A Quality Study of the OpenStreetMap Dataset for Tehran


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
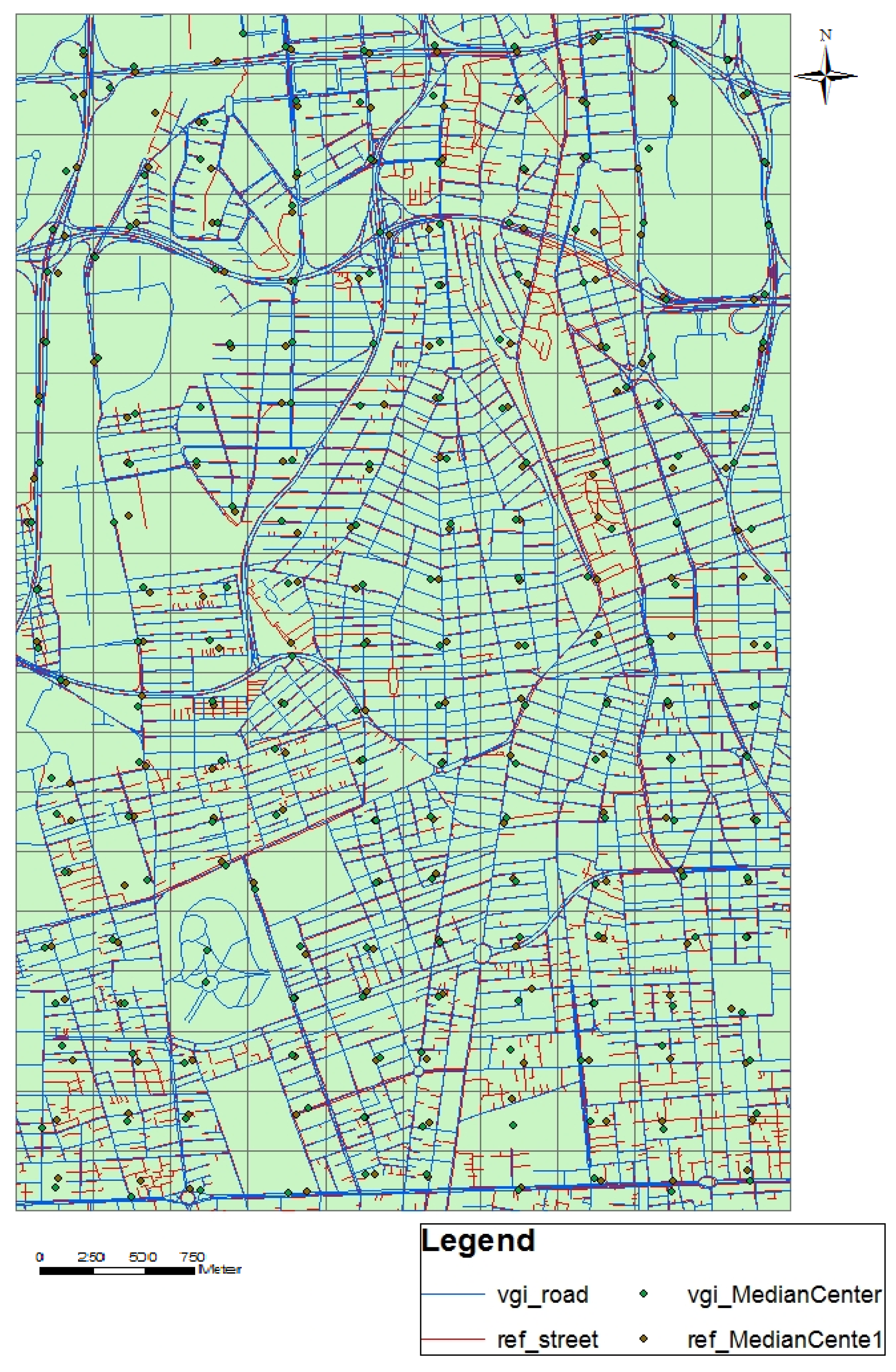
2. Methodology
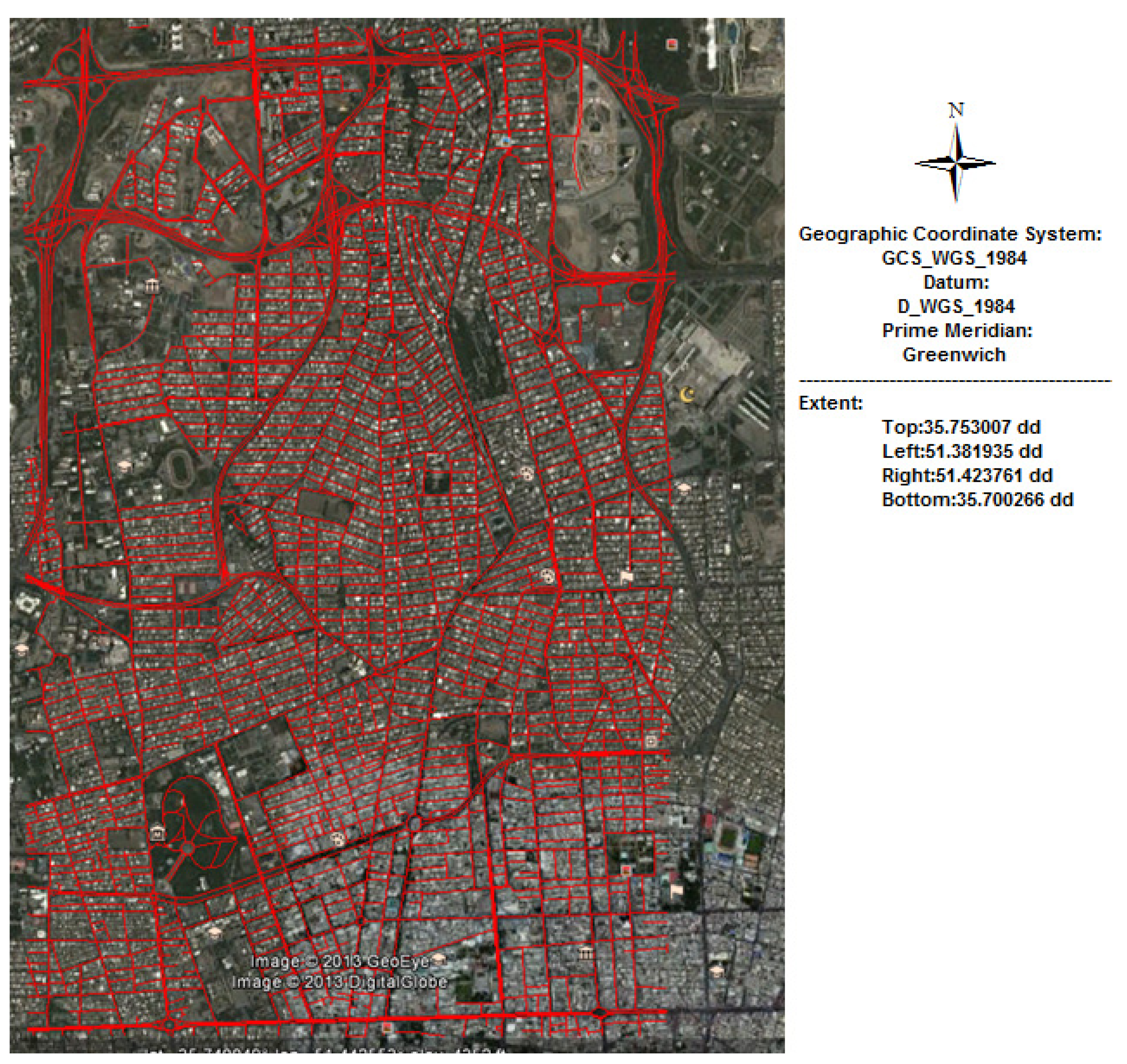
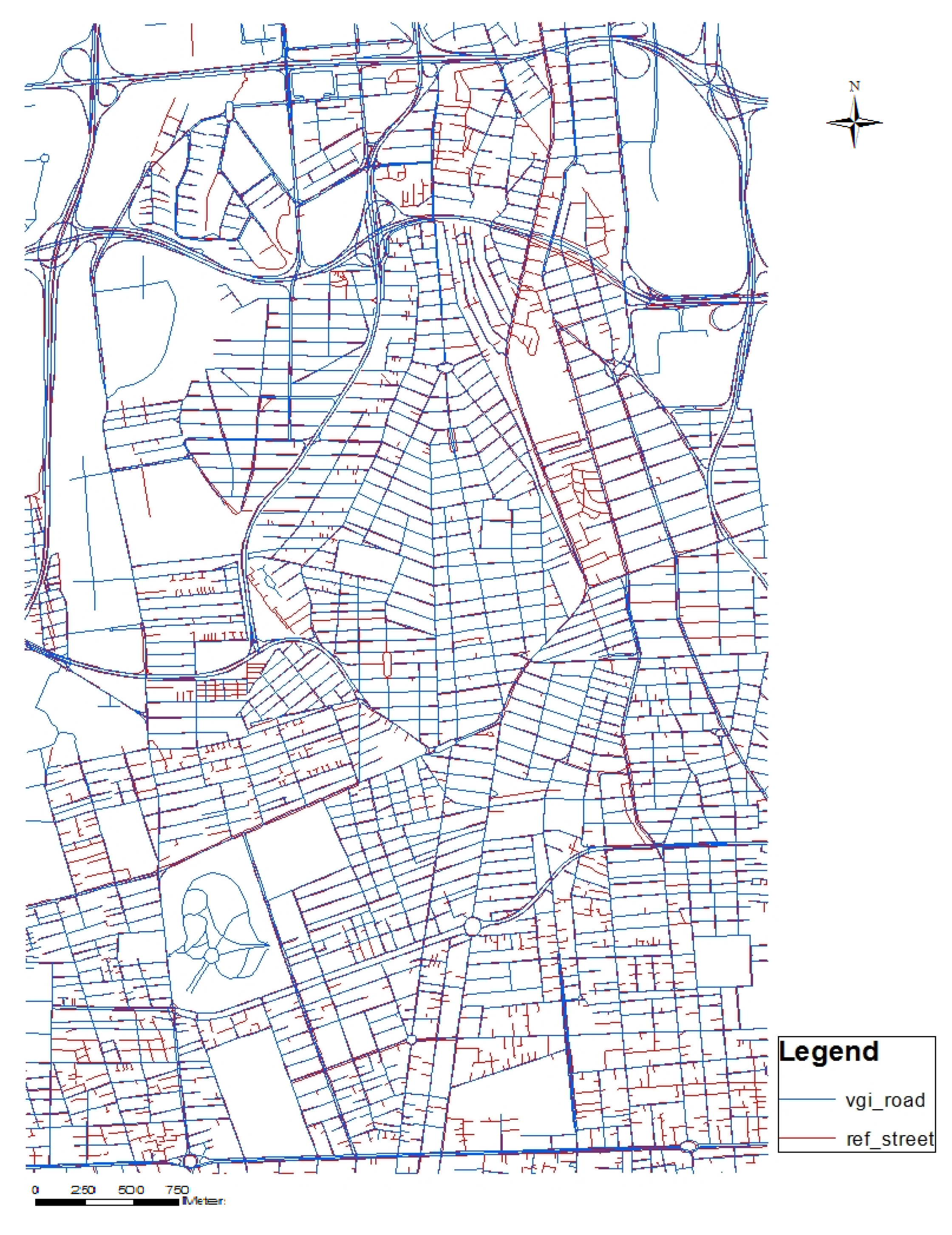
2.1. Available Datasets

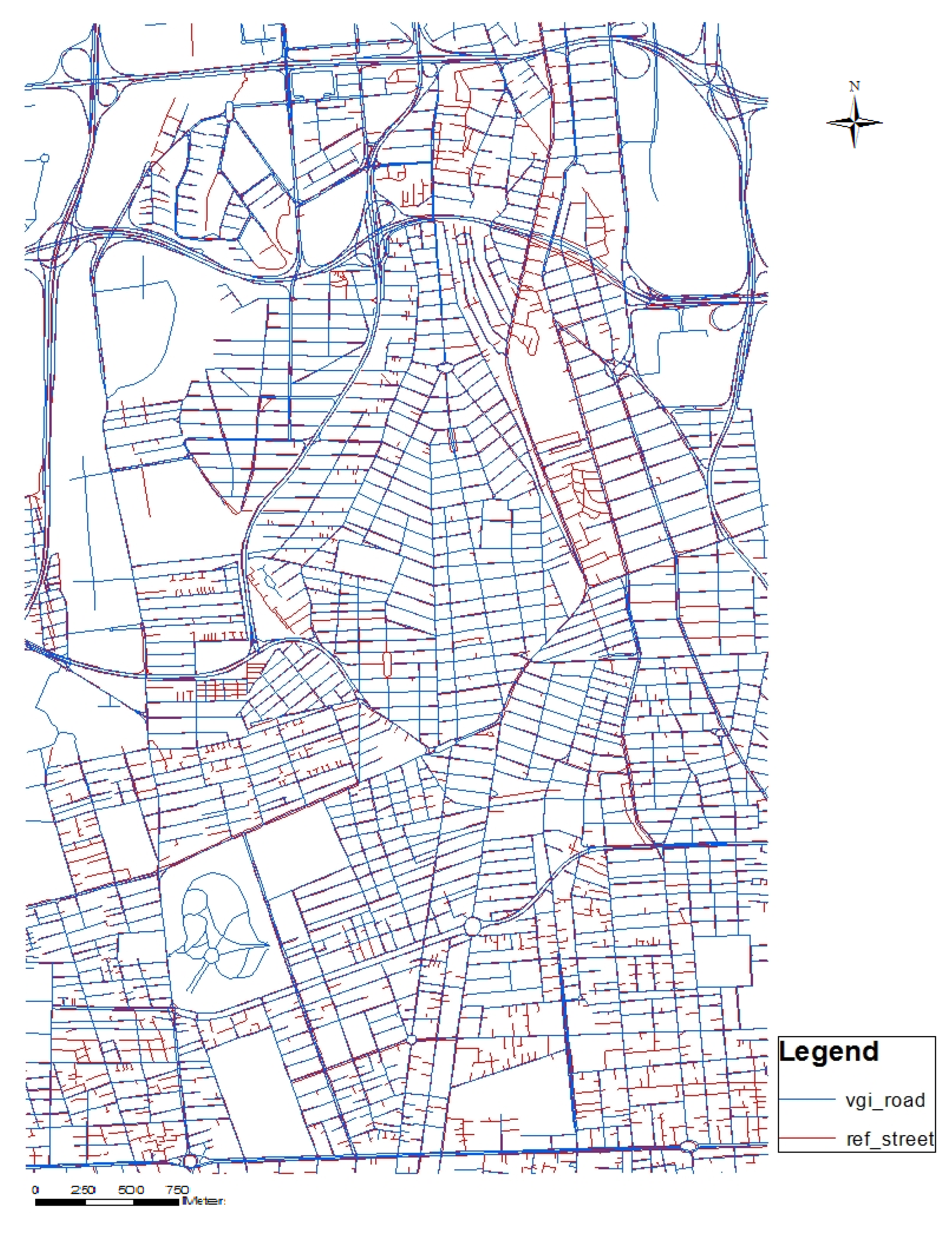
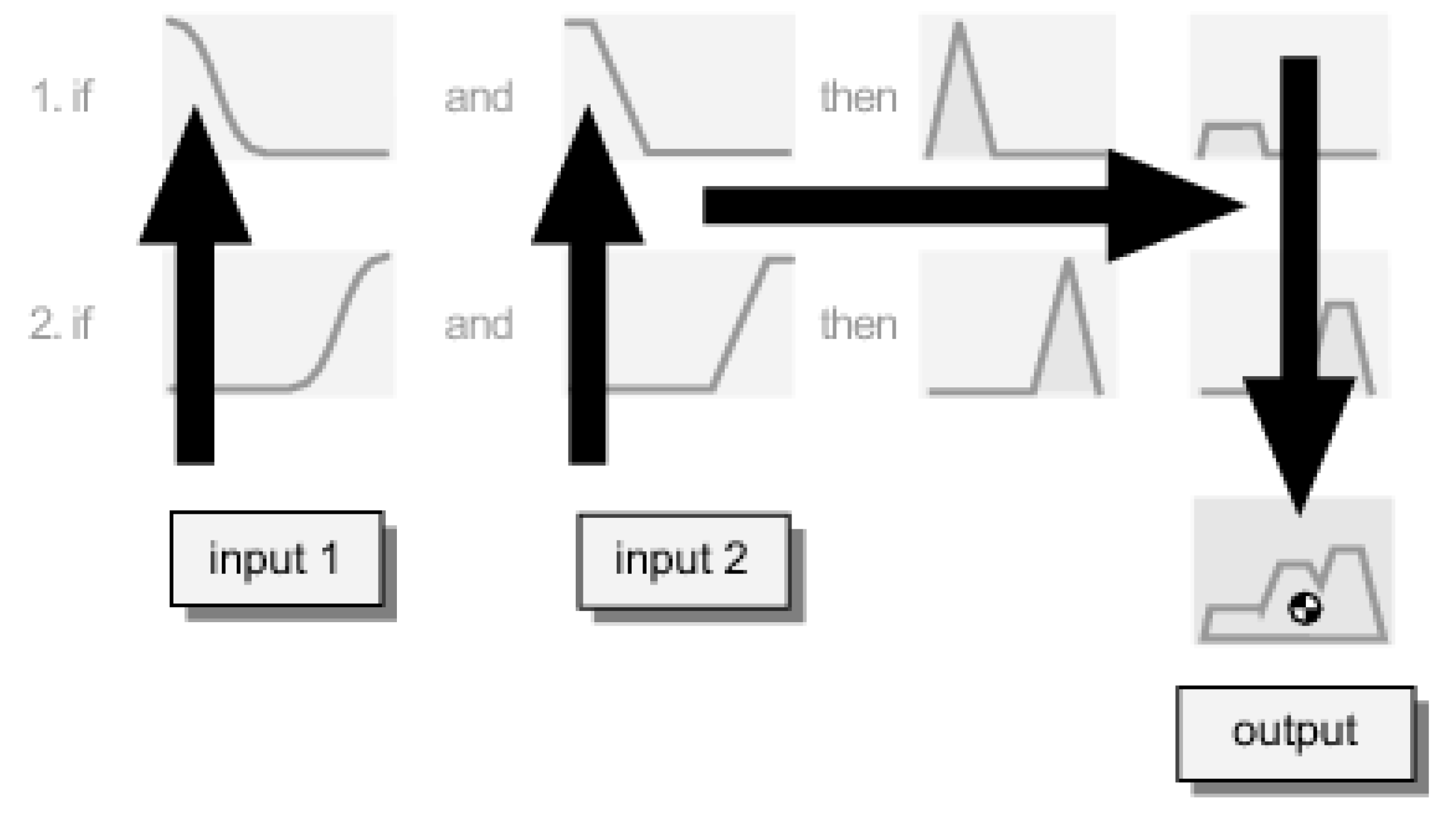
2.2. Assessment Method
- Split of datasets into tiles using grids. This step enables the comparison of the two sets in each cell grid;
- Evaluation of quality metrics on a tile-by-tile basis for both VGI and reference maps;
- Combination of the evaluated metrics through a fuzzy set approach and calculation of a quantitative term representing the quality of OSM data in each cell.
2.3. Quality Metrics
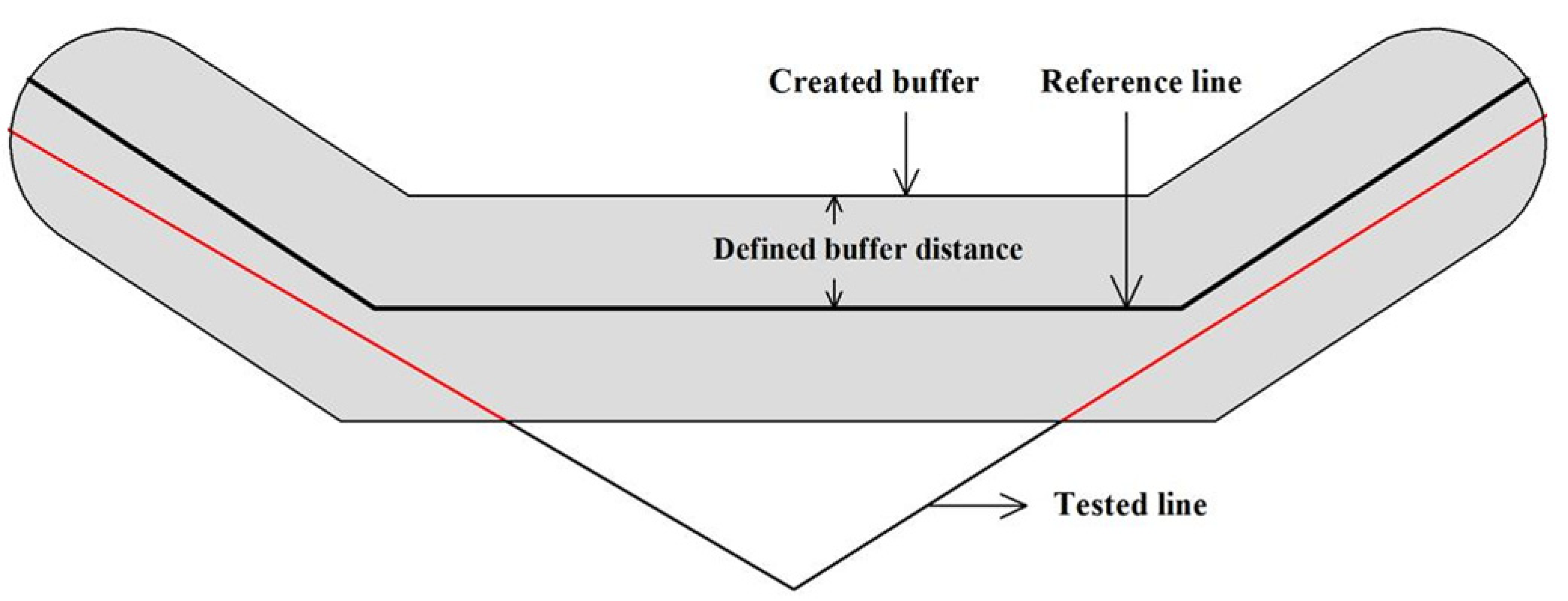
2.3.1. Road Length
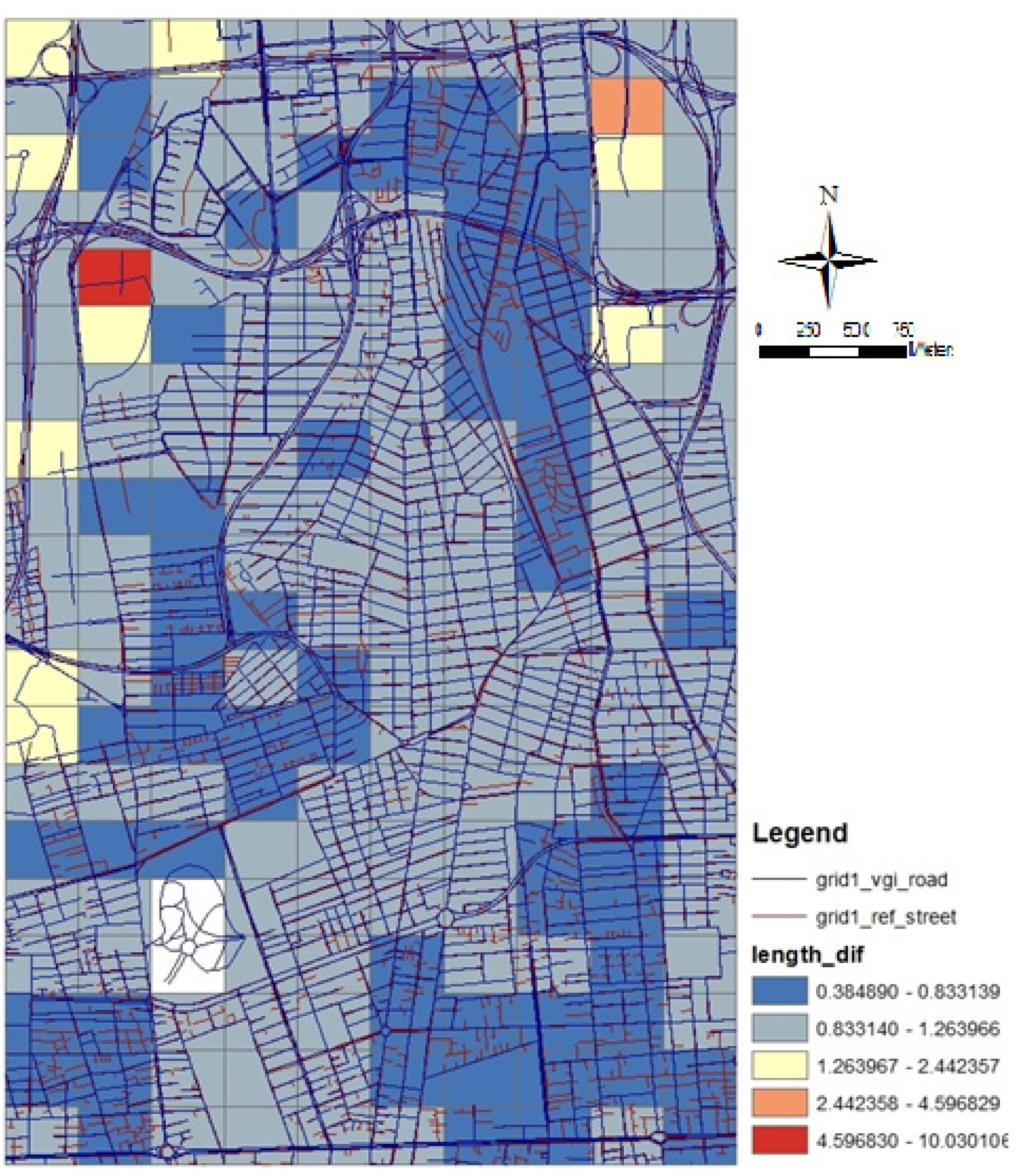
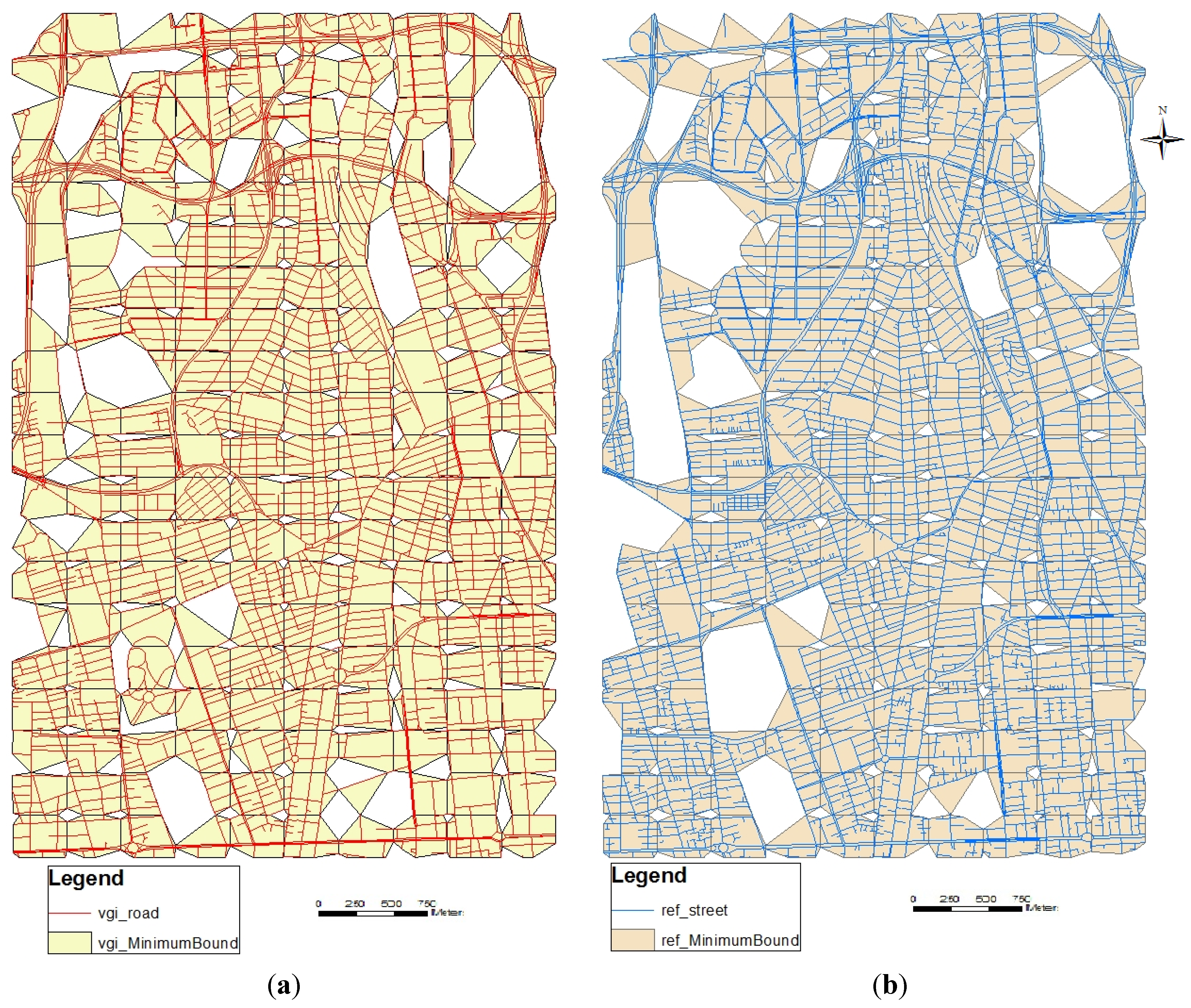
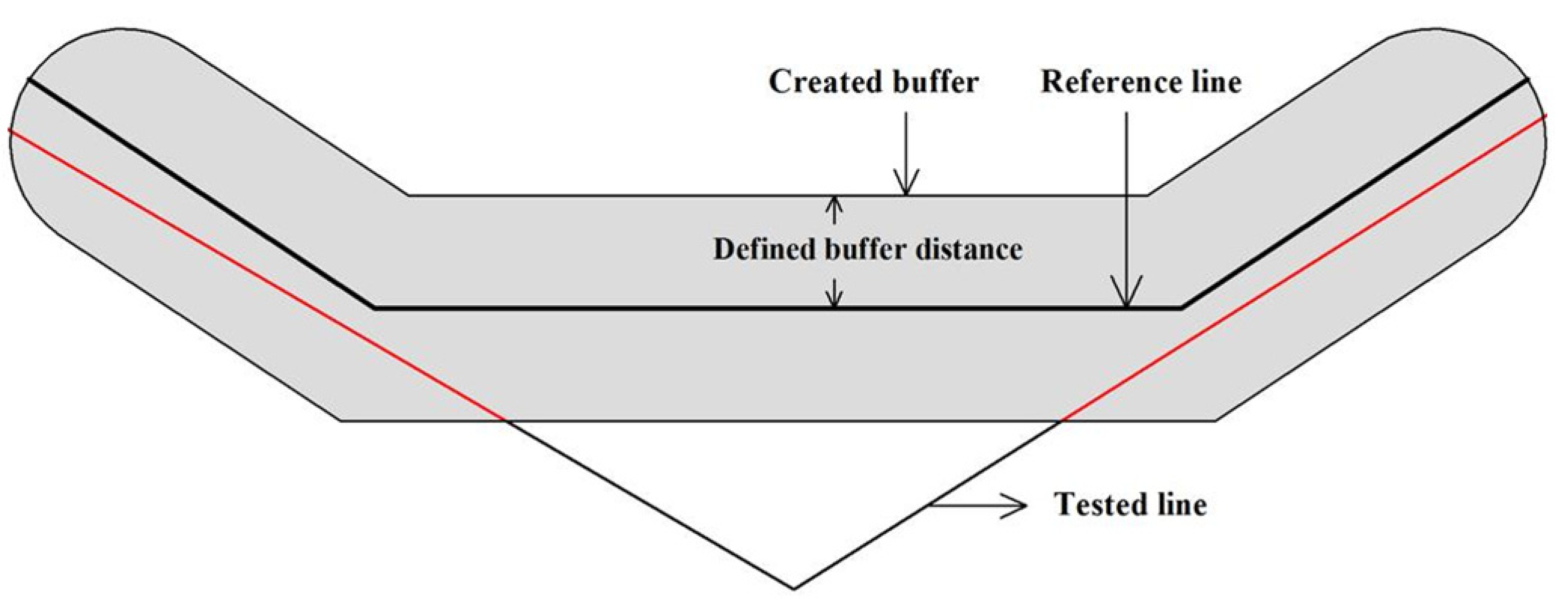
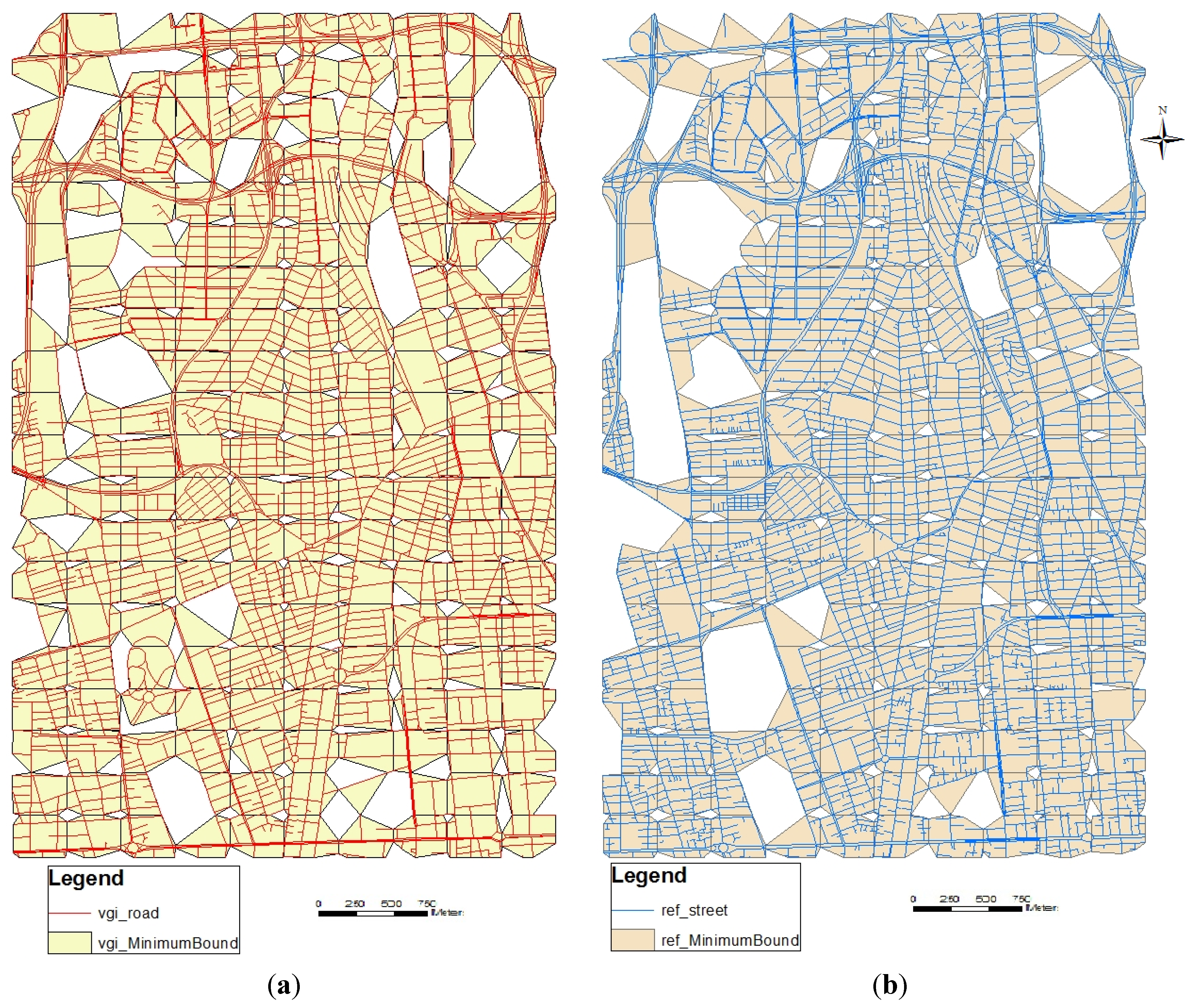
2.3.2. Minimum Bounding Geometry
2.3.3. Directional Distribution (Standard Deviational Ellipse)
2.3.4. Median Center
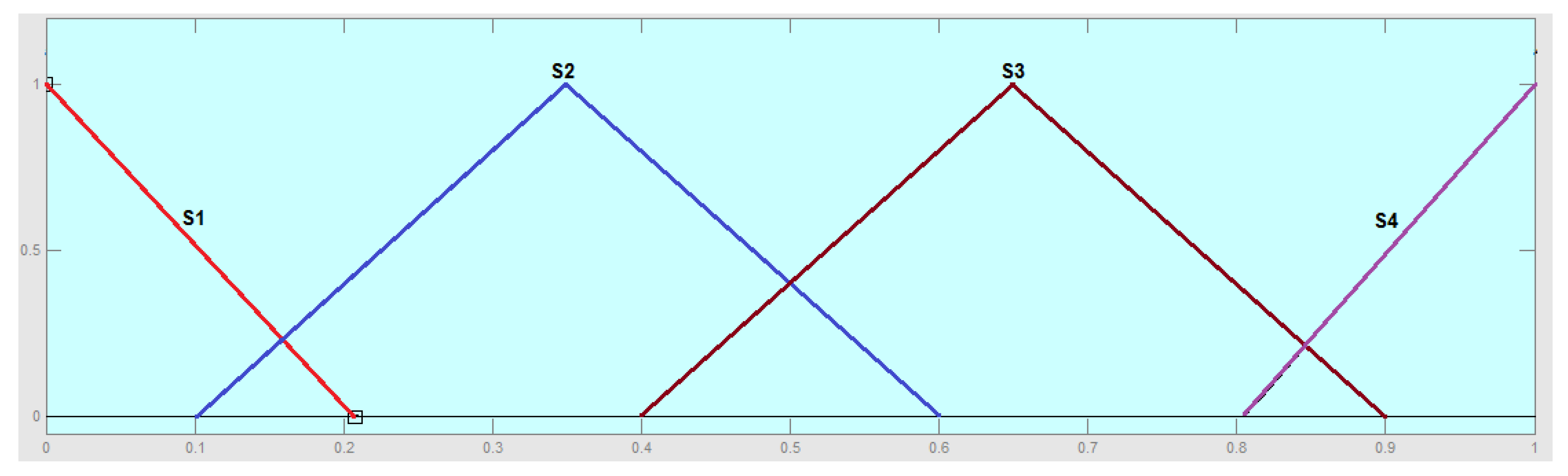
2.4. Fuzzy Model

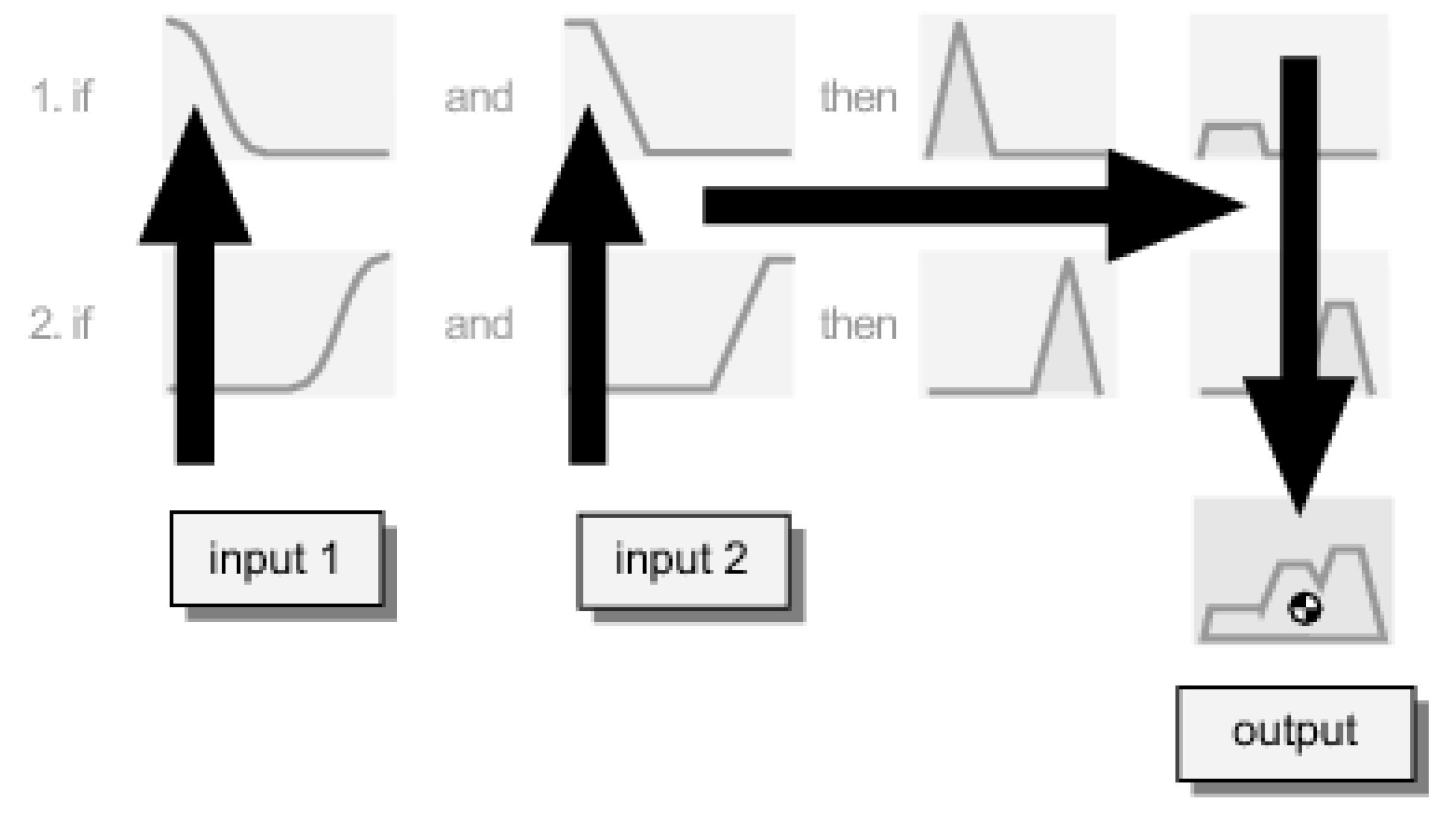

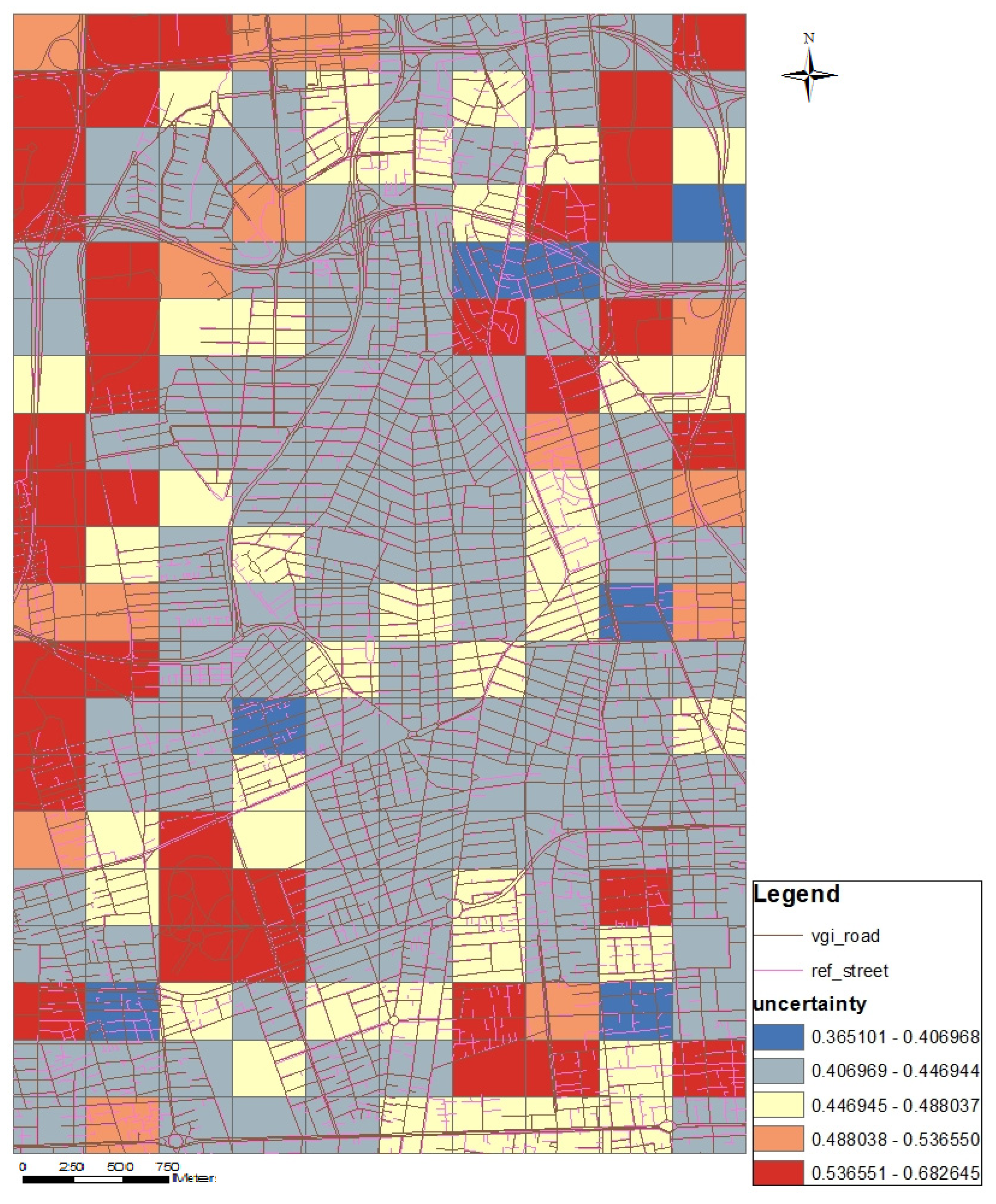
3. Conclusions
Author Contributions
Conflicts of Interest
References
- Zielstra, D.; Zipf, A. A Comparative Study of Proprietary Geodata and Volunteered Geographic Information for Germany. In Proceedings of the 13th AGILE International Conference on Geographic Information Science, Guimarães, Portugal, 10–14 May 2010; pp. 1–15.
- Goodchild, M.F. Citizens as sensors: The world of volunteered geography. GeoJournal 2007, 69, 211–221. [Google Scholar] [CrossRef]
- Hudson-Smith, A.; Crooks, A.; Gibin, M.; Milton, R.; Batty, M. NeoGeography and Web 2.0: Concepts, tools and applications. J. Locat. Based Serv. 2009, 3, 118–145. [Google Scholar] [CrossRef]
- Sui, D.Z. The wikification of GIS and its consequences: Or Angelina Jolie’s new tattoo and the future of GIS. Comput. Environ. Urban Syst. 2008, 32, 1–5. [Google Scholar]
- Cooper, A.; Coetzee, S.; Kaczmarek, I.; Kourie, D.; Iwaniak, A.; Kubik, T. Challenges for Quality in Volunteered Geographical Information. In Proceedings of the AfricaGEO 2011 Conference, Cape Town, South Africa, 31 May–2 June 2011.
- Goodchild, M.F.; Li, L. Assuring the quality of volunteered geographic information. Spat. Stat. 2012, 1, 110–120. [Google Scholar] [CrossRef]
- Haklay, M. How good is volunteered geographical information? A comparative study of OpenStreetMap and Ordnance Survey datasets. Environ. Plan. B Plan. Design 2010, 37, 682–703. [Google Scholar] [CrossRef]
- Ciepluch, B.; Jacob, R.; Mooney, P.; Winstanley, A. Comparison of the Accuracy of OpenStreetMap for Ireland with Google Maps and Bing Maps. In Proceedings of the Ninth International Symposium on Spatial Accuracy Assessment in Natural Resources and Environmental Science, Leicester, UK, 20–23 July 2010.
- Neis, P.; Zielstra, D.; Zipf, A. The street network evolution of crowdsourced maps: OpenStreetMap in Germany 2007–2011. Future Internet 2011, 4, 1–21. [Google Scholar] [CrossRef]
- Girres, J.F.; Touya, G. Quality assessment of the French OpenStreetMap dataset. Trans. GIS 2010, 14, 435–459. [Google Scholar] [CrossRef]
- Goodchild, M.F.; Hunter, G.J. A simple positional accuracy measure for linear features. Int. J. Geogr. Inf. Sci. 1997, 11, 299–306. [Google Scholar] [CrossRef]
- Servigne, S.; Lesage, N.; Libourel, T. Approaches to Uncertainty in Spatial Data. In Fundamentals of Spatial Data Quality; Devillers, R., Jeansoulin, R., Eds.; ISTE Ltd.: London, UK, 2006; pp. 179–210. [Google Scholar]
- Bordogna, G.; Carrara, P.; Criscuolo, L.; Pepe, M.; Rampini, A. A linguistic decision making approach to assess the quality of volunteer geographic information for citizen science. Inf. Sci. 2014, 258, 312–327. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef]
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Forghani, M.; Delavar, M.R. A Quality Study of the OpenStreetMap Dataset for Tehran. ISPRS Int. J. Geo-Inf. 2014, 3, 750-763. https://doi.org/10.3390/ijgi3020750
Forghani M, Delavar MR. A Quality Study of the OpenStreetMap Dataset for Tehran. ISPRS International Journal of Geo-Information. 2014; 3(2):750-763. https://doi.org/10.3390/ijgi3020750
Chicago/Turabian StyleForghani, Mohammad, and Mahmoud Reza Delavar. 2014. "A Quality Study of the OpenStreetMap Dataset for Tehran" ISPRS International Journal of Geo-Information 3, no. 2: 750-763. https://doi.org/10.3390/ijgi3020750
APA StyleForghani, M., & Delavar, M. R. (2014). A Quality Study of the OpenStreetMap Dataset for Tehran. ISPRS International Journal of Geo-Information, 3(2), 750-763. https://doi.org/10.3390/ijgi3020750