LandQv2: A MapReduce-Based System for Processing Arable Land Quality Big Data

 ,
, 


 , ,
, ,
Abstract
:1. Introduction
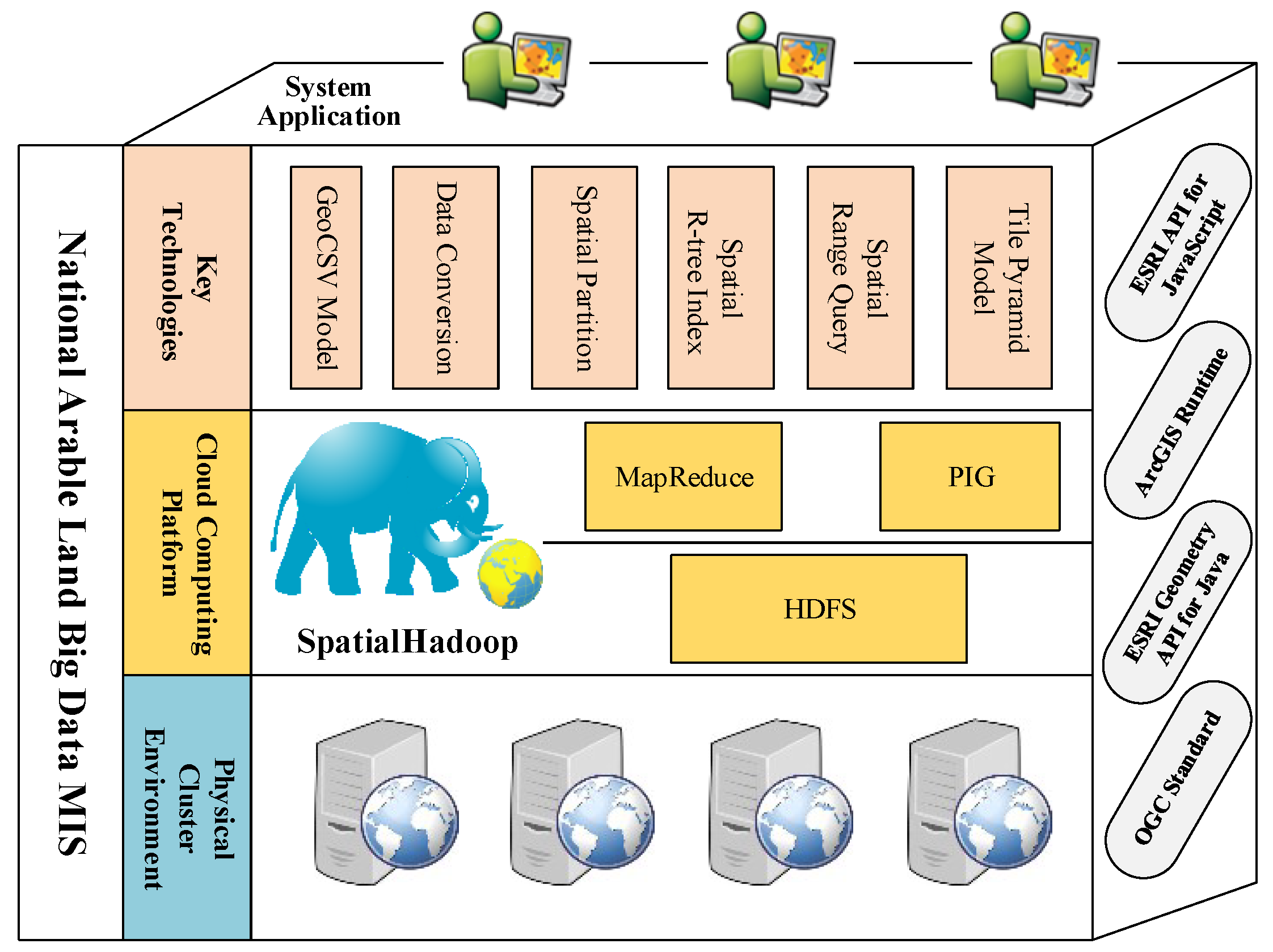
2. LandQv2 System Overview
3. Key Technologies in LandQv2
3.1. Data Preprocessing
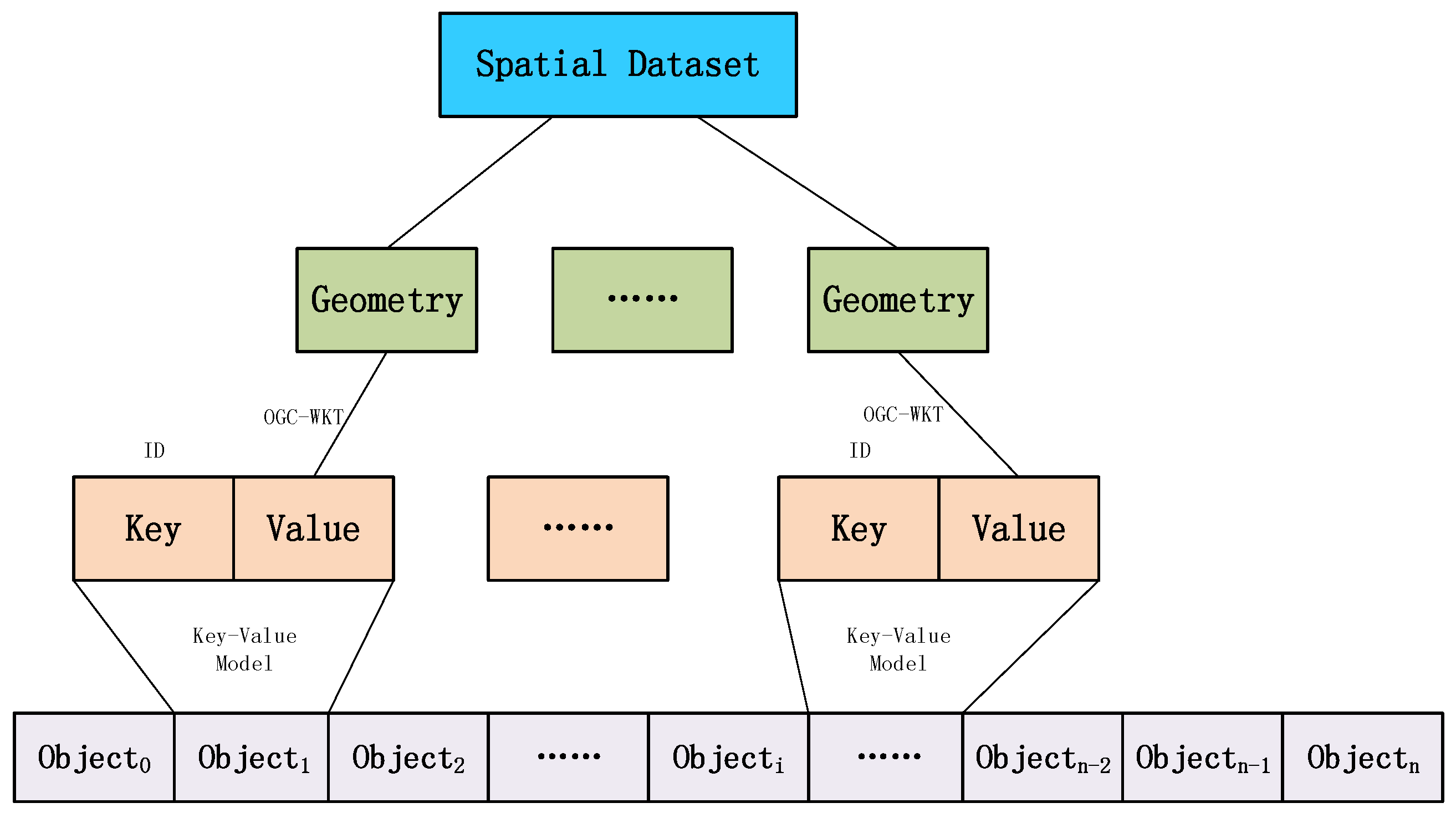
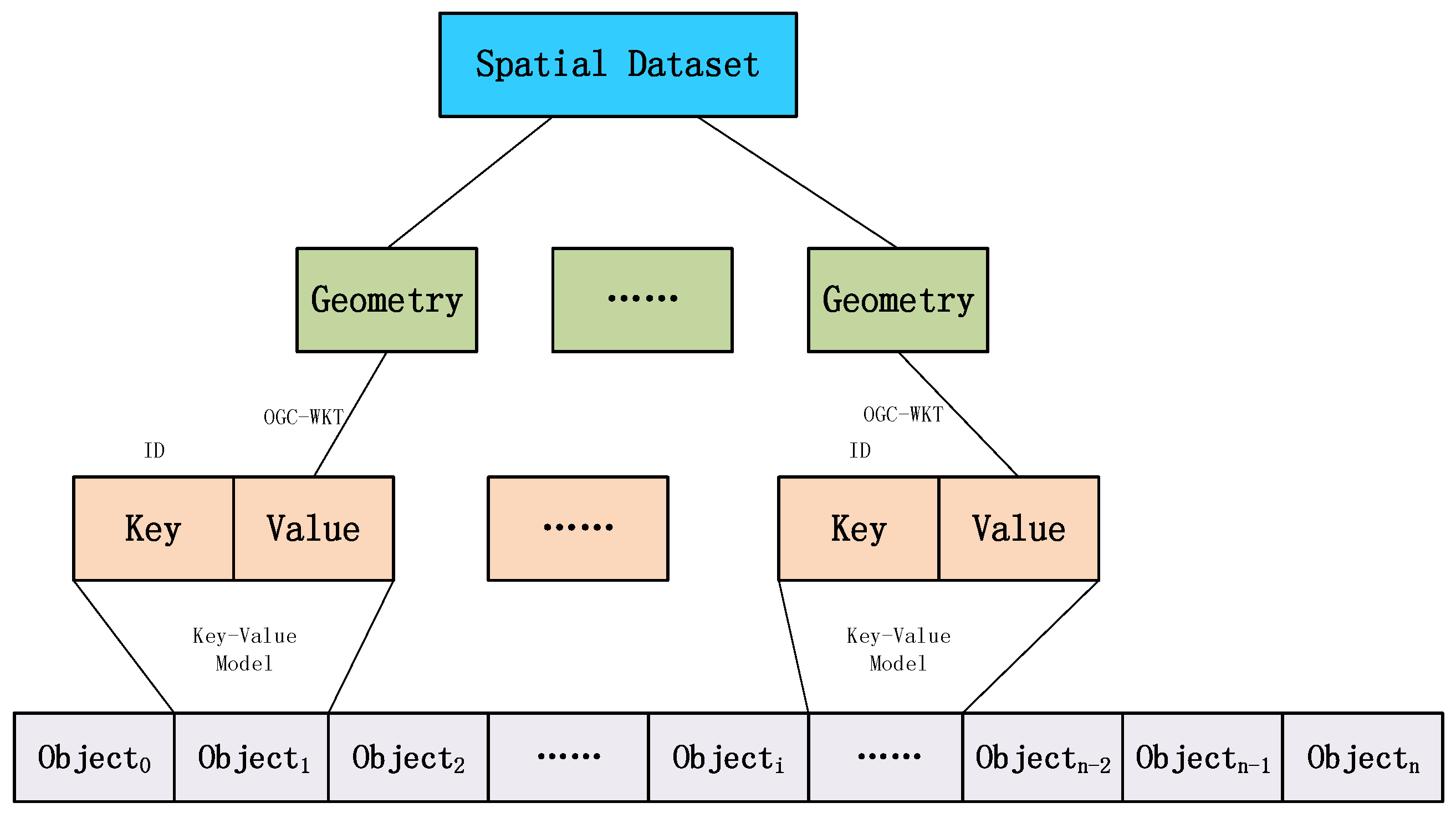
3.1.1. Vector Data Cloud Storage Model
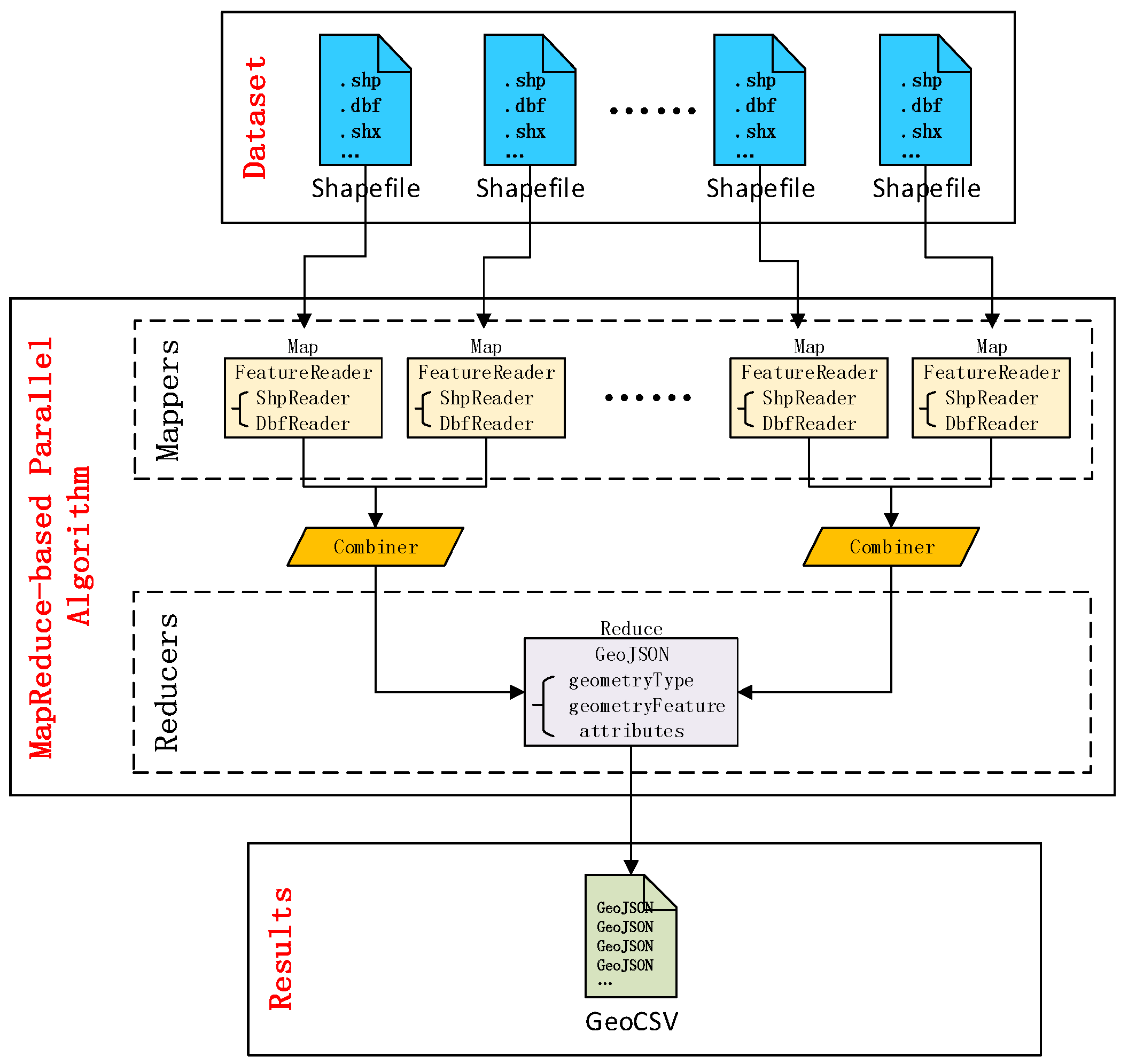
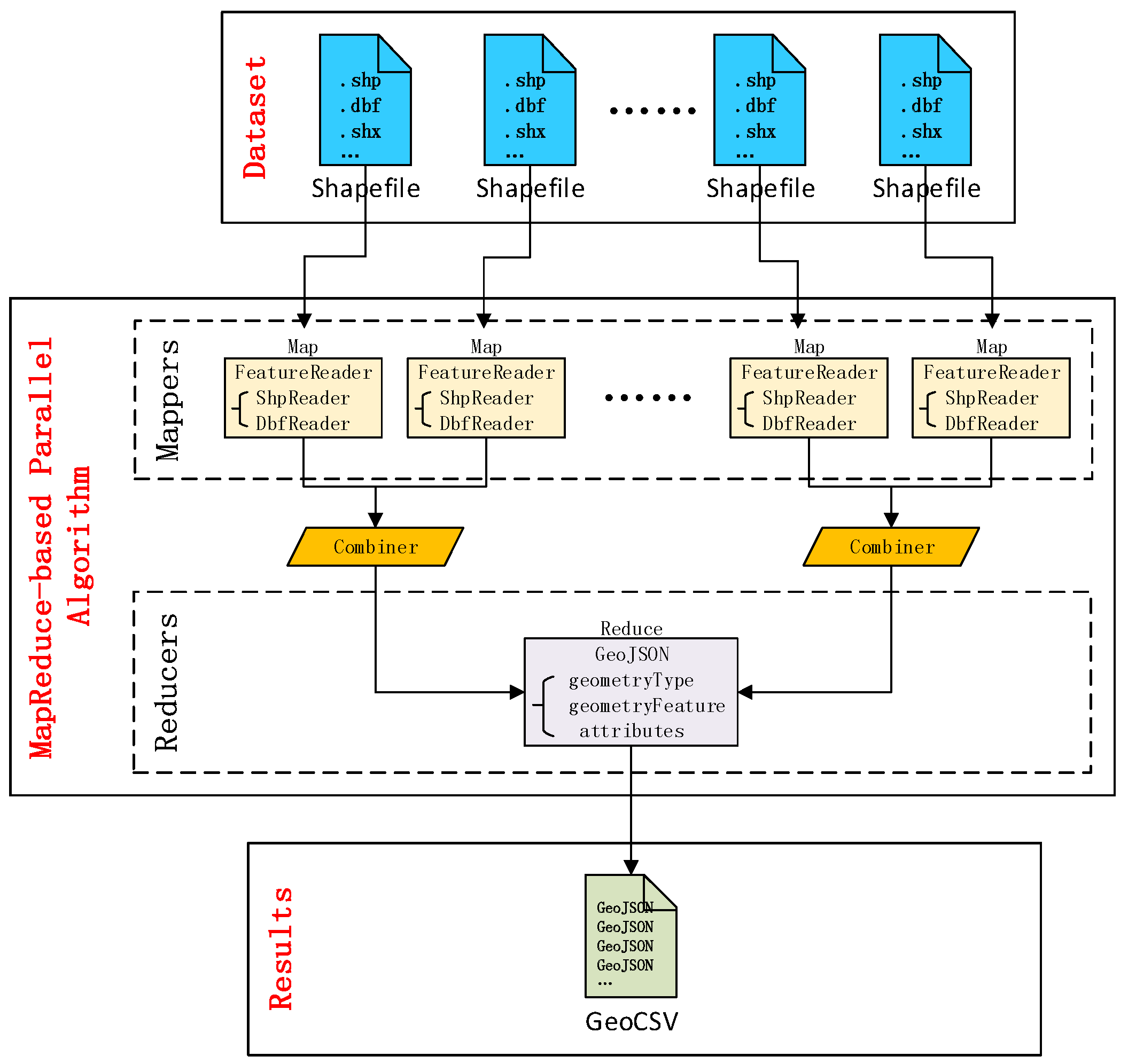
3.1.2. Data Conversion
3.2. Spatial Index
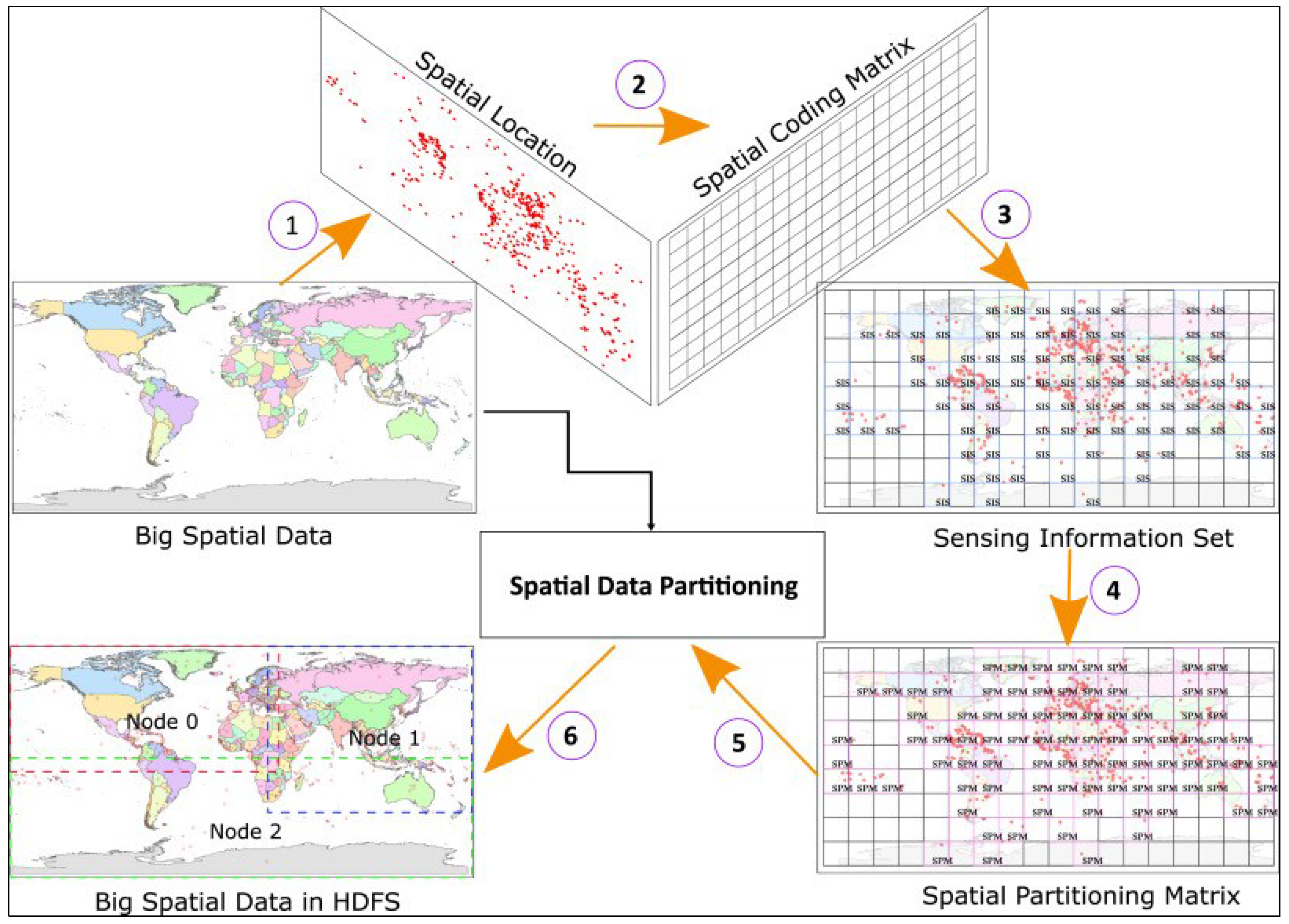
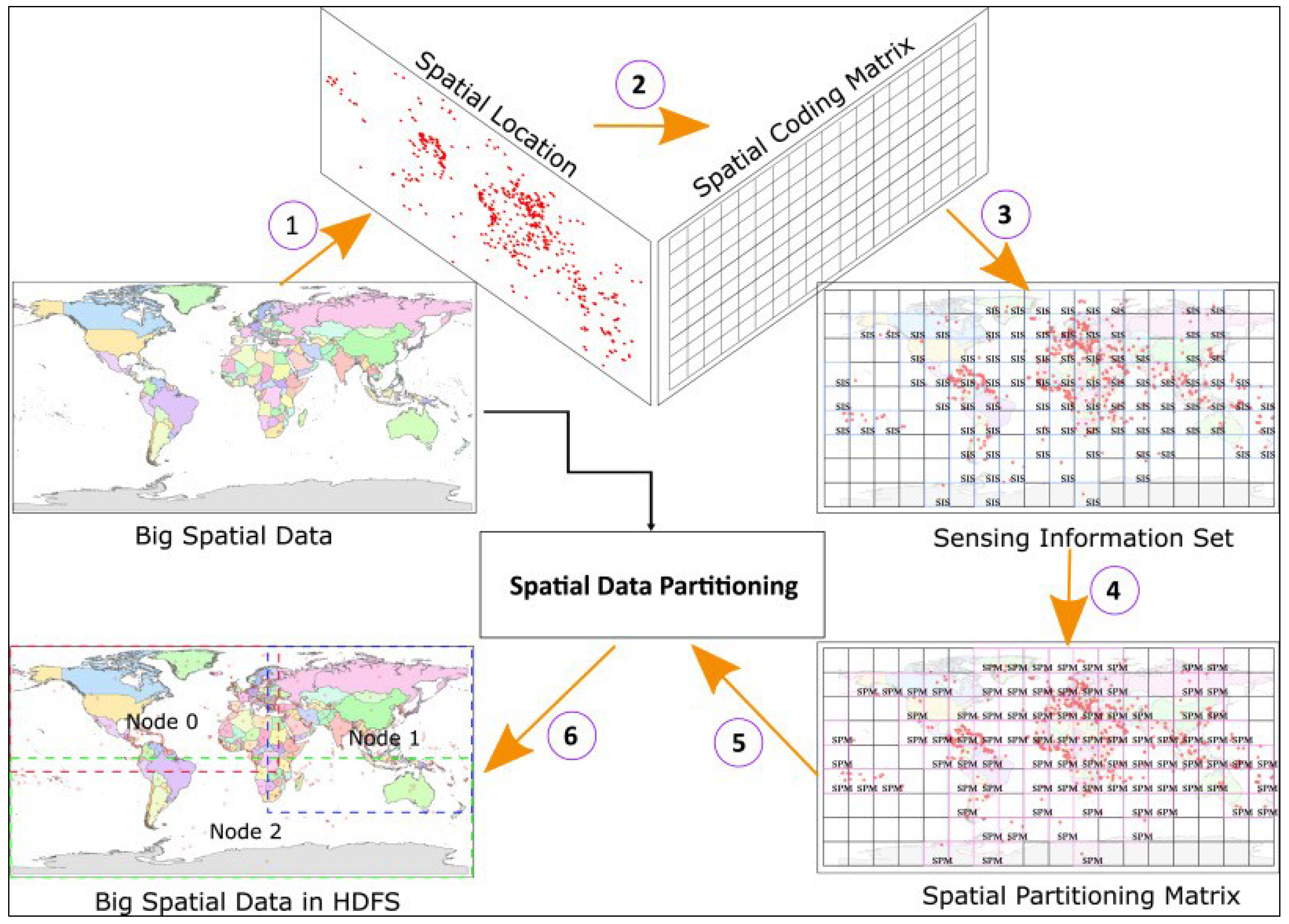
3.2.1. Data Partitioning
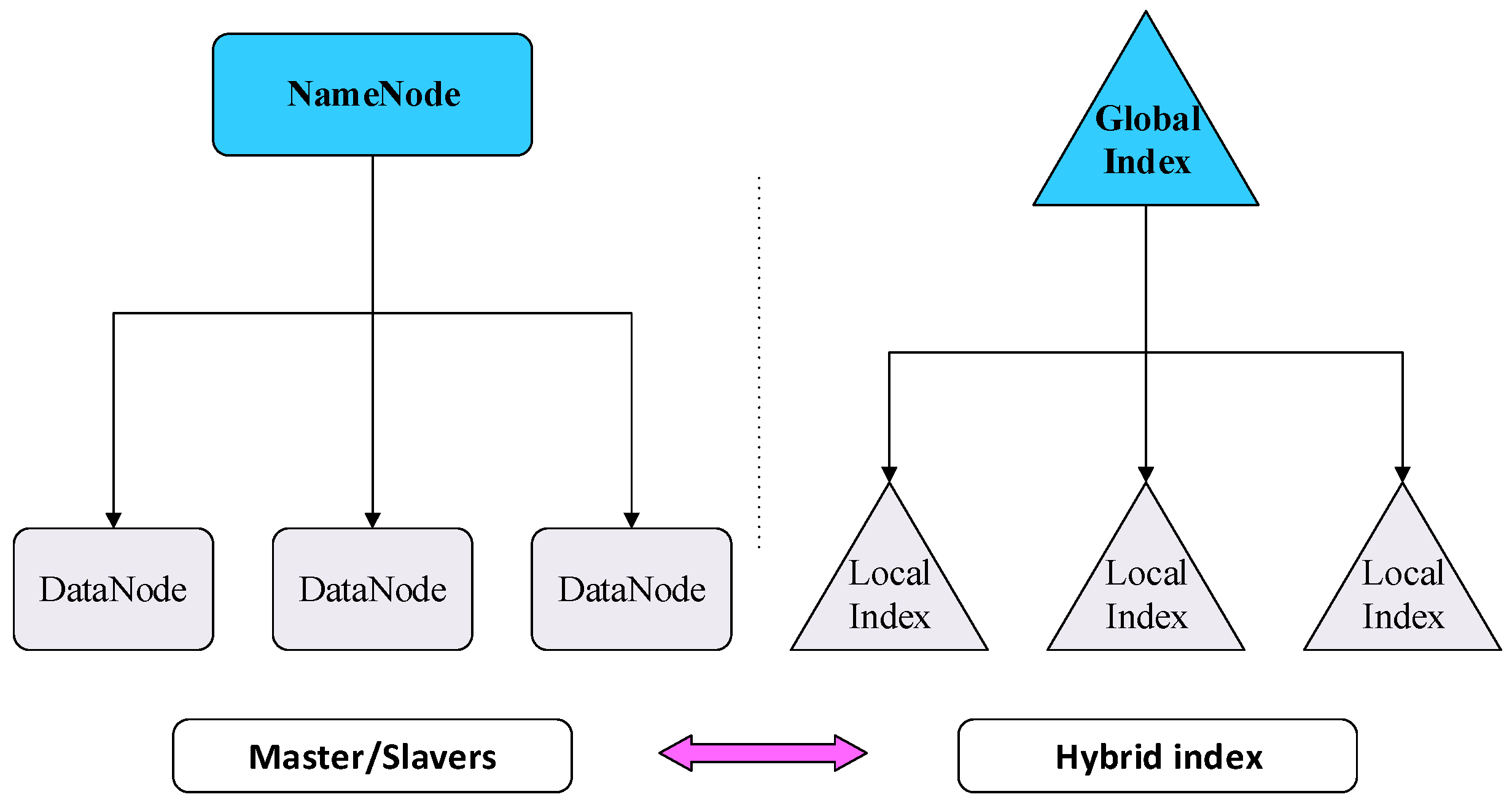
3.2.2. Distributed R-Tree Index
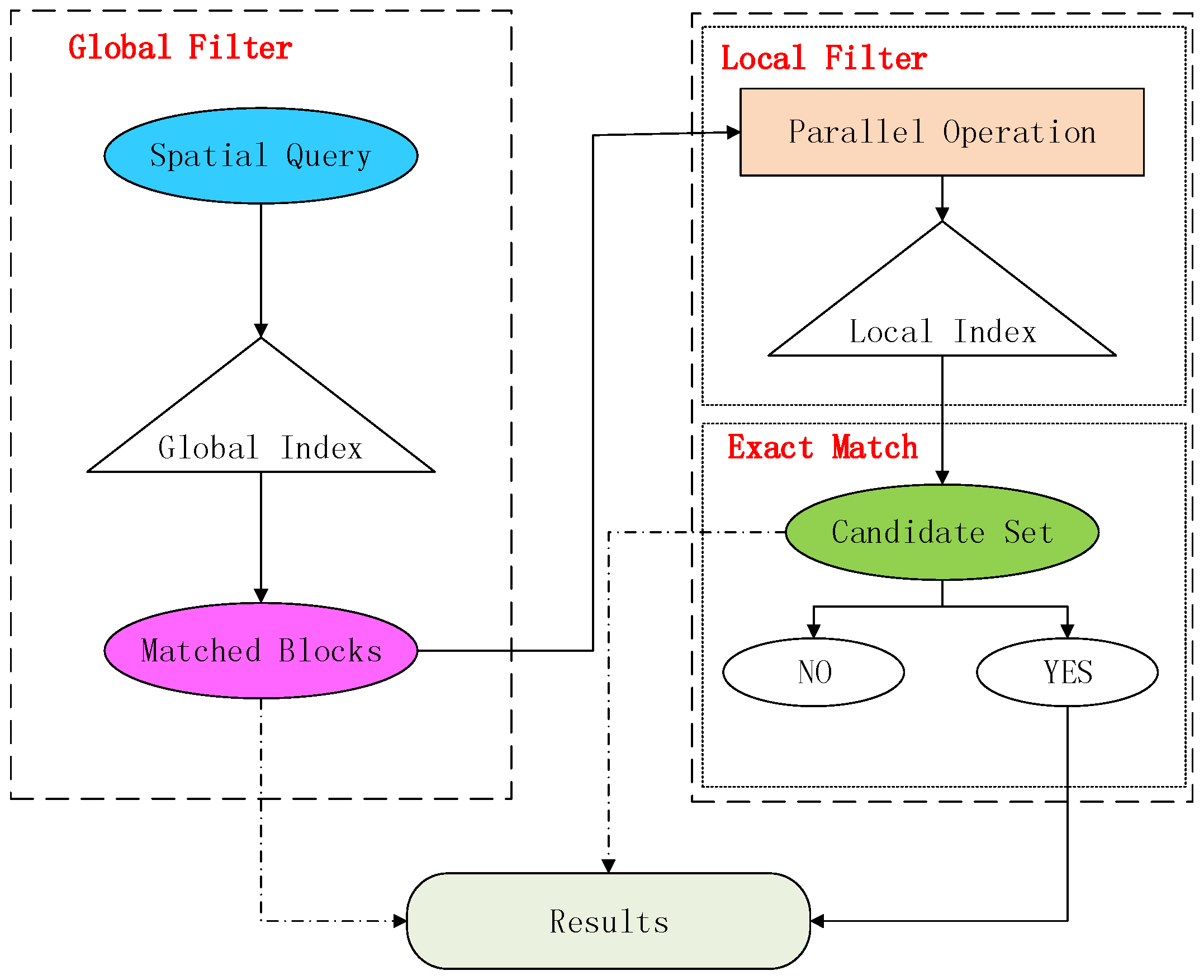
3.3. Spatial Range Query
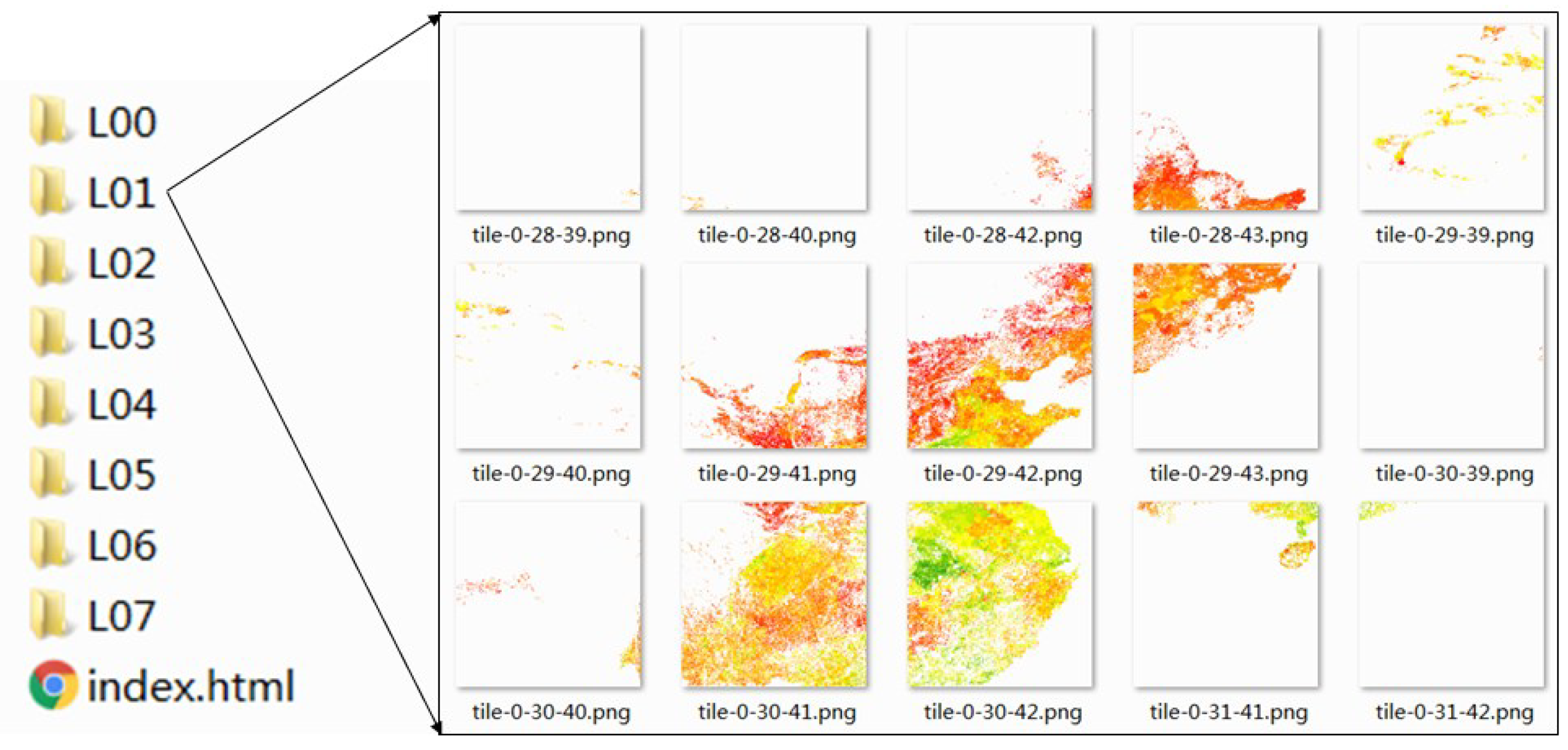
3.4. Data Visualization
4. System Test and Results
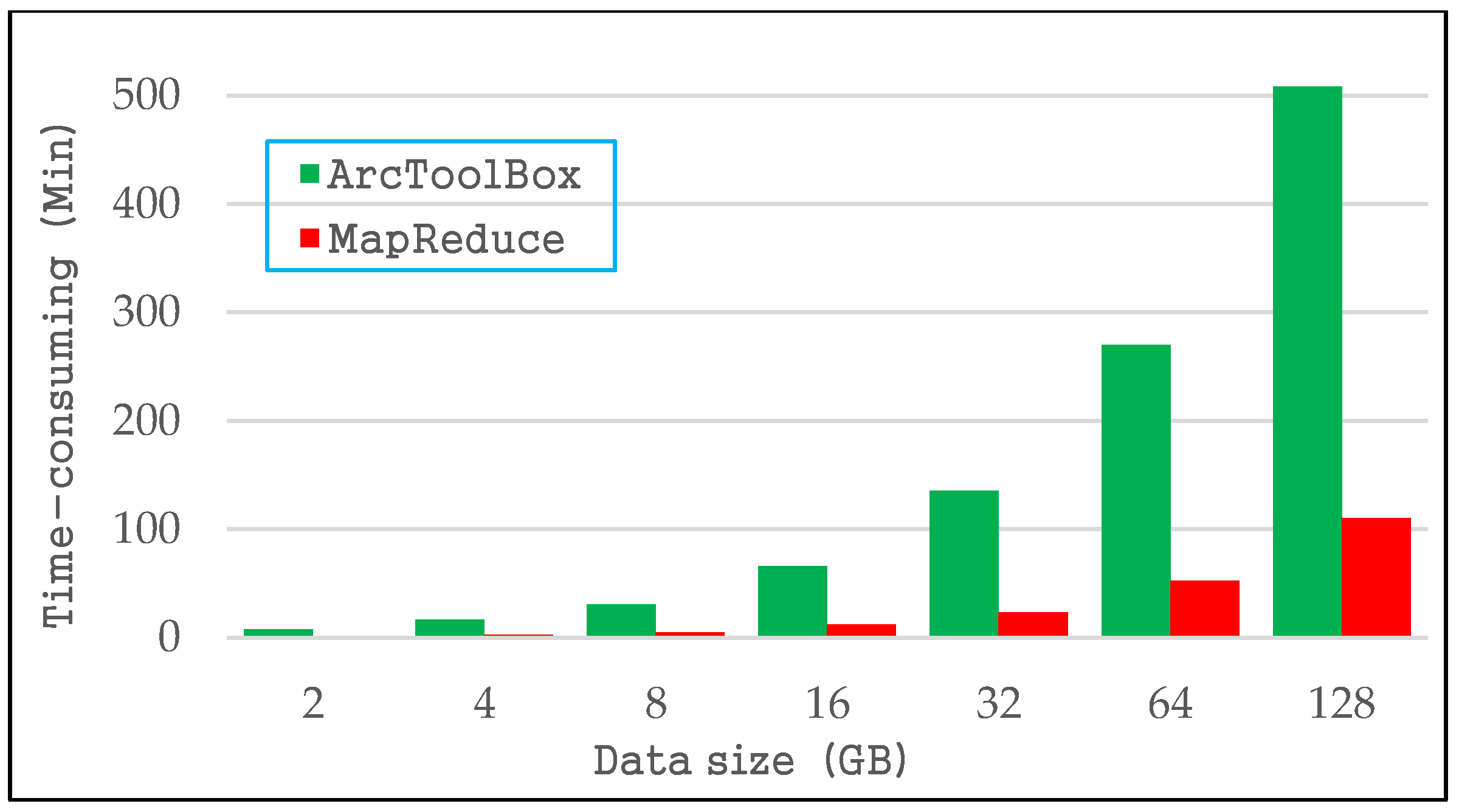
4.1. Data Conversion
4.2. Data Query
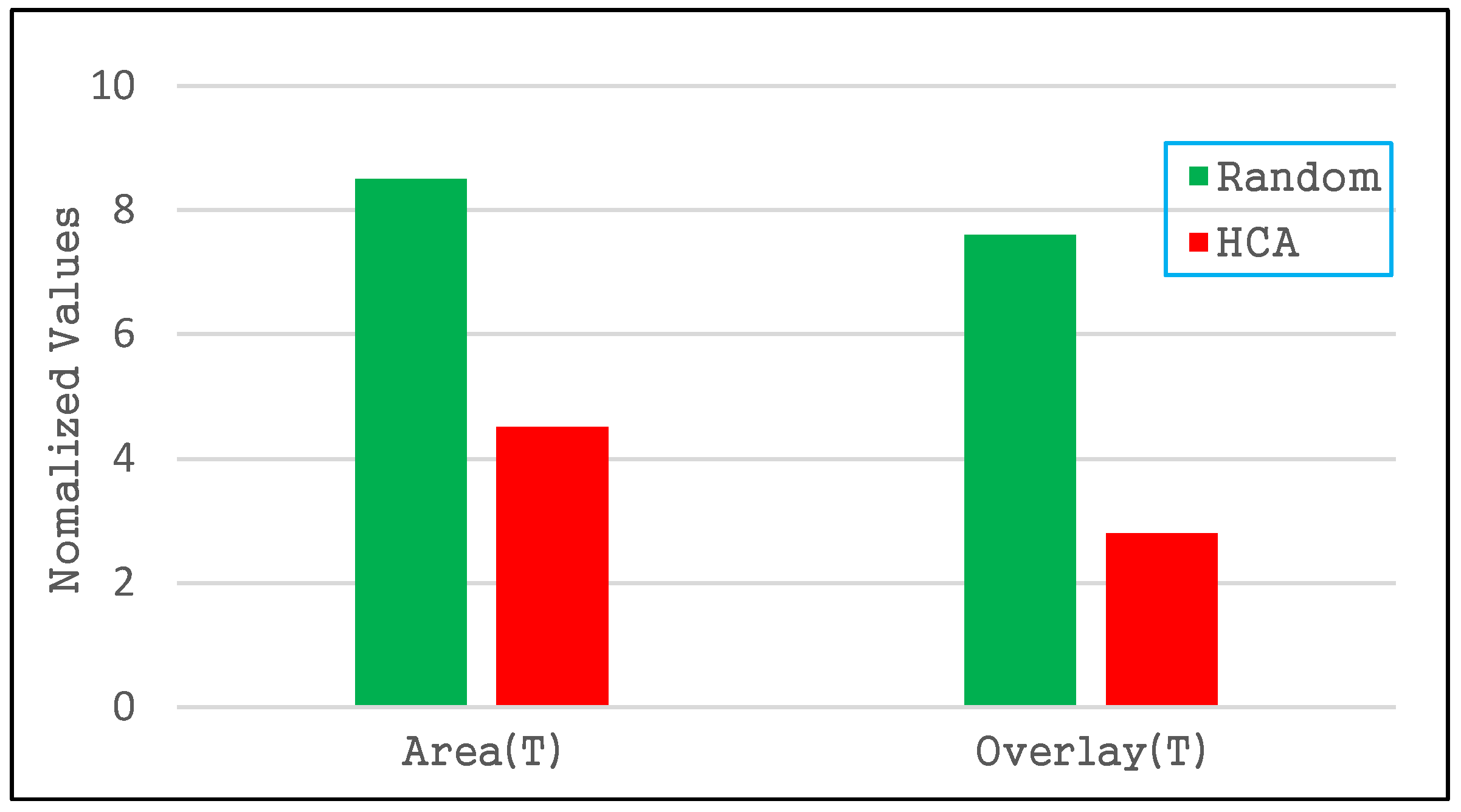
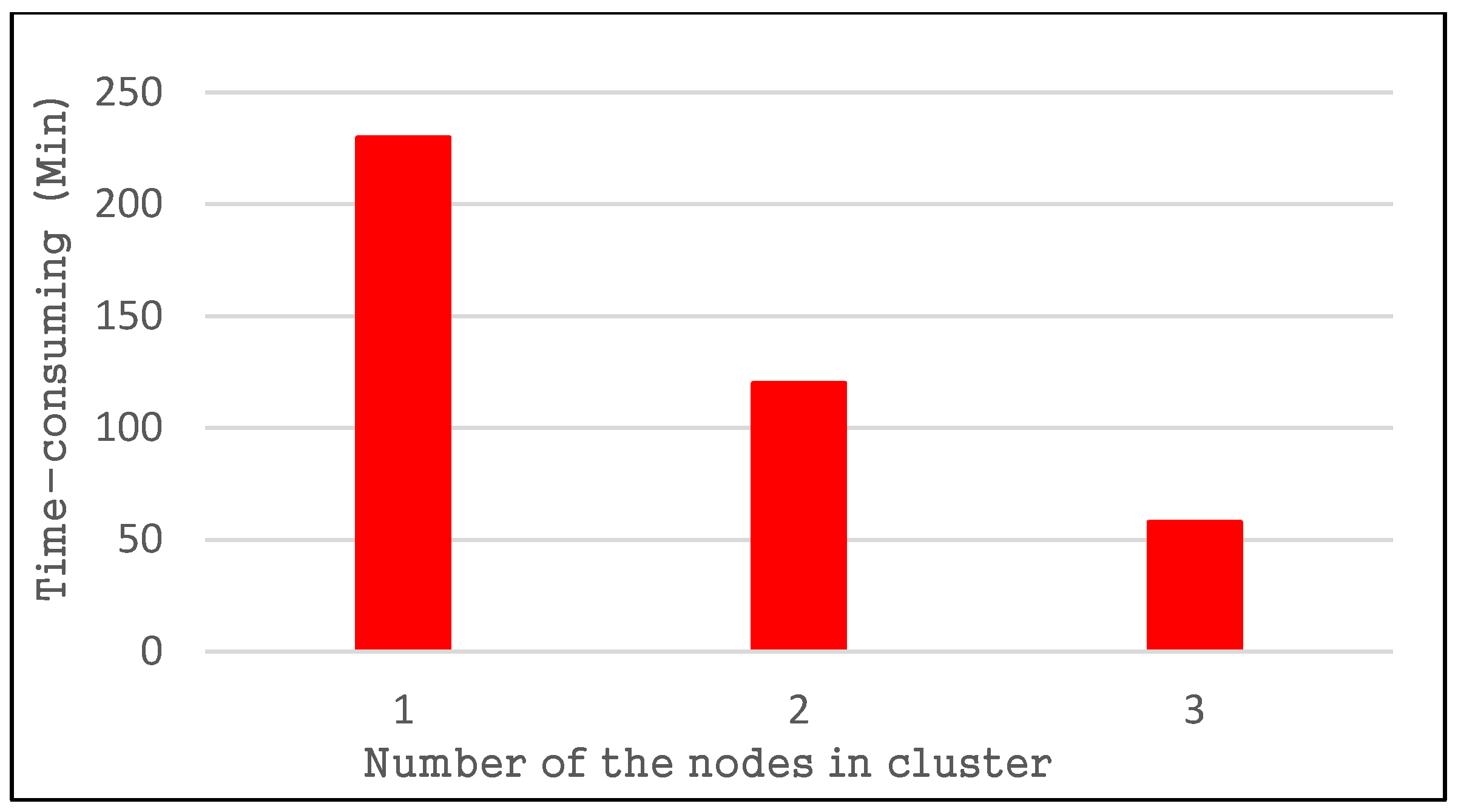
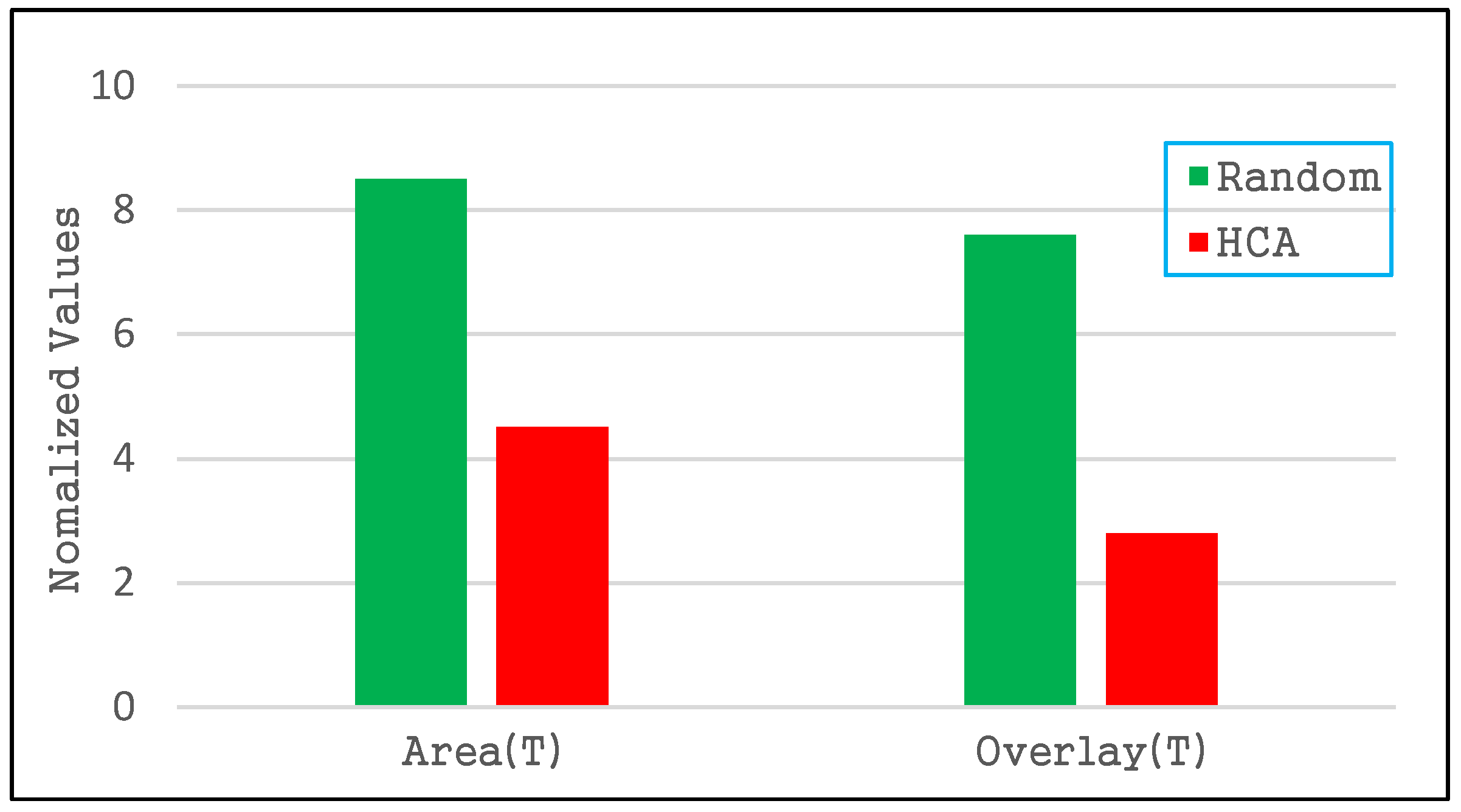
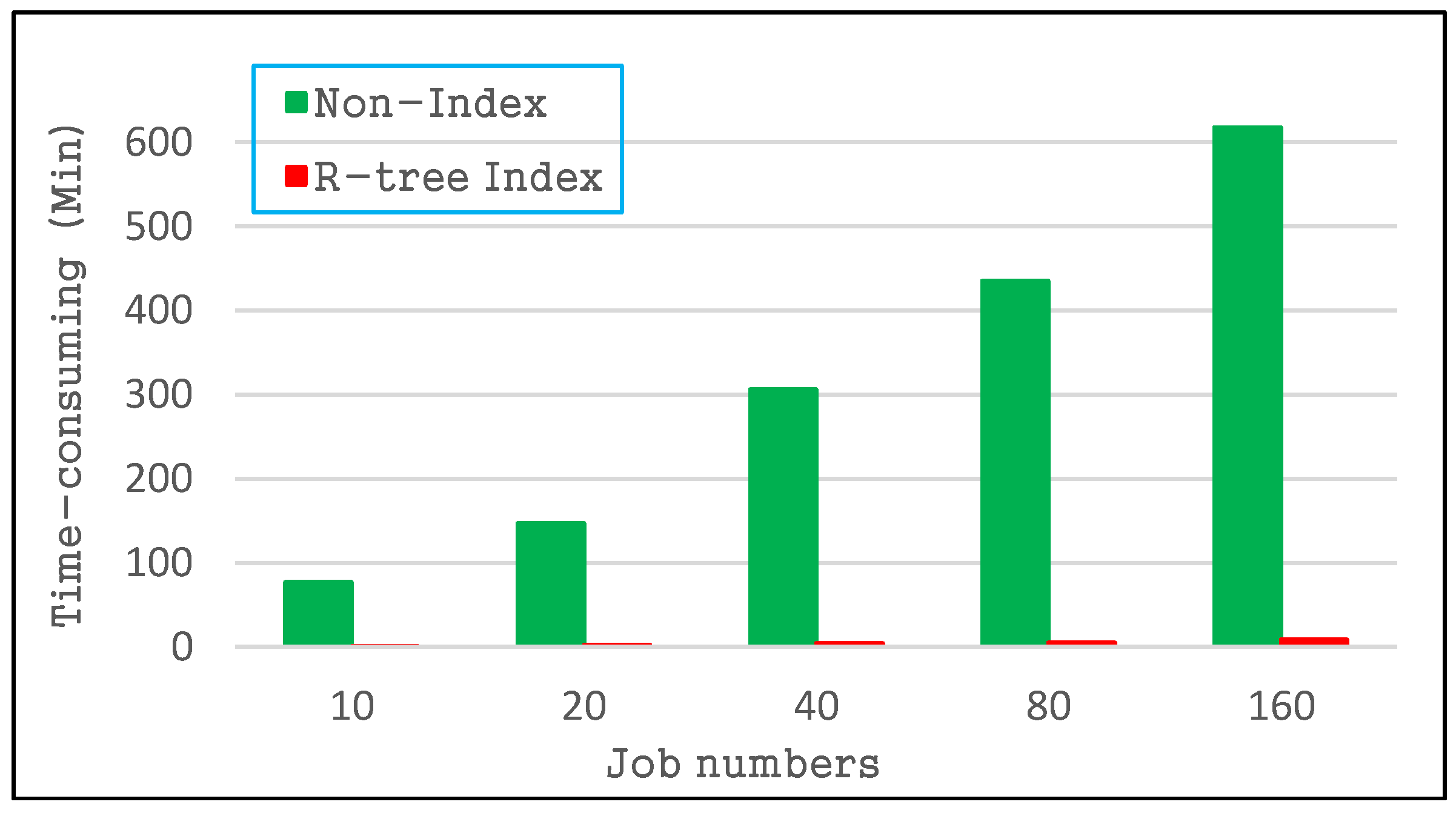
4.2.1. Index Quality of the R-Tree
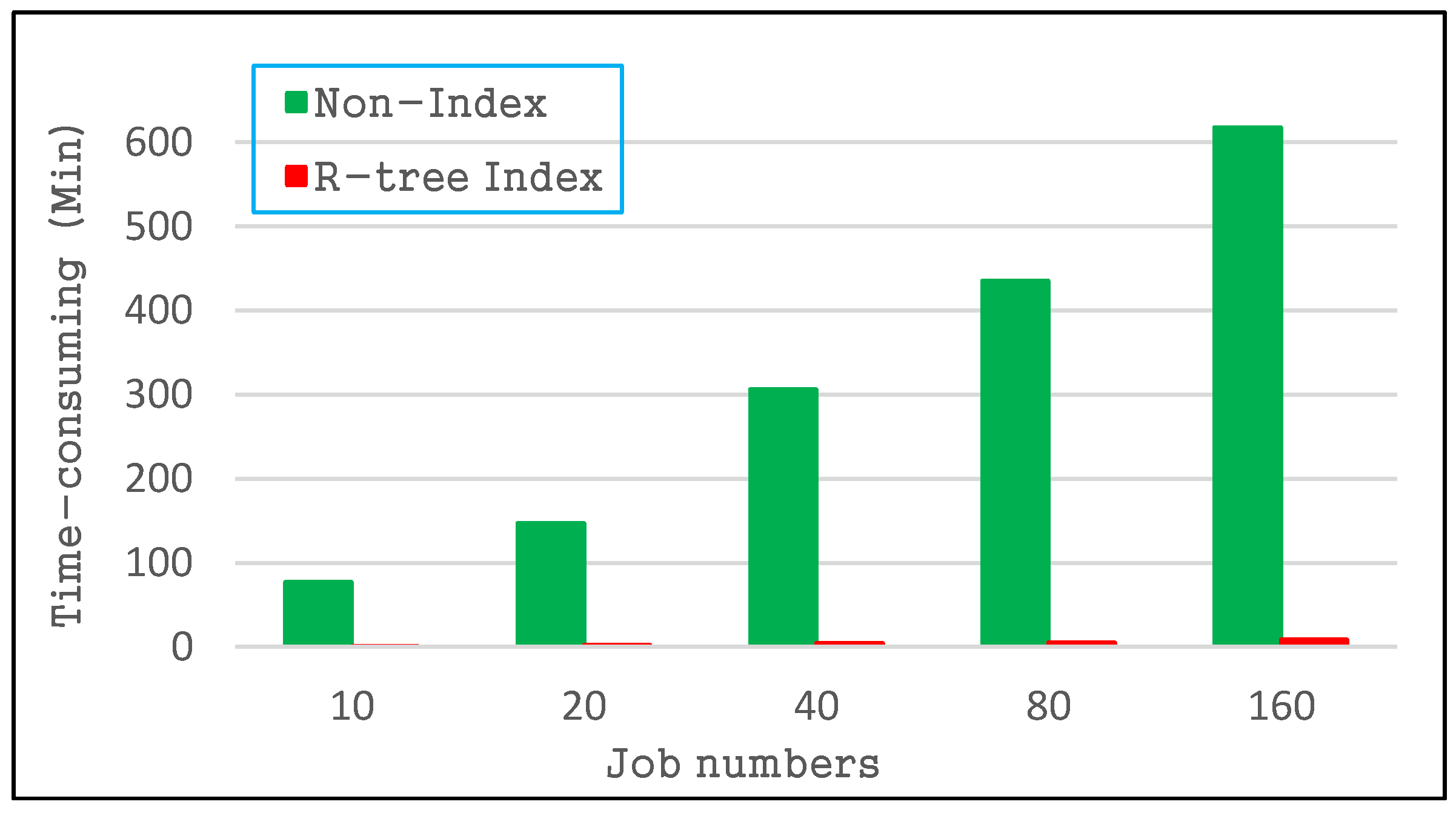
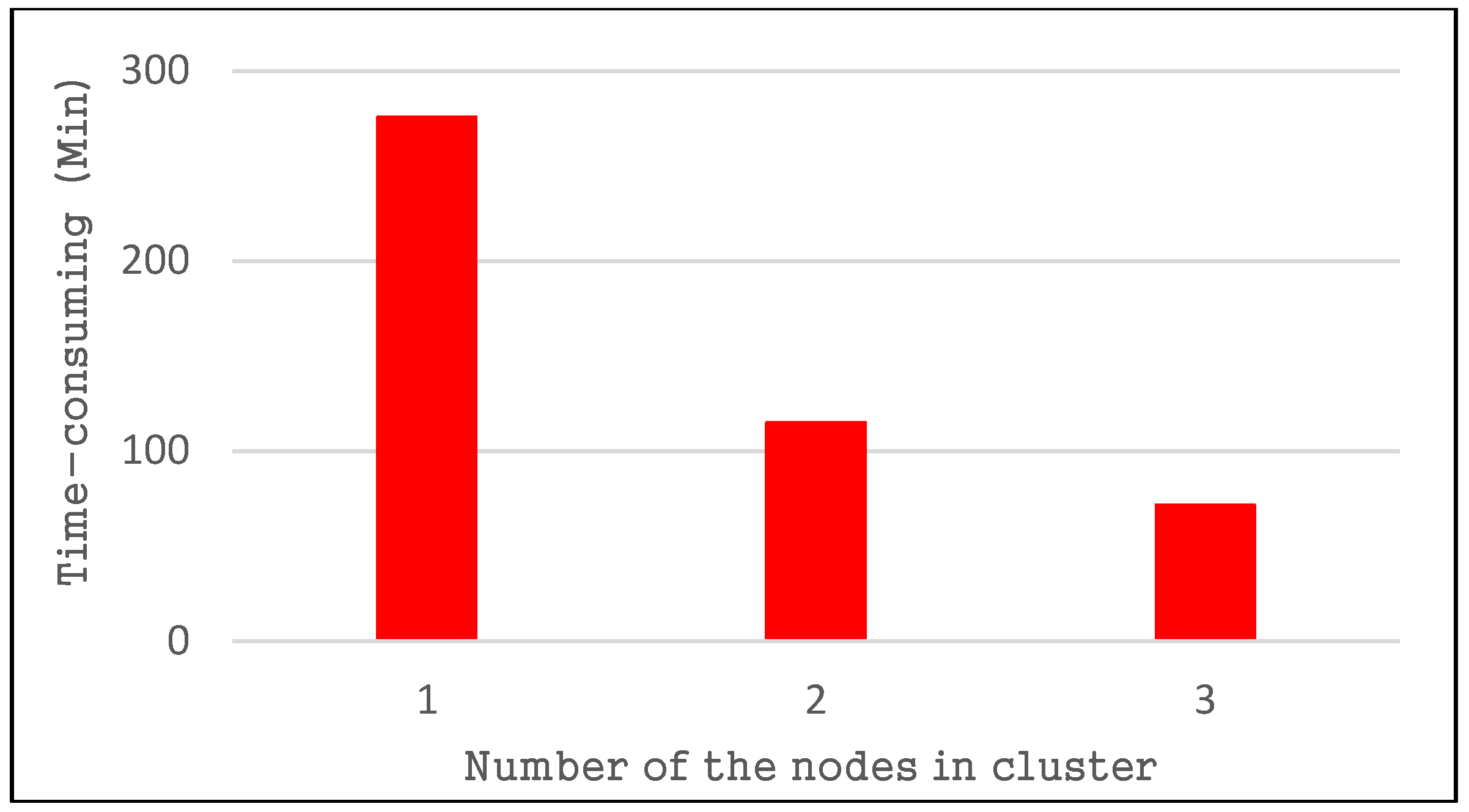
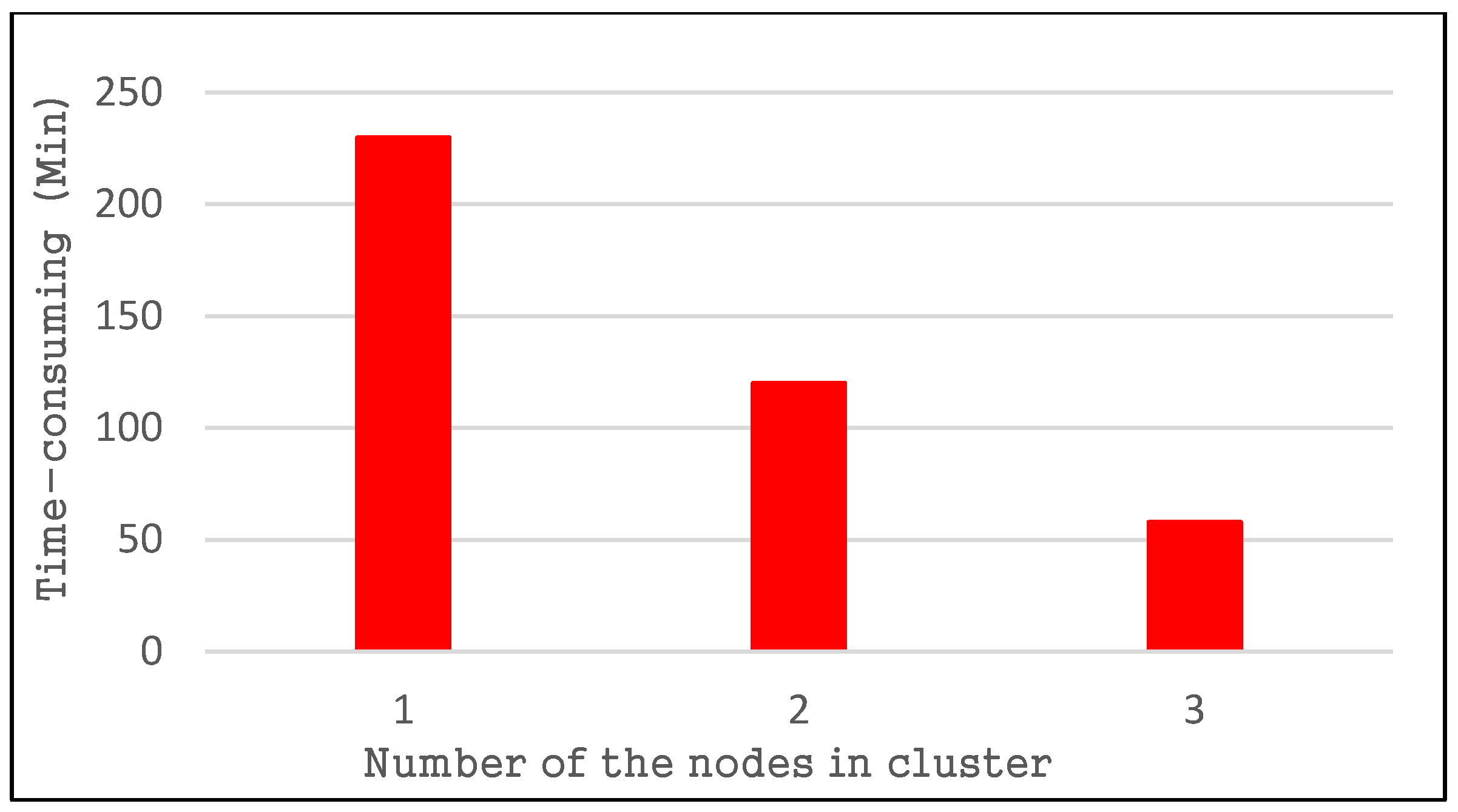
4.2.2. Spatial Query Performance
4.3. Visualization Performance
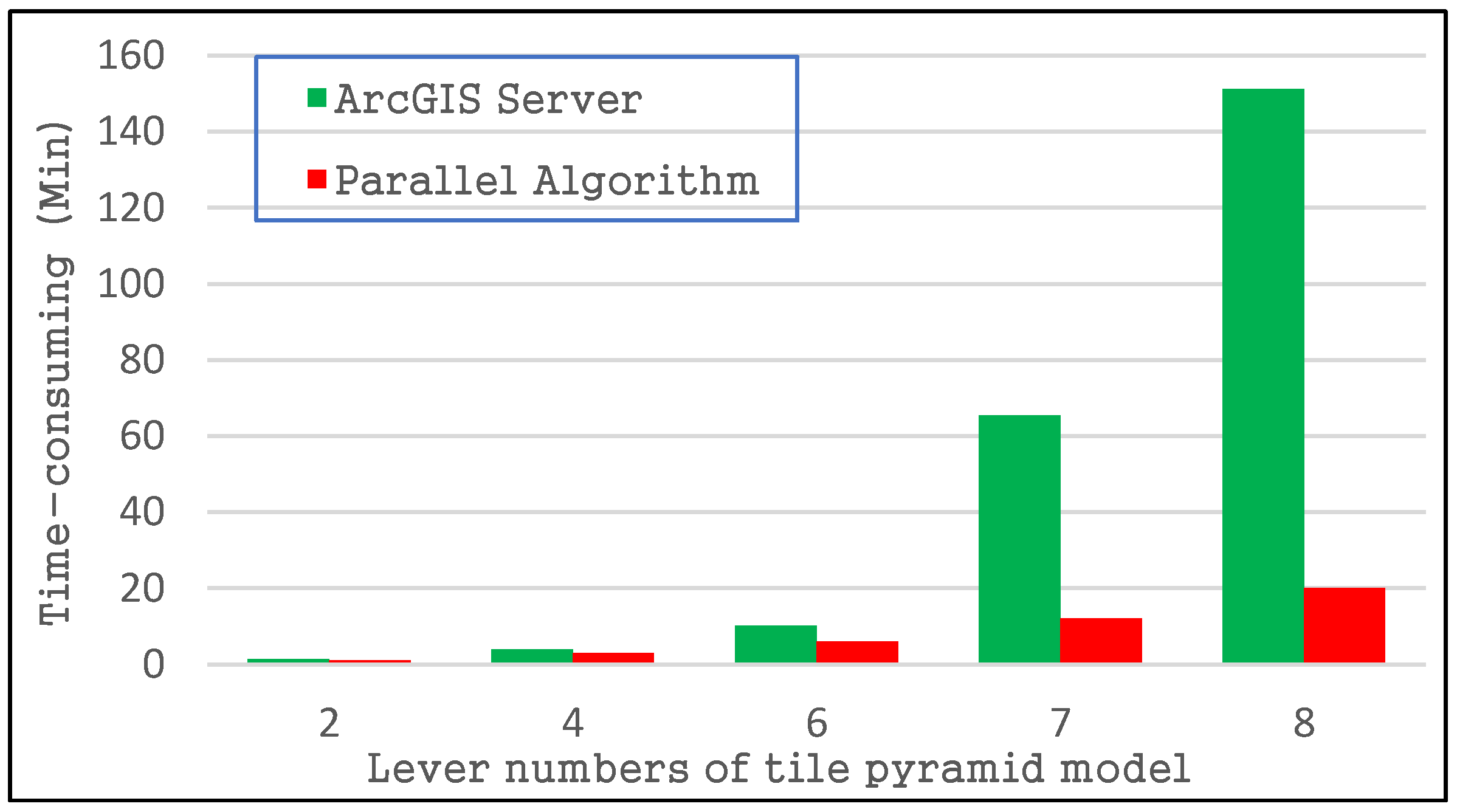
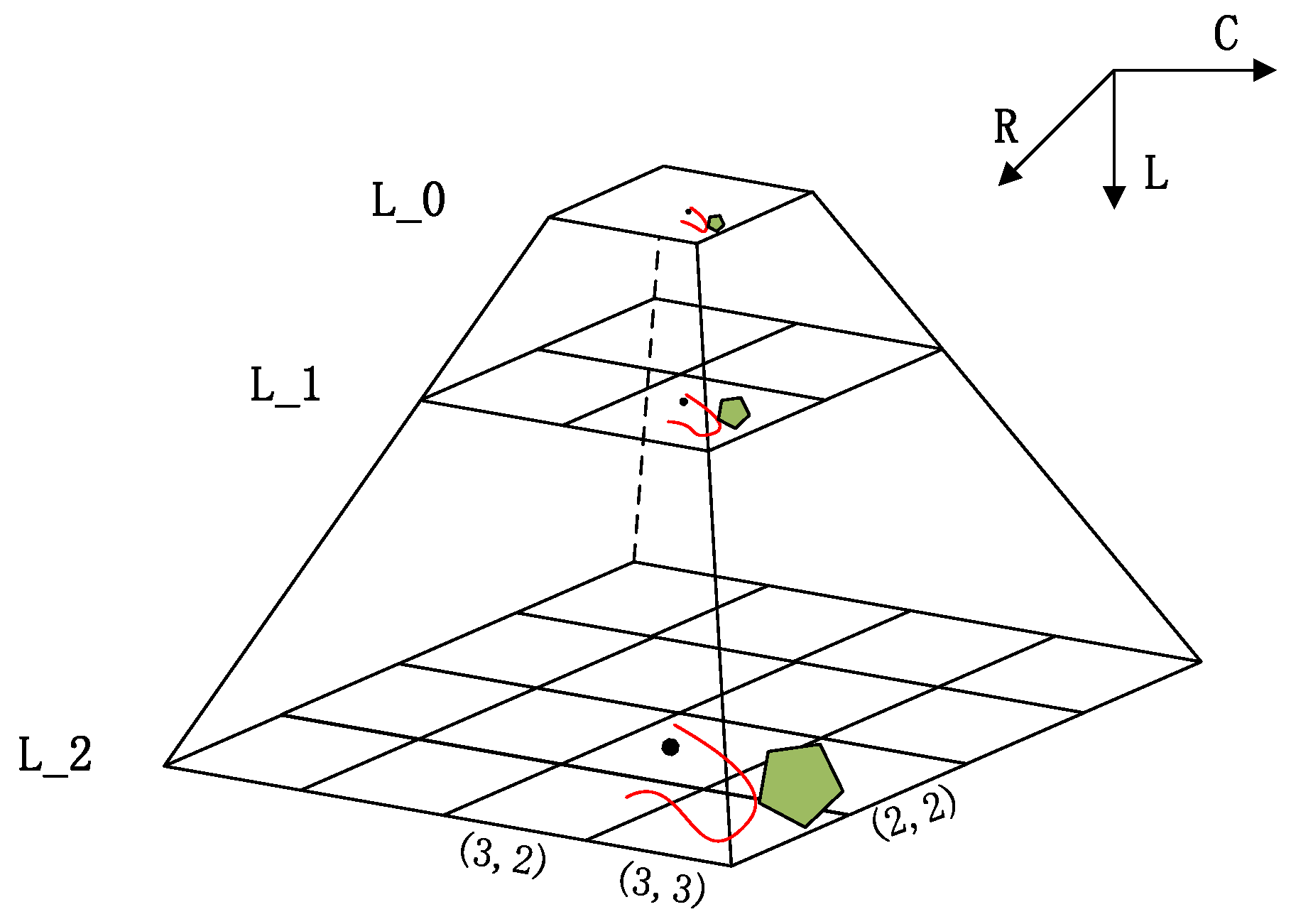
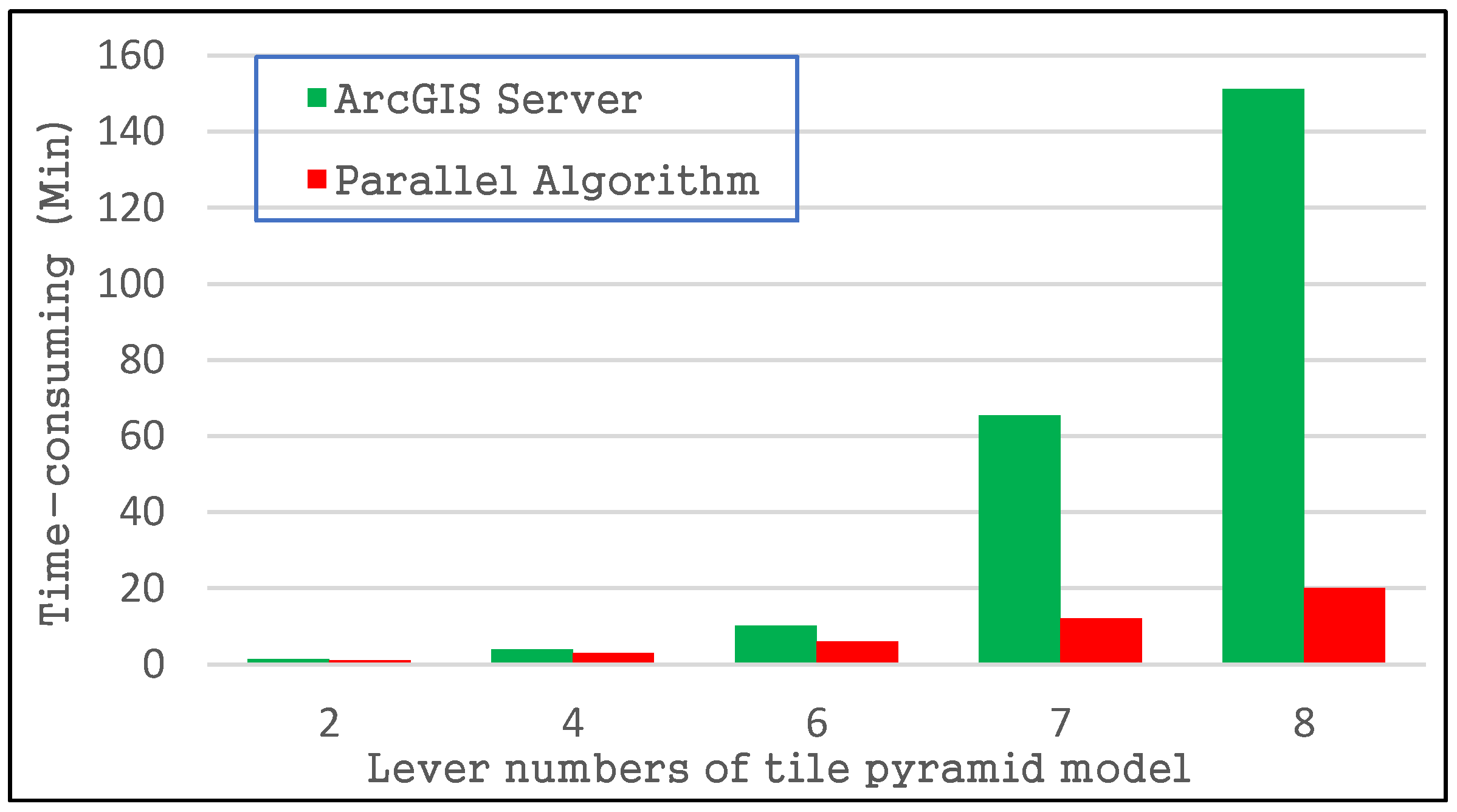
4.3.1. Tile Pyramid Construction Performance
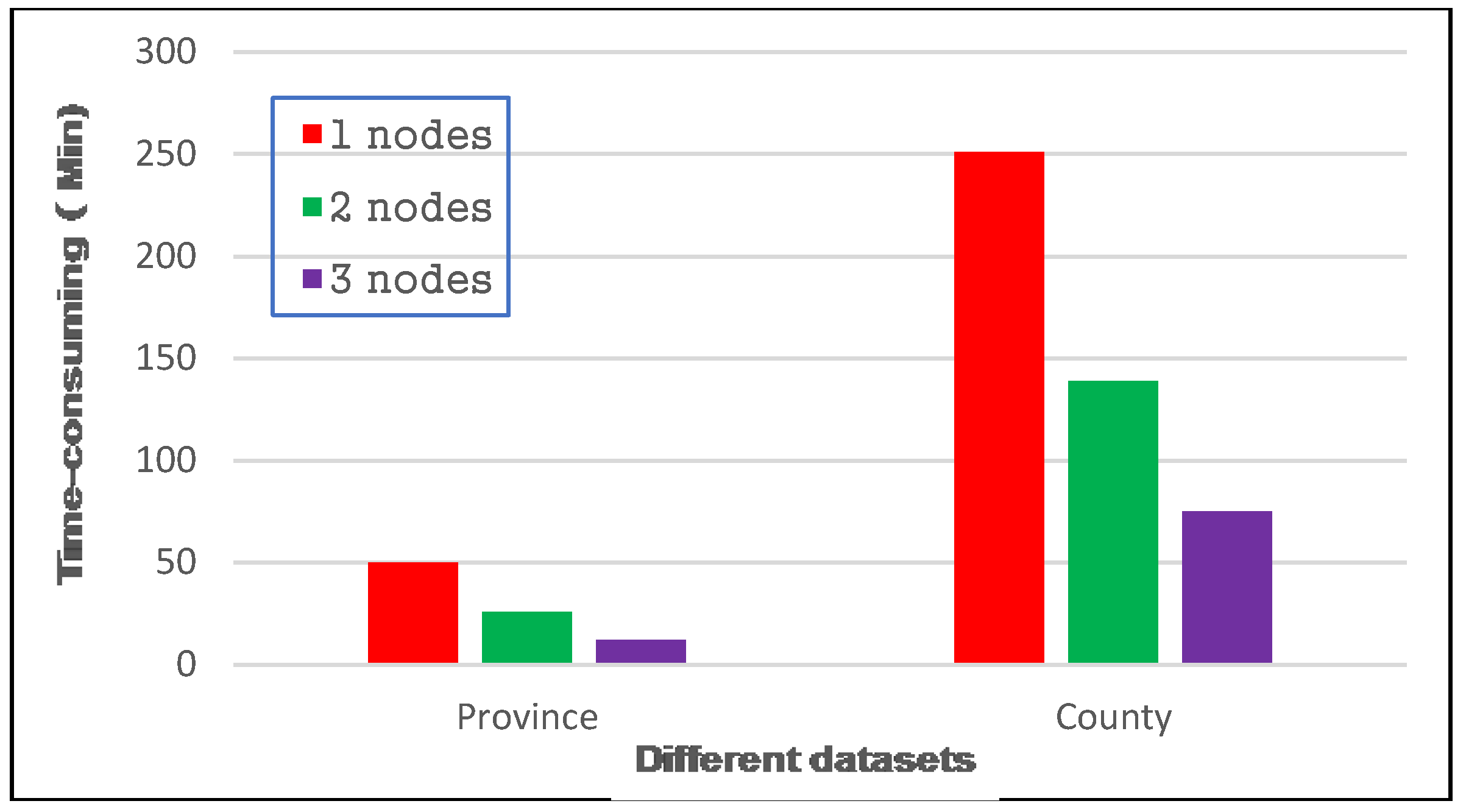
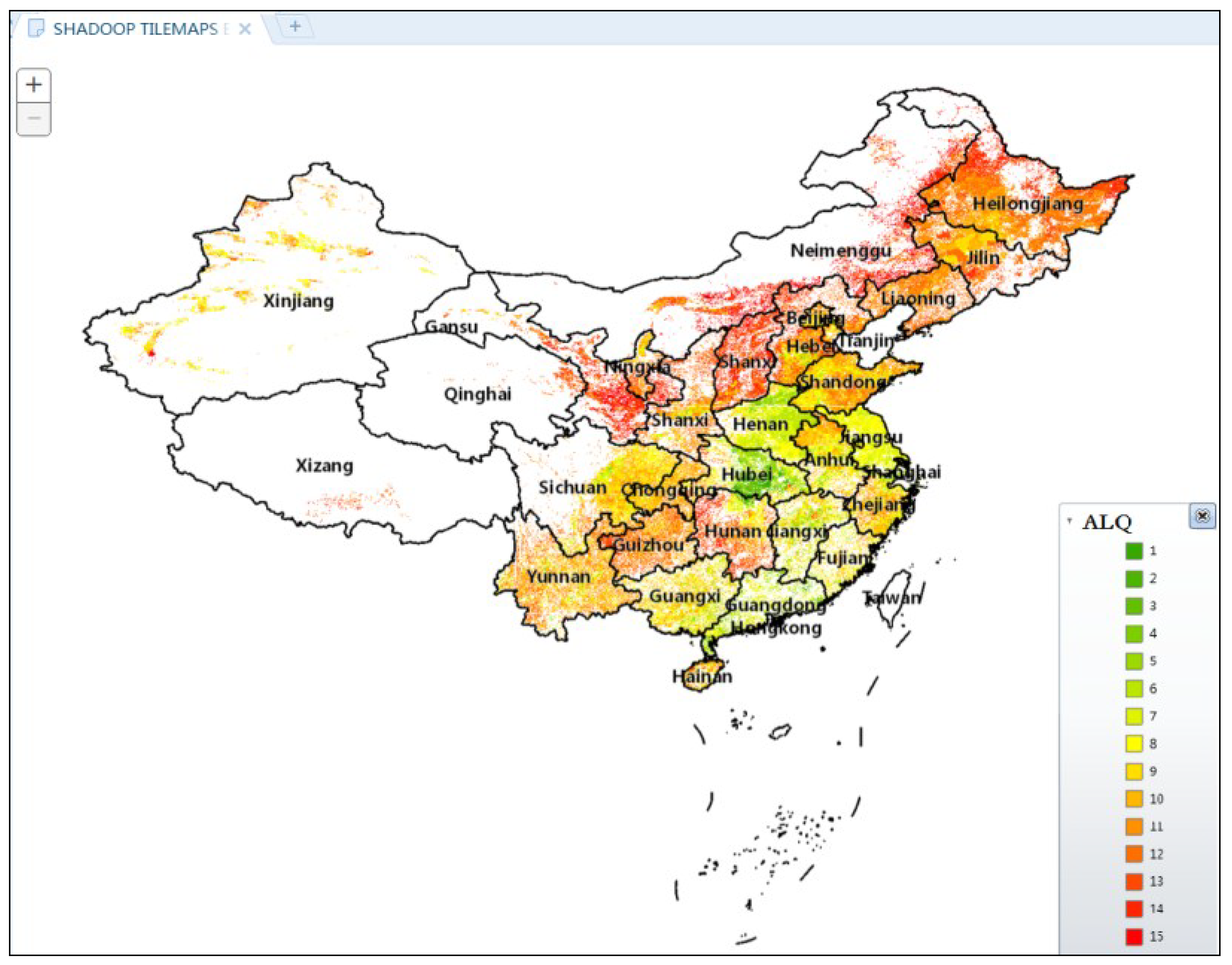
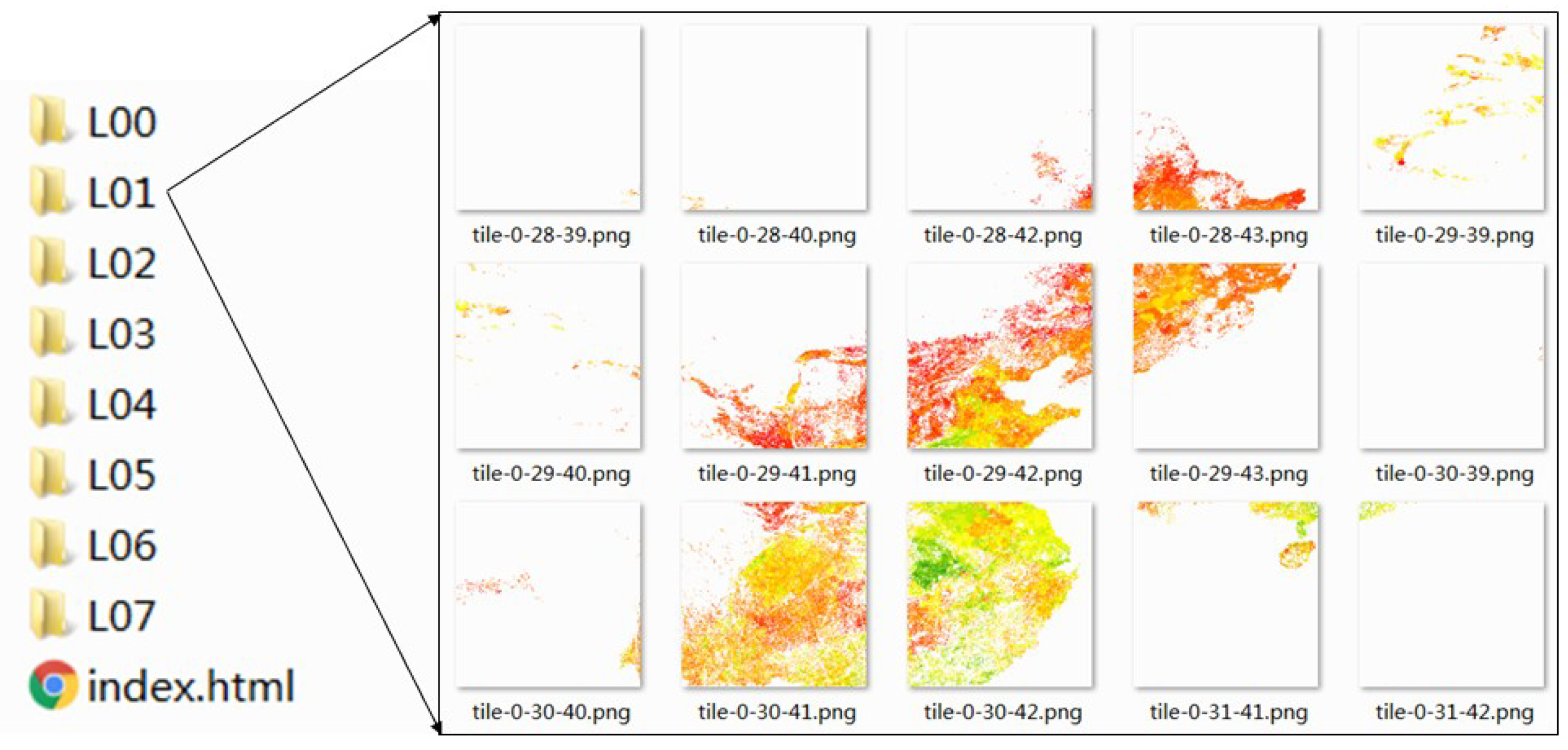
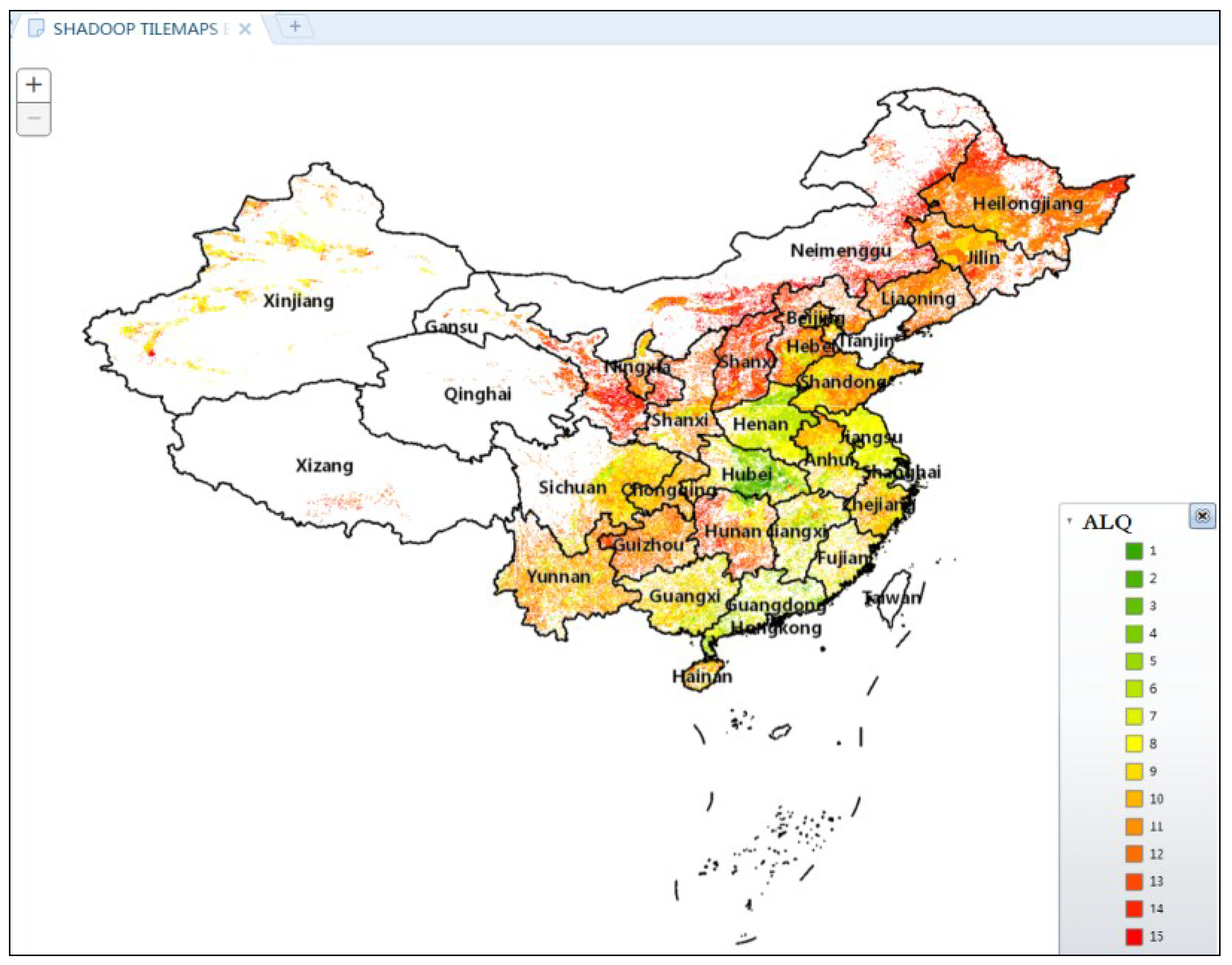
4.3.2. Visualization for Arable Land Quality Big Data
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Yao, X.; Zhu, D.; Ye, S.; Yun, W.; Zhang, N.; Li, L. A field survey system for land consolidation based on 3S and speech recognition technology. Comput. Electron. Agric. 2016, 127, 659–668. [Google Scholar] [CrossRef]
- Ye, S.; Zhu, D.; Yao, X.; Zhang, N.; Fang, S.; Li, L. Development of a highly flexible mobile GIS-based system for collecting arable land quality data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 4432–4441. [Google Scholar] [CrossRef]
- Yao, X.; Yang, J.; Li, L.; Yun, W.; Zhao, Z.; Ye, S.; Zhu, D. LandQv1: A GIS cluster-based management information system for arable land quality big data. In Proceedings of the 6th International Conference on Agro-Geoinformatics (Agro-Geoinformatics), Fairfax, VA, USA, 7–10 August 2017; pp. 1–6. [Google Scholar]
- Huang, Q.Y.; Yang, C.W.; Liu, K.; Xia, J.Z.; Xu, C.; Li, J.; Gui, Z.P.; Sun, M.; Li, Z.L. Evaluating open-source cloud computing solutions for geosciences. Comput. Geosci. 2013, 59, 41–52. [Google Scholar] [CrossRef]
- Li, Z.; Yang, C.; Liu, K.; Hu, F.; Jin, B. Automatic scaling Hadoop in the cloud for efficient process of big geospatial data. ISPRS Int. Geo-Inf. 2016, 5, 173. [Google Scholar] [CrossRef]
- Aji, A.; Sun, X.; Vo, H.; Liu, Q.; Lee, R.; Zhang, X.; Saltz, J.; Wang, F. Demonstration of Hadoop-GIS: A spatial data warehousing system over mapreduce. In Proceedings of the 21st ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Orlando, FL, USA, 5–8 November 2013; ACM: New York, NY, USA, 2013; pp. 528–531. [Google Scholar]
- Eldawy, A.; Mokbel, M.F. A demonstration of spatialhadoop: An efficient mapreduce framework for spatial data. Proc. VLDB Endow. 2013, 6, 1230–1233. [Google Scholar] [CrossRef]
- Hughes, J.N.; Annex, A.; Eichelberger, C.N.; Fox, A.; Hulbert, A.; Ronquest, M. Geomesa: A distributed architecture for spatio-temporal fusion. In Proceedings of the Geospatial Informatics, Fusion, and Motion Video Analytics V, Baltimore, MD, USA, 20–21 April 2015; p. 94730F. [Google Scholar]
- Yu, J.; Wu, J.; Sarwat, M. Geospark: A cluster computing framework for processing large-scale spatial data. In Proceedings of the 23rd ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 3–6 November 2015; ACM: New York, NY, USA, 2015; pp. 1–4. [Google Scholar]
- Alarabi, L. St-Hadoop: A mapreduce framework for big spatio-temporal data. In Proceedings of the ACM International Conference on Management of Data, Chicago, IL, USA, 14–19 May 2017; ACM: New York, NY, USA, 2017; pp. 40–42. [Google Scholar]
- Mueller, N.; Lewis, A.; Roberts, D.; Ring, S.; Melrose, R.; Sixsmith, J.; Lymburner, L.; McIntyre, A.; Tan, P.; Curnow, S.; et al. Water observations from space: Mapping surface water from 25 years of landsat imagery across Australia. Remote Sens. Environ. 2016, 174, 341–352. [Google Scholar] [CrossRef]
- Li, J.; Meng, L.; Wang, F.Z.; Zhang, W.; Cai, Y. A map-reduce-enabled solap cube for large-scale remotely sensed data aggregation. Comput. Geosci. 2014, 70, 110–119. [Google Scholar] [CrossRef]
- Zhong, Y.; Fang, J.; Zhao, X. Vegaindexer: A distributed composite index scheme for big spatio-temporal sensor data on cloud. In Proceedings of the 33rd IEEE International Geoscience and Remote Sensing Symposium, IGARSS, Melbourne, VIC, Australia, 21–26 July 2013; pp. 1713–1716. [Google Scholar]
- Magdy, A.; Mokbel, M.F.; Elnikety, S.; Nath, S.; He, Y. Venus: Scalable real-time spatial queries on microblogs with adaptive load shedding. IEEE Trans. Knowl. Data Eng. 2016, 28, 356–370. [Google Scholar] [CrossRef]
- Addair, T.G.; Dodge, D.A.; Walter, W.R.; Ruppert, S.D. Large-scale seismic signal analysis with Hadoop. Comput. Geosci. 2014, 66, 145–154. [Google Scholar] [CrossRef]
- Zou, Z.Q.; Wang, Y.; Cao, K.; Qu, T.S.; Wang, Z.M. Semantic overlay network for large-scale spatial information indexing. Comput. Geosci. 2013, 57, 208–217. [Google Scholar] [CrossRef]
- Jhummarwala, A.; Mazin, A.; Potdar, M.B. Geospatial Hadoop (GS-Hadoop) an efficient mapreduce based engine for distributed processing of shapefiles. In Proceedings of the the 2nd International Conference on Advances in Computing, Communication, & Automation, Bareilly, India, 30 September–1 October 2016; pp. 1–7. [Google Scholar]
- Yao, X.; Li, G. Big spatial vector data management: A review. Big Earth Data 2018, 2, 108–129. [Google Scholar] [CrossRef]
- OGC. Geographic Information-Well-Known Text Representation of Coordinate Reference Systems. Available online: http://docs.opengeospatial.org/is/12-063r5/12-063r5.html (accessed on 20 June 2018).
- Zhao, L.; Chen, L.; Ranjan, R.; Choo, K.-K.R.; He, J. Geographical information system parallelization for spatial big data processing: A review. Clust. Comput. 2015, 19, 139–152. [Google Scholar] [CrossRef]
- Singh, H.; Bawa, S. A mapreduce-based scalable discovery and indexing of structured big data. Future Gener. Comput. Syst. 2017, 73, 32–43. [Google Scholar] [CrossRef]
- Yao, X.; Mokbel, M.F.; Alarabi, L.; Eldawy, A.; Yang, J.; Yun, W.; Li, L.; Ye, S.; Zhu, D. Spatial coding-based approach for partitioning big spatial data in Hadoop. Comput. Geosci. 2017, 106, 60–67. [Google Scholar] [CrossRef]
- Hadjieleftheriou, M.; Manolopoulos, Y.; Theodoridis, Y.; Tsotras, V.J. R-trees—A dynamic index structure for spatial searching. In Encyclopedia of GIS; Shekhar, S., Xiong, H., Eds.; Springer: Boston, MA, USA, 2008; pp. 993–1002. [Google Scholar]
- Eldawy, A.; Alarabi, L.; Mokbel, M.F. Spatial partitioning techniques in spatialhadoop. Proc. VLDB Endow. 2015, 8, 1602–1605. [Google Scholar] [CrossRef]
- Zhang, J.; You, S. High-performance quadtree constructions on large-scale geospatial rasters using GPGPU parallel primitives. Int. J. Geogr. Inf. Sci. 2013, 27, 2207–2226. [Google Scholar] [CrossRef]
- Eldawy, A.; Mokbel, M.F.; Jonathan, C. Hadoopviz: A mapreduce framework for extensible visualization of big spatial data. In Proceedings of the 32nd IEEE International Conference on Data Engineering, Helsinki, Finland, 16–20 May 2016; pp. 601–612. [Google Scholar]
- Liu, Y.; Chen, L.; Jing, N.; Xiong, W. Parallel batch-building remote sensing images tile pyramid with mapreduce. Wuhan Daxue Xuebao (Xinxi Kexue Ban)/Geomat. Inf. Sci. Wuhan Univ. 2013, 38, 278–282. [Google Scholar]
- Lin, W.; Zhou, H.; Xia, P. An effective NOSQL-based vector map tile management approach. ISPRS Int. Geo-Inf. 2016, 5, 1–25. [Google Scholar]
- Lee, J.-G.; Kang, M. Geospatial big data: Challenges and opportunities. Big Data Res. 2015, 2, 74–81. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Test Environment | System Configuration |
|---|---|
| Stand-alone | Windows 10, 64 GB Memory, 600 GB Hard disk ArcGIS 10.2 |
| Ubuntu 15, 64 GB Memory, 600 GB Hard disk Hadoop 2.7 | |
| Cluster | Ubuntu 15, 24 GB Memory, 2 TB Hard disk Hadoop 2.7 |
| Size/GB | Shapefile Number | Feature Number |
|---|---|---|
| 2 | 86 | 1,361,127 |
| 4 | 257 | 2,512,413 |
| 8 | 304 | 5,218,028 |
| 16 | 680 | 11,077,580 |
| 32 | 1120 | 21,615,328 |
| 64 | 3008 | 43,847,424 |
| 128 | 5561 | 85,558,229 |
| Dataset | Size | Shapefile Count | Feature Count |
|---|---|---|---|
| Province | 3.4 GB | 31 | 359,227 |
| County | 154.5 GB | 2673 | 63,033,494 |
| Level | Scale (million) | Tile Number (County) | Size (County) | Tile Number (Province) | Size (Province) |
|---|---|---|---|---|---|
| 0 | 1:4000 | 6 | 35.1 KB | 6 | 36.4 KB |
| 1 | 1:2000 | 15 | 103 KB | 15 | 100 KB |
| 2 | 1:1000 | 44 | 331 KB | 44 | 504 KB |
| 3 | 1:500 | 124 | 1.06 MB | 123 | 837 KB |
| 4 | 1:250 | 390 | 3.71 MB | 380 | 2.41 MB |
| 5 | 1:125 | 1312 | 12.3 MB | 1265 | 6.6 MB |
| 6 | 1:62.5 | 4523 | 36.9 MB | 4311 | 16.6 MB |
| 7 | 1:31.25 | 15,138 | 111 MB | 15,183 | 40.1 MB |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, X.; Mokbel, M.F.; Ye, S.; Li, G.; Alarabi, L.; Eldawy, A.; Zhao, Z.; Zhao, L.; Zhu, D. LandQv2: A MapReduce-Based System for Processing Arable Land Quality Big Data. ISPRS Int. J. Geo-Inf. 2018, 7, 271. https://doi.org/10.3390/ijgi7070271
Yao X, Mokbel MF, Ye S, Li G, Alarabi L, Eldawy A, Zhao Z, Zhao L, Zhu D. LandQv2: A MapReduce-Based System for Processing Arable Land Quality Big Data. ISPRS International Journal of Geo-Information. 2018; 7(7):271. https://doi.org/10.3390/ijgi7070271
Chicago/Turabian StyleYao, Xiaochuang, Mohamed F. Mokbel, Sijing Ye, Guoqing Li, Louai Alarabi, Ahmed Eldawy, Zuliang Zhao, Long Zhao, and Dehai Zhu. 2018. "LandQv2: A MapReduce-Based System for Processing Arable Land Quality Big Data" ISPRS International Journal of Geo-Information 7, no. 7: 271. https://doi.org/10.3390/ijgi7070271
APA StyleYao, X., Mokbel, M. F., Ye, S., Li, G., Alarabi, L., Eldawy, A., Zhao, Z., Zhao, L., & Zhu, D. (2018). LandQv2: A MapReduce-Based System for Processing Arable Land Quality Big Data. ISPRS International Journal of Geo-Information, 7(7), 271. https://doi.org/10.3390/ijgi7070271