
Using VGI and Social Media Data to Understand Urban Green Space: A Narrative Literature Review



Abstract
:1. Introduction
- What were the research aims and the research topics in studies that explored VGI in relation to urban green space?
- What types of social media websites or platforms were generally selected in these studies?
- What were the methods used in collecting data, processing data and analysing data?
- What were the potential challenges and problems not yet resolved and researched?
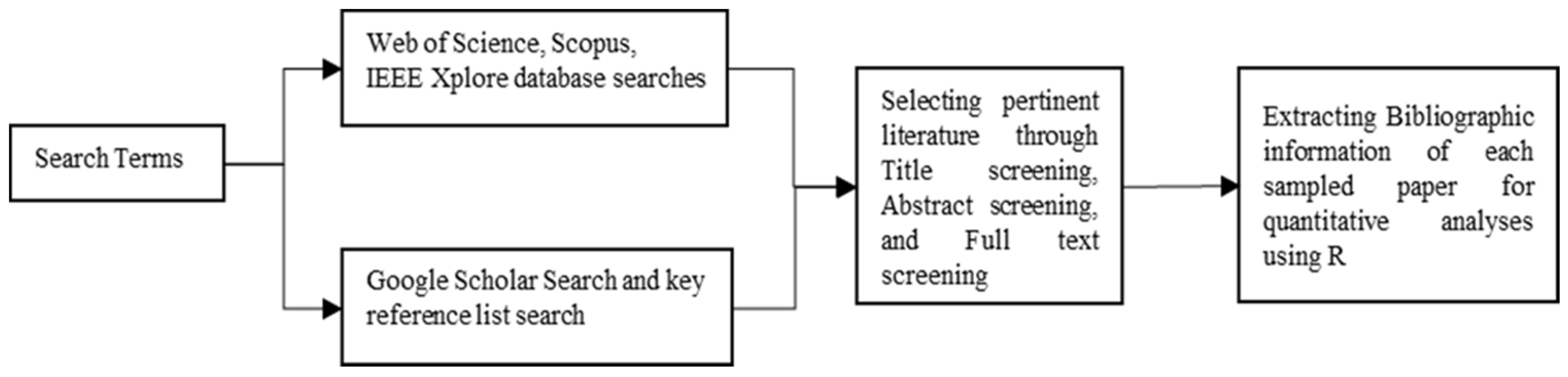
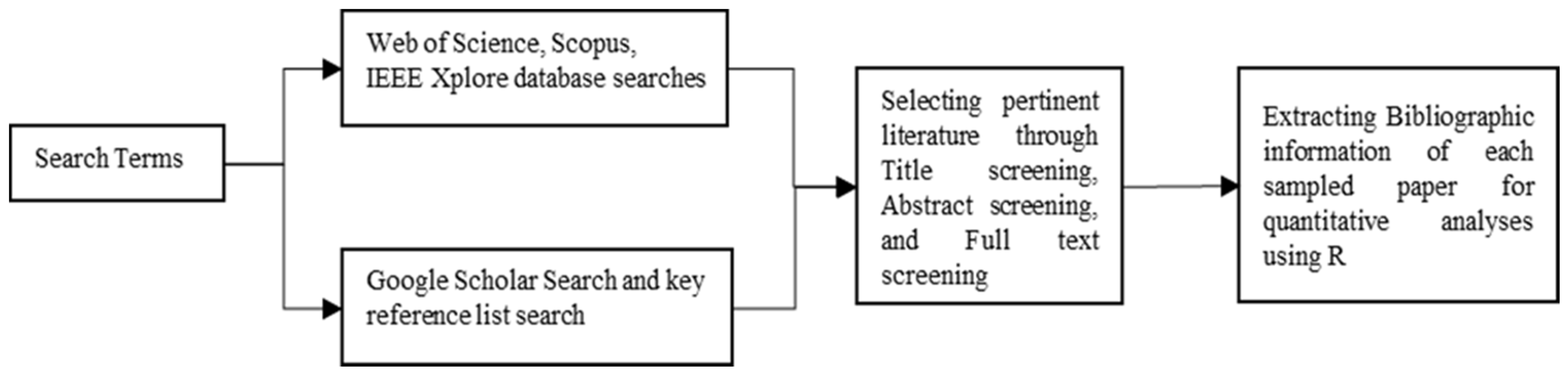
2. Materials and Methods
2.1. Bibliometric Literature Search
2.2. Data Processing
3. Results
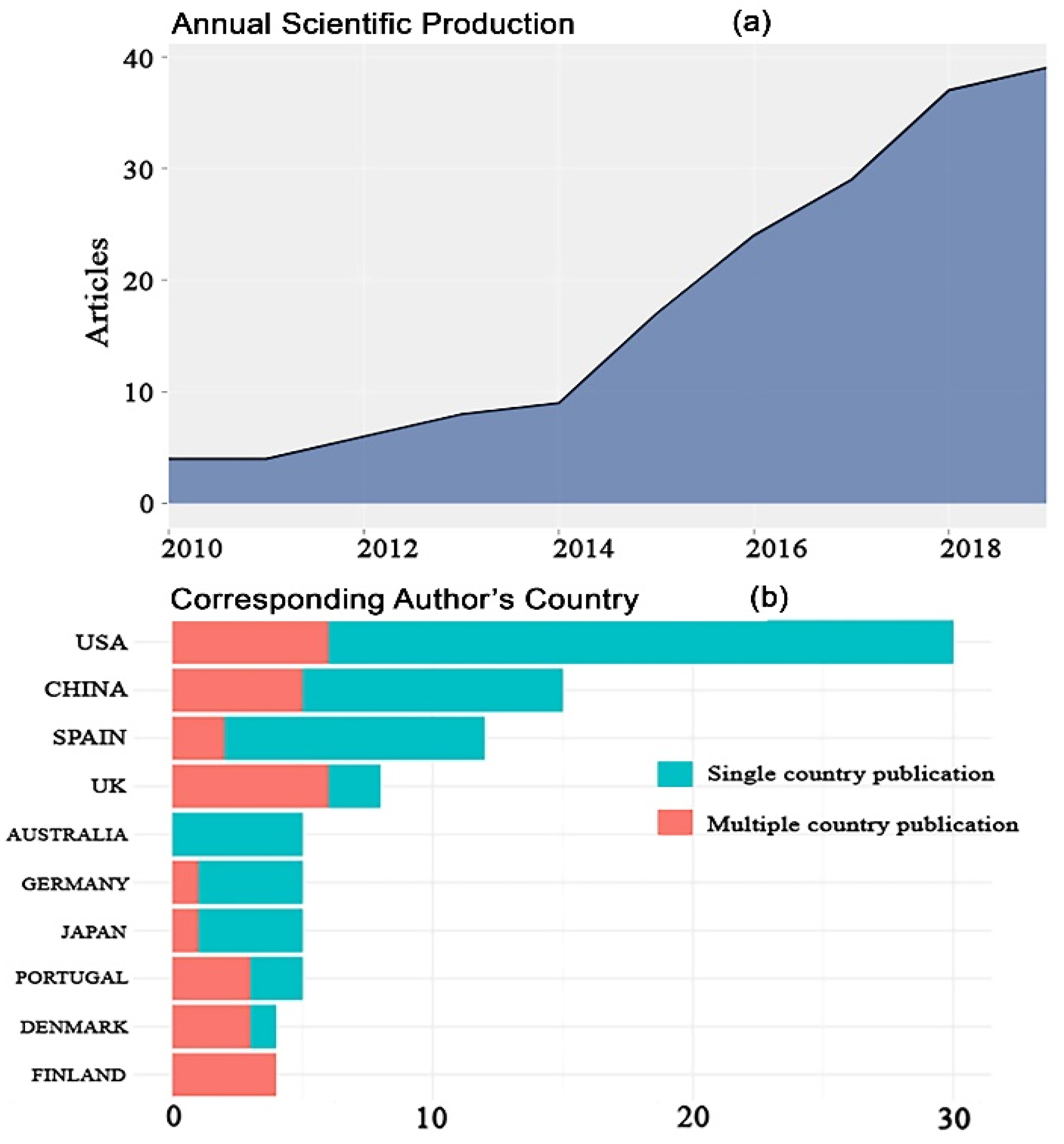
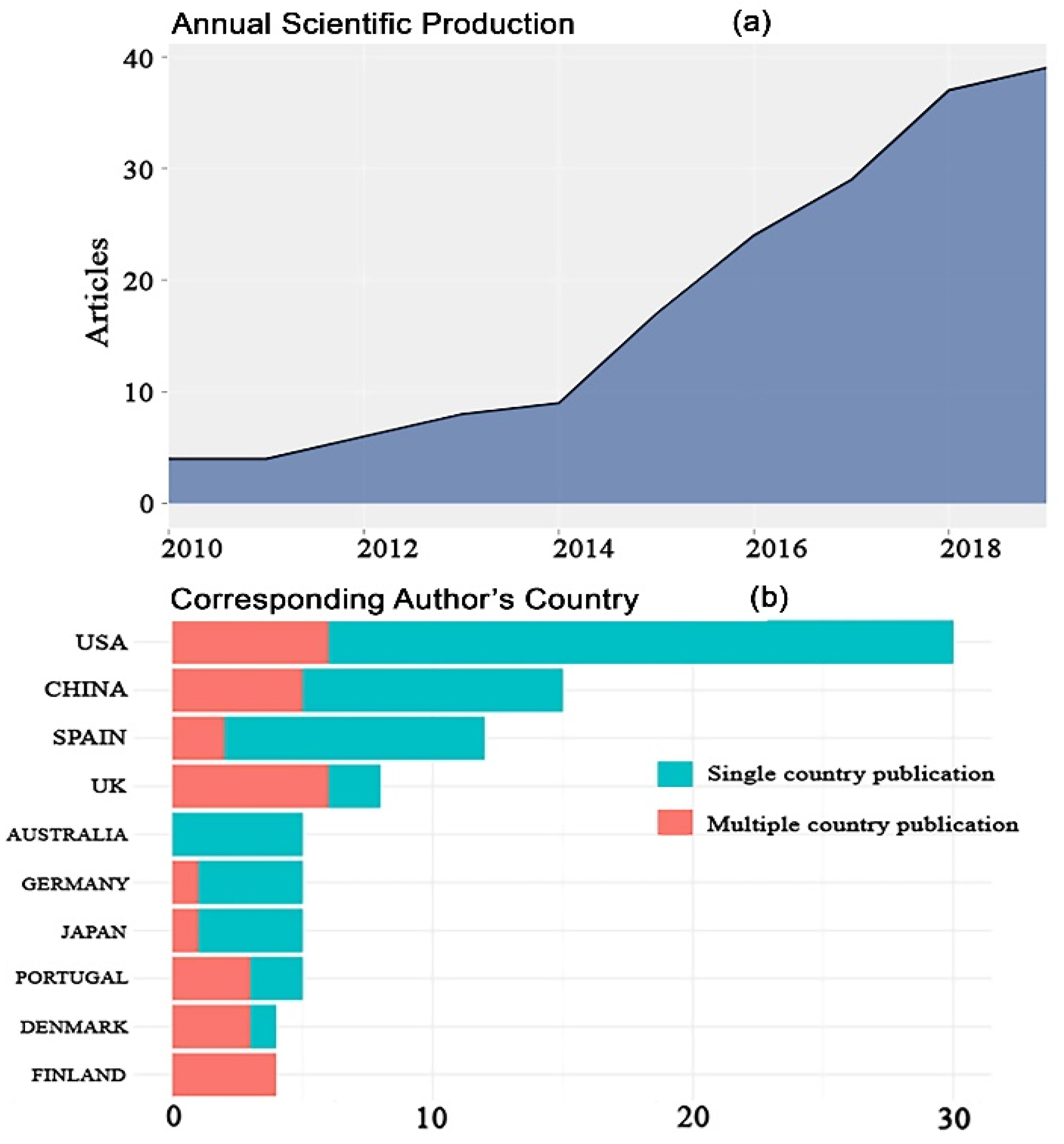
3.1. Main Characteristics of Included Studies
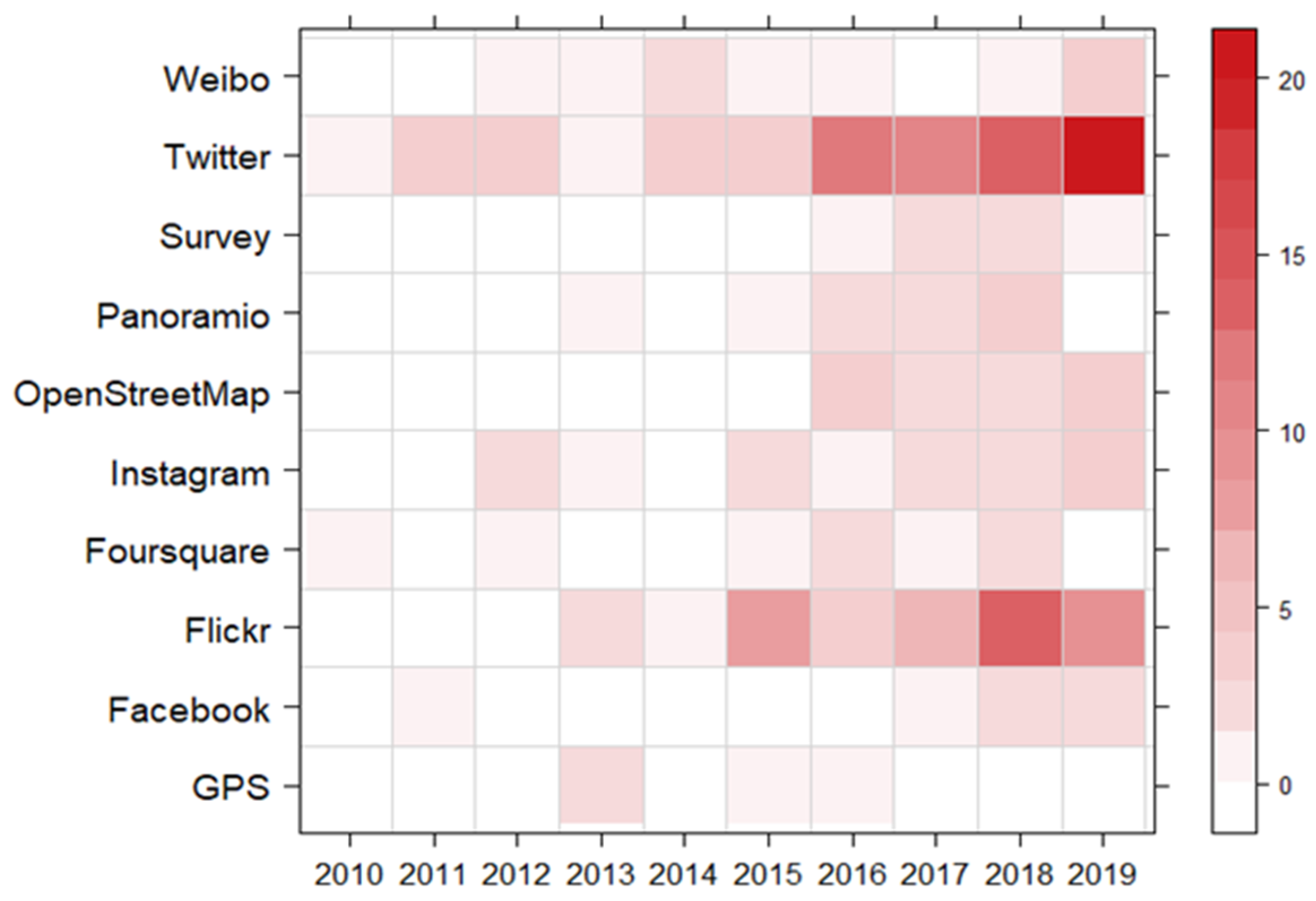
3.2. Data Sources in Relation to UGS Analysis
- The time of text-based data (i.e., Tweets) creation can support investigations into the temporal patterns of park visitation [74].
- Shared pictures provide access to real-time information, allowing researchers to generate temporal patterns of urban green space use [79]. Additionally, images are taken and posted throughout the year, enabling longitudinal analysis.
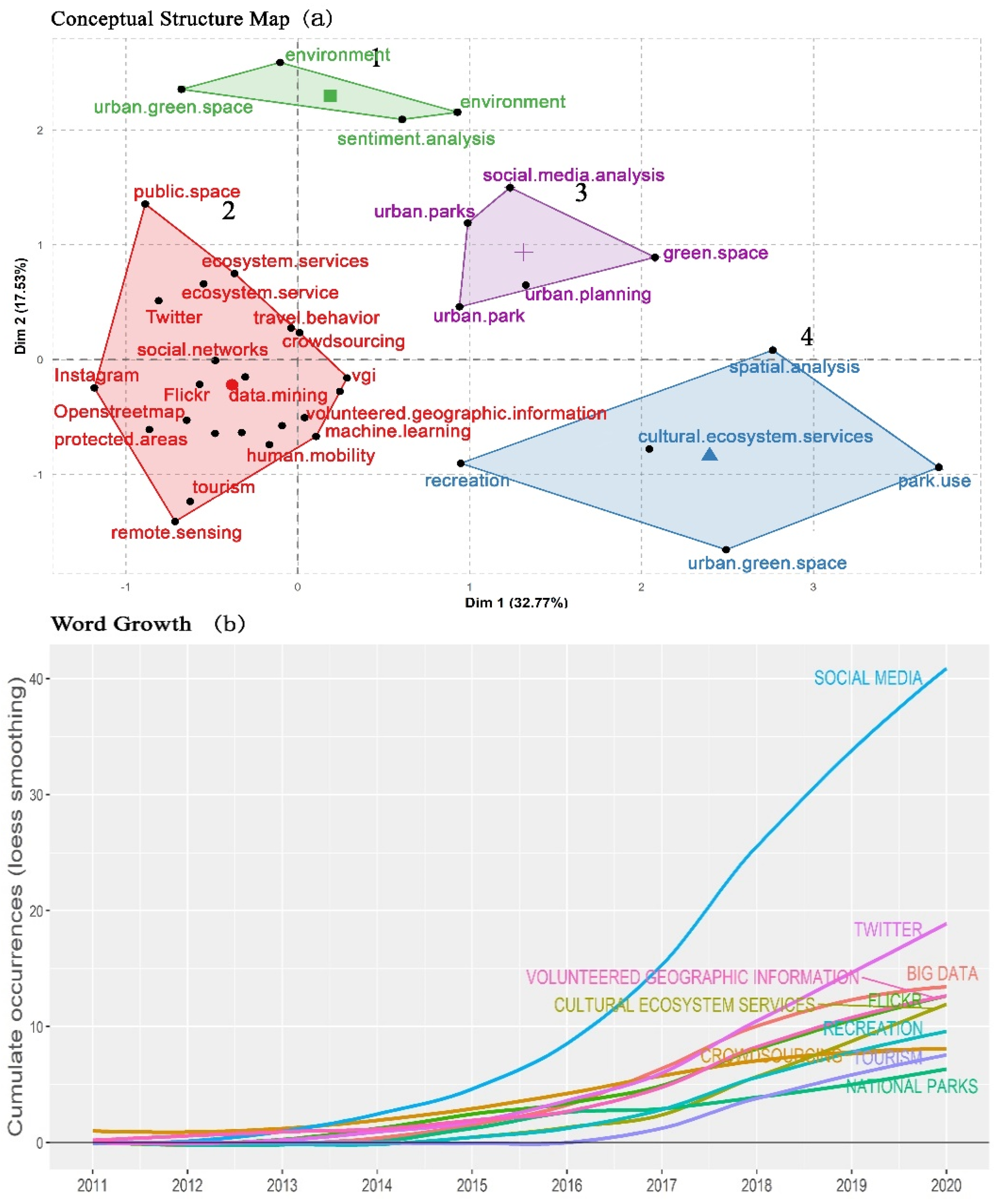
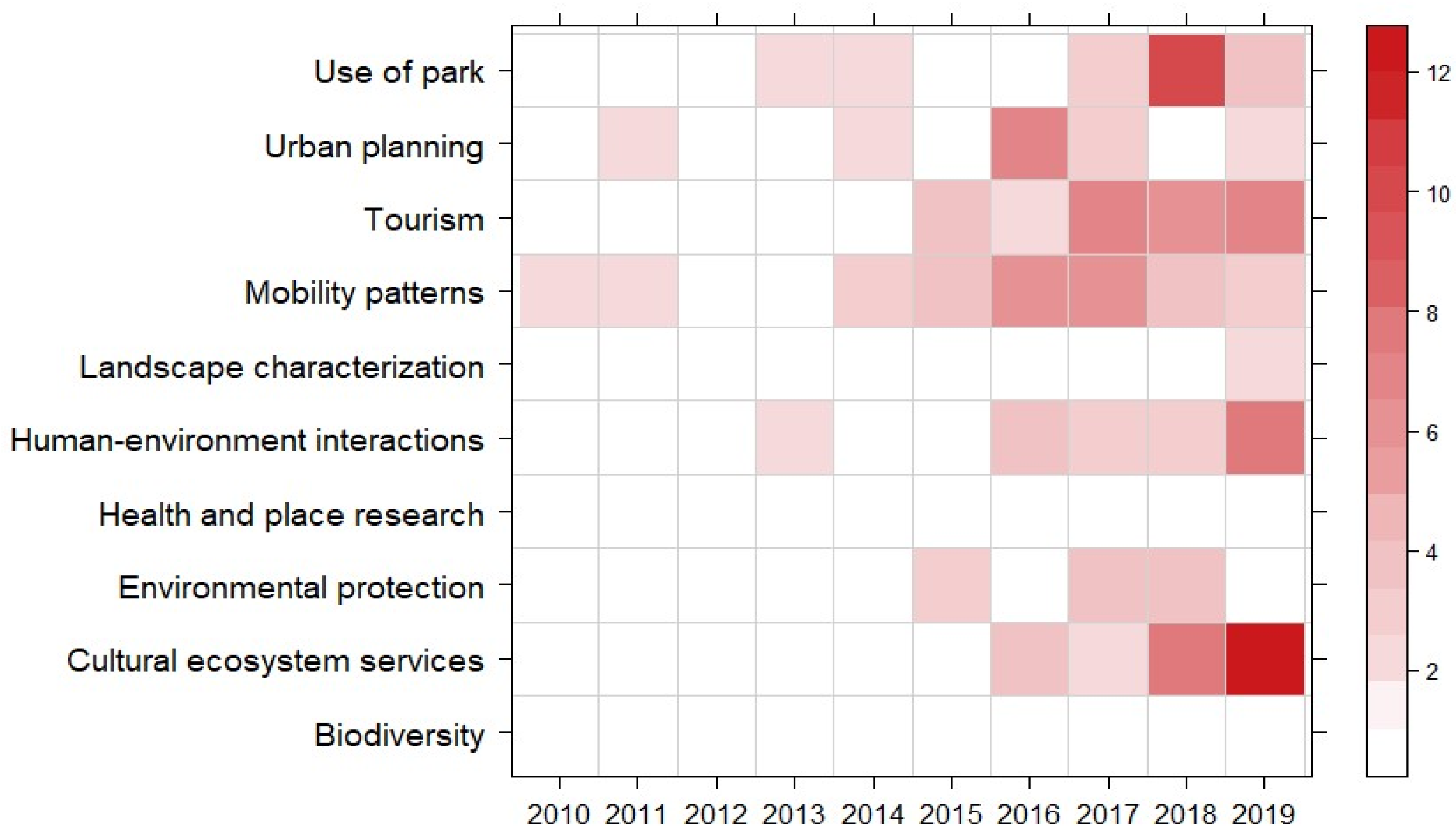
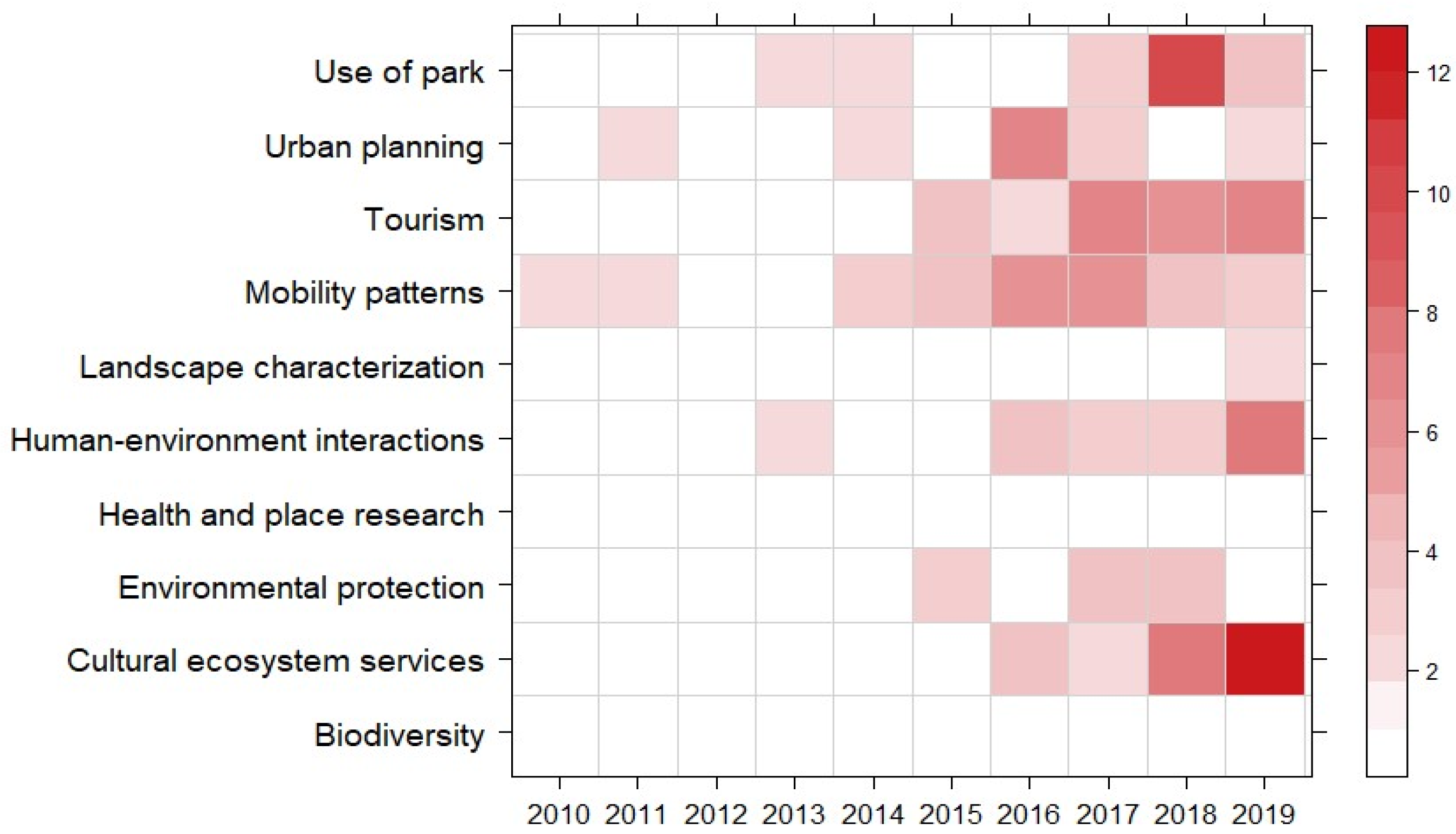
3.3. Research Themes in Relation to UGS Analysis
3.4. Methods Used in Data Analysis
3.4.1. Methods Used in Pre-Processing
3.4.2. Methods Used in Spatial Data Analysis
3.4.3. Methods Used in Temporal Analysis
3.4.4. Methods Used in Semantic Analysis
3.5. Data Quality Issues and Improvement
4. Discussion
4.1. Research Gaps and Opportunities
- Using data from multiple sources
- The need for combining personal information with data analysis
- Improving information mining analysis and models
- The representativeness and validation of social media data in UGS research
4.2. Analysis Methods and Approaches
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Niemelä, J. Ecology and urban planning. Biodiv. Conserv. 1999, 8, 119–131. [Google Scholar] [CrossRef]
- Chiesura, A. The role of urban parks for the sustainable city. Landsc. Urban Plan. 2004, 68, 129–138. [Google Scholar] [CrossRef]
- Kabisch, N.; Qureshi, S.; Haase, D. Human–environment interactions in urban green spaces—A systematic review of contemporary issues and prospects for future research. Environ. Impact Asses. 2015, 50, 25–34. [Google Scholar] [CrossRef]
- Wolch, J.R.; Byrne, J.; Newell, J.P. Urban green space, public health, and environmental justice: The challenge of making cities ‘just green enough’. Landsc. Urban Plan. 2014, 125, 234–244. [Google Scholar] [CrossRef] [Green Version]
- Cohen, D.A.; Lapham, S.; Evenson, K.R.; Williamson, S.; Golinelli, D.; Ward, P.; Hillier, A.; McKenzie, T.L. Use of neighbourhood parks: Does socio-economic status matter? A four-city study. Public Health 2013, 127, 325–332. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Yang, J.; Ma, L.; Huang, C. Factors affecting the use of urban green spaces for physical activities: Views of young urban residents in Beijing. Urban For. Urban Green. 2015, 14, 851–857. [Google Scholar] [CrossRef]
- Roe, J.J.; Thompson, C.W.; Aspinall, P.A.; Brewer, M.J.; Duff, E.I.; Miller, D.; Mitchell, R.; Clow, A. Green space and stress: Evidence from cortisol measures in deprived urban communities. Int. J. Environ. Res. Public Health 2013, 10, 4086–4103. [Google Scholar] [CrossRef] [Green Version]
- Comber, A.; Brunsdon, C.; Green, E. Using a GIS-based network analysis to determine urban greenspace accessibility for different ethnic and religious groups. Landsc. Urban Plan. 2008, 86, 103–114. [Google Scholar] [CrossRef] [Green Version]
- Fan, P.; Xu, L.; Yue, W.; Chen, J. Accessibility of public urban green space in an urban periphery: The case of Shanghai. Landsc. Urban Plan. 2017, 165, 177–192. [Google Scholar] [CrossRef]
- Campbell, L.K.; Svendsen, E.S.; Sonti, N.F.; Johnson, M.L. A social assessment of urban parkland: Analyzing park use and meaning to inform management and resilience planning. Environ. Sci. Policy 2016, 62, 34–44. [Google Scholar] [CrossRef]
- Grose, M.J. Changing relationships in public open space and private open space in suburbs in south-western Australia. Landsc. Urban Plan. 2009, 92, 53–63. [Google Scholar] [CrossRef]
- Kim, D.; Jin, J. Does happiness data say urban parks are worth it? Landsc. Urban Plan. 2018, 178, 1–11. [Google Scholar] [CrossRef]
- United Nations. The Sustainable Development Goals Report 2019. Sustain. Develop. Goals Rep. 2019, 7, 1–61. Available online: https://unstats.un.org/sdgs/report/2019/The-Sustainable-Development-Goals-Report-2019.pdf (accessed on 3 March 2021).
- Haaland, C.; van Den Bosch, C.K. Challenges and strategies for urban green-space planning in cities undergoing densification: A review. Urban For. Urban Green. 2015, 14, 760–771. [Google Scholar] [CrossRef]
- Kashef, M. Urban livability across disciplinary and professional boundaries. Front. Archit. Res. 2016, 5, 239–253. [Google Scholar] [CrossRef] [Green Version]
- Roberts, H.V. Using Twitter data in urban green space research: A case study and critical evaluation. Appl. Geogr. 2017, 81, 13–20. [Google Scholar] [CrossRef]
- Larson, L.R.; Jennings, V.; Cloutier, S.A. Public parks and wellbeing in urban areas of the United States. PLoS ONE 2016, 11, e0153211. Available online: https://pubmed.ncbi.nlm.nih.gov/27054887/ (accessed on 3 March 2021). [CrossRef]
- Tsai, W.L.; McHale, M.R.; Jennings, V.; Marquet, O.; Hipp, J.A.; Leung, Y.F.; Floyd, M.F. Relationships between Characteristics of Urban Green Land Cover and Mental Health in US Metropolitan Areas. Int. J. Environ. Res. Public Health 2018, 15, 340. [Google Scholar] [CrossRef] [Green Version]
- Taylor, M.; Wells, G.; Howell, G.; Raphael, B. The role of social media as psychological first aid as a support to community resilience building. Aust. J. Emerg. Manag. 2012, 27, 20–26. Available online: https://search.informit.org/doi/pdf/10.3316/informit.046721101149317 (accessed on 3 March 2021).
- See, L.; Estima, J.; Pődör, A.; Arsanjani, J.J.; Bayas, J.C.L.; Vatseva, R. Sources of VGI for Mapping. Mapp. Citiz. Sens. 2017, 13, 13–35. Available online: https://www.ubiquitypress.com/site/chapters/e/10.5334/bbf.b/ (accessed on 3 March 2021).
- See, L.; Mooney, P.; Foody, G.; Bastin, L.; Comber, A.; Estima, J.; Fritz, S.; Kerle, N.; Jiang, B.; Laakso, M.; et al. Crowdsourcing, citizen science or volunteered geographic information? The current state of crowdsourced geographic information. ISPRS Int. J. Geo-Inf. 2016, 5, 55. [Google Scholar] [CrossRef]
- Ghermandi, A.; Sinclair, M. Passive crowdsourcing of social media in environmental research: A systematic map. Glob. Environ. Chang. 2019, 55, 36–47. [Google Scholar] [CrossRef]
- Mitchell, L.; Frank, M.R.; Harris, K.D.; Dodds, P.S.; Danforth, C.M. The geography of happiness: Connecting twitter sentiment and expression, demographics, and objective characteristics of place. PLoS ONE 2013, 8, e64417. [Google Scholar] [CrossRef] [Green Version]
- Lyu, F.; Zhang, L. Using multi-source big data to understand the factors affecting urban park use in Wuhan. Urban For. Urban Green. 2019, 43, 126367. [Google Scholar] [CrossRef]
- Hennig, S. OpenStreetMap used in protected area management. The example of the recreational infrastructure in Berchtesgaden National Park. Eco. Mont. 2017, 9, 30–41. Available online: https://pdfs.semanticscholar.org/d301/0f968f2166ffb75ecb1c6f8288a979bf5f39.pdf (accessed on 3 March 2021). [CrossRef] [Green Version]
- Liu, H.; Li, F.; Xu, L.; Han, B. The impact of socio-demographic, environmental, and individual factors on urban park visitation in Beijing, China. J. Clean. Prod. 2017, 163, S181–S188. [Google Scholar] [CrossRef]
- Chen, W.; Huang, H.; Dong, J.; Zhang, Y.; Tian, Y.; Yang, Z. Social functional mapping of urban green space using remote sensing and social sensing data. ISPRS J. Photogramm. Remote Sens. 2018, 146, 436–452. [Google Scholar] [CrossRef]
- Cohen, D.A.; Marsh, T.; Williamson, S.; Derose, K.P.; Martinez, H.; Setodji, C.; McKenzie, T.L. Parks and physical activity: Why are some parks used more than others? Prev. Med. 2010, 50, S9–S12. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Figueroa-Alfaro, R.W.; Tang, Z. Evaluating the aesthetic value of cultural ecosystem services by mapping geo-tagged photographs from social media data on Panoramio and Flickr. Eco. Mont. 2017, 60, 266–281. [Google Scholar] [CrossRef]
- Paracchini, M.L.; Zulian, G.; Kopperoinen, L.; Maes, J.; Schägner, J.P.; Termansen, M.; Zandersen, M.; Perez-Soba, M.; Scholefield, P.A.; Bidoglio, G. Mapping cultural ecosystem services: A framework to assess the potential for outdoor recreation across the EU. Ecol. Ind. 2014, 45, 371–385. [Google Scholar] [CrossRef] [Green Version]
- Shi, B.; Zhao, J.; Chen, P. Exploring urban tourism crowding in Shanghai via crowdsourcing geospatial data. Curr. Issues Tour. 2017, 20, 1186–1209. [Google Scholar] [CrossRef]
- Wood, S.A.; Guerry, A.D.; Silver, J.M.; Lacayo, M. Using social media to quantify nature-based tourism and recreation. Sci. Rep. 2013, 3, 2976. [Google Scholar] [CrossRef]
- Al-Kodmany, K. Improving Understanding of City Spaces for Tourism Applications. Buildings 2019, 9, 187. [Google Scholar] [CrossRef] [Green Version]
- Hao, J.; Zhu, J.; Zhong, R. The rise of big data on urban studies and planning practices in China: Review and open research issues. J. Urban Manag. 2015, 4, 92–124. [Google Scholar] [CrossRef] [Green Version]
- Nitoslawski, S.A.; Galle, N.J.; Van Den Bosch, C.K.; Steenberg, J.W. Smarter ecosystems for smarter cities? A review of trends, technologies, and turning points for smart urban forestry. Sustain. Cities Soc. 2019, 51, 101770. [Google Scholar] [CrossRef]
- Basiri, A.; Haklay, M.; Foody, G.; Mooney, P. Crowdsourced geospatial data quality: Challenges and future directions. Int. J. Geo. Inf. Sci. 2019, 33, 1588–1593. [Google Scholar] [CrossRef] [Green Version]
- Stock, K. Mining location from social media: A systematic review. Comput. Environ. Urban Syst. 2018, 71, 209–240. [Google Scholar] [CrossRef]
- Wang, A.; Zhang, A.; Chan, E.H.; Shi, W.; Zhou, X.; Liu, Z. A Review of Human Mobility Research Based on Big Data and Its Implication for Smart City Development. ISPRS Int. J. Geo-Inf. 2021, 10, 13. [Google Scholar] [CrossRef]
- Martí, P.; Serrano-Estrada, L.; Nolasco-Cirugeda, A. Social media data: Challenges, opportunities and limitations in urban studies. Compt. Environ. Urban Syst. 2019, 74, 161–174. [Google Scholar] [CrossRef]
- Hecht, B.; Stephens, M. A tale of cities: Urban biases in volunteered geographic information. In Proceedings of the International AAAI Conference on Web and Social Media, Ann Arbor, MI, USA, 1–4 June 2014; Volume 8. Available online: https://ojs.aaai.org/index.php/ICWSM/issue/view/274 (accessed on 3 March 2021).
- Petticrew, M. Systematic reviews from astronomy to zoology: Myths and misconceptions. BMJ 2001, 322, 98–101. Available online: http://bmj.com/cgi/content/full/322/7278/9842 (accessed on 3 March 2021). [CrossRef] [Green Version]
- Konijnendijk, C.C.; Annerstedt, M.; Nielsen, A.B.; Maruthaveeran, S. Benefits of urban parks. A systematic review. A Rep. IFPRA 2013, 1, 1–70. Available online: http://worldurbanparks.org/images/Members_Login_Area/IfpraBenefitsOfUrbanParks.pdf (accessed on 3 March 2021).
- Sheng, T.; Chen, X.J.; Gao, S.; Liu, Q.Z.; Li, X.F.; Fu, Q.Y. Pollution characteristics and health risk assessment of VOCs in areas surrounding a petrochemical park in Shanghai. Huan Jing Ke Xue 2018, 39, 4901–4908. Available online: https://pubmed.ncbi.nlm.nih.gov/30628211/ (accessed on 3 March 2021).
- Blancaflor, E.B.; Butalon, J.M.T.; Pascual, P.E.S.; Yaneza, B.A.U.; Samonte, M.J.C. Parkpal: A park sharing and crowdsource park monitoring mobile application. In Proceedings of the 10th International Conference on E-Education, E-Business, E-Management and E-Learning (IC4E’2019), Tokyo, Japan, 10–13 January 2019; Volume 1, pp. 383–388. [Google Scholar] [CrossRef]
- Sadhukhan, P. An IoT-based E-parking system for smart cities. In Proceedings of the 2017 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Udupi, India, 13–16 September 2017; Volume 9, pp. 1062–1066. Available online: https://ieeexplore.ieee.org/abstract/document/8125982 (accessed on 3 March 2021).
- Sprake, J.; Rogers, P. Crowds, citizens and sensors: Process and practice for mobilising learning. Pers. Ubiquitous Comput. 2014, 18, 753–764. [Google Scholar] [CrossRef]
- Jung, J.; Uejio, C.K.; Duclos, C.; Jordan, M. Using web data to improve surveillance for heat sensitive health outcomes. Environ. Health 2019, 18, 59. [Google Scholar] [CrossRef] [Green Version]
- Ben-Harush, O.; Carroll, J.A.; Marsh, B. Using mobile social media and GIS in health and place research. Cotinuum 2012, 26, 715–730. [Google Scholar] [CrossRef] [Green Version]
- Zhe, L.; Yong, G.; Hung-Suck, P.; Huijuan, D.; Liang, D.; Tsuyoshi, F. An emergy-based hybrid method for assessing industrial symbiosis of an industrial park. J. Clean. Prod. 2016, 114, 132–140. [Google Scholar] [CrossRef]
- Weiler, A.; Grossniklaus, M.; Scholl, M. Situation monitoring of urban areas using social media data streams. Inf. Syst. 2016, 57, 129–141. [Google Scholar] [CrossRef] [Green Version]
- Barros, R.; Kislansky, P.; do Nascimento Salvador, L.; Almeida, R.; Breyer, M.; Pedraza, L.G. EDXL-RESCUER ontology: Conceptual Model for Semantic Integration. In Proceedings of the ISCRAM 2015 Conference, Kristiansand, Norway, 24–27 May 2015; Volume 5, pp. 1–9. Available online: http://idl.iscram.org/files/rebecabarros/2015/1183_RebecaBarros_etal2015.pdf (accessed on 3 March 2021).
- Broadus, R. Toward a definition of “bibliometrics”. Scientometrics 1987, 12, 373–379. [Google Scholar] [CrossRef]
- Daim, T.U.; Rueda, G.; Martin, H.; Gerdsri, P. Forecasting emerging technologies: Use of bibliometrics and patent analysis. Technol. Forecast. Soc. Chang. 2006, 73, 981–1012. [Google Scholar] [CrossRef]
- Aria, M.; Cuccurullo, C. bibliometrix: An R-tool for comprehensive science mapping analysis. J. Inform. 2017, 11, 959–975. [Google Scholar] [CrossRef]
- Greenacre, M.; Blasius, J. Multiple Correspondence Analysis and Related Methods; CRC Press: Boca Raton, FL, USA, 2006; pp. 197–219. [Google Scholar]
- Abdi, H.; Valentin, D. Multiple correspondence analysis. Encycl. Meas. Stat. 2007, 2, 651–657. Available online: http://bis.net.vn/files/storage/20121203214658733.pdf (accessed on 3 March 2021).
- Kwak, H.; Lee, C.; Park, H.; Moon, S. What is Twitter, a social network or a news media? In Proceedings of the 19th International Conference on World Wide Web (WWW’10), Raleigh, NC, USA, 26–30 April 2010; Volume 4, pp. 591–600. [Google Scholar] [CrossRef] [Green Version]
- Tenkanen, H.; Di Minin, E.; Heikinheimo, V.; Hausmann, A.; Herbst, M.; Kajala, L.; Toivonen, T. Instagram, Flickr, or Twitter: Assessing the usability of social media data for visitor monitoring in protected areas. Sci. Rep. 2017, 7, 17615. [Google Scholar] [CrossRef] [Green Version]
- Di Minin, E.; Tenkanen, H.; Toivonen, T. Prospects and challenges for social media data in conservation science. Environ. Sci. 2015, 3, 63. [Google Scholar] [CrossRef] [Green Version]
- Gu, Z.; Zhang, Y.; Chen, Y.; Chang, X. Analysis of Attraction Features of Tourism Destinations in a Mega-City Based on Check-in Data Mining—A Case Study of Shenzhen, China. ISPRS Int. J. Geo-Inf. 2016, 5, 210. [Google Scholar] [CrossRef] [Green Version]
- Norman, P.; Pickering, C. Factors influencing park popularity for mountain bikers, walkers and runners as indicated by social media route data. J. Environ. Manag. 2019, 249, 109413. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, X.; Gao, W.; Wang, R.Y.; Li, Y.; Tu, W. Emerging social media data on measuring urban park use. Urban For. Urban Green. 2018, 31, 130–141. [Google Scholar] [CrossRef]
- Dai, P.; Zhang, S.; Chen, Z.; Gong, Y.; Hou, H. Perceptions of cultural ecosystem services in urban parks based on social network data. Sustainability 2019, 11, 5386. [Google Scholar] [CrossRef] [Green Version]
- Senaratne, H.; Mobasheri, A.; Ali, A.L.; Capineri, C.; Haklay, M. A review of volunteered geographic information quality assessment methods. Int. J. Geo. Inf. Sci. 2017, 31, 139–167. [Google Scholar] [CrossRef]
- Hamstead, Z.A.; Fisher, D.; Ilieva, R.T.; Wood, S.A.; McPhearson, T.; Kremer, P. Geolocated social media as a rapid indicator of park visitation and equitable park access. Compt. Environ. Urban Syst. 2018, 72, 38–50. [Google Scholar] [CrossRef]
- Li, F.; Li, F.; Li, S.; Long, Y. Deciphering the recreational use of urban parks: Experiments using multi-source big data for all Chinese cities. Sci. Total Environ. 2020, 701, 134896. [Google Scholar] [CrossRef] [PubMed]
- Sim, J.; Miller, P. Understanding an Urban Park through Big Data. Int. J. Environ. Res. Public Health 2019, 16, 3816. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Jin, Y.; Liu, Y.; Li, D.; Zhang, B. Comparing social media data and survey data in assessing the attractiveness of Beijing Olympic Forest Park. Sustainability 2018, 10, 382. [Google Scholar] [CrossRef] [Green Version]
- Roberts, H.; Sadler, J.; Chapman, L. Using Twitter to investigate seasonal variation in physical activity in urban green space. Geo. 2017, 4, e00041. [Google Scholar] [CrossRef]
- Santos, T.; Mendes, R.N.; Vasco, A. Recreational activities in urban parks: Spatial interactions among users. J. Outdoor Rec. Tour. 2016, 15, 1–9. [Google Scholar] [CrossRef]
- Song, Y.; Huang, B.; Cai, J.; Chen, B. Dynamic assessments of population exposure to urban greenspace using multi-source big data. Sci. Total Environ. 2018, 634, 1315–1325. [Google Scholar] [CrossRef]
- Plunz, R.A.; Zhou, Y.; Vintimilla, M.I.C.; Mckeown, K.; Yu, T.; Uguccioni, L.; Sutto, M.P. Twitter sentiment in New York City parks as measure of well-being. Landsc. Urban Plan. 2019, 189, 235–246. [Google Scholar] [CrossRef]
- Roberts, H.; Sadler, J.; Chapman, L. The value of Twitter data for determining the emotional responses of people to urban green spaces: A case study and critical evaluation. Urban Stud. 2019, 56, 818–835. [Google Scholar] [CrossRef]
- Kovacs-Györi, A.; Ristea, A.; Kolcsar, R.; Resch, B.; Crivellari, A.; Blaschke, T. Beyond Spatial Proximity—Classifying Parks and Their Visitors in London Based on Spatiotemporal and Sentiment Analysis of Twitter Data. ISPRS Int. J. Geo-Inf. 2018, 7, 378. [Google Scholar] [CrossRef] [Green Version]
- Gliozzo, G.; Pettorelli, N.; Haklay, M. Using crowdsourced imagery to detect cultural ecosystem services: A case study in South Wales, UK. Ecol. Soc. 2016, 21, 1–12. Available online: https://www.jstor.org/stable/26269952 (accessed on 3 March 2021). [CrossRef] [Green Version]
- Guerrero, P.; Møller, M.S.; Olafsson, A.S.; Snizek, B. Revealing cultural ecosystem services through Instagram images: The potential of social media volunteered geographic information for urban green infrastructure planning and governance. Urban Plan. 2016, 1, 1–17. [Google Scholar] [CrossRef]
- Sinclair, M.; Ghermandi, A.; Sheela, A.M. A crowdsourced valuation of recreational ecosystem services using social media data: An application to a tropical wetland in India. Sci. Total Environ. 2018, 642, 356–365. [Google Scholar] [CrossRef]
- Dallimer, M.; Davies, Z.G.; Irvine, K.N.; Maltby, L.; Warren, P.H.; Gaston, K.J.; Armsworth, P.R. What personal and environmental factors determine frequency of urban greenspace use? Int. J. Environ. Res. Public Health 2014, 11, 7977–7992. [Google Scholar] [CrossRef] [PubMed]
- Heikinheimo, V.; Minin, E.D.; Tenkanen, H.; Hausmann, A.; Erkkonen, J.; Toivonen, T. User-Generated Geographic Information for Visitor Monitoring in a National Park: A Comparison of Social Media Data and Visitor Survey. ISPRS Int. J. Geo-Inf. 2017, 6, 85. [Google Scholar] [CrossRef] [Green Version]
- Oteros-Rozas, E.; Martín-López, B.; Fagerholm, N.; Bieling, C.; Plieninger, T. Using social media photos to explore the relation between cultural ecosystem services and landscape features across five european sites. Ecol. Indic. 2017, 94, 74–86. [Google Scholar] [CrossRef]
- Johnson, M.L.; Campbell, L.K.; Svendsen, E.S.; McMillen, H.L. Mapping Urban Park Cultural Ecosystem Services: A Comparison of Twitter and Semi-Structured Interview Methods. Sustainability 2019, 11, 6137. [Google Scholar] [CrossRef] [Green Version]
- Steiger, E.; Resch, B.; Zipf, A. Exploration of spatiotemporal and semantic clusters of Twitter data using unsupervised neural networks. Int. J. Geo. Inf. Sci. 2015, 30, 1694–1716. [Google Scholar] [CrossRef]
- Salas-Olmedo, M.H.; Rojas Quezada, C. The use of public spaces in a medium-sized city: From Twitter data to mobility patterns. J. Maps 2017, 13, 40–45. [Google Scholar] [CrossRef] [Green Version]
- Blank, G.; Lutz, C. Representativeness of social media in great britain: Investigating Facebook, Linkedin, Twitter, Pinterest, Google+, and Instagram. Am. Behav. Sci. 2017, 61, 741–756. [Google Scholar] [CrossRef]
- Lenormand, M.; Picornell, M.; Cantú-Ros, O.G.; Tugores, A.; Louail, T.; Herranz, R.; Barthelemy, M.; Frias-Martinez, E.; Ramasco, J.J. Cross-checking different sources of mobility information. PLoS ONE 2014, 9, e105184. [Google Scholar] [CrossRef]
- Dunkel, A. Visualizing the perceived environment using crowdsourced photo geodata. Landsc. Urban Plan. 2015, 142, 173–186. [Google Scholar] [CrossRef]
- Lee, J.Y.; Tsou, M.H. Mapping spatiotemporal tourist behaviors and hotspots through location-based photo-sharing service (Flickr) data. In Proceedings of the LBS 2018: 14th International Conference on Location Based Services, Zurich, Switzerland, 15–17 January 2018; Volume 12, pp. 315–334. [Google Scholar] [CrossRef]
- Pickering, C.; Walden-Schreiner, C.; Barros, A.; Rossi, S.D. Using social media images and text to examine how tourists view and value the highest mountain in Australia. J. Outdoor Rec. Tour. 2020, 29, 100252. [Google Scholar] [CrossRef]
- Levin, N.; Lechner, A.M.; Brown, G. An evaluation of crowdsourced information for assessing the visitation and perceived importance of protected areas. Appl. Geogr. 2017, 79, 115–126. [Google Scholar] [CrossRef] [Green Version]
- Sai, Z.; Landscape, Z.W. Recreational visits to urban parks and factors affecting park visits: Evidence from geotagged social media data. Landsc. Urban Plan. 2018, 180, 27–35. [Google Scholar] [CrossRef]
- Vieira, F.A.; Bragagnolo, C.; Correia, R.A.; Malhado, A.C.; Ladle, R.J. A salience index for integrating multiple user perspectives in cultural ecosystem service assessments. Ecosyst. Serv. 2018, 32, 182–192. [Google Scholar] [CrossRef]
- Park, S.B.; Kim, H.J.; Ok, C.M. Linking emotion and place on Twitter at Disneyland. J. Travel Tour. Mark. 2018, 35, 664–677. [Google Scholar] [CrossRef]
- Song, X.P.; Richards, D.R.; He, P.; Tan, P.Y. Does geo-located social media reflect cultural ecosystem services: The case of a Natural Park in Portugal. Ecol. Indic. 2019, 96, 59–68. [Google Scholar] [CrossRef]
- Song, Y.; Zhang, B. Using social media data in understanding site-scale landscape architecture design: Taking Seattle Freeway Park as an example. Lands. Res. 2020, 45, 627–648. [Google Scholar] [CrossRef]
- Giannoulakis, S.; Tsapatsoulis, N. Topic modelling on Instagram hashtags: An alternative way to Automatic Image Annotation? In Proceedings of the 13th International Workshop on Semantic and Social Media Adaptation and Personalization (SMAP), Zaragoza, Spain, 6–7 September 2018; pp. 61–67. Available online: https://ieeexplore.ieee.org/document/8501887 (accessed on 25 March 2021).
- Boy, J.D.; Uitermark, J. How to study the city on Instagram. PLoS ONE 2016, 11, e0158161. [Google Scholar] [CrossRef]
- Devkota, B.; Miyazaki, H.; Witayangkurn, A.; Kim, S.M. Using Volunteered Geographic Information and Nighttime Light Remote Sensing Data to Identify Tourism Areas of Interest. Sustainability 2019, 11, 4718. [Google Scholar] [CrossRef] [Green Version]
- Vaz, A.S.; Gonçalves, J.F.; Pereira, P.; Santarém, F.; Vicente, J.R.; Honrado, J.P. Earth observation and social media: Evaluating the spatiotemporal contribution of non-native trees to cultural ecosystem services. Remote Sens. Environ. 2019, 230, 111193. [Google Scholar] [CrossRef]
- Gosal, A.S.; Geijzendorffer, I.R.; Václavík, T.; Poulin, B.; Ziv, G. Using social media, machine learning and natural language processing to map multiple recreational beneficiaries. Ecosyst. Serv. 2019, 38, 100958. [Google Scholar] [CrossRef] [Green Version]
- Li, L.; Goodchild, M.F.; Bo, X.J.C.; Science, G.I. Spatial, temporal, and socioeconomic patterns in the use of Twitter and Flickr. Cartogr. Geogr. Inf. Sci. 2013, 40, 61–77. [Google Scholar] [CrossRef]
- Boyd, D.; Crawford, K. Critical questions for big data: Provocations for a cultural, technological, and scholarly phenomenon. Inf. Commun. Soc. 2012, 15, 662–679. [Google Scholar] [CrossRef]
- Greenwood, S.; Perrin, A.; Duggan, M. Social Media Update 2016. Pew Res. Center 2016, 11, 1–18. Available online: https://assets.pewresearch.org/wp-content/uploads/sites/14/2016/11/10132827/PI_2016.11.11_Social-Media-Update_FINAL.pdf (accessed on 15 March 2021).
- Maeda, T.N.; Yoshida, M.; Toriumi, F.; Ohashi, H. Extraction of tourist destinations and comparative analysis of preferences between foreign tourists and domestic tourists on the basis of geotagged social media data. ISPRS Int. J. Geo-Inf. 2018, 7, 99. [Google Scholar] [CrossRef] [Green Version]
- Ullah, H.; Wan, W.; Haidery, S.A.; Khan, N.U.; Ebrahimpour, Z.; Muzahid, A.A.M. Spatiotemporal Patterns of Visitors in Urban Green Parks by Mining Social Media Big Data Based Upon WHO Reports. IEEE Access 2020, 8, 39197–39211. Available online: https://ieeexplore.ieee.org/document/8993712 (accessed on 3 March 2021). [CrossRef]
- Maia, M.; Almeida, J.; Almeida, V. Identifying user behavior in online social networks. In Proceedings of the 1st Workshop on Social Network Systems (Eurosys’08), Glasgow, Scotland, 1 April 2008; Volume 4, pp. 1–6. [Google Scholar] [CrossRef]
- Rizwan, M.; Wan, W. Big data analysis to observe check-in behavior using location-based social media data. Information 2018, 9, 257. [Google Scholar] [CrossRef] [Green Version]
- Han, S.Y.; Tsou, M.H.; Clarke, K.C. Do global cities enable global views? Using Twitter to quantify the level of geographical awareness of US cities. PLoS ONE 2015, 10, e0132464. [Google Scholar] [CrossRef]
- Hasnat, M.M.; Hasan, S. Identifying tourists and analyzing spatial patterns of their destinations from location-based social media data. Transp. Res. Part C Emerg. Technol. 2018, 96, 38–54. [Google Scholar] [CrossRef]
- Schirpke, U.; Meisch, C.; Marsoner, T.; Tappeiner, U. Revealing spatial and temporal patterns of outdoor recreation in the European Alps and their surroundings. Ecosyst. Serv. 2018, 31, 336–350. [Google Scholar] [CrossRef]
- Wakamiya, S.; Lee, R.; Sumiya, K. Crowd-based urban characterization: Extracting crowd behavioral patterns in urban areas from twitter. In Proceedings of the 3rd ACM SIGSPATIAL International Workshop on Location-Based Social Networks, Chicago, IL, USA, 1 November 2011; Volume 11, pp. 77–84. Available online: https://dl.acm.org/doi/abs/10.1145/2063212.2063225 (accessed on 3 March 2021).
- Gonçalves, P.; Araújo, M.; Benevenuto, F.; Cha, M. Comparing and combining sentiment analysis methods. In Proceedings of the First ACM Conference on Online Social Networks (COSN’13), Boston, MA, USA, 7–8 October 2013; Volume 8, pp. 27–38. [Google Scholar] [CrossRef] [Green Version]
- Martínez-Cámara, E.; Martín-Valdivia, M.T.; Urena-López, L.A.; Montejo-Ráez, A.R. Sentiment analysis in Twitter. Nat. Lang. Eng. 2014, 20, 1–28. [Google Scholar] [CrossRef]
- Antonakaki, D.; Fragopoulou, P.; Ioannidis, S. A survey of Twitter research: Data model, graph structure, sentiment analysis and attacks. Expert Syst. Appl. 2021, 164, 114006. [Google Scholar] [CrossRef]
- Lyu, K.; Kim, H. Sentiment analysis using word polarity of social media. Wirel. Pers. Commun. 2016, 89, 941–958. [Google Scholar] [CrossRef]
- Chapman, L.; Resch, B.; Sadler, J.; Zimmer, S.; Roberts, H.; Petutschnig, A. Investigating the emotional responses of individuals to urban green space using twitter data: A critical comparison of three different methods of sentiment analysis. Urban Plann. 2018, 3, 21–33. [Google Scholar] [CrossRef]
- Warriner, A.B.; Kuperman, V.; Brysbaert, M. Norms of valence, arousal, and dominance for 13,915 English lemmas. Behav. Res. Methods 2013, 45, 1191–1207. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Park, W.; You, Y.; Lee, K. Detecting potential insider threat: Analyzing insiders’ sentiment exposed in social media. Secur. Commun. Netw. 2018, 2018, 7243296. [Google Scholar] [CrossRef]
- Donahue, M.L.; Keeler, B.L.; Wood, S.A.; Fisher, D.M.; Hamstead, Z.A.; McPhearson, T. Using social media to understand drivers of urban park visitation in the Twin Cities, MN. Landsc. Urban Plan. 2018, 175, 1–10. [Google Scholar] [CrossRef]
- Lee, Y.; Kwon, P.; Yu, K.; Park, W.J.I.I.J.o.G.-I. Method for determining appropriate clustering criteria of location-sensing data. ISPRS Int. J. Geo-Inf. 2016, 5, 151. [Google Scholar] [CrossRef] [Green Version]
- García-Palomares, J.C.; Gutiérrez, J.; Mínguez, C. Identification of tourist hot spots based on social networks: A comparative analysis of European metropolises using photo-sharing services and GIS. Appl. Geogr. 2015, 63, 408–417. [Google Scholar] [CrossRef]
- Li, J.; Li, J.; Yuan, Y.; Li, G. Spatiotemporal distribution characteristics and mechanism analysis of urban population density: A case of Xi’an, Shaanxi, China. Cities 2019, 86, 62–70. [Google Scholar] [CrossRef]
- Sun, Y.; Du, Y.; Wang, Y.; Zhuang, L. Examining associations of environmental characteristics with recreational cycling behaviour by street-level Strava data. Int. J. Environ. Res. Public Health 2017, 14, 644. [Google Scholar] [CrossRef] [Green Version]
- Vich, G.; Marquet, O.; Miralles-Guasch, C. Green streetscape and walking: Exploring active mobility patterns in dense and compact cities. J. Transp. Health 2019, 12, 50–59. [Google Scholar] [CrossRef]
- Oksanen, J.; Bergman, C.; Sainio, J.; Westerholm, J. Methods for deriving and calibrating privacy-preserving heat maps from mobile sports tracking application data. J. Transp. Geogr. 2015, 48, 135–144. [Google Scholar] [CrossRef] [Green Version]
- Goodchild, M.F.; Li, L. Assuring the quality of volunteered geographic information. Spat. Stat. 2012, 1, 110–120. [Google Scholar] [CrossRef]
- Chen, E.; Deb, A.; Ferrara, E. # Election2020: The first public Twitter dataset on the 2020 US Presidential election. J. Comput. Soc. Sci. 2021, 4, 1–18. [Google Scholar] [CrossRef]
- Toivonen, T.; Heikinheimo, V.; Fink, C.; Hausmann, A.; Hiippala, T.; Järv, O.; Tenkanen, H.; Di Minin, E. Social media data for conservation science: A methodological overview. Biol. Conserv. 2019, 233, 298–315. [Google Scholar] [CrossRef]
- Butler, A.; Schafran, A.; Carpenter, G. What does it mean when people call a place a shithole? Under-standing a discourse of denigration in the United Kingdom and the Republic of Ireland. Trans. Inst. Br. Geogr. 2018, 43, 496–510. [Google Scholar] [CrossRef]
- Koblet, O.; Purves, R.S. From online texts to Landscape Character Assessment: Collecting and analysing first-person landscape perception computationally. Lands. Urban Plan. 2020, 197, 103757. [Google Scholar] [CrossRef]
- Comber, A.; Batty, M.; Brunsdon, C.; Hudson-Smith, A.; Neuhaus, F.; Gray, S. Exploring the geography of communities in social networks. In Proceedings of the GIS Research UK 20th Annual Conference, Lancaster, UK, 11–13 April 2012; pp. 33–37. Available online: https://www.geos.ed.ac.uk/~gisteac/proceedingsonline/GISRUK2012/Papers/presentation-25.pdf (accessed on 8 April 2021).
- Shou, Z.; Cao, Z.; Di, X. Similarity Analysis of Spatial-Temporal Mobility Patterns for Travel Mode Prediction Using Twitter Data. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; Volume 9, pp. 1–6. Available online: https://ieeexplore.ieee.org/abstract/document/9294709 (accessed on 3 March 2021).
- Nugroho, R.; Paris, C.; Nepal, S.; Yang, J.; Zhao, W. A survey of recent methods on deriving topics from Twitter: Algorithm to evaluation. Knowl. Inf. Syst. 2020, 62, 2485–2519. [Google Scholar] [CrossRef]
- Wong, G.; Greenhalgh, T.; Westhorp, G.; Buckingham, J.; Pawson, R. RAMESES publication standards: Meta-narrative reviews. J. Adv. Nurs. 2013, 69, 987–1004. [Google Scholar] [CrossRef] [Green Version]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| UGS | Data | |||
|---|---|---|---|---|
| Urban | AND | Green space/Greenspace | AND | Social media |
| OR | Green infrastructure | OR | Volunteer geographic information/ VGI | |
| OR | Park | OR | Crowd sourced geographic information | |
| OR | Recreation area | OR | Crowd source/Crowdsource/Crowdsourcing | |
| OR | Garden | OR | Citizen science/Citizen contributed science | |
| OR | Playing field | OR | Flikr/Twitter/Weibo/Foursquare/Instagram | |
| OR | WeChat/WhatsApp/Facebook | |||
| No. | Exclusion Criteria | Examples |
|---|---|---|
| 1 | Studies not written in English | [43] |
| 2 | Studies concerned with intelligent parking systems | [44,45] |
| 3 | Studies concerned with app information monitoring | [46] |
| 4 | Surveillance of health by using web data | [47] |
| 5 | Studies not related to green space | [48] |
| 6 | Studies that selected industrial parks as study areas | [49] |
| 7 | Studies concerned with disaster detection | [50] |
| 9 | Studies concerned with emergency situations | [51] |
| Data | Platforms | ||||
|---|---|---|---|---|---|
| Flickr | OpenStreetMap | ||||
| Data collection website | [74,81] https://developer.twitter.com) (accessed on 3 March 2021) | [86] www.flickr.com/api (accessed on 3 March 2021) | [91] www.instagram.com/developer (accessed on 3 March 2021) | [24,90] https://open.weibo.com/development/datacenter (accessed on 3 March 2021) | [25,86] http://www.openstreetmap.org (accessed on 3 March 2021) |
| Data type | Text-based VGI | Image-based VGI | Image-based VGI | Text-based VGI | Map-based VGI |
| Collection methods | Twitter’s search API, streaming API, Rest API, research API, and Twitter’s Firehose [16,39]. Python wrapper. Tweepy (https://www.tweepy.org/) (accessed on 3 March 2021) python library [91]. Tweet R package [81]; TAGS Version 6.0 [92]. | Search on the Flickr developer site [32]. Using standard Hypertext Transfer Protocol (HTTP) methods to retrieve and manipulate data [93]. The Flickr API (https://www.flickr.com/services/api/) (accessed on 3 March 2021) [94]. | Using a custom-made tool written for the Python programming language [95]. Using the API of Instagram by (https://www.instagram.com/developer/) (accessed on 3 March 2021) [96]. | The location service dynamic reading interface of the Sina Weibo open platform (https://api.weibo.com/2/place/nearby/photos.json) (accessed on 3 March 2021) as the data source [66]. Data collection was facilitated by Weibo application program interfaces (APIs). Through the “to obtain nearby locations” API [90]. | QuickOSM (https://plugins.qgis.org/plugins/QuickOSM/) (accessed on 3 March 2021) Python module for QGIS was used for collecting data from OSM.The OSM data are freely downloadable from geofabrik website (http://download.geofabrik.de/asia/nepal.html) (accessed on 3 March 2021). |
| Geography | With geo-coordinates | Geotagged posts (including pictures, titles and text) | Geotagged posts (including pictures, titles and text) | With geo-coordinates | Active mapper communities in many locations |
| Content | User ID, Tweet text, timestamp, geotags and volunteered geolocations | Photo ID and owner ID, title, description, geotags, time when a photo was taken and upload time | Photo photo ID, photo title, description, tags, upload time, time when a photo was taken, location, and owner ID | Text and metadata in Weibo with geolocation, and user ID, photographs location, device type | OpenStreetMap encodes data in different formats such as points, polylines, and polygons |
| Advantages | Free, high spatio-temporal resolution; Lots of Twitter users post messages at various locations, including school, home, restaurants, and touristic sites. Real-time information that potentially reaches a huge audience [91]. | Free, spatially and temporally explicit, visitation hotspots. Allows for image analysis and content. User characteristic analysis, actual visitation [89]. | Online mobile application focused on sharing photographs and providing a platform for social networking [76]. | Weibo users (462 million according to the 2018 Weibo User Development Report) can upload their real-time locations and share their preferences and activities on the Internet. Data from Weibo check-ins can well represent the preferences and activities of people in urban areas [86]. | A free and up-to-date map of the world accessible and obtainable for everyone; millions of registered contributors; provides free and flexible contribution mechanisms for data (useful for map provision, routing, planning, geo-visualisation, point of interest search). Insight into people’s individual perspectives and perceptions [86]. |
| Disadvantages | Twitter data have some biases, such as age, gender, and education. Not all the collected Tweets are usable since some of them may have been generated by spammers [97]. | Unclear meaning, confounding factors. Potential sampling and selection biases, noise in the data [93]. | Locational accuracy. The issues of anonymity and privacy arise. No information was gathered concerning the users, no socio-economic data exist, which makes it difficult to assess representability in detail [76]. | Sina Weibo check-in data have some biases, such as age, gender, a temporal change and social class bias. Weibo users are mainly composed of people between 18 and 40 years old, accounting for 89% of the total number of users. | Though OSM has no strict quality control mechanism, studies have indicated that data obtained from OSM are good enough and comparable to authoritative data to some extent [89]. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, N.; Malleson, N.; Houlden, V.; Comber, A. Using VGI and Social Media Data to Understand Urban Green Space: A Narrative Literature Review. ISPRS Int. J. Geo-Inf. 2021, 10, 425. https://doi.org/10.3390/ijgi10070425
Cui N, Malleson N, Houlden V, Comber A. Using VGI and Social Media Data to Understand Urban Green Space: A Narrative Literature Review. ISPRS International Journal of Geo-Information. 2021; 10(7):425. https://doi.org/10.3390/ijgi10070425
Chicago/Turabian StyleCui, Nan, Nick Malleson, Victoria Houlden, and Alexis Comber. 2021. "Using VGI and Social Media Data to Understand Urban Green Space: A Narrative Literature Review" ISPRS International Journal of Geo-Information 10, no. 7: 425. https://doi.org/10.3390/ijgi10070425
APA StyleCui, N., Malleson, N., Houlden, V., & Comber, A. (2021). Using VGI and Social Media Data to Understand Urban Green Space: A Narrative Literature Review. ISPRS International Journal of Geo-Information, 10(7), 425. https://doi.org/10.3390/ijgi10070425