The discussion presented here is broken down into several pieces. We start in
Section 3.1 by introducing the study area and datasets that will be used in the rest of this paper. Next, in
Section 3.2 we will present the rationale for the development of our method. Following that, in
Section 3.3, we discuss data processing issues; this will be followed by a presentation of the automatic methods, in
Section 3.4, and manual methods, in
Section 3.5, which are part of our procedure. Finally, in
Section 3.6, we present summary statistics, which will aid in the later analysis for completeness and accuracy.
3.1. Case Study
As has been illustrated in the previous section, geospatial data quality is an ongoing concern; however, ideas have been presented for comparing reference and test datasets with each other. Quantifying completeness and accuracy will allow users of the data to better understand the data’s utility, but require that reference and test datasets be available. Fortunately, some recent work in the US has generated data that is appropriate for these analyses. This research uses three data sources including a government-provided reference source and two different VGI test sources.
The reference data is based upon information from the Department of Education’s lists of public and private schools. On behalf of the Federal government, Oak Ridge National Laboratory (ORNL) was asked to geospatially improve the location accuracy of the Department of Education data using repeatable methods. The ORNL data was created by geocoding address information for the schools [
40]. The resulting dataset is used extensively across the Federal government as the definitive national level database of the location and attribute information for both public and private schools in the US. In addition to this reference dataset, two test datasets are also used in this case study.
The first VGI test dataset comprises school locations from the POI layer of OSM. The POI layer represents each specific feature as a node and may include: churches, schools, town halls, distinctive buildings, Post Offices, shops, pubs, and tourist attractions as noted by the OSM wiki-site [
41]. Over
et al. indicate that the primary key in OSM for these nodes is “amenity”, which is broken down into categories, including: accommodations, eating, education, enjoyment, health, money, post, public facilities and transportation, shops, and traffic [
42]. From the above-referenced OSM wiki, instructions are provided to contributors to identify schools as areas when possible; however, when the boundaries of the area are unknown, the contributor is instructed to place a node in the middle of the area to represent the school compound. Because no limitations are placed on OSM contributors regarding the preferred placement of a representative location, significant variation in actual point location should be expected, whether the contribution is created from a personal GPS, smartphone, or online using heads-up digitizing with imagery of unspecified accuracy. We will use the OSM dataset to provide a direct assessment of point feature accuracy in VGI contributions.
We also use a second test dataset, which is a product of the US Geological Survey (USGS) OpenStreetMap Collaborative Project (OSMCP)—2nd Phase [
43]. OSMCP represents a hybrid variant of VGI in that it introduces limited oversight to the VGI process: the data are collected through VGI processes, peer-edited by volunteers, and a government agency (USGS in this case) provides quality control feedback to the volunteers, in an effort to improve the overall accuracy of their products. The USGS provided guidelines to the volunteers and instructed them to place features at the center of the building they represent [
44]; however, the OSMCP data collection method did not involve visiting any sites, but rather relied upon online research coupled with heads-up digitization using imagery that was provided to the users. The motivation behind the OSMCP effort is the desire of USGS to use such VGI data as a complement to their official datasets and incorporate the OSMCP results into
The National Map [
43].
It is important to recognize that one possible source of inconsistency between the datasets is the use of different feature classification schemes between each of the data sources. The ORNL and OSMCP data represents elementary and secondary education in the US [
44,
45,
46]. The OSM data includes the same definition for schools; however, the word “kindergarten” is used in OSM to represent day care facilities while in OSMCP and ORNL, it represents the first year of elementary school and as a result, some schools may be inconsistently tagged within OSM [
47]. A cursory examination of the OSM data for the study area revealed no instances where “kindergarten” was used when elementary school was intended. Within the research for this paper, we noted this discrepancy; however, based upon the substantial overlap between these definitions, we do not feel that these differences strongly affect the results.
OSMCP focused on the collection of data (point features) for selected structures that are similar to the POI from OSM. In the case of OSMCP though, the data collection was performed by a select group of 85 non-expert college student volunteers, and the process also underwent an iterative but limited quality control process by volunteers and USGS [
43,
48]. OSMCP can therefore be viewed as a hybrid VGI effort for two reasons. First, as we mentioned above, it introduces the notion of partial oversight to VGI. Second, with a relatively small group of college student volunteers performing the data collection, it resembles focused crowdsourcing efforts like Ushahidi, rather than the participation of “large and diverse groups of people” that Heipke considered as a representative participation pattern [
8,
49].
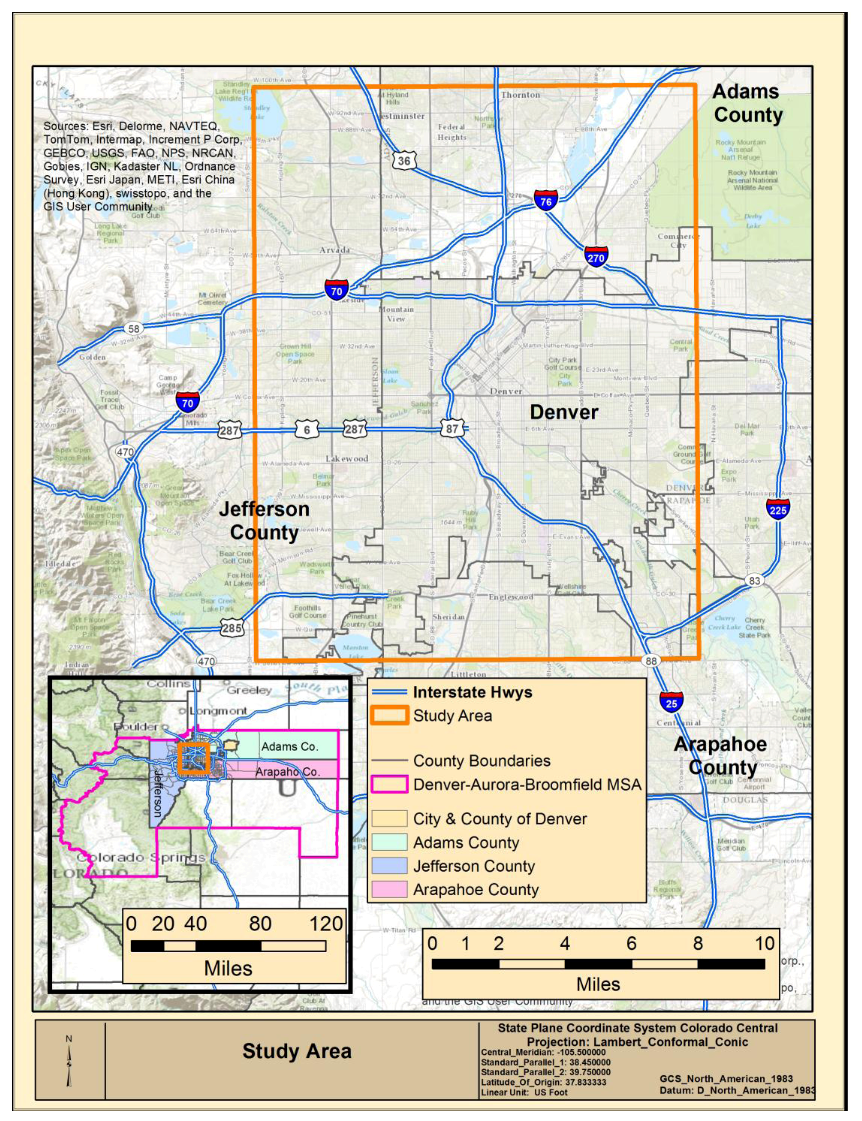
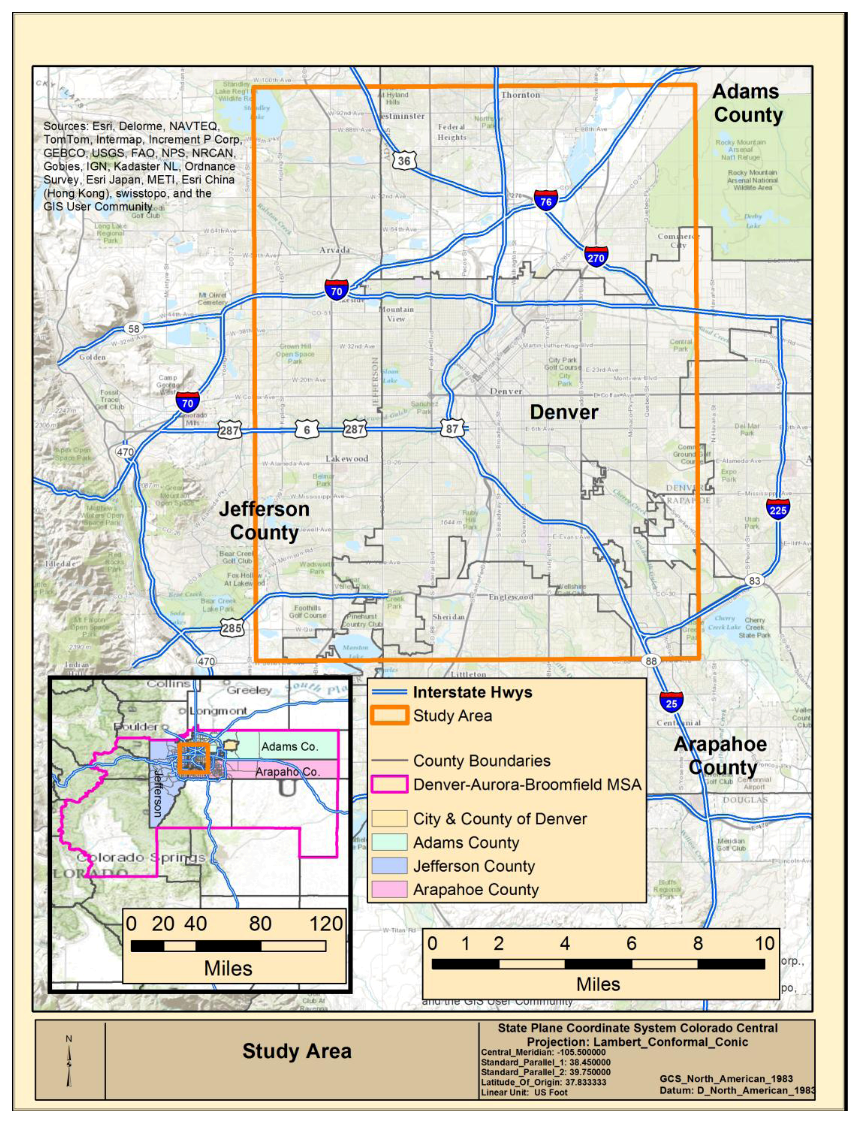
The study area for the comparison presented here is dictated by the footprint of the OSMCP data since both the ORNL and OSM data include the entire US. The OSMCP study area is located completely within the Denver-Aurora-Broomfield Colorado Metropolitan Statistical Area (MSA) as defined by the Census Bureau [
50]. The study area covers a large percentage of the City and County of Denver, including downtown Denver, extends into portions of the surrounding Arapahoe, Jefferson, and Adams Counties as shown in
Figure 1, and encompasses approximately 228.5 square miles. The study area consists predominately of commercial, industrial and residential neighborhoods commonly found in heavily urban areas, and includes a population of just under 1,100,000 people, or approximately 43% of total MSA population of 2.54 million.
While the ORNL data was generated using pre-prescribed methods and standards [
40], it is unlikely to be perfect; however, Goodchild affirms the use of an imperfect reference source data by pointing out that many users are willing to ascribe authority to data sources which are common regardless of the methods under which they may have been developed [
4]. While unlikely to be perfect, the ORNL data is likely to be more consistent than the OSM or OSMCP datasets because of the collection methods used; however, the methods for updating the ORNL data are slow and some schools, particularly newly opened or recently closed schools, are unlikely to be reflected in the ORNL data. Others have demonstrated how VGI has been shown to be more appropriate, because of their currency, than sources like ORNL during disasters [
51]. Matyas
et al. point out that data, like OSM, collected through VGI methodologies are often done so in a game-like atmosphere because the users contribute when and how they like with little or no oversight and as a result does not promote the idea of self-editing [
52]. In contrast, OSMCP addressed the issue noted above by including editors from both student volunteers and USGS in a hybrid environment [
53] and provided the volunteer contributors and editors with guidelines regarding the appropriate representative location for each feature. One of the stated goals of OSMCP was to gain a better understanding of the quality and quantity of data produced by volunteers by implementing the two-step quality phase after data collection [
48]. The methodology used to develop the OSMCP data included an editing phase, which included a provision allowing users to add records, which were not identified in the reference dataset. As has been previously discussed, the methodology outlined in this paper uses the ORNL data as a reference dataset because it is the best available from the federal government. However, the authors acknowledge that discrepancies between the datasets will exist due to the interpretation of the contributor as discussed above. Records identified in test datasets but not present in the reference dataset are useful for completeness measures because they highlight the possible shortcomings of the reference dataset.
3.2. Rationale
Quantifying the quality aspects of the schools within OSMCP, with its relatively limited spatial extent and restricted contributor set as compared with the equivalent OSM data, offers a unique opportunity to assess the question: Do the quality controls instituted by the USGS measurably improve the completeness and accuracy of volunteered contributions? Additionally, are the spatial biases noted in OSM data consistent between linear features and the point features focused on in this study [
15]? If so, are the biases present in both the OSM and OSMCP data? The findings from this study could then be applied by other researchers during implementation of other VGI projects so that they could work to mitigate any bias that may exist in data which was collected using VGI data collection methods.
Table 1 presents the total count of schools within the study area for each data source. While the total numbers of schools are reasonably close across the three sources, it is important to note ORNL and OSMCP data represent only active schools while OSM data includes approximately 12% historic schools which are likely no longer in existence and would, therefore, not match schools in either ORNL or OSMCP. A limited review of raw OSM data indicated that the majority of the records were derived from the USGS Geographic Names Information System (GNIS) which includes historic points of interest. GNIS data was likely bulk uploaded into OSM and users have not removed the historic records.
Table 1.
School count by data source.
Table 1.
School count by data source.
| Source | School Count |
|---|
| Oak Ridge National Laboratory (ORNL) | 402 |
| OpenStreetMap (OSM) | 406 * |
| OpenStreetMap Collaborative Project (OSMCP) | 412 |
Following the work of Haklay, the results shown in
Table 1 imply that these datasets are similar [
15]. However, a deeper assessment of the schools showed that only 281 schools are common to all three datasets illustrating that simple feature count may not adequately evaluate spatial accuracy or completeness.
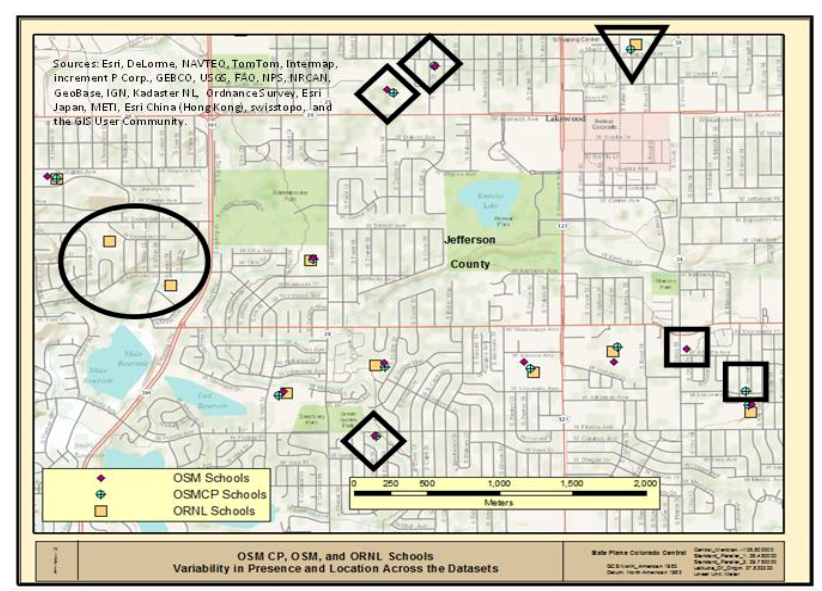
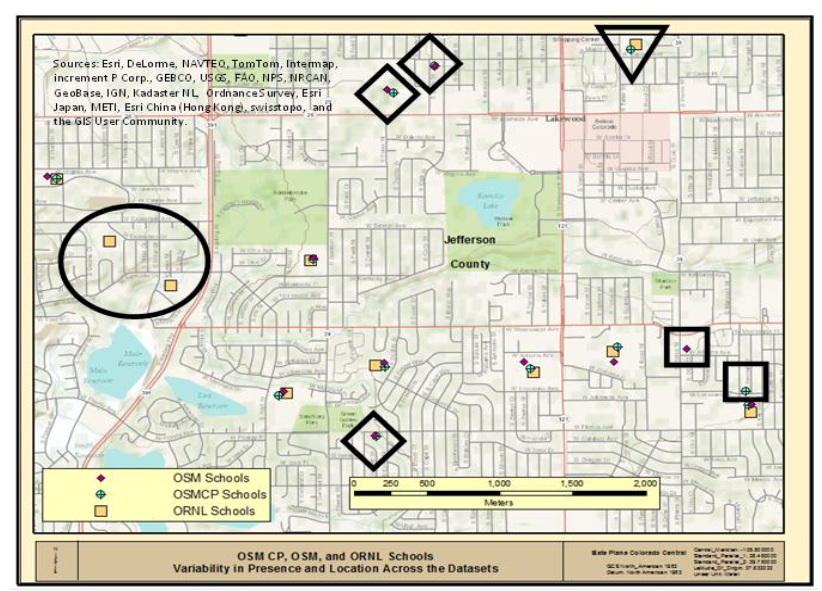
Figure 2 presents a portion of the study area that included 33 schools from the three datasets: 11 OSM; 12 OSMCP; and 10 ORNL, respectively. Review of
Figure 2 indicates that there is very good spatial correlation across the three data sources for seven locations where each data source indicates the presence of a school. However, the review also allows identification of two ORNL reference schools that do not have either an OSMCP or OSM school located nearby (black circle). In addition, there are three areas where both OSMCP and OSM schools are indicated, but there is no ORNL school associated (black diamonds), and there is one location where ORNL and OSMCP data correlate without an associated OSM school (black triangle). Lastly, there are two locations (black squares) where only one data source indicates the presence of a school, one from OSM and one from the OSMCP data source. The above visual assessment clearly indicates that while there are similar numbers of schools within the study area, as shown in
Table 1, the spatial variability suggests that a detailed evaluation of the data sources is required to understand the similarities and differences between the datasets. The above assessment only looked at the spatial “association” of features, and did not address the specific attribution associated with those locations.
Figure 2.
Comparison of OSM, OSMCP, and ORNL data.
Figure 2.
Comparison of OSM, OSMCP, and ORNL data.
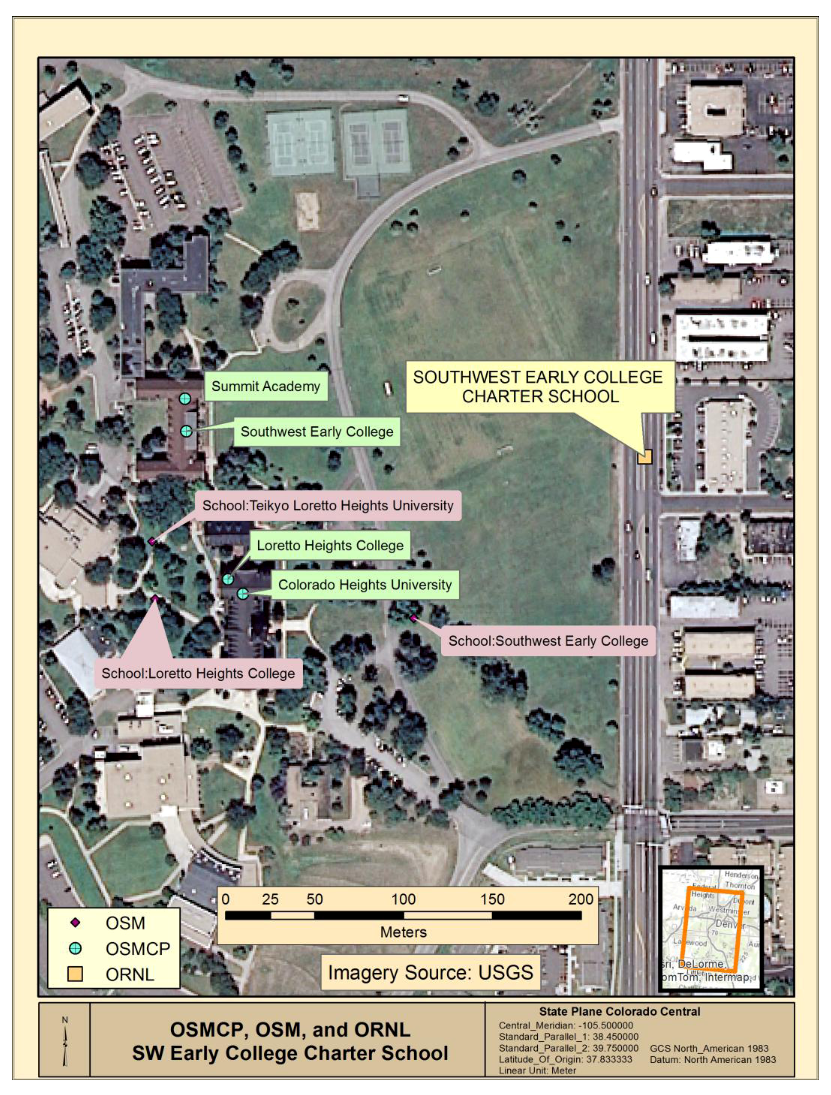
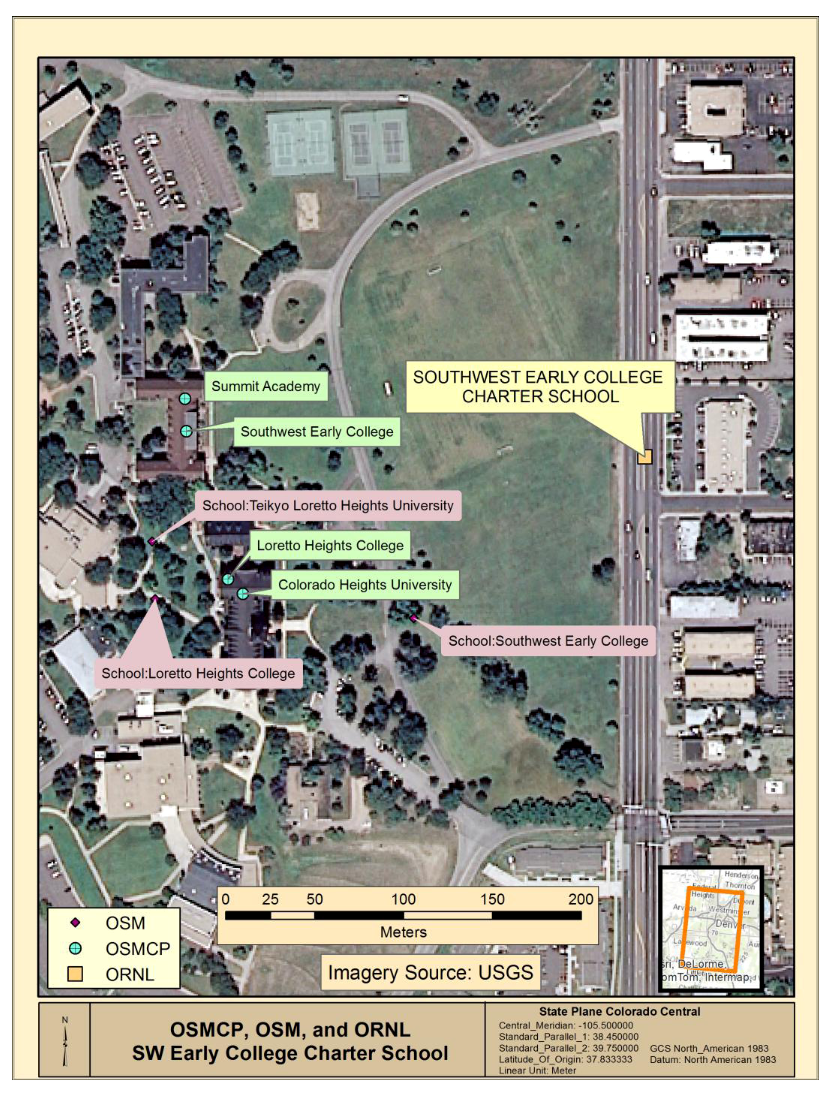
Figure 3 depicts the ORNL, OSMCP and OSM feature locations for the vicinity of Southwest Early College within the study area and presents an example where the effects of spatial variability discussed above, as well as variation in attribution, impact dataset comparison. There is only one school identified in the ORNL reference dataset in the vicinity. The ORNL location is denoted by a tan square and is located several hundred meters east of the OSMCP and OSM locations. OSMCP data indicates four separate schools (Summit Academy; Southwest Early College; Loretto Heights College; and Colorado Heights College from north to south) on what appear to be the same school grounds while the OSM data indicate three schools (Teikyo Loretto Heights University; Loretto Heights College; and Southwest Early College, from northwest to east). The presence of multiple schools noted in the OSMCP and OSM data suggest that the reference ORNL data may have errors of omission.
Figure 3 illustrates the concept of spatial vagueness within datasets discussed above and demonstrates that the traditional concept of geographic accuracy is likely an unnecessary goal when examining crowdsourced point feature data. Using any of the sources for Southwest Early College would allow navigation to the school property, although the OSMCP point feature location visually appears more accurate in that it falls on an actual building while the OSM location is on the school grounds and the ORNL location is mapped to a road centerline, furthest from the school buildings and off the campus entirely.
Figure 3.
Various identified locations of Southwest Early College.
Figure 3.
Various identified locations of Southwest Early College.
Based on the limited assessments presented above, and the discussion regarding attribution and source differences, it is clear that a systematic comparison of the datasets is required in order to evaluate the quality of the VGI test data in comparison to the reference data. The following section outlines that systematic approach.
3.3. Data Preparation
The ORNL data was provided in shapefile format projected in WGS84 but was re-projected into the Central Colorado State Plane system. The data was then clipped to the boundary of the OSMCP study area, yielding 402 school locations within the study area.
The OSM data was downloaded from the Internet [
54]. The data was downloaded on 13 December 2011 and represented OSM data as of 16 November 2011. The OSM points of interest data, provided in shapefile format projected in WGS84, was extracted and then clipped to the boundary of the OSMCP study area, yielding 4,285 points. The data attribution consists of four attributes: FID, Shape, Category, and Name. Significantly, to this study, the “Name” attribute is a concatenation of function and name. For example, “Place of Worship:Applewood Baptist Church”, “Restaurant:Bonefish Grill”, “Café:Einstein Brothers”, “Pub:Baker Street Pub and Grill” and “School:Alpine Valley School”. The 4,285 OSM points of interest were queried to extract records including the phrase “School”: yielding 406 schools in the study area. One concern with this method of extraction is that it relies upon the OSM data contributor to properly tag the schools; however, for this research we did not attempt to identify any improperly tagged entities to search for missing schools. The data was then projected into the Central Colorado State Plane system. Unfortunately, address was not included in the OSM extracted data and as a result, only the names can be used for comparing the data. As was discussed above, the GNIS data was used to bulk upload schools data into OSM and GNIS data does not include address information.
The OSMCP data provided by the USGS is bounded by the study area; however, it includes data beyond education, so schools were extracted from the overall dataset using an attribute called FType (Feature Type) yielding 412 schools [
55]. The OSMCP data was projected into the Central Colorado State Plane system. After that, the procedures outlined in
Section 3.4,
Section 3.5 were repeated for each comparison of a test dataset to a reference dataset.
3.4. Automated Methods
Automated matching of the datasets was carried out using four different methods across each of the name and address fields from the dataset attributes. The automated matching process begins with verifying that the spatial reference of each dataset is the same and in units that are useful for measuring the spatial error between two features. For example, WGS84 data is unlikely to yield useful matching results because the distance measures will be in degrees whereas a projection based on feet or meters would yield more useful distance measurements. Next, a spatial join of the test dataset to the reference dataset is conducted (using the Spatial Join tool within the Analysis Toolbox of ArcGIS™) as the most-likely match for each record is the physically closest record and the spatial join identifies the closest record.
Before further analysis can begin, an attribute, called “MatchMethod” is added to the joined dataset’s attribute table. This attribute is populated by a script that was developed by the authors as a part of this research utilizing the Python™ scripting language within the ArcGIS™ environment. The valid values for MatchMethod are from 0 to 11 as shown in
Table 2. The script moves through the records looking for matches between the reference and test dataset and records the MatchMethod used. Initially, all records have a MatchMethod value of 0, which indicates that the records have not yet been evaluated. MatchMethod values 1 through 5 are “name” matches with the first four being automated and denoted by the ‘AN’ prefix. MatchMethod values 6 through 10 mirror MatchMethod values 1 through 5 in function except that the address field is used to find a match instead of the name field. Automated methods based on the address are denoted by the “AA” prefix. As was previously discussed, the OSM data did not include address information so the “AA” methods did not yield results in that specific comparison, but they are included here because the algorithm does leverage address information when it is available, such as for the OSMCP data.
Table 2.
Values used to track record matching.
Table 2.
Values used to track record matching.
| Match Method Value | Description |
|---|
| 0 | Record not yet analyzed |
| 1 (AN-C) | Fully automated name match derived from closest record |
| 2 (AN-O) | Fully automated name match using any other record |
| 3 (AN-DC) | Fully automated name match using difflib string comparison to closest record |
| 4 (AN-DO) | Fully automated name match using difflib string comparison to any other record |
| 5 (MN) | Manual match using name |
| 6 (AA-C) | Fully automated address match derived from closest record |
| 7 (AA-O) | Fully automated address match using any other record |
| 8 (AA-DC) | Fully automated address match using difflib string comparison to closest record |
| 9 (AA-DO) | Fully automated address match using difflib string comparison to any other record |
| 10 (MA) | Manual match using map/address |
| 11 | No match identified |
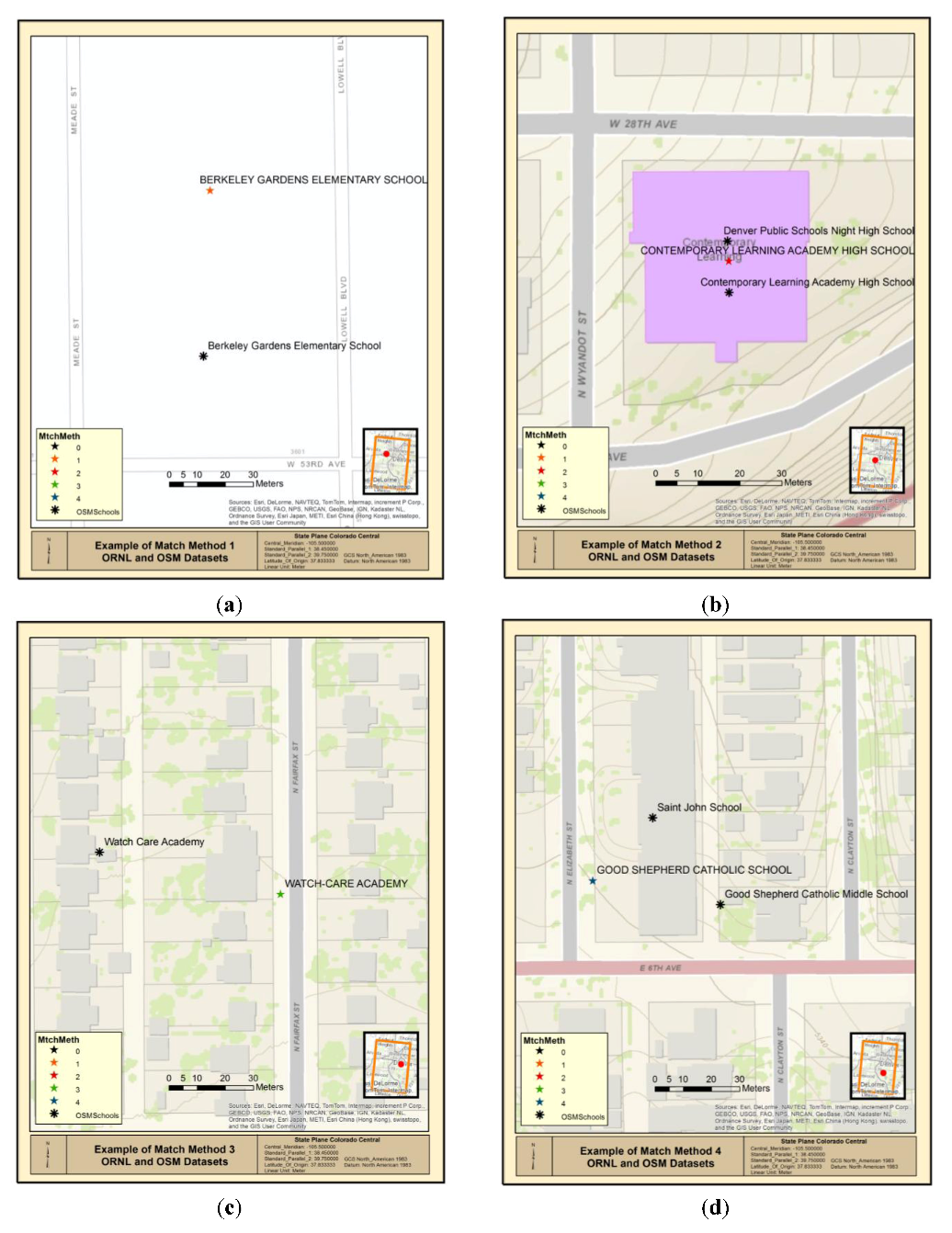
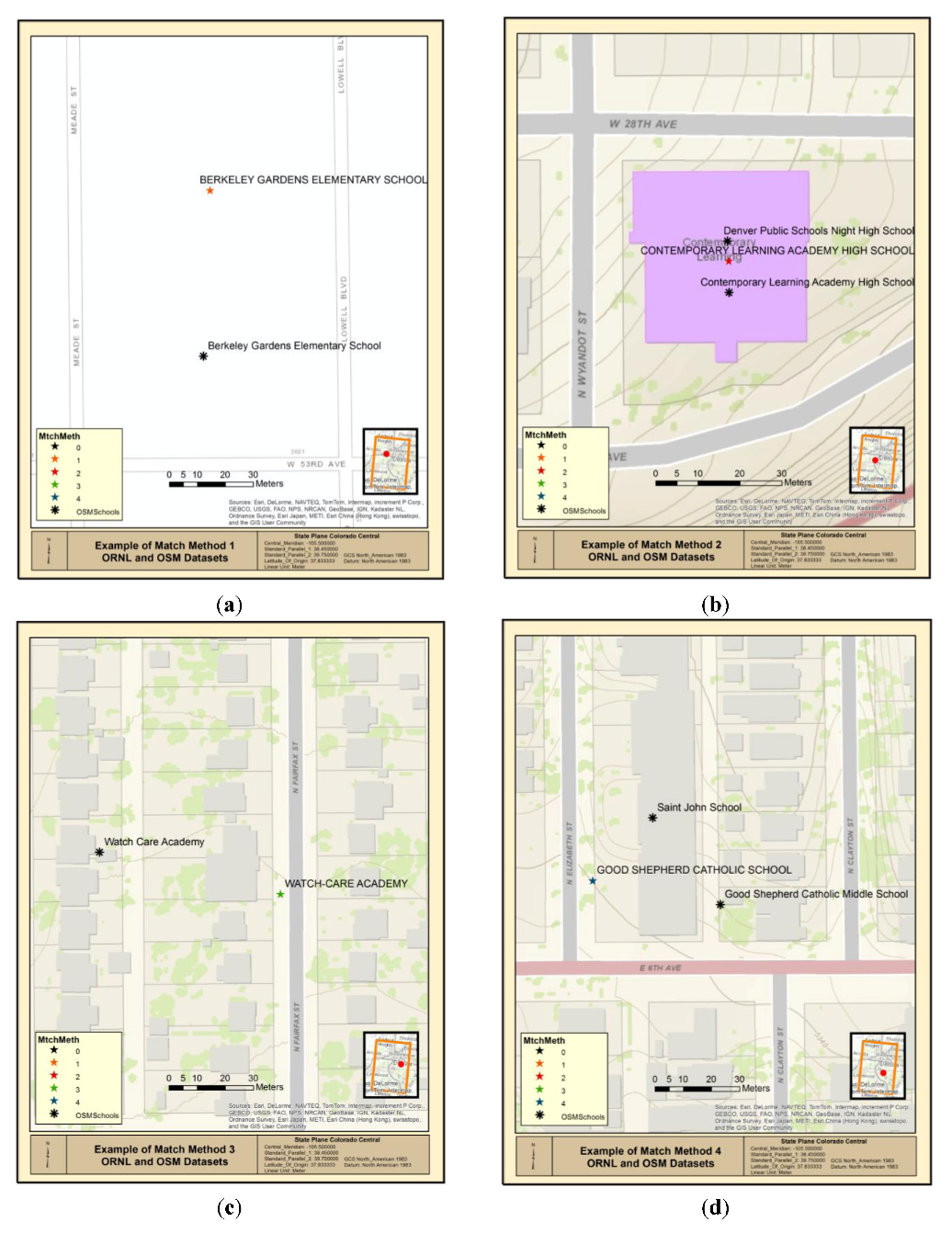
Initially, the algorithm attempts to identify a perfect match between the test and reference dataset. The test record nearest to each reference record was identified using a spatial join as described above. Perfect matches of the nearest records are denoted by the suffix “C” in
Table 2. If the nearest record is not found to be an exact match for the reference dataset, then the algorithm examines the test records to identify another exact match within the test dataset. If one is found, then the match is denoted by the suffix “O” in
Table 2. Examples of MatchMethod values AN-C and AN-O are shown in
Figure 4(a,b).
The MatchMethod values ending with “DC” and “DO” use the Python™ difflib library to identify similarities in the attribute values. The difflib method is based on a pattern matching algorithm developed in the late 1980s by Ratcliff and Obershelp [
56]. The two methods listed in
Table 2 that used the “DC” suffix examine the nearest test record to each reference record using the SequenceMatcher class and the ratio method to find a match. The ratio method returns a value between 0 (no match) and 1 (perfect match) when comparing two values. The pattern matching methods implemented in Python™ are used in this analysis because they are fast and effective for our purposes and they provide a result, the ratio, which can be quickly interpreted. In essence, the method counts the number of matching characters between the two strings and divides that number by the total number of characters in the two strings and returns that result as a value (ratio) which can then be compared to a minimum value to determine whether an appropriate match was identified. Through trial and error, appropriate minimum ratios for matching the name and address attributes were identified. These ratio values were selected with a focus on minimizing false positives. Similarly, the methods from
Table 2 that have the suffix “DO” leverage the get_close_matches method to find the closest match between the reference record and all test records. The get_close_matches method returns an ordered list of close matches. The script developed for this paper selects the highest match value and compares that value to the minimum acceptable ratio to determine whether the record is a match or not. Examples of MatchMethod values AN-DC and AN-DO are shown in
Figure 4(c,d).
Figure 4.
(a) MatchMethod value AN-C between ORNL and OSM Data; (b) MatchMethod value AN-O between ORNL and OSM Data; (c) MatchMethod value AN-DC between ORNL and OSM Data; (d) MatchMethod value AN-DO between ORNL and OSM Data.
Figure 4.
(a) MatchMethod value AN-C between ORNL and OSM Data; (b) MatchMethod value AN-O between ORNL and OSM Data; (c) MatchMethod value AN-DC between ORNL and OSM Data; (d) MatchMethod value AN-DO between ORNL and OSM Data.
After completing the automated methods, one school, Adams City High School, was observed to have over a 3,000 m difference between the reference and test datasets. Review of the school information from online sources indicated that the original school buildings (represented in the ORNL data) had been closed after the development of the ORNL data and a new school, bearing the same name was built in a different location (represented in both the OSMCP and OSM data) [
57]. Therefore, this school was omitted from further analysis of accuracy.
3.5. Manual Methods
MatchMethod values 5 and 10 are manual matching methods. Our automated methods are incapable of dealing with these cases; therefore, the user must manually examine the unmatched records which remain after the automated processes to determine if any potential matches were missed. In concept, the user will display both the reference and test datasets along with their labels within a Geographic Information System (GIS). The user then examines all records that have yet to be matched (i.e., they retain a MatchMethod value of 0), in order to determine if a match might exist. If a record with a similar name is identified as a match, then the user would update the MatchMethod value to 5, measure the distance between the two features, and then update the distance, name, and address fields to match those of the matched record. In rare cases, the automated methods fail to match two records because their names and/or addresses are too different for the pattern matching algorithm to recognize; however, during the manual process, the user can identify these two records as a match. One example of manual match is “Escuela Tlatelolco Centro de Estudios” and “Escuela Tlatelolco” where the automated matching methods failed to identify these two records due to the difference in the length of the corresponding records. In order for the pattern-matching algorithm to identify these records as a match, the minimum ratio would have to be set so low that many false matches would be generated for other features and as was previously stated, the minimum values were selected to minimize false matches. The ratio describing the similarity of these two strings is 0.65, which is well below the minimum ratio of 0.83 that was developed through trial and error. Fortunately, very few cases of missed records, like the one illustrated above, were discovered during the manual matching process which confirmed the decision to set higher ratios to avoid false matches.
A very similar process would be followed looking for an adjacent record with a similar address except that the user would update the MatchMethod value to 10 and then update the distance, name, and address. If no match can be found through manual means, then the user would update the MatchMethod value to 11 indicating that no match was found. The user would repeat the process until no record with a MatchMethod value of 0 remains, completing the matching process.
3.6. Computation of Summary Statistics
Once the matches had been identified, as outlined above, an additional processing step is required before analysis can take place. The final process in the analysis includes computation of the intersection, union, and complement. These values can then be used in the computation of the accuracy and completeness [
58].
The Intersection (Reference ∩ Test) dataset includes all records that are in both of the datasets. The records are identified by selecting records that have a MatchMethod value of 1–10 in the joined dataset.
The Reference Complement Test (Reference/Test) dataset includes those records that are in the Reference dataset, but not in the Test dataset. To identify these records, the records with a MatchMethod value of 11 are selected from the joined dataset.
The Test Complement Reference (Test/Reference) dataset includes those records that are in the Test dataset, but not in the Reference dataset. The method for identifying these records is a bit less straightforward than the previous method. The reason for the added complexity is that the joined dataset does not include all of the records from the Test dataset but instead only those records that had matches. In order to determine which Test records are not in the joined dataset, the two datasets were compared using a table join on attributes using a unique identifier in the Test dataset and then all unjoined records were extracted since they were not identified in the joined dataset.
The Union (Reference Test) represents all records that are in the Reference or Test dataset. The previously described intersection and complement datasets were merged to derive the Union.
Computation of these four parameters will facilitate the completeness and accuracy calculations, which will be presented later in this paper.

 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}