1. Introduction
In recent years, with the rapid development of remote sensing technology, computer technology, and emerging technologies such as big data and cloud computing, humans have acquired vast, multisource, heterogeneous remote sensing data resources. These data are characterized by their large volume, diversity, high accuracy, and rapid change [
1], providing new opportunities for the precise extraction of land use and land cover (LULC) remote sensing information. However, they also pose higher demands on extraction methods. Traditional LULC information extraction methods can no longer meet current needs. At the same time, the rise of artificial intelligence offers crucial support for the efficient analysis and in-depth mining of remote sensing big data [
2,
3]. Intelligent extraction of LULC information has become a research hotspot in remote sensing [
4]. Therefore, effectively integrating these emerging data and technologies, fully exploiting the spatial, temporal, and attribute dimensions of remote sensing data [
5], and developing new LULC remote sensing information extraction methods have become urgent issues to address.
With the gradual application of deep learning in remote sensing, significant progress and achievements have been made in intelligently extracting LULC information from remote sensing images. However, existing methods still have notable shortcomings. Firstly, the studies focus on extraction of single land cover type, such as roads [
6,
7,
8], croplands [
9,
10], buildings [
11,
12,
13], water bodies [
14,
15], woodlands [
16,
17], grasslands [
18,
19], and impervious surfaces [
20,
21], with few studies on extracting multielement LULC information. There is an urgent need to extract more types of LULC information [
22]. Most deep learning algorithms perform well on specific classic datasets but require improvements in generalization and applicability to remote sensing images and study areas [
23,
24,
25,
26,
27]. Secondly, due to the diversity of LULC types and their significant spatial heterogeneity and similarity, errors and confusion can quickly occur during extraction, often resulting in low accuracy [
28]. This is particularly true when dealing with small target objects whose information is widely distributed and complex, making them susceptible to background noise interference. Traditional CNN models have limited recognition capabilities, struggling to accurately parse complex spatial relationships, leading to inaccurate or missing feature extraction of small target objects. Researchers are committed to designing more complex and efficient network structures [
29,
30] to extract small target features from remote sensing images accurately. However, small target objects in remote sensing images often have significant scale differences with their surrounding environment. These improvements mainly focus on local features, which limits the capture of extensive contextual information, especially cross-scale semantic information. Additionally, there is considerable variability in the fusion of small target features. If improper multiscale feature fusion methods are used, it may lead to mismatches in object information, weakening the fusion capability between different small target features and limiting effective extraction. Therefore, further exploration and innovation of more efficient and precise methods and techniques are needed to extract small target features in remote sensing images. Meanwhile, there is a significant difference in the number of different categories of land cover targets in remote sensing images, leading to a prominent class imbalance phenomenon. Some scholars have attempted to use improved loss functions to address this issue and alleviate the class imbalance problem [
31,
32]. However, in cases of extreme class imbalance, these single-loss functions often focus on the more abundant classes while neglecting the less abundant ones. This makes it challenging to extract compelling features from minority class samples, quickly causing overfitting to the more numerous land cover categories, resulting in poor extraction performance of CNN models for minority class information.
Therefore, given the urgent need to extract more types of LULC information from remote sensing images and to enhance the accuracy and generalization of models in handling small target objects and addressing class imbalance issues, this paper proposes an innovative spatial context information and multiscale feature fusion encoder–decoder network—SCIMF-Net. SCIMF-Net employs and improves ResNeXt as the backbone network to achieve multiscale feature extraction and fusion, significantly enhancing the expressiveness and richness of features and thereby improving the model’s understanding of complex scenes. Additionally, the network incorporates a channel attention mechanism to understand better the relationship between small target objects and their surrounding environment, thus increasing segmentation accuracy. To effectively address the issue of class imbalance, SCIMF-Net uses a weighted joint loss function that dynamically adjusts the weights of different classes, enabling the model to focus more on samples from less abundant land cover categories. Experimental results demonstrate that SCIMF-Net not only effectively extracts more types of LULC information but also successfully addresses the challenges of class imbalance and small target object information extraction, showcasing its significant advantages and application potential in LULC information extraction from remote sensing images.
Based on the above analysis, addressing the challenges faced by existing mainstream CNN models in extracting LULC information from remote sensing images—such as difficulties in understanding the complex spatial relationships and semantic information between land cover types, insufficient capture of contextual information, the imbalance in land cover categories making it difficult to extract information from less common categories, and the imprecision in extracting small-object land cover information—this paper proposes a new network, SCIMF-Net (spatial context information and multiscale feature fusion encoding–decoding network), for LULC information extraction from remote sensing images.
Overall, the main contributions are as follows:
The SCIMF-Net employs an enhanced ResNeXt-101 deep backbone network, which markedly improves the extraction capability of features related to small target objects.
A new PMFF module is developed to facilitate the integration of features at various scales, thereby enriching the model’s comprehension of spatial context at both global and local levels.
We introduce a weighted joint loss function that further enhances the SCIMF-Net’s performance in LULC information extraction, especially when addressing class imbalances among different object categories.
3. Method
3.1. Overview
The SCIMF-Net spatial context information and multiscale feature fusion encoder–decoder network, as shown in
Figure 4, consists of three main components: the SCIMF-Net encoder, the PMFF module, and the SCIMF-Net decoder. SCIMF-Net Encoder: Responsible for extracting features from remote sensing images by progressively reducing the spatial dimensions to capture high-level abstract features. PMFF Module: Captures mid-to-high-level multiscale features, extracting rich contextual information. SCIMF-Net Decoder: Gradually restores the spatial resolution of remote sensing images through upsampling, convolution, and activation functions. It uses skip connections to combine low-level features from the encoder with mid- to high-level features from the PMFF module, continuously acquiring multiscale information to generate the segmented remote sensing image.
3.2. Encoder of SCIMF-Net
ResNeXt-101 [
33] is an advanced convolutional neural network that incorporates the design principles of the Inception architecture. Utilizing grouped convolutions and multiple parallel branches effectively expands the network’s capacity, achieving high-dimensional feature representation. ResNeXt-101 demonstrates strong adaptability for extracting complex semantic information when applied to remote sensing image processing. Its multibranch structure allows for multiscale feature fusion at different levels, significantly enhancing boundary and local information accuracy in LULC extraction. However, ResNeXt-101 has limitations in identifying small target information in complex scenes due to background noise and redundant irrelevant features. It also struggles with small-scale variations in remote-sensing images. To address these limitations, this paper improves the basic structure of the original ResNeXt-101 network, specifically the ResNeXt Residual block, by integrating the SE attention mechanism [
34]. This mechanism recalibrates feature channels, enabling the model to focus more on essential features needed for land cover information extraction while suppressing unnecessary features, thereby enhancing the backbone network’s expressive and generalization capabilities. The proposed SE-ResNeXt Residual block, as shown in
Figure 5, helps the backbone network more accurately identify and segment different semantic regions in images, improving segmentation precision and efficiency.
To adjust the feature map dimensions, a 1 × 1 convolution is used for effective dimensionality reduction or expansion, specifically enlarging the feature map size by four times. Subsequently, 64 groups of grouped convolutions are applied to images with a size of 1/16 of the original, aiming to capture rich features from various perspectives and integrate them through concatenation. Next, another 1 × 1 convolution is used to restore the feature map dimensions, ensuring that they match the original input, as calculated using Equation (4). On this basis, the SE attention mechanism is introduced to enhance focus on critical features and suppress irrelevant information, thereby improving feature map precision. Finally, the precise features processed by the SE attention mechanism are added to the output obtained from a specific residual function calculated using Equation (5), as shown in Equation (6), forming the final output feature map. This approach optimizes the feature extraction process and enhances the accuracy and efficiency of remote sensing image analysis.
In this context, denotes the attention applied to channel C of the input feature map , specifically the c-th channel. The dimensions H and W represent the height and width of the feature map, respectively. The variable signifies the ReLU activation function, while indicates the sigmoid activation function that normalizes the weights to the interval [0, 1]. Additionally, and are the weights of the fully connected layer, and refers to the value of the element at position i, j in the d-th channel of the input feature map.
Let the input feature map be denoted as X. The residual function can be expressed as
Here,
represents the parameter set,
corresponds to the i-th group of the input feature map X,
denotes the convolutional kernel parameters for the i-th group,
indicates the batch normalization operation,
refers to the ReLU activation function, and
signifies the number of groups in the grouped convolution.
Let the output feature map be denoted as Y. The formula for Y is as follows:
In this context, S denotes the function of the attention mechanism.
The original ResNeXt-101 network is primarily used for classification tasks in computer vision, but it has limitations when applied to LULC information extraction. This paper redesigns and improves the original ResNeXt-101 structure and parameters to expand its applicability, resulting in the SE-ResNeXt-101 network. This improved network serves as the backbone encoder for SCIMF-Net, used for multiscale feature extraction in remote sensing images. The SE-ResNeXt-101 architecture consists of multiple SE-ResNeXtBlock modules, basic convolution operations, and pooling layers stacked together. The specific improved parameters are detailed in
Table 2. These enhancements aim to improve network performance and applicability for LULC information extraction tasks.
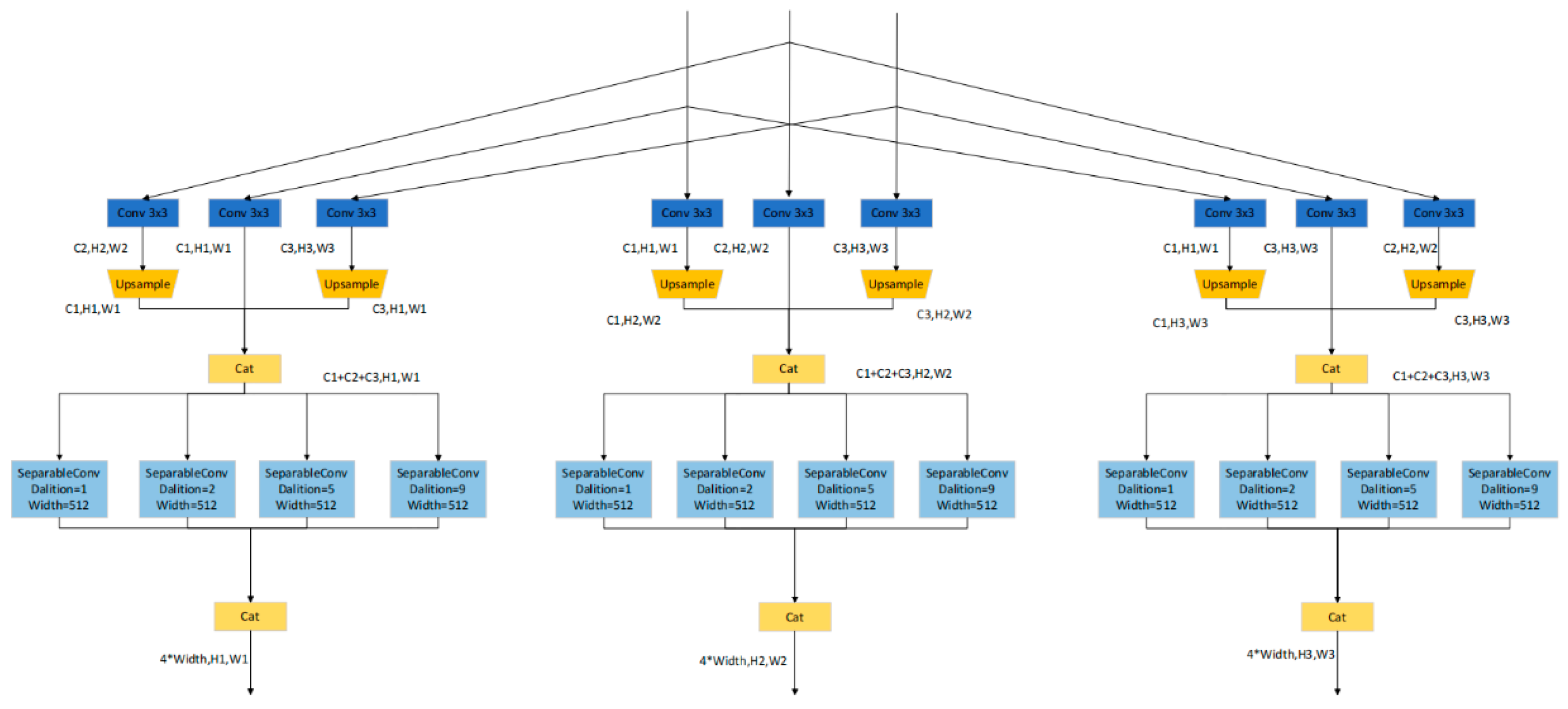
3.3. Parallel Multiscale Feature Extraction Fusion Module (PMFF)
In response to the problems of insufficient spatial context information acquisition and poor multiscale feature fusion capabilities in the encoding stage of traditional convolutional neural networks, this paper innovatively designs a parallel multiscale feature extraction and fusion module (PMFF). As shown in
Figure 6, this module parallelly processes the low-level features
, intermediate features
, and high-level features
extracted by the SE-ResNeXt-101 backbone network, uses 3 × 3 convolution blocks for feature extraction, and then splices and fuses them after upsampling to unify the feature map size. Furthermore, 3 × 3 hole-depth separable convolutions are used for multiscale feature extraction, and are then spliced and fused again to obtain new output low-level features
, intermediate features
, and high-level features
. This design enables the latest features to have more refined information than the original features, effectively improving the feature expression ability and network performance.
The overall process of the PMFF multiscale feature extraction and fusion is as follows: the original remote sensing images are processed through the improved ResNeXt-101 backbone network to extract features
,
, and
. Let K represent the number of standard convolution branches, M the number of modules, and L the number of depthwise separable convolution branches. Using Equation (7), each branch employs a specific standard convolution function
for feature extraction. The scale of the feature maps is adjusted using the upsampling operation S as described in Equation (8), resulting in resized feature maps
. In the multibranch parallel structure, feature maps are concatenated using function C as defined in Equation (9), yielding the concatenated feature map
. Subsequently, Equation (10) applies the dilated depthwise separable convolution function
for multiscale feature extraction on the concatenated feature maps. Finally, Equation (11) uses a concatenation function to produce the output feature map
.
3.4. Weighted Joint Loss Function
The formula for the cross-entropy loss function is as follows:
In this context, N represents the total number of pixels in the remote sensing image, while J denotes the total number of land cover types. The label is equal to 1 if the actual pixel i belongs to category j, and 0 otherwise. indicates the probability predicted by the model that pixel i belongs to category j, and refers to the natural logarithm.
The formula for the focal loss function is as follows:
In this context, represents the weight for category i, is the modulation parameter, and denotes the probability predicted by the model for pixel i.
The formula for the Dice loss function is as follows:
The formula for the Dice loss function is as follows: where N represents the total number of pixels in the remote sensing image, and denotes the probability predicted by the model for pixel i.
This study employs a weighted joint loss function, as expressed in Equation (15):
In this context, , , , and denote the joint loss, cross-entropy loss, focal loss, and Dice loss, respectively. The variables , , and refer to adaptive percentage parameters.
3.5. SCIMF-Net Decoder
The structure of the SCIMF-Net decoder, as shown in
Figure 7, integrates features extracted from the pretrained network in the encoder structure, including ConV_Head and features from the SE-ResNeXt-101 backbone network’s Stage1, Stage2, Stage3, and Stage4. Skip connections incorporate multistage features from the encoder into corresponding levels of the decoder. Starting from Stage 4, two consecutive 3 × 3 convolutional blocks are used for feature refinement, followed by upsampling to increase the feature map size, fused with features from the corresponding encoder stage. This process is repeated until the final layer is fused, resulting in the output feature map. This design effectively leverages the rich features of the encoder, providing strong support for the decoder.
The SCIMF-Net decoder significantly enhances multiscale feature fusion by using skip connections, effectively leveraging local and global contextual information. Additionally, incorporating batch normalization in the crucial 3 × 3 convolutional blocks accelerates the decoder’s training process and ensures stability, making the model more robust during training. To further improve generalization, dropout is employed, enhancing the model’s robustness and adaptability. These improvements endow the SCIMF-Net decoder with excellent performance and generalization capabilities.
4. Experiments
4.1. Ablation Experiments
As shown in
Figure 8, the performance experiments of the SCIMF-Net model demonstrate that incorporating the original design modules significantly enhances training effectiveness. Using the improved SE-ResNeXt-101 as the backbone network initially resulted in relatively low training accuracy. Subsequently, by adding the PMFF module, training accuracy improved by approximately 3.58%, and training loss decreased by 0.076, significantly enhancing the model’s feature extraction capability. Finally, with the inclusion of the weighted Combined Loss function, training accuracy increased by an additional 6.85%, and training loss decreased by 0.119. These experimental results fully validate the effectiveness of each module and their positive contribution to the performance of the SCIMF-Net model.
This study utilizes a predicted dataset obtained from original Landsat remote sensing images to conduct ablation experiments, aiming to verify the effectiveness of the module combinations within the SCIMF-Net model. The ablation experiments for the three components of SCIMF-Net are presented in
Table 3, where “×” indicates that the module is not used, and “√” indicates that the module is employed. Combination A represents the SE-ResNeXt-101 backbone network, B indicates the SE-ResNeXt-101 with the PMFF module, and C denotes the SE-ResNeXt-101 with the PMFF module along with the weighted combined loss function (Combined Loss).
This study optimizes land cover information extraction through three combinations. Combination A uses an improved SE-ResNeXt-101 backbone network with an attention mechanism to enhance the network’s contextual awareness and improve the representation of practical features. Combination B captures richer feature information from different scales to enhance understanding of various land cover types and effectively integrates multiscale information to improve spatial information comprehension. Experimental results show that after adding the PMFF module, the PA, MPA, and MIOU metrics increased by 0.65%, 0.1%, and 3.4%, respectively, indicating a continuous improvement in LULC information extraction accuracy across different land cover categories. Combination C incorporates the weighted Combined Loss function, which optimizes LULC information extraction accuracy across various land cover types more comprehensively by combining different types of losses. This effectively mitigates class imbalance, further enhancing the stability and accuracy of LULC information extraction, with PA, MPA, and MIOU metrics improving by 1.07%, 2.07%, and 1.95%, respectively.
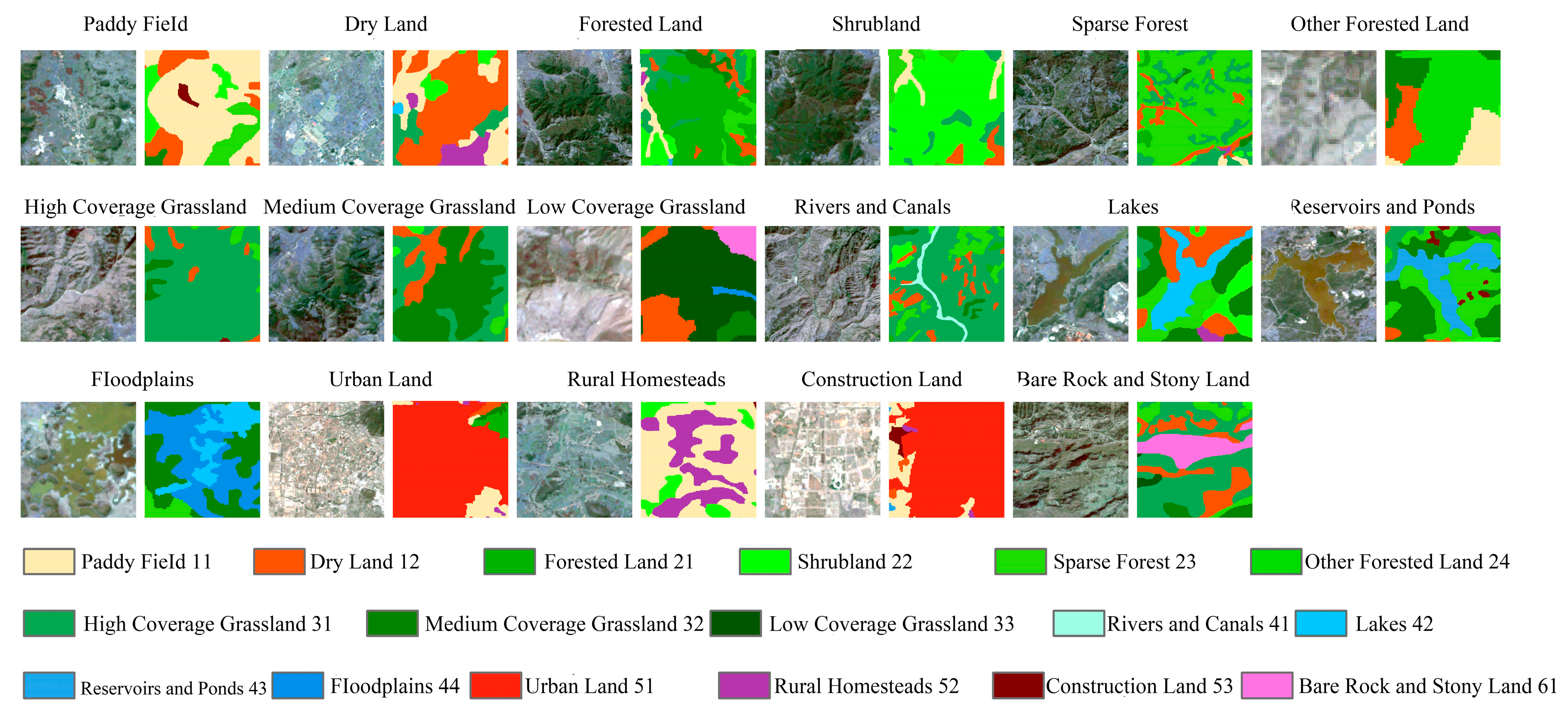
To provide a more precise comparison of the specific effects of each module in the proposed network on LULC information extraction, a visual analysis was conducted to compare the secondary class information extracted by all modules, as illustrated in
Figure 9 and
Figure 10.
All combination methods achieved satisfactory results in extracting rice paddy (11) information. However, in extracting dry land (12) information, Combination A experienced some loss of dry land data. For forested land (21) information extraction, Combinations A and B encountered interference and misclassification issues. In extracting shrubland (22) information, Combination A failed to extract shrubland data successfully. For sparse forest (23) information extraction, Combination B did not effectively capture edge information. In extracting other forested land (24), Combination B exhibited significant errors in information extraction. Combination C demonstrated a more complete edge representation in extracting smaller other forested areas. All combination methods performed well in information extraction of high-cover grassland (31) and medium-cover grassland (32). However, in low-cover grassland (33), Combination A suffered severe information loss. In extracting highly imbalanced land cover types such as channels (41), both Combination A and Combination B were ineffective in extracting the continuous linear features of channels. At the same time, Combination C successfully captured all the information in the channel. In the extraction of lakes (42) and reservoirs (43), Combination A also showed detail loss and misclassification. All combination methods performed poorly in the extraction of wetlands (44). In the extraction of urban land (51), rural homesteads (52), and construction land (53), Combination A exhibited incomplete extraction and significant detail loss. For bare rock (61) information extraction, Combination B performed poorly. The results indicate that using only Combination A does not achieve high precision in LULC information extraction. However, as Modules B and C are incorporated, the extraction of more minor features becomes clearer, effectively addressing the issues of data loss and difficulty in accurately extracting minor land cover types due to class imbalance.
4.2. Comparison of SCIMF-Net with Other Convolutional Neural Networks
To fully validate the effectiveness of the proposed SCIMF-Net convolutional neural network, it was compared with classic networks such as U-Net++ [
35], Res-FCN [
36], U-Net [
37], and SE-U-Net. As shown in
Figure 11, under the same training conditions (150 epochs), SCIMF-Net achieved the highest training accuracy. Comparatively, SCIMF-Net’s training accuracy was 6.71% higher than Res-FCN, 5.58% higher than U-Net, 6.43% higher than SE-U-Net, and 4.34% higher than U-Net++. Additionally, when comparing the error between predicted and actual values (i.e., Loss), SCIMF-Net had the lowest loss, being 0.287 lower than Res-FCN, 0.192 lower than U-Net, 0.239 lower than SE-U-Net, and 0.126 lower than U-Net++. Throughout the training process, SCIMF-Net outperformed the other four convolutional neural networks in both training accuracy and loss, thus demonstrating its effectiveness.
As shown in
Table 4, SCIMF-Net was comprehensively compared with other convolutional neural networks in terms of performance metrics for predicting data. For the per-class PA metric, SCIMF-Net demonstrated a significant advantage, outperforming Res-FCN, U-Net, SE-U-Net, and U-Net++ by 0.68%, 0.54%, 1.61%, and 3.39%, respectively. In the multiclass MPA comparison, SCIMF-Net also excelled, improving by 2.96%, 4.51%, 2.37%, and 3.45% over the aforementioned networks. To address class imbalance, this study used the MIOU as a more comprehensive and accurate evaluation metric. SCIMF-Net showed significant improvements in MIOU, surpassing Res-FCN, U-Net, SE-U-Net, and U-Net++ by 3.27%, 4.89%, 4.2%, and 5.68%, respectively. Through a comprehensive comparison of these three performance metrics, the proposed SCIMF-Net achieved better results in LULC information extraction under class imbalance, demonstrating its outstanding performance and advantages.
As shown in
Figure 12, a comparison of SCIMF-Net with four other convolutional neural networks in extracting 17 secondary LULC categories reveals that SCIMF-Net achieves higher pixel accuracy in most tasks. Specifically, SCIMF-Net outperforms the other networks in extracting secondary categories such as paddy fields (11), shrubland (22), open forests (23), high-coverage grassland (31), medium-coverage grassland (32), low-coverage grassland (33), canals (41), reservoirs and ponds (43), rural homesteads (52), and construction land (53). In a few categories, it slightly underperforms specific networks: other forests (24) are slightly lower than Res-FCN; dryland (12), forested land (21), and urban land (51) are slightly lower than U-Net; beaches (44) and bare rock (61) are slightly lower than U-Net++. However, the accuracy gap with the best results remains small, underscoring SCIMF-Net’s effectiveness in LULC extraction tasks. Additionally, all networks show relatively low extraction accuracy for reservoirs and ponds (43), likely due to the complex features of this category that are difficult to capture accurately. U-Net++ has the lowest extraction accuracy for secondary LULC categories, possibly due to insufficient feature representation caused by class imbalance.
To compare the performance of the proposed network with other convolutional neural networks in extracting secondary LULC information, we visualized and compared the results of U-Net, U-Net++, Res-FCN, SE-U-Net, and the proposed SCIMF-Net, as shown in
Figure 13 and
Figure 14. In extracting paddy fields (11), U-Net and U-Net++ lost some edge contour information. For dryland (12), Res-FCN and SE-U-Net provided incomplete information. SE-U-Net showed misclassification in forested land (21) and shrubland (22). All networks performed well in extracting open forests (23). For other forests (24), Res-FCN had many misclassifications, and U-Net++ needed to extract complete contours. In high-coverage grassland (31), SE-U-Net and U-Net had poor accuracy due to class imbalance. SE-U-Net showed many misclassifications in medium-coverage grassland (32), and Res-FCN failed to extract low-coverage grassland. For canals (41), Res-FCN and U-Net could not extract continuous linear information. In lakes (42), U-Net and SE-U-Net lost some edge information. U-Net showed partial misclassification in reservoirs and ponds (43). All networks performed poorly in beach (44) extraction. U-Net needed to find some information on urban land (51). U-Net, SE-U-Net, and U-Net++ failed to extract complete contours in rural homesteads (52). Res-FCN, U-Net, and SE-U-Net had misclassifications in construction land (53). All networks performed well in extracting bare rock (61). These results indicate that traditional convolutional networks like Res-FCN, U-Net, SE-U-Net, and U-Net++ perform poorly in extracting small target information and are less effective with class imbalance in LULC information. In contrast, SCIMF-Net excels in extracting more minor LULC information and accurately handles class imbalance.
5. Discussion
From the comparison experiment between SCIMF-Net and U-Net, ResFCN, Unet++, and SE-U-Net, we can see that the original backbone network in the U-Net network mainly adopts the shallow structure of VGG16 [
38]. Since remote sensing images often contain rich and delicate ground object information and many small targets, the shallow backbone network of VGG16 has difficulty effectively extracting these fine-grained semantic features. The network structure mainly uses feature splicing to fuse remote sensing image features, which makes it difficult to obtain fine details of ground objects and loses the deep information of target information in remote sensing images. It has poor performance when dealing with sample imbalance problems and has difficulty effectively extracting ground object categories with a small proportion. As an improved fully convolutional neural network, Res-FCN can recover the category of each pixel from the abstract features of remote sensing images and realize the extraction of pixel-level ground object category information. However, when extracting small target information, its receptive field is not enough to cover enough context information, resulting in the network only extracting local features, resulting in poor extraction of small target information. Due to the limitation of the original FCN structure [
39], when dealing with the problem of sample imbalance, Res-FCN also finds it difficult to fully learn the features of fewer samples, thus affecting the accuracy of ground object information extraction. Although SE-U-Net borrows the idea of FPN network based on the U-Net structure and realizes the fusion of multiscale features, its feature fusion is still not sufficient when extracting small target information, resulting in the loss of details of small target information during the fusion process, and insufficient attention paid to the spatial position information of small targets, which affects the accuracy of small target information extraction. When dealing with the problem of sample imbalance, the loss function is not optimized in a targeted manner, resulting in insufficient learning of fewer category samples by the network model during the training process, making it difficult to extract less ground object category information. In the structure of U-Net++, the feature layers of the encoder and decoder networks are directly connected. This design simplifies the network architecture, but it leads to the loss of detailed information when fusing features of different scales, which in turn affects the results of small target information extraction. When dealing with the problem of sample imbalance, U-Net++ does not perform special optimization design on its network structure, which makes the information extraction effect of less common object categories poor, limiting the application performance of the model in complex remote sensing images.
In this paper, the backbone network used by SCIMF-Net is ResNeXt-101. As an architecture designed for image type classification, the original ResNeXt-101 network cannot be directly applied to LULC information extraction from remote sensing images [
40]. Therefore, this paper makes targeted modifications to the original ResNeXt-101 network. First, by utilizing the powerful multiscale feature extraction capability of ResNeXt-101, a grouped convolution strategy is adopted to effectively extract low-level, medium-level and high-level features from remote sensing images. In order to further enhance the accuracy of feature extraction, the SE (squeeze-and-excitation) channel attention mechanism is integrated into the residual block, the basic structural block of ResNeXt, to obtain the improved SE-ResNeXt residual block. This improvement enables the SE-ResNeXt-101 backbone network to focus more on important small-scale feature channels while suppressing useless feature information, thereby improving the overall feature extraction capability. Compared with models that use shallow backbone networks such as U-Net, ResFCN, Unet++, and SE-U-Net, SE-ResNeXt-101, as a deeper network architecture, can significantly enhance the ability to extract LULC features in remote sensing images. In addition, the four stages of SE-ResNeXt-101 extract multiscale features of LULC features in remote sensing images, allowing SCIMF-Net to better adapt to LULC features of different sizes, thereby improving the overall performance and adaptability of the model. The PMFF module designed in this paper, through the mid- and high-level features extracted by the SE-ResNeXt-101 backbone network, strengthens the fusion between its spatial context information extraction and multiscale features, effectively improves the overall network’s understanding of local areas, enhances the coherence of global information, and fully utilizes the semantics and detail information of various types of objects by integrating features of different scales. Compared with the network structures of U-Net, ResFCN, Unet++, and SE-U-Net, the PMFF module enables SCIMF-Net to have an overall in-depth understanding of the spatial relationship and changes in small-scale object information in remote sensing images, helping the overall network to better obtain coarse-grained and fine-grained feature information in remote sensing images, and improving the accuracy of LULC information extraction at different scales. At the same time, the structural design of multimodule parallel computing is adopted to avoid and reduce the parameter redundancy and repeated calculation caused by a single module structure, and to improve the computing efficiency. In view of the imbalance of ground object categories, improving the loss function is one of the effective means to solve the imbalance of ground object categories when extracting LULC information from remote sensing images. In traditional LULC information extraction, most methods use a single loss function for training. There are three main types. One is the cross-entropy loss function, which does not consider the imbalance between the number of LULC categories. The cross-entropy loss function has difficulty learning the characteristics of fewer ground object categories and easily causes the risk of overfitting after the overall model training. Another is the focal loss loss function. The focal loss loss function effectively alleviates the LULC imbalance phenomenon by improving the cross-entropy loss function. However, the focal loss loss function has an unstable training process and is not effective for large differences within the LULC class. Another is the Dice loss loss function. The Dice loss loss function is suitable for dealing with the LULC imbalance problem, but Dice loss will also cause unstable gradient changes during model training, affecting model convergence, and resulting in insufficient performance optimization for ground object categories. In order to effectively solve the problem of unbalanced LULC distribution categories, in view of the shortcomings of the abovementioned single loss function, this paper adopts a weighted joint loss function to overcome the performance limitations of a single loss function. Compared with the single loss function used by U-Net, ResFCN, Unet++, and SE-U-Net, the weighted joint loss function reduces the overfitting risk of a single loss function, adjusts the weights of fewer ground object categories, enhances the effectiveness of feature extraction of fewer ground object categories, and improves the ability to extract poor information of fewer ground object categories caused by unbalanced ground object categories. Through ablation experiments, the effectiveness of the above three modules and their positive contribution to the performance of the SCIMF-Net model are fully demonstrated, effectively improving the overall performance of SCIMF-Net for feature extraction.
The study area of this experiment is the central Yunnan Urban Agglomeration in Yunnan Province, China, with an area of about 114,600 square kilometers. The remote sensing image datasets used are mainly from Landsat 5 TM in 2000 and 2010 and Landsat 8 OLI in 2020. The spatial resolution of these datasets is 30 m, which belongs to the medium-resolution category. SCIMF-Net, as an improved convolutional neural network model, shows the highest accuracy of LULC information extraction compared with the extraction results of U-Net, ResFCN, Unet++, and SE-U-Net. However, the SCIMF-Net proposed in this paper is a deep convolutional neural network, which has increased network depth and width compared with models such as U-Net, ResFCN, Unet++, and SE-U-Net. Although this design enables SCIMF-Net to achieve the highest accuracy in the experiment, it also brings higher computing resource requirements and larger storage space occupancy. Therefore, in terms of computing cost, SCIMF-Net does not have an advantage. In the future, in order to further improve the practicality of this model, it is necessary to carry out in-depth optimization work on it and focus on developing its lightweight structure to reduce computational complexity and storage space requirements.
As high-resolution remote sensing image acquisition technology becomes increasingly mature and convenient [
41], the limitations of the global modeling capabilities of traditional CNN models in processing such images have become increasingly prominent. In order to break through this bottleneck, it is necessary to further improve the uniqueness of high-resolution remote sensing images. Future research work will focus on developing and applying more advanced network model structures, aiming to achieve significant performance improvements in the field of high-resolution remote sensing image processing. At the same time, with the continuous innovation and development of deep learning and artificial intelligence technologies, the RS-Mamba model [
42] has shown significant advantages over traditional methods in terms of computational efficiency and LULC information extraction accuracy. With its stronger linear complexity and excellent global modeling capabilities, the model has shown extremely high applicability in processing LULC information extraction tasks for large-scale remote sensing images. This feature not only greatly broadens the application scope of remote sensing technology, but also points out the direction for future research. Future research should further explore and optimize the application potential of the remote sensing Mamba model in large-scale, high-precision LULC information extraction, in order for it to play a greater role in key areas such as land use monitoring, and continuously promote the integrated development of remote sensing technology and deep learning.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}