An Automatic User Grouping Model for a Group Recommender System in Location-Based Social Networks

Abstract
:
1. Introduction
2. Related Work
- Established group: a number of individuals who explicitly choose to be part of a group, because of shared long-term interests. These groups have the property to be persistent and users actively join the group. Online communities that share preferences [12], people attending a party [13], and communities of like-minded users [14] are examples of this type of group.
- Occasional group: a group of people who occasionally do something together, for example, visiting a museum. Members have a common aim at a particular moment. They might not know each other, but they share interest for a common place. People who want to see a movie together [15], people traveling together [16], and people who want to dine together [17] are examples of the existing occasional groups.
- Random group: a group of people who share an environment at a particular moment without explicit interests that link them. Its nature is heterogeneous and its members might not share interests. People that browse the web together [18] and people in a public room [19] are some of the existing random groups.
- Automatically identified group: a group that is automatically detected considering the user preferences and/or the available resources. Such an approach is interesting for various reasons: (I) manual grouping can be very time consuming in large data sets, and (II) interests of people vary and usually change with time, so user grouping is a complex and continuous process requiring regular updates.
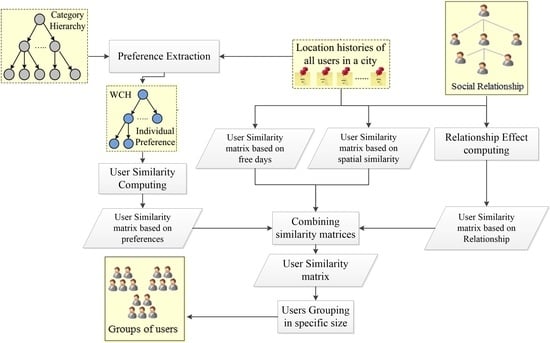
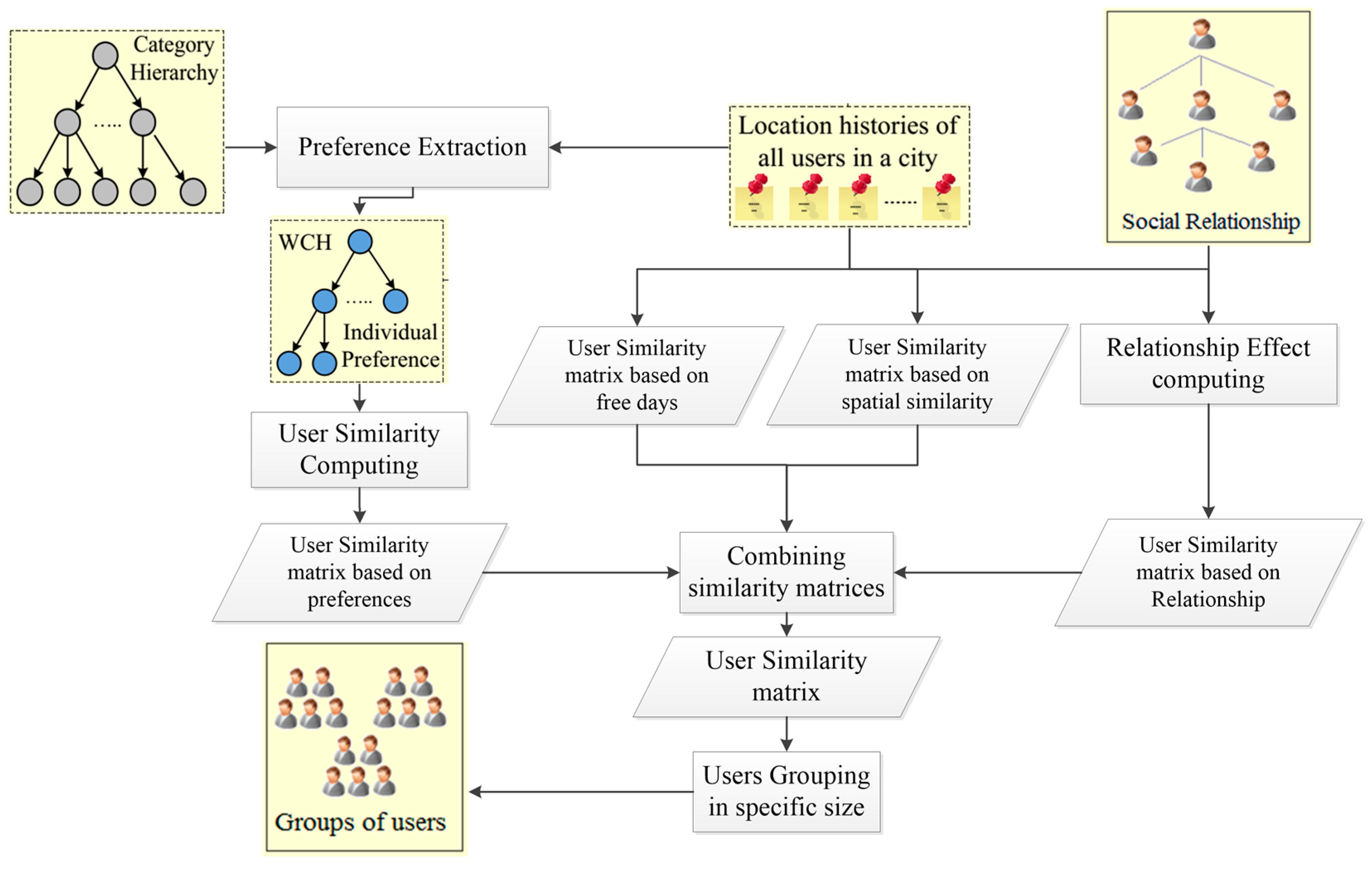
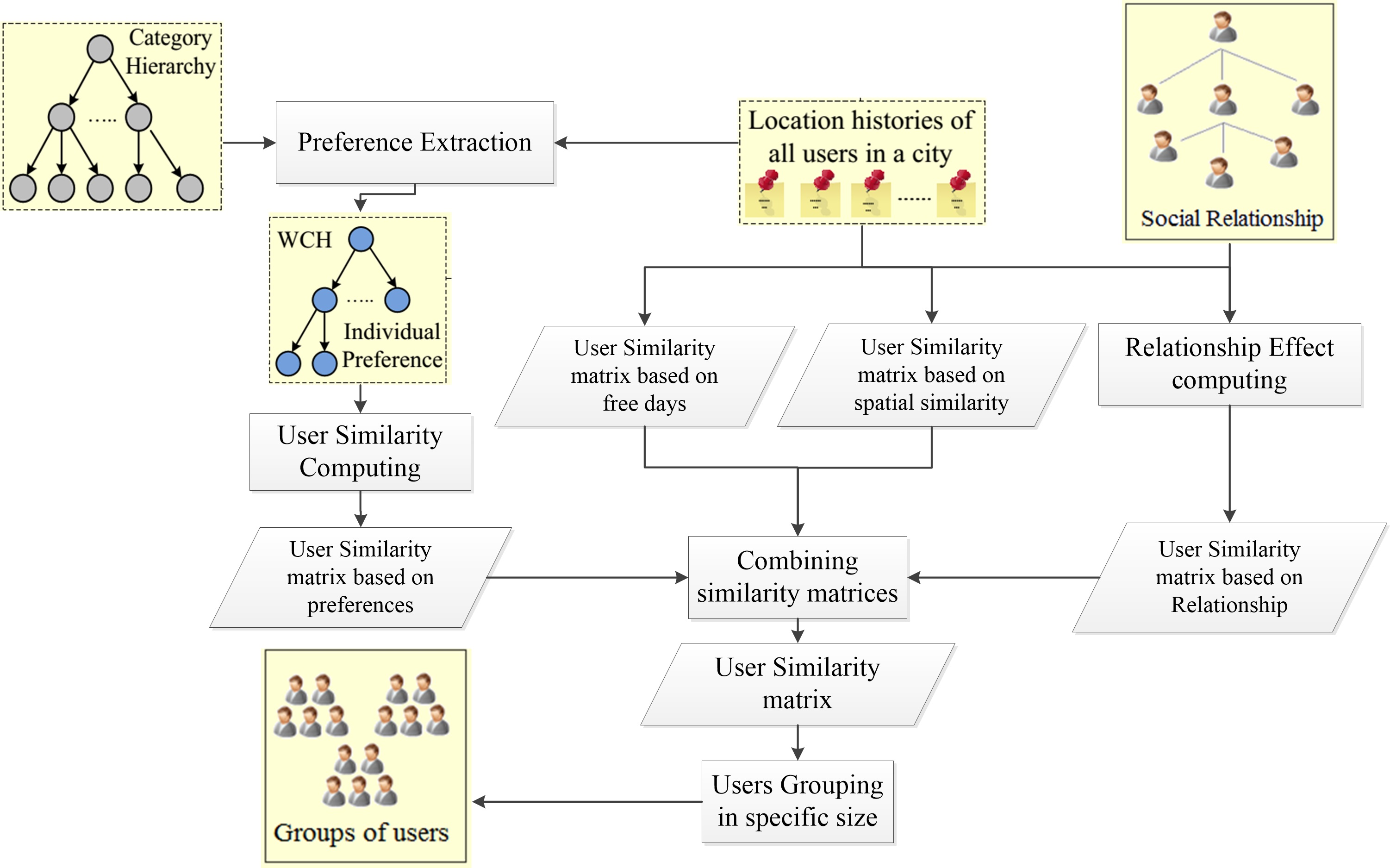
3. System Overview
3.1. Preliminary
3.2. Application Scenario
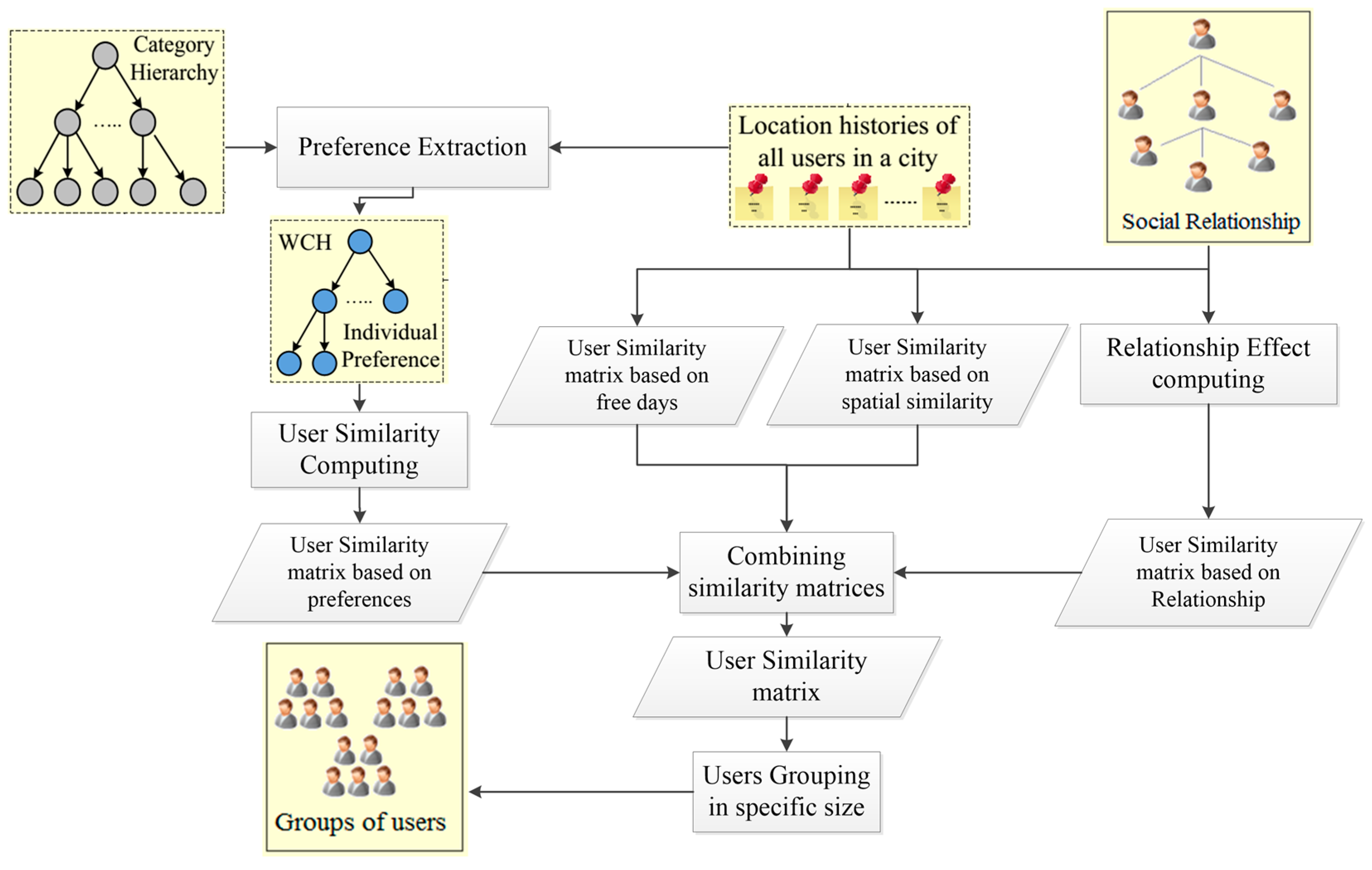
3.3. System Architecture
4. Materials and Methods
4.1. User Similarity
4.1.1. Analysing User Preferences
4.1.2. Similarity Based on User Preferences
4.1.3. Similarity Based on Relationship
4.1.4. Similarity Based on the User’s Free Days
4.1.5. Spatial Similarity
4.1.6. Combining Preferences, Relationships, Free Days, and Spatial Similarity
4.2. User Grouping for a Given Group Size
4.2.1. Multilevel k-Way Partitioning
4.2.2. Hungarian Algorithm
4.2.3. k-Medoids Algorithm
- Randomly select k data points as medoids.
- Assignment step: Assign each data point to the closest medoids.
- Update step: find new medoids of each cluster to minimize within cluster variance.
- Repeat assignment step and update step until the medoids do not change.
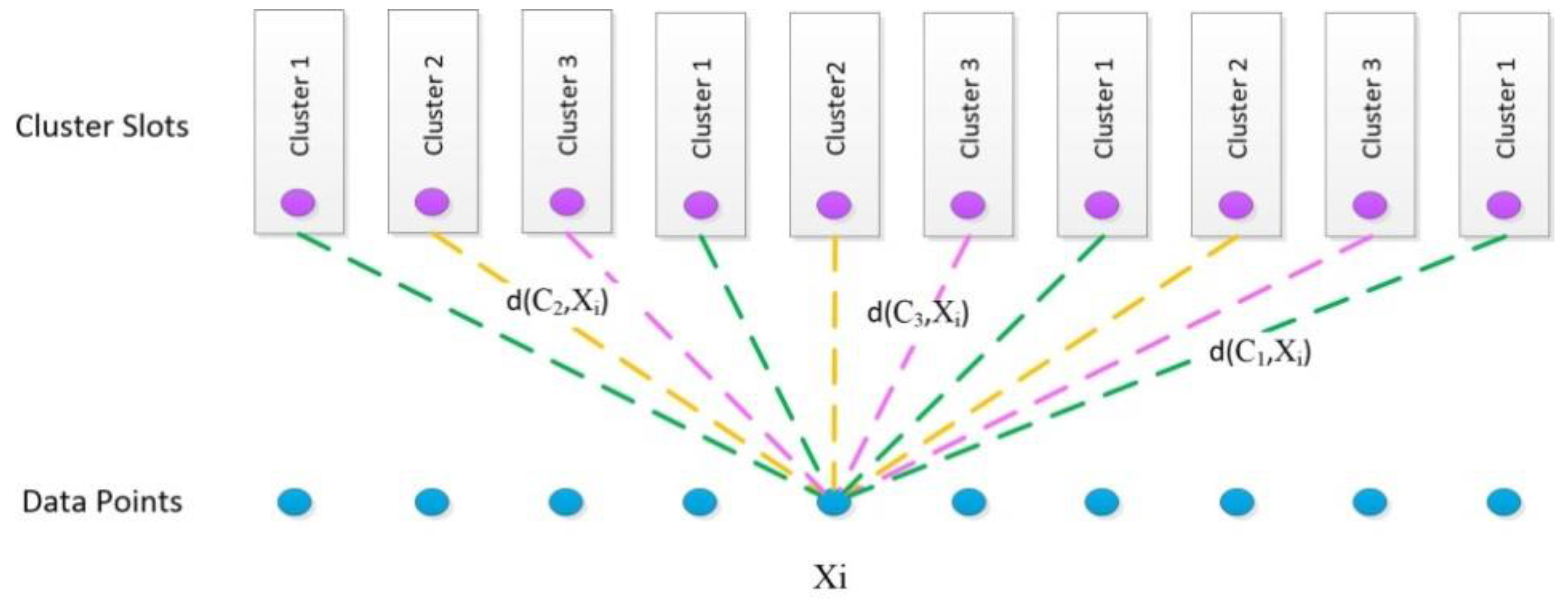
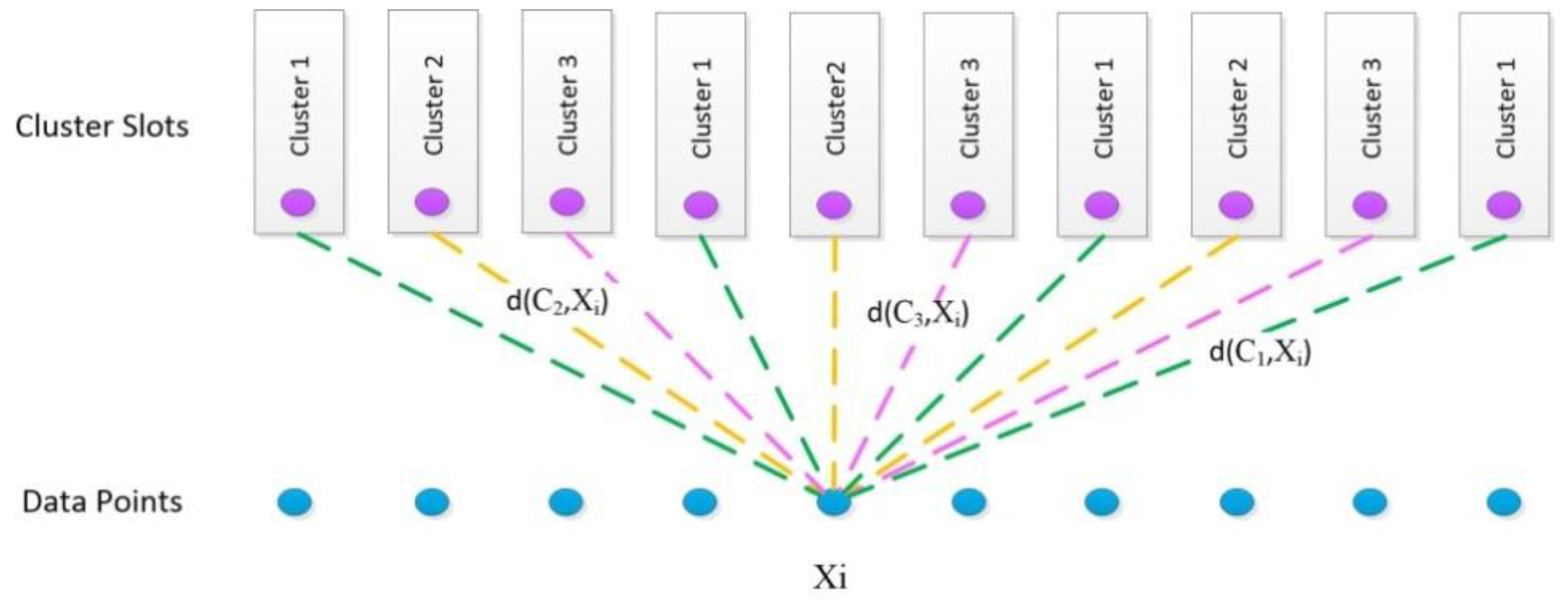
4.2.4. Modified k-Medoids for Grouping People into Groups of a Specific Size
- Data set is divided in multiple parts with k-way partitioning. For each part, the following procedure is repeated.
- The cluster slots are partitioned into clusters with the largest possible even number of slots (it is assumed that all clusters have the same size, if different cluster size is given, cluster slots are divided based on different cluster size.)
- The initial medoids can be select randomly from all data points. (In this study, k-means++ is used to select the initial medoids from all data points.)
- Assignment step: The edge weight is the similarity between the point and the assigned cluster medoid. It is updated according to newly medoids. With using Hungarian algorithm, data points are assigned to cluster slots based on the edge weight.
- Update step: New medoid of each cluster are calculated based on similarity between the points and medoids. The update step is similar to that of the k-medoids method.
- The last two steps are repeated until the medoids do not change.
| Algorithm 1. Modified k-medoids |
Input: data set X, number of member in group Output: partitioning of data set. Partition data set to multi part with k-way partitioning part ← 0 repeat Initialize medoid locations C0 with k-means++ t ← 0 repeat Assignment step: Calculate edge weights. Solve an Assignment problem. Update step: Calculate new medoid locations Ct+1 t ← t + 1 Until medoid locations do not change. Until all parts are clustering |
4.3. Experimental Evaluation
Experimental Settings
5. Results and Discussion
6. Conclusions
Author Contributions
Conflicts of Interest
References
- Bao, J.; Zheng, Y.; Wilkie, D.; Mokbel, M. Recommendations in location-based social networks: A survey. Geoinformatica 2015, 19, 525–565. [Google Scholar] [CrossRef]
- Abbasi, O.; Alesheikh, A.; Sharif, M. Ranking the City: The Role of Location-Based Social Media Check-Ins in Collective Human Mobility Prediction. ISPRS Int. J. Geo-Inf. 2017, 6, 136. [Google Scholar] [CrossRef]
- Wang, H.; Li, G.; Feng, J. Group-Based Personalized Location Recommendation on Social Networks. In APWeb; Chen, L., Jia, Y., Sellis, T., Liu, G., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2014; Volume 8709, pp. 68–80. ISBN 978-3-319-11115-5. [Google Scholar]
- Wang, H.; Terrovitis, M.; Mamoulis, N. Location recommendation in location-based social networks using user check-in data. In Proceedings of the 21st ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems - SIGSPATIAL’13; ACM Press: New York, New York, USA, 2013; pp. 364–373. [Google Scholar]
- Guo, J.; Zhu, Y.; Li, A.; Wang, Q.; Han, W. A Social Influence Approach for Group User Modeling in Group Recommendation Systems. IEEE Intell. Syst. 2016, 31, 40–48. [Google Scholar] [CrossRef]
- Butler, C.T.L.; Rothstein, A. On Conflict and Consensus: A Handbook on Formal Consensus Decisionmaking, 3rd ed.; Food Not Bombs: Santa Cruz, CA, USA, 2007. [Google Scholar]
- Kompan, M.; Bielikova, M. Group Recommendations: Survey and Perspectives. Comput. Inform. 2014, 33, 446–476. [Google Scholar]
- Purushotham, S.; Kuo, C.-C.J.; Shahabdeen, J.; Nachman, L. Collaborative Group-activity Recommendation in Location-based Social Networks. In Proceedings of the 3rd ACM SIGSPATIAL International Workshop on Crowdsourced and Volunteered Geographic Information; GeoCrowd’14; ACM: New York, NY, USA, 2014; pp. 8–15. [Google Scholar]
- Ludovico, B.; Salvatore, C.; Satta, M. Groups identification and individual recommendations in group recommendation algorithms. Proceedings of Workshop on the Practical Use of Recommender Systems, Algorithms and Technologies (PRSAT 2010), Barcelona, Spain, 30 September 2010. [Google Scholar]
- Chang, X.; Nie, F.; Ma, Z.; Yang, Y. Balanced k-Means and Min-Cut Clustering. arXiv preprint 2014. [Google Scholar]
- Boratto, L.; Carta, S. State-of-the-Art in Group Recommendation and New Approaches for Automatic Identification of Groups. In Information Retrieval and Mining in Distributed Environments; Soro, A., Vargiu, E., Armano, G., Paddeu, G., Eds.; Studies in Computational Intelligence; Springer Berlin Heidelberg: Berlin/Heidelberg, Germany, 2011; pp. 1–20. [Google Scholar]
- Kim, J.K.; Kim, H.K.; Oh, H.Y.; Ryu, Y.U. A group recommendation system for online communities. Int. J. Inf. Manage. 2010, 30, 212–219. [Google Scholar] [CrossRef]
- Pizzutilo, S.; De Carolis, B.; Cozzolongo, G.; Ambruoso, F. Group modeling in a public space: Methods, techniques, experiences. In Proceedings of the 5th WSEAS International Conference on Applied Informatics and Communications, Stevens Point, WI, USA, 15–17 September 2005; pp. 175–180. [Google Scholar]
- Smyth, B.; Balfe, E. Anonymous personalization in collaborative web search. Inf. Retr. Boston. 2006, 9, 165–190. [Google Scholar] [CrossRef]
- O’Connor, M.; Cosley, D.; Konstan, J.A.; Riedl, J. PolyLens: A recommender system for groups of users. In ECSCW 2001: Proceedings of the Seventh European Conference on Computer Supported Cooperative Work 16–20 September 2001, Bonn, Germany; Springer: Dordrecht, The Netherlands, 2001; pp. 199–218. [Google Scholar]
- Ardissono, L.; Goy, A.; Petrone, G.; Segnan, M.; Torasso, P. Intrigue: Personalized recommendation of tourist attractions for desktop and hand held devices. Appl. Artif. Intell. 2003, 17, 687–714. [Google Scholar] [CrossRef]
- McCarthy, J.F. Pocket Restaurant Finder: A situated recommender systems for groups. In Proceedings of the Workshop on Mobile Ad-Hoc Communication at the 2002 ACM Conference on Human Factors in Computer Systems, Minneapolis, MN, USA, 20–25 April 2002; pp. 1–10. [Google Scholar]
- Lieberman, H.; Van Dyke, N.W.; Vivacqua, A.S. Let’s Browse: A Collaborative Web Browsing Agent. In Proceedings of the 4th International Conference on Intelligent User Interfaces; IUI ’99; ACM: New York, NY, USA, 1999; pp. 65–68. [Google Scholar]
- Crossen, A.; Budzik, J.; Hammond, K. J. Flytrap. In Proceedings of the 7th International Conference on Intelligent User Interfaces - IUI ’02; ACM Press: New York, NY, USA, 2002; p. 184. [Google Scholar]
- Newman, M.E.J.; Girvan, M. Finding and evaluating community structure in networks. Phys. Rev. E 2004, 69, 26113. [Google Scholar] [CrossRef] [PubMed]
- Newman, M.E.J. Analysis of weighted networks. Phys. Rev. 2004, 70. [Google Scholar] [CrossRef] [PubMed]
- Blondel, V.D.; Guillaume, J.-L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, 2008, P10008. [Google Scholar] [CrossRef]
- Cantador, I.; Castells, P. Extracting multilayered Communities of Interest from semantic user profiles: Application to group modeling and hybrid recommendations. Comput. Human Behav. 2011, 27, 1321–1336. [Google Scholar] [CrossRef]
- Li, Y.-M.; Chou, C.-L.; Lin, L.-F. A social recommender mechanism for location-based group commerce. Inf. Sci. 2014, 274, 125–142. [Google Scholar] [CrossRef]
- Ganganath, N.; Cheng, C.-T.; Tse, C.K. Data Clustering with Cluster Size Constraints Using a Modified K-Means Algorithm. In Proceedings of the 2014 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery, Shanghai, China, 13–15 October 2014; pp. 158–161. [Google Scholar]
- Malinen, M. I.; Fränti, P. Balanced K-Means for Clustering. In Structural, Syntactic, and Statistical Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2014; pp. 32–41. [Google Scholar]
- Bao, J.; Zheng, Y.; Mokbel, M. F. Location-based and preference-aware recommendation using sparse geo-social networking data. In Proceedings of the 20th International Conference on Advances in Geographic Information Systems - SIGSPATIAL’12; ACM Press: New York, NY, USA, 2012; p. 199. [Google Scholar]
- Dong, L.; Li, Y.; Yin, H.; Le, H.; Rui, M.; Dong, L.; Li, Y.; Yin, H.; Le, H.; Rui, M. The Algorithm of Link Prediction on Social Network. Math. Probl. Eng. 2013, 2013, 1–7. [Google Scholar] [CrossRef]
- Liben-Nowell, D.; Kleinberg, J. The Link Prediction Problem for Social Networks. Proc. Twelfth Annu. ACM Int. Conf. Inf. Knowl. Manag. 2003, 556–559. [Google Scholar] [CrossRef]
- Wu, J.; Hou, Y.; Jiao, Y.; Li, Y.; Li, X.; Jiao, L. Density shrinking algorithm for community detection with path based similarity. Phys. A Stat. Mech. Appl. 2015, 433, 218–228. [Google Scholar] [CrossRef]
- Cheng, C.; Yang, H.; King, I.; Lyu, M.R. Fused matrix factorization with geographical and social influence in location-based social networks. Proceedings of Twenty-Sixth AAAI Conference on Artificial Intelligence, Toronto, ON, Canada, 22–26 July 2012; pp. 17–23. [Google Scholar]
- Ye, M.; Yin, P.; Lee, W.-C.; Lee, D.-L. Exploiting geographical influence for collaborative point-of-interest recommendation. In Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information - SIGIR’11; ACM Press: New York, NY, USA, 2011; p. 325. [Google Scholar]
- Hu, L.; Sun, A.; Liu, Y. Your Neighbors Affect Your Ratings: On Geographical Neighborhood Influence to Rating Prediction. In Proceedings of the 37th International ACM SIGIR Conference on Research & Development in Information Retrieval; SIGIR ’14; ACM: New York, NY, USA, 2014; pp. 345–354. [Google Scholar]
- Rahimi, S.M.; Wang, X. Location Recommendation Based on Periodicity of Human Activities and Location Categories. In Advances in Knowledge Discovery and Data Mining; Springer: Berlin/ Heidelberg, Germany, 2013; pp. 377–389. [Google Scholar]
- Zhou, D.; Rahimi, S.M.; Wang, X. Similarity-based probabilistic category-based location recommendation utilizing temporal and geographical influence. Int. J. Data Sci. Anal. 2016, 1, 111–121. [Google Scholar] [CrossRef]
- Heith, M. T.; Raghavan, P. A Cartesian parallel nested dissection algorithm. SIAM J. Matrix Anal. Appl. 1992, 19, 235–253. [Google Scholar] [CrossRef]
- Karypis, G.; Kumar, V. Multilevelk-way Partitioning Scheme for Irregular Graphs. J. Parallel Distrib. Comput. 1998, 48, 96–129. [Google Scholar] [CrossRef]
- Kuhn, H.W. The Hungarian method for the assignment problem. Nav. Res. Logist. Q. 1955, 2, 83–97. [Google Scholar] [CrossRef]
- Kuhn, H.W. Variants of the hungarian method for assignment problems. Nav. Res. Logist. Q. 1956, 3, 253–258. [Google Scholar] [CrossRef]
- Berkhin, P. Survey of Clustering Data Mining Techniques; Technical Report; Accrue Software Inc.: San Jose, CA, USA, 2002. [Google Scholar]
- Velmurugan, T.; Santhanam, T. Computational Complexity between K-Means and K-Medoids Clustering Algorithms for Normal and Uniform Distributions of Data Points. J. Comput. Sci. 2010, 6, 363–368. [Google Scholar] [CrossRef]
- Wang, K.; Wang, B.; Peng, L. CVAP: Validation for Cluster Analyses. Data Sci. J. 2009, 8, 88–93. [Google Scholar] [CrossRef]
- Dudoit, S.; Fridlyand, J. A prediction-based resampling method for estimating the number of clusters in a dataset. Genome Biol. 2002, 3, RESEARCH0036. [Google Scholar] [CrossRef]
- Baarsch, J.; Celebi, M.E. Investigation of internal validity measures for K-means clustering. In Proceedings of the International Multiconference of Engineers and Computer Scientists, Hong Kong, China, 14–16 March 2012; pp. 14–16. [Google Scholar]
- Quattrone, G.; Capra, L.; De Meo, P. There’s No Such Thing as the Perfect Map: Quantifying Bias in Spatial Crowd-sourcing Datasets. In Proceedings of the 18th ACM Conference on Computer Supported Cooperative Work & Social Computing, Vancouver, BC, Canada, 14–18 March 2015; pp. 1021–1032. [Google Scholar]
- Zhang, J.; Sheng, V.S.; Li, Q.; Wu, J.; Wu, X. Consensus algorithms for biased labeling in crowdsourcing. Inf. Sci. 2017, 382–383, 254–273. [Google Scholar] [CrossRef]
- Chakraborty, A.; Messias, J.; Benevenuto, F.; Ghosh, S.; Ganguly, N.; Gummadi, K.P. Who Makes Trends? Understanding Demographic Biases in Crowdsourced Recommendations. In Proceedings of the 11th AAAI International Conference on Web and Social Media (ICWSM 2017), Montreal, CA, USA, 15–18 May 2017. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Home City | QUERY City | Total Users | Tips in City | Tips/User |
|---|---|---|---|---|
| LA | LA | 977 | 11,700 | 11.9 |
| NJ | LA | 228 | 2553 | 11.20 |
| NY | NY | 3630 | 52,282 | 14.4 |
| NJ | NY | 2886 | 72,170 | 25.01 |
| Parameters Value (λ, γ, δ) | λ = 1, γ = 0, δ = 0 | λ = 0, γ = 1, δ = 0 | λ = 0, γ = 0, δ = 1 | λ = 0, γ = 0, δ = 0 | λ = 0.3, γ = 0.2, δ = 0.25 |
|---|---|---|---|---|---|
| Silhouette Index | -0.066 | -0.035 | 0.048 | 0.082 | 0.015 |
| Mean intra-cluster distance | 0.072 | 0.281 | 0.023 | 0.094 | 0.192 |
| Parameters Value (λ, γ, δ) | |||||
|---|---|---|---|---|---|
| Mean Intra-Cluster Distance | λ = 1, γ = 0, δ = 0 | λ = 0, γ = 1, δ = 0 | λ = 0, γ = 0, δ = 1 | λ = 0, γ = 0, δ = 0 | λ = 0.3, γ = 0.2, δ = 0.25 |
| User preferences distances | 0.072 | 0.369 | 0.365 | 0.370 | 0.170 |
| Social relationships distances | 0.481 | 0.281 | 0.485 | 0.478 | 0.338 |
| Spatial distances | 0.265 | 0.259 | 0.023 | 0.273 | 0.112 |
| Temporal distance | 0.488 | 0.490 | 0.491 | 0.094 | 0.242 |
| Final grouping | 0.191 | ||||
| Number of Group’s Member | Proposed Method | Multilevel k-Way Partitioning | k-Medoids Clustering | Spectral Clustering |
|---|---|---|---|---|
| 1 | 5.2 | 45.0 | ||
| 2 | 6.1 | 16.3 | ||
| 3 | 12.2 | 4.0 | ||
| 4 | 10.4 | 2.4 | ||
| 5 | 15.7 | 1.6 | ||
| 6 | 87.9 | 93.6 | 13.0 | 0.8 |
| 7 | 12.1 | 6.4 | 7.0 | 1.6 |
| 8 | 8.7 | 4.0 | ||
| 9 | 5.2 | 0.8 | ||
| 10+ | 16.5 | 23.4 |
| Method | Database #1 | Database #2 | Database #3 | Database #4 |
|---|---|---|---|---|
| Proposed method | 0.191 | 0.187 | 0.198 | 0.173 |
| Multilevel k-way partitioning | 0.269 | 0.255 | 0.277 | 0.253 |
| k-medoids clustering | 0.171 | 0.165 | 0.183 | 0.162 |
| k-medoids clustering without cluster size 1, 2, 3 | 0.292 | 0.268 | 0.305 | 0.281 |
| Spectral clustering | 0.098 | 0.096 | 0.112 | 0.094 |
| Spectral clustering without cluster size 1, 2, 3 | 0.281 | 0.277 | 0.295 | 0.264 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khazaei, E.; Alimohammadi, A. An Automatic User Grouping Model for a Group Recommender System in Location-Based Social Networks. ISPRS Int. J. Geo-Inf. 2018, 7, 67. https://doi.org/10.3390/ijgi7020067
Khazaei E, Alimohammadi A. An Automatic User Grouping Model for a Group Recommender System in Location-Based Social Networks. ISPRS International Journal of Geo-Information. 2018; 7(2):67. https://doi.org/10.3390/ijgi7020067
Chicago/Turabian StyleKhazaei, Elahe, and Abbas Alimohammadi. 2018. "An Automatic User Grouping Model for a Group Recommender System in Location-Based Social Networks" ISPRS International Journal of Geo-Information 7, no. 2: 67. https://doi.org/10.3390/ijgi7020067
APA StyleKhazaei, E., & Alimohammadi, A. (2018). An Automatic User Grouping Model for a Group Recommender System in Location-Based Social Networks. ISPRS International Journal of Geo-Information, 7(2), 67. https://doi.org/10.3390/ijgi7020067