1. Introduction
Multi-temporal remote sensing data can be used to describe changes in vegetation characteristics over time [
1,
2,
3], and these data have been employed to produce crop distributions from regional to national scales using both, supervised and unsupervised classifiers [
4,
5,
6,
7,
8,
9,
10]. Moreover, the crop maps are the foundation for crop modeling, irrigation water distributions and land water management, which are important for decision makers [
11,
12,
13,
14,
15]. However, most of the previous studies relied on the field reference data in the mapping year to train the classifiers [
16,
17]. When the cropland map need to be provided on yearly basis, the ground-reference data will be collected at annual frequency, which leads to considerable financial, time and labor costs [
18]. In addition, national or local authorities do not pay much attention to collecting ground-reference data sometimes, which lead to the difficulties in obtaining the ground reference data annually [
19].
In areas with a stable cropping system, phenological metrics of the same specific crop are usually more similar than that of different crops among multi-years [
18,
20,
21]. Thus, vegetation indices (VI), such as Normalized Difference Vegetation Index (NDVI) and Enhanced Vegetation Index (EVI), time series and the phenological metrics extracted from the VI time series have been used to transfer the knowledge of training samples from one year to another [
21,
22,
23,
24,
25]. On the one hand, coarse spatial resolution data (such as Advanced Very High Resolution Radiometer, AVHRR and Moderate Resolution Imaging Spectroradiometer, MODIS), which are characterized by density temporal resolution, have shown the potential to identify crop types using the classification model built from the adjacent years [
21], whereas a drawback is the relatively coarse spatial resolution cannot discriminate crop types in heterogeneous landscape [
26,
27,
28,
29]. Some pixel unmixing attempts, which are based on both linear and non-linear regression principles, have been proposed to solve this situation [
30,
31,
32,
33], but there are still some limitations: (1) the unmixing approaches can solely derive sub-pixel fractions of crop area in a pixel, and hardly provide the crop distribution within the pixel; (2) the VI profiles of some crops maybe too similar to be reliably separated; and (3) if the endmembers were extracted across multiple years, the inter-annual differences will result in the variable temporal signatures of endmembers of the same crop [
30].
On the other hand, the image time series at finer spatial resolution, such as Landsat Thematic Mapper (TM) and Satellite Pour l’Observationde la Terre (SPOT), have shown the potential to discriminate crops [
5,
15,
34]. Note that there have been some attempts at identifying crop types without ground reference data of the classification year using the spectrum at specific phenological periods [
22,
23]. The limitation of these methods is that they have to extract phenological metrics using high resolution image time series (such as Landsat) in the classification year, which result in the difficulty of the application of these methods in large area for the following reasons: (1) within one year, it is difficult to obtain cloud-free image time series that are dense enough to extract phenological metrics in large areas by a single sensor (such as Landat 5); and (2) although the temporal resolution of the image time series can be improved by combining the data from multi-sensor [
35,
36], the radiometric differences among different sensors may have negative influence on the accuracy of the phenological metrics [
37].
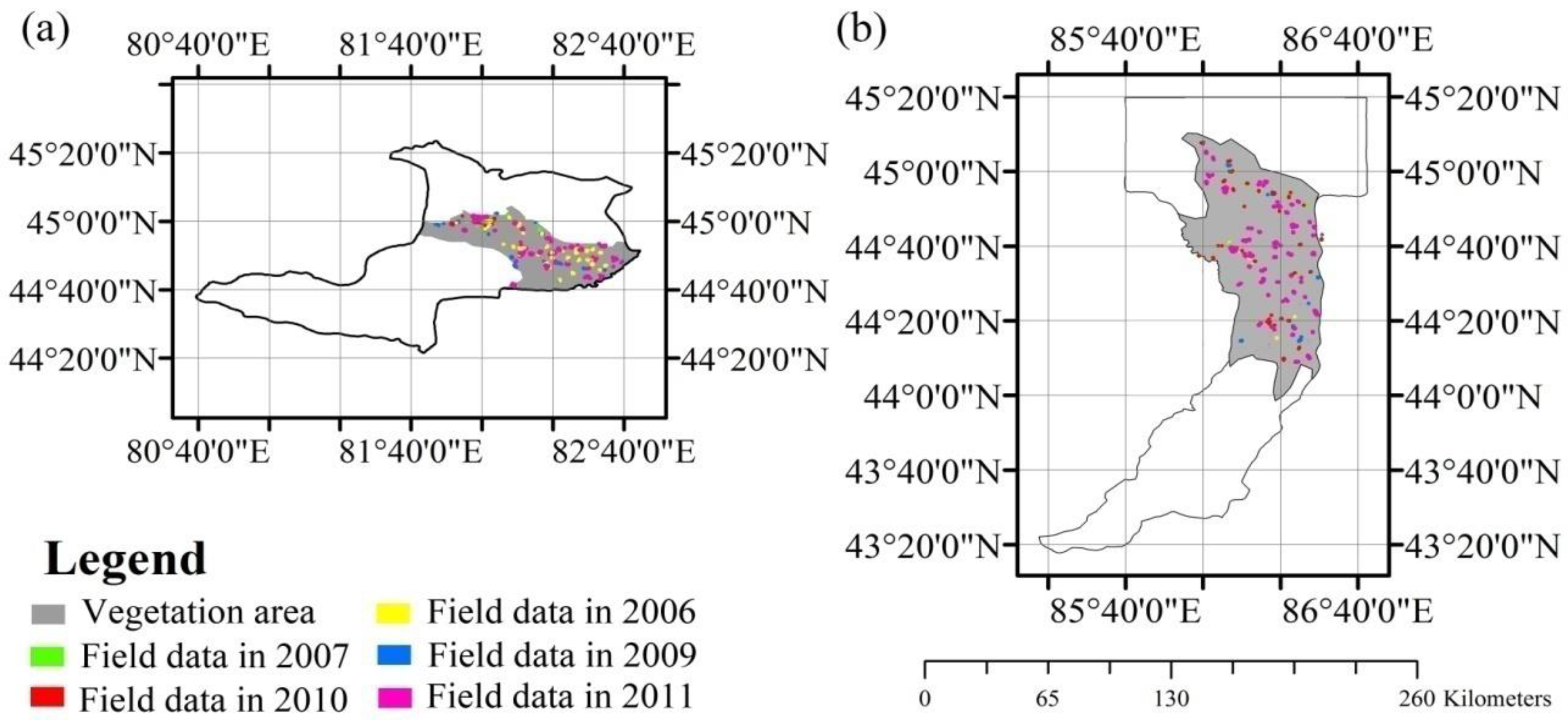
The objective of this study is to propose a method and classify crop types at high resolution (30 m) without the use of the ground reference samples in the classification year. To achieve this purpose, we combined the advantages of both moderate resolution (MODIS) and high resolution (Landsat and Huan Jing) data. First, we acquired the historical ground reference data of multiple years (2006, 2007, 2009 and 2010); the NDVI profiles of the crops were extracted from MODIS NDVI time series using historical ground reference data; and reference NDVI time series were then obtained from the historical NDVI profiles. Afterwards, the linear relations between Landsat/HJ NDVI and MODIS NDVI during the entire crop-growing season were obtained, and the reference NDVI time series were transformed using the linear relations. Finally, the transformed reference NDVI time series were utilized to identify crop types at 30 m resolution.
3. Methods
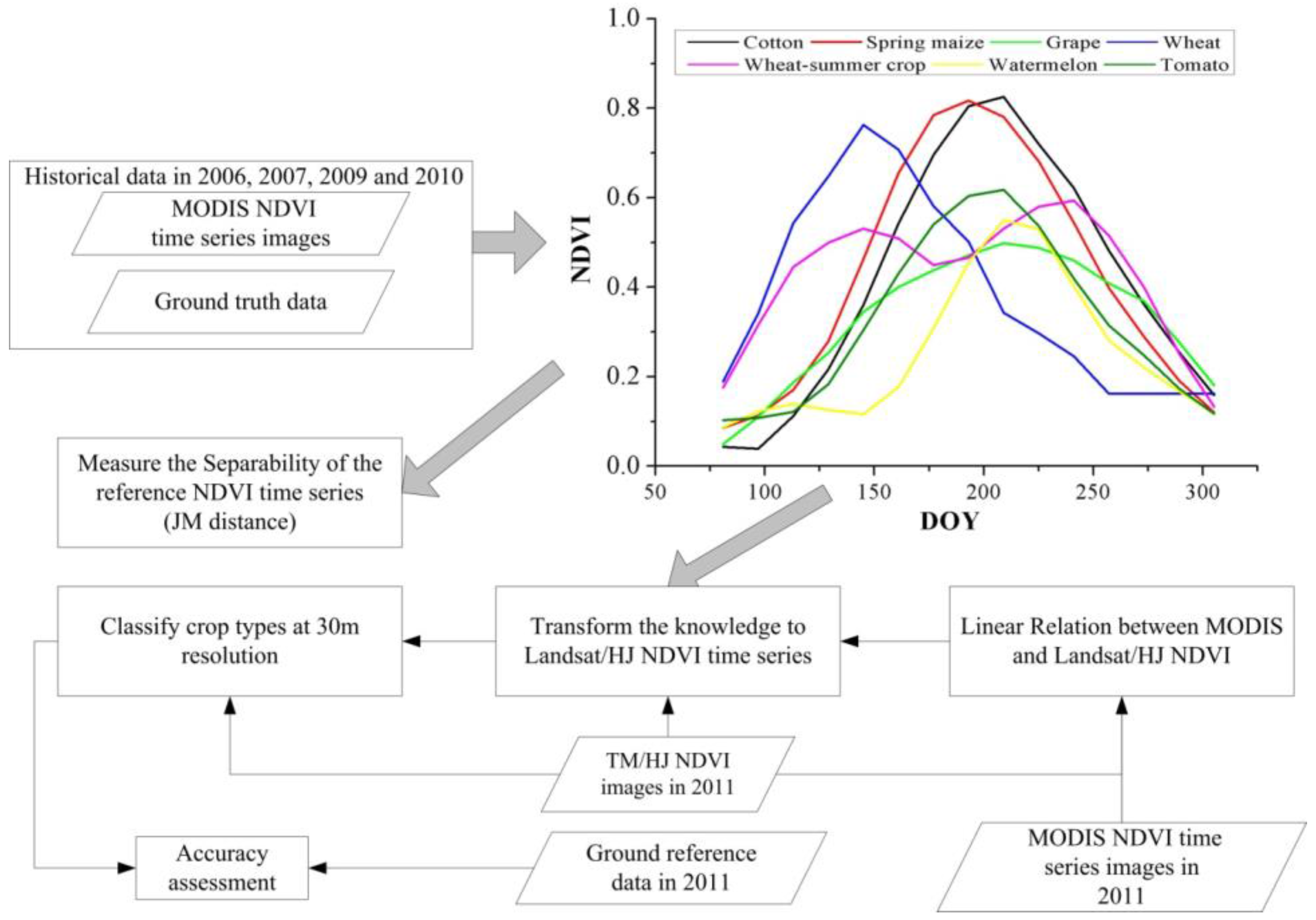
The methodology of the study was presented in
Figure 4. This study was composed of six main parts: (1) extracting NDVI time series profiles from MODIS data using ground reference data in 2006, 2007, 2009 and 2010; (2) building historical reference NDVI time series (between 2006 and 2010) for each crop using ABNet based on the historical NDVI time series profiles, and measuring the separability of reference NDVI for crop classification; (3) using Landsat-5 TM and HJ data to build multi-source NDVI time series at 30 m resolution in 2011; (4) testing the linear relationship between Landsat/HJ and MODIS NDVI, and then transforming the reference NDVI time series using the linear relation; (5) using the transformed reference time series to classify crop types at 30 m spatial resolution; and (6) assessing classification accuracy. Additionally, the classification accuracy was compared with the result derived from ground-reference data of 2011.
3.1. Artificial Antibody Network
The Artificial Antibody Network (ABNet) was proposed by Zhong and Zhang [
42] based on artificial immune network principles (AIN). The antibody model was used as the basic component for the ABNet and each antibody contained three attributes: the crop type of the antibody, center vector and the recognizing radius. The ABNet have two procedures: training and classification. During the training procedure, the training antigens were used as input of the ABNet, and the antibodies were obtained. Then, in the classification procedure, the antibodies were used to identify new antigens.
The training procedure of the ABNet contained five steps for each class: pre-selection, cloning, mutation, adaptive calculation of new antibodies and antibody reorganization. The detailed training process can be found in work of Zhong and Zhang [
42]. While training the ABNet, an important issue was to select a similarity measure, and we used Euclidean distance (Equation (2)) [
43], which can easily measure the similarity in the training process:
where
and
are the values of time series a and b at moment t, respective, and N is the number of samples in the time series. Moreover, the ABNet can build up a network and guarantee its convergence adaptively, and no more parameters need further optimized.
The classification procedure was to calculate the Euclidean distance between vector of a new antigen and the center vector of each antibody, and the new antigen was labeled as the crop type of the antibody with the minimum distance if the minimum distance was less than the recognizing radius of the antibody. Otherwise, the spectral angle (Equation (3)) was calculated between the vector of the new antigen and the center vector of the antibodies [
44], and the antigen was labeled as the crop type of antibody with the minimum spectral angle.
We employed ABNet in this study to build the reference NDVI time series for each crop because ABNet can adaptively build up the network and guarantee its convergence without any parameters. In addition, one crop type can contain many antibodies, and the ABNet could recognize different distinctive patterns that are suitable for identifying the same crop in different situations with variable NDVI time series. In this study, the ABNet was interpreted in IDL.
3.2. Building the Reference NDVI Time Series for the Crops
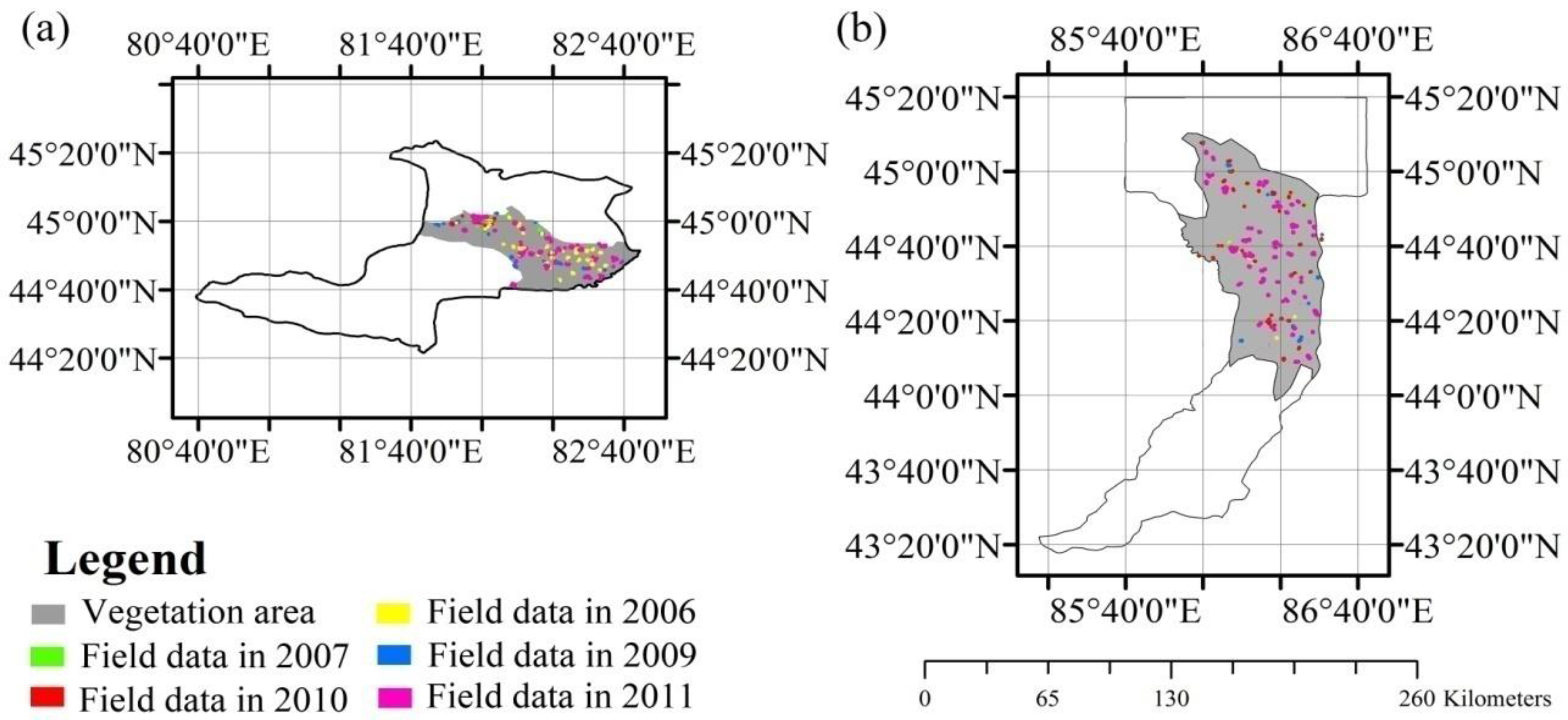
We used the ABNet to build the reference NDVI time series. First, we extracted the NDVI time series from the ground reference samples of both Bole and Manas. Then, all historical NDVI profiles were used as input of the ABNet training process, and the antibodies were then obtained. The center vectors of the antibodies were the reference NDVI time series for each crop type, and multiple reference NDVI time series profiles were obtained to describe the same crop under different conditions.
3.3. Measuring the Separability of Reference NDVI Time Series
In this study, we used the Jeffries-Matusita (JM) distance to measure the separability of the reference NDVI time series for each pair of crops because previous studies showed that JM distance could better measure the separability among different classes than other distances, such as Euclidean distance or divergence [
41,
45]. The JM distance between a pair of class and specific functions was given by:
where x denotes a span of VI time series values and
and
(lowercase c) denote the two crop classes under consideration. Under normality assumptions, Equation (2) was reduced to
, where:
and
and
(uppercase C) are the covariance matrixes of class i and j, respectively. Additionally,
and
are the determinants of
and
, respectively. The JM distance ranged from 0 to 2, with a large value indicating a high level of separability between two classes [
46].
3.4. Testing the Relation between MODIS and Landsat/HJ NDVI
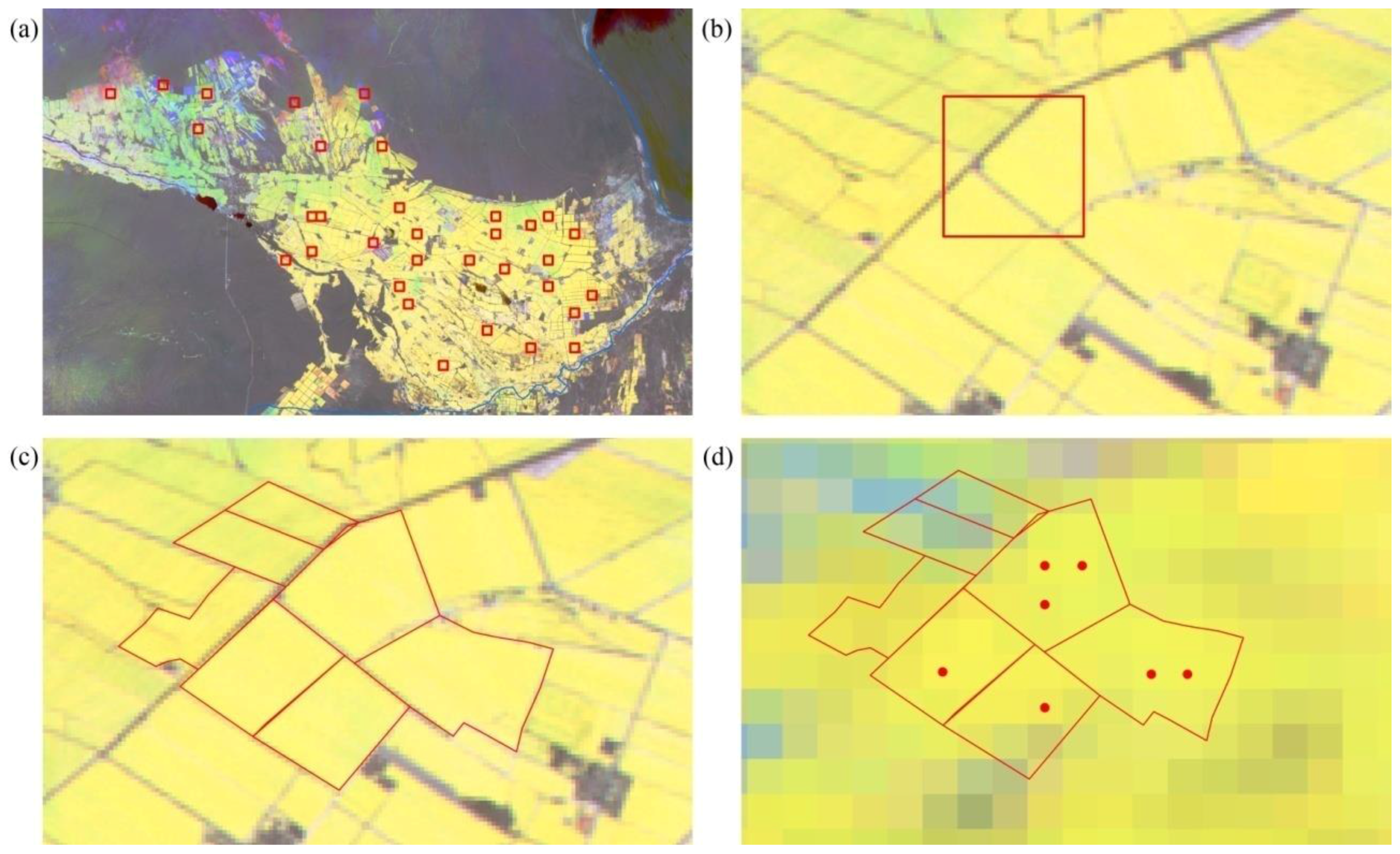
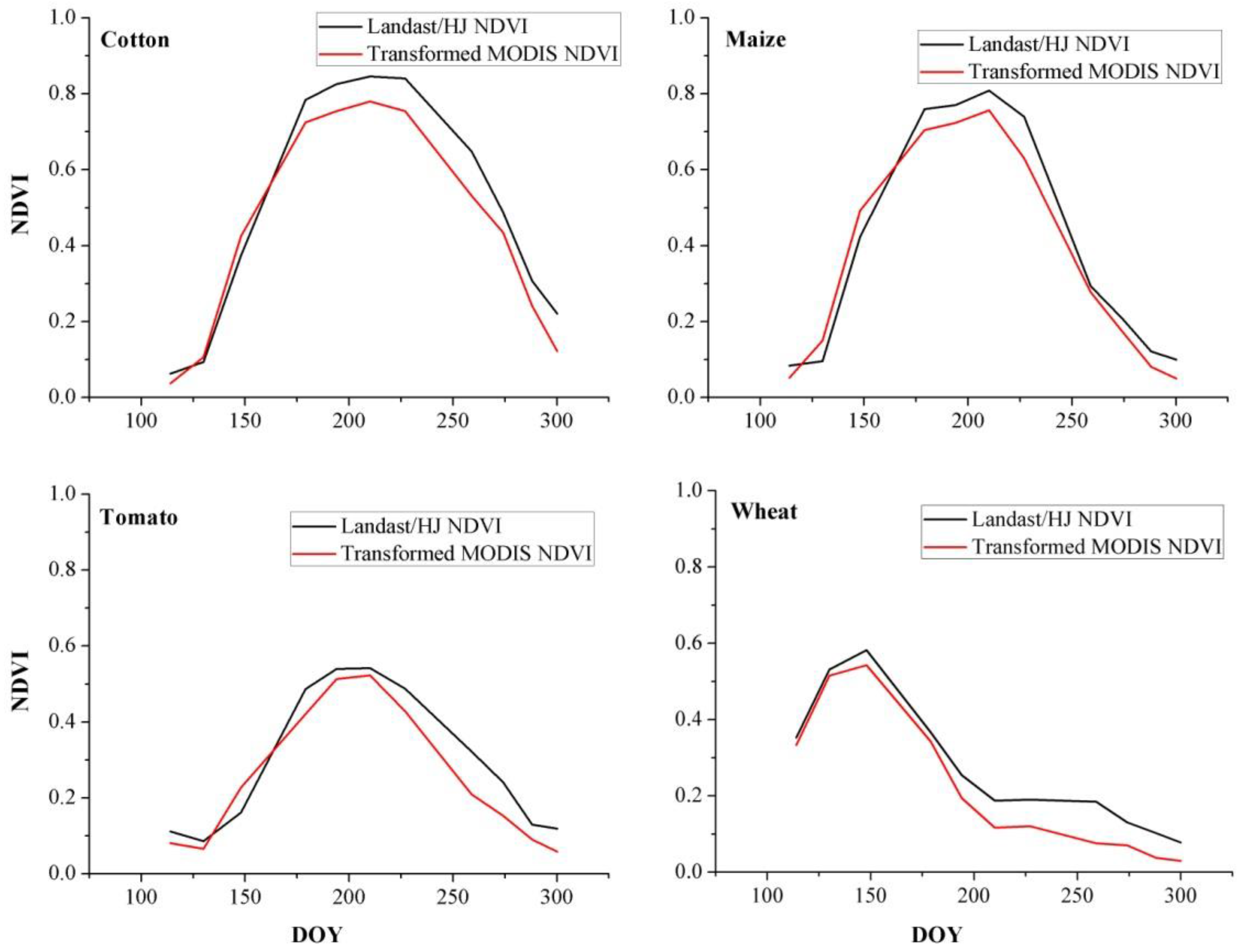
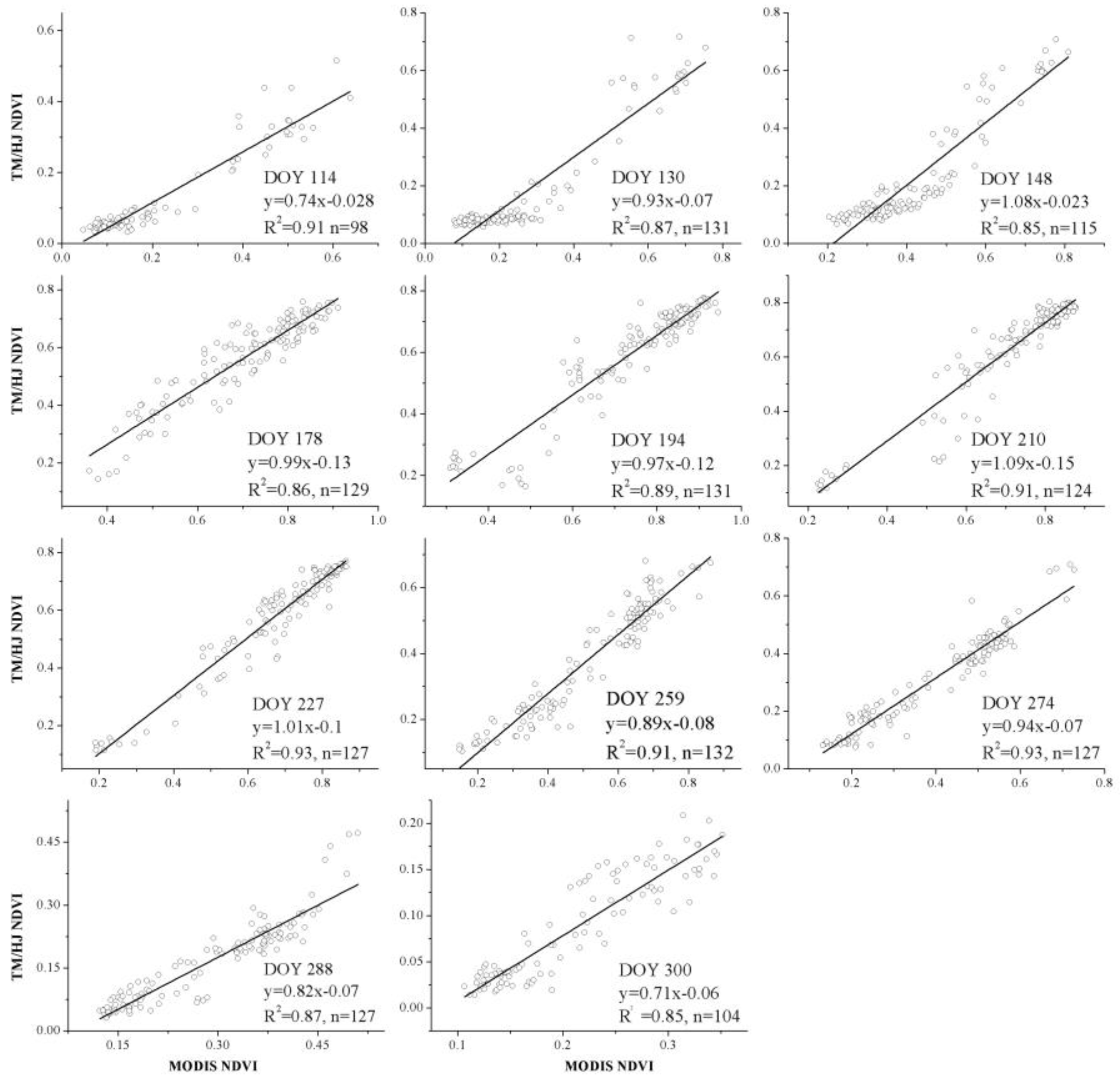
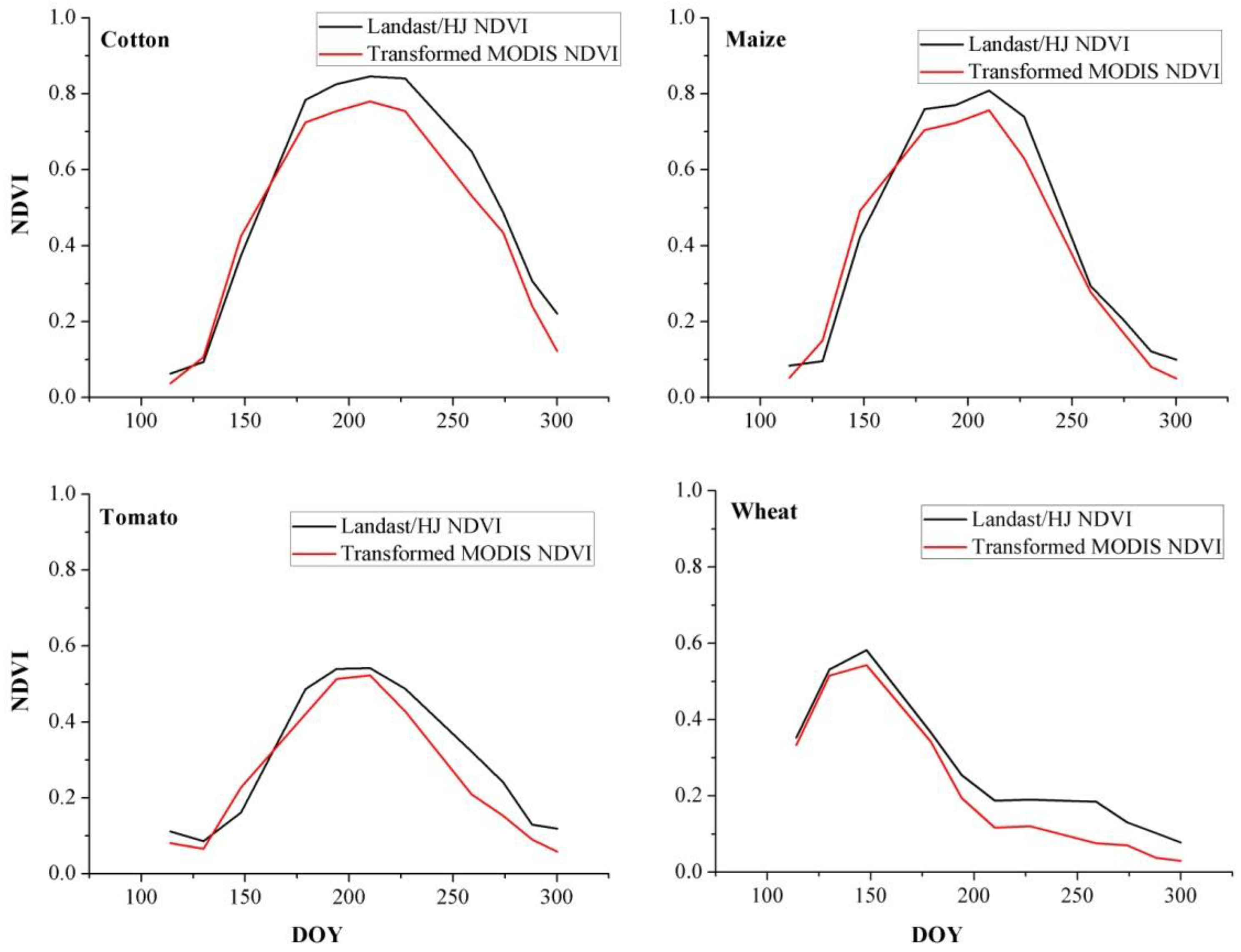
We combined the Landsat-5 TM and HJ-1 NDVI in 2011 to increase the temporal resolution of NDVI time series at 30 m resolution. For each Landsat TM/HJ CCD NDVI image, we selected the MODIS image whose temporal flag is the nearest to the date that Landsat TM/HJ CCD images were acquired. When testing the relationship between Landsat TM/HJ CCD NDVI and MODIS NDVI, the samples were selected in homogenous crop fields, and the average NDVI of all Landsat TM/HJ CCD pixels to the corresponding MODIS pixel were calculated. Coinciding with some previous studies, Landsat TM/HJ CCD NDVI and MODIS NDVI showed strong linear relationships (
R2 > 0.8 in
Figure 5 and
Figure 6) [
37,
47,
48]. Then, all reference NDVI time series were transformed to Landsat/HJ NDVI using corresponding linear relation, and the transformed reference NDVI time series were used to identifying crop types in the next step.
3.5. Crop Classification at 30 m Resolution
We first masked the non-agricultural area using the “agriculture land” of Finer Resolution Observation and Monitoring of Global Land Cover (FROM-GLC) at 30 m spatial resolution [
49]. Before the masking, we randomly selected 300 validation pixels in both study regions using Hawths Tools [
50]; all validation samples were visually interpreted as crop/non-crop (
Table 6), and these validation samples were used to verify the accuracy of the crop mask. The overall accuracies were above 90% for both study areas, which indicated that the crop mask of both study regions were accurate enough to mask non-crop area. Next, we classified the crops at 30 m resolution using the transformed reference NDVI time series by the classification procedure of ABNet. In addition, we used a portion of the ground-reference data as training samples to classify the agricultural area for comparison. The classifier was also ABNet.
4. Results
4.1. Reference NDVI Time Series
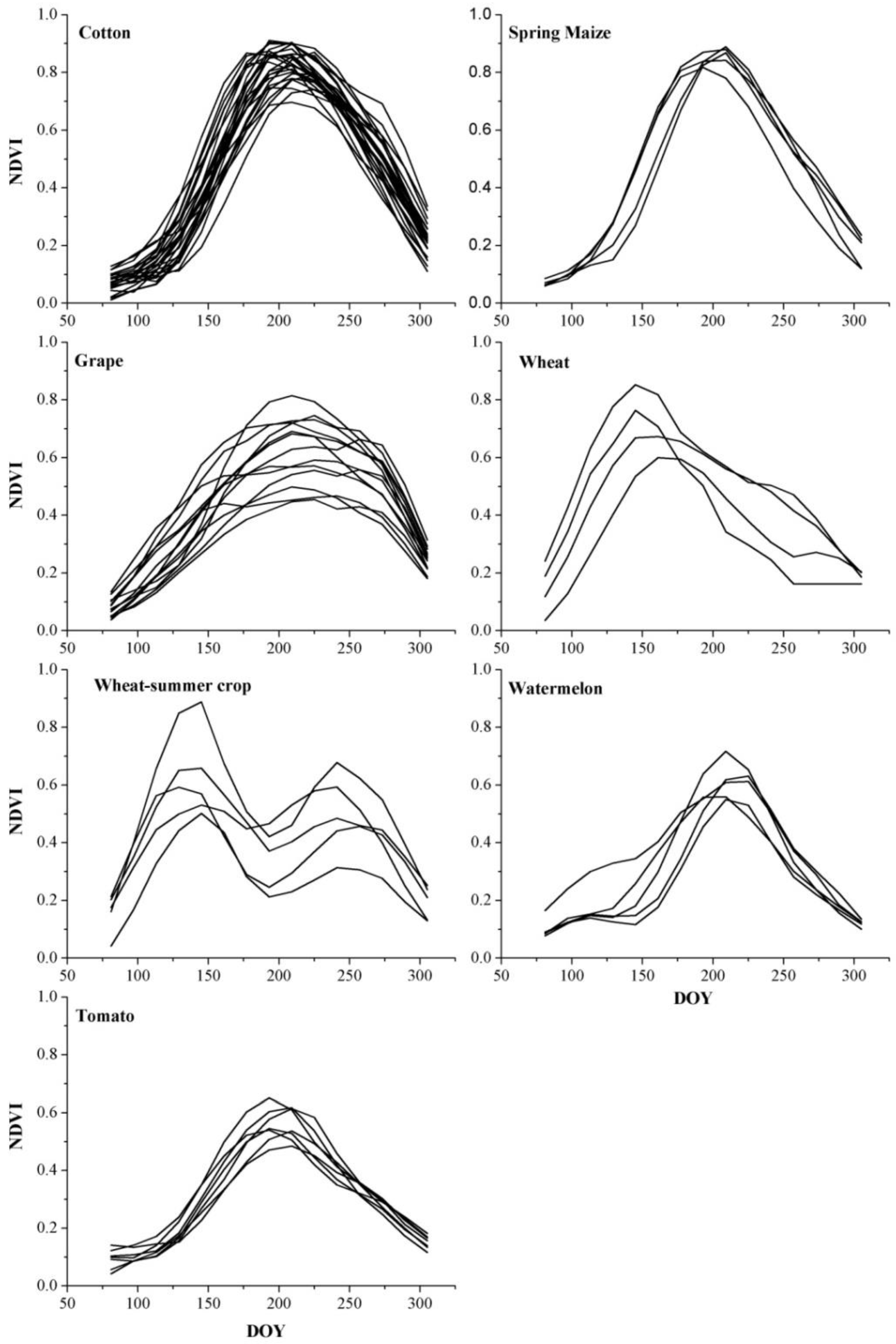
For each crop type, the reference NDVI time series were plotted in
Figure 7. Among the summer crops, cotton was the major crop type in the study region, and had the largest amount of reference NDVI time series among all crops. The highest NDVI value of cotton was between 0.75 and 0.9 around Day 190 (late July). For spring maize, the highest value was similar to cotton, but after the peak, NDVI of spring maize decreased faster than cotton, and at around Day 250 (September), NDVI of spring maize was relatively lower than cotton. Tomato also had the highest NDVI around Day 190, but the NDVI value was between 0.5 and 0.6, which was significantly lower than cotton and spring maize. For grape, NDVI was high during Days 170–250 (from late June to early September). In addition, the variability of grape was the largest among all crops in the study region (between 0.4 and 0.7). Another summer crop was watermelon, which had a relatively short growing season, with NDVI peak at around Day 210 (late July). The major winter crop in the study areas was winter wheat, the time period of high NDVI (above 0.5) value was between Days 120 and 130. After the harvest of the winter wheat, some filed were used to plant the summer crops. The crops were sown at about Day 200 and then reach NDVI peak between Days 230 and 270. As there are various crop types, the NDVI profile differed, while we did not identify the summer crop types and just labeled all pixels with a NDVI peak after the harvest of wheat as wheat-summer crop.
Period-by-period JM distances were calculated using the reference NDVI time series of different crop types. The result (
Figure 8) showed that the winter wheat and wheat-summer crop can be distinguished from the other crops between day 120 and 140 with the early NDVI peak. In addition, wheat could be discriminated from wheat-summer crop at day 170 because of the development of the summer crops. Grape had the lowest separability among all crops, and the average JM distance between grape and all other crops were around 0.5 in each time period. This was attributed to the large variability of the reference NDVI time series of grape. For example, some grape reference profiles had low NDVI, but some other grape reference time series had high NDVI values, which were similar to the cotton profiles. Moreover, cotton and spring maize had relatively low separability (1.994 in
Table 7) because of the similar NDVI during the majority of the growing season (between Days 81 and 225 in
Figure 8), and the similarity between cotton and spring maize was also observed by [
51,
52] in Uzbekistan. Generally, JM distances for all pair-wise crop comparisons were above 1.9 when all time periods in the entire growing season were used (
Table 7), which indicated that the reference NDVI time series of each crop was separable in the study region.
4.2. Classification Accuracy Assessment
The results of the accuracy assessment (overall accuracy, Kappa coefficient, user’s and producer’s accuracy) for the two study areas are summarized in
Table 8 and
Table 9 [
53,
54]. If the historical NDVI time series of single year is used to build the reference NDVI profiles, the classification accuracies were low. For example, when the historical NDVI time series of 2007 were used to build the reference NDVI time series, the overall accuracy was 73.01%. The summer crops, such as spring maize, watermelon and grape were seriously mislabeled as cotton. Moreover, the reference tomato NDVI time series were not collected in 2006 and 2007; as a result, the reference profiles obtained from only 2006 and 2007 cannot identify tomato in 2011.
When the historical NDVI time series among 2006 and 2010 were used to build the reference time series, the classification accuracy improved significantly. The overall accuracy in Bole and Manas were 87.13% and 83.48%, respectively, which were acceptable for crop mapping without the use of ground reference data in the classification year. In Bole, both producer’s and user’s accuracy (PA and UA) of cotton, watermelon, wheat and wheat-summer crop were above 80%; but PA and UA of grape were about 70% because cotton and grape were confused: 280 cotton pixels were mislabeled as grape, while 260 grape pixels were wrongly classified as cotton. Spring maize had low UA (70.16%) because more than 200 cotton pixels were labeled as spring maize. In Manas, PA of cotton, spring maize, wheat and wheat-summer crop were higher than 80%, but the UA of spring maize and wheat were low (only 71.54% and 65.43%, respectively) because 272 and cotton samples were mislabeled as spring maize and wheat, respectively.
To assess the quality of the classification process based on the historical reference NDVI time series, a portion of the ground-reference data were used to classify the crops using the same classifier (ABNet). The overall accuracies for Bole and Manas were found to be 90.21% and 86.87%, respectively, which were higher compared to the accuracies for the historical reference NDVI-derived classification. In Bole, the increase of the accuracy was mainly caused by the better identification of wheat and wheat-summer crop (both PA and UA of wheat and wheat-summer crop were higher than 98%). In Manas, more correctly classified cotton and tomato pixels contributed to the improvement of the overall accuracy.
Figure 9 shows the crop map in Bole and Manas for year 2011. Cotton was the major crop type in both study areas, comprising 67.79% and 62.68% of cropland in Bole and Manas, respectively. In Bole, cotton was mainly distributed in the central county, and spring maize was mainly planted in the northwest of the county. Other crops, such as grape and watermelon were planted in the northern county. In Manas, cotton was mainly planted in the central and northern counties; and spring maize was planted in the southern county. As the crop identification were conducted at pixel level, there were some inter-field misclassifications, which was mainly due to the crop situation variation. In addition, the field boundaries were always misclassified. This was mainly because the boundary pixels were always mixed pixels combining crops and the road beside the crop fields. The mixed NDVI signature was perhaps more similar to the NDVI of a different crop, which led to the misclassification. As the training and validation samples did not contain field boundary pixels, these misclassification were not reported in the accuracy assessment confusion matrix.
6. Conclusions
Most existing crop classification methods rely on ground-reference data from the same year, which have led to high labor and financial costs. In this study, we presented a crop classification method using the historical NDVI time series of multiple years (from 2006 to 2010) to classify crop at 30 m resolution. The main conclusions are as follows.
- (1)
The method proposed in this study could identify the dominant crops in the study areas, as the overall classification accuracies were 87.13% and 83.48% in Bole and Manas, respectively. Notably, no ground-reference data of the classification year were required in the classification process.
- (2)
Reference NDVI time series obtained by historical NDVI profiles of multiple years could achieve higher accuracy than that from a single year. This is because there are phenological inter-annual variations among different years, and the reference NDVI profiles obtained from multiple years could contain more crop conditions and showed better classification performance.
- (3)
The combination of Landsat and HJ data could increase the acquisition frequency of the 30 m image time series to 15-day, which is similar to the temporal resolution of the reference NDVI profiles. Moreover, the reference NDVI was transformed to Landsat/HJ NDVI; thus, we do not need to consider the radiation difference between Landsat and HJ images.
The limitation of this method is that we have to find homogenous areas that could contain pure MODIS pixels when transforming MODIS NDVI to Landsat/HJ NDVI. Therefore, the classification accuracy might be affected in some heterogeneous area. Additionally, the historical NDVI profiles should be collected as much as possible to enrich the knowledge of the reference NDVI time series. Generally, the method proposed in this study could be used to identify crop types at 30 m resolution when the ground reference data of the classification year is absent. As the results obtained depended on the specifics of the study area, other combinations of crop types and might have new problems. Therefore, further studies are essential to illustrate the feasibility of this approach in various study regions.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}