
Spatial Prediction of High-Risk Areas for Asthma in Metropolitan Areas: A Machine Learning Approach Applied to Tehran, Iran



Abstract
1. Introduction
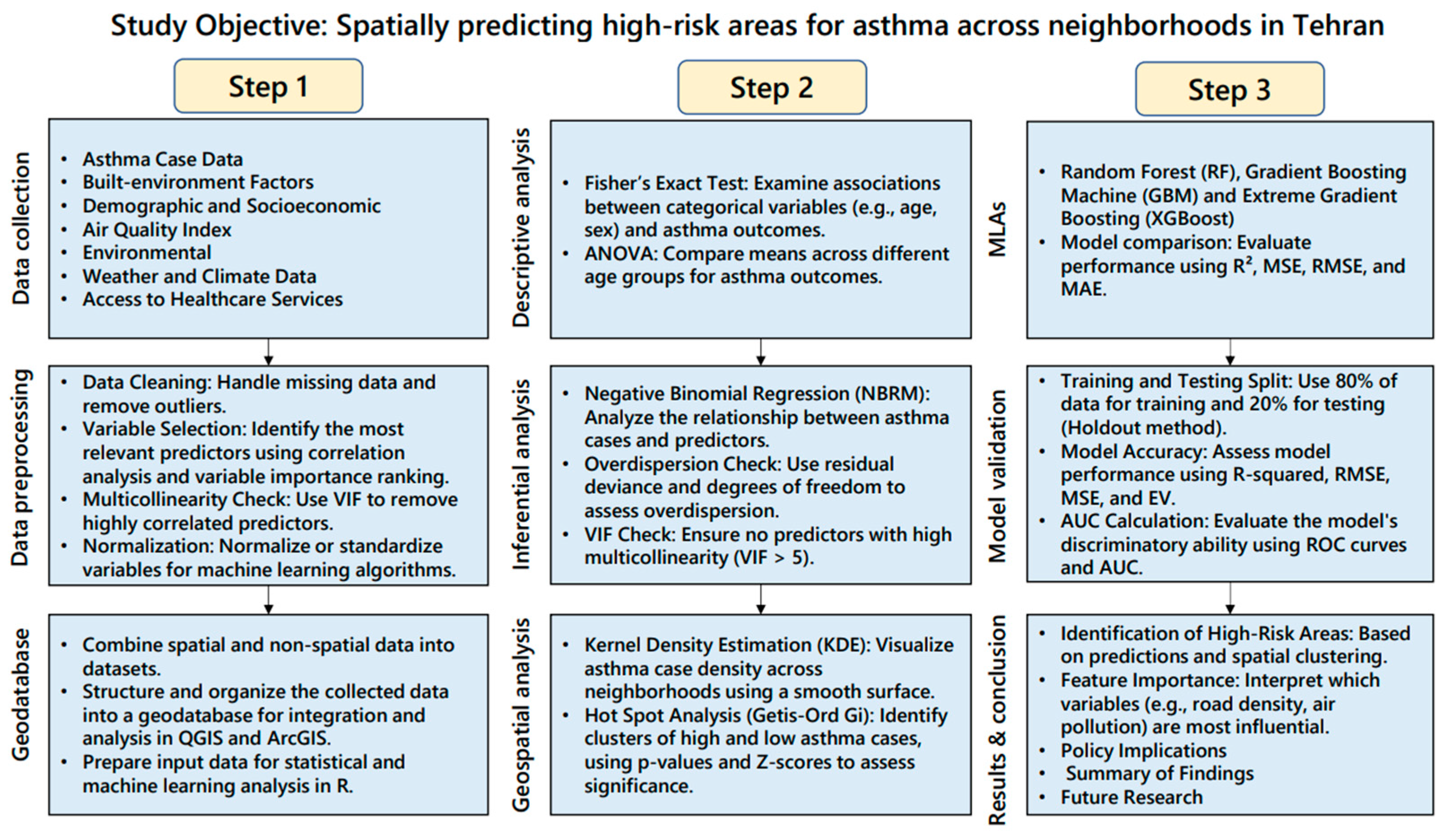
2. Materials and Methods
2.1. Study Setting
2.2. Data Source and Its Processing
2.3. Analytical Methods
2.3.1. Statistical Methods Used for Descriptive Analysis
2.3.2. Statistical Methods Used for Inferential Analysis
Negative Binomial Regression Model (NBRM)
2.3.3. Geospatial and Spatial Statistics Methods for Spatial Analysis
Kernel Density Estimation (KDE)
The Hot Spot Analysis (Getis-Ord Gi*)
2.3.4. Methods for Spatial Predictions Using MLAs
Random Forest (RF)
Gradient Boosting Machine (GBM)
Extreme Gradient Boosting (XGBoost)
MLA Implementation Procedure
MLAs Accuracy Assessment
3. Results
3.1. Non-Spatial Descriptive Findings
3.2. Spatial Analysis Findings
3.2.1. KDE Method Results
3.2.2. Hot Spot Analysis Results
3.3. Results from Negative Binomial Regression Model (NBRM)
3.4. Results and Performance of MLAs
3.5. Visualizing Risk Prediction of Disease
4. Discussion
4.1. Strengths, Limitations, and Future Directions
4.2. Policy Implications
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- World Health Organization. Asthma. Available online: https://www.who.int/news-room/fact-sheets/detail/asthma (accessed on 9 September 2024).
- Merhej, T.; Zein, J.G. Epidemiology of Asthma: Prevalence and Burden of Disease. Adv. Exp. Med. Biol. 2023, 1426, 3–23. [Google Scholar] [CrossRef] [PubMed]
- Rabe, A.P.J.; Loke, W.J.; Gurjar, K.; Brackley, A.; Lucero-Prisno, D.E. Global Burden of Asthma, and Its Impact on Specific Subgroups: Nasal Polyps, Allergic Rhinitis, Severe Asthma, Eosinophilic Asthma. J. Asthma Allergy 2023, 16, 1097–1113. [Google Scholar] [CrossRef] [PubMed]
- Seyedrezazadeh, E.; Gilani, N.; Ansarin, K.; Yousefi, M.; Sharifi, A.; Rouhi, A.H.J.; Aftabi, Y.; Najmi, M.; Dastan, I.; Moghaddam, M.P. Economic Burden of Asthma in Northwest Iran. Iran. J. Med. Sci. 2023, 48, 156–166. [Google Scholar] [CrossRef] [PubMed]
- Fazlollahi, M.R.; Najmi, M.; Fallahnezhad, M.; Sabetkish, N.; Kazemnejad, A.; Bidad, K.; Shokouhi Shoormasti, R.; Mahloujirad, M.; Pourpak, Z.; Moin, M. The Prevalence of Asthma in Iranian Adults: The First National Survey and the Most Recent Updates. Clin. Respir. J. 2018, 12, 1872–1881. [Google Scholar] [CrossRef] [PubMed]
- Holmes, L.; Enwere, M.; Williams, J.; Ogundele, B.; Chavan, P.; Piccoli, T.; Chinaka, C.; Comeaux, C.; Pelaez, L.; Okundaye, O.; et al. Black–White Risk Differentials in COVID-19 (SARS-CoV2) Transmission, Mortality and Case Fatality in the United States: Translational Epidemiologic Perspective and Challenges. Int. J. Environ. Res. Public Health 2020, 17, 4322. [Google Scholar] [CrossRef] [PubMed]
- Shin, S.; Bai, L.; Burnett, R.T.; Kwong, J.C.; Hystad, P.; van Donkelaar, A.; Lavigne, E.; Weichenthal, S.; Copes, R.; Martin, R.V.; et al. Air Pollution as a Risk Factor for Incident Chronic Obstructive Pulmonary Disease and Asthma: A 15-Year Population-Based Cohort Study. Am. J. Respir. Crit. Care Med. 2021, 203, 1138–1148. [Google Scholar] [CrossRef] [PubMed]
- Aslam, R.; Sharif, F.; Baqar, M.; Nizami, A.S.; Ashraf, U. Role of Ambient Air Pollution in Asthma Spread among Various Population Groups of Lahore City: A Case Study. Environ. Sci. Pollut. Res. 2023, 30, 8682–8697. [Google Scholar] [CrossRef] [PubMed]
- Nanda, A.; Baptist, A.P.; Divekar, R.; Parikh, N.; Seggev, J.S.; Yusin, J.S.; Nyenhuis, S.M. Asthma in the Older Adult. J. Asthma 2020, 57, 241–252. [Google Scholar] [CrossRef] [PubMed]
- Khosa, J.K.; Louie, S.; Moreno, P.L.; Abramov, D.; Rogstad, D.K.; Alismail, A.; Matus, M.J.; Tan, L.D. Asthma Care in the Elderly: Practical Guidance and Challenges for Clinical Management-A Framework of 5 “Ps.”. J. Asthma Allergy 2023, 16, 33–43. [Google Scholar] [CrossRef]
- Zaeh, S.E.; Ramsey, R.; Bender, B.; Hommel, K.; Mosnaim, G.; Rand, C. The Impact of Adherence and Health Literacy on Difficult-to-Control Asthma. J. Allergy Clin. Immunol. Pract. 2022, 10, 386–394. [Google Scholar] [CrossRef]
- Jabre, N.A.; Keet, C.A.; McCormack, M.; Peng, R.; Balcer-Whaley, S.; Matsui, E.C. Material Hardship and Indoor Allergen Exposure among Low-Income, Urban, Minority Children with Persistent Asthma. J. Community Health 2020, 45, 1017–1026. [Google Scholar] [CrossRef] [PubMed]
- Perez, M.F.; Coutinho, M.T. An Overview of Health Disparities in Asthma. Yale J. Biol. Med. 2021, 94, 497–507. [Google Scholar]
- Qin, P.; Luo, X.; Zeng, Y.; Zhang, Y.; Li, Y.; Wu, Y.; Han, M.; Qie, R.; Wu, X.; Liu, D.; et al. Long-Term Association of Ambient Air Pollution and Hypertension in Adults and in Children: A Systematic Review and Meta-Analysis. Sci. Total Environ. 2021, 796, 148620. [Google Scholar] [CrossRef] [PubMed]
- Singh, G.K.; Rai, S.; Jadon, N. Major Ambient Air Pollutants and Toxicity Exposure on Human Health and Their Respiratory System: A Review. J. Environ. Manag. Tour. 2021, 12, 1774–1788. [Google Scholar] [CrossRef]
- Ayres-Sampaio, D.; Teodoro, A.C.; Sillero, N.; Santos, C.; Fonseca, J.; Freitas, A. An Investigation of the Environmental Determinants of Asthma Hospitalizations: An Applied Spatial Approach. Appl. Geogr. 2014, 47, 10–19. [Google Scholar] [CrossRef]
- Alvarez-Mendoza, C.I.; Teodoro, A.; Freitas, A.; Fonseca, J. Spatial Estimation of Chronic Respiratory Diseases Based on Machine Learning Procedures—An Approach Using Remote Sensing Data and Environmental Variables in Quito, Ecuador. Appl. Geogr. 2020, 123, 102273. [Google Scholar] [CrossRef]
- Sonwani, S.; Madaan, S.; Arora, J.; Suryanarayan, S.; Rangra, D.; Mongia, N.; Vats, T.; Saxena, P. Inhalation Exposure to Atmospheric Nanoparticles and Its Associated Impacts on Human Health: A Review. Front. Sustain. Cities 2021, 3, 690444. [Google Scholar] [CrossRef]
- Naclerio, R.; Ansotegui, I.J.; Bousquet, J.; Canonica, G.W.; D’Amato, G.; Rosario, N.; Pawankar, R.; Peden, D.; Bergmann, K.C.; Bielory, L.; et al. International Expert Consensus on the Management of Allergic Rhinitis (AR) Aggravated by Air Pollutants: Impact of Air Pollution on Patients with AR: Current Knowledge and Future Strategies. World Allergy Organ. J. 2020, 13, 100106. [Google Scholar] [CrossRef]
- Manisalidis, I.; Stavropoulou, E.; Stavropoulos, A.; Bezirtzoglou, E. Environmental and Health Impacts of Air Pollution: A Review. Front. Public Health 2020, 8, 14. [Google Scholar] [CrossRef]
- Altman, M.C.; Kattan, M.; O’Connor, G.T.; Murphy, R.C.; Whalen, E.; LeBeau, P.; Calatroni, A.; Gill, M.A.; Gruchalla, R.S.; Liu, A.H.; et al. Associations between Outdoor Air Pollutants and Non-Viral Asthma Exacerbations and Airway Inflammatory Responses in Children and Adolescents Living in Urban Areas in the USA: A Retrospective Secondary Analysis. Lancet Planet. Health 2023, 7, e33–e44. [Google Scholar] [CrossRef]
- Keet, C.A.; McCormack, M.C.; Pollack, C.E.; Peng, R.D.; McGowan, E.; Matsui, E.C. Neighborhood Poverty, Urban Residence, Race/Ethnicity, and Asthma: Rethinking the Inner-City Asthma Epidemic. J. Allergy Clin. Immunol. 2015, 135, 655–662. [Google Scholar] [CrossRef] [PubMed]
- Sullivan, P.W.; Ghushchyan, V.; Kavati, A.; Navaratnam, P.; Friedman, H.S.; Ortiz, B. Health Disparities Among Children with Asthma in the United States by Place of Residence. J. Allergy Clin. Immunol. Pract. 2019, 7, 148–155. [Google Scholar] [CrossRef]
- Roy, S.; Majumder, S.; Bose, A.; Chowdhury, I.R. The Rich-Poor Divide: Unravelling the Spatial Complexities and Determinants of Wealth Inequality in India. Appl. Geogr. 2024, 166, 103267. [Google Scholar] [CrossRef]
- Stewart, I.T.; Clow, G.L.; Graham, A.E.; Bacon, C.M. Disparate Air Quality Impacts from Roadway Emissions on Schools in Santa Clara County (CA). Appl. Geogr. 2020, 125, 102354. [Google Scholar] [CrossRef]
- Khreis, H. Traffic, Air Pollution, and Health. In Advances in Transportation and Health; Elsevier: Amsterdam, The Netherlands, 2020; pp. 59–104. [Google Scholar]
- Gasana, J.; Dillikar, D.; Mendy, A.; Forno, E.; Ramos Vieira, E. Motor Vehicle Air Pollution and Asthma in Children: A Meta-Analysis. Environ. Res. 2012, 117, 36–45. [Google Scholar] [CrossRef] [PubMed]
- Yu, H.; Zhou, Y.; Wang, R.; Qian, Z.; Knibbs, L.D.; Jalaludin, B.; Schootman, M.; McMillin, S.E.; Howard, S.W.; Lin, L.Z.; et al. Associations between Trees and Grass Presence with Childhood Asthma Prevalence Using Deep Learning Image Segmentation and a Novel Green View Index. Environ. Pollut. 2021, 286, 117582. [Google Scholar] [CrossRef] [PubMed]
- Zeng, X.W.; Lowe, A.J.; Lodge, C.J.; Heinrich, J.; Roponen, M.; Jalava, P.; Guo, Y.; Hu, L.W.; Yang, B.Y.; Dharmage, S.C.; et al. Greenness Surrounding Schools Is Associated with Lower Risk of Asthma in Schoolchildren. Environ. Int. 2020, 143, 105967. [Google Scholar] [CrossRef] [PubMed]
- Buteau, S.; Shekarrizfard, M.; Hatzopolou, M.; Gamache, P.; Liu, L.; Smargiassi, A. Air Pollution from Industries and Asthma Onset in Childhood: A Population-Based Birth Cohort Study Using Dispersion Modeling. Environ. Res. 2020, 185, 109180. [Google Scholar] [CrossRef]
- Ly, B.-T.; Kajii, Y.; Nguyen, T.-Y.L.; Shoji, K.; Van, D.-A.; Do, T.-N.N.; Nghiem, T.-D.; Sakamoto, Y. Characteristics of Roadside Volatile Organic Compounds in an Urban Area Dominated by Gasoline Vehicles, a Case Study in Hanoi. Chemosphere 2020, 254, 126749. [Google Scholar] [CrossRef]
- Arunab, K.S.; Mathew, A. Quantifying Urban Heat Island and Pollutant Nexus: A Novel Geospatial Approach. Sustain. Cities Soc. 2024, 101, 105117. [Google Scholar] [CrossRef]
- Aghamohammadi, N.; Ramakreshnan, L.; Supramanian, R.K.; Lim, Y.C. Climate Change Adaptation and Public Health Strategies in Malaysia. In Climate Change and Human Health Scenarios: International Case Studies; Springer: Berlin/Heidelberg, Germany, 2023; pp. 99–113. [Google Scholar]
- D’Amato, G.; Chong-Neto, H.J.; Monge Ortega, O.P.; Vitale, C.; Ansotegui, I.; Rosario, N.; Haahtela, T.; Galan, C.; Pawankar, R.; Murrieta-Aguttes, M.; et al. The Effects of Climate Change on Respiratory Allergy and Asthma Induced by Pollen and Mold Allergens. Allergy Eur. J. Allergy Clin. Immunol. 2020, 75, 2219–2228. [Google Scholar] [CrossRef] [PubMed]
- Simich, C.S.; Jones, M.P. Chapter Asthma. In Urban Emergency Medicine; Cambridge University Press & Assessment: Cambridge, UK, 2023; p. 98. [Google Scholar]
- Yasaratne, D.; Idrose, N.S.; Dharmage, S.C. Asthma in Developing Countries in the Asia-Pacific Region (APR). Respirology 2023, 28, 992–1004. [Google Scholar] [CrossRef] [PubMed]
- Sabeti, Z.; Ansarin, K.; Seyedrezazadeh, E.; Asghari Jafarabadi, M.; Zafari, V.; Dastgiri, S.; Shakerkhatibi, M.; Gholampour, A.; Ghanbari Ghozikali, M.; Ghasemzadeh, R.; et al. A Comparison of Asthma Prevalence in Adolescents Living in Urban and Semi-Urban Areas in Northwestern Iran. Hum. Ecol. Risk Assess. 2021, 27, 2051–2068. [Google Scholar] [CrossRef]
- Rahimian, N.; Aghajanpour, M.; Jouybari, L.; Ataee, P.; Fathollahpour, A.; Lamuch-Deli, N.; Kooti, W.; Kalmarzi, R.N. The Prevalence of Asthma among Iranian Children and Adolescent: A Systematic Review and Meta-Analysis. Oxid. Med. Cell. Longev. 2021, 2021, 6671870. [Google Scholar] [CrossRef] [PubMed]
- Shariat, M.; Rostamian, E.; Moayeri, H.; Shariat, M.; Sharifi, L. A Review on the Relation between Obesity and Vitamin D with Pediatric Asthma, and a Report of a Pilot Study in Tehran, Iran: Review Article. Tehran Univ. Med. J. 2020, 78, 274–283. [Google Scholar]
- Masoud, F.; Kashi, G. Air Pollution on Mortality from Asthma in Tehran during the Years 1391 to 1394. Iran. J. Allergy Asthma Immunol. 2018, 17, 181–182. [Google Scholar]
- Sharifi, L.; Pourpak, Z.; Fazlollahi, M.R.; Bokaie, S.; Moezzi, H.R.; Kazemnejad, A.; Moin, M. Asthma Economic Costs in Adult Asthmatic Patients in Tehran, Iran. Iran. J. Public Health 2015, 44, 1212–1218. [Google Scholar]
- Razavi-termeh, S.V.; Sadeghi-niaraki, A.; Choi, S.M. Spatial Modeling of Asthma-prone Areas Using Remote Sensing and Ensemble Machine Learning Algorithms. Remote Sens. 2021, 13, 3222. [Google Scholar] [CrossRef]
- Razavi-Termeh, S.V.; Sadeghi-Niaraki, A.; Choi, S.M. Spatio-Temporal Modelling of Asthma-Prone Areas Using a Machine Learning Optimized with Metaheuristic Algorithms. Geocarto Int. 2022, 37, 9917–9942. [Google Scholar] [CrossRef]
- Razavi-Termeh, S.V.; Sadeghi-Niaraki, A.; Choi, S.M. Asthma-Prone Areas Modeling Using a Machine Learning Model. Sci. Rep. 2021, 11, 1912. [Google Scholar] [CrossRef] [PubMed]
- Morrison, C.N.; Mair, C.F.; Bates, L.; Duncan, D.T.; Branas, C.C.; Bushover, B.R.; Mehranbod, C.A.; Gobaud, A.N.; Uong, S.; Forrest, S.; et al. Defining Spatial Epidemiology: A Systematic Review and Re-Orientation. Epidemiology 2024, 35, 542–555. [Google Scholar] [CrossRef] [PubMed]
- Kappas, M. GIS and Remote Sensing for Public Health. In Geospatial Data Science in Healthcare for Society 5.0; Springer: Berlin/Heidelberg, Germany, 2022; pp. 79–97. [Google Scholar]
- Cushing, A.M.; Khan, M.A.; Kysh, L.; Brakefield, W.S.; Ammar, N.; Liberman, D.B.; Wilson, J.; Shaban-Nejad, A.; Espinoza, J. Geospatial Data in Pediatric Asthma in the United States: A Scoping Review Protocol. JBI Evid. Synth. 2022, 20, 2790–2798. [Google Scholar] [CrossRef] [PubMed]
- Studies, P. Spatial Analysis and Determinants of Asthma Health and Health Services Use Outcomes in Ontario. Master's Thesis, University of Ottawa, Ottawa, ON, Canada, 2016. [Google Scholar]
- Spyroglou, I.I.; Spöck, G.; Chatzimichail, E.A.; Rigas, A.G.; Paraskakis, E.N. A Bayesian Logistic Regression Approach in Asthma Persistence Prediction. Epidemiol. Biostat. Public Health 2018, 15, e12777-1–e12777-14. [Google Scholar] [CrossRef]
- Roy, S.; Chowdhury, I.R. Intoxication in the City: Investigating Spatial Patterns and Determinants of Drugs and Alcohol-Related Illegal Activities in India's Geostrategic Corridor. Appl. Geogr. 2024, 171, 103386. [Google Scholar] [CrossRef]
- Grekousis, G. Spatial Analysis Methods and Practice: Describe-Explore-Explain Through GIS; Cambridge University Press: Cambridge, UK, 2020; ISBN 9781108614528. [Google Scholar]
- Amaral, J.L.M.; Sancho, A.G.; Faria, A.C.D.; Lopes, A.J.; Melo, P.L. Differential Diagnosis of Asthma and Restrictive Respiratory Diseases by Combining Forced Oscillation Measurements, Machine Learning and Neuro-Fuzzy Classifiers. Med. Biol. Eng. Comput. 2020, 58, 2455–2473. [Google Scholar] [CrossRef]
- Placido, D.; Yuan, B.; Hjaltelin, J.X.; Zheng, C.; Haue, A.D.; Chmura, P.J.; Yuan, C.; Kim, J.; Umeton, R.; Antell, G.; et al. A Deep Learning Algorithm to Predict Risk of Pancreatic Cancer from Disease Trajectories. Nat. Med. 2023, 29, 1113–1122. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Wang, Y.; Niu, M.; Wang, C.; Wang, Z. Machine Learning for Characterizing Risk of Type 2 Diabetes Mellitus in a Rural Chinese Population: The Henan Rural Cohort Study. Sci. Rep. 2020, 10, 4406. [Google Scholar] [CrossRef]
- Oikonomou, E.K.; Khera, R. Machine Learning in Precision Diabetes Care and Cardiovascular Risk Prediction. Cardiovasc. Diabetol. 2023, 22, 259. [Google Scholar] [CrossRef]
- Razavi-Termeh, S.V.; Sadeghi-Niaraki, A.; Farhangi, F.; Choi, S.-M. COVID-19 Risk Mapping with Considering Socio-Economic Criteria Using Machine Learning Algorithms. Int. J. Environ. Res. Public Health 2021, 18, 9657. [Google Scholar] [CrossRef]
- World Population Review. Sharjah Population 2024; World Population Review: Walnut, CA, USA, 2024. [Google Scholar]
- Maghrebi, M.; Danandeh Mehr, A.; Karrabi, S.M.; Sadegh, M.; Partani, S.; Ghiasi, B.; Nourani, V. Spatiotemporal Variations of Air Pollution during the COVID-19 Pandemic across Tehran, Iran: Commonalities with and Differences from Global Trends. Sustainability 2022, 14, 16313. [Google Scholar] [CrossRef]
- Dehghan, A.; Khanjani, N.; Bahrampour, A.; Goudarzi, G.; Yunesian, M. The Relation between Air Pollution and Respiratory Deaths in Tehran, Iran- Using Generalized Additive Models. BMC Pulm. Med. 2018, 18, 49. [Google Scholar] [CrossRef] [PubMed]
- Kiavarz, M.; Hosseinbeigi, S.B.; Mijani, N.; Shahsavary, M.S.; Firozjaei, M.K. Predicting Spatial and Temporal Changes in Surface Urban Heat Islands Using Multi-Temporal Satellite Imagery: A Case Study of Tehran Metropolis. Urban Clim. 2022, 45, 101258. [Google Scholar] [CrossRef]
- Management and Planning Organization of Tehran Province. Results of the 2015 Census of Tehran Province and City; MPO: Tehran, Iran, 2016. [Google Scholar]
- Mohammadi, A.; Pishgar, E.; Fatima, M.; Lotfata, A.; Fanni, Z.; Bergquist, R.; Kiani, B. The COVID-19 Mortality Rate Is Associated with Illiteracy, Age, and Air Pollution in Urban Neighborhoods: A Spatiotemporal Cross-Sectional Analysis. Trop. Med. Infect. Dis. 2023, 8, 85. [Google Scholar] [CrossRef]
- Khoshakhlagh, A.H.; Mohammadzadeh, M.; Morais, S. Air Quality in Tehran, Iran: Spatio-Temporal Characteristics, Human Health Effects, Economic Costs and Recommendations for Good Practice. Atmos. Environ. X 2023, 19, 100222. [Google Scholar] [CrossRef]
- Banirazi Motlagh, S.H.; Pons-Valladares, O.; Hosseini, S.M.A. City-Scale Model to Assess Rooftops Performance on Air Pollution Mitigation; Validation for Tehran. Build. Environ. 2023, 244, 110746. [Google Scholar] [CrossRef]
- Ramyar, R.; Saeedi, S.; Bryant, M.; Davatgar, A.; Mortaz Hedjri, G. Ecosystem Services Mapping for Green Infrastructure Planning–The Case of Tehran. Sci. Total Environ. 2020, 703, 135466. [Google Scholar] [CrossRef] [PubMed]
- Gheshlaghpoor, S.; Abedi, S.S.; Moghbel, M. The Relationship between Spatial Patterns of Urban Land Uses and Air Pollutants in the Tehran Metropolis, Iran. Landsc. Ecol. 2023, 38, 553–565. [Google Scholar] [CrossRef]
- Statistical Centre of Iran (SCI). Tehran City Housing and Income Census Data and Reports 2016; Statistical Centre of Iran: Tehran, Iran, 2022. [Google Scholar]
- Roy, S.; Bose, A.; Majumder, S.; Roy Chowdhury, I.; Abdo, H.G.; Almohamad, H.; Abdullah Al Dughairi, A. Evaluating Urban Environment Quality (UEQ) for Class-I Indian City: An Integrated RS-GIS Based Exploratory Spatial Analysis. Geocarto Int. 2022, 38, 2153932. [Google Scholar] [CrossRef]
- Huang, S.; Tang, L.; Hupy, J.P.; Wang, Y.; Shao, G. A Commentary Review on the Use of Normalized Difference Vegetation Index (NDVI) in the Era of Popular Remote Sensing. J. For. Res. 2021, 32, 1–6. [Google Scholar] [CrossRef]
- U.S. Geological Survey. USGS Landsat Normalized Difference Vegetation Index|U.S. Geological Survey. Available online: https://www.usgs.gov/landsat-missions/landsat-normalized-difference-vegetation-index (accessed on 20 June 2024).
- Santamouris, M.; Cartalis, C.; Synnefa, A.; Kolokotsa, D. On the Impact of Urban Heat Island and Global Warming on the Power Demand and Electricity Consumption of Buildings—A Review. Energy Build. 2015, 98, 119–124. [Google Scholar] [CrossRef]
- Kumari, B.; Tayyab, M.; Shahfahad; Salman; Mallick, J.; Khan, M.F.; Rahman, A. Satellite-Driven Land Surface Temperature (LST) Using Landsat 5, 7 (TM/ETM+ SLC) and Landsat 8 (OLI/TIRS) Data and Its Association with Built-Up and Green Cover Over Urban Delhi, India. Remote Sens. Earth Syst. Sci. 2018, 1, 63–78. [Google Scholar] [CrossRef]
- Ufondu, A.N.; Shukla, U.C.; Stambaugh, C.; Huber, K.E.; Stambaugh, N. Categorical Variable Analyses: Chi-Square, Fisher's Exact, Mantel–Haenszel. In Translational Radiation Oncology; Eltorai, A.E.M., Bakal, J.A., Kim, D.W., Wazer, D.E., Eds.; Academic Press: Cambridge, MA, USA, 2023; pp. 165–170. ISBN 9780323884235. [Google Scholar]
- Jones, G.P.; Stambaugh, C.; Stambaugh, N.; Huber, K.E. Analysis of Variance. In Translational Radiation Oncology; Eltorai, A.E.M., Bakal, J.A., Kim, D.W., Wazer, D.E., Eds.; Academic Press: Cambridge, MA, USA, 2023; pp. 171–177. ISBN 9780323884235. [Google Scholar]
- ESRI. How Exploratory Regression Works. Available online: https://pro.arcgis.com/en (accessed on 26 October 2022).
- Chan, J.Y.; Leow, S.M.; Bea, K.T.; Cheng, W.K.; Phoong, S.W.; Hong, Z.-W.; Lin, J.-M.; Chen, Y.-L. A Correlation-Embedded Attention Module to Mitigate Multicollinearity: An Algorithmic Trading Application. Mathematics 2022, 10, 1231. [Google Scholar] [CrossRef]
- Fox, J.; Weisberg, S. An R Companion to Applied Regression, 3rd ed.; Sage: Thousand Oaks, CA, USA, 2011. [Google Scholar]
- Venables, W.N.; Ripley, B.D. Modern Applied Statistics with S, 4th ed.; Springer: New York, NY, USA, 2002; ISBN 0-387-95457-0. [Google Scholar]
- Stevens, R.S.; Dean, M.D.; Miller, J.S.; Dougald, L.E. Monitoring Crash Impacts of Exceptions to Entrance Spacing Standards: Lessons Learned from Virginia. Case Stud. Transp. Policy 2020, 8, 648–657. [Google Scholar] [CrossRef]
- Hilbe, J.M. Negative Binomial Regression; Cambridge University Press: Cambridge, UK, 2007; ISBN 9780511811852. [Google Scholar]
- Cappai, S.; Rolesu, S.; Coccollone, A.; Laddomada, A.; Loi, F. Evaluation of Biological and Socio-Economic Factors Related to Persistence of African Swine Fever in Sardinia. Prev. Vet. Med. 2018, 152, 1–11. [Google Scholar] [CrossRef]
- Silverman, B.W. Density Estimation: For Statistics and Data Analysis; Routledge: London, UK, 2018; ISBN 9781351456173. [Google Scholar]
- Carlos, H.A.; Shi, X.; Sargent, J.; Tanski, S.; Berke, E.M. Density Estimation and Adaptive Bandwidths: A Primer for Public Health Practitioners. Int. J. Health Geogr. 2010, 9, 39. [Google Scholar] [CrossRef] [PubMed]
- Chun, Y.; Griffith, D.A. Spatial Statistics and Geostatistics: Theory and Applications for Geographic Information Science and Technology; Sage Publishing: Thousand Oaks, CA, USA, 2012. [Google Scholar]
- ESRI. ArcGIS Pro Help. Available online: https://pro.arcgis.com/en/pro-app/latest/help/main/welcome-to-the-arcgis-pro-app-help.htm (accessed on 10 June 2024).
- Mitchel, A. Volume 2: Spartial Measurements and Statistics. In The ESRI Guide to GIS Analysis; ESRI Press: Bucharest, Romania, 2005; Volume 2. [Google Scholar]
- Bornmann, L.; de Moya Angeon, F. Hot and Cold Spots in the US Research: A Spatial Analysis of Bibliometric Data on the Institutional Level. J. Inf. Sci. 2019, 45, 84–91. [Google Scholar] [CrossRef]
- Ord, J.K. Art Getis and local spatial statistics. J. Geogr. Syst. 2024, 26, 191–200. [Google Scholar] [CrossRef]
- Farahani, M.; Razavi-Termeh, S.V.; Sadeghi-Niaraki, A. A Spatially Based Machine Learning Algorithm for Potential Mapping of the Hearing Senses in an Urban Environment. Sustain. Cities Soc. 2022, 80, 103675. [Google Scholar] [CrossRef]
- Environmental Systems Research Institute (ESRI). ArcGIS Professional GIS Help. Available online: https://pro.arcgis.com/en/pro-app/latest/help (accessed on 4 August 2024).
- Mienye, I.D.; Sun, Y. A Survey of Ensemble Learning: Concepts, Algorithms, Applications, and Prospects. IEEE Access 2022, 10, 99129–99149. [Google Scholar] [CrossRef]
- Ho, T.K. Random Decision Forests. In Proceedings of the International Conference on Document Analysis and Recognition, ICDAR, Montreal, QC, Canada, 14–16 August 1995; IEEE: New York, NY, USA, 1995; Volume 1, pp. 278–282. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Miller, A.; Panneerselvam, J.; Liu, L. A Review of Regression and Classification Techniques for Analysis of Common and Rare Variants and Gene-Environmental Factors. Neurocomputing 2022, 489, 466–485. [Google Scholar] [CrossRef]
- Natekin, A.; Knoll, A. Gradient Boosting Machines, a Tutorial. Front. Neurorobot. 2013, 7, 21. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Raschka, S. Model Evaluation, Model Selection, and Algorithm Selection in Machine Learning. arXiv 2018, arXiv:arXiv1811.12808. [Google Scholar]
- Dagli, B.Y. Application of a Statistical Regression Technique for Dynamic Analysis of Submarine Pipelines. J. Mar. Sci. Eng. 2024, 12, 955. [Google Scholar] [CrossRef]
- Eastman, J.R. TerrSet Geospatial Monitoring and Modeling System; Clark University: Worcester, MA, USA, 2016; pp. 345–389. Available online: https://www.clarku.edu/centers/geospatial-analytics/terrset/ (accessed on 12 June 2024).
- Barbur, V.A.; Montgomery, D.C.; Peck, E.A. Introduction to Linear Regression Analysis; John Wiley & Sons: Hoboken, NJ, USA, 1994; Volume 43, ISBN 1119578752. [Google Scholar]
- Kuhn, M. Building Predictive Models in R Using the Caret Package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar] [CrossRef]
- Vilinová, K. Spatial Autocorrelation of Breast and Prostate Cancer in Slovakia. Int. J. Environ. Res. Public Health 2020, 17, 4440. [Google Scholar] [CrossRef] [PubMed]
- Anselin, L. GeoDa [software]. Version 1.22.0.4. 2023. Available online: https://geodacenter.github.io/ (accessed on 10 June 2024).
- ESRI ArcGIS Pro. ArcGIS PRO Modul. 4—Data Anal; University of Toronto: Toronto, ON, Canada, 2022; p. 3. [Google Scholar]
- Pishgar, E.; Fanni, Z.; Tavakkolinia, J.; Mohammadi, A.; Kiani, B.; Bergquist, R. Mortality Rates Due to Respiratory Tract Diseases in Tehran, Iran during 2008-2018: A Spatiotemporal, Cross-Sectional Study. BMC Public Health 2020, 20, 1414. [Google Scholar] [CrossRef] [PubMed]
- D’Amato, G.; Vitale, C.; Molino, A.; Stanziola, A.; Sanduzzi, A.; Vatrella, A.; Mormile, M.; Lanza, M.; Calabrese, G.; Antonicelli, L. Asthma-Related Deaths. Multidiscip. Respir. Med. 2016, 11, 37. [Google Scholar] [CrossRef] [PubMed]
- Dunn, R.M.; Busse, P.J.; Wechsler, M.E. Asthma in the Elderly and Late-Onset Adult Asthma. Allergy Eur. J. Allergy Clin. Immunol. 2018, 73, 284–294. [Google Scholar] [CrossRef] [PubMed]
- Fuhlbrigge, A.L.; Jackson, B.; Wright, R.J. Gender and Asthma. Immunol. Allergy Clin. N. Am. 2002, 22, 753–789. [Google Scholar] [CrossRef]
- Oraka, E.; Kim, H.J.E.; King, M.E.; Callahan, D.B. Asthma Prevalence among US Elderly by Age Groups: Age Still Matters. J. Asthma 2012, 49, 593–599. [Google Scholar] [CrossRef] [PubMed]
- Chan, K.-P.F.; Kwok, W.-C.; Ma, T.-F.; Hui, C.-H.; Tam, T.C.-C.; Wang, J.K.-L.; Ho, J.C.-M.; Lam, D.C.-L.; Sau-Man Ip, M.; Ho, P.-L. Territory-Wide Study on Hospital Admissions for Asthma Exacerbations in the COVID-19 Pandemic. Ann. Am. Thorac. Soc. 2021, 18, 1624–1633. [Google Scholar] [CrossRef] [PubMed]
- Bagheri, O.; Moeltner, K.; Yang, W. Respiratory Illness, Hospital Visits, and Health Costs: Is It Air Pollution or Pollen? Environ. Res. 2020, 187, 109572. [Google Scholar] [CrossRef]
- Chen, Y.; Kong, D.; Fu, J.; Zhang, Y.; Zhao, Y.; Liu, Y.; Chang, Z.; Liu, Y.; Liu, X.; Xu, K.; et al. Associations between Ambient Temperature and Adult Asthma Hospitalizations in Beijing, China: A Time-Stratified Case-Crossover Study. Respir. Res. 2022, 23, 38. [Google Scholar] [CrossRef] [PubMed]
- Ko, F.W.S.; Lau, L.H.S.; Ng, S.S.; Yip, T.C.F.; Wong, G.L.H.; Chan, K.P.; Chan, T.O.; Hui, D.S.C. Respiratory Admissions before and during the COVID-19 Pandemic with Mediation Analysis of Air Pollutants, Mask-Wearing and Influenza Rates. Respirology 2023, 28, 47–55. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions, and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions, or products referred to in the content. |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
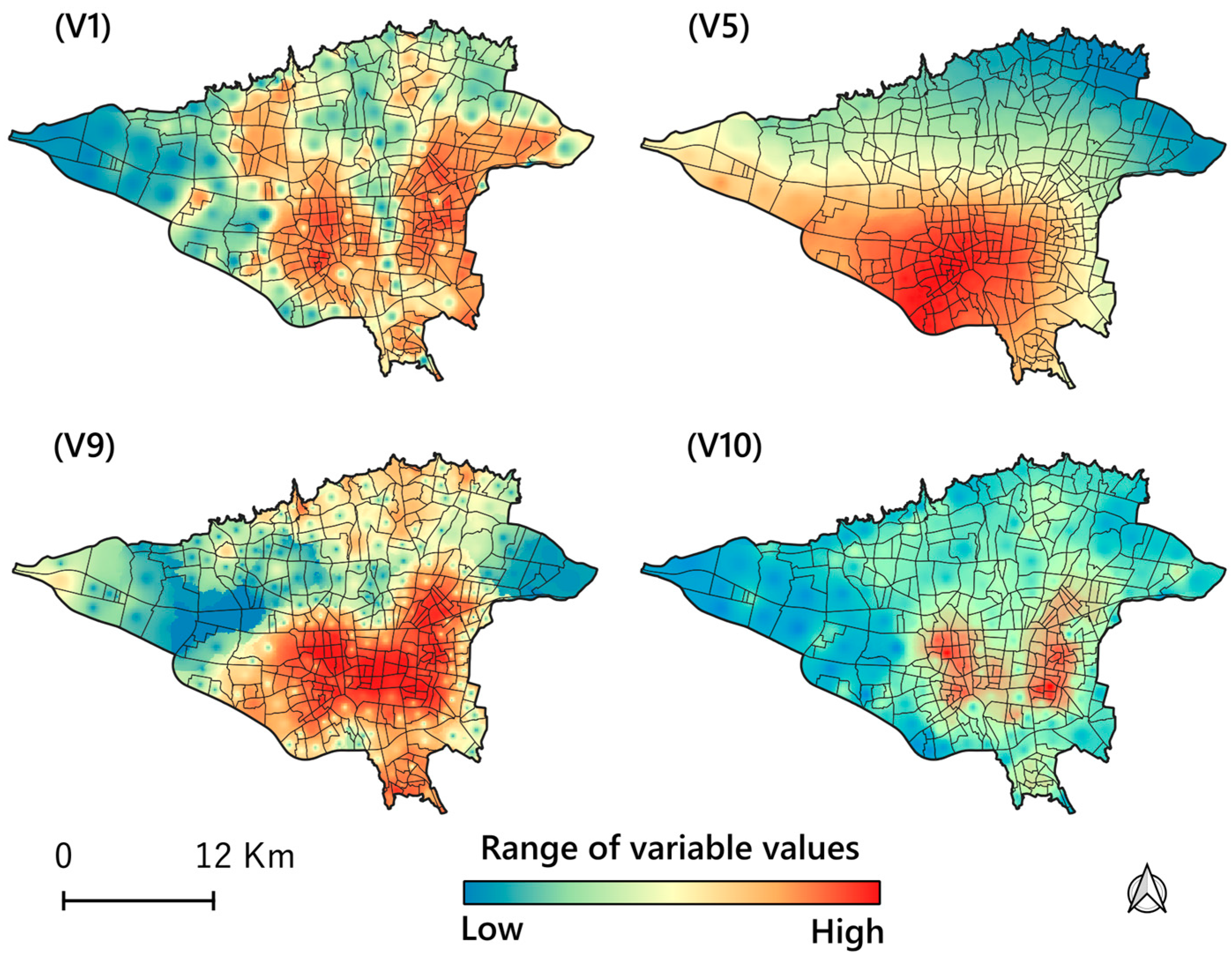
| Aspects | Indicator | Spatial Database and Data Type | Source |
|---|---|---|---|
| Demographic and Socioeconomic | V1: Population density (per sq.km) | Census, ESRI shapefile | [67] |
| V2: Proportion of elderly (%) | Census, ESRI shapefile | [67] | |
| V3: Proportion of illiterate people (%) | Census, ESRI shapefile | [67] | |
| V4: Proportion of unemployed people (%) | Census, ESRI shapefile | [67] | |
| Air Quality Index | V5: Particulate matter (AAI include PM2.5 and PM10) | Sentinel-5, Raster | Google Earth Engine |
| V6: Nitrogen dioxide (NO2) | Sentinel-5, Raster | Google Earth Engine | |
| V7: Ozone (O3) | Sentinel-5, Raster | Google Earth Engine | |
| V8: Sulfur dioxide (SO2) | Sentinel-5, Raster | Google Earth Engine | |
| Environmental | V9: Neighborhood deprivation index (%) | Land use map, ESRI shapefile | Tehran municipality, OpenStreetMap |
| V10: Road intersection density (per square kilometers) | OSM, ESRI shapefile, and Raster | OpenStreetMap | |
| V11: Normalized Difference Vegetation Index (NDVI) | Landsat 8, Raster | Google Earth Engine | |
| V12: Exposure to industrial emissions | Land use map, OSM, ESRI shapefile | OpenStreetMap | |
| V13: Proximity to fuel stations | Land use map, OSM, ESRI shapefile | Tehran Municipality, OpenStreetMap | |
| Weather and Climate | V14: Urban heat islands (UHIs) | Landsat 8, Raster | Google Earth Engine |
| Access and Utilization of Healthcare Services | V15: Access to healthcare facilities | Land use map, OSM, ESRI shapefile | Tehran municipality, OpenStreetMap |
| Predictor | Estimate | Std. Error | z Value | Pr (>|z|) |
|---|---|---|---|---|
| V1 | 1.9 × 10−5 | 4.9 × 10−6 | 3.8 × 100 | 1.5 × 10−4 *** |
| V2 | −3.2 × 10−2 | 1.9 × 10−2 | −1.6 × 100 | 1.0 × 10−1 |
| V3 | 8.8 × 10−3 | 1.1 × 10−2 | 7.7 × 10−1 | 4.4 × 10−1 |
| V4 | −3.2 × 10−2 | 4.1 × 10−2 | −7.7 × 10−1 | 4.4 × 10−1 |
| V5 | 1.4 × 100 | 6.2 × 10−1 | 2.2 × 100 | 2.6 × 10−2 * |
| V6 | 2.3 × 103 | 5.9 × 102 | 3.9 × 100 | 1.1 × 10−4 *** |
| V7 | −1.4 × 102 | 2.2 × 102 | −6.3 × 10−1 | 5.3 × 10−1 |
| V8 | 5.2 × 103 | 1.6 × 103 | 3.3 × 100 | 1.1 × 10−3 ** |
| V9 | −5.6 × 10−3 | 2.2 × 10−3 | −2.6 × 100 | 1.0 × 10−2 * |
| V10 | 5.9 × 10−4 | 1.5 × 10−4 | 4.0 × 100 | 7.6 × 10−5 *** |
| V11 | 9.5 × 10−1 | 1.1 × 100 | 8.7 × 10−1 | 3.8 × 10−1 |
| V12 | 3.4 × 10−3 | 4.6 × 10−3 | 7.4 × 10−1 | 4.6 × 10−1 |
| V13 | −2.1 × 10−5 | 3.6 × 10−5 | −5.7 × 10−1 | 5.7 × 10−1 |
| V14 | −2.7 × 10−2 | 4.1 × 10−2 | −6.6 × 10−1 | 5.1 × 10−1 |
| V15 | 6.7 × 10−3 | 2.3 × 10−2 | 2.9 × 10−1 | 7.7 × 10−1 |
| Predictor | Estimate | Std. Error | z Value | Pr (>|z|) |
|---|---|---|---|---|
| V1 | 1.97 × 10−5 | 3.07 × 10−6 | 6.433758 | 1.24 × 10−10 *** |
| V4 | −0.07422 | 0.034637 | −2.14278 | 0.032131 * |
| V5 | 1.404977 | 0.470555 | 2.985788 | 0.002828 ** |
| V6 | 1865.001 | 413.0592 | 4.515094 | 6.33 × 10−6 *** |
| V8 | 4250.563 | 1240.331 | 3.426957 | 0.00061 *** |
| V9 | −0.00491 | 0.002075 | −2.36894 | 0.017839 * |
| V10 | 0.000556 | 0.000138 | 4.041288 | 5.32 × 10−5 *** |
| MLAs | RMSE | R-Squared | MAE | EV | Moran’s I | ||||
|---|---|---|---|---|---|---|---|---|---|
| (Train) | (Test) | (Train) | (Test) | (Train) | (Test) | (Train) | (Test) | (Train) | |
| RF | 0.56 | 1.08 | 0.96 | 0.75 | 0.40 | 0.84 | 1 | 0.74 | 0.29 |
| GBM | 0.56 | 1.07 | 0.95 | 0.76 | 0.43 | 0.88 | 0.95 | 0.75 | 0.17 |
| XGBoost | 0.22 | 1.21 | 0.99 | 0.69 | 0.16 | 0.91 | 0.99 | 0.68 | 0.12 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the International Society for Photogrammetry and Remote Sensing. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mohammadi, A.; Pishgar, E.; Aguilera, J. Spatial Prediction of High-Risk Areas for Asthma in Metropolitan Areas: A Machine Learning Approach Applied to Tehran, Iran. ISPRS Int. J. Geo-Inf. 2025, 14, 105. https://doi.org/10.3390/ijgi14030105
Mohammadi A, Pishgar E, Aguilera J. Spatial Prediction of High-Risk Areas for Asthma in Metropolitan Areas: A Machine Learning Approach Applied to Tehran, Iran. ISPRS International Journal of Geo-Information. 2025; 14(3):105. https://doi.org/10.3390/ijgi14030105
Chicago/Turabian StyleMohammadi, Alireza, Elahe Pishgar, and Juan Aguilera. 2025. "Spatial Prediction of High-Risk Areas for Asthma in Metropolitan Areas: A Machine Learning Approach Applied to Tehran, Iran" ISPRS International Journal of Geo-Information 14, no. 3: 105. https://doi.org/10.3390/ijgi14030105
APA StyleMohammadi, A., Pishgar, E., & Aguilera, J. (2025). Spatial Prediction of High-Risk Areas for Asthma in Metropolitan Areas: A Machine Learning Approach Applied to Tehran, Iran. ISPRS International Journal of Geo-Information, 14(3), 105. https://doi.org/10.3390/ijgi14030105