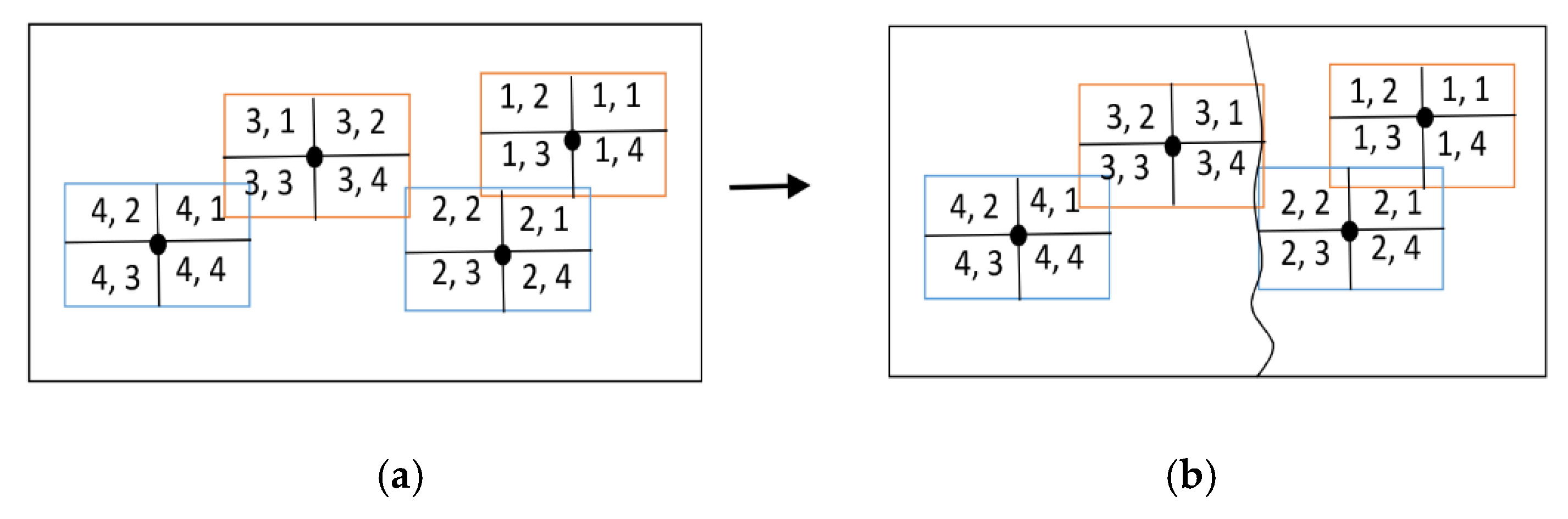
While segmenting the map, several criteria must be considered based on the existing problem. In the case of map feature label placement, two influential variables are viable: label conflict and label–feature conflict, which are fundamentally substantial in automatic label placement. All types of geographical features are connected; regardless of whether they are closer or farther, there is a spatial correlation among them [
39]. Thereby, it is essential to consider a proper model of map segmentation to partition the input features uniformly and proportionately. Many studies have been conducted on decomposing large-scale data and then assigning each decomposed problem on a separate CPU to gain high-performance computing [
40,
41,
42]. During the process of map segmentation, two fundamental issues have arisen, namely un-uniform and unequal distribution of features in each segment, which cause unload balancing on separate central processing units (CPUs). To cope with the aforementioned issues, map segmentation is the compromise of the initial map segmentation and adjusting phase, in this study.
3.1.1. Initial Map Segmentation
The given map contains a set of features (
) within a specific domain
, noting that the domain refers to the segment. The features are then partitioned in a set of
subdomains
of
into
subset such that no feature is located more than once in the subdomain. Let
be the number of subdomains
, for each feature
and subdomain
with
. A binary variable, then, is defined:
, where
represents the feature and
is one of the subdomains. If
, the feature
is located in subdomain
; otherwise, it is not. The equations are defined as follows:
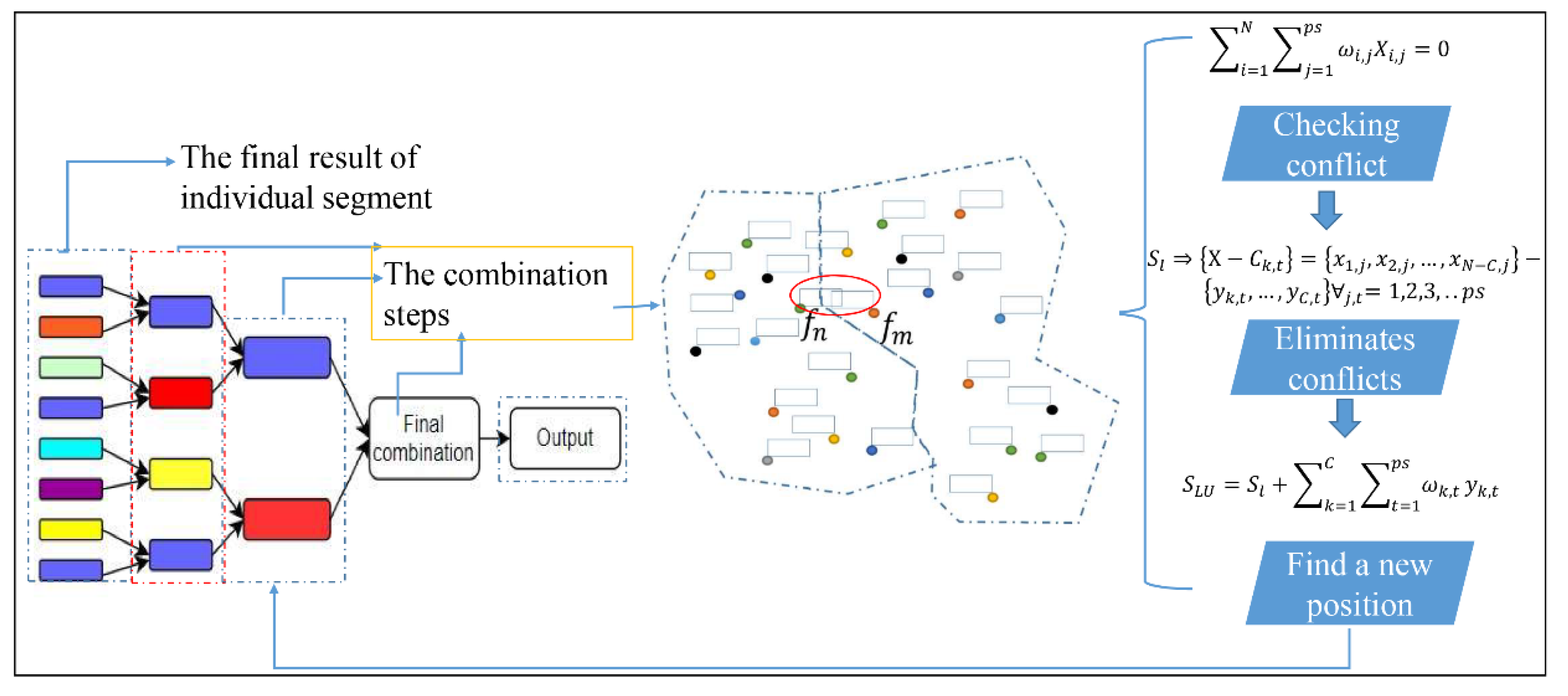
Equation (1) is defined to make sure that each feature is positioned only once in one subdomain. Thus, a set of subdomains is defined as by Equation (2), and a variable is introduced to count the number of features in each segment, as formulated in Equation (3). In some cases, due to the complexity of feature structure, presumably the number of features distributed disproportionately in the initial map segmentation phase is high, which leads to a reduction in the overall performance of the algorithm. One of the substantial steps in parallel processing, nonetheless, is to distribute the amount of workload on each CPU proportionately due to the dependency of processors. Therefore, a tremendous potential of parallel processing can be achieved by balancing the workload among all parallel processing units, greatly improving the performance of the algorithm.
3.1.2. Adjusting the Number of Features
Parallel processing provides high-performance computing capabilities if the input features are divided proportionately in each segment. In a system with multiple processes, there is a very high chance that some processes be idle while others are overloaded. Therefore, the aim of the load balancing is to maintain the load on each processing element such that all the processing elements become neither overloaded nor idle and each processing element ideally has equal load during execution, as shown in Equations (4) and (5). Thus, the proper design of load balancing is crucial in accelerating the process of automatic label placement. To illustrate the correlation between computational time and the workload, the speedup of each segment is formulated as Equation (4), where
is the execution time of the segment
on processor
, and the workload in each segment is formulated as Equation (5), where
is the execution time for the segment
.
To address the issue of unequal distribution of features, the adjusting phase is implemented, which removes some features from one segment and adds them to others. However, deciding which features are better to move from one segment to other segments requires high consideration, including examining which segment has enough space and also which is more suitable to accept these features [
43]. To ensure that all segments have an equal number of features after the initial map segmentation, the number of distributed features is counted in every segment based on the maximum and minimum values that are defined; these values define the range value of the workload in each segment and are termed as
and
, respectively. Therefore, after the initial map segmentation, the number of distributed features must be adjusted on the basis of load balancing strategy if any segment breaches the defined range value. The adjusting steps are defined as follows:
Equation (6) ensures that the number of features in subdomain
does not violate the range value; otherwise, this segment violates the principle of load balancing, and in such a case, some features should be removed from this segment and added to others based on the maximum and minimum values of subdomains. The following equations are set to appoint which features are more appropriate to be moved from one segment to others:
In Equation (7),
is the Euclidean distance between feature
, which is a random feature, and other features (
); this procedure continues for all features in order to find a feature that presents the centroid.
is the number of features. The feature that stands as the centroid (
) of the considered segment is the feature that has the lowest value of
.
is the Euclidean distance between the feature that is selected as the centroid (
) and other features (
), which is used to find the features with longer distances from the extracted centroid of features, using Equation (8). The visualization of Equation (7) is shown in
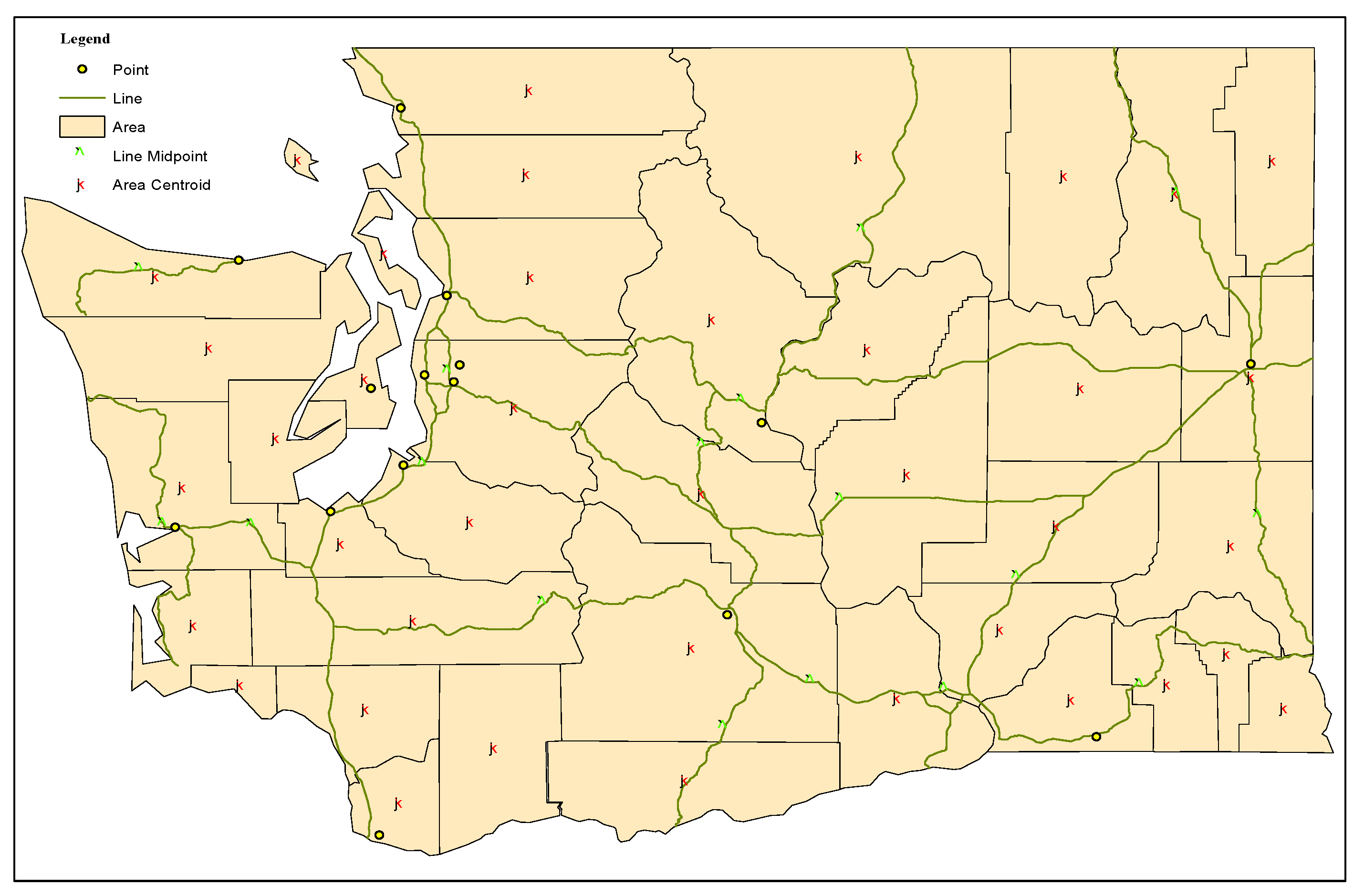
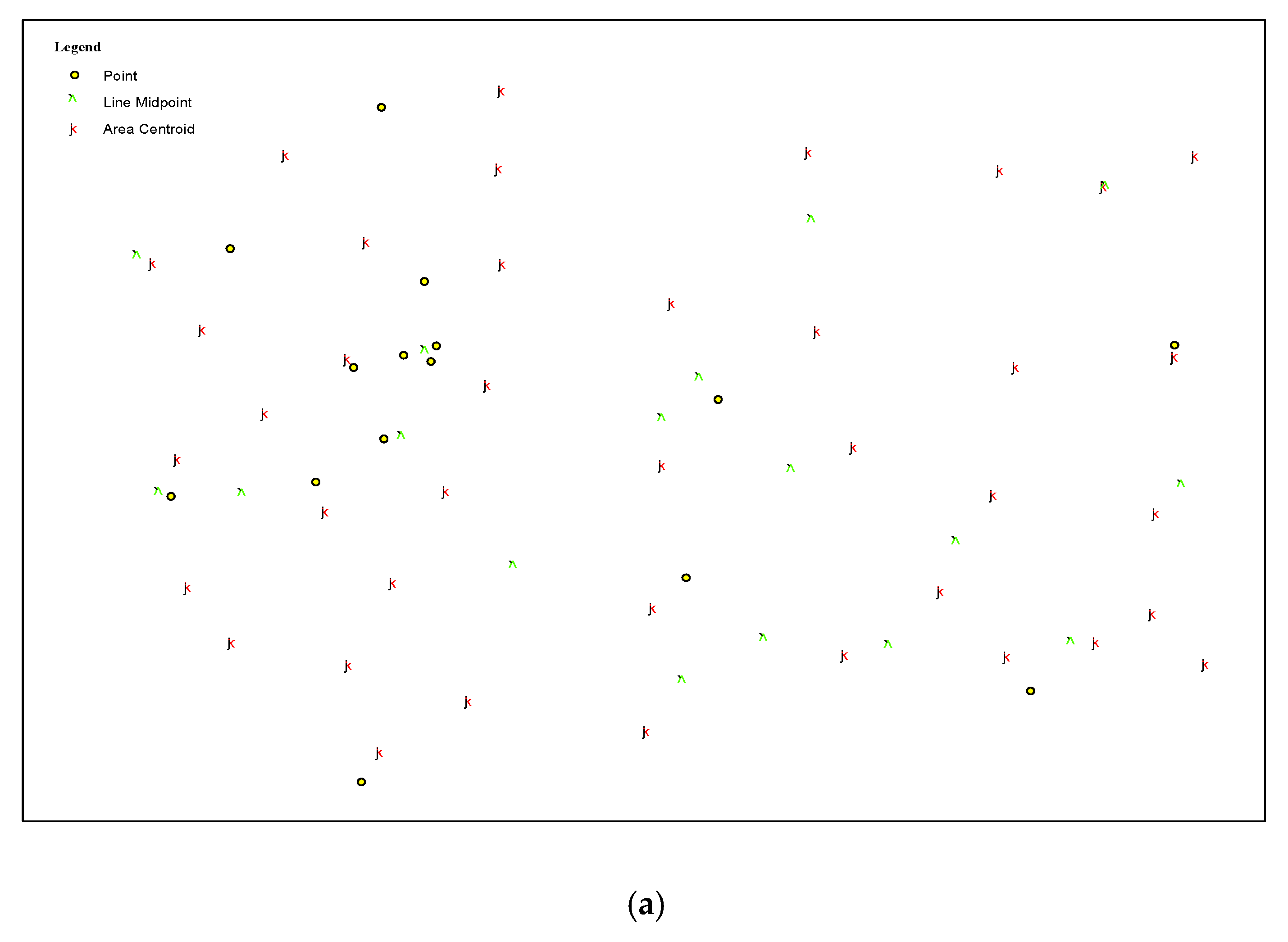
Figure 5. Then, it must be determined which neighboring segments are appropriate to accept the new features. Suppose
is a set of features that are identified to be moved from one segment to other segments, as illustrated in
Figure 5b. This set of features can be different types of features, as the area features are presented by their centroids and the lines are presented by their midpoints in the map segmentation step.
As shown in
Figure 5, three subdomains exist; however, the segment with the centroid
has more features in contrast to the two neighboring segments with the centroids
and
. Some features have to be removed from the segment having the centroid
and added to the neighboring segments accordingly. To adjust the distribution of the features, feature types are applied as the basis for devising in the adjusting phase. According to the cartographic standardization for feature labeling, the labels of line and area features are placed at various angles, horizontal, vertical, or along the direction of features. While the label of point features is often positioned horizontally, in this case, the probability of label conflict and label–feature conflicts increases during the process of feature label placement.
In
Figure 5, assume the segment with the centroid
violated Equation (6), and three features with indices
are identified as the features to be removed from the segment with centroid
and added to other segments based on Equation (8). To investigate the relationship between features in set
, five factors are considered: the distance between the features, the length of the label box for point feature, the height of the label box, the angle between features, and the buffer distance for the area and line features. Since the position of each label has an influence on the position of neighboring labels, the aforementioned factors are set to minimize the probability of label conflict. As shown in
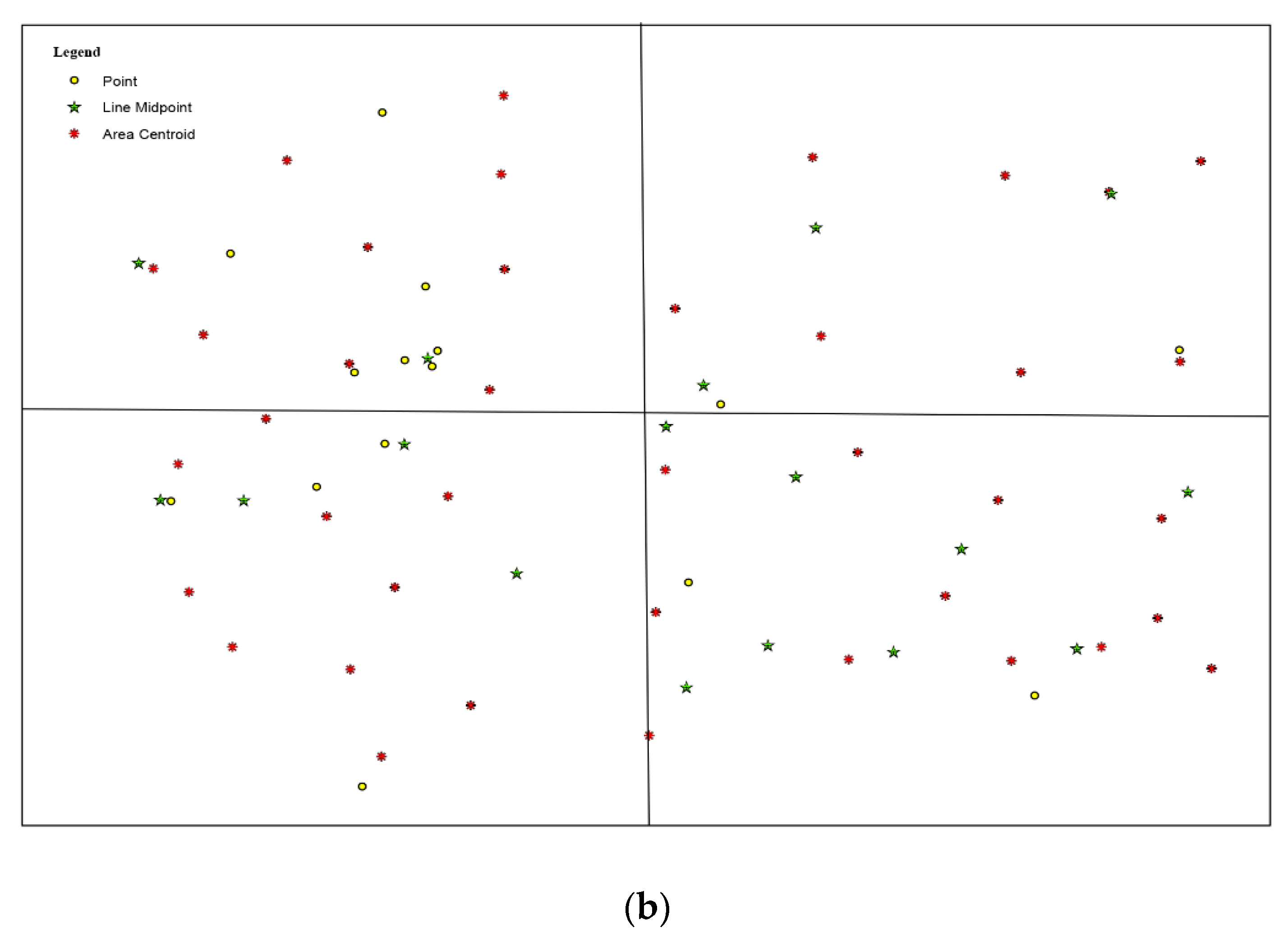
Figure 5a–f, features in set
, can have a variety of relationships.
To study the relationship between features in set
, Equation (10) is formulized, where
stands for the length of the label box. Note that the length of the label box is calculated according to the number of letters of labels. First, the dimension of each letter is measured based on the scale of the dataset and then multiplied by the number of letters; in this case, the label box generated is approximately the same size as the actual label.
stands for the Euclidean distance between features
. If the distance is less than the length of the label box of any of these two features, the features are assumed to be dependent; otherwise, they are assumed to be two independent features.
Figure 5b shows that there is no possible relationship between features in set
, according to Equation (10); in such a case, each feature is added in different neighboring segments regardless of other features in set
. However, if there is any dependency between features in set
, as shown in
Figure 5c, the feature with index
has relationships with the two other features. On the other hand, none of the neighboring segments can accept all three features. The following equations are defined to identify which segment is appropriate to accept the features from set
by assigning a weight value based on the condition of feature relationships:
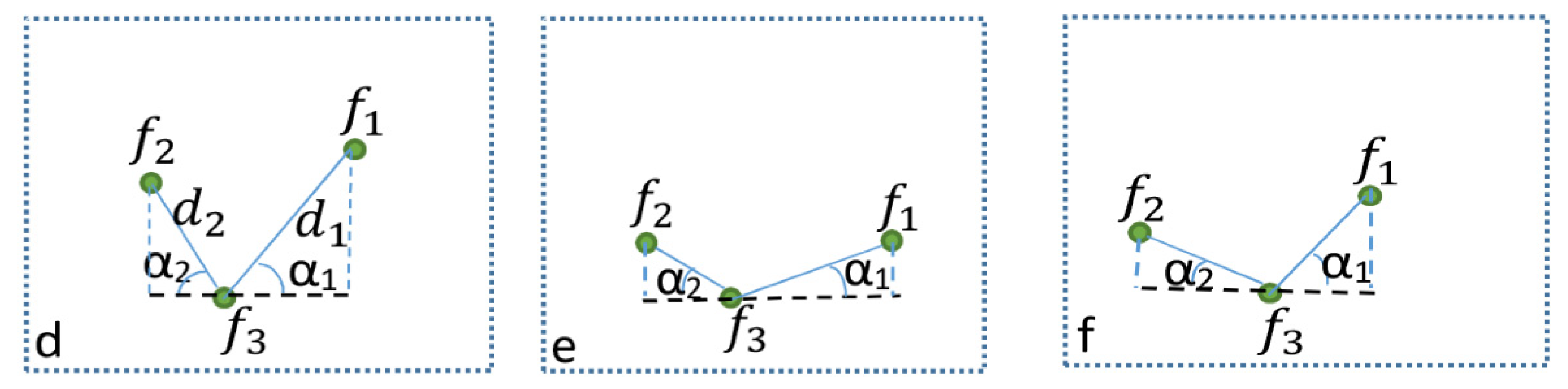
In Equation (11), if the angle
is greater than 45 degrees, the height of the label box and vertical distance are considered to assign weight values, as presented in
Figure 5d.
stands for the height of the label box;
are the vertical distances between features, as shown with blue dash line in
Figure 5d; and
are the weight values. If
, the features
are grouped as one category and can be moved in the same segment, and feature
is assumed to be an independent feature and can be added to another segment.
In Equation (12), if the angle
is less than or equal to 45 degrees, the length of the label box for point features, buffer distance for the area and line features, and horizontal distances are considered to assign weight values.
presents the length of label box for point feature and buffer distance for the line and area features;
are the horizontal distances between features, as shown with a black dash line in
Figure 5e; and
are the weight values. The greater weight value shows that the features must be grouped as one category and the lower weight value indicates that the dependency of features can be regarded as independent.
Equation (13) describes the condition where the features in set
are located in such a way that the angles
between them are less and greater than or equal to 45 degrees, as shown in
Figure 5f. Therefore, these metrics are considered to assign weight values according to feature relationship to minimize the possibility of labels being positioned in conflict, which are the height (
) and length (
) of the label box and the horizontal (
) and vertical (
) distances between features. Ultimately, based on the assigned weight values, the features in set
will be categorized into different groups. Algorithm 1 presents the procedure of map segmentation.
| Algorithm 1. Map segmentation
|
| 1: Specify the number of segments (n) |
| 2: Count the number of features on the map (N) |
| 3: Ideal feature division; I = N/n |
| 4: maxv = I + 2; minv = I − 2 |
| 5: for i = 1…P do |
| 6: for j = 1…N do |
| 7: intersect i and j |
| 8: end for |
| 9: end for |
| 10: for i = 1…P do |
| 11: if the number of features (Ki) > maxv do // Ki the number of features in segment (i) |
| 12: for L = 1…K do |
| 13: find the centroid of features (Ki) in segment (i) |
| 14: end for |
| 15: F = K − maxv // how many features are more than the defined range |
| 16: for f = 1…F do |
| 17: find the farthest features based on the centroid of segment (i) |
| 18: end for |
| 19: m = // features need to be added to another segment |
| 20: check the dependency of features in set (A) based on Equations (10)–(13) |
| 21: for ii = 1…P do |
| 22: find the neighboring of segment (i) |
| 23: if Kii < max do // if its features are less than the max value in this neighbor |
| 24: n = one possible segment to accept new features |
| 25: end if |
| 26: end for |
| 27: neighbors = // All possible neighbors of segment (Ri) |
| 28: find the centroid features of each neighbor (C) |
| 29: for c = 1…C do |
| 30: measure the distance of each feature in set (A) to c |
| 31: add features from set (A) to the closest neighbor |
| 32: update the number of features of the neighbor segment that accepted from segment (i) |
| 33: end if |
| 34: end for |



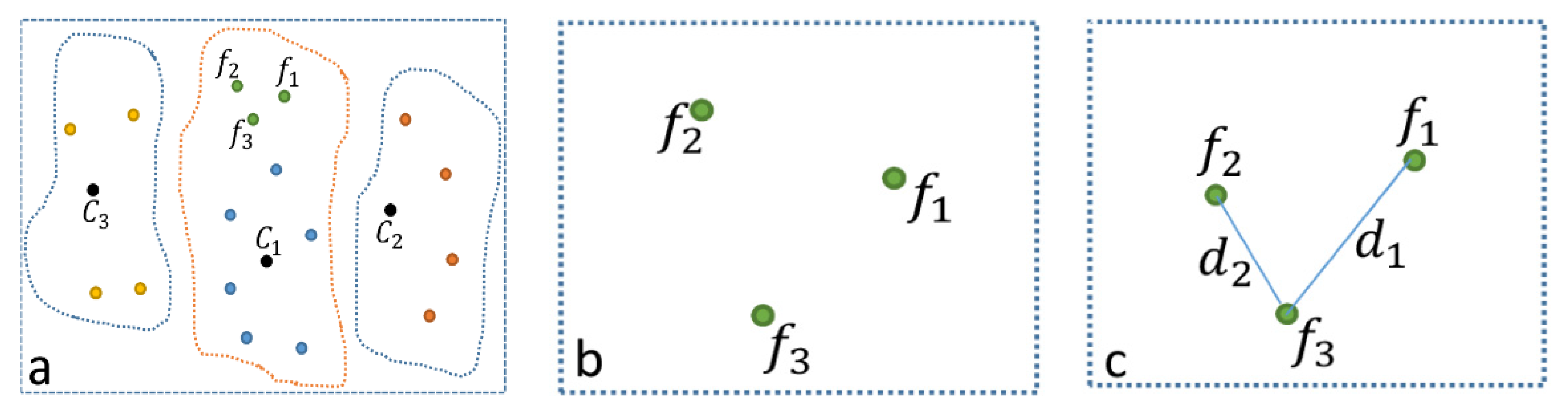


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}