The Ordered Capacitated Multi-Objective Location-Allocation Problem for Fire Stations Using Spatial Optimization


Abstract
1. Introduction
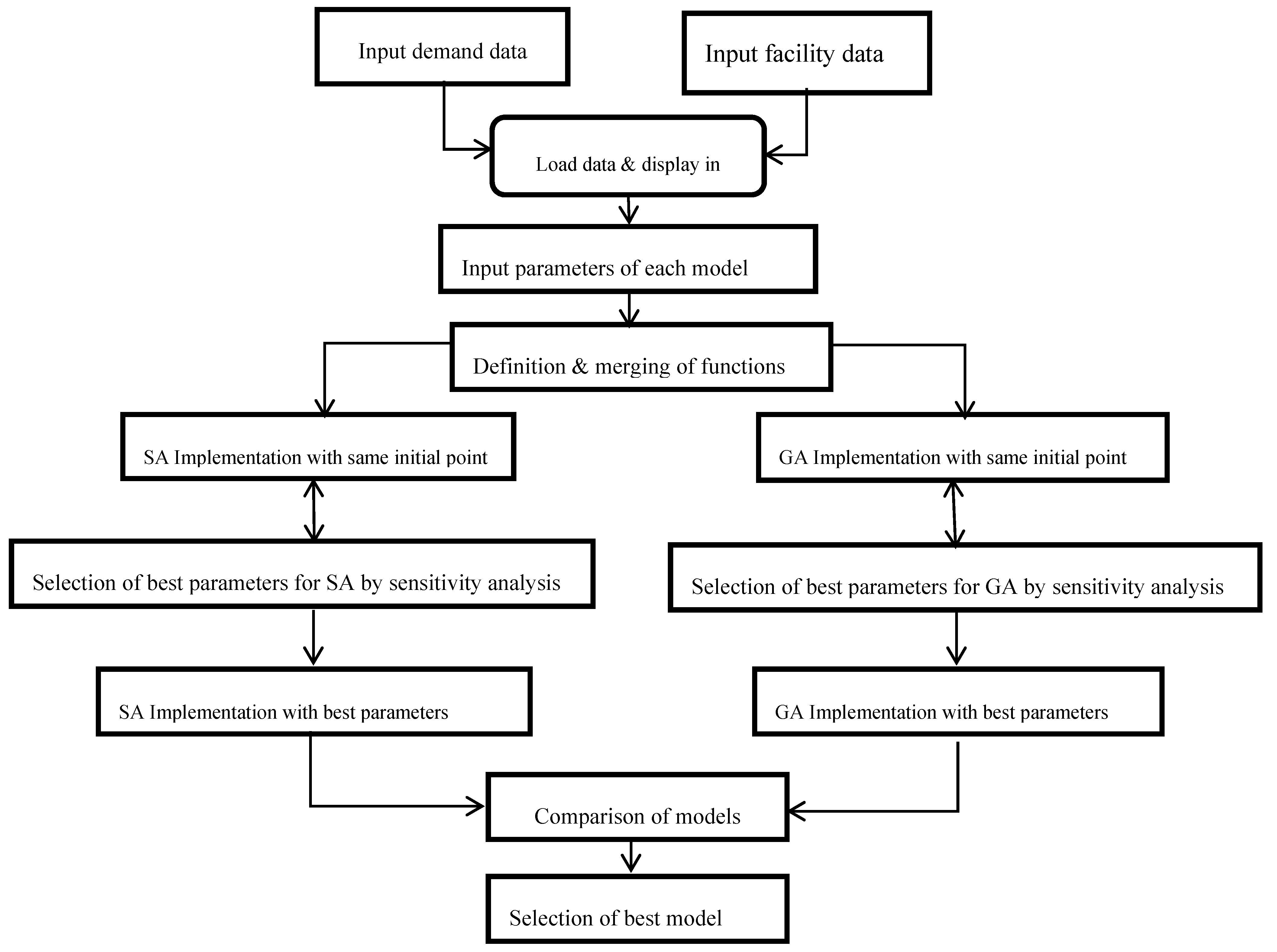
2. Materials and Methods
2.1. Minimizing the Distance between the Demand and the Fire Station
2.2. Minimizing the Time for Reaching the Demand from the Fire Station
2.3. Maximizing the Fire Station’s Coverage
3. Proposed Solution Approaches
3.1. Genetic Optimization
3.2. Simulated Annealing (SA) Optimization
4. Study Area and Data
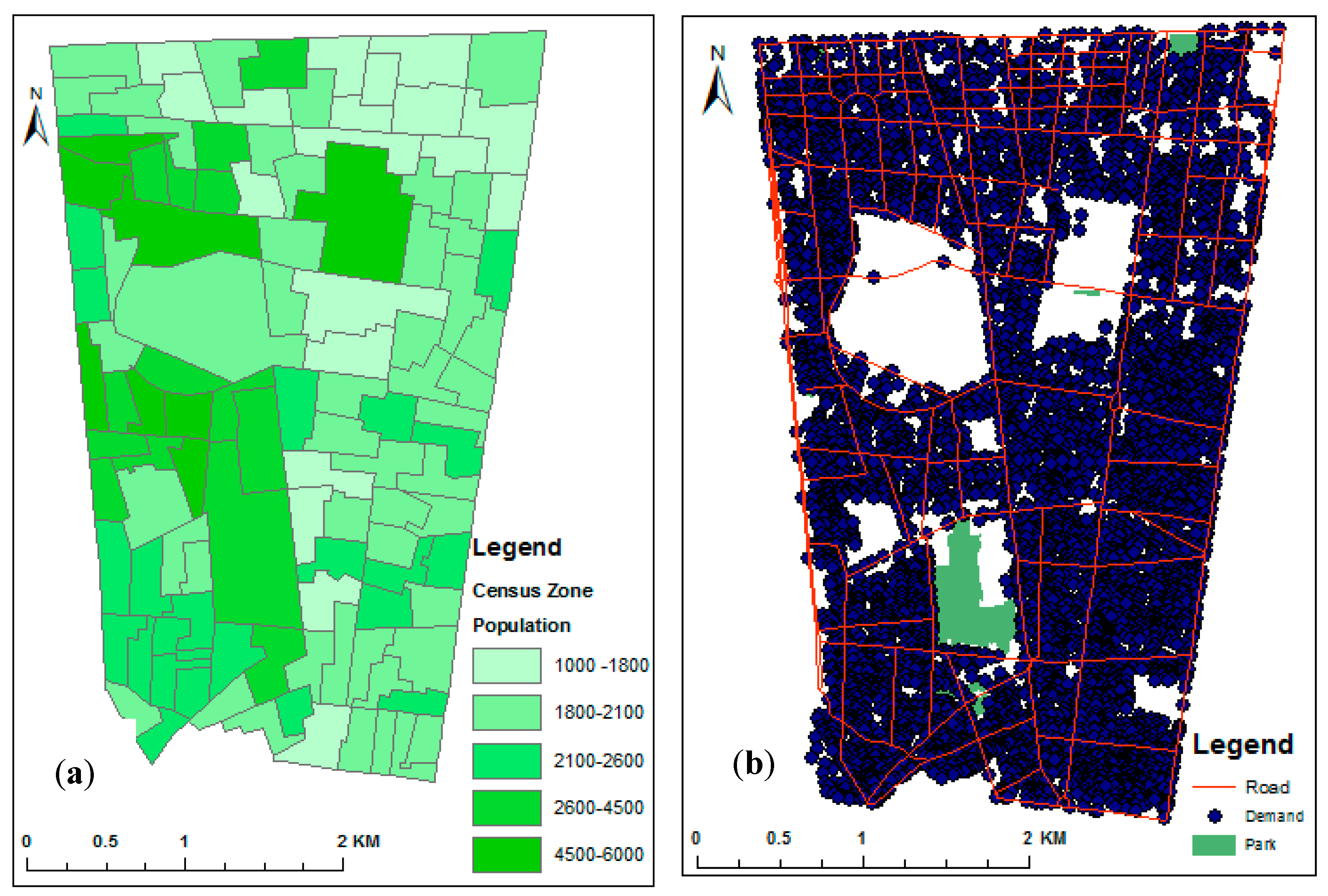
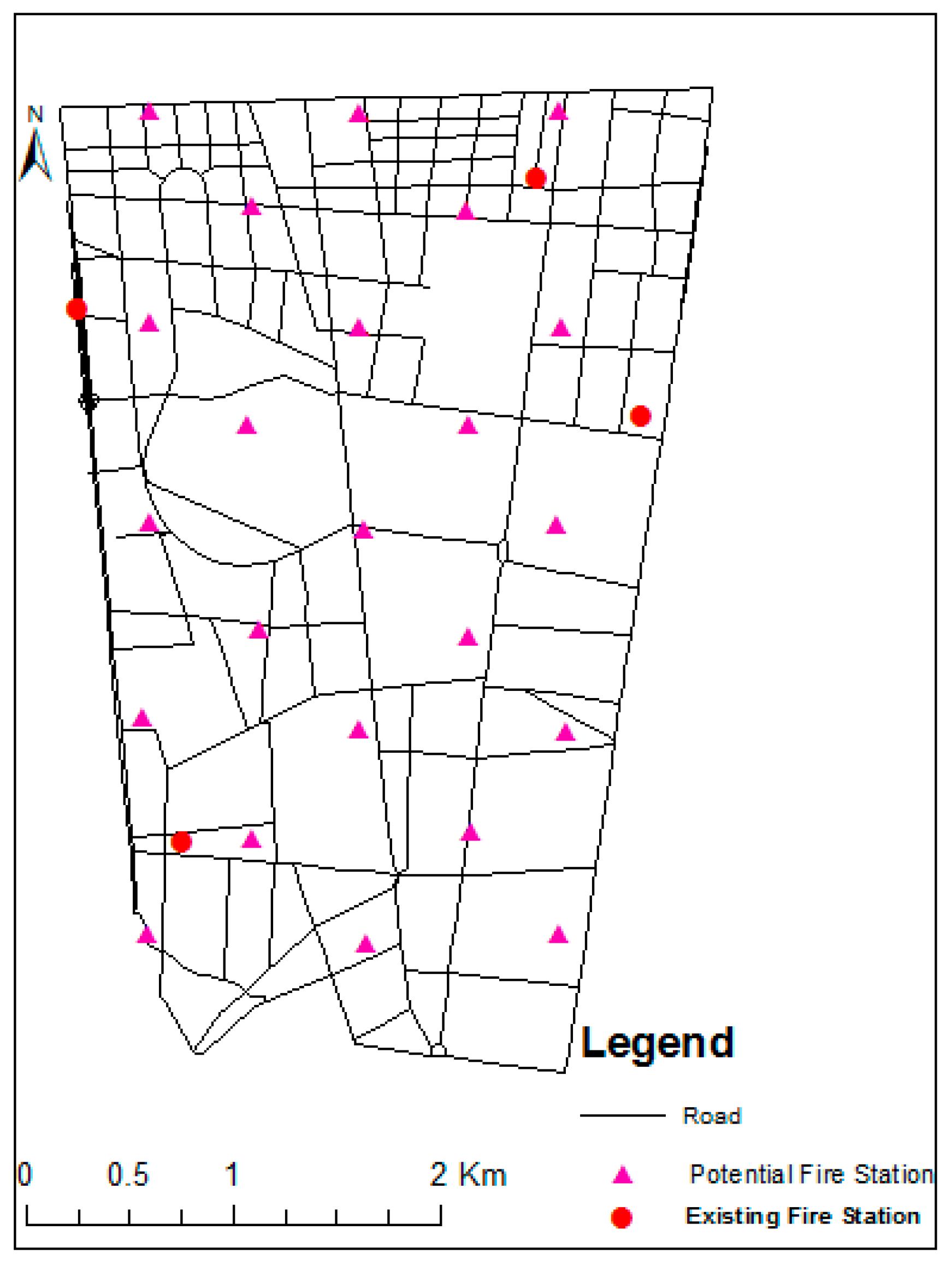
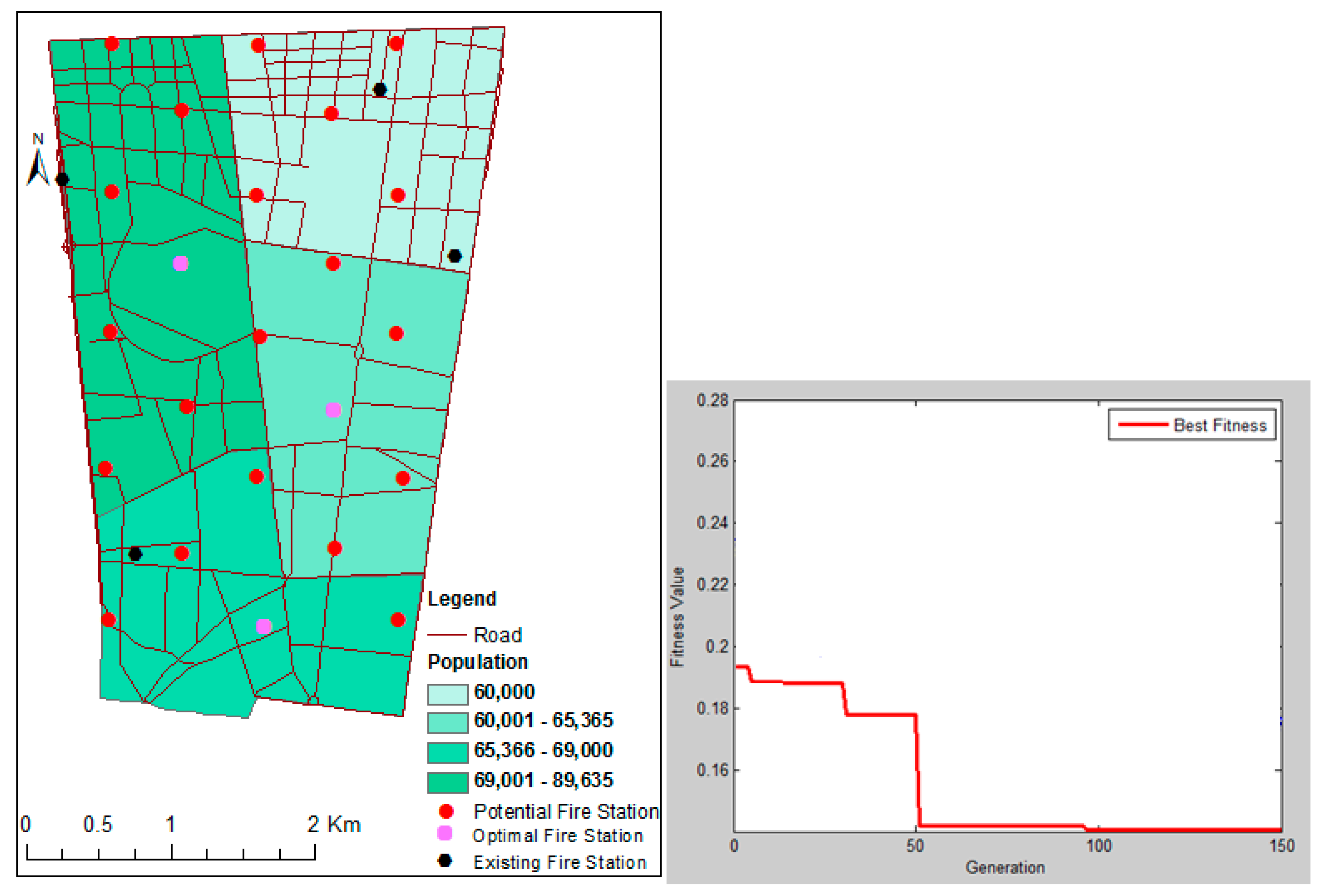
4.1. Study Area
4.2. Data
5. Results and Discussion
5.1. Sensitivity Analysis and Tuning the Model Parameters
5.2. Evaluation of the Algorithms
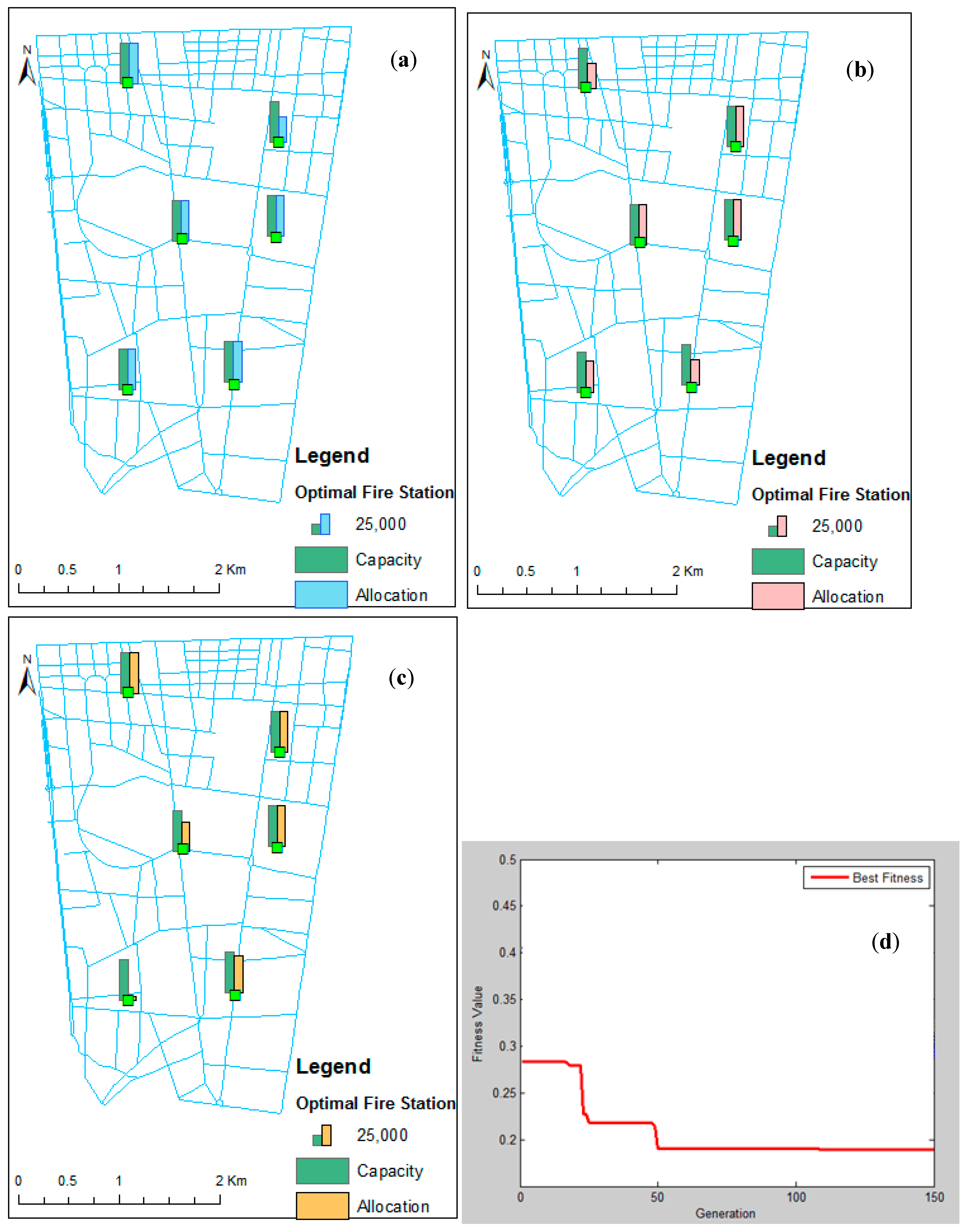
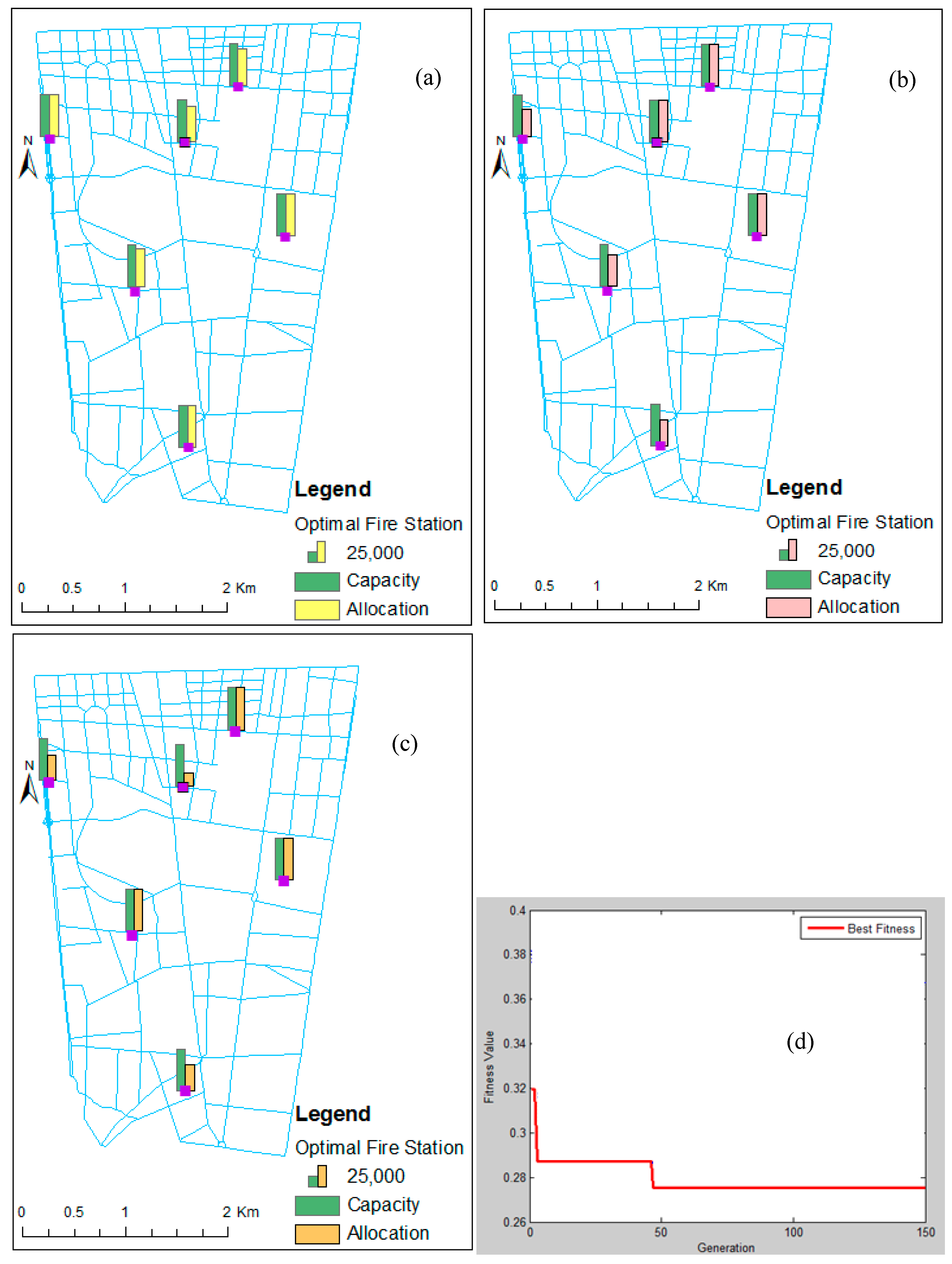
5.3. Implementation of Genetic Model in Case Study
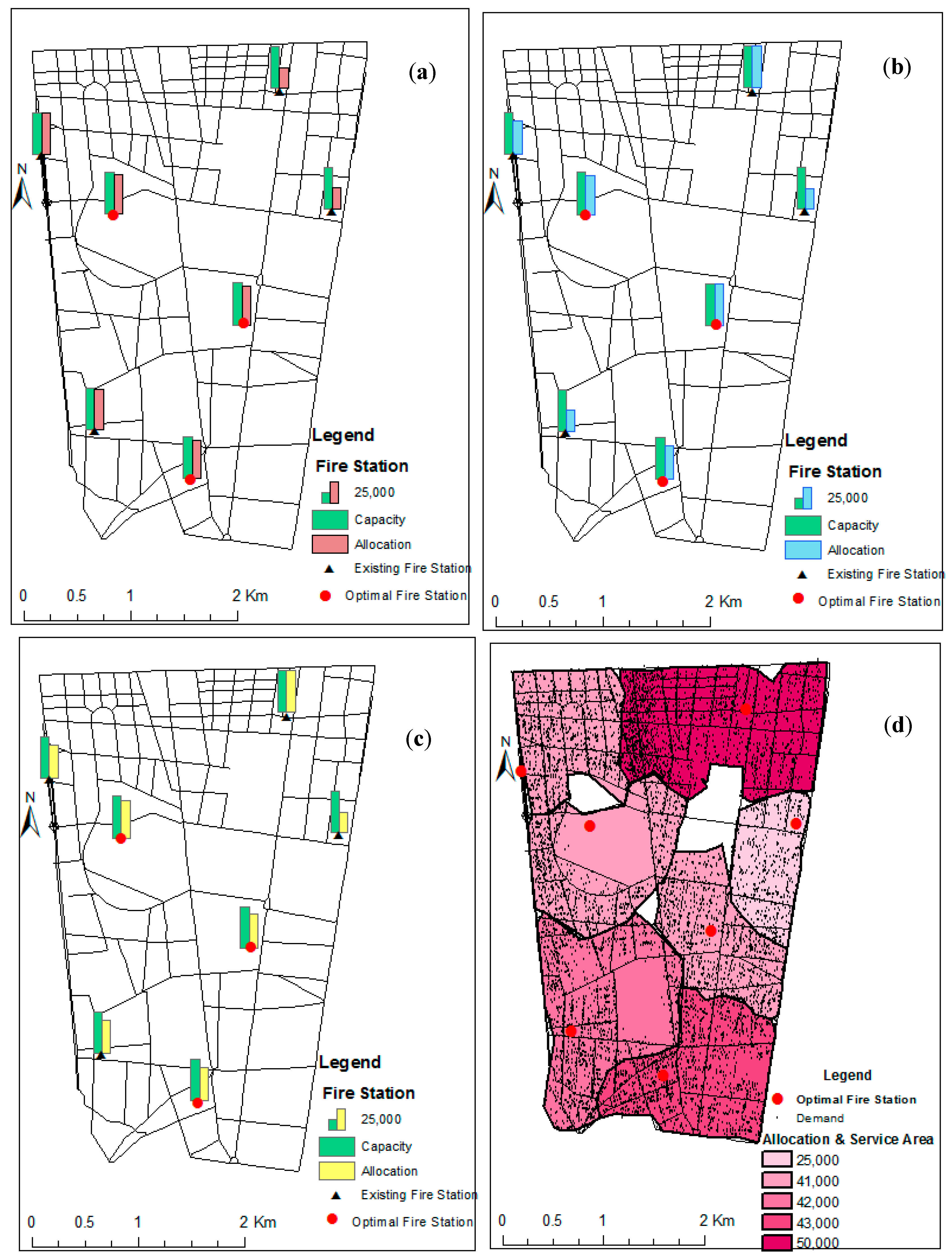
5.3.1. Increasing the Number of Fire Stations While Retaining Existing Fire Stations
5.3.2. Non-Dominated Solutions Retaining the Existing Fire Stations
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Macit, I. Solving fire department station location problem using modified binary genetic algorithm: A case study of Samsun in Turkey. Eur. Sci. J. 2015, 11, 10–25. [Google Scholar]
- Aghamohammadi, H.; Mesgari, M.; Molaei, D.; Aghamohammadi, H. Development a heuristic method to locate and allocate the medical centers to minimize the earthquake relief operation time. Iran. J. Public Health 2013, 42, 63–71. [Google Scholar] [PubMed]
- Saeedi Mehrabad, M.; Aazami, A.; Goli, A. A location-allocation model in the multi-level supply chain with multi-objective evolutionary approach. J. Ind. Syst. Eng. 2017, 10, 140–160. [Google Scholar]
- Storme, T.; Witlox, F. Location-Allocation models. In The International Encyclopedia of Geography; Wiley: Hoboken, NJ, USA, 2017. [Google Scholar]
- Xie, Y.; Runck, B.; Shekhar, S.; Kne, L.; Mulla, D.; Jordan, N.; Wiringa, P. Collaborative Geodesign and Spatial Optimization for Fragmentation-Free Land Allocation. ISPRS Int. J. Geo-Inf. 2017, 6, 226. [Google Scholar] [CrossRef]
- Zhu, Y.; Du, Q.; Tian, F.; Ren, F.; Liang, S.; Chen, Y. Location Optimization Using a Hierarchical Location-Allocation Model for Trauma Centers in Shenzhen, China. ISPRS Int. J. Geo-Inf. 2016, 5, 190. [Google Scholar] [CrossRef]
- Zuidgeest, M.; Brussel, M.; van Maarseveen, M. GIS for Sustainable Urban Transport. ISPRS Int. J. Geo-Inf. 2015, 4, 2583–2585. [Google Scholar] [CrossRef]
- Li, X.; Yeh, A. Integration of genetic algorithms and GIS for optimal location search. Int. J. Geogr. Inf. Sci. 2005, 19, 581–601. [Google Scholar] [CrossRef]
- Murray, A.; Tong, D. GIS and Spatial analysis in the media. Appl. Geogr. 2009, 29, 250–259. [Google Scholar] [CrossRef]
- Tsai, Y.; Chow-In Ko, P.; Huang, C.; Wen, T. Optimizing locations for the installation of automated external defibrillators (AEDs) in urban public streets through the use of spatial and temporal weighting schemes. Appl. Geogr. 2012, 35, 394–404. [Google Scholar] [CrossRef]
- Yin, P.; Mu, L. Modular capacitated maximal covering location problem for the optimal siting of emergency vehicles. Appl. Geogr. 2012, 34, 247–254. [Google Scholar] [CrossRef]
- Liu, C.M.; Kao, R.L.; Wang, A.H. Solving Location-Allocation problems with rectilinear distances by Simulated Annealing. J. Oper. Res. Soc. 1994, 45, 1304–1315. [Google Scholar] [CrossRef]
- Gonzalez-Monroy, L.I.; Cordoba, A. Optimization of energy supply systems: Simulated Annealing versus Genetic Algorithm. Int. J. Mod. Phys. C 2000, 11, 675–690. [Google Scholar] [CrossRef]
- Neema, M.N.; Ohgai, A. Multi-objective location modeling of urban parks and open spaces: Continuous optimization. Comput. Environ. Urban Syst. 2010, 34, 359–376. [Google Scholar] [CrossRef]
- Bashiri, M.; Bakhtiarifar, M.H. Finding the optimal location in a one-median network problem with correlated demands using simulated annealing. Sci. Iran. 2013, 20, 793–800. [Google Scholar]
- Yu, H.; Solvang, W. A multi-objective location-allocation optimization for sustainable management of municipal solid waste. Environ. Syst. Decis. 2017, 37, 289–308. [Google Scholar] [CrossRef]
- Ma, X.; Zhao, X. Land use allocation based on a multi-objective artificial immune optimization model: An application in Anlu County, China. Sustainability 2015, 7, 15632–15651. [Google Scholar] [CrossRef]
- Vafaeinezhad, A.; Alesheikh, A.; Nouri, J. Developing a spatio-temporal model of risk management for earthquake life detection rescue team. Int. J. Environ. Sci. Technol. 2010, 7, 243–250. [Google Scholar] [CrossRef]
- Zhou, G.; Min, H.; Gen, M. A genetic algorithm approach to the bi-criteria allocation of customers to warehouses. Int. J. Prod. Econ. 2003, 86, 35–45. [Google Scholar] [CrossRef]
- Duh, J.; Brown, D. Knowledge-informed pareto simulated annealing for multi-objective spatial allocation. Comput. Environ. Urban Syst. 2007, 31, 253–281. [Google Scholar] [CrossRef]
- Murata, T.; Ishibuchi, H.; Tanaka, H. Multi-objective genetic algorithm and its applications to flow shop scheduling. Comput. Ind. Eng. 1996, 30, 957–968. [Google Scholar] [CrossRef]
- Rakas, J.; Teodorović, D.; Kim, T. Multi-objective modeling for determining location of undesirable facilities. Transp. Res. Part D Transp. Environ. 2004, 9, 125–138. [Google Scholar] [CrossRef]
- Özcan, T.; Çelebi, N.; Esnaf, Ş. Comparative analysis of multi-criteria decision making methodologies and implementation of a warehouse location selection problem. Expert Syst. Appl. 2011, 38, 9773–9779. [Google Scholar] [CrossRef]
- Erkut, E.; Karagiannidis, A.; Perkoulidis, G.; Tjandra, S.A. A multicriteria facility location model for municipal solid waste management in North Greece. Eur. J. Oper. Res. 2008, 182, 1402–1421. [Google Scholar] [CrossRef]
- Lei, T.; Church, R. Vector assignment ordered median problem: A unified median problem. Int. Reg. Sci. Rev. 2012, 37, 194–224. [Google Scholar] [CrossRef]
- Maliszewski, P.; Kuby, M.; Horner, M. A comparison of multi-objective spatial dispersion models for managing critical assets in urban areas. Comput. Environ. Urban Syst. 2012, 36, 331–341. [Google Scholar] [CrossRef]
- Erden, T.; Coskun, M.Z. Multi criteria site selection for fire services: The interaction with analytic hierarchy process and geographic information systems. Nat. Hazards Earth Syst. Sci. 2010, 10, 2127–2134. [Google Scholar] [CrossRef]
- Melanie, M. An Introduction to Genetic Algorithms; Fifth Printing; MIT Press: Cambridge, MA, USA; London, UK, 1999. [Google Scholar]
- Didier Lins, I.; López Droguett, E. Redundancy allocation problems considering systems with imperfect repairs using multi-objective genetic algorithms and discrete event simulation. Simul. Model. Pract. Theory 2011, 19, 362–381. [Google Scholar] [CrossRef]
- Shamsul Arifin, M.D. Location Allocation Problem Using Genetic Algorithm and Simulated Annealing: A Case Study Based on School in Enschede. Master’s Thesis, Department of Geo-information Science and Earth Observation, University of Twente, Enschede, The Netherlands, 2011. [Google Scholar]
- Liu, N.; Huang, B.; Chandramouli, M. Optimal Siting of Fire Stations Using GIS and ANT Algorithm. J. Comput. Civ. Eng. 2006, 20, 361–369. [Google Scholar] [CrossRef]
- Srinivas, C.; Ramgopal Reddy, B.; Ramji, K.; Naveen, R. Sensitivity analysis to determine the Parameters of genetic algorithm for machine layout. Procedia Mater. Sci. 2014, 6, 866–876. [Google Scholar] [CrossRef]
- Wang, K.; Makond, B.; Liu, S.Y. Location and Allocation decisions in a two-echelon supply chain with stochastic demand-A Genetic-Algorithm based solution. Expert Syst. Appl. 2011, 38, 6125–6131. [Google Scholar] [CrossRef]
- Murray, A.; Church, R. Applying simulated annealing to location-planning models. J. Heuristics 1996, 2, 31–53. [Google Scholar] [CrossRef]
- Manikas, T.; Cain, J. Genetic Algorithms vs. Simulated Annealing: A Comparison of Approaches for Solving the Circuit Partitioning Problem; Technical Report: 96-101; Computer Science and Engineering, University of Pittsburg: Pittsburgh, PA, USA, 1996. [Google Scholar]
- Vafaeinezhad, A.; Alesheikh, A.; Hamrah, M.; Nourjou, R.; Shad, R. Using GIS to develop an efficient Spatio-temporal task allocation algorithm to human groups in an entirely dynamic environment case study: Earthquake rescue teams. In Proceedings of the Computational Science and Its Applications ICCSA 2009, Seoul, Korea, 29 June–2 July 2009; pp. 66–78. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Crossover | Mutation | Pop Size | Fitness |
|---|---|---|---|
| Data set 1 | |||
| 0.4 | 0.1 | 10 | 0.2009 |
| 0.2 | 0.1921 | ||
| 0.3 | 0.1925 | ||
| 0.4 | 0.1889 | ||
| 0.5 | 0.1 | 10 | 0.2099 |
| 0.2 | 0.2108 | ||
| 0.3 | 0.2217 | ||
| 0.4 | 0.2011 | ||
| 0.6 | 0.1 | 10 | 0.2099 |
| 0.2 | 0.2094 | ||
| 0.3 | 0.2092 | ||
| 0.4 | 0.2001 | ||
| 0.7 | 0.1 | 10 | 0.2148 |
| 0.2 | 0.2155 | ||
| 0.3 | 0.2287 | ||
| 0.4 | 0.1999 | ||
| 0.8 | 0.1 | 10 | 0.2148 |
| 0.2 | 0.2196 | ||
| 0.3 | 0.2199 | ||
| 0.4 | 0.2019 | ||
| 0.9 | 0.1 | 10 | 0.2542 |
| 0.2 | 0.2012 | ||
| 0.3 | 0.2227 | ||
| 0.4 | 0.2007 | ||
| Data set 2 | |||
| 0.4 | 0.1 | 20 | 0.2109 |
| 0.2 | 0.1995 | ||
| 0.3 | 0.1984 | ||
| 0.4 | 0.1971 | ||
| 0.5 | 0.1 | 20 | 0.2198 |
| 0.2 | 0.2199 | ||
| 0.3 | 0.2200 | ||
| 0.4 | 0.1993 | ||
| 0.6 | 0.1 | 20 | 0.2195 |
| 0.2 | 0.2191 | ||
| 0.3 | 0.2201 | ||
| 0.4 | 0.2001 | ||
| 0.7 | 0.1 | 20 | 0.2455 |
| 0.2 | 0.2222 | ||
| 0.3 | 0.2280 | ||
| 0.4 | 0.2021 | ||
| 0.8 | 0.1 | 20 | 0.2317 |
| 0.2 | 0.2264 | ||
| 0.3 | 0.2266 | ||
| 0.4 | 0.2017 | ||
| 0.9 | 0.1 | 20 | 0.2431 |
| 0.2 | 0.2132 | ||
| 0.3 | 0.2241 | ||
| 0.4 | 0.2019 |
| Initial Temperature | Cooling Rate | Fitness |
|---|---|---|
| Data set 1 | ||
| 50 | 0.8 | 0.3222 |
| 0.9 | 0.3015 | |
| 0.95 | 0.3110 | |
| 100 | 0.8 | 0.2914 |
| 0.9 | 0.2999 | |
| 0.95 | 0.2814 | |
| Data set 2 | ||
| 200 | 0.8 | 0.2805 |
| 0.9 | 0.2807 | |
| 0.95 | 0.2799 | |
| 300 | 0.8 | 0.2791 |
| 0.9 | 0.2774 | |
| 0.95 | 0.2764 |
| Model | Time (min) | Fitness |
|---|---|---|
| SA | 10.46 | 0.2771 |
| GA | 5.41 | 0.1892 |
| Data Set | ||||
|---|---|---|---|---|
| 1 | 0.210017 | 0.000188 | 0.301233 | 0.012312 |
| 2 | 0.216258 | 0.000187 | 0.279000 | 0.019462 |
| Run | Min Dist (m) | Max Dist (m) | Sum | Demand Allocations of f3 | Number of Solutions | |||
|---|---|---|---|---|---|---|---|---|
| 1 | 0.1537 | 0.0081 | 0.5576 | 1019.776 | 2625.404 | −0.3024 | 274,253 | 10 |
| 0.0145 | 0.0238 | 0.4922 | 993.009 | 1738.385 | 254,578 | |||
| 0.2622 | 0.0006 | 0.3068 | 1061.513 | 2309.535 | 258,854 | |||
| 0.0005 | 0.2376 | 0.3635 | 973.342 | 2625.404 | 264,658 | |||
| 0.0934 | 0.0202 | 0.6232 | 1022.032 | 2625.404 | 274,589 | |||
| 0.1756 | 0.0027 | 0.3636 | 1002.435 | 1839.701 | 249,858 | |||
| 0.0033 | 0.0849 | 0.6478 | 1047.78 | 2309.535 | 274,548 | |||
| 0.0045 | 0.0244 | 0.6163 | 1047.78 | 1794.085 | 270,001 | |||
| 0.5262 | 0.0005 | 0.0993 | 782.465 | 2025.198 | 252,157 | |||
| 0.0492 | 0.0419 | 0.6825 | 635.148 | 2913.485 | 276,671 | |||
| 2 | ------- | ------- | ------- | ------- | ------- | −0.2852 | ------- | 7 |
| 3 | ------- | ------- | ------- | ------- | ------- | −0.2820 | ------- | 9 |
| 4 | ------- | ------- | ------- | ------- | ------- | −0.2334 | ------- | 17 |
| 5 | 0.0140 | 0.0771 | 0.6456 | 983.523 | 2875.103 | −0.3437 | 278,621 | 17 |
| 0.0248 | 0.0606 | 0.5994 | 990.272 | 1941.282 | 271,894 | |||
| 0.0005 | 0.1846 | 0.4826 | 1098.580 | 1941.282 | 269,995 | |||
| 0.1343 | 0.0001 | 0.3958 | 661.675 | 2625.404 | 248,444 | |||
| 0.1000 | 0.0061 | 0.4351 | 661.675 | 2625.404 | 256,841 | |||
| 0.0418 | 0.0482 | 0.4703 | 661.675 | 2309.535 | 259,654 | |||
| 0.1133 | 0.0098 | 0.4802 | 661.675 | 2309.535 | 269,415 | |||
| 0.0711 | 0.0447 | 0.4355 | 661.675 | 2309.535 | 280,000 | |||
| 0.0503 | 0.0474 | 0.4514 | 635.148 | 2309.535 | 259,587 | |||
| 0.0002 | 0.2447 | 0.2358 | 1022.032 | 2625.404 | 262,356 | |||
| 0.0857 | 0.0136 | 0.4546 | 928.856 | 2625.404 | 262,221 | |||
| 0.1086 | 0.0354 | 0.4566 | 585.251 | 2937.662 | 262,549 | |||
| 0.0841 | 0.0373 | 0.4587 | 585.251 | 2937.662 | 266,425 | |||
| 0.0131 | 0.1456 | 0.5803 | 585.251 | 2625.404 | 275,527 | |||
| 0.0000 | 0.2508 | 0.3526 | 585.251 | 2625.404 | 277,458 | |||
| 0.0120 | 0.0780 | 0.5754 | 585.251 | 2625.404 | 276,457 | |||
| 0.0995 | 0.0502 | 0.6200 | 585.251 | 2937.662 | 275,248 | |||
| 6 | ------- | ------- | ------- | ------- | ------- | −0.1496 | ------- | 10 |
| 7 | ------- | ------- | ------- | ------- | ------- | −0.3346 | ------- | 8 |
| 8 | ------- | ------- | ------- | ------- | ------- | −0.1648 | ------- | 16 |
| 9 | ------- | ------- | ------- | ------- | ------- | −0.3434 | ------- | 7 |
| 10 | ------- | ------- | ------- | ------- | ------- | −0.1996 | ------- | 10 |
| Min | # of Execution | Max | # of Execution | |
|---|---|---|---|---|
| 0 | 5 | 0.5262 | 1 | |
| 0 | 10 | 0.4808 | 6 | |
| −0.6825 | 1 | −0.0477 | 4 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bolouri, S.; Vafaeinejad, A.; Alesheikh, A.A.; Aghamohammadi, H. The Ordered Capacitated Multi-Objective Location-Allocation Problem for Fire Stations Using Spatial Optimization. ISPRS Int. J. Geo-Inf. 2018, 7, 44. https://doi.org/10.3390/ijgi7020044
Bolouri S, Vafaeinejad A, Alesheikh AA, Aghamohammadi H. The Ordered Capacitated Multi-Objective Location-Allocation Problem for Fire Stations Using Spatial Optimization. ISPRS International Journal of Geo-Information. 2018; 7(2):44. https://doi.org/10.3390/ijgi7020044
Chicago/Turabian StyleBolouri, Samira, Alireza Vafaeinejad, Ali Asghar Alesheikh, and Hossein Aghamohammadi. 2018. "The Ordered Capacitated Multi-Objective Location-Allocation Problem for Fire Stations Using Spatial Optimization" ISPRS International Journal of Geo-Information 7, no. 2: 44. https://doi.org/10.3390/ijgi7020044
APA StyleBolouri, S., Vafaeinejad, A., Alesheikh, A. A., & Aghamohammadi, H. (2018). The Ordered Capacitated Multi-Objective Location-Allocation Problem for Fire Stations Using Spatial Optimization. ISPRS International Journal of Geo-Information, 7(2), 44. https://doi.org/10.3390/ijgi7020044