1. Introduction
Integrating geo-spatial information has become a crucial task in the current world. In fact, in the era of Open Data and Big Data, a plethora of sources can provide both authoritative and non-authoritative data sets concerning places. The situation is further complicated by the fact that social media provide people with tools for describing places in a non-controlled way. For example, Facebook provides its users with the functionality to define a “page”; a specific category of the page describes a “public place”, such as restaurants, pubs, air dressers, universities, parks and so on; through its API (Application Programming Interface), pages could be queried, on the basis of their category, location, coordinates, and so on. Another interesting service is called Google Places: it is a sub-service of Google Maps; Google Places API can be used to query its corpus to find places of interest, on the basis of category, location, and so on; this corpus is built by Google Maps by integrating both authoritative and non-authoritative data, these latter ones given by users through the social interface provided by Google Maps.
In the current scenario, it is very easy to collect data sets from multiple sources, such that these data sets provide geo-tagged information about public places. Since current APIs of social media and Open-Data portals provide data as (possibly) geo-tagged
JSON documents (
JSON stands for JavaScript Object Notation, see [
1]),
JSON document stores are the natural storage where to save such data sets. Consequently, integrating geo-tagged data sets describing public places asks for suitable tools, which are able to work on
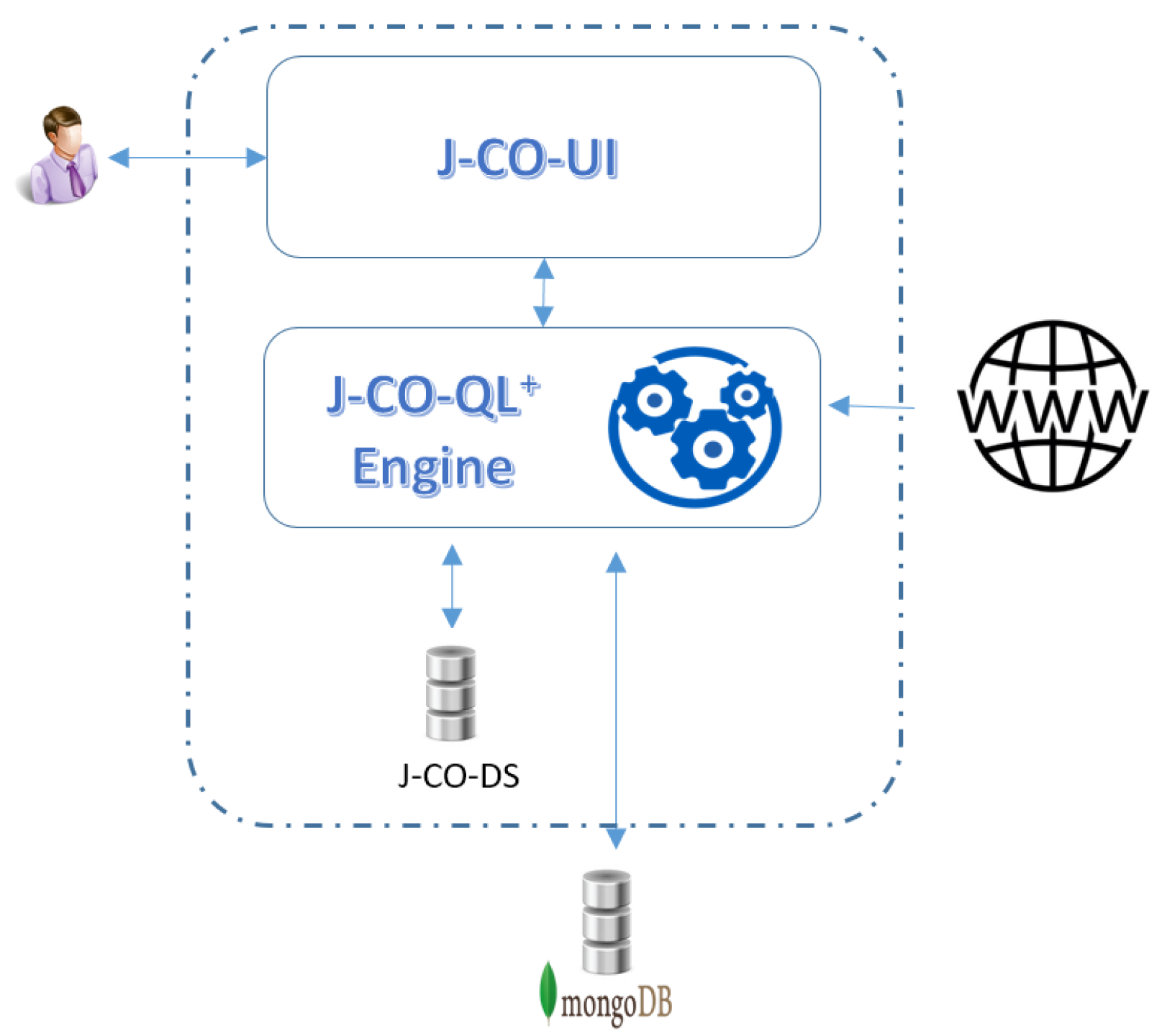
JSON document stores. This is the reason why at University of Bergamo (Italy), we are devising [
2,
3,
4,
5] an innovative tool, called
J-CO Framework, to perform the complex integration and querying of (possibly geo-tagged)
JSON data sets.
Nevertheless, integrating geo-tagged data sets describing public places is not a novel problem; in general, traditional approaches rely on machine-learning techniques that require a preliminary training phase. In [
6], the problem was addressed in a different way, because the context of “on-line” aggregation was considered; a fuzzy relation was defined, which provides an easy-to-compute metric that is suitable for on-line integration of data about public places; the experiments demonstrated that the approach is effective and comparable, in terms of effectiveness, with off-line classification techniques. However, the technique presented in [
6] was hard-coded within the software prototype; this fact made us able to include some pre-processing steps on strings that were performed on the fly, immediately after place descriptors were acquired. However, the approach seems to be general and could be applied for integrating data sets in an off-line way too, with data sets stored within
JSON stores. Paradoxically, this apparently small change of context constitutes a significant challenge: in fact, the straightforward solution could be to still hard-code the technique into a software tool, but this approach is not coherent with the world of
JSON document stores. We think that exploiting a stand-alone tool able to query
JSON stores is preferable, since it is transparent and comprehensible for analysts; however, a stand-alone tool for processing
JSON data sets is necessarily less flexible than a programming language. Thus, the challenge is the following: is it possible to identify a stand-alone tool and adapt the integration technique presented in [
6] to the case of off-line integration of geo-tagged
JSON data sets from
JSON stores?
The current evolution of
J-CO-QL, the query language of the
J-CO Framework, provides constructs for evaluating membership of
JSON documents to fuzzy sets [
7,
8,
9]. Thus, the straightforward idea of checking the current capability of
J-CO-QL for integrating
JSON data sets describing public places has come out: specifically, since
J-CO-QL is able to deal with complex soft querying of
JSON data sets and the technique presented in [
6] for on-line integration of data sets concerning public places is based on fuzzy relations, we had the intuition of mixing the two approaches. In other words, given two sets of place descriptors represented as
JSON documents and stored within a
JSON document store, in this paper, we experiment with the application of the fuzzy technique presented in [
6] (to be precise, a slightly evolved version of it) by means of the
J-CO Framework, in an off-line manner. The goal is to verify that this approach is suitable in an off-line context, without previous training activities and intervention by humans to label data sets for driving the learning phase (typical of classification techniques). Definitely, we want to demonstrate that the availability of a stand-alone tool such as the
J-CO Framework, which is able to process
JSON data sets by applying soft computing and fuzzy sets, indeed provides analysts with a powerful tool to address a problem faced by data analysts, in an effective and (possibly) efficient way.
Summarizing, the contribution of the paper is manifold: (1) Presenting a soft-computing technique for integrating data sets describing public places, without any preliminary pre-processing, cleaning and training, which can be applied from scratch; (2) presenting current capabilities for soft integration of
JSON data sets, as they are provided by
J-CO-QL; (3) demonstrating the effectiveness of the soft integration technique in a harder context than that considered in [
6]; (4) showing how a stand-alone tool able to support soft computing (as
J-CO-QL) can be effective and efficient in performing data-integration tasks from scratch.
The paper is organized as follows.
Section 2 presents relevant related work concerned with the paper.
Section 3 provides a brief introduction to relevant concepts concerning fuzzy-set theory.
Section 4 introduces the main features of the
J-CO Framework.
Section 5 precisely explains the addressed problem and introduces the methodology we follow, which relies on the concept of fuzzy relation.
Section 6 presents and discusses the script written by means of
J-CO-QL, which practically applies the methodology presented in
Section 5; each single instruction is explained, in order to illustrate how it behaves and its contribution within the script.
Section 7 reports the results of an experimental evaluation, in which we evaluated effectiveness and, marginally, execution times. Finally,
Section 8 draws the conclusions and possible future work.
3. Basic Notions on Fuzzy Sets
In [
36], Zadeh introduced the Fuzzy-Set Theory. It was rapidly clear that it had (and still has) an enormous potentiality to be successfully applied to many areas of computer science, such as decision making, control theory, expert systems, artificial intelligence, natural-language processing, and so on. Here, we report some basic concepts, which constitute the basis to understand the main contribution of this paper.
Definition 1. Fuzzy Set. Consider a “universe set” U. A fuzzy set (or type-1 fuzzy set) A in U () is a mapping . The value is referred to as the membership degree of the element x to the fuzzy set A. Alternatively, the notation can be used.
Clearly, given an item , if , this means that x does not belong at all to A; an intermediate value means that x partially belongs to A (the greater the value, the higher its degree of membership); if , this means that the item x fully belongs to A.
Consequently, a fuzzy set is “empty” if and only if its membership function is identically zero for each .
Furthermore, given two fuzzy sets A in U and B in U, they are “equal” (denoted as ), if and only if (alternatively, ) for all .
Operators on fuzzy sets can be easily defined, by extending the classical operators on traditional sets.
Definition 2. Union, Intersection and Complement.Consider a universe U and two fuzzy sets A in U and B in U.
The union of two fuzzy sets A and B, denoted as , generates a novel fuzzy set S whose membership function is , for each (alternatively, ).
The Intersection of two fuzzy sets A and B, denoted as , generates a novel fuzzy set S whose membership function is , for each (alternatively, ).
The Complement of a fuzzy set A, denoted as , generates a novel fuzzy set C whose membership function is , for each (alternatively, ).
Classical logical operators are mapped onto operators on fuzzy sets: the OR operator is mapped onto the union; the AND operator is mapped onto the intersection; the NOT operator is mapped onto the complement.
Fuzzy sets are useful to represent vague concepts, which characterize many real-life application contexts. For example, if the universe is the set of people, we could think to divide them into “young” and “old”. However, is a person whose age is 40 actually young or old? He/she is a little bit young and a little bit old, neither fully young nor fully old.
Various other operators on fuzzy sets can be defined. In the following definition, we introduce the “weighted aggregation” operator.
Definition 3. Weighted Aggregation. Given a universe U and two fuzzy sets A in U and B in U, the weighted aggregation operator (with ) generates a new fuzzy set W whose membership function is defined as (alternatively, ).
Example 1. Through the membership degree, it is possible to denote partial membership of an item to A; this way, vague linguistic concepts can be modeled. For example, given a public place p, its membership to the fuzzy set could be partial, denoting a place that is not so popular; thus, the membership degree measures its degree of popularity, for example on the basis of the number of likes obtained on social media.
Suppose that on the same universe of public places, we conceive the fuzzy set, whose membership degree denotes the perception that a public place is cheap (this perception could be induced by analyzing menus published on social media).
We now illustrate how to aggregate the and the fuzzy sets to obtain interesting places.
If we are looking for “popularandcheap restaurants”, we could formulate the search as “AND” (in terms of fuzzy sets, it is ). Clearly, the lower membership degree determines the actual relevance of a place p.
If we are looking for “popularorcheap restaurants”, we could formulate the search as “OR” (in terms of fuzzy sets, it is ). Clearly, the higher membership degree determines the actual relevance of a place p (a place could be not popular, but highly cheap).
If we are looking for “popularand possiblycheap restaurants”, we could formulate the search as “70% AND30% ” (in terms of fuzzy sets, it is ). Clearly, the final membership degree is dominated by the degree of popularity, but a popular place that is also a cheap restaurant has a higher membership degree than a popular place that is not at all a cheap restaurant.
The three above-mentioned searches are examples of “soft queries”, where selection conditions are expressed in a vague way; the resulting membership degree denotes the “relevance” of an item to the soft query.
Furthermore, notice that when the names given to fuzzy sets linguistically characterize items in a proper way, these names can be used in soft conditions to linguistically express them.
Definition 4. Fuzzy Relation. Consider two universes and . A fuzzy relation R on and , is defined as . , with and , is the membership degree of the relation between and ; the meaning of the relation is linguistically expressed by the name of the relation.
Through the concept of fuzzy relation, it is possible to model the strength of a relation between two items and . Nevertheless, notice that a fuzzy relation is a particular case of fuzzy set in the universe . Thus, we can reformulate the relation as , where ; consequently, we can write, in an equivalent way, either or .
In this paper, we work on the universe of JSON documents. So, given a document , the focus will be on the evaluation of its membership degrees to one or more fuzzy sets.
6. Presenting the Script
In this section, we provide the technical contribution of the paper. Specifically, we demonstrate how the current version of J-CO-QL is able to perform the soft integration of two collections containing JSON documents that describe public places, obtained from two different data sources.
6.1. Data Set
A
MongoDB database called
ijgiDb contains two collections of
JSON documents: the first one is called
FacebookDescriptors and its documents are descriptors of pages that present public places mostly located in the area of Manchester (UK); the second collection is called
GoogleDescriptors and its documents are descriptors of places mostly located in the area of Manchester (UK) as well, obtained from
Google Places. The
FacebookDescriptors collection contains 5738 documents, while the
GoogleDesciptors collection contains 5214 documents.
Figure 3a shows a sample document in the
FacebookDescriptors collection, while
Figure 3b reports a sample document in the
GoogleDescriptors collection. The reader can notice that
Facebook descriptors clearly distinguish the address (in the
fbStreet field) from the city name (in the
fbCity field) from the ZIP code (in the
fbZip field). In contrast, within a
Google Places descriptor, the content of the
gAddress field is less clean, because it contains the city name too. This also demonstrates that we are working on names and addresses as they are provided by
Facebook and
Google Places, without any pre-processing or cleaning (in [
6], addresses were cleaned from numbers and urban designations, such as “street”). Consequently, here, we are addressing a less favorable situation.
6.2. Defining Fuzzy Operators
We start presenting the J-CO-QL script. The first part of the script is reported in Listing 1.
The key concept provided by J-CO-QL to evaluate membership degrees of JSON documents is the concept of “fuzzy operator”. Such an operator is called within soft conditions: given some actual parameters (expressions based on document fields), the operator returns a membership degree. This degree will be used to evaluate the overall membership degree of a document to a specific fuzzy set.
Listing 1.
J-CO-QL script: fuzzy operators.
Listing 1.
J-CO-QL script: fuzzy operators.
6.2.1. The Close Fuzzy Operator
The instruction on line 1 of the J-CO-QL script in Listing 1 defines the Close fuzzy operator: it evaluates the degree of closeness of two places, on the basis of the distance between them. Hereafter, we describe the instruction in details.
The PARAMETERS clause defines the formal parameters of the operator. Specifically, only the distance parameter is defined.
The PRECONDITION clause defines a condition on the parameters: if the condition is not satisfied, the evaluation of the fuzzy operator stops and an error signal is raised. Specifically, the precondition says that the distance must be no less than 0.
The EVALUATE clause specifies a mathematical expression on the parameters, whose value is used as x-axis coordinate against the membership function defined by the subsequent POLYLINE clause. In the Close fuzzy operator, the expression simply takes the value of the distance parameter.
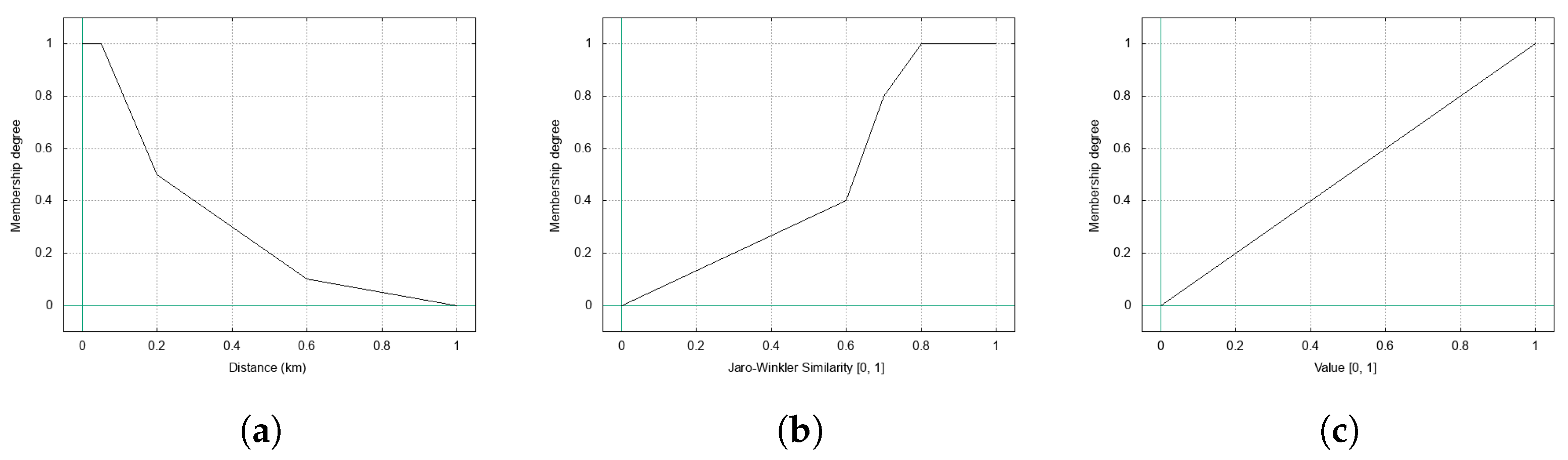
The POLYLINE clause specifies the membership function actually used to compute the membership value. The function is defined as a polyline, by a sequence of pairs , where can be any real value, while ; given two consecutive points and , it must be . Each pair of consecutive points defines a segment. Given an x value, if it is between and (in the case of n points), the corresponding y value is considered as a membership degree; if , the membership degree is ; if , the membership degree is .
Figure 4a reports the polyline defined for the
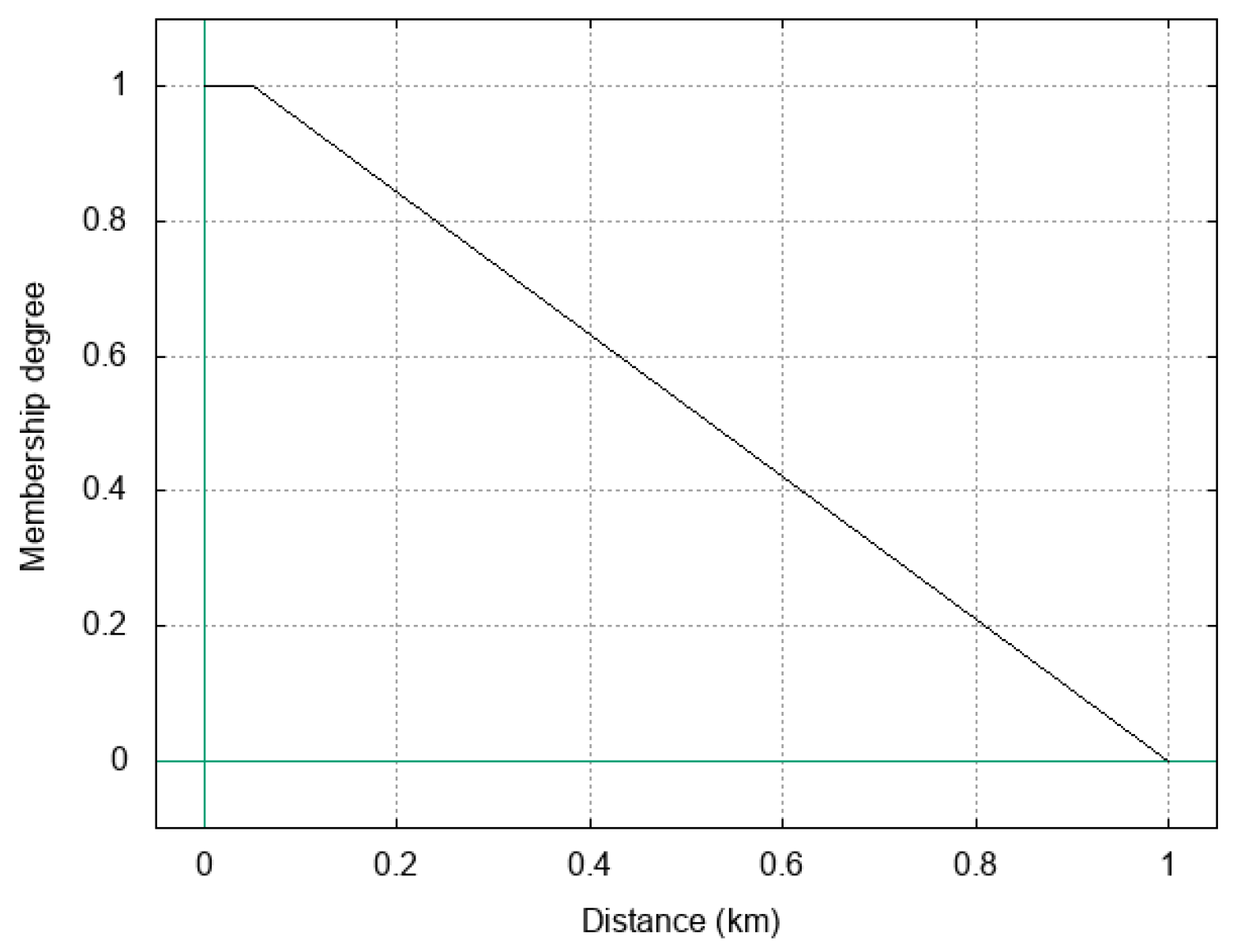
Close fuzzy operator. Notice that it is not the same defined in [
6] (reported in
Figure 2): in fact, we opted for a function that immediately penalizes distances that are between 50 m and 600 m, because two places in the same neighborhood are not perceived as very close when their distance becomes greater than 100 m.
6.2.2. The Similar Fuzzy Operator
The instruction on line 2 of the J-CO-QL script in Listing 1 creates the Similar fuzzy operator. Its goal is to evaluate a membership degree on the basis of the similarity degree of two strings. The operator is described in detail hereafter.
The operator receives two parameters, called st1 and st2; they are the two strings to compare.
No precondition is specified: in the case of empty or null strings, the operator returns 0 as membership degree, because the similarity degree is 0.
The EVALUATE clause calls the built-in (i.e., provided by J-CO-QL) function named JARO_WINKLER_SIMILARITY, to obtain the similarity degree of the two strings. The similarity degree is a value in the range . In the case of null or zero-length strings, the returned similarity degree is 0.
The
POLYLINE clause defines the membership function depicted in
Figure 4b. Notice that it penalizes similarity degrees that are less than
, while membership degrees that are greater than
are rewarded: this is due to the sometimes bizarre behavior of the Jaro-Winkler similarity, that returns high similarity degrees even when strings only shares some characters, but are not actually similar; furthermore, for strings such as “
The Gray Horse” and “
GrayHorse”, the similarity degree is around
, although they clearly have to be considered very similar. With this shape, we try to compensate the behavior of the Jaro-Winkler similarity, so as to deal with raw addresses and names (i.e., not cleaned from articles, numbers, punctuation, and so on).
6.2.3. The WeightedAggregationBeta Fuzzy Operator
The instruction on line 3 of the J-CO-QL script in Listing 1 defines the third fuzzy operator. This is called WeightedAggregationBeta and its goal is to perform the “weighted aggregation” (see Definition 3). In fact, J-CO-QL does not provide such an operator in its language; through the WeightedAggregationBeta fuzzy operator, we show how to introduce novel fuzzy concepts. The fuzzy operator is described in detail hereafter.
The operator receives three parameters: f1 and f2 are the two values in the range to aggregate, while beta is the aggregation weight (in the range too) of f1 with respect to f2.
The PRECONDITION clause ensures that the actual values of the three parameters are in the range (notice the IN_RANGE predicate).
The EVALUATE clause actually performs the weighted aggregation.
The
POLYLINE clause defines a very simple membership function, which is reported in
Figure 4c: it is a straight segment from the point
to the point
; this way, the value computed by the
EVALUATE clause is returned, as it is, as membership degree.
6.3. Retrieving and Pairing Descriptors
Once the three fuzzy operators are defined, it is time to start working on the data set. This is conducted by the second part of the J-CO-QL script, which is reported in Listing 2.
Listing 2.
J-CO-QL script: retrieving and joining collections.
Listing 2.
J-CO-QL script: retrieving and joining collections.
The instruction on line 4 connects the query process to the database. After this instruction, it will be possible to access the ijgiDb database to retrieve and store collections.
The JOIN OF COLLECTIONS instruction on line 5 retrieves the two source collections (called FacebookDescriptors and GoogleDescriptors) and creates all possible pairs of documents contained in the two collections. Then, the subsequent CASE clause evaluates a pool of conditions on these pairs to possibly evaluate fuzzy sets on the actually-interesting pairs and discards the others. The instruction is explained in detail hereafter.
The instruction retrieves the FacebookDescriptors collection from the ijgiDb database and aliases it as f; similarly, it retrieves the GoogleDescriptors collection from the same database and aliases it as g.
For each f document from the f collection and for each g document from the g collection, a new d document is created. This document contains two fields: the first one is called f and its value is the source f document; the second one is called g and its value is the source g document. The d document is further processed by the subsequent CASE clause.
Figure 5 reports an example of
d document, which is obtained by joining the two sample documents reported in
Figure 3; notice the names of the root-level fields.
The CASE clause evaluates a pool of selection conditions expressed within a WHERE clause; if a d document is selected by a condition, it is processed according to the subsequent sub-clauses. Many WHERE branches are possible: a d document is processed by the branch associated with the first WHERE condition that it satisfies; if no condition is satisfied, d is discarded (it will not appear in the output temporary collection).
Specifically, the CASE clause in the instruction on line 5 in Listing 2 contains three WHERE branches: each of them deals with one of the three situations considered for defining the relation by Definitions 5–7. Hereafter, we separately discuss the behavior of the three branches.
- -
The first WHERE branch deals with the case A of the fuzzy relation, defined in Definition 5. The condition is true if either the value for the fbStreet field is missing or the value for the gAddress field is missing or both are missing, and all coordinates are available. If a d document meets the condition, the GENERATE block further processes d through the CHECK FOR clause, whose goal is to evaluate the membership degrees of d to fuzzy sets.
Specifically, two FUZZY SET branches are present: the former evaluates the ClosePlaces fuzzy set, the latter evaluates the SameLocation fuzzy set.
The membership degree to the
ClosePlaces fuzzy set is obtained by the associated
USING clause: this is a “soft condition”, in which fuzzy operators (such as those defined in
Section 6.2) and fuzzy-set names can be composed by the usual (fuzzy) logical operators
AND,
OR and
NOT; the resulting membership degree is the membership degree to the evaluated fuzzy set. If this is the first membership degree evaluated for
d, then
d does not have the special
~fuzzysets field: in this case, the field is added and within it only one single field is present, having the same name of the evaluated fuzzy set, whose value is the computed membership degree. In contrast, if the
~fuzzysets field is already present, it is extended with one extra internal field, describing the membership degree to the new evaluated fuzzy set.
Specifically, the first branch evaluates the membership degree to the ClosePlaces fuzzy set, by means of the Close fuzzy operator (see Listing 1), which is called passing the geodesic distance computed by the GEODESIC_DISTANCE built-in function.
The second
FUZZY SET branch evaluates the membership degree to the
SameLocation fuzzy set, by assuming that it coincides with the
ClosePlaces fuzzy set (see Definition 5). Finally, the
ALPHACUT clause discards the
d document from the output temporary collection if its membership degree to the
SameLocation fuzzy set is less than
; remember that this is the
threshold mentioned within Definition 8.
Figure 6a reports a sample document generated by the first
WHERE branch; notice the presence of the
~fuzzysets field and its inner fields.
- -
The second WHERE branch deals with case B of the relation (see Definition 6), i.e., at least one coordinate is null but both addresses are present.
In this case (see Definition 6), the membership degree to the SimilarAddress fuzzy set is evaluated by means of the Similar fuzzy operator, which evaluates the fuzzy similarity relation between two strings (in this case, the two addresses).
Then, as defined by Definition 6, the second
FUZZY SET branch tells that the
SameLocation fuzzy set coincides with the
SimilarAddress fuzzy set. Again, the
ALPHACUT clause puts the
d document into the output temporary collection if the membership degree to the
SameLocation fuzzy set is no less than
(the
threshold in Definition 8).
Figure 6b shows a sample document generated by the second
WHERE branch.
- -
The third WHERE branch deals with case C of the fuzzy relation (see Definition 7), i.e., both all addresses and all coordinates are available. Consequently, the membership degrees to three different fuzzy sets are evaluated: the first one is the SimilarAddress fuzzy set, by means of the Similar fuzzy operator applied to addresses; the second one is the ClosePlaces fuzzy set, by means of the Close fuzzy operator applied to the geodesic distance between the two points.
The third FUZZY SET branch evaluates the membership degree to the fuzzy set named SameLocation: according to Definition 7, it is obtained by calling the WeightedAggregationBeta fuzzy operator, whose goal is to perform the weighted aggregation: it receives the two values (in the range ) to aggregate and the weight.
The USING soft condition calls the WeightedAggregationBeta fuzzy operator, passing the membership values to the SimilarAddress fuzzy set and to the ClosePlaces fuzzy set, which are obtained by means of the MEMBERSHIP_OF built-in function (that extracts the membership degree from within the ~fuzzysets field). The third parameter is the constant value : thisis the weight presented and discussed in Definition 7. The ALPHACUT clause discards the evaluated document if its membership degree to the SameLocation fuzzy set is less than (the threshold mentioned in Definition 8).
Figure 6c reports a sample document generated by the third branch; notice that the
~fuzzysets field has three inner fields.
The temporary collection produced by the instruction on line 5 of Listing 2 contains heterogeneous documents, as far as the structure of the ~fuzzysets field is concerned, but all have the inner SameLocation field, denoting the membership degree to the SameLocation fuzzy set; it will be used in the next instruction, to evaluate the membership degree to the MatchingPlaces fuzzy set.
Furthermore, notice that
SameLocation,
ClosePlaces and
SimilarAddresses are called “fuzzy sets”, while they were defined in
Section 5 as “fuzzy relations”: this is not a mistake, but the consequence of the fact that
JSON documents represent pairs of descriptors; consequently, fuzzy relation on pairs are translated into fuzzy sets on
JSON documents.
6.4. Relevant Pairs
All documents contained in the temporary collection produced by the instruction on line 5 (Listing 2) have the membership degree to the SameLocation fuzzy set no less than , as required by Definition 8. The FILTER instruction on line 6 in Listing 3 actually evaluates the membership degree to the MatchingPlaces fuzzy set, which corresponds to the relation defined in Definition 8. The FILTER instruction on line 6 is described in detail hereafter.
The FILTER statement takes the temporary collection as input and generates a new temporary collection by applying a CASE clause. The behavior of this clause is the same as in the JOIN OF COLLECTIONS statement.
On line 6, only one WHERE branch is present: if a document does not meet the selection condition, it is discarded from the output temporary collection.
Specifically, the selection condition selects those documents having both the names in the two paired descriptors, so as to evaluate the membership degree to the SimilarName fuzzy set.
The first FUZZY SET branch in the CHECK FOR clause evaluates the membership degree to the SimilarName fuzzy set; again, in the USING soft condition, the Similar fuzzy operator (see Listing 1) is called, this time passing names (instead of addresses).
The second FUZZY SET branch can finally evaluate the membership degree to the MatchingPlaces fuzzy set, corresponding to the fuzzy relation defined by Definition 8. Remember that the fuzzy relations named and are aggregated by means of the weighted aggregation operator. In Listing 1, we defined the WeightedAggregationBeta fuzzy operator, which here is used to aggregate the SimilarName fuzzy set and the SameLocation fuzzy set; the SimilarName fuzzy set weights for the of the final membership degree (this is the weight mentioned in Definition 8), so that similarity between names moderately prevails over geographical similarity (whose goal is to cofirm that two places having similar or identical names are actually the same place). The resulting membership degree becomes the membership degree to the MatchingPlaces fuzzy set.
The three sample documents reported in
Figure 6 become as reported in
Figure 7; notice the presence of the
MatchingPlaces inner field within the
~fuzzysets field.
At this point, only relevant pairs must be kept, i.e., those pairs whose membership degree to the MatchingPlaces fuzzy set is no less than . The ALPHACUT clause does that.
The final BUILD section (which is optional, this is why it was not present in the JOIN OF COLLECTIONS instruction on line 5 in Listing 2) restructures all survived documents.
Specifically, a novel rank field is added, whose value is the membership degree to the MatchingPlaces fuzzy set. This field is necessary, because the subsequent DEFUZZIFY option discards the ~fuzzysets field (as a consequence, documents are “defuzzified”).
Figure 8 reports the final state of the three sample documents reported in
Figure 7. Notice the presence of the
rank field, whose value is the membership degree of the
MatchingPlaces fuzzy set.
Listing 3.
J-CO-QL script: matching places.
Listing 3.
J-CO-QL script: matching places.
The instruction on line 7 in Listing 3 saves the temporary collection into the
ijgiDb database, with name
RelevantPairs. Its documents contain the most promising pairs of descriptors (remember the
set mentioned in
Section 5.2), but it could happen that, e.g., the same
Google Places descriptor is associated with more than one
Facebook descriptor. Clearly, it is the case to choose the pair having the highest rank (i.e., building the final
set mentioned in
Section 5.2). This is discussed in
Section 6.5.
6.5. Choosing the Best Pairs
The last part of the
J-CO-QL script is reported in Listing 4. It actually chooses the best pairs that involves each single
Google Places descriptor obtained by line 6 in Listing 3. Indeed, the original
J-CO-QL language (from which
J-CO-QL derives) was designed to cope with this kind of task too (see [
3,
4]). Hereafter, we briefly describe this last part of the script.
The GET COLLECTION instruction on line 8 again obtains the RelevantPairs collection from the database, again making it the temporary collection.
The
GROUP instruction on line 9 groups documents in the temporary collection, on the basis of the
gId field, which is the identifier of
Google Places descriptors. For each group, a novel document is generated into the output collection, such that it has the
gId field and an array called
gGroup, in which all grouped documents are reported. This array is sorted in reverse order of value of the
rank field within grouped documents.
Figure 9a reports an example of the grouped document.
The EXPAND instruction on line 10 unnests again all grouped documents. For each output document, the gPair field is added to the global ones (apart from the expanded array); this new field contains two inner fields: the item field contains the unnested document; the position field denotes the position occupied by the unnested item in the gGroup array.
As a result, the temporary collection generated by line 10 contains as many documents in the
RankedPairs collection, but now they are tagged with the relative order for
Google Places descriptors on the basis of the
rank field.
Figure 9b reports an example of an unnested document.
The
FILTER instruction on line 11 actually selects only documents that previously occupied the first position in their group (based on the reverse order of
rank, they are the ones with the highest rank). The
BUILD section builds the same structure again, as in the
RelevantPairs collection.
Figure 9c reports an example of resulting document.
Finally (on line 12) the last temporary collection is saved into the ijgiDb database with name SamePlaces, which is the desired output of the process.
Listing 4.
J-CO-QL script: Selecting the best pairs.
Listing 4.
J-CO-QL script: Selecting the best pairs.
7. Experimental Evaluation
In this section, we report a brief evaluation of the results that can be obtained by the
J-CO-QL script. We exploited the same data set adopted in [
6], related with the city of Manchester (UK). Remember, from
Section 6.1, that the
FacebookDescriptors collection contains 5738 descriptors, while the
GoogleDescriptors collection contains 5214 descriptors. Both collections contain descriptors about a variety of different public places, such as restaurants, pubs, hairdressers, universities, parks and so on.
7.1. Effectiveness
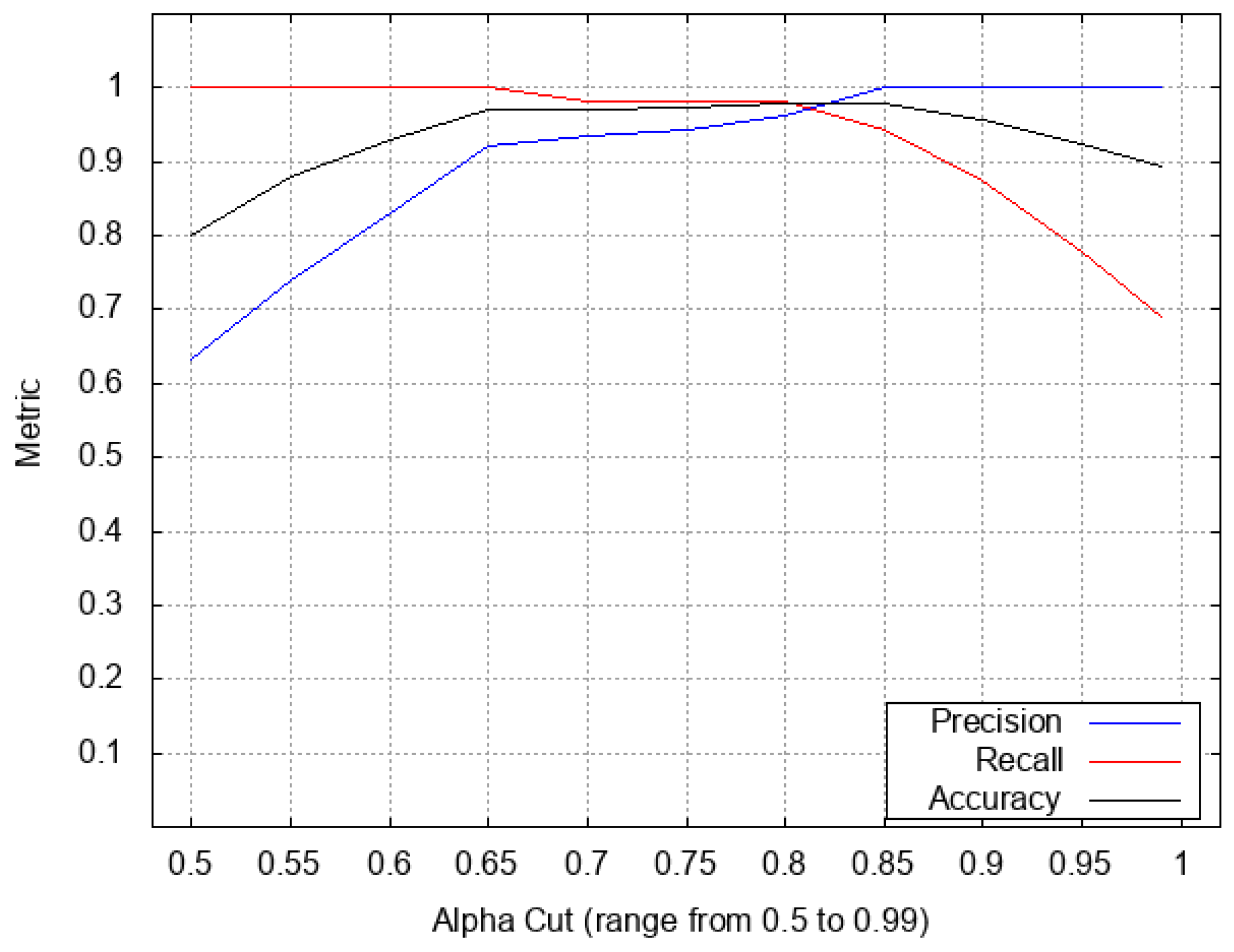
In order to evaluate the effectiveness of the method, we performed a sensitivity analysis by varying the value of the threshold from to .
We used the same test set again, which was used in the work [
6]: it contained a total of 400 pairs, selected among the
total pairs, evaluated by a human as
or
. We randomly selected 300 pairs from the starting 400 pairs, and from each pair we extracted the related 300
Google Places descriptors and 300
Facebook descriptors; among all possible pairs, 103 pairs were labeled as
pairs (and obviously the remaining 197 were labeled as
).
Then, we run the script on these two reduced collections of descriptors.
Table 1 reports the results of our experiments. Specifically, the first colum reports the single values for the alpha-cut
; the second and third columns report the number of relevant pairs saved by line 7 of the
J-CO-QL script (Listing 3) into the
RelevantPairs collection and the number of pairs generated by line 12 of the script (Listing 4) and saved into the
SamePlaces collection, respectively. The, columns from 4 to 7 reports the number
of true positive pairs, the number
of negative pairs, the number
of false positive pairs and the number
of false negative pairs, respectively. Finally, the last three columns reports “Precision” (defined as
), “Recall” (defined as
) and “Accuracy” (defined as
), respectively. These three latter values are depicted in
Figure 10: the
x-axis reports the values of the alpha-cut
parameter; precision is depicted by the blue line, recall is depicted by the red line and accuracy is depicted by the black line.
Analyzing
Table 1 and
Figure 10, it is possible to see that the best combination of values for precision, recall and accuracy were obtained for
: precision is
, recall is
and accuracy is
. Indeed, this value for
appears to be the best compromise between the need to keep as many pairs as possible and the fact that those pairs actually describe the same place, even though names, addresses and coordinates are different. The reader can further notice that higher values of
give rise to a precision of 1 with poor recall, while lower values for
give rise to a recall of 1 with poor precision. To conclude this analysis, notice that with
, the accuracy is the same as the one obtained for
; it could be considered as a valid alternative choice, with better precision but low recall.
Thus, we can state that the novel formulation for the relation and the complex membership functions adopted for the Similar fuzzy operator and for the Close fuzzy operator are effective, provided that .
We can consider the results reported in [
6] as a baseline for further evaluating the effectiveness of the novel formulation of the technique.
Remember that the version presented in [
6] (for on-line aggregation) performed pre-processing tasks on names and addresses, so as to clean them from urban designations and numbers. In contrast, the present version does not. The main reason is that such a kind of pre-processing and cleaning is not easy to do within
J-CO-QL scripts; however, the flexibility of the
CREATE FUZZY OPERATOR statement as far as the possibility to define complex shapes for membership functions seems to be effective. Consequently, the proper baseline to consider is the best result presented in [
6]. There, a comparison with a machine-learning technique, namely “Random Forest” classification, was performed, by applying it on the same data set. Results are reported in
Table 2: for the three considered techniques, precision, recall and F1-score (defined as
) are reported. Notice that in [
6], the proposed technique was as effective as random-forest classifiers; the current version outperform them, even though names and addresses are neither pre-processed nor cleaned. Observe that the old version of the fuzzy technique and the Random-Forest technique, applied on the data set describing public places in Manchester (UK), obtain the same identical effectiveness; this is why [
6] states that the two techniques are comparable.
Consequently, we can say that the current version improves the old one and is suitable to be executed as a J-CO-QL script. Furthermore, it still maintains the advantage provided by the old version in comparison with classification techniques, i.e., it can be applied from scratch, without knowing the data set; in contrast, classification techniques ask for a training step on previously labeled training sets, which is a time-consuming and critical activity.
7.2. About Execution Times
Before concluding this work, we report some considerations about execution times.
Usually, this aspect is not considered in the literature about integration of geographical data sets: authors were focused on the effectiveness of the proposed techniques, but did not consider efficiency. However, in our opinion, this is not a negligible aspect for the practical use of integration techniques, in particular with large data sets to integrate.
In this paper, the goal is neither to provide the most efficient technique, nor to evaluate execution times of a plethora of techniques proposed in the literature. Here, the goal is to observe “what to expect” while running the J-CO-QL script on a real data set, such as the one we used for our experiments.
We decided to consider a working environment that could be a common situation: analysts are equipped with stand-alone PCs, on which they perform their daily activities. On these PCs, they might have a running instance of MongoDB, which stores their data sets about geographical places, as well as an installation of the J-CO Framework; indeed, not necessarily analysts are equipped with super-computers. Consequently, we run experiments on a laptop PC powered by an Intel quad-Core i7-8550-U processor, running at GHz, equipped with 16 GB RAM and 250 GB Solid-State Drive and running the Java Virtual Machine version (the J-CO-QL Engine is written in the Java programming language).
Table 3 reports the execution times of the script discussed in this paper. We used the full data set reporting descriptors of public places located in Manchester (UK). Remember that it contains 5738
Facebook descriptors and 5214
Google descriptors.
Table 3 reports the execution times observed for each single instruction in the script; the right-most column reports the cumulative execution time after each instruction. Clearly, the overall execution time is dominated by the
JOIN OF COLLECTIONS instruction, which actually builds
pairs of descriptors; it takes
s. Looking at the other instructions they contribute only less than 4 s, so that the overall execution time is
s, i.e., about
min.
In terms of user perception, waiting for about 3 min is acceptable in this context, in which near-real time performances are not expected. Furthermore, we want to remark that once the two data sets to integrate are available, the J-CO-QL script can be applied from scratch, and a few minutes later the integrated data set is obtained. This is an incredible advantage if compared with the adoption of classification techniques, because there is no need to build training sets labeled by humans; this activity can take from several hours to several days (depending on the size of the training set) and is prone to errors and misunderstanding, as well as its effectiveness depends on the way the training sets are built before labeling.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













