
MLLM-Search: A Zero-Shot Approach to Finding People Using Multimodal Large Language Models



Abstract
1. Introduction
2. Related Works
2.1. Person Search by Robots
2.1.1. Lookahead Planners
2.1.2. MDP-Based Planners
2.1.3. Graph-Based Planners
2.2. Visual Prompting Methods
2.3. Summary of Limitations
3. Person Search Problem Under Event-Driven Scenarios with Varying User Schedules
Problem Definition
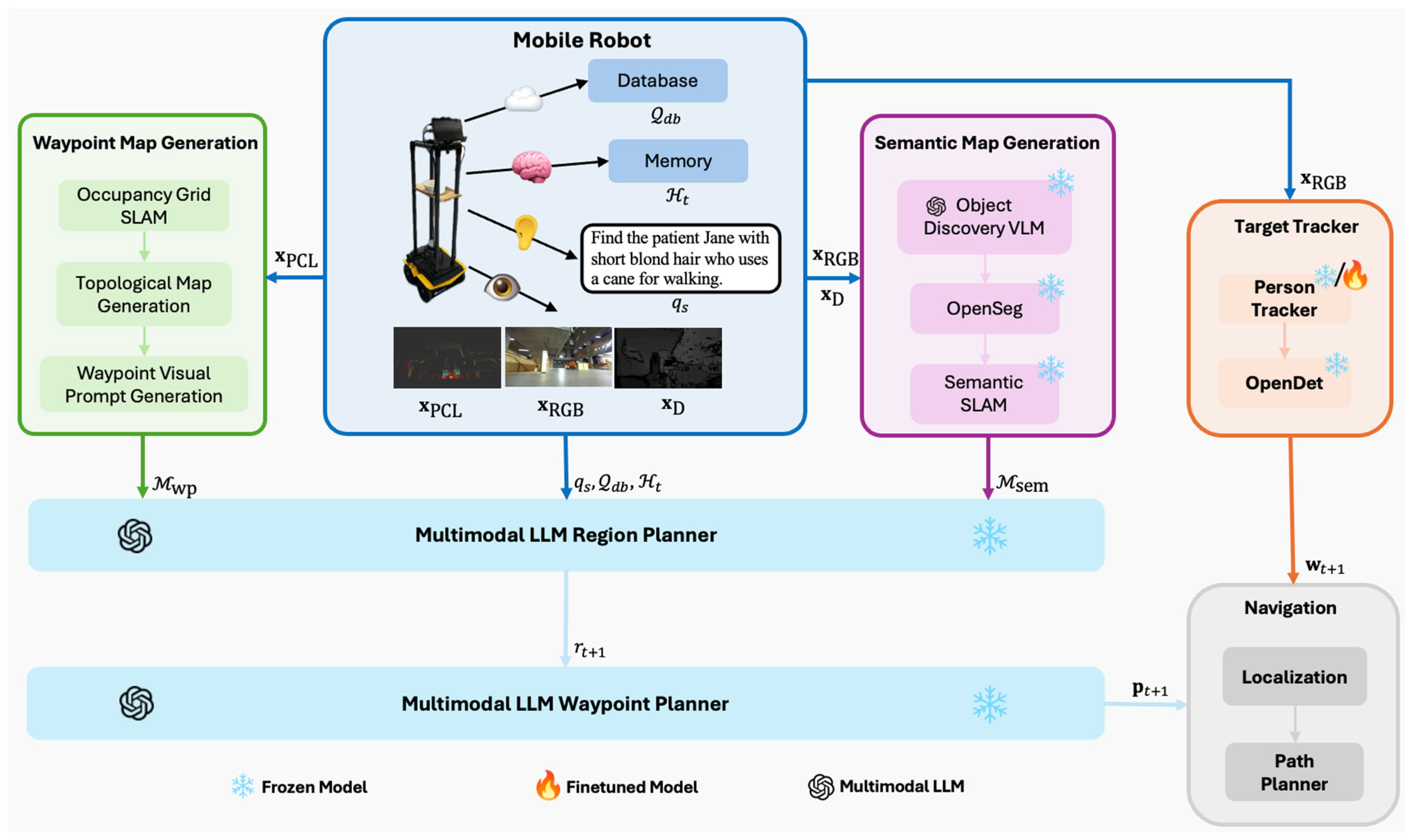
4. MLLM-Search Architecture
4.1. Map Generation Subsystem (MGS)
4.1.1. Semantic Map Generation (SMG)
4.1.2. Waypoint Map Generation (WMG)
4.2. Person Search Subsystem
4.2.1. Multimodal LLM Region Planner
4.2.2. Multimodal LLM Waypoint Planner
4.2.3. Target Tracking
4.2.4. Navigation
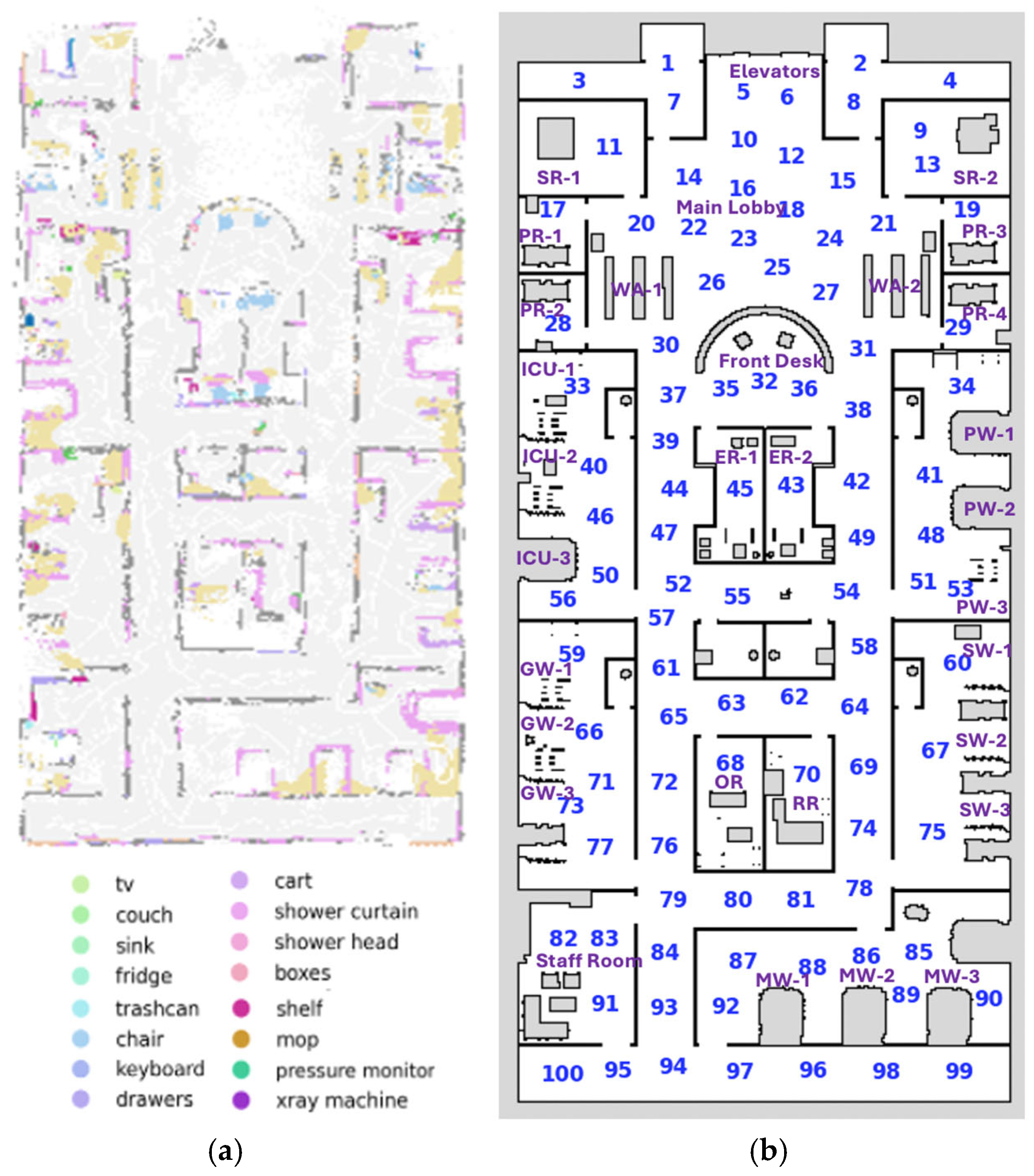
5. Simulated Experiments
5.1. Environment
5.2. Performance Metrics
- Mean Success Rate (SR): the proportion of searches where the robot successfully locates the target user.
- Success weighted by Path Length (SPL): the efficiency of the search method: , where is the total number of search trials, represents whether the search was successful, is the shortest path, and is the robot path.
- Mean Search Time (ST): the average time to complete the search and locate the target person across all trials.
5.3. Search Scenarios
- Complete Schedules: scenarios involving schedules with all information provided;
- Shifted Schedules: scenarios where schedules have been shifted back or forward due to real-time events (i.e., meetings running late or emergencies occurring);
- Partial/Incomplete Schedules: scenarios with partial schedules involving a 1–2 h gap. Scenarios with incomplete schedules involve larger time gaps of more than 2 h;
- No Schedules: scenarios with no prior schedule information available. GPT-4o [33] was used to generate the above scenarios using the waypoint map and object locations and . Handcrafted example scenarios of each schedule type were also provided to GPT-4o for in-context learning to generate 10 scenarios for each schedule type.
5.4. Ablation Methods
- MLLM-Search: our proposed method;
- MLLM-Search with (w/) Single Stage (SS): a variant of MLLM-Search using a single MLLM to perform both region and waypoint planning.
- 3.
- MLLM-Search without (w/o) likelihood : a variant with no likelihood score ;
- 4.
- MLLM-Search w/o proximity : a variant with no proximity score ;
- 5.
- MLLM-Search w/o recency : a variant with no recency score ; and
- 6.
- MLLM-Search w/o scores a variant with no scores.
- 7.
- MLLM-Search w/o SCoT: a variant with no SCoT prompting.
5.5. SOTA Methods
- MDP-based planner [23]: This planner selects a region to search based on the expected reward, which is determined using transition probabilities between regions and the user location PDF. It was selected as a representative decision-making approach.
- HMM-based planner: This planner predicts the target person’s region by modeling movement as a sequence of hidden states with transition probabilities between regions. It was selected as a representative probabilistic inference approach.
- Random walk planner (RW): RW selects a region to search uniformly at random. It was selected as a naïve baseline. For all methods, GPT-4o is used to generate transition and user location probabilities for each scenario.
5.6. Simulation Results
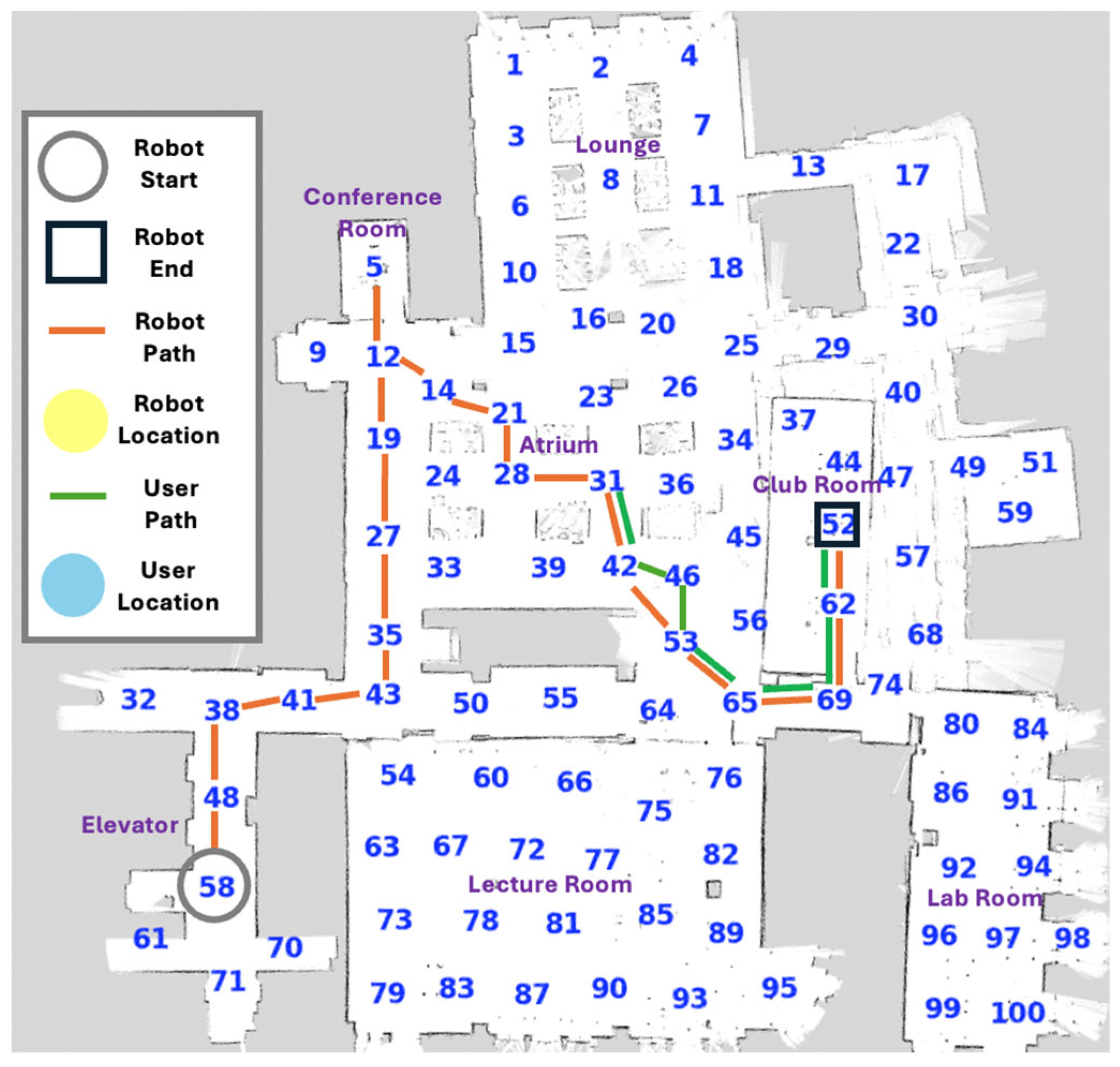
6. Real-World Experiments
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mohamed, S.C.; Rajaratnam, S.; Hong, S.T.; Nejat, G. Person Finding: An Autonomous Robot Search Method for Finding Multiple Dynamic Users in Human-Centered Environments. IEEE Trans. Autom. Sci. Eng. 2020, 17, 433–449. [Google Scholar] [CrossRef]
- Mohamed, S.C.; Fung, A.; Nejat, G. A Multirobot Person Search System for Finding Multiple Dynamic Users in Human-Centered Environments. IEEE Trans. Cybern. 2023, 53, 628–640. [Google Scholar] [CrossRef]
- Wilson, G.; Pereyda, C.; Raghunath, N.; de la Cruz, G.; Goel, S.; Nesaei, S.; Minor, B.; Schmitter-Edgecombe, M.; Taylor, M.E.; Cook, D.J. Robot-Enabled Support of Daily Activities in Smart Home Environments. Cogn. Syst. Res. 2019, 54, 258–272. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.J.; Atrash, A.; Glas, D.F.; Fu, H. Developing Autonomous Behaviors for a Consumer Robot to Be near People in the Home. In Proceedings of the 2023 32nd IEEE International Conference on Robot and Human Interactive Communication, Busan, Republic of Korea, 28 August 2023; pp. 197–204. [Google Scholar]
- Bayoumi, A.; Karkowski, P.; Bennewitz, M. Speeding up Person Finding Using Hidden Markov Models. Robot. Auton. Syst. 2019, 115, 40–48. [Google Scholar] [CrossRef]
- Elinas, P.; Hoey, J.; Little, J.J. Homer: Human Oriented Messenger Robot. In AAAI Spring Symposium on Human Interaction with Autonomous Systems in Complex Environments; AAAI: Washington, DC, USA, 2003. [Google Scholar]
- Fung, A.; Benhabib, B.; Nejat, G. LDTrack: Dynamic People Tracking by Service Robots Using Diffusion Models. Int. J. Comput. Vis. 2025, 133, 3392–3412. [Google Scholar] [CrossRef]
- Veloso, M.; Biswas, J.; Coltin, B.; Rosenthal, S.; Kollar, T.; Mericli, C.; Samadi, M.; Brandao, S.; Ventura, R. CoBots: Collaborative Robots Servicing Multi-Floor Buildings. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; IEEE: Vilamoura-Algarve, Portugal, 2012. [Google Scholar]
- Lin, X.; Lu, R.; Kwan, D.; Shen, X. (Sherman) REACT: An RFID-Based Privacy-Preserving Children Tracking Scheme for Large Amusement Parks. Comput. Netw. 2010, 54, 2744–2755. [Google Scholar] [CrossRef]
- Dworakowski, D.; Fung, A.; Nejat, G. Robots Understanding Contextual Information in Human-Centered Environments Using Weakly Supervised Mask Data Distillation. Int. J. Comput. Vis. 2023, 131, 407–430. [Google Scholar] [CrossRef]
- Fung, A.; Wang, L.Y.; Zhang, K.; Nejat, G.; Benhabib, B. Using Deep Learning to Find Victims in Unknown Cluttered Urban Search and Rescue Environments. Curr. Robot. Rep. 2020, 1, 105–115. [Google Scholar] [CrossRef]
- Shiomi, M.; Kanda, T.; Glas, D.F.; Satake, S.; Ishiguro, H.; Hagita, N. Field Trial of Networked Social Robots in a Shopping Mall. In Proceedings of the 2009 IEEE/RSJ International Conference on Intelligent Robots and Systems, St. Louis, MO, USA, 10–15 October 2009; pp. 2846–2853. [Google Scholar]
- Mehdi, S.A.; Berns, K. Probabilistic Search of Human by Autonomous Mobile Robot. In Proceedings of the 4th International Conference on PErvasive Technologies Related to Assistive Environments, Crete, Greece, 25–27 May 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 1–8. [Google Scholar]
- Nauta, J.; Mahieu, C.; Michiels, C.; Ongenae, F.; De Backere, F.; De Turck, F.; Khaluf, Y.; Simoens, P. Pro-Active Positioning of a Social Robot Intervening upon Behavioral Disturbances of Persons with Dementia in a Smart Nursing Home. Cogn. Syst. Res. 2019, 57, 160–174. [Google Scholar] [CrossRef]
- Cruces, A.; Jerez, A.; Bandera, J.P.; Bandera, A. Socially Assistive Robots in Smart Environments to Attend Elderly People—A Survey. Appl. Sci. 2024, 14, 5287. [Google Scholar] [CrossRef]
- Tipaldi, G.D.; Arras, K.O. I Want My Coffee Hot! Learning to Find People under Spatio-Temporal Constraints. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 1217–1222. [Google Scholar]
- Fung, A.; Benhabib, B.; Nejat, G. Robots Autonomously Detecting People: A Multimodal Deep Contrastive Learning Method Robust to Intraclass Variations. IEEE Robot. Autom. Lett. 2023, 8, 3550–3557. [Google Scholar] [CrossRef]
- Kodur, K.; Kyrarini, M. Patient–Robot Co-Navigation of Crowded Hospital Environments. Appl. Sci. 2023, 13, 4576. [Google Scholar] [CrossRef]
- Hasan, M.K.; Hoque, A.; Szecsi, T. Application of a Plug-and-Play Guidance Module for Hospital Robots. In Proceedings of the 2010 International Conference on Industrial Engineering and Operations Management (IEOM), Dhaka, Bangladesh, 9–10 January 2010. [Google Scholar]
- Volkhardt, M.; Gross, H.-M. Finding People in Home Environments with a Mobile Robot. In Proceedings of the 2013 European Conference on Mobile Robots, Barcelona, Spain, 25–27 September 2013; IEEE: Barcelona, Spain, 2013; pp. 282–287. [Google Scholar]
- Lau, H.; Huang, S.; Dissanayake, G. Optimal Search for Multiple Targets in a Built Environment. In Proceedings of the 2005 IEEE/RSJ International Conference on Intelligent Robots and Systems, Edmonton, AB, Canada, 2–6 August 2005; IEEE: Edmonton, AB, Canada, 2005; pp. 3740–3745. [Google Scholar]
- Lin, S.; Nejat, G. Robot Evidence Based Search for a Dynamic User in an Indoor Environment. In Proceedings of the Volume 5B: 42nd Mechanisms and Robotics Conference, Quebec City, QC, Canada, 26 August 2018; American Society of Mechanical Engineers: Quebec City, QC, Canada, 2018; p. V05BT07A029. [Google Scholar]
- Mehdi, S.A.; Berns, K. Behavior-Based Search of Human by an Autonomous Indoor Mobile Robot in Simulation. Univers. Access Inf. Soc. 2014, 13, 45–58. [Google Scholar] [CrossRef]
- Yu, B.; Kasaei, H.; Cao, M. L3MVN: Leveraging Large Language Models for Visual Target Navigation. In Proceedings of the 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Detroit, MI, USA, 1 October 2023; pp. 3554–3560. [Google Scholar]
- Kuang, Y.; Lin, H.; Jiang, M. OpenFMNav: Towards Open-Set Zero-Shot Object Navigation via Vision-Language Foundation Models 2024. arXiv 2024, arXiv:2402.10670. [Google Scholar]
- Shah, D.; Osinski, B.; Ichter, B.; Levine, S. LM-Nav: Robotic Navigation with Large Pre-Trained Models of Language, Vision, and Action 2022. arXiv 2022, arXiv:2207.04429. [Google Scholar]
- Zhou, G.; Hong, Y.; Wu, Q. NavGPT: Explicit Reasoning in Vision-and-Language Navigation with Large Language Models 2023. arXiv 2023, arXiv:2305.16986. [Google Scholar]
- Rajvanshi, A.; Sahu, P.; Shan, T.; Sikka, K.; Chiu, H.-P. SayCoNav: Utilizing Large Language Models for Adaptive Collaboration in Decentralized Multi-Robot Navigation 2025. arXiv 2025, arXiv:2505.13729. [Google Scholar]
- Cai, Y.; He, X.; Wang, M.; Guo, H.; Yau, W.-Y.; Lv, C. CL-CoTNav: Closed-Loop Hierarchical Chain-of-Thought for Zero-Shot Object-Goal Navigation with Vision-Language Models 2025. arXiv 2025, arXiv:2504.09000. [Google Scholar]
- Shen, Z.; Luo, H.; Chen, K.; Lv, F.; Li, T. Enhancing Multi-Robot Semantic Navigation Through Multimodal Chain-of-Thought Score Collaboration 2025. arXiv 2024, arXiv:2412.18292. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners 2020. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Liu, H.; Ning, R.; Teng, Z.; Liu, J.; Zhou, Q.; Zhang, Y. Evaluating the Logical Reasoning Ability of ChatGPT and GPT-4 2023. arXiv 2023, arXiv:2304.03439. [Google Scholar]
- OpenAI GPT-4o. Available online: https://openai.com (accessed on 5 September 2024).
- Chen, B.; Xu, Z.; Kirmani, S.; Ichter, B.; Driess, D.; Florence, P.; Sadigh, D.; Guibas, L.; Xia, F. SpatialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities 2024. arXiv 2024, arXiv:2401.12168. [Google Scholar]
- Hao Tan, A.; Fung, A.; Wang, H.; Nejat, G. Mobile Robot Navigation Using Hand-Drawn Maps: A Vision Language Model Approach. arXiv 2025, arXiv:2502.00114. [Google Scholar]
- Lei, X.; Yang, Z.; Chen, X.; Li, P.; Liu, Y. Scaffolding Coordinates to Promote Vision-Language Coordination in Large Multi-Modal Models 2024. arXiv 2024, arXiv:2402.12058. [Google Scholar]
- Yang, J.; Zhang, H.; Li, F.; Zou, X.; Li, C.; Gao, J. Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V 2023. arXiv 2023, arXiv:2310.11441. [Google Scholar]
- Cheng, A.-C.; Yin, H.; Fu, Y.; Guo, Q.; Yang, R.; Kautz, J.; Wang, X.; Liu, S. SpatialRGPT: Grounded Spatial Reasoning in Vision Language Model 2024. arXiv 2024, arXiv:2406.01584. [Google Scholar]
- Nasiriany, S.; Xia, F.; Yu, W.; Xiao, T.; Liang, J.; Dasgupta, I.; Xie, A.; Driess, D.; Wahid, A.; Xu, Z.; et al. PIVOT: Iterative Visual Prompting Elicits Actionable Knowledge for VLMs 2024. arXiv 2024, arXiv:2402.07872. [Google Scholar]
- Tang, W.; Sun, Y.; Gu, Q.; Li, Z. Visual Position Prompt for MLLM Based Visual Grounding 2025. arXiv 2025, arXiv:2503.15426. [Google Scholar]
- Liu, D.; Wang, C.; Gao, P.; Zhang, R.; Ma, X.; Meng, Y.; Wang, Z. 3DAxisPrompt: Promoting the 3D Grounding and Reasoning in GPT-4o 2025. arXiv 2025, arXiv:2503.13185. [Google Scholar]
- Stuede, M.; Lerche, T.; Petersen, M.A.; Spindeldreier, S. Behavior-Tree-Based Person Search for Symbiotic Autonomous Mobile Robot Tasks. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 2414–2420. [Google Scholar]
- Ren, T.; Liu, S.; Zeng, A.; Lin, J.; Li, K.; Cao, H.; Chen, J.; Huang, X.; Chen, Y.; Yan, F.; et al. Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks 2024. arXiv 2024, arXiv:2401.14159. [Google Scholar]
- Chaplot, D.S.; Gandhi, D.P.; Gupta, A.; Salakhutdinov, R.R. Object Goal Navigation Using Goal-Oriented Semantic Exploration. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–12 December 2020; Curran Associates, Inc.: New York, NY, USA, 2020; Volume 33, pp. 4247–4258. [Google Scholar]
- Rebello, J.; Fung, A.; Waslander, S.L. AC/DCC: Accurate Calibration of Dynamic Camera Clusters for Visual SLAM. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 6035–6041. [Google Scholar]
- Grisetti, G.; Stachniss, C.; Burgard, W. Improved Techniques for Grid Mapping with Rao-Blackwellized Particle Filters. IEEE Trans. Robot. 2007, 23, 34–46. [Google Scholar] [CrossRef]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A K-Means Clustering Algorithm. J. R. Stat. Soc. Ser. C Appl. Stat. 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Bresenham, J.E. Algorithm for Computer Control of a Digital Plotter. IBM Syst. J. 1965, 4, 25–30. [Google Scholar] [CrossRef]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.; Rocktäschel, T.; et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv 2020, arXiv:2005.11401. [Google Scholar]
- Thanasi-Boçe, M.; Hoxha, J. From Ideas to Ventures: Building Entrepreneurship Knowledge with LLM, Prompt Engineering, and Conversational Agents. Educ. Inf. Technol. 2024, 29, 24309–24365. [Google Scholar] [CrossRef]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Ichter, B.; Xia, F.; Chi, E.; Le, Q.; Zhou, D. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models 2023. arXiv 2022, arXiv:2201.11903. [Google Scholar]
- Hang, C.N.; Tan, C.W.; Yu, P.-D. MCQGen: A Large Language Model-Driven MCQ Generator for Personalized Learning. IEEE Access 2024, 12, 102261–102273. [Google Scholar] [CrossRef]
- Hart, P.E.; Nilsson, N.J.; Raphael, B. A Formal Basis for the Heuristic Determination of Minimum Cost Paths. IEEE Trans. Syst. Sci. Cybern. 1968, 4, 100–107. [Google Scholar] [CrossRef]
- Ho, J.; Jain, A.; Abbeel, P. Denoising Diffusion Probabilistic Models. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–12 December 2020; Curran Associates, Inc.: New York, NY, USA, 2020; Volume 33, pp. 6840–6851. [Google Scholar]
- Liu, S.; Zeng, Z.; Ren, T.; Li, F.; Zhang, H.; Yang, J.; Li, C.; Yang, J.; Su, H.; Zhu, J.; et al. Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection 2023. arXiv 2023, arXiv:2303.05499. [Google Scholar]
- Rösmann, C.; Feiten, W.; Woesch, T.; Hoffmann, F.; Bertram, T. Trajectory Modification Considering Dynamic Constraints of Autonomous Robots. In Proceedings of the 7th German Conference on Robotics (ROBOTIK 2012), Munich, Germany, 15–16 May 2012; pp. 1–6. [Google Scholar]
- Dellaert, F.; Fox, D.; Burgard, W.; Thrun, S. Monte Carlo Localization for Mobile Robots. In Proceedings of the Proceedings 1999 IEEE International Conference on Robotics and Automation, Detroit, MI, USA, 10–15 May 1999; Volume 2, pp. 1322–1328. [Google Scholar]
- AWS Robomaker: Amazon Cloud Robotics Platform. Available online: https://aws.amazon.com/robomaker (accessed on 20 May 2024).
- Helbing, D.; Molnar, P. Social Force Model for Pedestrian Dynamics. Phys. Rev. E 1995, 51, 4282–4286. [Google Scholar] [CrossRef]
- Liu, N.F.; Lin, K.; Hewitt, J.; Paranjape, A.; Bevilacqua, M.; Petroni, F.; Liang, P. Lost in the Middle: How Language Models Use Long Contexts 2023. arXiv 2023, arXiv:2307.03172. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Environment Type | Hospital | Office | |||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Complete Schedule | Shifted Schedule | Partial/Incomplete Schedule | No Schedule | Complete Schedule | Shifted Schedule | Partial/Incomplete Schedule | No Schedule | ||||||||||||||||||
| Method | SR | SPL | ST | SR | SPL | ST | SR | SPL | ST | SR | SPL | ST | SR | SPL | ST | SR | SPL | ST | SR | SPL | ST | SR | SPL | ST | |
| Ablation Methods | |||||||||||||||||||||||||
| MLLM-Search | 1.00 | 0.55 | 8.1 | 1.00 | 0.45 | 10.4 | 0.90 | 0.47 | 12.3 | 0.80 | 0.44 | 15.6 | 1.00 | 0.54 | 9.3 | 1.00 | 0.51 | 11.2 | 1.00 | 0.48 | 13.4 | 0.80 | 0.50 | 14.1 | |
| MLLM-Search w/ SS | 0.80 | 0.40 | 15.2 | 0.70 | 0.30 | 22.6 | 0.70 | 0.27 | 25.5 | 0.40 | 0.21 | 32.8 | 0.80 | 0.35 | 18.3 | 0.70 | 0.31 | 24.0 | 0.70 | 0.28 | 27.2 | 0.50 | 0.22 | 29.3 | |
| MLLM-Search w/o | 0.80 | 0.44 | 12.5 | 0.70 | 0.33 | 18.3 | 0.60 | 0.35 | 15.2 | 0.50 | 0.31 | 22.4 | 0.90 | 0.38 | 16.6 | 0.80 | 0.36 | 21.1 | 0.70 | 0.37 | 19.3 | 0.50 | 0.32 | 22.9 | |
| MLLM-Search w/o | 0.90 | 0.38 | 18.3 | 0.60 | 0.26 | 26.7 | 0.70 | 0.30 | 23.1 | 0.50 | 0.30 | 24.9 | 0.90 | 0.32 | 20.1 | 0.70 | 0.28 | 29.3 | 0.70 | 0.29 | 25.7 | 0.40 | 0.26 | 27.8 | |
| MLLM-Search w/o | 0.80 | 0.35 | 25.8 | 0.40 | 0.25 | 30.5 | 0.40 | 0.22 | 29.7 | 0.30 | 0.19 | 35.7 | 0.80 | 0.27 | 22.4 | 0.50 | 0.23 | 31.2 | 0.60 | 0.23 | 33.2 | 0.40 | 0.21 | 34.8 | |
| MLLM-Search w/o | 0.60 | 0.25 | 28.1 | 0.30 | 0.15 | 32.9 | 0.40 | 0.16 | 34.7 | 0.30 | 0.17 | 37.1 | 0.60 | 0.25 | 25.7 | 0.50 | 0.22 | 36.0 | 0.50 | 0.15 | 37.7 | 0.30 | 0.18 | 35.3 | |
| MLLM-Search w/o SCoT | 1.00 | 0.51 | 21.2 | 1.00 | 0.43 | 28.2 | 0.90 | 0.45 | 28.8 | 0.70 | 0.43 | 35.3 | 1.00 | 0.50 | 20.4 | 1.00 | 0.47 | 25.6 | 1.00 | 0.46 | 32.1 | 0.70 | 0.46 | 36.8 | |
| Comparison Methods | |||||||||||||||||||||||||
| MDP-based Planner | 0.80 | 0.31 | 26.3 | 0.40 | 0.22 | 32.5 | 0.40 | 0.26 | 28.4 | 0.30 | 0.15 | 38.0 | 0.80 | 0.24 | 23.4 | 0.50 | 0.21 | 33.1 | 0.60 | 0.22 | 32.7 | 0.40 | 0.20 | 36.5 | |
| HMM-based Planner | 0.80 | 0.34 | 18.7 | 0.60 | 0.23 | 28.4 | 0.70 | 0.35 | 22.2 | 0.50 | 0.20 | 30.5 | 0.90 | 0.28 | 20.9 | 0.70 | 0.26 | 31.2 | 0.70 | 0.28 | 25.3 | 0.40 | 0.23 | 32.2 | |
| Random Walk | 0.30 | 0.14 | 36.3 | 0.20 | 0.08 | 44.8 | 0.20 | 0.11 | 43.4 | 0.20 | 0.12 | 39.1 | 0.30 | 0.11 | 40.7 | 0.40 | 0.16 | 35.2 | 0.50 | 0.17 | 33.4 | 0.30 | 0.10 | 42.3 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fung, A.; Tan, A.H.; Wang, H.; Benhabib, B.; Nejat, G. MLLM-Search: A Zero-Shot Approach to Finding People Using Multimodal Large Language Models. Robotics 2025, 14, 102. https://doi.org/10.3390/robotics14080102
Fung A, Tan AH, Wang H, Benhabib B, Nejat G. MLLM-Search: A Zero-Shot Approach to Finding People Using Multimodal Large Language Models. Robotics. 2025; 14(8):102. https://doi.org/10.3390/robotics14080102
Chicago/Turabian StyleFung, Angus, Aaron Hao Tan, Haitong Wang, Bensiyon Benhabib, and Goldie Nejat. 2025. "MLLM-Search: A Zero-Shot Approach to Finding People Using Multimodal Large Language Models" Robotics 14, no. 8: 102. https://doi.org/10.3390/robotics14080102
APA StyleFung, A., Tan, A. H., Wang, H., Benhabib, B., & Nejat, G. (2025). MLLM-Search: A Zero-Shot Approach to Finding People Using Multimodal Large Language Models. Robotics, 14(8), 102. https://doi.org/10.3390/robotics14080102