

HierLabelNet: A Two-Stage LLMs Framework with Data Augmentation and Label Selection for Geographic Text Classification

Abstract
1. Introduction
2. Related Works
2.1. Data Synthesis with LLM
2.2. Text Classification with LLM
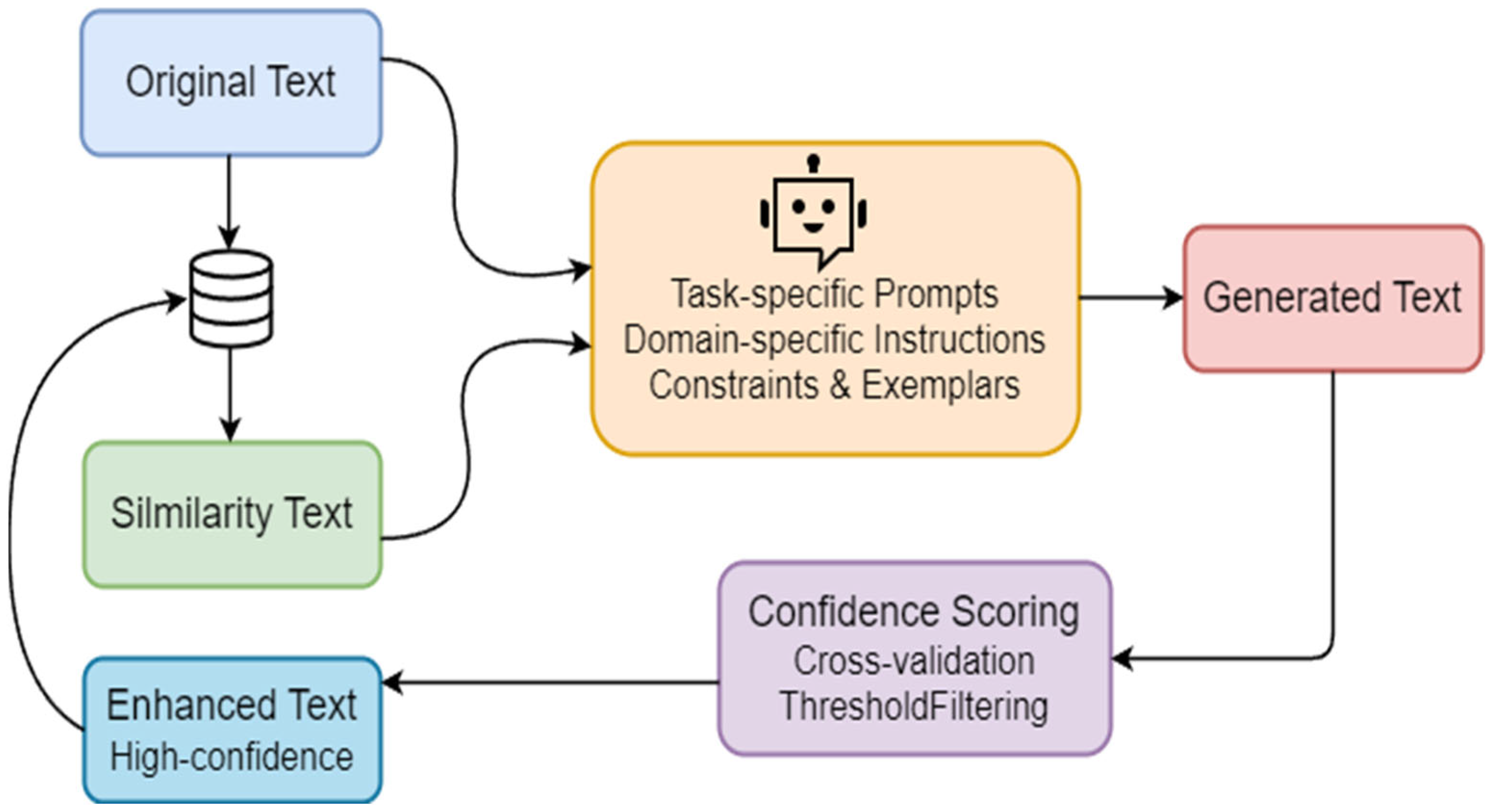
3. Methodology
3.1. Data Synthesis Method
3.2. Retrieval Label
4. Experiments
4.1. Dataset and Evaluation Metrics
4.1.1. Dataset
4.1.2. Evaluation Metrics
4.2. Experimental Settings
4.3. Main Results
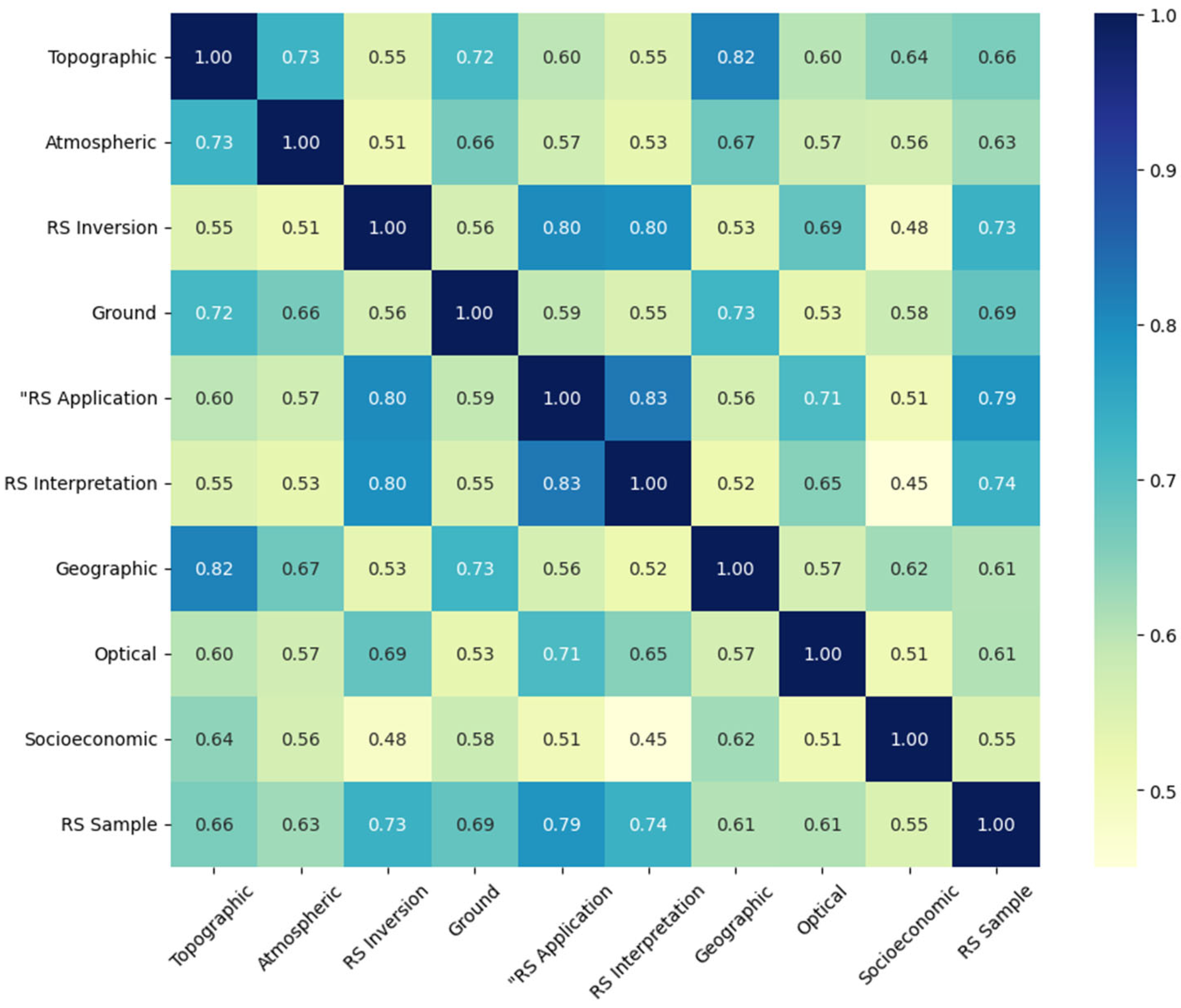
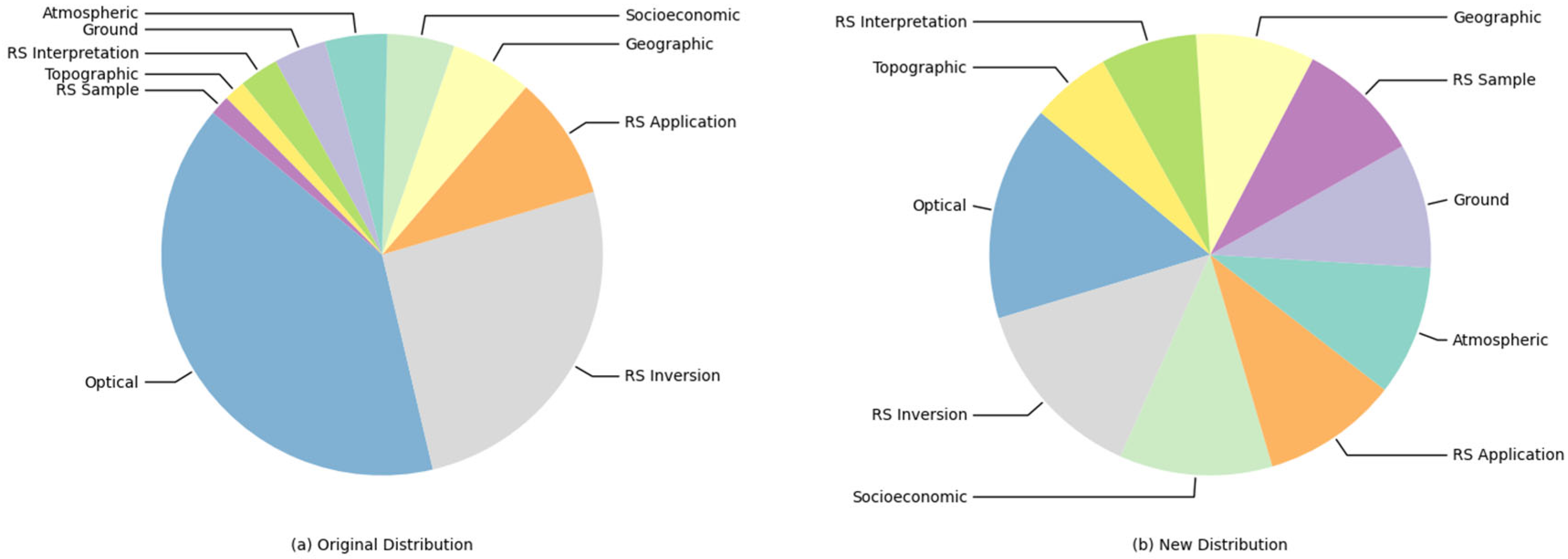
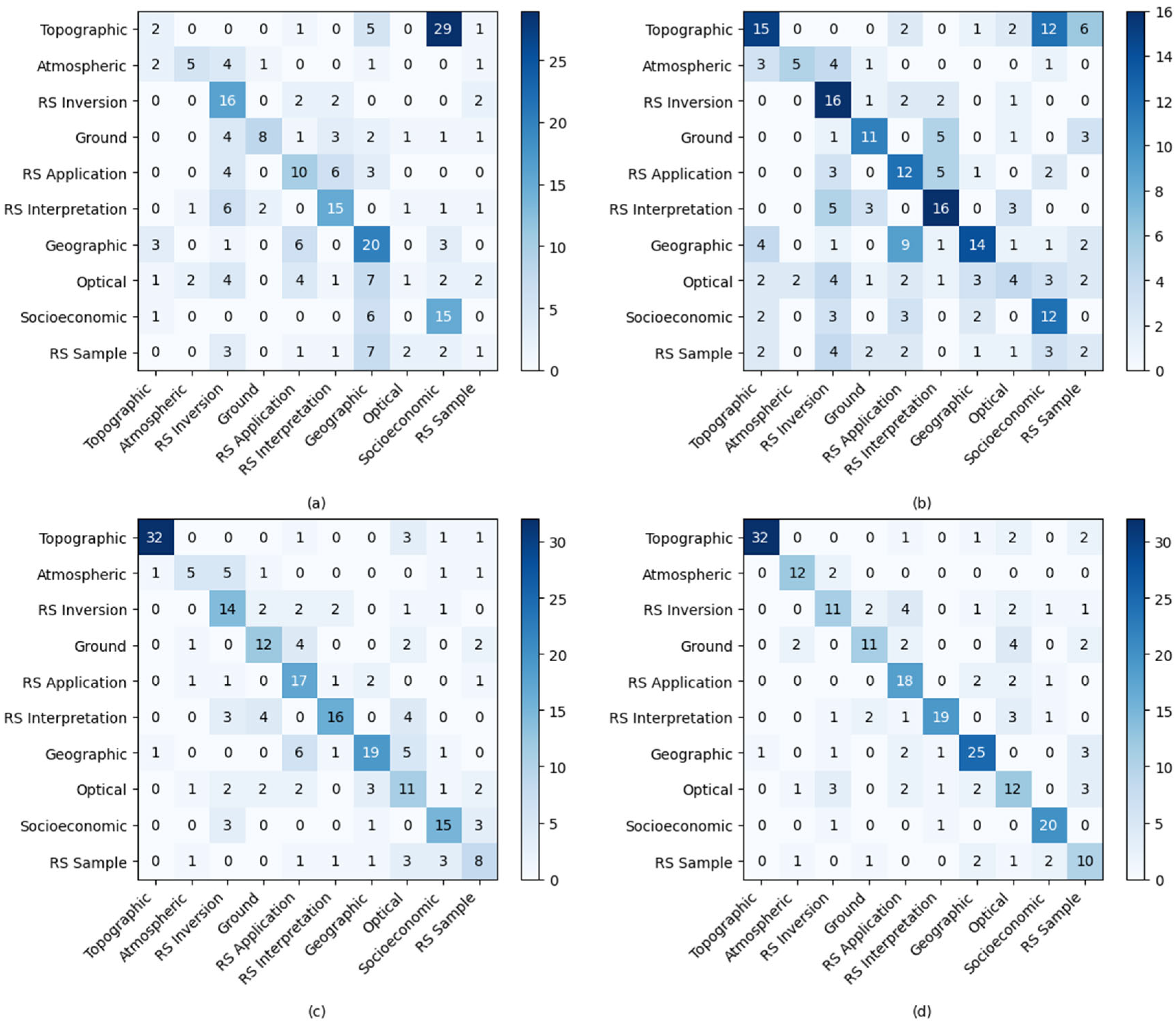
4.4. Data Synthesis Analysis
4.5. Ablation Study of R-Label
- Retrieved labels provide essential semantic constraints for task understanding.
- Contextual samples offer crucial domain-specific grounding.
- Their layered integration enables complementary knowledge fusion. The non-linear performance drop under joint ablation confirms the components’ multiplicative rather than additive interaction.
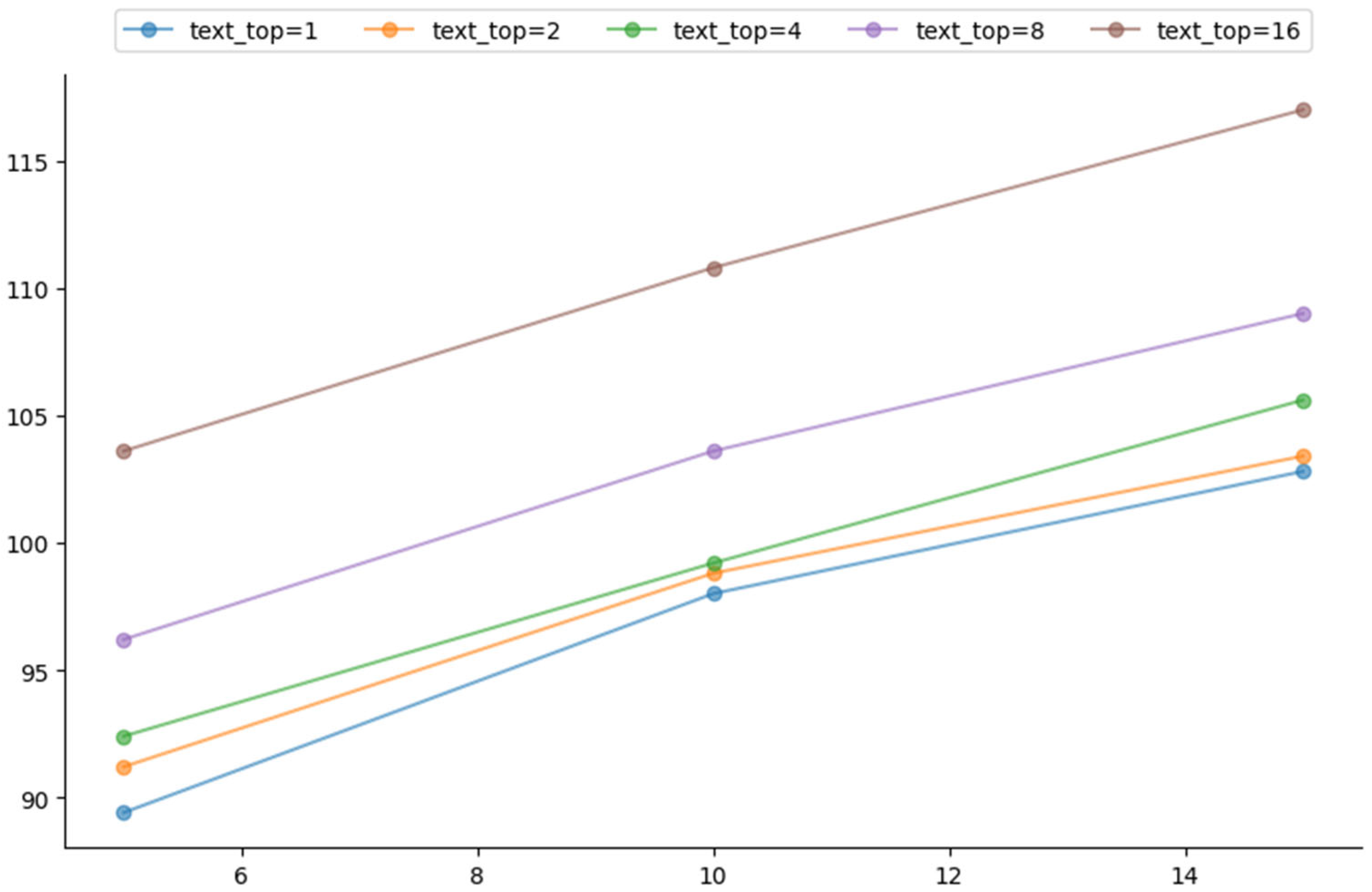
4.6. Sample and Label Quantity in Context Learning
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Behnke, J.; Mitchell, A.; Ramapriyan, H. NASA’s Earth Observing Data and Information System—Near-Term Challenges. Data Sci. J. 2019, 18, 40. [Google Scholar] [CrossRef]
- Zhang, Z.; Lu, L.; Zhao, Y.; Wang, Y.; Wei, D.; Wu, X.; Ma, X. Recent Advances in Using Chinese Earth Observation Satellites for Remote Sensing of Vegetation. ISPRS J. Photogramm. Remote Sens. 2023, 195, 393–407. [Google Scholar] [CrossRef]
- He, L.; Guo, K.; Gan, H.; Wang, L. Collaborative Data Offloading for Earth Observation Satellite Networks. IEEE Commun. Lett. 2022, 26, 1116–1120. [Google Scholar] [CrossRef]
- Roncella, R.; Zhang, L.; Boldrini, E.; Santoro, M.; Mazzetti, P.; Nativi, S. Publishing China Satellite Data on the GEOSS Platform. Big Earth Data 2023, 7, 398–412. [Google Scholar] [CrossRef]
- Ochiai, O.; Harada, M.; Hamamoto, K. Earth Observation Data Utilization for SDGs Indicators: 15.4.2 and 11.3.1. In Proceedings of the 2022 IEEE International Conference on Big Data (Big Data), Osaka, Japan, 17–20 December 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 2339–2342. [Google Scholar]
- Rinaldi, M.; Ruggieri, S.; Ciavarella, F.; De Santis, A.P.; Palmisano, D.; Balenzano, A.; Mattia, F.; Satalino, G. How Can Be Used Earth Observation Data in Conservation Agriculture Monitoring? In Proceedings of the IGARSS 2023—2023 IEEE International Geoscience and Remote Sensing Symposium, Pasadena, CA, USA, 16–21 July 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 2022–2025. [Google Scholar]
- Kavvada, A. Knowledge Generation Using Earth Observations to Support Sustainable Development. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 915–917. [Google Scholar]
- Caon, M.; Ros, P.M.; Martina, M.; Bianchi, T.; Magli, E.; Membibre, F.; Ramos, A.; Latorre, A.; Kerr, M.; Wiehle, S.; et al. Very Low Latency Architecture for Earth Observation Satellite Onboard Data Handling, Compression, and Encryption. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 7791–7794. [Google Scholar]
- Rousi, M.; Sitokonstantinou, V.; Meditskos, G.; Papoutsis, I.; Gialampoukidis, I.; Koukos, A.; Karathanassi, V.; Drivas, T.; Vrochidis, S.; Kontoes, C.; et al. Semantically Enriched Crop Type Classification and Linked Earth Observation Data to Support the Common Agricultural Policy Monitoring. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 529–552. [Google Scholar] [CrossRef]
- Minaee, S.; Kalchbrenner, N.; Cambria, E.; Nikzad, N.; Chenaghlu, M.; Gao, J. Deep Learning Based Text Classification: A Comprehensive Review. arXiv 2021, arXiv:2004.03705. [Google Scholar]
- Boukhers, Z.; Khan, A.; Ramadan, Q.; Yang, C. Large Language Model in Medical Informatics: Direct Classification and Enhanced Text Representations for Automatic ICD Coding. In Proceedings of the 2024 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Lisbon, Portugal, 3–6 December 2024; pp. 3066–3069. [Google Scholar]
- Beliveau, V.; Kaas, H.; Prener, M.; Ladefoged, C.N.; Elliott, D.; Knudsen, G.M.; Pinborg, L.H.; Ganz, M. Classification of Radiological Text in Small and Imbalanced Datasets in a Non-English Language. arXiv 2024, arXiv:2409.20147. [Google Scholar]
- Wang, J.; Zhao, Z.; Wang, Z.J.; Cheng, B.D.; Nie, L.; Luo, W.; Yu, Z.Y.; Yuan, L.W. GeoRAG: A Question-Answering Approach from a Geographical Perspective. arXiv 2025, arXiv:2504.01458. [Google Scholar]
- Decoupes, R.; Interdonato, R.; Roche, M.; Teisseire, M.; Valentin, S. Evaluation of Geographical Distortions in Language Models: A Crucial Step towards Equitable Representations. In Discovery Science, Proceedings of the 27th International Conference, DS 2024, Pisa, Italy, 14–16 October 2024; Springer: Cham, Switzerland, 2025; Volume 15243, pp. 86–100. [Google Scholar]
- Chen, P.; Xu, H.; Zhang, C.; Huang, R. Crossroads, Buildings and Neighborhoods: A Dataset for Fine-Grained Location Recognition. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, WA, USA, 10–15 July 2022; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 3329–3339. [Google Scholar]
- Hu, Y.; Mao, H.; McKenzie, G. A Natural Language Processing and Geospatial Clustering Framework for Harvesting Local Place Names from Geotagged Housing Advertisements. Int. J. Geogr. Inf. Sci. 2019, 33, 714–738. [Google Scholar] [CrossRef]
- Liu, H.; Qiu, Q.; Wu, L.; Li, W.; Wang, B.; Zhou, Y. Few-Shot Learning for Name Entity Recognition in Geological Text Based on GeoBERT. Earth Sci. Inform. 2022, 15, 979–991. [Google Scholar] [CrossRef]
- Vajjala, S.; Shimangaud, S. Text Classification in the LLM Era—Where Do We Stand? arXiv 2025, arXiv:2502.11830. [Google Scholar]
- Kong, E.; Zhang, J.; Yu, D.; Shen, M. Chinese Short Text Classification Method Based on Enhanced Prompt Learning. In Proceedings of the 2024 7th International Conference on Computer Information Science and Application Technology (CISAT), Hangzhou, China, 12–14 July 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 423–427. [Google Scholar]
- Sun, Z.; Harit, A.; Cristea, A.I.; Yu, J.; Shi, L.; Al Moubayed, N. Contrastive Learning with Heterogeneous Graph Attention Networks on Short Text Classification. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–6. [Google Scholar]
- Chen, J.; Hu, Y.; Liu, J.; Xiao, Y.; Jiang, H. Deep Short Text Classification with Knowledge Powered Attention. Proc. AAAI Conf. Artif. Intell. 2019, 33, 6252–6259. [Google Scholar] [CrossRef]
- Kuo, C.-L.; Chou, H.-C. An Ontology-Based Framework for Semantic Geographic Information Systems Development and Understanding. Comput. Geosci. 2023, 181, 105462. [Google Scholar] [CrossRef]
- Chen, H.; Zhao, Y.; Chen, Z.; Wang, M.; Li, L.; Zhang, M.; Zhang, M. Retrieval-Style In-Context Learning for Few-Shot Hierarchical Text Classification. Trans. Assoc. Comput. Linguist. 2024, 12, 1214–1231. [Google Scholar] [CrossRef]
- Li, Z.; Zhu, H.; Lu, Z.; Yin, M. Synthetic Data Generation with Large Language Models for Text Classification: Potential and Limitations. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–10 December 2023; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; pp. 10443–10461. [Google Scholar]
- Liu, P.; Wang, X.; Xiang, C.; Meng, W. A Survey of Text Data Augmentation. In Proceedings of the 2020 International Conference on Computer Communication and Network Security (CCNS), Xi’an, China, 21–23 August 2020; pp. 191–195. [Google Scholar]
- Wei, J.; Zou, K. EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 6382–6388. [Google Scholar]
- Bayer, M.; Kaufhold, M.-A.; Reuter, C. A Survey on Data Augmentation for Text Classification. ACM Comput. Surv. 2022, 55, 146. [Google Scholar] [CrossRef]
- Tan, Z.; Li, D.; Wang, S.; Beigi, A.; Jiang, B.; Bhattacharjee, A.; Karami, M.; Li, J.; Cheng, L.; Liu, H. Large Language Models for Data Annotation and Synthesis: A Survey. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Miami, FL, USA, 12–16 November 2024; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 930–957. [Google Scholar]
- Long, L.; Wang, R.; Xiao, R.; Zhao, J.; Ding, X.; Chen, G.; Wang, H. On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey. In Findings of the Association for Computational Linguistics, Proceedings of the ACL 2024, Bangkok, Thailand, 11–16 August 2024; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 11065–11082. [Google Scholar]
- Guo, X.; Chen, Y. Generative AI for Synthetic Data Generation: Methods, Challenges and the Future. arXiv 2024, arXiv:2403.04190. [Google Scholar]
- Choi, J.; Kim, Y.; Yu, S.; Yun, J.; Kim, Y. UniGen: Universal Domain Generalization for Sentiment Classification via Zero-Shot Dataset Generation. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Miami, FL, USA, 12–16 November 2024; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 1–14. [Google Scholar]
- Tao, C.; Fan, X.; Yang, Y. Harnessing LLMs for API Interactions: A Framework for Classification and Synthetic Data Generation. In Proceedings of the 2024 5th International Conference on Computers and Artificial Intelligence Technology (CAIT), Hangzhou, China, 20–22 December 2024; pp. 628–634. [Google Scholar]
- Patwa, P.; Filice, S.; Chen, Z.; Castellucci, G.; Rokhlenko, O.; Malmasi, S. Enhancing Low-Resource LLMs Classification with PEFT and Synthetic Data. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), Torino, Italia, 20–25 May 2024; ELRA and ICCL: Paris, France, 2024; pp. 6017–6023. [Google Scholar]
- Ubani, S.; Polat, S.O.; Nielsen, R. ZeroShotDataAug: Generating and Augmenting Training Data with ChatGPT. arXiv 2023, arXiv:2304.14334. [Google Scholar]
- Dai, H.; Liu, Z.; Liao, W.; Huang, X.; Cao, Y.; Wu, Z.; Zhao, L.; Xu, S.; Zeng, F.; Liu, W.; et al. AugGPT: Leveraging ChatGPT for Text Data Augmentation. IEEE Trans. Big Data 2025, 11, 907–918. [Google Scholar] [CrossRef]
- Yehudai, A.; Carmeli, B.; Mass, Y.; Arviv, O.; Mills, N.; Shnarch, E.; Choshen, L. Achieving Human Parity in Content-Grounded Datasets Generation. In Proceedings of the Twelfth International Conference on Learning Representations (ICLR), Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Li, Z.; Chen, W.; Li, S.; Wang, H.; Qian, J.; Yan, X. Controllable Dialogue Simulation with In-Context Learning. In Findings of the Association for Computational Linguistics, Proceedings of the EMNLP 2022, Abu Dhabi, United Arab Emirates, 7–11 December 2022; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 4330–4347. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; Volume 1 (Long and Short Papers), pp. 4171–4186. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Gretz, S.; Halfon, A.; Shnayderman, I.; Toledo-Ronen, O.; Spector, A.; Dankin, L.; Katsis, Y.; Arviv, O.; Katz, Y.; Slonim, N.; et al. Zero-Shot Topical Text Classification with LLMs—An Experimental Study. In Findings of the Association for Computational Linguistics, Proceedings of the EMNLP 2023, Singapore, 6–10 December 2023; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; pp. 9647–9676. [Google Scholar]
- Tian, K.; Chen, H. ESG-GPT:GPT4-Based Few-Shot Prompt Learning for Multi-Lingual ESG News Text Classification. In Proceedings of the Joint Workshop of the 7th Financial Technology and Natural Language Processing, the 5th Knowledge Discovery from Unstructured Data in Financial Services, and the 4th Workshop on Economics and Natural Language Processing, Torino, Italia, 20–25 May 2024; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 279–282. [Google Scholar]
- Liu, Y.; Li, M.; Pang, W.; Giunchiglia, F.; Huang, L.; Feng, X.; Guan, R. Boosting Short Text Classification with Multi-Source Information Exploration and Dual-Level Contrastive Learning. Proc. AAAI Conf. Artif. Intell. 2025, 39, 24696–24704. [Google Scholar]
- Kostina, A.; Dikaiakos, M.D.; Stefanidis, D.; Pallis, G. Large Language Models For Text Classification: Case Study And Comprehensive Review. arXiv 2025, arXiv:2501.08457. [Google Scholar]
- Ahmadnia, S.; Jordehi, A.Y.; Heyran, M.H.K.; Mirroshandel, S.A.; Rambow, O.; Caragea, C. Active Few-Shot Learning for Text Classification. arXiv 2025, arXiv:2502.18782. [Google Scholar]
- Lu, Z.; Tian, J.; Wei, W.; Qu, X.; Cheng, Y.; Xie, W.; Chen, D. Mitigating Boundary Ambiguity and Inherent Bias for Text Classification in the Era of Large Language Models. In Findings of the Association for Computational Linguistics, Proceedings of the ACL 2024, Bangkok, Thailand, 11–16 August 2024; Ku, L.-W., Martins, A., Srikumar, V., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 7841–7864. [Google Scholar]
- Yang, A.; Yang, B.; Zhang, B.; Hui, B.; Zheng, B.; Yu, B.; Li, C.; Liu, D.; Huang, F.; Wei, H.; et al. Qwen2.5 Technical Report. arXiv 2025, arXiv:2412.15115. [Google Scholar]
- Grattafiori, A.; Dubey, A.; Jauhri, A.; Pandey, A.; Kadian, A.; Al-Dahle, A.; Letman, A.; Mathur, A.; Schelten, A.; Vaughan, A.; et al. The Llama 3 Herd of Models. arXiv 2024, arXiv:2407.21783. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Root | Child |
|---|---|
| Earth Observation | Optical |
| Information and Deep-Processing | Remote Sensing Inversion (RS Inversion), Remote Sensing Interpretation (RS Interpretation), Remote Sensing Application (RS Application) |
| Remote Sensing Foundational | Remote Sensing Sample (RS Sample) |
| Other | Fundamental Geographic (Geographic), Socioeconomic, Topographic, Ground Monitoring (Ground), Atmospheric and Oceanic (Atmospheric) |
| Dataset | Q | 1 | 2 | 4 | 8 | ||||
|---|---|---|---|---|---|---|---|---|---|
| Models | Micro-F1 | Macro-F1 | Micro-F1 | Macro-F1 | Micro-F1 | Macro-F1 | Micro-F1 | Macro-F1 | |
| EO | Bert | 36.51 ± 0.00 | 28.50 ± 0.00 | 45.23 ± 0.00 | 40.47 ± 0.00 | 59.83 ± 0.21 | 57.19 ± 0.26 | 63.90 ± 0.00 | 61.31 ± 0.00 |
| Roberta | 7.05 ± 0.00 | 2.96 ± 0.00 | 21.16 ± 0.00 | 12.36 ± 0.00 | 39.83 ± 0.00 | 33.08 ± 0.00 | 43.98 ± 0.00 | 39.95 ± 0.00 | |
| Qwen2.5-1.5B-Instruct | 60.58 ± 0.72 | 45.41 ± 3.07 | 57.93 ± 1.07 | 42.29 ± 4.45 | 57.68 ± 0.99 | 47.48 ± 3.07 | 62.99 ± 1.23 | 56.89 ± 7.43 | |
| Llama3.1-8B-Instruct | 59.67 ± 1.46 | 58.76 ± 1.19 | 62.66 ± 1.37 | 60.13 ± 3.37 | 62.91 ± 1.86 | 60.26 ± 1.65 | 63.76 ± 2.17 | 62.20 ± 2.58 | |
| Qwen2.5-7B-Instruct | 69.79 ± 0.35 | 67.06 ± 0.41 | 68.96 ± 0.50 | 66.16 ± 0.57 | 68.63 ± 0.21 | 65.68 ± 0.23 | 68.79 ± 0.50 | 66.38 ± 0.50 | |
| Qwen2.5-1.5B-Instruct(HierLabelNet) | 62.58 ± 1.07 | 58.53 ± 2.83 | 61.91 ± 0.77 | 53.54 ± 0.93 | 62.82 ± 0.99 | 60.36 ± 0.52 | 64.15 ± 0.50 | 62.37 ± 0.47 | |
| Llama3.1-8B-Instruct(HierLabelNet) | 60.03 ± 1.67 | 59.69 ± 1.77 | 64.24 ± 1.19 | 62.76 ± 0.79 | 64.98 ± 1.57 | 62.93 ± 1.80 | 66.22 ± 0.73 | 63.34 ± 0.79 | |
| Qwen2.5-7B-Instruct(HierLabelNet) | 72.70 ± 0.62 | 71.18 ± 0.62 | 71.53 ± 0.21 | 69.50 ± 0.30 | 71.12 ± 0.35 | 69.62 ± 0.38 | 70.37 ± 0.91 | 68.53 ± 0.98 | |
| Q | Methods | Original Data | Augmented Data | ||
|---|---|---|---|---|---|
| Micro-F1 | Macro-F1 | Micro-F1 | Macro-F1 | ||
| 1 | Full Labels | 71.51 ± 4.15 | 67.27 ± 6.20 | 74.27 ± 0.62 | 67.91 ± 4.15 |
| Ours | 68.74 ± 0.62 | 65.98 ± 0.75 | 78.42 ± 0.63 | 77.34 ± 0.79 | |
| 2 | Full Labels | 74.82 ± 0.42 | 72.77 ± 0.45 | 76.62 ± 0.21 | 68.24 ± 0.34 |
| Ours | 72.89 ± 0.42 | 70.61 ± 0.40 | 79.67 ± 0.42 | 78.71 ± 0.44 | |
| 4 | Full Labels | 77.73 ± 0.42 | 76.02 ± 0.59 | 78.15 ± 0.63 | 76.23 ± 0.59 |
| Ours | 72.20 ± 0.42 | 69.58 ± 0.56 | 80.08 ± 0.42 | 78.62 ± 0.40 | |
| EO | ||
|---|---|---|
| Micro-F1 | Macro-F1 | |
| Ours | 71.12 ± 0.35 | 69.62 ± 0.38 |
| w/o R-Label | 68.63 ± 0.21 | 65.68 ± 0.23 |
| w/o similar samples | 57.51 ± 2.08 | 51.42 ± 3.14 |
| w/o samples | 62.82 ± 0.89 | 54.58 ± 3.57 |
| w/o samples + R-Label | 39.78 ± 0.42 | 31.61 ± 3.63 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the International Society for Photogrammetry and Remote Sensing. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Zhao, L. HierLabelNet: A Two-Stage LLMs Framework with Data Augmentation and Label Selection for Geographic Text Classification. ISPRS Int. J. Geo-Inf. 2025, 14, 268. https://doi.org/10.3390/ijgi14070268
Chen Z, Zhao L. HierLabelNet: A Two-Stage LLMs Framework with Data Augmentation and Label Selection for Geographic Text Classification. ISPRS International Journal of Geo-Information. 2025; 14(7):268. https://doi.org/10.3390/ijgi14070268
Chicago/Turabian StyleChen, Zugang, and Le Zhao. 2025. "HierLabelNet: A Two-Stage LLMs Framework with Data Augmentation and Label Selection for Geographic Text Classification" ISPRS International Journal of Geo-Information 14, no. 7: 268. https://doi.org/10.3390/ijgi14070268
APA StyleChen, Z., & Zhao, L. (2025). HierLabelNet: A Two-Stage LLMs Framework with Data Augmentation and Label Selection for Geographic Text Classification. ISPRS International Journal of Geo-Information, 14(7), 268. https://doi.org/10.3390/ijgi14070268