The Role of Visibility in Pursuit/Evasion Games

Abstract
:1. Introduction
2. Preliminaries
2.1. Notation
- We use the following notations for sets: denotes ; denotes ; denotes ; ; denotes the cardinality of A (i.e., the number of its elements).
- A graph consists of a node set V and an edge set E, where every has the form . In other words, we are concerned with finite, undirected, simple graphs; in addition we will always assume that G is connected and that G contains n nodes: . Furthermore, we will assume, without loss of generality, that the node set is . We let . We also define by (it is the set of “diagonal” node pairs).
- A directed graph (digraph) consists of a node set V and an edge set E, where every has the form . In other words, the edges of a digraph are ordered pairs.
- In graphs, the (open) neighborhood of some is ; in digraphs it is . In both cases, the closed neighborhood of is .
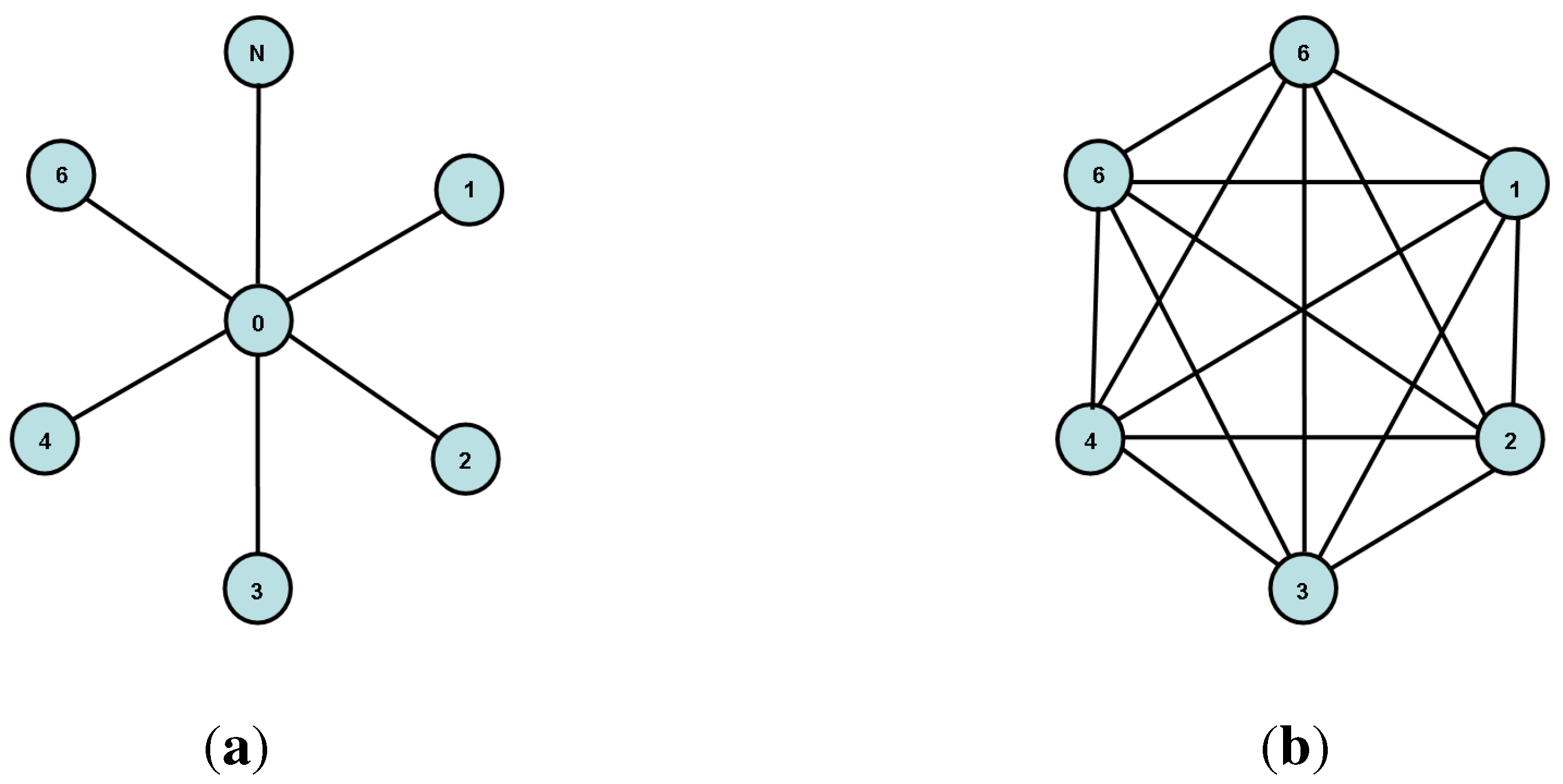
- Given a graph , its line graph is defined as follows: the node set is , i.e., it has one node for every edge of G; the edge set is defined by having the nodes connected by an edge if and only if (i.e., if the original edges of G are adjacent).
- We will write if and only if . Note that in this asymptotic notation n denotes the parameter with respect to which asymptotics are considered. So in later sections we will write , etc.
2.2. The CR Game Family

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Adversarial Visible Robber | av-CR |
| Adversarial Invisible Robber | ai-CR |
| Drunk Visible Robber | dv-CR |
| Drunk Invisible Robber | di-CR |
3. Cop Number and Capture Time
3.1. The Node av-CR Game
- Nodes of the form correspond to positions (in the original CR game) with the cops located at , the robber at and player being next to move.
- There is single node which corresponds to the starting position of the game: neither the cops nor the robber have been placed on G; it is C’s turn to move (recall that λ denotes the empty sequence).
- Finally, there exist n nodes of the form : the cops have just been placed in the graph (at positions ) but the robber has not been placed yet; it is R’s turn to move.
3.2. The Node dv-CR Game
3.3. The Node ai-CR Game
3.4. The Node di-CR Game
3.5. The Edge CR Games
4. The Cost of Visibility
4.1. Cost of Visibility in the Node CR Games
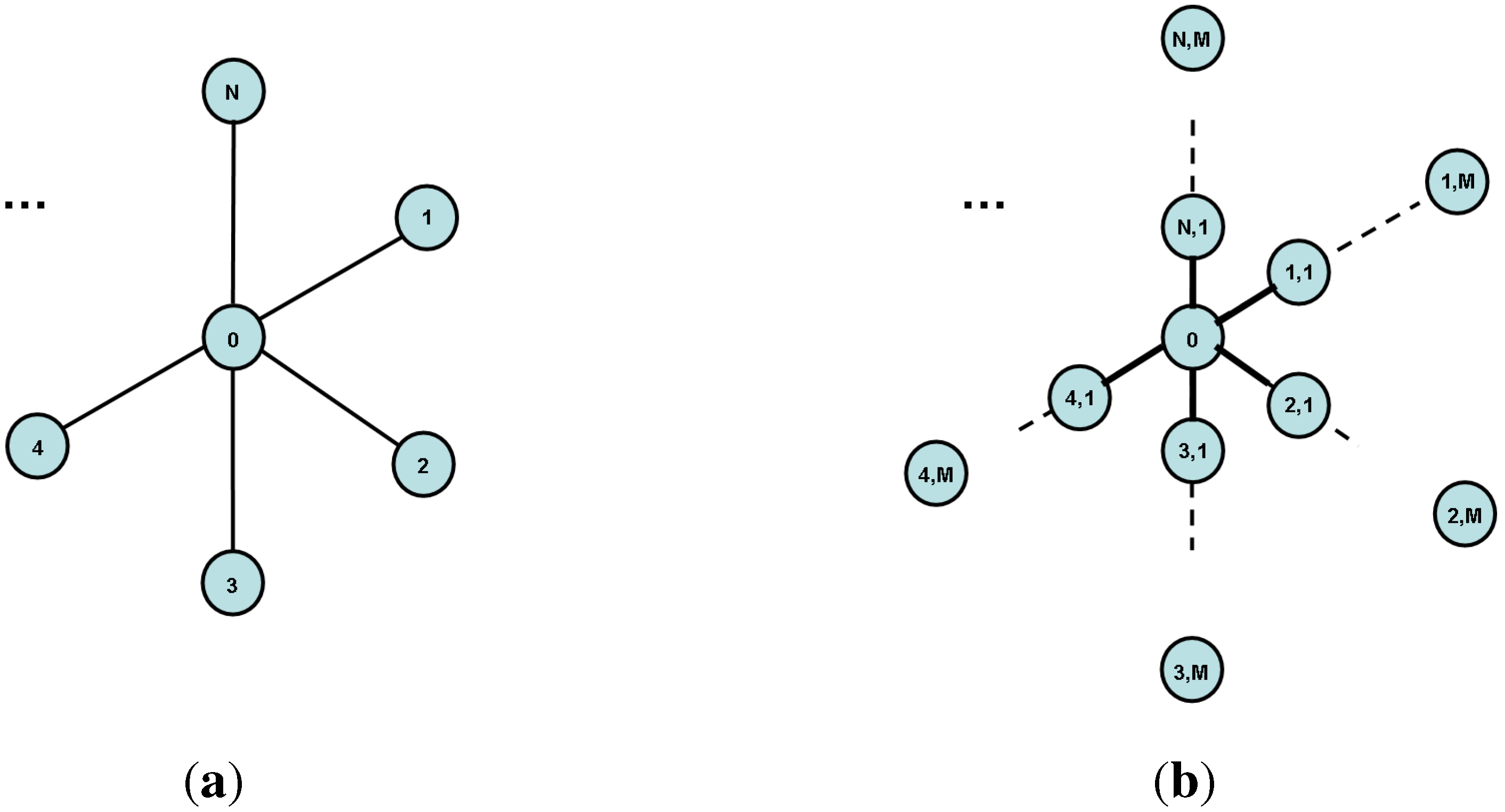
- With probability , the robber starts on the same ray as the cop but farther away from the center. Conditioning on this event, the expected capture time is .
- With probability , the robber starts on the same ray as the cop but closer to the center. Conditioning on this event, the expected capture time is .
- With probability , the robber starts on different ray than the cop. Conditioning on this event, the expected capture time is .
- With probability , the robber starts on the same ray as the cop. Conditioning on this event, the expected capture time is .
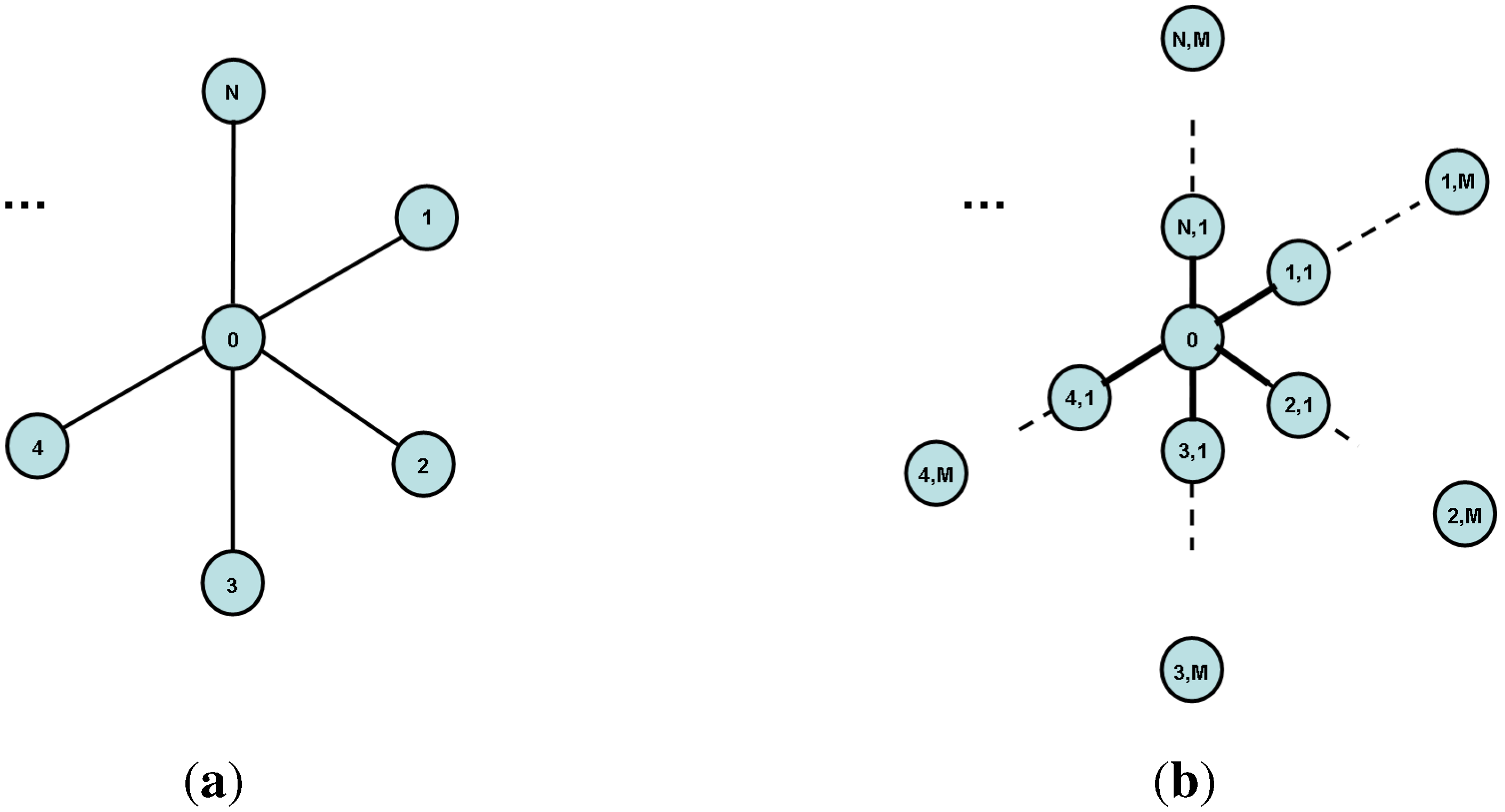
- With probability , the robber starts on the -th ray visited by the cop. Conditioning on this event, the expected capture time is . ( steps are required to move from the end of the first ray to the center, steps are `wasted’ to check rays, and steps are needed to catch the robber on the -th ray, on expectation.)
4.2. Cost of Visibility in the Edge CR Games
5. Algorithms for COV Computation
5.1. Algorithms for Visible Robbers
5.1.1. Algorithm for Adversarial Robber
- , the optimal game duration when the cop/robber configuration is and it is C’s turn to play;
- , the optimal game duration when the cop/robber configuration is and it is R’s turn to play.
| Algorithm 1: Cops Against Adversarial Robber (CAAR) |
| Input: |
| 01 For All |
| 02 |
| 03 |
| 04 EndFor |
| 05 For All |
| 06 |
| 07 |
| 08 EndFor |
| 09 |
| 10 While |
| 11 For All |
| 12 |
| 13 |
| 14 EndFor |
| 15 If And |
| 16 Break |
| 17 EndIf |
| 18 |
| 19 EndWhile |
| 20 |
| 21 |
| Output: C, R |
5.1.2. Algorithm for Drunk Robber
| Algorithm 2: Cops Against Drunk Robber (CADR) |
| Input: , ε |
| 01 For All |
| 02 |
| 03 EndFor |
| 04 For All |
| 05 |
| 06 EndFor |
| 07 |
| 08 While |
| 09 For All |
| 10 |
| 11 EndFor |
| 12 If |
| 13 Break |
| 14 EndIf |
| 15 |
| 16 EndWhile |
| 17 |
| Output: C |
5.2. Algorithms for Invisible Robbers
5.2.1. Algorithms for Adversarial Robber
5.2.2. Algorithm for Drunk Robber
| Algorithm 3: Pruned Cop Search (PCS) |
| Input: , , , ε |
| 01 |
| 02 , , |
| 03 |
| 04 |
| 05 While |
| 06 |
| 07 For All |
| 08 , , |
| 09 For All |
| 10 |
| 11 |
| 12 |
| 13 , , |
| 14 |
| 15 EndFor |
| 16 EndFor |
| 17 |
| 18 |
| 19 If |
| 20 Break |
| 21 Else |
| 22 |
| 23 |
| 24 EndIf |
| 25 EndWhile |
| Output: , . |
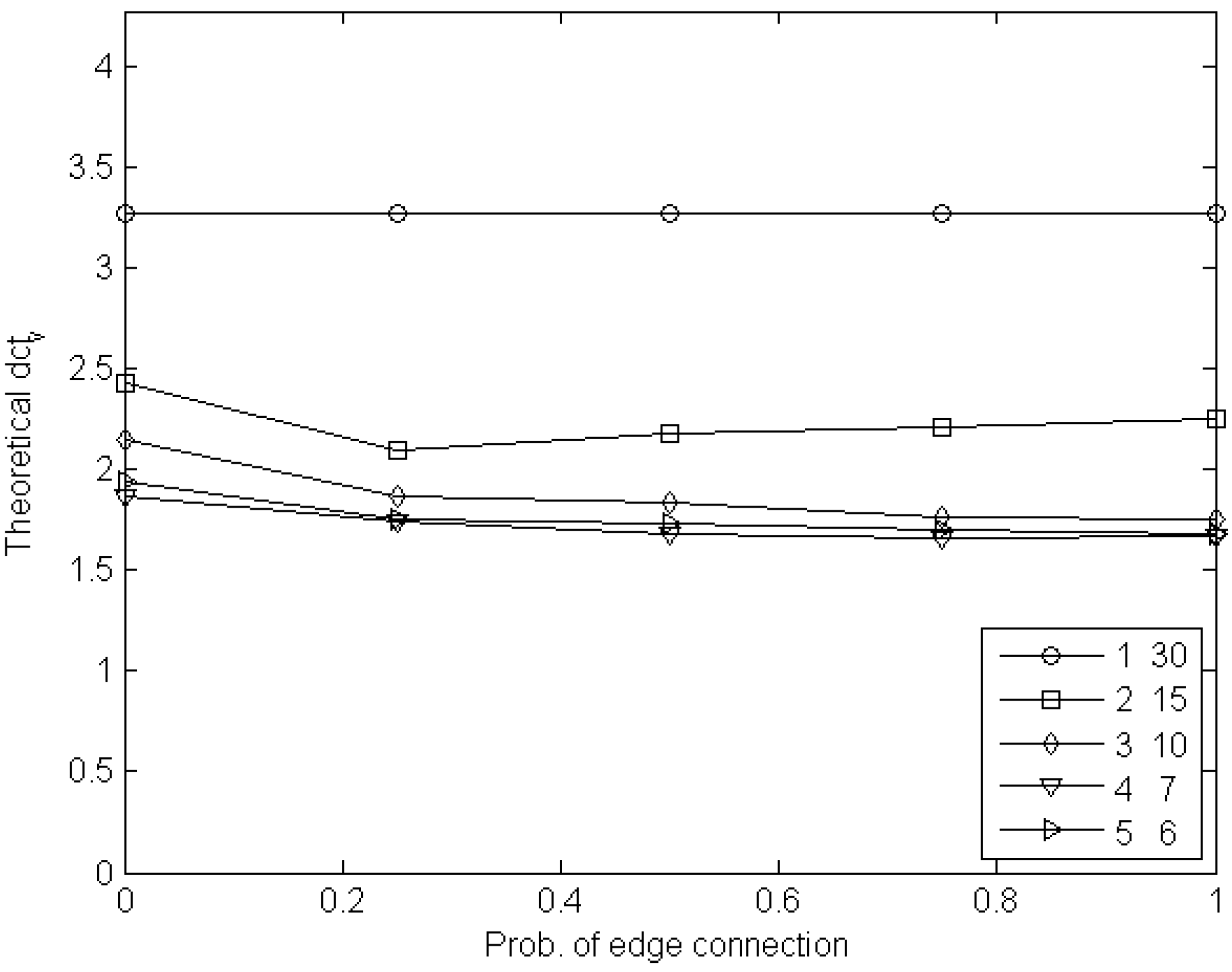
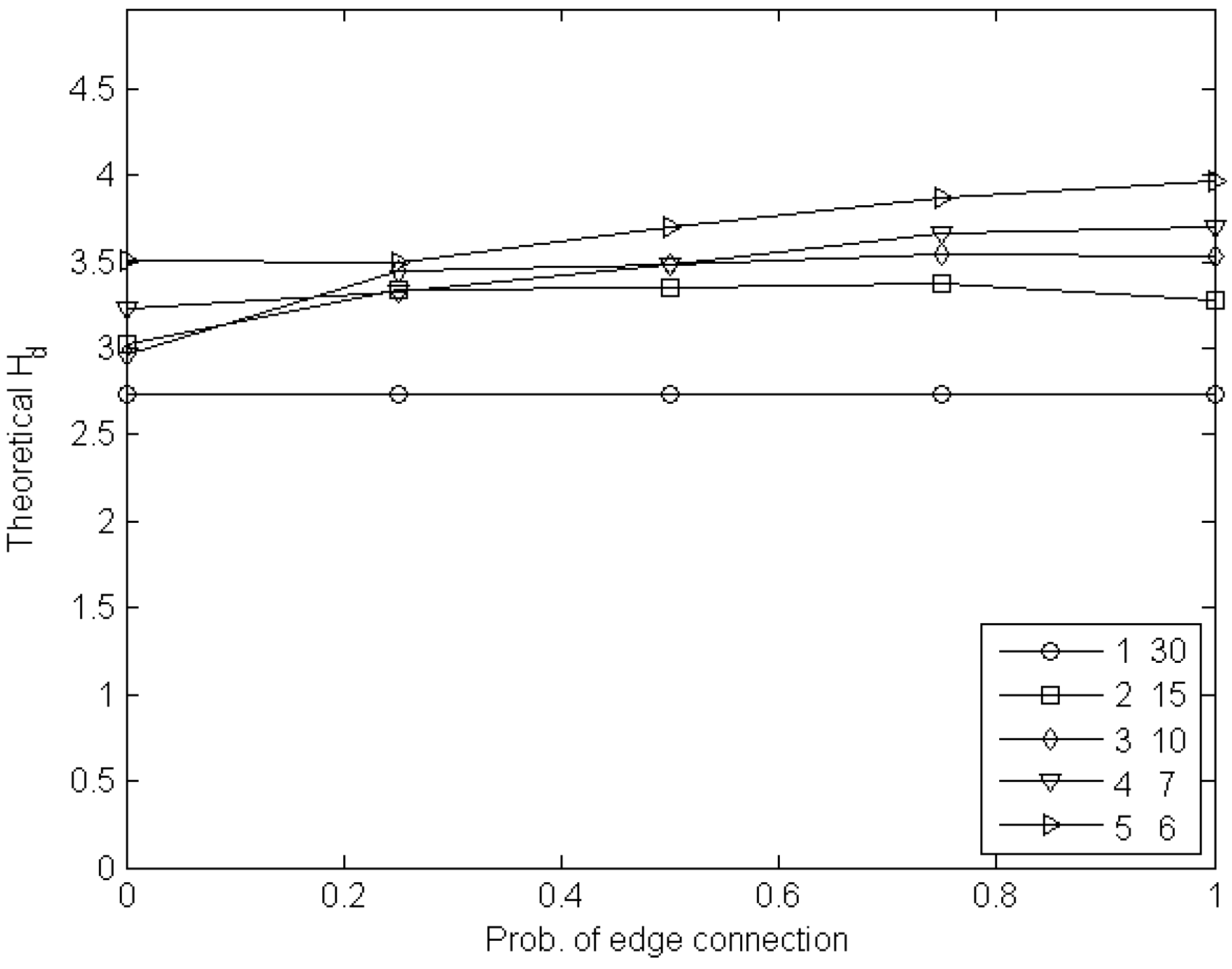
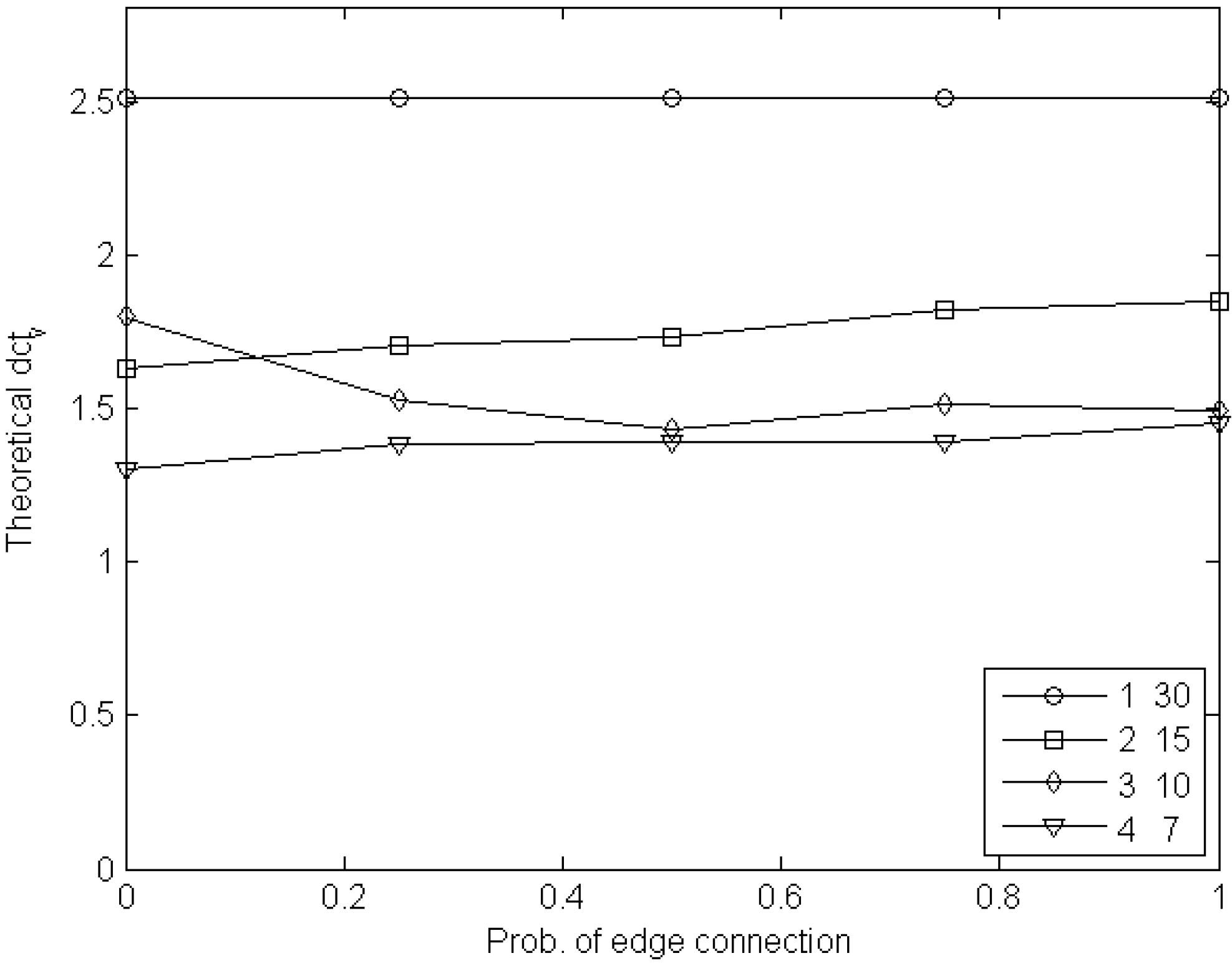
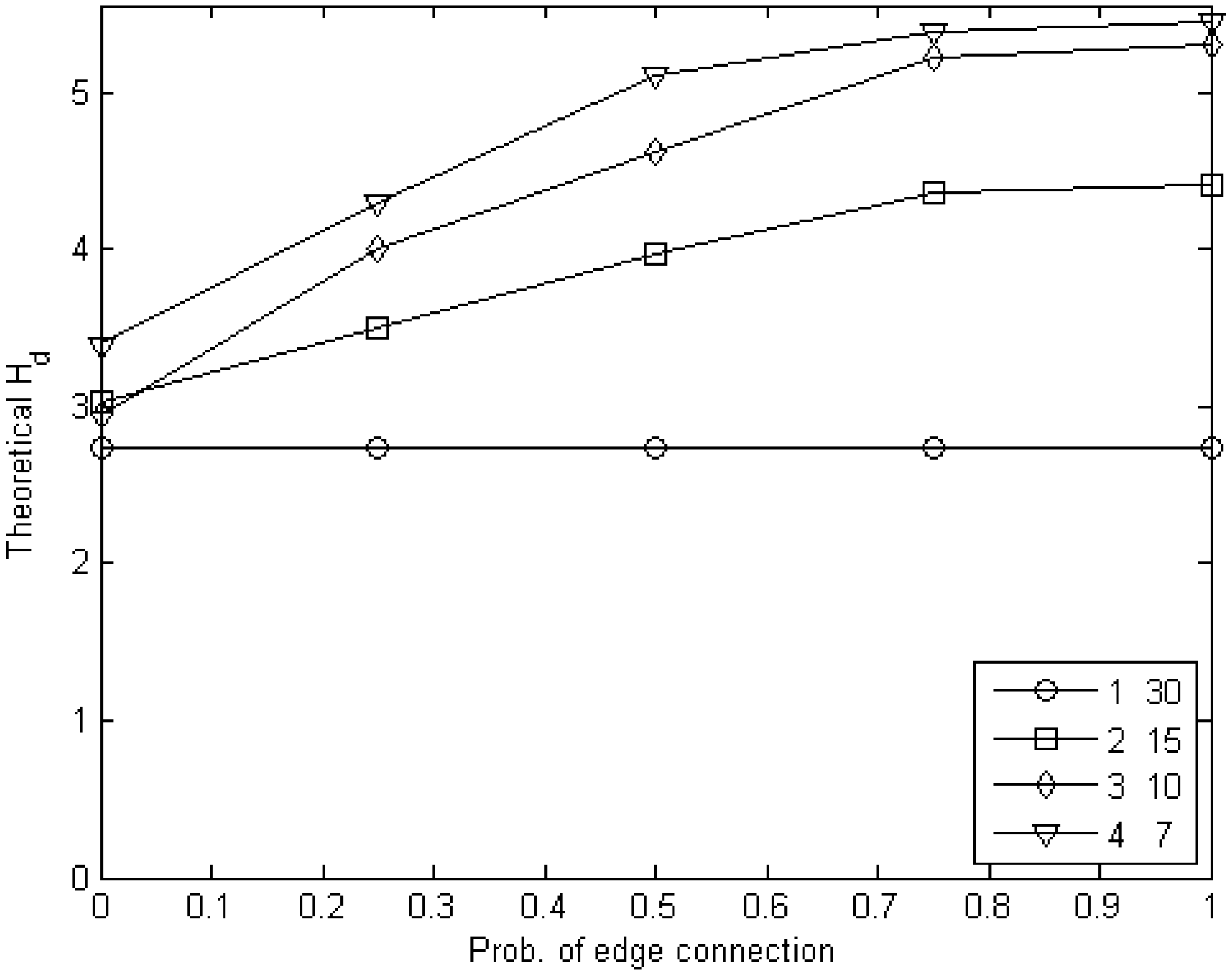
6. Experimental Estimation of the Cost of Visibility
6.1. Experiments with Node Games
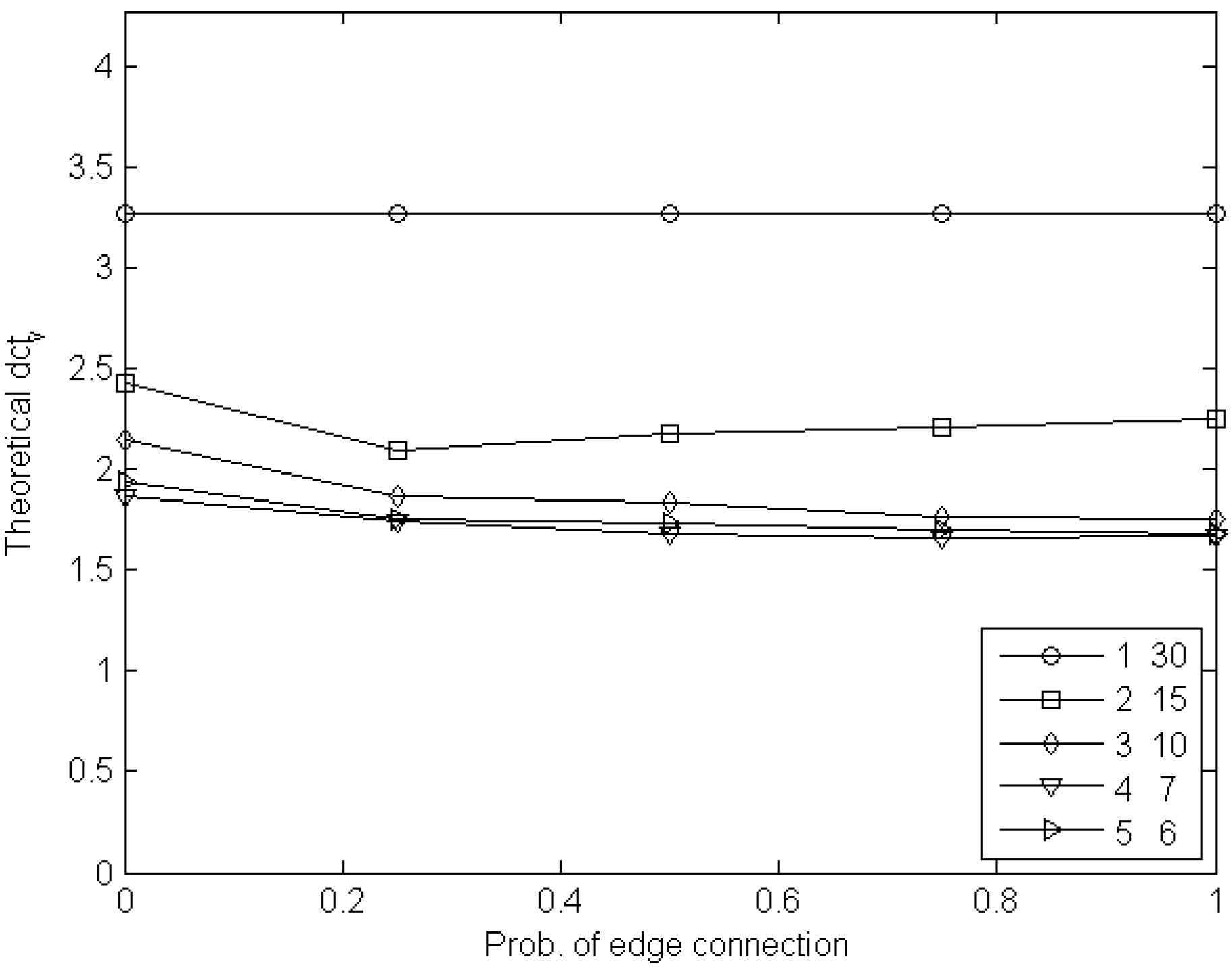
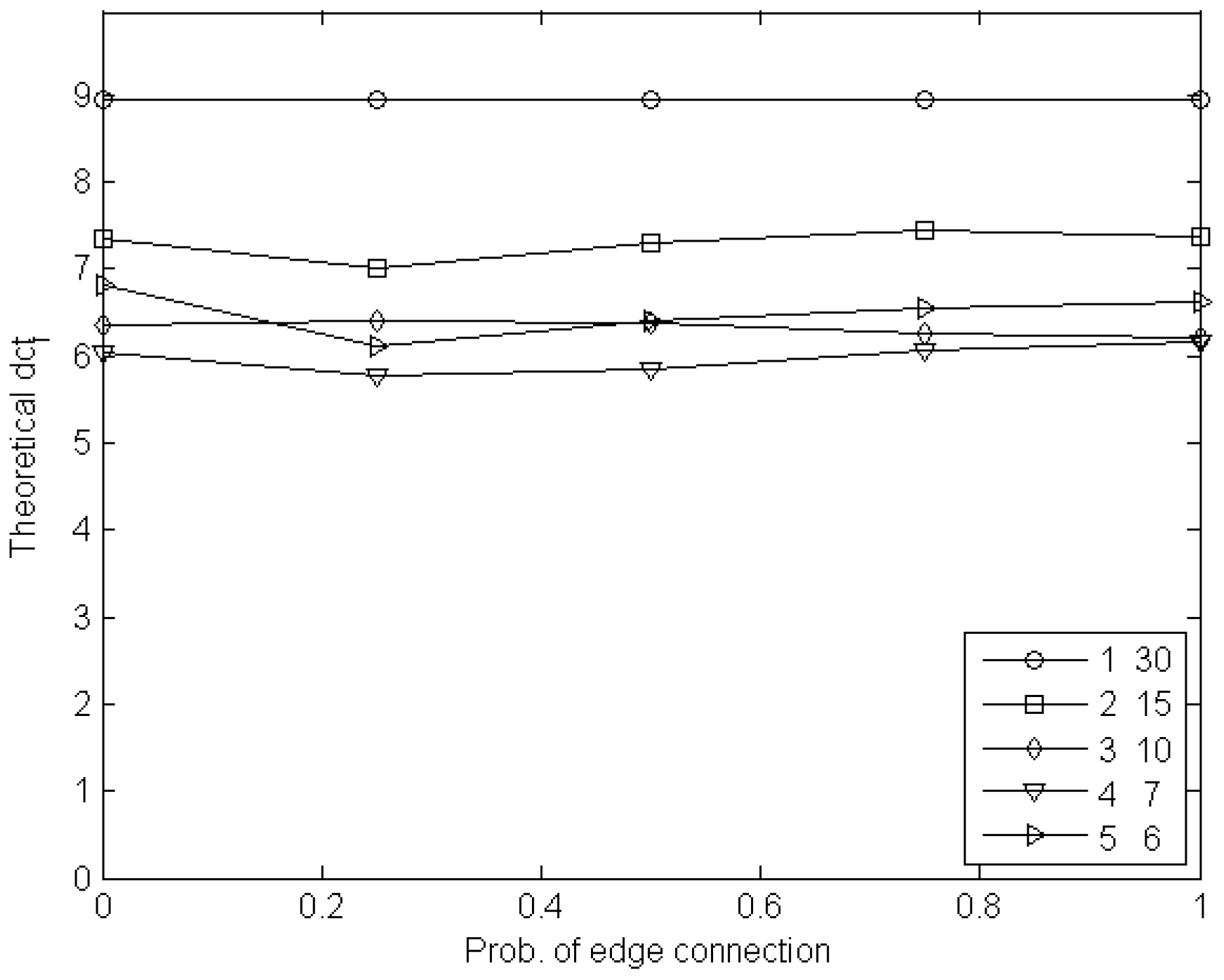
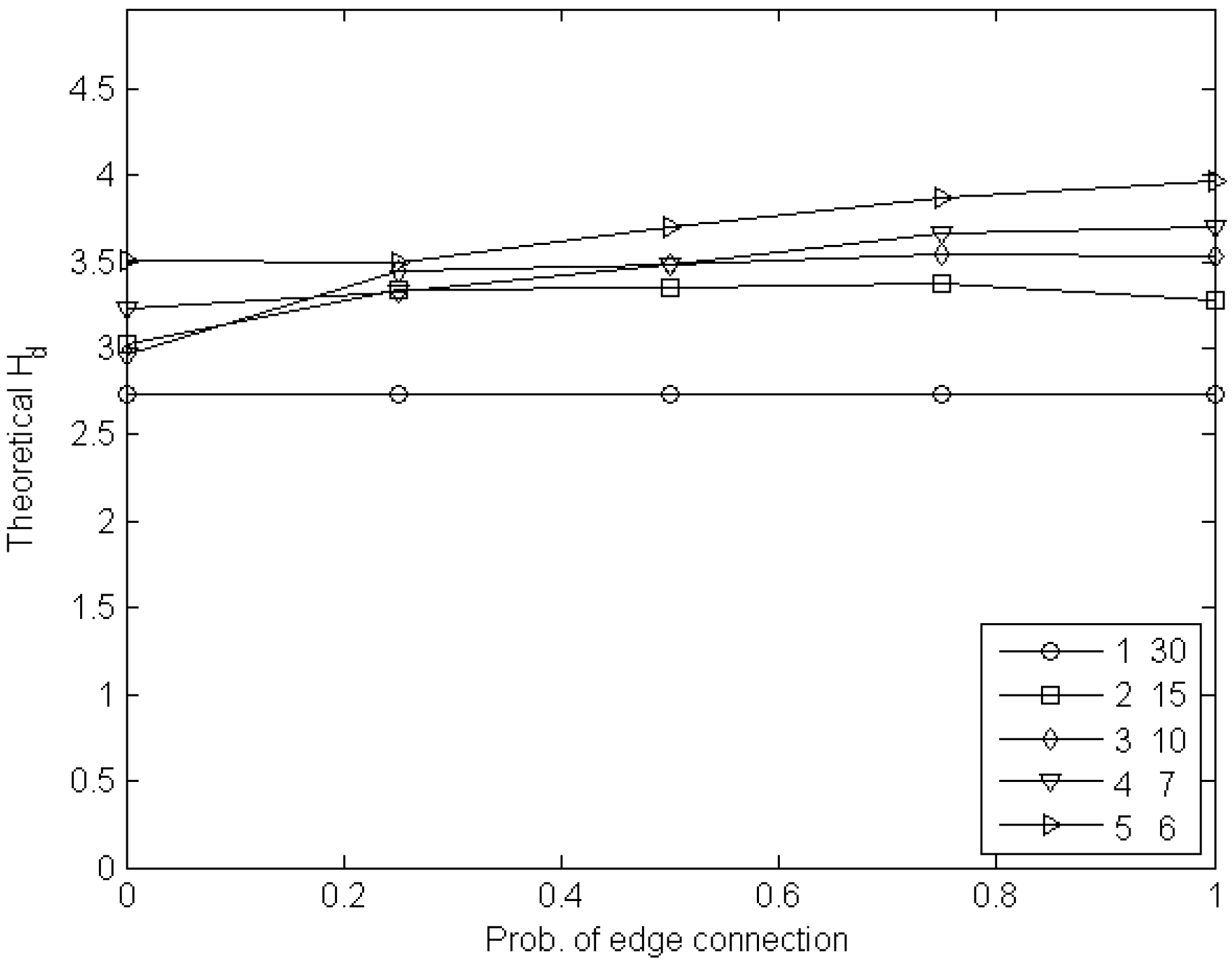
6.2. Experiments with Edge Games
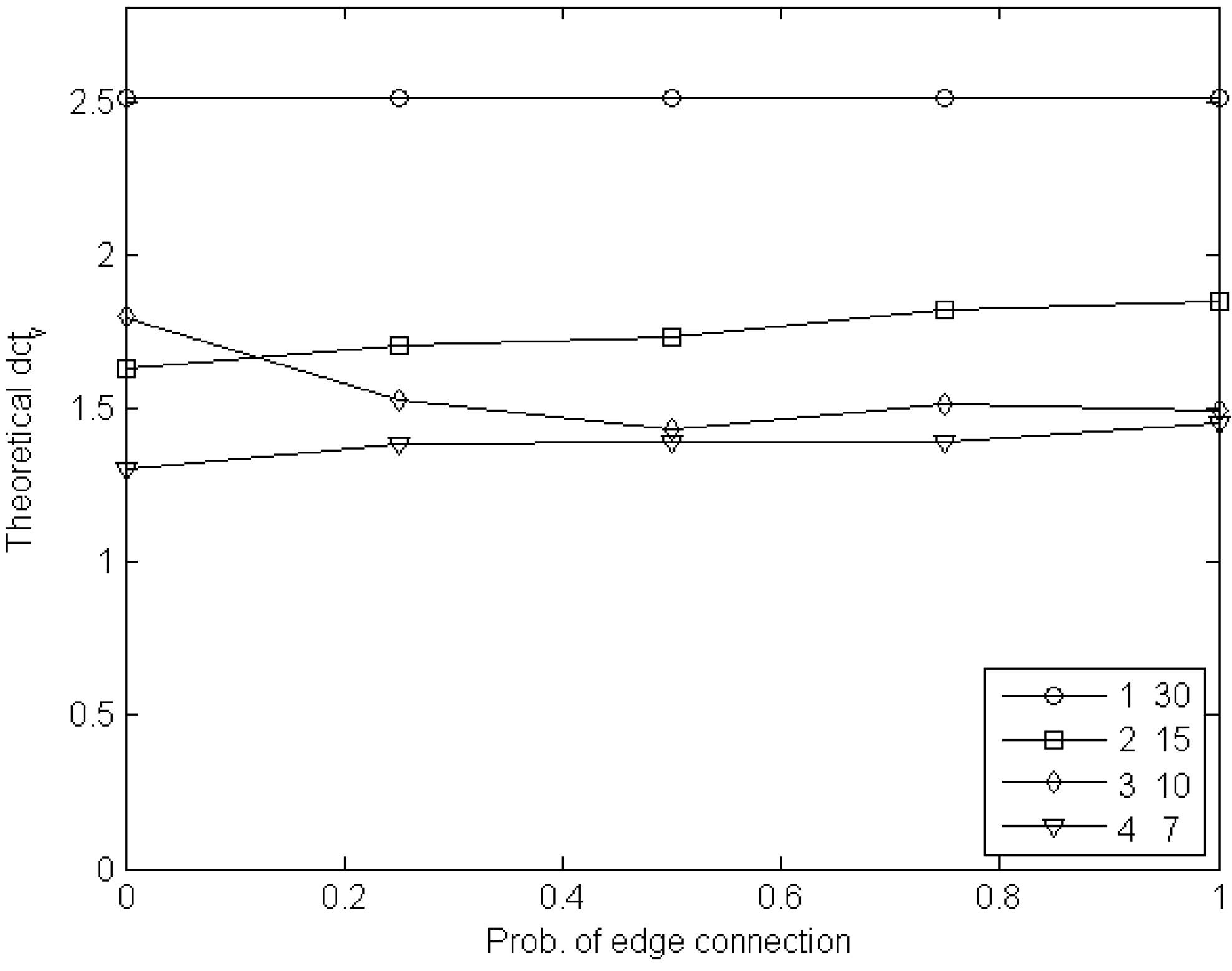
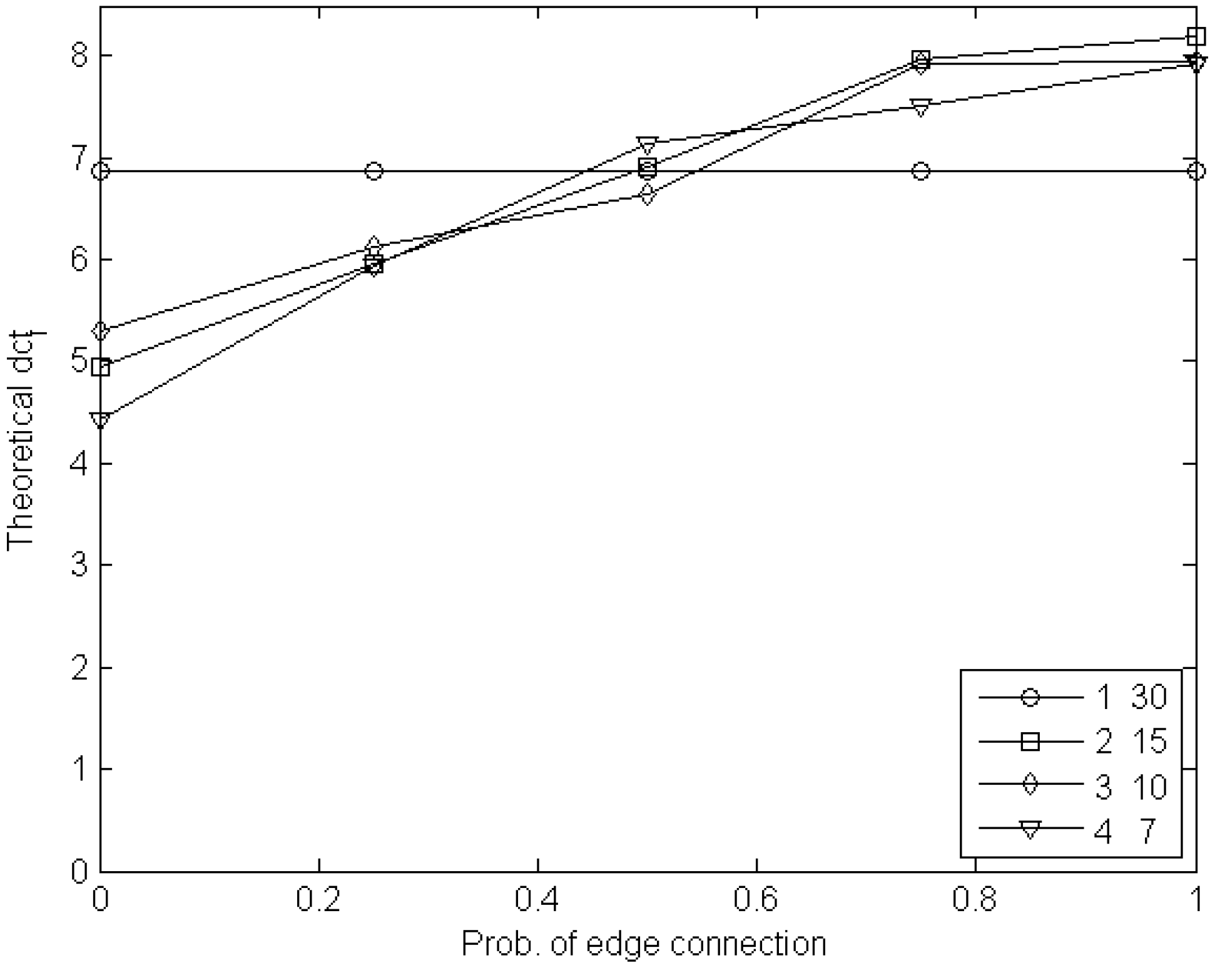
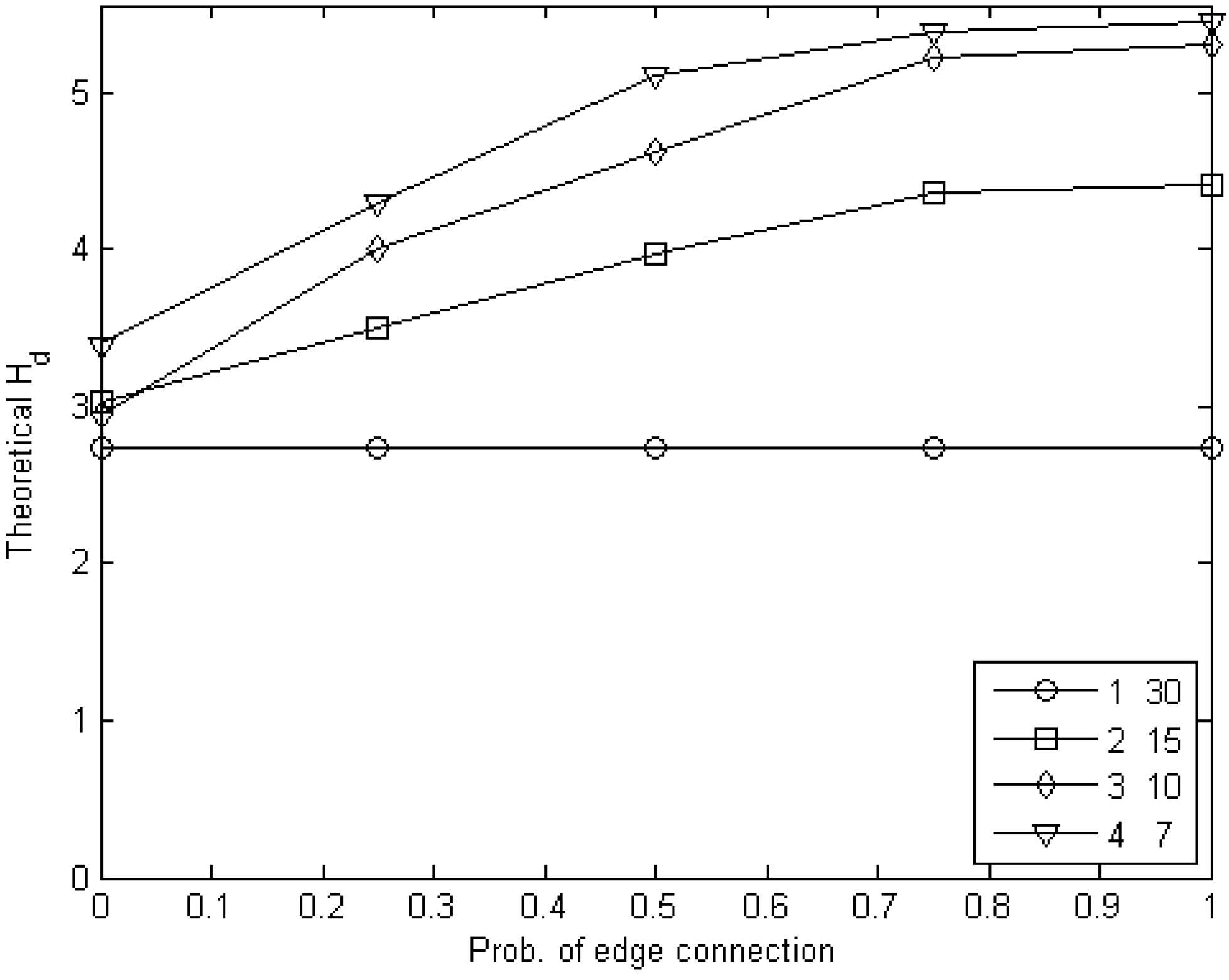
7. Conclusions
Author Contributions
Conflicts of Interest
References
- Chung, T.H.; Hollinger, G.A.; Isler, V. Search and pursuit-evasion in mobile robotics. Auton. Robots 2011, 31, 299–316. [Google Scholar] [CrossRef]
- Isler, V.; Karnad, N. The role of information in the cop-robber game. Theor. Comput. Sci. 2008, 399, 179–190. [Google Scholar] [CrossRef]
- Alspach, B. Searching and sweeping graphs: A brief survey. Le Matematiche 2006, 59, 5–37. [Google Scholar]
- Bonato, A.; Nowakowski, R. The Game of Cops and Robbers on Graphs; AMS: Providence, RI, USA, 2011. [Google Scholar]
- Fomin, F.V.; Thilikos, D.M. An annotated bibliography on guaranteed graph searching. Theor. Comput. Sci. 2008, 399, 236–245. [Google Scholar] [CrossRef]
- Nowakowski, R.; Winkler, P. Vertex-to-vertex pursuit in a graph. Discret. Math. 1983, 43, 235–239. [Google Scholar] [CrossRef]
- Dereniowski, D.; Dyer, D.; Tifenbach, R.M.; Yang, B. Zero-visibility cops and robber game on a graph. In Frontiers in Algorithmics and Algorithmic Aspects in Information and Management; Springer: Berlin, Germany, 2013; pp. 175–186. [Google Scholar]
- Isler, V.; Kannan, S.; Khanna, S. Randomized pursuit-evasion with local visibility. SIAM J. Discret. Math. 2007, 20, 26–41. [Google Scholar] [CrossRef]
- Kehagias, A.; Mitsche, D.; Prałat, P. Cops and invisible robbers: The cost of drunkenness. Theor. Comput. Sci. 2013, 481, 100–120. [Google Scholar] [CrossRef]
- Adler, M.; Racke, H.; Sivadasan, N.; Sohler, C.; Vocking, B. Randomized pursuit-evasion in graphs. Lect. Notes Comput. Sci. 2002, 2380, 901–912. [Google Scholar]
- Vieira, M.; Govindan, R.; Sukhatme, G.S. Scalable and practical pursuit-evasion. In Proceedings of the 2009 IEEE Second International Conference on Robot Communication and Coordination (ROBOCOMM’09), Odense, Denmark, 31 March–2 April 2009; pp. 1–6.
- Gerkey, B.; Thrun, S.; Gordon, G. Parallel stochastic hill-climbing with small teams. In Multi-Robot Systems. From Swarms to Intelligent Automata; Springer: Dordrecht, Netherlands, 2005; Volume III, pp. 65–77. [Google Scholar]
- Hollinger, G.; Singh, S.; Djugash, J.; Kehagias, A. Efficient multi-robot search for a moving target. Int. J. Robot. Res. 2009, 28, 201–219. [Google Scholar] [CrossRef]
- Hollinger, G.; Singh, S.; Kehagias, A. Improving the efficiency of clearing with multi-agent teams. Int. J. Robot. Res. 2010, 29, 1088–1105. [Google Scholar] [CrossRef]
- Lau, H.; Huang, S.; Dissanayake, G. Probabilistic search for a moving target in an indoor environment. In Proceedings of the 2006 IEEE/RSJ International Conference on Intelligent Robots and Systems, Beijing, China, 9–15 October 2006; pp. 3393–3398.
- Sarmiento, A.; Murrieta, R.; Hutchinson, S.A. An efficient strategy for rapidly finding an object in a polygonal world. In Proceedings of the 2003 IEEE/RSJ International Conference on Intelligent Robots and Systems(IROS 2003), Las Vegas, NV, USA, 27–31 October 2003; Volume 2, pp. 1153–1158.
- Hsu, D.; Lee, W.S.; Rong, N. A point-based POMDP planner for target tracking. In Proceedings of the 2008 IEEE International Conference on Robotics and Automation (ICRA 2008), Pasadena, CA, USA, 19–23 May 2008; pp. 2644–2650.
- Kurniawati, H.; Hsu, D.; Lee, W.S. Sarsop: Efficient point-based POMDP planning by approximating optimally reachable belief spaces. In Proceedings of Robotics: Science and Systems, Zurich, Switzerland, 25–28 June 2008.
- Pineau, J.; Gordon, G. POMDP planning for robust robot control. Robot. Res. 2007, 28, 69–82. [Google Scholar]
- Smith, T.; Simmons, R. Heuristic search value iteration for POMDPs. In Proceedings of the 20th Conference on Uncertainty in Artificial Intelligence, Banff, Canada, 7–11 July 2004; pp. 520–527.
- Spaan, M.T.J.; Vlassis, N. Perseus: Randomized point-based value iteration for POMDPs. J. Artif. Intel. Res. 2005, 24, 195–220. [Google Scholar]
- Hauskrecht, M. Value-function approximations for partially observable Markov decision processes. J. Artif. Intel. Res. 2000, 13, 33–94. [Google Scholar]
- Littman, M.L.; Cassandra, A.R.; Kaelbling, L.P. Efficient Dynamic-Programming Updates in Partially Observable Markov Decision Processes; Technical Report CS-95-19; Brown University: Providence, RI, USA, 1996. [Google Scholar]
- Monahan, G.E. A survey of partially observable Markov decision processes: Theory, models, and algorithms. Manag. Sci. 1982, 28, 1–16. [Google Scholar] [CrossRef]
- Canepa, D.; Potop-Butucaru, M.G. Stabilizing Flocking Via Leader Election in Robot Networks. In Proceedings of the 9th International Symposium on Stabilization, Safety, and Security of Distributed Systems (SSS 2007), Paris, France, 14–16 November 2007; pp. 52–66.
- Gervasi, V.; Prencipe, G. Robotic Cops: The Intruder Problem. In Proceedings of the 2003 IEEE Conference on Systems, Man and Cybernetics (SMC 2003), Washington, DC, USA, 5–8 October 2003; pp. 2284–2289.
- Prencipe, G. The effect of synchronicity on the behavior of autonomous mobile robots. Theory Comput. Syst. 2005, 38, 539–558. [Google Scholar] [CrossRef]
- Dudek, A.; Gordinowicz, P.; Pralat, P. Cops and robbers playing on edges. J. Comb. 2013, 5, 131–153. [Google Scholar] [CrossRef]
- Kuhn, H.W. Extensive games. Proc. Natl. Acad. Sci. USA 1950, 36, 570–576. [Google Scholar] [CrossRef] [PubMed]
- Bonato, A.Y.; Macgillivray, G. A General Framework for Discrete-Time Pursuit Games, preprint.
- Hahn, G.; MacGillivray, G. A note on k-cop, l-robber games on graphs. Discret. Math. 2006, 306, 2492–2497. [Google Scholar] [CrossRef]
- Berwanger, D. Graph Games with Perfect Information, preprint.
- Mazala, R. Infinite games. Automata, Logics and Infinite Games 2002, 2500, 23–38. [Google Scholar]
- Aigner, M.; Fromme, M. A game of cops and robbers. Discret. App. Math. 1984, 8, 1–12. [Google Scholar] [CrossRef]
- Osborne, M.J. A Course in Game Theory; MIT Press: Cambridge, MA, USA, 1994. [Google Scholar]
- Puterman, M.L. Markov Decision Processes: Discrete Stochastic Dynamic Programming; John Wiley & Sons, Inc.: New York, NY, USA, 1994. [Google Scholar]
- Kehagias, A.; Prałat, P. Some remarks on cops and drunk robbers. Theor. Comput. Sci. 2012, 463, 133–147. [Google Scholar] [CrossRef]
- De la Barrière, R.P. Optimal Control Theory: A Course in Automatic Control Theory; Dover Pubns: New York, NY, USA, 1980. [Google Scholar]
- Eaton, J.H.; Zadeh, L.A. Optimal pursuit strategies in discrete-state probabilistic systems. Trans. ASME Ser. D J. Basic Eng. 1962, 84, 23–29. [Google Scholar] [CrossRef]
- Howard, R.A. Dynamic Probabilistic Systems, Volume Ii: Semi-Markov and Decision Processes; Dover Publications: New York, NY, USA, 1971. [Google Scholar]
- Raghavan, T.E.S.; Filar, J.A. Algorithms for stochastic games—A survey. Math. Methods Oper. Res. 1991, 35, 437–472. [Google Scholar] [CrossRef]
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kehagias, A.; Mitsche, D.; Prałat, P. The Role of Visibility in Pursuit/Evasion Games. Robotics 2014, 3, 371-399. https://doi.org/10.3390/robotics3040371
Kehagias A, Mitsche D, Prałat P. The Role of Visibility in Pursuit/Evasion Games. Robotics. 2014; 3(4):371-399. https://doi.org/10.3390/robotics3040371
Chicago/Turabian StyleKehagias, Athanasios, Dieter Mitsche, and Paweł Prałat. 2014. "The Role of Visibility in Pursuit/Evasion Games" Robotics 3, no. 4: 371-399. https://doi.org/10.3390/robotics3040371
APA StyleKehagias, A., Mitsche, D., & Prałat, P. (2014). The Role of Visibility in Pursuit/Evasion Games. Robotics, 3(4), 371-399. https://doi.org/10.3390/robotics3040371