2.2.2. Obstacle Data
Within this work, we focus on domestic environments such as apartments and offices. In these environments, room borders commonly occur at narrow passageways such as doors. These passageways are implicitly represented in the structure of the map graph: rooms separated by a narrow passageway tend to be connected by fewer edges. Since our method attempts to minimize the normalized cut, it is thus more likely to create a room border at a narrow passageway.
However, this behavior may also pose a problem: below a certain width, very narrow passageways are less likely to correspond to room borders in our maps: for edges passing through a passageway with a width of
(as defined below), only 0.5% cross a room border. This is much lower than the overall fraction for all edges, which
Table 1 lists as 2.6%. Thus, placing a room border at such a passageway is less likely to be correct. Instead, these very narrow passageways tend to occur between furniture or similar obstacles. We therefore include the passageway width
L as an edge feature, hoping to improve the classification of these edges.
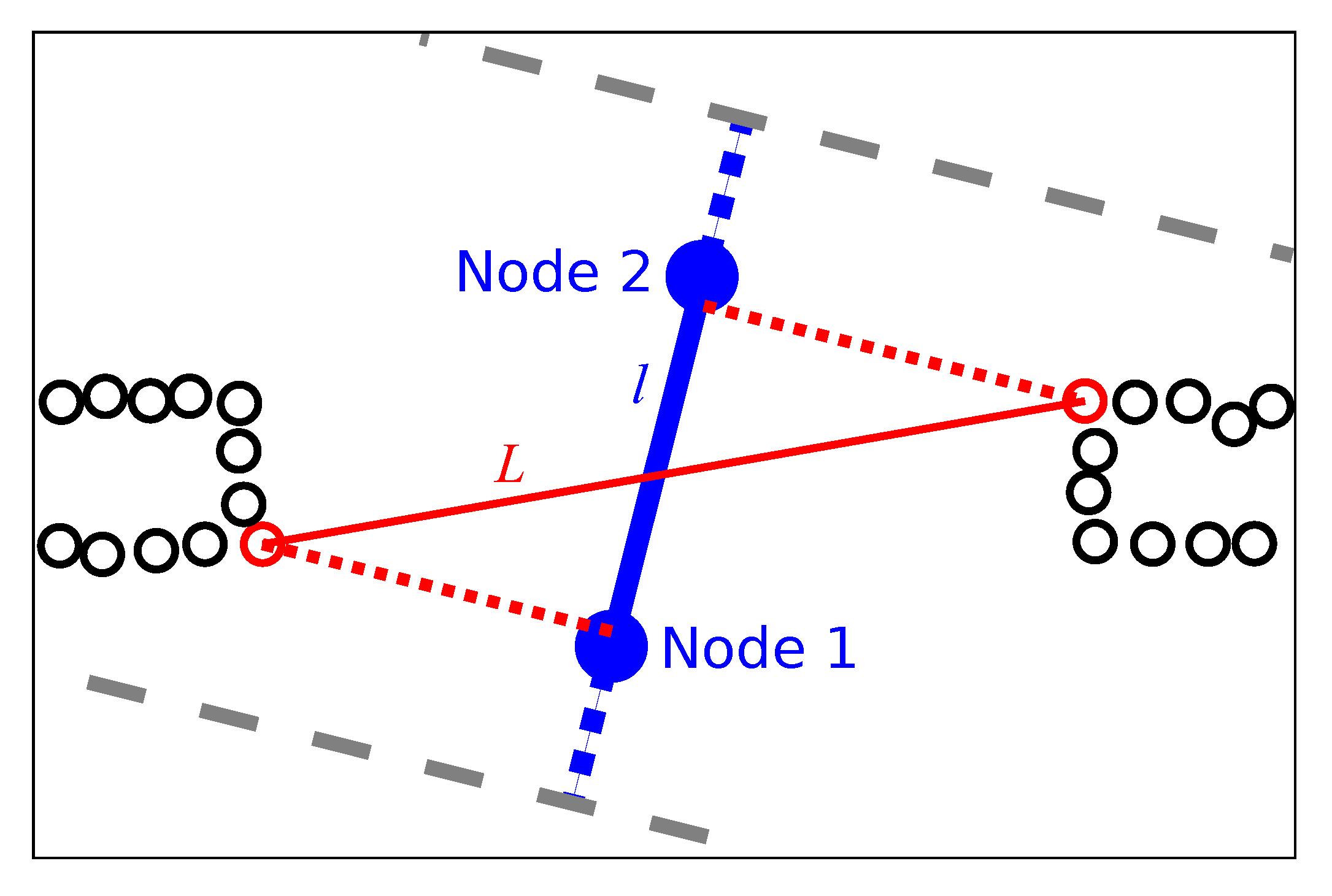
We estimate the passageway width
L from the robot’s obstacle map. Our cleaning-robot prototype does not carry a dedicated laser range sensor. Instead, it uses the beams emitted by eight laser diodes mounted on its chassis, as shown in
Figure 1. Our robot measures the distance to obstacles by detecting the laser reflections with its on-board camera. Due to the low number of beams, camera refresh rate, and maximum detection range of 1
, the resulting map is comparatively sparse. Like our topo-metric map, the obstacle map also lacks global metric consistency.
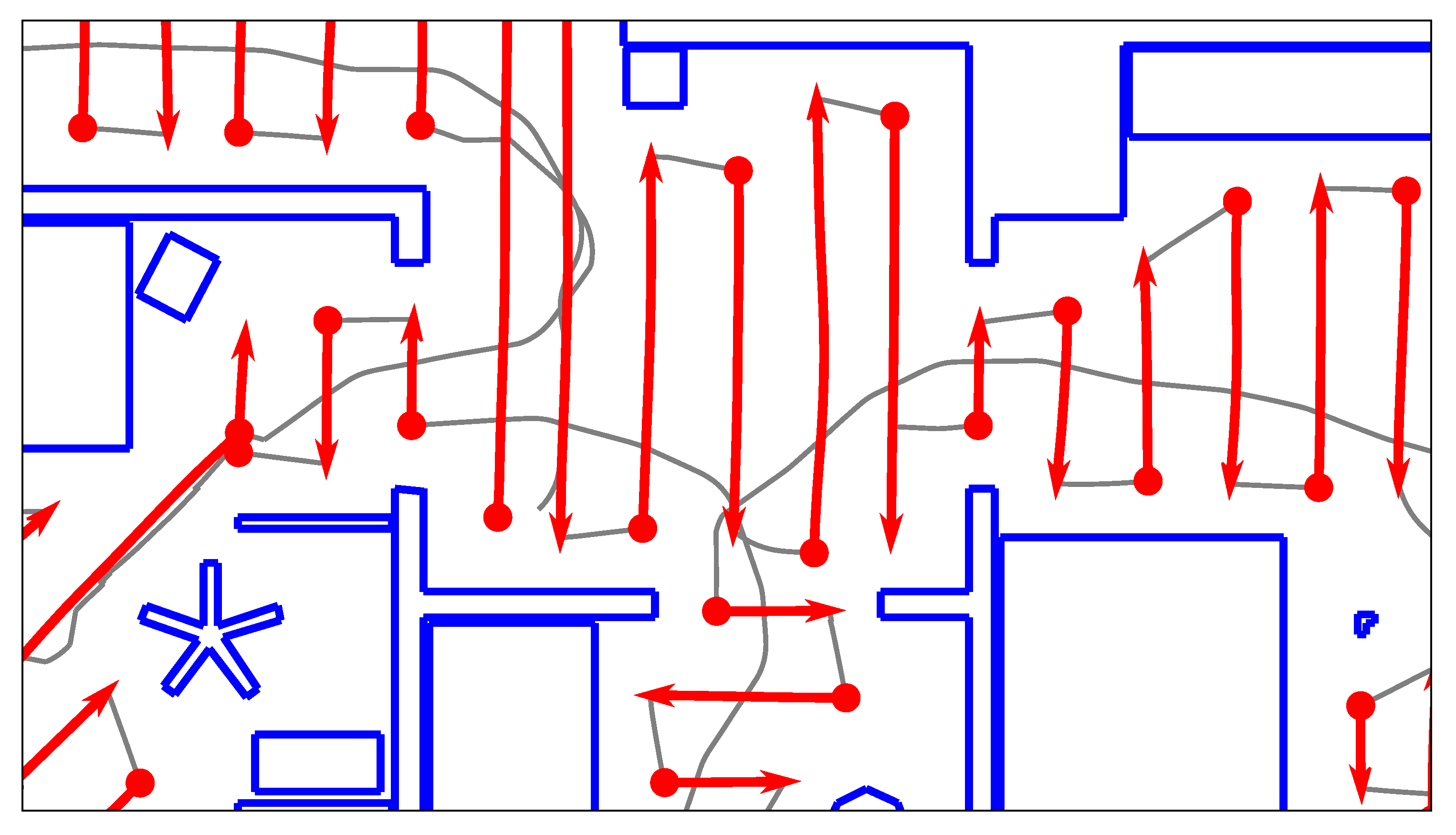
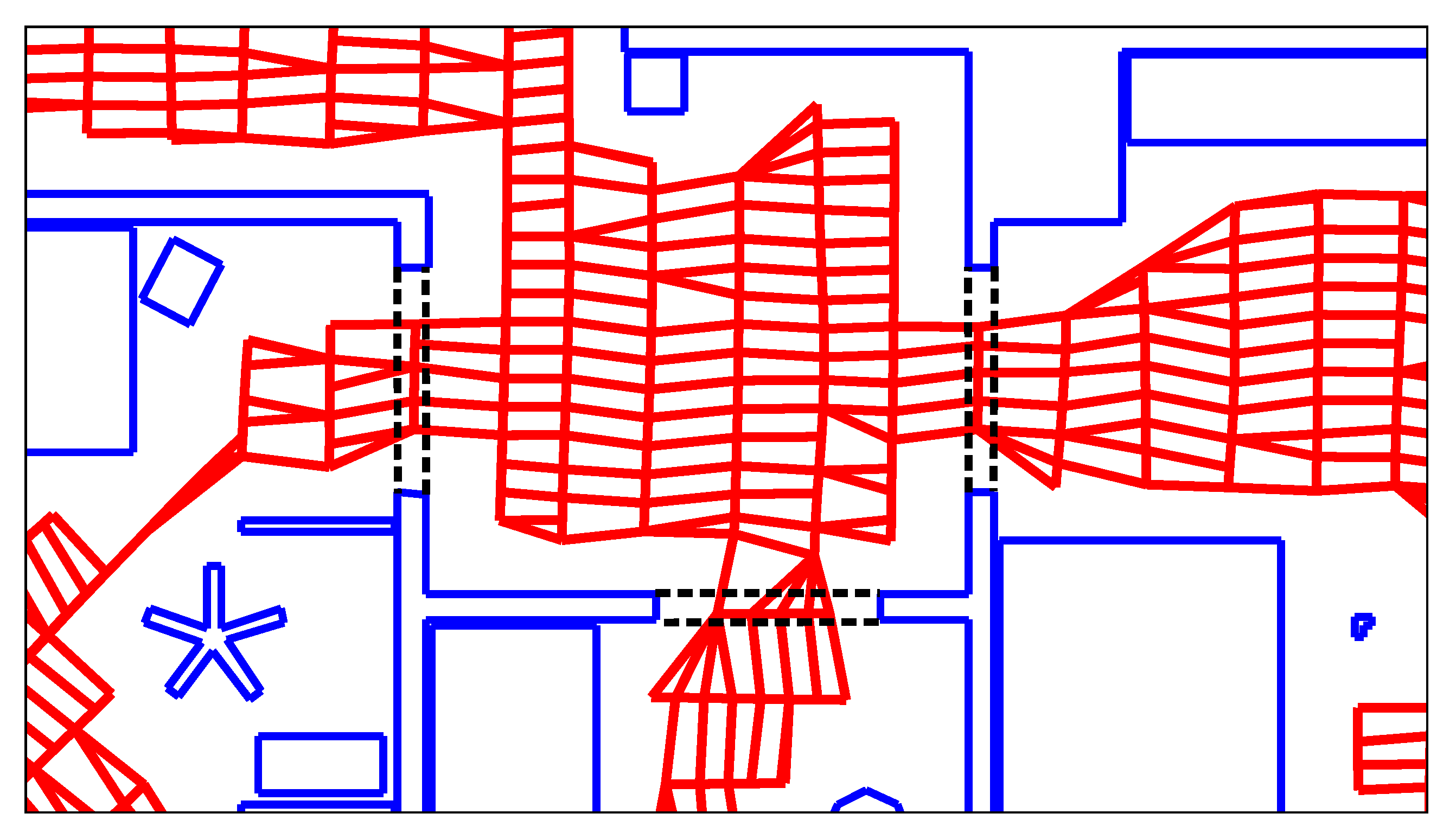
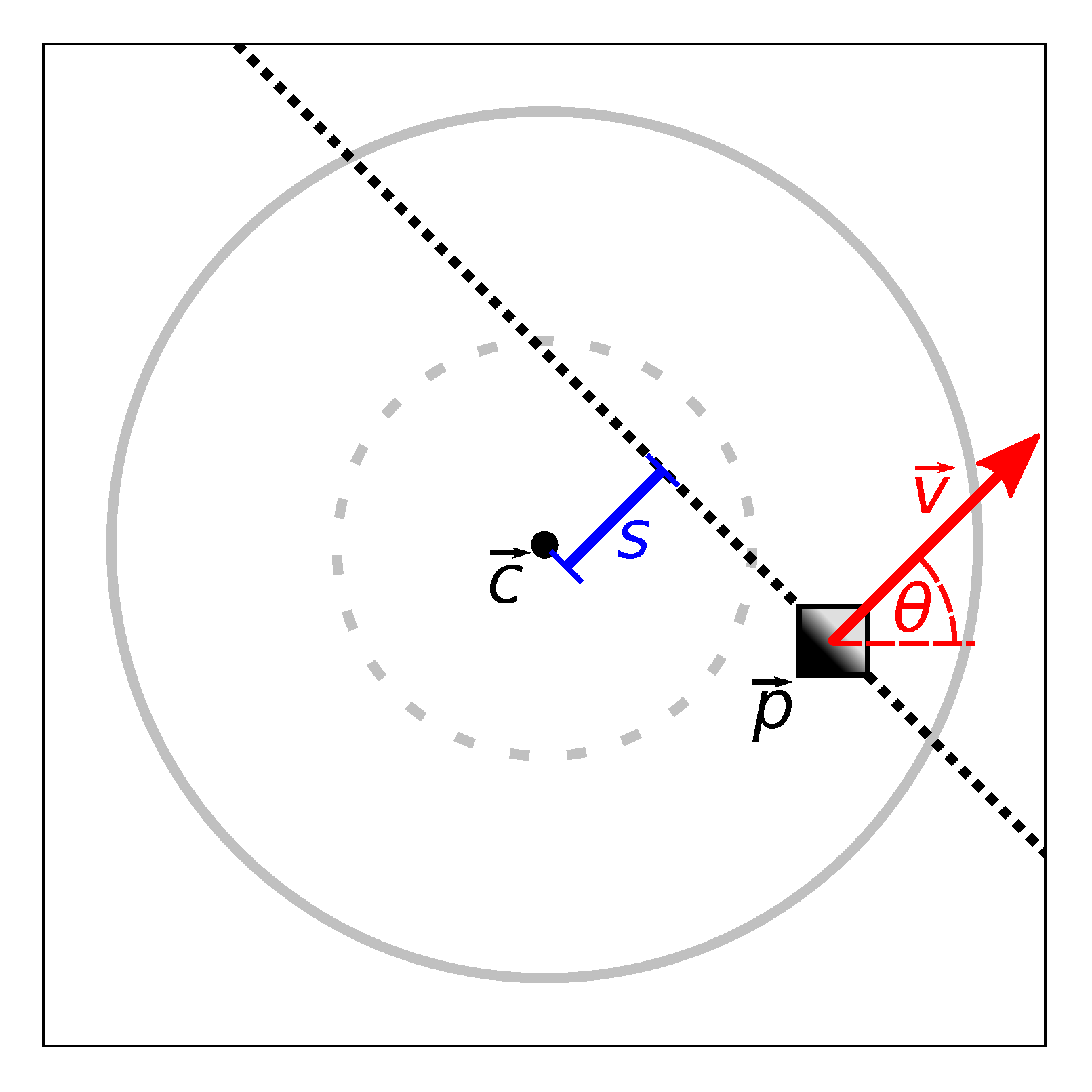
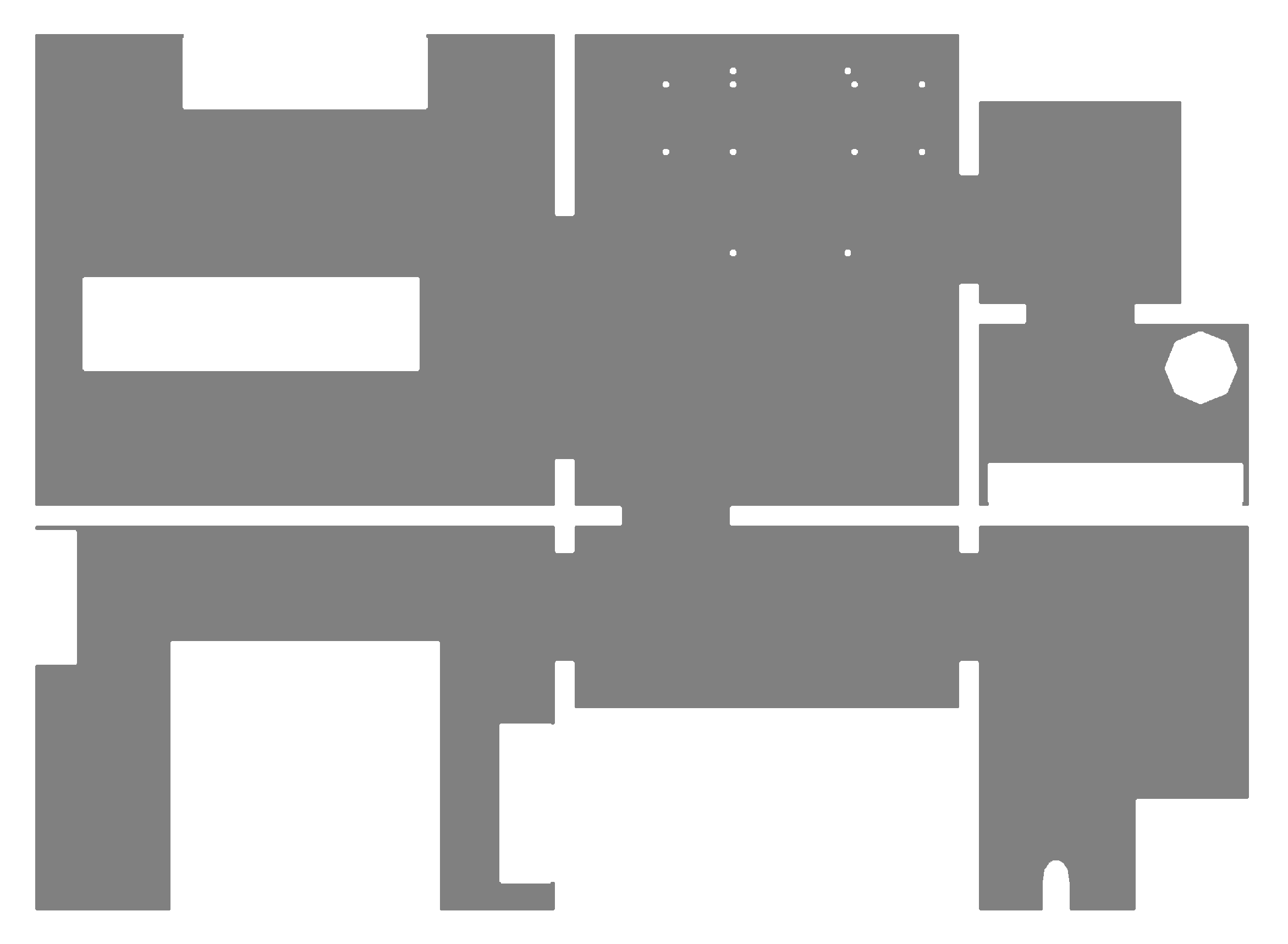
We therefore operate on individual, local obstacle-points, as illustrated in
Figure 7: initially, all obstacles detected near the edge are retrieved according to
Appendix A. However, some of these points may be the result of incorrect range measurements. These occur only sparsely, but can cause incorrect passageway-width estimates. To identify these points, we perform density-based clustering using the DBSCAN algorithm [
28]. DBSCAN identifies obstacle points which are not part of a sufficiently large, dense cluster. In our case, clusters of less than three points within a distance of 10
are discarded as false measurements.
We also discard obstacles that lie outside of a search area around the edge. This area runs orthogonal to the edge direction. As shown in
Figure 7, the search area is somewhat wider than the length of the edge. We consider this necessary to avoid overlooking obstacles when calculating
L for short edges. The width of the search area is equal to
on either side;
is the robot radius. If the edge is short (
) and connects subsequent nodes on a lane, the area is further extended by up to 5
on either side. For edges that connect nodes on the same lane, this may not extend the search area beyond that lane’s beginning or end. We search this area for the closest obstacle points on both sides of the edge, using the preprocessed points described above. The metric distance between these closest points is the passageway width
L. Note that
L is only an approximation of the true width of the passageway. Its accuracy depends on the geometry of the passageway and on the position and orientation of the edge.
As mentioned above, we only consider obstacle data that was detected in the vicinity of the map edge. We cannot use obstacle data from far-away locations, as our map lacks global metric consistency. Due to this limited range, there may not be enough local obstacle data to compute
L. In our maps, this occurred for ≈47% of all edges. To allow the room–border classifier to work with these edges, we substitute a fixed value for
L. This value should be distinct from the
L calculated from actual obstacle measurements. The naive approach would be to use a very large value, such as
. However, such a large value would cause problems with the edge-feature scaling discussed in
Section 2.3. In our maps, the highest obstacle-derived value is
. In this work, we therefore use a default value of
.
2.2.3. Visual Passageway Detection
In the environments considered in this work, room borders commonly occur at passageways. We therefore wish to detect passageways in the images recorded by our robot’s on-board camera. In the literature, there are numerous methods for visually detecting doors, for example by Chen and Birchfield [
29], Murillo et al. [
30], Yang and Tian [
31]. These methods usually attempt to detect doors from afar, for example to guide a robot towards them. As mentioned before, our map lacks global metric consistency. After detecting a distant door, we are thus unable to estimate its location in our map. Subsequently, we also cannot determine which edges cross through such a doorway. We therefore decided to use a simple heuristic instead. This method merely checks for passageways in close proximity to each map node. To estimate whether an edge crosses a passageway, we then combine the results from the edge’s two nodes.
Our method is based on detecting image edges associated with passageways in the robot’s camera image. These edges are often visually distinctive, as shown in
Figure 8a. We note at least two approaches: one approach is based on the vertical posts on the sides, the other on the horizontal lintel at the top of the passageway. We found that vertical edges—such as from walls, window frames, or furniture—are quite common in our environments. During preliminary experiments, this frequently led to incorrect passageway detections. In comparison, non-passageway edges directly overhead the robot were less common. Additionally, detecting these edges does not require a panoramic camera. As shown below, a ceiling-facing camera with a field-of-view as low as 38° could be sufficient. Although not immune to incorrect detections, we focus on the overhead lintels. Egido et al. [
32] previously employed an upward-facing sonar to detect these lintels with a mobile robot. Since we wish to use our existing camera images, we instead utilize an edge histogram to detect straight image edges above the robot. This histogram technique is similar to the modification of the popular Hough transform (survey: [
33]) presented by Davies [
34], although our specific formulation differs.
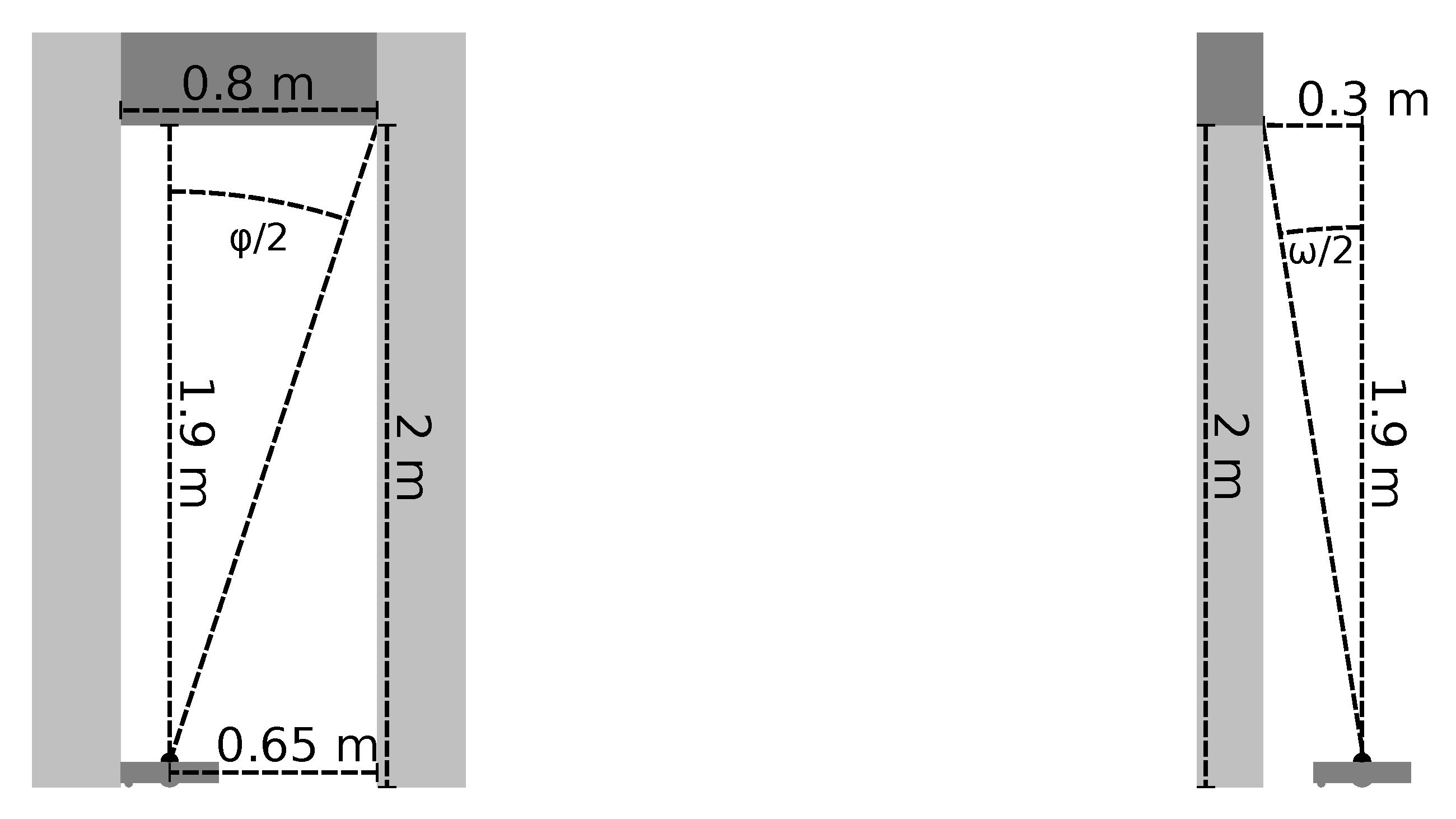
Since we wish to detect lintels above the robot, we only consider a limited part of each camera image. However, we do not know the true dimensions of the passageways and lintels within a specific environment. We therefore assume that a typical passageway has a width of
and a height of
. These dimensions are similar to those of real passageways we found in household and office environments. We now assume that the robot is located at one side of such a passageway, with the lintel directly above the robot’s camera as shown in
Figure 9a. In this case, the distance between the furthest point of the lintel and the camera is
horizontally and
vertically. The entire lintel thus lies within a cone with an opening angle of
. Using a calibrated camera model [
35], we identify the camera pixels corresponding to this search cone. These pixels form the area shown by the solid circle in
Figure 8b. In the following steps, we only search for image edges within this search area.
Our robot’s on-board camera uses a fisheye lens with an approximately equidistant projection. As this projection is nonlinear, a straight edge might appear curved in the camera image. However, our search is limited to a small disc around the image center, corresponding to an opening angle of
. Inside this disc, the projection is approximately linear, as shown in
Figure 8a. We thus do not reproject the images, as we found that using the fisheye images gives adequate results.
To detect edges, we now apply a Scharr operator to the search area, which is similar to the well-known Sobel operator. However, the Scharr operator is specifically optimized for rotational invariance [
36,
37]. This property is useful, as we wish to detect edges independent of their orientation within the image. In our experiments, we use the implementation from the OpenCV library [
38]. We now know the horizontal and vertical gradients
and
for each pixel within the search area. Next, we construct the edge-pixel gradient vector
from these values. For passageway detection, light-dark and dark-light edges should be treated equally. We therefore use a definition of
that is invariant to an inversion in pixel intensities:
We also calculate the pixel’s edge intensity
. For pixels with a low edge intensity
I, the comparatively strong camera noise leads to high uncertainty in
. We therefore discard pixels for which
I is lower than the threshold
. This also reduces the overall processing time.
Figure 8b shows the result of this step.
Next, we use a histogram to identify lintel edges from the individual edge pixels. The two axes of the histogram are the edge–gradient orientation
and the edge offset
. Here,
is the edge pixel position,
is the image center, and atan2 is the quadrant-aware arctangent. Note that
due to the definition of
in Equation (
1). We assign each pixel to the bin
, with
where
and
are the bin widths. All pixels of a straight edge would share the same
and
s, and thus the same histogram bin. Conversely, a bin with a high number of pixels indicates that an edge is present in the image.
Figure 8c demonstrates this through an example histogram.
The edge offset
s represents the distance between an edge and the image center
, as shown in
Figure 10. Using the calibrated camera model, we use a
that corresponds to the camera’s viewing direction. As our robot’s camera faces upwards,
also corresponds to a point directly above the robot. Given a map node and image, we want to reject lintels that are unlikely to intersect any map edge connected to this node. In our map graphs, few edges are longer than 30
. Thus, we wish to exclude edge pixels from passageways more than 30
away. We do this by limiting the edge-pixel histogram to
. As before, we assume a typical passageway of
. The geometry resulting from these assumptions is illustrated in
Figure 9b: here, the maximum distance between the camera and a lintel is 30
horizontally and 190
vertically. A lintel within this horizontal distance must intersect a cone above the camera with an opening angle of
. From this value of
, we then calculate
using the calibrated camera model.
Figure 8b demonstrates the effect of
: the colored edge pixels clearly intersect the dotted inner circle, which corresponds to
. Thus, the
s of these pixels is less than
, and they are added to the histogram. We also illustrate this in
Figure 10.
We can now detect a straight image edge from the the histogram: if is high, many edge pixels share a similar direction and offset, and we thus assume that an edge is present. Here, is the number of edge pixels in the histogram bin at index . Note that this method cannot differentiate between one uninterrupted edge or multiple ones with the same . On one hand, this makes the method robust against interrupted edges. Such interruptions could occur through occlusion, or low-contrast pixels with an I below . On the other hand, a large number of very short edges might cause a false passageway detection. For the purpose of this article, we are willing to accept this trade-off.
In practice, camera noise also causes noise in each pixel’s
and
s. As a result, pixels from a single, straight edge might be spread across neighboring histogram bins. This could reduce the value of
, causing a false negative detection. We therefore calculate three additional histograms, where
and/or
s are shifted by half a bin width: pixels are assigned to the bins
,
, or
, with
We then search for the maximum
across all four histograms. This reduces the influence of the noise, as long as its effect on
and
s is smaller than the bin sizes.
Finally, we calculate the passageway edge feature for the edge between the map nodes k and l. We could simply use the minimum of the two per-node passageway-detection results . Here, is the passageway-detection result for the map node with index k. However, this solution does not consider the direction of the passageway relative to the edge. A passageway running approximately parallel to an edge would still lead to a high E. This is undesirable, as the edge feature E should represent passageways that intersect the edge.
To solve this problem, we calculate the edge direction
from the nodes’ position estimates. We also calculate
, which is the value of
for the center of the histogram bin
. Recall that
is the direction of the edge-pixel gradient vector
. It is perpendicular to the direction of the passageway itself, as shown in
Figure 10. If
, the image edge from the bin
is approximately perpendicular to the map edge
. For any given edge direction
, we therefore only consider bins
with
From this, we arrive at the angle-dependent edge feature
with
Here,
is the entry
from the histogram
of the node
k.
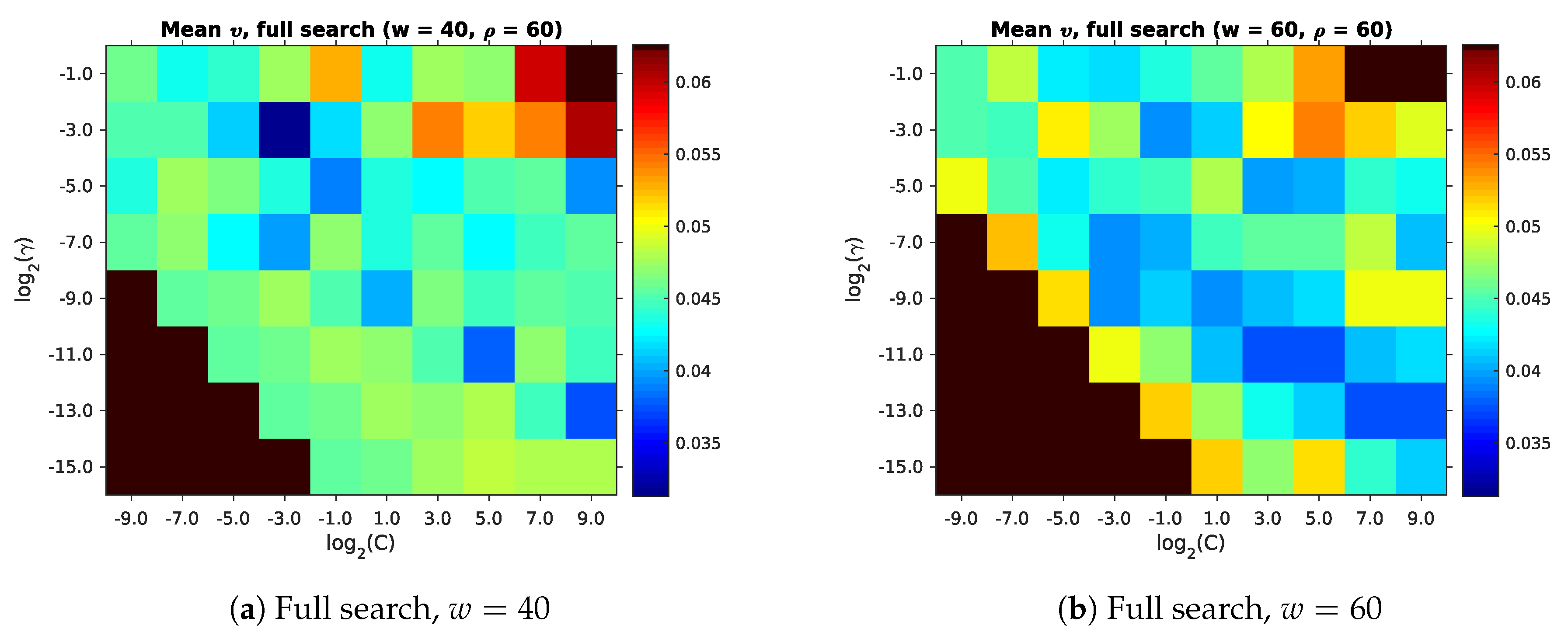
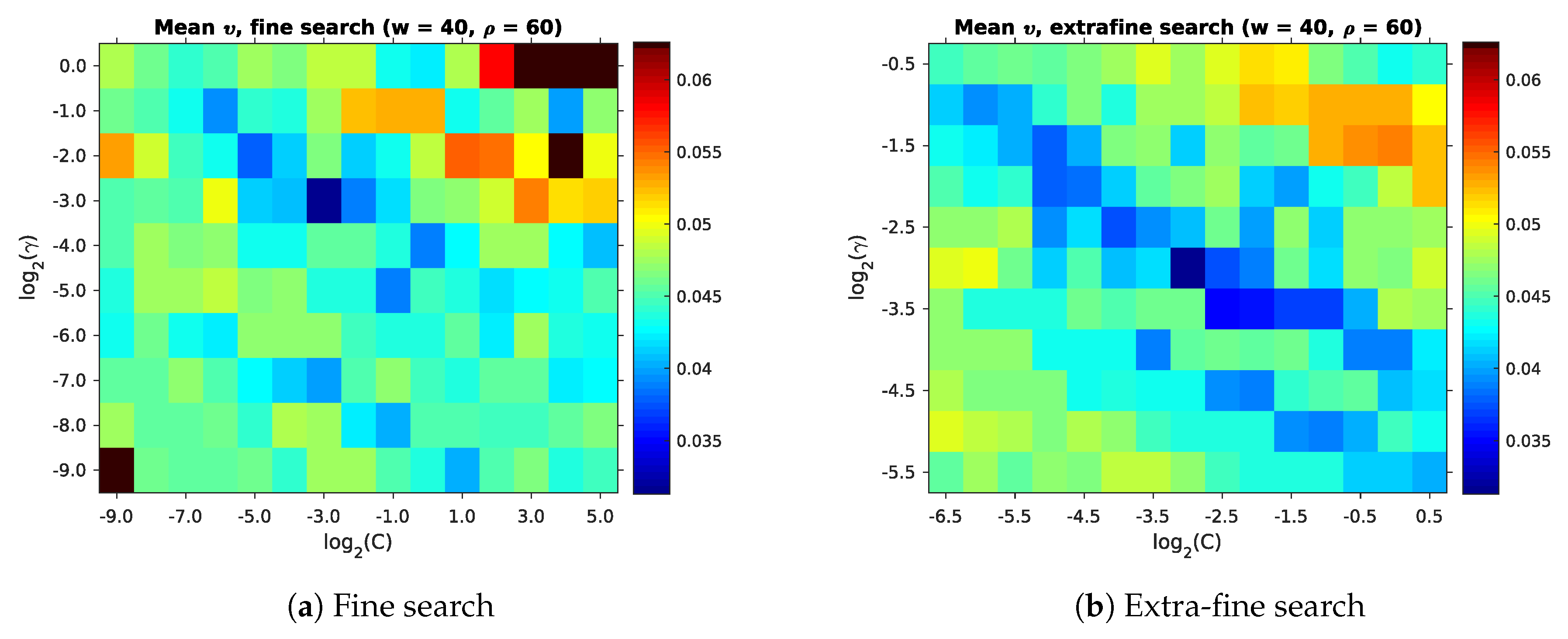
Finally, we need to choose the parameters
,
,
, and
. Unlike
and
, we cannot easily estimate these parameters from the environment. Instead, we perform a search across a number of reasonable values, as listed in
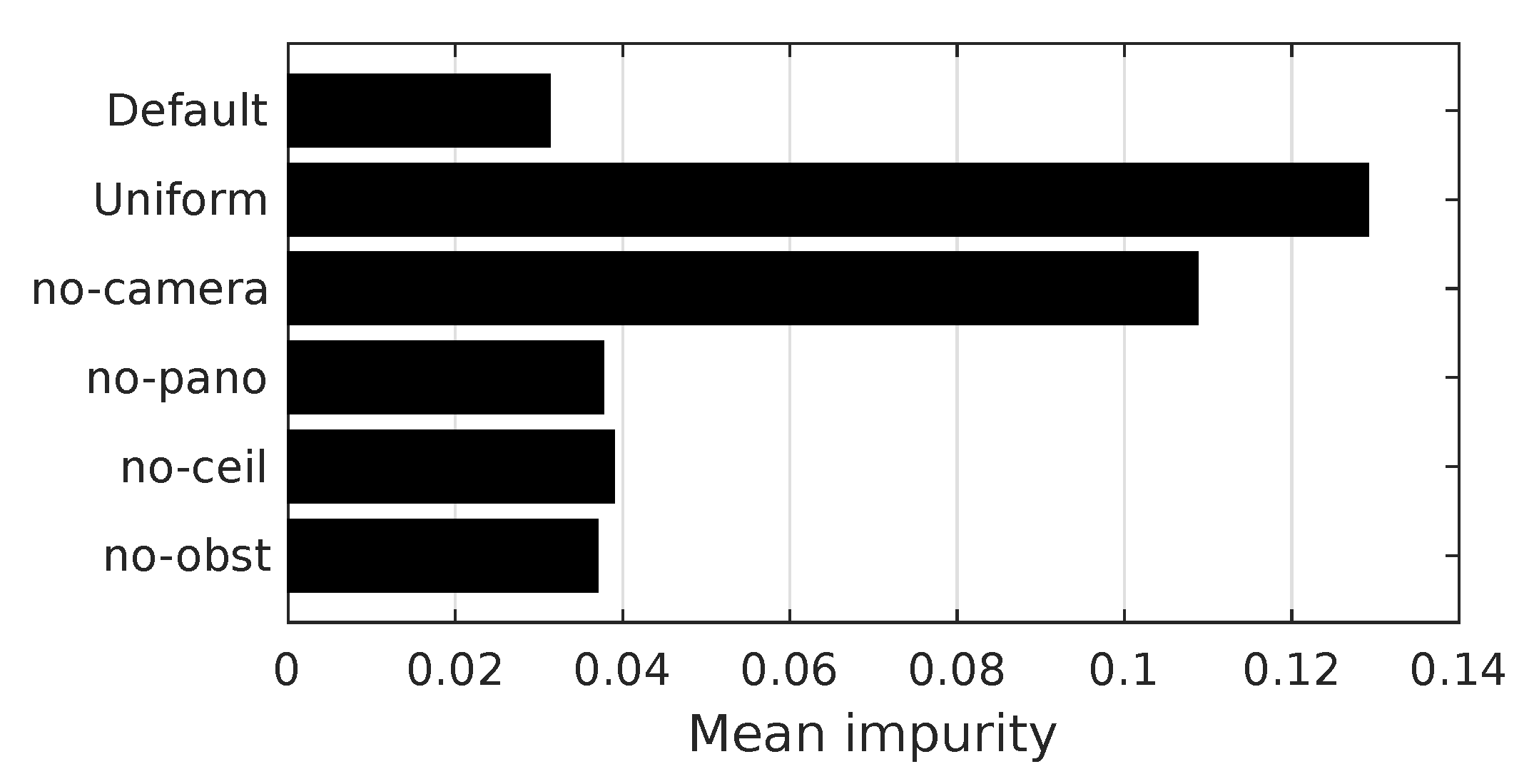
Table 2. Ideally, we could determine which values give the best overall room segmentation result for our maps. However, this is not practical, since this also depends on other parameters, as explained in
Section 2.3.3.
We thus optimize the passageway-detection parameters in isolation, using a criterion further discussed in
Section 2.2.5: first, we identify room–border edges by merely applying a threshold to the edge feature
. Second, we construct the Receiver Operating Characteristics (ROC) [
39] curve for this simple classifier. Finally, we select the
,
,
, and
, which maximize the area under the resulting ROC curve.
Table 2 contains the parameter combinations and actually selected values.
2.2.4. Image Distances
As previously mentioned, each node k in our map is associated with an image . is the panoramic fisheye image captured at the position of the node k. Each map edge connects two nodes k and l, and, thus, the two images and . We suspect that the image distance will tend to be greater if the edge crosses a room border. This could be due to occlusion and differences in the visual appearance between rooms. We therefore use as an image–distance edge feature.
We now select specific image distance functions
d, based on several criteria:
d should not depend on specific local image structures, such as corners or edges. Relying on such specific structures could lead to problems in environments where they are not present. Instead,
d should incorporate all pixels in the input images. This is a major difference compared to the visual passageway detection described in
Section 2.2.3.
Our robot uses panoramic low-resolution images for navigation and mapping. These images are “unfolded” through reprojection, as described in [
40]. Examples of unfolded images for the maps from our experiments are shown in Figure 19 and Figure 21. All pixels from the same image column correspond to the same azimuth in robot coordinates. Similarly, all pixels of the same row have the same elevation angle. In this work, we use unfolded images with a resolution of
pixels. These panoramic images are cyclic in azimuth and include elevation angles from 0
to 75
. To avoid aliasing, we apply an averaging filter with a
mask before unfolding. This blurs the unfolded image, lowering the effective resolution. Note that our robot’s camera captures higher-resolution images, as used for the visual passageway detection in
Section 2.2.3. However, in this work, we calculate
d from the low-resolution, unfolded images
and
. The resulting edge feature would therefore still be suitable for a robot with only a low-resolution camera. The lower resolution also speeds up computations.
The images and are usually recorded under different robot orientations. However, the image–distance edge feature should be independent of the robot orientation. As a simple solution, we require that the distance function d should be invariant under rotation. Given these requirements, we evaluate two different distance functions and . Each one will individually be used as an edge feature.
is based on the visual compass introduced by Zeil et al. [
41]. To determine
, we calculate the Euclidean image distance
for the relative azimuthal image-orientation offset
. Here,
refers to the intensity of the pixel
in the image
, while
w is the width of the unfolded images.
is then the lowest image distance across all possible
, with
The second distance function
is based on the image signatures introduced by Menegatti et al. [
42] and expanded in [
43];
is the Euclidean distance between the image signatures
of the two images
and
. To calculate the signature
, the
unfolded image
is split into eight equally-sized horizontal segments. A segment consists of
image rows and spans
of elevation. We then average the rows of each segment, resulting in eight vectors of 288 entries. Next, we calculate the first twelve Fourier coefficients for each of these eight vectors. Finally,
is a vector containing the absolute values of all
Fourier coefficients. Using the absolute values eliminates the phase information from the Fourier coefficients. This makes the signatures invariant to the image orientation.

































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}