
All Burglaries Are Not the Same: Predicting Near-Repeat Burglaries in Cities Using Modus Operandi


Abstract
:1. Introduction
2. Theoretical Background
2.1. Theories of Criminal Behavior
2.2. Empirical Regularities of Temporal, Spatial and Repetitive Aspects of Crime
2.3. Research Questions
- 1.
- Are there characterizing features of near-repeat crimes that are different from non-repeat crimes?
- 2.
- To what extent can near-repeat crimes be predicted based on the features of the crime scene and the offender(s) MOs?
- 3.
- Are characterizing feature signatures for near-repeat crimes different depending on spatial location?
3. Methodology
3.1. Data
3.2. Experiment Setup
3.3. Evaluation Metrics
4. Results
4.1. Distribution Comparison
4.2. Near-Repeat Prediction
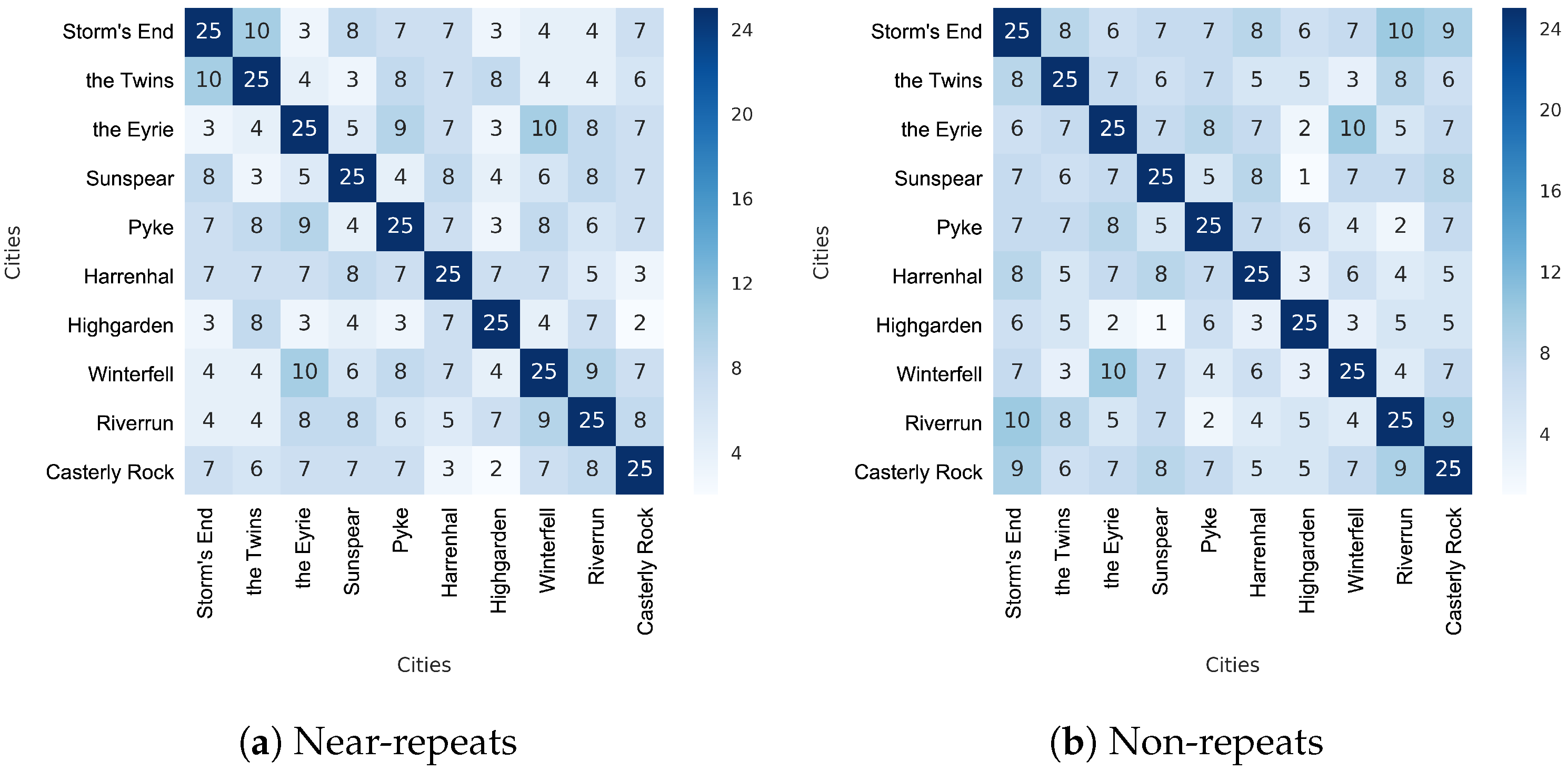
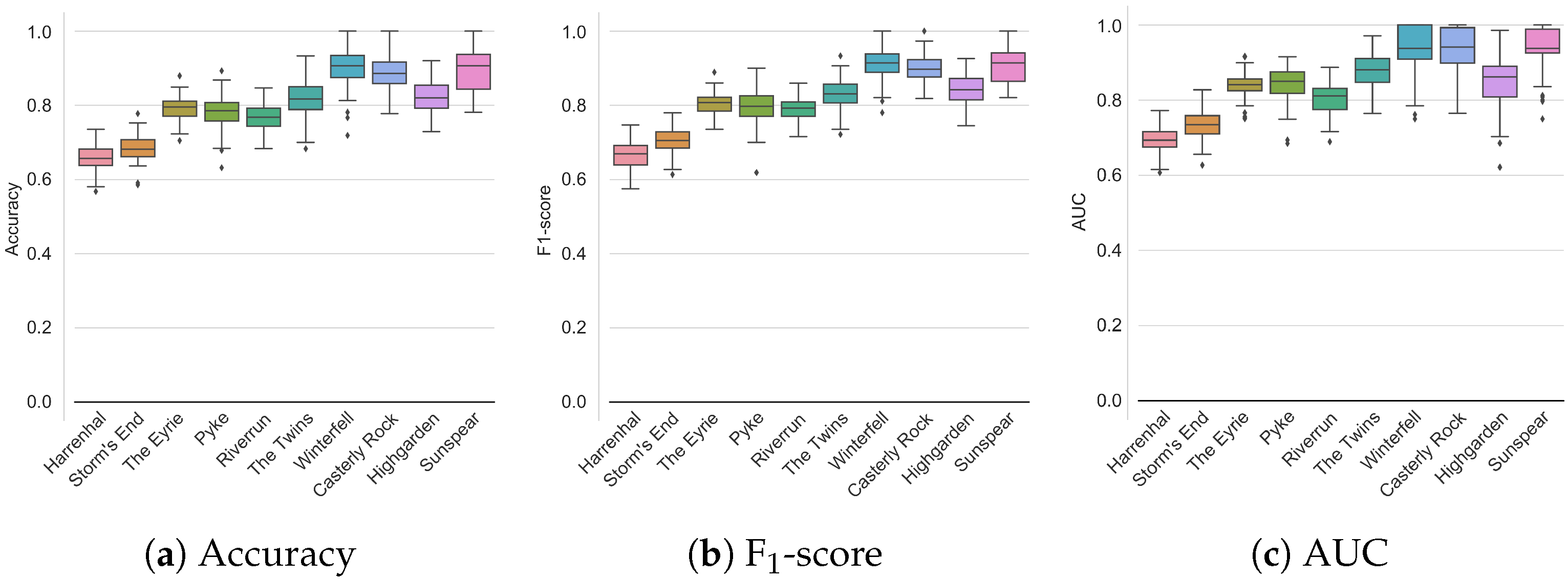
4.3. City Comparison
5. Analysis of Two Cities
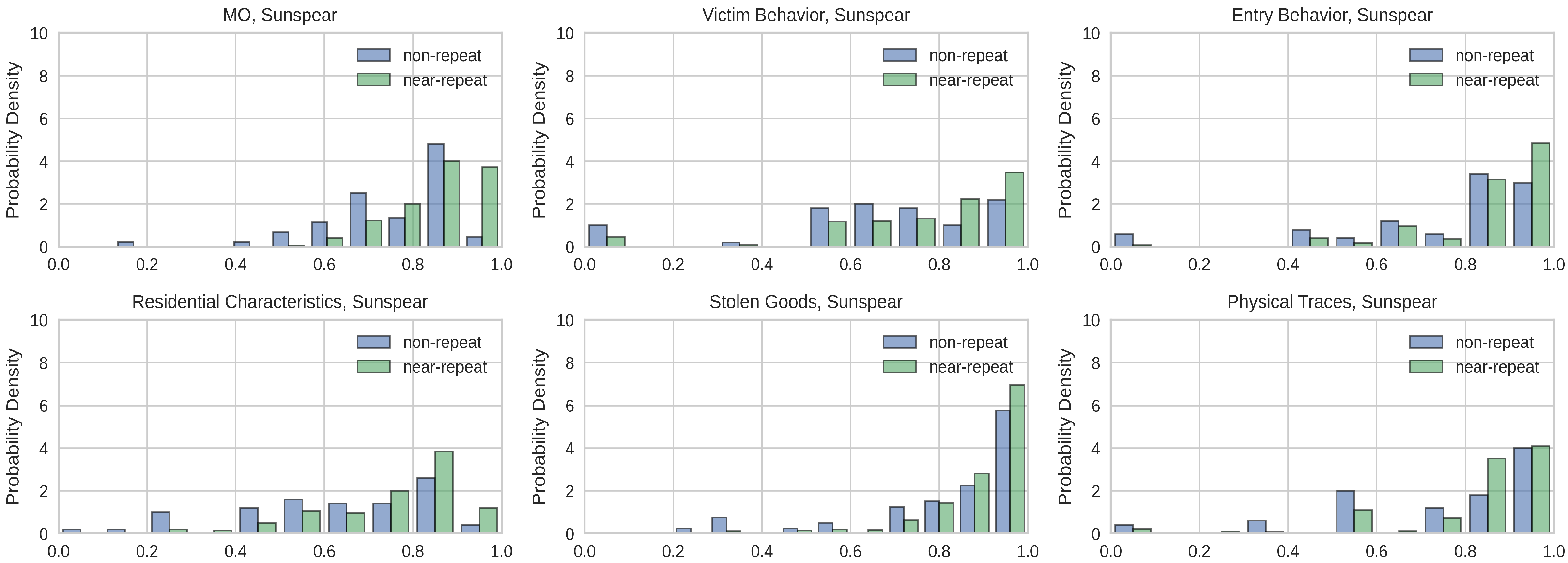
5.1. Case: Sunspear
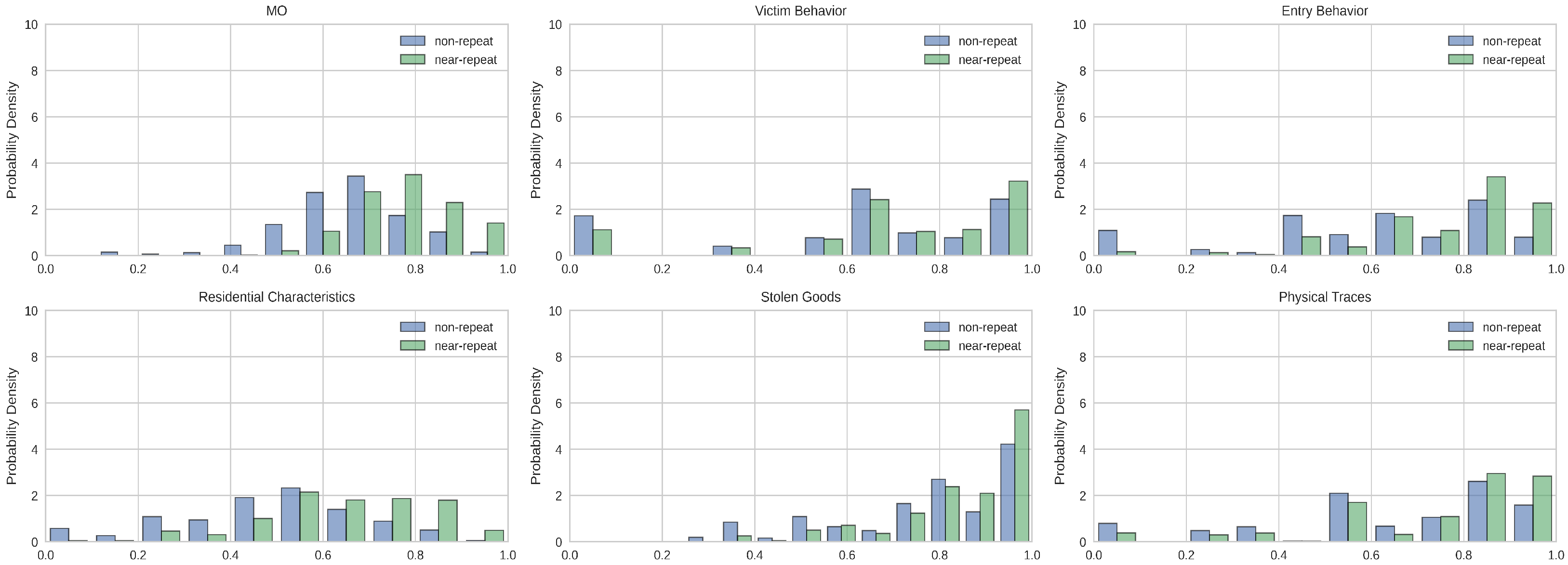
5.1.1. Distribution Comparison
5.1.2. Near-Repeat Prediction
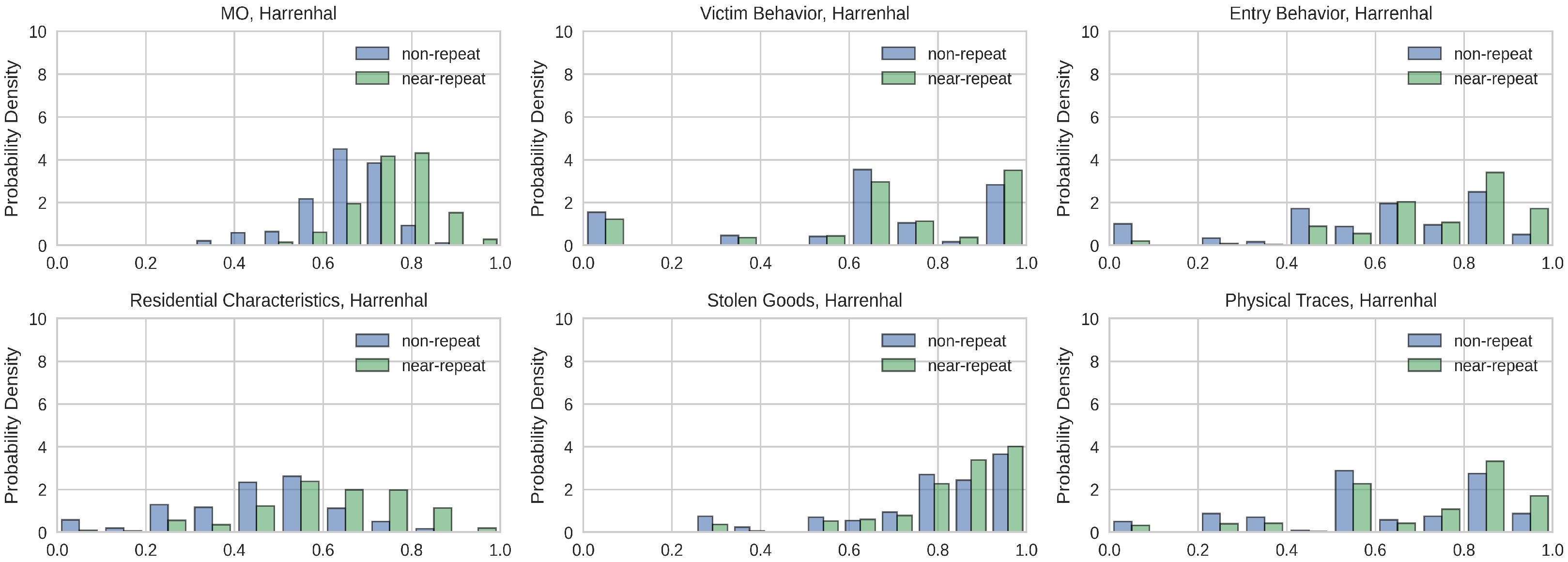
5.2. Case: Harrenhal
5.2.1. Distribution Comparison
5.2.2. Near-Repeat Prediction
6. Discussion
6.1. Contributions
6.2. Avenues for Future Research
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Unbalanced Wilcoxon Test
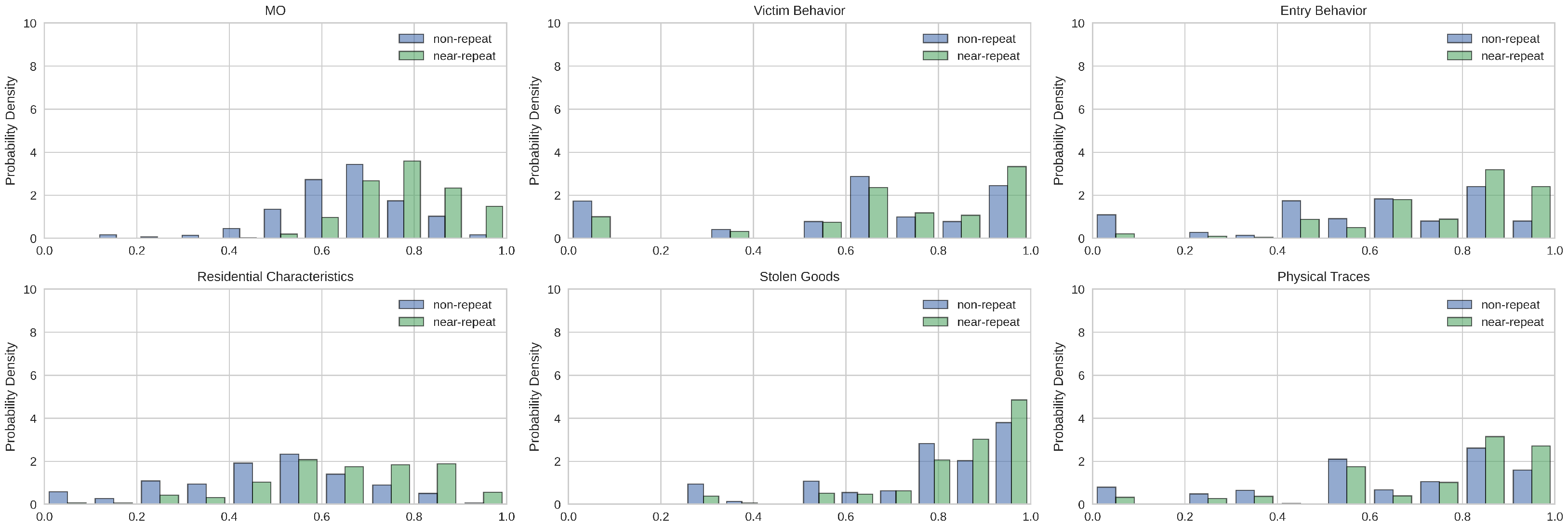
Appendix B. Feature Ratios

References
- Quetelet, A. Sur L’Homme et le Développement de ses Facultés ou Essai de Physique Sociale; Bachelier, Imprimeur-Libraire: Paris, France, 1835; Volume 1, p. 1835. [Google Scholar]
- Andresen, M.A.; Malleson, N. Spatial Heterogeneity in Crime Analysis. In Crime Modeling and Mapping Using Geospatial Technologies; Springer: Dordrecht, The Netherlands, 2013; pp. 3–23. [Google Scholar]
- Bowers, K.J.; Johnson, S.D.; Pease, K. Prospective Hot-Spotting The Future of Crime Mapping? Br. J. Criminol. 2004, 44, 641–658. [Google Scholar] [CrossRef]
- Johnson, S.D.; Bernasco, W.; Bowers, K.J.; Elffers, H.; Ratcliffe, J.; Rengert, G.; Townsley, M. Space–Time Patterns of Risk: A Cross National Assessment of Residential Burglary Victimization. J. Quant. Criminol. 2007, 23, 201–219. [Google Scholar] [CrossRef] [Green Version]
- Bernasco, W.; Johnson, S.D.; Ruiter, S. Learning where to offend: Effects of past on future burglary locations. Appl. Geogr. 2015, 60, 120–129. [Google Scholar] [CrossRef] [Green Version]
- Chainey, S.P.; Silva, B.F.A. Examining the extent of repeat and near repeat victimisation of domestic burglaries in Belo Horizonte, Brazil. Crime Sci. 2016, 5, 1. [Google Scholar] [CrossRef] [Green Version]
- Johnson, D. The space/time behaviour of dwelling burglars: Finding near repeat patterns in serial offender data. Appl. Geogr. 2013, 41, 139–146. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, X. Analysis of burglary hot spots and near-repeat victimization in a large Chinese city. ISPRS Int. J. Geo-Inf. 2017, 6, 148. [Google Scholar] [CrossRef] [Green Version]
- Rossmo, K. Geographic Profiling; CRC Press: Boca Raton, FL, USA, 1999. [Google Scholar]
- Song, C.; Qu, Z.; Blumm, N.; Barabási, A.L. Limits of Predictability in Human Mobility. Science 2010, 327, 1018–1021. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chainey, S.P.; Curtis-Ham, S.J.; Evans, R.M.; Burns, G.J. Examining the extent to which repeat and near repeat patterns can prevent crime. Polic. An Int. J. 2018, 41, 608–622. [Google Scholar] [CrossRef]
- Oatley, G.; Ewart, B.; Zeleznikow, J. Decision support systems for police: Lessons from the application of data mining techniques to “soft” forensic evidence. Artif. Intell. Law 2006, 14, 35–100. [Google Scholar] [CrossRef]
- Roman, J.; Reid, S.; Reid, J.; Chalfin, A.; Adams, W.; Knight, C. The DNA Field Experiment: Cost-Effectiveness Analysis of the Use of DNA in the Investigation of High-Volume Crimes. 2008. Available online: https://www.ojp.gov/pdffiles1/nij/grants/222318.pdf (accessed on 31 January 2022).
- O’Hara, C.; O’Hara, G. Fundamentals of Criminal Investigation, 7th ed.; Charles C Thomas Publisher Ltd.: Springfield, IL, USA, 1956. [Google Scholar]
- Woodhams, J.; Hollin, C.R.; Bull, R. The psychology of linking crimes: A review of the evidence. Leg. Criminol. Psychol. 2010, 12, 233–249. [Google Scholar] [CrossRef]
- Bennell, C.; Jones, N.J.; Melnyk, T. Addressing problems with traditional crime linking methods using receiver operating characteristic analysis. Leg. Criminol. Psychol. 2010, 14, 293–310. [Google Scholar] [CrossRef]
- Tonkin, M.; Woodhams, J.; Bull, R.; Bond, J.W.; Palmer, E.J. Linking Different Types of Crime Using Geographical and Temporal Proximity. Crim. Justice Behav. 2011, 38, 1069–1088. [Google Scholar] [CrossRef]
- Godwin, M. Reliability, Validity, and Utility of Criminal Profiling Typologies. J. Police Crim. Psychol. 2002, 17, 1–18. [Google Scholar] [CrossRef]
- Boldt, M.; Borg, A.; Svensson, M.; Hildeby, J. Predicting burglars’ risk exposure and level of pre-crime preparation using crime scene data. Intell. Data Anal. 2018, 22, 167–190. [Google Scholar] [CrossRef]
- Vandeviver, C.; Neutens, T.; Van Daele, S.; Geurts, D.; Vander Beken, T. A discrete spatial choice model of burglary target selection at the house-level. Appl. Geogr. 2015, 64, 24–34. [Google Scholar] [CrossRef] [Green Version]
- Bowers, K.J.; Johnson, S.D. Who commits near repeats? A test of the boost explanation. West. Criminol. Rev. 2004, 5, 12–24. [Google Scholar]
- Glaeser, E.L.; Sacerdote, B.; Scheinkman, J.A. Crime and social interactions. Q. J. Econ. 1996, 111, 507–548. [Google Scholar] [CrossRef] [Green Version]
- Reich, B.; Porter, M. Partially supervised spatiotemporal clustering for burglary crime series identification. J. R. Stat. Soc. Ser. A Stat. Soc. 2015, 178, 465–480. [Google Scholar] [CrossRef] [Green Version]
- Brantingham, P.; Brantingham, P. Crime pattern theory. In Environmental Criminology and Crime Analysis; Willan: London, UK, 2013; pp. 100–116. [Google Scholar]
- Becker, G.S. Crime and Punishment: An Economic Approach. In The Economic Dimensions of Crime; Palgrave Macmillan UK: London, UK, 1968; pp. 13–68. [Google Scholar]
- Cohen, L.E.; Felson, M. Social Change and Crime Rate Trends: A Routine Activity Approach. Am. Sociol. Rev. 1979, 44, 588. [Google Scholar] [CrossRef]
- Clarke, R.V.; Felson, M. Introduction: Criminology, Routine Activity, and Rational Choice. Routine Act. Ration. Choice Adv. Criminol. Theory 1993, 5, 1–14. [Google Scholar]
- Brantingham, P.L.; Brantingham, P.J. Environment, Routine, and Situation: Toward a Pattern Theory of Crime. Routine Act. Ration. Choice 1993, 5, 259. [Google Scholar]
- Johnson, S.D.; Bowers, K.J.; Birks, D.J.; Pease, K. Predictive Mapping of Crime by ProMap: Accuracy, Units of Analysis, and the Environmental Backcloth. In Putting Crime in its Place; Springer New York: New York, NY, USA, 2009; pp. 171–198. [Google Scholar]
- Lammers, M.; Menting, B.; Ruiter, S.; Bernasco, W. Biting once, twice: The influence of prior on subsequent crime location choice. Criminology 2015, 53, 309–329. [Google Scholar] [CrossRef]
- Glaeser, E.L.; Sacerdote, B.I.; Scheinkman, J.A. The social multiplier. J. Eur. Econ. Assoc. 2003, 1, 345–353. [Google Scholar] [CrossRef]
- Townsley, M.; Homel, R.; Chaseling, J. Infectious Burglaries. A Test of the Near Repeat Hypothesis. Br. J. Criminol. 2003, 43, 615–633. [Google Scholar] [CrossRef]
- Farrell, G.; Pease, K. Once Bitten, Twice Bitten: Repeat Victimisation and Its Implications for Crime Prevention; Crime Prevention Unit, Paper 46; Home Office Police Research Group: London, UK, 1993.
- Andresen, M.A.; Malleson, N. Testing the stability of crime patterns: Implications for theory and policy. J. Res. Crime Delinq. 2011, 48, 58–82. [Google Scholar] [CrossRef]
- Andresen, M.A.; Linning, S.J. The (in) appropriateness of aggregating across crime types. Appl. Geogr. 2012, 35, 275–282. [Google Scholar] [CrossRef]
- Weisburd, D.; Amram, S. The law of concentrations of crime at place: The case of Tel Aviv-Jaffa. Police Pract. Res. 2014, 15, 101–114. [Google Scholar] [CrossRef]
- Hu, Y.; Wang, F.; Guin, C.; Zhu, H. A spatio-temporal kernel density estimation framework for predictive crime hotspot mapping and evaluation. Appl. Geogr. 2018, 99, 89–97. [Google Scholar] [CrossRef]
- Xue, Y.; Brown, D.E. A decision model for spatial site selection by criminals: A foundation for law enforcement decision support. Syst. Man Cybern. Part C Appl. Rev. IEEE Trans. 2003, 33, 78–85. [Google Scholar]
- Wang, S.; Li, X.; Cai, Y.; Tian, J. Spatial and temporal distribution and statistic method applied in crime events analysis. In Proceedings of the 2011 19th International Conference on Geoinformatics, Shanghai, China, 24–26 June 2011; pp. 1–6. [Google Scholar]
- Zhou, G.; Lin, J.; Zheng, W. A web-based geographical information system for crime mapping and decision support. In Proceedings of the 2012 International Conference on Computational Problem-Solving (ICCP), Leshan, China, 19–21 October 2012; pp. 147–150. [Google Scholar]
- Phillips, P.; Lee, I. Crime analysis through spatial areal aggregated density patterns. Geoinformatica 2011, 15, 49–74. [Google Scholar] [CrossRef]
- Chainey, S.; Ratcliffe, J. GIS and Crime Mapping; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2005. [Google Scholar]
- Glasner, P.; Leitner, M. Evaluating the impact the weekday has on near-repeat victimization: A spatio-temporal analysis of street robberies in the city of Vienna, Austria. ISPRS Int. J. Geo-Inf. 2017, 6, 3. [Google Scholar] [CrossRef] [Green Version]
- Sagovsky, A.; Johnson, S.D. When Does Repeat Burglary Victimisation Occur? Aust. N. Z. J. Criminol. 2007, 40, 1–26. [Google Scholar] [CrossRef]
- Markson, L.; Woodhams, J.; Bond, J.W. Linking serial residential burglary: Comparing the utility of modus operandi behaviours, geographical proximity, and temporal proximity. J. Invest. Psychol. Offender Profiling 2010, 7, 91–107. [Google Scholar] [CrossRef]
- Martin, G. A Game of Thrones (A Song of Ice and Fire, Book 1); A Song of Ice and Fire, HarperCollins Publishers: London, UK, 2010. [Google Scholar]
- Bennell, C.; Jones, N.J. Between a ROC and a hard place: A method for linking serial burglaries bymodus operandi. J. Investig. Psychol. Offender Profiling 2005, 2, 23–41. [Google Scholar] [CrossRef]
- Sheskin, D. Handbook of Parametric and Nonparametric Statistical Procedures; Chapman & Hall: Boca Raton, FL, USA, 2007. [Google Scholar]
- Wendt, H.W. Dealing with a common problem in Social science: A simplified rank-biserial coefficient of correlation based on the U statistic. Eur. J. Soc. Psychol. 1972, 2, 463–465. [Google Scholar] [CrossRef]
- Cohen, J. Statistical Power Analysis for the Behavioral Sciences; Taylor & Francis: New York, NY, USA, 2013. [Google Scholar]
- Flach, P. Machine Learning: The Art and Science of Algorithms that Make Sense of Data; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Rogati, M.; Yang, Y. High-performing feature selection for text classification. In Proceedings of the Eleventh International Conference on Information and Knowledge Management, McLean, VA, USA, 4–9 November 2002; pp. 659–661. [Google Scholar]
- Yang, Y.; Pedersen, J. A comparative study on feature selection in text categorization. ICML 1997, 97, 412–421. [Google Scholar]
- Liu, H.; Motoda, H. Feature Selection for Knowledge Discovery and Data Mining; The Springer International Series in Engineering and Computer Science; Springer: Boston, MA, USA, 2012. [Google Scholar]
- Fisher, R.A. Statistical methods for research workers. In Breakthroughs in Statistics; Springer: New York, NY, USA, 1992; pp. 66–70. [Google Scholar]
- Wilson, D.J. The harmonic mean p-value for combining dependent tests. Proc. Natl. Acad. Sci. USA 2019, 116, 1195–1200. [Google Scholar] [CrossRef] [Green Version]
- Witten, I.H.; Frank, E. Data Mining: Practical Machine Learning Tools and Techniques; Morgan Kaufmann Publications: San Francisco, CA, USA, 2005. [Google Scholar]
- Steyerberg, E.W.; Harrell, F.E., Jr.; Borsboom, G.; Eijkemans, M.J.C.; Vergouwe, Y.; Habbema, J.D.F. Internal validation of predictive models: Efficiency of some procedures for logistic regression analysis. J. Clin. Epidemiol. 2001, 54, 774–781. [Google Scholar] [CrossRef]
- Harrell, F.E. Regression Modeling Strategies: With Applications to Linear Models, Logistic Regression, and Survival Analysis; Springer: Cham, Switzerland, 2001. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Bennell, C.; Bloomfield, S.; Snook, B.; Taylor, P.; Barnes, C. Linkage analysis in cases of serial burglary: Comparing the performance of university students, police professionals, and a logistic regression model. Psychol. Crime Law 2010, 16, 507–524. [Google Scholar] [CrossRef] [Green Version]
- Cromwell, P.F.; Olson, J.N.; Avary, D.W. Breaking and Entering: An Ethnographic Analysis of Burglary; Sage: Newbury Park, CA, USA, 1991; Volume 8. [Google Scholar]
- Ratcliffe, J.H. Aoristic Signatures and the Spatio-Temporal Analysis of High Volume Crime Patterns. J. Quant. Criminol. 2002, 18, 23–43. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Features | # | Description |
|---|---|---|
| Time and place | 7 | Date and time range, as well as residence address |
| Residential area | 7 | Rural or urban, number of neighbors, etc. |
| Type of residency | 12 | {House, townhouse, apartment, farm}, number of flats, etc. |
| Burglary alarm | 5 | If an alarm existed, if enabled, activated or sabotaged |
| Object description | 10 | Lights lit in/outside, member in neighborhood watch, etc. |
| Plaintiff | 16 | Plaintiff away or home, prior suspicious events, etc. |
| Break in | 33 | Method and location of break in |
| Search strategy | 3 | How the residence was searched for goods |
| Stolen goods | 21 | Categories of stolen goods, e.g., cash, gold, medicine, etc. |
| Trace evidence | 10 | Trace evidence secured, e.g., DNA, fingerprint, etc. |
| Miscellaneous | 13 | Witness, confidential hints, and searchable goods |
| Parameter count: | 137 |
| City | Near-Repeat | Non-Repeat | Size of City |
|---|---|---|---|
| Harrenhal | 166 | 1169 | Large |
| Storm’s End | 155 | 984 | Large |
| The Eyrie | 86 | 824 | Medium |
| Pyke | 81 | 565 | Medium |
| Riverrun | 75 | 485 | Small |
| The Twins | 47 | 303 | Medium |
| Winterfell | 11 | 157 | Small |
| Casterly Rock | 12 | 172 | Small |
| Highgarden | 38 | 242 | Medium |
| Sunspear | 14 | 158 | Small |
| Total | 685 | 5059 | ≈1460 K |
| City | AUC | Accuracy | F1-Score |
|---|---|---|---|
| Harrenhal | ( | () | () |
| Storm’s End | ( | () | () |
| the Eyrie | ( | () | () |
| Pyke | ( | () | () |
| Riverrun | ( | () | () |
| the Twins | ( | () | () |
| Winterfell | ( | () | () |
| Casterly Rock | ( | () | () |
| Highgarden | ( | () | () |
| Sunspear | ( | () | () |
| Mean | ( | ( | () |
| Feature | Mean Coefficient (SD) | Mean T-Value (SD) | Class |
|---|---|---|---|
| Alarm activated | () | () | Not near-repeat |
| Non-bulky goods stolen | () | () | |
| Bulky goods stolen | () | () | |
| Large mark left | () | () | |
| Alcohol/tobacco stolen | () | () | |
| Entry through cellar door | () | () | |
| Kids at home during burglary | () | () | |
| Active in neighbourhood watch | () | () | |
| Small mark left | () | () | |
| Electronics stolen | () | () | |
| Drills used to enter | () | () | |
| Fingerprint left | () | () | |
| Nothing Stolen | () | () | |
| Disabled/elderly targeted | () | () | |
| View cover when entering | () | () | Near-repeat |
| Apartment at ground-level | () | () | |
| Goods are searchable | () | () | |
| Big mess during burglary | () | () | |
| Messy burglary | () | () | |
| DNA left | () | () | |
| Entry through balcony door | () | () | |
| Vehicle keys stolen | () | () | |
| Unknown call prior | () | () | |
| Entry through basement | () | () | |
| Careful search during burglary | () | () | |
| Shoe print left | () | () | |
| Villa targeted | () | () | |
| Perfume stolen | () | () |
| Feature | Mean Coefficient (SD) | Mean T-Value (SD) | Class |
|---|---|---|---|
| Victim owns company | () | () | Not near-repeat |
| Ventilation window open | () | () | |
| Apartment at ground-level | () | () | |
| Alarm activated | () | () | |
| Medium marks left | () | () | |
| Single-level residence | () | () | |
| Weapons stolen | () | () | |
| Careful search during burglary | () | () | |
| Electronics stolen | () | () | |
| Vehicle on driveway during burglary | () | () | |
| Small marks left | () | () | |
| Triple-pane window on residence | () | () | |
| =<5 marks left | () | () | |
| Large marks left | () | () | |
| Low standard residence | −2.9989 × (1.8334 × ) | () | Near-repeat |
| Drills used to enter | () | () | |
| Alcohol/tobacco stolen | () | () | |
| Victim in company register | () | () | |
| Glove prints left | () | () | |
| Victim uses household services | () | () | |
| Tips received | () | () | |
| Non-bulky goods stolen | () | () | |
| Passport/ID stolen | () | () | |
| Grass/Snow maintained | () | () | |
| Rental Apartment | −1.1740 × (1.3930 × ) | () | |
| Bulky goods stolen | () | () | |
| Active in neighborhood watch | () | () | |
| Tool-marks left | () | () |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Borg, A.; Svensson, M. All Burglaries Are Not the Same: Predicting Near-Repeat Burglaries in Cities Using Modus Operandi. ISPRS Int. J. Geo-Inf. 2022, 11, 160. https://doi.org/10.3390/ijgi11030160
Borg A, Svensson M. All Burglaries Are Not the Same: Predicting Near-Repeat Burglaries in Cities Using Modus Operandi. ISPRS International Journal of Geo-Information. 2022; 11(3):160. https://doi.org/10.3390/ijgi11030160
Chicago/Turabian StyleBorg, Anton, and Martin Svensson. 2022. "All Burglaries Are Not the Same: Predicting Near-Repeat Burglaries in Cities Using Modus Operandi" ISPRS International Journal of Geo-Information 11, no. 3: 160. https://doi.org/10.3390/ijgi11030160
APA StyleBorg, A., & Svensson, M. (2022). All Burglaries Are Not the Same: Predicting Near-Repeat Burglaries in Cities Using Modus Operandi. ISPRS International Journal of Geo-Information, 11(3), 160. https://doi.org/10.3390/ijgi11030160