
A Systematic Review of Multi-Scale Spatio-Temporal Crime Prediction Methods
Abstract
1. Introduction
- Studies related to crime prediction are systematically reviewed from various temporal and spatial perspectives.
- Common temporal and spatial crime prediction methods and evaluation metrics are summarized.
- The limitations of the current study are reviewed, and reasonable suggestions for future directions of exploration are provided.
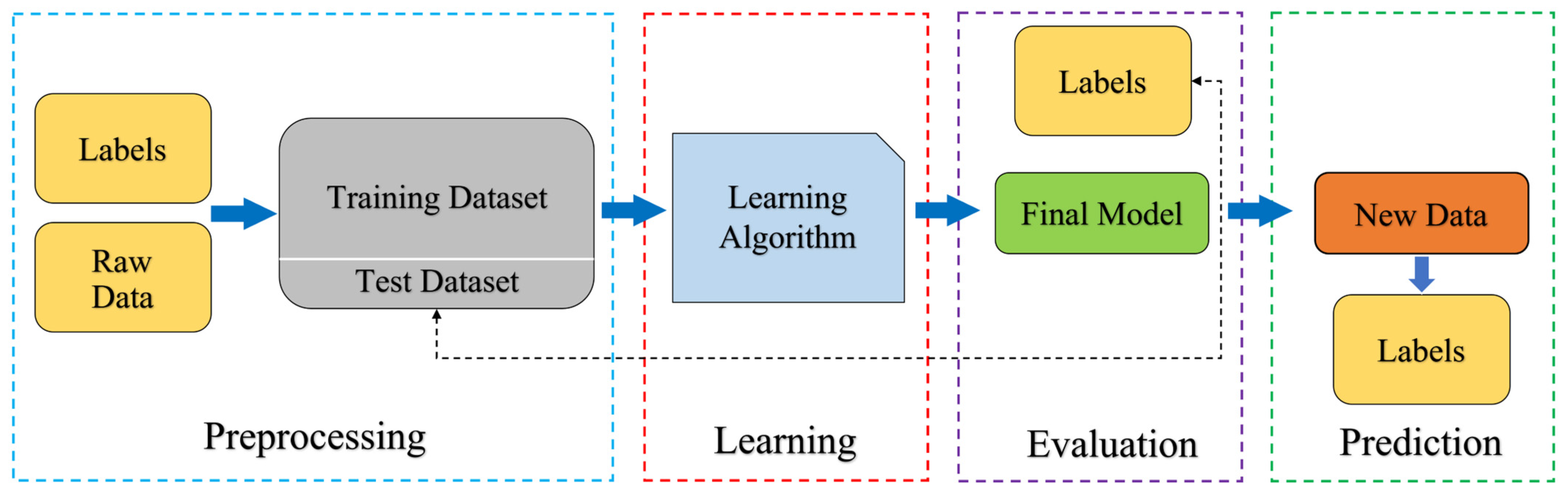
2. Materials and Methods
2.1. Publications Sources
2.1.1. Publications Search
2.1.2. Publications Screening
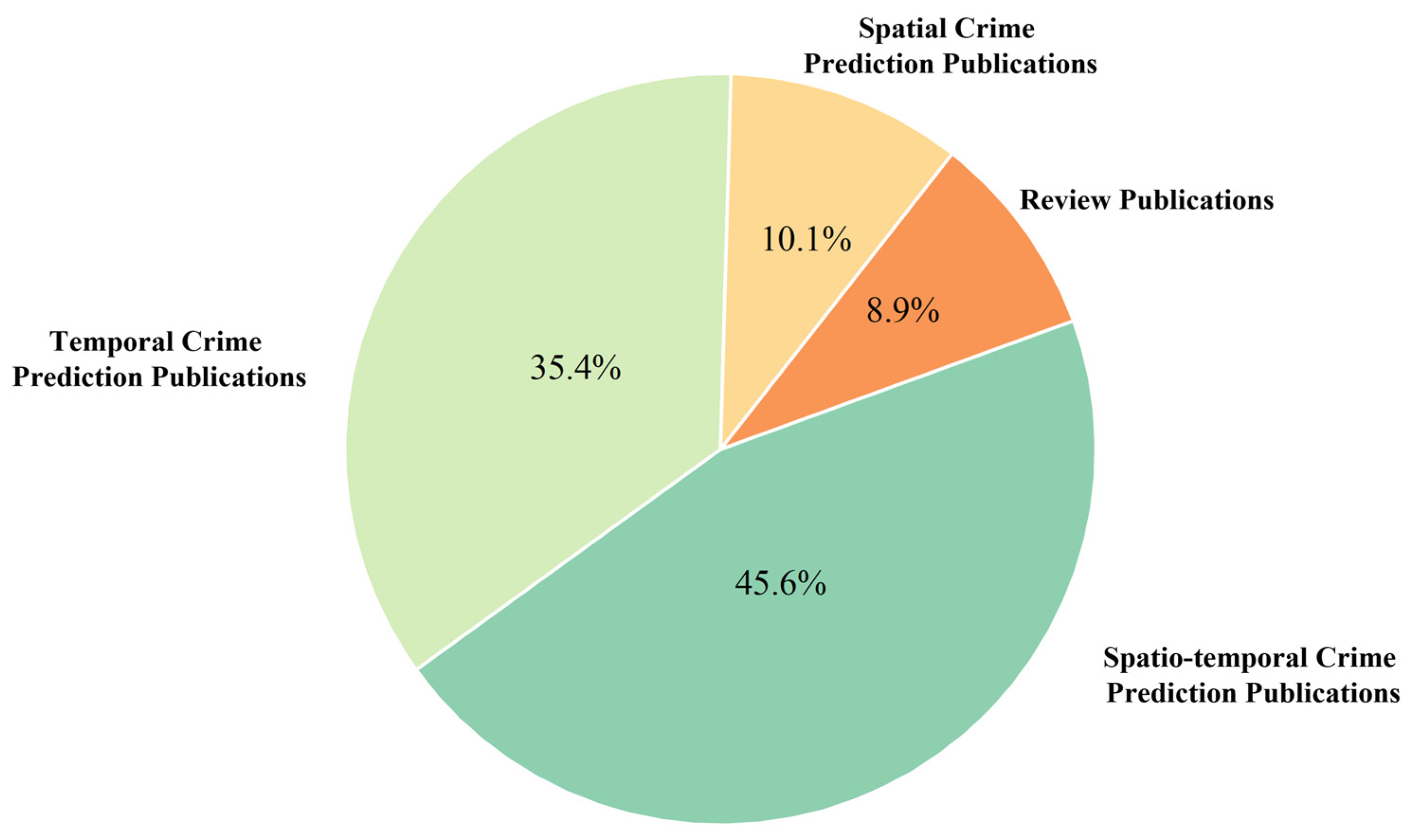
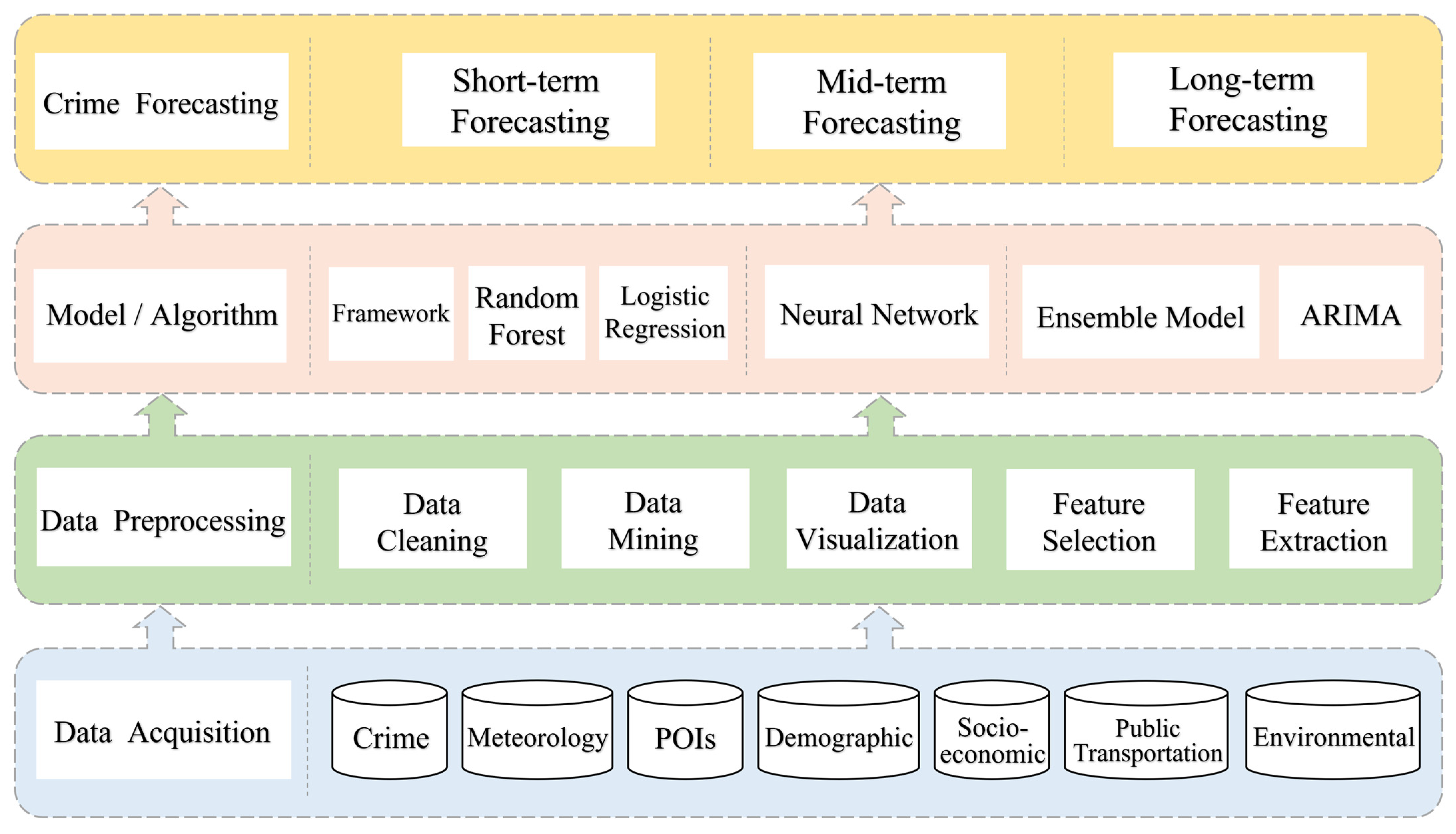
2.2. Research Overview
2.2.1. Research Content
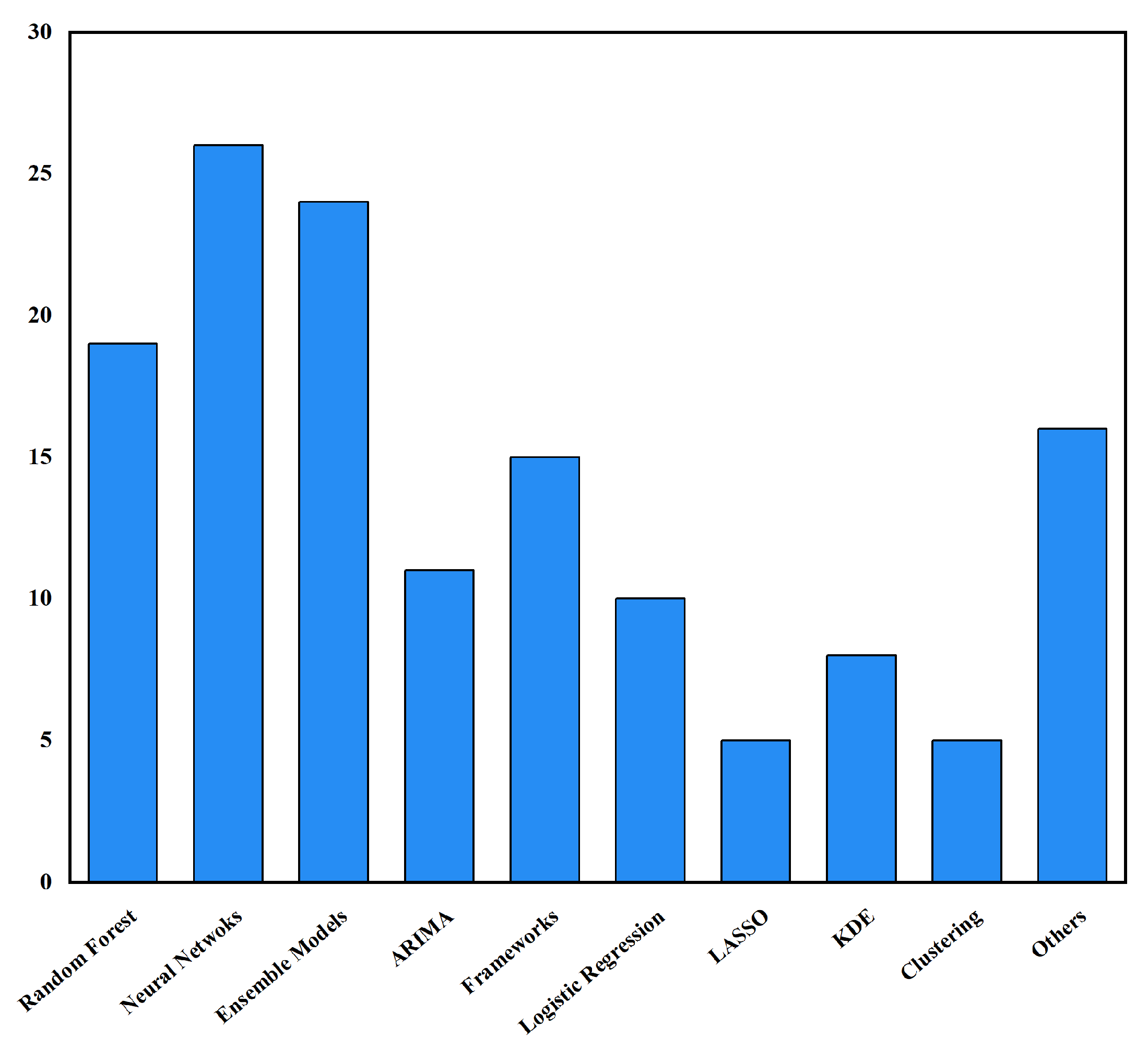
2.2.2. Prediction Methods
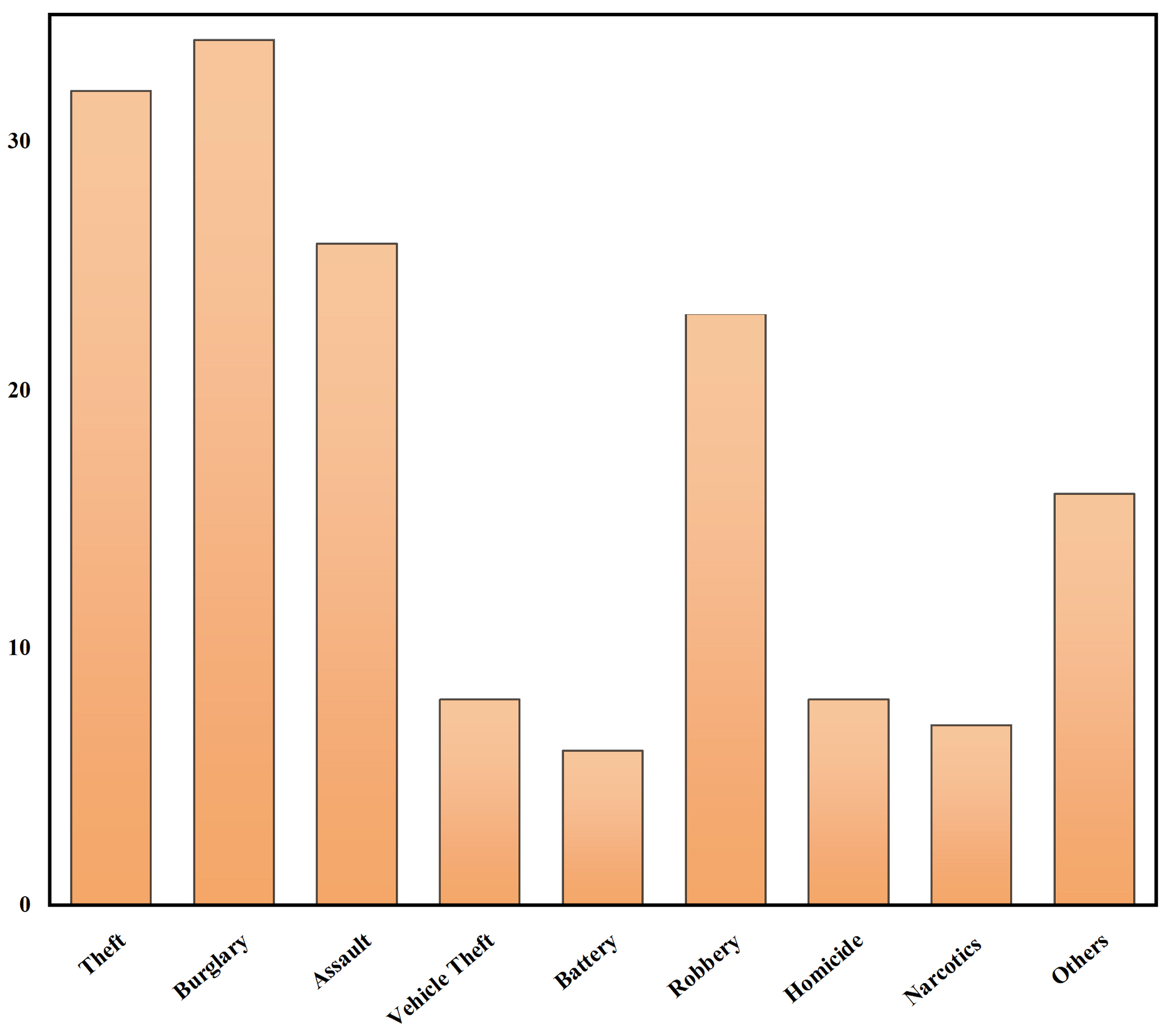
2.2.3. Types of Crime Predicted
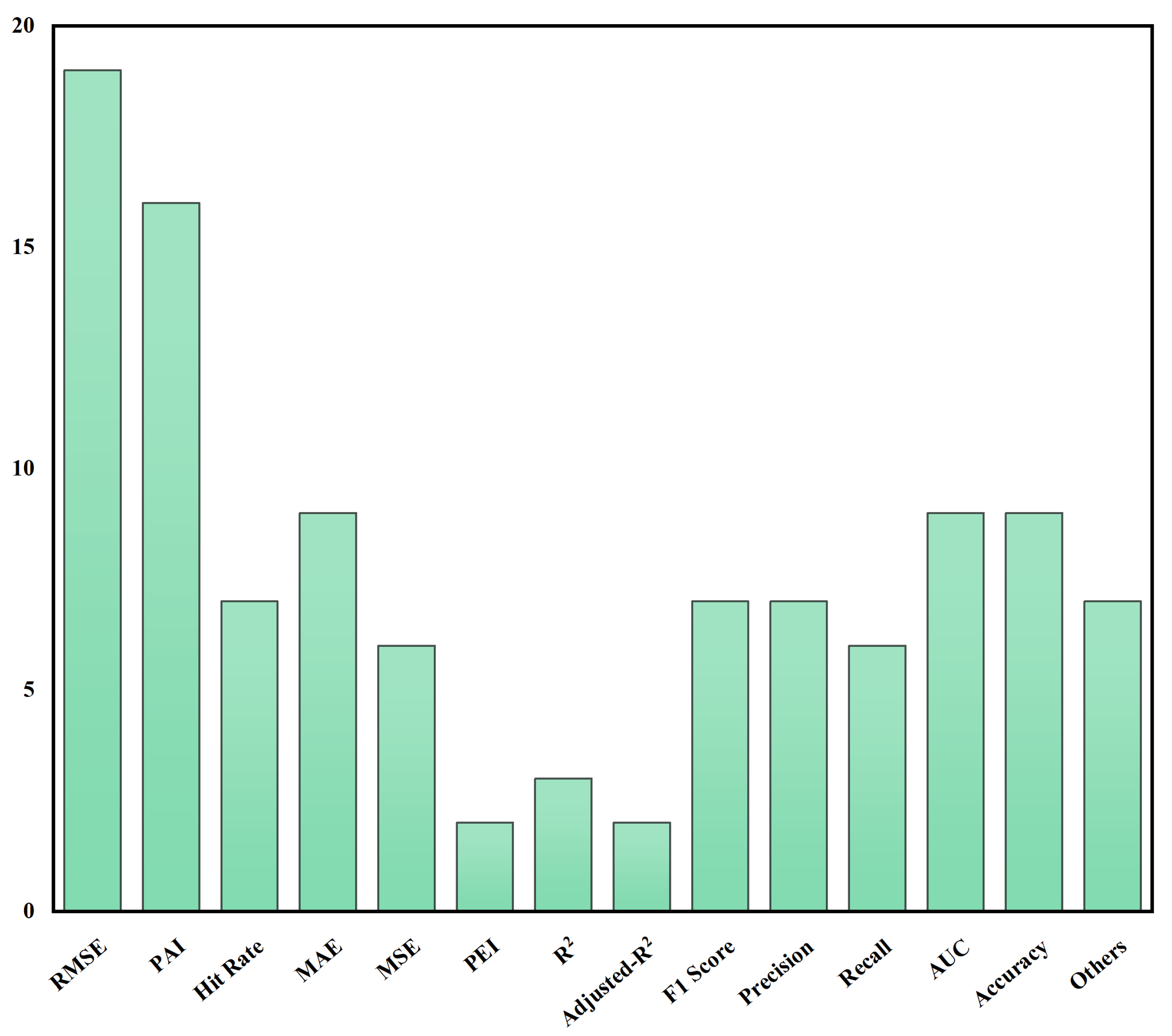
2.2.4. Evaluation Metrics
3. Crime Prediction Methods and Evaluation Metrics
3.1. Crime Prediction Methods
3.1.1. Machine Learning
- (1)
- Logistic Regression
- (2)
- Random Forest
- (3)
- Ensemble Model
- (4)
- Neural Networks
3.1.2. Crime Mapping
- (1)
- KDE
- (2)
- RTM
3.1.3. Other Prediction Methods
- (1)
- ARIMA
- (2)
- LASSO
- (3)
- ABM
3.2. Evaluation Metrics
3.2.1. Hit Rate
3.2.2. PAI and PEI
3.2.3. Accuracy and F1 Score
3.2.4. ROC and AUC
3.2.5. MSE and RMSE
3.2.6. R2 and Adjusted R2
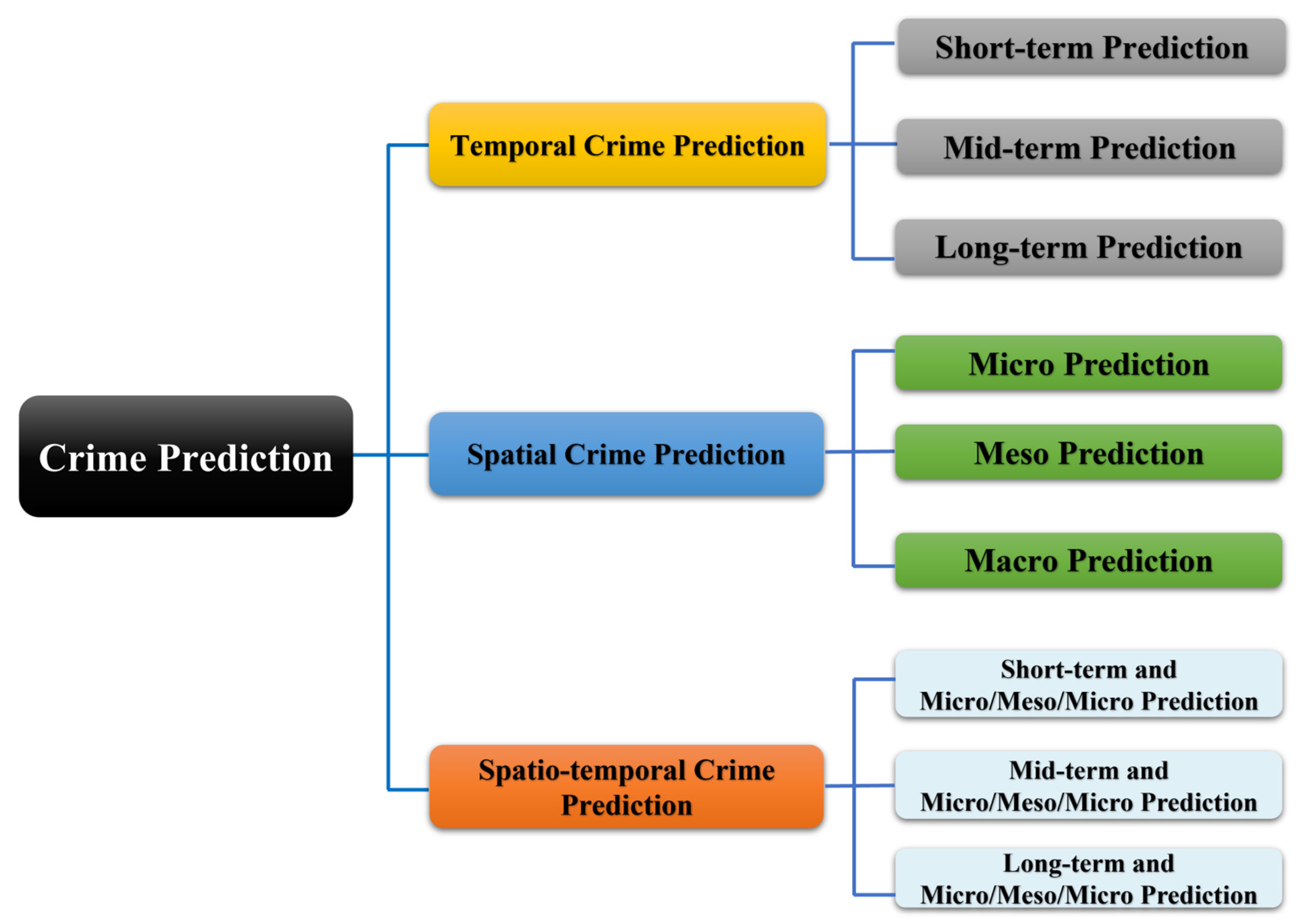
4. Temporal Crime Prediction
4.1. Temporal Crime Prediction Based on Crime Data Only
4.1.1. Short-Term Prediction
4.1.2. Medium-Term and Long-Term Prediction
- (1)
- STEP
- (2)
- ARIMA
- (3)
- ST-AR
- (4)
- CBMF
- (5)
- Spatial Beta Convergence
4.2. Temporal Crime Prediction Based on Crime and External Data
4.2.1. Short-Term Prediction
- (1)
- LKDE
- (2)
- Neural Networks
- (3)
- Ensemble Model
- (4)
- NAHC
4.2.2. Medium-Term Prediction
- (1)
- LDA
- (2)
- DeepCrime, AIST, and INLA
4.2.3. Long-Term Prediction
- (1)
- LASSO and Extra Trees
- (2)
- Ensemble Model
4.3. Limitations of Temporal Prediction Research
- Data sparsity. Despite the advancements in improving the accuracy of the models, most prediction models are driven by data and still have difficulties in dealing with data sparsity. Some study areas have limited crime data, making it challenging to support crime prediction. Furthermore, as the granularity of time and space becomes finer, the data become sparser and the amount of irrelevant information gradually increases, leading to difficulties in modeling crime. It also exposes issues regarding the difficulty involved in using data-driven models to accurately identify and extract crime-related features. Adding external features may result in reduced correlation between data and crime or even the phenomenon of the “Curse of Dimensionality”, where the model cannot converge quickly in a short time.
- Insufficient practicality, interpretability, and transparency of the model. ML-based prediction models often lack interpretability due to their “black-box” nature. The improved performance of the model comes at the cost of interpretability. As the complexity of the model increases, its performance becomes stronger, but its interpretability becomes worse. It is not enough to evaluate a model based on accuracy alone; understanding the mechanics behind how the model works is crucial. It is important to know how prediction results are given and which features are crucial for the model, among other considerations. Otherwise, full trust in the prediction results cannot be established. Thus, there is a strong need to introduce model interpretability methods to improve the understanding of how the models function. Additionally, since the crime situation varies between regions, models trained in one region may not necessarily transfer well to other regions.
- Single evaluation system. The evaluation metrics and data used in the above studies vary, making it impossible to judge the merits of the models accurately. Some studies rely solely on historical crime data, while others use a combination of crime and external data, such as demographic, socio-economic, and environmental factors. Moreover, the evaluation metrics are often too narrow, making it challenging to compare the performance of the models accurately. Thus, there is a need to establish a comprehensive evaluation system that considers various data types and evaluation metrics to truly judge the merit of the models.
- Limited studies on short-term crime prediction. Most of the studies discussed above focus primarily on medium- and long-term crime prediction (monthly, quarterly, and annual), which has a positive impact on macro-level policy making. However, few studies concentrate on short-term prediction at the hourly, daily, and weekly levels. Short-term prediction better serves the needs of most police departments since crimes such as burglary and robbery are typically short-lived, and they require rapid action to prevent and combat the crimes effectively. The lack of research in short-term prediction models makes it difficult to prevent crime from happening, such as by deploying officers and planning patrol routes aimed at targeted areas. When an offense occurs, the perpetrators cannot be caught in time, resulting in a significant blow to law enforcement.
5. Spatial Crime Prediction
5.1. Micro- and Meso-Level Prediction
- (1)
- GLDNet
- (2)
- Clustering
- (3)
- ANROC
- (4)
- KDE and RTM
5.2. Macro-Level Prediction
- (1)
- STDC Detector
- (2)
- RTM
- (3)
- ABM
- (4)
- DNN Framework
5.3. Limitations of Spatial Crime Prediction Research
- Research on spatial crime prediction has made significant strides in identifying potential risk factors and crime hotspots, while also validating relevant criminology theories. However, despite the progress made thus far, this field still faces numerous challenges. For instance, the accuracy of crime prediction models heavily relies on the quality of crime data and the availability of relevant urban features. Moreover, the effective integration of various data sources remains a significant challenge in the development of reliable crime prediction models. There are fewer studies at the micro-level. While most studies in the spatial crime prediction field focus on macro-level predictions due to the availability of city-related data, they often overlook the importance of micro-level predictions. Conducting micro-level research would prove invaluable as it could assist the police in achieving scientific resource allocation and dispatch for specific areas and roads. Moreover, such research could enable enterprises to choose suitable business locations and to help citizens select safe travel routes and times, thus mitigating crime opportunities and promoting crime deterrence. The incorporation of micro-level predictions could provide more nuanced and context-specific insights and recommendations to a diverse group of stakeholders, thereby improving the effectiveness and efficiency of crime prevention strategies.
- Lack of research on decision-making applications. Some studies lack practical support for assisted decision making, which impedes their practical applications. Going forward, there should be a stronger emphasis on the implementation of research results in assisting the development of scientific police decisions. For instance, integrating patrol route planning research and other decision-making tools would be valuable in optimizing crime prevention efforts. By bridging the gap between research and practice, stakeholders can more effectively employ spatial crime prediction models for actionable insights and evidence-based decision making.
- Insufficient research on crime mechanisms. Although most spatial crime prediction studies successfully validate criminology-related theories and achieve the task of crime prediction to some extent, the directionality of some studies neglects the theoretical level. Consequently, these studies tend to only verify existing criminological theories, without sufficiently enriching or expanding the research on crime mechanisms. Additionally, the current research fails to consider the impact of criminal behavior patterns on crime prediction results. For instance, the presence of police on an offender’s travel route could deter the offender from committing the crime, which would subsequently affect the crime prediction accuracy. Therefore, future studies on spatial crime prediction should consider these contextual factors and aim to expand and advance crime mechanism research to improve the accuracy and applicability of crime prediction models.
- Unreasonable grid cell size. Most spatial crime prediction studies employ grid cells with side lengths of 100 m, 150 m, and 200 m. The research indicates that larger grid sizes generally result in better prediction performance. However, the theoretical limit range of a police patrol is 150 m, which should be considered when considering the relationship between grid size and police patrol range in practical crime prediction and police work. Flexibly adjusting grid size according to actual conditions and police patrol frequencies is essential. For areas with frequent police patrol, smaller grid cells should be used for prediction and analysis to improve prediction accuracy, while for areas with insufficient police patrol, larger grid cells should be employed to maximize the use of limited police resources and ensure comprehensive coverage. Striking a balance between prediction performance and practical application is key in optimizing the implementation of spatial crime prediction models.
6. Spatio-Temporal Crime Prediction
6.1. Short-Term and Micro-Level Prediction
6.2. Short-Term and Meso-Level Prediction
6.3. Short-Term and Macro-Level Prediction
6.4. Medium-Term and Macro-Level Prediction
6.5. Long-Term and Meso-Level Prediction
6.6. Long-Term and Macro-Level Prediction
6.7. Limitations of Spatio-Temporal Crime Prediction Research
- Spatio-temporal correlation. Crime is influenced by various factors, such as time, environment, weather, and networks, resulting in strong spatio-temporal correlations that make it difficult for traditional machine learning and time series analysis models to fully capture local or global spatio-temporal correlations. Blindly adding spatio-temporal crime data to some studies may lead to the overfitting of the model.
- Spatio-temporal heterogeneity. The spatial and temporal distribution of crime is not uniform. Crime data in different times and regions often show differences, making it difficult for the same model to capture crime patterns in different times and regions simultaneously.
7. Conclusions and Future Perspectives
- The continuous development of big data technology has enabled the use of advanced machine learning, hotspot mapping, and other methods for precise spatio-temporal crime prediction, resulting in significant progress and breakthroughs in this field. However, it is important to acknowledge that some prediction methods and techniques may not be able to fully address the complex and dynamic nature of contemporary crime. Thus, based on the literature review and analysis, this paper proposes reasonable and practical solutions to address the pressing issues and challenges in the research on spatial crime prediction. By addressing these challenges, we can further optimize and improve the efficiency and applicability of spatial crime prediction models in real-world settings. Data sparsity can be dealt with using transfer learning technologies. Data sparsity is a common challenge in the crime prediction field; it can limit the accuracy and generalizability of prediction models. The use of transfer learning techniques, a novel machine learning approach, offers a viable solution to this problem. Transfer learning allows the application of information and knowledge from existing domains to related domains, thereby enabling the training of deep learning models to capture connections between data and avoid overfitting, even with limited crime data. Additionally, when dealing with more data features and larger dimensions, feature selection, feature extraction, and cross-validation methods can be employed to optimize the performance and efficiency of spatial crime prediction models. By incorporating these techniques, researchers can more effectively address data sparsity issues and enhance the ability of spatial crime prediction models to capture and extrapolate meaningful patterns and trends.
- Introducing model interpretability methods to improve the interpretability of models. Model interpretability is essential in enhancing the understanding and trustworthiness of prediction models. The issue of “black-box” models that produce predictions that are difficult to comprehend can be partially addressed by utilizing model interpretability methods, such as the LIME and SHAP models. LIME is a widely applicable model that facilitates both global and local interpretation of prediction results. On the other hand, the SHAP model considers all features as “contributors” and assigns SHAP values to each feature that are positively correlated with the contribution made by the variable. This approach enables the ranking of variables according to the SHAP value, thereby improving the interpretability of the model while retaining a high predictive performance. Incorporating model interpretability methods enhances our understanding of crime patterns and levels and enables the development of more scientific, accurate, timely, and effective prevention and control measures.
- Establishing a set of data use and evaluation systems for multiple scales. A standard dataset usage and model evaluation system is crucial for crime prediction studies to promote accuracy, consistency, and interoperability. To this end, it is recommended to establish a set of data use and evaluation systems at each scale. Firstly, the standardization of the data use is essential to facilitate model comparison and ensure that models with the same prediction objectives and requirements employ the same type of dataset. Secondly, developing a comprehensive evaluation system is vital to facilitate the accurate performance measurement of such models. Using consistent evaluation metrics for models with the same prediction objectives is critical in gauging the efficacy of different models and developing a cross-comparable model evaluation framework. By incorporating these measures, we can establish a standard data usage and model evaluation system that promotes the accuracy, validity, and practical viability of crime prediction models at multiple scales.
- Integrating other technologies to promote research in decision making. To address the current issues of low correlation between spatio-temporal crime prediction models and lack of targeted prevention and control strategies, innovative technologies such as crime simulation and reinforcement learning can be incorporated to enhance decision-making applications. With further advancements in crime simulation and reinforcement learning technologies, we can enhance the decision-making applications in the spatial crime prediction field and develop effective prevention and control strategies to combat crime more efficiently. Integrating spatio-temporal elements into a crime simulation model can provide a comprehensive approach to spatial crime prediction. Through crime simulation, the potential time and place of crime occurrences can be predicted, and the process of crime can be visually presented. Such information can be input into a deep reinforcement learning framework to optimize crime prevention and control strategies through a continuous learning process. The deep reinforcement learning (DRL) crime prevention and control strategy optimization model continuously learns and evaluates strategies for a wide range of crime scenarios, while selecting the optimal strategy for resource allocation in specific spatio-temporal environments [99,100]. Police agencies can utilize the reinforcement learning strategy selection mechanism to deploy police resources, develop patrol plans, and implement arrest operations effectively. In addition, this approach can also enable prompt apprehension of perpetrators and can minimize losses in the event of a crime occurrence. By combining simulation modeling, deep reinforcement learning, and crime prevention strategies, we can enhance the implementation and effectiveness of spatial crime prediction models, contributing to more efficient and targeted crime prevention and control measures.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Malleson, N. Using agent-based models to simulate crime. In Agent-Based Models of Geographical Systems; Springer: Dordrecht, The Netherlands, 2011; pp. 411–434. [Google Scholar] [CrossRef]
- Brantingham, P.L.; Brantingham, P.J. Mobility, Notoriety, and Crime: A Study in the Crime Patterns of Urban Nodal Points. J. Environ. Syst. 1981, 11, 89–99. [Google Scholar] [CrossRef]
- Weisburd, D. The law of crime concentration and the criminology of place. Criminology 2015, 53, 133–157. [Google Scholar] [CrossRef]
- Curman, A.S.N.; Andresen, M.A.; Brantingham, P.J. Crime and Place: A Longitudinal Examination of Street Segment Patterns in Vancouver, BC. J. Quant. Criminol. 2015, 31, 127–147. [Google Scholar] [CrossRef]
- Ratcliffe, J.H. Crime Mapping and the Training Needs of Law Enforcement. Eur. J. Crim. Policy Res. 2002, 10, 65–83. [Google Scholar] [CrossRef]
- Wang, Q.; Jin, G.; Zhao, X.; Feng, Y.; Huang, J. CSAN: A neural network benchmark model for crime forecasting in spatio-temporal scale. Knowl.-Based Syst. 2020, 189, 105120. [Google Scholar] [CrossRef]
- Weisburd, D.; Braga, A.A.; Groff, E.R.; Wooditch, A. Can hot spots policing reduce crime in urban areas? An agent-based simulation. Criminology 2017, 55, 137–173. [Google Scholar] [CrossRef]
- Zhu, H.; Wang, F. An agent-based model for simulating urban crime with improved daily routines. Comput. Environ. Urban Syst. 2021, 89, 101680. [Google Scholar] [CrossRef]
- Liberati, A.; Altman, D.G.; Tetzlaff, J.; Mulrow, C.; Gøtzsche, P.C.; Ioannidis, J.P.; Clarke, M.; Devereaux, P.J.; Kleijnen, J.; Moher, D. The PRISMA Statement for Reporting Systematic Reviews and Meta-Analyses of Studies That Evaluate Health Care Interventions: Explanation and Elaboration. Ann. Intern. Med. 2009, 151, W65–W94. [Google Scholar] [CrossRef]
- Jordan, M.I.; Mitchell, T.M. Machine learning: Trends, perspectives, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef]
- Liakos, K.G.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D. Machine learning in agriculture: A review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef]
- Brunton, S.L.; Noack, B.R.; Koumoutsakos, P. Machine learning for fluid mechanics. Annu. Rev. Fluid Mech. 2020, 52, 477–508. [Google Scholar] [CrossRef]
- Bühlmann, P. Bagging, boosting and ensemble methods. In Handbook of Computational Statistics; Springer: Berlin/Heidelberg, Germany, 2012; pp. 985–1022. [Google Scholar]
- Bentéjac, C.; Csörgő, A.; Martínez-Muñoz, G. A comparative analysis of gradient boosting algorithms. Artif. Intell. Rev. 2020, 54, 1937–1967. [Google Scholar] [CrossRef]
- Song, K.; Yan, F.; Ding, T.; Gao, L.; Lu, S. A steel property optimization model based on the XGBoost algorithm and improved PSO. Comput. Mater. Sci. 2019, 174, 109472. [Google Scholar] [CrossRef]
- Wang, B.; Zhang, D.; Zhang, D.; Brantingham, P.J.; Bertozzi, A.L. Deep learning for real time crime forecasting. arXiv 2017, arXiv:1707.03340. [Google Scholar] [CrossRef]
- Kang, H.-W.; Kang, H.-B. Prediction of crime occurrence from multi-modal data using deep learning. PLoS ONE 2017, 12, e0176244. [Google Scholar] [CrossRef] [PubMed]
- Dong, Q.; Ye, R.; Li, G. Crime amount prediction based on 2D convolution and long short-term memory neural network. ETRI J. 2022, 44, 208–219. [Google Scholar] [CrossRef]
- Andresen, M.A.; Hodgkinson, T. Predicting Property Crime Risk: An Application of Risk Terrain Modeling in Vancouver, Canada. Eur. J. Crim. Policy Res. 2018, 24, 373–392. [Google Scholar] [CrossRef]
- Boppuru, P.R.; Ramesha, K. Geo-Spatial Crime Analysis Using Newsfeed Data in Indian Context. Int. J. Web-Based Learn. Teach. Technol. 2019, 14, 49–64. [Google Scholar] [CrossRef]
- Hart, T.; Zandbergen, P. Kernel density estimation and hotspot mapping: Examining the influence of interpolation method, grid cell size, and bandwidth on crime forecasting. Polic. Int. J. 2014, 37, 305–323. [Google Scholar] [CrossRef]
- Caplan, J.M.; Kennedy, L.W.; Miller, J. Risk Terrain Modeling: Brokering Criminological Theory and GIS Methods for Crime Forecasting. Justice Q. 2011, 28, 360–381. [Google Scholar] [CrossRef]
- Marchment, Z.; Gill, P. Systematic review and meta-analysis of risk terrain modelling (RTM) as a spatial forecasting method. Crime Sci. 2021, 10, 12. [Google Scholar] [CrossRef]
- Brantingham, P.; Brantingham, P. Criminality of place. Eur. J. Crim. Policy Res. 1995, 3, 5–26. [Google Scholar] [CrossRef]
- Kennedy, L.W.; Caplan, J.M.; Piza, E. Risk Clusters, Hotspots, and Spatial Intelligence: Risk Terrain Modeling as an Algorithm for Police Resource Allocation Strategies. J. Quant. Criminol. 2010, 27, 339–362. [Google Scholar] [CrossRef]
- Drawve, G.; Grubb, J.; Steinman, H.; Belongie, M. Enhancing Data-Driven Law Enforcement Efforts: Exploring how Risk Terrain Modeling and Conjunctive Analysis Fit in a Crime and Traffic Safety Framework. Am. J. Crim. Justice 2018, 44, 106–124. [Google Scholar] [CrossRef]
- Islam, K.; Raza, A. Forecasting crime using ARIMA model. arXiv 2020, arXiv:2003.08006. [Google Scholar] [CrossRef]
- Nitta, G.R.; Rao, B.Y.; Sravani, T.; Ramakrishiah, N.; BalaAnand, M. LASSO-based feature selection and naïve Bayes classifier for crime prediction and its type. Serv. Oriented Comput. Appl. 2019, 13, 187–197. [Google Scholar] [CrossRef]
- Malleson, N.; Heppenstall, A.; See, L. Crime reduction through simulation: An agent-based model of burglary. Comput. Environ. Urban Syst. 2010, 34, 236–250. [Google Scholar] [CrossRef]
- Swaraj, A.; Verma, K.; Kaur, A.; Singh, G.; Kumar, A.; de Sales, L.M. Implementation of stacking based ARIMA model for prediction of COVID-19 cases in India. J. Biomed. Inform. 2021, 121, 103887. [Google Scholar] [CrossRef]
- Alabdulrazzaq, H.; Alenezi, M.N.; Rawajfih, Y.; Alghannam, B.A.; Al-Hassan, A.A.; Al-Anzi, F.S. On the accuracy of ARIMA based prediction of COVID-19 spread. Results Phys. 2021, 27, 104509. [Google Scholar] [CrossRef]
- Chainey, S.; Tompson, L.; Uhlig, S. The Utility of Hotspot Mapping for Predicting Spatial Patterns of Crime. Secur. J. 2008, 21, 4–28. [Google Scholar] [CrossRef]
- Kajita, M.; Kajita, S. Crime prediction by data-driven Green’s function method. Int. J. Forecast. 2019, 36, 480–488. [Google Scholar] [CrossRef]
- Farjami, Y.; Abdi, K. A genetic-fuzzy algorithm for spatio-temporal crime prediction. J. Ambient. Intell. Humaniz. Comput. 2021, 1–13. [Google Scholar] [CrossRef]
- Langton, S.; Dixon, A.; Farrell, G. Six months in: Pandemic crime trends in England and Wales. Crime Sci. 2021, 10, 6. [Google Scholar] [CrossRef]
- Jha, S.; Yang, E.; Almagrabi, A.O.; Bashir, A.K.; Joshi, G.P. RETRACTED ARTICLE: Comparative analysis of time series model and machine testing systems for crime forecasting. Neural Comput. Appl. 2020, 33, 10621–10636. [Google Scholar] [CrossRef]
- Shoesmith, G.L. Space–time autoregressive models and forecasting national, regional and state crime rates. Int. J. Forecast. 2013, 29, 191–201. [Google Scholar] [CrossRef]
- Zhang, Y.; Siriaraya, P.; Kawai, Y.; Jatowt, A. Predicting time and location of future crimes with recommendation methods. Knowl.-Based Syst. 2020, 210, 106503. [Google Scholar] [CrossRef]
- Santos-Marquez, F. Spatial beta-convergence forecasting models: Evidence from municipal homicide rates in Colombia. J. Forecast. 2021, 41, 294–302. [Google Scholar] [CrossRef]
- Boivin, R. Routine activity, population(s) and crime: Spatial heterogeneity and conflicting Propositions about the neighborhood crime-population link. Appl. Geogr. 2018, 95, 79–87. [Google Scholar] [CrossRef]
- Altindag, D.T. Crime and unemployment: Evidence from Europe. Int. Rev. Law Econ. 2012, 32, 145–157. [Google Scholar] [CrossRef]
- Groot, W.; Brink, H.M.V.D. The effects of education on crime. Appl. Econ. 2010, 42, 279–289. [Google Scholar] [CrossRef]
- Jonathan, O.E.; Olusola, A.J.; Bernadin, T.C.A.; Inoussa, T.M. Impacts of Crime on Socio-Economic Development. Mediterr. J. Soc. Sci. 2021, 12, 71. [Google Scholar] [CrossRef]
- Ranson, M. Crime, weather, and climate change. J. Environ. Econ. Manag. 2014, 67, 274–302. [Google Scholar] [CrossRef]
- Inlow, A.R. A comprehensive review of quantitative research on crime, the built environment, land use, and physical geography. Sociol. Compass 2021, 15, e12889. [Google Scholar] [CrossRef]
- Vo, T.; Sharma, R.; Kumar, R.; Son, L.H.; Pham, B.T.; Bui, D.T.; Priyadarshini, I.; Sarkar, M.; Le, T. Crime rate detection using social media of different crime locations and Twitter part-of-speech tagger with Brown clustering. J. Intell. Fuzzy Syst. 2020, 38, 4287–4299. [Google Scholar] [CrossRef]
- Sypion-Dutkowska, N.; Leitner, M. Land Use Influencing the Spatial Distribution of Urban Crime: A Case Study of Szczecin, Poland. ISPRS Int. J. Geo-Inf. 2017, 6, 74. [Google Scholar] [CrossRef]
- Clancy, K.; Chudzik, J.; Snowden, A.J.; Guha, S. Reconciling data-driven crime analysis with human-centered algorithms. Cities 2022, 124, 103604. [Google Scholar] [CrossRef]
- Andresen, M.A. Unemployment, GDP, and Crime: The Importance of Multiple Measurements of the Economy. Can. J. Criminol. Crim. Justice 2015, 57, 35–58. [Google Scholar] [CrossRef]
- Hipp, J.R.; Bates, C.; Lichman, M.; Smyth, P. Using Social Media to Measure Temporal Ambient Population: Does it Help Explain Local Crime Rates? Justice Q. 2019, 36, 718–748. [Google Scholar] [CrossRef]
- Gerell, M. Does the Association Between Flows of People and Crime Differ Across Crime Types in Sweden? Eur. J. Crim. Policy Res. 2021, 27, 433–449. [Google Scholar] [CrossRef]
- Ding, N.; Zhai, Y. Crime prevention of bus pickpocketing in Beijing, China: Does air quality affect crime? Secur. J. 2019, 34, 262–277. [Google Scholar] [CrossRef]
- Venter, Z.S.; Shackleton, C.; Faull, A.; Lancaster, L.; Breetzke, G.; Edelstein, I. Is green space associated with reduced crime? A national-scale study from the Global South. Sci. Total. Environ. 2022, 825, 154005. [Google Scholar] [CrossRef] [PubMed]
- Hou, K.; Zhang, L.; Xu, X.; Yang, F.; Chen, B.; Hu, W.; Shu, R. High ambient temperatures are associated with urban crime risk in Chicago. Sci. Total. Environ. 2023, 856, 158846. [Google Scholar] [CrossRef]
- Ye, C.; Chen, Y.; Li, J. Investigating the Influences of Tree Coverage and Road Density on Property Crime. ISPRS Int. J. Geo-Inf. 2018, 7, 101. [Google Scholar] [CrossRef]
- Xu, Y.; Fu, C.; Kennedy, E.; Jiang, S.; Owusu-Agyemang, S. The impact of street lights on spatial-temporal patterns of crime in Detroit, Michigan. Cities 2018, 79, 45–52. [Google Scholar] [CrossRef]
- Ristea, A.; Al Boni, M.; Resch, B.; Gerber, M.S.; Leitner, M. Spatial crime distribution and prediction for sporting events using social media. Int. J. Geogr. Inf. Sci. 2020, 34, 1708–1739. [Google Scholar] [CrossRef]
- Stec, A.; Klabjan, D. Forecasting crime with deep learning. arXiv 2018, arXiv:1806.01486. [Google Scholar] [CrossRef]
- Hu, J. A Hybrid GCN and LSTM Structure Based on Attention Mechanism for Crime Prediction. Converter 2021, 328–338. [Google Scholar] [CrossRef]
- Han, X.; Hu, X.; Wu, H.; Shen, B.; Wu, J. Risk Prediction of Theft Crimes in Urban Communities: An Integrated Model of LSTM and ST-GCN. IEEE Access 2020, 8, 217222–217230. [Google Scholar] [CrossRef]
- Liang, X.; Liu, X.; Lan, M.; Song, G.; Xiao, L.; Chen, J. Interpretable machine learning models for crime prediction. Comput. Environ. Urban Syst. 2022, 94, 101789. [Google Scholar] [CrossRef]
- Liang, W.; Wang, Y.; Tao, H.; Cao, J. Towards hour-level crime prediction: A neural attentive framework with spatial–temporal-categorical fusion. Neurocomputing 2022, 486, 286–297. [Google Scholar] [CrossRef]
- Aghababaei, S.; Makrehchi, M. Mining Twitter data for crime trend prediction. Intell. Data Anal. 2018, 22, 117–141. [Google Scholar] [CrossRef]
- Huang, C.; Zhang, J.; Zheng, Y.; Chawla, N.V. DeepCrime: Attentive hierarchical recurrent networks for crime prediction. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 1423–1432. [Google Scholar]
- Rayhan, Y.; Hashem, T. AIST: An Interpretable Attention-Based Deep Learning Model for Crime Prediction. ACM Trans. Spat. Algorithms Syst. 2023, 9, 1–31. [Google Scholar] [CrossRef]
- Mahfoud, M.; Bernasco, W.; Bhulai, S.; van der Mei, R. Forecasting Spatio-Temporal Variation in Residential Burglary with the Integrated Laplace Approximation Framework: Effects of Crime Generators, Street Networks, and Prior Crimes. J. Quant. Criminol. 2020, 37, 835–862. [Google Scholar] [CrossRef]
- Wang, J.; Hu, J.; Shen, S.; Zhuang, J.; Ni, S. Crime risk analysis through big data algorithm with urban metrics. Phys. A Stat. Mech. Its Appl. 2020, 545, 123627. [Google Scholar] [CrossRef]
- Bappee, F.K.; Soares, A.; Petry, L.M.; Matwin, S. Examining the impact of cross-domain learning on crime prediction. J. Big Data 2021, 8, 96. [Google Scholar] [CrossRef] [PubMed]
- Kadar, C.; Pletikosa, I. Mining large-scale human mobility data for long-term crime prediction. EPJ Data Sci. 2018, 7, 26. [Google Scholar] [CrossRef]
- Alves, L.G.; Ribeiro, H.V.; Rodrigues, F.A. Crime prediction through urban metrics and statistical learning. Phys. A Stat. Mech. Its Appl. 2018, 505, 435–443. [Google Scholar] [CrossRef]
- Rummens, A.; Hardyns, W. The effect of spatio-temporal resolution on predictive policing model performance. Int. J. Forecast. 2021, 37, 125–133. [Google Scholar] [CrossRef]
- Zhang, Y.; Cheng, T. Graph deep learning model for network-based predictive hotspot mapping of sparse spatio-temporal events. Comput. Environ. Urban Syst. 2020, 79, 101403. [Google Scholar] [CrossRef]
- Rashidi, P.; Wang, T.; Skidmore, A.; Vrieling, A.; Darvishzadeh, R.; Toxopeus, B.; Ngene, S.; Omondi, P. Spatial and spatiotemporal clustering methods for detecting elephant poaching hotspots. Ecol. Model. 2015, 297, 180–186. [Google Scholar] [CrossRef]
- Drawve, G.; Thomas, S.A.; Walker, J.T. Bringing the physical environment back into neighborhood research: The utility of RTM for developing an aggregate neighborhood risk of crime measure. J. Crim. Justice 2016, 44, 21–29. [Google Scholar] [CrossRef]
- Drawve, G. A Metric Comparison of Predictive Hot Spot Techniques and RTM. Justice Q. 2014, 33, 369–397. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, L.; Zhou, H.; Lan, M. Crime Geographical Displacement: Testing Its Potential Contribution to Crime Prediction. ISPRS Int. J. Geo-Inf. 2019, 8, 383. [Google Scholar] [CrossRef]
- Garnier, S.; Caplan, J.M.; Kennedy, L.W. Predicting Dynamical Crime Distribution From Environmental and Social Influences. Front. Appl. Math. Stat. 2018, 4, 13. [Google Scholar] [CrossRef]
- Rosés, R.; Kadar, C.; Malleson, N. A data-driven agent-based simulation to predict crime patterns in an urban environment. Comput. Environ. Urban Syst. 2021, 89, 101660. [Google Scholar] [CrossRef]
- Stalidis, P.; Semertzidis, T.; Daras, P. Examining Deep Learning Architectures for Crime Classification and Prediction. Forecasting 2021, 3, 741–762. [Google Scholar] [CrossRef]
- Saraiva, M.; Matijošaitienė, I.; Mishra, S.; Amante, A. Crime Prediction and Monitoring in Porto, Portugal, Using Machine Learning, Spatial and Text Analytics. ISPRS Int. J. Geo-Inf. 2022, 11, 400. [Google Scholar] [CrossRef]
- Belesiotis, A.; Papadakis, G.; Skoutas, D. Analyzing and Predicting Spatial Crime Distribution Using Crowdsourced and Open Data. ACM Trans. Spat. Algorithms Syst. 2018, 3, 1–31. [Google Scholar] [CrossRef]
- Dong, Q.; Li, Y.; Zheng, Z.; Wang, X.; Li, G. ST3DNetCrime: Improved ST-3DNet Model for Crime Prediction at Fine Spatial Temporal Scales. ISPRS Int. J. Geo-Inf. 2022, 11, 529. [Google Scholar] [CrossRef]
- Liu, L.; Ji, J.; Song, G.; Song, G.; Liao, W.; Yu, H.; Liu, W. Hotspot prediction of public property crime based on spatial differentiation of crime and built environment. J. Geo-Inf. Sci. 2019, 21, 1655–1668. [Google Scholar]
- Fitterer, J.; Nelson, T.; Nathoo, F. Predictive crime mapping. Police Pract. Res. 2014, 16, 121–135. [Google Scholar] [CrossRef]
- Hou, M.; Hu, X.; Cai, J.; Han, X.; Yuan, S. An Integrated Graph Model for Spatial–Temporal Urban Crime Prediction Based on Attention Mechanism. ISPRS Int. J. Geo-Inf. 2022, 11, 294. [Google Scholar] [CrossRef]
- Yu, H.; Liu, L.; Yang, B.; Lan, M. Crime Prediction with Historical Crime and Movement Data of Potential Offenders Using a Spatio-Temporal Cokriging Method. ISPRS Int. J. Geo-Inf. 2020, 9, 732. [Google Scholar] [CrossRef]
- Zhou, B.; Chen, L.; Zhou, F.; Li, S.; Zhao, S.; Das, S.K.; Pan, G. Escort: Fine-Grained Urban Crime Risk Inference Leveraging Heterogeneous Open Data. IEEE Syst. J. 2020, 15, 4656–4667. [Google Scholar] [CrossRef]
- Boppuru, P.R.; Ramesha, K. Spatio-Temporal Crime Analysis Using KDE and ARIMA Models in the Indian Context. Int. J. Digit. Crime Forensics 2020, 12, 1–19. [Google Scholar] [CrossRef]
- Zhao, X.; Tang, J. Modeling Temporal-Spatial Correlations for Crime Prediction. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 497–506. [Google Scholar] [CrossRef]
- Kocher, M.; Leitner, M. Forecasting of crime events applying risk terrain modeling. GI_Forum–J. Geogr. Inf. 2015, 1, 30–40. [Google Scholar] [CrossRef]
- Rummens, A.; Hardyns, W.; Pauwels, L. The use of predictive analysis in spatiotemporal crime forecasting: Building and testing a model in an urban context. Appl. Geogr. 2017, 86, 255–261. [Google Scholar] [CrossRef]
- Hu, Y.; Wang, F.; Guin, C.; Zhu, H. A spatio-temporal kernel density estimation framework for predictive crime hotspot mapping and evaluation. Appl. Geogr. 2018, 99, 89–97. [Google Scholar] [CrossRef]
- Lin, Y.-L.; Yen, M.-F.; Yu, L.-C. Grid-Based Crime Prediction Using Geographical Features. ISPRS Int. J. Geo-Inf. 2018, 7, 298. [Google Scholar] [CrossRef]
- Solomon, A.; Kertis, M.; Shapira, B.; Rokach, L. A deep learning framework for predicting burglaries based on multiple contextual factors. Expert Syst. Appl. 2022, 199, 117042. [Google Scholar] [CrossRef]
- Law, J.; Quick, M.; Chan, P. Bayesian Spatio-Temporal Modeling for Analysing Local Patterns of Crime Over Time at the Small-Area Level. J. Quant. Criminol. 2014, 30, 57–78. [Google Scholar] [CrossRef]
- Kadar, C.; Maculan, R.; Feuerriegel, S. Public decision support for low population density areas: An imbalance-aware hyper-ensemble for spatio-temporal crime prediction. Decis. Support Syst. 2019, 119, 107–117. [Google Scholar] [CrossRef]
- Hu, T.; Zhu, X.; Duan, L.; Guo, W. Urban crime prediction based on spatio-temporal Bayesian model. PLoS ONE 2018, 13, e0206215. [Google Scholar] [CrossRef] [PubMed]
- Lamari, Y.; Freskura, B.; Abdessamad, A.; Eichberg, S.; De Bonviller, S. Predicting Spatial Crime Occurrences through an Efficient Ensemble-Learning Model. ISPRS Int. J. Geo-Inf. 2020, 9, 645. [Google Scholar] [CrossRef]
- Vimala Devi, J.; Kavitha, K.S. Adaptive deep Q learning network with reinforcement learning for crime prediction. Evolutionary Intelligence 2023, 16, 685–696. [Google Scholar] [CrossRef]
- Lim, M.; Abdullah, A.; Jhanjhi, N.Z.; Khan, M.K. Situation-aware deep reinforcement learning link prediction model for evolving criminal networks. IEEE Access 2019, 8, 16550–16559. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Variable |
|---|---|
| Crime | Number of crime incidents |
| Number of primary crimes | |
| Crime type | |
| Criminal ID | |
| Criminal acquaintances | |
| Date | |
| Time | |
| Area | |
| Geographical location (longitude and latitude) |
| Dataset | Variable |
|---|---|
| Demographic | Population |
| Age | |
| Race | |
| Gender | |
| Family size | |
| Socio-economic | Income |
| Education | |
| Unemployment | |
| Gross domestic product (GDP) | |
| Number of rental and owned units | |
| Number of occupied and vacant houses | |
| Environmental | Number of bars |
| Number of shops | |
| Number of hotels | |
| Number of parks | |
| Number of banks | |
| Number of schools | |
| Number of restaurants | |
| Number of supermarkets | |
| Number of police stations | |
| Number of streetlight poles | |
| Public transportation | Subway |
| Taxi | |
| Bus | |
| Train | |
| Road | |
| Bridge | |
| Social media | Twitter data |
| News feed | |
| Public service complaints | Noise |
| Heating | |
| Illegal parking | |
| Garbage and bulky items removal | |
| Meteorological | Weather |
| Temperature | |
| Air quality | |
| Humidity | |
| Wind strength | |
| Barometric pressure |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, Y.; Ding, N. A Systematic Review of Multi-Scale Spatio-Temporal Crime Prediction Methods. ISPRS Int. J. Geo-Inf. 2023, 12, 209. https://doi.org/10.3390/ijgi12060209
Du Y, Ding N. A Systematic Review of Multi-Scale Spatio-Temporal Crime Prediction Methods. ISPRS International Journal of Geo-Information. 2023; 12(6):209. https://doi.org/10.3390/ijgi12060209
Chicago/Turabian StyleDu, Yingjie, and Ning Ding. 2023. "A Systematic Review of Multi-Scale Spatio-Temporal Crime Prediction Methods" ISPRS International Journal of Geo-Information 12, no. 6: 209. https://doi.org/10.3390/ijgi12060209
APA StyleDu, Y., & Ding, N. (2023). A Systematic Review of Multi-Scale Spatio-Temporal Crime Prediction Methods. ISPRS International Journal of Geo-Information, 12(6), 209. https://doi.org/10.3390/ijgi12060209