1. Introduction
In the era of big data, where everything is connected, geographic information services have moved from map databases to real 3D reality and digital twins [
1,
2]. The superior advantages of big data GIS, such as high performance, high availability, scalability, and economy, provide a solid technical guarantee for future WebGIS development and construction of real 3D reality and digital twin systems [
3,
4,
5,
6]. One of the hot issues today in big data GIS is how to use a big data technology platform to efficiently store and process the massive, multi-source, and heterogeneous spatial tile map image data generated in the construction of smart cities [
7,
8]. Presently, the research addressing this issue mainly falls into two categories: row-key-based auxiliary index technologies and memory-based distributed computing framework technologies.
Research in the first stream is based on accessing data using the continuously ordered keys in the key-value data model of non-relational databases on big data platforms [
9]. In this situation, the lexicographical order of the data keys in the key-value model is used to store key-value tuples on cluster nodes in a distributed manner. All operations upon the data are implemented through “row keys” [
10]. For query operations within a specified geospatial range, if most geographical features with similar spatial locations are concentrated in a narrow range of row key sequences, it is possible to reduce the scanning time for query operations on the row key sequences, thereby improving the efficiency of query retrieval operations. To this end, some scholars use space-filling curves to build auxiliary indexes based on row keys. For example, Hajjaji et al. [
11], Shen et al. [
12], Zheng et al. [
13], and Yu et al. [
14] proposed mapping the longitude and latitude coordinates in two-dimensional space into a one-dimensional row key index based on Hilbert curve rules. When querying tile data within the specified spatial range, the longitude and latitude coordinates are first used to calculate the row key range of tile data stored in the key-value database, and then all of the tiles stored in the specified spatial range on the cluster are retrieved through a scanning operation [
15,
16]. However, although a Hilbert curve can improve the efficiency of some spatial query operations to some extent, a Hilbert curve cannot group the tiles together for any spatial range that might be specified. The query operation often needs to scan a large range containing the key values, and in extreme cases, it may even need to scan the entire node cluster.
The second stream of research, the distributed memory computing framework, exploits the fact that memory access speed is much faster than the speed of external storage devices, and the cost of memory has dropped significantly in recent years [
17,
18,
19]. Based on the characteristics of spatial query and the Spark distributed memory computing model, Fang et al. [
20] designed the spatial region query algorithm for distributed storage, the distributed spatial index, the distributed memory computing framework, and the Spark Streaming spatial query algorithm to provide real-time online spatial query service. Cui et al. [
21] and Wang et al. [
22] proposed distributed storage and comprehensive processing strategies for spatial big data based on a memory database and a non-relational database to solve the complex problems that arise in big data storage and management. Although such technology significantly improves the reading speed for tile data, it consumes a large amount of the host’s memory resources, requires a high-performance cluster service node, and has several other problems, such as difficult implementation and high operation and maintenance costs.
In summary, existing studies all begin with the spatial characteristics of tile data and try to use a single cluster scanning operation to obtain all tiles in the specified spatial range. When visualizing tile map data based on WebGIS technology, the front-end display components concurrently generate HTTP requests for each tile and load the tiles retrieved from the big data GIS platform. Therefore, regarding the demand for basic base map services for the development of WebGIS-based true 3D real-world and digital twin systems, the key issue is the big data GIS platform’s response speed for a single tile data request under concurrent conditions, rather than the time efficiency of a single batch retrieval of tile data delineated by spatial scope. This paper’s research object is the key-value non-relational database of the big data platform. We analyze the core factor, hotspotting, that determines the efficiency of accessing tile data on a big data platform based on the big data platform’s architecture and the data access principle, and we use the analysis to create a tile data access model with absolute load balancing characteristics for the non-relational database architectures of big data platforms. The model improves concurrent access performance for massive tile map data and provides high-performance, scalable, and highly available basic tile map services for the construction of true 3D real-world and digital twin systems.
2. The Hotspotting Issue
The adoption of a big data storage platform with good horizontal scalability to store structured, semi-structured, and unstructured massive data is an inevitable choice for effectively coping with the explosive growth of all kinds of data in the era of big data. The excellent horizontal scalability of big data platforms is generally achieved using a non-relational database (NoSQL) architecture. At present, non-relational databases are mainly classified as document databases, wide-column databases, graph databases, and key-value databases. Among these, the key-value database is a perfect application choice for storing large amounts of data without supporting complex conditional queries. Since the storage of tile data generated by the tile pyramid model is uniquely determined on a disk, the storage path can be used as the key value for the tiles, allowing a key-value database to be used to realize the storage of massive tile data.
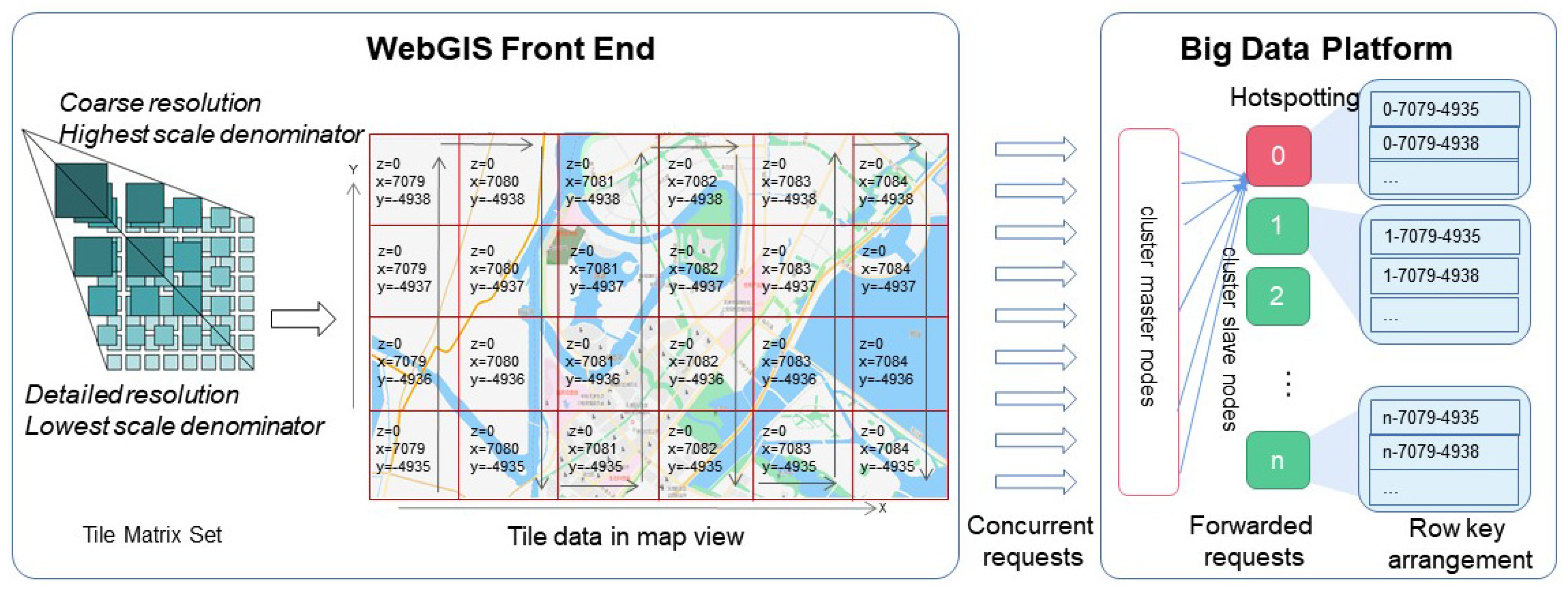
Big data platforms with horizontal scalable performance generally adopt a master–slave architecture in which the hosts within a cluster are divided into two categories: master nodes and slave (data) nodes. Master nodes receive data requests and forward the requests to data nodes that will store the key-value tuples. In the process of requesting tile data from a cluster through the WebGIS front end, as shown in
Figure 1, the front-end WebGIS software first generates a unique corresponding key value, which is composed of level
z, tile column index
x, and tile row index
y defined by the WMTS standard called Tile Matrix Set [
23], for each tile within the geographic view, and then concurrently sends tile data retrieval requests corresponding to the key value to the big data platform. When the cluster master node receives the tile retrieval request, it forwards the request to a slave node that stores the tile based on the key value, which completes the tile data retrieval.
It is easy to see that the key to the cluster’s efficiency in responding to a large number of concurrent requests is a uniform distribution of the key tuples across the data nodes (load balancing). Since the keys constituting the tile data are based on the Tile Matrix Set defined in the Web Tile Map Service standard, which consists of the map scaling level (
z), the column index (
x), and the row index (
y) of the raster in which the tiles are located, the arrangement of the keys has an obvious monotonic increasing character [
24,
25,
26]. At the time of tile data entry, since the cluster does not know the distribution range of the key values, the cluster will store all of the data into one block of a data node, and a split will automatically be triggered only when the size of the block exceeds a certain threshold value (e.g., 10G for HBase). Similarly, during data query retrieval, as the data is stored in one block, all GET requests must be sent to the same node in the cluster. This uneven distribution of data across the target storage nodes due to row key monotonicity is the decisive factor in creating hotspots when accessing tiled data in non-relational databases, and it leads to a sharp performance degradation [
27,
28].
Thus, to achieve efficient access to tile data, it is necessary to create a data model that enables uniform distribution of the data stored on server nodes to prevent the formation of access hotspots and then take full advantage of the random read performance of key-value non-relational databases.
3. Data Access Model Based on the Jump Consistency Hashing Method
Assuming there are n slots for storing key-value tuple data on a cluster, an effective strategy to achieve cluster load balancing and avoid the hotspotting problem is to distribute the key-value data evenly among these slots. If the number of these slots is identified in the header of the row key, then, combined with the pre-partitioning technology of the key-value non-relational database, the key-value data can be stored in exactly the corresponding slots. That is, using the identification information for the tile data and assigning an appropriate slot to each tile is the key to achieving efficient access to tile data on the cluster. To this end, we offer the following proposition:
For any given map view, there exists a function
f such that,
holds for any tile in the map view, where
key is a combination of characters consisting of the tile’s level (
z), its column index (
x), and its row index (
y),
n is the total number of pre-established slots, and
N is the target slot number where the key value should be stored. In addition, the function
f satisfies consistency and equal probability, where consistency means that there is always a unique
N that corresponds to any given
key and
n, while equal probability means that the value of
N is uniformly (with equal probability) distributed on the target slot interval [0,
n − 1].
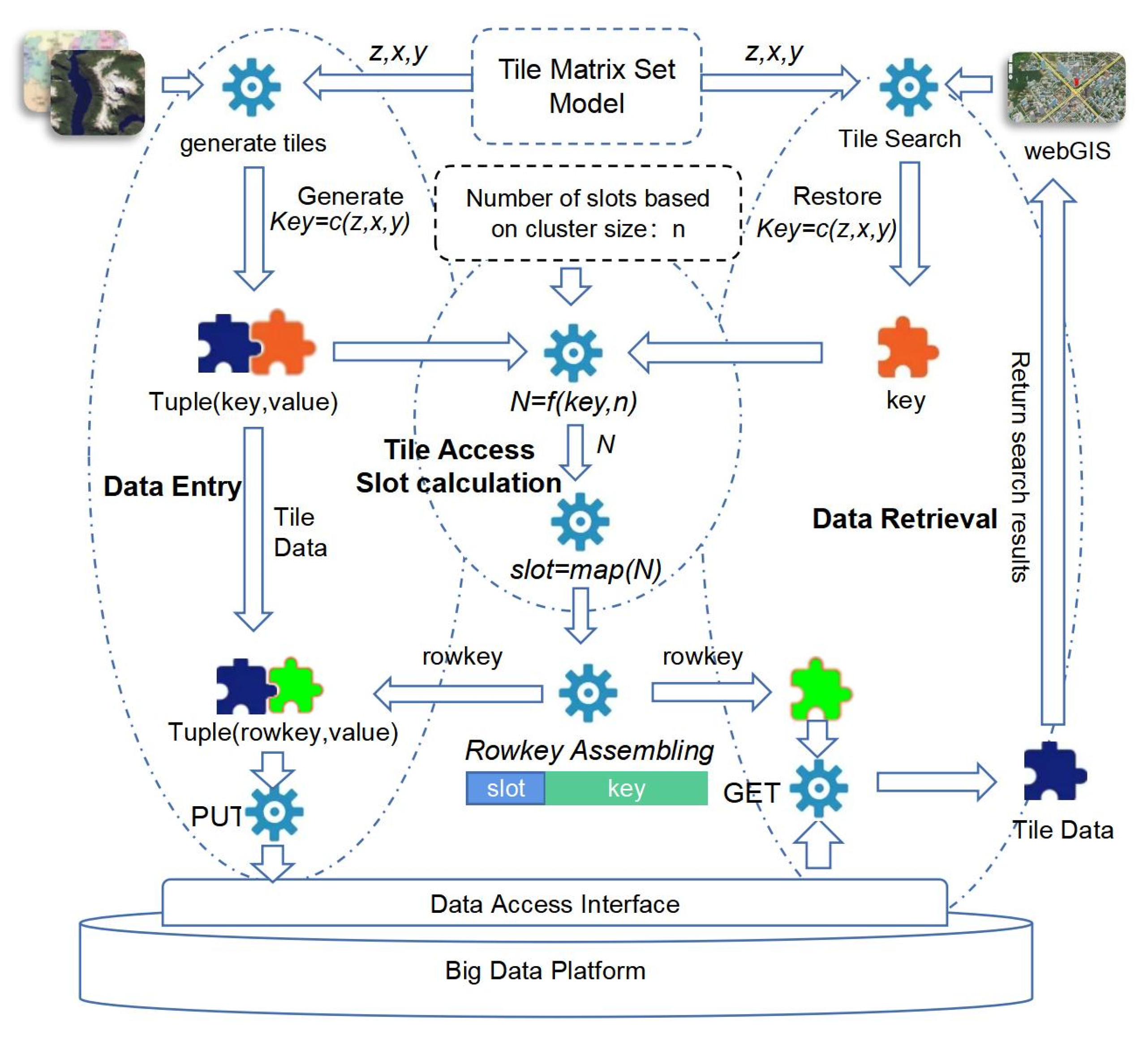
Given the Tile Matrix Set Model used in the process of tile map data generation and retrieval, we propose the tile data access model shown in
Figure 2, which has the tile access slot calculation function
f as its core.
At the time of data entry, from
Figure 2, we can see there are several key steps to implement tile data storage. Firstly, using level (
z), column index (
x), and row index (
y) defined in the Tile Matrix Set Model, the key which can identify tile data uniquely can be generated through a
c function. Composing the tile data itself, the original key-value tuple, which is noted as Tuple(key, value) in
Figure 2, is formed. Then, taking
key as the first parameter and
n as the second parameter of function
f, the target slot where the tile should be saved is pre-calculated by function
f. Next, the slot number is converted to ASCII code through the mapping function
map. The ASCII code is then used as the header of the row key together with the tile index information (
key) to form the row key (rowkey, represented in green in
Figure 2), and the key in the original tuple is updated by rowkey. Finally, the PUT method of the big data platform’s date storage interface is called upon to save the Tuple(rowkey, value) data.
At the time of data retrieval, it is similar to data entry. WebGIS software, such as Openlayers, can generate a unique identification marked as level (
z), column index (
x), and row index (
y) defined in the Tile Matrix Set Model for each tile in a map view. Using the same function c, level (
z), column index (
x), and row index (
y) can be composed as a key(represented in brown in
Figure 2). Taking
key as the first parameter and
n as the second parameter, the target slot number N can be restored. Using the map function, the target slot, which will be the rowkey header, is obtained. At last, the rowkey is restored, and the GET method of the big data platform’s data retrieval interface is called upon to retrieve the tile data.
3.1. Target Slot Calculation
The data that is generated using the tile map pyramid model is uniquely identified by the level (
z), horizontal coordinate (
x), and vertical coordinate (
y) of the raster where the tile is located. In this paper, we use function
c(
z,
x,
y) to obtain the tile’s unique identification key. Then, using the key and the total number of slots in the target storage environment as parameters, we call upon function
f to calculate the target slot number where the key value should be stored. Assuming that the cluster is predefined with
n target storage slots, based on the cluster size, the target slot number
N calculated by the function
f is required to satisfy the following equation
That is, for any key, the distribution probability that N is in the target slot interval [0, n − 1] is 1/n.
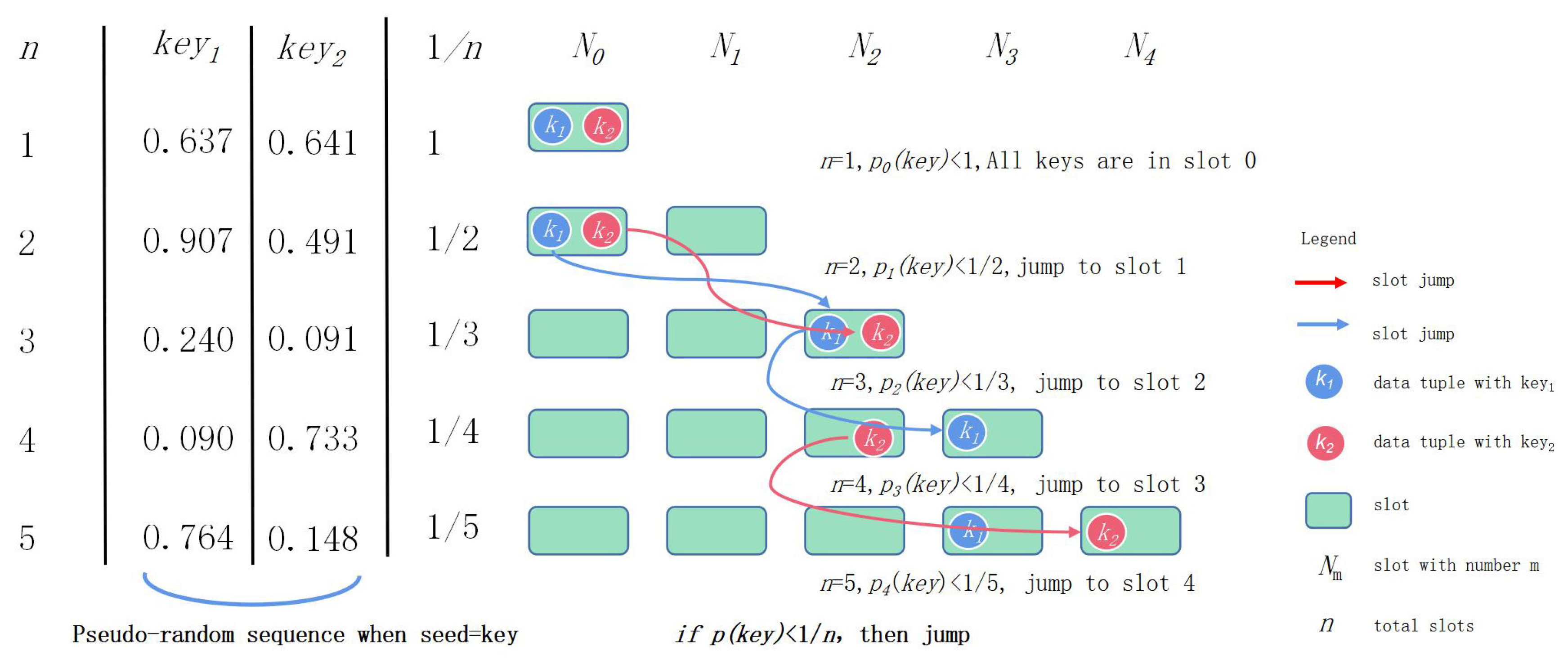
Function
f is implemented using the jump consistent hash algorithm proposed by Lamping and Veach [
29]. The core idea of this algorithm is illustrated by
Figure 3.
For an arbitrary key value, a pseudo-random function is first used to generate a sequence of random numbers corresponding to the number of the cluster’s data nodes. The pseudo-random function ensures that the generated sequence of pseudo-random numbers is uniformly (with equal probability) distributed over the interval [0, 1]. In the process of changing the total number of slots from 1 to
n (
n = 1 to
n = 5 are shown in
Figure 3), whenever the node serial number changes from
j to
j + 1, there will be a total of 1/(
j + 1) keys that must migrate from
j slots to
j + 1 slots. Since the probability that the key is located in slot
j + 1 is 1/(
j + 1), a key corresponding to a random series value less than 1/(
j + 1) is specified to jump to slot
j + 1.
The jump consistent hash Algorithm 1 is described by the following code:
| Algorithm 1: Jump Consistent Hash Algorithm |
1 int ch(int k, int n) {
2 random.seed(k); // Initialize the pseudo-random function
3 int b = 0;
4 for (int j = 1; j < n; j++) {
5 if (random.next() < 1.0/(j + 1))
6 b = j + 1; //A tuple with a pseudo-random number less than 1/(j + 1), then jumps to slot j + 1
7 }
8 return b;
9 } |
For
n nodes, the algorithm requires
n comparisons to calculate the sequence of nodes corresponding to the key, and the time complexity is O(
n). Since the probability that random.next() < 1/(
j + 1) is relatively small, the hit rate of the decision condition in the algorithm is not high. Then, since the probability of deciding that a node needs to migrate is a low-probability event, the probability of staying in the source node without moving is a high-probability event. Based on this idea, the algorithm can be further optimized, which in turn decreases the time complexity to O(ln(
n)). The optimized Algorithm 2 is described by the following code:
| Algorithm 2: Optimized Jump Consistent Hash Algorithm |
1 int ch(int k, int n) {
2 random.seed(k); // Initialize the pseudo-random function
3 int b = −1, j = 0;
4 while (j < n) {
5 b = j;
6 r = random.next();
// Skip the number of slots where the pseudo-random number is greater than 1/(j + 1)
7 j = floor((b + 1)/r);
8 }
9 return b;
10 } |
The jump consistent hash algorithm has the advantages of requiring no memory and a high speed. However, the algorithm requires the target slot numbers to begin with 0 and be consecutive, which means that slots must be added and deleted at the end. In order to overcome the shortcomings of the algorithm in terms of scalability, further optimization of the value
N produced by Equation (1) is required using the following equation:
where
slot is the slot number of the final tag in the row key header, and
map is the mapping function. The mapping of the slot number to the final slot mark in the slot pool is achieved by a custom map function.
3.2. Tile Data Entry
In order to clearly illustrate the application of the model to a specific database, the Apache HBase database, a distributed and scalable big data storage platform, is introduced as a research object for tile data access. HBase manages huge datasets as key-value tuples and uses key-value mapping to achieve highly consistent, real-time access to big data. Because HBase has many advantages, such as being open source and maturely developed as well as having broad application in various industries, HBase is widely used in the field of big data platforms.
3.2.1. Table Structure Design
The HBase database is an open-source implementation of Google’s paper “Bigtable: A Distributed Storage System for Structured Data” [
30]. The heart of an HBase table is a HashMap relying on the simple concept of storing and retrieving a key-value pair. Therefore, every individual data value is indexed on a key in the HBase universe. Further, the HashMap is always stored as a sorted map, the sorting being based on the lexicographical ordering of the various labels that are present in a key [
31,
32].
Key to the design of HBase table keys is the design of the row key [
33,
34]. Since the tile data mainly include parts of the tile image itself, indexes, and tile metadata information, the HBase table for saved tiles adopts the principle of high table design (only one column family is defined in the big table) [
31] and thus compresses the space occupied by tile storage to the maximum extent.
The number of bytes for saving slot information in the row key is based on the size of the data nodes. In this paper, one byte is used to identify the slot in which the tile data is stored. A second byte in the row key is used to save the metadata index for the tile data. The tile metadata includes the projection coordinates, control points, categories, producers, and other information regarding the tile data to support the storage of different batches and categories of remote sensing data. The following eight bytes of the row key, a long integer, are used to identify the tile data’s storage path, including the scaling level
z and the
x- and
y-coordinates of the tile pyramid model. Single characters are used to identify the column family and column name. The structure of the row key can be depicted by
Figure 4.
3.2.2. Storage Area Pre-Segmentation
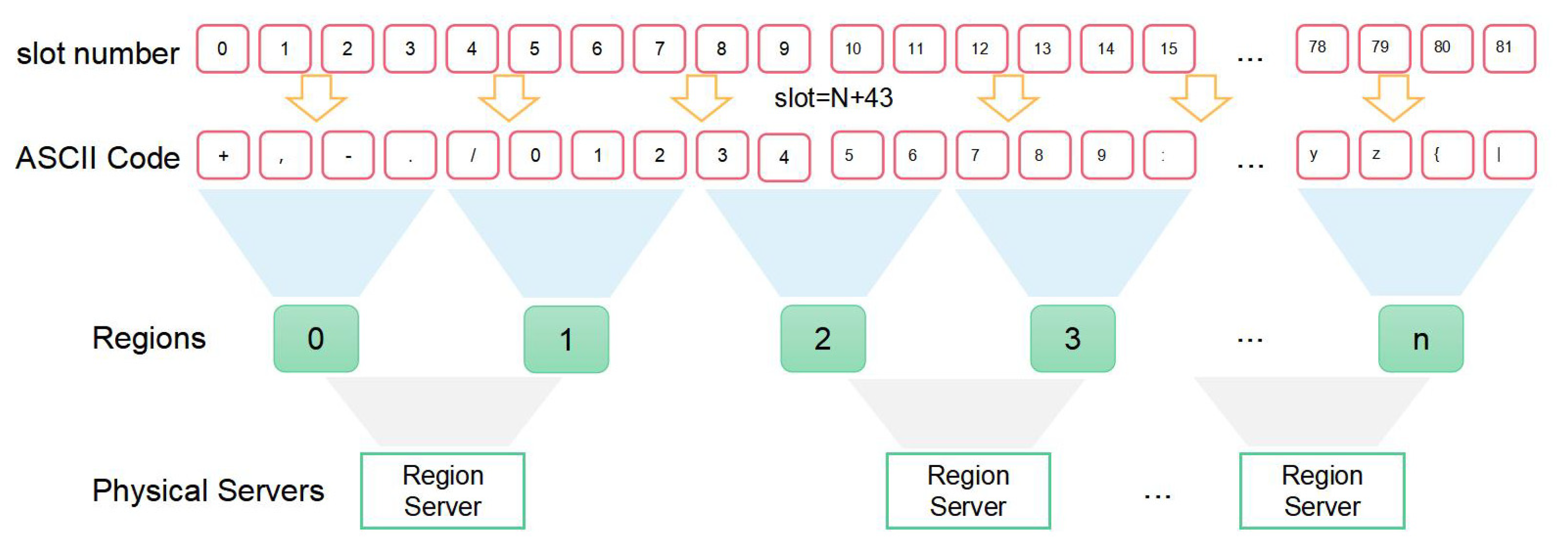
Since the “slot” token occupies only one byte in the row key, the slot token takes a value in the range [0, 255]. HBase master nodes assign the data triplet (key, field, value) to a pre-specified target region partition based on the slot information in the row key header. The scalable storage architecture for tile data can be illustrated by
Figure 5. There are four layers in this architecture. The first layer is the slot number composed of consecutive integers. The second layer is a mapping of first layer, which is composed of discrete characters. According to the order of ASCII codes, multiple characters are grouped to a region, which is an element of third layer called regions. To the last layer, it is physical servers which composed by several regions in the third layer.
Because the row key cannot contain the asterisk character (*), ASCII sequences without this character are used to map the slot numbers to ASCII codes. To obtain the correct assignment of row keys marked with slot information to the target region, it is also necessary to use pre-partitioning techniques when creating HBase tables. The pre-partitioning script run under the HBase SHELL is as follows:
$>create ‘Tiles’, {NAME=>‘f’,VERSIONS=>1},SPLITS=>[‘4’,‘=,‘F’,‘O’,‘X’,‘a’,‘j’,‘s’].
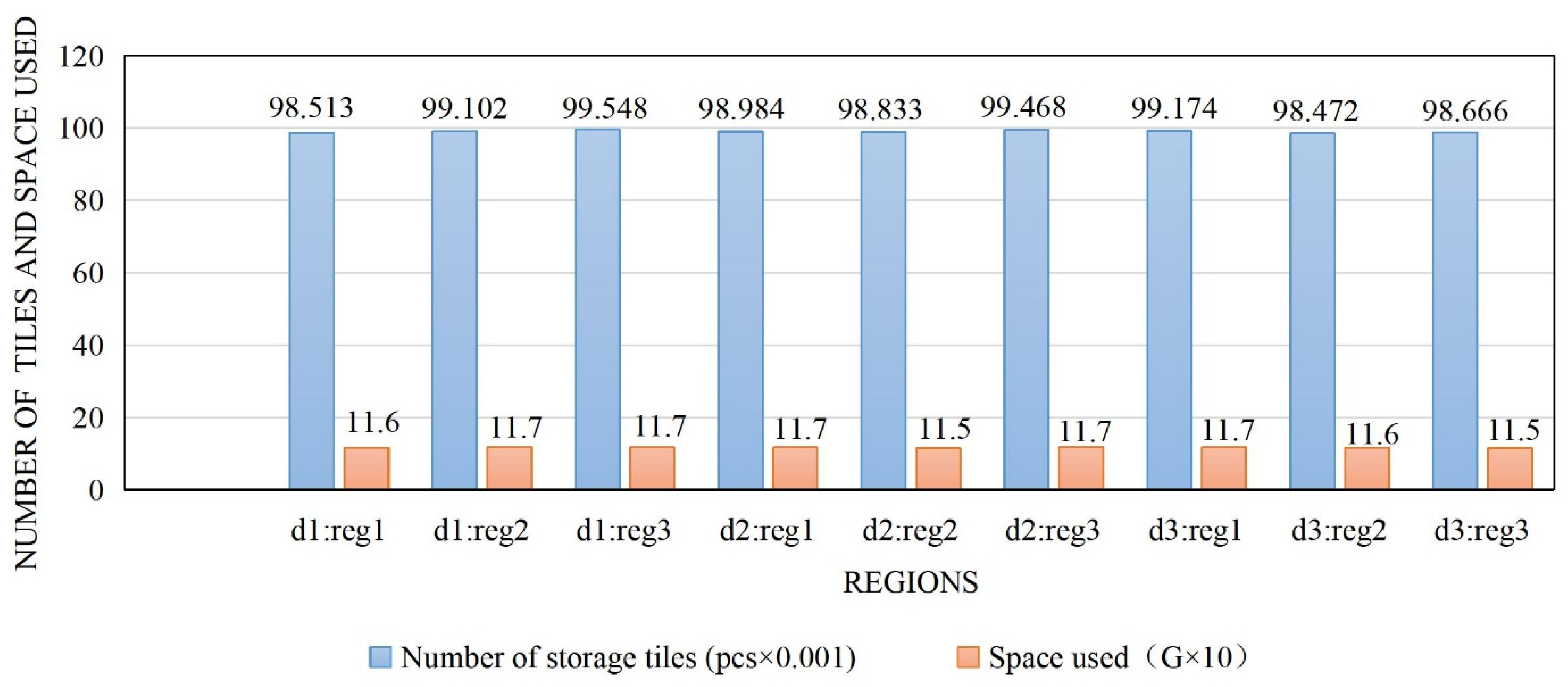
This script creates large table tiles on the HBase cluster and pre-partitions these large tables into nine regions. The number of pre-partitions is determined based on the actual number of physical nodes in the cluster. In accordance with the load balancing principle, HBase distributes these regions evenly among the physical servers running the region server application.
3.3. Tile Data Access
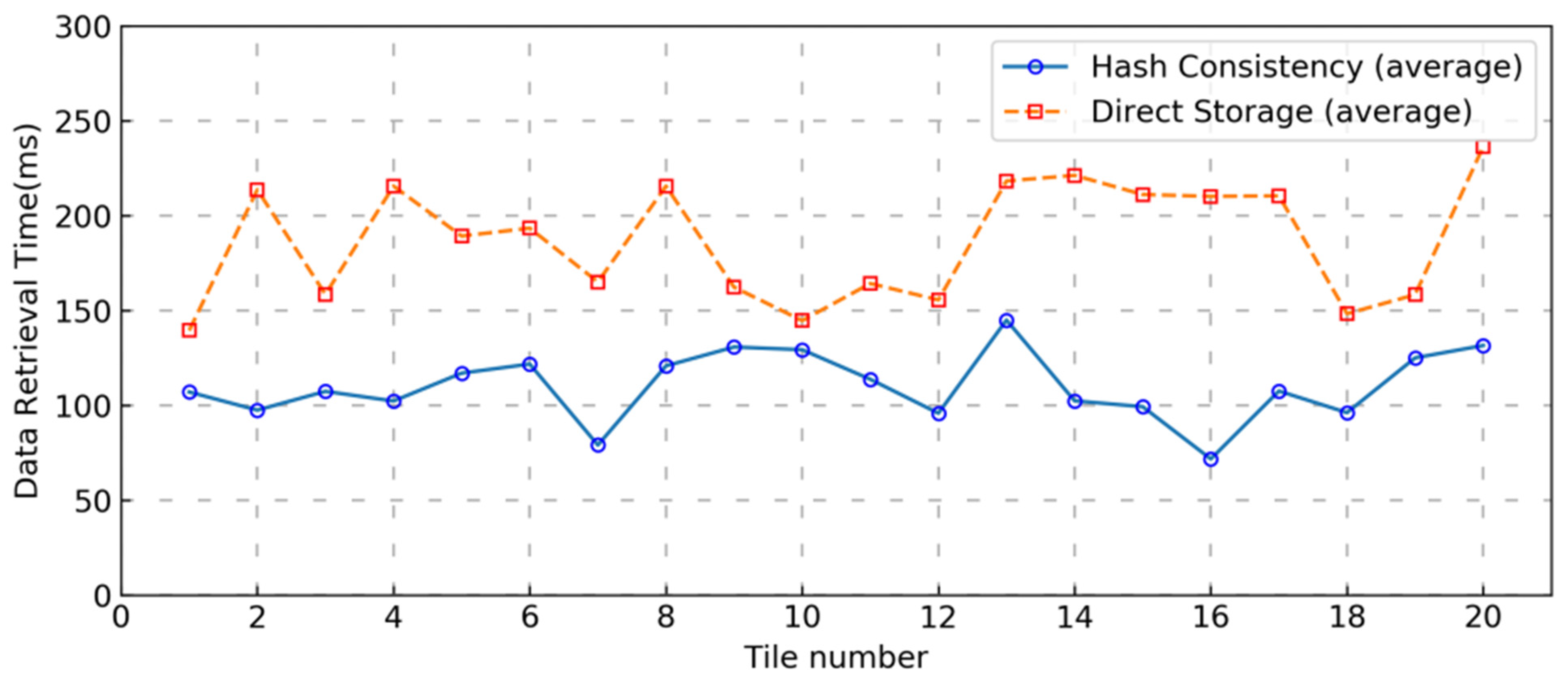
Since the pseudo-random function random() is consistent, that is, the resulting random series is consistent for a determined value (seed), to read tile data for a certain map zoom level with coordinates z, x, y, it is possible to restore the slot information from the time of data entry by using the index key z, x, y as the seed for the random function. This will generate the row key for the tile that has been saved in the large table. Each piece of tile data in the map view can then be quickly read by concurrent GET requests.
5. Conclusions
To address the problem of efficiently storing and publishing massive tile data on a big data storage platform, this paper proposed a tile data access model that used the jump consistent hashing algorithm at its core. By constructing a storage environment with an absolutely uniform distribution of tile data in the cluster storage nodes, the model achieved load balancing on the cluster under concurrent access conditions, successfully solved the data hotspot problem when massive tile data was concurrently stored and retrieved, and significantly improved the tile data retrieval efficiency under concurrent access conditions. Since the total number of slots, n, needs to be determined when calculating the slots using the jump consistent hashing algorithm, the data size must first be predicted when a specific access scheme is implemented using this model. In practical applications, the value of n can be set as large as possible, taking the data size and efficiency into account, in order to meet the demand for horizontal expansion of clusters in future data growth explosion environments. In future research, we plan to address the implementation of hashing algorithms that support variable values of n.
The model described in this paper can be applied not only directly to tile data access but also to all data access processes that have monotonic key values (e.g., time-series data). The model addresses the deficiencies of key-value model databases in handling multi-conditional combinatorial queries with the efficiency of clustering to handle concurrent requests and thus provides a new technical idea for other kinds of tile data access.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}