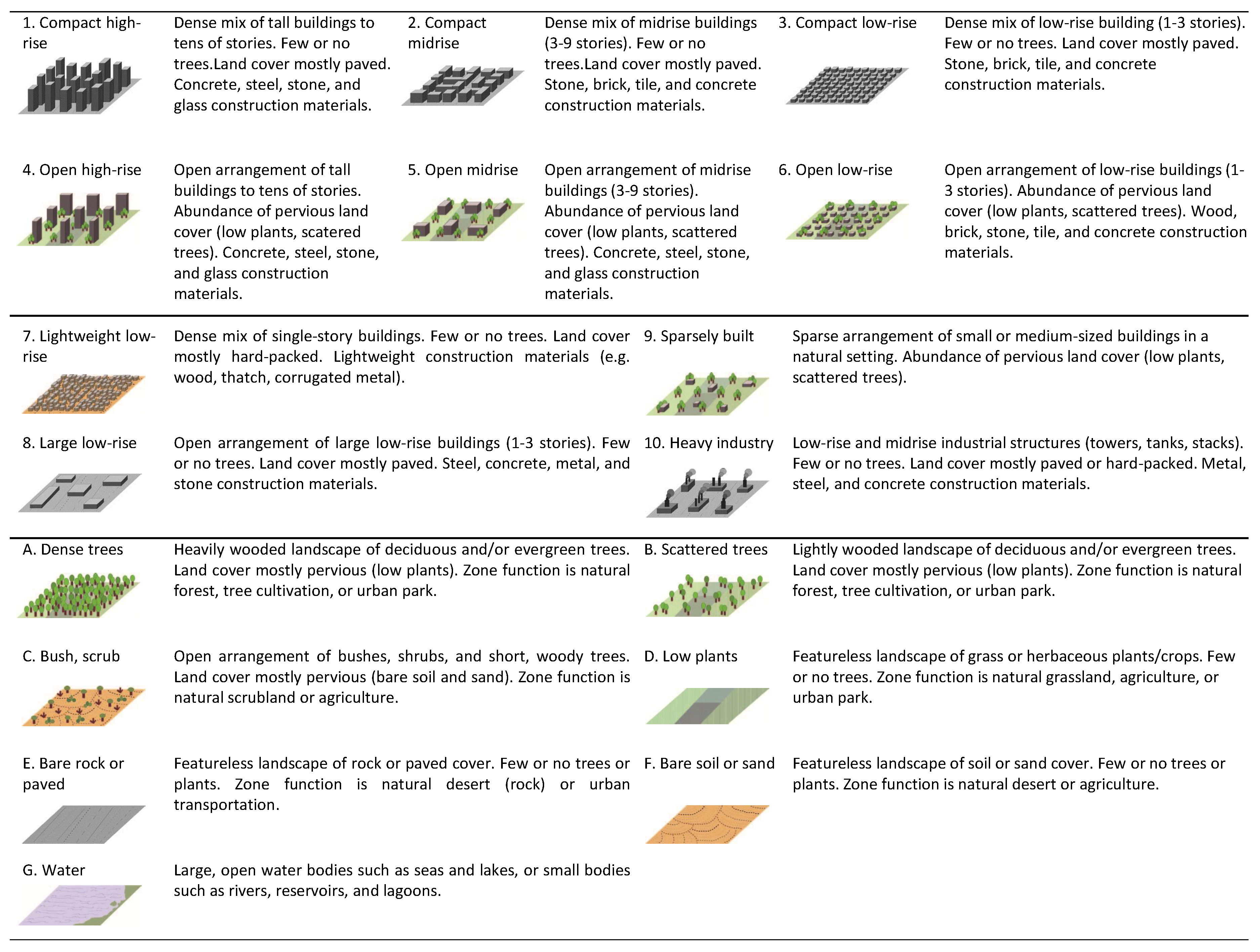
2.2. Ground Truth
2.3. Sentinel-1 Dual-Pol Data
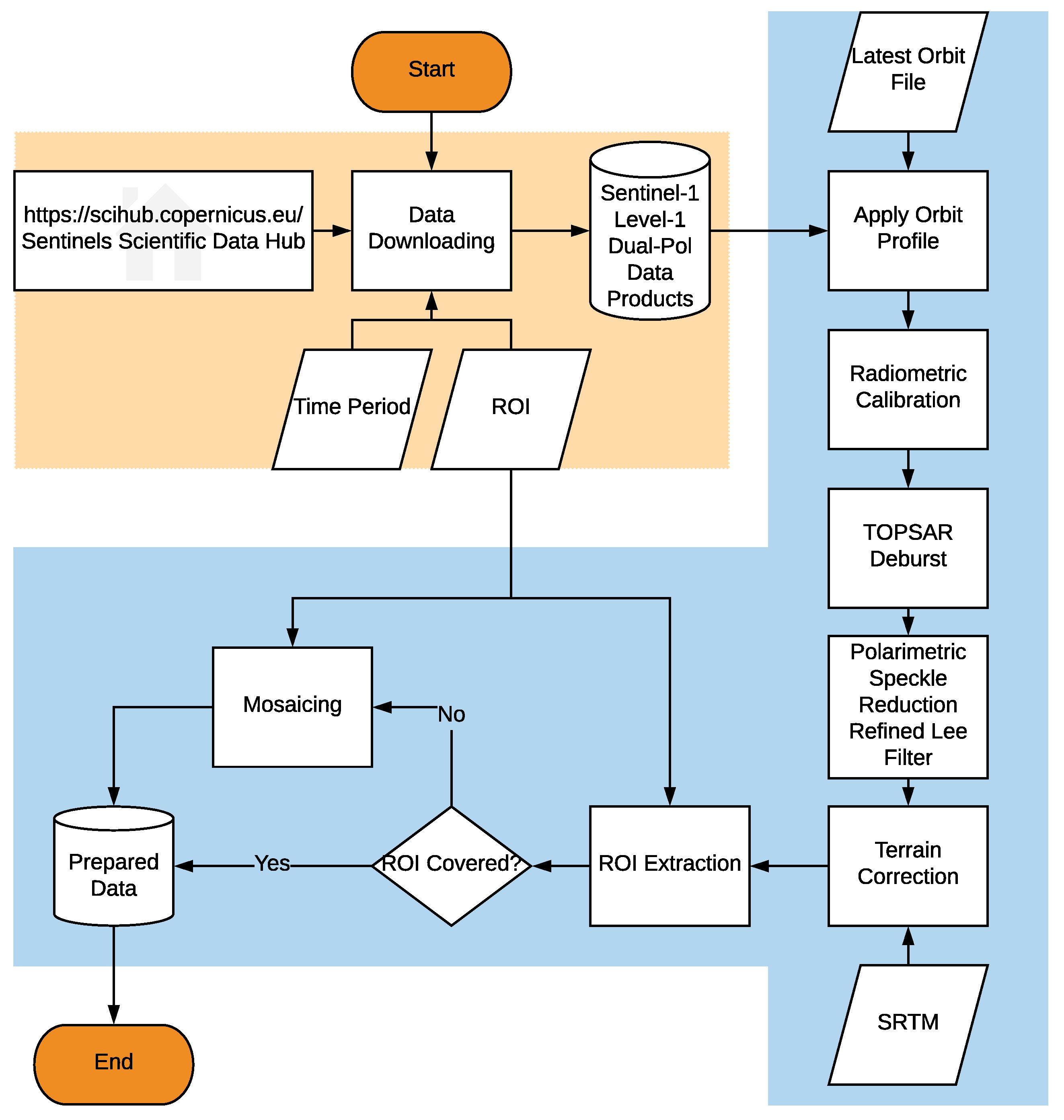
2.4. Data Preparation
- Apply Orbit Profile: This module of preprocessing downloads the latest released orbit profile so that a precisely geocoded product can be achieved.
- Radiometric Calibration: Radiometric calibration aims to convert the digital number of the pixel to a radiometrically calibrated backscatter, which is directly related to the radar backscatter of the scene. To extract the relative phase and the correlation between VV and VH, the product of calibration was chosen as a complex valued image.
- TOPSAR Deburst: For each polarization channel, the Sentinel-1 IW product has three swaths. Each swath image consists of a series of bursts. TOPSAR Deburst merges all these bursts and swaths into a single SLC image.
- Terrain Correction: Terrain correction eliminates the distortion introduced by the topographical variations. To accomplish the correction, the SRTM was used as the DEM to provide height information. The data was re-sampled to a 10-m GSD by the nearest-neighbor interpolation. The data was geocoded into the WGS84/UTM coordinate system, in which the manually labeled ground truth data was coordinated, so that the ground truth data and Sentinel-1 data could be matched in terms of geo-location.
3. Methodology
3.1. Feature Extraction
3.1.1. Polarimetric
3.1.2. Local Statistical
3.1.3. Texture
3.1.4. Mathematical Morphological
3.2. Classifiers
3.2.1. Canonical Correlation Analysis (CCA)
3.2.2. CCFs
3.2.3. Feature Importance Analysis
4. Experiments and Discussion
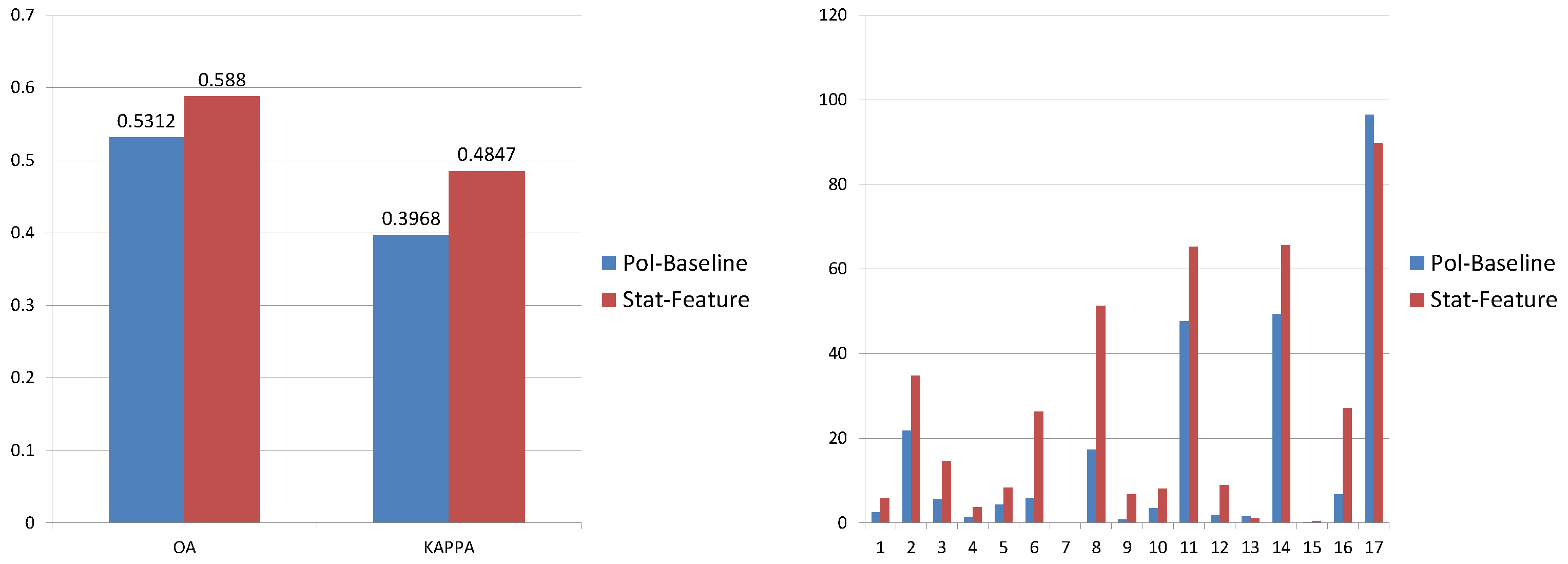
4.1. Benchmark Feature Selection
4.2. Texture Feature
4.3. Morphological Feature
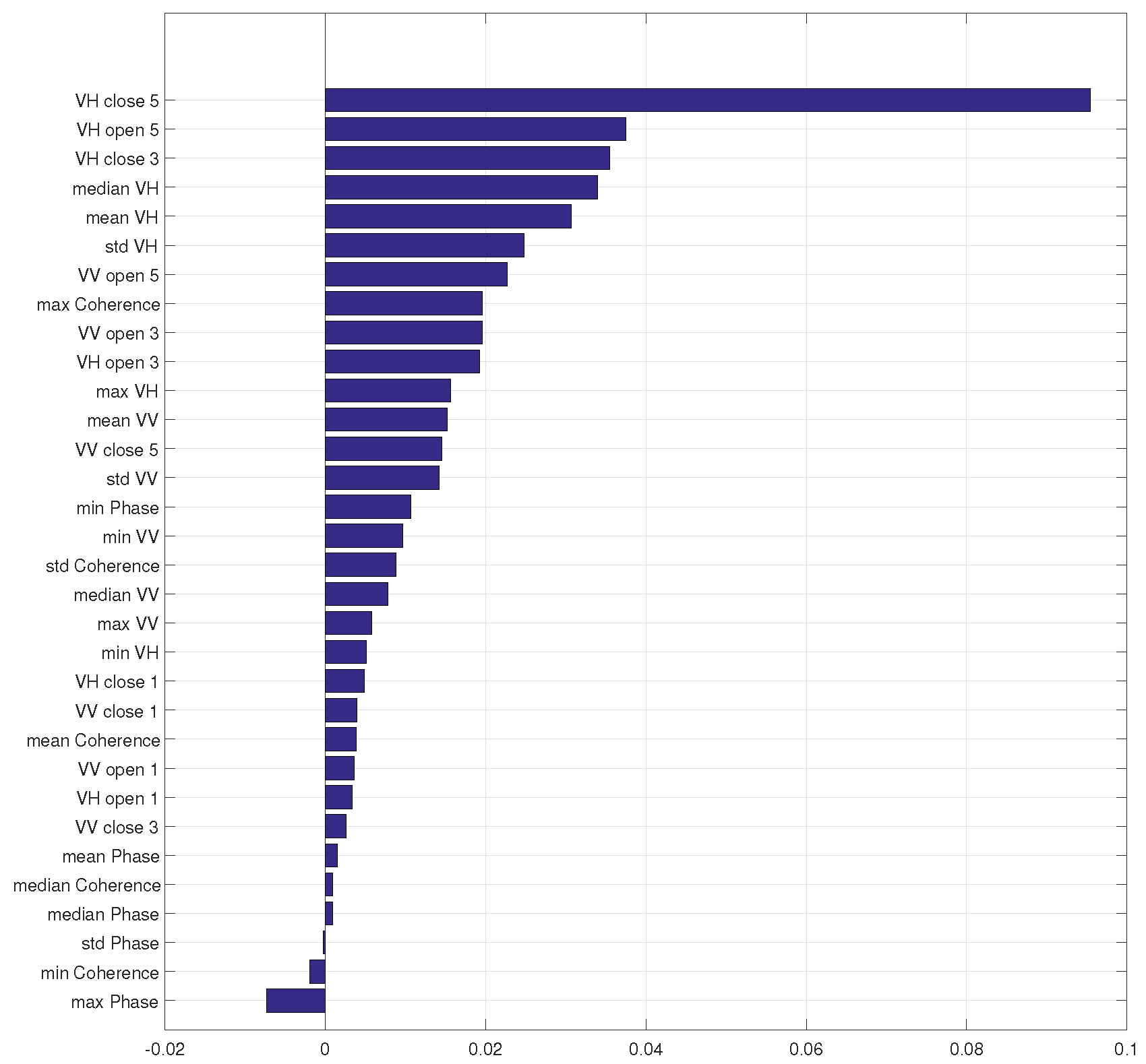
4.4. Analysis of Feature Importance
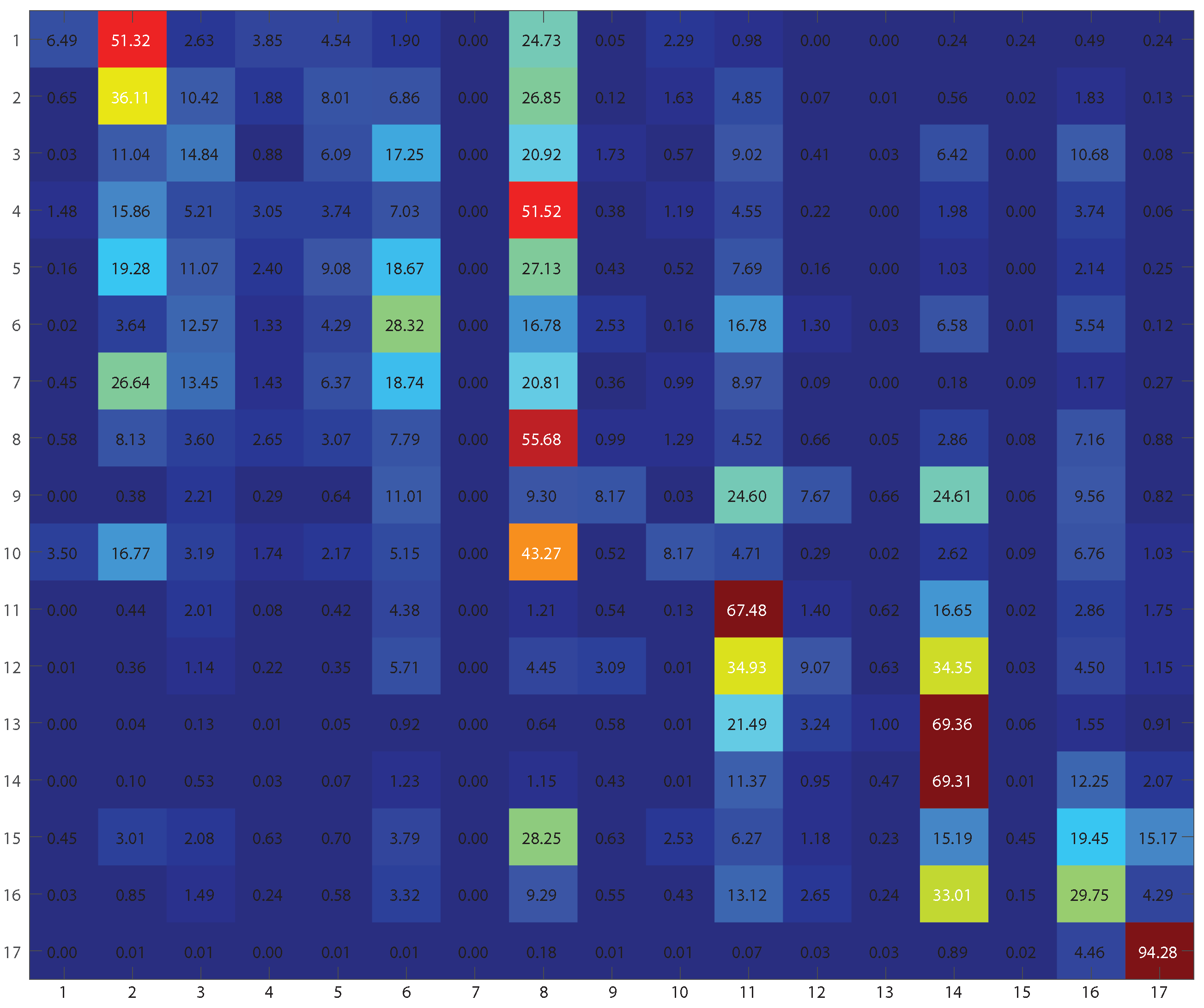
4.5. Class-Wise Analysis
4.6. Sentinel-1 Data for LCZ Classification
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Stewart, I.D.; Oke, T.R. Local climate zones for urban temperature studies. Bull. Am. Meteorol. Soc. 2012, 93, 1879–1900. [Google Scholar] [CrossRef]
- Stewart, I.D.; Oke, T.R.; Krayenhoff, E.S. Evaluation of the ‘local climate zone’ scheme using temperature observations and model simulations. Int. J. Climatol. 2014, 34, 1062–1080. [Google Scholar] [CrossRef]
- Bechtel, B.; Alexander, P.J.; Böhner, J.; Ching, J.; Conrad, O.; Feddema, J.; Mills, G.; See, L.; Stewart, I. Mapping local climate zones for a worldwide database of the form and function of cities. ISPRS Int. J. Geo-Inf. 2015, 4, 199–219. [Google Scholar] [CrossRef]
- WUDAPT. Available online: http://www.wudapt.org/ (accessed on 10 April 2018).
- See, L.; Comber, A.; Salk, C.; Fritz, S.; van der Velde, M.; Perger, C.; Schill, C.; McCallum, I.; Kraxner, F.; Obersteiner, M. Comparing the quality of crowdsourced data contributed by expert and non-experts. PLoS ONE 2013, 8, e69958. [Google Scholar] [CrossRef] [PubMed]
- Foody, G.M.; See, L.; van der Velde, M.; Perger, C.; Schill, C.; Boyd, D.S. Assessing the accuracy of volunteered geographic information arising from multiple contributors to an internet based collaborative project. Trans. GIS 2013, 17, 847–860. [Google Scholar] [CrossRef]
- Bayas, J.C.L.; See, L.; Fritz, S.; Sturn, T.; Perger, C.; Dürauer, M.; Karner, M.; Moorthy, I.; Schepaschenko, D.; Domian, D.; McCallum, I. Crowdsourcing In-Situ data on land cover and land use using gamification and mobile technology. Remote Sens. 2016, 8, 905. [Google Scholar] [CrossRef]
- Yokoya, N.; Ghamisi, P.; Xia, J.; Sukhanov, S.; Heremans, R.; Tankoyeu, I.; Bechtel, B.; Saux, B.L.; Moser, G.; Tuia, D. Open data for global multimodal land use classification: Outcome of the 2017 IEEE GRSS data fusion contest. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1–15. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Bechtel, B. Multitemporal landsat data for urban heat island assessment and classification of local climate zones. In Proceedings of the 2011 Joint Urban Remote Sensing Event (JURSE), Munich, Germany, 11–13 April 2011; pp. 129–132. [Google Scholar]
- Danylo, O.; See, L.; Bechtel, B.; Schepaschenko, D.; Fritz, S. Contributing to WUDAPT: A local climate zone classification of two cities in Ukraine. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 1841–1853. [Google Scholar] [CrossRef]
- Xu, Y.; Ren, C.; Cai, M.; Edward, N.Y.Y.; Wu, T. Classification of local climate zones using ASTER and Landsat data for high-density cities. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3397–3405. [Google Scholar] [CrossRef]
- Bechtel, B.; Daneke, C. Classification of local climate zones based on multiple earth observation data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 1191–1202. [Google Scholar] [CrossRef]
- Xu, Z.; Chen, J.; Xia, J.; Du, P.; Zheng, H.; Gan, L. Multisource earth observation data for land-cover classification using random forest. IEEE Geosci. Remote Sens. Lett. 2018, 15, 789–793. [Google Scholar] [CrossRef]
- Hearst, M.A.; Dumais, S.T.; Osuna, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Their Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef]
- Lelovics, E.; Unger, J.; Gál, T.; Gál, C.V. Design of an urban monitoring network based on Local Climate Zone mapping and temperature pattern modelling. Clim. Res. 2014, 60, 51–62. [Google Scholar] [CrossRef]
- Gál, T.; Bechtel, B.; Unger, J. Comparison of two different Local Climate Zone mapping methods. In Proceedings of the 9th International Conference on Urban Climates, Toulouse, France, 20–24 July 2015. [Google Scholar]
- Geletič, J.; Lehnert, M. GIS-based delineation of local climate zones: The case of medium-sized Central European cities. Morav. Geogr. Rep. 2016, 24, 2–12. [Google Scholar] [CrossRef]
- Bechtel, B.; See, L.; Mills, G.; Foley, M. Classification of local climate zones using SAR and multispectral data in an arid environment. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 3097–3105. [Google Scholar] [CrossRef]
- Kaloustian, N.; Tamminga, M.; Bechtel, B. Local climate zones and annual surface thermal response in a Mediterranean city. In Proceedings of the 2017 Joint Urban Remote Sensing Event (JURSE), Dubai, UAE, 6–8 March 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Hu, J.; Mou, L.; Schmitt, A.; Zhu, X.X. FusioNet: A two-stream convolutional neural network for urban scene classification using PolSAR and hyperspectral data. In Proceedings of the 2017 Joint Urban Remote Sensing Event (JURSE), Dubai, UAE, 6–8 March 2017. [Google Scholar]
- Mou, L.; Ghamisi, P.; Zhu, X.X. Deep recurrent neural networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3639–3655. [Google Scholar] [CrossRef]
- Mou, L.; Ghamisi, P.; Zhu, X.X. Unsupervised spectral-spatial feature learning via deep residual conv-deconv network for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 391–406. [Google Scholar] [CrossRef]
- Kang, J.; Körner, M.; Wang, Y.; Taubenböck, H.; Zhu, X.X. Building instance classification using street view images. ISPRS J. Photogramm. Remote Sens. 2018, in press. [Google Scholar] [CrossRef]
- Yokoya, N.; Ghamisi, P.; Xia, J. Multimodal, multitemporal, and multisource global data fusion for local climate zones classification based on ensemble learning. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 1197–1200. [Google Scholar]
- Wurm, M.; Taubenböck, H.; Weigand, M.; Schmitt, A. Slum mapping in polarimetric SAR data using spatial features. Remote Sens. Environ. 2017, 194, 190–204. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E.; Rogan, J.; Kellndorfer, J. Assessment of spectral, polarimetric, temporal, and spatial dimensions for urban and peri-urban land cover classification using Landsat and SAR data. Remote Sens. Environ. 2012, 117, 72–82. [Google Scholar] [CrossRef]
- Ban, Y.; Jacob, A.; Gamba, P. Spaceborne SAR data for global urban mapping at 30 m resolution using a robust urban extractor. ISPRS J. Photogramm. Remote Sens. 2015, 103, 28–37. [Google Scholar] [CrossRef]
- Geng, J.; Fan, J.; Wang, H.; Ma, X.; Li, B.; Chen, F. High-resolution SAR image classification via deep convolutional autoencoders. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2351–2355. [Google Scholar] [CrossRef]
- Du, P.; Samat, A.; Waske, B.; Liu, S.; Li, Z. Random forest and rotation forest for fully polarized SAR image classification using polarimetric and spatial features. ISPRS J. Photogramm. Remote Sens. 2015, 105, 38–53. [Google Scholar] [CrossRef]
- Dalla Mura, M.; Atli Benediktsson, J.; Waske, B.; Bruzzone, L. Extended profiles with morphological attribute filters for the analysis of hyperspectral data. Int. J. Remote Sens. 2010, 31, 5975–5991. [Google Scholar] [CrossRef]
- Plaza, A.; Benediktsson, J.A.; Boardman, J.W.; Brazile, J.; Bruzzone, L.; Camps-Valls, G.; Chanussot, J.; Fauvel, M.; Gamba, P.; Gualtieri, A.; et al. Recent advances in techniques for hyperspectral image processing. Remote Sens. Environ. 2009, 113, S110–S122. [Google Scholar] [CrossRef]
- Ghamisi, P.; Dalla Mura, M.; Benediktsson, J.A. A survey on spectral–spatial classification techniques based on attribute profiles. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2335–2353. [Google Scholar] [CrossRef]
- United Nations. The World’s Cities in 2016. Available online: http://www.un.org/en/development/desa/population/publications/pdf/urbanization/theworldscitiesin2016databooklet.pdf (accessed on 10 April 2018).
- Veci, L.; Lu, J.; Foumelis, M.; Engdahl, M. ESA’s Multi-mission Sentinel-1 Toolbox. In Proceedings of the 19th EGU General Assembly, EGU2017, Vienna, Austria, 23–28 April 2017; p. 19398. [Google Scholar]
- Lee, J.S.; Grunes, M.R.; De Grandi, G. Polarimetric SAR speckle filtering and its implication for classification. IEEE Trans. Geosci. Remote Sens. 1999, 37, 2363–2373. [Google Scholar]
- Lee, J.; Ainsworth, T.L.; Wang, Y.; Chen, K. Polarimetric SAR Speckle Filtering and the Extended Sigma Filter. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1150–1160. [Google Scholar] [CrossRef]
- Lee, J.S.; Pottier, E. Polarimetric Radar Imaging: from Basics to Applications, 1st ed.; CRC Press: Boca Raton, FL, USA, 2009. [Google Scholar]
- Moreira, A.; Prats-Iraola, P.; Younis, M.; Krieger, G.; Hajnsek, I.; Papathanassiou, K.P. A tutorial on synthetic aperture radar. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–43. [Google Scholar] [CrossRef]
- Schmitt, A.; Wendleder, A.; Hinz, S. The Kennaugh element framework for multi-scale, multi-polarized, multi-temporal and multi-frequency SAR image preparation. ISPRS J. Photogramm. Remote Sens. 2015, 102, 122–139. [Google Scholar] [CrossRef]
- Yokoya, N. Texture-Guided multisensor superresolution for remotely sensed images. Remote Sens. 2017, 9, 316. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I. Textural features for image classification. IEEE Trans. Syst. Man Cybern. 1973, SMC-3, 610–621. [Google Scholar] [CrossRef]
- Benediktsson, J.A.; Arnason, K.; Pesaresi, M. The use of morphological profiles in classification of data from urban areas. In Proceedings of the IEEE/ISPRS Joint Workshop on Remote Sensing and Data Fusion over Urban Areas, Rome, Italy, 8–9 November 2001; pp. 30–34. [Google Scholar]
- Benediktsson, J.A.; Palmason, J.A.; Sveinsson, J.R. Classification of hyperspectral data from urban areas based on extended morphological profiles. IEEE Trans. Geosci. Remote Sens. 2005, 43, 480–491. [Google Scholar] [CrossRef]
- Benediktsson, J.; Ghamisi, P. Spectral-Spatial Classification of Hyperspectral Remote Sensing Images; Artech House Publishers: Boston, MA, USA, 2015. [Google Scholar]
- Fauvel, M.; Benediktsson, J.A.; Chanussot, J.; Sveinsson, J.R. Spectral and Spatial Classification of Hyperspectral Data Using SVMs and Morphological Profiles. IEEE Trans. Geosci. Remote Sens. 2008, 46, 3804–3814. [Google Scholar] [CrossRef]
- Crespo, J.; Serra, J.; Schafer, R.W. Theoretical aspects of morphological filters by reconstruction. Signal Process. 1995, 47, 201–225. [Google Scholar] [CrossRef]
- Rainforth, T.; Wood, F. Canonical Correlation Forests. Available online: https://arxiv.org/abs/1507.05444 (accessed on 10 April 2018).
- Hotelling, H. Relations between two sets of variates. Biometrika 1936, 28, 321–377. [Google Scholar] [CrossRef]
- Xia, J.; Yokoya, N.; Iwasaki, A. Hyperspectral image classification with canonical correlation forests. IEEE Trans. Geosci. Remote Sens. 2017, 55, 421–431. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Ho, T.K. The random subspace method for constructing decision forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Elghazel, H.; Aussem, A.; Perraud, F. Trading-off diversity and accuracy for optimal ensemble tree selection in random forests. In Ensembles in Machine Learning Applications; Springer: Berlin, Germany, 2011; pp. 169–179. [Google Scholar]
- Ghamisi, P.; Benediktsson, J.A.; Ulfarsson, M.O. Spectral–spatial classification of hyperspectral images based on hidden Markov random fields. IEEE Trans. Geosci. Remote Sens. 2014, 52, 2565–2574. [Google Scholar] [CrossRef]
- Ghamisi, P.; Benediktsson, J.A.; Sveinsson, J.R. Automatic spectral-spatial classification framework based on attribute profiles and supervised feature extraction. IEEE Trans. Geosci. Remote Sens. 2014, 52, 5771–5782. [Google Scholar] [CrossRef]
- Fauvel, M.; Tarabalka, Y.; Benediktsson, J.A.; Chanussot, J.; Tilton, J.C. Advances in spectral-spatial classification of hyperspectral images. Proc. IEEE 2013, 101, 652–675. [Google Scholar] [CrossRef]
- Hu, J.; Guo, R.; Zhu, X.; Baier, G.; Wang, Y. Non-local means filter for polarimetric SAR speckle reduction-experiments using TerraSAR-x data. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, 2, 71. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Region | City | Training City | Testing City | Polulation at Year | ||
|---|---|---|---|---|---|---|
| 2000 | 2016 | 2030 | ||||
| Australia | Melbourne | Y | - | 3,461,000 | 4,258,000 | 5,071,000 |
| Sydney | - | Y | 4,052,000 | 4,540,000 | 5,301,000 | |
| Eastern Asia | Beijing | Y | - | 10,162,000 | 21,240,000 | 27,706,000 |
| Nanjing | Y | - | 6,160,000 | 8,270,000 | 9,750,000 | |
| Wuhan | Y | - | 6,638,000 | 7,979,000 | 9,442,000 | |
| Hong Kong | Y | - | 6,835,000 | 7,365,000 | 7,885,000 | |
| Shanghai | - | Y | 13,959,000 | 24,484,000 | 30,751,000 | |
| Western Asia | Tehran | Y | - | 7,128,000 | 8,516,000 | 9,990,000 |
| Istanbul | - | Y | 8,744,000 | 14,365,000 | 16,694,000 | |
| Africa | Cairo | Y | - | 13,626,000 | 19,128,000 | 24,502,000 |
| Nairobi | - | Y | 2,214,000 | 4,070,000 | 7,140,000 | |
| Europe | Amsterdam | Y | - | 1,005,000 | 1,099,000 | 1,213,000 |
| Berlin | Y | - | 3,384,000 | 3,578,000 | 3,658,000 | |
| London | Y | - | 8,613,000 | 10,434,000 | 11,467,000 | |
| Paris | Y | - | 9,737,000 | 10,925,000 | 11,803,000 | |
| Zurich | Y | - | 1,078,000 | 1,259,000 | 1,494,000 | |
| Milan | Y | - | 2,985,000 | 3,104,000 | 3,162,000 | |
| Rome | Y | - | 3,385,000 | 3,738,000 | 3,842,000 | |
| Lisbon | Y | - | 2,672,000 | 2,902,000 | 3,192,000 | |
| Moscow | Y | - | 10,005,000 | 12,260,000 | 12,200,000 | |
| Cologne | - | Y | 963,000 | 1,042,000 | 1,095,000 | |
| Munich | - | Y | 1,202,000 | 1,454,000 | 1,548,000 | |
| North America | Washington DC | Y | - | 3,949,000 | 5,013,000 | 5,690,000 |
| Los Angeles | Y | - | 11,798,000 | 12,317,000 | 13,257,000 | |
| San Francisco | - | Y | 3,230,000 | 3,299,000 | 3,615,000 | |
| Vancouver | - | Y | 1,959,000 | 2,523,000 | 2,930,000 | |
| South America | Rio de Janeiro | Y | - | 11,307,000 | 12,981,000 | 14,174,000 |
| Santiago de Chile | Y | - | 5,658,000 | 6,544,000 | 7,122,000 | |
| Sao Paulo | - | Y | 17,014,000 | 21,297,000 | 23,444,000 | |
| Beam ID | IW 1 | IW 2 | IW 2 |
|---|---|---|---|
| Spatial resolution rg × az m | 2.7 × 22.5 | 3.1 × 22.7 | 3.5 × 22.6 |
| Pixel spacing rg × az m | 2.3 × 14.1 | 2.3 × 14.1 | 2.3 × 14.1 |
| Incidence angle | 32.9 | 38.3 | 43.1 |
| Product ID | IW SLC |
|---|---|
| Pixel value | Complex |
| Coordinate system | Slant range |
| Bits per pixel | 16 I and 16 Q |
| Polarization | VV and VH |
| Ground range coverage km | 251.8 |
| Equivalent number of looks (ENL) | 1 |
| Radiometric resolution | 3 |
| Number of looks (range × azimuth) | 1 × 1 |
| Class | Train | Test | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|---|
| Compact high-rise | 4402 | 2050 | 2.54 | 5.9 | 14.29 | 4.93 | 6.49 | 6 |
| Compact mid-rise | 21,708 | 8426 | 21.84 | 34.75 | 46.24 | 31.34 | 36.11 | 35.06 |
| Compact low-rise | 19,502 | 21,004 | 5.5 | 14.66 | 12.06 | 13.97 | 14.84 | 14.38 |
| Open high-rise | 11,683 | 3185 | 1.44 | 3.77 | 8.7 | 2.35 | 3.05 | 2.95 |
| Open mid-rise | 17,085 | 5618 | 4.34 | 8.26 | 18.08 | 10.89 | 9.08 | 7.17 |
| Open low-rise | 26,126 | 17,951 | 5.83 | 26.27 | 18.37 | 19.93 | 28.32 | 26.64 |
| Light weight low-rise | 722 | 1115 | 0 | 0 | 0 | 0 | 0 | 0 |
| Large low-rise | 34,792 | 17,874 | 17.33 | 51.27 | 49 | 47.76 | 55.68 | 54.64 |
| Sparsely built | 14,640 | 6924 | 0.81 | 6.69 | 6.04 | 2.47 | 8.17 | 7.32 |
| Heavy industry | 9129 | 5801 | 3.45 | 8.08 | 4.67 | 4.4 | 8.17 | 7.74 |
| Dense trees | 69,731 | 43,652 | 47.64 | 65.26 | 53.36 | 51.39 | 67.48 | 67.51 |
| Scattered trees | 21,926 | 8938 | 1.83 | 8.97 | 5 | 5.65 | 9.07 | 7.56 |
| Bush, scrub | 19,396 | 14,864 | 1.53 | 1.08 | 3.61 | 0.45 | 1 | 0.91 |
| Low plants | 97,243 | 35,064 | 49.31 | 65.56 | 56.8 | 64.29 | 69.31 | 68.34 |
| Bare rock or paved | 6119 | 3989 | 0.15 | 0.45 | 0.28 | 1 | 0.45 | 0.3 |
| Bare soil or sand | 78,543 | 3284 | 6.76 | 27.13 | 35.99 | 5.85 | 29.75 | 27.92 |
| Water | 309,387 | 137,753 | 96.42 | 89.72 | 68.56 | 81.7 | 94.28 | 93.11 |
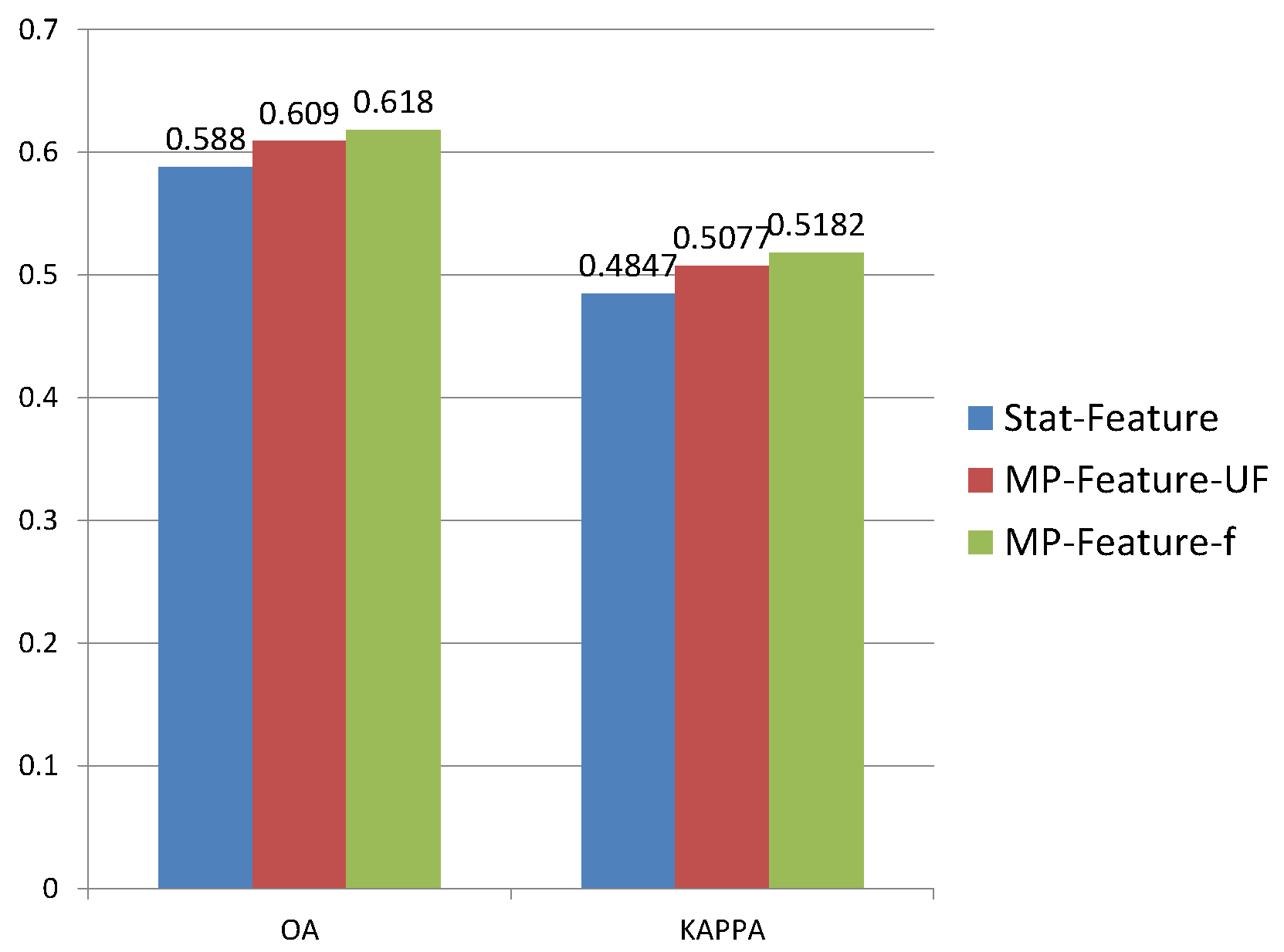
| OA | 53.12 | 58.8 | 47.58 | 52.51 | 61.8 | 60.9 | ||
| KAPPA | 0.3968 | 0.4847 | 0.3746 | 0.4152 | 0.5182 | 0.5077 |
| Feature Name | Feature Combination Code | |||||
|---|---|---|---|---|---|---|
| A | B | C | D | E | F | |
| Pol-Feature | Y | - | - | - | - | - |
| Stat-Feature | - | Y | Y | Y | Y | Y |
| GLCM-Feature-F | - | - | Y | - | - | - |
| GLCM-Feature-UF | - | - | - | Y | - | - |
| MP-Feature-F | - | - | - | - | Y | - |
| MP-Feature-UF | - | - | - | - | - | Y |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, J.; Ghamisi, P.; Zhu, X.X. Feature Extraction and Selection of Sentinel-1 Dual-Pol Data for Global-Scale Local Climate Zone Classification. ISPRS Int. J. Geo-Inf. 2018, 7, 379. https://doi.org/10.3390/ijgi7090379
Hu J, Ghamisi P, Zhu XX. Feature Extraction and Selection of Sentinel-1 Dual-Pol Data for Global-Scale Local Climate Zone Classification. ISPRS International Journal of Geo-Information. 2018; 7(9):379. https://doi.org/10.3390/ijgi7090379
Chicago/Turabian StyleHu, Jingliang, Pedram Ghamisi, and Xiao Xiang Zhu. 2018. "Feature Extraction and Selection of Sentinel-1 Dual-Pol Data for Global-Scale Local Climate Zone Classification" ISPRS International Journal of Geo-Information 7, no. 9: 379. https://doi.org/10.3390/ijgi7090379
APA StyleHu, J., Ghamisi, P., & Zhu, X. X. (2018). Feature Extraction and Selection of Sentinel-1 Dual-Pol Data for Global-Scale Local Climate Zone Classification. ISPRS International Journal of Geo-Information, 7(9), 379. https://doi.org/10.3390/ijgi7090379