An Approach to Measuring Semantic Relatedness of Geographic Terminologies Using a Thesaurus and Lexical Database Sources


Abstract
:1. Introduction
2. Background
3. Thesaurus Lexical Relatedness Measure
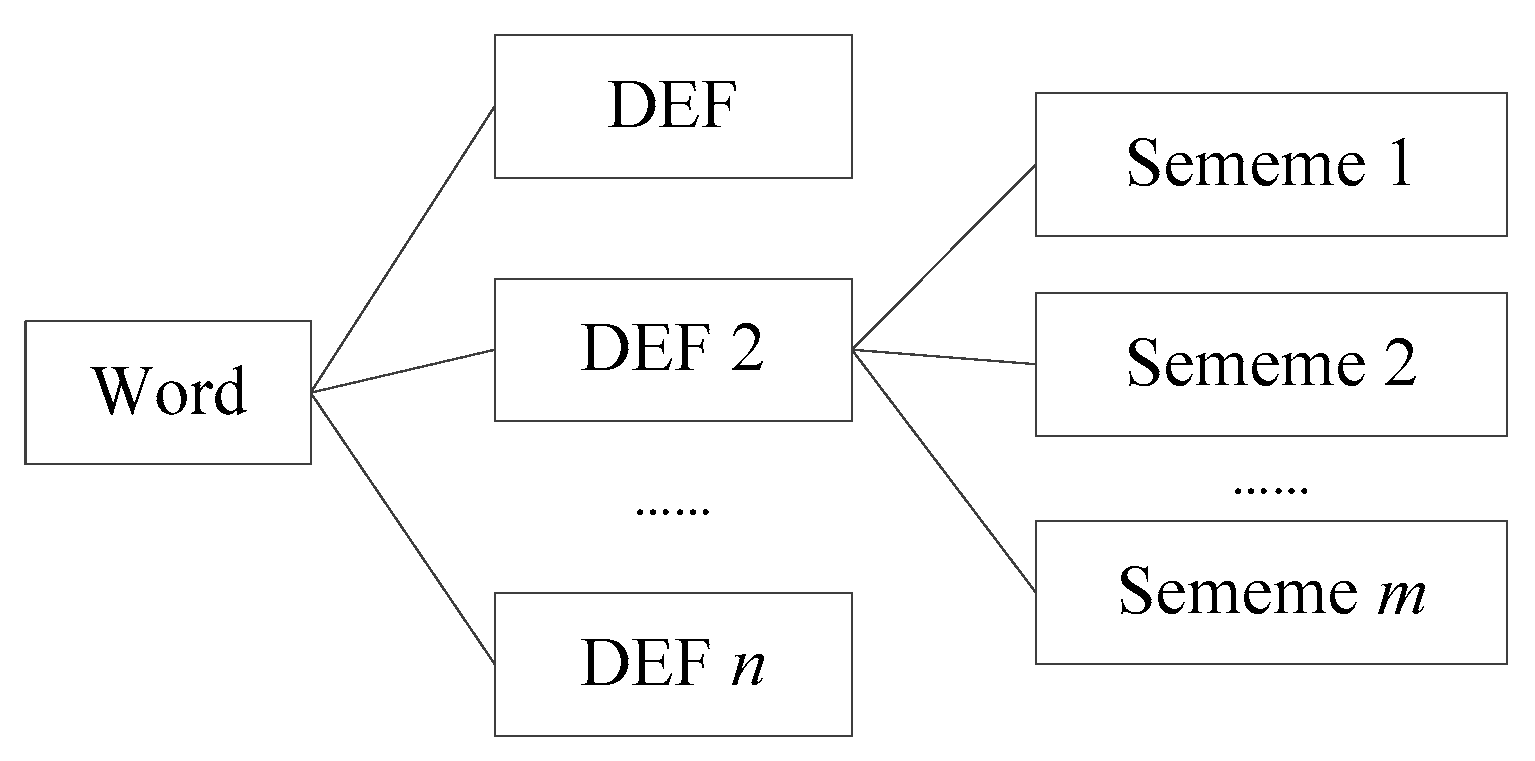
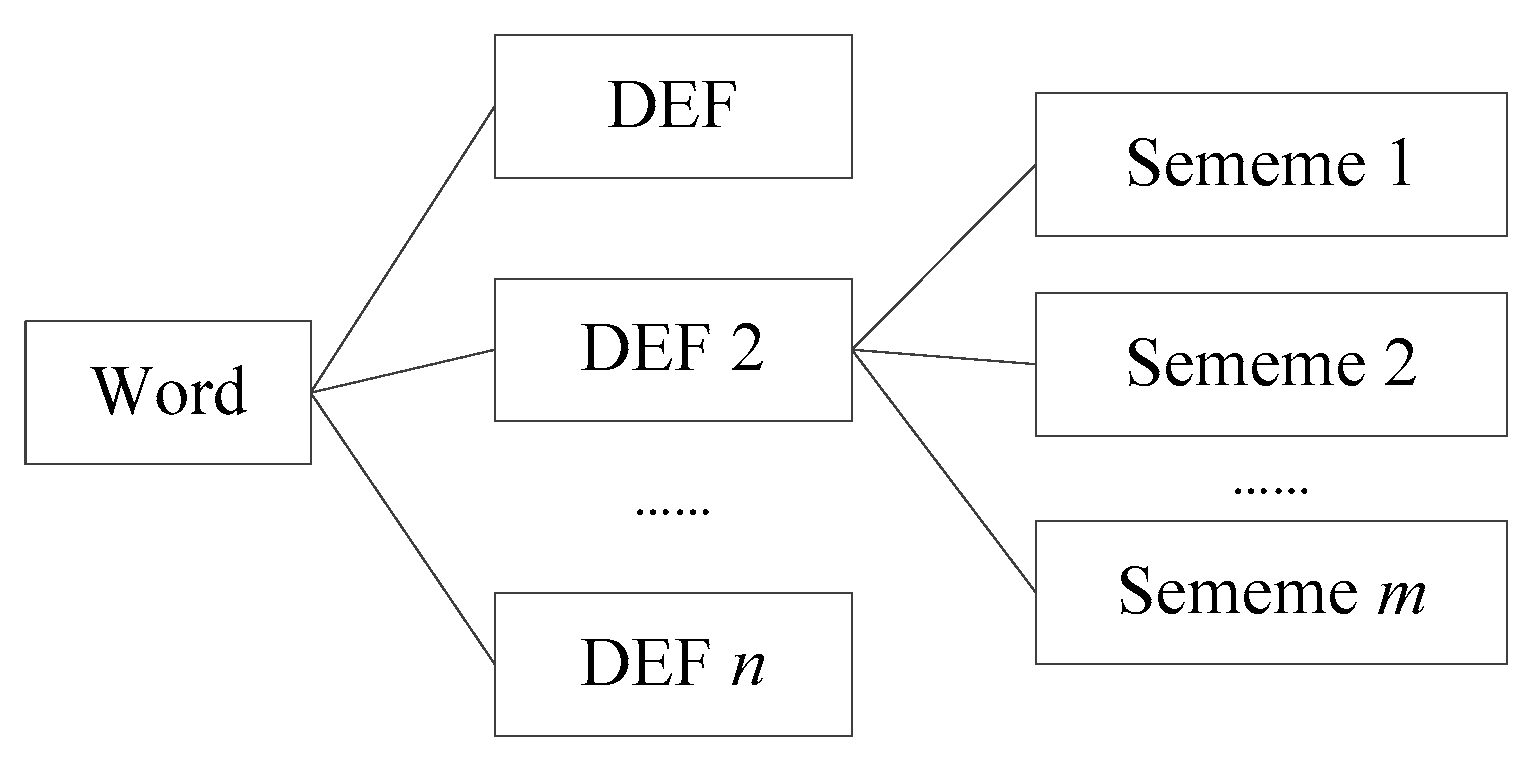
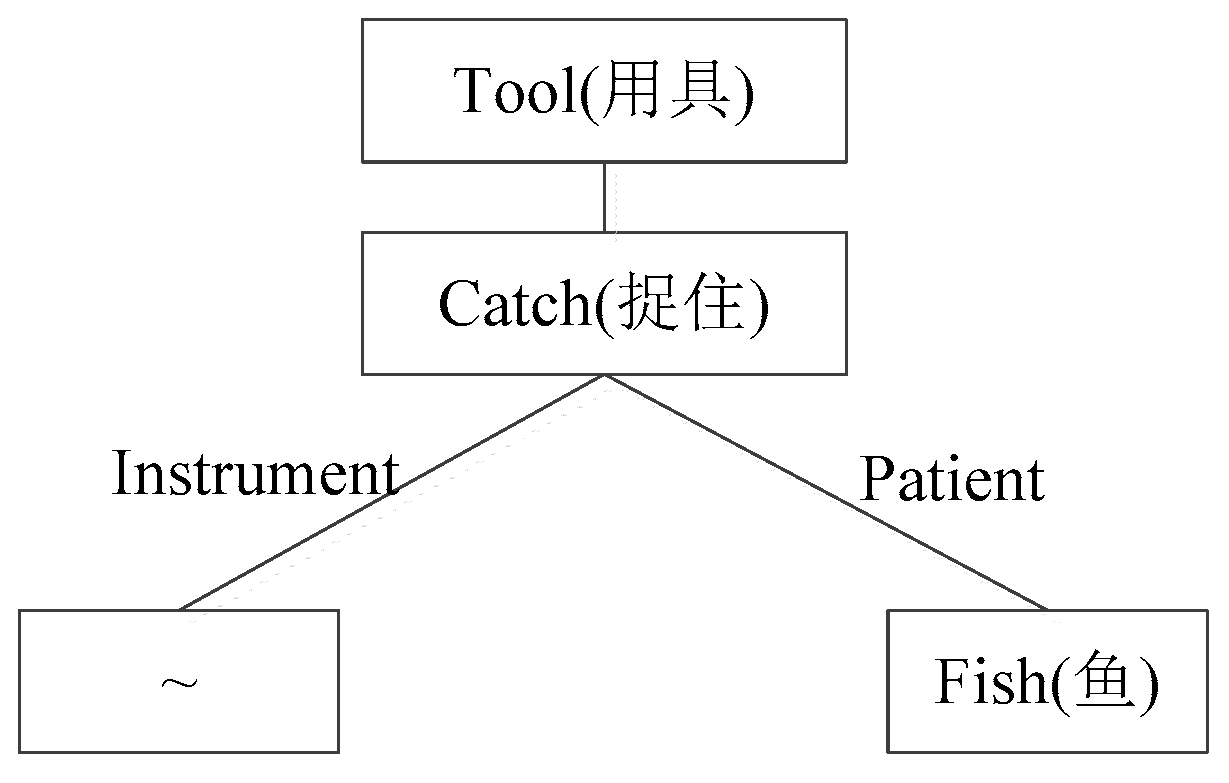
3.1. Related Definition
3.2. Algorithms
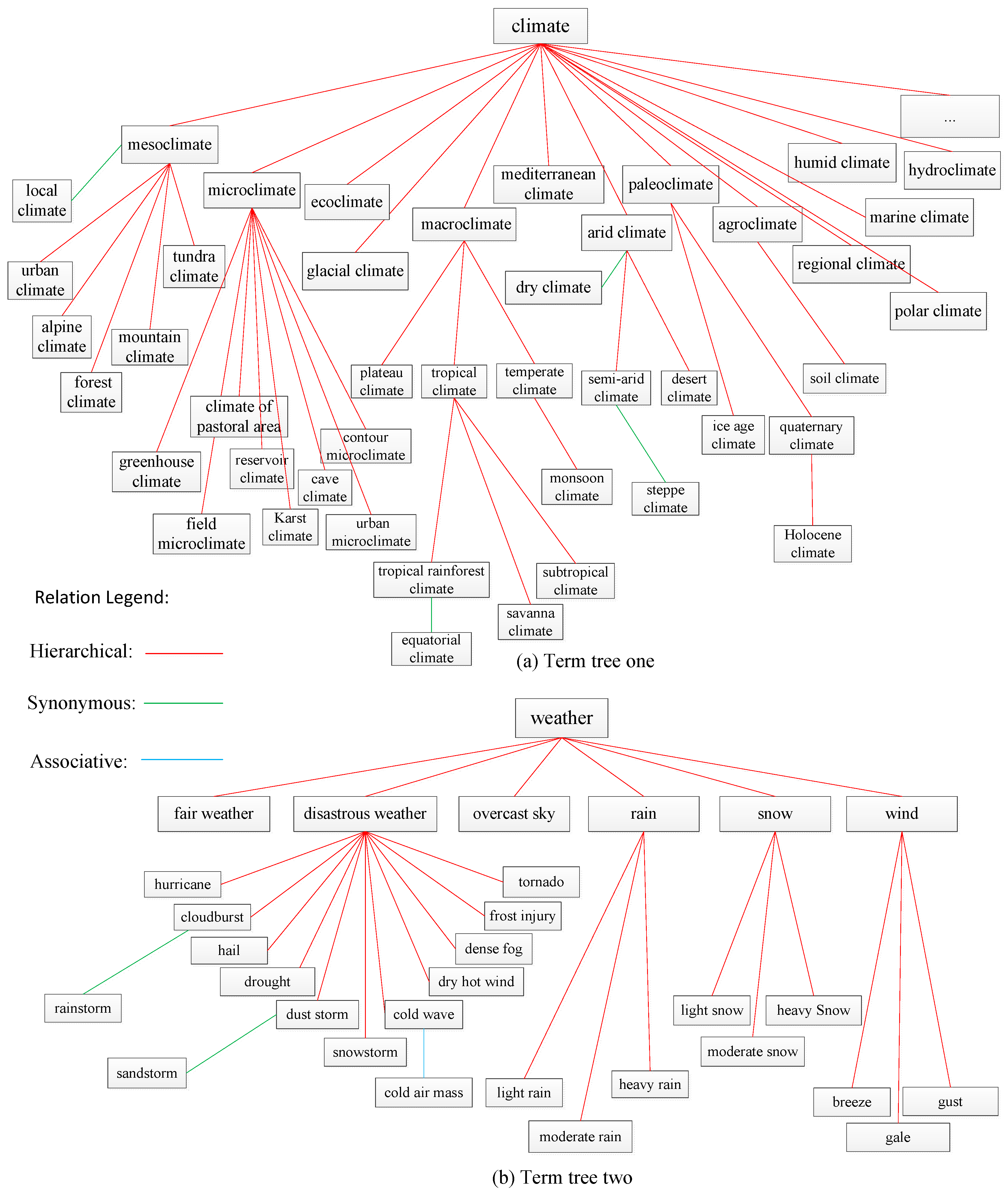
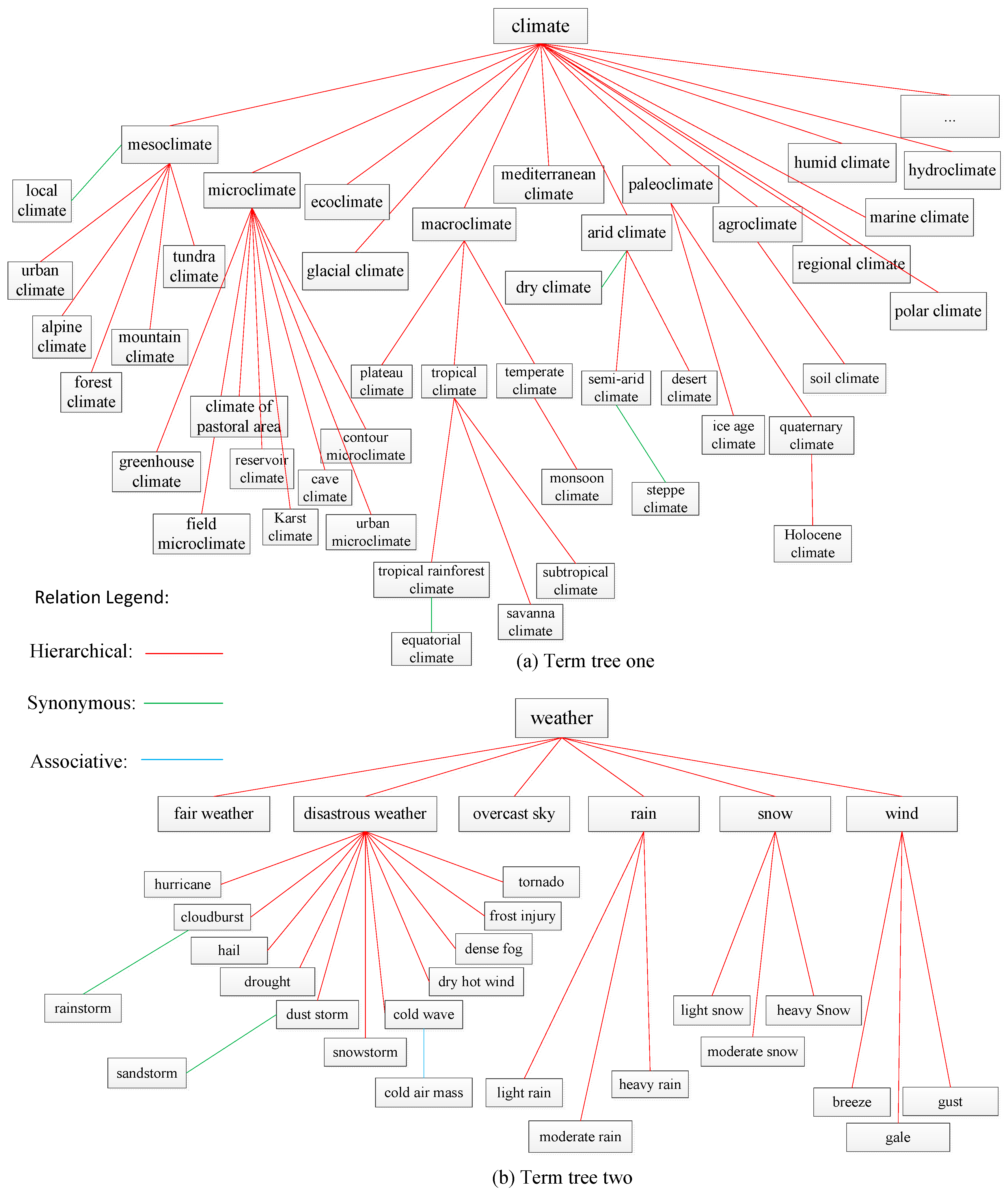
3.2.1. and Are in the Same Term Tree
3.2.2. and Are in Different Term Trees
4. Evaluation
4.1. Survey Design and Results
4.2. Determination of Parameters
5. Application of TLRM
6. Discussion
6.1. Findings of Simulating Functions for Relatedness Computing
6.2. Influence of Lexical Databases
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Rada, R.; Mili, H.; Bicknell, E.; Blettner, M. Development and application of a metric on semantic nets. IEEE Trans. Syst. Man Cybern. 1989, 19, 17–30. [Google Scholar] [CrossRef]
- Ballatore, A.; Bertolotto, M.; Wilson, D.C. An evaluative baseline for geo-semantic relatedness and similarity. Geoinformatica 2014, 18, 747–767. [Google Scholar] [CrossRef]
- Ballatore, A.; Wilson, D.C.; Bertolotto, M. Computing the semantic similarity of geographic terms using volunteered lexical definitions. Int. J. Geogr. Inf. Sci. 2013, 27, 2099–2118. [Google Scholar] [CrossRef]
- Rissland, E.L. Ai and similarity. IEEE Intell. Syst. 2006, 21, 39–49. [Google Scholar] [CrossRef]
- Harispe, S.; Ranwez, S.; Janaqi, S.; Montmain, J. Semantic Similarity from Natural Language and Ontology Analysis; Morgan & Claypool: Nımes, France, 2015; pp. 2–7. [Google Scholar]
- Li, Y.; Bandar, Z.A.; McLean, D. An approach for measuring semantic similarity between words using multiple information sources. IEEE Trans. Knowl. Data Eng. 2003, 15, 871–881. [Google Scholar]
- Rodríguez, M.A.; Egenhofer, M.J. Comparing geospatial entity classes: An asymmetric and context-dependent similarity measure. Int. J. Geogr. Inf. Sci. 2004, 18, 229–256. [Google Scholar] [CrossRef]
- Purves, R.S.; Jones, C.B. Geographic Information Retrieva; Sigspatial Special: New York, NY, USA, 2011; pp. 2–4. [Google Scholar]
- Zhu, Y.; Zhu, A.-X.; Song, J.; Zhao, H. Multidimensional and quantitative interlinking approach for linked geospatial data. Int. J. Digit. Earth 2017, 10, 1–21. [Google Scholar] [CrossRef]
- Ballatore, A.; Bertolotto, M.; Wilson, D.C. A structural-lexical measure of semantic similarity for geo-knowledge graphs. ISPRS Int. J. Geo-Inf. 2015, 4, 471–492. [Google Scholar] [CrossRef]
- Krzysztof, J.; Keßler, C.; Mirco, S.; Marc, W.; Ilija, P.; Martin, E.; Boris, B. Algorithm, implementation and application of the sim-dl similarity server. In Proceedings of the International Conference on Geospatial Semantics, Mexico City, Mexico, 29–30 November 2007; Volume 4853, pp. 128–145. [Google Scholar]
- International Organization for Standardization (ISO). Information and Documentation-Thesauri and Interoperability with Other Vocabularies—Part 1: Thesauri for Information Retrieval (International Standard No. ISO 25964-1); ISO-25964-1; International Organization for Standardization: Geneva, Switzerland, 2011. [Google Scholar]
- Kless, D.; Milton, S.K.; Kazmierczak, E.; Lindenthal, J. Thesaurus and ontology structure: Formal and pragmatic differences and similarities. J. Assoc. Inf. Sci. Technol. 2014, 66, 1348–1366. [Google Scholar] [CrossRef]
- Kless, D.; Milton, S.K.; Kazmierczak, E. Relationships and relata in ontologies and thesauri: Differences and similarities. Appl. Ontol. 2012, 7, 401–428. [Google Scholar]
- Riekert, W.-F. Automated retrieval of information in the internet by using thesauri and gazetteers as knowledge sources. J. Univ. Comput. Sci. 2002, 8, 581–590. [Google Scholar]
- Guo, Y.; An, F.T.; Liu, Z.T.; Sun, Y.H.; Yang, Y.F.; Cai, G.B.; Ding, H.Y.; Wen, C.S.; Zhang, Y.H.; Zhang, Y.B.; et al. Thesaurus for Geographic Sciences; Science Press: Beijing, China, 1995; pp. 1–615. [Google Scholar]
- Miller, G.A. Wordnet: A lexical database for english. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- About Wordnet. Available online: http://wordnet.princeton.edu (accessed on 20 December 2017).
- Resnik, P. Using information content to evaluate semantic similarity in a taxonomy. In Proceedings of the 14th International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 20–25 August 1995; pp. 448–453. [Google Scholar]
- Jiang, J.J.; Conrath, D.W. Semantic similarity based on corpus statistics and lexical taxonomy. In Proceedings of the International Conference Research on Computational Linguistics, Taipei, Taiwan, 22–24 August 1997. [Google Scholar]
- Lin, D. An information-theoretic definition of similarity. In Proceedings of the Fifteenth International Conference on Machine Learning, San Francisco, CA, USA, 24–27 July 1998; pp. 296–304. [Google Scholar]
- Leacock, C.; Chodorow, M. Combining local context and wordnet similarity for word sense identification. In WordNet: An Electronic Lexical Database; MIT Press: Cambridge, MA, USA, 1998; pp. 265–283. [Google Scholar]
- Wu, Z.; Palmer, M.S. Verbs semantics and lexical selection. In Proceedings of the 32nd Annual Meeting on Association for Computational Linguistics, Las Cruces, NM, USA, 27–30 June 1994; pp. 133–138. [Google Scholar]
- Patwardhan, S.; Pedersen, T. Using wordnet-based context vectors to estimate the semantic relatedness of concepts. In Proceedings of the Eacl Workshop on Making Sense of Sense: Bringing Computational Linguistics and Psycholinguistics Together, Trento, Italy, 3–7 April 2006. [Google Scholar]
- Ballatore, A.; Bertolotto, M.; Wilson, D.C. The semantic similarity ensemble. J. Spat. Inf. Sci. 2013, 27–44. [Google Scholar] [CrossRef]
- Hownet Knowledge Database. Available online: http://www.keenage.com/ (accessed on 10 December 2017).
- Li, H.; Zhou, C.; Jiang, M.; Cai, K. A hybrid approach for chinese word similarity computing based on hownet. In Proceedings of the Automatic Control and Artificial Intelligence, Xiamen, China, 3–5 March 2012; pp. 80–83. [Google Scholar]
- Liu, Q.; Li, S. Word similarity computing based on hownet. Comput. Linguist. Chin. Lang. Process. 2002, 7, 59–76. [Google Scholar]
- Introduction to HowNet. Available online: http://www.keenage.com/zhiwang/e_zhiwang.html (accessed on 25 December 2017).
- Landauer, T.K.; McNamara, D.S.; Deniss, S.; Kintsch, W. Handbook of Latent Semantic Analysis; Lawrence Erlbaum Associates: Mahwah, NJ, USA, 2007. [Google Scholar]
- Turney, P.D. Mining the web for synonyms: Pmi-ir versus lsa on toefl. In Proceedings of the 12th European Conference on Machine Learning, Freiburg, Germany, 5–7 September 2001; pp. 491–502. [Google Scholar]
- Mihalcea, R.; Corley, C.; Strapparava, C. Corpus-based and knowledge-based measures of text semantic similarity. In Proceedings of the 21st National Conference on Artificial Intelligence, Boston, MA, USA, 16–20 July 2006; pp. 775–780. [Google Scholar]
- Qiu, H.; Yu, W. Conceptual similarity measurement of term based on domain thesaurus. In Proceedings of the Seventh International Conference on Machine Learning and Cybernetics, Kunming, China, 12–15 July 2008; pp. 2519–2523. [Google Scholar]
- McMath, C.F.; Tamaru, R.S.; Rada, R. A graphical thesaurus-based information retrieval system. Int. J. Man-Mach. Stud. 1989, 31, 121–147. [Google Scholar] [CrossRef]
- Rada, R.; Barlow, J.; Potharst, J.; Zanstra, P.; Bijstra, D. Document ranking using an enriched thesaurus. J. Doc. 1991, 47, 240–253. [Google Scholar] [CrossRef]
- Golitsyna, O.L.; Maksimov, N.V.; Fedorova, V.A. On determining semantic similarity based on relationships of a combined thesaurus. Autom. Doc. Math. Linguist. 2016, 50, 139–153. [Google Scholar] [CrossRef]
- Qichen, H.; Dongmei, L. Semantic model with thesaurus for forestry information retrieval. J. Front. Comput. Sci. China 2016, 10, 122–129. [Google Scholar]
- Cerba, O.; Jedlicka, K. Linked forests: Semantic similarity of geographical concepts “forest”. Open Geosci. 2016, 8, 556–566. [Google Scholar]
- Tversky, A. Features of similarity. Psychol. Rev. 1977, 84, 327–352. [Google Scholar] [CrossRef]
- Schwering, A.; Martin, R. Spatial relations for semantic similarity measurement. In Proceedings of the International Conference on Perspectives in Conceptual Modeling, Klagenfurt, Austria, 24–28 October 2005; pp. 259–269. [Google Scholar]
- Cruz, I.F.; Sunna, W. Structural alignment methods with applications to geospatial ontologies. Trans. GIS 2008, 12, 683–711. [Google Scholar] [CrossRef]
- Ballatore, A.; Bertolotto, M.; Wilson, D.C. Geographic knowledge extraction and semantic similarity in openstreetmap. Knowl. Inf. Syst. 2013, 37, 61–81. [Google Scholar] [CrossRef]
- Ballatore, A.; Wilson, D.C.; Bertolotto, M. A holistic semantic similarity measure for viewports in interactive maps. In Proceedings of the Web andWireless Geographical Information Systems 11th International Symposium, Naples, Italy, 12–13 April 2012; pp. 151–166. [Google Scholar]
- Index Term. Available online: https://en.wikipedia.org/wiki/Index_term (accessed on 25 December 2017).
- Shepard, R.N. Toward a universal law of generalization for psychological science. Science 1987, 237, 1317–1323. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.-Z.; Bao, H. Concept vector for similarity measurement based on hierarchical domain structure. Comput. Inform. 2011, 30, 881–900. [Google Scholar]
- Corley, C.; Mihalcea, R. Measuring the semantic similarity of texts. In Proceedings of the ACL Workshop on Empirical Modeling of Semantic Equivalence and Entailment, Ann Arbor, MI, USA, 30 June 2005; pp. 13–18. [Google Scholar]
- Miller, G.A.; Charles, W.G. Contextual correlates of semantic similarity. Lang. Cogn. Neurosci. 1991, 6, 1–28. [Google Scholar] [CrossRef]
- Rubenstein, H.; Goodenough, J. Contextual correlates of synonymy. Commun. ACM 1965, 8, 627–633. [Google Scholar] [CrossRef]
- Finkelstein, L.; Gabrilovich, E.; Matias, Y.; Rivlin, E.; Solan, Z.; Wolfman, G.; Ruppin, E. Placing search in context: The concept revisited. ACM Trans. Inf. Syst. 2002, 20, 116–131. [Google Scholar] [CrossRef]
- Nelson, D.L.; Dyrdal, G.M.; Goodmon, L.B. What is preexisting strength? Predicting free association probabilities, similarity ratings, and cued recall probabilities. Psychon. Bull. Rev. 2005, 12, 711–719. [Google Scholar] [CrossRef] [PubMed]
- Stigler, S.M. Francis galton’s account of the invention of correlation. Stat. Sci. 1989, 4, 73–79. [Google Scholar] [CrossRef]
- Lebreton, J.; Burgess, J.R.D.; Kaiser, R.B.; Atchley, E.K.P.; James, L.R. The restriction of variance hypothesis and interrater reliability and agreement: Are ratings from multiple sources really dissimilar? Organ. Res. Methods 2003, 6, 80–128. [Google Scholar] [CrossRef]
- James, L.R.; Demaree, R.G.; Wolf, G. An assessment of within-group interrater agreement. J. Appl. Psychol. 1993, 78, 306–309. [Google Scholar] [CrossRef]
- Lebreton, J.; Senter, J.L. Answers to 20 questions about interrater reliability and interrater agreement. Organ. Res. Methods 2008, 11, 815–852. [Google Scholar] [CrossRef]
- Rodgers, J.; Nicewander, A. Thirteen ways to look at the correlation coefficient. Am. Stat. 1988, 42, 59–66. [Google Scholar] [CrossRef]
- Kruskal, W.H. Ordinal measures of association. J. Am. Stat. Assoc. 1958, 53, 814–861. [Google Scholar] [CrossRef]
- Kendall, M.G.; Smith, B.B. The problem of m rankings. Ann. Math. Stat. 1939, 10, 275–287. [Google Scholar] [CrossRef]
- James, L.R.; Demaree, R.G.; Wolf, G. Estimating within-group interrater reliability with and without response bias. J. Appl. Psychol. 1984, 69, 85–98. [Google Scholar] [CrossRef]
- Levenberg, K.A. A method for the solution of vertain problems in least squares. Q. Appl. Math. 1944, 2, 164–168. [Google Scholar] [CrossRef]
- Marquardt, D.W. An algorithm for least-squares estimation of nonlinear parameter. J. Soc. Ind. Appl. Math. 1963, 11, 431–441. [Google Scholar] [CrossRef]
- Powell, M.J.D. A Fortran Subroutine for Solving Systems of Non-Linear Algebraic Equations; Atomic Energy Research Establishment: London, UK, 1968; pp. 115–161. [Google Scholar]
- ISO. Geographic Information—Metadata; ISO-19115; ISO: Geneva, Switzerland, 2003. [Google Scholar]
- Frontiera, P.; Larson, R.R.; Radke, J. A comparison of geometric approaches to assessing spatial similarity for gir. Int. J. Geogr. Inf. Sci. 2008, 22, 337–360. [Google Scholar] [CrossRef]
- Bordogna, G.; Ghisalberti, G.; Psaila, G. Geographic information retrieval: Modeling uncertainty of user’s context. Fuzzy Sets Syst. 2012, 196, 105–124. [Google Scholar] [CrossRef]
- Aissi, S.; Gouider, M.S.; Sboui, T.; Said, L.B. Enhancing spatial data warehouse exploitation: A solap recommendation approach. In Proceedings of the 17th IEEE/ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing (SNPD), Shanghai, China, 30 May–1 June 2016; pp. 457–464. [Google Scholar]
- Saaty, T.L. How to make a decision: The analytic hierarchy process. Eur. J. Oper. Res. 1990, 48, 9–26. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index Type | Index Name | Minimum | Median | Max | Means |
| IRR | Pearson’s | 0.816 | 0.86 | 0.922 | 0.86 |
| Spearman’s | 0.797 | 0.858 | 0.925 | 0.858 | |
| Kendall’s | 0.657 | 0.734 | 0.807 | 0.731 | |
| Index Type | Index Name | Value | Index type | Index name | Value |
| IRA | Kendall’s | 0.731 | IRA | 0.927 |
| Term One | Term Two | Relatedness |
|---|---|---|
| oasis city | oasis city | 1 |
| tropical rainforest climate | equatorial climate | 0.8720 |
| city | cities and towns | 0.8598 |
| plateau permafrost | frozen soil | 0.7805 |
| cold wave | cold air mass | 0.7744 |
| geographical environment | environment | 0.7134 |
| highway transportation | transportation | 0.7073 |
| semi-arid climate | steppe climate | 0.7073 |
| climate | weather | 0.6890 |
| dairy Industry | food industry | 0.6829 |
| processing industry | light industry | 0.6646 |
| coal industry | heavy industry | 0.6280 |
| ecological environment | water environment | 0.5915 |
| alpine desert soil | subalpine soil | 0.5732 |
| low productive soil | soil fertility | 0.5671 |
| automobile industry | basic industry | 0.5122 |
| social environment | external environment | 0.4756 |
| plateau climate | ecological environment | 0.4268 |
| technique intensive city | small city | 0.4146 |
| feed industry | sugar industry | 0.3902 |
| fair weather | overcast sky | 0.3902 |
| Mediterranean climate | semi-arid environment | 0.3415 |
| gas industry | manufacturing industry | 0.2988 |
| agroclimate | natural landscape | 0.2805 |
| petroleum industry | aluminum industry | 0.25 |
| textile industry | shipbuilding industry | 0.25 |
| monsoon climate | meadow cinnamon soil | 0.2134 |
| quaternary climate | steppe landscape | 0.1646 |
| humid climate | dust storm | 0.1585 |
| marine environment | soil | 0.1098 |
| ecoclimate | science city | 0.0549 |
| marine climate | pipeline transportation | 0.0366 |
| desert climate | inland water transportation | 0.0305 |
| Term One | Term Two | GTRD | TLRM (WordNet) | TLRM (HowNet) |
|---|---|---|---|---|
| waterway transportation | waterway transportation | 1 | 1 | 1 |
| port city | harbor city | 0.9085 | 1 | 1 |
| transportation | communication and transportation | 0.8293 | 1 | 1 |
| near shore environment | coastal environment | 0.7805 | 0.7596 | 0.7301 |
| near shore environment | sublittoral environment | 0.7805 | 0.5776 | 0.5302 |
| iron and steel industry | metallurgical industry | 0.7256 | 0.763 | 0.7444 |
| cultural landscape | landscape | 0.6707 | 0.5851 | 0.5633 |
| cold wave | disastrous weather | 0.6524 | 0.7623 | 0.7416 |
| agricultural product processing industry | industry | 0.6098 | 0.4535 | 0.4473 |
| gray desert soil | brown desert soil | 0.6037 | 0.5776 | 0.5302 |
| marine environment | geographical environment | 0.5976 | 0.5902 | 0.5861 |
| tropical soil | subtropical soil | 0.5732 | 0.5776 | 0.5302 |
| alpine meadow soil | chestnut soil | 0.4634 | 0.3508 | 0.3514 |
| power industry | mechanical industry | 0.4512 | 0.4502 | 0.4316 |
| hydroclimate | agricultural environment | 0.4146 | 0.1664 | 0.3341 |
| marine transportation | air transportation | 0.3780 | 0.4502 | 0.4316 |
| arid climate | paleoclimate | 0.3780 | 0.5776 | 0.5303 |
| environment | disastrous weather | 0.3659 | 0.1301 | 0.0335 |
| marine climate | cold air mass | 0.3171 | 0.0847 | 0.2994 |
| desert soil | permafrost | 0.3171 | 0.5038 | 0.1676 |
| global environment | human landscape | 0.2805 | 0.1651 | 0.3003 |
| tropical climate | coastal environment | 0.2744 | 0.0623 | 0.1574 |
| computer industry | building material industry | 0.2317 | 0.3508 | 0.3514 |
| climate | city | 0.2134 | 0.1463 | 0.2087 |
| city | textile industry | 0.2012 | 0.1841 | 0.0661 |
| regional climate | megalopolis | 0.1829 | 0.0497 | 0.0641 |
| water environment | steppe landscape | 0.1829 | 0.1005 | 0.2018 |
| temperate climate | superaqual landscape | 0.1707 | 0.1120 | 0.1574 |
| glacial climate | cinnamon soil | 0.1402 | 0.1480 | 0.2042 |
| semi-arid environment | subaqual landscape | 0.1037 | 0.0603 | 0.1258 |
| Holocene climate | coastal transportation | 0.0366 | 0.0193 | 0.0152 |
| polar climate | mining industry | 0.0244 | 0.0583 | 0.0516 |
| desert climate | labor intensive industry | 0.0061 | 0.0353 | 0.0337 |
| Index Name | Value | Lexical Database |
|---|---|---|
| Spearman’s | 0.911 | WordNet |
| Spearman’s | 0.907 | HowNet |
| ID | Theme | Location | Keyword Matching | Semantic Retrieval | ||
|---|---|---|---|---|---|---|
| Recall | Precision | Recall | Precision | |||
| 1 | Basic geographic data | China | 6/20 | 6/6 | 6/20 | 6/6 |
| 2 | Land use | China | 20/38 | 20/20 | 38/38 | 38/38 |
| 3 | Population | China | 19/161 | 19/19 | 19/161 | 19/19 |
| 4 | Social economy | China | 26/30 | 26/26 | 30/30 | 30/55 |
| 5 | Landform | China | 5/7 | 5/5 | 6/7 | 6/7 |
| 6 | Soil | China | 49/63 | 49/49 | 50/63 | 50/50 |
| 7 | Desert | China | 4/4 | 4/4 | 4/4 | 4/4 |
| 8 | Lake | China | 18/20 | 18/19 | 19/20 | 19/20 |
| 9 | Natural resources | China | 4/26 | 4/4 | 18/26 | 18/21 |
| 10 | Wetland | China | 5/6 | 5/5 | 5/6 | 5/5 |
| 11 | Water environment | Taihu Lake | 22/23 | 22/22 | 22/23 | 22/22 |
| 12 | Administrative division | Shanghai | 14/44 | 14/14 | 14/44 | 14/14 |
| 13 | Remote sensing inversion | China | 16/33 | 16/16 | 16/33 | 16/16 |
| 14 | Meteorological observation | Tibet Plateau | 8/9 | 8/8 | 9/9 | 9/9 |
| 15 | Cyanobacterial bloom inversion | Taihu Lake | 18/20 | 18/18 | 18/20 | 18/18 |
| 16 | Precipitation | Tibet Plateau | 20/26 | 20/20 | 26/26 | 26/33 |
| 17 | Remote-sensing image | China | 9/28 | 9/20 | 28/28 | 28/35 |
| 18 | River | Yangtze River Basin | 5/7 | 5/5 | 7/7 | 7/7 |
| 19 | Hydro-meteorological data | Yangtze River | 15/16 | 15/15 | 16/16 | 16/16 |
| 20 | Aerosol | China | 5/10 | 5/5 | 10/10 | 10/11 |
| 21 | Biological resources | China | 1/20 | 1/1 | 19/20 | 19/24 |
| 22 | Land Cover | China | 17/46 | 17/17 | 46/46 | 46/46 |
| 23 | Climate | Tibet Plateau | 10/39 | 10/10 | 32/39 | 32/32 |
| 24 | Geomagnetism | Beijing Ming Tombs | 19/19 | 19/19 | 19/19 | 19/19 |
| 25 | Ecosystem | Tibet Plateau | 13/66 | 13/17 | 13/66 | 13/17 |
| 26 | Ecological environment | Xinjiang | 8/54 | 8/9 | 16/54 | 16/17 |
| 27 | Water quality | Taihu Lake | 6/24 | 6/6 | 6/24 | 6/6 |
| 28 | Air temperature | China | 5/12 | 5/5 | 9/12 | 9/16 |
| 29 | Natural disaster | China | 5/8 | 5/5 | 7/8 | 7/7 |
| 30 | Fish | China | 12/13 | 12/12 | 12/13 | 12/12 |
| ID | Data Set Title | MS |
|---|---|---|
| 1 | 1988 the distribution data set of natural resources in china on 1:4000,000 | 1 |
| 2 | 1992 the distribution data set of natural resources in china on 1:4000,000 | 1 |
| 3 | 1993 the distribution data set of natural resources in china on 1:4000,000 | 1 |
| 4 | 1977 the distribution data set of natural resources in china on 1:4000,000 | 1 |
| ID | Data Set Title | MS |
|---|---|---|
| 1 | 1988 the distribution data set of natural resources in china on 1:4000,000 | 1 |
| 2 | 1992 the distribution data set of natural resources in china on 1:4000,000 | 1 |
| 3 | 1993 the distribution data set of natural resources in china on 1:4000,000 | 1 |
| 4 | 1977 the distribution data set of natural resources in china on 1:4000,000 | 1 |
| 5 | 1997 forest and biological resources data set of china | 0.84 |
| 6 | 2002 the third-level basin classification data set in china on 1:250,000 | 0.838 |
| 7 | 2002 the second-level basin classification data set in china on 1:250,000 | 0.838 |
| 8 | 2002 the primary-level basin classification data set in china on 1:250,000 | 0.838 |
| 9 | 2000 industrial water data set of China on 1 KM Grid | 0.838 |
| 10 | 2000 total water consumption data set of China on 1 KM Grid | 0.838 |
| 11 | 1986–2003 the energy resources data set of China | 0.837 |
| 12 | 2003 the energy resources statistics data set of China | 0.837 |
| 13 | 2004 the energy resources statistics data set of China | 0.837 |
| 14 | 2005 the energy resources statistics data set of China | 0.837 |
| 15 | 2006 the energy resources statistics data set of China | 0.837 |
| 16 | 2007 the energy resources statistics data set of China | 0.837 |
| 17 | 1980s data set of arable land suitable for farmland in china on 1:4,000,000 | 0.836 |
| 18 | 1980s quality of cultivated land data set in china on 1:4,000,000 | 0.836 |
| 19 | 1980s land resources data set in china on 1:1,000,000 | 0.836 |
| 20 | China 1 KM classification of suitability land Grid Dataset (1980s) | 0.836 |
| 21 | 1990s land resources data set in china on 1:1,000,000 | 0.836 |
| Terminology Pair | WordNet Relatedness [24] | HowNet Relatedness [28] |
|---|---|---|
| soil—frozen soil | 0.8708 | 0.348 |
| climate—landscape | 0.4203 | 0.6186 |
| city—industry | 0.3164 | 0.120 |
| climate—environment | 0.2975 | 0.7222 |
| environment—landscape | 0.2914 | 0.619 |
| climate—soil | 0.265 | 0.4444 |
| climate—weather | 0.2532 | 1.000 |
| environment—soil | 0.2146 | 0.0444 |
| environment—weather | 0.1686 | 0.0444 |
| climate—city | 0.1463 | 0.2087 |
| climate—industry | 0.1042 | 0.11628 |
| climate—transportation | 0.0933 | 0.211 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Song, J.; Yang, Y. An Approach to Measuring Semantic Relatedness of Geographic Terminologies Using a Thesaurus and Lexical Database Sources. ISPRS Int. J. Geo-Inf. 2018, 7, 98. https://doi.org/10.3390/ijgi7030098
Chen Z, Song J, Yang Y. An Approach to Measuring Semantic Relatedness of Geographic Terminologies Using a Thesaurus and Lexical Database Sources. ISPRS International Journal of Geo-Information. 2018; 7(3):98. https://doi.org/10.3390/ijgi7030098
Chicago/Turabian StyleChen, Zugang, Jia Song, and Yaping Yang. 2018. "An Approach to Measuring Semantic Relatedness of Geographic Terminologies Using a Thesaurus and Lexical Database Sources" ISPRS International Journal of Geo-Information 7, no. 3: 98. https://doi.org/10.3390/ijgi7030098
APA StyleChen, Z., Song, J., & Yang, Y. (2018). An Approach to Measuring Semantic Relatedness of Geographic Terminologies Using a Thesaurus and Lexical Database Sources. ISPRS International Journal of Geo-Information, 7(3), 98. https://doi.org/10.3390/ijgi7030098