Abstract
Values (why to conserve) and Attributes (what to conserve) are essential concepts of cultural heritage. Recent studies have been using social media to map values and attributes conveyed by the public to cultural heritage. However, it is rare to connect heterogeneous modalities of images, texts, geo-locations, timestamps, and social network structures to mine the semantic and structural characteristics therein. This study presents a methodological framework for constructing such multi-modal datasets using posts and images on Flickr for graph-based machine learning (ML) tasks concerning heritage values and attributes. After data pre-processing using pre-trained ML models, the multi-modal information of visual contents and textual semantics are modelled as node features and labels, while their social relationships and spatio-temporal contexts are modelled as links in Multi-Graphs. The framework is tested in three cities containing UNESCO World Heritage properties—Amsterdam, Suzhou, and Venice— which yielded datasets with high consistency for semi-supervised learning tasks. The entire process is formally described with mathematical notations, ready to be applied in provisional tasks both as ML problems with technical relevance and as urban/heritage study questions with societal interests. This study could also benefit the understanding and mapping of heritage values and attributes for future research in global cases, aiming at inclusive heritage management practices. Moreover, the proposed framework could be summarized as creating attributed graphs from unstructured social media data sources, ready to be applied in a wide range of use cases.
1. Introduction
In the context of the UNESCO World Heritage (WH) Convention, “values” (why to conserve) and “attributes” (what to conserve) have been used extensively to detail the cultural significance of heritage [1,2]. Meanwhile, researchers have provided categories and taxonomies for heritage values and attributes, respectively, [3,4,5]. Both concepts are essential for understanding the significance and meaning of cultural and natural heritage, and for formulating more comprehensive management plans [5]. However, the heritage values and attributes are not only to define the significance of Outstanding Universal Value (OUV) in the specific context of the World Heritage List (WHL), but all kinds of significance, ranging from listed to unlisted, natural to cultural, tangible to intangible, and from global to national, regional and local [4,6,7,8,9]. Moreover, the 2011 UNESCO Recommendation on the Historic Urban Landscape (HUL) stressed that heritage should also be recognized through the lens of local citizens, tourists and experts, calling for tools for civic engagement and knowledge documentation [8,9,10].
Thereafter, in the past decade, analyses have been performed on User-Generated Content (UGC) from social media platforms to actively collect opinions of the [online] public, and to map heritage values and attributes conveyed by various stakeholders in urban environments [11,12]. In Machine Learning (ML) literature, a modality is defined as “the way in which something happens or is experienced”, which can include natural language, visual contents, vocal signals, etc., [13]. Most of the studies mapping heritage values and attributes from UGC focused only on a few isolated modalities, such as textual topics of comments and/or tags [14,15,16], visual content of depicted scenes [17,18], social interactions [19,20,21], and geographical distribution of the posts [22,23].
However, the heterogeneous multi-modal information from social media can enrich the understanding of posts, as textual and visual content, temporal and geographical contexts, and underlined social network structures could show both complementary and contradictory messages [9,24]. A few studies have analysed different modalities to reveal the discussed topics and depicted scenes about cultural heritage [25,26]. However, since they (mostly) adapted analogue approaches during analyses and the multi-modal information was not explicitly paired, linked, and analysed together, these studies could not yet be classified as Multi-modal Machine Learning (MML), aiming to “build models that can process and relate information from multiple modalities” [13] to enrich the conclusions that could not be easily achieved with isolated modalities. On the other hand, Crandall et al. [27] proposed a global dataset collected from Flickr with visual and textual features, as well as geographical locations. Graphs were constructed with multi-modal information to map, cluster, and retrieve the most representative landmark images for major global cities. Gomez et al. [28] trained multi-modal representation models of images, captions, and neighbourhoods with Instagram data from within Barcelona, able to retrieve the most relevant photos and topics for each municipal district, being used to interpret the urban characteristics of different neighbourhoods. More recently, the continuous research line demonstrated in Kang et al. [29] and Cho et al. [30] applied transfer learning [31] techniques to classify geo-tagged images into hierarchical scene categories and connected the depicted tourist activities to the urban environments where these cultural activities took place. Although not all of them explicitly referred to heritage, these studies could provide useful information for scholars and practitioners to gather knowledge from the public about their perceived heritage values and attributes in urban settings, as suggested by HUL [9,10]. Among the five main MML challenges summarized by Baltrusaitis et al. [13], representation (to present and summarize multi-modal data in a joint or coordinated space) and fusion (to join information for prediction) can be the most relevant ones for heritage and urban studies, with respect to (1) retrieving visual and/or textual information related to certain heritage values and attributes, and (2) aggregating individual posts in different geographic and administrative levels as the collective summarized knowledge of a place.
Furthermore, according to the First Law of Geography [32], “everything is related to everything else, but near things are more related than distant things”. This argument can also be assumed to be valid in distance measures other than geographical ones where a random walk could be performed [33], such as in a topological space abstracted from spatial structure [34,35,36,37] or a social network constructed based on common interests [38,39,40,41]. In this light, it would be beneficial to construct graphs of UGC posts where Social Network Analysis (SNA) could be performed, showing the socio-economic and spatio-temporal context among them, reflecting the inter-related dependent nature of the posts [42]. Such a problem definition could help with both the classification and the aggregation tasks mentioned above, as has been demonstrated as effective and powerful by applications in the emerging field of Machine and Deep Learning on Graphs [43,44].
This paper describes the methodological framework of creating multi-modal graph-based datasets about heritage values and attributes using unstructured social media data. The core question from generating such datasets could be formulated as: while heritage values and attributes have been historically inspected from site visiting and document reviewing by experts, can computational methods and/or artificial intelligence aid the process of knowledge documentation and comparative studies by mapping and mining multi-modal social media data? Even if acceleration of the processes is not a priority, the provision of such a framework is aimed to encourage consistency and inclusion of communities in the discourse of cherishing, protecting, and preserving cultural heritage. In other words, the machine can eventually represent the voice of the community [9]. The main contributions of this manuscript can be summarized as:
- Domain-specific multi-modal attributed graphsocial network datasets about heritage values and attributes (or more precisely, the values and attributes conveyed by the public to urban cultural heritage) are collected and structured with user-generated content from the social media platform Flickr in three cities (Amsterdam, Suzhou, and Venice) containing UNESCO World Heritage properties, which could benefit the knowledge documentation and mapping for heritage and urban studies, aiming at a more inclusive heritage management process;
- Several pre-trained machine learning and deep learning models have been extensively applied and tested for generating multi-modal features and [pseudo-]labels with full mathematical formulations as its problem definition, providing a reproducible methodological framework that could also be tested in other cases worldwide;
- Multi-graphs have been constructed to reflect the temporal, spatial, and social relationships among the data samples of collected user-generated content, ready to be further tested on several provisional tasks with both scientific relevance for Graph-based Multi-modal Machine Learning and Social Network research, and societal interests for Urban Studies, Urban Data Science, and Heritage Studies.
2. Materials and Methods
2.1. General Framework
Before delving into the domain-specific case studies with technological details, this section first describes the general process of creating multi-modal datasets as attributed graphs from unstructured volunteered information content harvested from social media. These graphs would encode connections between posts of content publishers on social media; connections that can be established by virtue of similarities or proxmities in spatial, temporal, or social domains. The whole process consists of five core components: data acquisition and cleaning (Section 2.3), multi-modal feature representation (Section 2.4), [pseudo-] label generation (Section 2.5), contextual graph construction (Section 2.6), and qualitative inspection and validation (Section 3), as visualized in Figure 1.
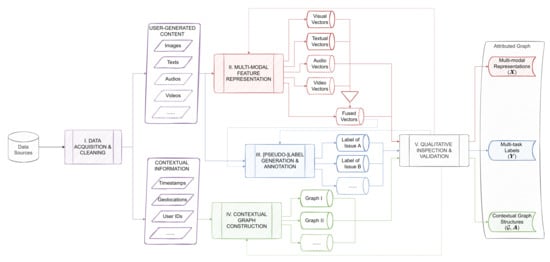
Figure 1.
The framework to create multi-modal machine learning datasets as attributed graphs from unstructured data sources.
As argued in Aggarwal [24] and Bai et al. [9], the analyses on social media (or social network data) could be categorized as studying its content (traditionally texts and images, possibly also audio and video), structure (social linkages among users entailing interactions), and context (spatio-temporal and socio-economic manifolds). While the former is mainly about constituent data points themselves, the latter two (both are contextual information under different scenarios) provide explicit data about the potential linkage between the data points. For any data source (social media platform) of interest, the proposed framework suggests acquiring both content and contextual information for a rigid understanding of the social network. After data acquisition and cleaning, the input data would be highly unstructured and non-standard and thus challenging to feed into data science workflows, which need to be transformed as machine-readable formats-presumably vectors-using certain feature representation techniques. For different modalities, various techniques could be employed: from hand-engineered features, to pre-trained embeddings, and to other end-to-end techniques such as auto-encoders. Moreover, the fusion of different modalities could happen in various forms, from the most simple concatenation, to more complex techniques using neural networks [13]. Even though unsupervised learning applications of spatial clustering and auto-correlation are not uncommon, it is still preferable to have semantic labels concerning various issues of interest to make more sense out of the data points. In situations where human annotation can be expensive and challenging, semi-automatic labeling with transfer learning, pseudo-label generation and/or active learning using either the raw data or the generated multi-modal features could be applied to efficiently circumvent this bottle-neck process [31,45,46,47,48,49]. Furthermore, the graph construction process makes use of the proximity or similarity of the contextual information to link the data points as [multi-] graphs. Contextualization of the data points and creating a coherent picture of the datasets are necessary tasks, without which the task of data analysis would remain at the level of dealing with a bag containing powder-like data points. Graph datasets can be of essential value in interpolation and extrapolation tasks, simply put for diffusing or transferring information from the neighbours of a data point to it. In cases where some graph attribute is missing on a data point, a graph representation can help in creating consistency and coherence. This is especially important for semi-supervised learning scenarios on social media data, where missing features could be very common [50]. Before storing the results as valid attributed graph datasets with graph structures () and node features (), a bundle of processes for qualitatively and quantitatively inspecting the quality, consistency, and validity of the generated results is necessary. This could also possibly include humans in the loop.
The rest of this manuscript will explain each component in detail with specific instances tailored for the use case of mapping heritage values and attributes as demonstration (such as the selection of the three cities in Section 2.2, the choice of Flickr as data source in Section 2.3, and the decisions of pre-trained ML models in Section 2.4 and Section 2.5). However, in principle, the case study to be instantiated and technology to be employed could be specified, enhanced, and updated based on the actual use cases within a wide range of scenarios, taking advantage of the most suitable tools and the most current technological developments. This will be further discussed in Section 4.2.
2.2. Selection of Case Studies
Without loss of generality, this research selected three cities in Europe and China that are related to UNESCO WH and HUL as case studies: Amsterdam (AMS), the Netherlands; Suzhou (SUZ), China; and Venice (VEN), Italy. All three cities themselves are either entirely or partially inscribed in the WHL, such as Venice and its Lagoon (https://whc.unesco.org/en/list/394, accessed on 8 March 2022) and Seventeenth-Century Canal Ring Area of Amsterdam inside the Singelgracht (https://whc.unesco.org/en/list/1349/, accessed on 8 March 2022), or contain WHL in multiple parts of the city, such as the Classical Gardens of Suzhou (http://whc.unesco.org/en/list/813, accessed on 8 March 2022), showcasing different spatial typologies of cultural heritage in relation to its urban context [51,52].
As shown in Table 1, the three cases have very different scales, yet all strongly demonstrate the relationship between urban fabric and the water system. Interestingly, Amsterdam and Suzhou have been, respectively, referred to as “the Venice of the North/East” by the media and public. Moreover, the concept of OUV introduced in Section 1 reveals the core cultural significance of WH properties. The OUV of a property would be justified with ten selection criteria, where criteria (i)–(vi) reflect various cultural values, and criteria (vii)–(x) natural ones [2,53,54,55], as explained in Appendix Table A3. The three selected cases include a broad variety of all cultural heritage OUV selection criteria, implying the representativeness of the datasets constructed in this study.

Table 1.
The case studies and their World Heritage status.
2.3. Data Collection and Pre-Processing
Numerous studies have collected, annotated, and distributed open-source datasets from the image-sharing social media platform Flickr owing to its high-quality image data, searchable metadata, and convenient Application Programming Interface (API), although its possible drawbacks include relatively low popularity, limited social and geographical coverage of users, and unbalanced information quantities of images and texts [56,57,58,59]. A collection of Flickr-based datasets could includeincluding MirFlickr-1M [60], NUS-WIDE [61], Flickr [62], ImageNet [63,64], Microsoft Common Object in COntext (MS COCO) [57], Flickr30k [65], SinoGrids [66], and GRAPH Saint [67], etc. These datasets containing one or more of the visual, semantic, social, and/or geographical information of UGC are widely used, tested, but also sometimes challenged by different ML communities including Computer Vision, Multi-modal Machine Learning, and Machine Learning on Graphs. However, they are more or less suitable for bench-marking general ML tasks and testing computational algorithms, which are not necessarily tailor-made for heritage and urban studies. On the other hand, theThe motivation of data collection in this research is to provide datasets that could be both directly applicable for ML communities as a test-bed, and theoretically informative for heritage and urban scholars to draw conclusions on for informing the decision-making process. Therefore, instead of adapting the existing datasets that can be weakly related to the problems of interest in this study, new data are directly collected and processed from Flickr as an instance of the proposed framework in Section 2.1. Further possibilities of merging other existing datasets and data from other sources in response to the limitations of Flickr will be briefly addressed in Section 4.2.
FlickrAPI python library (https://stuvel.eu/software/flickrapi/, accessed on 8 March 2022) was used to access the API method provided by Flickr (https://www.flickr.com/services/api/, accessed on 8 March 2022), using the Geo-locations in Table 1 as the centroids to search a maximum of 5000 IDs of geo-tagged images within a fixed radius covering the major urban area, to form comparable and compatible datasets from the three cities, since only 4229 IDs were found in Suzhou during the time of data collection, reflecting the relatively scarse use of Flickr in China. To test the scalability of the methodological workflow, another larger dataset without an ID number limit has also been collected in Venice (VEN-XL). Only images with a candownload flag indicated by the owner were further queried, respecting the privacy and copyrights of Flickr users. The following information of each post was collected: owner’s ID; owner’s registered location on Flickr; the title, description, and tags provided by user; geo-tag of the image; timestamp marking when the image was taken, and URLs to download the Large Square (150 × 150 px) and Small 320 (320 × 240 px) versions of the original image. Furthermore, the public friend and subscription lists of all the retrieved owners were queried, while all personal information was only considered as a [semi-] anonymous ID with respect to the privacy policy. The data collection procedure took place from 28 December 2020–10 January 2021 and 10 February 2022–25 February 2022, respectively. The earliest captured photos collected date back to 1946 in AMS, 2007 in SUZ, 1954 in VEN, and 1875 in VEN-XL, and for all cities the most recent photos were taken in 2021–2022.
The retrieved textual fields of description, title, and tags could all provide useful information, yet not all posts have these fields, and not all posts are necessarily written to express thoughts and share knowledge about the place (considered as “valid” in the context of this study). The textual fields of the posts were cleaned, translated, and merged into a Revised Text field as raw English textual data, after recording the detected original language of posts on the sentence level using Google Translator API from the Deep Translator Python library (https://deep-translator.readthedocs.io/en/latest/, accessed on 8 March 2022). Moreover, many posts shared by the same user were uploaded at once, thus having the same duplicated textual fields for all of them. To handle such redundancy, a separate dataset of all the unique processed textual data on sentence level was saved for each city, while the original post ID of each sentence was marked and could easily be traced back.
Detailed description of the data collection and pre-processing proceduremethods could be found in Appendix A. Table 2 shows the number of data samples (posts) and owners (users) for the three case study cities at each stage. Note the numbers of posting owners are relatively unbalanced in different cities. Intuitionally, a larger number of owners could suggest a better coverage of social groups and provide better representativeness for the datasets. However, since the unit of data points in this study is a single post, not a unique social media user (content publisher), it could be assumed that the latter only provides sufficient [social] contextual information for the former.
Table 2.
The number of data samples collected at each stage, the bold numbers mark the sample size of the final datasets.
To formally describe the data, define the problem, and propose a generalizable workflow as a methodological framework, mathematical notations are used in the rest of this manuscript. Since the same process is valid for all three cities (and probably also for other unselected cases worldwide) and has been repeated exactly three times, no distinctions would be made among the cities, except for the cardinality of sets reflecting sample sizes. Let i be the index of a generic sample of the dataset for one city, then its raw data could be denoted as a tuple , where K is the sample size of the dataset in a city (as shown in Table 2), is a three-dimensional tensor of the image size with three RGB channels, is a set of revised English sentences that can also be an empty set for samples without any valid textual data, is a user ID that is one instance from the user set , is a timestamp that is one instance from the ordered set of all the unique timestamps from the dataset at the level of weeks, and is a geographical coordinate of latitude () and longitude () marking the geo-location of the post. A complete nomenclature of all notations used in this paper can be found in the Appendix Table A1 and Table A2. Figure 2 demonstrates the data flow of one sample post in Venice, which will be formally explained in the following sections.
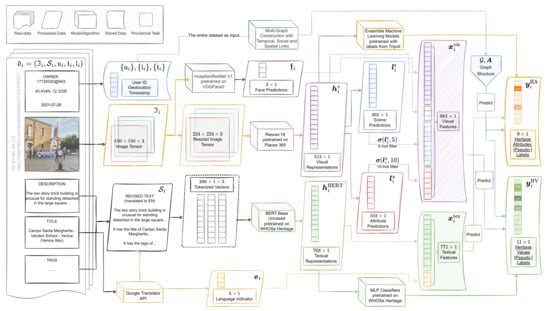
Figure 2.
Data flow of the multi-modal feature generation process of one sample post in Venice, while graph construction requires all data points of the dataset. The original post owned by user 17726320@N03 is under CC BY-NC-SA 2.0 license.
2.4. Multi-Modal Feature Generation
2.4.1. Visual Features
Places365 is a dataset containing 1.8 million images from 365 scene categories, which includes a relatively comprehensive collection of indoor and outdoor places [68,69]. The categories can be informative for urban and heritage studies to identify depicted scenes of images and to further infer heritage attributes [5,26]. A few Convolutional Neural Network (CNN) models were pre-trained by Zhou et al. [69] using state-of-the-art backbones to predict the depicted scenes in images, reaching a top-1 accuracy of around 55% and top-5 accuracy of around 85%. Furthermore, the same set of pre-trained models have been used to predict 102 discriminative scene attributes based on SUN Attribute dataset [70,71], reaching top-1 accuracy of around 92% [69]. These scene attributes are conceptually different from heritage attributes, as the former are mostly adjectives and present participles describing the scene and activities taking place. Therefore, both heritage values and attributes could be effectively inferred therefrom.
This study used the openly-released ResNet-18 model [72] pre-trained on Places365 with PyTorch (https://github.com/CSAILVision/places365, accessed on 9 March 2022). This model was adjusted to effectively yield three output vectors: (1) the last softmax layer of the model as logits (formally a probability distribution) over all scene categories; (2) the last hidden layer of the model; (3) a vector as logits over all scene attributes. Such a process for any image input could be described as:
or preferably in a vectorized format:
where
Considering that the models demonstrate reasonable performance in top-n accuracy, to keep the visual features explainable, a n-hot soft activation filter is performed on both logit outputs, to keep the top-n prediction entries active, while smoothing all the others based on the confidence of top-n predictions ( for scene categories and for scene attributes ). Let denote the maximum element of a d-dimensional logit vector (the sum of all d entries of equals 1), then the activation filter could be described as:
where is a mask vector indicating the positions of top-n entries, and is effectively the total confidence of the model for top-n predictions. Note that this function could also take a matrix as input and process it as several column vectors to be concatenated back.
Furthermore, as the Places365 dataset is tailor-made for scene detection tasks rather than facial recognition [69], the models pre-trained on it may become confused when a new image is mainly composed of faces as “typical tourism pictures” and self-taken photos, which is not uncommon in the case studies as popular tourism destinations. As the ultimate aim of constructing such datasets is not to precisely predict the scene each image depicts, but to help infer heritage values and attributes, it would be unfair to simply exclude those images containing a significant proportion of faces. Rather, the existence of humans in images showing their activities would be a strong cue of intangible dimension of heritage properties. Under such consideration, an Inception ResNet-V1 model (https://github.com/timesler/facenet-pytorch, accessed on 9 March 2022) pre-trained on the VGGFace2 Dataset [73,74] has been used to generate features about depicted faces in the images. A three-dimensional vector was obtained for any image input , where the non-negative first entry counts the number of faces detected in the image, the second entry records the confidence of the model for face detection, and the third entry calculates the proportion of area of all the bounding boxes of detected faces to the total area of the image. Similarly, the vectorized format could be written as over the entire dataset.
Finally, all obtained visual features were concatenated vertically to generate the final visual feature :
where denotes the horizontal concatenation of matrices.
This final matrix is to be used in future MML tasks as the vectorized descriptor of the uni-modal visual contents of the posts, with both more abstract hidden features only to be understood by machines, and more specific information about predicted categories interpretable by humans, which is common practice in MML literature [13]. All models are tested on both and px images to compare the consistency of generated features. The workflow of generating visual features is illustrated in the top part of Figure 2.
2.4.2. Textual Features
In the last decade, attention- and Transformer-based pre-trained models have taken over the field of Natural Language Processing (NLP), increasing the performance of models in both general machine learning tasks, and domain-specific transfer-learning scenarios [75]. As an early version, the pre-trained Bidirectional Encoder Representations from Transformers (BERT) [76] is still regarded as a powerful base model to be fine-tuned on specific downstream datasets and for various NLP tasks. Specifically, the output on the [CLS] token of BERT models is regarded as an effective representation of the entire input sentence, being used extensively for classification tasks [77,78]. In the heritage studies domain, Bai et al. [79] fine-tuned BERT on the dataset WHOSe Heritage that they constructed from the UNESCO World Heritage inscription document, followed by a Multi-Layer Perceptron (MLP) classifier to predict the OUV selection criteria that a sentence is concerned with, showing top-1 accuracy of around 71% and top-3 accuracy of around 94%.
This study used the openly-released BERT model fine-tuned on WHOSe Heritage with PyTorch (https://github.com/zzbn12345/WHOSe_Heritage, accessed on 10 March 2022). The BERT model took both the entire sentence sets and individual sentences of the sets as paragraph- and sentence-level inputs, respectively, for the comparison of consistency on predicted outputs of this new dataset. Furthermore, taking the entire sentence sets as input, the 768-dimensional output vector of the [CLS] token was retrieved on samples that have valid textual data:
or preferably in a vectorized format:
Moreover, the original language of each sentence may provide additional information to the verbal context of posts, informative to effectively identify and compare locals and tourists. A three-dimensional vector was obtained with Google Translator API. The three entries, respectively, marked whether there were sentences in English, local languages (Dutch, Chinese, or Italian, respectively), and other languages in the set . The elements of vector or the matrix form could be in a range from all zeros (when there were no textual data at all) to all ones (where the post comprised different languages in separate sentences).
Similar to visual features, final textual features could be obtained as:
The workflow of generating textual features is illustrated in the bottom part of Figure 2.
2.4.3. Contextual Features
As mentioned in Section 2.3, the user ID and timestamp of a post are both an instance from their respective set and , since multiple posts could be posted by the same user, and multiple images could be taken during the same week. To help formulate and generalize the problem under the practice of relational database [80], the information from both could be transformed as one-hot embeddings and , such that:
Furthermore, Section 2.3 and Appendix A also mentioned the collection of the public contacts and groups of all the users from the set . To keep the problem simple, only direct contact pairs were considered to model the back-end social structure of the users, effectively filtering out the other contacts a user had that were not in the set of interest , resulting in an adjacency matrix among the users marking their direct friendship:
Let denote the set of public groups a user follows (can be an empty set if follows no group), and let denote the Jaccard Index (size of Intersection over size of Union) of two generic sets :
where is a small number to avoid zero-division. Then another weighted adjacency matrix among the users could be constructed: , marking the mutual interests among the users as group subscription on Flickr:
To further simplify the problem, although the geo-location of each post was typically distributed in a continuous 2D geographical space, it would be beneficial to further aggregate and discretize the distribution in a topological abstraction of spatial network [34,35,81], which has also been proven to be effective in urban spatial analysis, including but not limited to Space Syntax [82,83,84,85]. The OSMnx python library (https://osmnx.readthedocs.io/en/stable/, accessed on 28 February 2022) was used to inquire the simplified spatial network data on OpenStreetMap including all means of transportation [86] in each city with the same centroid location and radius described in Section 2.3. This operation effectively saved a spatial network as an undirected weighted graph , where is the set of all street intersection nodes, is the set of all links possibly connecting two spatial nodes (by different sorts of transportation such as walking, biking, and driving), and is a vector with the same dimension as the cardinality of the edge set, marking the average travel time needed between node pairs (dissimilarity weights). The distance.nearest_nodes method of OSMnx library was used to retrieve the nearest spatial nodes to any post location . By only retaining the spatial nodes that bear at least one data sample posted nearby, and restricting the link weights between nodes so that the travel time on any link is no more than 20 min, which ensures a comfortable temporal distance forming neighbourhoods and communities [87], a subgraph of could be constructed, so that , and . As a result, another one-hot embedding matrix could be obtained:
The contextual features constructed as matrices/graphs would be further used in Section 2.6 to link the posts together.
2.5. Pseudo-Label Generation
2.5.1. Heritage Values as OUV Selection Criteria
Various categories on heritage values (HV) have been provided by scholars [3,4,53,54]. To keep the initial step simple, this study arbitrarily applied the value definition in UNESCO WHL with regard to ten OUV selection criteria, as listed in Appendix Table A3 with an additional class Others representing scenarios where no OUV selection criteria suit the scope of a sentence (resulting in an 11-class category). It must be noted that the OUV selection criteria and the corresponding Statements of OUV include elements that could be identified and categorized as either heritage values or heritage attributes. Therefore, they are not necessarily heritage value per se, a detailed discussion on which falls out of the scope of this paper. However, for pragmatic purposes of demonstrating a framework, this study omits this distinction and considers the OUV selection criteria as a proxy of HV during label generation. A group of ML models were trained and fine-tuned to make such predictions by Bai et al. [79] as introduced in Section 2.4.2. Except for BERT already used to generate textual features as mentioned above, a Universal Language Model Fine-tuning (UMLFiT) [88] has also been trained and fine-tuned, reaching a similar performance in accuracy. Furthermore, it has been found that the average confidence by both BERT and ULMFiT models on the prediction task showed significant correlation with expert evaluation, even on social media data [79]. This suggests that it may be possible to use both trained models to generate labels about heritage values in a semi-supervised active learning setting [45,89], since this task is overly knowledge-demanding for crowd-workers, yet too time-consuming for experts [90].
The pseudo-label generation step could be formulated as:
where is an end-to-end function including both pre-trained models and MLP classifiers; and is an 11-dimensional logit vector as soft-label predictions. Let denote the function returning the index set of the largest n elements of a vector , together with the previously defined , the confidence and [dis-]agreement of models for top-n predictions could be computed as:
This confidence indicator matrix could be presumably regarded as a filter for the labels on heritage values , to only keep the samples with high inter-annotator (model) agreement [46] as the “ground-truth” [pseudo-] labels, while treating the others as unlabeled [49,91].
2.5.2. Heritage Attributes as Depicted Scenery
Heritage attributes (HA) also have multiple categorization systems [5,26,92,93,94], and are arguably more vaguely defined than HV. For simplicity, this study arbitrarily combined the attribute definitions of Veldpaus [5] and Ginzarly et al. [26], and kept a 9-class category of tangible and/or intangible attributes visible from an image. More precisely, this category should be framed as “depicted scenery” of an image [26] that heritage attributes could possibly be induced from. The depicted scenes themselves are not yet valid heritage attributes. This semantic/philosophical discussion, however, is out of the scope of this paper. The definitions of the nine categories are listed in Appendix Table A4.
An image dataset collected in Tripoli, Lebanon and classified with expert-based annotations presented by Ginzarly et al. [26] was used to train a few ML models to replicate the experts’ behaviour on classifying depicted scenery with Scikit-learn python library [95]. For each image, a unique class label was provided, effectively forming a multi-class classification task. The same 512-dimensional visual representation introduced in Section 2.4.1 was generated from the images as the inputs. Classifiers including Multi-layer Perceptron (MLP) (shallow neural network) [96], K-Nearest Neighbours (KNN) [97], Gaussian Naive Bayes (GNB) [98], Support Vector Machine (SVM) [99], Random Forest (RF) [100], and Bagging Classifier [101] with SVM core (BC-SVM) were first trained and tuned for optimal hyperparameters using 10-fold cross validation (CV) with grid search [102]. Then, the individually-trained models were put into ensemble-learning settings as both a voting [103] and a stacking classifier [104]. All trained models were tested on validation and test datasets to evaluate their performance. Details of the machine learning models are given in Appendix B. Both ensemble models were further applied in images collected in this study. Similar to the HV labels described in Section 2.5.1, the label generation step of HA could be formulated as:
where is an ensemble model taking all parameters from each ML model in set ; and is a 9-dimensional logit vector as soft-label predictions. Similarly, the confidence of models for top-n prediction is:
This matrix could also be regarded the filter for heritage attributes labels .
2.6. Multi-Graph Construction
Three types of similarities/relations among posts were considered to compose the links connecting the post nodes: temporal similarity (posts with images taken during the same time period), social similarity (posts owned by the same people, by friends, and by people who share mutual interests), and spatial similarity (posts with images taken at the same or nearby locations). All three could be deduced from the contextual information in Section 2.4.3. As a result, an undirected weighted multi-graph (also known as Multi-dimensional Graph [44]) with the same node set and three different link sets could be constructed as , where is the node set of all the posts, is the set of all links connecting two posts of one similarity type, and the weight vector marks the strength of connections. The multi-graph could also be easily split into three simple undirected weighted graphs , , and concerning each type of similarities. Each corresponds to a weighted adjacency matrix , such that:
The three weighted adjacency matrices could be, respectively, obtained as follows:
2.6.1. Temporal Links
Let denote a symmetric tridiagonal matrix where the diagonal entries are all 1 and off-diagonal non-zero entries are all , where is a parametric scalar:
then the weighted adjacency matrix for temporal links could be formulated as:
where is the one-hot embedding of timestamp for posts mentioned in Equation (11). For simplicity, is set to 0.5. With such a construction, all posts from which the images were originally taken in the same week would have a weight of connecting them in , and posts with images taken in nearby weeks in a chronological order would have a weight of . Note, however, that the notion of “nearby” may not necessarily correspond to temporally adjacent weeks, as the interval of timestamps marking the date when a photo was taken could be months and even years in earlier time periods. In use cases sensitive to the time intervals, the value of could also be weighted: i.e., the longer the time interval actually is, the smaller becomes.
2.6.2. Social Links
Let denote a symmetric matrix as a linear combination of three matrices marking the social relations among the users:
where is a diagonal matrix of 1s for the self relation, is the matrix mentioned in Equation (12) for the friendship relation, is a mask on the matrix introduced in Equation (14) for the common-interest relation above a certain threshold , and are parametric scalars to balance the weights of different social relations. The weighted adjacency matrix for social links could be formulated as:
where is the one-hot embedding of owner/user for posts mentioned in Equation (10). For simplicity, the threshold is set to 0.05 and the scalars are all set to 1. With such a construction, all posts uploaded by the same user would have a weight of connecting them in , posts by friends with common interests (of more than 5% common groups subscriptions) would have a weight of , and posts by either friends with little common interests or strangers with common interests would have a weight of .
2.6.3. Spatial Links
Let denote a symmetric matrix computed with simple rules showing the spatial closeness (conductance) of nodes from the spatial graph mentioned in Section 2.4.3, whose weights originally showed the distance of nodes (resistance):
The weighted adjacency matrix for spatial links could be formulated as:
where is the one-hot embedding of spatial location for posts mentioned in Equation (15). With such a construction, posts located at the same spatial node would have a weight of in , and posts from nearby spatial nodes would have a weight linearly decayed based on distance within a maximum transport time of 20 min.
Additionally, the multi-graph could be simplified as a simple composed graph with a binary adjacency matrix , such that:
which connects two nodes of posts if they are connected and similar in at least one contextual relationship.
All graphs were constructed with NetworkX python library [105]. The rationale under constructing various graphs was briefly described in Section 1: the posts close to each other (in temporal, social, or spatial contexts) could be arguably similar in their contents, and therefore, also similar in the heritage values and attributes they might convey. Instead of regarding these similarities as redundant and, e.g., removing duplicated posts by the same user to avoid biasing the analysis, such as in Ginzarly et al. [26], this study intends to take advantage of as much available data as possible, since similar posts may enhance and strengthen the information, compensating the redundancies and/or nuances using back-end graph structures. At later stages of the analysis, the graph of posts could be even coarsened with clustering and graph partitioning methods [44,106,107,108], to give an effective summary of possibly similar posts.
3. Analyses as Qualitative Inspection
3.1. Sample-Level Analyses of Datasets
3.1.1. Generated Visual and Textual Features
Table 3 shows the consistency of generated visual and textual features. The visual features compared the scene and attribute predictions on images of difference sizes (150 × 150 and 320 × 240 px); and the textual features compared the OUV selection criteria with aggregated (averaged) sentence-level predictions on each sentence from set and paragraph-/post-level predictions on set .
Table 3.
The consistency (the mean and standard deviation of top-n IoU Jaccard Index on predicted sets) of generated features. For visual features, predictions with different input image sizes (150 × 150 px and 320 × 240 px) are compared; for textual features, average sentence-level predictions and paragraph-/post-level predictions are compared. The best scores for each feature are in bold, and the selected ones for future tasks are underlined. “#” means “the number of” in the table.
For both scene and attribute predictions, the means of top-1 Jaccard Index were always higher than that of top-n, however, the smaller variance proved the necessity of using top-n prediction as features. Note the attribute prediction was more stable than the scene prediction when the image shape changed, this is probably because the attributes usually describe low-level features which could appear in multiple parts in the image, while some critical information to judge the image scene may be lost during cropping and resizing in the original ResNet-18 model. Considering the relatively high consistency of model performance and the storage cost of images when the dataset would ultimately scale up (e.g., VEN-XL), the following analyses would only be performed on smaller square images of 150 × 150 px.
The high Jaccard Index of OUV predictions showed that averaging the textual features derived from sub-sentences of a paragraph would yield a similar performance of directly feeding the whole paragraph into models, especially when the top-3 predictions are of main interest. Note that the higher consistency in Suzhou was mainly a result of the higher proportion of posts only consisting of one sentence.
Table 4 gives descriptive statistics of results that were not compared against different scenarios as in Table 3. Only a small portion of posts had detected faces in them. While Amsterdam has the highest proportion of face pictures (17.9%), Venice has larger average area of faces on the picture (i.e., more self-taken photos and tourist pictures). These numbers are also assumed to help associate a post to human-activity-related heritage values and attributes. Considering the languages of the posts, Amsterdam showed a balance between Dutch-speaking locals and English-speaking tourists, Venice showed a balance between Italian-speaking people and non-Italian-speaking tourists, while Suzhou showed a lack of Chinese posts. This is consistent with the popularity of Flickr as social media in different countries, which also implies that data from other social media could compensate this unbalance if the provisional research questions would be sensitive to the nuance between local and tourist narratives.
Table 4.
Descriptive statistics (mean and standard deviation or counts, respectively) of the facial recognition results as visual features and original language as textual features. “#” means “the number of” in the table.
3.1.2. Pseudo-Labels for Heritage Values and Attributes
As argued in Section 2.5.1, the label generation process of this paper did not involve human annotators. Instead, it used thoroughly trained ML models as machine replica of annotators and considered their confidences and agreements as a filter to maintain the “high-quality” labels as pseudo-labels. Similar operations can be found in semi-supervised learning [48,49,91].
For heritage values, an average top-3 confidence of and top-3 agreement (Jaccard Index) of was used as the filter for . This resulted in around 40–50% of the samples with textual data in each city as “labelled”, and the rest as “unlabelled”. Figure 3 demonstrates the distribution of “labelled” data about heritage values in each city. For all cities, cultural values are far more frequent than natural values, consistent with their status of cultural WH. However, elements related to natural values could still be found and were mostly relevant. The actual OUV inscribed in WHL mentioned in Table 1 could all be observed as significantly present (e.g., criteria (i),(ii),(iv) for Amsterdam) except for criterion (v) in Venice and Suzhou, which might be caused by the relatively fewer examples and poorer class-level performance of criterion (v) in the original paper [79]. Remarkably, criterion (iii) in Amsterdam and criterion (vi) in Amsterdam and Suzhou were not officially inscribed, but appeared to be relevant inducing from social media, inviting further heritage-specific investigations. The distributions of Venice and Venice-large were more similar in sentence-level predictions (Kullback–Leibler Divergence , Chi-square ) than post-level (), which might be caused by the specific set of posts sub-sampled in the smaller dataset.

Figure 3.
The proportion of posts and sentences that are predicted and labeled as each heritage value (OUV selection criterion) as top-3 predictions by both BERT and ULMFiT. One typical sentence from each category is also given in the right part of the figure.
For heritage attributes, Table 5 shows the performance of ML models mentioned in Section 2.5.2 and Appendix B. The two ensemble models with voting and stacking settings performed equally well and significantly better than other models (except for CV accuracy of SVM), proving the rationale of using both classifiers for heritage attribute label prediction. An average top-1 confidence of and top-1 agreement of was used as the filter for . This filter resulted in around 35–50% of the images in each city as “labelled”, and the rest as “unlabelled”. Figure 4 demonstrates the distribution of “labelled” data about heritage attributes in each city. It is remarkable that although the models were only trained on data from Tripoli, they performed reasonably well in unseen cases of Amsterdam, Suzhou, and Venice, capturing typical scenes of monumental buildings, architectural elements, and gastronomy, etc., respectively. Although half of the collected images were treated as “unlabelled” due to low confidence, the negative examples are not necessarily incorrect (e.g., with Monuments and Buildings). For all cities, Urban Form Elements and People’s Activity and Association are the most dominant classes, consistent with the fact that most Flickr images are taken on the streets. Seen from the bar plots in Figure 4, the classes were relatively unbalanced, suggesting that more images from small classes might be needed or at least augmented in future applications. Furthermore, the distributions of Venice and Venice-large are similar to each other (), suggesting a good representativeness of the sampled small dataset.
Table 5.
The performance of models during the cross validation (CV) parameter selection, on the validation set, and on the test set of data from Tripoli. The best two models for each performance are in bold typeface, and the best underlined.

Figure 4.
Typical image examples in each city labelled as each heritage attribute category (depicted scene) and bar plots of their proportions in the datasets (length of bright blue background bars represent 50%). Three examples with high confidence and one negative example with low confidence (in red frame) are given. All images are 150 × 150 px “thumbnails” flagged as “downloadable”.
3.2. Graph-Level Analyses of Datasets
3.2.1. Back-End Geographical Network
The back-end spatial structures of post locations as graphs were visualized in Figure 5. Further graph statistics in all cities were given in Table 6. The urban fabric is more visible in Venice than the other two cities, as there is always a dominant large component connecting most nodes in the graph, leaving fewer unconnected isolated nodes alone. While in Amsterdam, more smaller connected components exist together with a large one; and in Suzhou, the graph is even more fragmented with smaller components. This is possibly related to the distribution of tourism destinations, collectively forming bottom-up tourism districts (or “tourist city” as proposed in Encalada-Abarca et al. [109]), which is also consistent with the zoning typology of WH property concerning urban morphology [51,52]: for Venice, the Venetian islands are included together with a larger surrounding lagoon in the WH property (formerly referred to as core zone), and are generally regarded as a tourism destination as a whole; for Amsterdam, the WH property is only a part of the old city being mapped where tourists can freely wander and take photos in areas not listed yet as interesting tourism destinations; while for Suzhou, the WH properties are themselves fragmented gardens distributed in the old city, also representing the main destinations visited by (foreign) tourists.
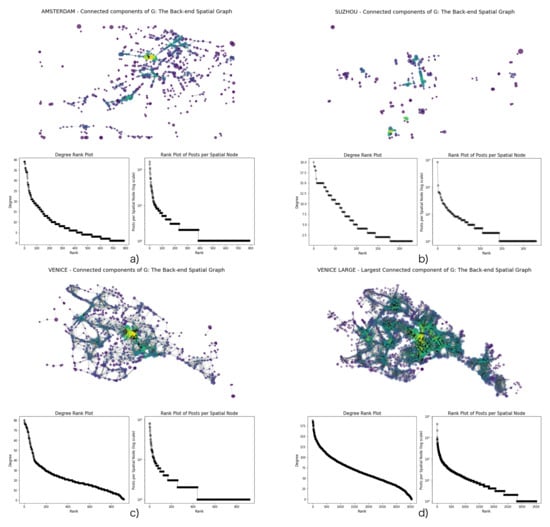
Figure 5.
The back-end geographical networks for three case studies, respectively, showing the graph structure, degree ranking distribution, and the ranking distribution of posts per geo-spatial node (on a logarithm scale) in Amsterdam, Suzhou, Venice, and Venice-XL. The sizes of nodes denote the number of nearby posts allocated to the nodes, and the colors of nodes illustrate the degree of the node on the graph. Each link connects two nodes reachable to each other within 20 min.
Table 6.
The statistics for the back-end Geographical Network . “#” means “the number of” in the table.
Furthermore, the two types of rank-size plots showing, respectively, the degree distribution and the posts-per-node distribution revealedshowed similar patterns, the latter being more heavy-tailed, a typical characteristic of large-scale complex networks [40,110], while the back-end spatial networks are relatively more regular.
3.2.2. Multi-Graphs and Sub-Graphs of Contextual Information
Table 7 shows graph statistics of three constructed sub-graphs with different link types within the multi-graph , and the simple composed graph for each city, while Figure 6 plots their [weighted] degree distributions, respectively. The multi-graphs are further visualized in Appendix Figure A1.
Table 7.
The statistics for the multi-graphs. “#” means “the number of” in the table.

Figure 6.
The rank-size plots of the degree distributions in the three cases of Amsterdam, Suzhou, and Venice, with regard to the temporal links, social links, spatial links, as well as the entire multi-graph.
The three link types provided heterogeneous characteristics: (1) the temporal graph is by definition connected, where the highest density in Amsterdam suggested the largest number of photos taken in consecutive time periods, while the largest diameter in Venice suggested the broadest span of time; (2) the social graph is structured by the relationship of users, where the largest connected components showed clusters of posts shared either by the same user, or by users who are friends or with mutual interests, the size of which in Suzhou is small because of the fewest users shown in Table 1; (3) the spatial graph shows a similar connectivity pattern with the back-end spatial networks/graphs, where the extremely small diameter and the largest density in Suzhou reassured the fragmented positions of posts; (4) although the degree distribution of three sub-graphs fluctuated due to the different socio-economic and spatio-temporal characteristics of different cities, that of the simple composed graph showed similar elbow-shaped patterns, with similar density and diameter. Moreover, the heterogeneous graph structures suggest that different parameters and/or backbone models need to be fit and fine-tuned with each link type, a common practice for deep learning on multi-graphs.
As the heterogeneous characteristics of constructed multi-graphs in the three cities are shown to be logically correspondent to reality, substantiating the generality of the methodological framework, they could be used as contextual information to aid future semi-supervised classification tasks concerning heritage values and attributes.
4. Discussion
4.1. Provisional Tasks for Urban Data Science
The datasets introduced could be used to answer questions from the perspectives of machine learning and social network analysis as well as heritage and urban studies. Table 8 gives a few provisional tasks that could be realised using the collected datasets of this paper, and further datasets to be collected using the same introduced framework.
These problems would use some or all of extracted features (visual, textual, contextual), generated labels (heritage values and attributes), constructed graph structures, and even raw data as input and output components to find the relationship function among them. Some problems are more interesting as ML/SNA problems (such as 4, 7 and 8), some are more fundamental for heritage studies and urban data science (such as 0, 1 and 6). While the former tends towards the technical and theoretical end of the whole potential range of the datasets, the latter tends towards the application end. However, to reach a reasonable performance during applications and discoveries, as is the main concern and interest for urban data science, further technical investigations and validations would be indispensable.
Even before performing such provisional tasks with the datasets created using the proposed framework in this study, the dataset creation and qualitative inspection process can already reveal interesting facts related to heritage studies, though they are performed primarily to check the quality of the created datasets in terms of their coherence and consistency. The analyses shown in Section 3.1.2 about the pseudo-labels generated for the topics of heritage values and attributes provide the most trivial contribution to cultural heritage studies. On the one hand, it demonstrates that the proposed framework could transfer knowledge from pre-trained models and provide meaningful predictions as replica of authoritarian views to justify heritage values and attributes. On the other hand, the distribution of generated labels both give an expected (as examples visualized in Figure 3 and Figure 4) and unexpected (for example the significant appearance of OUV selection criteria originally not inscribed in WHL) outcomes that could invite further heritage investigations. The analyses of generated features shown in Section 3.1.1, however, could also provide strong clues informative to heritage studies. As argued in Section 2.4, both machine-readable abstract features such as hidden-layer vectors and human-interpretable prediction categories are stored as multi-modal features. While conducting future machine learning training, sensitivity checks on such human-interpretable features could give insights on how and what the models learn. For example, one would expect a model predicting the heritage value of “criterion (vi)—association” and heritage attributes of “People’s Activity and Association” to pay much attention to the number and proportion of human faces in the image, and vice versa, hence the extraordinary appearance of both categories in the city of Amsterdam. As for the graph analyses in Section 3.2, while providing a basis for further graph-based semi-supervised learning of similar posts in nearby places, from the same time period, and by alike social groups, the spatio-temporal and socio-economic distribution of posts (as a proxy to social behaviour) already tells a story. For instance, as has been extensively argued by researchers such as Bill Hillier et al., one can often find a clear correspondence between the “buzz” or vitality of human activities in cities with the inherent centrality distributions on the network representation of the underlying space [82,83,84]. The co-appearance of large circles (large number of posts, thus high vitality) and warm colours (high centrality), and the visible clustering of warms colours (around places with good connectivity, such as the Rialto bridge and San Marco in Venice, confirming the conclusions drawn by Psarra [111]) shown in Figure 5 could further demonstrate such findings. Culturally significant locations are often important not only due to their individual attributes but also due to the embedding in their contexts, which inevitably renders cultural heritage studies contextual.
Table 8.
A few provisional tasks with formal problem definitions that could be performed. Potential scientific and social relevance for the Machine Learning community, and urban and/or heritage researchers, respectively, are given. The gray texts in the third column give a high-level categorization for each specific type of task in the context of machine learning.
Table 8.
A few provisional tasks with formal problem definitions that could be performed. Potential scientific and social relevance for the Machine Learning community, and urban and/or heritage researchers, respectively, are given. The gray texts in the third column give a high-level categorization for each specific type of task in the context of machine learning.
| ID | Problem Definition | Type of Task | As a Machine Learning/Social Network Analysis Problem | As an Urban/Heritage Study Question |
|---|---|---|---|---|
| 0 | Image Classification (semi-supervised) | Using visual features to infer categories originally induced from (possibly missing) texts with co-training [112] in few-shot learning settings [113]. | As the latest advances in heritage value assessment have been discovering the added value of inspecting texts [4], can values also be seen and retrieved from scenes of images? | |
| 1 | Text Classification (semi-supervised) | Using textual features to infer categories originally induced from images possibly with attention mechanisms [75]. | How to relate the textual descriptions to certain heritage attributes [28]? Are there crucial hints other than appeared nouns? | |
| 2 | Multi-modal Classification (semi-supervised) | Using multi-modal (multi-view) features to make inference, either with training joint representations or by making early and/or late fusions [13,112]. | How can heritage values and attributes be jointly inferred from the combined information of both visual scenes and textual expressions [26]? How can they complement each other? | |
| 3 | Node Classification (semi-supervised) | Test-beds for different graph filters such as Graph Convolution Networks [50] and Graph Attention Networks [114]. | How can the contextual information of a post contribute to the inference of its heritage values and attributes? What is the contribution of time, space, and social relations [115]? | |
| 4 | Link Prediction and Recommendation System (semi-supervised) | Test-beds for link prediction algorithms [116] considering current graph structure and node features. What is the probability that other links also should exist? | Considering the similarity of posts, would there be heritage values and attributes that also suit the interest of another user, fit another location, and/or reflect another period of time [117]? | |
| 5 | Graph Coarsening (unsupervised) | Test-beds for graph pooling [44] and graph partitioning [106] algorithms to generate coarsened graphs [118] in different resolutions. | How can we summarize, aggregate, and eventually visualize the large-scale information from the social media platforms based on their contents and contextual similarities [30]? | |
| 6 | Graph Classification (supervised) | Test-beds for graph classification algorithms [119] when more similar datasets have been collected and constructed in more case study cities. | Can we summarize the social media information of any city with World Heritage property so that the critical heritage values and attributes could be directly inferred [25]? | |
| 7 | Image/Text Generation (supervised) | Using multi-modal features to generate the missing and/or unfit images and/or textual descriptions, probably with Generative Adversarial Network [120]. | How can a typical image and/or textual description of certain heritage values and attributes at a certain location in a certain time by a certain type of user in a specific case study city be queried or even generated [28]? | |
| 8 | Attributed Multi-Graph Embedding (self-supervised) | Respectively generating a universal embedding and a context-specific embedding for each type of links in the multi-dimensional network [121], probably with random walks on graphs. | How are heritage values and attributes distributed and diffused in different contexts? Is the First Law of Geography [32] still valid in the specific social, temporal and spatial graphs? | |
| 9 | Dynamic Prediction (self-supervised) | Given the current graph structure and its features stamped with time steps, how shall it further evolve in the next time steps [36,122]? | How are the current expressions of heritage values and attributes in a city influencing the emerging post contents, the tourist behaviours, and the planning decision making [9,37]? |
Further advanced analyses for directly answering domain-specific questions in cultural heritage studies (such as Questions 3 and 8 about the mechanism of contextual influence of posts to the mapping, extraction, and inference of heritage values and attributes) have been categorized in Table 8. Note that a further distinction needs to be made within the extracted heritage values and attributes, as they may essentially be clustered into three categories: (1) core heritage values and attributes officially listed and recognized that thoroughly define the heritage status; (2) values and attributes relevant to conservation and preservation practice; (3) other values and attributes not specifically heritage-related yet are conveyed to the same heritage property by ordinary people. This distinction should be made clear for practitioners intending to make planning decisions based on the conclusions drawn from studying such datasets.
One advantage of the proposed framework is that it allows for the creation of multi-graphs from multiple senses of proximity or similarity in geographical, temporal, and/or the social space. In cases where one cannot easily find a ground truth, i.e., in exploratory analyses, having the possibility to treat the dataset as a set of connected data points instead of a powder-like set will be advantageous. The sense of similarity between data points by virtue of geographical/spatial proximity is arguably the oldest type of connection between them. However, when there is no exact physical sense of proximity in a geographical space, or when other forms of connection, e.g., through social media, are of influence, data scientists can benefit from other clues such as temporal connections related to the events or the social connections related to community structures. These can all inform potential questions to be answered in future studies.
Moreover, after retrieving knowledge of heritage values and attributes in case study cities from multi-modal UGC, for the sake of visualization, assessment and comparison during decision-making processes, further bundling and aggregation of individual data points would be desirable, as was briefly mentioned in Section 1 and also formulated in Table 8 as Question 5. This could be performed with all three proposed contextual information types denoting the proximity of data points. Data bundling and aggregation in the spatial domain would be the first action for creating a map. Depending on different use cases, this could be performed either on scale-dependent representations of geographical/administrative units (such as the natural islands divided by canals, or the so-called parish islands/communities in Venice [111]), or on identified clusters based on regular grids at different scales (such as the “tourism districts” [109]). While the use of the former (i.e., top-down boundaries) is trivial for administrative purposes, the latter (i.e., bottom-up clusters) could be arguably more generalizable in other cases, reflecting a universal collective sense of place [109]. Data bundling and aggregation in the temporal domain would map the generated features and labels on a discrete timeline at different scales (e.g., months, years, decades, etc.), presumably of sufficiently high resolution to capture the temporal dynamics and variations of data. For example, one may find that some topics are extensively mentioned in only a short period of time, while others pertain for longer spans, suggesting different patterns of public perception and communal attention, which may also help with heritage-related event detection and contribute to further planning and management strategies [9,42]. Data bundling and aggregation in the social domain, on the other hand, could help to profile the interests of user communities or user groups (e.g., local residents and tourists), which is beneficial for instance in devising recommendation systems. As argued in Section 2.6, multiple posts by the same user were not necessarily considered redundant in this study. Instead, the consistency and/or variations revealed in posted content by the same user [community/group] profile could further categorize their preference and opinions related to the cultural significance of heritage [117].
4.2. Limitations and Future Steps
No thorough human evaluations and annotations were performed during the construction of the datasets presented in this paper. This manuscript provides a way to circumvent this step by using only the confidence and [dis-]agreement of presumably well-trained models as a proxy for the more conventional “inter-annotator” agreement to show the quality of datasets and generate [pseudo-]labels [46]. This resembles the idea of using the consistency, confidence, and disagreement to improve the model performance in semi-supervised learning [48,49,91]. For the purpose of introducing a general framework that could generate more graph datasets, it is preferable to exclude humans from the loop as this would function as a bottleneck limiting the process, both in time and monetary resources, and in demanded domain knowledge. However, for applications where more accurate conclusions are needed, human evaluations on the validity, reliability, and coherence of the models are still needed. In order to gain a clear sense of the performance before implementation, the inspection of some predicted results is a prudent suggestion. As the step of [pseudo-]label generation was relatively independent from the other steps introduced in this paper, higher-quality labels annotated and evaluated by experts and/or crowd-workers could still be added at a later stage as augmentation or even replacement, as an active learning process [45,47,89]. For example, future studies are invited to integrate the more recognized classification frameworks for heritage values and heritage attributes [3,4,5], in response to the possible imprecision of concepts as pointed out in Section 2.5. Moreover, generating labels of heritage values and attributes was only a choice motivated by the use-case at hand which suffices to show the utility of the framework for exploratory analyses on attributed graphs in cases where the sources of data are inherently unstructured and the connections between data points are inherently multi-faceted. Yet, it is also possible to apply the same framework as well as parts of the implemented workflow while only replacing the classifiers mentioned in Section 2.5 with domain-specific modules appropriated to the use-cases, to answer other exploratory questions in urban data science and computational social sciences, as suggested in Section 2.1.
While scaling up the dataset construction process, such as from VEN to VEN-XL, a few changes need to be adopted. For data collection, an updated strategy is described in Appendix A. For feature and label generation, mini-batches and GPU computing significantly accelerated the process. However, the small graphs from case study cities containing around 3000 nodes already contained edges at the scale of millions, making it challenging to scale up in cases such as VEN-XL, the adjacency list of which would be at the scale of billions, easily exceeding the limits of computer memory. As a result, VEN-XL has not yet been constructed as a multi-graph. Further strategies such as using sparse matrices [123] and parallel computing should be considered. Moreover, the issue of scalability should also be considered for later graph neural network training, since the multi-graphs constructed in this study can become quite dense locally. Sub-graph sampling methods should be applied to avoid “neighbourhood explosion” [44].
Although the motivation of constructing datasets regarding heritage values and attributes from social media was to promote inclusive planning processes, the selection of social media platforms already automatically excluded those not using, or not even aware of, the platform, let alone those not using internet. The scarce usage of Flickr in China, as an example of its limitation, also suggested that conclusions drawn from such datasets may reflect perspectives from the “tourist gaze” [124] rather than local communities, and therefore losing some representativeness and generality. However, the main purpose of this paper is to provide a reproducible methodological framework with mathematical definitions, not limited to Flickr as a specific instance. Images, texts, and even audio files and videos from other platforms such as Weibo, Dianping, RED, and TikTok that are more popular in China could also add complementary local perspectives. With careful adaptions, archives, official documents, news articles, academic publications, and interview transcripts could also be constructed in similar formats for fairer comparisons, which again would fit in the general framework proposed in Section 2.1 as specified instances.
5. Conclusions
This paper introduced a novel methodological framework to construct graph-based multi-modal datasets Heri-Graphs concerning heritage values and attributes using data from the social media platform Flickr. Pre-trained machine learning models were applied to generate multi-modal features and domain-specific pseudo-labels. A full mathematical formulation is provided for the feature extraction, label generation, and graph construction processes. Temporal, spatial, and social relationships among the posts are used to construct multi-graphs, ready to be utilised as the contextual information for further semi-supervised machine learning tasks. Three case study cities, namely Amsterdam, Suzhou, and Venice containing UNESCO World Heritage properties are tested with the framework to construct sample datasets, being evaluated and filtered with the consistency of models and qualitative inspections. The datasets in the three sample cities are shown to provide meaningful information concerning the spatio-temporal and socio-economic distributions of heritage values and attributes conveyed by social media users, useful for knowledge documentation and mapping for heritage and urban studies. Such understanding is strongly aligned with the Sustainable Development Goal (SDG) 11, with its ultimate objective of making the urban heritage management processes more inclusive. The datasets created through the proposed framework provide a basis for revisiting or generalizing the First Law of Geography as formulated by Tobler to include the new senses of proximity or similarity caused by crowd behaviour and other social connections through electronic media that are arguably not directly related to geographical matters. This is especially important since heritage studies in particular, urban studies, and computational social sciences in general are almost always concerned with contextual information, which is arguably not limited to the geographical context but also to the social and temporal contexts. Such datasets have the potential to be applied by both the machine learning community and urban data scientists to help answer interesting questions of scientific/technical and social relevance, which could also be applied globally with a broad range of use cases.
Author Contributions
Conceptualization, Nan Bai, Pirouz Nourian, Renqian Luo and Ana Pereira Roders; Methodology, Nan Bai and Renqian Luo; Software, Nan Bai; Validation, Nan Bai, Pirouz Nourian, Renqian Luo and Ana Pereira Roders; Formal Analysis, Nan Bai and Pirouz Nourian; Investigation, Nan Bai; Resources, Pirouz Nourian and Ana Pereira Roders; Data Curation, Nan Bai;Writing—Original Draft Preparation, Nan Bai;Writing—Review and Editing, Nan Bai, Pirouz Nourian, Renqian Luo and Ana Pereira Roders; Visualization, Nan Bai and Pirouz Nourian; Supervision, Pirouz Nourian and Ana Pereira Roders; Project Administration, Ana Pereira Roders; Funding Acquisition, Ana Pereira Roders. All authors have read and agreed to the published version of the manuscript.
Funding
The presented study is within the framework of the Heriland-Consortium. HERILAND is funded by the European Union’s Horizon 2020 research and innovation programme under the Marie Sklodowska-Curie grant agreement No. 813883.
Institutional Review Board Statement
The study was approved by the Institutional Review Board of TU Delft with Data Protection Impact Assessment (DPIA).
Informed Consent Statement
Not applicable.
Data Availability Statement
The dataset and codes to generate datasets introduced in this paper can be found at https://github.com/zzbn12345/Heri_Graphs (accessed on 31 May 2022).
Acknowledgments
This project collected data from the Flickr social media platform only when the original owners had indicated that their posted images were “downloadable”. The copyright of all the downloaded and processed images belongs to the image owners. We are grateful to the constructive and insightful suggestions and comments from the anonymous reviewers and the editors, the discussions from our fellow colleagues, and the support from the Heriland community.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| Acc | Accuracy |
| AMS | Data of Amsterdam, The Netherlands |
| API | Application Programming Interface |
| BC-SVM | Bagging Classifier with SVMs as the internal base estimators |
| BERT | Bidirectional Encoder Representations from Transformers |
| CNN | Convolutional Neural Network |
| CC | Connected Components |
| CV | Cross-Validation |
| GNB | Gaussian Naive Bayes |
| HA | Heritage Attributes |
| HUL | Historic Urban Landscape |
| HV | Heritage Values |
| KNN | K-Nearest Neighbours |
| ML | Machine Learning |
| MLP | Multi-layer Perceptron |
| MML | Multi-modal Machine Learning |
| NLP | Natural Language Processing |
| OUV | Outstanding Universal Value |
| RF | Random Forest |
| SDG | Sustainable Development Goal |
| SNA | Social Network Analysis |
| SUZ | Data of Suzhou, China |
| SVM | Support Vector Machine |
| UGC | User-Generated Content |
| ULMFiT | Universal Language Model Fine-tuning |
| UNESCO | The United Nations Educational, Scientific and Cultural Organization |
| VEN | Data of Venice, Italy |
| VEN-XL | The extra-large version of Venice data |
| w. | with |
| WH | World Heritage |
| WHL | World Heritage List |
Appendix A. Details of Collecting the Raw Dataset
For each case study city, FlickrAPI python library was used to access the photo.search API method provided by Flickr, using the Geo-locations in Table 1 as the centroids to search the IDs of geo-tagged images within a fixed radius (5 km for Venice and Suzhou, and 2 km for Amsterdam) that covers the major urban area of the corresponding UNESCO World Heritage property. To construct comparable and compatible datasets from the three cities, a maximum of 5000 IDs were given to the search engine for each city, since Flickr users are relatively scarce in China. For all the image IDs, only those with a flag of candownload indicated by the owner were further queried, in order to respect the privacy and copyrights of Flickr users. Those images were further queried through photo.getInfo and photo.getSizes API methods to retrieve the following information: the owner’s ID; the owner’s registered location on Flickr; the title, description, and tags provided by the user; the geo-tag of the image; the timestamp of the image marking when it was taken, and URLs to download the Large Square (150 × 150 px) and Small 320 (320 × 240 px) versions of the original image. The images that contained the user tag of “erotic” were excluded from the query. Then, all the images of both sizes were saved and transformed into RGB format as raw visual data.
A stop-word list was used to remove the HTML symbols and other formatting elements from the texts and to filter out textual data that were mainly (1) a description of the camera used, (2) a default image name generated by the camera, (3) an advertisement or a promotion. Google Translator API from the Deep Translator python library was used to detect the languages of the posts on the sentence level to mark whether the sentence was written in English, the local language (Dutch, Chinese, and Italian, respectively, for the three cities), or any other languages. The same API was used to translate the non-English sentences into English. Then, all the valid sentences from any textual field of the same post were merged into a new field named Revised Text as the raw textual data.
Furthermore, the public contact lists and group (subscription) lists of all the retrieved owners were queried through the contacts.getPublicList and the people.getPublicGroups API methods, while all user and group information was only considered as a [semi]-anonymous ID with respect to the privacy policy.
To test the scalability of the methodological workflow, another larger dataset without the limit of maximum 5000 IDs was also collected in Venice (VEN-XL). The API of Flickr has a limitation at the scale of queries, which would return occasional errors during times when the server was experiencing functional issues. This requires a different strategy during data collection of the larger dataset. In this study, a 20 × 20 grid was tiled in the area of Venice (from 45.420855 N 12.291054 E to 45.448286 N 12.369234 E) to collect the post IDs from the centroid of each tile within a radius of 0.3 km, which were later aggregated by removing the duplicated IDs collected by multiple tiles to form the entire large dataset, similar to the strategy applied by Bekker [125]. The further steps of data cleaning and pre-processing remained the same with the smaller datasets.
Appendix B. Details for Machine Learning Models
A dataset with 902 sample images collected in Tripoli, Lebanon and classified with expert-based annotations presented in Ginzarly et al. [26] was used to train several ML models to replicate the experts’ behaviour on classifying depicted scenery. For each image, a unique class label among the 9 depicted scenes mentioned in Table A4 was provided. In total, 10% of the images were separated and kept away during training as the test dataset and the remaining 812 images were used to train ML models with Scikit-learn python library [95]. Among the 812 data points, train_test_split method of the library was further used to split out a validation dataset with 203 samples (25%). The 512-dimensional visual representation introduced in Section 2.4.1 was generated from the images as the input of ML models, while the class label was used as categorical output of the multi-class single-label classification task.
For each of the selected ML models, GridSearchCV function with 10-fold cross-validation was used to wrap the model with a set of tunable parameters in a small range to be selected, while the average top-1 accuracy was used as the criterion for model selection. All 812 samples were input to the cross-validation (CV) to tune the hyper-parameters, after which the trained models with their optimal hyper-parameters were tested on the 203 validation data samples and the unseen test dataset with the remaining 90 samples. For the latter steps, the top-1 accuracy and macro-average F1 scores (harmonic average of the precision and recall scores) of all classes were used as the evaluation metrics. All experiments were conducted using a 12th Gen Intel(R) Core(TM) i7-12700KF CPU.
The implementation details of the models are as follows:
Appendix B.1. MLP
The model used L2 penalty of , solver of stochastic gradient descent, adaptive learning rate and early stopping with maximum 300 iterations. It was tuned on the initial learning rate in , and hidden sizes of one layer in or two layers in . The best model had two hidden layers of (256,128) with a learning rate of 0.05.
Appendix B.2. KNN
The model was tuned on the number of neighbours in range , and the weights of uniform, Manhattan distance, or Euclidean distance. The best model had six neighbours in Euclidean distance.
Appendix B.3. GNB
The model did not have a tunable hyper-parameter.
Appendix B.4. SVM
The model was tuned on the kernel type in , regularization parameter C in range , kernel coefficient gamma in , and degree of the polynomial kernel function in range . The best model used RBF kernel with scaled weights and regularization parameter of 1.8.
Appendix B.5. RF
The model did not restrict the maximum depth of the trees. It was tuned on the class weight in settings of uniform, balanced, and balanced over sub-samples, and the minimum samples required to split a tree node in . The best model had a balanced class weight and a minimum of 17 samples to split a tree node.
Appendix B.6. Bagging
The model had 10 base estimators in the ensemble. It was tuned on the base estimator in SVM, Decision Tree, and KNN classifiers, and the proportion of maximum features used to train internal weak classifiers within the range . The best model used maximum 50% of all features to fit SVM as internal base estimator.
Appendix B.7. Voting
The model took the first six aforementioned trained models as inputs in the ensemble to vote for the output and was tuned on the choice of hard (voting on top-1 prediction) and soft (voting on the averaged logits) voting mechanism. The best model used the soft voting mechanism.
Appendix B.8. Stacking
The model stacked the outputs of the first six aforementioned trained models in the ensemble followed by a final estimator and was tuned on the choice of final estimator among SVM and Logistic Regression. The best model used Logistic Regression as the final estimator.
Appendix C. Nomenclature
Table A1 and Table A2 give an overview of the mathematical notations and functions used in this paper.
Table A1.
The nomenclature of mathematical notations used in this paper in alphabetic order. All superscripts of matrices are merely tags, not to be confused with exponents and operations, with the exception of transpose operator .
Table A1.
The nomenclature of mathematical notations used in this paper in alphabetic order. All superscripts of matrices are merely tags, not to be confused with exponents and operations, with the exception of transpose operator .
| Symbol | Data Type/Shape | Description |
|---|---|---|
| Matrix of Boolean | The adjacency matrix of all post nodes in the set that have at least one link connecting them as a composed simple graph. | |
| Matrix of Float , | The weighted adjacency matrix of each of the three sub-graphs of the multi-graph , “(*)” represents one of the link types in {TEM, SOC, SPA}. | |
| Matrix of Boolean | The adjacency matrix of all unique users marking their direct friendship which also included the relationship among themselves. | |
| Matrix of Float | The weighted adjacency matrix of all unique users marking their mutual interest in terms of the Jaccard Index of the public groups that they follow. | |
| Float scalars | Parameters adjusting the weights of linear combination in relationship matrices and . | |
| Float scalar | The threshold to define mutual interest of two users as the Jaccard Index of public groups. | |
| Float Scalar | The Chi-square statistics of two distributions. | |
| Object Tuples | The tuple of all raw data (image, sentences, user ID, timestamp, and geo-location) from one sample point. | |
| Float Scalar | The Kullback–Leibler (KL) divergence of two distributions. | |
| Float Scalar | An arbitrary small number to avoid zero-division. | |
| Matrix of Integers and Floats | The face recognition result of an image sample in terms of the number of faces detected , the model confidence for the prediction , and the proportion of total area of bounding boxes of detected faces to the total area of images . | |
| Undirected weighted graph | The complete spatial network in a city weighted by the travel time with all sorts of transportation between spatial nodes. | |
| G | Undirected weighted graph | The spatial network in a city weighted by the travel time between spatial nodes (no more than 20 min) that have at least one sample posted near them. |
| Weighted multi-graph | The graph including the temporal, social, and spatial links among the post nodes from set , weighted by the respective connection strengths . | |
| Undirected weighted graph , | The sub-graph of the multi-graph , while “(*)” represents one of the link types in {TEM, SOC, SPA}. | |
| Matrix of Floats | The last hidden layer for [CLS] token of BERT model pre-trained on WHOSe_Heritage. | |
| Matrix of Floats | The last hidden layer of ResNet-18 model pre-trained on Places365. | |
| Integer Indices | The index of samples in the dataset of one case city. | |
| Tensor of Integers within of size or | The raw image data of one sample post with RGB channels. | |
| Matrix of Boolean | The diagonal identity matrix marking the identity of unique users in . | |
| Integer Indices | The index of users in the ordered set of all unique users from one case city. | |
| k | Integer Indices | The index of timestamps in the ordered set of all unique timestamps from one case city. |
| K | Integer | The sample size (number of posts) collected in one case city. |
| Matrix of Floats | The confidence indicator matrix for heritage attributes labels including the top-n confidence and agreement between VOTE and STACK models. | |
| Matrix of Floats | The confidence indicator matrix for heritage values labels including the top-n confidence and agreement between BERT and ULMFiT models. | |
| Integer Indices | The index of nodes in the ordered set V of all spatial nodes from one case city. | |
| Tuple of Floats | The geographical coordinate of latitude () and longitude () as location of one sample. | |
| Matrix of logit vectors | The last softmax layer of ResNet-18 model pre-trained on SUN predicting scene attributes. | |
| Matrix of logit vectors | The last softmax layer of ResNet-18 model pre-trained on Places365 predicting scene categories. | |
| A set of objects | The set of machine learning models used to train classifiers on Tripoli data. | |
| Matrix of Boolean | The language detection result of the original language appearance of the sentences in each sample, in terms of English , local language , and other languages . | |
| Matrix of Float , | The embedding matrices of each of the samples to a N-dimensional vector based on the general structure of the multi-graph and the specific types of links. | |
| Set of Strings or Empty Set | The processed textual data as a set of individual sentences that have a valid semantic meaning and have been translated into English. | |
| Boolean Matrix | The one-hot embedding matrix of the samples corresponding to the geo-node set V. | |
| Matrix of Float | A matrix marking the spatial closeness of all the unique spatial nodes from set V that can be reached within 20 min. | |
| An ordered Set | The ordered set of all unique timestamps from one case city. | |
| Timestamp | A timestamp in the ordered set of all unique timestamps. | |
| Timestamp | A timestamp indexed with sample ID in the ordered set of all unique timestamps. | |
| Boolean Matrix | The one-hot embedding matrix of the samples corresponding to the timestamp set . | |
| Matrix of Float | A matrix marking the temporal similarity of all the unique timestamps from set . | |
| An ordered Set | The ordered set of all unique users from one case study city. | |
| User ID Object | An instance of user in the ordered set of all unique users. | |
| User ID Object | An instance of user indexed with sample ID in the ordered set of all unique users. | |
| Boolean Matrix | The one-hot embedding matrix of the samples corresponding to the user set . | |
| Matrix of Float | A matrix marking the social similarity of all the unique users from set , as a linear combination of identity matrix and adjacency matrices . | |
| V | A set of nodes | The set of all the spatial nodes that have at least one sample posted near them. |
| Spatial node | A node in the set V of all spatial nodes that have at least one sample posted near them. | |
| A set of nodes | The set of all nodes of posts in one case city. | |
| Post/Sample node | A node in the set of all nodes of posts in one case city. | |
| Vector of Float | The weight vector of spatial network G and post graphs , these weights are directly interchangeable with the adjacency matrices. | |
| Matrix of Floats and Integers | The final visual feature concatenating the hidden layer , the face detection results , the filtered top-5 scene prediction , and the filtered top-10 attribute prediction . | |
| Matrix of Floats and Integers | The final textual feature concatenating the hidden layer of BERT on [CLS] token, and the original language detection results . | |
| Matrix of Floats | The final generated label of heritage attributes on 9 depicted scenes, as the average of prediction from VOTE and STACK models. | |
| Matrix of Floats | The final generated label of heritage values on 10 OUV selection criteria and an additional negative class, as the average of prediction from BERT and ULMFiT models. |
Table A2.
The nomenclature of functions defined and used in this paper in alphabetic order.
Table A2.
The nomenclature of functions defined and used in this paper in alphabetic order.
| Symbol | Data Type/Shape | Description |
|---|---|---|
| Function outputting a set of floats or objects | The set of largest n elements of any float vector . | |
| Function inputting a sentence/paragraph or a batch of sentences/paragraphs, outputting a vector or a matrix of vectors | The pre-trained uncased BERT model fine-tuned on WHOSe_Heritage with the model parameters that can process some textual inputs into the 768-dimensional hidden output vector of the [CLS] token. | |
| Function inputting a tensor or a batch of tensors, outputting three vectors or three matrices of vectors | The ResNet-18 model pre-trained on Places365 dataset with the model parameters that can process the image tensor into the predicted vectors of scenes , predicted vectors of attributes , and the last hidden layer . | |
| Function inputting a sentence/paragraph or a batch of sentences/paragraphs, outputting a vector or a matrix of vectors | The end-to-end pre-trained uncased BERT model fine-tuned on WHOSe_Heritage with the model parameters together with the MLP classifiers that can process some textual inputs into the logit prediction vector of 11 heritage value classes concerning OUV. | |
| Function inputting a sentence/paragraph or a batch of sentences/paragraphs, outputting a vector or a matrix of vectors | The end-to-end pre-trained ULMFiT model fine-tuned on WHOSe_Heritage with the model parameters together with the MLP classifiers that can process some textual inputs into the logit prediction vector of 11 heritage value classes concerning OUV. | |
| Function inputting a vector or a batch of vectors, outputting a vector or a matrix of vectors | The ensemble Voting Classifier with model parameter of machine learning models from with their respective model parameters , which processes the visual feature vector into the logit prediction vector of 9 heritage attribute classes concerning depicted scenes. | |
| Function inputting a vector or a batch of vectors, outputting a vector or a matrix of vectors | The ensemble Stacking Classifier with model parameter of machine learning models from with their respective model parameters , which processes the visual feature vector into the logit prediction vector of 9 heritage attribute classes concerning depicted scenes. | |
| Function outputting an ordered set of objects | The set of public groups that are followed by user . | |
| Function outputting a non-negative float | The Jaccard Index of any two sets as the cardinality of the intersection of the two sets over that of the union of them. | |
| Function outputting a float | The largest element of any float vector . | |
| Function both inputting and outputting a logit vector | The activation filter to keep the top-n entries of any logit vector and smooth all the others entries based on the total confidence (sum) of top-n entries. |
Appendix D. Definition of Categories for Heritage Values and Attributes
Table A3 and Table A4, respectively, give a detailed definition of heritage values (in terms of Outstanding Universal Value selection criteria) and heritage attributes (in terms of depicted scenes) categories applied in this paper.
Table A3.
The definition for each UNESCO World Heritage OUV selection criterion as heritage value category in this dataset and its main topic according to previous scholars [2,54,55].
Table A3.
The definition for each UNESCO World Heritage OUV selection criterion as heritage value category in this dataset and its main topic according to previous scholars [2,54,55].
| Criterion | Focus | Definition |
|---|---|---|
| (i) | Masterpiece | To represent a masterpiece of human creative genius; |
| (ii) | Values/Influence | To exhibit an important interchange of human values, over a span of time or within a cultural area of the world, on developments in architecture or technology, monumental arts, town-planning or landscape design; |
| (iii) | Testimony | To bear a unique or at least exceptional testimony to a cultural tradition or to a civilization which is living or which has disappeared; |
| (iv) | Typology | To be an outstanding example of a type of building, architectural or technological ensemble or landscape which illustrates (a) significant stage(s) in human history; |
| (v) | Land-Use | To be an outstanding example of a traditional human settlement, land-use, or sea-use which is representative of a culture (or cultures), or human interaction with the environment especially when it has become vulnerable under the impact of irreversible change; |
| (vi) | Associations | To be directly or tangibly associated with events or living traditions, with ideas, or with beliefs, with artistic and literary works of outstanding universal significance; |
| (vii) | Natural Beauty | To contain superlative natural phenomena or areas of exceptional natural beauty and aesthetic importance; |
| (viii) | Geological Process | To be outstanding examples representing major stages of earth’s history, including the record of life, significant on-going geological processes in the development of landforms, or significant geomorphic or physiographic features; |
| (ix) | Ecological Process | To be outstanding examples representing significant on-going ecological and biological processes in the evolution and development of terrestrial, fresh water, coastal and marine ecosystems and communities of plants and animals; |
| (x) | Bio-diversity | To contain the most important and significant natural habitats for in situ conservation of biological diversity, including those containing threatened species of outstanding universal value from the point of view of science or conservation. |
Table A4.
The definition for depicted scenery as heritage attribute category in this dataset and its tangible/intangible type according to previous scholars [5,26,93].
Table A4.
The definition for depicted scenery as heritage attribute category in this dataset and its tangible/intangible type according to previous scholars [5,26,93].
| Attribute | Type | Definition |
|---|---|---|
| Monuments and Buildings | Tangible | The exterior of a whole building, structure, construction, edifice, or remains that host(ed) human activities, storage, shelter or other purpose; |
| Building Elements | Tangible | Specific elements, details, or parts of a building, which can be constructive, constitutive, or decorative; |
| Urban Form Elements | Tangible | Elements, parts, components, or aspects of/in the urban landscape, which can be a construction, structure, or space, being constructive, constitutive, or decorative; |
| Urban Scenery | Tangible | A district, a group of buildings, or specific urban ensemble or configuration in a wider (urban) landscape or a specific combination of cultural and/or natural elements; |
| Natural Features and Landscape Scenery | Tangible | Specific flora and/or fauna, such as water elements of/in the historic urban landscape produced by nature, which can be natural and/or designed; |
| Interior Scenery | Tangible/Intangible | The interior space, structure, construction, or decoration that host(ed) human activity, showing a specific (typical, common, special) use or function of an interior place or environment; |
| People’s Activity and Association | Intangible | Human associations with a place, element, location, or environment, which can be shown with the activities therein; |
| Gastronomy | Intangible | The (local) food-related practices, traditions, knowledge, or customs of a community or group, which may be associated with a community or society and/or their cultural identity or diversity; |
| Artifact Products | Intangible | The (local) artifact-related practices, traditions, knowledge, or customs of a community or group, which may be associated with a community or society and/or their cultural identity or diversity. |
Appendix E. Multi-Graph Visualization
The connected components of each type of temporal, social, and spatial links in each case study city are visualized in Figure A1, respectively. The spring_layout algorithm of NetworkX python library with optimal distance between nodes k of 0.1 and random seed of 10396953 are used to output the graphs.
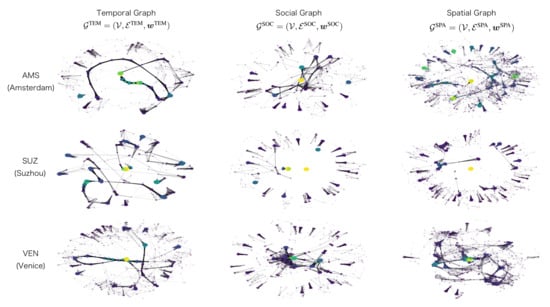
Figure A1.
The subgraphs of the multi-graphs in each case study city visualized using spring layout in NetworkX. The node size and colour reflect the degrees, and link thickness the edge weights.
References
- UNESCO. Convention Concerning the Protection of the World Cultural and Natural Heritage; Technical Report; UNESCO: Paris, France, 1972. [Google Scholar]
- UNESCO. Operational Guidelines for the Implementation of the World Heritage Convention; Technical Report; UNESCO World Heritage Centre: Paris, France, 2008. [Google Scholar]
- Pereira Roders, A. Re-Architecture: Lifespan Rehabilitation of Built Heritage. Ph.D. Thesis, Technische Universiteit Eindhoven, Eindhoven, The Netherlands, 2007. [Google Scholar] [CrossRef]
- Tarrafa Silva, A.; Pereira Roders, A. The cultural significance of World Heritage cities: Portugal as case study. In Proceedings of the 2nd International Conference on Heritage and Sustainable Development (HERITAGE 2010), Evora, Portugal, 22–26 June 2010; pp. 255–263. [Google Scholar] [CrossRef]
- Veldpaus, L. Historic Urban Landscapes: Framing the Integration of Urban and Heritage Planning in Multilevel Governance. Ph.D. Thesis, Technische Universiteit Eindhoven, Eindhoven, The Netherlands, 2015. [Google Scholar]
- Rakic, T.; Chambers, D. World Heritage: Exploring the Tension Between the National and the ‘Universal’. J. Herit. Tour. 2008, 2, 145–155. [Google Scholar] [CrossRef]
- Bonci, A.; Clini, P.; Martin, R.; Pirani, M.; Quattrini, R.; Raikov, A. Collaborative Intelligence Cyber-physical System for the Valorization and Re-use of Cultural Heritage. J. Inf. Technol. Constr. 2018, 23, 305–323. [Google Scholar]
- Pereira Roders, A. The Historic Urban Landscape Approach in Action: Eight Years Later. In Reshaping Urban Conservation; Springer: Berlin/Heidelberg, Germany, 2019; pp. 21–54. [Google Scholar] [CrossRef]
- Bai, N.; Nourian, P.; Pereira Roders, A. Global Citizens and World Heritgae: Social Inclusion of Online Communities in Heritage Planning. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2021, XLVI-M-1-2021, 23–30. [Google Scholar] [CrossRef]
- UNESCO. Recommendation on the Historic Urban Landscape; Technical Report; UNESCO: Paris, France, 2011. [Google Scholar]
- Lu, W.; Stepchenkova, S. User-Generated Content as a Research Mode in Tourism and Hospitality Applications: Topics, Methods, and Software. J. Hosp. Mark. Manag. 2015, 24, 119–154. [Google Scholar] [CrossRef]
- Pickering, C.; Rossi, S.D.; Hernando, A.; Barros, A. Current Knowledge and Future Research Directions for the Monitoring and Management of Visitors in Recreational and Protected Areas. J. Outdoor Recreat. Tour. 2018, 21, 10–18. [Google Scholar] [CrossRef]
- Baltrusaitis, T.; Ahuja, C.; Morency, L.P. Multimodal Machine Learning: A Survey and Taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 423–443. [Google Scholar] [CrossRef]
- Marine-Roig, E.; Anton Clavé, S. Tourism Analytics with Massive User-Generated Content: A Case Study of Barcelona. J. Destin. Mark. Manag. 2015, 4, 162–172. [Google Scholar] [CrossRef]
- Amato, F.; Cozzolino, G.; Di Martino, S.; Mazzeo, A.; Moscato, V.; Picariello, A.; Romano, S.; Sperlí, G. Opinions Analysis in Social Networks for Cultural Heritage Applications. Smart Innov. Syst. Technol. 2016, 55, 577–586. [Google Scholar] [CrossRef]
- Lee, H.; Kang, Y. Mining Tourists’ Destinations and Preferences through LSTM-based Text Classification and Spatial Clustering Using Flickr Data. Spat. Inf. Res. 2021, 29, 825–839. [Google Scholar] [CrossRef]
- Zhang, F.; Zhou, B.; Ratti, C.; Liu, Y. Discovering Place-informative Scenes and Objects Using Social Media photos. R. Soc. Open Sci. 2019, 6, 181375. [Google Scholar] [CrossRef]
- Giglio, S.; Bertacchini, F.; Bilotta, E.; Pantano, P. Using Social Media to Identify Tourism Attractiveness in Six Italian Cities. Tour. Manag. 2019, 72, 306–312. [Google Scholar] [CrossRef]
- Campillo-Alhama, C.; Martinez-Sala, A.M. Events 2.0 in the Transmedia Branding Strategy of World Cultural Heritage Sites. Prof. Inf. 2019, 28, e280509. [Google Scholar] [CrossRef]
- Liew, C.L. Participatory Cultural Heritage: A Tale of Two Institutions’ Use of Social Media. D-Lib Mag. 2014, 20, 1–17. [Google Scholar] [CrossRef]
- Williams, N.L.; Inversini, A.; Ferdinand, N.; Buhalis, D. Destination eWOM: A Macro and Meso Network Approach? Ann. Tour. Res. 2017, 64, 87–101. [Google Scholar] [CrossRef]
- Giglio, S.; Bertacchini, F.; Bilotta, E.; Pantano, P. Machine Learning and Point of Interests: Typical Tourist Italian Cities. Curr. Issues Tour. 2019, 23, 1646–1658. [Google Scholar] [CrossRef]
- Gabrielli, L.; Rinzivillo, S.; Ronzano, F.; Villatoro, D. From Tweets to Semantic Trajectories: Mining Anomalous Urban Mobility Patterns. In Citizen in Sensor Networks; Lecture Notes in Artificial Intelligence; Nin, J., Villatoro, D., Eds.; Springer: Berlin, Germany, 2014; Volume 8313, pp. 26–35. [Google Scholar] [CrossRef]
- Aggarwal, C.C. An Introduction to Social Network Data Analytics. In Social Network Data Analytics; Aggarwal, C.C., Ed.; Springer: Berlin/Heidelberg, Germany, 2011; Chapter 1; pp. 1–15. [Google Scholar] [CrossRef]
- Monteiro, V.; Henriques, R.; Painho, M.; Vaz, E. Sensing World Heritage An Exploratory Study of Twitter as a Tool for Assessing Reputation. In Proceedings of the Computational Science and Its Applications—ICCSA 2014, Guimarães, Portugal, 30 June–3 July 2014; Pt II. Volume 8580, pp. 404–419. [Google Scholar]
- Ginzarly, M.; Pereira Roders, A.; Teller, J. Mapping Historic Urban Landscape Values through Social Media. J. Cult. Herit. 2019, 36, 1–11. [Google Scholar] [CrossRef]
- Crandall, D.; Backstrom, L.; Huttenlocher, D.; Kleinberg, J. Mapping the World’s Photos. In Proceedings of the 18th International World Wide Web Conference—WWW’09, Madrid, Spain, 20–24 April 2009; pp. 761–770. [Google Scholar] [CrossRef]
- Gomez, R.; Gomez, L.; Gibert, J.; Karatzas, D. Learning from #Barcelona Instagram data what Locals and Tourists post about its Neighbourhoods. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018; pp. 530–544. [Google Scholar] [CrossRef]
- Kang, Y.; Cho, N.; Yoon, J.; Park, S.; Kim, J. Transfer Learning of a Deep Learning Model for Exploring Tourists’ Urban Image Using Geotagged Photos. ISPRS Int. J. Geo-Inf. 2021, 10, 137. [Google Scholar] [CrossRef]
- Cho, N.; Kang, Y.; Yoon, J.; Park, S.; Kim, J. Classifying Tourists’ Photos and Exploring Tourism Destination Image Using a Deep Learning Model. J. Qual. Assur. Hosp. Tour. 2022, 1–29. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Tobler, W.R. A Computer Movie Simulating Urban Growth in the Detroit Region. Econ. Geogr. 1970, 46, 234–240. [Google Scholar] [CrossRef]
- Pearson, K. The Problem of the Random Walk. Nature 1905, 72, 294. [Google Scholar] [CrossRef]
- Batty, M. The New Science of Cities; MIT Press: Cambridge, MA, USA, 2013. [Google Scholar]
- Nourian, P. Configraphics: Graph Theoretical Methods for Design and Analysis of Spatial Configurations; TU Delft: Delft, The Netherlands, 2016. [Google Scholar]
- Ren, Y.; Cheng, T.; Zhang, Y. Deep Spatio-temporal Residual Neural Networks for Road-network-based Data Modeling. Int. J. Geogr. Inf. Sci. 2019, 33, 1894–1912. [Google Scholar] [CrossRef]
- Zhang, Y.; Cheng, T. Graph Deep Learning Model for Network-based Predictive Hotspot Mapping of Sparse Spatio-temporal Events. Comput. Environ. Urban Syst. 2020, 79, 101403. [Google Scholar] [CrossRef]
- Wasserman, S.; Faust, K. Social Network Analysis: Methods and Applications; Cambridge University Press: Cambridge, UK, 1994. [Google Scholar]
- Lazer, D.; Pentland, A.; Adamic, L.; Aral, S.; Barabasi, A.L.; Brewer, D.; Christakis, N.; Contractor, N.; Fowler, J.; Gutmann, M.; et al. Social science. Computational Social Science. Science 2009, 323, 721–723. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Barabási, A.L. Network science. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2013, 371, 20120375. [Google Scholar] [CrossRef] [PubMed]
- Pentland, A. Social Physics: How Social Networks Can Make Us Smarter; Penguin: New York, NY, USA, 2015. [Google Scholar]
- Cheng, T.; Wicks, T. Event Detection Using Twitter: A Spatio-temporal Approach. PLoS ONE 2014, 9, e97807. [Google Scholar]
- Zhang, Z.; Cui, P.; Zhu, W. Deep Learning on Graphs: A Survey. IEEE Trans. Knowl. Data Eng. 2022, 34, 249–270. [Google Scholar] [CrossRef]
- Ma, Y.; Tang, J. Deep Learning on Graphs; Cambridge University Press: Cambridge, UK, 2021. [Google Scholar]
- Prince, M. Does Active Learning Work? A Review of the Research. J. Eng. Educ. 2004, 93, 223–231. [Google Scholar] [CrossRef]
- Nowak, S.; Rüger, S. How Reliable are Annotations via Crowdsourcing. In Proceedings of the International Conference on Multimedia Information Retrieval, Philadelphia, PA, USA, 29–31 March 2010; pp. 557–566. [Google Scholar] [CrossRef]
- Settles, B. From Theories to Queries: Active Learning in Practice. In Proceedings of the Active Learning and Experimental Design Workshop in Conjunction with AISTATS 2010, JMLR Workshop and Conference Proceedings, Sardinia, Italy, 16 May 2010; pp. 1–18. [Google Scholar]
- Zhou, Z.H.; Li, M. Semi-supervised Learning by Disagreement. Knowl. Inf. Syst. 2010, 24, 415–439. [Google Scholar] [CrossRef]
- Lee, D.H. Pseudo-label: The Simple and Efficient Semi-supervised Learning Method for Deep Neural Networks. In Proceedings of the Workshop on Challenges in Representation Learning, ICML 2013, Atlanta, GA, USA, 6–21 June 2013; Volume 3, p. 896. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017; pp. 1–14. [Google Scholar]
- Pereira Roders, A. Revealing the World Heritage Cities and their Varied Natures. In Proceedings of the 2nd International Conference on Heritage and Sustainable Development (HERITAGE 2010), Evora, Portugal, 22–26 June 2010; pp. 245–253. [Google Scholar]
- Valese, M.; Noardo, F.; Pereira Roders, A. World Heritage Mapping in a Standard-based Structured Geographical Information System. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, XLIII-B4-2020, 81–88. [Google Scholar] [CrossRef]
- Jokilehto, J. Aesthetics in the World Heritage Context. In Proceedings of the International Conference of ICOMOS, ICCROM and Fondazione Romualdo Del Bianco, Florence, Italy, 2–4 March 2007; Polistampa: Florence, Italy, 2008; pp. 183–194. [Google Scholar]
- Jokilehto, J. What Is OUV? Defining the Outstanding Universal Value of Cultural World Heritage Properties; Technical Report; ICOMOS: Berlin, Germany, 2008. [Google Scholar]
- Bai, N.; Nourian, P.; Luo, R.; Pereira Roders, A. “What is OUV” Revisited: A Computational Interpretation on the Statements of Outstanding Universal Value. ISPRS Ann. Photogramm. Remote. Sens. Spat. Inf. Sci. 2021, VIII-M-1-2021, 25–32. [Google Scholar] [CrossRef]
- Van Dijck, J. Flickr and the Culture of Connectivity: Sharing views, Experiences, Memories. Mem. Stud. 2011, 4, 401–415. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Tenkanen, H.; Di Minin, E.; Heikinheimo, V.; Hausmann, A.; Herbst, M.; Kajala, L.; Toivonen, T. Instagram, Flickr, or Twitter: Assessing the Usability of Social Media Data for Visitor Monitoring in Protected Areas. Sci. Rep. 2017, 7, 17615. [Google Scholar] [CrossRef] [PubMed]
- Li, D.; Zhou, X.; Wang, M. Analyzing and Visualizing the Spatial Interactions between Tourists and Locals: A Flickr Study in ten US Cities. Cities 2018, 74, 249–258. [Google Scholar] [CrossRef]
- Huiskes, M.J.; Lew, M.S. The MIR Flickr Retrieval Evaluation. In Proceedings of the 1st International ACM Conference on Multimedia Information Retrieval, MIR2008, Co-Located with the 2008 ACM International Conference on Multimedia, MM’08, Vancouver, BC, Canada, 30–31 October 2008; pp. 39–43. [Google Scholar] [CrossRef]
- Chua, T.S.; Tang, J.; Hong, R.; Li, H.; Luo, Z.; Zheng, Y. NUS-WIDE: A Real-world Web Image Database from National University of Singapore. In Proceedings of the ACM International Conference on Image and Video Retrieval, Santorini Island, Greece, 8–10 July 2009; pp. 1–9. [Google Scholar]
- Tang, L.; Liu, H. Relational Learning via Latent Social Dimensions. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; pp. 817–826. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. ImageNet: A Large-scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: New York, NY, USA, 2009; pp. 248–255. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Annual Conference on Neural Information Processing Systems, Lake Tahoe, CA, USA, 3–8 December 2012. [Google Scholar]
- Plummer, B.A.; Wang, L.; Cervantes, C.M.; Caicedo, J.C.; Hockenmaier, J.; Lazebnik, S. Flickr30k Entities: Collecting Region-to-phrase Correspondences for Richer Image-to-sentence Models. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2641–2649. [Google Scholar]
- Zhou, Y.; Long, Y. SinoGrids: A Practice for Open Urban Data in China. Cartogr. Geogr. Inf. Sci. 2016, 43, 379–392. [Google Scholar] [CrossRef]
- Zeng, H.; Zhou, H.; Srivastava, A.; Kannan, R.; Prasanna, V. GraphSAINT: Graph Sampling based Inductive Learning Method. arXiv 2019, arXiv:1907.04931. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Xiao, J.; Torralba, A.; Oliva, A. Learning Deep Features for Scene Recognition Using Places Database. In Proceedings of the Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 1–9. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 Million Image Database for Scene Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1452–1464. [Google Scholar] [CrossRef]
- Patterson, G.; Hays, J. SUN Attribute Database: Discovering, Annotating, and Recognizing Scene Attributes. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE: New York, NY, USA, 2012; pp. 2751–2758. [Google Scholar]
- Patterson, G.; Xu, C.; Su, H.; Hays, J. The SUN Attribute Database: Beyond Categories for Deeper Scene Understanding. Int. J. Comput. Vis. 2014, 108, 59–81. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A Unified Embedding for Face Recognition and Clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Cao, Q.; Shen, L.; Xie, W.; Parkhi, O.M.; Zisserman, A. VGGFace2: A Dataset for Recognising Faces across Pose and Age. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; IEEE: New York, NY, USA, 2018; pp. 67–74. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; Volume 1 (Long and Short Papers), pp. 4171–4186. [Google Scholar]
- Clark, K.; Khandelwal, U.; Levy, O.; Manning, C.D. What Does BERT Look at? In An Analysis of BERT’s Attention. In Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, BlackboxNLP@ACL 2019, Florence, Italy, 1 August 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 276–286. [Google Scholar] [CrossRef]
- Sun, C.; Qiu, X.; Xu, Y.; Huang, X. How to Fine-Tune BERT for Text Classification? In Proceedings of the China National Conference on Chinese Computational Linguistics, Kunming, China, 18–20 October 2019; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). Springer: Cham, Switzerland, 2019; Volume 11856 LNAI, pp. 194–206. [Google Scholar] [CrossRef]
- Bai, N.; Luo, R.; Nourian, P.; Pereira Roders, A. WHOSe Heritage: Classification of UNESCO World Heritage Statements of ”Outstanding Universal Value” with Soft Labels. In Findings of the Association for Computational Linguistics: EMNLP 2021; Association for Computational Linguistics: Punta Cana, Dominican Republic, 2021; pp. 366–384. [Google Scholar]
- Reiter, R. Towards a Logical Reconstruction of Relational Database Theory. In Topics in Information Systems; Brodie, M.L., Mylopoulos, J., Schmidt, J.W., Eds.; Springer: New York, NY, USA, 1984; pp. 191–238. [Google Scholar] [CrossRef]
- Nourian, P.; Rezvani, S.; Sariyildiz, I.; van der Hoeven, F. Spectral Modelling for Spatial Network Analysis. In Proceedings of the Symposium on Simulation for Architecture and Urban Design (simAUD 2016), London, UK, 16–18 May 2016; pp. 103–110. [Google Scholar]
- Hillier, B.; Hanson, J. The Social Logic of Space; Cambridge University Press: Cambridge, UK, 1989. [Google Scholar]
- Penn, A. Space Syntax and Spatial Cognition: Or why the Axial Line? Environ. Behav. 2003, 35, 30–65. [Google Scholar] [CrossRef]
- Ratti, C. Space Syntax: Some Inconsistencies. Environ. Plan. Plan. Des. 2004, 31, 487–499. [Google Scholar] [CrossRef]
- Blanchard, P.; Volchenkov, D. Mathematical Analysis of Urban Spatial Networks; Springer: Berlin, Germany, 2008. [Google Scholar]
- Boeing, G. OSMnx: New Methods for Acquiring, Constructing, Analyzing, and Visualizing Complex Street Networks. Comput. Environ. Urban Syst. 2017, 65, 126–139. [Google Scholar] [CrossRef] [Green Version]
- Howley, P.; Scott, M.; Redmond, D. Sustainability versus Liveability: An Investigation of Neighbourhood Satisfaction. J. Environ. Plan. Manag. 2009, 52, 847–864. [Google Scholar] [CrossRef]
- Howard, J.; Ruder, S. Universal Language Model Fine-tuning for Text Classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, ACL 2018, Melbourne, Australia, 15–20 July 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; Volume 1: Long Papers, pp. 328–339. [Google Scholar] [CrossRef]
- Zhu, X.; Goldberg, A.B. Introduction to Semi-supervised Learning. Synth. Lect. Artif. Intell. Mach. Learn. 2009, 3, 1–130. [Google Scholar]
- Pustejovsky, J.; Stubbs, A. Natural Language Annotation for Machine Learning: A Guide to Corpus-Building for Applications; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2012. [Google Scholar]
- Sohn, K.; Berthelot, D.; Carlini, N.; Zhang, Z.; Zhang, H.; Raffel, C.A.; Cubuk, E.D.; Kurakin, A.; Li, C.L. FixMatch: Simplifying Semi-supervised Learning with Consistency and Confidence. Adv. Neural Inf. Process. Syst. 2020, 33, 596–608. [Google Scholar]
- Veldpaus, L.; Roders, A.P. Learning from a Legacy: Venice to Valletta. Chang. Over Time 2014, 4, 244–263. [Google Scholar] [CrossRef]
- Gustcoven, E. Attributes of World Heritage Cities, Sustainability by Management—A Comparative Study between the World Heritage Cities of Amsterdam, Edinburgh and Querétaro. Master’s Thesis, KU Leuven, Leuven, Belgium, 2016. [Google Scholar]
- UNESCO. Heritage in Urban Contexts: Impact of Development Projects on World Heritage Properties in Cities; Technical Report; UNESCO World Heritage Centre: Paris, France, 2020. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Hinton, G.E. Connectionist Learning Procedures. In Machine Learning; Elsevier: Amsterdam, The Netherlands, 1990; pp. 555–610. [Google Scholar]
- Altman, N.S. An Introduction to Kernel and Nearest-neighbor Nonparametric Regression. Am. Stat. 1992, 46, 175–185. [Google Scholar]
- Rish, I. An Empirical Study of the Naive Bayes Classifier. In Proceedings of the IJCAI 2001 Workshop on Empirical Methods in Artificial Intelligence, Seattle, WA, USA, 4–10 August 2001; Volume 3, pp. 41–46. [Google Scholar]
- Platt, J. Probabilistic Outputs for Support Vector Machines and Comparisons to Regularized Likelihood Methods. Adv. Large Margin Classif. 1999, 10, 61–74. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Breiman, L. Bagging Predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Arlot, S.; Celisse, A. A Survey of Cross-validation Procedures for Model Selection. Stat. Surv. 2010, 4, 40–79. [Google Scholar] [CrossRef]
- Zhou, Z.H. Ensemble Methods: Foundations and Algorithms; CRC Press: Boca Raton, FL, USA, 2012. [Google Scholar]
- Breiman, L. Stacked Regressions. Mach. Learn. 1996, 24, 49–64. [Google Scholar] [CrossRef]
- Hagberg, A.; Swart, P.; S Chult, D. Exploring Network Structure, Dynamics, and Function Using NetworkX; Technical Report; Los Alamos National Lab. (LANL): Los Alamos, NM, USA, 2008. [Google Scholar]
- Karypis, G.; Kumar, V. Analysis of Multilevel Graph Partitioning. In Proceedings of the 1995 ACM/IEEE Conference on Supercomputing—Supercomputing’95, San Diego, CA, USA, 3–8 December 1995; IEEE: New York, NY, USA, 1995; p. 29. [Google Scholar] [CrossRef]
- Lafon, S.; Lee, A.B. Diffusion Maps and Coarse-Graining: A Unified Framework for Dimensionality Reduction, Graph Partitioning, and Data Set Parameterization. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1393–1403. [Google Scholar] [CrossRef]
- Gao, H.; Ji, S. Graph U-Nets. In Proceedings of the International Conference on Machine Learning, PMLR 2019, Long Beach, CA, USA, 9–15 June 2019; pp. 2083–2092. [Google Scholar]
- Encalada-Abarca, L.; Ferreira, C.C.; Rocha, J. Measuring Tourism Intensification in Urban Destinations: An Approach based on Fractal Analysis. J. Travel Res. 2022, 61, 394–413. [Google Scholar] [CrossRef]
- Eom, Y.H.; Jo, H.H. Tail-scope: Using Friends to Estimate Heavy Tails of Degree Distributions in Large-scale Complex Networks. Sci. Rep. 2015, 5, 09752. [Google Scholar] [CrossRef]
- Psarra, S. The Venice Variations: Tracing the Architectural Imagination; UCL Press: London, UK, 2018. [Google Scholar]
- Blum, A.; Mitchell, T. Combining Labeled and Unlabeled Data with Co-training. In Proceedings of the Eleventh Annual Conference on Computational Learning Theory, Madison, WI, USA, 24–26 July 1998; pp. 92–100. [Google Scholar]
- Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from a few Examples: A Survey on Few-shot Learning. ACM Comput. Surv. 2020, 53, 1–34. [Google Scholar] [CrossRef]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lió, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–12. [Google Scholar]
- Miah, S.J.; Vu, H.Q.; Gammack, J.; McGrath, M. A Big Data Analytics Method for Tourist Behaviour Analysis. Inf. Manag. 2017, 54, 771–785. [Google Scholar] [CrossRef]
- Adamic, L.A.; Adar, E. Friends and Neighbors on the Web. Soc. Netw. 2003, 25, 211–230. [Google Scholar] [CrossRef]
- Majid, A.; Chen, L.; Chen, G.; Mirza, H.T.; Hussain, I.; Woodward, J. A Context-aware Personalized Travel Recommendation System based on Geotagged Social Media Data Mining. Int. J. Geogr. Inf. Sci. 2013, 27, 662–684. [Google Scholar] [CrossRef]
- Pang, Y.; Zhao, Y.; Li, D. Graph Pooling via Coarsened Graph Infomax. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 11–15 July 2021; pp. 2177–2181. [Google Scholar]
- Zhang, M.; Cui, Z.; Neumann, M.; Chen, Y. An End-to-end Deep Learning Architecture for Graph Classification. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 4438–4445. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Ma, Y.; Ren, Z.; Jiang, Z.; Tang, J.; Yin, D. Multi-dimensional Network Embedding with Hierarchical Structure. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Los Angeles, CA, USA, 5–9 February 2018; pp. 387–395. [Google Scholar]
- Nguyen, G.H.; Lee, J.B.; Rossi, R.A.; Ahmed, N.K.; Koh, E.; Kim, S. Continuous-time Dynamic Network Embeddings. In Proceedings of the Companion Proceedings of the The Web Conference 2018, Lyon, France, 23–27 April 2018; pp. 969–976. [Google Scholar]
- Yuster, R.; Zwick, U. Fast Sparse Matrix Multiplication. ACM Trans. Algorithms 2005, 1, 2–13. [Google Scholar] [CrossRef] [Green Version]
- Urry, J.; Larsen, J. The Tourist Gaze 3.0; SAGE: Thousand Oaks, CA, USA, 2011. [Google Scholar]
- Bekker, R. Creating Insights in Tourism with Flickr Photography, Visualizing and Analysing Spatial and Temporal Patterns in Venice. Master’s Thesis, Rijksuniversiteit Groningen, Groningen, The Netherlands, 2020. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).