1. Introduction
In the last decade, terms including Open Data [
1], Linked Data [
2], RDF [
3], and SPARQL [
4] have been more and more associated with open-ness and data interoperability. In fact, the emergence of Semantic Web technologies [
5,
6] established new practices for addressing two essential components of data management at large (i.e., data representation and access) and also provided means for (limited) processing of information by harnessing
ontologies for formal description of schemata. To address management of geospatial resources in the framework proposed by the Semantic Web, metadata management cannot disregard the novel techniques that are elicited by the standards and practices defined in this context. Unfortunately, these technologies did not induce so far a consistent, interlinked baseline in the geospatial domain.
In this paper, we propose a methodology for
delegated, evolving metadata that combines compliance with the normative standards and novel semantics-aware features: Native RDF representation allows for turning single-tenanted, monolithic metadata records into
living documents. First, our methodology allows
normalizing metadata descriptions by pinpointing the entities (individuals, institutions, terms from controlled vocabularies, toponyms, etc.) that can be mapped to unique, externally managed resources identified with URIs [
7] (or a specific fragment of these resources) and expressed as RDF. Instead, current metadata management practices express multiple references to each of these entities as independent metadata fragments that require manual update and are prone to inconsistencies and heterogeneities.
Semantic characterization of metadata is essential because, despite its structured encoding, resource descriptions often fall short of providing the intended interoperability because of the textual nature of property values. Recourse to code lists (i.e., sets of terms that represent the controlled vocabularies for specific metadata fields), as opposed to free text, clearly constitutes a sub-optimal solution. Moreover, not all property values can be constrained by code lists (e.g., the e-mail associated with a point of contact) and, nevertheless these can be related to unambiguously identified and authoritative data structures: As an example, a point of contact could be expressed by the URL of the ORCID profile (
http://orcid.org/) of the researcher, whose information could then be retrieved, through content negotiation, as RDF.
Beside normalization, another important achievement of our research is delegation, that is, referring to external data structures for specification of a metadata property value: This is a direct by-product of the open-world vocation of URIs. We demonstrate the approach by means of the tools we developed in our projects, implementing ex-ante semantic lift of metadata. In this paper, among the advantages of semantics-aware metadata, we show that this methodology enables a paradigm shift in preserving metadata consistency. Specifically, we demonstrate that it is possible to automatically update individual metadata items, as well as more complex metadata structures, by associating the entities that are referred to in metadata with URIs and extracting individual property values at metadata-request time with SPARQL queries.
Further abstracting from schema-dependent metadata representation, our methodology also allows descriptions that are based on different schemas to refer to the same resources and extract the appropriate information subset: As an example, the fragments defining a point of contact in INSPIRE [
8,
9,
10] and SensorML [
11] metadata descriptions can be consistently drawn from the same authoritative source, even if they feature different components. Native XML metadata only allows for normalized representation on a per-schema basis by using XLink [
12] techniques. Finally, notwithstanding the overall decentralized approach to metadata, our methodology allows retaining control on those information items that need to be controlled (
Section 3.2 shows that it is possible to interleave proprietary RDF data structures in order to restrain the effects of delegation).
The remaining of the paper is organized as follows.
Section 2 introduces the issues that stimulated this research and highlights the limitations of metadata representation techniques currently in use in the geospatial domain. Then, it presents relevant related work and a use case that typically leads to metadata inconsistency unless manual update is executed catalog-wide.
Section 2.4 presents the application we used for injection of semantic information in metadata at editing-time and the workflow we implemented.
Section 3 presents a general, qualitative evaluation of the possible usages of delegation in metadata management and then focuses on the use case that has been proposed. Specifically,
Section 3.1 demonstrates that this practice can be employed to address automatic update of metadata items while
Section 3.2 refines the approach, relaxing delegation for a specific metadata item while preserving its advantages. This is achieved by adding a further indirection step to augment flexibility in articulating organizational roles.
Section 4 generalizes the approach to application domains different from the geospatial one, pinpoints the components that are necessary to implement delegation with a different application stack, and elaborates on the advantages of implementing the approach in a pure Linked Data scenario. Finally,
Section 5 draws conclusions and outlines future work.
2. Methodology
This work can be broadly ascribed to the context of geospatial semantics. In particular, it relates to
encoding of metadata in a semantics-aware fashion, as opposed to
modeling of data and metadata by using ontologies [
13]. Consequently, important features that are in the scope of the latter, such as inference and subsumption, are not pertinent to this paper. Nevertheless, the expressiveness of the data structures that are associated with metadata via URIs (e.g., a SKOS thesaurus [
14] rather than a full-fledged OWL ontology [
15]) is important because it determines the extent of the fine-grained discovery mechanisms that can be implemented, such as query expansion (another topic not directly in the scope of this research).
Metadata are essential to effective provisioning of geospatial information through an SDI [
16,
17,
18]. Consequently, much effort has been devoted in the last twenty years to the creation of metadata schemas that could encompass the variety of data categories and requirements by the stakeholders, from data providers to end users; a comprehensive but rather outdated view on these can be found in [
19,
20]. However, elaborating on the differences between the many metadata schemas that have been defined in the geospatial domain is out of the scope of this work, primarily because its aim is to abstract from the specific schema that is required by a given application scenario. The development of software tools for editing and maintenance of metadata progressed in parallel—a good survey of the available solutions is that provided by the US Federal Geographic Data Committee-Geospatial Metadata Tools (FGDC:
https://www.fgdc.gov/metadata/geospatial-metadata-tools) but this activity is hampered by the intrinsic complexity of this task. In fact, it is difficult to conceive a one-size-fits-all solution in a landscape where requirements, established practices, and de-facto standards easily yield to custom profiles. We tackle schema heterogeneity issues by providing a schema-agnostic solution that can be tailored to the specific domain under consideration.
Assisted metadata creation is the approach we implemented to transparently associate URIs with metadata properties. As opposed to automatic metadata generation, such as the techniques proposed in [
21,
22,
23], assisted metadata editing allows complementing the metadata properties that can be directly extracted from the dataset itself with the thematic and attribution characterizations that are very important for discovery and citation purposes. Instead, the aforementioned works rely on placement of datasets in specific sub-folders of a directory tree for thematic characterization of datasets (a practice we deem as error prone as manual specification of the corresponding metadata property values). In addition, points of contact are automatically derived from system-wide configuration of catalog software, a practice that cannot address attribution at the required granularity level (e.g., consider the management of shared SaaS catalogs).
In the development of our tools for assisting metadata creation, we investigated a broad range of schemas, from Unidata’s NcML (the NetCDF Markup Language (NcML):
http://www.unidata.ucar.edu/software/thredds/current/netcdf-java/ncml/ exploited within THREDDS servers for the annotation of NetCDF resources, to the OGC SWE family and in particular SensorML, the XML language aimed at the description of sensors. This choice of example schemas helps to mark the two ends of such spectrum: NcML, to enable some degree of interoperability among catalogs and resources, relies on the CF conventions [
24] but, at the end of the day, metadata present code values as plain text; SensorML definition, instead, provides several XML attributes for complementing textual property values with unambiguous identifiers, such as URIs.
In this paper, we apply our methodology to the INSPIRE profile of the reference ISO standard as an in-between example of metadata format. On the one hand, it provides several code lists (defined in the schema itself or inherited from ISO 19115/19119) for property values. On the other hand, code values must be represented in metadata as plain text. It should be noted that recent updates to the technical guidelines for creation of INSPIRE metadata [
25] allows for complementing any plain-text property value with URIs (included as
xlink:href attributes). Nevertheless, adequate support for this functionality in editors is still missing.
To our knowledge, no prior works addressed conjunct production of heterogeneous geospatial metadata (to populate geoportals) and their RDF representation (aimed at extending metadata management capabilities). Although many works propose techniques for exposing geospatial metadata (complying with selected profiles) as RDF (e.g., [
26]), we claim that only native RDF representation can prevent the information loss that is typical in metadata crosswalks. This is the approach followed in [
27], which also hints at the benefits of normalization that are inherent to this approach. However, the next section draws the state of the art with regard to metadata provisioning, the starting point of our implementation of the delegation paradigm. In doing this, we focus on independence of a specific schema and “pluggability” of external RDF data sources. The former is a requirement in many application scenarios. The latter is a prerequisite to relating information items to heterogeneous resources in the Web of Data.
2.1. Related Works: Schema Independence
From a theoretical viewpoint, the approach implemented in the CatMEDit editor (
http://catmdedit.sourceforge.net/) and described in [
28] is valuable because it addresses schema heterogeneity issues by harnessing the MDA techniques developed by Object Management Group-Model Driven Architecture (OMG:
http://www.omg.org/mda/) In a nutshell, in this work, the authors abstract from the specific metadata schema by defining distinct
metamodels that can then be translated into the corresponding editing interface, reflecting all the constraints defined by the former. In principle, this can address any possible custom profile derived from ISO 19115/19119 but requires background knowledge on the distinct phases that, in MDA, allow for translating the abstract model into implementation. Unfortunately, geospatial projects are increasingly requiring support to multiple metadata schemas for implementation, which calls for major modifications to the application. In addition, in the pragmatic framework of our research, we opted for a gentler learning curve, decoupling customization from implementation by requiring modification of a
template, a schema definition, rather than of the application itself. Moreover, we wanted to develop a SaaS solution (although our editor can be used as a desktop application as well) while CatMEDit is solely available as a desktop application.
In line with this vocation, among the many products available in the state of the art for the provision of geospatial metadata (please refer to the aforementioned survey by FGDC for a list of these), the one provided by the GeoNetwork open source project software (
http://geonetwork-opensource.org/), version 2.8 and later, is to our knowledge the only tool allowing for easily “pluggable” metadata schemas, but lacks support for external semantic sources. We can still consider the tools that, separately, address the most widely acknowledged metadata schemas for geographic and observational data, that is, ISO 19100 profiles and SensorML descriptions. The use case presented in this work is focusing on the first category of metadata schemas, which is also the one most widely supported by editing tools. The survey by FGDC makes it apparent that, whereas mature editors provide advanced features, existing ISO metadata editors only have partial support to customization of the governing metadata schema and no support at all for third-party data sources.
2.2. Related Works: Normalization and Delegation
The resource-oriented vocation of ISO 19115/19119 metadata [
29] and the graph-oriented capabilities of GML [
30] suggest that normalization of metadata has been in the air long before this paper. Metadata schemas that are harnessing the W3C XLink technology, such as SWE-related standards and GML, or that have been extended to do so, can easily realize a similar normalization (and delegation) philosophy. In fact, metadata implementing these schemas could be stored in fully normalized fashion (i.e., substituting multiple references to the same metadata item, such as the aforementioned specification of a point of contact, with XLink references to a single metadata fragment) and use an XLink processor to generate the denormalized version of the record.
Unfortunately, this can only be done on a per-schema basis because, as soon as support for a different metadata schema is required (e.g., SensorML in conjunction with INSPIRE metadata), a second metadata fragment shall be mint and updated separately from the former. Our methodology realizes full normalization of metadata items by combining identification via URIs, RDF representation of information items, and a template language specifying how to retrieve individual property values for producing the intended denormalized output. To pinpoint the research problem we are addressing, we provide a use case exemplifying consistency issues that, in traditional metadata management, call for manual update of metadata records. We are going to see that, by adopting our metadata representation paradigm, it is possible to address these issues in an automated fashion.
As already mentioned, normalization of metadata records is among the achievements of [
27]. Drawing inspiration from the digital library domain (a more mature context with respect to the geospatial one), the author articulates native RDF descriptions and provides multi-format translations that are uniquely identified as composite objects. However, this work focuses on schema selection and access protocols, while our work primarily focuses on referring to instances of RDF schemata and ontologies as metadata property values. Normalization is also the topic of [
31] as a prerequisite to effective metadata maintenance. The paper proposed three approaches for achieving this but the first is strictly proprietary while the others are ex-post techniques aimed at system administrators as they involve the XSLT and Python scripting/programming languages. Moreover, in this work normalization does not imply (open-world) unique identification of the principals involved (researchers, institutes, and keywords) and this impedes delegation.
2.3. Use Case: John Doe Changes Employer
Since 2007, the implementation of the INSPIRE Directive indicated interoperability recipes to the geospatial community, basing them on international standards. Since the formulation of the Directive, however, the data management landscape has inevitably changed. The INSPIRE prototypical implementation with respect to metadata has been driven by the reference ISO 19100 standard series for geographic information [
32,
33,
34], but the latter has become inadequate, mostly because of the increasing focus on data access and processing, as opposed to data representation (i.e., the search for mechanisms to appropriately encode data and metadata with respect to a specific domain).
It should be noted that this standard series also constituted the starting point for non-European standards, such as the NAP [
35], the PCGIAP [
36], and the ANZLIC [
37] metadata profiles. Moreover, in the case of adoption or recommendation of different metadata standards, the ISO 19100 standard series is still acknowledged as the reference specification for Geographic Information: As an example, both the NASA ECHO Metadata Standard (
https://earthdata.nasa.gov/standards/echo-metadata-standard) and the Directory Interchange Format of GCMD (
http://gcmd.nasa.gov/add/standards/) are mapped to the core ISO elements. Finally, ISO metadata is the schema implemented in widely acknowledged geoportals, such as GeoServer (
http://geoserver.org/) and GeoNode (
http://geonode.org/). Hence, it makes sense questioning the aptness of these standards for tackling the aforementioned new challenges in geospatial metadata management.
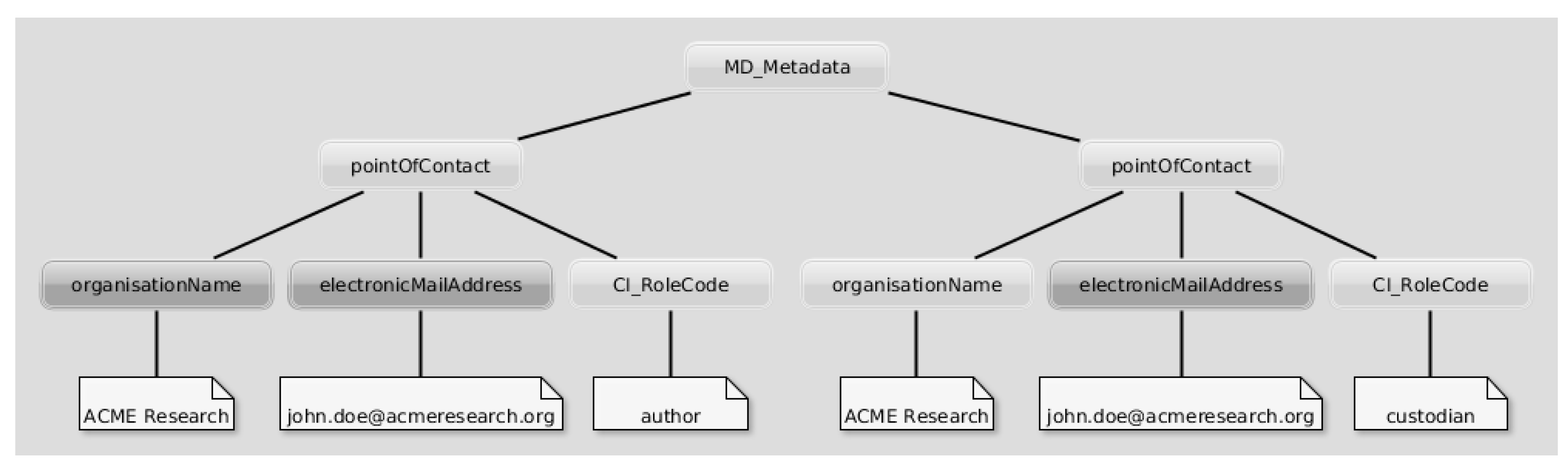
To exemplify and test our approach in the context of this widely acknowledged standard, we consider the following use case: The institute “ACME Research” manages geospatial resources through an ISO-compliant catalog service. Its researcher “John Doe” is the creator of “Dataset ABC”. He is also the custodian of all datasets within the institute’s SDI, hence he is referred to twice in the metadata record associated with“Dataset ABC”.
Figure 1 provides a visual representation of the XML nodes indicating “John Doe” as both the creator and the custodian of the resource in ISO metadata. Note that arcs abridge the traditional verbosity of nested XML structures in ISO 19139 encoding; in addition,
Figure 1 highlights only the metadata items that are going to require update in the worked-out example presented in this paper.
“John Doe”, at some point, changes employer and hence the metadata records of all datasets provided by the SDI of “ACME Research” are made inconsistent: Specifically, when referring to him as the creator of “Dataset ABC”, his e-mail address and the name of the institute he works for have to be changed. Moreover, the company is likely to appoint a new custodian for the resources in the SDI, requiring update of all metadata records. We keep quotes when indicating the three entities involved in the use case (i.e., the individual, the institute, and the dataset) to stress that what one may intuitively consider complex data structures are actually mere character strings in (traditional) metadata records.
Such update must be manually carried out, a process that can be prone to errors or simply overlooked. Instead, the worked-out example in the following of this paper involves unambiguous identification of both the individual and his new employer: This allows up-to-date property values to be retrieved on demand as soon as the metadata record is requested.
Rationale for Use Case Selection
The requirements that drove selection of an appropriate use case were the following:
The use case shall feature metadata items whose update can be triggered by an agent that is completely detached from the system hosting the metadata records themselves. Otherwise, one could argue that automatic update can be carried out by some procedure or daemon residing on this system.
The update shall affect multiple metadata records in order to show the breadth of automatic update.
Finally, the use case shall make it possible to exemplify the indirection mechanism presented in
Section 3.2.
It is apparent that those metadata items that are overtly geospatial, such as spatial and temporal extents, violate all requirements. On the one hand, their update typically is due to addition of data instances in a series, an activity that can easily trigger update of the corresponding metadata. On the other hand, their update is likely to affect a single dataset. Moreover, they can not exemplify indirection. Another essential characterization of geospatial metadata is the thematic component expressed by keywords [
38]. These are prone to change due to versioning of the corresponding thesauri or ontologies but whether (and how) they shall change in the metadata containing them is questionable. The remaining metadata item that is crucial for assessing aptness of a geospatial dataset, lineage information, is amenable to delegation but violates requirement 3.
2.4. The Proposed Approach
In this Section, we show how the tools we developed have been articulated in a workflow allowing metadata maintainers for the editing of descriptions that refer to external resources identified by URIs. Although different methodologies can produce similar results, such as the semantic lift of pre-existing metadata we investigated in [
39], ex-ante characterization of metadata is more reliable with respect to the associated RDF resources. In addition, the second part of the workflow we describe in this Section is specifically aimed at addressing the inconsistency issues in the use case.
The core ingredient of our implementation of metadata delegation is EDI (
http://edidemo.get-it.it) [
40], a metadata editing tool for the production of metadata records in accordance to generic XML-based schemas by relying on a metalanguage: The EDI template language, a formalism defined by an appropriate XML Schema [
41]. Specifically, EDI templates express custom metadata schemas that drive creation of web-based authoring interfaces to assist the user in providing the metadata. The client-side component of EDI is a JavaScript application that connects to SPARQL-compliant endpoints to ground autocompletion functionalities and context-based validation.
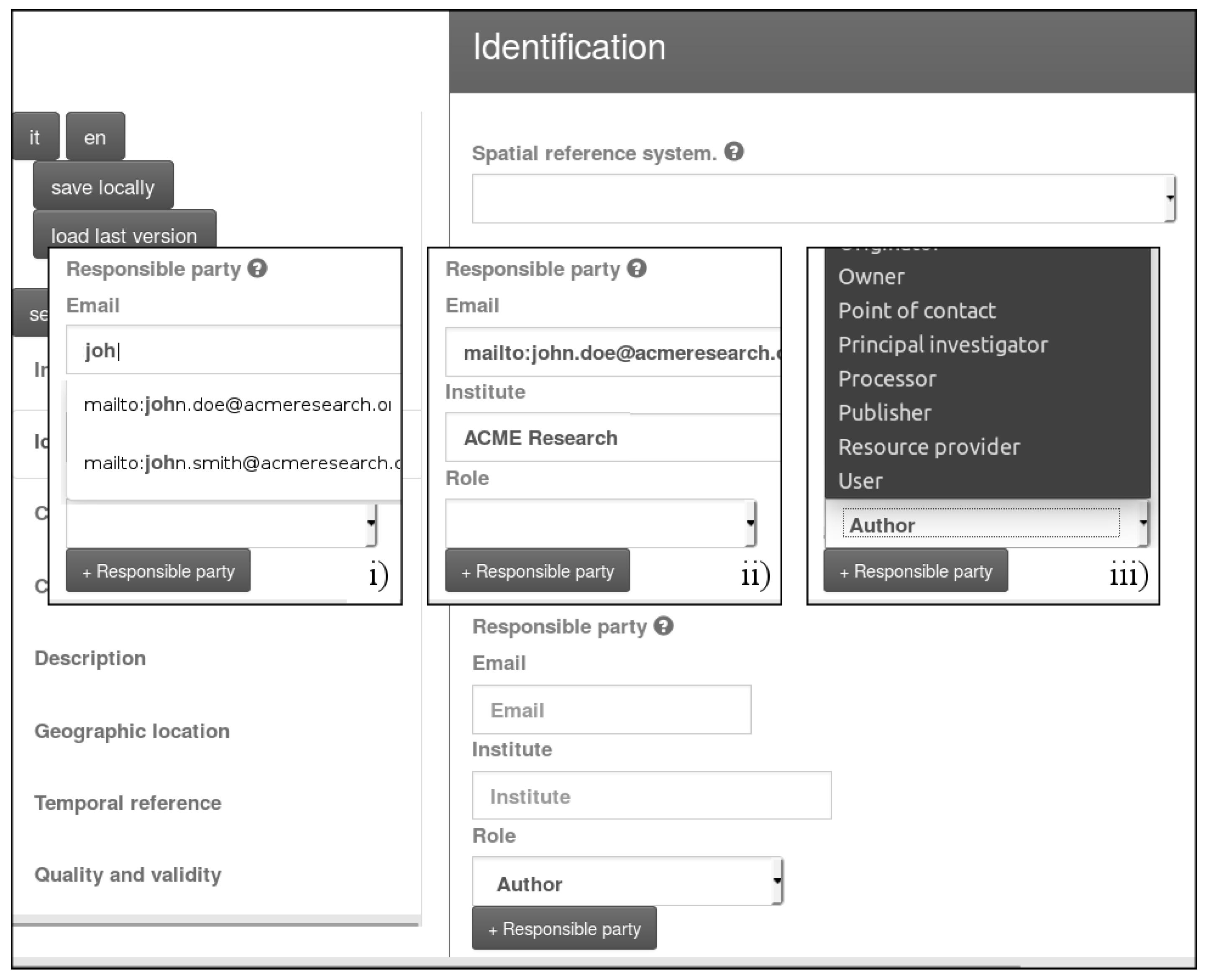
Figure 2 shows the “Responsible party” section of the editing interface for INSPIRE metadata. It illustrates the three main features for assisted metadata editing that leverage external data sources: (i) autocompletion functionalities; (ii) conditional automatic compiling of fields; and (iii) dynamic populating of dropdown lists. These fields can be used to generate the metadata items in
Figure 1 and are created on the basis of the template definitions in Listing 1.

The best deployment option for EDI is as part of the workflow set by the catalog software of choice for the provision of datasets. In fact, this strategy allows system administrators to narrow the number of property values that shall be provided by metadata maintainers. On the one hand, naming conventions used by the catalog software can be matched in template structures to keep some fields, such as resource identifiers, transparent to the end user. On the other hand, a number of fields (e.g., the spatial extent of the dataset) can be computed at resource upload-time and passed on to the editing interface as request parameters. As an example, integration of EDI with GeoNode allowed us to dramatically narrow the number of required fields for the provision of RNDT metadata [
42] (the Italian profile of INSPIRE metadata): Out of 34 mandatory fields, the number of those that the metadata maintainer has to provide from scratch was reduced to six.
A server-side component, written in Java, executes the actual translation of the user input in both the XML and RDF representations that allow us to demonstrate metadata delegation in this paper. This tool (please refer [
40,
43,
44,
45] for further information) allows for a threefold exploitation of RDF data structures; namely:
It is possible to plug in generic RDF data sources available as SPARQL endpoints. Based on query results, property values of metadata items can be filled in.
A semantics-aware version of the metadata record can be created and encoded as RDF, beside the XML profile the editing tool is configured to produce.
The metadata in the original XML profile can be reconstructed on demand (refer to the use case in the previous Section), thus relying on up-to-date information for reducing as possible inconsistency issues.
A mantra in contributing to the Semantic Web is reuse of existing schemata. Hence, for the translation into RDF of ISO-based geospatial metadata, our primary reference was the OWL representation of the ISO/TC 211 UML Model for geographic information developed by CSIRO [
46]. The W3C vocabulary DCAT [
47], the data schema underlying the existing Open Data portals based on the open source software CKAN (
http://ckan.org/), constituted another source of direction. Moreover, the DCAT application profile for data portals in Europe [
48] has been recently complemented by an extension for representing INSPIRE metadata as RDF [
49]. Having in mind to ease integration with CKAN-based portals, we adopted the DCAT schema as the baseline but, when choosing between the aforementioned contributions to the state of the art to express geospatial-related metadata, we opted for [
46]. In fact, the GeoDCAT extension [
49] is primarily aimed at integration with CKAN while we need broader support for URI-based metadata property values.
2.5. Semantic Lift of Resource Metadata
Semantic lift of metadata essentially amounts to relating data items in metadata records to entities in the Web of Data through their identifiers, their URIs. This is done at metadata creation-time via EDI: On the one hand, the tool draws information from SPARQL endpoints for assisting editing of metadata and, on the other hand, the tool stores the URIs of the entities that are selected by the metadata maintainer for future use.
Of course, this does not imply that all fields in a metadata description shall be decentralized in this fashion. In fact, we acknowledge that a number of these should change only as a consequence of voluntary update by the metadata maintainer. Nevertheless, there are metadata fields that are plainly useless or even misleading if not consistent (e.g., the details regarding a point of contact) and could therefore take great advantage of the delegation mechanism presented in this paper. The proposed solution does not envisage versioning of the metadata descriptions, of the data structures referred to by the former, as well as of the individual data items that are included in metadata. However, it should be noted that unique identification of the entities under consideration is a prerequisite to all these functionalities that can then be built on top of the RDF data structures.
Similarly, if concerns on the availability of the data structures that are referred to by metadata descriptions are raised, one could easily apply a caching layer so that, whenever a given value cannot be retrieved from the data source, the value can be taken from the static metadata description that have been previously generated and stored. In fact, if a given metadata item is related to a URI, it means that the identified data structure has been found at least once, at metadata creation-time, and then the corresponding static XML output can be stored and subsequently looked up if something goes awry.
In the following, we use the application described above to provide a prototypical implementation of the delegation principle presented in this paper.
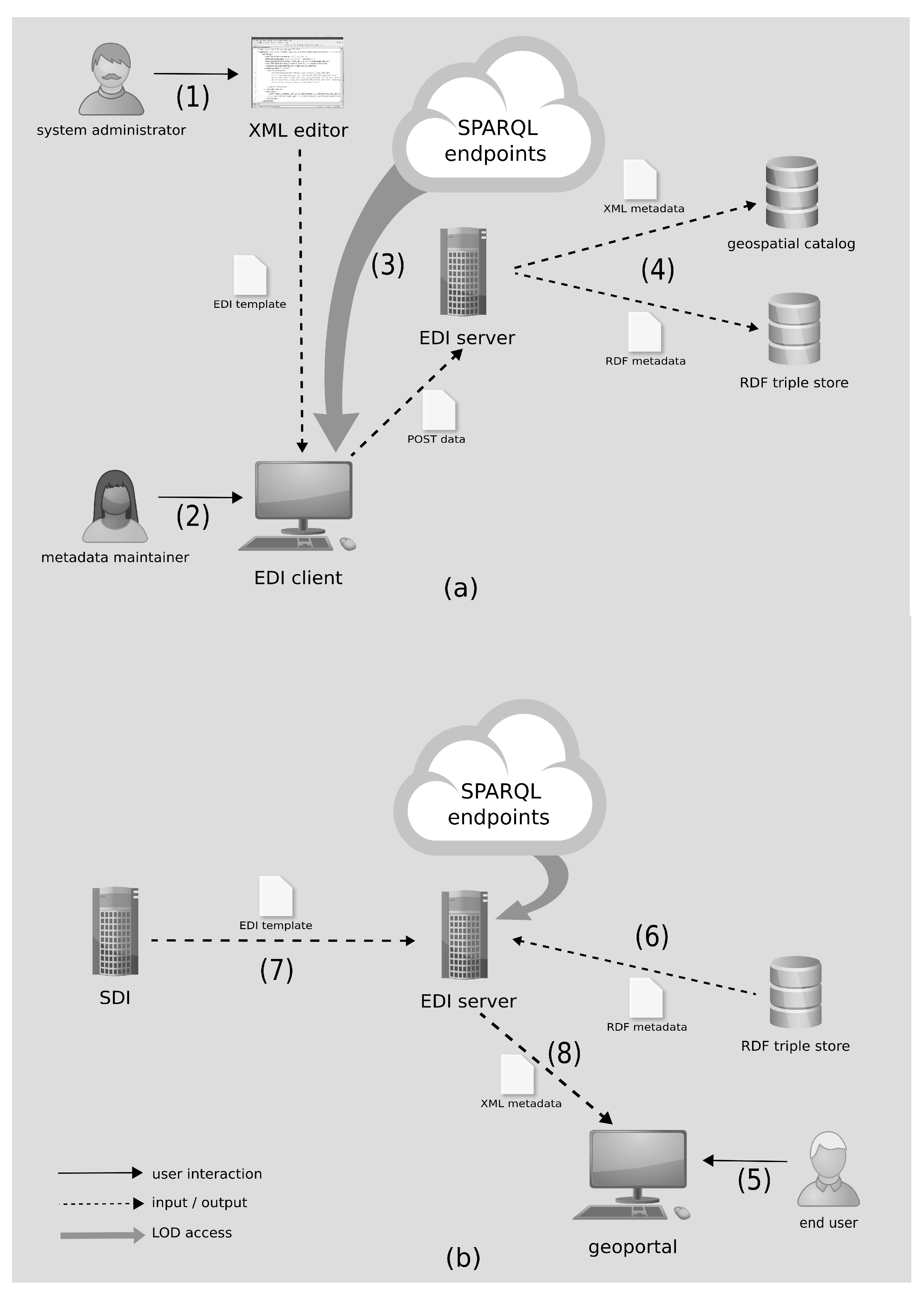
Figure 3a depicts the workflow that allow metadata maintainers to provide semantics-aware metadata. Albeit developed in the context of one of our projects, the methodology can be customized to any XML-based profile of geospatial metadata. To do so, a necessary preliminary activity is constituted by tailoring of the EDI template reflecting the metadata schema that shall be produced by the tool (
Figure 3a, 1) Specifically, the system administrator (the person customizing EDI for the specific application scenario) can create the template from scratch, supported by the XML Schema provided in the software package. Alternatively, the administrator can customize one of the example templates (
https://github.com/SP7-Ritmare/EDI-NG_templates) which implement a number of different INSPIRE and SensorML metadata profiles.
The template can now be fed to EDI to create the web form that metadata maintainers can use to edit metadata records (
Figure 3a, 2).The form is going to reflect the constraints encoded in the template (e.g., mandatory fields, multiplicities, data types, etc.) and connect to the remote data sources (
Figure 3a, 3). Once the data are posted to the server-side component of EDI, the XML metadata record is generated alongside the corresponding RDF representation (
Figure 3a, 4). The XML files can then be passed on to geospatial catalogs that can understand the specific formalism (in our scenario, these were either CSW catalogs or SOS servers) for traditional discovery: In this case, the advanced features described in this work can not be made available.
In the fragment of the template for INSPIRE-compliant metadata (Listing 1), we highlight the logics underlying the three usages enumerated in the beginning of this Section. Note that the code is omitting a number of elements and attributes that, albeit necessary to enactment of the template, may be misleading to the reader. Specifically, Lines 3–13 define a datasource named “person” by specifying the SPARQL query to be issued to the endpoint specified on Line 12. The datasource is later referred to on Line 18, in the definition of the metadata field corresponding to the e-mail address of the point of contact, thus enabling autocompletion of the field on the basis of query results. Specifically, parameter “
$search_param” will be replaced run time by the text pattern entered by the metadata maintainer. In addition, the metadata item on Lines 27–30 will be autocompleted on the basis of the specific point of contact that is selected (see
Figure 2, ii). Moreover, the field on Lines 31–35 can be selected from a drop-down list of roles that is dynamically created according to datasource “roleCodes” (as in
Figure 2, iii). The mechanics of completion of the last two fields is omitted in Listing 1 for brevity. Further assisted editing functionalities include autocompletion on the basis of HTTP parameters in the call to the editing interface, on-demand generation of field values (e.g., to generate unique identifiers), and combination of values from other metadata fields.
The server-side component of the tool takes care of generating the prescribed XML output on the basis of XPath expressions (such as those on Lines 20, 29, and 33). Additionally, the
rdfOut element on Lines 37–43 specify the RDF triples that shall be produced and inserted in the triple store used for metadata storage. In the example, Lines 37-43 contain the
blueprint of the RDF data structures expressing the point of contact in
Figure 1. Specifically, parameter “
$resp_1_uri” retrieves the first item in element “resp” (containing the e-mail address of the point of contact) and looks up the corresponding URI (the unique identifier of the selected individual). The e-mail of the point of contact, as well as the name of the institute he works for, are not comprised in the triples defined by the
rdfOut element: These values will be retrieved on demand, when the metadata of the resource is looked up. At mere syntactic level, this is the major difference between our approach and any of the possible one-to-one translations of INSPIRE metadata into RDF, such as those in [
46,
49]. In the next Sections, we provide a qualitative analysis of the novel capabilities that are elicited by our metadata representation strategy.
3. Results
Unique identification of the entities related to metadata property values improves overall interoperability of SDIs: Beside easing processing by automated agents, this practice helps addressing discovery issues related to multilingualism and semantic heterogeneity. It should be noted that association of URIs with metadata items also constitute a pivotal prerequisite to further functionalities that are elicited by Semantic Web technologies, such as query expansion and inference. These are not considered in this work as they are dependent on the specific discovery facilities that are implemented on top of metadata.
The potential of multilingual queries combined with query expansion is exemplified in [
50]: In that paper, a search pattern expressed in Arabic is first turned into a language-neutral URI by looking up a geospatial thesaurus. Then, the inner structure of the latter is exploited in order to enrich the search parameters with additional terms. Multiple language-dependent queries can now be formulated, one for each language supported by the thesaurus, and they are likely to return more results than the original one. In the scenario proposed in that work, this technique can only be applied to the search pattern entered by the user but it is apparent that native URI-based metadata provide the same benefits without requiring back translation into language-dependent terms (for traditional discovery).
Normalization of metadata is a direct by-product of unique identification of property values. In and of itself, this feature implies the improvements with respect to metadata maintenance described in [
27,
31]. However, we remove the issues due to proprietary software and technological barriers by providing, respectively, a FOSS solution and a user-friendly template language. Moreover, relying on SPARQL endpoints for the provision of the data structures that are referred to in metadata allows decoupling management of the latter, implemented by the catalog software of choice, and management of the RDF data structures, which can take advantage of the broader set of tools made available in the Semantic Web context.
The following focuses on the use case presented in
Section 2.3, addressed by the workflow in
Figure 3b and assuring consistency of metadata records by leveraging on the delegated metadata created in the first part of the workflow (
Figure 3a). Specifically, once the end user has discovered the dataset of interest and requests the corresponding XML metadata (
Figure 3b, 5), the EDI server retrieves the RDF metadata (
Figure 3b, 6) and looks up the template (
Figure 3b, 7) to access the correct data structures by the SPARQL endpoints that are defined. Then, the up-to-date XML representation of the former can be generated (
Figure 3b, 8).
3.1. Basic Metadata Delegation
Each metadata element definition in the template can specify a number of
rdfIn nodes that specify the SPARQL queries that return the values for the distinct metadata fields. As an example, Lines 44–49 in Listing 1 contain the query fragment retrieving the metadata items that are stored in the local triple store. Instead, individual
item nodes define the query fragments that shall be executed against the remote endpoint that is defined for the specific
item. Specifically, Lines 21–25 define the triples that shall be matched against the endpoint specified on Line 12. Note that, in Listing 1, we omitted namespace declarations for the sake of conciseness; in addition,
rdfIn elements only contain the triple patterns that are necessary to address the use case in
Section 2. Listing 2 presents the query compiled from the information in Listing 1. This straightforward query is directed to a data source which is expected to model information using the
vcard schema; it could however be formulated in a more general way, by allowing for alternative values, multiple schemata, etc.
With respect to the use case of John Doe changing institute (
Section 2.3), our representation of metadata as RDF exploits the information generated by the
rdfOut element on Lines 37–43 of Listing 1. Suppose that John Doe updated his FOAF profile in order to feature his new e-mail address and point to the FOAF profile of the new employer. Now, the metadata for “Dataset ABC” can be composed on the fly: The generated XML tree is analogous to that in
Figure 1, except that the two inconsistent leaf nodes in the leftmost sub-tree are automatically updated to the new values. One may argue that, to enable update of the metadata associated with “Dataset ABC”, John Doe is required to update his FOAF profile, a modification that is clearly not automatic. However, a closer look will show that this modification is completely independent of the workflow for managing metadata that is implemented by ACME Research (actually, the research institute may not be aware of any change in John Doe’s FOAF profile).

3.2. Adding Indirection to Delegation
We have seen thus far that, by indicating the entities referred to in metadata via their URIs, it is possible to achieve on-demand generation of ISO-compliant metadata records that have higher quality assurance with regard to consistency of metadata fields. In fact, every time the description of resource “Dataset ABC” is requested, the e-mail address of the creator of the dataset and the name of the institute he works for are updated to their current values without requiring manual update of the metadata record every time these values change. Unfortunately, this functionality is, in and of itself, of little use for addressing the second inconsistency issue described in
Section 2.3. In fact, unless all the metadata records in the SDI of ACME Research are updated, they are going to point to John Doe, the old custodian, and provide incorrect information (albeit up-to-date). This happens because the mechanics described so far work well for individual property values of the entities that are referred to but fall short of extending their behavior to whole entities (e.g., the specification of the new custodian for ACME Research). Moreover, since basic delegation takes control over metadata property values out of the party maintaining metadata, there is a need for upholding this control on those information items that require this (e.g., custodian information in the use case we presented). A straightforward means to achieve this is disallowing delegation for these values, that is, reverting to good old plain-text metadata (an option our methodology does not rule out) but this would not retain the advantages described in the previous Section.
Instead, it is possible to achieve automatic update of custodian information in all metadata records by using an in-between data structure whose purpose is to act as a signpost for the person fulfilling this role. This can be achieved by minting a URI representing the custodian signpost (that, in the example, is set to “http://.../custodian”). This URI can then be associated with the real individual fulfilling this role: As an example, Listing 3 contains the SPARQL query appointing John Doe as custodian of the resources in the SDI of ACME Research. Note that the specific property expressing this relation between the abstract signpost and the actual individual (in the example, rdfs:seeAlso) can be whatever because it is just a convention between the local triple store and the template. Specifically, Lines 6 and 7 in Listing 3 retrieve the triple that specifies the current custodian, whoever she is, while Lines 2 and 3 appoint John Doe to this role. The second step is constituted by creating a datasource in the template that is capable of taking into account this new information, such as the one shown in Listing 4. The query is very similar to that of datasource person in Listing 1, except that the query is run against the local triple store (where the triple inserted by the query in Listing 3 is residing) and only then the remote endpoint is interrogated.


Finally, the EDI template shall contain the element definition that is going to access the triple in Listing 3 according to the data source definition in Listing 4, as shown in Listing 5. Specifically, the first item definition refers to datasource “custodian” and variable “email” in Listing 4 to retrieve the e-mail of the individual acting as the custodian for the SDI. The second item (corresponding to the name of the research institute) is known in advance. Moreover, the content of the rdfOut tag and of the outermost rdfIn tag shall be modified accordingly: The former features the same triple patterns as in Listing 1 except that the property values are statically set; the second is modified to take into account the indirection step.
Back to the use case presented in
Section 2; when John Doe changes workplace, it is sufficient to run the query in Listing 3, after substituting his URI with that of the new custodian. This is going to automatically update all custodian information in the metadata records hosted by the SDI. In this second flavor of metadata delegation we present, one may argue that manual update is required to assign the role of custodian to the successor of John Doe, but a closer look is going to put this objection in perspective. Firstly, this manual update is actually pursued by ACME Research in order to keep control on who is the custodian for the whole SDI, a modification that is less prone to be overlooked. Secondly, this individual update is going to produce catalog-wide update of metadata that does not require modification of all XML metadata records. Finally, this update may easily be the consequence of a company workflow different from that of metadata management, such as the update of registry information describing the employees of ACME Research.

4. Discussion
The example provided in this paper can be replicated in different application scenarios as the metadata profiles that are made available by our tool are of general interest to the INSPIRE and SWE communities [
51]. Moreover, it should also be noted that the issues our research aims at solving affect a broader range of metadata formats, thus hampering efficient retrieval of resources in a number of different domains. The schema-agnostic approach that has been exemplified with a specific use case in the geospatial domain can then be applied to heterogeneous domains by tailoring the metadata template to the latter and by selecting the appropriate semantic sources.
Besides improved discovery functionalities (such as those described in [
52,
53]), our methodology aims at fostering distributed metadata management. Specifically, adoption of RDF as the native metadata storage format and extensive usage of URIs as property values enable management of geospatial metadata in a decentralized, multi-tenanted fashion. In fact, since the Semantic Web is a distributed corpus of information whose data resources can often be directly accessed, via the associated URIs, as Linked Data, it makes little sense sticking to the notion of metadata as data structures that are single-handedly maintained by the institution providing a given resource. Instead, a distributed approach could induce a
metadata fabric that is more resilient to change. In addition, referring to semantics-aware entities in metadata allows making the latter more usable through formal specification of information items via RDF schemas and ontologies. The big picture our research is contributing to, on which we elaborate in the following paragraph, is fully hypermedia-driven metadata.
Throughout this paper, we draw the RDF descriptions of information items from SPARQL endpoints, the rationale for this being expressiveness of the query language and the need for readily usable facilities for assisting provision of metadata. However, it is apparent that the delegation paradigm can be employed to its full potential only in a pure Linked Data ecosystem. Referring to Listing 2, the query is assumed to return bindings for variables ?1 and ?2, corresponding to the hasIndex attributes of the related items in Listing 1. Should any of these values be missing (e.g., because of removal of the record associated with John Doe from the remote endpoint), the result set still contains the necessary information, the URI bound to variable ?contact, to try a Linked Data lookup and retrieve the value of the missing properties. Similarly, John Doe’s FOAF description is supposed to define the URI of the institute he works for, expressed in the example as a vcard:org property definition. Then, the approach described so far can be reiterated and the name of the institute can be retrieved. If a triple store is used to cache the Linked Data chunks corresponding to the FOAF descriptions of John Doe and his new employer, the remote endpoint in the SERVICE clause of Listing 2 (Line 7) can be replaced with the endpoint of this caching layer so that the query can return the intended property values.
The delegation principle can also be implemented in a metadata management framework and with tools that are different from those employed in the worked-out example we presented in this paper. In this case, it should be noted that relating metadata property values to URIs is not sufficient to pinpointing the required property values. The missing component is specification of the search pattern that in our example implementation is constituted by the SPARQL queries defined in the template. From-scratch implementation of metadata delegation may consider
property paths as a means to specify the data fragments that shall be retrieved but, because of the low expressiveness of property paths in the SPARQL 1.1 specification, recourse to extensions, such as those described in [
54,
55], may be necessary.
Finally, referring to the use case that was presented, beside keeping the metadata record consistent (allowing researchers interested in the dataset to contact its creator), delegation is also functional to maintaining authorship on the dataset by John Doe. This cannot be enforced in state-of-the-art metadata management and nevertheless it is important to uphold this principle in the framework of the author’s digital identity. In fact, researchers are increasingly appointing third parties for the purpose of shaping their identities on the Web (e.g., through ORCIDs) and then leveraging the data structures created by the latter is just one step farther. Essentially, researchers should start considering management of their digital identities as a task that is complementary to ordinary metadata provision. This practice allows the former to maintain full control over the products they are providing across heterogeneous geoportals.
5. Conclusions and Future Work
This paper addresses piecewise articulation of metadata descriptions based on heterogeneous resources in the Semantic Web. We demonstrate the advantages of delegated management of metadata with an example implementation set in the geospatial domain. In the worked-out example, besides traditional metadata representation that is processable by traditional geospatial catalogs, we generate a semantics-aware RDF representation to be used at a later stage for providing increased features. Among the many functionalities that this characterization can ground, we propose a use case addressing automatic update of metadata properties in either individual records and catalog-wide. However, it should be noted that adopting RDF as the metalanguage for resource description contributes to moving close to the long-term intent expressed in the abstract—that is, creating a trait d’union among datasets, the scientific literature related to them, and the researchers behind these products. State-of-the-art infrastructures rely on centralized metadata management and compliance with outdated representation formats for their implementation. Instead, fluidity of research environments calls for managing metadata at a finer granularity.
Our current research is also focusing on extending the approach to encompass pre-existing metadata descriptions via ex-post processing [
39] and on sharing of the semantic information that is produced for reuse by third parties, such as the principals that created the resource descriptions in the first place. The semantic lift task featured in that work repurposes the same template structures described in this paper in a “reverse engineering” fashion and is complementary to the approach presented in this work. Specifically, pre-existing metadata that have been processed that way can then be re-edited by using the same application we used to demonstrate delegation. Instead, sharing semantic information relates to provision of the semantics-aware portion of a metadata description according to the WADM format proposed by W3C [
56]. In fact, while exhaustive translation of metadata into RDF is primarily meant for storage and serialization of resource descriptions, pinpointing the semantic information that is produced is crucial in the interplay with traditional discovery, as widely implemented in state-of-the-art geoportals.

 ,
, 


{kind=link}
{kind=link}
{kind=link}







