
Improving Victimization Risk Estimation: A Geographically Weighted Regression Approach

Abstract
1. Introduction
1.1. Literature on Crime Standardization and the Estimation of Victimization Risk
1.2. Literature on Geographically Weighted Regression
2. Materials and Methods
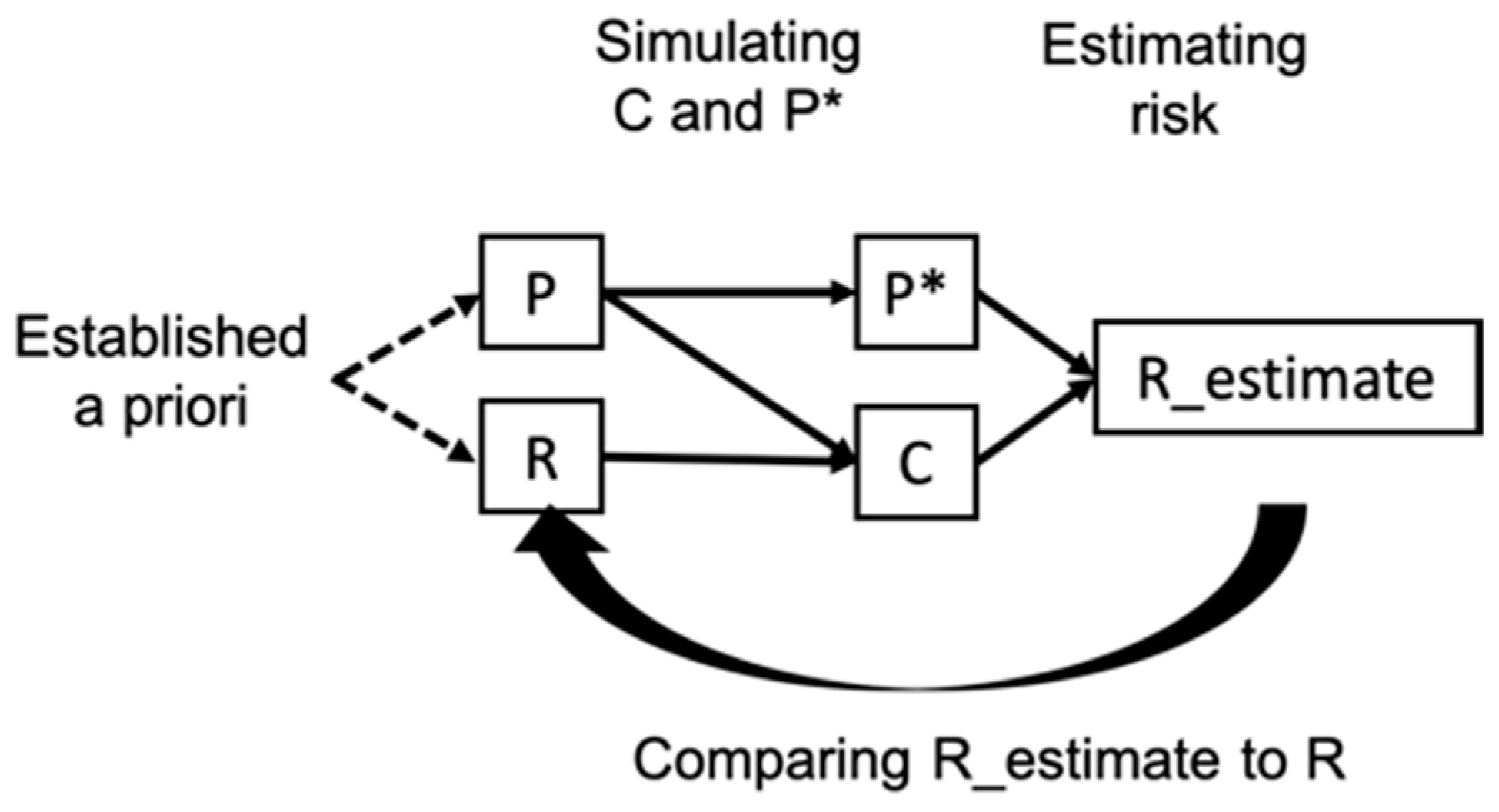
2.1. Problem Specification
- Crime counts are often a fraction of the victimization rates, being also subject to other types of error (e.g., missing data, geocoding errors, multiple reports of the same crime, and other less systematic forms of error affecting the relation between victimization and crime counts):
- Population data may not be a perfect measure of the actual pool of potential victims of the crime we are considering:
- Actual victimization rates may not be exactly the expected ones, but fluctuate around it:
2.2. Proposed Solution
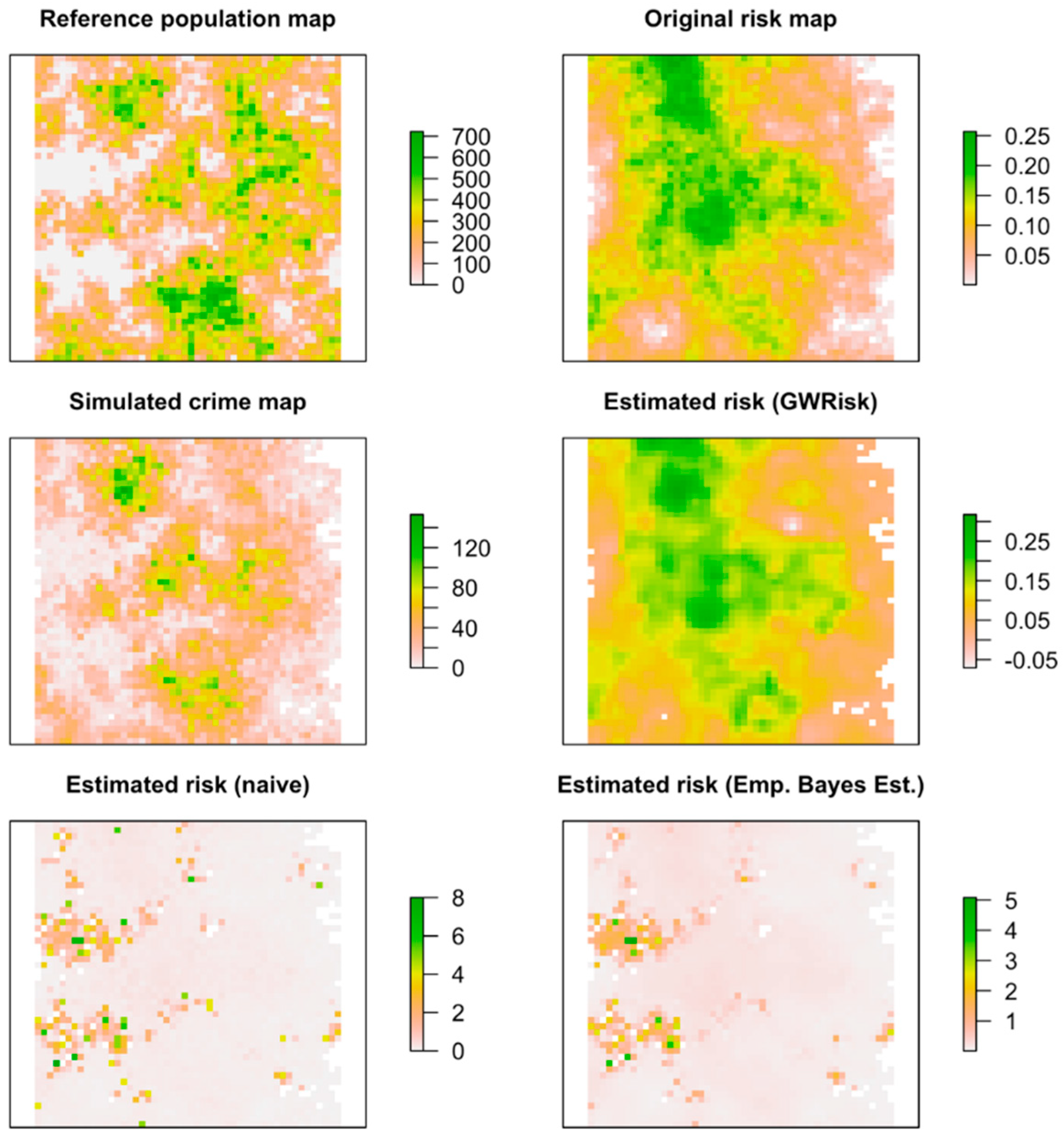
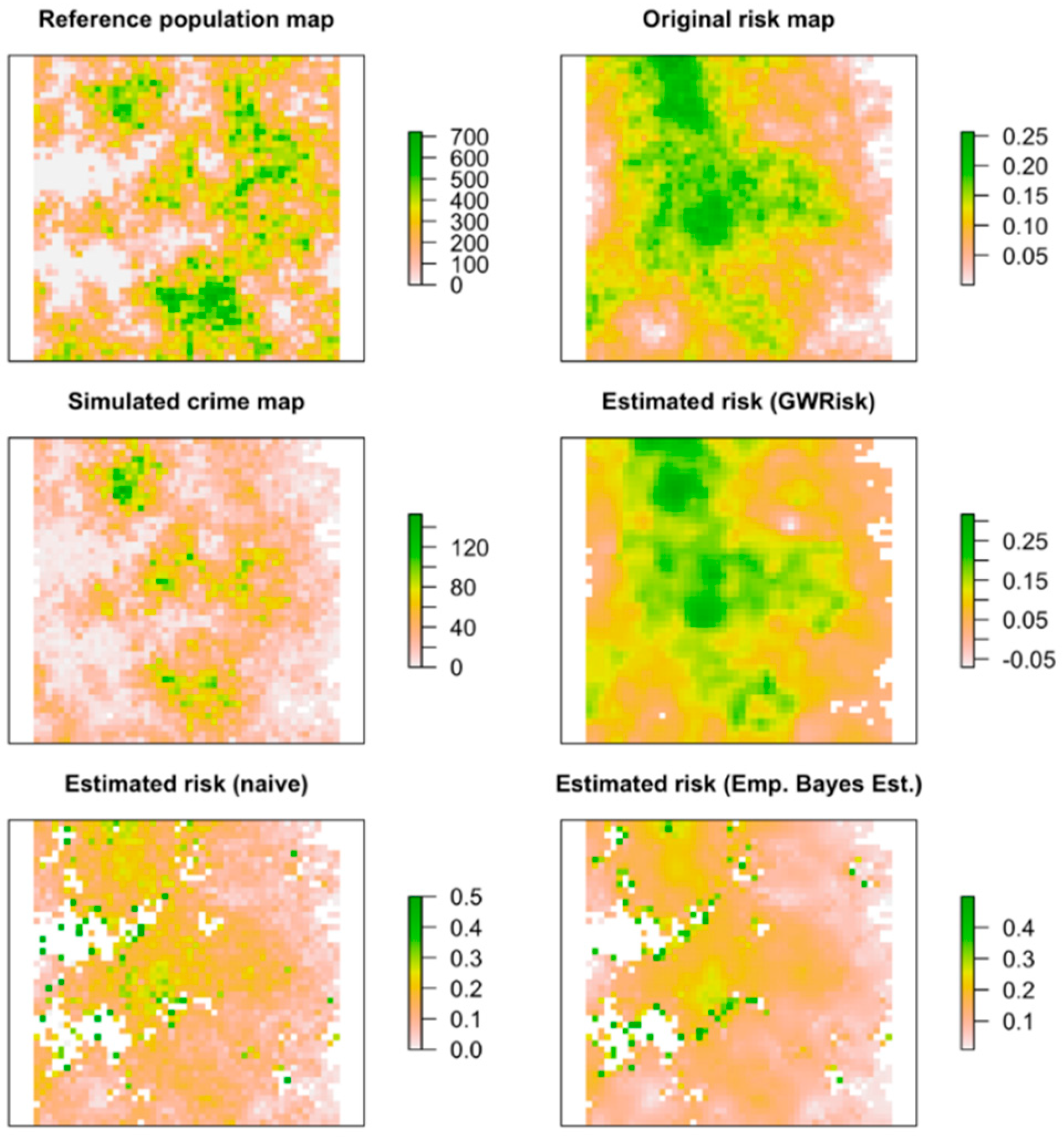
2.3. Validating the Method via a Simulation Study
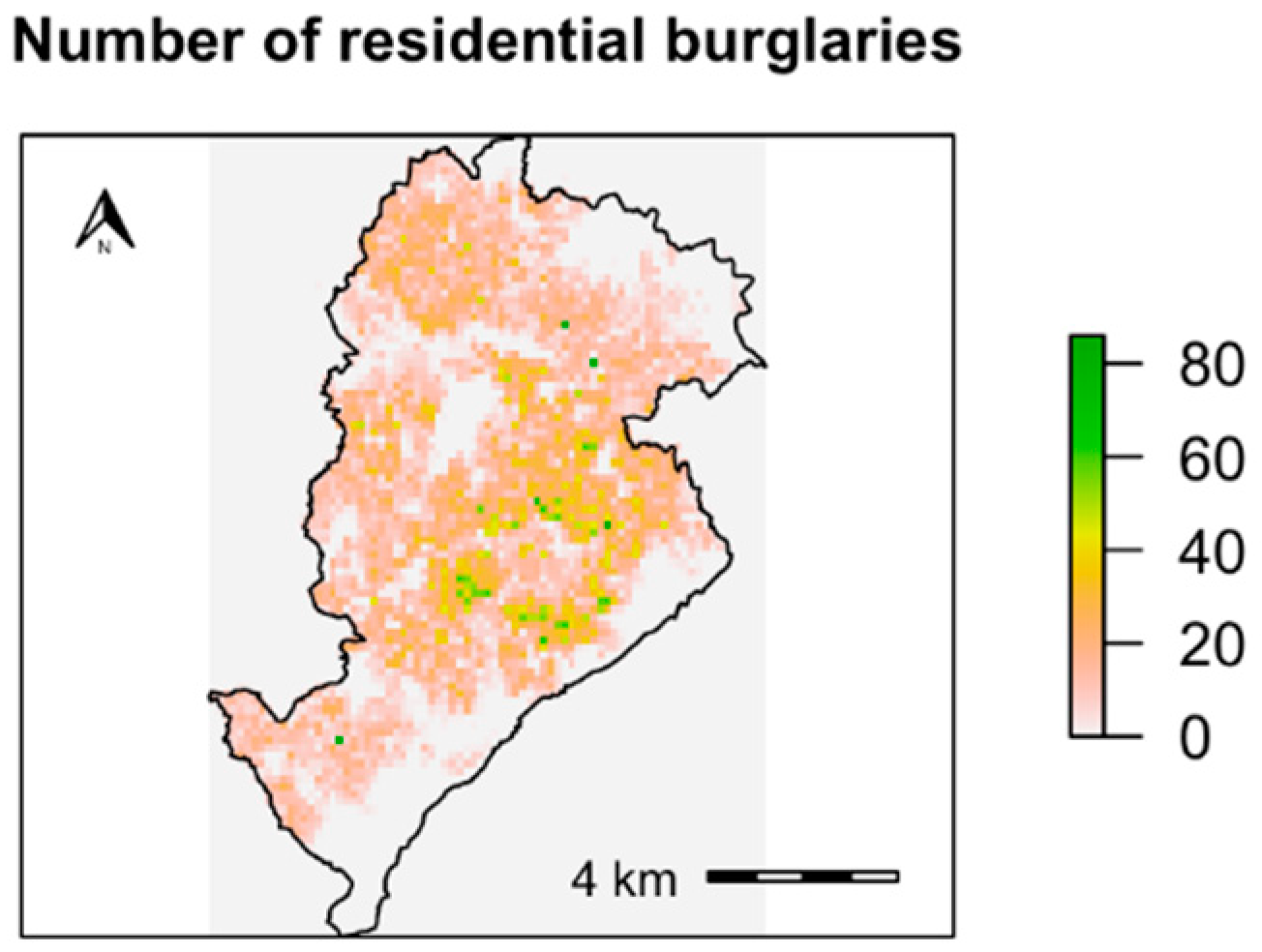
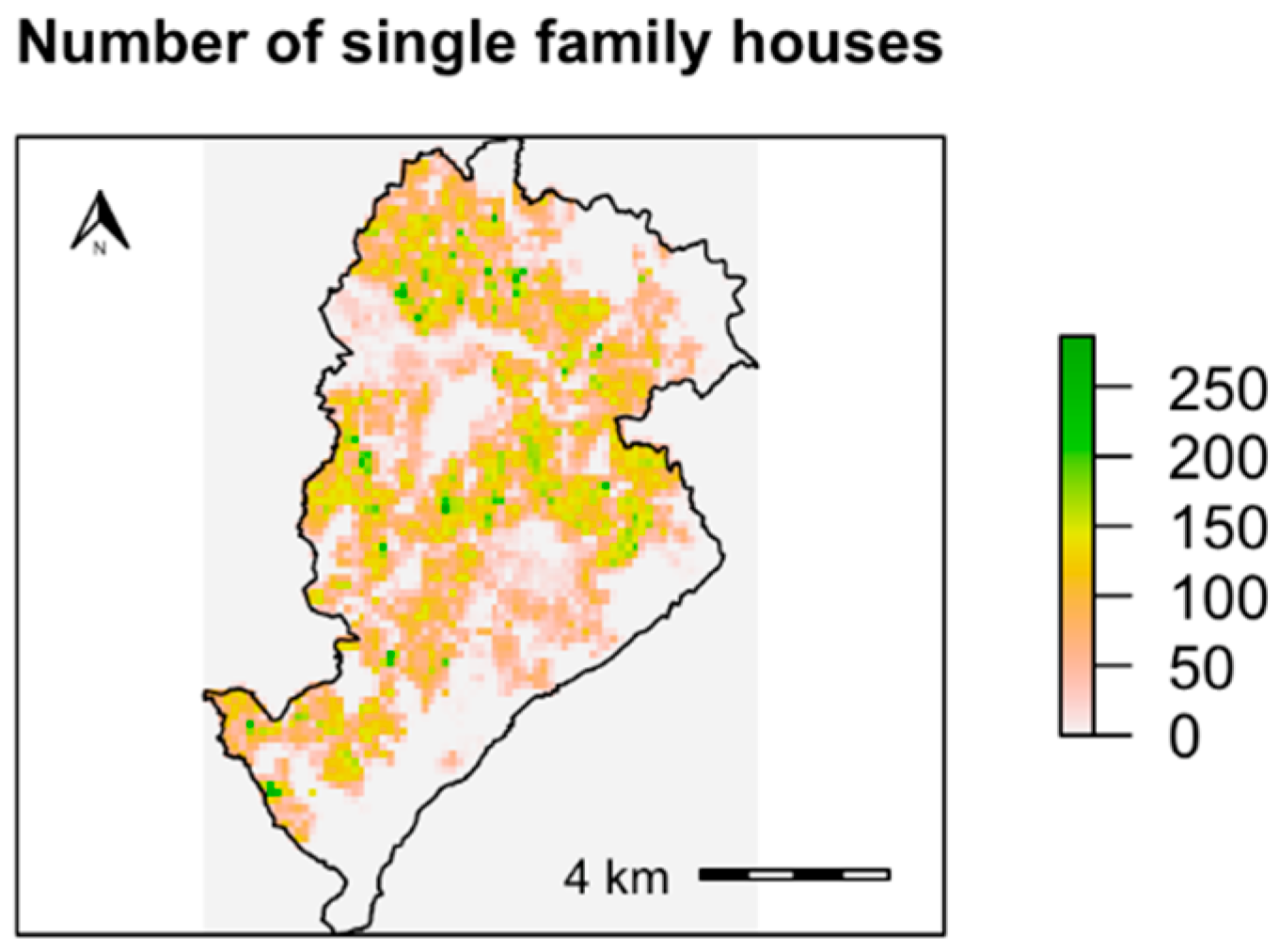
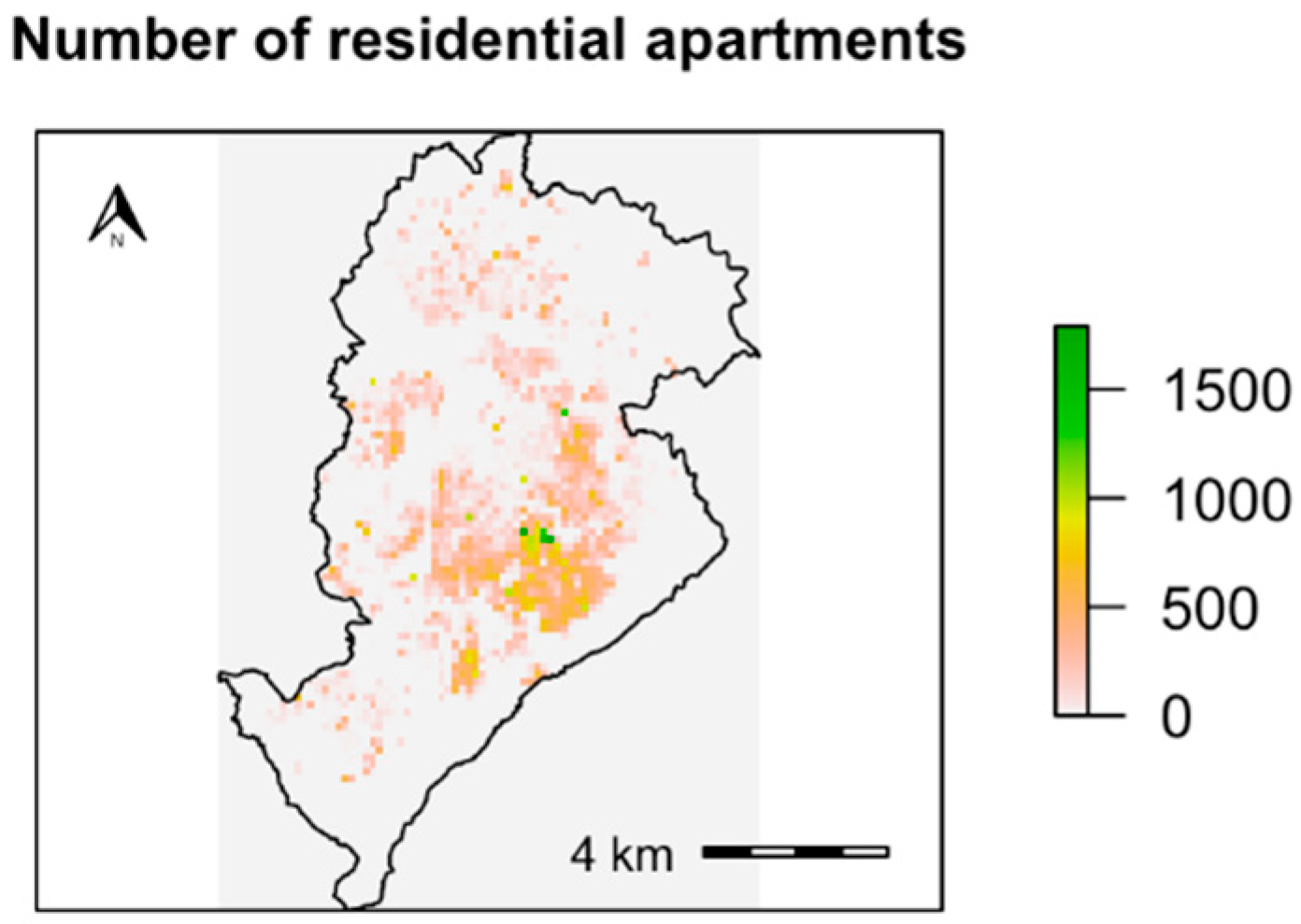
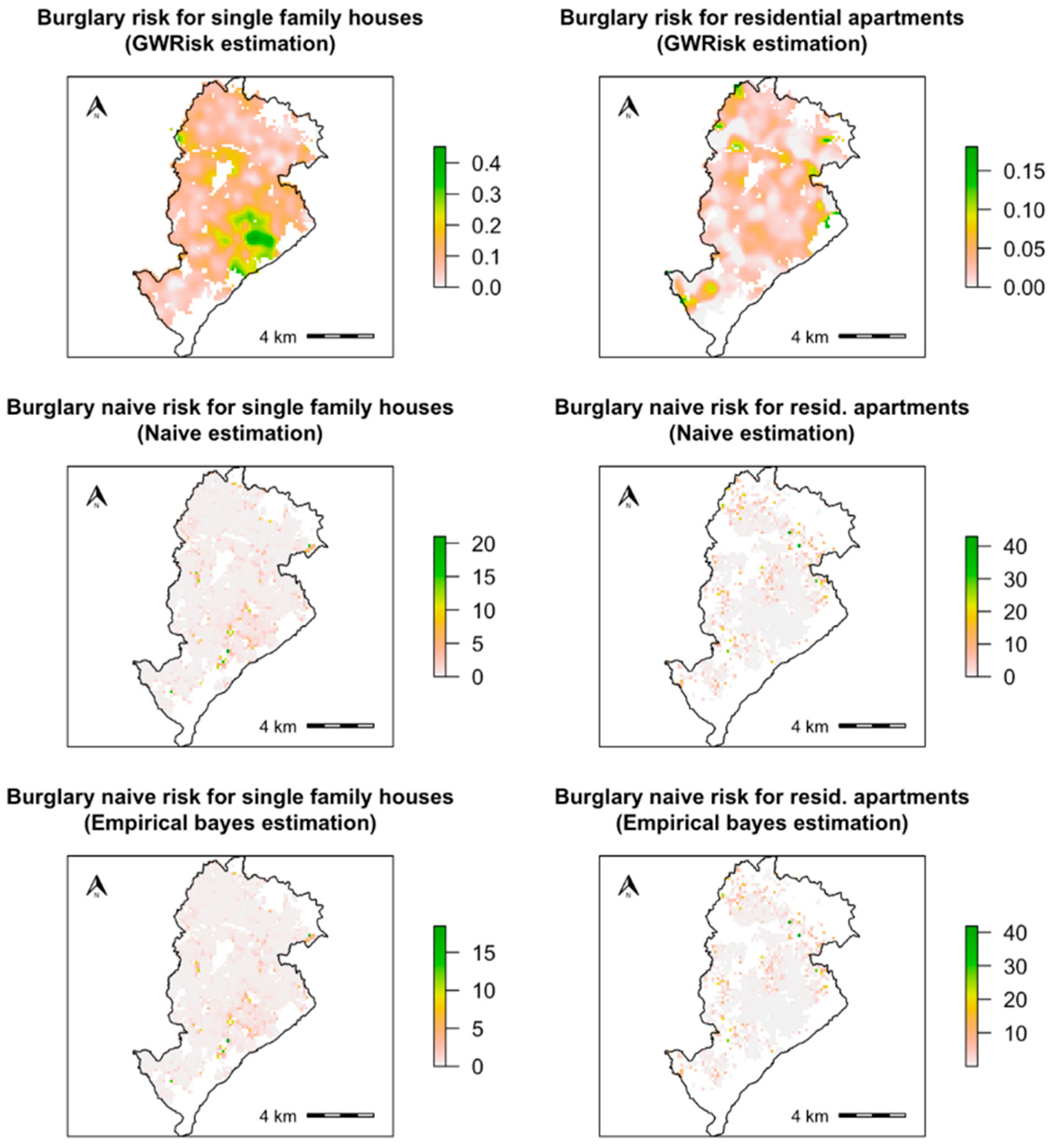
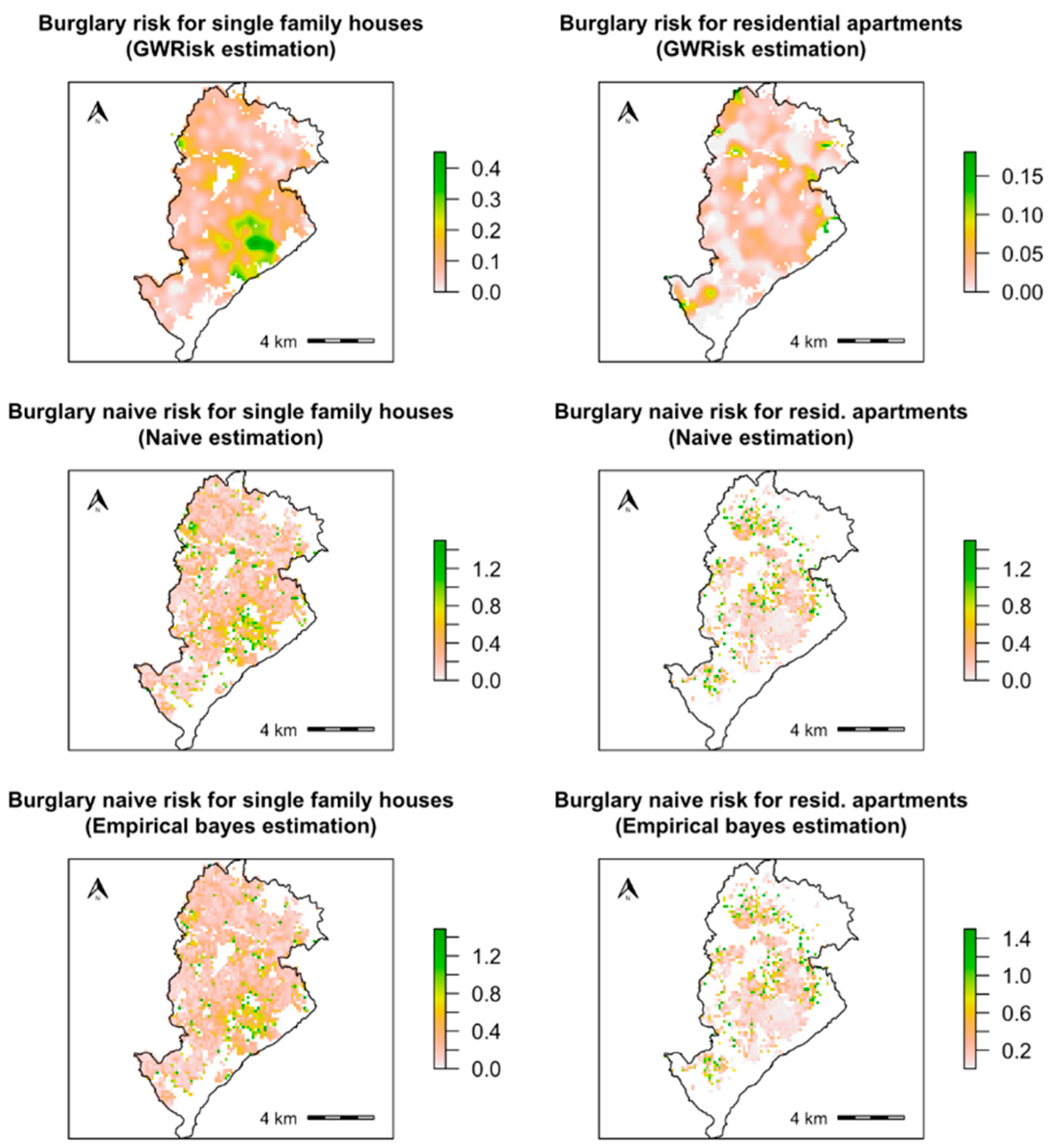
2.4. Application: Residential Burglaries in the City of Belo Horizonte, Brazil
3. Results
3.1. Results for the Validation Study
3.1.1. Simulation Study with One Reference Population
3.1.2. Simulation Study with Two Reference Population
3.2. Results for the Application Study
4. Discussion
Supplementary Materials
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix B

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Fit for Estimated R | ||||||
|---|---|---|---|---|---|---|---|
| rangeR | rangeP | sillP | nuggetP | Fit (naïve) | Fit (GWRisk) | Fit (Bayes) | |
| 50 | 7 | 16,500 | 1250 | 15% | 0.17 | 0.66 | 0.46 |
| 50 | 7 | 16,500 | 2500 | 15% | 0.11 | 0.65 | 0.37 |
| 50 | 7 | 16,500 | 5000 | 15% | 0.13 | 0.71 | 0.43 |
| 50 | 7 | 16,500 | 10,000 | 15% | 0.17 | 0.71 | 0.48 |
| 75 | 7 | 16,500 | 1250 | 15% | 0.13 | 0.65 | 0.39 |
| 25 | 7 | 16,500 | 1250 | 15% | 0.17 | 0.68 | 0.46 |
| 10 | 7 | 16,500 | 1250 | 15% | 0.17 | 0.57 | 0.50 |
| 5 | 7 | 16,500 | 1250 | 15% | 0.23 | 0.39 | 0.50 |
| 50 | 3.5 | 16,500 | 1250 | 15% | 0.12 | 0.73 | 0.42 |
| 50 | 14 | 16,500 | 1250 | 15% | 0.16 | 0.60 | 0.44 |
| 50 | 28 | 16,500 | 1250 | 15% | 0.26 | 0.59 | 0.55 |
| 50 | 56 | 16,500 | 1250 | 15% | 0.40 | 0.57 | 0.60 |
| 50 | 7 | 10,000 | 1250 | 15% | 0.18 | 0.66 | 0.52 |
| 50 | 7 | 20,000 | 1250 | 15% | 0.14 | 0.69 | 0.44 |
| 50 | 7 | 40,000 | 1250 | 15% | 0.12 | 0.71 | 0.34 |
| 50 | 7 | 80,000 | 1250 | 15% | 0.09 | 0.68 | 0.28 |
| 50 | 7 | 16,500 | 1250 | 5% | 0.32 | 0.68 | 0.76 |
| 50 | 7 | 16,500 | 1250 | 25% | 0.08 | 0.63 | 0.20 |
| 50 | 7 | 16,500 | 1250 | 50% | 0.03 | 0.65 | 0.06 |
| 50 | 7 | 16,500 | 1250 | 100% | 0.01 | 0.54 | 0.02 |
Appendix C


References
- Biderman, A.D.; Reiss, A.J., Jr. On exploring the “dark figure" of crime. Ann. Am. Acad. Political. Soc. Sci. 1967, 374, 1–15. [Google Scholar] [CrossRef]
- Radzinowicz, L.; King, J.F. The Growth of Crime: The International Experience; Basic Books: New York, NY, USA, 1977; pp. 3–9. [Google Scholar]
- Payne, J.L.; Hutton, F. Mapping Common Crime. In The Palgrave Handbook of Australian and New Zealand Criminology, Crime and Justice; Palgrave Macmillan: Cham, Switzerland, 2017; pp. 113–129. [Google Scholar] [CrossRef]
- Langton, L.; Planty, M.; Lynch, J.P. Second major redesign of the national crime victimization survey (ncvs). Criminol. Pub. Pol’y 2017, 16, 1049. [Google Scholar] [CrossRef]
- Williams, D.; Edwards, S.; Giambo, P.; Kena, G. Cost Effective Mail Survey Design. In Proceedings of the Federal Committee on Statistical Methodology Research and Policy Conference, Washington, DC, USA, 1–3 December 2018. [Google Scholar]
- Ratcliffe, J. Crime mapping: Spatial and temporal challenges. In Handbook of Quantitative Criminology; Springer: New York, NY, USA, 2010; pp. 5–24. [Google Scholar] [CrossRef]
- Boggs, S.L. Urban crime patterns. Am. Sociol. Rev. 1965, 899–908. [Google Scholar] [CrossRef]
- Solymosi, R.; Ashby, M.; Cohen, T.; Sidebottom, A. Alternative denominators in transport crime rates. SocArXiv 2017. [Google Scholar] [CrossRef]
- Rengert, G.F. Burglary in Philadelphia: A critique of an opportunity structure model. In Environmental Criminology; Brantingham, P.J., Brantingham, P.L., Eds.; Sage: Beverly Hills, CA, USA, 1981; pp. 189–201. [Google Scholar]
- Stipak, B. Alternatives to population-based crime rates. Int. J. Comp. Appl. Crim. Justice 1988, 12, 247–260. [Google Scholar] [CrossRef]
- Pettiway, L.E. Measures of opportunity and the calculation of the arson rate: The connection between operationalization and association. J. Quant. Criminol. 1985, 1, 241–268. [Google Scholar] [CrossRef]
- Kounadi, O.; Ristea, A.; Leitner, M.; Langford, C. Population at risk: Using areal interpolation and Twitter messages to create population models for burglaries and robberies. Cartogr. Geogr. Inf. Sci. 2018, 45, 205–220. [Google Scholar] [CrossRef]
- Malleson, N.; Andresen, M.A. The impact of using social media data in crime rate calculations: Shifting hot spots and changing spatial patterns. Cartogr. Geogr. Inf. Sci. 2015, 42, 112–121. [Google Scholar] [CrossRef]
- Andresen, M.A.; Jenion, G.W.; Reid, A.A. An evaluation of ambient population estimates for use in crime analysis. Crime Mapp. J. Res. Pract. 2012, 4, 7–30. [Google Scholar]
- Chainey, S.; Desyllas, J. Modelling pedestrian movement to measure on-street crime risk. In Movement-Aware Applications for Sustainable Mobility: Technologies and Approaches; Wachowicz, M., Ed.; IGI Global: Hershey, PA, USA, 2010; pp. 243–263. [Google Scholar] [CrossRef]
- Andresen, M.A. Crime measures and the spatial analysis of criminal activity. Br. J. Criminol. 2006, 46, 258–285. [Google Scholar] [CrossRef]
- Eck, J.E.; Weisburd, D.L. Crime places in crime theory. In Crime and Place: Crime Prevention Studies; Hebrew University of Jerusalem Legal Research Paper: Jerusalem, Israel, 2015; Volume 4, pp. 1–33. Available online: https://ssrn.com/abstract=2629856 (accessed on 15 May 2021).
- Weisburd, D.; Groff, E.R.; Yang, S.M. The Criminology of Place: Street Segments and Our Understanding of the Crime Problem; Oxford University Press: Oxford, UK, 2012. [Google Scholar]
- Sherman, L.W.; Gartin, P.R.; Buerger, M.E. Hot spots of predatory crime: Routine activities and the criminology of place. Criminology 1989, 27, 27–56. [Google Scholar] [CrossRef]
- Kafadar, K. Smoothing geographical data, particularly rates of disease. Stat. Med. 1996, 15, 2539–2560. [Google Scholar] [CrossRef]
- Anselin, L.; Kim, Y.W.; Syabri, I. Web-based analytical tools for the exploration of spatial data. J. Geogr. Syst. 2014, 6, 197–218. [Google Scholar] [CrossRef]
- Beato Filho, C.C.; Assunção, R.M.; Silva, B.F.A.D.; Marinho, F.C.; Reis, I.A.; Almeida, M.C.D.M. Conglomerados de homicídios e o tráfico de drogas em Belo Horizonte, Minas Gerais, Brasil, de 1995 a 1999. Cadernos de Saúde Pública 2001, 17, 1163–1171. [Google Scholar] [CrossRef]
- Santos, A.E.; Rodrigues, A.L.; Lopes, D.L. Aplicações de Estimadores Bayesianos Empíricos para Análise Espacial de Taxas de Mortalidade. In Proceedings of the Simpósio Brasilerio de Geoinformática, 7 (GeoInfo), Campos do Jordão, Brazil, 20–23 November 2005; pp. 300–309. [Google Scholar]
- Liu, H.; Zhu, X. Exploring the influence of neighborhood characteristics on burglary risks: A Bayesian random effects modeling approach. ISPRS Int. J. Geo-Inf. 2016, 5, 102. [Google Scholar] [CrossRef]
- Zhu, L.; Gorman, D.M.; Horel, S. Hierarchical Bayesian spatial models for alcohol availability, drug" hot spots" and violent crime. Int. J. Health Geogr. 2006, 5, 54. [Google Scholar] [CrossRef]
- Song, C.; He, Y.; Bo, Y.; Wang, J.; Ren, Z.; Yang, H. Risk assessment and mapping of hand, foot, and mouth disease at the county level in mainland China using spatiotemporal zero-inflated Bayesian hierarchical models. Int. J. Environ. Res. Public Health 2018, 15, 1476. [Google Scholar] [CrossRef]
- Lai, Y.S.; Zhou, X.N.; Pan, Z.H.; Utzinger, J.; Vounatsou, P. Risk mapping of clonorchiasis in the People’s Republic of China: A systematic review and Bayesian geostatistical analysis. PLoS Negl. Trop. Dis. 2017, 11. [Google Scholar] [CrossRef] [PubMed]
- Tzala, E.; Best, N. Bayesian latent variable modelling of multivariate spatio-temporal variation in cancer mortality. Stat. Methods Med Res. 2008, 17, 97–118. [Google Scholar] [CrossRef]
- Bailey, T.C.; Cordeiro, R.; Lourenço, R.W. Semiparametric modeling of the spatial distribution of occupational accident risk in the casual labor market, Piracicaba, Southeast Brazil. Risk Anal. Int. J. 2007, 27, 421–431. [Google Scholar] [CrossRef] [PubMed]
- Kelsall, J.E.; Diggle, P.J. Spatial variation in risk of disease: A nonparametric binary regression approach. J. R. Stat. Soc. Ser. C 1998, 47, 559–573. [Google Scholar] [CrossRef]
- Brunsdon, C.; Fotheringham, A.S.; Charlton, M.E. Geographically weighted regression: A method for exploring spatial nonstationarity. Geogr. Anal. 1996, 28, 281–298. [Google Scholar] [CrossRef]
- Fotheringham, A.S.; Charlton, M.E.; Brunsdon, C. Geographically weighted regression: A natural evolution of the expansion method for spatial data analysis. Environ. Plan. A 1998, 30, 1905–1927. [Google Scholar] [CrossRef]
- Bitter, C.; Mulligan, G.F.; Dall’erba, S. Incorporating spatial variation in housing attribute prices: A comparison of geographically weighted regression and the spatial expansion method. J. Geogr. Syst. 2007, 9, 7–27. [Google Scholar] [CrossRef]
- Chang, L.F.; Lin, C.H.; Su, M.D. Application of geographic weighted regression to establish flood-damage functions reflecting spatial variation. Water SA 2008, 34, 209–216. [Google Scholar] [CrossRef]
- Cardozo, O.D.; García-Palomares, J.C.; Gutiérrez, J. Application of geographically weighted regression to the direct forecasting of transit ridership at station-level. Appl. Geogr. 2012, 34, 548–558. [Google Scholar] [CrossRef]
- Huang, B.; Wu, B.; Barry, M. Geographically and temporally weighted regression for modeling spatio-temporal variation in house prices. Int. J. Geogr. Inf. Sci. 2010, 24, 383–401. [Google Scholar] [CrossRef]
- Fotheringham, A.S.; Yang, W.; Kang, W. Multiscale geographically weighted regression (MGWR). Ann. Am. Assoc. Geogr. 2017, 107, 1247–1265. [Google Scholar] [CrossRef]
- Wu, C.; Ren, F.; Hu, W.; Du, Q. Multiscale geographically and temporally weighted regression: Exploring the spatiotemporal determinants of housing prices. Int. J. Geogr. Inf. Sci. 2019, 33, 489–511. [Google Scholar] [CrossRef]
- Tobler, W.R. A computer movie simulating urban growth in the Detroit region. Econ. Geogr. 1970, 46, 234–240. [Google Scholar] [CrossRef]
- Comber, A.; Brunsdon, C.; Charlton, M.; Dong, G.; Harris, R.; Lu, B.; Lü, Y.; Murakami, D.; Nakaya, T.; Wang, Y.; et al. The GWR route map: A guide to the informed application of Geographically Weighted Regression. arXiv 2020, arXiv:2004.06070. [Google Scholar]
- Farber, S.; Páez, A. A systematic investigation of cross-validation in GWR model estimation: Empirical analysis and Monte Carlo simulations. J. Geogr. Syst. 2007, 9, 371–396. [Google Scholar] [CrossRef]
- Chiles, J.P.; Delfiner, P. Geostatistics: Modeling Spatial Uncertainty; John Wiley & Sons: Hoboken, NJ, USA, 2009; Volume 487. [Google Scholar] [CrossRef]
- Oliver, M.A.; Webster, R. Basic Steps in Geostatistics: The Variogram and Kriging; Springer International Publishing: New York, NY, USA, 2015. [Google Scholar] [CrossRef]
- Schabenberger, O.; Gotway, C.A. Statistical Methods for Spatial Data Analysis; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar] [CrossRef]
- Ramos, R.G.; Silva, B.F.; Clarke, K.C.; Prates, M. Too Fine to be Good? Issues of Granularity, Uniformity and Error in Spatial Crime Analysis. J. Quant. Criminol. 2020, 1–25. [Google Scholar] [CrossRef]






| Fit for Estimated R | Mean | Std. Dev. | Coef. Var. |
|---|---|---|---|
| Fit (naïve) | 0.16 | 0.08 | 52% |
| Fit (GWR) | 0.61 | 0.08 | 14% |
| Fit (Bayes) | 0.42 | 0.16 | 39% |
| Mean | Std. Dev. | Coef. Var | |
|---|---|---|---|
| Fit for estimated R1 | |||
| Fit (naïve) | 0.01 | 0.02 | 147% |
| Fit (GWR) | 0.67 | 0.07 | 11% |
| Fit (Bayes) | 0.02 | 0.03 | 148% |
| Fit for estimated R2 | |||
| Fit (naïve) | 0.01 | 0.00 | 47% |
| Fit (GWR) | 0.28 | 0.08 | 29% |
| Fit (Bayes) | 0.01 | 0.01 | 48% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ramos, R.G. Improving Victimization Risk Estimation: A Geographically Weighted Regression Approach. ISPRS Int. J. Geo-Inf. 2021, 10, 364. https://doi.org/10.3390/ijgi10060364
Ramos RG. Improving Victimization Risk Estimation: A Geographically Weighted Regression Approach. ISPRS International Journal of Geo-Information. 2021; 10(6):364. https://doi.org/10.3390/ijgi10060364
Chicago/Turabian StyleRamos, Rafael G. 2021. "Improving Victimization Risk Estimation: A Geographically Weighted Regression Approach" ISPRS International Journal of Geo-Information 10, no. 6: 364. https://doi.org/10.3390/ijgi10060364
APA StyleRamos, R. G. (2021). Improving Victimization Risk Estimation: A Geographically Weighted Regression Approach. ISPRS International Journal of Geo-Information, 10(6), 364. https://doi.org/10.3390/ijgi10060364