3.3. Model Indicator Weights and Matching Results
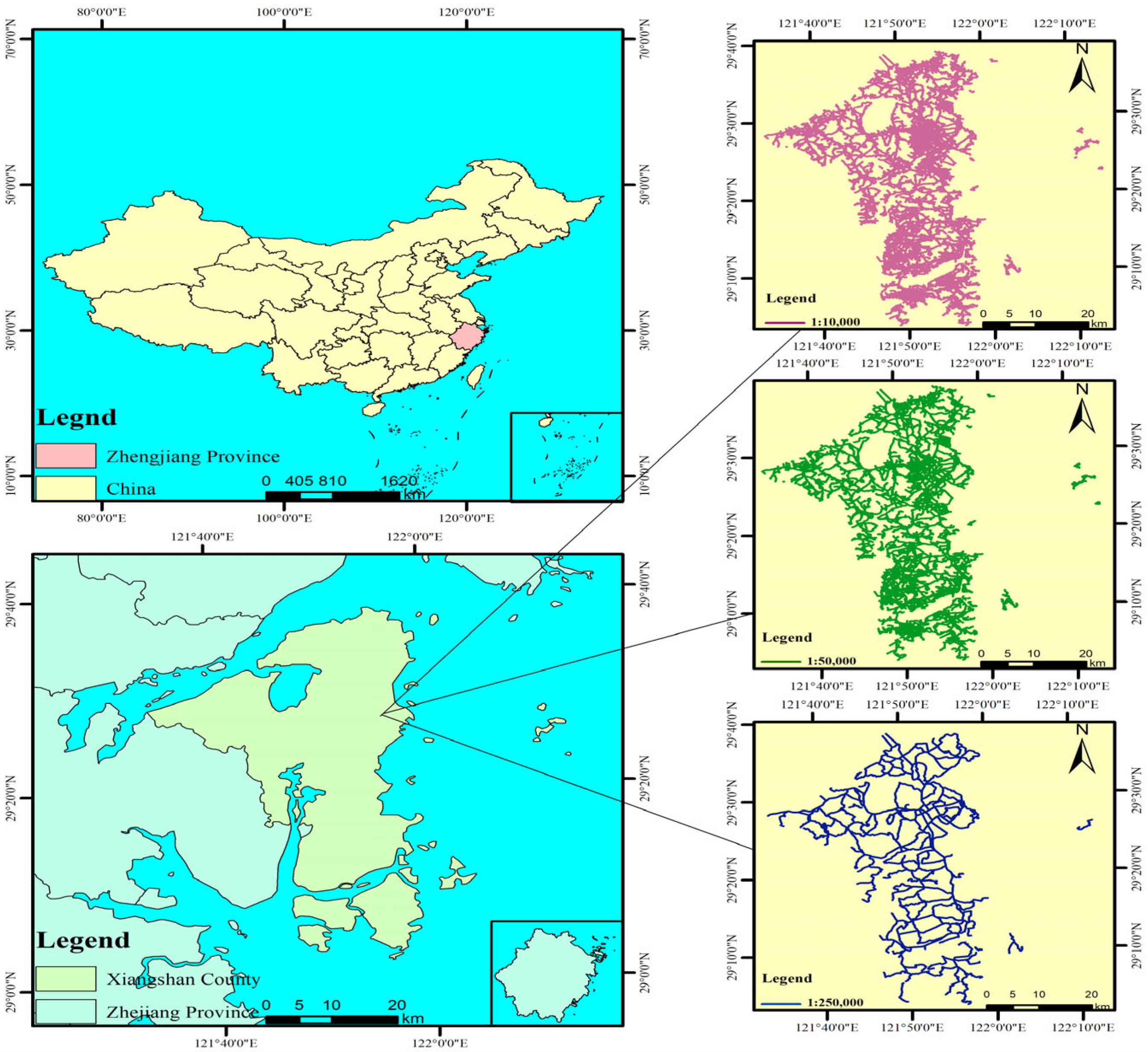
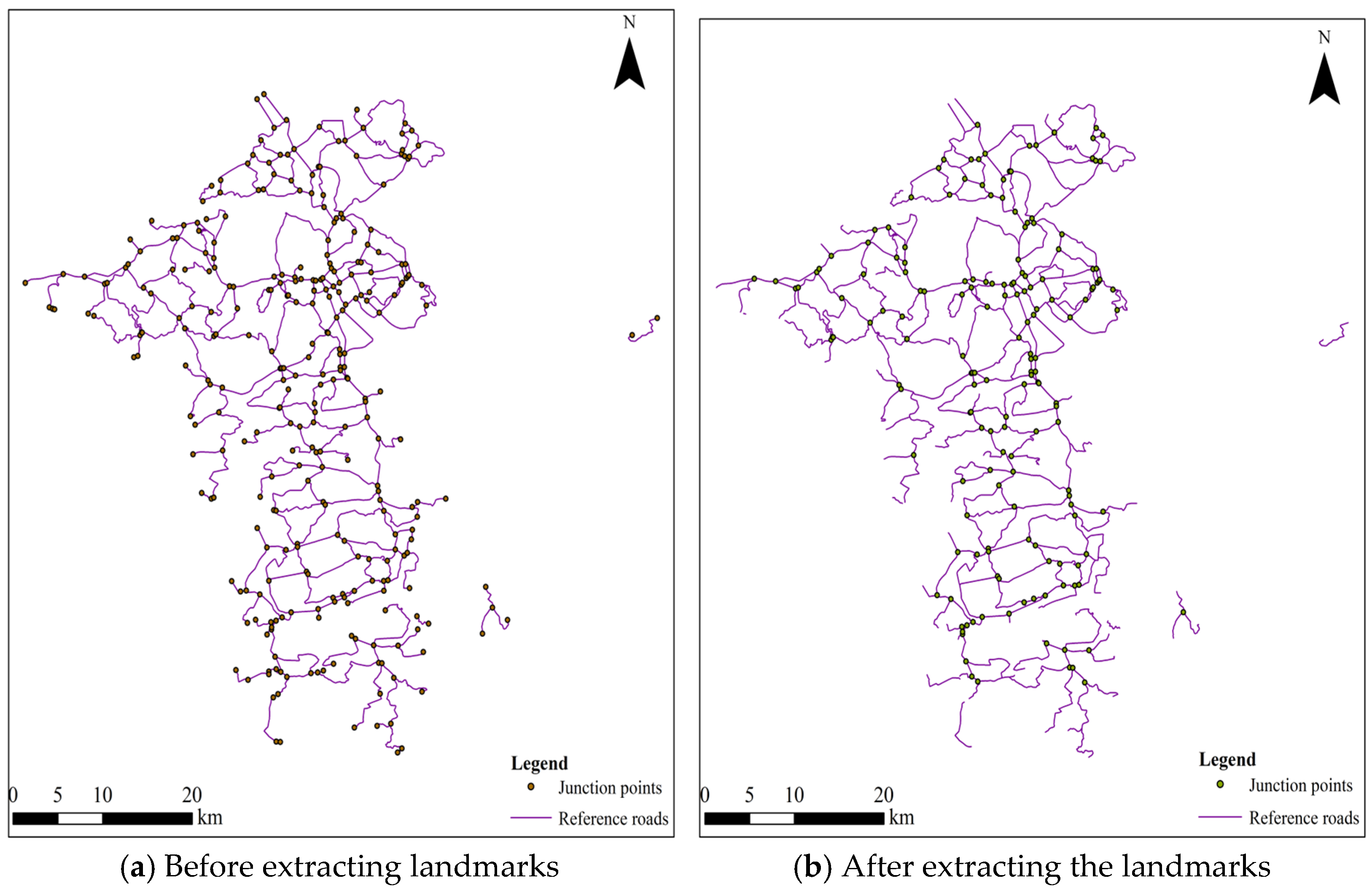
Considering that the span of the scales 1:10,000 and 1:250,000 is large and the accuracy of the experimental results is low, in this paper, the road dataset with scales 1:50,000 and 1:250,000 and the road data with scales 1:10,000 and 1:50,000 are respectively named as Group A and Group B for road-matching experiments. The road dataset with a scale of 1:250,000 is the reference road dataset in Group A, and the road dataset with a scale of 1:50,000 is the reference road dataset in Group B. In this paper, a total of seven road-matching models are selected to be applied in the matching of the experimental road dataset. Among them, length, direction, and Hausdorff distance are used as the common matching indices for these seven road datasets, while the ISOD descriptor, included angle chain, and camber variance are added to the road-matching models either individually or in combination. In this paper, the weight of each metric in each model is determined by controlling a single variable. When determining the weights for a particular model, the weights of one of the features are first changed; the weights of the other features are set and kept constant, and then, multiple comparison experiments are conducted. The weight corresponding to the indicator with the best matching result is the weight of that indicator in that model. Subsequently, the weight of the next indicator is changed; the weights of the other indicators are kept unchanged, and then, several comparison experiments are conducted to select the weight with the best matching result. By analogy, the weights of each indicator in the model can be determined to match those in groups A and B, respectively. The weights of each indicator in the seven models were normalized.
Table 6 and
Table 7 show the allocation of each metric for the seven models in the Group A and Group B experiments, respectively. The matching results were then output, as shown in
Figure 9 and
Figure 10. In Group A, the matching results can be directly compared with the original data, allowing for an intuitive assessment of the matching model’s performance. In contrast, the experimental data in Group B is more complex, making it difficult to clearly demonstrate the model’s performance through direct comparison. A detailed analysis and comparison of the relevant matching results will be presented step by step in the discussion section.
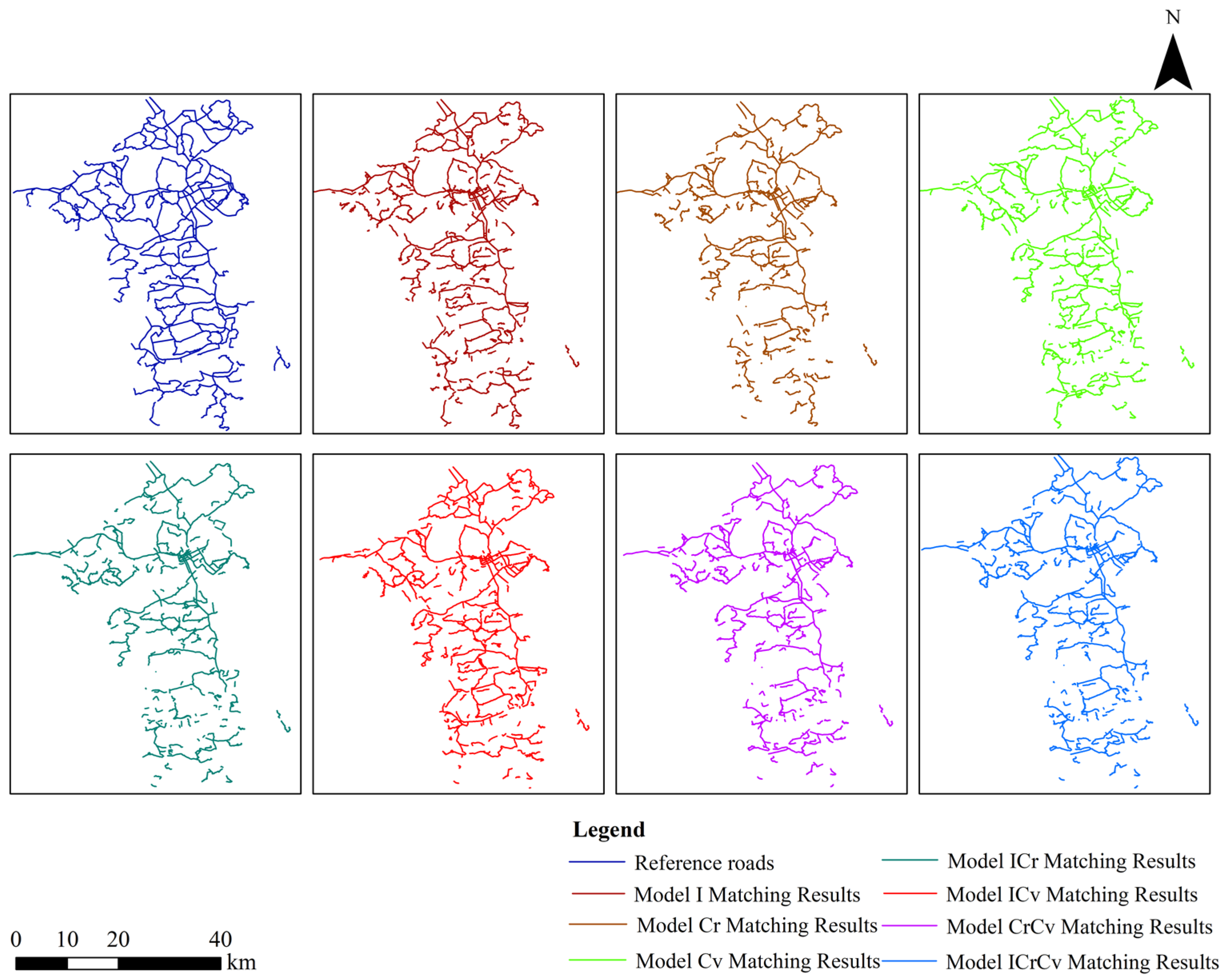
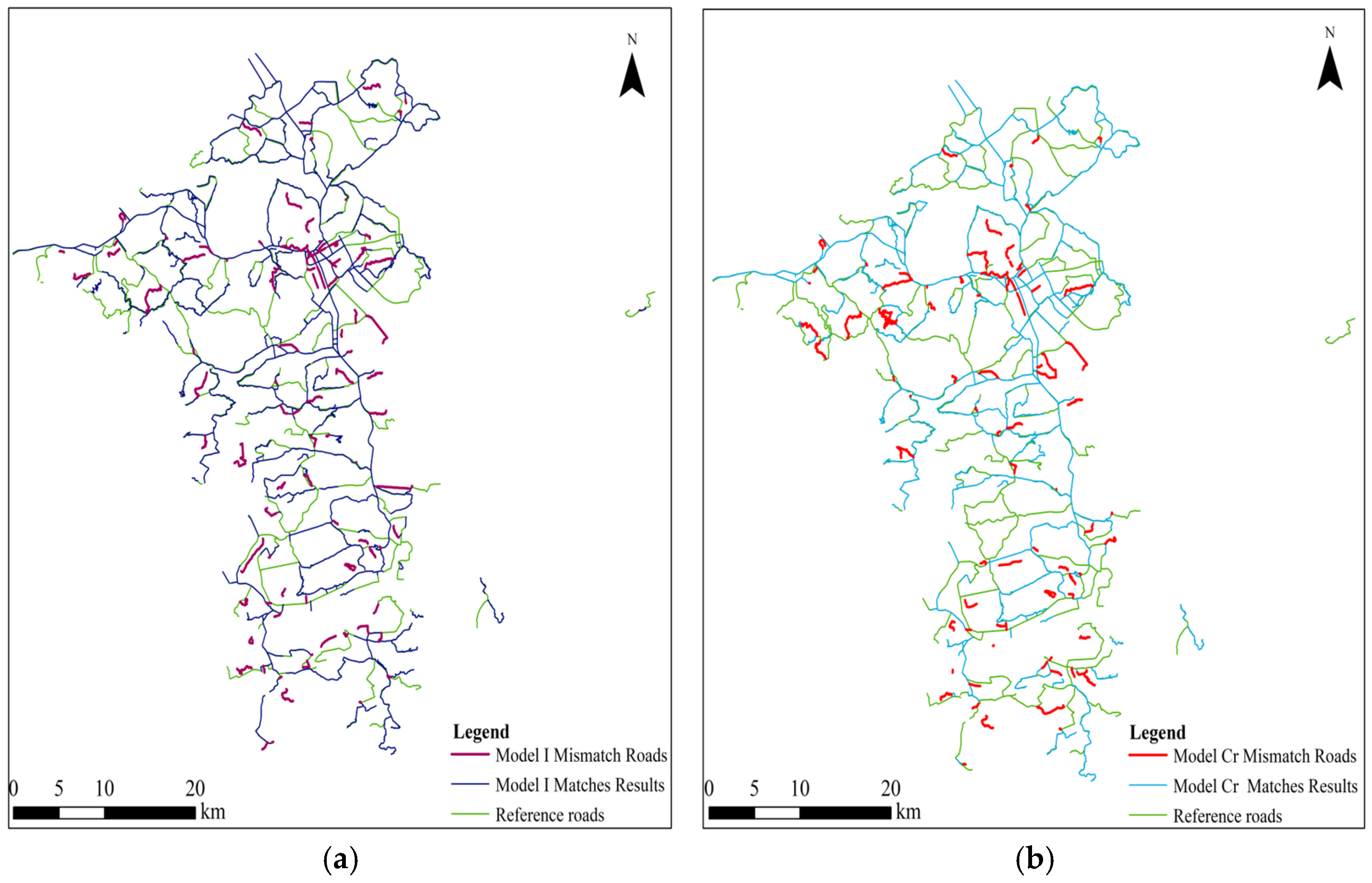
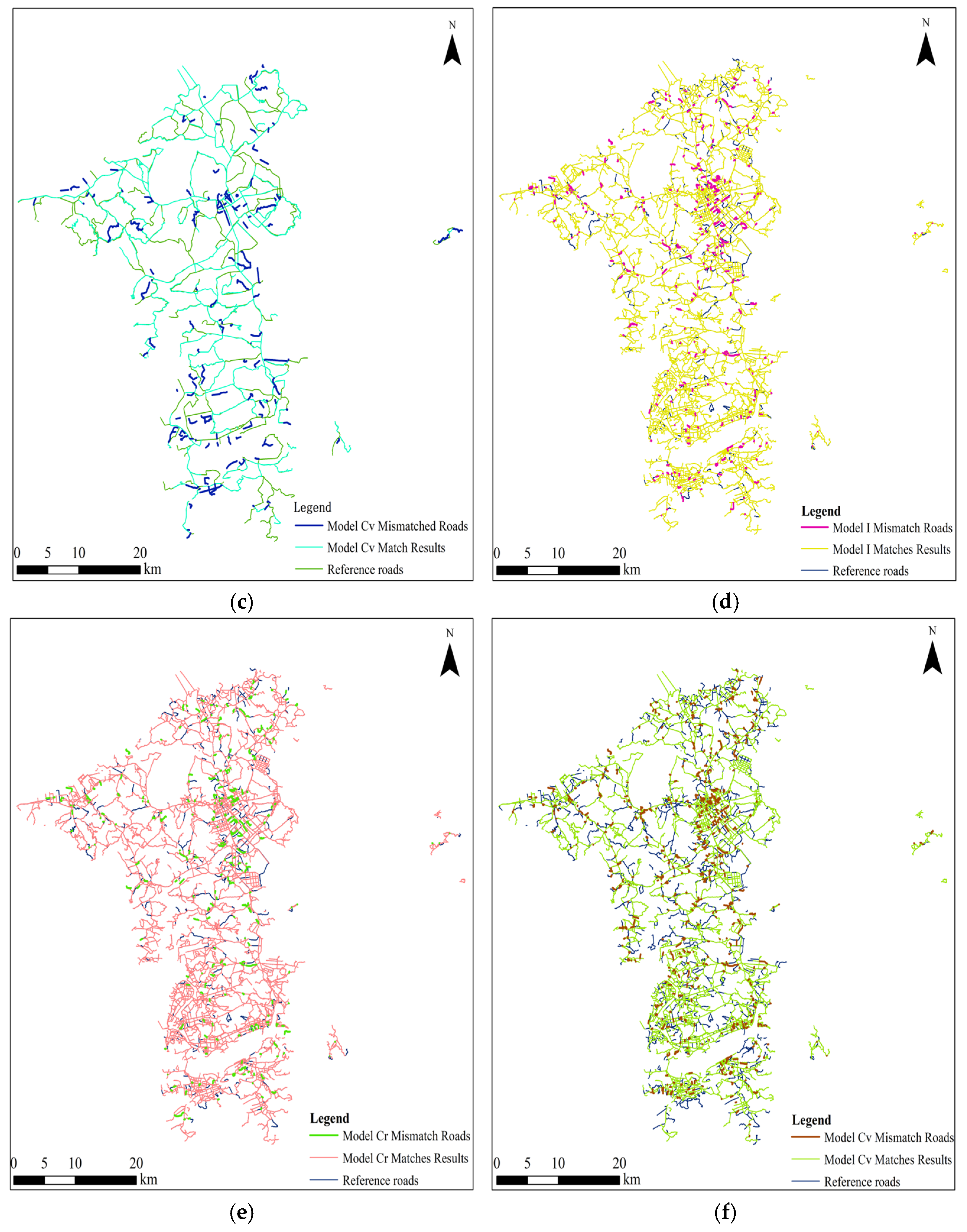
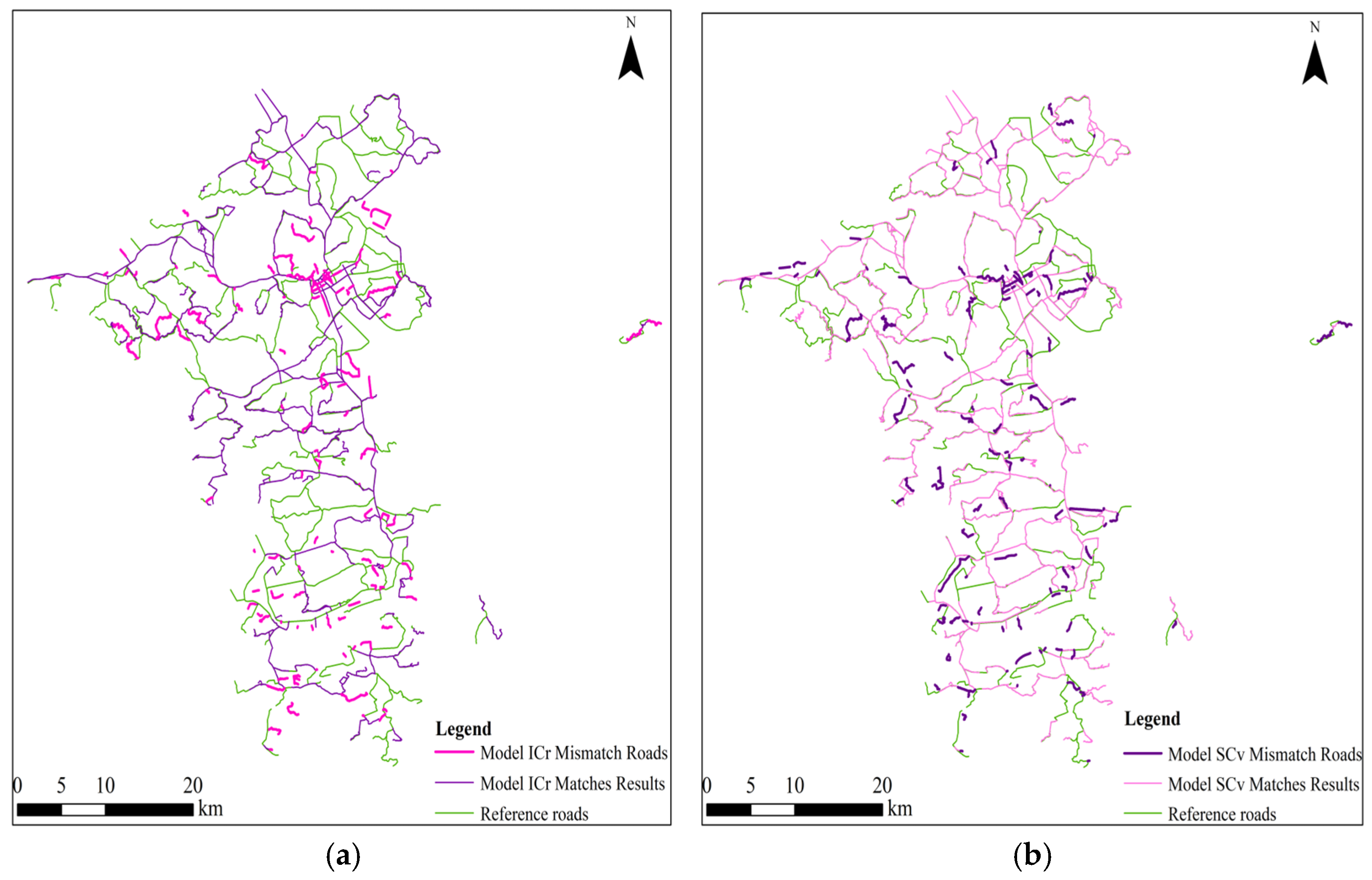
Firstly, this paper compares and analyzes the matching results of models I, Cr, and Cv. The similarity features shared by these three models are length, direction, and Hausdorff distance, and the differences are that the three models combine ISOD descriptors, included angle chain, and camber variance, respectively. The result output plots of the integrated metric models combining the four similarity features, as well as the data, were output (as shown in
Table 8 and
Table 9, and
Figure 11), and comparative analyzes were carried out by comparing the allocation of mismatched roads in the target roads as well as the evaluation metrics.
Based on the above results, the three features are analyzed from the perspective of how individual geometric features influence the outcomes.
Overall, in the matching experiments of Group A, under the condition that the three common indicators remain unchanged, the model I combined with the improved SOD achieves the highest F-score value, indicating the best matching performance. The reference dataset in Group A has a scale of 1:250,000, where most roads are main roads and only a few are branch roads. According to the result graphs, missed matches are primarily found on main roads, while incorrect matches are more frequently observed on branch roads. In the matching experiment of Group B, under the condition that the three indicators remain unchanged, the model Cr combined with the included angle chain achieves the highest F-score value, indicating the best matching performance. The reference dataset in Group B has a larger scale of 1:50,000, providing more detailed road representations. The distinction between trunk and branch roads is clearer. Missed matches are mainly distributed along branch roads, whereas incorrect matches are predominantly found on trunk roads. It can be seen that when matching small-scale road datasets, we can consider combining spatial relationship indicators based on geometric similarity indicators, i.e., ISOD descriptors, to match road datasets, and the matching effect is better. When matching between large-scale road datasets, the geometric similarity index can be considered to be combined with the included angle chain, and the matching effect is better.
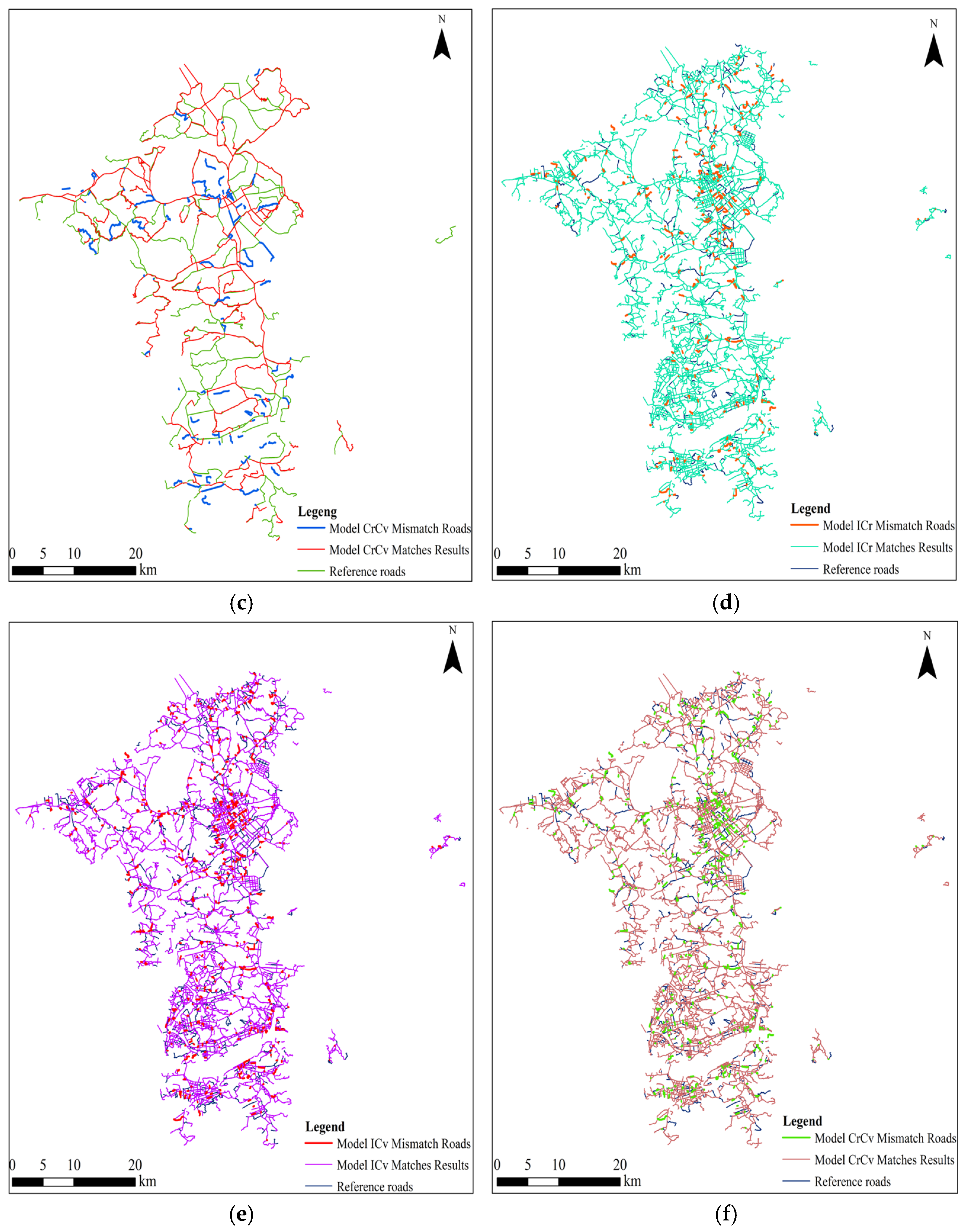
Subsequently, this paper outputs the output plots of the matching results of the integrated metric models ICr, ICv, and CrCv, which combine the five similarity features, as well as the data (as shown in
Table 10 and
Table 11, and
Figure 12), and performs comparative analyzes by comparing the allocation of the mismatched roads among the target roads, as well as evaluating the metrics.
From the perspective of geometric feature complementarity, the three indicators are analyzed in pairs to evaluate the matching capability of the models from multiple angles.
In the road dataset matching experiments of Group A, under the condition that the three common indicators remain unchanged, the model ICv, which combines ISOD descriptors and camber variance, achieves the highest F-score value, indicating the best matching performance. Mismatches are mainly distributed on trunk roads, while mismatches are more evenly distributed on trunk and branch roads, but are more concentrated in areas with dense branch roads. In the road dataset-matching experiments of Group B, the model ICr, which combines ISOD descriptors and the included angle chain, achieves the highest F-score value under the condition that the three common indicators remain unchanged, indicating the best matching performance. Mismatches are distributed in both main roads and branch roads, while incorrect matches are mainly distributed in branch roads.
When performing the matching of small-scale road datasets while keeping length, distance, and direction constant, the combination of the ISOD descriptor and camber variance can be considered for matching since it has the best matching effect. When matching large-scale road datasets, the ISOD descriptor and the included angle chain have the best matching effect. Spatial relationships can be used for the matching of both large-scale and small-scale road datasets since the matching effect is more accurate.
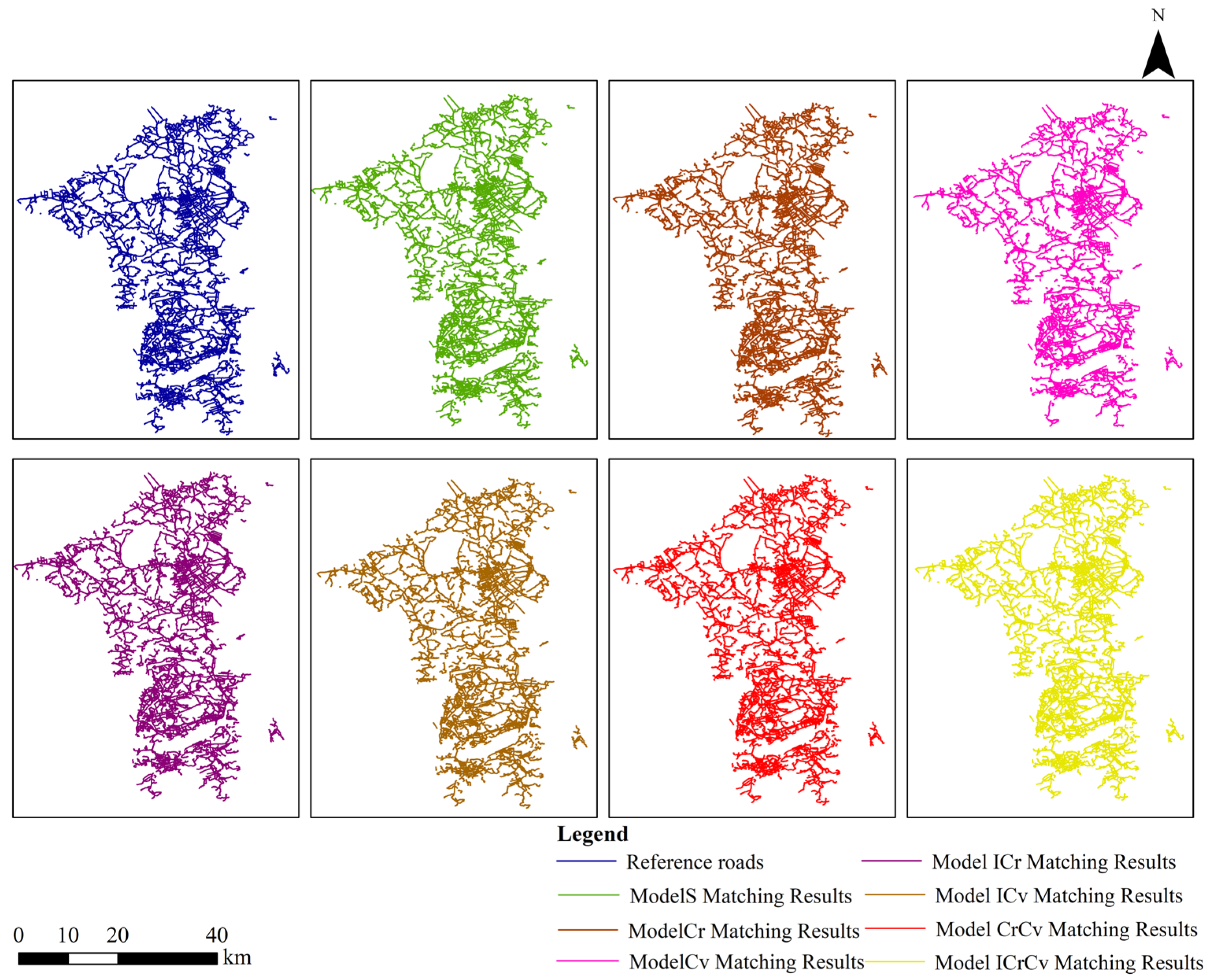
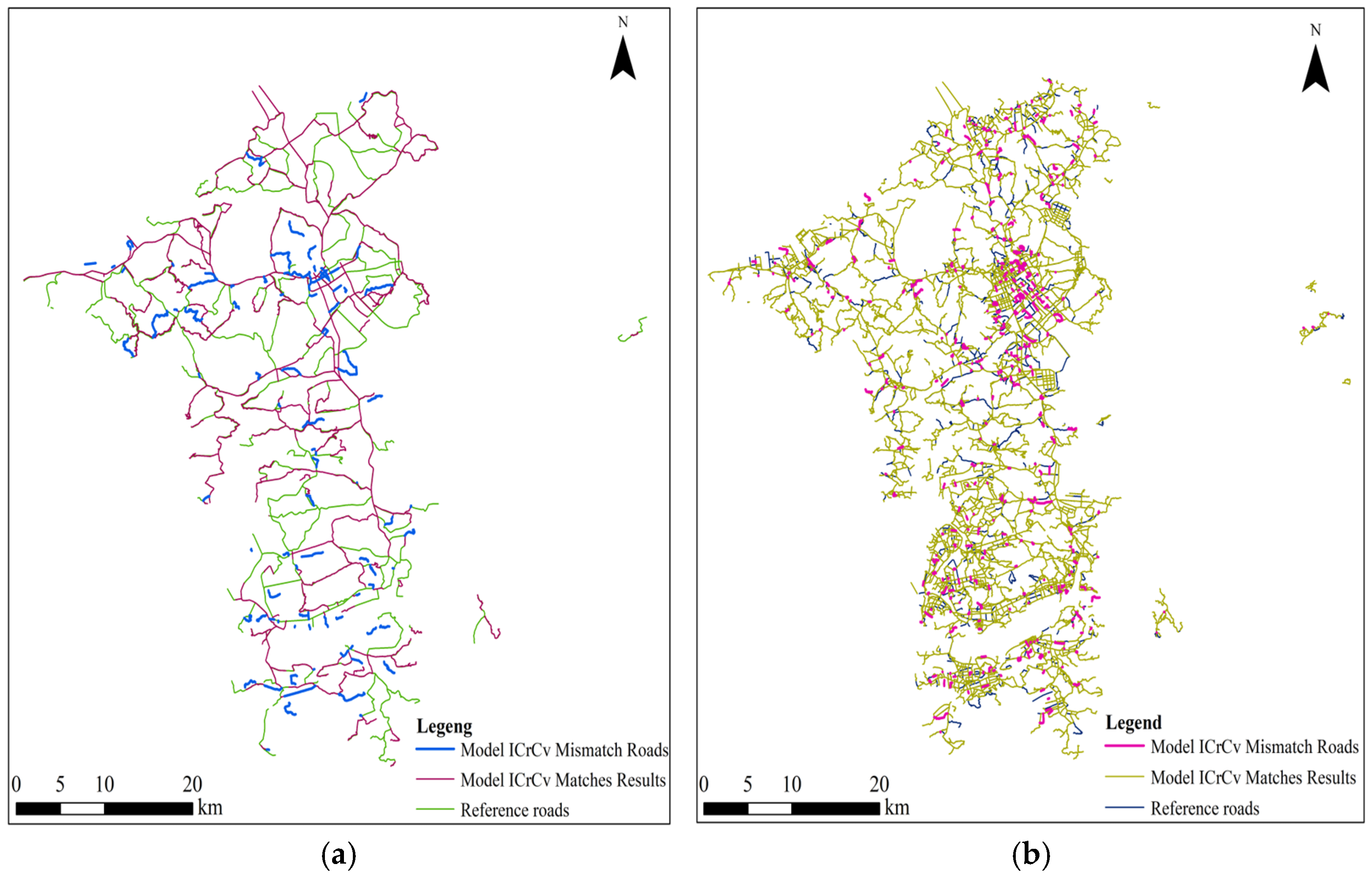
Subsequently, the matching results of the model ICrCv in Groups A and B experiments are compared and analyzed in this paper (as shown in
Table 12 and
Table 13, and
Figure 13). With the increase in similarity index, the matching model is more constrained for road-matching, and ISOD descriptors, included angle chain, and camber variance are added at the same time while keeping the distance, length, and direction unchanged. By comparing the matching results, this model is more suitable for road matching between large-scale road datasets. In Group A experiments, mismatching cases are distributed in the main roads, and incorrect matching cases are mainly distributed in the branch roads. In Group B experiments, the mismatches are mainly distributed in branch roads. Incorrect matches are distributed in both main roads and branch roads, and these matches are more concentrated in areas with dense branch roads.
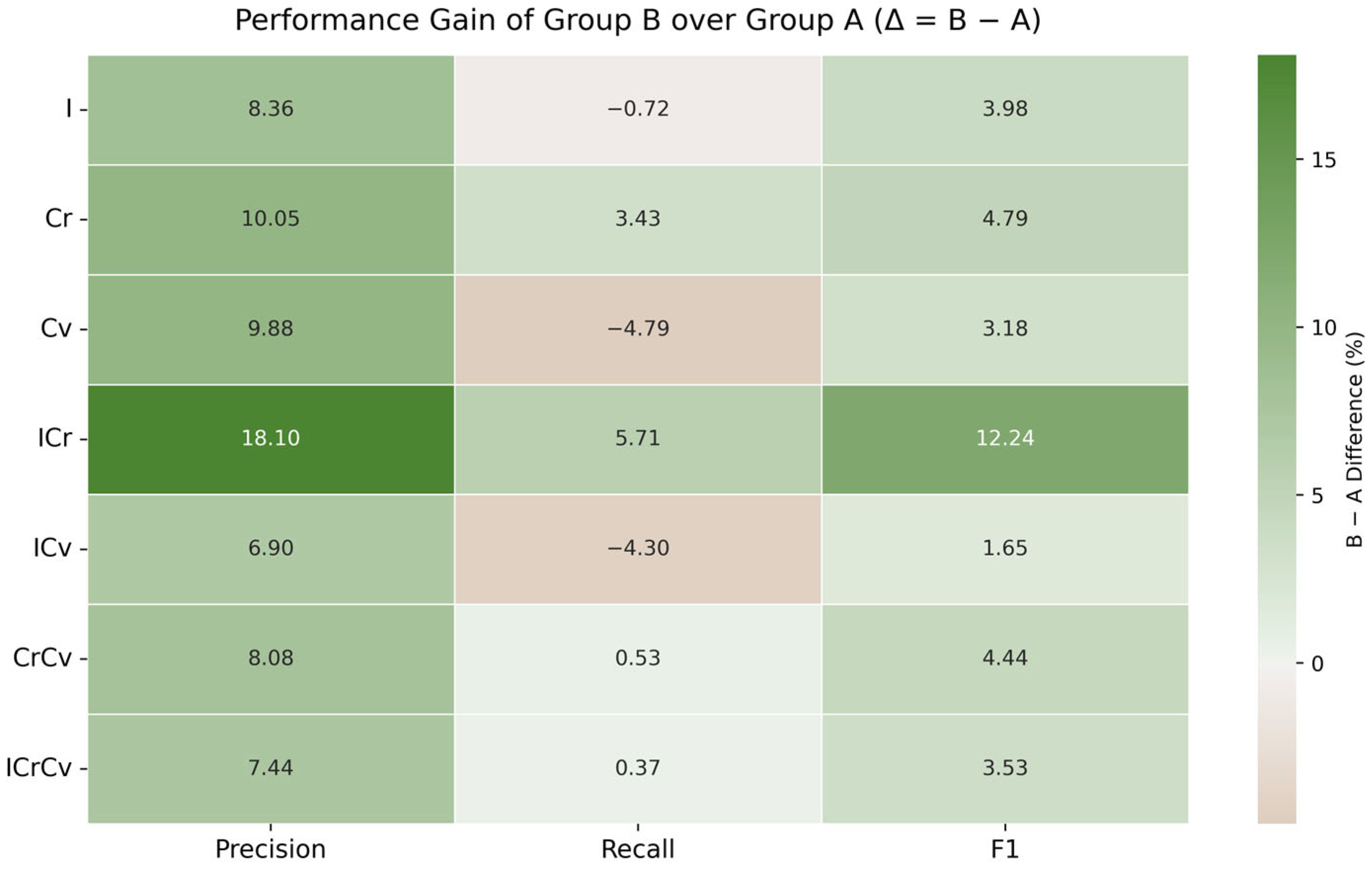
Ultimately, this study compares the matching results of the seven models in the two groups of road datasets and analyzes the matching results in terms of the precision, recall, and F-score values. The overall matching results for the road datasets in Groups A and B are shown in
Table 14 and
Table 15.
After multiple experimental verifications, we found that selecting the 20 nearest landmarks for each road segment can not only achieve a slight improvement in accuracy but also significantly enhance computational efficiency. As shown in
Table 16 and
Table 17, in large-scale datasets, the computational efficiency of the ISOD descriptor is improved by more than 20% compared with the SOD descriptor. Meanwhile, due to avoiding the interference of irrelevant landmarks, its accuracy has a more obvious improvement compared with small-scale datasets.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}