
Inferring Urban Land Use from Multi-Source Urban Mobility Data Using Latent Multi-View Subspace Clustering



Abstract
1. Introduction
1.1. Extraction of Features from Urban Mobility Datasets
1.2. Land use Classification/Clustering Methods
1.3. Annotation and Analysis of Classified Regions
- Multi-source and noisy urban mobility data (for example, GPS signal may be blocked by urban buildings, thus leading to noise) were fused by first applying the variation in the number of origin/destination points over time to characterize land use types, and then a latent multi-view representation [32] was applied to construct the common underlying structure, shared by multi-source urban mobility data;
- The high-dimensional features were handled by using the subspace clustering method [33] to infer the land use types based on the latent multi-view representation;
- Experimental results revealed that, compared with the method using a single type of urban mobility dataset and the weighted fusion method, the approach presented in this study obtains the highest detection rate of land use and provides a reference for urban planning.
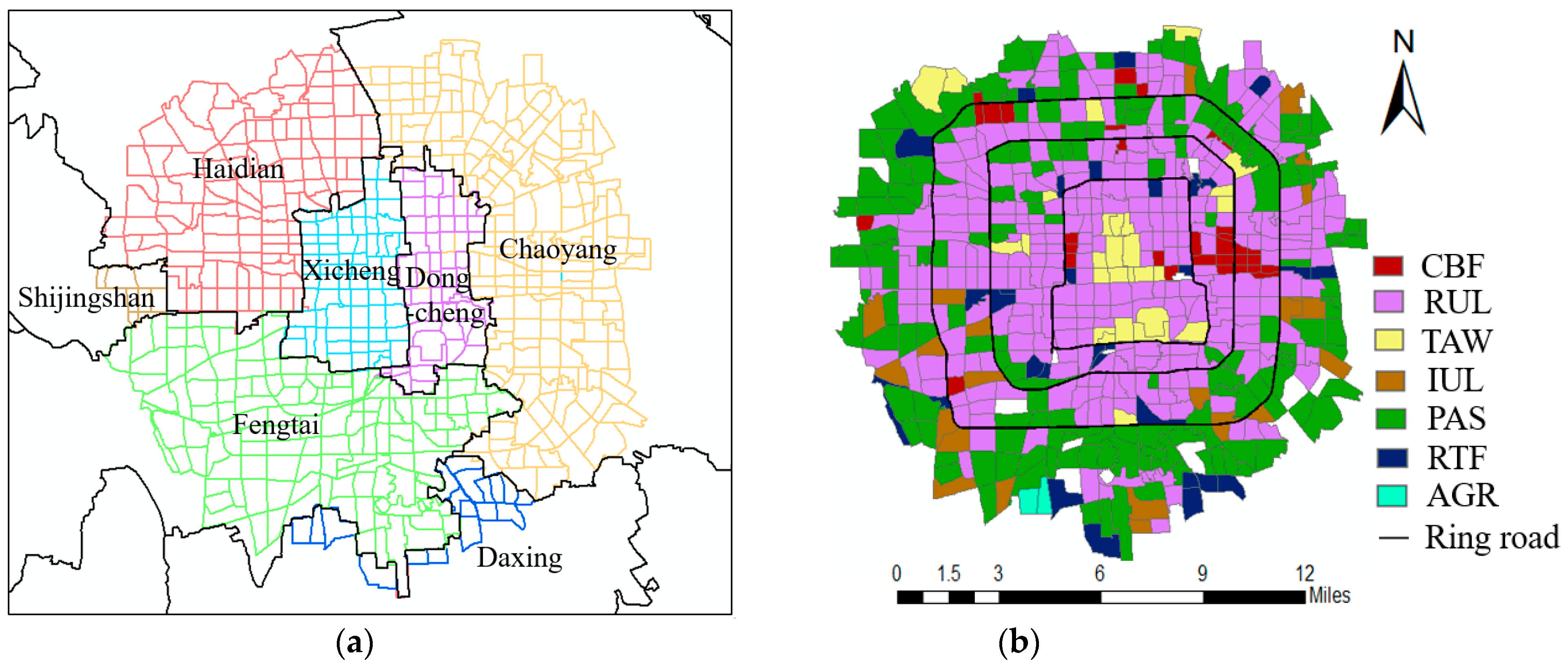
2. Study Area and Datasets
2.1. Extraction of Features from Urban Mobility Datasets
2.2. Datasets
3. Method
3.1. Clustering Feature Extraction
- (I)
- Weekday/weekend pick-up feature vector: it was used to measure the number of passengers boarding the bus during weekdays or weekends, which can be denoted as a 16-dimension vector as the formulation ofwhere and represent the number of pick-ups in the hour on weekdays and weekends. The symbols below have the same meaning.
- (II)
- Weekday/weekend set-down feature vector: similar to feature I, this is also a 16-dimension vector, which can be denoted asand represent the number of set-downs in the hour on weekdays and weekends.
- (III)
- Daily pick-up feature vector: This feature is the combination of the weekday and weekend pick-up features, which measures the total number of pick-ups, on both weekdays and weekends. The form of this 32-dimensional vector is
- (IV)
- Daily set-down feature vector: Similar to feature III, the daily set-down feature vector is also a 32-dimensional vector denoted as
- (V)
- Pick-up/set-down difference feature vector: This feature measures the difference between the pick-up number and set-down number as
- (VI)
- Pick-up/set-down ratio feature vector: similar to feature V, the 32-dimensional vector measures the ratio of pick-up number and set-down number as
- (VII)
- Daily pick-up and set-down combination vector: this feature is a 64-dimensional vector measuring the total flow over days as
3.2. Latent Multi-View Representation
3.3. Subspace Clustering
- (i)
- Updating BP neural network parameters using the gradient descent algorithm. The BP neural network is composed of two hidden layers and . First, and were randomly initialized. Second, the loss function and activation function were defined. For each view, updated and , and can be outputted until the reconstruction error is sufficiently small.
- (ii)
- Solving and optimization. First, was updated by using the gradient descent algorithm with . Second, was iteratively updated by using the alternating direction method of multiplier algorithm [41].
4. Results and Discussion
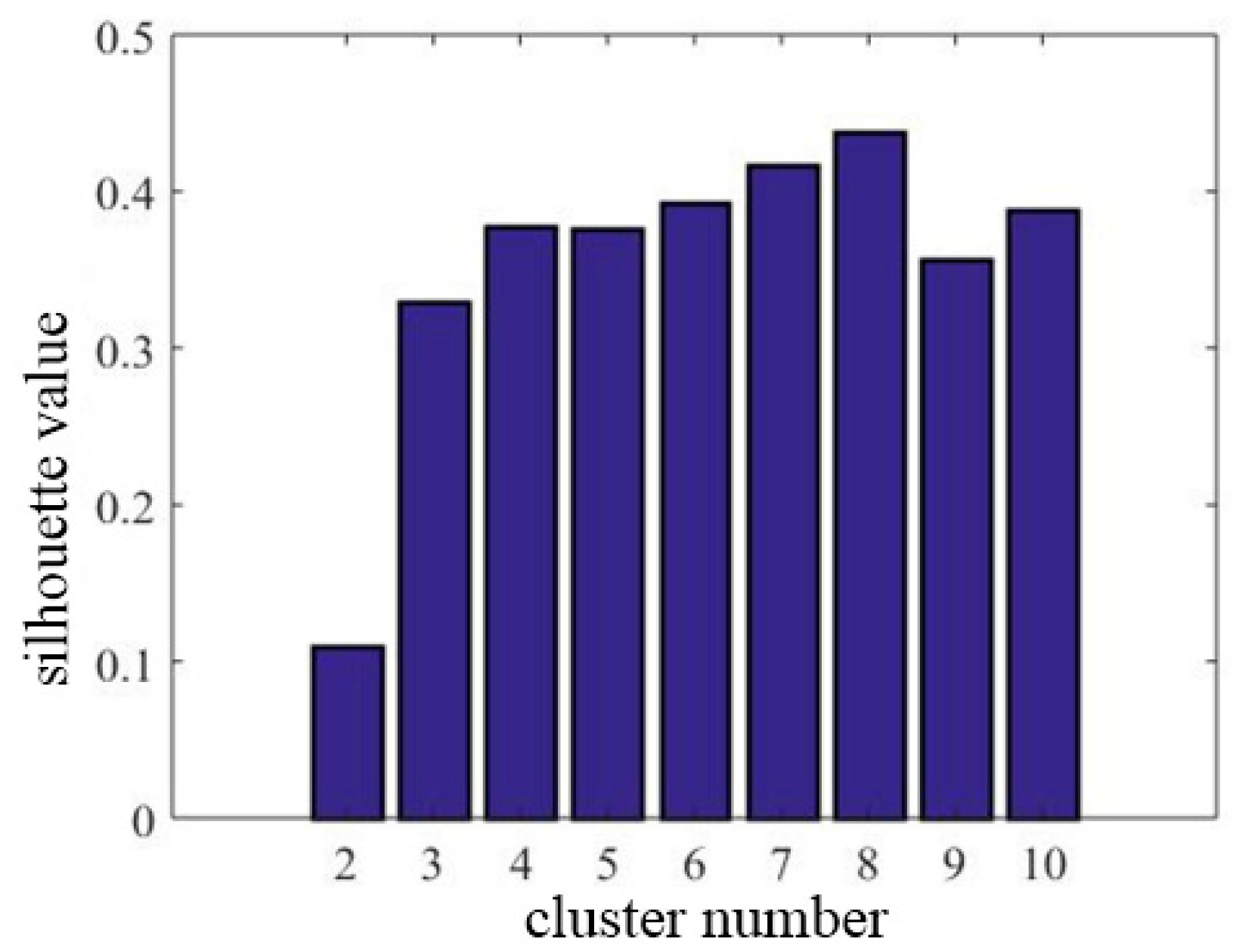
4.1. Comparative Methods and Parameter Setting
- (i)
- Methods using a single type of urban mobility data [9]: Taxi GPS trajectory or bus smart card data were used to construct feature vectors. Spectral clustering was employed to cluster the TAZs into land use types based on their extracted feature vectors.
- (ii)
- Weighted fusion method [23]: Two similarity matrices , were first calculated for taxi trajectory and bus smart card data. Then, the integrated similarity matrix was computed as . and are two weights determined by the proportion of taxi ridership and bus ridership. In the experiment, and were 96.34% and 4.66%, respectively. The similarity matrix W was provided as an input for spectral clustering.
4.2. Annotation of Urban Land Use Types
- (i)
- (ii)
- Arriving/leaving transition matrices: As shown in Figure 7, the horizontal axes represent the time over the day from 8:00 to 24:00, and the vertical axes represent the clusters for which passengers either arrive or leave.
4.2.1. Tourist Attraction and Water Areas (C1)
4.2.2. Developed Commercial Areas (C2)
4.2.3. Less Developed Residential Areas (C3)
4.2.4. Emerging Residential Areas (C4)
4.2.5. The Developed Residential Areas (C5)
4.2.6. Residential/Entertainment/Commercial Areas (C6)
4.2.7. Public Administration and Service (C8)
4.2.8. Industrial/Transportation Service Areas (C7)
4.3. Quantitative Comparison and Analysis
4.4. Discussion
4.4.1. Mismatch between Physical Characteristics and Social Function of Urban Land
4.4.2. The Influence of Feature Construction
4.4.3. The Influence of Latent Multi-View Representation Model
- (i)
- By using the latent multi-view subspace clustering method, more sophisticated land use types can be identified. For example, residential areas can be further divided into developed residential areas, less developed residential areas, and emerging residential areas. This sophisticated division will help urban planners formulate more targeted and effective policies for urban planning.
- (ii)
- Some calibrations may be presented for urban land use planning. In the governmental land use map, areas A, B, C, and D were labeled as transportation service, industrial, public administration and service, and residential areas, respectively. Areas A, B, and C all developed into commercial areas. As shown in Figure 9, the landmark of area A is Wangjing Street, which is one of the emerging business areas in Beijing. Area B primarily contains the Hengtong International Business Center and some technology companies. Area C is an embassy gathering area that includes the U.S. Embassy, Korean Embassy, Japanese Embassy, and Israeli Embassy. Area D is a mixture of residential, entertainment, and commercial areas. The clusters discovered using the latent multi-view subspace clustering method are useful for identifying land use types from the perspective of human activities, and can make urban planning more human-centered.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ellis, E. Land-Use and Land-Cover Change. Available online: https://editors.eol.org/eoearth/wiki/Land-use_and_land-cover_change (accessed on 8 March 2021).
- Williamson, I.; Enemark, S.; Wallace, J.; Rajabifard, A. Land Administration for Sustainable Development; Emerald Group Publishing Limited: Emerald, UK, 2010; p. 324. [Google Scholar]
- Li, S.; Dragicevic, S.; Castro, F.A.; Sester, M.; Winter, M.; Coltekon, A. Geospatial big data handling theory and methods: A review and research challenges. ISPRS J. Photogramm. Remote Sens. 2016, 115, 119–133. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L. An SVM ensemble approach combining spectral, structural, and semantic features for the classification of high-resolution remotely sensed imagery. IEEE Trans. Geosci. Remote Sens. 2013, 51, 257–272. [Google Scholar] [CrossRef]
- Blaschke, T.; Hay, G.J.; Kelly, M.; Lang, S.; Hofmann, P.; Addink, E. Geographic object-based image analysis–towards a new paradigm. ISPRS J. Photogramm. Remote Sens. 2014, 87, 180–191. [Google Scholar] [CrossRef]
- Zhou, W.; Ming, D.; Lv, X.; Zhou, K.; Bao, H. SO–CNN based urban functional zone fine division with VHR remote sensing image. Remote Sens. Environ. 2019, 236, 111458. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, X.; Gao, S.; Gong, L.; Kang, C.; Zhi, Y.; Chi, G.; Shi, L. Social Sensing: A New Approach to Understanding Our Socioeconomic Environments. Ann. Assoc. Am. Geogr. 2015, 105, 512–530. [Google Scholar] [CrossRef]
- Yao, Y.; Li, X.; Liu, X.; Liu, P.; Liang, Z.; Zhang, J.; Mai, K. Sensing spatial distribution of urban land use by integrating points-of-interest and Google Word2Vec model. Int. J. Geogr. Inf. Sci. 2017, 31, 825–848. [Google Scholar] [CrossRef]
- Pan, G.; Qi, G.; Wu, Z.; Zhang, D.; Li, S. Land-use classification using taxi gps traces. IEEE Trans. Intell. Transp. Syst. 2013, 14, 113–123. [Google Scholar] [CrossRef]
- Long, Y.; Shen, Z. Discovering functional zones using bus smart card data and points of interest in Beijing. In Geospatial Analysis to Support Urban Planning in Beijing; Long, Y., Shen, Z., Eds.; Springer: Berlin, Germany, 2015; Volume 116, pp. 193–217. [Google Scholar]
- Song, C.; Qu, Z.; Blumm, N.; Barabasi, A. Limits of predictability in urban mobility. Science 2010, 327, 1018–1021. [Google Scholar] [CrossRef]
- Sevtsuk, A.; Ratti, C. Does Urban Mobility Have a Daily Routine? Learning from the Aggregate Data of Mobile Networks. J. Urban Technol. 2010, 17, 41–60. [Google Scholar] [CrossRef]
- Pei, T.; Sobolevsky, S.; Ratti, C.; Li, T.; Zhou, C. A new insight into land use classification based on aggregated mobile phone data. Int. J. Geogr. Inf. Sci. 2014, 28, 1988–2007. [Google Scholar] [CrossRef]
- Ahas, R.; Mark, Ü. Location based services-new challenges for planning and public administration? Futures 2015, 37, 547–561. [Google Scholar] [CrossRef]
- Qi, G.; Li, X.; Li, S.; Pan, G.; Wang, Z.; Zhang, D. Measuring social functions of city regions from large-scale taxi behaviors. In Proceedings of the 2011 IEEE International Conference on Pervasive Computing and Communications Workshops, Seattle, WA, USA, 21–25 March 2011; pp. 384–388. [Google Scholar]
- Liu, Y.; Wang, F.; Xiao, Y.; Gao, S. Urban land uses and traffic “source-sink areas”: Evidence from GPS-enabled taxi data in Shanghai. Landsc. Urban Plan. 2012, 106, 73–87. [Google Scholar] [CrossRef]
- Soto, V.; Frias-Martinez, E. Automated land use identification using cell-phone records. In Proceedings of the 3rd ACM International Workshop on MobiArch, Bethesda, MD, USA, 28 June 2011; pp. 17–22. [Google Scholar]
- Toole, J.; Ulm, M.; Bauer, D.; Gonzalez, M. Inferring land use from mobile phone activity. In Proceedings of the ACM SIGKDD International Workshop on Urban Computing, Beijing, China, 12 August 2012; pp. 1–8. [Google Scholar]
- Fan, K.; Zhang, D.; Wang, Y.; Zhao, S. Discovering Urban Social Functional Regions Using Taxi Trajectories. In Proceedings of the 2015 IEEE 12th International Conference on Ubiquitous Intelligence and Computing, Beijing, China, 10–14 August 2015; pp. 356–359. [Google Scholar]
- Mazimpaka, J.D.; Timpf, S. Exploring the potential of combining taxi GPS and flickr data for discovering functional regions. In Proceedings of the 18th Association-of-Geographic-Information-Laboratories-for-Europe Conference on Geographic Information Science, Lisbon, Portugal, 9–12 June 2015; pp. 3–18. [Google Scholar]
- Mou, X.; Cai, F.; Zhang, X.; Chen, J.; Zhu, R.R. Urban Function Identification Based on POI and Taxi Trajectory Data. In Proceedings of the 2019 3rd International Conference on Big Data Research, Paris, France, 20 November 2019; pp. 152–156. [Google Scholar]
- Liu, X.; Tian, Y.; Zhang, X.; Wan, Z. Identification of Urban Functional Regions in Chengdu Based on Taxi Trajectory Time Series Data. Int. J. Geo-Inf. 2020, 9, 158. [Google Scholar] [CrossRef]
- Yue, M.; Kang, C.; Andris, A.; Qin, K.; Liu, Y.; Meng, Q. Understanding the interplay between bus, metro, and cab ridership dynamics in Shenzhen, China. Trans. GIS 2018, 22, 855–871. [Google Scholar] [CrossRef]
- Zhai, W.; Bai, X.; Shi, Y.; Han, Y.; Peng, Z.; Gu, C. Beyond word2vec: An approach for urban functional region extraction and identification by combining place2vec and POIs. Comput. Environ. Urban Syst. 2019, 74, 1–12. [Google Scholar] [CrossRef]
- Yuan, J.; Zheng, Y.; Xie, X. Discovering regions of different functions in a city using urban mobility and POIs. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 186–194. [Google Scholar]
- Yuan, N.; Zheng, Y.; Xie, X.; Wang, Y.; Zheng, K.; Xiong, H. Discovering Urban Functional Zones Using Latent Activity Trajectories. IEEE Trans. Knowl. Data Eng. 2015, 27, 712–725. [Google Scholar] [CrossRef]
- Zhang, X.; Xu, Y.; Tu, W.; Ratti, C. Do different datasets tell the same story about urban mobility—A comparative study of public transit and taxi usage. J. Transp. Geogr. 2018, 70, 78–90. [Google Scholar] [CrossRef]
- Tu, W.; Cao, R.; Yue, Y.; Zhou, B.; Li, Q. Spatial variations in urban public ridership derived from GPS trajectories and smart card data. J. Transp. Geogr. 2018, 69, 45–57. [Google Scholar] [CrossRef]
- Tu, W.; Zhu, T.; Xia, J.; Zhou, Y.; Lai, Y.; Jiang, J.; Li, Q. Portraying the spatial dynamics of urban vibrancy using multisource urban big data. Comput. Environ. Urban Syst. 2020, 80, 101428. [Google Scholar] [CrossRef]
- Miller, H.; Goodchild, M. Data-driven geography. GeoJournal 2015, 80, 449–461. [Google Scholar] [CrossRef]
- Liu, J.; Li, J.; Li, W.; Wu, J. Rethinking big data: A review on the data quality and usage issues. ISPRS J. Photogramm. Remote Sens. 2016, 115, 134–142. [Google Scholar] [CrossRef]
- Zhang, C.; Fu, H.; Hu, Q.; Cao, X.; Xie, Y.; Tao, D.; Xu, D. Generalized Latent Multi-View Subspace Clustering. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 86–99. [Google Scholar] [CrossRef]
- Parsons, L. Subspace clustering for high dimensional data: A review. In ACM SIGKDD Explorations Newsletter; Fayyad, U., Ed.; Association for Computing Machinery: New York, NY, USA, 2004; Volume 6, pp. 90–105. [Google Scholar]
- Cheng, J.; Liu, J.; Gao, Y. Analyzing the spatio-temporal characteristics of Beijing′s OD trip volume based on time series clustering method. Int. J. Geo-Inf. 2016, 18, 1227–1239. [Google Scholar]
- Zhang, C.; Hu, Q.; Fu, H.; Zhu, P.; Cao, X. Latent Multi-view Subspace Clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Hawaii, 22–25 July 2017; pp. 79–4287. [Google Scholar]
- Liu, G.; Lin, Z.; Yan, S.; Sun, J.; Yu, Y.; Ma, Y. Robust recovery of subspace structures by low-rank representation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 35, 171–184. [Google Scholar] [CrossRef]
- Guo, Y. Convex subspace representation learning from multi-view data. In Proceedings of the AAAI Conference on Artificial Intelligence, Bellevue, WA, USA, 14–18 July 2013; pp. 387–393. [Google Scholar]
- Gao, H.; Nie, F.; Li, X.L.; Huang, H. Multi-view Subspace Clustering. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4238–4246. [Google Scholar]
- Elhamifar, E.; Vidal, R. Sparse Subspace Clustering: Algorithm, Theory, and Applications. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 2765–2781. [Google Scholar] [CrossRef]
- Ng, A.; Jordan, M.; Weiss, Y. On spectral clustering: Analysis and an algorithm. In Advances in Neural Information Processing Systems; Tenenbaum, J., Griffiths, T., Eds.; Morgan Kaufmann Publishers: San Francisco, CA, USA, 2001; Volume 14, pp. 849–856. [Google Scholar]
- Han, D.; Yuan, X. A note on the alternating direction method of multipliers. J. Optim. Theory Appl. 2012, 155, 227–238. [Google Scholar] [CrossRef]
- Rousseeuw, P. Silhouettes: A Graphical Aid to the Interpretation and Validation of Cluster Analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Liu, X.; He, J.; Yao, Y.; Zhang, J.; Liang, H.; Wang, H.; Hong, Y. Classifying urban land use by integrating remote sensing and social media data. Int. J. Geogr. Inf. Sci. 2017, 31, 1675–1696. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Full Name |
|---|---|
| GPS | Global positioning system |
| BTS | Base transceiver station |
| POI | Point of interest |
| FD | Frequency density |
| CR | Category ratio |
| TAZ | Traffic analysis zone |
| CBF | Commercial and business facility |
| RUL | Residential land |
| TAW | Tourist attraction and water |
| IUL | Industrial land |
| PAS | Public administration and service |
| RTF | Road and transportation facility |
| AGR | Agriculture |
| OA | Overall accuracy |
| Feature | I | II | III | IV | V | VI | VII |
|---|---|---|---|---|---|---|---|
| OA | 40.73% | 36.92% | 47.83% | 47.66% | 41.07% | 42.81% | 57.7% |
| POI | C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FD | CR | FD | CR | FD | CR | FD | CR | FD | CR | FD | CR | FD | CR | FD | CR | |
| Attraction | 22.41 | 0.87% | 3.02 | 0.09% | 1.14 | 0.05% | 3.53 | 0.17% | 3.74 | 0.15% | 16.27 | 0.56% | 3.39 | 0.28% | 1.46 | 0.17% |
| Doorplate | 88.96 | 2.77% | 83.61 | 2.85% | 126.87 | 5.08% | 94.73 | 4.06% | 115.92 | 4.17% | 117.43 | 2.93% | 57.81 | 3.57% | 47.30 | 4.16% |
| Building | 10.88 | 0.58% | 34.44 | 1.05% | 19.38 | 0.49% | 16.54 | 0.73% | 18.17 | 0.79% | 23.51 | 0.59% | 10.00 | 0.42% | 2.70 | 0.32% |
| Company | 97.26 | 5.21% | 352.31 | 10.7% | 113.85 | 5.36% | 133.28 | 6.29% | 156.78 | 6.38% | 164.88 | 4.12% | 88.27 | 5.26% | 48.66 | 5.72% |
| Shopping | 4.37 | 0.23% | 21.69 | 0.66% | 9.41 | 0.38% | 11.85 | 0.72% | 10.24 | 0.82% | 35.17 | 0.88% | 2.28 | 0.19% | 1.80 | 0.21% |
| Theater | 1.28 | 0.06% | 3.30 | 0.17% | 1.38 | 0.05% | 1.92 | 0.09% | 1.79 | 0.07% | 3.29 | 0.15% | 0.88 | 0.07% | 0.17 | 0.02% |
| Public toilet | 32.24 | 1.73% | 31.41 | 1.02% | 23.65 | 0.95% | 21.35 | 0.92% | 22.42 | 0.91% | 37.96 | 1.45% | 14.38 | 0.78% | 13.43 | 0.58% |
| Industry | 0.55 | 0.03% | 0.63 | 0.05% | 0.70 | 0.03% | 0.23 | 0.05% | 0.09 | 0.05 | 0.67 | 0.02% | 1.12 | 0.10% | 0.88 | 0.07% |
| Restaurant | 26.85 | 1.43% | 72.78 | 2.22% | 39.81 | 1.59% | 37.64 | 1.80% | 38.98 | 1.57% | 15.88 | 1.56% | 15.48 | 1.60% | 13.12 | 1.54% |
| Healthcare | 9.59 | 0.32% | 10.23 | 0.48% | 10.98 | 0.49% | 14.66 | 0.59% | 14.29 | 0.58% | 18.76 | 0.47% | 7.10 | 0.58% | 4.85 | 0.57% |
| Dwelling | 61.79 | 2.31% | 72.86 | 2.22% | 61.20 | 2.93% | 91.63 | 3.07% | 88.31 | 3.17% | 85.19 | 2.13% | 29.41 | 2.42% | 21.99 | 2.19% |
| Living service | 105.44 | 5.65% | 112.53 | 6.18% | 125.74 | 6.42% | 164.20 | 6.58% | 161.96 | 6.73% | 220.77 | 5.52% | 76.93 | 5.33% | 48.21 | 5.67% |
| Science/Education | 5.29 | 0.29% | 8.22 | 0.37% | 19.88 | 0.80% | 11.03 | 0.51% | 22.10 | 0.69% | 11.12 | 0.28% | 3.83 | 0.31% | 2.54 | 0.30% |
| Sport center | 7.21 | 0.39% | 5.10 | 0.62% | 11.36 | 0.45% | 12.37 | 0.59% | 20.52 | 0.50% | 12.39 | 0.51% | 4.82 | 0.40% | 3.64 | 0.43% |
| Bank | 6.70 | 0.16% | 15.64 | 0.28% | 7.67 | 0.31% | 8.23 | 0.40% | 10.49 | 0.42% | 11.66 | 0.29% | 3.99 | 0.23% | 1.74 | 0.12% |
| Hospital | 10.66 | 0.17% | 3.55 | 0.11% | 7.24 | 0.24% | 5.05 | 039% | 12.95 | 0.57% | 7.66 | 0.32% | 4.02 | 0.13% | 1.48 | 0.17% |
| Courier service | 6.68 | 0.36% | 14.48 | 0.44% | 9.17 | 0.64% | 15.97 | 0.78% | 11.51 | 0.94% | 12.56 | 0.31% | 9.49 | 0.44% | 8.02 | 0.47% |
| Hotel | 16.72 | 0.90% | 20.90 | 0.64% | 13.38 | 0.78% | 13.37 | 0.64% | 18.86 | 0.86% | 36.74 | 0.82% | 9.10 | 0.75% | 5.07 | 0.60% |
| Convenient store | 13.38 | 0.75% | 17.32 | 0.83% | 24.87 | 0.98% | 20.98 | 1.01% | 27.24 | 1.11% | 26.16 | 1.15% | 15.41 | 0.72% | 14.29 | 0.86% |
| Administrative place | 0.08 | 0.00% | 0.28 | 0.00% | 0.24 | 0.00% | 0.25 | 0.01% | 0.25 | 0.01% | 0.27 | 0.00% | 0.21 | 0.01% | 0.65 | 0.03% |
| Recreation | 16.85 | 0.55% | 18.57 | 0.67% | 14.18 | 0.52% | 14.28 | 0.54% | 13.45 | 0.48% | 42.72 | 1.07% | 9.21 | 0.57% | 4.07 | 0.48% |
| Tolls | 0 | 0.00% | 0 | 0.00% | 0 | 0.00% | 0 | 0.00% | 0 | 0.00% | 0 | 0.00% | 0.26 | 0.03% | 0 | 0.00% |
 Low
Low  Medium
Medium  High.
High.| Methods | Single-View Method (Taxi) | Single-View Method (Bus) | Weighted Fusion Method | The Adopted Method |
|---|---|---|---|---|
| OA | 36.6% | 37.6% | 44.5% | 57.7% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Q.; Huan, W.; Deng, M.; Zheng, X.; Yuan, H. Inferring Urban Land Use from Multi-Source Urban Mobility Data Using Latent Multi-View Subspace Clustering. ISPRS Int. J. Geo-Inf. 2021, 10, 274. https://doi.org/10.3390/ijgi10050274
Liu Q, Huan W, Deng M, Zheng X, Yuan H. Inferring Urban Land Use from Multi-Source Urban Mobility Data Using Latent Multi-View Subspace Clustering. ISPRS International Journal of Geo-Information. 2021; 10(5):274. https://doi.org/10.3390/ijgi10050274
Chicago/Turabian StyleLiu, Qiliang, Weihua Huan, Min Deng, Xiaolin Zheng, and Haotao Yuan. 2021. "Inferring Urban Land Use from Multi-Source Urban Mobility Data Using Latent Multi-View Subspace Clustering" ISPRS International Journal of Geo-Information 10, no. 5: 274. https://doi.org/10.3390/ijgi10050274
APA StyleLiu, Q., Huan, W., Deng, M., Zheng, X., & Yuan, H. (2021). Inferring Urban Land Use from Multi-Source Urban Mobility Data Using Latent Multi-View Subspace Clustering. ISPRS International Journal of Geo-Information, 10(5), 274. https://doi.org/10.3390/ijgi10050274