
Simulation of Dynamic Urban Growth with Partial Least Squares Regression-Based Cellular Automata in a GIS Environment


Abstract
:1. Introduction
2. Material
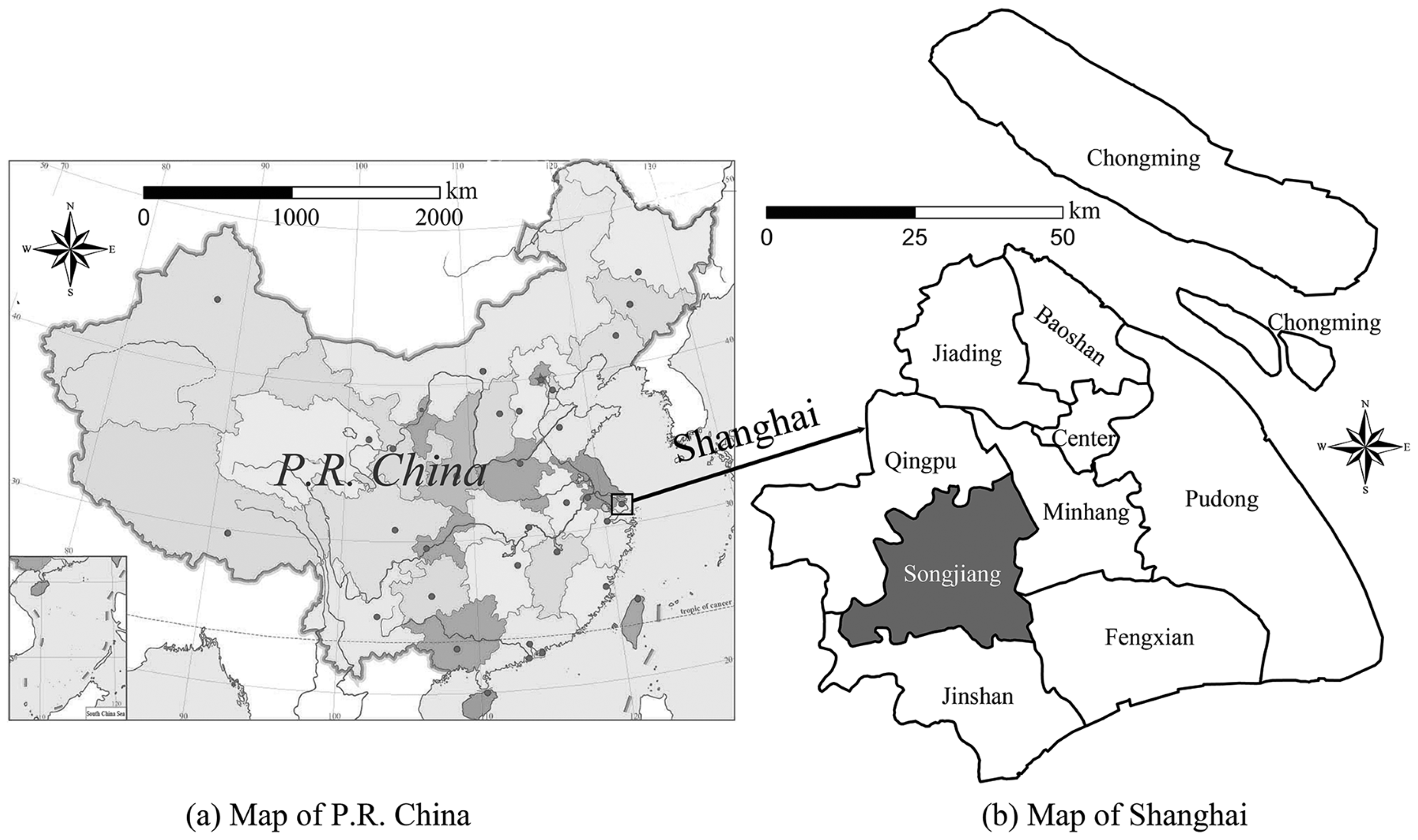
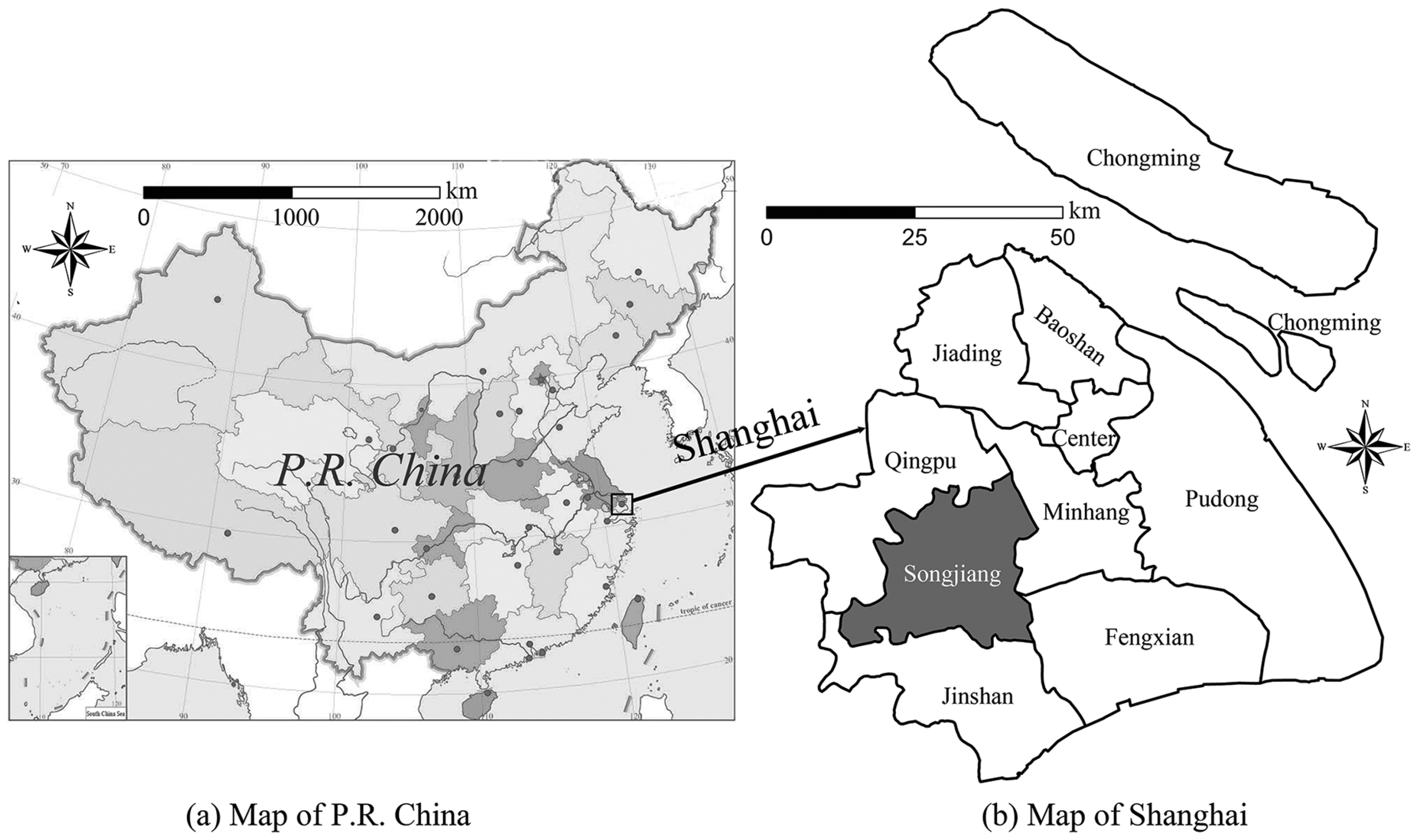
2.1. Study Area and Data
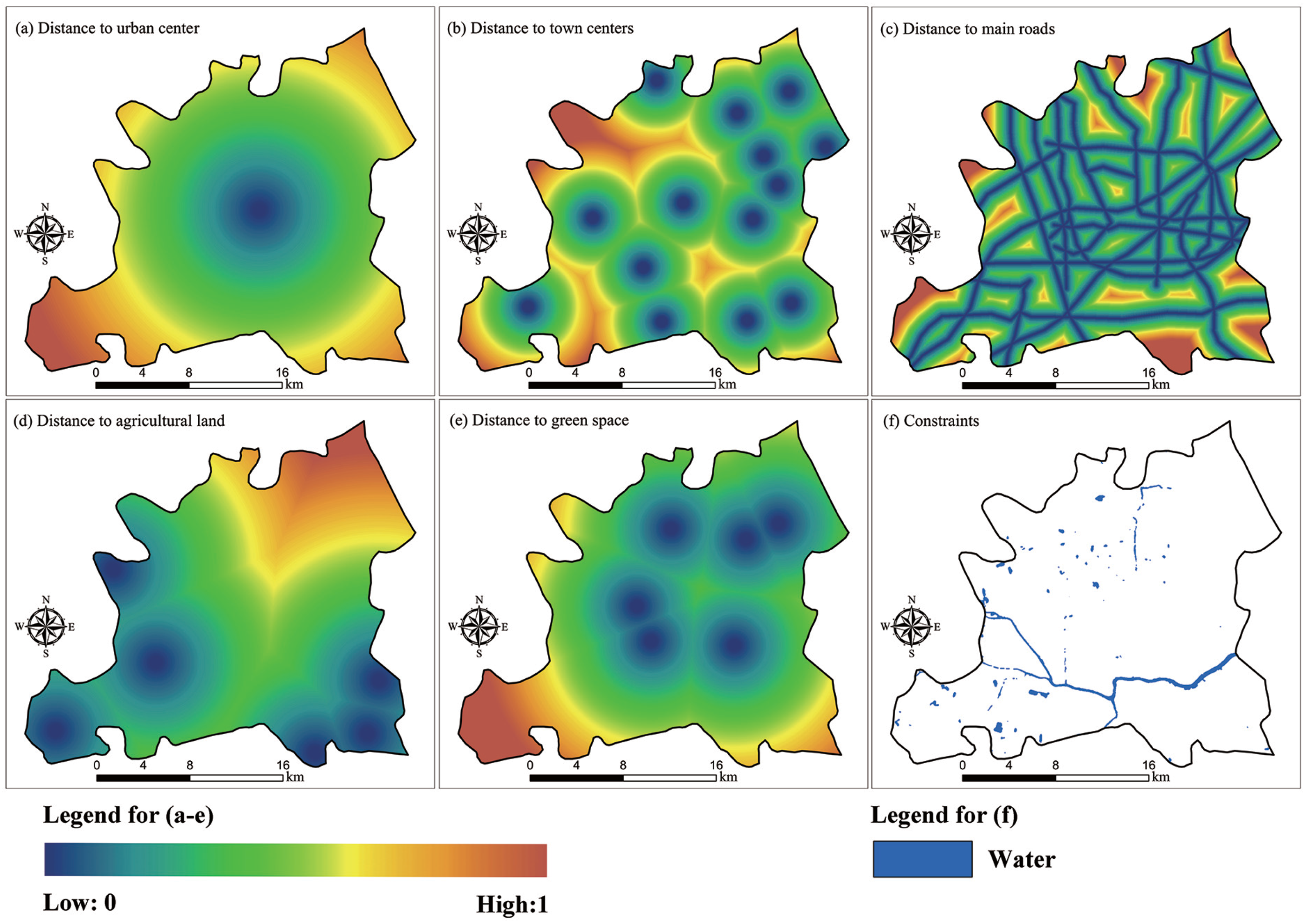
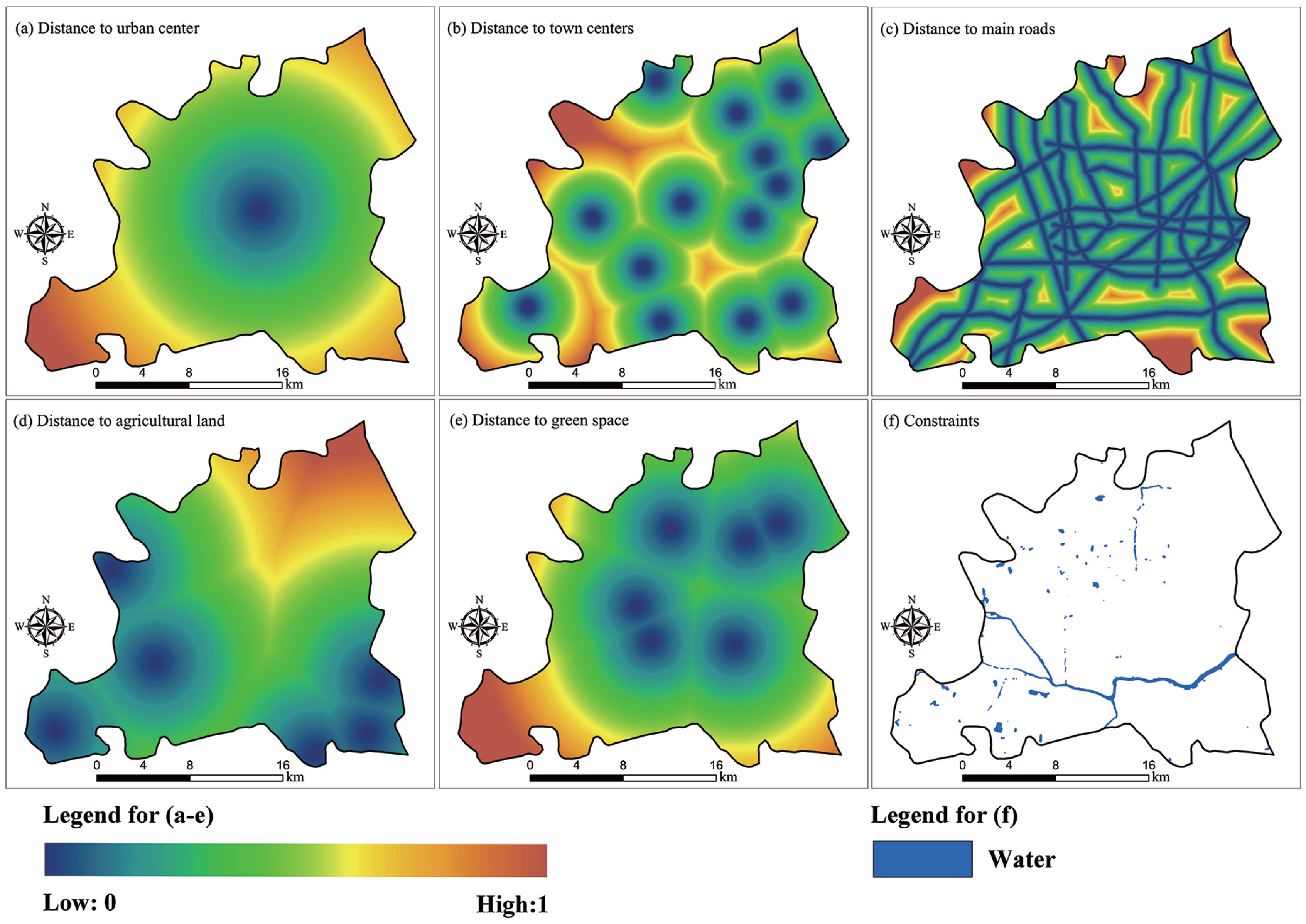
2.2. Input Variables
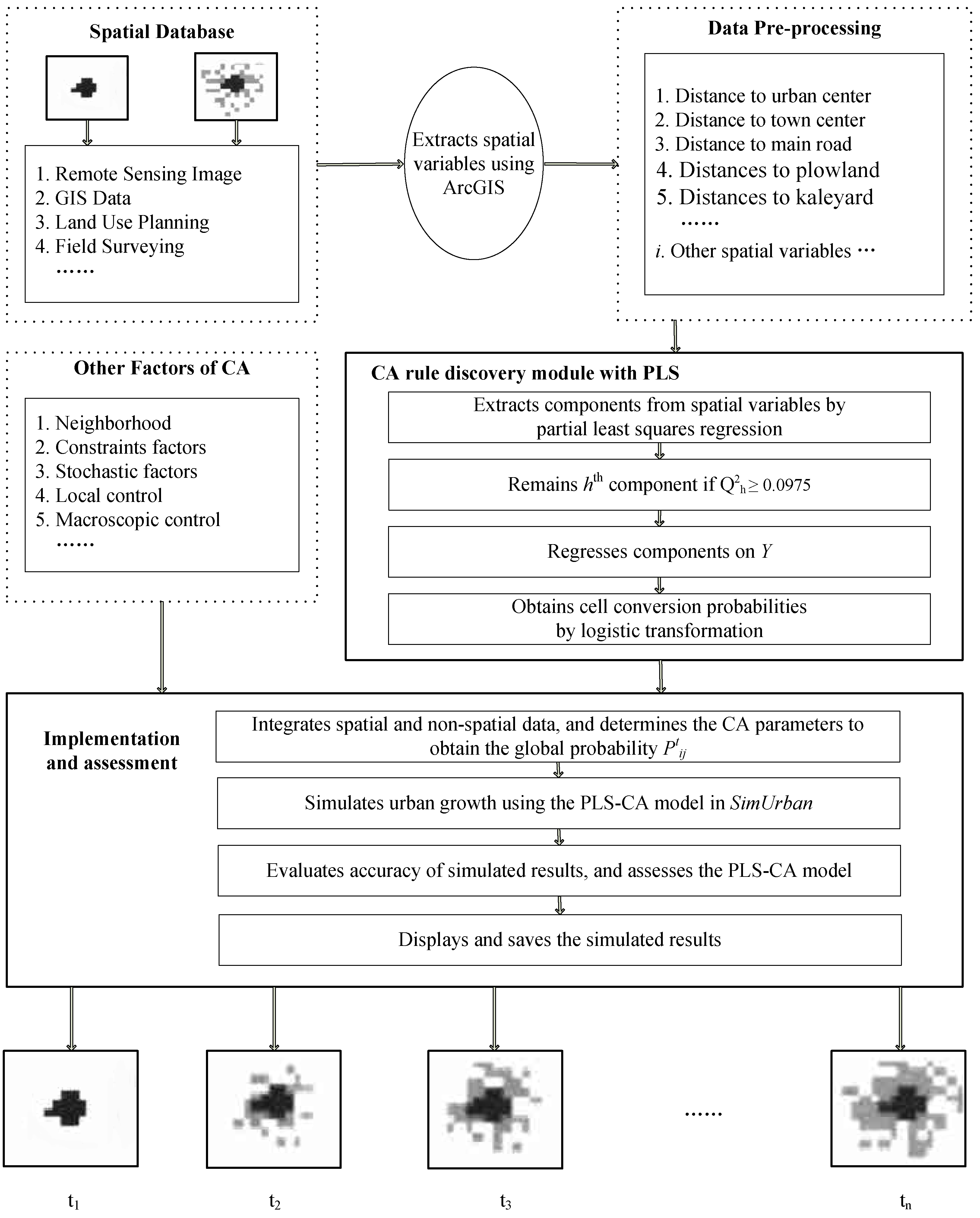
3. The PLS-CA Model
3.1. A Generic CA Model
3.2. The PLS Method
3.3. PLS-Based CA Model
3.4. Structure of the PLS-CA Model
4. Results and Discussion
4.1. Assessment of Correlation
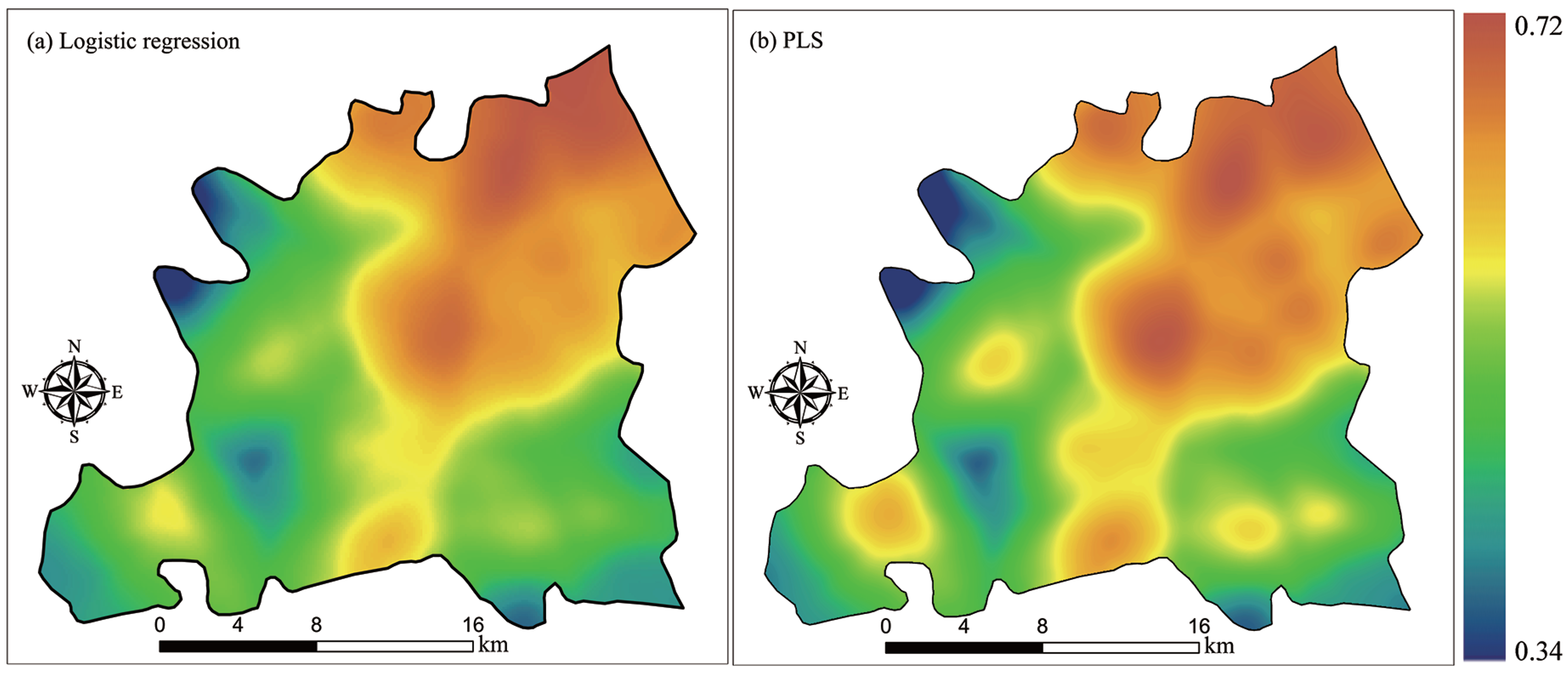
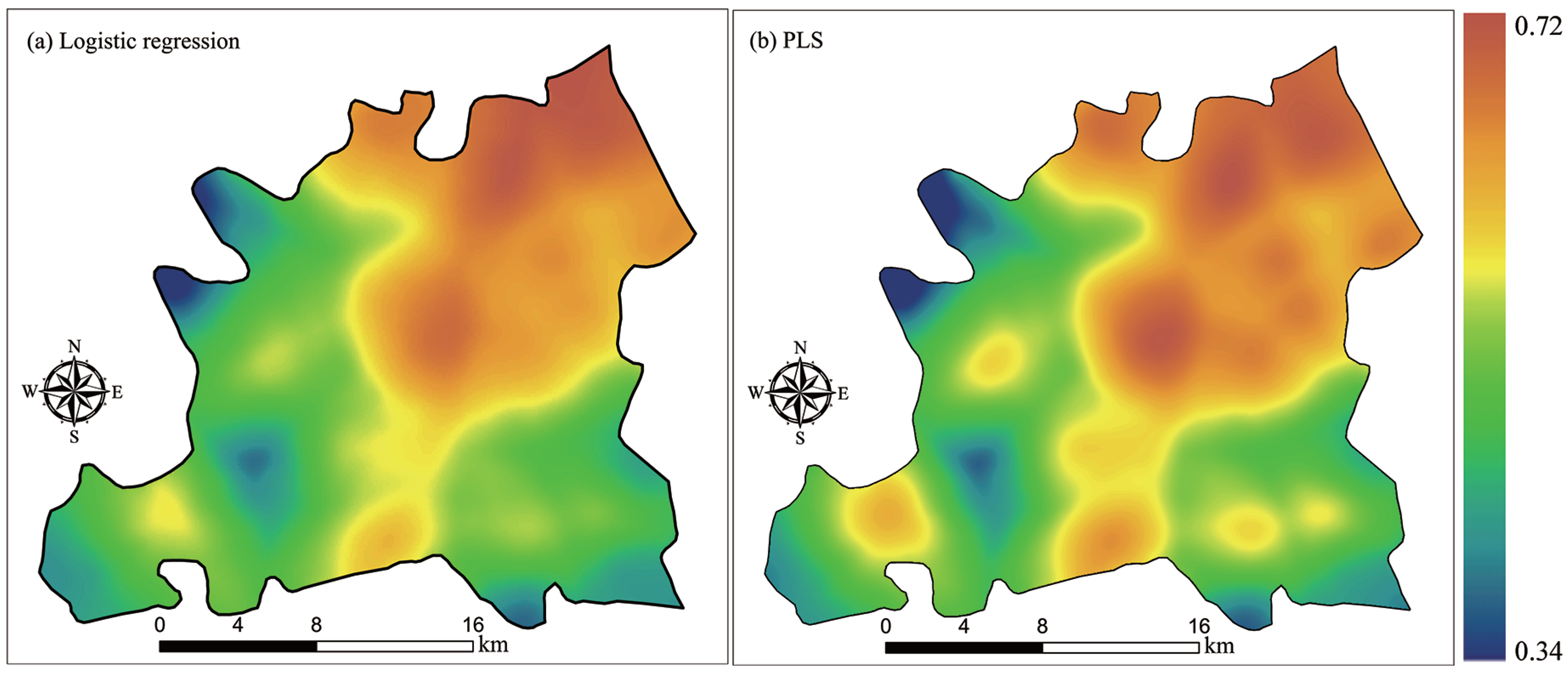
4.2. CA Transition Rules
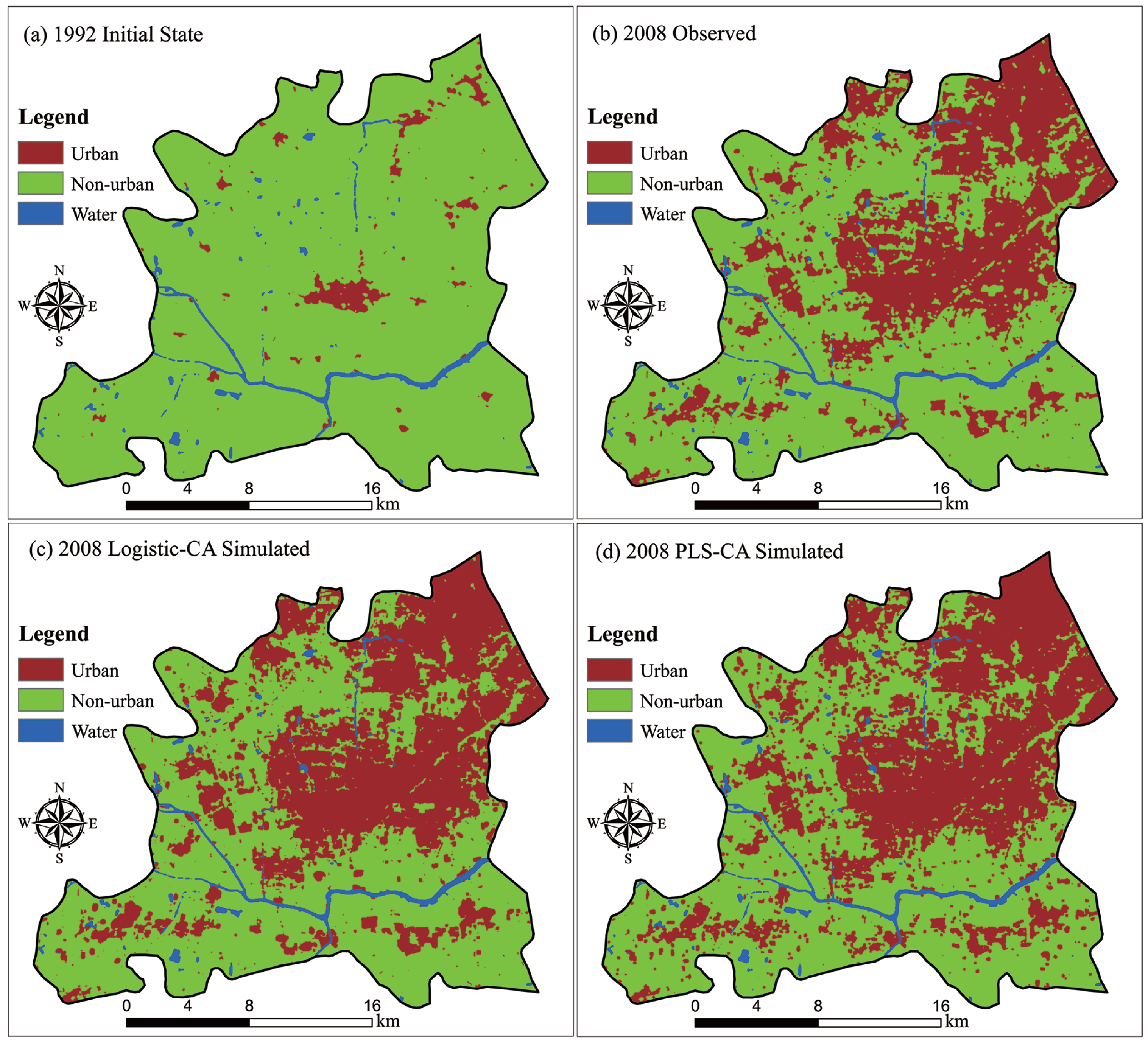
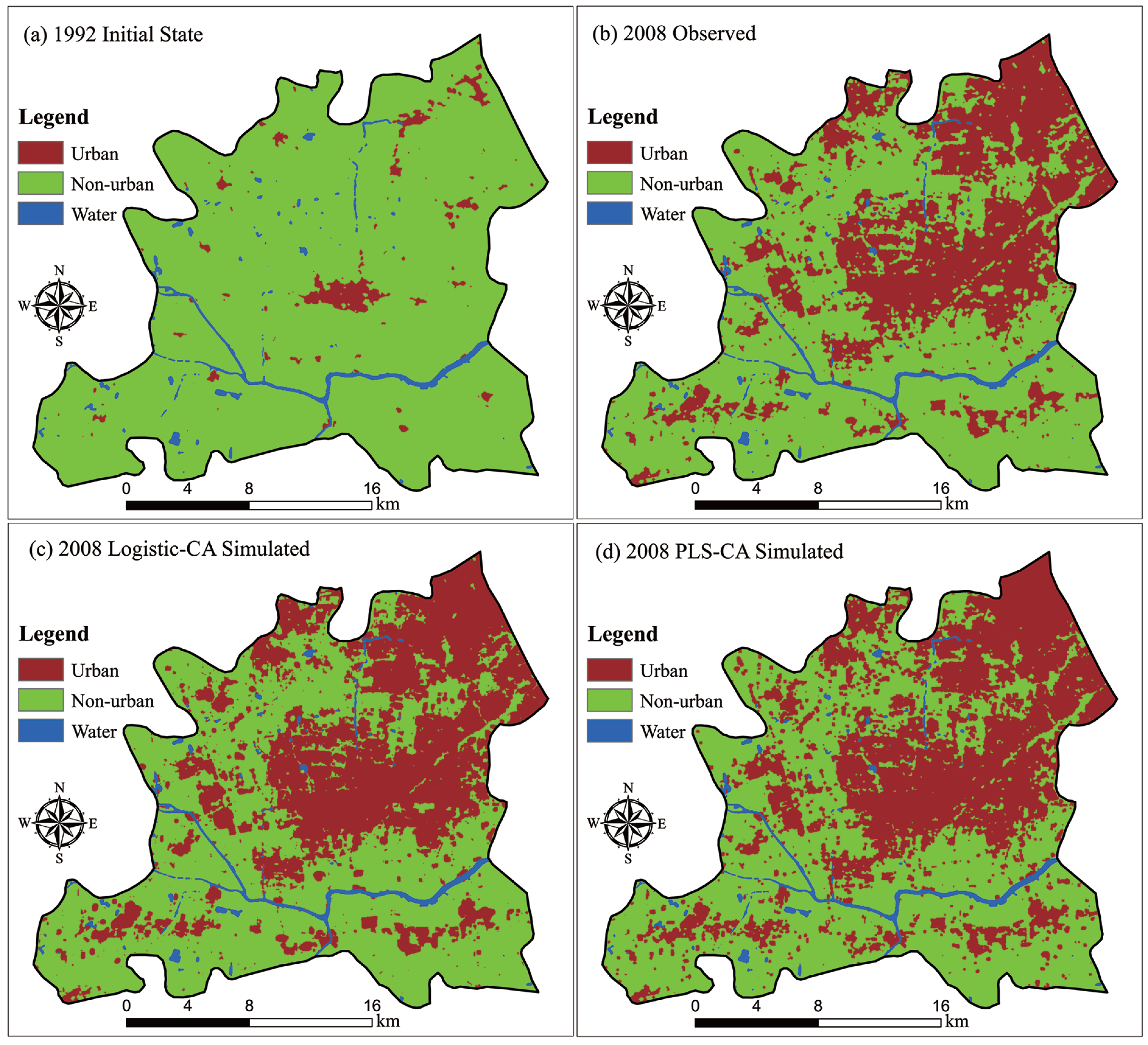
4.3. Simulation Results
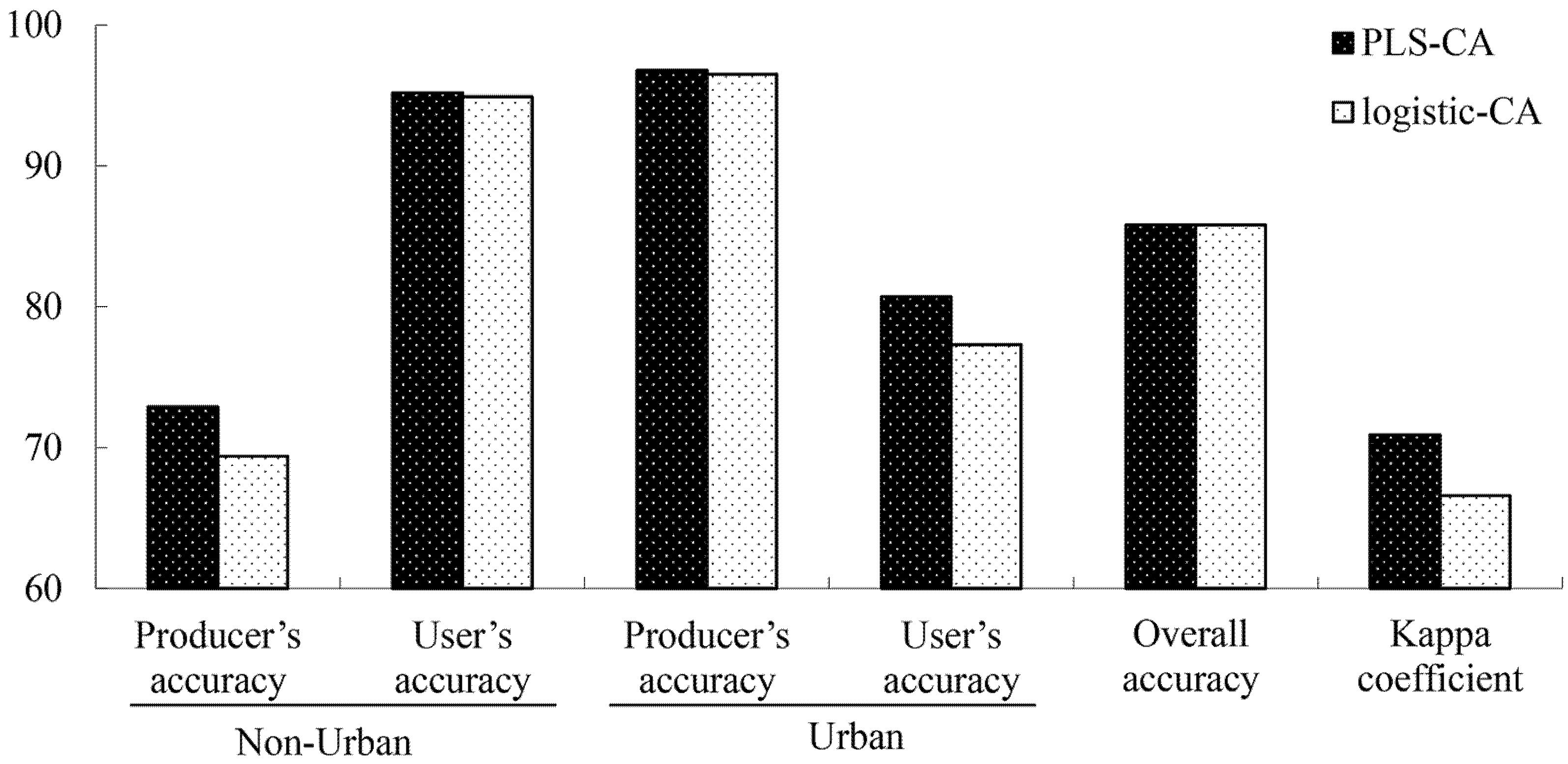
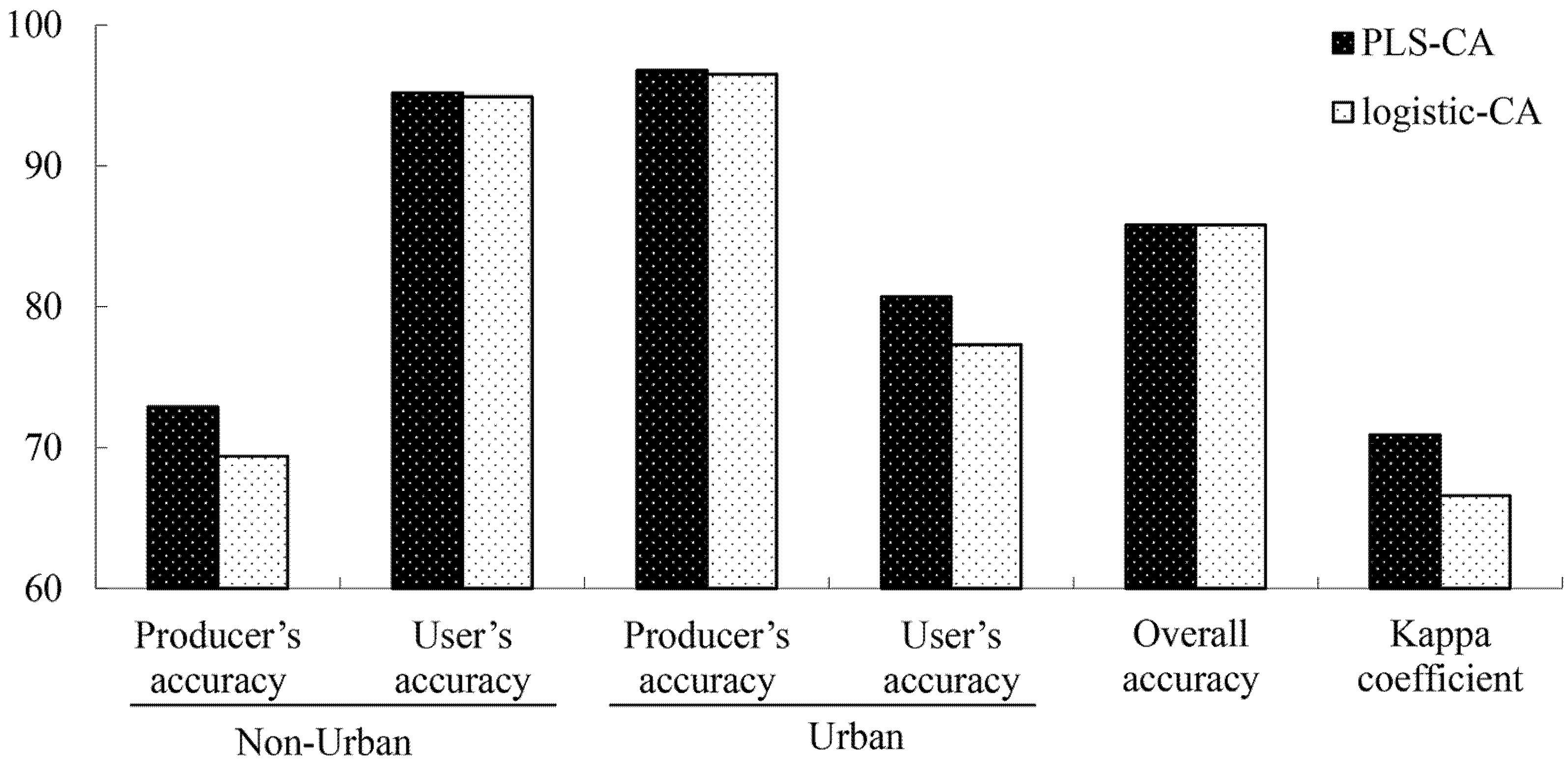
4.4. Accuracy Analysis
4.5. Discussion
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Mondal, B.; Das, D.N.; Bhatta, B. Integrating cellular automata and Markov techniques to generate urban development potential surface: A study on Kolkata agglomeration. Geocarto. Int. 2016. [Google Scholar] [CrossRef]
- Feng, Y.; Liu, Y.; Batty, M. Modeling urban growth with GIS based cellular automata and least squares SVM rules: A case study in Qingpu–Songjiang area of Shanghai, China. Stoch. Env. Res. Risk Assess. 2016, 30, 1387–1400. [Google Scholar] [CrossRef]
- Barredo, J.I.; Kasanko, M.; McCormick, N.; Lavalle, C. Modelling dynamic spatial processes: Simulation of urban future scenarios through cellular automata. Landsc. Urban Plan. 2003, 64, 145–160. [Google Scholar] [CrossRef]
- Jantz, C.A.; Goetz, S.J.; Shelley, M.K. Using the SLEUTH urban growth model to simulate the impacts of future policy scenarios on urban land use in the Baltimore-Washington metropolitan area. Environ. Plan. B 2004, 31, 251–271. [Google Scholar] [CrossRef]
- Tobler, W. Cellular geography. In Philosophy in Geography; Springer: Berlin, Germany, 1979; pp. 379–386. [Google Scholar]
- Batty, M.; Xie, Y.; Sun, Z. Modeling urban dynamics through GIS-based cellular automata. Comput. Environ. Urban 1999, 23, 205–233. [Google Scholar] [CrossRef]
- Verburg, P.H.; Schot, P.P.; Dijst, M.J.; Veldkamp, A. Land use change modelling: Current practice and research priorities. GeoJournal 2004, 61, 309–324. [Google Scholar] [CrossRef]
- Batty, M. Cities and Complexity: Understanding Cities with Cellular Automata, Agent-based Models, and Fractals; The MIT Press: Cambridge, MA, USA, 2007. [Google Scholar]
- Clarke, K.C.; Gaydos, L.J. Loose-coupling a cellular automaton model and GIS: Long-term urban growth prediction for San Francisco and Washington/Baltimore. Int. J. Geogr. Inf. Sci. 1998, 12, 699–714. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Yeh, A.G.-O. Modelling sustainable urban development by the integration of constrained cellular automata and GIS. Int. J. Geogr. Inf. Sci. 2000, 14, 131–152. [Google Scholar] [CrossRef]
- Wu, F. Calibration of stochastic cellular automata: The application to rural-urban land conversions. Int. J. Geogr. Inf. Sci. 2002, 16, 795–818. [Google Scholar] [CrossRef]
- Cao, K.; Batty, M.; Huang, B.; Liu, Y.; Yu, L.; Chen, J. Spatial multi-objective land use optimization: Extensions to the non-dominated sorting genetic algorithm-II. Int. J. Geogr. Inf. Sci. 2011, 25, 1949–1969. [Google Scholar] [CrossRef]
- Cao, M.; Bennett, S.J.; Shen, Q.; Xu, R. A bat-inspired approach to define transition rules for a cellular automaton model used to simulate urban expansion. Int. J. Geogr. Inf. Sci. 2016, 30, 1–19. [Google Scholar] [CrossRef]
- Feng, Y.; Liu, Y. Scenario prediction of emerging coastal city using CA modeling under different environmental conditions: A case study of Lingang New City, China. Environ. Monit. Assess. 2016, 188, 540. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Ma, L.; Li, X.; Ai, B.; Li, S.; He, Z. Simulating urban growth by integrating landscape expansion index (LEI) and cellular automata. Int. J. Geogr. Inf. Sci. 2014, 28, 148–163. [Google Scholar] [CrossRef]
- Liu, Y.; Feng, Y. Simulating the impact of economic and environmental strategies on future urban growth scenarios in Ningbo, China. Sustainability 2016, 8, 1045. [Google Scholar] [CrossRef]
- Liu, X.; Li, X.; Shi, X.; Zhang, X.; Chen, Y. Simulating land-use dynamics under planning policies by integrating artificial immune systems with cellular automata. Int. J. Geogr. Inf. Sci. 2010, 24, 783–802. [Google Scholar] [CrossRef]
- Liu, Y.; Feng, Y. A logistic based cellular automata model for continuous urban growth simulation: A case study of the Gold Coast City, Australia. In Agent-based Models of Geographical Systems; Springer: Berlin, Germany, 2012; pp. 643–662. [Google Scholar]
- Liao, J.; Tang, L.; Shao, G.; Qiu, Q.; Wang, C.; Zheng, S.; Su, X. A neighbor decay cellular automata approach for simulating urban expansion based on particle swarm intelligence. Int. J. Geogr. Inf. Sci. 2014, 28, 720–738. [Google Scholar] [CrossRef]
- Verstegen, J.A.; Karssenberg, D.; Van Der Hilst, F.; Faaij, A.P. Identifying a land use change cellular automaton by Bayesian data assimilation. Environ. Model. Softw. 2014, 53, 121–136. [Google Scholar] [CrossRef]
- Li, X.; Yeh, A.G.-O. Neural-network-based cellular automata for simulating multiple land use changes using GIS. Int. J. Geogr. Inf. Sci. 2002, 16, 323–343. [Google Scholar] [CrossRef]
- Feng, Y.; Liu, Y. A heuristic cellular automata approach for modelling urban land-use change based on simulated annealing. Int. J. Geogr. Inf. Sci. 2013, 27, 449–466. [Google Scholar] [CrossRef]
- Liu, Y.; Tang, W.; He, J.; Liu, Y.; Ai, T.; Liu, D. A land-use spatial optimization model based on genetic optimization and game theory. Comput. Environ. Urban 2015, 49, 1–14. [Google Scholar] [CrossRef]
- Kamusoko, C.; Gamba, J. Simulating urban growth using a Random Forest-Cellular Automata (RF-CA) model. ISPRS Int. J. Geo-Inf. 2015, 4, 447–470. [Google Scholar] [CrossRef]
- Triantakonstantis, D.; Mountrakis, G. Urban growth prediction: A review of computational models and human perceptions. J. Geogr. Inf. Syst. 2012, 4, 26323. [Google Scholar] [CrossRef]
- Cao, K.; Huang, B.; Li, M.; Li, W. Calibrating a cellular automata model for understanding rural–urban land conversion: A Pareto front-based multi-objective optimization approach. Int. J. Geogr. Inf. Sci. 2014, 28, 1028–1046. [Google Scholar] [CrossRef]
- Feng, Y.; Liu, Y. An optimised cellular automata model based on adaptive genetic algorithm for urban growth simulation. In Advances in Spatial Data Handling and GIS; Springer: Berlin, Germany, 2012; pp. 27–38. [Google Scholar]
- Feng, Y.; Liu, Y.; Tong, X.; Liu, M.; Deng, S. Modeling dynamic urban growth using cellular automata and particle swarm optimization rules. Landsc. Urban Plan. 2011, 102, 188–196. [Google Scholar] [CrossRef]
- Guan, D.; Li, H.; Inohae, T.; Su, W.; Nagaie, T.; Hokao, K. Modeling urban land use change by the integration of cellular automaton and Markov model. Ecol. Model. 2011, 222, 3761–3772. [Google Scholar] [CrossRef]
- Yang, X.; Zheng, X.-Q.; Lv, L.-N. A spatiotemporal model of land use change based on ant colony optimization, Markov chain and cellular automata. Ecol. Model. 2012, 233, 11–19. [Google Scholar] [CrossRef]
- Munshi, T.; Zuidgeest, M.; Brussel, M.; van Maarseveen, M. Logistic regression and cellular automata-based modelling of retail, commercial and residential development in the city of Ahmedabad, India. Cities 2014, 39, 68–86. [Google Scholar] [CrossRef]
- Alqurashi, A.F.; Kumar, L.; Al-Ghamdi, K.A. Spatiotemporal modeling of urban growth predictions based on driving force factors in five Saudi Arabian cities. ISPRS Int. J. Geo-Inf. 2016, 5, 139. [Google Scholar] [CrossRef]
- Lin, Y.-P.; Chu, H.-J.; Wu, C.-F.; Verburg, P.H. Predictive ability of logistic regression, auto-logistic regression and neural network models in empirical land-use change modeling—A case study. Int. J. Geogr. Inf. Sci. 2011, 25, 65–87. [Google Scholar] [CrossRef]
- Li, X.; Yeh, A.G.-O. Urban simulation using principal components analysis and cellular automata for land-use planning. Photogramm. Eng. Remote Sens. 2002, 68, 341–352. [Google Scholar]
- Dunn, W.; Scott, D.; Glen, W. Principal components analysis and partial least squares regression. Tetrahedron Comput. Method 1989, 2, 349–376. [Google Scholar] [CrossRef]
- Geladi, P.; Kowalski, B.R. Partial least-squares regression: A tutorial. Anal. Chim. Acta 1986, 185, 1–17. [Google Scholar] [CrossRef]
- Abdi, H. Partial least square regression (PLS regression). Encycl. Res. Methods Soc. Sci. 2003, 2003, 792–795. [Google Scholar]
- Deng, X.; Huang, J.; Rozelle, S.; Uchida, E. Growth, population and industrialization, and urban land expansion of China. J. Urban Econ. 2008, 63, 96–115. [Google Scholar] [CrossRef]
- Feng, Y.; Liu, Y. Fractal dimension as an indicator for quantifying the effects of changing spatial scales on landscape metrics. Ecol. Indic. 2015, 53, 18–27. [Google Scholar] [CrossRef]
- Feng, Y.; Liu, Y.; Liu, Y. Spatially explicit assessment of land ecological security with spatial variables and logistic regression modeling in Shanghai, China. Stoch. Environ. Res. Risk Assess. 2016. [Google Scholar] [CrossRef]
- Wu, F.; Webster, C.J. Simulation of land development through the integration of cellular automata and multicriteria evaluation. Environ. Plan. B 1998, 25, 103–126. [Google Scholar] [CrossRef]
- White, R.; Engelen, G. Cellular automata as the basis of integrated dynamic regional modelling. Environ. Plan. B 1997, 24, 235–246. [Google Scholar] [CrossRef]
- Feng, Y.; Liu, Y.; Liu, D. Shoreline mapping with cellular automata and the shoreline progradation analysis in Shanghai, China from 1979 to 2008. Arab. J. Geosci. 2015, 8, 4337–4351. [Google Scholar] [CrossRef]
- He, C.; Okada, N.; Zhang, Q.; Shi, P.; Zhang, J. Modeling urban expansion scenarios by coupling cellular automata model and system dynamic model in Beijing, China. Appl. Geogr. 2006, 26, 323–345. [Google Scholar] [CrossRef]
- Blecic, I.; Cecchini, A.; Trunfio, G.A. How much past to see the future: A computational study in calibrating urban cellular automata. Int. J. Geogr. Inf. Sci. 2015, 29, 349–374. [Google Scholar] [CrossRef]
- Feng, Y.; Liu, Y. A cellular automata model based on nonlinear kernel principal component analysis for urban growth simulation. Environ. Plan. B 2013, 40, 117–134. [Google Scholar] [CrossRef]
- García, A.M.; Santé, I.; Crecente, R.; Miranda, D. An analysis of the effect of the stochastic component of urban cellular automata models. Comput. Environ. Urban 2011, 35, 289–296. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2013. [Google Scholar]
- Clarke, K.C.; Hoppen, S.; Gaydos, L. A self-modifying cellular automaton model of historical urbanization in the San Francisco Bay area. Environ. Plan. B 1997, 24, 247–261. [Google Scholar] [CrossRef]
- Almeida, C.; Gleriani, J.; Castejon, E.F.; Soares-Filho, B. Using neural networks and cellular automata for modelling intra-urban land-use dynamics. Int. J. Geogr. Inf. Sci. 2008, 22, 943–963. [Google Scholar] [CrossRef]
- Liu, X.; Li, X.; Liu, L.; He, J.; Ai, B. A bottom-up approach to discover transition rules of cellular automata using ant intelligence. Int. J. Geogr. Inf. Sci. 2008, 22, 1247–1269. [Google Scholar] [CrossRef]
- Campbell, J.B.; Wynne, R.H. Introduction to Remote Sensing; Guilford Press: New York, NY, USA, 2011. [Google Scholar]
- Liu, Y. Modelling Urban Development with Geographical Information Systems and Cellular Automata; CRC Press: New York, NY, USA, 2008. [Google Scholar]
- Yeh, A.G.-O.; Li, X. Errors and uncertainties in urban cellular automata. Comput. Environ. Urban 2006, 30, 10–28. [Google Scholar] [CrossRef]
- Ménard, A.; Marceau, D.J. Exploration of spatial scale sensitivity in geographic cellular automata. Environ. Plan. B 2005, 32, 693–714. [Google Scholar] [CrossRef]
- Wang, F.; Hasbani, J.-G.; Wang, X.; Marceau, D.J. Identifying dominant factors for the calibration of a land-use cellular automata model using Rough Set Theory. Comput. Environ. Urban 2011, 35, 116–125. [Google Scholar] [CrossRef]
- Verburg, P.H.; de Nijs, T.C.; van Eck, J.R.; Visser, H.; de Jong, K. A method to analyse neighbourhood characteristics of land use patterns. Comput. Environ. Urban 2004, 28, 667–690. [Google Scholar] [CrossRef]
- Pan, Y.; Roth, A.; Yu, Z.; Doluschitz, R. The impact of variation in scale on the behavior of a cellular automata used for land use change modeling. Comput. Environ. Urban 2010, 34, 400–408. [Google Scholar] [CrossRef]
- Feng, Y.; Yang, Q.; Hong, Z.; Cui, L. Modelling coastal land use change by incorporating spatial autocorrelation into cellular automata models. Geocarto. Int. 2016, 1–44. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Meaning | Type | Acquisition Method |
|---|---|---|---|
| y | Conversion probability | Criterion variable | Remote sensing classification |
| Durban | Distance to urban center | Spatial variable | Euclidean Distance tool in ArcGIS |
| Dtown | Distance to town centers | ||
| Dmrd | Distance to main roads | ||
| Dagri | Distance to agricultural land | ||
| Dgs | Distance to green space | ||
| Neighborhood | 3 × 3 neighborhood | Local variable | Retrieved dynamically during simulation |
| Constraints | Local constraints | ||
| Global constraints | |||
| Stochastic | Stochastic factors | Global variable | Assigned randomly |
| Variable | Dtown | Dmrd | Dagri | Dgs | y |
|---|---|---|---|---|---|
| Durban | 0.6462 | 0.6109 | −0.5372 | −0.5280 | 0.2264 |
| Dtown | 0.7058 | −0.4496 | −0.7754 | 0.5635 | |
| Dmrd | −0.4714 | −0.4971 | 0.2518 | ||
| Dagri | 0.8537 | −0.1572 | |||
| Dgs | −0.1893 |
| Component | Cross-Validation | Spatial Variables | ||||||
|---|---|---|---|---|---|---|---|---|
| R | Critical Value | Urban Center | Town Center | Main Road | Agricultural Land | Green Space | ||
| 1 | 0.8625 | 0.8517 | −0.0975 | −0.8156 | −0.4744 | 0.3012 | −0.2290 | −0.2967 |
| 2 | 0.3240 | 0.1054 | −0.0975 | −0.3694 | −0.2536 | −0.5515 | 0.6557 | 0.3553 |
| 3 | 0.1572 | −0.0092 | −0.0975 | −0.0916 | 0.1228 | 0.2031 | 0.1232 | 0.0802 |
| Models | Variable | ||||
|---|---|---|---|---|---|
| Durban | Dtown | Dmrd | Dagri | Dgs | |
| PLS-CA | −1.1063 | −0.5841 | −0.8274 | 0.1924 | 0.1513 |
| logistic-CA | −0.5846 | −0.2837 | −1.7590 | 2.0263 | 1.5978 |
| Item | Observed (%) | |||
|---|---|---|---|---|
| Urban | Non-Urban | Total | ||
| Simulated (%) | Urban | 33.6 | 12.5 | 46.1 |
| Non-Urban | 1.7 | 52.2 | 53.9 | |
| Total | 35.3 | 64.7 | 100 | |
| User’s Accuracy | Commission error | |||
| Non-urban | = 33.6/46.1 = 72.9% | 27.1% | ||
| Urban | = 52.2/53.9 = 96.8% | 3.2% | ||
| Producer’s Accuracy | Omission error | |||
| Non-urban | = 33.6/35.3 = 95.2% | 4.8% | ||
| Urban | = 52.2/64.7 = 80.7% | 19.3% | ||
| Overall accuracy | 85.8% | |||
| Kappa coefficient | 70.9% | |||
| Urban Growth | Urban | Non-urban | |
|---|---|---|---|
| Observed | Area 1992 (km2) | 17.9 | 565.1 |
| Area 2008 (km2) | 205.2 | 377.8 | |
| logistic-CA | Area 2008 (km2) | 248.4 | 334.6 |
| CUGR (%) | 121.1 | 88.6 | |
| PLS-CA | Area 2008 (km2) | 234.3 | 348.7 |
| CUGR (%) | 114.2 | 92.3 | |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, Y.; Liu, M.; Chen, L.; Liu, Y. Simulation of Dynamic Urban Growth with Partial Least Squares Regression-Based Cellular Automata in a GIS Environment. ISPRS Int. J. Geo-Inf. 2016, 5, 243. https://doi.org/10.3390/ijgi5120243
Feng Y, Liu M, Chen L, Liu Y. Simulation of Dynamic Urban Growth with Partial Least Squares Regression-Based Cellular Automata in a GIS Environment. ISPRS International Journal of Geo-Information. 2016; 5(12):243. https://doi.org/10.3390/ijgi5120243
Chicago/Turabian StyleFeng, Yongjiu, Miaolong Liu, Lijun Chen, and Yu Liu. 2016. "Simulation of Dynamic Urban Growth with Partial Least Squares Regression-Based Cellular Automata in a GIS Environment" ISPRS International Journal of Geo-Information 5, no. 12: 243. https://doi.org/10.3390/ijgi5120243
APA StyleFeng, Y., Liu, M., Chen, L., & Liu, Y. (2016). Simulation of Dynamic Urban Growth with Partial Least Squares Regression-Based Cellular Automata in a GIS Environment. ISPRS International Journal of Geo-Information, 5(12), 243. https://doi.org/10.3390/ijgi5120243