A Generalized Model for Indoor Location Estimation Using Environmental Sound from Human Activity Recognition

 ,
,  , ,
, ,  and
and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Set Description
2.2. Recording Devices
2.3. Spatial Environments
2.4. Meta-Data
2.5. Data Preparation
2.6. Feature Extraction
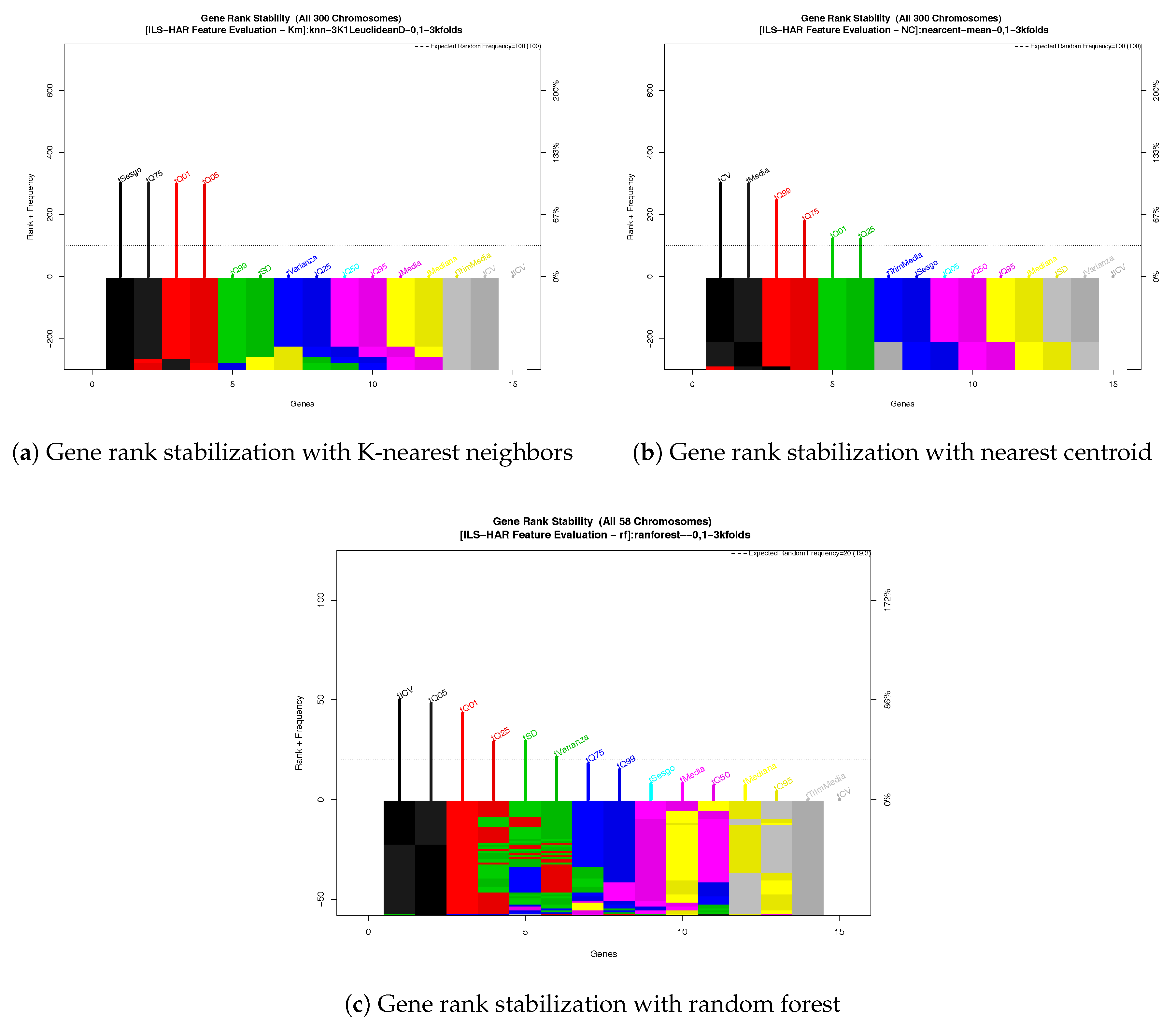
2.7. Feature Validation
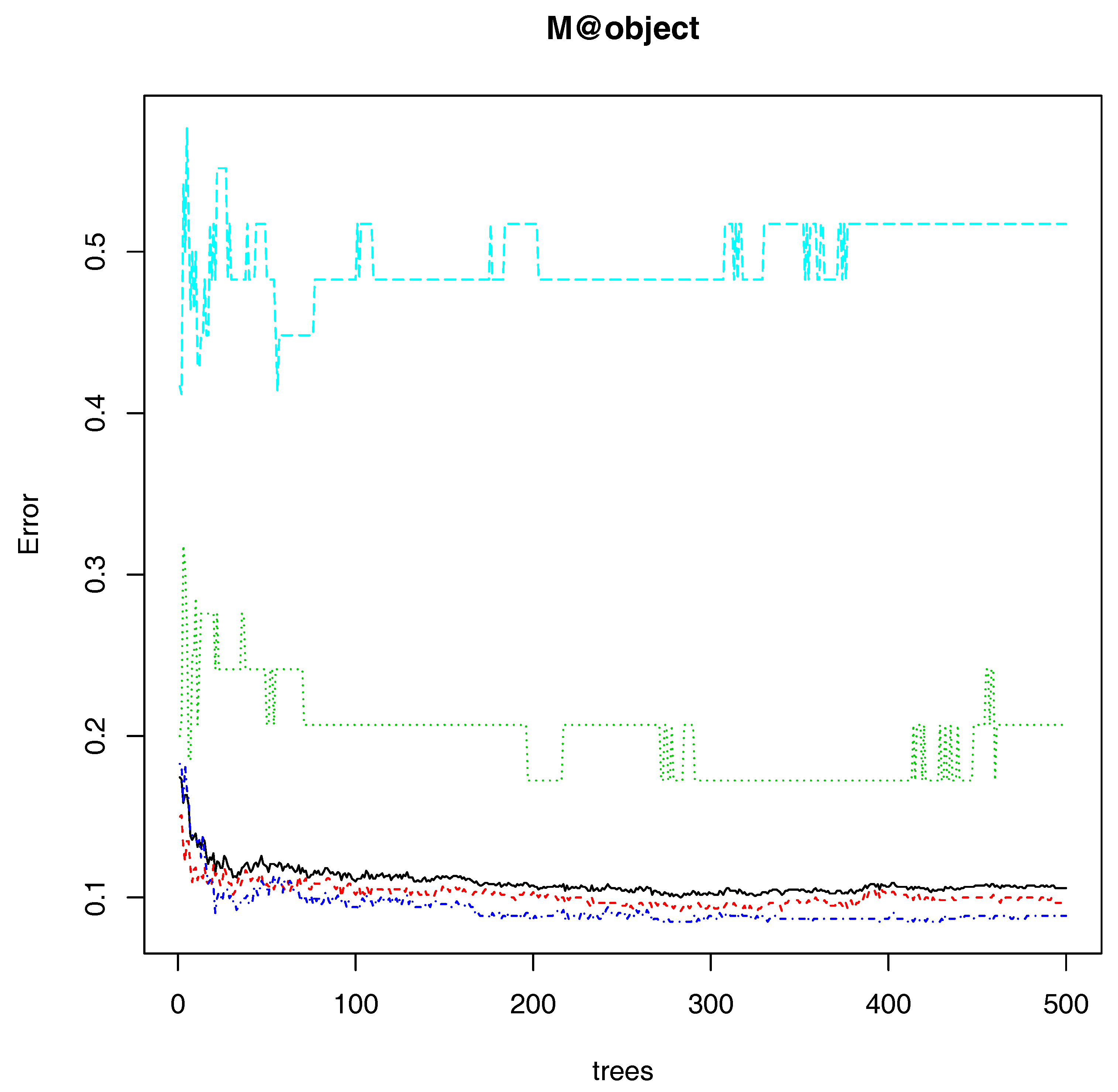
2.8. Model Generation with Random Forest
2.9. Random Forest Model Validation
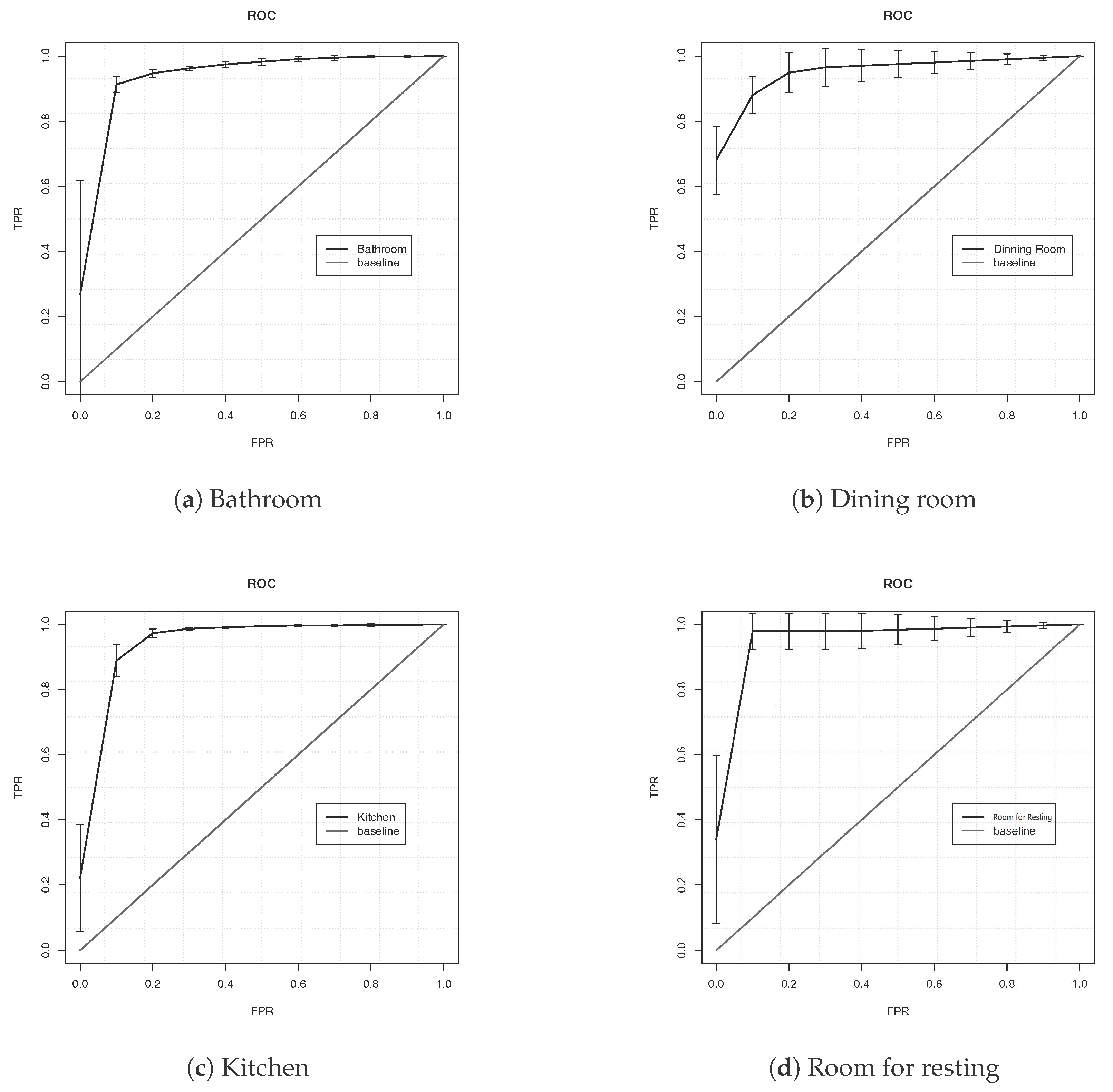
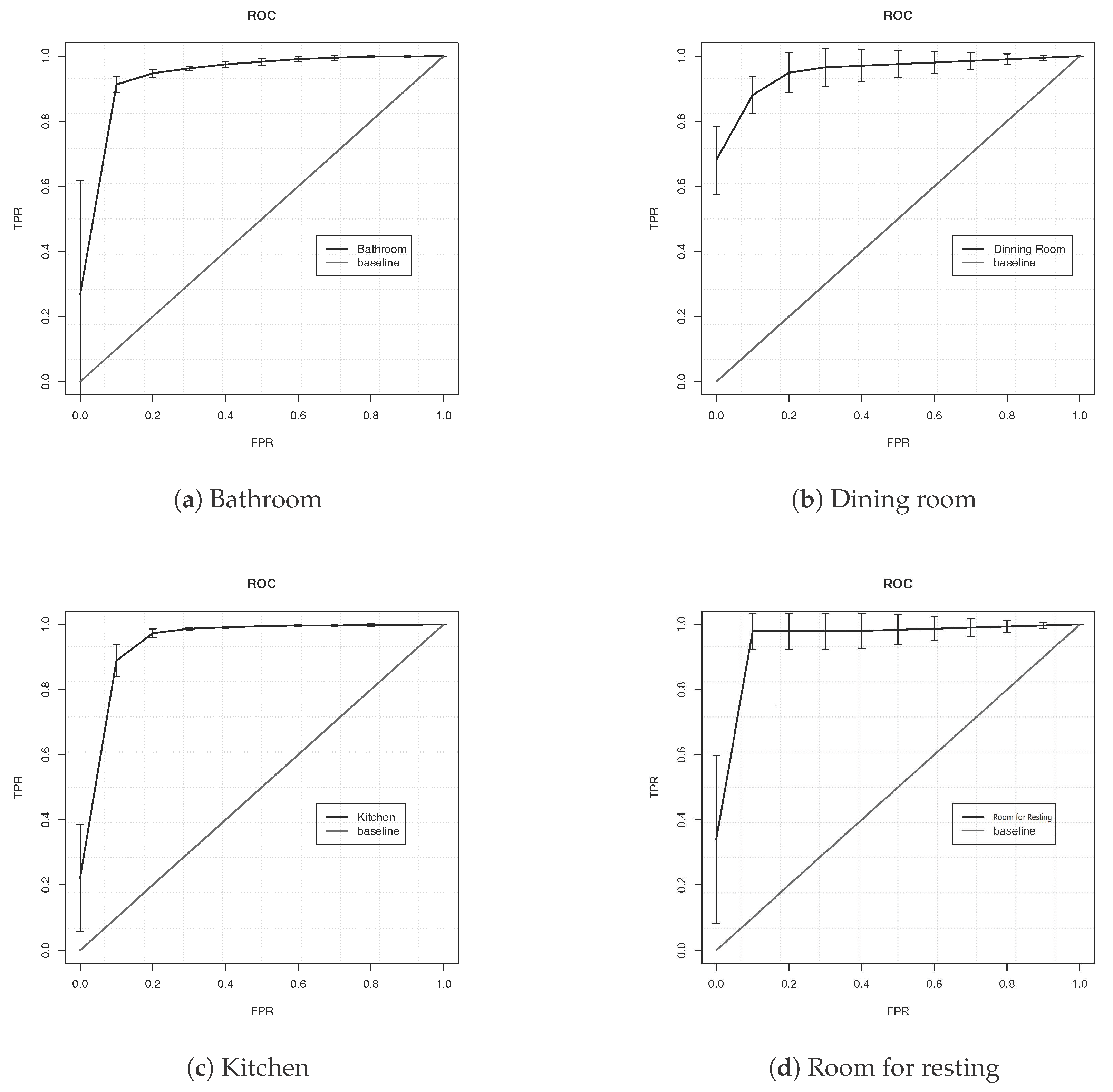
3. Experiments and Results
4. Discussion and Conclusions
- Human activity sound can correctly describe an indoor location: Human activity sounds have enough data that they can be used to describe indoor environments. Therefore, an indoor location estimation can be developed using human activity recognition context information with environmental sound as data source.
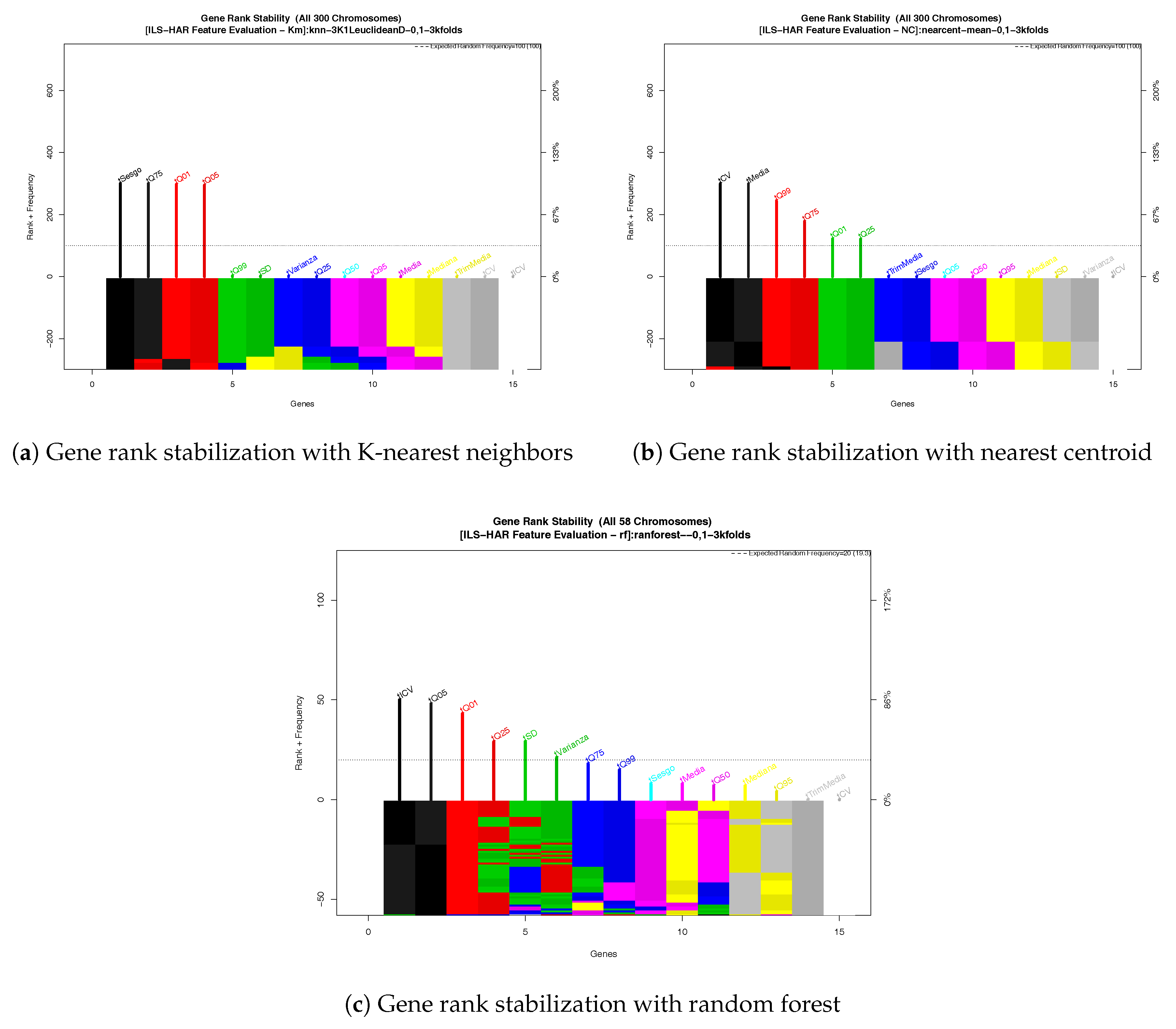
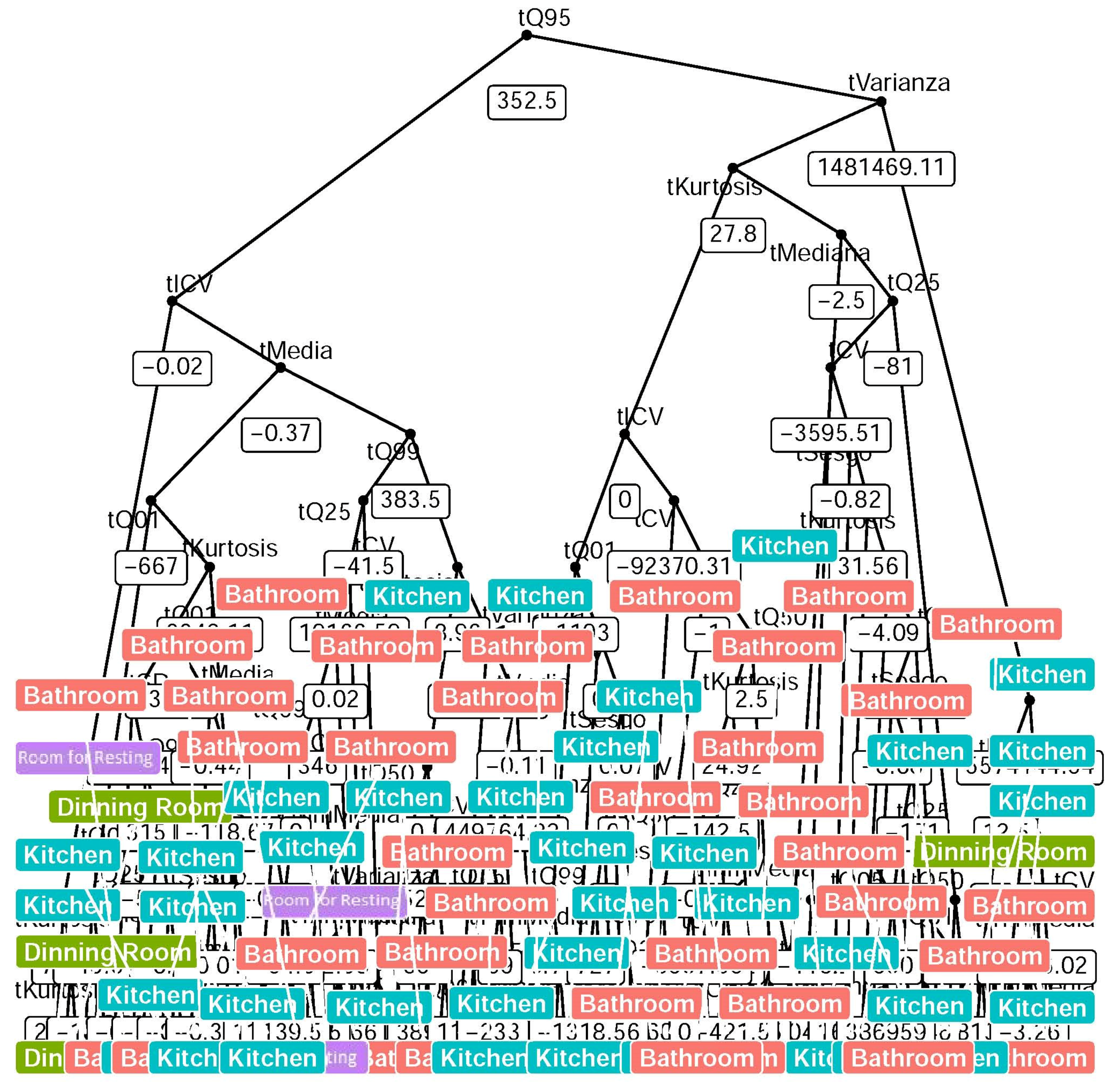
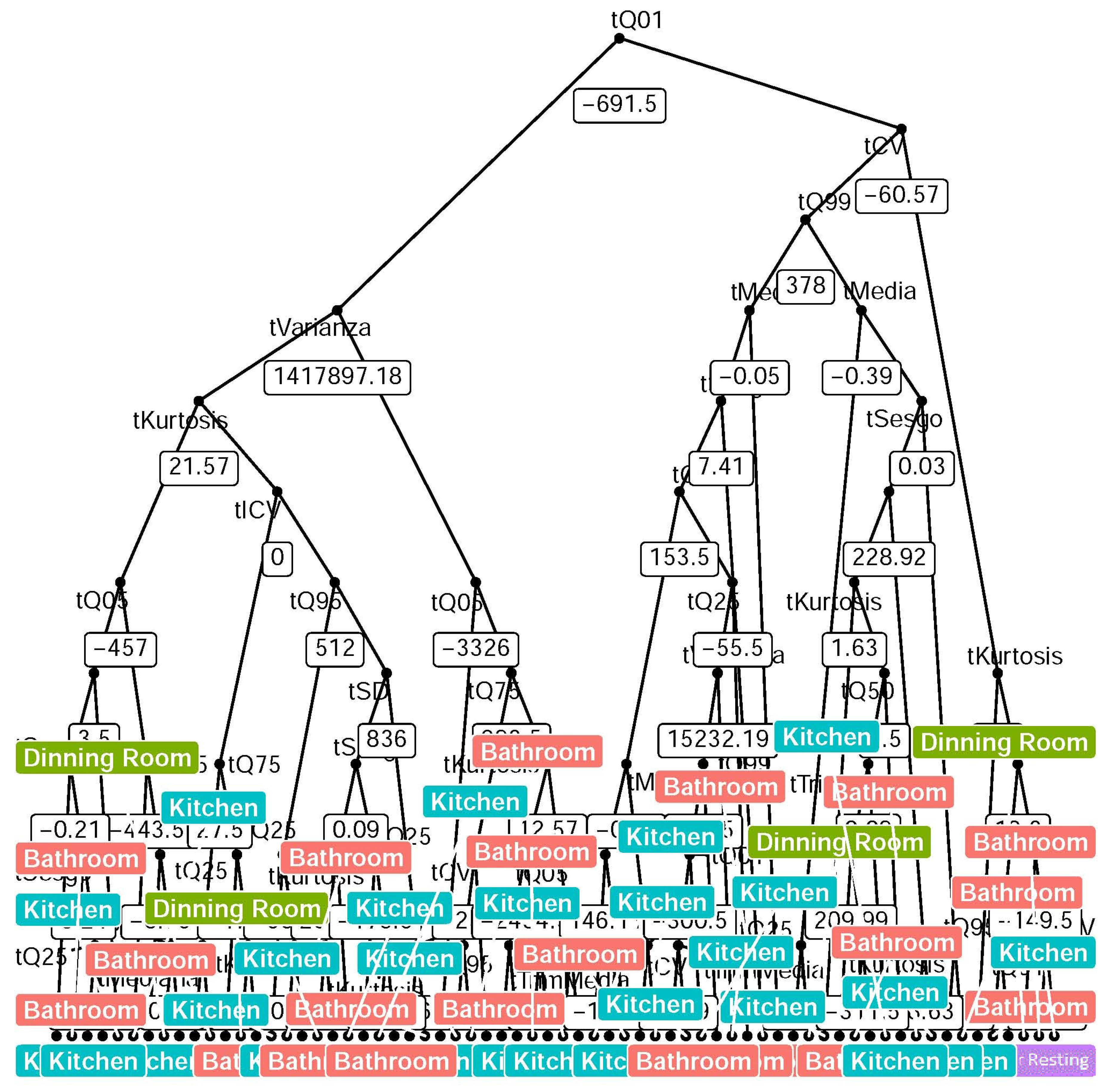
- Quantile statistic features correctly describe the behavior of the signal: Statistical features that are independent of time (i.e., ordered features as quantiles) can describe the behavior of the signal to estimate the location based on the human activity. Minimal and maximum trees from the RF has as root a quantile n feature; meanwhile, descriptive statistics features tend to appear near to the final nodes (final classification).
- Context information can be used to provide LBS: Providing a system with contextual information—such as location and activity—can be useful to provide services to the user; in this case, location can be recognized with human activity that is done in a certain room in an indoor environment.
5. Future Work
- To study other indoor locations that can be described by human activities,
- To include spectral evolution features that are commonly used to summarize the behavior of sounds,
- To use Net Reclassification Index (NRI) as feature selection approach to promote the reduction of redundant information,
- To implement a probabilistic algorithm (e.g., Petri nets),
- To propose an ontology to add contextual information to the final estimation.
Author Contributions
Conflicts of Interest
References
- Schilit, B.; Adams, N.; Want, R. Context-Aware Computing Applications. In Proceedings of the 1994 First Workshop on Mobile Computing Systems and Applications, Santa Cruz, CA, USA, 8–9 December 1994; IEEE Computer Society: Washington, DC, USA; pp. 85–90. [Google Scholar]
- Brena, R.F.; García-Vázquez, J.P.; Galván-Tejada, C.E.; Muñoz-Rodriguez, D.; Vargas-Rosales, C.; Fangmeyer, J. Evolution of Indoor Positioning Technologies: A Survey. J. Sens. 2017, 2017. [Google Scholar] [CrossRef]
- Liu, H.; Darabi, H.; Banerjee, P.; Liu, J. Survey of wireless indoor positioning techniques and systems. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2007, 37, 1067–1080. [Google Scholar] [CrossRef]
- Gu, Y.; Lo, A.; Niemegeers, I. A survey of indoor positioning systems for wireless personal networks. IEEE Commun. Surv. Tutor. 2009, 11, 13–32. [Google Scholar] [CrossRef]
- Mautz, R. Overview of current indoor positioning systems. Geodezija Ir Kartografija 2009, 35, 18–22. [Google Scholar] [CrossRef]
- Galvan-Tejada, C.E.; Garcia-Vazquez, J.P.; Brena, R.F. Natural or generated signals for indoor location systems? An evaluation in terms of sensitivity and specificity. In Proceedings of the 2014 International Conference on Electronics, Communications and Computers (CONIELECOMP), Cholula, Mexico, 26–28 February 2014; pp. 166–171. [Google Scholar]
- Galvan-Tejada, I.; Sandoval, E.I.; Brena, R. Wifi bluetooth based combined positioning algorithm. Proced. Eng. 2012, 35, 101–108. [Google Scholar]
- Baniukevic, A.; Sabonis, D.; Jensen, C.S.; Lu, H. Improving wi-fi based indoor positioning using bluetooth add-ons. In Proceedings of the 2011 IEEE 12th International Conference on Mobile Data Management, Lulea, Sweden, 6–9 June 2011; Volume 1, pp. 246–255. [Google Scholar]
- Want, R.; Hopper, A.; Falcao, V.; Gibbons, J. The active badge location system. ACM Trans. Inf. Syst. (TOIS) 1992, 10, 91–102. [Google Scholar] [CrossRef]
- Ward, A.; Jones, A.; Hopper, A. A new location technique for the active office. IEEE Personal Commun. 1997, 4, 42–47. [Google Scholar] [CrossRef]
- Priyantha, N.B.; Chakraborty, A.; Balakrishnan, H. The cricket location-support system. In Proceedings of the 6th Annual International Conference on Mobile Computing and Networking, Boston, MA, USA, 6–11 August 2000; pp. 32–43. [Google Scholar]
- Ni, L.M.; Liu, Y.; Lau, Y.C.; Patil, A.P. LANDMARC: Indoor location sensing using active RFID. Wirel. Netw. 2004, 10, 701–710. [Google Scholar] [CrossRef]
- King, T.; Lemelson, H.; Farber, A.; Effelsberg, W. BluePos: Positioning with Bluetooth. In Proceedings of the 2009 IEEE International Symposium on Intelligent Signal Processing, Budapest, Hungary, 26–28 August 2009; pp. 55–60. [Google Scholar]
- Schweinzer, H.; Syafrudin, M. LOSNUS: An ultrasonic system enabling high accuracy and secure TDoA locating of numerous devices. In Proceedings of the 2010 International Conference on Indoor Positioning and Indoor Navigation, Zurich, Switzerland, 15–17 September 2010; pp. 1–8. [Google Scholar]
- Noh, Y.; Yamaguchi, H.; Lee, U.; Vij, P.; Joy, J.; Gerla, M. CLIPS: Infrastructure-free collaborative indoor positioning scheme for time-critical team operations. In Proceedings of the 2013 IEEE International Conference on Pervasive Computing and Communications (PerCom), San Diego, CA, USA, 18–22 March 2013; pp. 172–178. [Google Scholar]
- Kim, S.E.; Kim, Y.; Yoon, J.; Kim, E.S. Indoor positioning system using geomagnetic anomalies for smartphones. In Proceedings of the 2012 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Sydney, Australia, 13–15 November 2012; pp. 1–5. [Google Scholar]
- Han, J.; Owusu, E.; Nguyen, L.T.; Perrig, A.; Zhang, J. Accomplice: Location inference using accelerometers on smartphones. In Proceedings of the 4th International Conference on Communication Systems and Networks, Bangalore, India, 3–7 January 2012; pp. 1–9. [Google Scholar]
- Haverinen, J.; Kemppainen, A. Global indoor self-localization based on the ambient magnetic field. Robot. Auton. Syst. 2009, 57, 1028–1035. [Google Scholar] [CrossRef]
- Gozick, B.; Subbu, K.P.; Dantu, R.; Maeshiro, T. Magnetic maps for indoor navigation. IEEE Trans. Instrum. Meas. 2011, 60, 3883–3891. [Google Scholar] [CrossRef]
- Randall, J.; Amft, O.; Bohn, J.; Burri, M. LuxTrace: Indoor positioning using building illumination. Personal Ubiquitous Comput. 2007, 11, 417–428. [Google Scholar] [CrossRef]
- Vildjiounaite, E.; Malm, E.J.; Kaartinen, J.; Alahuhta, P. Location estimation indoors by means of small computing power devices, accelerometers, magnetic sensors, and map knowledge. In Proceedings of the International Conference on Pervasive Computing, Zurich, Switzerland, 26–28 August 2002; pp. 211–224. [Google Scholar]
- Delgado-Contreras, J.R.; Garcia-Vazquez, J.P.; Brena, R.F. Classification of environmental audio signals using statistical time and frequency features. In Proceedings of the 2014 International Conference on Electronics, Communications and Computers, Cholula, Mexico, 26–28 February 2014; pp. 212–216. [Google Scholar]
- Zhu, C.; Sheng, W. Motion-and location-based online human daily activity recognition. Pervasive Mobile Comput. 2011, 7, 256–269. [Google Scholar]
- Filippoupolitis, A.; Oliff, W.; Takand, B.; Loukas, G. Location-Enhanced Activity Recognition in Indoor Environments Using Off the Shelf Smart Watch Technology and BLE Beacons. Sensors 2017, 17, 1230. [Google Scholar] [CrossRef] [PubMed]
- Guo, S.; Xiong, H.; Zheng, X.; Zhou, Y. Activity Recognition and Semantic Description for Indoor Mobile Localization. Sensors 2017, 17, 649. [Google Scholar] [CrossRef] [PubMed]
- Scheurer, S.; Tedesco, S.; Brown, K.N.; O’Flynn, B. Human activity recognition for emergency first responders via body-worn inertial sensors. In Proceedings of the 14th International Conference on Wearable and Implantable Body Sensor Networks, Eindhoven, The Netherlands, 9–12 May 2017; pp. 5–8. [Google Scholar]
- Ghourchian, N.; Allegue-Martinez, M.; Precup, D. Real-Time Indoor Localization in Smart Homes Using Semi-Supervised Learning. In Proceedings of the 29th AAAI Conference on Innovative Applications, San Francisco, CA, USA, 6–9 February 2017; pp. 4670–4677. [Google Scholar]
- Crespo, J.; Barber, R.; Mozos, O. Relational Model for Robotic Semantic Navigation in Indoor Environments. J. Intell. Robot. Syst. 2017, 86, 617–639. [Google Scholar] [CrossRef]
- Shah, M.A.; Raj, B.; Harras, K.A. Inferring Room Semantics Using Acoustic Monitoring. arXiv, 2017; arXiv:1710.08684. [Google Scholar]
- Garcia-Ceja, E.; Brena, R. Building Personalized Activity Recognition Models with Scarce Labeled Data Based on Class Similarities. In Ubiquitous Computing and Ambient Intelligence. Sensing, Processing, and Using Environmental Information: 9th International Conference, UCAmI 2015, Puerto Varas, Chile, December 1–4, 2015, Proceedings; García-Chamizo, J.M., Fortino, G., Ochoa, S.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 265–276. [Google Scholar]
- Brena, R.F.; Garcia-Ceja, E. A crowdsourcing approach for personalization in human activities recognition. Intell. Data Anal. 2017, 21, 721–738. [Google Scholar] [CrossRef]
- Carlos, E.; Galván-Tejada, J.P.; García-Vázquez, R.F.B. Magnetic Field Feature Extraction and Selection for Indoor Location Estimation. Sensor J. 2014, 14, 11001–11005. [Google Scholar]
- Tarzia, S.P.; Dinda, P.A.; Dick, R.P.; Memik, G. Indoor localization without infrastructure using the acoustic background spectrum. In Proceedings of the 9th International Conference on Mobile Systems, Applications, and Services, Bethesda, MD, USA, 28 June–1 July 2011; pp. 155–168. [Google Scholar]
- Galván-Tejada, C.E.; García-Vázquez, J.P.; Galván-Tejada, J.I.; Delgado-Contreras, J.R.; Brena, R.F. Infrastructure-less indoor localization using the microphone, magnetometer and light sensor of a smartphone. Sensors 2015, 15, 20355–20372. [Google Scholar] [CrossRef] [PubMed]
- Martinez-Torteya, A.; Rodriguez-Rojas, J.; Celaya-Padilla, J.M.; Galván-Tejada, J.I.; Treviño, V.; Tamez-Peña, J. Magnetization-prepared rapid acquisition with gradient echo magnetic resonance imaging signal and texture features for the prediction of mild cognitive impairment to Alzheimer’s disease progression. J. Medic. Imaging 2014, 1, 031005. [Google Scholar] [CrossRef] [PubMed]
- Celaya-Padilla, J.M.; Guzmán-Valdivia, C.H.; Galván-Tejada, C.E.; Galván-Tejada, J.I.; Gamboa-Rosales, H.; Garza-Veloz, I.; Martinez-Fierro, M.L.; Cid-Báez, M.A.; Martinez-Torteya, A.; Martinez-Ruiz, F.J. Contralateral asymmetry for breast cancer detection: A CADx approach. Biocybern. Biomed. Eng. 2017, 38, 115–125. [Google Scholar] [CrossRef]
- Galván-Tejada, J.I.; Celaya-Padilla, J.M.; Martínez-Torteya, A.; Rodriguez-Rojas, J.; Treviño, V.; Tamez-Peña, J.G. Wide association study of radiological features that predict future knee OA pain: Data from the OAI. In Proceedings of the Medical Imaging 2014: Computer-Aided Diagnosis, International Society for Optics and Photonics, San Diego, CA, USA, 15–20 February 2014; Volume 9035, p. 903539. [Google Scholar]
- Trevino, V.; Falciani, F. GALGO: An R package for multivariate variable selection using genetic algorithms. Bioinformatics 2006, 22, 1154–1156. [Google Scholar] [CrossRef] [PubMed]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Galván-Tejada, C.E.; Zanella-Calzada, L.A.; Galván-Tejada, J.I.; Celaya-Padilla, J.M.; Gamboa-Rosales, H.; Garza-Veloz, I.; Martinez-Fierro, M.L. Multivariate Feature Selection of Image Descriptors Data for Breast Cancer with Computer-Assisted Diagnosis. Diagnostics 2017, 7, 9. [Google Scholar] [CrossRef] [PubMed]
- Huang, L.; Jin, Y.; Gao, Y.; Thung, K.H.; Shen, D.; Initiative, A.D.N. Longitudinal clinical score prediction in Alzheimer’s disease with soft-split sparse regression based random forest. Neurobiol. Ag. 2016, 46, 180–191. [Google Scholar] [CrossRef] [PubMed]
- Biau, G.; Devroye, L. On the layered nearest neighbour estimate, the bagged nearest neighbour estimate and the random forest method in regression and classification. J. Multivar. Anal. 2010, 101, 2499–2518. [Google Scholar] [CrossRef]
- Torteya, A.M.; Peña, J.G.T.; Alvarado, V.M.T. Multivariate predictors of clinically relevant cognitive decay: A wide association study using available data from ADNI. Alzheimer’s Dement. 2012, 8, P285–P286. [Google Scholar] [CrossRef]
- Celaya-Padilla, J.M.; Rodriguez-Rojas, J.; Galván-Tejada, J.I.; Martínez-Torteya, A.; Treviño, V.; Tamez-Peña, J.G. Bilateral image subtraction features for multivariate automated classification of breast cancer risk. In Proceedings of the SPIE Medical Imaging, International Society for Optics and Photonics, San Diego, CA, USA, 15–20 February 2014. 90351T. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Location | Activity | Description of Action Recorded |
|---|---|---|
| Kitchen | Brewing coffee | Brewing coffee from putting a coffee pot on the stove to turning off the stove or coffee machine turning from on to off. |
| Frying meat | From putting meat into the frying pan to turning the stove off. | |
| Cooking eggs | From cracking the egg to finishing with it cooked. | |
| Using microwave oven | From set-up time to opening the microwave oven’s door. | |
| Dish washing | Dishes washed by hand individually or in groups of different dishes; water noise in the background. | |
| Bathroom | Taking a shower | Taking a shower in different environments, in some cases water fall was interrupted in intervals. |
| Hand washing | Washing hands with bar soap. | |
| Teeth brushing | Audio clips include from opening the tap to closing it. | |
| Dining Room Room for resting | Chewing food | Sounds produced by chewing crispy potatoes and apples. |
| No activity | No activity audio clips, which mostly comprise noises added by the device used to record. | |
| Reading a Book | Whispering and page changing. |
| Smartphone | System on Chip (SoC) | Operating System |
|---|---|---|
| Lanix Ilium s600 | Qualcomm Snapdragon 210 MSM8909 | Android 5.1 |
| LG G Pro Lite | MediaTek MT6577 | Android 4.1.2 |
| iPhone 4 | Apple A4 APL0398 | iOS 4 |
| iPhone 3GS | Samsung S5PC100 | iOS 3 |
| HTC One M7 | Qualcomm Snapdragon 600 APQ8064T | Android 4.1.2 |
| Activity | Sample Rate | Encoding Format | Channels |
|---|---|---|---|
| Brewing coffee | 8000–44,100 Hz | m4a, amr | Stereo, Mono |
| Frying meat | 44,100 Hz | m4a | Stereo |
| Cooking eggs | 44,100 Hz | m4a | Stereo |
| Use microwave oven | 44,100 Hz | m4a | Stereo |
| Take a shower | 44,100 Hz | m4a, mp3 | Stereo |
| Dish washing | 44,100 Hz | m4a | Stereo |
| Hand washing | 8000–44,100 Hz | m4a, amr | Stereo, Mono |
| Brushing teeth | 44,100 Hz | m4a | Stereo |
| Chewing Food | 44,100 Hz | m4a | Stereo |
| Reading a book | 8000–44,100 Hz | m4a, amr | Stereo, Mono |
| No activity | 8000–44,100 Hz | m4a, amr | Stereo, Mono |
| Features |
| Kurtosis of the probability distribution of the integer array |
| Skewness of the probability distribution of the integer array |
| Mean of the integer array |
| Median of the integer array |
| Standard deviation of the integer array |
| Variance of the integer array |
| Coefficient of variation (CV) of the probability distribution of the integer array |
| Inverse CV |
| 1st, 5th, 25th, 50th, 75th, 95th, and 99th percentile of the probability distribution of the integer array |
| Mean of the integer array after trimming the bottom and top 5% elements |
| Location | Activity | Recordings | 10 s Instances | Total Sounds Per Room |
|---|---|---|---|---|
| Kitchen | Brewing coffee | 9 | 245 | 553 |
| Cooking (Meat and Eggs) | 6 | 132 | ||
| Use microwave oven | 3 | 42 | ||
| Washing dishes | 6 | 134 | ||
| Bathroom | Take a shower | 11 | 428 | 590 |
| Brushing teeth | 9 | 92 | ||
| Washing hands | 15 | 70 | ||
| Dining Room | Chewing food | 6 | 29 | 29 |
| Room for resting | Reading books | 7 | 13 | 29 |
| No activity | 5 | 16 |
| Bathroom | Dining Room | Kitchen | Room for Resting | Error | |
|---|---|---|---|---|---|
| Bathroom | 534 | 1 | 53 | 2 | 0.094 |
| Dining Room | 1 | 23 | 4 | 1 | 0.20 |
| Kitchen | 47 | 0 | 505 | 1 | 0.086 |
| Room for Resting | 5 | 1 | 9 | 14 | 0.51 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Galván-Tejada, C.E.; López-Monteagudo, F.E.; Alonso-González, O.; Galván-Tejada, J.I.; Celaya-Padilla, J.M.; Gamboa-Rosales, H.; Magallanes-Quintanar, R.; Zanella-Calzada, L.A. A Generalized Model for Indoor Location Estimation Using Environmental Sound from Human Activity Recognition. ISPRS Int. J. Geo-Inf. 2018, 7, 81. https://doi.org/10.3390/ijgi7030081
Galván-Tejada CE, López-Monteagudo FE, Alonso-González O, Galván-Tejada JI, Celaya-Padilla JM, Gamboa-Rosales H, Magallanes-Quintanar R, Zanella-Calzada LA. A Generalized Model for Indoor Location Estimation Using Environmental Sound from Human Activity Recognition. ISPRS International Journal of Geo-Information. 2018; 7(3):81. https://doi.org/10.3390/ijgi7030081
Chicago/Turabian StyleGalván-Tejada, Carlos E., F. E. López-Monteagudo, O. Alonso-González, Jorge I. Galván-Tejada, José M. Celaya-Padilla, Hamurabi Gamboa-Rosales, Rafael Magallanes-Quintanar, and Laura A. Zanella-Calzada. 2018. "A Generalized Model for Indoor Location Estimation Using Environmental Sound from Human Activity Recognition" ISPRS International Journal of Geo-Information 7, no. 3: 81. https://doi.org/10.3390/ijgi7030081
APA StyleGalván-Tejada, C. E., López-Monteagudo, F. E., Alonso-González, O., Galván-Tejada, J. I., Celaya-Padilla, J. M., Gamboa-Rosales, H., Magallanes-Quintanar, R., & Zanella-Calzada, L. A. (2018). A Generalized Model for Indoor Location Estimation Using Environmental Sound from Human Activity Recognition. ISPRS International Journal of Geo-Information, 7(3), 81. https://doi.org/10.3390/ijgi7030081