1. Introduction
Transradial robotic prostheses are essential devices to improve amputees’ activities of daily living (ADL). Despite current advances in the actuators and control systems, these devices lack the ability to adapt movements during the ADL [
1]. Myoelectric prostheses are the state of art in upper limb prostheses and aim to translate superficial electromyography (sEMG) signals into the desired user’s movement using artificial intelligence algorithms [
1,
2,
3]. The sEMG measures the electric potentials generated by the muscular motor units, i.e., it is a non-invasive technique to read neuronal commands, which is crucial for an ideal prosthesis control system [
2,
4,
5]. For example, Liao et al. [
6] propose a neural network-based recognition algorithm for sEMG signal envelopes in order to develop a low-cost interface for collaborative wearable robots.
The prediction of the desired movement through sEMG occurs using pattern recognition (PR) algorithms, where the sEMG is correlated with a grasp motion, and the movement that is closest to the natural movement is selected [
7,
8]. This correlation could be structured using classic techniques, e.g., artificial neural networks (ANNs), linear discriminant analysis (LDA) and support vector machines (SVMs) [
9,
10]. Although the accuracy, which is superior to 90%, as shown in Guo et al. [
11] and Vásconez et al. [
8], demonstrates their effectiveness, the insufficiency of these strategies lies in the adjustability of the movements, because after selection, the grasp is perform by the device using a state machine, i.e., the motion is always the same and does not adapt to environmental conditions [
9]. This inability to adapt limits the user’s capabilities with the devices during their ADL, since the motions are non-patterned and require complex combinations of the joints’ movements [
9,
12].
In order to adapt to the environment, some authors have studied and investigated new ways of controlling the devices. The high-density sEMG sensors can be used to determine the desired movement by indicating which fingers should be flexed or extended instead of associating them with only a grasping movement [
13]. Another way of achieving better integration of the device with the environment is through exclusive control of the contact force on the fingers, thus ensuring that once objects are grasped by the prosthesis, they do not slip. To do this, there are studies in the literature that demonstrate the great effectiveness of these systems using proportional derivative controllers (PIDs) and Fuzzy and predictive modeling with Kalman filters [
14,
15]. Although they manage to improve the way the device manipulates the objects, these controllers still do not control the movement of the fingers, but rather ensure that the objects are firmly grasped by the prosthesis.
To improve the integration of the user with the prosthesis during the ADL, a new controller system is needed, using the sEMG signal to determine the kinematic state of each joint, to induce the device to perform non-patterned movements [
1,
9]. Some authors tried to use regression algorithms to discretize the joints’ positions; however, these models depend on several parameters (e.g., joint stiffness, mass, center of mass), which change for each user [
16,
17]. In order to make the prosthesis more adaptive to the environment and to users, it is essential to develop systems capable of implementing control strategies that are adaptive to both the environment and the user. In the literature, some authors have shown that in the iterations of robots with humans it is necessary to introduce adaptive controls such as torque and impedance [
18,
19]. In addition, the use of deep reinforcement learning (DRL) techniques has shown great ability to create adaptive robots, such as a robotic eel, that are able to extract optimal movement strategies from the environment in which they are inserted [
20]. Thus, DRL techniques have enabled the creation of intelligent controllers that can control complex mechanical systems with a degree of disturbance, a scenario observed in upper limb prostheses during ADLs [
20,
21].
One of the most used DRL techniques is the deep deterministic policy gradient (DDPG), which has been used to perform the motion planning of multi degree of freedom (DOF) robots [
22]. The DDPG method, proposed by Lillicrap [
23], is being used to solve diverse challenging tasks in different fields, and is gaining popularity in the scientific literature [
24,
25,
26]. The DDPG is a model-free and off-policy algorithm based on a combination of the actor–critic approach and the Deep Q Network (DQN) method [
27], which allows the use of a neural network as an approximator function, the implementation of a replay buffer and the use of a separate target network [
28]. This RL technique is designed to learn policies in a continuous action space, in a high-dimensional state and with complex non-linear dynamics, making it a competitive solution compared to planning algorithms with full access to the dynamics and derivatives of the domain [
29]. Given these properties, the DDPG is widely used in the robotics field because it has demonstrated its efficiency in learning optimal policies for locomotion tasks and complex motor skills by controlling joint angles and speeds [
30]. Other RL algorithms can also be used to control robotic devices, such as Proximal Policy Optimization (PPO) and the Soft Actor–Critic (SAC). PPO is a variant of the traditional gradient methods, so it optimizes the policy functions directly without learning the value function, reducing the variance of the gradients and improving convergence as the number of samples increases. Despite this improvement, it has been shown in the literature that for complex tasks, PPO does not present a significant improvement when compared to the DDPG [
31]. The SAC algorithm is stochastic and based on the maximum entropy framework, which tends to improve the stability and exploration of the model [
20,
32]. Although, in theory, the SAC has better efficiency than the DDPG, it has been shown in the literature that as the complexity of the reward function is increased, the performance of the SAC is surpassed by the DDPG [
33]. Thus, among the algorithms observed, the DDPG tends to performs successfully when the problem to be solved is complex and when the reward function is complex, which is observed in the problem of controlling robotic prostheses.
Some studies are being conducted to test and evaluate the viability of the DDPG in different controlling systems. Sun et al. [
34] designed a traditional Adaptive Cruise Control algorithm, based on the DDPG, covering driving assistance technology, to improve the safety and traffic efficiency performance of three-axle heavy vehicles. Chen and Han [
35] proposed an improvement in power extraction efficiency, stabilization of power generation and load decrease in wind turbines, using the DDPG-based adaptive reward technique in wind farms. Chen et al. [
36] used the DDPG algorithm to improve the motion performance of hydraulic robotic arms. Despite the extensive use of the DDPG technique in the literature for solutions in different fields of knowledge, the authors did not find any studies using the DDPG for the adaptive control of upper limb prostheses, since the primary focus in the literature was on developing systems to discretize the desired movements or to control grasping, and not to adapt the prosthetic trajectories.
In this context, the aim of this study is to explore the versatility of the DDPG method to train a controller capable of moving a finger of an upper limb prosthesis in multiple adaptive trajectories proportional to the desired trajectory selection. For this purpose, a learning environment was developed, assuming a finger prosthesis with physiological characteristics, using different trajectories for the relative rotation of the phalanges’ joints: a linear trajectory, a sinusoidal trajectory and a combination of linear and sinusoidal trajectories. To investigate the ANN’s performance, the computational model developed as a training environment was used, evaluating the control capabilities in performing the trajectories with different inputs and finger sizes. Therefore, this study proposes a new method for controlling the motion of upper limb prostheses, seeking the evolution of this device.
2. Materials and Methods
In order to better understand the development of this work, the methodological description will be divided as follows: first, we will present the learning environment, defining the dynamic model of the finger and the reward function; and finally, we will present the algorithm used in the learning phase and the ANN model, showing how the trajectories were inserted into the model.
2.1. Learning Environment
The learning environment consisted of a simplified index finger model, where the objective of the ANN model was to find the ideal continuous torque for each finger joint, in such a way that the fingertip followed a predetermined trajectory. To determine the joint states, a rigid body mechanical model was elaborated, which gave, for each torque defined by the ANN, the states desired. The reward function was developed to compare the fingertip spatial position desired with the position calculated using the applied torque. In this section, we present the mathematical model of the index finger, the physical and geometric parameters of the finger, the desired fingertip trajectories and the reward function applied in the learning environment algorithm.
2.1.1. Mathematical Model
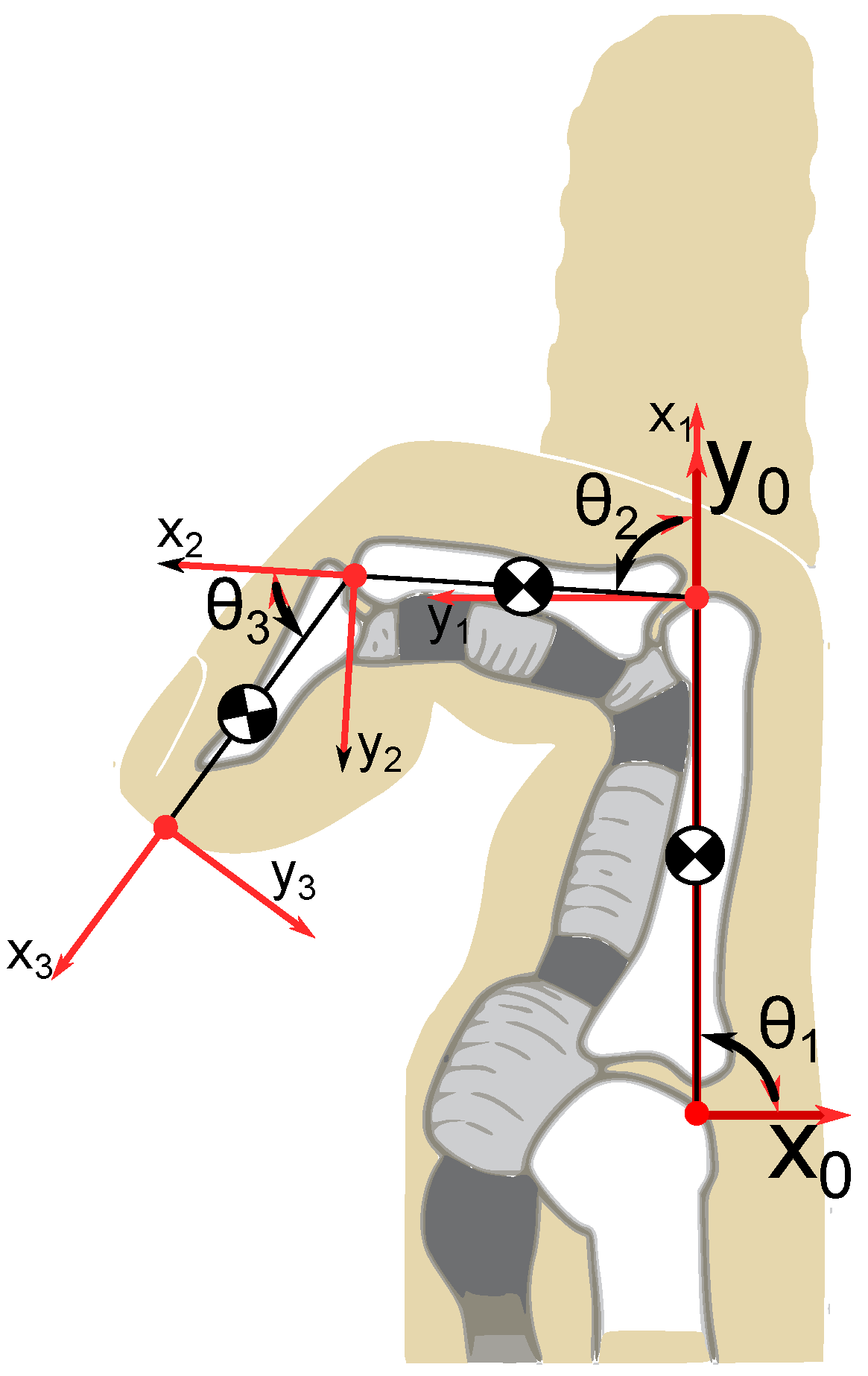
For the development of the mathematical description of the model, the method proposed by Spong et al. [
37] was used. The index finger was considered to consist of three rigid links (phalanges) connected by three revolutional joints. The joint axes
,
,
and
were normal to the page. The base frame o
0x
0y
0z
0 was defined with the origin at the intersection of the z
0 axis and the page, and the x
0 axis was chosen in the horizontal direction. Once the base frame was established, the o
1x
1y
1z
1, o
2x
2y
2z
2 and o
3x
3y
3z
3 frames were defined, considering the Denavit–Hartenberg convention (
Figure 1).
The Euler–Lagrange method was adopted for the development of the motion equations for the three phalanges. Assuming
to be the phalanges’ angles with respect to the
-axis,
to be the mass of link i,
to be the length of link i,
to be the distance from the previous joint to the center of mass of link i and
to be the moment of inertia of link i about an axis coming out of the page, passing through the center of mass of link i, we have the following equation:
where
represents the inertia matrix (D(
)) elements,
the Christoffel symbols,
the term associated with total gravitational potential energy (P(
)) and
the external torques applied to the joints. The terms,
,
and
, of Equation (
1), were obtained as follows:
where
is the linear velocity geometric Jacobian with respect to the center of mass of each link. The explicit Runge–Kutta method of order 5(4) was used to solve the mathematical model, using a time step of 10
−5 s. The angles
rad,
rad and
rad were considered for the resting position of the finger (fully extended). The motion range of each joint was
rad from the resting position, and the ANN model was constrained to be unable to lead any joints to positions beyond this defined range.
2.1.2. Index Finger Parameters
The index finger phalanges were approximated by rigid links with a constant and uniform density equal to 1160 kg·m
−3 [
38], and with geometric characteristics represented by the mean anthropometric measurements of the adult male Spanish population reported in the paper by Vergara et al. [
39].
Table 1 indicates the values for the properties used.
2.1.3. Trajectory Equations
Two different expected trajectories were considered for the finger of the upper limb prosthesis to follow during the motion: the linear trajectory and the sinusoidal trajectory. The equations for the two trajectories were developed considering a total range of motion of
rad in a total time of 1 s for each of the three phalanges. To simulate an sEMG time interaction with the model, the joint states were calculated in a time range of 40 ms [
40].
For the linear trajectory, the relative angular rotation equations are shown in Equations (
5) and (
6), and the relative angular velocities equation is shown in Equation (
7).
where
t is time. In another way, for the sinusoidal trajectory, the relative angular rotation equations are shown in Equations (
8) and (
9), and the relative angular velocities equation is shown in Equation (
10).
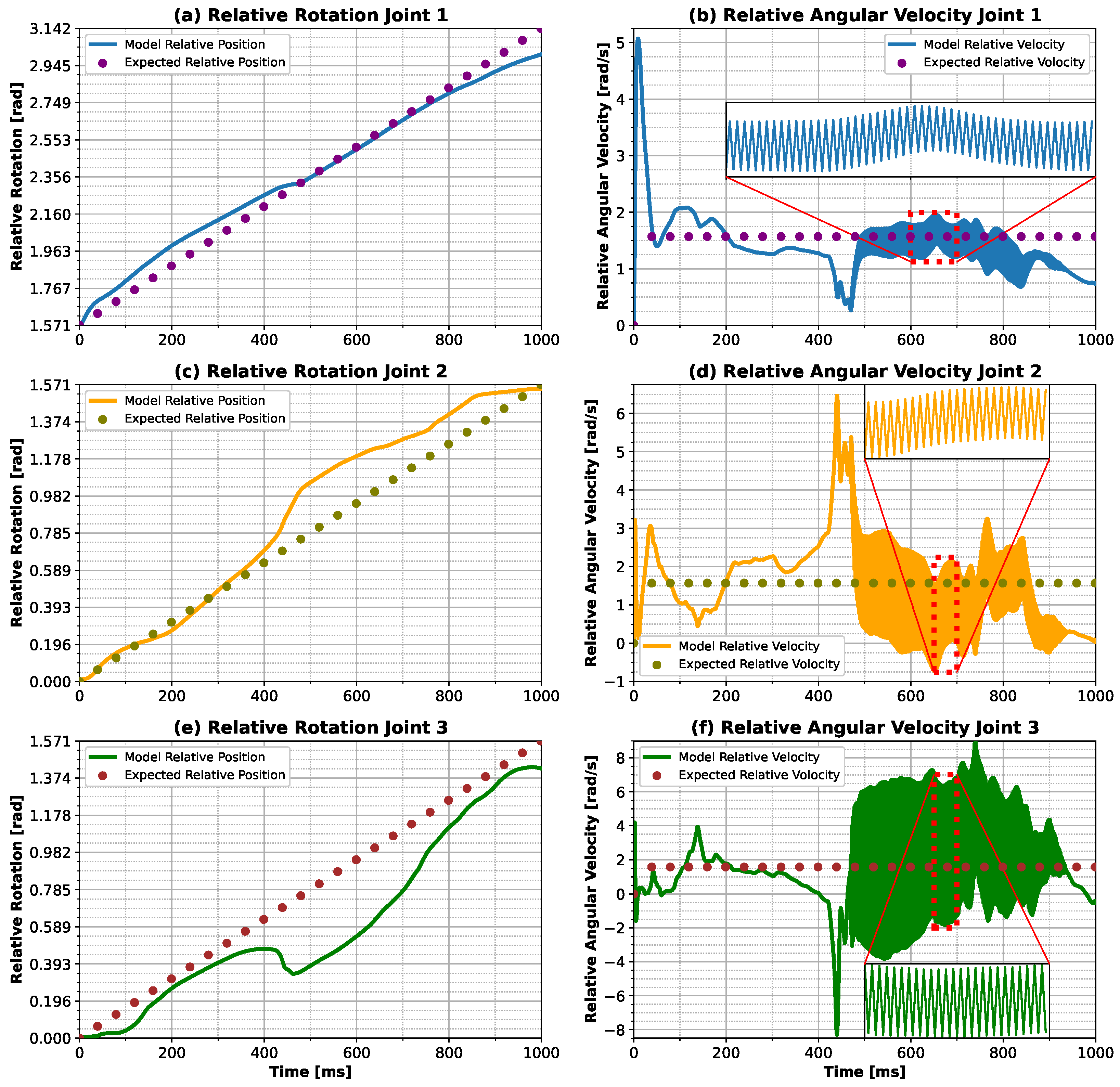
At the end of the learning procedure, the responses obtained by the neural network and the expected responses, given by the previous equations, were compared, as well as the strategies adopted by the ANN to perform the control.
2.1.4. Reward Function and Learning Environment Algorithm
The learning environment has two reward functions: one for situations where the torque determined by the ANN causes a joint angle beyond the allowed range (penalty function), and another reward function that encompasses all the positions allowed for performing the finger motion (reward function). In order to capture the error, an exponential function was used as the basis for both reward functions. The penalty funtion was used when the angle of joint 1 was smaller than
rad or greater than
rad, or if joint 2 or 3 was smaller than 0 rad or greater than
rad, as shown by Equation (
11):
where
is the amount by which the angle has exceeded the maximum or minimum joint position defined by Equations (
12) and (
13):
The penalty reward function gives penalties between −10 and −20, and was capable of determining better differences between errors in the range between 0 and 0.5 rad. For errors greater than 0.5 rad, the penalty given for the model was approximately the same. In addition, when the angle of any joint was out of the range, the training episode was interrupted.
When the angle of the joints was in the range, the reward function was defined by Equation (
14).
where
and
were the errors between the desired fingertip position and the results obtained by the ANN action, on the x and y coordinates, respectively. The reward function must always give rewards greater than the penalty function, to ensure that the model distinguishes the out-of-range positions in the joints and the allowable positions. In that way, the range of the reward function varied between 0 and −5, and the map absolute errors varied between 0 and 0.2 m, resulting in approximately the same reward for an error greater than 0.2 m. The learning environment and the reward function were implemented with a Gym library, developed for Python programming language [
41].
2.2. ANN Model and Learning Algorithm
The ANN model proposed in this work has two distinct inputs. The first consists of two input neurons, where one of the neurons is activated when the finger needs to make a sinusoidal trajectory (input ), while the other is activated to perform the linear trajectory (input ). Following the first input, 3 hidden layers were defined with 8, 4 and 4 neurons, respectively, and the last hidden layer of the first input was concatenated with the neurons of the second input. The second input referred to the current states of the finger, i.e., it had six input neurons. Following the neurons of the second input that were concatenated with the last layer of hidden neurons of the first input, 4 hidden layers were used, with 256, 256, 128 and 32 neurons, respectively. The leaky RELU activation function was used for all the neurons in the hidden layer, with a coefficient of 0.3 for the negative slope. The output layer had three neurons with the hyperbolic tangent activation function and represented the torque commands for the joints. The initialization parameters were randomly set between −0.05 and 0.05 to start the training. The output neurons were scaled by a factor of 0.1 to limit the range of torque applied to the joints.
We used the DDPG training algorithm to determinate the ANN parameter sets. To do this, it was necessary to develop a critic model, represented by another ANN. Three inputs were defined for the critic model: the first input was used for trajectory selection; the second input for the current kinematic states; and the third input for the actions of the ANN actor. The first input was connected to 3 hidden layers with 8, 4 and 4 neurons, respectively, with the last hidden layer concatenated to the second input. Futhermore, the second input was connected to two hidden layers with 64 neurons. The third input was also connected to two hidden layers with 64 neurons; however, it was also concatenated with the last hidden layer of the combination of the first and second inputs. Finally, the combination of all the inputs was connected to three hidden layers with 256 neurons that were connected to a linear output neuron. As in the actor model, all the hidden neurons used the leaky RELU activation function, with a coefficient of 0.3 for the negative slope.
For each training interaction, the ANN tried to perform the sinusoidal trajectory, followed by the linear trajectory. The ANN time step was 1 ms, i.e., the actor had a thousand steps to complete the task and 40 attempts to lead the finger to the next desired position, as previously described. This was determined to emulate an sEMG classifier that determines the desired motion every 40 ms. To ensure the exploration, the Ornstein–Uhlenbeck process was used to generate the noise on the actions, as indicated by the TensorFlow [
42] and Keras [
43] libraries manual for Python. To periodically check the real performance of the actor ANN every fifty epochs, or if the reward threshold was outperformed, the actor tried to perform the task without the noise, and the training stopped when the reward threshold was overcome. The learning algorithm is presented in Algorithm 1.
All of the training process was performed using the TensorFlow library for Python, and the following parameters were used: an actor learning rate of
; a critic learning rate of
; a buffer size of
; a batch size of 32; the update of the targets networks using a factor
of
; a discount factor
of 0.99; and a reward threshold of −650. As shown by Li et al. [
22], the efficiency of the training was reduced when only the task failure data were used in training. To maintain the efficiency of the training, we limited the failure samples on buffer and batch to 20% of the total size, i.e.,
and 6, respectively.
| Algorithm 1 Modified DDPG Learning Algorithm |
Randomly initialize the actor network with the weights varying between −0.05 and 0.05 Randomly initialize the critic network with the weights Initialize the target networks and Initialize the replay buffer Initialize episodes counter while (sinusoidal and linear trajectory reward ≤ −650) and (sinusoidal and linear < 1000) do Initialize the environment, the agent sinusoidal reward and sinusoidal train steps Determine the trajectory input for t = 0, 1000 do Select an action with a noise based on the actual polices Execute the action and receive the next states , the step reward and fail or not fail state Store the data on buffer Randomly sample a minibatch with 6 fail samples and 26 not fail samples Get Update the critic minimizing the loss: Update the actor minimizing the loss: Update the targets network: and if any joint is out of range then break end if Set: and end for Initialize the environment, the agent linear reward and linear train steps Determine the trajectory input for t = 0, 1000 do Select a action with a noise based on the actual polices Execute the action and receive the next states , the step reward and fail not fail state Store the data on buffer Randomly sample a minibatch whith 6 fail samples and 26 not fail samples Get Update the critic minimizing the loss: Update the actor minimizing the loss: Update the target network: and if any joint is out of range then break end if Set: and end for Set if E is multiple of 50 or ( and = 1000) or ( and = 1000) then Get the agent reward for sinusoidal input without noise: Compute the complete steps with sinusoidal input Get the agent reward for linear input without noise: Compute the complete steps with linear input end if end while
|
4. Discussion
Observing our results, we could see that the ANN model developed was capable of differentiating the trajectories and creating distinct control strategies according to the trajectory selection inputs, which was the main objective of this study. However, the most promising results were found for the mixed inputs situation. Examining the perspective of controlling upper limb prostheses using sEMG, the pattern recognition technique, which is currently employed, also presents the capacity to select different trajectories inserted into the model. However, the prosthesis tasks are limited by the patterned grips, as presented in work by on Sadikoglu et al. [
7] and Vásconez et al. [
8]. As demonstrated by the results of the combination of trajectories, we trained the ANN model with only two trajectories and used combinations of different proportions (linear and sinusoidal) to control the motion of the finger. Evaluating the possibility of using sEMG data in conjunction with the ANN model, it would be possible to use kinematic quantities to associate the finger motion with the sEMG features, establishing an indirect relationship between the acquired signal and the prosthesis dynamics. In this way, the ANN model would be capable of providing the user with the possibility of using a different input signal to perform new movements with the prosthesis, as observed with the combination of trajectories. These characteristics demonstrate that the controller developed in this study exhibited a distinct control strategy depending on the previously desired trajectory, suggesting its potential for widespread use in controlling the movement of prostheses. Contrary to existing studies, which have focused on standardized movement control and execution without considering user-specific or activity-specific needs, this controller was designed to adapt to non-standardized movement and activity types [
7,
8,
13]. This adjustment of the control strategy performed by the ANN also reflects a new way of adapting the movement of the prosthesis in various trajectories, focusing more on the execution of the movement by the finger and not just on controlling the contact force acting on the finger, as is usually found in the literature referring to adaptive controllers [
14,
15]. This indicates that it would be possible to develop a non-standardized sEMG-based controller, using our DDPG learning algorithm, with the potential to adapt the device to different ADLs and in a customized way for each user, adapting to situations and the current environment.
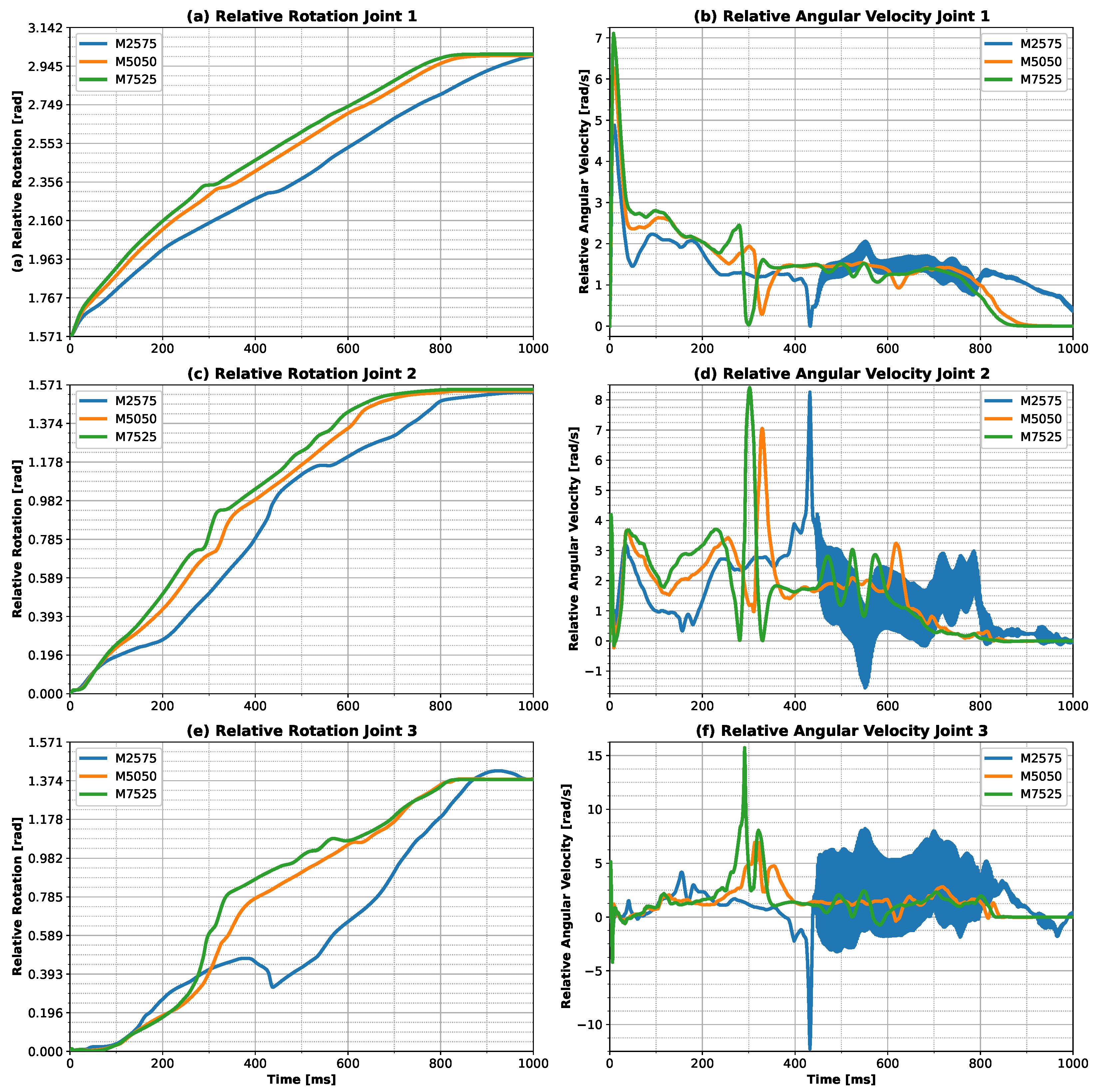
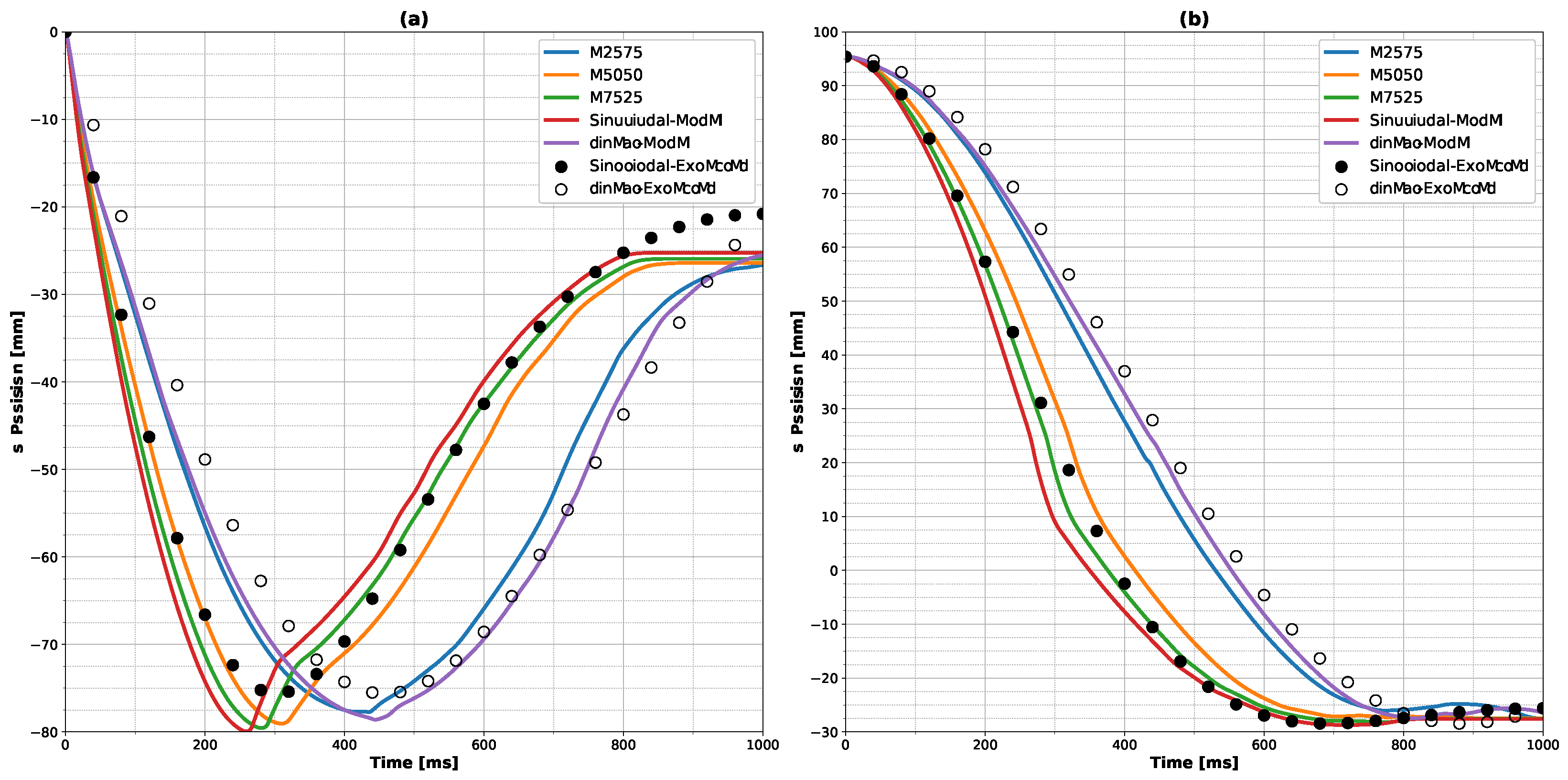
Although this work used a limited amount of data in an attempt to develop a generalized controller for upper limb prostheses, our ANN model was able to make adjustments during the execution of a simple finger movement, and could be extrapolated to more complex movements performed by prostheses. Furthermore, regarding the use of our strategy to develop a controller for upper limb prostheses, it can be seen that there is the possibility for the user to change the inputs, and, consequently, adapt the trajectory, without the need for retraining or online training, as illustrated by changing the linear input for the M2575 combination (
Figure 6 and
Figure 9). This emphasizes a greater adaptability to and unique control regarding the user’s needs. The main challenge of using an sEMG-based controller can be overcome, that is, the user training process, which is difficult and not very encouraging for amputees. It requires several training sessions, even though pattern classifiers provide high accuracy and virtual training can be used, as shown by Leccia et al. [
44]. Using our premises to train a prosthesis controller, we were able to show the possibility of the user changing the inputs, and consequently, the trajectory could be adjusted; for example, the input trajectory could be changed from purely linear to M2575 (
Figure 9), providing more adaptability and a unique potential for control, which the user needs. This possibility could facilitate the training process, since the user has the ability to generate their own individual strategies for combining trajectories.
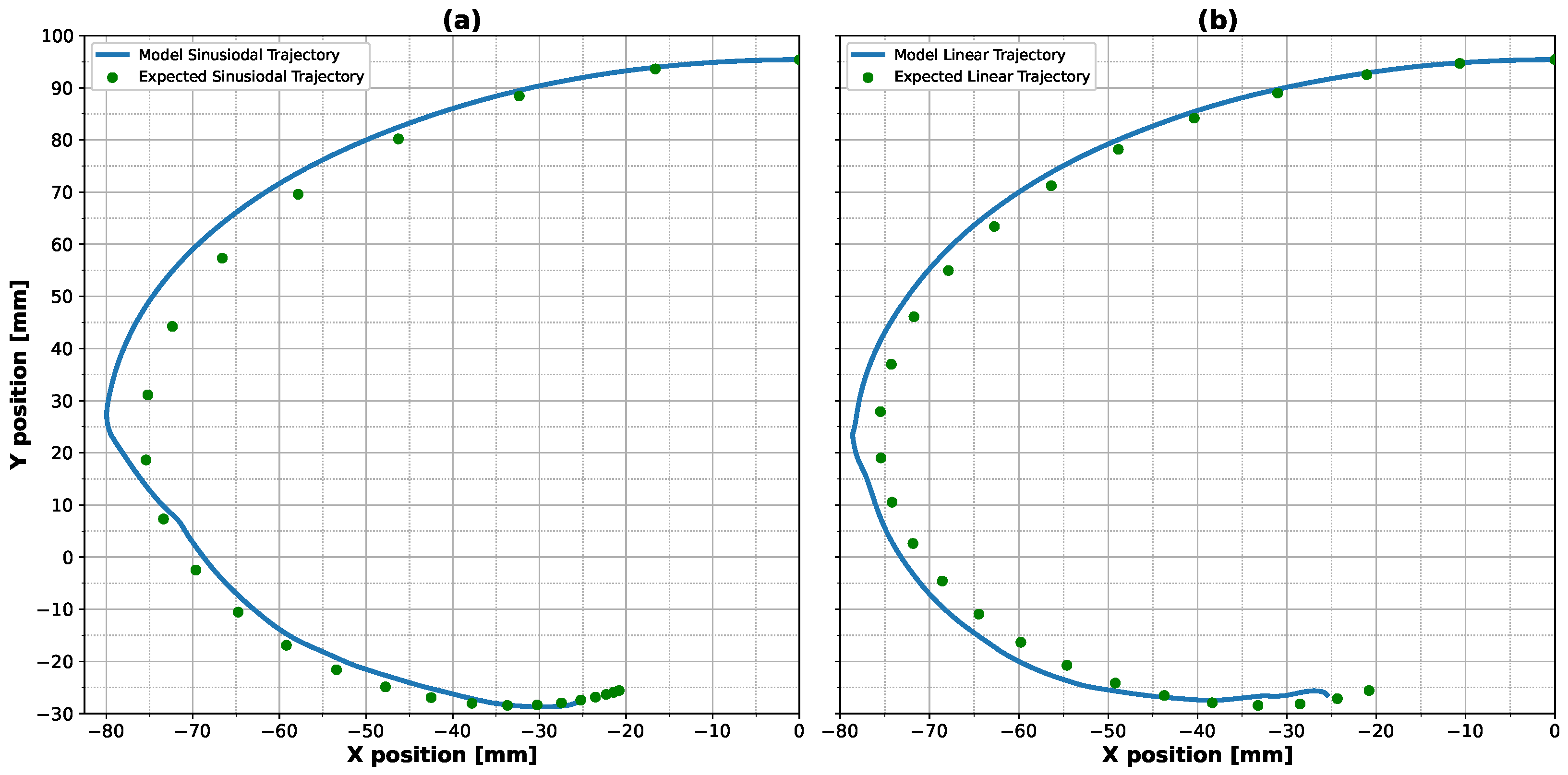
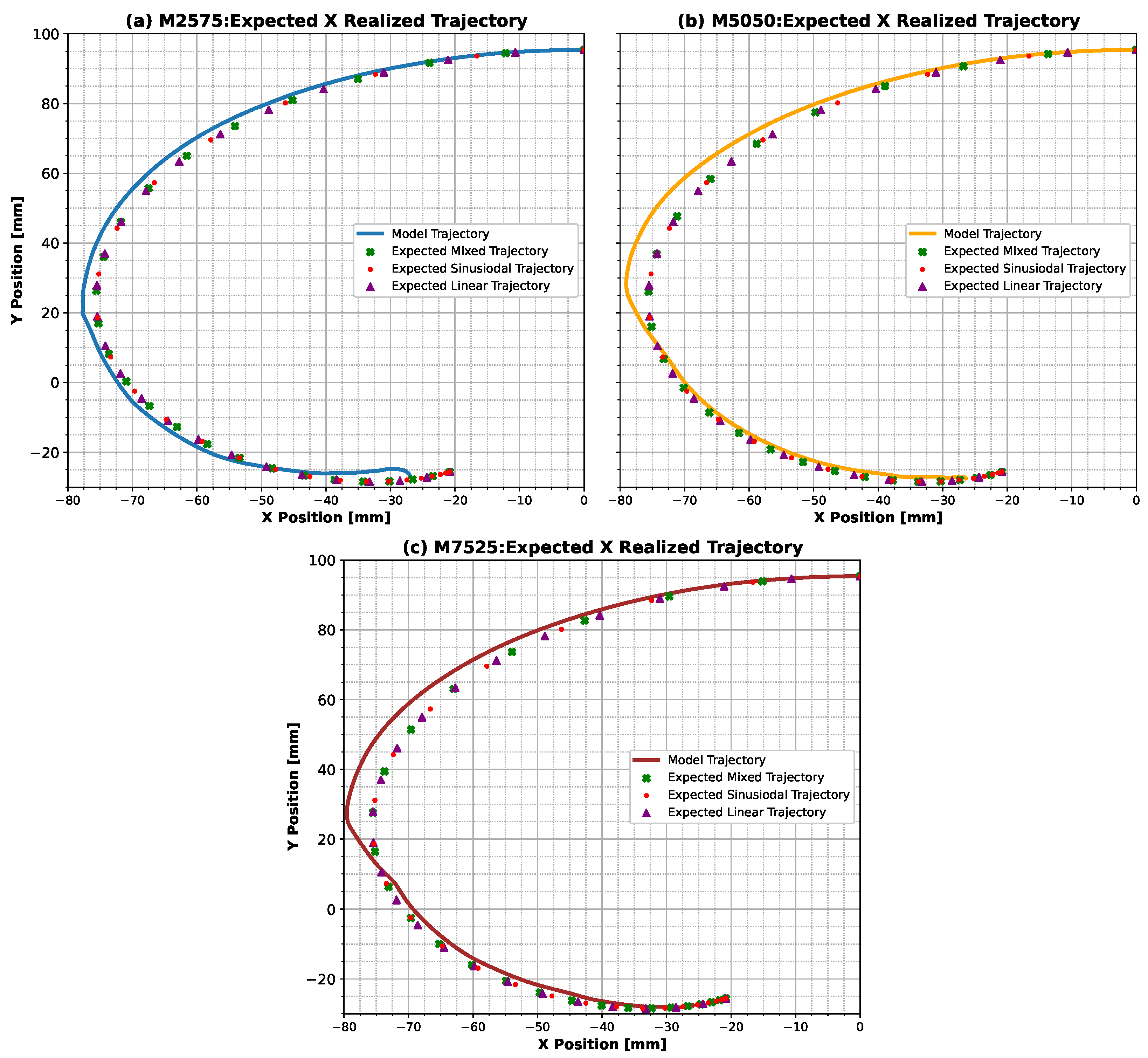
Analyzing the results of the ANN model, it was observed that the different strategies adopted for each case evaluated occurred after the point of maximum distance on the X axis (
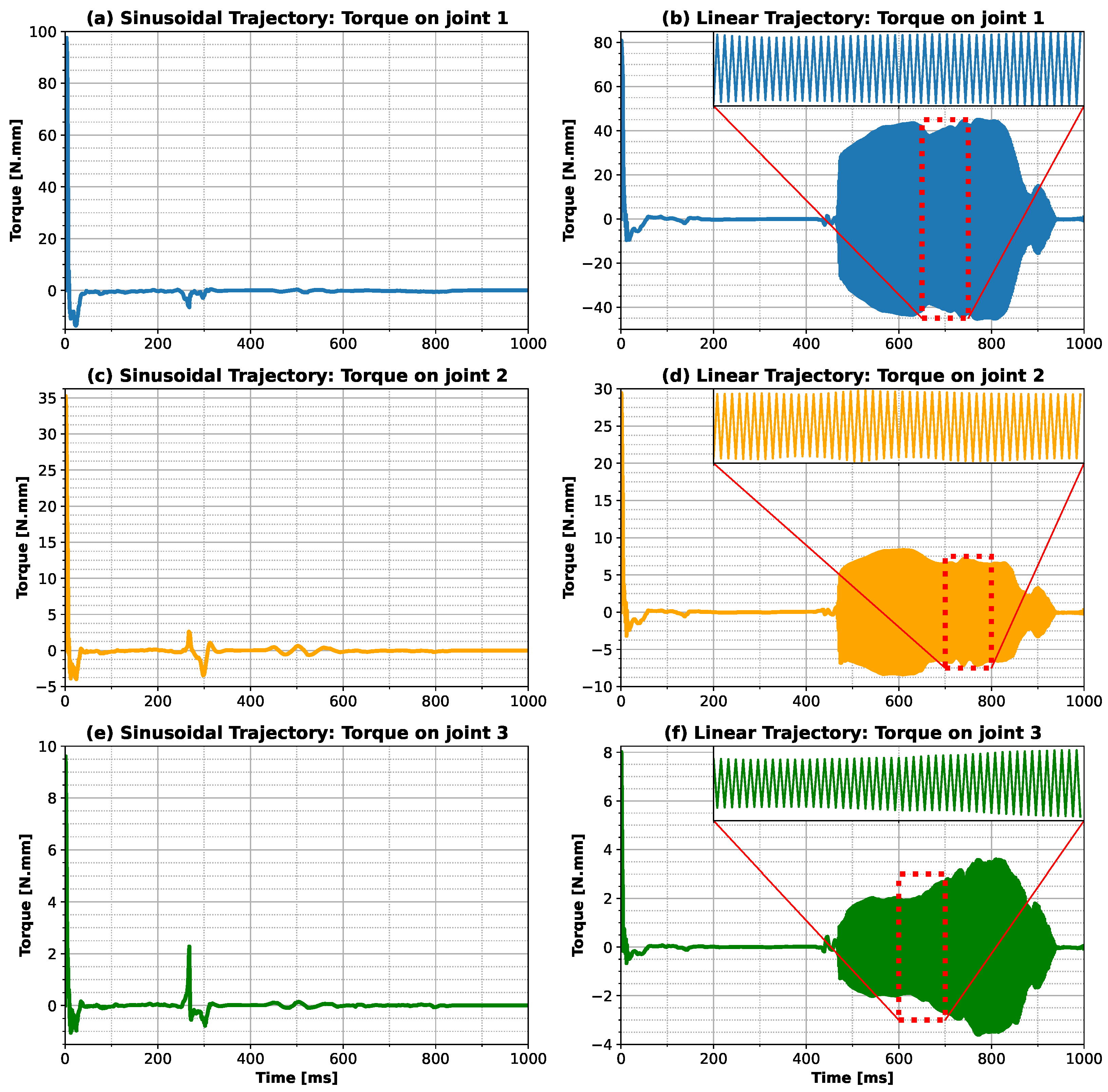
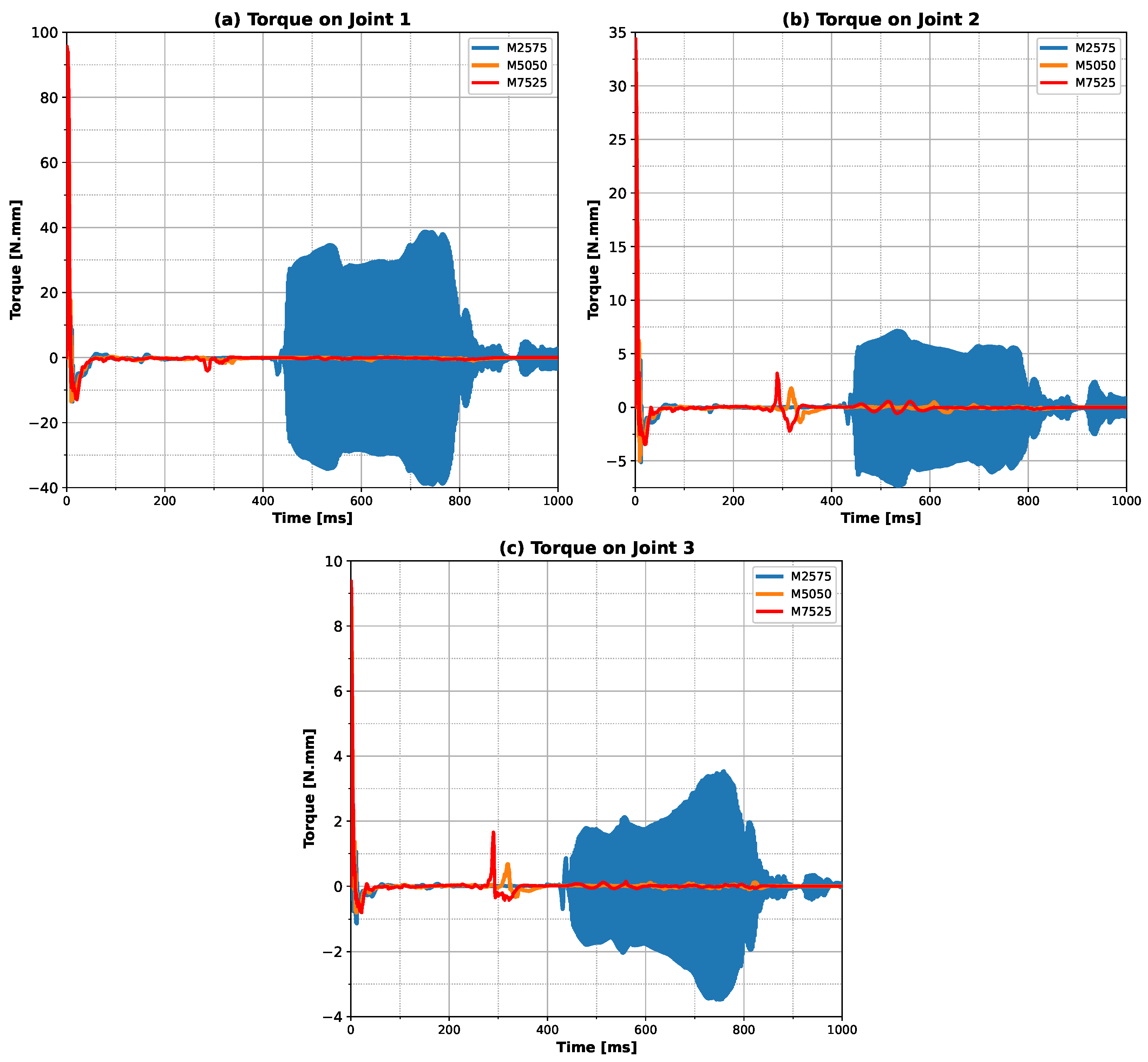
Figure 2). The main noticeable difference was the oscillatory behavior for the linear case and for the M2575 combination (higher proportion of linear input). In addition, comparing the torque (
Figure 3 and
Figure 7) with the position with time (
Figure 9), we noticed that the points coincided with the abrupt change in the slope of the X component of the trajectory (X component of velocity). This may indicate that the ANN model developed is sensitive to these sudden changes in the kinematic quantities of the finger’s motion. Another observation that can be noticed in
Figure 2a is the distribution of trajectory points over time. For the sinusoidal trajectory, the density of points changes over time, with more points in the final stages of the motion (showing less error at this stage). The linear trajectory, on the other hand, has a more uniform density of points (showing less error when X is maximum). This difference in the distribution of the points is due to the velocity expected for each trajectory, which explains why the control strategy for the sinusoidal trajectory is more stable. As the finger approaches the end of the movement, the velocity tends toward zero, resulting in a decreasing torque. On the other hand, in the linear trajectory, the velocity is constant throughout the movement, so, to maintain this velocity, it is necessary to constantly stimulate the movement, which causes instability in the control signal. In this case, the proposed controller is more capable of capturing abrupt changes in the position slope and the density of points along the trajectory, demonstrating the ability to differentiate between the features of different trajectories.
Examining the physics of the problem, it can be observed that the ANN model was able to correctly capture the behavior of the system studied. In the first step, it can be noticed that the peak of the velocity and torque distribution (
Figure 3,
Figure 4,
Figure 5,
Figure 7 and
Figure 8) was produced to move the finger from the stationary position to the first desired position. After this state, the torque was inverted, however with a less expressive value, since the finger had already started to move.
Figure 3 and
Figure 7 show that the torque was almost zero during all times until the maximum absolute X distance, at which moment the control strategies were changed. One hypothesis to explain this behavior is the application of a higher torque to reverse it, taking advantage of the body’s inertial forces to perform the motion, by the ANN model when a negative slope is developed for the X component of the position (
Figure 9a). However, when the slope was positive, the behavior was different for the linear trajectory, which required a constant reversion. The difference may be due to the velocity, which for the sinusoidal trajectory was decreasing as a cosine function, while for the linear trajectory, it was constant. For the sinusoidal situation, the positions showed greater difficulty in reaching the desired final positions (
Figure 4,
Figure 5 and
Figure 8). This was caused by the distribution of points, as discussed earlier. For the linear input, the points were equally spaced without changing the velocity magnitude. In contrast, with the sinusoidal trajectory, the spacing between the points was reduced in the final stages, at the same time that the velocity approached zero, making it difficult for the model to reach the desired points at the end of the motion. Another hypothesis that can be formulated is that the controller utilizes both inertia and the desired velocity to formulate the control strategy. This hypothesis can be substantiated by the findings presented in
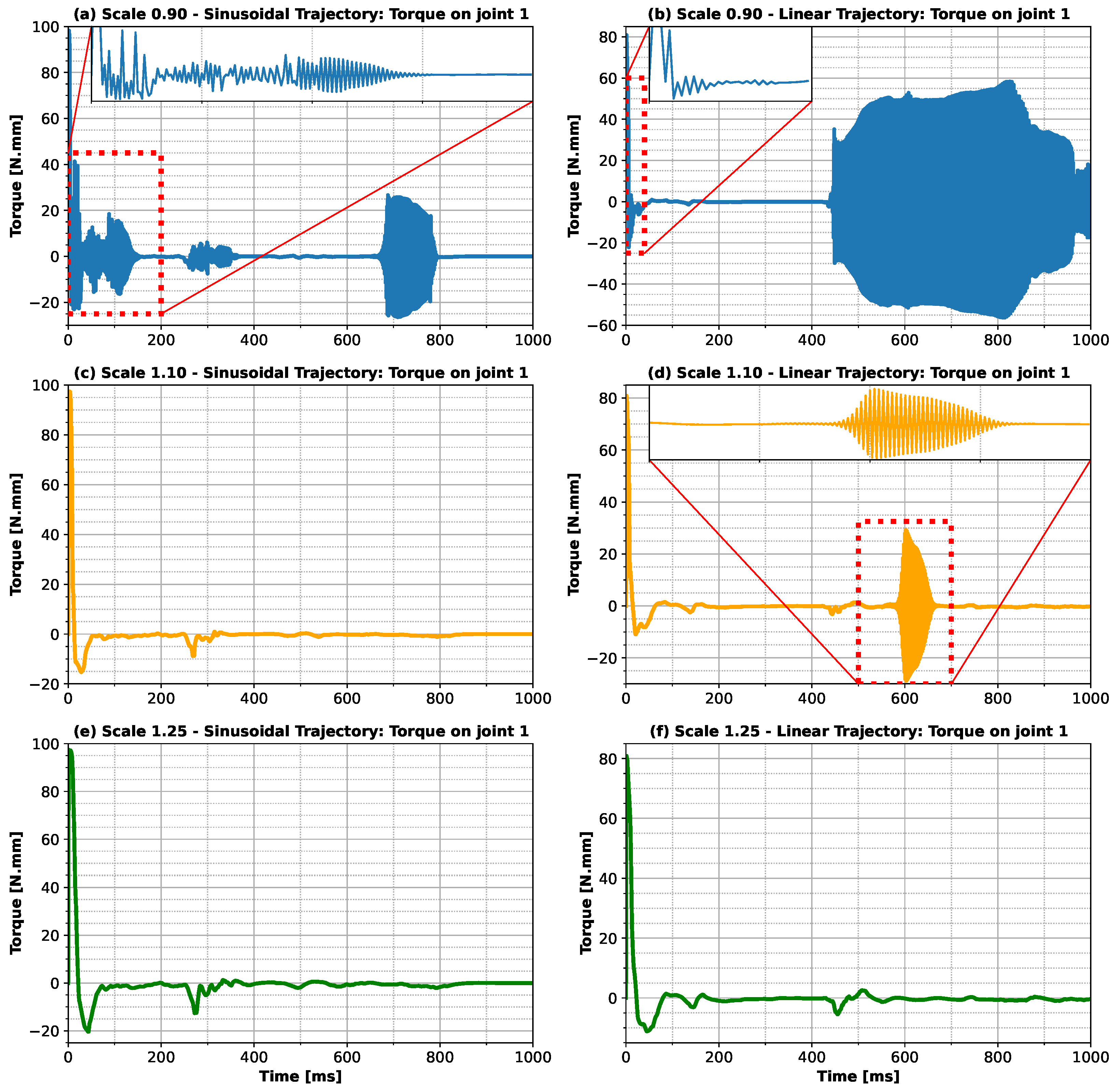
Figure 10, which illustrate the influence of inertia on the control strategy. The analysis reveals that for the larger finger, i.e., with greater inertia, the strategy used for both trajectories was more stable, whereas for the smaller body, i.e., with less inertia, the control strategies were unstable. Considering the situations where different combinations of linear and sinusoidal trajectories were applied (
Figure 7), it was possible to see a non-linear relationship established by our ANN model, since no proportionality was observed in the torques. This can be seen from the results obtained for the M5050 case, which was closer to the response for the sinusoidal trajectory than for the other combinations considered (M2575 and M7525).
Finally, by examining the position of the fingertip over time (
Figure 9), it was possible to see that the influence on the trajectory error occurred due to the increase in the absolute distance in X between the fingertip and the inertial coordinate axis. One hypothesis to explain this behavior is the increase in torque that the fingertip is subjected to in these positions, generating less stability for the controller, and, consequently, greater difficulty in maintaining the position. The correction that the ANN model chose to avoid the increase in the error in the trajectories may have been the action of the ANN’s actor, in the sense of increasing the absolute value of the reward. Another observation that can be made about the corrections that the ANN model performed along the finger motion is the change in slope position, as demonstrated in
Figure 9a, where the slope changes from negative to positive. This change can drastically affect the model’s response, given the observed correction. This fact may be related to the model’s inability to reach the X components of the final positions (
Figure 9a), since there is a reduction in the magnitude of the slope of the position X component, making it difficult for the model to determine the correct torque, and leading the torque toward zero in the final stage of the motion (
Figure 3 and
Figure 7).
Limitations
This work presents some limitations; the main limitations involve the environment of the model and the selected trajectories. The model developed assumes that the phalanges are rigid elements, i.e., any type of deformation that the finger could present was disregarded. Despite the application of this simplifying hypothesis, the dynamics of the finger would not be significantly impacted, since the finger presents small deformations during movement. Another limitation of the model is that the phalanges are represented by elliptical cone trunks with a uniformly distributed density. This consideration has the potential to affect the overall dynamics of the finger, since both the geometry and the distribution of mass along the finger can change the position of the system’s center of mass. Refinements should be performed on these characteristics to improve the quality of the dynamic responses of the model developed. Furthermore, the stiffness and damping terms of the joints between the phalanges were disregarded. This choice was made due to the difficulty of defining these terms, as well as their dependence on the individual. These complexities were outside the scope of the present work, which was focused on evaluating only the ANN model’s ability to perform and adapt different trajectories. The insertion of these elements in the model could affect the stability of the responses generated by the ANN, since they insert a resistive torque and energy dissipation components in each of the joints. Despite this limitation,
Figure 10 demonstrates the model’s capacity to modify the control strategy when the dimensions and mass of the finger are changed. This finding suggests the model’s potential to adapt the torque applied to each joint in realistic conditions, where the damping and stiffness parameters of the joints are included. It was also observed that the trajectory errors exhibited no significant differences in relation to the original finger, without applying the scales, which reinforces the hypothesis that a controller using the model proposed in this work could perform the tasks in real environments. In addition, the results presented here have not been validated with experimental data to verify the accuracy of the model in predicting the real dynamics of the finger. However, the aim of this work was to assess the model’s ability to adapt the movement of the finger to different conditions, and these limitations do not negatively affect this type of analysis.
While the present study concentrates on the evaluation of the viability of the DDPG in the development of an adaptive controller, it is acknowledged that other algorithms, such as PPO and SAC, could also be evaluated. This is considered to be a limitation of the present study, since the DDPG is sensitive to buffer hyperparameters, learning rate and the initial parameters of the network, which could affect the results presented [
31]. It is believed that both algorithms, PPO and SAC, are the best methods for dealing with a large number of samples, since they show faster convergence and overcome the sensitivities present in the DDPG [
20,
31,
32]. Consequently, if the training was performed using these algorithms, the actor would reach a reward greater than -650 more quickly, which would enable the model to reach higher rewards, thereby improving the overall performance of the ANN. One consequence, despite the rapid convergence, would be a tendency for the model to overflow, which could affect the observed adaptive characteristics. It is, therefore, necessary to evaluate the problem with other deep reinforcement learning algorithms in order to ascertain the real capacity of RL-trained ANNs to adaptively control upper limb prostheses. However, despite the limitations in terms of applicability, the developed controller demonstrated its capacity to generate diverse control signals, according to trajectories and environments, as can be seen in
Figure 10 and in the
Supplementary Materials.
5. Conclusions
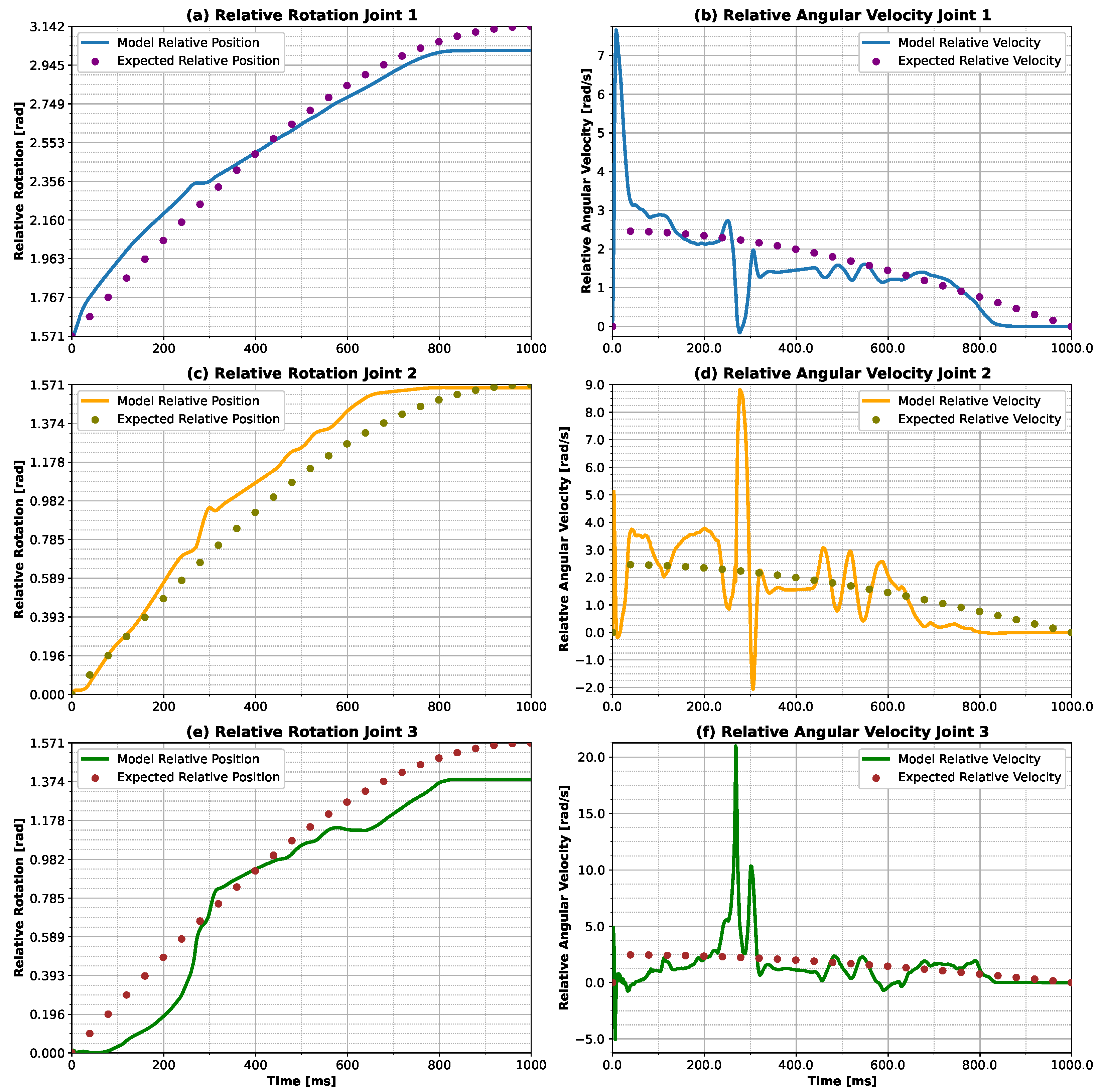
In this study, we evaluated the suitability of using the DDPG algorithm to train an ANN model and propose a new adaptive controller for myoelectric prostheses of the upper limb. We intended to show that it was possible to control physiological finger prostheses in different trajectories and adapt them using trajectory selection through a computational model evaluation. The algorithm demonstrated its efficiency in leading the finger along different trajectories, showing an average magnitude error of mm for sinusoidal input and mm for linear input. The results revealed that the model developed different control strategies to achieve the trajectories, demonstrating the ability of the model to distinguish the strategy with only changes in the trajectory’s selected input.
Furthermore, it was possible to observe the model’s compatibility in adapting to different types of trajectory inputs that were not contemplated in the training stage. Considering three combinations of linear and sinusoidal trajectory proportions, the model completed the entirety range of motion without any collisions or failures. This may indicate that the model has the ability to adapt according to the user’s requirements.
Finally, this work proposed the development of a controller to be used in association with myoelectric signals, using RL training. By defining different trajectories, it was possible to develop an adaptive control, which could provide users with easier use and training, offering better integration between the prosthesis and the amputee. As future work, we intend to extrapolate the ANN model to cover the complete hand, using physiological trajectories and classification patterns obtained from sEMG.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}